
Sometimes the data that you have requires further processing; that is, not just moving around but also changing some values.
A quite flexible node is the Rule Engine node that creates or replaces a column based on certain rules involving other columns. It might contain logical and relational operators for texts, and it can even check for inclusion (IN) for a certain set of values or limited pattern matching (LIKE as in SQL). The result can be either a constant, a column's value, or a flow variable. It can also handle the missing values.
When you want to fill the metadata, you should use the Domain Calculator node. With the help of this node, you can create nominal columns from textual (String) columns.
The most generic cell transformation nodes are the Java snippet nodes (Java Snippet and Java Snippet (Simple)). They allow you to use the third-party libraries, custom code to transform a row's values, or append new columns with those values. This is considered a last resort option though, because it makes it harder to get a visual overview of the workflow, when there are multiple snippet nodes used and requires Java knowledge of the user.
You have been warned, so now we can introduce how to use it when you need it.
Let us see what is in the configuration dialog:
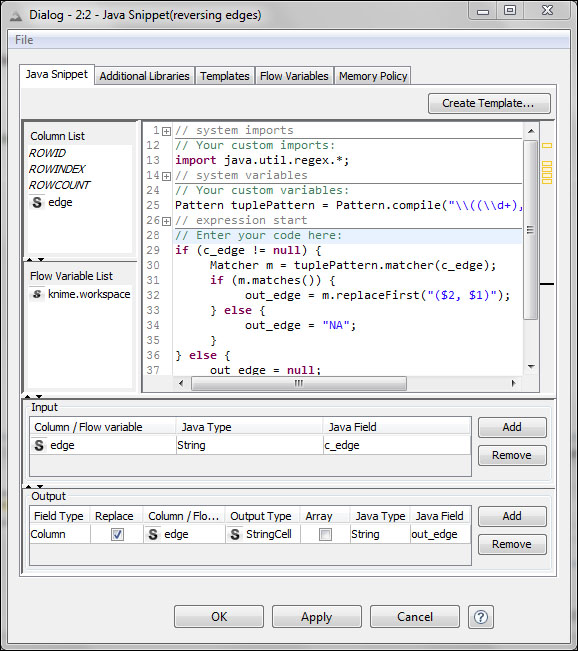
The main configuration tab of the Java Snippet node
As you can see, to the left of the window, there is a columns list and the flow variables list, while to the right you can see a coding area with the syntax highlighted (also code completion and error highlighting). Beneath them you can specify the values in the input and output columns. The output can be not only columns, but also the flow variables (With the simple version, you can only have a single column as the output). You can use the mouse to insert references to flow variables, columns, or row/table properties; just double-click them. The code completion can be activated using Ctrl + spacebar or just waiting after writing a method/field selector (.) for an object.
In the coding area, the menu which appears on right-clicking also works, just like the undo (Ctrl+Z)/redo (Ctrl+Y) commands. Some of the parts of the surrounding code are hidden (folded) initially, but if you are curious, you can see them.
The regular exceptions are swallowed, so it will not stop the execution; however, missing cells and null flow variables will be created for that row. If you want to stop the execution, you should throw an Abort exception.
When you do not want to import a reference to a certain column or flow variable, you use the snippets methods, which are described in the node description at: http://www.knime.org/files/nodedetails/_misc_java_snippet_Java_Snippet.html.
In the Additional Libraries tab, you can specify which jars should also be loaded for this snippet. This way, you can use quite complex libraries besides the standard Java Runtime Environment.
The Templates tab allows you to load a template from the available repositories. You can create your own using the Create Template... button on the main tab of the Java Snippet configuration.
The flow control category contains similar, yet specialized, nodes to change flow variables named Java Edit Variables and Java Edit Variables (simple), but as a row filter, you can either use Java Snippet Row Filter or Java Snippet Row Splitter.
The KNIME Math Expression (JEP) extension is available from the standard KNIME update site and adds the Math Formula node to the repository.
The Math Formula node is similar to the String Manipulation node, but it works with numbers and not with texts. Here you also have different kinds of composable functions and a few helper variables and constants. The following are the main categories of functions:
- Trigonometric
- Logarithmic/exponential
- Rounding
- Statistical
- Other (rand, abs, sqrt, if, and binom)
Using these functions, you can transform the values from a row without knowing the Java syntax.
We previously mentioned that "upcasting" can be performed using the Column Rename node, although usually we are not that lucky to have only that kind of transformation. If you want to sort the numeric data by their textual representation (for example, "1"<"10"<"2"), the Number
To String node will help to do that. (Unfortunately, you cannot specify precision or number format this way. The format uses scientific notation (no thousands separators) and use point (.) as a decimal delimiter.) Another use case might be needed to append the units to the number.
The Round Double node allows you to select the precision and the rounding mode, and can convert to the data to textual format, but can keep the floating point representation too. When you convert to text, it might not use the scientific notation; so, it might suit your needs better in certain cases.
The other way, using the String To Number node, you can specify whether you want to parse the values as floating point numbers or integers. You can also set what should be the decimal and the thousands separator.
Another option to convert the textual column values to numbers is using the Category To Number and apply helper nodes, Category To Number (Apply), if you want to use the same transformation on a different table. These are creating a transformation (PMML) model, which specifies which numbers should be assigned to certain values of the selected textual columns.
The Double To Int node can be used to convert the floating point numbers to integers. You can select the columns and the rounding mode.
When you have (hexadecimal or binary) numbers represented as a text, or the bit positions separated by spaces, you can create a bitvector from them using the Bitvector Generator node. You can also use this node to assign 0 or 1 to each selected numeric columns based on a fix separator value or relative to the mean of the individual columns. These values are then combined to bitvectors.
The String to Date/Time and the Time to String nodes allow you to convert between dates and texts. You can specify the date format in both cases, but you cannot set the locale.
With the Column To XML node, you can convert multiple columns (row-wise) to a single XML column, and the XPath node can extract information from XML cells as texts. If you want to parse an XML document from a text column to the KNIME XML data type, you should use the String To XML node.
When your preferred modeling algorithm cannot handle the numeric classes, but there are too many values to use them for classification without overfitting, a good option is creating intervals (bins) based on the values, and using those interval labels (or their One2Many variables) for learning. Fortunately, KNIME has good tools to solve this problem too.
First of all, you should decide whether you want to specify the boundaries manually, or an automatic way is preferred. If you want manual bins, the Numeric Binner node should be used. This node allows you to set the different ranges for selected numeric columns in the configuration dialog. If you have a mapping already available as a table, you should use the Binner (Dictionary) node. The rule table should contain the label and the lower and the upper bounds (you cannot specify for each rule how the end points of the interval should be included for the rule set).
The automatic binning construction can be done using the Auto-Binner node. You can specify how many bins you want or just select the percentiles for the bin boundaries. With the Auto-Binner (Apply) node, you can use the result of that binning in other tables or columns, but in this case the boundary labels could be misleading if there are values outside the original interval.
The other options for automatic binning are the CAIM Binner and CAIM Applier nodes. These nodes learn binning based on a class label column that tries to minimize the class interdependency measure.
Several algorithms do not work well when the range of the numeric values are on a different scale. Think of those that use a difference metric. In such cases, a relatively large change in a variable with small range is not recognizable. For this reason, KNIME supports normalization of values using the Normalizer node, which also creates a transformation model that can be applied to other tables using the Normalizer (Apply) node. You can select from three different normalization methods as follows:
- Min-max
- Z-score
- Decimal scaling
The min-max normalization scales the values to a user-defined range, while Z-score will transform the values such that the mean will be zero and the standard deviation will be one. Decimal scaling converts the values such that they are not larger than one in their absolute values. This is achieved by finding the smallest power of 10 that satisfies this condition.
The Denormalizer node inputs a model from Normalizer and applies its inverse version on the data. This way, you can show the data in the original range.
Not only the numeric values should be normalized, but also the text in columns might need some further processing. For this purpose, you can use the Cell Replacer, String Replacer, String Replace (Dictionary), Case Converter, and String Manipulation nodes. The Rule Engine node can also be used for related tasks, while the Missing Value node can be used to specify alternative values for the missing values.
The Cell Replacer node is a general whole-content replacer node (or appends for certain preferences). You have to specify a dictionary table and the column to change. In the dictionary table, you also have to select the two columns (from and to).
This functionality is a little bit similar to the String Replace (Dictionary) node; however, in the String Replace (Dictionary) node, the input is not another table, but a file similar to prolog rules, where the term to generate is the first, whereas the conditions are the rest. Although, unlike prolog, the conditions are "or"-ed, not "and"-ed in the same rows; so, if any of the keys match, the head will be used as a replacement. You can think of this as an ordinary dictionary table that was grouped by the replacement values. This can be a compact form of the rules, although you still can have multiple rows with the same replacement (first column) values.
The String Replacer node can be handy when you want to replace only certain parts of the input text. It uses the wildcard pattern or regular expressions. You can replace the whole string or just the parts that match.
The Case Converter node can do a simple task; that is, normalize the texts to all uppercase or to all lowercase.
The String Manipulation node, on the other hand, can do that and much more with texts. You can use multiple (even non-textual) columns in the expression that generate a result (which can also be not just text but logical or numeric values too). The functions which you can use fall into the following categories:
- Change case
- Comparison
- Concatenate
- Convert type
- Count
- Extract
- Miscellaneous (only reverse yet)
- Remove
- Replace
- Search
These functions cannot handle date and time or collection values; however, for positional or exact matches, these are great tools as they allow you to compose the provided functions.
With the Java Snippet node, you can perform the changes using regular expressions too. Here is an example of the code snippet:
// system imports // Your custom imports: import java.util.regex.*; // system variables // Your custom variables: Pattern tuplePattern = Pattern.compile("\((\d+),\s*(\d+)\)"); // expression start // Enter your code here: if (c_edge != null) { Matcher m = tuplePattern.matcher(c_edge); if (m.matches()) { out_edge = m.replaceFirst("($2, $1)"); } else { out_edge = "NA"; } } else { out_edge = null; } // expression end
The automatically generated parts are hidden in this code. We have the c_edge field as an input and out_edge as an output. First, we import the Pattern and Matcher classes using the import statement. The pattern we used translates to the following: find an opening parenthesis, then a nonnegative integer number (within a group, so it is interesting for us, which is group number 1), a comma, possibly a few white spaces, another nonnegative number (also interesting, group number 2), and closing parenthesis. You might notice that to escape the character, we had to double them between the quotes.
For each row's edge text, we test whether the edge is missing or not. After that, we check (when not missing) whether it fully matches our pattern; if yes, we replace the whole matching pattern with the opening parenthesis, the second number ($2), a comma, a space, and the first number ($1) followed by a closing parenthesis. If there is no proper match, we return NA, but if it is missing, we return the missing value (null).
You can see this code in action if you import the project from ReverseEdges.zip.
It is worth noting that such a similar task can be more easily done with the String Replacer node, but this technique can be used in more complex cases too, and can be a template for extension.
When you want to create a single value from multiple columns, you have several options: Column Aggregator, Column Combiner, Column Merger, and Create Collection Column.
The Create Collection Column option is quite specific and does what its name suggests. The Column Aggregator option can do the same function as The Create Collection Column option and also various other aggregation methods, such as computing statistics, summarizing the selected columns, or performing set operations among collections. For details about the available functions, check its Description tab.
When you just want a single string from multiple columns, you should use the Column Combiner option. You can set the parameters to make it reversible for text values.
The Column Merger node is useful when you want to merge two columns, based on the presence of values; for example, imagine the state and country columns for persons. When a country has no states, you might want the country name present in the state column too (or you might want to keep only the state column with the country value if it was missing previously). It is easy to solve using this node.
We already mentioned the Many2One node during structural transformations, but it is worth referring to that here too. You can create a single column from the binary columns with at most one inclusion value.
The XML transformation nodes are a part of the KNIME XML-Processing extension, available from the standard KNIME update site.
With the XML Column Combine node, you can create new XML values row-wise from the existing XML columns. In case you do not have XML values yet, you can still create a new value with custom or data bound attributes for each row.
To create a single XML from a column's values, you should use the XML Row Combine node. This can be useful when you want to generate parts for the XLSX or ODS files. With the file handling nodes, you can replace data within templates.
There are Java libraries that can be used to transform XML content or even HTML; for example, Web-Harvest (http://web-harvest.sourceforge.net/index.php). These libraries are useful when something complex should be performed, but for standard transformation tasks, the XSLT node is sufficient. It can collect values/parts from the XML values; so, it is a form of extraction and search too, just like the XPath node.
When you have too many details available, it might be hard to focus on the important parts. In case of dates, you might be not interested in the actual time of day, the actual day, month, or year, or the date is not important, because all of your data points are within a day. We can split the date column to have this information in separate (numeric valued) columns using the Date Field Extractor and the Time Field Extractor nodes.
The Mask Date/Time node does a similar thing, but it works on the time column and keeps/removes the time of day, the date, or the milliseconds information (but only one at a time).
With Preset Date/Time, you can specify the removed/missing parts of the date or time to a preset value, but you can also use this node to set the date/time values for missing values.
Computing the difference between the dates and time is a common task. With the Time Difference node, you can not only find out the difference in various units between two columns, but also a fixed date (and time), or the current time, or the previous row.