
In the next few sections, we will introduce some problems and our solution to them using KNIME.
Sometimes you are fine with the moving average for date type values, but in certain situations, you need the range of values for a window. In the workflow available in the sliding_minmax.zip file, we will do exactly this. We are assuming an equidistant distribution of date values in the rows; you can try to generalize to remove this restriction.
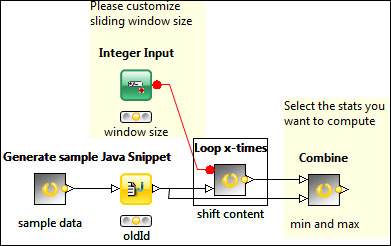
In the preceding screenshot, first (after generating some sample data) we add an ID based on the row index, then shift the content by the specified value in the Integer Input node, and finally combine the tables to find min and max values.
The main idea we use is described in the following steps: create a new table for each position in the sliding window (each shifted according to the position), and combine these tables using an identifier. Finally, we use the GroupBy node to select the values. Alternatively, we could also use the Group Loop Start node, but that would be quite slow and harder to understand. However, if you have to calculate the unsupported aggregation option(s), you should use the looping construct.
Let's see the details. The sample data was generated using the Data Generator node and the Java Snippet node. The latter was adding a column with daily time information to the generated table. If those were not equidistant consecutive dates, you should sort the table and fill the holes with, for example, the SMOTE node.
The Integer Input quick form node allows you to specify the window size easily, because we are using flow variables for this purpose. You might also create a meta node from the part that computes the statistics and wrap it around with a (counting) loop to try multiple options for the parameter.
We generate an integer ID to make it easy to combine the shifted tables later; this is quite simple. We could also use the Math Formula node, but to reduce the dependencies, we used the Java Snippet node with the row index as the values.
In the loop meta node (shift content), we first decrease the window size variable, because the first shift is the no shift (that is, the original table), but the Row Filter node does not support filtering by position, so we will have to generate the shifted values and concatenate it to the result of the loop. In the loop, we delete the first n (currentIteration) row and assign it a new ID. The Loop End node will take care of the concatenation of the tables.
We add the original table to the shifted ones as the last step in the Shift and combine custom meta node.
To summarize the values in the sliding window, we use the GroupBy node. You might think it would be very laborious to set all of these columns for the minimum and the maximum too, but the KNIME configuration dialog is user-friendly and makes this easy.
- In the Groups tab, select only the ID column (
old_idin this case) for inclusion - In the Options tab, select add all >>, right-click on them, and select Minimum from the context menu
- Now, select add all >> again, select the new aggregation columns, and from the context menu, select Maximum.
Now everything is configured and ready to start.
Tip
Exercise
Would you prefer other ways of sliding windows? I do. We implemented the analogous version of the Forward simple method of the Moving Average node. Can you construct a Backward simple method? What about a Center simple method? It would be nice if the user could select between these methods using a String Radio Buttons node.
We hope you will find the trick useful to shift the rows. It can be useful in other situations too.