
11
Business Logic Pattern
In this chapter, we will discuss the business logic pattern of serving models. In this pattern, we add some business logic, along with the model inference code. This is essential for successfully serving models because model inference code alone can’t meet the client’s requirements. We need additional business logic, such as user authentication, data validation, and feature transformation.
At a high level, we are going to cover the following main topics in this chapter:
- Introducing the business logic pattern
- Technical approaches to business logic in model serving
Technical requirements
In this chapter, we will use the same libraries that we used in previous chapters. You should have Postman or another REST API client installed to be able to send API calls and see the response. All the code for this chapter is provided at this link: https://github.com/PacktPublishing/Machine-Learning-Model-Serving-Patterns-and-Best-Practices/tree/main/Chapter%2011.
If you ModuleNotFoundError appears while trying to import a library, then you should install that module using the pip3 install <module_name> command.
Introducing the business logic pattern
In this section, we will introduce you to the business logic pattern of serving models.
When we bring our model to production, some business logic will be required. Business logic is any code that is not directly related to inference by the ML model. We have used some business logic throughout the book for various purposes, such as checking the threshold for updating models and checking the input type. Some examples of business logic are as follows:
- Authenticating the user: This kind of business logic is used to check whether a user has permission to call the APIs. We can’t keep our APIs public in most cases because this might be very risky, as our critical information can be compromised. If the models are involved in critical business decisions, then the APIs may be restricted to only a few groups of people as well. We need to check the user credentials at the very beginning of the API call. The code snippet that performs authentication in this way is a critical part of model inference code.
- Determining which model to access: Sometimes, we will have multiple models. We have to determine which model to access from the server side. The choice of model can be based on the user’s role. For example, someone from HR may want to access a model to get the current happiness index of the employees, or an engineering manager may be interested in accessing a model that will provide the performance index of the employees. Based on the user role, we can redirect to different models for inference. The choice of the model may be based on the type of input. Suppose there are different models for detecting flowers and fruits. Based on the input features, we have to determine which model to use during inference. This logical operation becomes critical when multiple models are served together in an ensemble model serving approach.
- Data validation: The validation of input data is important in model serving to reduce the number of inference errors. If we have data validation, we can throw an appropriate error to the customer, indicating that this is a client-side error and our model is still in good health. If we do not have this data validation, then due to the wrong data passed by clients, the errors might give a false impression that the model is bad. This will affect the reputation of the engineering team and will result in poor client satisfaction. Therefore, we should have different data validations, such as the dimensions of the data, the type of data, and the normalization of the data. All these validations ensure some properties of data. That’s why these validations are placed within the category of data validation.
- Writing logs to server: We have to write logs from our server code. This is essential for auditing user access, errors, warnings, data access patterns, and so on, and in understanding how our system behaves over different calls. We can also use logs to create operational metrics such as failure rate and latency. Writing logs can happen before the inference as well as after the inference. For example, let’s say we want to monitor the time taken by an inference call. We can write a log, "INFO: Starting the inference at {datetime.now()}", and after the call, we can have another log, "INFO: Finished the inference at {datetime.now}". From these two logs, we can determine how much time was needed for inference. Without these logs, we do not know how our served model is performing, how many times the model is being accessed, or who is accessing our model.
- Database lookup for pre-computed information: In ML, we might use a lot of pre-computed information. For example, if we need to retrain a model, we can load the features from a database instead of recreating them. If there is some new data, we can recompute the features for that new data; otherwise, we can load the features from the database. We need to add this logic before the model inference.
- Feature transformation: If we have raw data, we need to transform the raw data into features. For example, let’s say the input has a Boolean feature with [True, False] values. We might have to encode the feature to [0, 1]. This logic is essential not only during training but also during inference because, during inference, the user might pass raw data.
- Sending notifications: Sending notifications to different stakeholders after the inference can also be necessary in some cases. We need to add this business logic after the model inference is complete. The notifications might be sent via email, simple notification service, text message, or using various other methods.
We have learned about some examples of business logic under different categories. Next, we will how we can divide a lot of the business logic into two types of business logic.
Type of business logic
In the previous section, we looked at different types of business logic. However, based on the location of the business logic code in the inference file, we can divide the business logic in the ML model into two types:
- Pre-inference business logic: This business logic needs to be written before the call to the model is made, and this business logic can also work as a guard to prevent unwanted calls to the model. Examples include business logic to authenticate the user, validate the data, and select the right model.
- Post-inference business logic: This business logic needs to be implemented after the model inference is complete. Examples include business logic to write the inference results to a database, mapping the inference classes to appropriate labels, and sending notifications.
The location of these types can be seen in Figure 11.1. We can see that the model is called only if the pre-inference logic passes. Otherwise, an error is shown to the caller. After the model is invoked, we have the post-inference logic.
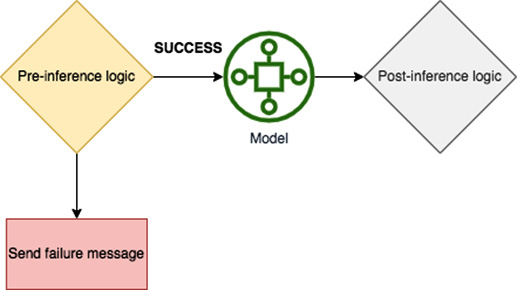
Figure 11.1 – Location of the pre-inference and post-inference business logic
In this section, we have seen some of the business logic that is used as part of serving an ML model. We have also seen that business logic can come before the model inference as well as after the model inference. In the next section, we will see technical approaches to some business logic, along with examples.
Technical approaches to business logic in model serving
In the last section, we have learned about the different types of business logic along with examples. Some business logic is exclusive to ML serving, such as data validation, feature transformation, and so on. Some business logic is common to any kind of application – for example, user authentication, writing logs, and accessing databases. We will explain some business logic that is crucial to ML in the following sub-sections.
Data validation
Data validation is very important in serving ML models. In most of the models in our previous chapters, we have assumed the user will pass data in the right format, but that may not always be the case. For example, let’s say the model needs input in the format of [[int, int]] to make inferences, and if the user does not follow the format, we will get errors.
For example, let’s consider the following code snippet:
model = RandomForestRegressor(max_depth=2) model.fit(X, y) print(model.predict([0, 0]))
Here, we are trying to pass [0, 0] to the model for prediction. However, we get the following error:
raise ValueError( ValueError: Expected 2D array, got 1D array instead: array=[0. 0.].
Therefore, we can add validation business logic before passing the input to the model that will check whether the shape of the input is correct.
We can add the following business logic before passing the input to the model for prediction:
Xt = np.array([0, 0])
if len(Xt.shape) != 2:
print(f"Shape {Xt.shape} is not correct ")
else:
print(model.predict(Xt))We are passing Xt data of the wrong shape in the preceding code snippet, so we get the following output:
Shape (2,) is not correct
We previously got an error that stopped our program. Now, as we are validating the input, we can avoid that exception. We can also raise a 4XX error from this if block by telling the client that the error is a client-side error with a readable error message.
We can also check the type of data that is passed as input to the model before the model is called. For example, let’s look at the following inference, where the input is a string that can’t be converted into a floating-point number:
Xt = np.array([["Zero", "Zero"]]) print(model.predict(Xt))
Therefore, we get the following error from the code snippet:
ValueError: could not convert string to float: 'Zero'
To solve this error, we can add the following validation code:
Xt = np.array([["Zero", "Zero"]])
try:
Xt = Xt.astype(np.float64)
print("Floating point data", Xt)
print(model.predict(Xt))
except:
print("Data type is not correct!")The preceding code snippet will throw the following output:
Data type is not correct!
However, if you pass the Xt = np.array([["0", "0"]]) input, you will get the following output:
Floating point data [[0. 0.]] [6.941918]
So, the 0 string could be converted into a floating point. We can add many other validations such as this. We have to think about the kinds of validation that are needed for our model. The validations may be different for different models. The data validation happens before inference and that’s why this logic can be called pre-inference logic.
Feature transformation
Feature transformation is very important for an ML model. Converting the raw data into some suitable features is very important if we want a good ML model. This transformation is also needed during inference. For example, suppose a feature in the input data is climate and can contain values of ["Sunny", "Cloudy", "Rainy"]. Now, the question is how we can pass this information to an ML model. The ML model can only deal with numeric data. The solution to this is one-hot encoding. For example, see the following code snippet:
import pandas as pd
df = pd.DataFrame({"climate": ["Sunny","Rainy","Cloudy"]})
print("Initial data")
print(df.head())
df2 = pd.get_dummies(df)
print("Data after one hot encoding")
print(df2)In this code snippet, we are encoding the data that will convert the categorical data for the climate feature into numerical data. The output from the preceding code snippet is as follows:
Initial data climate 0 Sunny 1 Rainy 2 Cloudy Data after one hot encoding climate_Cloudy climate_Rainy climate_Sunny 0 0 0 1 1 0 1 0 2 1 0 0
After encoding, three features are created from the single climate feature. The new features are climate_Cloudy, climate_Rainy, and climate_Sunny. The value for the particular feature is 0 in the row for which the feature is present. For example, for the first row at index 0, the climate is Sunny, that’s why the value of climate_Sunny for the first row is 1.
The feature transformation logic needs to come before the model inference or training. That’s why this business logic is a pre-inference logic.
Prediction post-processing
Sometimes, the predictions from the model are in a raw format that can’t be understood by the client. For example, let’s say we have a model predicting the names of flowers. The dataset that is used to train the model has four flowers:
- Rose
- Sunflower
- Marigold
- Lotus
The model can only work with numeric data. Therefore, the model can’t provide these names directly during prediction. After the predictions or inferences are done, we need a post-processing logic to map the predictions to the actual names. For example, the model detecting the four flowers can simply provide one of the following predictions:
- 0: The output prediction for roses will be 0
- 1: If the model identifies the flower as a sunflower, then it will predict 1
- 2: If the flower is a marigold, then the model will predict 2
- 3: If the flower is a lotus, then the model will predict 3
Now, suppose we got a batch prediction from the model as follows:
[0, 0, 0, 1, 0, 1, 0, 2, 3]
We need to map this prediction to the following:
['Rose', 'Rose', 'Rose', 'Sunflower', 'Rose', 'Sunflower', 'Marigold', 'Lotus']
To do this mapping, we will add business logic such as the following:
response = [0, 0, 0, 1, 0, 1, 0, 2, 3]
mapping = {0: "Rose", 1: "Sunflower", 2: "Marigold", 3: "Lotus"}
converter = lambda x : mapping[x]
final_response = [converter(x) for x in response]
print(final_response)We get the following output from the preceding code snippet:
['Rose', 'Rose', 'Rose', 'Sunflower', 'Rose', 'Sunflower', 'Rose', 'Marigold', 'Lotus']
So, we can see that final_response is a user-friendly response that can be returned to the client. As this business logic is used after the inference, we call it post-inference logic.
In this section, we have discussed some business logic with code examples that are critical for ML model serving and can be found in almost all serving cases.
Summary
In this chapter, we discussed the business logic pattern of serving ML models. We saw how different business logic can be added as preconditions before calling a model. We discussed different kinds of business logic that are essential for serving ML models. With this chapter, we have concluded our discussions of all the patterns of model serving that we wanted to cover in this book.
In the next few chapters, we will discuss some tools for serving ML models, starting with TensorFlow Serving.