
Chapter 11
Amazon DynamoDB
WHAT'S IN THIS CHAPTER
- Introduction to DynamoDB—Amazon's NoSQL database
- Create a DynamoDB table
- Use the Amazon Comprehend management console to analyze text
- Adding items to a DynamoDB table
- Performing scans and queries on a DynamoDB table
- NOTE Amazon occasionally updates the user interface of the Amazon DynamoDB management console. As a result, some of the screenshots in this chapter may not match what you see in your web browser. However, the general concepts that you will learn in this chapter will still be applicable.
DynamoDB is Amazon's cloud-based, highly scalable, redundant NoSQL database service. Amazon removes the hassle involved in building and maintaining a redundant scalable database service by taking care of administrative tasks such as hardware procurement, setup, replication, and scaling for you.
Using Amazon DynamoDB, you can create database tables in the AWS cloud and read/write to these tables using a web-based management console or the AWS CLI, or directly from your projects using one of the AWS SDKs. Amazon DynamoDB stores your data on fast SSD storage and spreads the data in your tables across a number of servers to allow for fast and consistent access times. All the data in your tables is also automatically replicated across all the availability zones (AZs) in your chosen region.
In addition to a cloud-based DynamoDB service, Amazon provides a downloadable version of DynamoDB that you can run locally on your computer. For more information on the downloadable version of DynamoDB, visit https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DynamoDBLocal.html.
Key Concepts
In this section you will learn some of the key concepts you will encounter while working with Amazon DynamoDB.
Tables
DynamoDB stores your data in tables, which are just collections of data. The concept of a table is present in virtually every database management system.
Unlike traditional relational database management systems (RDBMSs), DynamoDB does not require tables to have a predefined schema or any kind of predefined relationships between tables. Behind the scenes, data in a DynamoDB table is stored in JSON files.
DynamoDB tables are AWS region–specific, and are automatically replicated across all AZs within the region.
Global Tables
A global table is a collection of one or more identical replica tables spread across different AWS regions. Each replica table stores the same set of items. Global tables allow changes to be propagated across the underlying region-specific replica tables automatically.
Items
A DynamoDB table is a collection of objects called items. An item is a group of attributes and can be thought of as rows within a table. For example, each item within a table called BankAccounts would correspond to a bank account. There is no limit to the number of items that can exist within a table.
Attributes
An attribute is a fundamental unit of data within an item and is not broken down further. You can think of attributes as columns within a table. For example, attributes in a table called BankAccounts could be AccountNumber, AccountType, and CurrentBalance.
There is no restriction on the number of attributes that an item can contain. items within the same table can contain different attributes. This is quite different from tables in relational databases where the schema for the table is predefined and each row within the table contains the same number of columns.
An attribute can be one of the following data types:
- Scalar types: Number, String, Binary, Boolean
- Document types: List (Array), Map (Dictionary)
- Set types: String Set, Number Set, Binary Set
For more information on attribute data types, visit http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/HowItWorks.NamingRulesDataTypes.html.
Primary Keys
Every table in DynamoDB has a primary key that identifies items within. The primary key is an attribute defined when the table is created and every item (row) must have a unique value for the primary key. The primary key attribute must be a scalar of type Number, String, or Binary. There are two types of primary keys in a DynamoDB table:
- Partition key: This is a simple primary key; it is a single attribute that must be unique across all items in the table. DynamoDB uses the value of this key to work out the partition (physical storage volume) on which to store the item.
- Partition key and sort key: This is a composite primary key composed of two attributes. The first attribute of the composite key is a partition key used by DynamoDB to determine the physical storage volume on which the item will be stored. The second part of the composite key is the sort key, which sorts values that are stored together on the same storage volume. Items in a table with a composite primary key can have the same value for the partition key, which means those items are stored together. However, the combination of partition key and sort key must be unique for each item in the table.
The partition key is also known as the hash key as its value is used as an input to a hash function to determine the storage volume where the item will be stored. The sort key is also known as the range key.
Secondary Indexes
When you create a table in DynamoDB, you are asked to provide a primary key (simple or composite). DynamoDB allows you to read data from the table by providing the values of the primary key attributes.
If, however, you want to read the data using other non-key attributes, you need to create a secondary index on the table. A secondary index is created using a combination of two attributes, the first attribute is known as the partition key and the second is known as the sort key.
There are two types of secondary indexes:
- Global secondary index: The partition key and sort key portions of the index can be any two attributes in the table, different from the attributes that make up the primary key.
- Local secondary index: The partition key of the index is the same as the partition key of the table; the sort key portion of the index can be any other attribute in the table.
Once you have created a secondary index on the table, you can use the index in queries and scans.
Queries
A query is an operation that searches for data in a DynamoDB table based on the value of the primary key attribute. You must provide the value of the partition key and the sort key (if using a composite primary key) and a comparison operator. The query returns a set with all the items in the table that match the query. By default, the query includes the value of all the attributes for each item in the set. You can provide an additional expression called a projection expression into a query to return fewer attributes for an item.
The projection expression is applied to filter the results of the query before presenting the results to you. Amazon charges you for the amount of data you read from DynamoDB and in the case of queries, the charges are calculated before the projection expression is applied. You can only build queries on the value of attributes that are part of the primary key or one of the secondary indexes on the table.
Scans
A scan is an operation that returns all the items in the table. Unlike a query, a scan does not retrieve specific items based on the value of a key or index; it provides all the data in the table.
You can provide an additional expression called a projection expression into a scan to return fewer attributes for an item. The projection expression is applied to filter the results of the scan before presenting the results to you.
Amazon charges you for the amount of data you read from DynamoDB, and since a scan will read the entire table you will be charged for all the data in the table—even if you filter the results to return a single item. In case of large tables this can quickly become an expensive proposition. Whenever possible, opt for a query instead of a scan.
Read Consistency
DynamoDB tables are scoped at the region level. It is possible to have two tables with the same name in different regions, and these tables will have no relationship with each other. When you create a table, it is created in the region you have selected in the management console.
Within a region, AWS stores redundant copies of the data in your DynamoDB tables across multiple AZs. When you write data to a DynamoDB table, AWS updates all copies of the data. However, it can take a small amount of time before all copies of your data have been updated.
When you read data from a DynamoDB table, you can choose from one of two different consistency models:
- Eventually consistent reads: The response may not reflect the results of the most recent write operation and may contain stale data. It takes about a second for AWS to update all copies of the table across multiple AZs within a region; however, the delay can be significant if you are using global tables.
- Strongly consistent reads: The response contains the data from all prior writes that were successful. The response is likely to take more time because DynamoDB has to wait for all prior update operations to conclude.
The default read consistency model for DynamoDB is eventual consistency, which can be interpreted to mean, “read operations will eventually be consistent.” DynamoDB queries and scans have an additional optional parameter that allows you to specify the read consistency model that you want to use.
Read/Write Capacity Modes
Amazon charges you for reading and writing data to DynamoDB and provides two options that allow you to control how these charges will be calculated:
- On Demand Mode: This is a flexible pay-per-request model for read and write requests and you only pay for what you use. This is a good option if your application has unpredictable usage patterns. The amount you are billed will depend on the number of read and write request units you have consumed.
One read request unit represents one strongly consistent read request, or two eventually consistent read requests for an item up to 4 KB in size. If the item being read is larger than 4 KB, additional read request units are required. For example, each time your application reads a 5 KB item with strongly consistent reads, it will consume two read request units.
One write request unit represents one write operation for an item 1 KB in size. If the item being written is larger than 1 KB, additional write request units will be consumed.
- Provisioned Mode: This mode allows you to specify, in advance, the I/O capacity for your table. If your application exceeds these limits, requests will be subject to throttling and will fail with an HTTP 400 error. DynamoDB allows you to set up an auto scaling rule when using provisioned mode. Auto scaling when used with a DynamoDB table will provide a margin by which the provisioned I/O capacity for a table can grow before throttling occurs. Provisioned throughput is specified in terms of read and write capacity units.
One read capacity unit represents one strongly consistent read per second, or two eventually consistent reads per second for items up to 4 KB in size. If the item being read is larger than 4 KB, additional read capacity units are required. For example, if your application requires reading 100 items per second, with each item being 2 KB in size, and you want strongly consistent reads, you need to provision 100 read capacity units. Even though each item is 2 KB in size, Amazon rounds up the item size to the nearest 4 KB boundary when calculating throughput capacity for reads. This means that if your items were 5 KB in size, you would need to provision twice the number of read capacity units (200 read capacity units).
One write capacity unit represents one write per second for items up to 1 KB in size. For example, if your application requires writing 100 items per second, with each item being 2 KB in size, you need to provision 200 write capacity units.
You are billed for the I/O units that you have reserved (or consumed) as well as an additional flat fee for data storage costs. For more information on the costs involved with DynamoDB, visit https://aws.amazon.com/dynamodb/pricing/.
When creating a table, you are asked to specify the read and write capacity mode. Once the table has been created, you can switch between read and write modes once every 24 hours.
Common Tasks
In this section you learn to use the AWS management console to create DynamoDB tables and manage the data in these buckets.
Log in to the AWS management console using the dedicated sign-in link for your development IAM user account. Use the region selector to select a region where the Amazon DynamoDB service is available. Click the Services menu and access the Amazon DynamoDB service home page (Figure 11.1).

FIGURE 11.1 Accessing the Amazon DynamoDB service home page
DynamoDB tables are scoped at the region level, so make sure you have set up the management console to use the appropriate region. The screenshots in this section assume that the console is connected to the EU (Ireland) region.
Creating a Table
If you have never used DynamoDB, you are presented with the splash screen (Figure 11.2).

FIGURE 11.2 Amazon DynamoDB splash screen
If you have used DynamoDB in the past, you arrive at the DynamoDB dashboard (Figure 11.3). Follow the steps outlined below to create a table.

FIGURE 11.3 Amazon DynamoDB dashboard
- Regardless of which screen you arrive at, click the Create Table button to get started with creating a DynamoDB table. On the Create DynamoDB Table screen (Figure 11.4), provide a table name between 3 and 255 characters in length. Unlike S3 buckets, DynamoDB table names are not globally unique; they only need to be unique for your account, within the selected region.

FIGURE 11.4 Specifying a table name - If you would like to follow along with the exercises in this chapter, call the table customer. Specify the name of the primary key attribute to be customerID. By default, the Create Table screen is configured to create a simple primary key. If you want to use a composite (partition + sort) key, check the Add Sort Key check box (Figure 11.5).

FIGURE 11.5 Specifying a composite key for a table - The default Create Table screen is also configured to not create secondary indexes, to reserve a provisioned throughput capacity of 5 read units and 5 write units, and to enable capacity auto scaling. Not having a secondary index at this point is not a problem because we don't have data in the table. However, as you are billed for provisioned throughput capacity you reserve, you should start with the smallest number of read and write units and increase these if needed in the future.
- Uncheck the Use Default Settings check box and scroll down to the bottom of the page to locate the Provisioned Capacity section. Disable auto scaling and change the number of read and write units to 1 each (Figure 11.6).

FIGURE 11.6 Changing the provisioned I/O capacity - Click the Create button to create the table. The table takes a few minutes to form. Once it is created, your screen should resemble Figure 11.7.
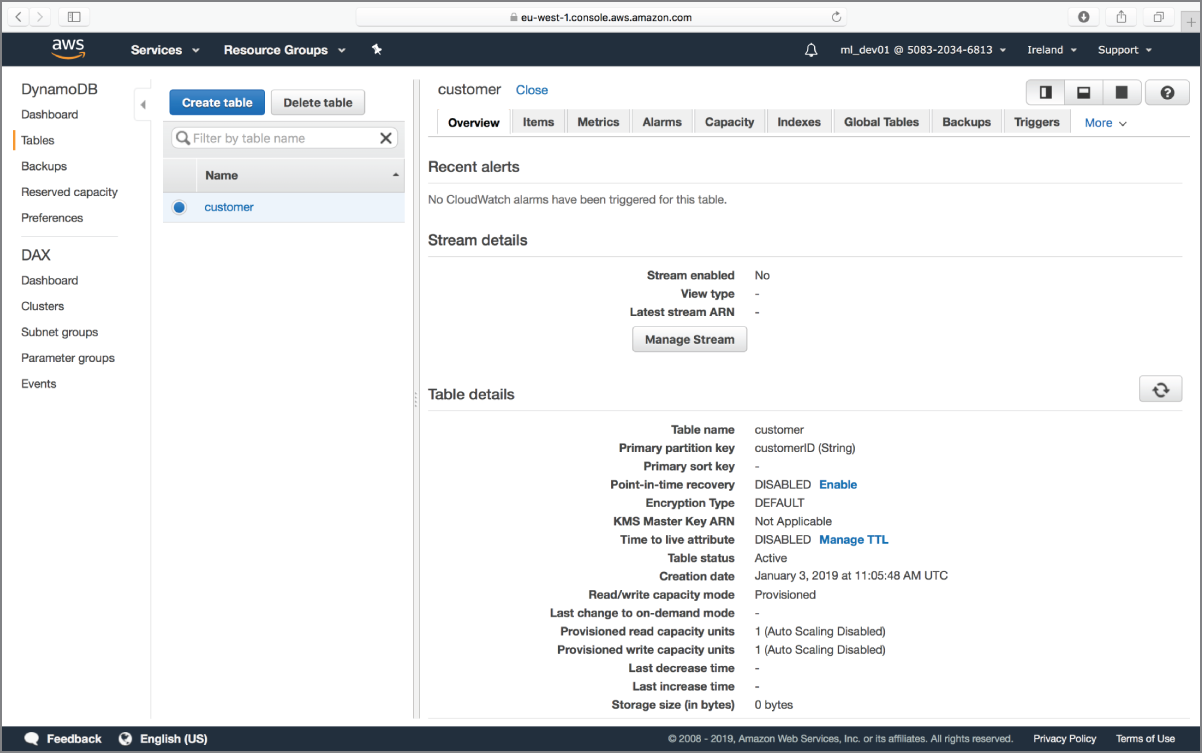
FIGURE 11.7 Amazon DynamoDB table overview
Adding Items to a Table
This section assumes you have created the customer table as described in the previous section.
- In the DynamoDB dashboard, select the
customertable, switch to the Items tab, and click the Create Item button (Figure 11.8).

FIGURE 11.8 Creating a new item in the customer table
You are presented with a dialog box that lets you add attributes for the new item. The only attribute that is available by default is the primary key attribute of the table (Figure 11.9).

FIGURE 11.9 Item attributes dialog showing default primary key attribute
You can add attributes by clicking the Add (+) button beside an existing attribute and selecting Append or Insert from the context menu. Append adds a new attribute after the selected attribute, whereas Insert adds the new attribute before the selected attribute (Figure 11.10).

FIGURE 11.10 Adding item attributes
- Set the value of
customerIDto 1 and use the Add (+) button to create the following string attributes with the specified values (Figure 11.11):
FIGURE 11.11 Specifying multiple attributes -
firstName: John -
lastName: Woods -
address: 17 Hollow Road, Bromley -
postcode: BR34 980 -
country: United Kingdom
-
- If you prefer to work directly with the JSON representation of the new item, select the Text option in the view mode drop-down combo box (Figure 11.12).

FIGURE 11.12 Viewing item attributes as JSON - Click the Save button to add the new item to the table. You should see the new item listed in the table (Figure 11.13).

FIGURE 11.13 Amazon DynamoDB table with one item - Add another item to the table with the following attributes:
-
customerID: 2 -
firstName: Sonam -
lastName: Mishra -
isHomeOwner: True
-
As you can see in Figure 11.14, items in a table can have different attributes. This is unlike a table in a traditional RDBMS system in which each row has to have the same columns.

FIGURE 11.14 Each item in an Amazon DynamoDB table can have different attributes.
Creating an Index
This section assumes you have created the customer table as described in the “Creating a Table” section.
- In the DynamoDB dashboard, select the
customertable, switch to the Indexes tab, and click the Create Index button (Figure 11.15).

FIGURE 11.15 Creating an index
You are presented with a dialog box that lets you set up the properties of the new index (Figure 11.16).

FIGURE 11.16 Index properties dialog
- Use the following properties to create the index:
- Primary Key: firstName
- Sort Key: lastName
- Index Name: Use default settings
- Projected Attributes: All
- Read Capacity Units: 1
- Write Capacity Units: 1
- Click the Create Index button to finish creating the index. Your index may take a few minutes to create. Once the index is created, you see it listed under the Indexes tab (Figure 11.17).

FIGURE 11.17 Amazon DynamoDB table index list
Once you have created this index, every new item you add to the table has three mandatory fields: customerID, firstName, and lastName (Figure 11.18).

FIGURE 11.18 Mandatory fields for new items
Even though you have created an index on firstName and lastName, you can still create a new item with the same values as the firstName and lastName attributes of an existing item. However, the value of the customerID attribute must be unique because it is the primary key attribute.
- Add another item to the table with the following attributes:
-
customerID:3 -
firstName: Sonam -
lastName: Mishra
-
The list of items in your table should resemble Figure 11.19. You should see two items having the same values for the firstName and lastName attributes.

FIGURE 11.19 Multiple items in an Amazon DynamoDB table
Performing a Scan
This section assumes you have created the customer table as described in the “Creating a Table” section.
- In the DynamoDB dashboard, select the
customertable, and switch to the Items tab. The default view that you see with all the items in the table listed is the result of a scan on the primary key customerID. You can verify this by looking at the dark gray area on top of the first item of the table (Figure 11.20).
FIGURE 11.20 List of items returned as a result of a scan operation - You can use the Add Filter button to add a filter expression that trims the results in the set. Figure 11.21 shows the results of the scan after a filter expression has been applied on the firstName attribute.

FIGURE 11.21 Adding a filter expression to a scan - If you have an index defined on the table, you can select it from the drop-down combo box (see Figure 11.22) and click the Start Search button to perform a scan based on the index.

FIGURE 11.22 Indexes can be used while performing a scan.
The difference between a scan on an index and a scan on the primary key is that the latter returns every item in the table (because all items, by definition, have a value for the primary key attribute). An index, on the other hand, is defined on a selection of attributes, and a scan on an index only returns the items in the table that have values for the attributes defined in the index.
It is important to keep in mind that a scan returns all the elements in a table based on a primary key or index and then applies optional filter expressions to trim down the result set. On a large table, a single scan operation could easily consume all the provisioned read capacity, even though the filter expression may trim the result set to a single row.
Performing a Query
This section assumes you have created the customer table as described in the “Creating a Table” section.
In the DynamoDB dashboard, select the customer table and switch to the Items tab. Switch from Scan mode to Query mode using the drop-down combo box (Figure 11.23).

FIGURE 11.23 Switching from Scan mode to Query mode
A query is similar to a scan in many respects, with one important difference: unlike a scan, a query only returns those items that match the criteria specified by query. Figure 11.24 depicts the results of a query that matches an item with customerId = 1.

FIGURE 11.24 Querying a DynamoDB table based on the partition key
You can choose to perform a query on the primary key or an index defined on the table. You can use filter expressions to trim the result set returned by a query.
Summary
- DynamoDB is Amazon's cloud-based, highly scalable, redundant NoSQL database service.
- DynamoDB stores your data on fast SSD storage and spreads the data in your tables across a number of servers to allow for fast and consistent access times.
- All the data in your tables is also automatically replicated across all the availability zones (AZs) in your chosen region.
- A global table is a collection of one or more identical replica tables spread across different AWS regions. Each replica table stores the same set of items. Global tables allow changes to be propagated across the underlying region-specific replica tables automatically.
- In addition to a cloud-based DynamoDB service, Amazon provides a downloadable version of DynamoDB that you can run locally on your computer.
- DynamoDB does not require tables to have a predefined schema or any kind of predefined relationships between tables.
- Behind the scenes, data in a DynamoDB table is stored in JSON files.
- A partition key is used to work out the partition (physical storage volume) on which to store the item.
- A composite primary key consists of both a partition key as well as a sort key. The sort key is used to sort values that are stored on the same storage volume.
- A secondary key can be thought of as an additional composite primary key.
- A query is an operation that searches for data in a DynamoDB table based on the value of the primary key attribute.
- A scan is an operation that returns all the items in the table. Unlike a query, a scan does not retrieve specific items based on the value of a key or index; it provides all the data in the table.
- DynamoDB streams allow tables to generate events when the table is modified.