As we talked about in the previous chapter, Machine Learning is a very vast field, and there are multiple algorithms that fall under various categories, but linear regression is one of the most fundamental Machine Learning algorithms. This chapter focuses on building a linear regression model with PySpark and dives deep into the workings of a LR model. It will cover various assumptions to be considered before using LR along with different evaluation metrics. But before even jumping into understanding linear regression, we must understand types of variables.
Variables
Variables capture data information in different forms. There are mainly two categories of variables that are used widely as depicted in Figure 4-1.
Figure 4-1
Variable types
We can even further break down these variables into subcategories, but we will stick to these two types throughout this book. Numerical variables are those kinds of values that are quantitative in nature such as numbers (integers/floats). For example, salary records, exam scores, age or height of a person, and stock prices all fall under the category of numerical variables.
Categorical variables on the other hand are qualitative in nature and mainly represent categories of data being measured, for example, colors, outcome (yes/no), and ratings (good/poor/average).
For building any sort of machine learning model, we need to have input and output variables. Input variables are those values that are used to build and train the machine learning model to predict the output or target variable. Let’s take a simple example. Suppose we want to predict the salary of a person given the age of the person using machine learning. In this case, the salary is our output/target/dependent variable as it depends on age, which is known as the input or independent variable. Now the output variable can be categorical or numerical in nature, and depending on its type, machine learning models are chosen.
Now coming back to linear regression, it is primarily used in cases where we are trying to predict a numerical output variable. Linear regression is used to predict a line that fits the input data points the best possible way and can help in predictions for unseen data, but the point to notice here is that how can a model learn just from “age” and predict the salary amount for a given person. For sure, there needs to be some sort of relationship between these two variables (salary and age). There are two major types of variable relationships:
Linear
Nonlinear
The notion of a linear relationship between any two variables suggests that both are proportional to each other in some ways. The correlation between any two variables gives us an indication on how strong or weak is the linear relationship between them. The correlation coefficient can range from –1 to +1. Negative correlation means as one of the variables increases, the other variable decreases. For example, power and mileage of a vehicle can be negatively correlated; as we increase power, the mileage of the vehicle goes down. On the other hand, salary and years of work experience are an example of positively correlated variables. Nonlinear relationships are comparatively complex in nature and hence require an extra amount of details to predict the target variables. For example, in a self-driving car, the relationship between input variables such as terrain, signal system, and pedestrian to the speed of the car is nonlinear.
Note
The next section includes theory behind linear regression and might be redundant for many readers. Please feel free to skip the section in that case.
Theory
Now that we understand basics of variables and relationships between variables, let’s build on the example of age and salary to understand linear regression in depth.
The overall objective of linear regression is to predict a straight line through the data such that the vertical distance of each of these points is minimal from that line. So, in this case, we will predict salary of a person given the age. Let’s assume we have records of four people, which capture age and their respective salaries, as shown in Table 4-1.
Table 4-1
Sample Data
Sr. No
Age
Salary (‘0000 $)
1
20
5
2
30
10
3
40
15
4
50
22
We have an input variable (age) at our disposal to make use of in order to predict the salary (which we will do at a later stage in this book), but let’s take a step back. Let’s assume all we have with us at the start is just the salary values of these four people. The salary is plotted for each person in Figure 4-2.
Figure 4-2
Scatter plot of salary
Now, we if we were to predict the salary of the fifth person (new person) based on the salaries of these earlier people, the best possible way to predict that would be to take an average/mean of the existing salary values. That would be the best prediction given this information. It is like building a Machine Learning model but without any input data (since we are using the output data as input data).
Let’s go ahead and calculate the average salary for these given salary values:
Avg. Salary = = 13
So the best prediction of the salary value for the next person is 13. Figure 4-3 showcases the salary values for each person along with the mean value (the best-fit line in the case of using only one variable).
Figure 4-3
Best-fit line plot
The line for the mean value as shown in Figure 4-3 is possibly the best-fit line in this scenario for these data points because we are not using any other variable apart from salary itself. If we take a look closely, none of the earlier salary values lies on this best-fit line. There seems to be some amount of separation from the mean salary value as shown in Figure 4-4. These are also known as errors. If we go ahead and add them up and calculate the total sum of this distance, it becomes 0, which makes sense since it’s the mean value of all the data points. So, instead of simply adding them, we square each error and then add them up.
Figure 4-4
Residuals plot
Sum of Squared Errors = 64 + 9 + 4 + 81 = 158
So adding up the squared residuals gives us a total value of 158, which is known as the sum of squared errors (SSE).
Note
We have not used any input variable so far to calculate the SSE.
Let us park this score for now and include the input variable (age of the person) as well to predict the salary of the person. Let’s start with visualizing the relationship between age and salary of the person as shown in Figure 4-5.
Figure 4-5
Correlation plot between salary and age
As we can observe, there seems to be a clear positive correlation between years of work experience and salary value, and it is a good thing for us because it indicates that the model would be able to predict the target value (salary) with good amount of accuracy due to a strong linear relationship between input (age) and output (salary). As mentioned earlier, the overall aim of linear regression is to come up with a straight line that fits the data points in such a way that the squared difference between actual target value and predicted value is minimized. Since it is a straight line, we know in linear algebra the equation of a straight line is y= mx + c (as shown in Figure 4-6).
Figure 4-6
Straight line plot
where
m = slope of the line
x = value at x-axis
y= value at y-axis
c = intercept (value of y at x = 0)
Since linear regression is also finding out the straight line, the linear regression equation becomes
(since we are using only one input variable, i.e., age)
where
y = salary (prediction)
B0 = intercept (value of salary when age is 0)
B1 = slope or coefficient of salary
x= age
Now, you may ask that there can be multiple lines that can be drawn through the data points (as shown in Figure 4-7) and how to figure out which is the best-fit line.
Figure 4-7
Possible straight lines through data
Figure 4-8
Centroids of data
The first criterion to find out the best-fit line is that it should pass through the centroids of the data points as shown in Figure 4-8. In our case, the centroid values are
mean (Age) =
= 35
mean (Salary) =
= 13
The second criterion is that it should be able to minimize the sum of squared errors. We know our regression line equation is equal to
Now the objective of using linear regression is to come up with the most optimal values of the intercept (B0) and coefficient (B1) so that the residuals/errors are minimized to the maximum extent.
We can easily find out the values of B0 and B1 for our dataset by using the following formulas:
B1=
B0=ymean − B1 ∗ (xmean)
Table 4-2 showcases the calculation of slope and intercept for linear regression using input data.
Table 4-2
Calculation of Slope and Intercept
Age
Salary
Age Variance
(Diff. from Mean)
Salary Variance
(Diff. from Mean)
Covariance
(Product)
Age Variance
(Squared)
20
5
-15
-8
120
225
30
10
-5
-3
15
25
40
15
5
2
10
25
50
22
15
9
135
225
Mean (Age) = 35
Mean (Salary) =13
The covariance between any two variables (age and salary) is defined as the product of the distances of each variable (age and salary) from their mean. In short, the product of the variances of age and salary is known as covariance. Now that we have the covariance and age variance squared values, we can go ahead and calculate the values of slope and intercept of the linear regression line:
B1 =
=
= 0.56
B0 = 13 – (0.56 * 35)
= –6.6
Our final linear regression equation becomes
Salary = –6.6 + (0.56 * Age)
We can now predict any of the salary values using this equation given any age. For example, the model would have predicted the salary of the first person something like this:
Salary (1st person) = –6.6 + (0.56*20)
= 4.6 ($ ‘0000)
Interpretation
Slope (B1= 0.56) here means for an increase of one year in age of the person, the salary also increases by an amount of $5600.
Intercept does not always make sense in terms of deriving meaning out of its value. Like in this example, the value of negative 6.6 suggests that if the person is not yet born (age = 0), the salary of that person would be negative $66000.
Figure 4-9 shows the final regression line for our dataset.
Figure 4-9
Regression line
Let’s predict the salary for all four records in our data using the regression equation and compare these with actual salaries and see the difference as shown in Table 4-3.
Table 4-3
Difference Between Predictions and Actual Values
Age
Salary
Predicted Salary
Difference/Error
20
5
4.6
-0.4
30
10
10.2
0.2
40
15
15.8
0.8
50
22
21.4
-0.6
In a nutshell, linear regression comes up with the most optimal values for the intercept (B0) and coefficients (B0, B1, B2) so that the difference (error) between the predicted values and the target variables is minimum.
But the question remains: Is it a good fit?
Evaluation
There are multiple ways to evaluate the goodness of fit of a regression line, but one of the ways is by using the coefficient of determination (rsquare) value. Remember we had calculated the sum of squared errors when we had only used the output variable itself, and its value was 158. Now let us recalculate the SSE for this model that we have built using the input variable. Table 4-4 shows the calculation for the new SSE after using linear regression.
Table 4-4
Reduction in SSE After Using Linear Regression
Age
Salary
Predicted Salary
Difference/Error
Squared Error
Old SSE
20
5
4.6
-0.4
0.16
64
30
10
10.2
0.2
0.04
9
40
15
15.8
0.8
0.64
4
50
22
21.4
-0.6
0.36
81
As we can observe, the total sum of squared errors has reduced significantly from 158 to only 1.2, which has happened because of using linear regression. The variance in the target variable (salary) can be explained with the help of regression (due to usage of the input variable – age). So OLS works toward reducing the overall sum of squared errors. The total sum of squared errors is a combination of two types:
TSS (Total Sum of Squared Errors ) = SSE (Sum of squared errors) + SSR (Residual sum of squared errors)
The TSS is the sum of the squared difference between the actual and the mean values, and it’s always fixed. This was equal to 158 in our example.
The SSE is the squared difference from actual to predicted values of target variable, which reduced to 1.2 after using linear regression.
SSR is the sum of squared errors explained by regression and can be calculated by TSS – SSE:
SSR = 158 – 1.2 = 156.8
rsquare (Coefficient of determination) = == = 0.99
This percentage indicates that our linear regression model can predict with 99% accuracy in terms of predicting the salary amount given the age of the person. The other 1% can be attributed toward errors, which cannot be explained by the model. Our linear regression line fits the model really well, but it can also be a case of overfitting. Overfitting occurs when your model predicts with high accuracy on training data but its performance drops on unseen/test data. The technique to address the issue of overfitting is known as regularization, and there are different types of regularization techniques. In terms of linear regression, one can use the Ridge, Lasso, or Elastic Net regularization technique to handle overfitting.
Ridge regression is also known as L2 regularization and focuses on restricting the coefficient values of input features close to zero, whereas Lasso regression (L1) makes some of the coefficients to zero in order to improve generalization of the model. Elastic Net is the combination of both techniques.
At the end of the day, regression is a still a parameter-driven approach and assumes few underlying patterns about distributions of input data points. If the input data does not affiliate with those assumptions, the linear regression model does not perform well. Hence, it is important to go over these assumptions very quickly in order to know them before using the linear regression model:
There must be a linear relationship between input variable and output variable.
The independent variables (input features) should not be correlated to each other (also known as multicollinearity).
There must be no correlation between the residuals/error values.
There must be a linear relationship between the residuals and the output variable
The residuals/error values must be normally distributed.
Code
This section of the chapter focuses on building a linear regression model from scratch using Pyspark and automating the steps using a pipeline. We saw a simple example of only one input variable to understand linear regression, but it is seldom the case. Majority of the times, the dataset would contain multiple variables, and hence building a multi-variable regression model makes more sense in such a situation. The linear regression equation then looks something like this:
? = ?? + ?? ∗ ?? + ?? ∗ ?? + ?? ∗ ?? + ⋯
Note
The complete dataset along with the code is available for reference on the GitHub repo of this book and executes best on Spark 2.7 or higher.
Let’s build a linear regression model using Spark’s MLlib library and predict the target variable using the input features. The dataset that we are going to use for this example is a small dataset and contains a total of 1232 rows and 6 columns. We have to use five input variables to predict the target variable using the linear regression model.
We start the Jupyter notebook and import SparkSession and create a new SparkSession object to use Spark:
In this section, we drill deeper into the dataset by viewing the dataset, validating the shape of the dataset, and discussing various statistical measures and correlations among input and output variables. We start with checking the shape of the dataset:
[In]: print((df.count(), len(df.columns)))
[Out]:
The preceding output confirms the size of our dataset, and we can validate the datatypes of the input values to check if we need to change/cast any column datatypes. In this example, all columns contain integer or double values:
[In]: df.printSchema()
[Out]:
There are a total of six columns, out of which five are input columns (var_1 to var_5), with one target column (output). We can now use the describe function to go over statistical measures of the dataset:
[In]: df.describe().show(3,False)
[Out]:
This allows us to get a sense of distribution and the measure of center and spread for our dataset columns. For keeping things simple, let’s rename the output column to label as it becomes relatively easier to compare the model performance on test data:
[In]: df=df.withColumnRenamed('output','label')
[In]: df.show()
[Out]:
We can check correlation between input variables and output variable using the corr function. In the following example, we validate the correlation between var_1 and label. As we can see, it is a pretty strong correlation:
[In]: from pyspark.sql.functions import corr
[In]: df.select(corr('var_1','label')).show()
[Out]:
[In]: from pyspark.ml.linalg import Vector
[In]: from pyspark.ml.feature import VectorAssembler
This is the part where we create a single vector combining all input features by using Spark’s VectorAssembler. It creates only a single feature that captures the input values for that row. So, instead of five input columns, it essentially merges all input columns into a single feature vector column. One can select the number of columns that would be used as input features and can pass only those columns through VectorAssembler. In our case, we will pass all the five input columns to create a single feature vector column:
We have to split the dataset into training and test data in order to train and evaluate the performance of the linear regression model built. We split it in 75/25 ratio and train our model on 70% of the dataset. We can print the shape of train and test data to validate the size:
In this part, we build and train the linear regression model using the features and output columns. We can fetch the coefficient (B1, B2, B3, B4, B5) and intercept (B0) values of the model as well. We can also evaluate the performance of the model on training and test data using r2 and RMSE:
[In]: from pyspark.ml.regression import LinearRegression
As we can see, the model is doing a decent job of predicting on the training data with r2 value of around 86%. The final part of the modeling exercise is to check the performance of the model on unseen or test data. We use the evaluate function to make predictions for test data and can use r2 and RMSE to check the accuracy of the model on test data. The performance seems to get bit better than that of training:
[In]: test_results=lr_model.evaluate(test_df)
[In]: print(test_results.r2)
[Out]: 0.8873805060206182
[In]: print(test_results.rootMeanSquaredError)
[Out]: 0.011586329962905937
Now that we have seen the steps to run the regression model, we can make use of a pipeline to automate some of these steps. We can leverage the power of Spark pipelines to do all the preprocessing, feature engineering, and model training for us. We only need to ensure that we declare the steps that need to be followed in a particular sequence.
We start by creating a fresh Spark Dataframe using the same source data. We call it as new_df this time around. We then rename the target column to label as done before. The final step before we move on to the pipeline is to split the data into train and test – we use the same ratio as used before:
Now we can start declaring the different stages of the pipeline for end-to-end prediction. We need to import Pipeline from Pyspark. Just to demonstrate the strength of pipelines, let us add scaling as an additional data processing step:
[In]: from pyspark.ml.feature import StandardScaler
[In]: from pyspark.ml import Pipeline
In essence, now we declare the different stages for our pipeline. We start with declaring the first stage where we create the feature vector using VectorAssembler followed by standardizing the input values using StandardScaler. We then apply the desired algorithm (linear regression in this case) on the training data. The pipeline can have any number of stages depending on the workflow:
Now that we have defined the pipeline stages, we can fit it on the training data and transform on test data. We end up with a Dataframe that contains the model prediction column. It also contains the feature vector:
[In]: model = pipeline.fit(train_df)
[In]: pred_result= model.transform(test_df)
[In]: pred_result.show(5)
[Out]:
Now that we have the predictions on the test data, we can evaluate the accuracy of the linear regression model using r2 and RMSE:
[In]: from pyspark.ml.evaluation import RegressionEvaluator
The model seems to be pretty consistent with the overall accuracy of 87% of r2. The slight variation that we observe in the r2 value here is due to the fact that data is split on a random basis. So using Spark pipelines, we were able to automate bulk of the steps involved in the model’s end-to-end prediction. In the coming chapters, we further build on this to see how pipelines can help reduce chances of errors and make the overall prediction process seamless.
Conclusion
In this chapter, we went over the fundamentals of linear regression along with the approach of building a regression model in PySpark. We also covered the process of automating the steps for end-to-end predictions.



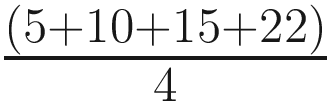 = 13
= 13







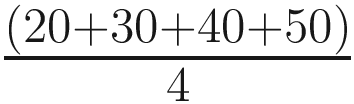

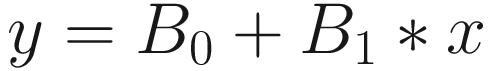


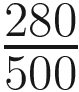
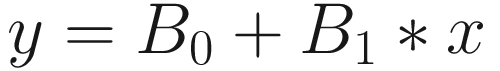

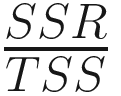 ==
== 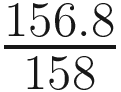 = 0.99
= 0.99








