
This chapter focuses on building a logistic regression model with Pyspark along with understanding the ideas behind logistic regression. Logistic regression is used for classification problems. We have already seen classification details in earlier chapters. Although it is used for classification, still it’s called logistic regression. It is due to the fact that under the hood, linear regression equations still operate to find the relationship between input variables and target variables. The main distinction between linear and logistic regression is that we use some sort of nonlinear function to convert the output of the latter into a probability to restrict it between 0 and 1. For example, we can use logistic regression to predict if a user would buy the product or not. In this case, the model would return a buying probability for each user. Logistic regression is used widely in many business applications.
Probability
To understand logistic regression, we will have to go over the concept of probability first. It is defined as the chances of occurrence of a desired event or interested outcomes upon all possible outcomes. Take for an example if we flip a coin. The chances of getting heads or tails are equal (50%) as shown in Figure 5-1.
If we roll a fair dice, then the probability of getting any of the number between 1 and 6 is equal to 16.7%.

Probability of events
Sample Data
Sr. No | Time Spent (mins) | Converted |
|---|---|---|
1 | 1 | No |
2 | 2 | No |
3 | 5 | No |
4 | 15 | Yes |
5 | 17 | Yes |
6 | 18 | Yes |

Conversion status vs. time spent
Using Linear Regression
Let’s try using linear regression instead of logistic regression to understand the reasons why logistic regression makes more sense in classification scenarios. In order to use linear regression, we will have to convert the target variable from categorical into numeric form. So let’s reassign the values for the Converted column:
Yes = 1
No = 0
Regression Output
Sr. No | Time Spent (mins) | Converted |
|---|---|---|
1 | 1 | 0 |
2 | 2 | 0 |
3 | 5 | 0 |
4 | 15 | 1 |
5 | 17 | 1 |
6 | 18 | 1 |

Conversion status (1 and 0) vs. time spent

Regression line for users


All looks good so far in terms of coming up with a straight line to distinguish between 1 and 0 values. It seems like linear regression is also doing a good job of differentiating between converted and non-converted users, but there is a slight problem with this approach.
Take for an example a new user spends 20 seconds on the website and we have to predict if this user will convert or not using the linear regression line. We use the preceding regression equation and try to predict the y value for 20 seconds of time spent.
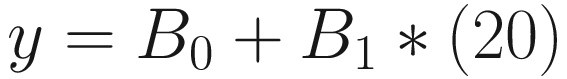

Predictions using a regression line
So, if we use linear regression for classification cases, it creates a situation where the predicted output values can range from –infinity to +infinity. Hence, we need another approach that can tie these values between 0 and 1 only. The notion of values between 0 and 1 is not unfamiliar anymore as we have already seen probability. So, essentially, logistic regression comes up with a decision boundary between positive and negative classes that is associated with a probability value.
Using Logit

And it always produces values between 0 and 1 independent of values of x.

We pass our output (y) through this nonlinear function (sigmoid) to change its values between 0 and 1:
Probability =
Probability = 

Logistic curve
The advantage of using the nonlinear function is that irrespective of any value of input (time spent), the output would always be the probability of conversion. This curve is also known as logistic curve. Logistic regression also assumes that there is a linear relationship between the input and the target variables, and hence the most optimal values of the intercept and coefficients are found out to capture this relationship.
Interpretation (Coefficients)

Let’s say after calculating for the data points in our example, we get the coefficient value of time spent as 0.75.
In order to understand what this 0.75 means, we have to take the exponential value of this coefficient:
e0.75=2.12
This 2.12 is known as odd ratio, and it suggests that per unit increase in time spent on the website, the odds of customer conversion increase by 112%.
Dummy Variables
Additional Data Column
Sr. No | Time Spent (mins) | Search Engine | Converted |
|---|---|---|---|
1 | 5 | 0 | |
2 | 2 | Bing | 0 |
3 | 10 | Yahoo | 1 |
4 | 15 | Bing | 1 |
5 | 1 | Yahoo | 0 |
6 | 12 | 1 |
- 1.
Find out the distinct number of categories in a categorical column. We have only three distinct categories as of now (Google, Bing, Yahoo).
- 2.
Create new columns for each of the distinct categories and add value 1 in the category column for when the corresponding search engine is used or else 0 as shown in Table 5-4.
- 3.
Remove the original category column. So the dataset now contains five columns in total (excluding index) because we have three additional dummy variables as shown in Table 5-5.
Column Representation
Sr. No | Time Spent (mins) | Search Engine | SE_Google | SE_Bing | SE_Yahoo | Converted |
|---|---|---|---|---|---|---|
1 | 1 | 1 | 0 | 0 | 0 | |
2 | 2 | Bing | 0 | 1 | 0 | 0 |
3 | 5 | Yahoo | 0 | 0 | 1 | 0 |
4 | 15 | Bing | 0 | 1 | 0 | 1 |
5 | 17 | Yahoo | 0 | 1 | 0 | 1 |
6 | 18 | 1 | 0 | 0 | 1 |
Refined Column Representation
Sr. No | Time Spent (mins) | SE_Google | SE_Bing | SE_Yahoo | Converted |
|---|---|---|---|---|---|
1 | 1 | 1 | 0 | 0 | 0 |
2 | 2 | 0 | 1 | 0 | 0 |
3 | 5 | 0 | 0 | 1 | 0 |
4 | 15 | 0 | 1 | 0 | 1 |
5 | 17 | 0 | 1 | 0 | 1 |
6 | 18 | 1 | 0 | 0 | 1 |
The whole idea is to represent the same information in a different manner so that the machine learning model can learn from categorical values as well.
Model Evaluation
Confusion Matrix
Actual/Prediction | Predicted Class (Yes) | Predicted Class (No) |
|---|---|---|
Actual Class (Yes) | True Positives (TP) | False Negatives (FN) |
Actual Class (No) | False Positives (FP) | True Negatives (TN) |
Let us understand the individual values in the confusion matrix.
True Positives
Actual Class: Positive (1)
ML Model Prediction Class: Positive (1)
True Negatives
Actual Class: Negative (0)
ML Model Prediction Class: Negative (1)
False Positives
Actual Class: Negative (0)
ML Model Prediction Class: Positive (1)
False Negatives
Actual Class: Positive (1)
ML Model Prediction Class: Negative (1)
Accuracy

But as said earlier, it is not always the preferred metric because of the target class imbalance. Most of the times, target class frequency is skewed (more number of TN examples compared to TP examples). Take for an example the dataset for fraud detection contains 99% of genuine transactions and only 1% fraud ones. Now, if our logistic regression model predicts all genuine transactions and no fraud case, it still ends up with 99% accuracy. The whole point is to find out the performance in regard to the positive class. Hence, there are a couple of other evaluation metrics that we can use.
Recall

It talks about the quality of the machine learning model when it comes to predicting the positive class. So out of the total positive class, it tells how many the model was able to predict correctly. This metric is widely used as an evaluation criterion for classification models.
Precision

This can also be used as an evaluation criterion.
F1 Score
F1 Score = 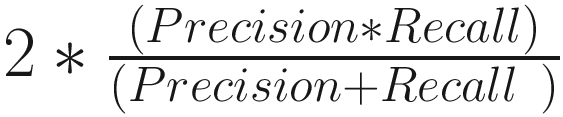
Probability Cut-Off/Threshold
Since we know the output of the logistic regression model is a probability score, it is very important to decide the cut-off or threshold limit of probability for prediction. By default, the probability threshold is set at 50%. It means, if the probability output of the model is below 50%, the model will predict it to be of the negative class (0) and, if it is equal and above 50%, it would be assigned the positive class (1).
If the threshold limit is very low, then the model will predict a lot of positive classes and would have a high recall rate. On the contrary, if the threshold limit is very high, then the model might miss out on positive cases, and the recall rate would be low, but precision would be higher. In this case, the model will predict very few positive cases. Deciding a good threshold value is often challenging. A Receiver Operator Characteristic curve, or ROC curve, can help to decide which value of the threshold is best.
ROC Curve

ROC curve
One would like to pick a threshold that offers a balance between both recall and precision. So, now that we have understood various components associated with logistic regression, we can go ahead and build a logistic regression model using PySpark.
Logistic Regression Code
This section of the chapter focuses on building a logistic regression model from scratch using PySpark and a Jupyter notebook.
The complete dataset along with the code is available for reference on the GitHub repo of this book and executes best on Spark 3.1 or higher.
Let’s build a logistic regression model using Spark’s MLlib library and predict the target class label.
Data Info
The dataset that we are going to use is a sample dataset that contains a total of 20000 rows and 6 columns. This dataset contains information regarding online users of a retail sports merchandise company. The data captures the country of the user, platform used, age, repeat visitor or first-time visitor, and number of web pages viewed at the website. It also has the information if the customer ultimately bought the product or not (conversion status). We will make use of five input variables to predict the target class using a logistic regression model.








We can see there is a strong connection between the conversion status and number of pages viewed along with repeat visits.
Since we are dealing with two categorical columns, we will have to convert the Country and Platform columns into numerical form.



As we can observe, the count values are same for each category in the Country column before one-hot encoding. Let’s interpret the new one-hot encoded vector to understand the components better.
(3,[0],[1.0]) represents a vector of length 3, with 1 value :
Size of vector: 3
Value contained in vector: 1.0
Position of 1.0 value in vector: 0th place





As we can observe, there are some cases where the model is misclassifying the target class, whereas at the majority of instances the model is doing a fine job of accurate prediction for both classes.
Confusion Matrix
Accuracy

The accuracy of the model that we have built is around 94%.
Recall
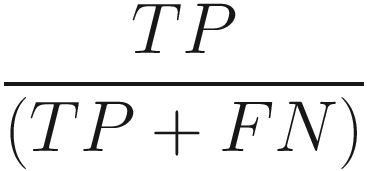
The recall rate of the model is around 0.94.
Precision


Conclusion
In this chapter, we went over the process of understanding the building blocks of logistic regression, converting categorical columns into numerical features in PySpark, training the logistic regression model, and automating it using a pipeline.