
Chapter 1
Fundamentals of complex communications networks
Abstract
This first chapter serves as an introduction to the broader scope, objectives, and specific topics addressed by this book. It primarily sets the application stage for the main content of the book by introducing the field of complex communication networks and the area of malicious software security. More specifically, it provides a brief overview of the evolution of networks in their recent (and short) history, paving the way for understanding the application environment within which the main topics, namely, the state-of-the-art malware modeling approaches are deployed. Additionally, this chapter provides a brief overview of the evolution of malicious software attacks and threats from their early emergence to today’s sophisticated attacks. Communication networks and malicious software presented here jointly motivate the need for sophisticated malicious software modeling methodologies and analysis techniques within the broader framework of complex network theory and Network Science, which will be extensively covered in the rest of the book.
1.1. Introduction to Communications Networks and Malicious Software
In complex networks [7,164,165] and the broader area of Network Science1[125,155], modern analysis methodologies developed lately have identified multiple and diverse types of interactions between and among peer entities. Such interactions regarding humans, computer devices, cells, animals, and in general, whatever one might think of, vary in their degree of criticality. Peer interactions have been holistically modeled by various research disciplines, e.g. in engineering, social sciences, biology, and financial sciences and lately systematically within the framework of Network Science, as different types of network structures, i.e. communications, social, biological, and financial networks. These network structures bear distinct and characteristic properties of broader interest for science and daily human lives. The key feature across all such different networks is the flow of information, which typically takes place spontaneously, e.g. in biological types of networks, or in specific cases in an on-demand manner, e.g. in communications networks. The information dissemination processes over networks are usually controlled, and typically they are of useful nature for all peers participating in the corresponding network. However, frequently, and especially in the prospect of potential financial benefit, information dissemination over networks can take a malicious form, either for the entities of the network individually or the whole network cumulatively.
In order to explain the latter better, nowadays, it is often observed that the disseminated information can be harmful, or it could be controlled by malicious peers, not the legitimate information owners/producers/consumers. Especially in communication networks, users experience almost on a daily basis several types of malicious software (malware), usually suffering personal, industrial, and/or financial consequences. Similarly, in biological networks, viruses can be transferring malicious signals through various blood cells or nerve networks of a living organism, leading eventually to diseases with sometimes lethal consequences, e.g. extreme cases of the flu virus and malaria. Also, this is especially evident in classic cases of virus spreading between humans, from the simplest seasonal flu scenarios to the more serious scenarios of, e.g. HIV and malaria. [87,99,160].
Especially for biological networks, their robustness against the aforementioned threats is very critical for sustaining all forms of life, while for science, such a feature is very fascinating with respect to the sustainability that these networks exhibit to the various forms of threats throughout so many years of evolution and virus spreads. Similarly, the study and analysis of malware behavior in communication networks are rather important for maintaining the coherency of modern information-based societies and the efficiency of the underlying networking infrastructures. The most frequent consequences of such malware infections render computer hosts at least dysfunctional, thus preventing the execution of routine or important tasks, while in more serious situations, the incurred cost may be much higher and diverse. Frequently, the targets of malicious attacks are public utility networks, e.g. water and electricity grids, or social networks, e.g. social network (facebook, twitter, instagram, linkedin, etc.) accounts and email accounts. For all these examples, the underlying computer/communications network operations are implicitly or explicitly targeted by the malicious attacks.
Motivated by the aforementioned observations, the main objective of this book is to present, classify, analyze, and compare the state-of-the-art methods for modeling malware diffusion in complex communications networks and especially wireless ones. The term malware diffusion cumulatively refers to all types of malicious software disseminating in various types of networks and could also be extended to characterize cumulatively all types of malicious information dissemination in complex networks, as will be explained in the following section. On the other hand, the term complex network characterizes generically the potential structure that a network might have and in this book we will present and analyze modeling frameworks for malware diffusion that are applicable to multiple types of diverse network structures. Thus, all of the presented approaches could be used to model malware or information dissemination in multiple and diverse types of networks, e.g. communications, social, and biological.
The main focus and application domain of the book will be focused on wireless complex networks , a term which includes all types of wireless networks cumulatively. Wireless complex networks can be characterized by the presence or absence of central infrastructure, e.g. cellular [168], ad hoc[39], sensor, mesh, and vehicular networks [5], in most of which nodes operate in a peer fashion, acting as both routers and relays [5]. The presented methodologies are also applicable to networks with centralized organization, e.g. wired types of network topologies, via straightforward extension of the corresponding approaches involving distributed network operations. Similarly to the scope of this book, for these types of networks, rather diverse modeling approaches have emerged lately aiming at modeling malware diffusion specially in wireless decentralized networks. Such approaches yield similar results with respect to the trends of malware diffusion dynamics, but more restricted in terms of generality or control potential compared to the results provided by the approaches that will be described in this book.
The book will focus on wireless complex networks primarily for demonstration purposes and in order to better facilitate the practical explanation of the concepts. Extrapolations of the presented methodologies in other types of networks and other types of application contexts, e.g. diffusion of information dissemination over communications networks or even social networks, will be provided across the book and especially in a dedicated chapter, namely, Chapter 9. Such extension will be straightforward and when more complicated extensions are required, the appropriate directions are pointed out and details on the required steps are provided as well.
In the main part (Part 2) of this book, we classify and present state-of-the-art techniques for malware modeling according to the type of mathematical framework employed for the modeling and analysis of the corresponding malware diffusion problems. In a comparative manner, we highlight the strengths and weaknesses of each methodology, thus enabling the interested researcher and professional engineer to select the most appropriate framework for a specific problem/application. Furthermore, we provide a concrete presentation of each different mathematical methodology, which will allow the reader to grasp the salient features and technical details that govern malware (and in general information) diffusion dynamics. Finally, we compare the complexity to obtain analytical results and implementation of solutions of the presented approaches. Within this framework and for those approaches addressing similar or comparable objectives under similar modeling settings, e.g. epidemic and optimally controlled epidemic approaches, we evaluate the obtained results with respect to factors that would be important in an operational environment. Thus, we qualitatively assess whether each framework is accurate and simple, tractable and scalable, etc., for dense or sparse regimes and other topological variations of each network.
Before we proceed with the main topics of the book, we next take a small detour and provide some background on the evolution of networks and malicious software, enabling a better understanding of the systems and applications over which malicious information typically spreads. This will also help understand better the dynamics of information spreading later in Part 3. In the next subsection, we will start with a brief history of networks, from the first academic interconnected systems to today’s complex commercial networks.
1.2. A Brief History of Communications Networks and Malicious Software
1.2.1. From Computer to Communications Networks
The emergence of the first network structures in nature took place in the form of messaging pathways in chemical bonds and biological elements [182]. Contrary to these naturally formed networks, humans have developed social interactions that led to various networked developments, such as friendships, smaller of larger communities, nations, and open markets. Eventually, other artificial and technological networks made their appearance, mainly aiming at making life easier, either through the transfer of commodities and resources, e.g. electricity grid/water pipe networks, or via transferring bits of information, i.e. computer and communications networks. Even though natural and social networks appeared much earlier than technological ones, the first networks to be systematically studied, analyzed, and controlled were the computer and communications networks. In fact, such networks were first conceived and designed and then developed. On the contrary, social networks have been long established before the first mathematical treatises of their structure, properties, and dynamics emerged. In addition, computer networks, and long before them telephone networks, were the first networks that were initially designed/studied by means of analytical methods before actually being developed/implemented.
The first data network, ARPANET , was built in 1973 in order to interconnect and promote research among the US American universities and various US research centers. The ARPANET was mainly based on the infamous TCP/Internet protocol (IP) stack suite, which was originally developed exactly to serve this network, i.e. provide a layered and modular substrate for developing the required mechanisms that will ensure the reliable, transparent, and efficient transfer of data between endpoints physically located in distinct places. For more information on the operation of TCP/IP, which is even today the protocol suite of choice for the majority of networks and its use in the ARPANET and later networks until today, there exists a vast amount of literature available, e.g. [55,148,208] and many relevant references provided in them. The evolution of the infrastructure of ARPANET, as well as the TCP/IP stack, followed the accumulated knowledge by their analysis-driven design and implementation. Ever since, computer networks have gone into a development loop, where progress is dictated either from technology or theory. Once technology develops due to deeper knowledge, it immediately spurs a research frantic, which in turn leads technology to even higher complexities and benefits.
In 1980–1981, two other networking projects, BITNET and CSNET, were initiated. BITNET adopted the IBM RSCS protocol suite and featured direct leased line connections between participating sites. Most of the original BITNET connections linked IBM mainframes to university data centers. This rapidly changed as protocol implementations became available for other machines. From the beginning, BITNET had been multidisciplinary in nature with users in all academic areas. It had also provided a number of unique services to its users (e.g. LISTSERV). BITNET and its parallel networks in other parts of the world (e.g. EARN in Europe) had several thousand participating sites. In its final years, BITNET had established a backbone that used the TCP/IP protocol suite with RSCS-based applications running above TCP. As of 2007, BITNET has essentially ceased operation.
CSNET was initially funded by the National Science Foundation (NSF) to provide networking for university, industry, and government computer science research groups. CSNET used the Phonenet MMDF protocol for telephone-based electronic mail relaying and, in addition, pioneered the first use of TCP/IP over X.25 using commercial public data networks. The CSNET name server provided an early example of a white pages directory service. At its peak, CSNET had approximately 200 participating sites and international connections to approximately fifteen countries.
In 1987, BITNET and CSNET merged to form the Corporation for Research and Educational Networking (CREN). In the Fall of 1991, CSNET service was discontinued having fulfilled its important early role in the provision of academic networking service. To help speed the connections, the NSF established five super computing centers in 1986, creating the NSFNET backbone. In 1987, the NSF signed a cooperative agreement to manage the NSFNET backbone with Merit Network, Inc., and by 1990, ARPANET had been phased out. NSFNET continued to grow, and more countries around the world were connected to this Internet backbone.
In 1986, the US NSF initiated the development of the NSFNET, which provided a major backbone communication service for the Internet. The National Aeronautics and Space Administration (NASA) and the US Department of Energy (DoE) contributed additional backbone facilities in the form of the NSINET and ESNET, respectively. This further spurred the development of national network infrastructures for research and experimentation. In a similar fashion, in Europe, major international backbones, such as GEANT, and other national ones, such as GRNET and NORDUNET, provide today connectivity to over millions of computers on a large number of networks. Back in 1986 commercial network providers in the US and Europe began to offer Internet backbone and access support.
The year of 1991 was a big year for the Internet: The National Research and Education Network (NREN) was founded and the World Wide Web was released. At the time, the Internet was still dominated by scientists and other academics, but had begun to attract public interest. With the release of the Mosaic Web browser in 1993 and Netscape in 1994, the interest in the use of the World Wide Web exploded. More and more communities became wired, enabling direct connections to the Internet. In 1995, the US Federal Government relinquished its management role in the Internet and NSFNET reverted back to being a research network. Interconnected network providers were strong enough at the time to support US backbone traffic on the Internet. However, the administration at the time encouraged continued development of the US backbone of the Internet, also known as the National Information Infrastructure (NII)—and, most commonly, as the “Information Superhighway.”
Throughout its lifetime, “regional” support for the Internet has been provided by various consortium networks and “local” support was provided through each of the research and educational institutions. Within the United States, much of this support had come from the federal and state governments, but a considerable contribution had been also made by industry. In Europe and elsewhere, support arose from cooperative international efforts and through national research organizations. During the course of its evolution, particularly after 1989, the Internet system began to integrate support for other protocol suites into its basic networking fabric. The present emphasis in the system is on multiprotocol internetworking, and in particular, with the integration of the open systems interconnection (OSI) protocols into the architecture. During the early 1990s, OSI protocol implementations also became available and, by the end of 1991, the Internet had grown to include some 5000 networks in over three dozen countries, serving over 700,000 host computers used by over 4,000,000 people.
Over its short history, the Internet has evolved as a collaboration among cooperating parties. Certain key functions have been critical for its operation. These were originally developed in the DARPA research program that funded ARPANET, but in later years, this work has been undertaken on a wider basis with support from US Government agencies in many countries, industry, and the academic community. The Internet Activities Board (IAB) was created in 1983 to guide the evolution of the TCP/IP suite and to provide research advice to the Internet community. During the course of its existence, the IAB has been reorganized several times. It now has two primary components: the Internet Engineering Task Force and the Internet Research Task Force. The former has primary responsibility for further evolution of the TCP/IP suite, its standardization with the concurrence of the IAB, and the integration of other protocols into Internet operation (e.g. the OSI protocols). The Internet Research Task Force continues to organize and explore advanced concepts in networking under the guidance of the IAB and with support from various government agencies.
The recording of Internet address identifiers, which is critical for translating names to actual addresses of machines requested, is provided by the Internet Assigned Numbers Authority (IANA) who has delegated one part of this responsibility to an Internet registry (IR) which acts as a central repository for Internet information and which provides central allocation of network and autonomous system identifiers, in some cases to subsidiary registries located in various countries. The IR [105] also provides central maintenance of the domain name system (DNS) [55,148,208], root database which points to subsidiary distributed DNS servers replicated throughout the Internet. The DNS distributed database is used to associate host and network names with their Internet addresses and it is critical to the operation of the higher level TCP/IP stack including electronic mail.
There are a number of network information centers (NICs) located throughout the Internet to serve its users with documentation, guidance, advice, and assistance. As the Internet continues to grow internationally, the need for high quality NIC functions increases. Although the initial community of users of the Internet was drawn from the ranks of computer science and engineering, its users now comprise a wide range of disciplines in the sciences, arts, letters, business, military, and government administration, and of course primarily and most importantly, private citizens (users) of the Internet.
This subsection provided a brief overview of the evolution of computer networks to communications networks, which are nowadays publicly and massively available. From this concise historical overview, it becomes evident that as networks become of more public use and as they grow (evolve) to serve more users, the initially introduced technology is still in use, or at least with minor adaptations. This means that malicious users have had the chance in the course of time to obtain deep knowledge on the operation of such infrastructures and in addition, to enhance their arsenal with sophisticated tools, which as will be shown later have allowed them to launch massive attacks, aiming at critical large-scale systems and individual users as well, with significant consequences.
There are a lot of references providing more details on the history and function of the Internet and its passage to broader communications networks in general. Some of these presentations can be found with [55,148,208] and references therein. In the following, we briefly touch on a special type of communications networks, i.e. wireless networks, which will constitute the main network application domain employed in the main part of the book.
1.2.2. The Emergence and Proliferation of Wireless Networks
Wireless communications have now a long history. The first one to discover and produce radio waves was Heinrich Hertz in 1888, while by 1894, Marconi demonstrated the modern way to send a message over telegraph wires. By 1899, Marconi sent a signal nine miles across the Bristol Channel and 31 miles across the English Channel to France. In 1901, he was able to transmit across the Atlantic Ocean.
However, it was during World War II, that the United States Army first used radio signals for data transmission. This inspired a group of researchers in 1971 at the University of Hawaii to create the first packet based radio communications network called ALOHANET [2]. ALOHANET was the very first wireless local area network (WLAN). This first WLAN consisted of seven computers that communicated in a bi-directional star topology and spurred the research for the development of more efficient protocols for wireless medium access.
The first generation of WLAN technology based on the previously mentioned ALOHA protocol used an unlicensed band (902–928 MHz-ISM), which later became very popular eventually becoming interference-crowded from networked small appliances and industrial machinery operating in this band [162]. A spread spectrum was used to minimize this interference, which operated at 500 kilobits per second (kbps). However, such rates were proving unsatisfactory in practice, calling for immediate improvements. The second generation (2G) of WLAN technology was four times faster and operating at 2 Mbps per second. The third generation WLAN technology operates on the same band as the 2G and we still use it today. It is popularly denoted as the IEEE 802.11 family, and with respect to the WLAN standardization, in 1990, the IEEE 802 Executive Committee established the 802.11 Working Group to create a WLAN standard to be widely adopted by professionals in the area. The 802.11 standard specified an operating frequency in the 2.4 GHz ISM band [110]. In 1997, the group approved IEEE 802.11 as the world’s first WLAN standard with data rates of 1 and 2 Mbps, now evolved into multiple and diverse variations with speeds that can reach up to 6.75 Gbps (802.11ad—December 2012) [110].
At the same time, mobile phone technology is continuously evolving, seemingly at an accelerating rate of innovation and adoption [103,227]. Examining the strides taken from 1G to 4G, the technology has both created new usage patterns and learned from unexpected use cases. Compared to the more distributed nature of the previously presented wireless networks, mobile networks operate in a more centralized manner throughout their inception.
In the 1970s, the first generation, colloquially referred to as 1G, of mobile networks was introduced [154]. These systems were referred to as cellular, which was later shortened to “cell,” due to the approach employed for the network architecture that covers the network area through cellular base stations (a simple example of such system is shown in Fig. 1.1). Cell phone signals were based on analog system transmissions, and 1G devices were comparatively less heavy and expensive than prior devices, e.g. portable military radios. Some of the most popular standards deployed for 1G systems and implementing the corresponding concepts were advanced mobile phone system (AMPS), total access communication systems (TACS), and Nordic mobile telephone (NMT). The global mobile phone market grew from 30% to 50% annually with the appearance of the 1G network, and the number of subscribers worldwide had reached approximately 20 million by 1990.

FIGURE 1.1 Simple architecture model of a cellular network and terminology employed (cell, terminal, base station, coverage area).
In the early 1990s, 2G phones deploying global system for mobile communications (GSM) technology were introduced. GSM is a standard developed by the European Telecommunications Standards Institute (ETSI) to describe protocols for 2G digital cellular networks used by mobile phones, first deployed in Finland in July 1992 [101]. GSM used digital modulation to improve voice quality but the network offered limited data service. Such systems are still partially in use in some countries around the world. As demand drove the uptake of cell phones, 2G carriers continued to improve transmission quality and coverage. The 2G carriers also began to offer additional services, such as paging, faxes, text messages, and voicemail. The limited data services under 2G included WAP, HSCSD, and MLS. An intermediary phase 2.5G was introduced in the late 1990s. It used the GPRS standard [101], which delivered packet-switched data capabilities to existing GSM networks. It allowed users to send graphics-rich data as packets. The importance for packet-switching increased with the rise of the Internet and the IP. The EDGE network is an example of 2.5G mobile technology.
The 3G revolution allowed mobile telephone customers to use audio, graphics, and video applications. Over 3G it is possible to watch streaming video and engage in video telephony, although such activities are severely constrained by network bottlenecks and over-usage. One of the main objectives behind 3G was to standardize on a single global network protocol instead of the different standards adopted previously in Europe, the US, and other regions. 3G phone speeds deliver up to 2 Mbps, but only under the best conditions and in stationary mode. Moving at a high speed can drop 3G bandwidth to a mere 145 Kbps. 3G cellular services, also known as UMTS [101], sustain higher data rates and open the way to Internet style applications. 3G technology supports both packet- and circuit-switched data transmission, and a single set of standards can be used worldwide with compatibility over a variety of mobile devices. UMTS delivers the first possibility of global roaming, with potential access to the Internet from any location.
The currently widely employed generation of mobile telephony, denoted as 4G [175], has been developed with the aim of providing transmission rates up to 20 Mbps while simultaneously accommodating quality of service (QoS) features. QoS will allow the device and the telephone carrier to prioritize traffic according to the type of application using user’s bandwidth and adjust between user’s different telephone needs at a moment’s notice. However, it is only recently that we are we beginning to realize the full potential of 4G applications. A 4G system, in addition to the usual voice and other services of 3G, provides mobile broadband Internet access, for example to laptops with wireless modems, to smartphones, and to other mobile devices. It is also expected to include high-performance streaming of multimedia content. The deployment of 4G networks will also improve video conference service functionality. It is also anticipated that 4G networks will deliver wider bandwidth to vehicles and devices moving at high speeds within the network area.
Nowadays, a very large portion of Internet connectivity occurs over wireless networks, either WLANs or 4G cellular, and it is expected that this tendency will further increase. Thus, the fraction of wireless connectivity is expected to further rise sharply, which is the main reason that relevant malware is anticipated to cause major problems. This is also the main reason that this book focuses and uses wireless complex networks as the main type of network demonstrator. In addition, it is expected that future patterns of wireless access are expected to further diversify. Additional communication and wireless access paradigms, such as machine-to-machine (M2M) communication,2 are expected to increase more the complexity of the network and allow more flexibility to malicious attackers. Thus, the malware diffusion process in future wireless networks is expected to be more complicated.
The future wireless and mobile networks, denoted as 5G, envisage a more converged environment that includes heterogeneous networks (4G, WLAN, ad hoc,3 cognitive radio networks,4 etc.) and devices under a holistic management and control framework. Within the 5G networks, performance and flexibility are expected to rise drastically, offering more capabilities and features, but at the same time creating more opportunities for exploiting vulnerabilities and management holes by malicious users and attackers, as will be explained in more detail in the following subsection and chapters of the book.
1.2.3. Malicious Software and the Internet
Malicious software (malware) is not new in computer and communications networks. In fact, it emerged as soon as the first publicly accessible infrastructures were made available. However, in 1986, most viruses were found in universities and their propagation was primarily via infected floppy disks from one machine to another, not through the network. A computer virus is a malware program that, when executed, replicates by inserting copies of itself (possibly modified) into other computer programs, data files, or the boot sector of the hard drive [13]. Viruses often perform some type of harmful activity on infected hosts, such as stealing hard disk space or CPU time, accessing private information, corrupting data, displaying political or humorous messages on the user’s screen, spamming user contacts, logging user keystrokes, or even rendering the computer useless. However, not all viruses carry a destructive payload or attempt to hide themselves. The defining characteristic of viruses is that they are self-replicating computer programs that install themselves without user consent. Notable virus instances during the era of their emergence included Brain (1986), Lehigh, Stoned, and Jerusalem (1987), and Michelangelo in 1991 (the first virus to make it to the news headlines) [126].
By the mid-1990s, businesses were equally impacted by malware and its propagation had moved to the network protocol layer, exploiting the flexibility allowed by the TCP/IP stack employed by networks, and thus allowing even more automated propagation capabilities. Notable malware for the period included the Morris worm5 (1988), i.e. the first instance of network malware, DMV (1994), the first proof-of-concept macrovirus,6 Cap.A (1997), the first high risk macro virus, and CIH (1998), the first virus to damage hardware [126]. By late 1990s, viruses had begun infecting the machines of home users as well, and virus propagation through email was increasing remarkably. Notable malware included Melissa (the first widespread email worm) and Kak, the first and one of the very few true email viruses, both in 1999 [126].
At the start of the new millennium, Internet and email worms were making headlines across the globe. Notable cases included Loveletter (May 2000), the first high-profile, profit-motivated malware, the Anna Kournikova email worm (February 2001), the March 2001 Magistr, the Sircam email worm (July 2001), which harvested files from the “My Documents” folder of windows operating systems (OSs), the CodeRed Internet worm (August 2001), and Nimda (September 2001), a Web email and network worm [126].
As the decade progressed, malware almost exclusively became a profit-motivated tool. Throughout 2002 and 2003, Web surfers were plagued by out-of-control popups and other Javascript bombs.7 FriendGreetings ushered in manually driven socially engineered worms in October 2002 and SoBig began surreptitiously installing spam proxies on victim computers [126]. Credit card frauds also took off during the period. Other notable threats included the Blaster and Slammer Internet worms.
In January 2004, an email worm war broke out between the authors of MyDoom, Bagle, and Netsky worms [126]. Ironically, this led to improved email scanning and higher adoption rates of email filtering, which eventually led to a near demise of mass-spreading email worms.
In November 2005, discovery and disclosure of the now infamous Sony rootkit led to the eventual inclusion of rootkits in the most modern day malware. Money mule and lottery scams grew rapidly in 2006. These kinds of attacks aim at novice users, typically through email, and invite them to follow hyperlinks that eventually prove harmful for the user machine. They do so by advertising potential winnings in lotteries and other claims for money-winning-related offers. Though not directly malware-related, such scams were a continuation of the theme of profit-motivated criminal activity launched via the Internet.
Website compromises escalated in 2007, in large part, due to the discovery and disclosure of MPack, a crimeware kit used to deliver exploits via the Web. An exploit is a piece of software, a chunk of data, or a sequence of commands that takes advantage of a bug or vulnerability in order to cause unintended or unanticipated behavior to occur on computer software, hardware, or something electronic (usually computerized). Such behavior frequently includes things like gaining control of a computer system, allowing privilege escalation, or a denial-of-service (DoS) attack. Notable compromises of this type included the Miami Dolphins website, Tomshardware.com, TheSun, MySpace, Bebo, Photobucket, and The India Times websites [126].
By the end of 2007, SQL injection attacks8 had begun to increase, netting victim sites, including world-famous company websites. In a 2012 study, security company Imperva observed that the average web application received four attack campaigns per month, and retailers received twice as many attacks as other industries. Following the evolution of malware, by January 2008, Web attackers were employing stolen FTP credentials and leveraging weak configurations to inject tens of thousands of pop style websites. In June 2008, the Asprox botnet facilitated automated SQL injection attacks, claiming famous commercial websites among its victims. A botnet9 is a number of Internet-connected computers communicating with other similar machines in an effort to complete repetitive tasks and objectives. This can be as mundane as keeping control of an Internet relay chat (IRC) channel, or it could be used to send spam email or participate in distributed DoS attacks.
Advanced persistent threats emerged during this same period as attackers began segregating victim computers and delivering custom configuration files to those of highest interest. In early 2009, Gumblar, the first dual botnet, emerged. Gumblar not only dropped a backdoor on infected PCs and used it to steal FTP credentials, it used those credentials to hide a backdoor on compromised websites as well. In a computer system (or cryptosystem or algorithm), a backdoor is a method of bypassing normal authentication, securing unauthorized remote access to a computer, obtaining access to plaintext, and so on, while attempting to remain undetected. The backdoor may take the form of a hidden part of a program, a separate program may subvert the system through a rootkit.10 This development was quickly adopted by other Web attackers. As a result, today’s website compromises no longer measure up to a handful of malicious domain hosts. Instead any of the thousands of compromised sites can interchangeably play the role of malware host.
The volume of malware is merely a byproduct of distribution and purpose. This can be best seen by tracking the number of known samples based on the era in which it occurred. For example, during the late 1980s, most malware were simple boot sector and file infectors spread via floppy disk. With limited distribution and less focused purpose, unique malware samples recorded in 1990 by AV-Test.org numbered just 9044. As computer network adoption and expansion continued through the first half of the 1990s, distribution of malware became easier and malware volume increased. In 1994, AV-Test.org reported 28,613 unique malware samples [149].
As technologies were standardized and their operational details became more specific and easy to obtain and study, certain types of malware were able to gain ground. Macroviruses not only achieved greater distribution by using the email service but they also gained a distribution boost as the email penetration increased in society (nowadays it is almost holistically adopted among connected users). In 1999, AV-Test.org recorded 98,428 unique malware samples [149].
As broadband Internet adoption increased, Internet worms became more viable. Distribution was further accelerated by increased use of the Web and the adoption of the so-called Web 2.0 technologies that fostered a more favorable malware environment. In 2005, AV-Test.org recorded 333,425 unique malware samples [149]. Increased awareness in Web-based exploit kits led to an explosion of Web-delivered malware throughout the later part of the millennium’s first decade. In 2006, the year MPack was discovered, AV-Test.org recorded 972,606 unique malware samples. As automated SQL injection and other forms of mass website compromises increased distribution capabilities in 2007, malware volume made its most dramatic jump, with 5,490,960 unique samples recorded by AV-Test.org in that year. Since 2007, the number of unique malware has sustained exponential growth, doubling or more each year. Currently, vendors’ estimates of new malware samples range from 30k to over 50k per day [149]. For comparison purposes, this scale is such that the current monthly volume of new malware samples is greater than the total volume of all malware before 2006 cumulatively.
Lately, following the proliferation of smart portable devices, e.g. smartphones, tablets, and handhelds, another emerging trend is observed regarding malware propagation. Malware has progressively moved to the wireless part of the infrastructures, where the main victims are plain users, with far less technical technological involvement than the average computer user, but the stakes are higher due to the current size of the wireless market and the sensitivity of the data now exchanged via smart handhelds. As will be presented in more detail in the next chapter, nowadays wireless malware propagation is a reality similar to the one presented above for the traditional (wired) broadband Internet.
This book will focus more on the malware dissemination over wireless complex network cases, presenting mathematical frameworks that allow the modeling of such malware spreading. Nevertheless, the presented approaches are possible to be easily adapted and extended in cases of other communications networks, as it will become more evident in the sequel. Before delving into such detail, in the next subsection, we present and explain the networking substrate considered.
1.3. Complex Networks and Network Science
In this section, we will introduce the notion of complex networks and Network Science research area, which cumulatively describe the network environments considered in this book. They describe not only the physical networks used for information exchange but also various mechanisms, functionalities, and emerging problems developing over these physical, or more abstract concepts of networks. From this perspective, the overall content of this book focusing on the propagation of malware over complex communications networks may be also considered as part of the Network Science and complex networks research fields. The following subsections set the stage for this purpose.
1.3.1. Complex Networks
In brief, and in order to facilitate the following discussion of complex networks toward Network Science, the “network” might be thought of as a set of entities (nodes) with a set of pairs from those entities denoted as links which interconnect pairs of nodes, representing some kind of interaction or association between them. In that sense, the network might be seen as an alternative term for the concept of graph [61,94] in mathematics. However, apart from the physical/systemic interpretation it has in, e.g. communications networks and power grids, it also refers to abstract notions of node-entities and their interactions, e.g. humans and their affiliations and diffusion of information. Thus, within complex network theory, the network is considered either as an abstract representation of potential entity interconnections, and/or a system of actual physical associations, depending on the application context.
The research and industrial interest for network functions and dynamics has increased substantially in the last decade [125,155]. Various forms of networked structures (systems) are nowadays omnipresent, e.g. public utility and communications, while many of them have been proven crucial in their operation. Computer and mobile networks have enabled pervasive communication across continents, in diverse conditions and situations of varying importance, e.g. search & rescue and monitoring. Other forms of abstract networks have been also developed, e.g. affiliations in the business world, researcher affiliations, and information distribution networks. In this sense, modern societies are nowadays characterized as connected, interconnected, and interdependent. They are connected due to the existence of interactions between various entities, interconnected since they can exchange various types of resources, most prominently information, and finally, they are interdependent in the sense that even though they act independently, they rely on their directly connected counterparts for sustaining their progress, e.g. connected open markets and unified smart grids.
A key observation for networks emerging across different disciplines is that the complexity of most interconnected systems forming networks is not in the behavior/operation of a single unit or larger component, but rather in the cumulative behavior/operation exhibited by their interconnection and exchange of information. Traditionally, the main research efforts were centered in the understanding and analysis of the behavior of individual entities (the nodes of the network), of the clusters they may form, or the interactions among them. However, lately, the interdependent behavior of such basic modules gains in interest and importance, and exploiting it yields progressively the desired level of control and flexibility over these networked structures.
A new term has been employed lately to refer cumulatively to all relevant newly observed and emerging behaviors, mechanisms, and dynamics regarding the network-oriented research in diverse disciplines, namely, complex networks[7,125,155,164].
The above definition does not explain the notion of a network, in general, but mainly asserts that complex networks exhibit cumulative behaviors that can be rather diverse and possibly different from each other, even within the same application context. For example, in social networks, different types of networks may form even when the network refers to the same set of social entities, e.g. the same group of people may yield a different network structure when the interactions refer to friendly affiliations or business associations. At the same time, networks emerging across different contexts can also exhibit unexpected similarities, e.g. malware propagation dynamics in wireless multihop networks resembling the virus propagation in animal species or humans.
The notion of network can be explained in its part via the generic network formation mechanism, which is observed in any type of application framework and diverse operation where network structures emerge.
Network formation: The main reason for the formation of any network observed in any aspect of nature or human society is an underlying tradeoff of gain versus cost of collaboration, either for each of the individual entities constituting the network or cumulatively for the whole network (Fig. 1.2).

FIGURE 1.2 Network formation tradeoff: cost versus benefit of collaboration. For the network tradeoff, the total cost and total gain, summed over all entities are considered.
The above “definition” exemplifies two aspects of network formation, in general, and complex networks, in particular. The first is some inherent type of collaboration, e.g. some common communication protocol, between pairs of network entities or among groups of entities forming in a network, even in the case where each of them unilaterally seeks to maximize its own benefit by acting selfishly, e.g. maximize the number of received/transmitted information in the previous case. The second aspect regards the dynamics of the network under formation. The evolution and mechanisms involved in such dynamics can be observed and quantified with measurable indicators in all types of emerging networks and within all application perspectives they appear through the identification of the corresponding underlying benefit-cost of collaboration tradeoffs. For instance, some indicators, such as the number of neighbors and their obtained utility, can be used/measured if properly defined and observed in the formation process. Thus, it should be emphasized that with every networking structure observed, regardless of whether it was spontaneously formed or artificially developed, there is one or more associated quantifiable benefit(s) (gain)-cost tradeoff(s) involving each of the network entities individually, or the whole network cumulatively.
The field of complex networks covers, in general, a very broad span of network types and their emerging features, developing problems and applied mechanisms of broader scientific interest. However, regarding the current information-based and network-dependent societies, two prominent features arise, namely, the diversity of emerging network structures first, and second, that networks consist of participating entities of varying intelligence and potentials.
Complex network analysis (CNA) [7,125,155,164] refers to the modeling and analysis of different networks and the behavior of the entities constituting such networks, with respect to their computational capabilities, properties, operations, etc. CNA is usually tightly combined with social network analysis (SNA). Examples of approaches combining CNA with SNA can be found in [201,202]. In CNA, a complex network represents as a generic model, diverse types of networks, thus providing a holistic framework for studying their properties, behaviors, etc., in a unified manner. In order to consider emerging variations, for instance, studying routing jointly over heterogeneous networks consisting of ad hoc and cellular components, a generic “complex” network type is assumed. The term “complex” in this occasion signifies the various and diverse properties exhibited by the different topologies, which need to be taken into account in the generic study of a process, i.e. packet routing in communication network, malware diffusion, and information pathways in cell networks. In the second case, the term “complex” refers to the actual nodes of a network, which can also vary in their application and scope, and characterizes the multiplicity/complexity of their features. More specifically, complex network nodes may vary in intelligence and processing capabilities. However, if nodes are capable of executing some type of computation, simple or more advanced, such as a numerical or algorithmic operation, then the cumulative behavior could exhibit various degrees of complexity and/or diversity, and thus, complex behavior may be observed in natural or engineered network cases.
From the above discussion, it becomes apparent that complex networks may be significantly different to each other. Thus, many possible classifications are possible with respect to different criteria. One of the most useful ones takes into account the origin of network formation and operation, namely, whether the network was formed spontaneously or artificially and whether its operation is dictated by natural or artificial factors as well. According to this parameter, complex networks may be characterized as natural, human-initiated, and artificial, as shown in Table 1.1 for various complex network examples. A more detailed analysis of various possible complex network classifications and features of the corresponding taxonomies can be found in [125] and references therein.
Table 1.1
Examples of Complex Network Classes Based on the Origin of their Formation
| Natural | Human-Initiated | Artificial |
| Biological | Social | Computer |
| Brain/cortex | Online social | Mobile |
| Genetic | Open markets | Sensor |
| Transcriptional | Corporate | Delay-tolerant |
| Immuno-suppressive | Production | Mesh |
| Neuron | GDP flow | Transportation |
| Ecologic | Scientific | Roadmap |
| Protein | Affiliation | Air-traffic |
| Food webs | Linguistic | Public utility |
| Virus/diseases | Malware | Artificial neural networks |
| Crystal structures | Newsfeeds | Electronic circuits |
Perhaps the most practical classification is the one considering the structural nature of networks, i.e. the interactions developed between the entities of a network and the properties/features of their interactions cumulatively. This structural classification of networks is based on the notions of connectivity, node degree, and degree distribution of the underlying graph, i.e. the graph corresponding to the structure of the network under discussion. A graph (network) is connected when there is a path between every pair of nodes [61,94]. The degree (or valency) of a node of a graph (network) is the number of links incident to the node, namely, the number of neighboring nodes incident to the specific node. In the study of graphs and networks, the degree distribution is the probability distribution of node degrees over the whole network. That is, the degree distribution  gives the probability that a node randomly chosen in the network has
gives the probability that a node randomly chosen in the network has 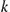 neighbors. Additional definitions on network structure and its properties are provided in Section 1.3.3. Table 1.2 contains such classification of complex networks (first column), as well as a nonexhaustive list of examples for each complex network type (second column). In this book, we will be especially concerned with all types of wireless complex networks in the first column of Table 1.2, at various capacities and with respect to the malware diffusion dynamics developing over them. In each case, the features of each wireless complex network will be explicitly mentioned and related to the corresponding malware diffusion processes and their properties.
neighbors. Additional definitions on network structure and its properties are provided in Section 1.3.3. Table 1.2 contains such classification of complex networks (first column), as well as a nonexhaustive list of examples for each complex network type (second column). In this book, we will be especially concerned with all types of wireless complex networks in the first column of Table 1.2, at various capacities and with respect to the malware diffusion dynamics developing over them. In each case, the features of each wireless complex network will be explicitly mentioned and related to the corresponding malware diffusion processes and their properties.
Table 1.2
Complex Network Classification Based on Topology Structure
| Complex Network Type | Main Features | Examples of Networks |
| Regular | Lattices, Grids | |
| Crystals | ||
| Optical ring networks | ||
| Uniform degree distribution | Cellular phones (hexagonal grid) | |
| Cloud infrastructures | ||
| Sensor | ||
| Random | Peer-to-peer | |
| Gas molecules (in equilibrium) | ||
| Normal degree distribution | Email viruses | |
| Online social networks | ||
| Immunization networks | ||
| Mesh | Sensor | |
| Delay-tolerant networks | ||
| Optical networks | ||
| Arbitrary degree distribution | Cognitive radio networks | |
| Zigbee/Bluetooth | ||
| LTE-Advanced (4G) | ||
| WiFi (802.11x networks) | ||
| Power-law | Metabolic | |
| Population of cities | ||
| Power-law degree distribution | Wordfrequencies | |
| Affiliation networks | ||
| Neurons (nerve cells) | ||
| Scale-free | (Mobile) Social networks | |
| WWW | ||
| Internet (AS/DNS routers) | ||
| Power-law degree distribution | Protein interaction networks | |
| Inter-bank payments | ||
| Airline connections | ||
| Multihop | Tactical networks | |
| TETRA | ||
| Packet radio networks (CSMA/CA) | ||
| Sensor | ||
| Arbitrary degree distribution | Vehicular | |
| Roadmaps (inter-city highways) | ||
| LTE-A (4G) networks | ||
| Cognitive radio networks |

It should be mentioned that some networks at large, e.g. sensor networks, belong to more than one class of complex network structure depending on the corresponding applications, e.g. some sensor nodes may have grid topologies, while others mesh or multihop layouts. More details on the structure and general features of the complex network types in Table 1.2, are given in [7,125,155,164] and their references.
The behavior of complex networks of any type cannot be currently predicted and/or controlled because the scientific basis for analyzing, building, and evaluating complex networks is yet immature [125,155]. Thus, getting a grip of the fundamental science of networks in terms of structure, dynamics, functionalities, and evolution is a topic of immense interest and significant value for the benefit and progress of human societies and activities, which has lately attracted the attention of the research community. Several books and monographs have been devoted to such topics from a general perspective, e.g. [7,125,155,164]. However, in this book, we shall focus on more targeted aspects, and specifically on the dissemination dynamics of malware over wireless complex networks. Furthermore, the methodologies presented in this book can be extrapolated to the broader topic of information diffusion in complex networks in general. In the next subsection, we briefly cover the current state of research in CNA, in order to set the methodologies presented in Part 2 into a more practical perspective and position them better in the corresponding roadmap for current and future network research.
1.3.2. Network Science
Nowadays there exists a cumulative effort to develop generic models for various types of network structures, irrespective of their application context and practical use. In many cases, it suffices to accurately identify the type of a complex network, then identify its features, and finally, employ more general methodologies developed to solve easier several network-related problems. However, as in all other scientific fields, for complex networks too, it is desired to develop a broader framework, where it will be possible to combine theory with application and create a strong bond between modeling and practice. The term “Network Science” has been used to denote this broader and more ambitious effort for a proper scientific field devoted solely to the study, analysis, and applications of networks, wherever and whenever they emerge [125,155].
Network systems are meant in the sense of a set of entities and their pairwise interconnections (network graph). The above definition segregates explicitly the scientific from the technological part of network study. Graph theory, probability, differential equations, stochastic, and other forms of optimization are only some of the formal scientific methods implied in the above definitions for CNA.
Taking as an example information networks, the components of modern communication and information networks are the results of technologies, which are based on fundamental knowledge emanating from physics, mathematics, and circuits and systems in various capacities. Especially for communications networks, several advances and novelties have enabled the design of modules critical for their operation/performance. However, the assembly of all such novelties into the development of networks is based extensively on empirical knowledge rather than on a deep understanding of the principles of network behaviors underlying the science of networks. For example, regarding the emergence of the protocol layering concept and the infamous TCP/IP stack used extensively in modern networks [55,148,208], the technology was first developed within the industry and it is only lately that it was possible to consider the whole of the protocol stack across layers through a uniform mathematical methodology (network utility maximization—NUM), and thus, essentially reverse engineer the whole stack [49].
Considering the field from a holistic perspective, it seems that practitioners in each major application area of Network Science have their own local nomenclatures to describe network models of the phenomena in which they are interested and their own notions of the content of Network Science. For example, spatially distributed networks, e.g. wireless sensor networks and street map networks, emerge both in communications networks and highway traffic engineering (multihop and roadmap networks, respectively). Scale-free (SF) networks emerge frequently in biology and the Internet. However, different terms have been traditionally employed for the same concepts and varying mechanisms/computational tools have been employed to solve the same problems. Consequently, Network Science is emerging as a cross-disciplinary network investigation, aspiring to reach the maturity level of other advanced scientific fields, such as fluid mechanics.
Until today, there is no complete theory offering the required fundamental knowledge for analyzing, designing, and controlling large (or any scale) complex networks. Network Science is currently lively evolving, yet there is still restricted concrete understanding of its potential long-term outcomes. However, as with so many other scientific disciplines in the past, such as medicine, where applications based on empirical knowledge were massively prevailing before the corresponding knowledge established, it is expected that this will be the case with Network Science. In fact, with all the aforementioned fields, it was their formal shaping that helped in better understanding the underlying phenomena and achieve more progress. This is also anticipated with Network Science. The fragmentation in Network Science is evident at large in that not all the involved disciplines scale at the same order, namely, some are progressing well, e.g. communications networks, while others at a much slower pace, e.g. financial networks. Network Science aspires to become a cross-disciplinary study of network representations of physical, logical, and social interactions, leading to predictive models of these phenomena and relations. This book will contribute toward this direction, by attempting a cross-disciplinary transfer of knowledge on malware diffusion modeling (and more generally of information dissemination modeling) from computer networks and more specifically wireless complex ones, to more general complex networks.
The communities from which Network Science is expected to emerge encompass many different and diverse disciplines of research or application areas. Among others, a characteristic example is the field of biology, which provides the most diverse observations of complex network structures of arbitrary order and capabilities, all of them working usually in conjunction to the rest and efficiently on their part. Computer networks have employed substantial mathematical tools for their analysis and development and could provide solid background for quantitative methods for many other disciplines in Network Science and complex networks. In fact, the first studies on computer viruses were inspired from epidemiological models developed by biologists or social scientists. Other disciplines expected to contribute in the development of Network Science include mathematics and physics, statistics, sociology, etc. This book will adopt a Network Science based approach and attempt to expand it within the field of information dissemination, thus, paving the way for similar attempts in other application frameworks.
1.3.3. Network Graphs Primer
A complex network is typically represented and analyzed through the mathematical notion of a graph. Thus, in this subsection, we provide a short primer on the involved notation, functions, and properties of the network graphs of interest.
A graph is an ordered pair  where
where  is the set of vertices (nodes) with cardinality
is the set of vertices (nodes) with cardinality  and
and  is the set of edges (links) with cardinality
is the set of edges (links) with cardinality  . The edges of a graph are two element subsets of . An edge between two vertices
. The edges of a graph are two element subsets of . An edge between two vertices  ,
,  is typically represented with
is typically represented with  (ordered or unordered for directed/undirected graphs, respectively). The neighborhood of a node
(ordered or unordered for directed/undirected graphs, respectively). The neighborhood of a node  , denoted by
, denoted by  , is the set of all nodes of
, is the set of all nodes of 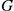 adjacent to
adjacent to  . The degree of a node ,
. The degree of a node ,  in an undirected graph is the number of edges having as one of their endpoints the vertex . In directed graphs, each vertex is characterized by two degrees, the in-degree
in an undirected graph is the number of edges having as one of their endpoints the vertex . In directed graphs, each vertex is characterized by two degrees, the in-degree  which counts all edges pointing to node and the out-degree
which counts all edges pointing to node and the out-degree  counting all vertices starting from node . The degree distribution
counting all vertices starting from node . The degree distribution  provides the probability that node has degree , namely, direct neighbors. In both the directed and the undirected cases, we denote by
provides the probability that node has degree , namely, direct neighbors. In both the directed and the undirected cases, we denote by  the adjacency matrix , where
the adjacency matrix , where  if there is a link from to , otherwise
if there is a link from to , otherwise  . Based on this matrix representation, spectral graph theory has emerged [53], offering several convenient computations and interpretations of graphs. A clique in an undirected graph is a subset of its vertices such that every two vertices in the subset are connected by an edge.
. Based on this matrix representation, spectral graph theory has emerged [53], offering several convenient computations and interpretations of graphs. A clique in an undirected graph is a subset of its vertices such that every two vertices in the subset are connected by an edge.
A graph (directed or undirected) is weighted, if a measurable quantity (referred to as weight and usually denoted by  ) is assigned to each edge:
) is assigned to each edge:  [19,24,169]. Similarly with the adjacency matrix, the weight matrix
[19,24,169]. Similarly with the adjacency matrix, the weight matrix  can be defined, where
can be defined, where  is the weight of the link . A joint metric of both node degree and adjacent link weights might be defined, denoted by strength of each node (or the in-strength
is the weight of the link . A joint metric of both node degree and adjacent link weights might be defined, denoted by strength of each node (or the in-strength  and the out-strength
and the out-strength  correspondingly for digraphs). Node strength expresses the total amount of weight that reaches or leaves node correspondingly [213]. Thus,
correspondingly for digraphs). Node strength expresses the total amount of weight that reaches or leaves node correspondingly [213]. Thus,  and
and  . In the case of undirected graph-network, if
. In the case of undirected graph-network, if  is the strength of node ,
is the strength of node ,  .
.
Connectivity is a fundamental notion in graphs and networks [144]. The connectivity  of a graph is the minimum number of nodes whose removal results in a disconnected or trivial graph. Two nodes are said to be connected whenever it is possible to find a sequence of edges belonging to the graph (path) from one node to another. Then, the average path length of a graph is a connectivity indicative metric [78,144]. The clustering coefficient is an important metric for complex networks [171,192], used to characterize the structure of a social network both locally, i.e. at the node level, and globally, i.e. at the network level. It computes the cliquishness of the network and more details on computing it can be found in [69,125,171]. In various network types, it has been required/desired to characterize the importance of network nodes. Centrality has been conceived as an evaluation metric for characterizing such aspect of networks [76,77,170]. Typically, the focus on the importance of nodes or connection links, but other features of the graph structure under consideration may also be considered. Such metric is, in principle, subjective, depending on numerous aspects of a network, such as the structure, the network objectives, network operation, and even other more context-oriented factors characterizing a network [75,77,150,181]. For these reasons, various centrality definitions have been established and employed in social and complex communication networks [150]. More detailed definitions of the above notions, computational methods, as well as other quantities and properties of graphs can be found in dedicated works [61,94].
of a graph is the minimum number of nodes whose removal results in a disconnected or trivial graph. Two nodes are said to be connected whenever it is possible to find a sequence of edges belonging to the graph (path) from one node to another. Then, the average path length of a graph is a connectivity indicative metric [78,144]. The clustering coefficient is an important metric for complex networks [171,192], used to characterize the structure of a social network both locally, i.e. at the node level, and globally, i.e. at the network level. It computes the cliquishness of the network and more details on computing it can be found in [69,125,171]. In various network types, it has been required/desired to characterize the importance of network nodes. Centrality has been conceived as an evaluation metric for characterizing such aspect of networks [76,77,170]. Typically, the focus on the importance of nodes or connection links, but other features of the graph structure under consideration may also be considered. Such metric is, in principle, subjective, depending on numerous aspects of a network, such as the structure, the network objectives, network operation, and even other more context-oriented factors characterizing a network [75,77,150,181]. For these reasons, various centrality definitions have been established and employed in social and complex communication networks [150]. More detailed definitions of the above notions, computational methods, as well as other quantities and properties of graphs can be found in dedicated works [61,94].
The structure of a network is represented by the corresponding network graph, the structure of which is determined in turn by the connections of each node, namely, by the node degree. Thus, the total degree distribution of the network that provides the probability for each node to have neighbors distinguishes different network structures. This was used in the classification of Table 1.2 (first and second columns). In the remaining of this chapter, we briefly overview the topologies of interest included in Table 1.2 and their properties.
A  -regular graph is an undirected graph where each node has the same degree equal to . A complete graph on
-regular graph is an undirected graph where each node has the same degree equal to . A complete graph on  vertices, denoted by
vertices, denoted by  , is an undirected graph where all vertices are connected with all other vertices and thus is a (
, is an undirected graph where all vertices are connected with all other vertices and thus is a ( )-regular graph. Regular networks emerge oftentimes in nature and occasionally in engineered applications as well, such as communications and power networks [23].
)-regular graph. Regular networks emerge oftentimes in nature and occasionally in engineered applications as well, such as communications and power networks [23].
In mathematics, a random graph is the general term to refer to probability distributions over graphs. Random graphs may be described simply by a probability distribution, or by a random process which generates them [67]. In general, one encounters two basic and closely related models of random graphs in the literature [34]. The probability space in each case consists of graphs on a fixed set of distinguishable vertices  . If
. If  , then for
, then for  , the space
, the space  consists of all
consists of all  subgraphs of with
subgraphs of with  edges. Thus, the model describes graphs which could be obtained by the subspace of that contains only graphs with edges. All elements (graphs) of this space are assumed equiprobable, and due to the assignment of a probability measure to its elements, the space becomes a probability space. It is customary to write
edges. Thus, the model describes graphs which could be obtained by the subspace of that contains only graphs with edges. All elements (graphs) of this space are assumed equiprobable, and due to the assignment of a probability measure to its elements, the space becomes a probability space. It is customary to write  for a random graph in the space . The probability that
for a random graph in the space . The probability that  is precisely a fixed graph
is precisely a fixed graph  on
on  with edges is
with edges is 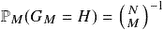 . The space
. The space  (
( ) is defined for probability
) is defined for probability  . A random element of this space corresponds to selecting edges independently with probability
. A random element of this space corresponds to selecting edges independently with probability  , for all possible existing edges in a graph of nodes. This means again that the potential probability space includes all possible subgraphs of the space of graphs. In this case however, only those corresponding to a selection process where each edge is selected with probability are selected. Similarly to the model, the probability of a fixed graph on with
, for all possible existing edges in a graph of nodes. This means again that the potential probability space includes all possible subgraphs of the space of graphs. In this case however, only those corresponding to a selection process where each edge is selected with probability are selected. Similarly to the model, the probability of a fixed graph on with  edges is
edges is  , where each of the edges of has to be selected, and none of the
, where each of the edges of has to be selected, and none of the  is allowed to be selected.
is allowed to be selected.
A small-world (SW) network is a type of mathematical graph in which most nodes are not neighbors of one another, but most nodes can be reached from every other by a small number of hops or steps [147,224]. Formally, a SW network is defined as a network where the typical distance  between two randomly chosen nodes grows proportionally to the logarithm of the number of nodes
between two randomly chosen nodes grows proportionally to the logarithm of the number of nodes  in the network, i.e.
in the network, i.e.  [125,164,225]. Practically, this means that nodes of the networks are linked by a small number of local neighbors; however, the average distance between nodes remains small. The most popular model of SW networks is the Watts-Strogatz (WS) model, which is a constructive process for obtaining SW and some other types of random graphs, beginning with a regular lattice. The WS model starts from a clustered structure (regular lattice) and adds random edges connecting nodes that are otherwise far apart in terms of hop distance [141]. These random “long” edges will be denoted as “shortcuts” in this book. The initial clustered structure ensures high clustering coefficient for the final network, while a suitable number of added shortcuts can further reduce the average path length, up to a sufficient level, so that the created graph may be characterized as SW. One significant question is whether various types of networks can be turned into SW via some evolutionary process. Some considerations of this issue have been presented in [45,51,65,202].
[125,164,225]. Practically, this means that nodes of the networks are linked by a small number of local neighbors; however, the average distance between nodes remains small. The most popular model of SW networks is the Watts-Strogatz (WS) model, which is a constructive process for obtaining SW and some other types of random graphs, beginning with a regular lattice. The WS model starts from a clustered structure (regular lattice) and adds random edges connecting nodes that are otherwise far apart in terms of hop distance [141]. These random “long” edges will be denoted as “shortcuts” in this book. The initial clustered structure ensures high clustering coefficient for the final network, while a suitable number of added shortcuts can further reduce the average path length, up to a sufficient level, so that the created graph may be characterized as SW. One significant question is whether various types of networks can be turned into SW via some evolutionary process. Some considerations of this issue have been presented in [45,51,65,202].
A scale-free network is a network whose degree distribution follows a power-law, at least asymptotically. Formally, the fraction of nodes in the network having connections to other nodes follows for large values of :  , where
, where  is a parameter whose value is typically in the range
is a parameter whose value is typically in the range  , although occasionally it may lie outside these bounds [1,15,16]. In SF networks, different node groups exhibit differences in scaling of their node degree, interpreted as scale difference in connectivity and neighborhood relations. The highest-degree nodes are often called “hubs,” and typically they serve specific purposes in their networks. SF networks exhibit two key features. The first one is “growth” [20,21,62,222]. The way a network evolves indicates that new nodes tend to link to existing ones. The second is what is most popularly known as preferential attachment[1,15]. The fact that when nodes form new connections, they tend to connect to other nodes with probability proportional to the popularity of the existing one. Since not all nodes are equally popular, some of them are more desirable than others.
, although occasionally it may lie outside these bounds [1,15,16]. In SF networks, different node groups exhibit differences in scaling of their node degree, interpreted as scale difference in connectivity and neighborhood relations. The highest-degree nodes are often called “hubs,” and typically they serve specific purposes in their networks. SF networks exhibit two key features. The first one is “growth” [20,21,62,222]. The way a network evolves indicates that new nodes tend to link to existing ones. The second is what is most popularly known as preferential attachment[1,15]. The fact that when nodes form new connections, they tend to connect to other nodes with probability proportional to the popularity of the existing one. Since not all nodes are equally popular, some of them are more desirable than others.
The SF property strongly correlates with the network’s robustness to failure. If failures occur at random and the vast majority of nodes are those with small degree, the likelihood that a hub would be affected is almost negligible. Even if a hub-failure occurs, the network will generally not lose its connectedness, due to the remaining hubs. On the other hand, if one chooses a few major hubs and take them out of the network, the network is turned into a set of rather isolated graphs. Thus, hubs are both a strength and a weakness of SF networks. Another important characteristic of SF networks is the clustering coefficient distribution, which decreases as the node degree increases. This distribution also follows a power-law. This implies that the low-degree nodes belong to very dense subgraphs and those subgraphs are connected to each other through hubs. A final characteristic concerns the average distance between two vertices in a network. As with most disordered networks, such as the SW network model, this distance is very small relative to a highly ordered network such as a lattice graph. Notably, an uncorrelated power-law graph having will have ultrasmall diameter  where is the number of nodes in the network, while the diameter of a growing SF network might be considered almost constant in practice.
where is the number of nodes in the network, while the diameter of a growing SF network might be considered almost constant in practice.
We should note that a SF network mentioned in Table 1.2 is essentially a network whose node degree distribution follows a power-law, at least asymptotically. Thus, for the rest of this book, we will employ the term “power-law” to denote networks following explicitly a power-law degree distribution and “scale-free” to denote those that follow power-law degree distribution asymptotically only.
Finally, a random geometric graph (RGG) is the simplest spatial network, namely, an undirected graph constructed by randomly placing nodes in some topological space (according to a specified probability distribution) and connecting two nodes by a link if their distance (according to some metric) is in a given range, e.g. smaller than a certain neighborhood radius,  [180]. It is customarily employed to model distributed multihop networks, e.g. ad hoc, sensor, mesh, and others.
[180]. It is customarily employed to model distributed multihop networks, e.g. ad hoc, sensor, mesh, and others.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.