
Chapter 7: Feature-First Development
So far in this book, we've learned all about analyzing and modeling requirements, turning them into executable specifications, that is, features, and organizing our specifications into a system backlog. This chapter is about the next step: turning our specifications into working, delivered software. We will see how to integrate our features within the two most popular Agile approaches to software development, the Scrum framework, and the Kanban method. We will learn how to create and manage a task board and how to use it as a springboard to deliver the software we have specified in our features, while effectively dealing with change. Specifically, we will learn about the following topics:
- Setting up for successful delivery
- Effecting just-in-time development
- Working with Scrum
- Working within Kanban
By the end of the chapter, you will know how to leverage accurate, durable, and well-scoped features – that you will know how to create – as the basis for the controlled and phased delivery of working software. Let's begin with the pre-requisites.
Setting up for successful delivery
Before we can embark on our development effort, we need to have in place the necessary infrastructure that will help us successfully deliver our system's capabilities.
Creating a staging environment
Software teams tend to use different environments under which they work at different stages of the development life cycle. An environment consists of the hardware, software, and configuration needed to develop and deploy our system. The development team usually works under a development environment, which includes the various tools and configurations needed for software development. When the system is about to be deployed, these tools are no longer required, so the system is deployed to other environments that are much more restricted, so as to emulate the target deployment environment more realistically.
In the context of the methodology presented in this book, we will need a dedicated environment on which to verify our delivered system against the specifications, that is, a staging environment.A staging environment is an almost exact replica of the production environment where our system will be deployed and used. It requires a copy of the same configurations of hardware, servers, databases, and caches as the production environment. The only difference between the staging and production environments is the data they contain. Real customer data must not be exposed on the staging environment, for privacy and compliance reasons, if nothing else. Instead, we copy customer data with all sensitive or personal data changed or otherwise obfuscated. We can then use this data to verify our system's behavior, without exposing sensitive information. Once we have somewhere to host and test our code, we need to be able to manage its development.
Creating a task board
A task board is where we track the progress of our features' development. Task boards are sometimes referred to as Scrum boards or Kanban boards (depending on whether they're being used under the Scrum or Kanban approaches), but the concept is the same—a list of columns representing the different stages of the development life cycle for our deliverable items. Items on a task board are usually represented as cards. Each card has a title, description, and other metadata, and can be colored and labeled in different ways.
Task boards are not strictly defined. Some have fewer columns than others. Some have differently named columns. It all comes down to what is important to the team and organization using them. What they all have in common, however, is that they allow us to visualize our workflow, to know how our team is doing and to get a feel for the direction our development is heading.
In this book, we shall be using the following six-column task board:
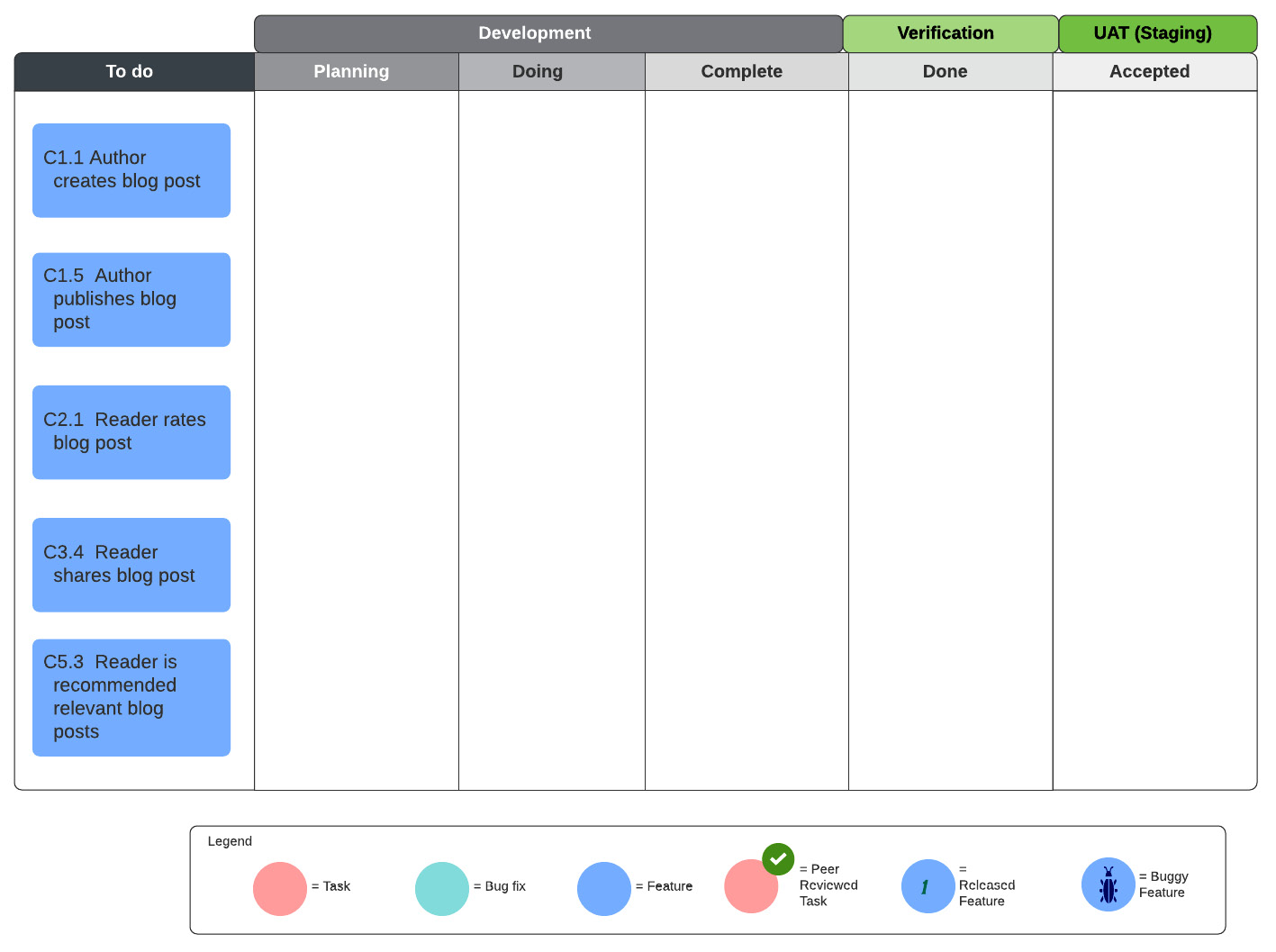
Fig. 7.1 – A task board with six columns
Let's examine its columns more closely:
- To do: This is the feeder column for our development cycle. This where we put the features that we select for current development from our backlog. The number of features we can put in here depends on the agile framework or methodology we are applying, as we shall see in the following sections. Only fully-formed features, that is, the features with a complete set of scenarios for our scope, can reside in this column.
- Planning: This is where we put the features we have started working on. When we put a feature in this column, we start analyzing it and producing a number of tasks necessary to implement the feature. Those tasks will be added to the Planning column too.
- Doing: Any tasks or bugs we started working on are moved into this column. They stay here until they are complete.
- Complete: When a developer working on a task or bug deems it to be complete then they move it to this column. Any card in this column will be subject to code reviews by the rest of the development team. This will also usually include checking that any unit tests for this card are passing.
- Done: When a task or bug has been reviewed and checked, then it's time to move it to the Done column. When all tasks or bugs related to a feature have been moved to this column, then that means that the feature is ready for verification. We can now run our automated step definitions using Cucumber, JBehave, Jasmine, among others. They will hopefully tell us that our feature is behaving as expected, that is, it is done.
- Accepted: After our feature is done, we deploy it to the staging environment, and we invite the relevant actors and other stakeholders to use it. Once they are all happy with the feature, we move it to the Accepted column.
Now that we know how to use our task board, let's look at one more thing we need to do before we start our system development.
Defining done
The ultimate aim of a development cycle is to implement the features in our backlog. This raises the question, How can we tell if a feature is done? Is it when the development team tells us that it's done? Is it when the testing team tells us so? Can we apply some criteria to it?
These are questions that have plagued many a development team throughout the years. This has led some Agile frameworks and methodologies to emphasize the importance of defining done. This is what the Scrum Guide (https://www.scrum.org/resources/scrum-guide) has to say on the matter:
Since, following the methodology in this book, we are leveraging BDD and writing our features as executable specifications, we already have a clear and concise definition of done:
In Chapter 3, Writing Fantastic Features with the Gherkin Language in the Features are Executable Specifications section, we talked about creating step definitions. This is the code that verifies each step in our scenarios against a delivered system. This is where step definitions come into their own. By using a BDD-aware tool, such as Cucumber, JBehave, Jasmine, and others, we can automatically verify whether our system behaves the way we said it would. It's an easy and objective way of knowing whether a feature is "done" or not. Auto-verification using Cucumber and similar tools can be done by anyone and produces legible, formatted output that can be read by anyone. Most of these tools can produce HTML reports, which can then be hosted on a website.
But even if you didn't get to write step definitions for your executable specifications, do not despair. All it takes is for someone to use the system while looking at the features (which are also contained in the specifications document). They can then manually verify whether a feature works or not.
Once we have all the pre-requisites in place, we can start our development process. But before we jump into that, let's take a quick look at the drive and motivation behind what we're about to do.
Actualizing just-in-time development
When people are first introduced to a feature-only backlog, they tend to ask questions like, But what about research tasks or spikes (product testing tasks in order to explore alternative solutions)?, What about generic tasks like applying style sheets?, or We need a separate task for setting up a Continuous Integration pipeline. The response to all these concerns is always the same:
As discussed in Chapter 3, Writing Fantastic Features with the Gherkin Language, features can reflect both functional and non-functional aspects of a functionality. So, that research you want to do into different indexing engines is almost certainly tied to a search-related feature somewhere in your backlog. If you start working on this task, it means you start working on that feature and that feature should be in the To do column. Those stylesheets you want to apply across the website help to implement a specific feature. If you don't have any features for these tasks, then now's the time to create some. The same goes for that Continuous Integration and Continuous Delivery (CI/CD) pipeline you want to set up. Having a CI/CD pipeline is extremely useful in an agile development life cycle. It is also a task that will be important to most of the features in your backlog. As explained in the upcoming Sprint development cycle section, generic tasks like this one apply to many features and can be denoted as such. You just need to know the feature in the To do column that's going to be the first to benefit from this task. As stated, no task lives in a bubble.
This feature-first approach contributes to a generic paradigm that I call Just-in-Time (JIT) development. JIT development helps focus the software production line on the most important things first. It helps deliver the software that is needed when it is needed. Often in agile development, the traditional product backlog will carry a large number of diverse and widely scoped tasks or user stories. This makes the backlog difficult to manage, prioritize, and plan for. By eliminating tasks that do not need to be in the backlog, we effectively eliminate waste, we increase our planning and delivery efficacy, and we help focus our team and our stakeholders on the ultimate prize: helping our stakeholders achieve their goals by delivering needed capabilities, implemented through features.
A feature-first approach fits in perfectly with the agile and lean philosophies of reducing waste and embracing simplicity. In the next two sections, we'll see how we can apply it within the scope of the two most popular agile approaches, Scrum and Kanban.
Working with Scrum
Scrum is the most popular agile approach. Scrum is a process framework that is fully centered around iterative and incremental delivery. A delivery iteration in Scrum is called a Sprint and it lasts between 2-4 weeks.
The Scrum framework consists of three components:
- The Scrum team: A self-organizing, cross-functional set of people who will deliver the working software. The team consists of the product owner, the Scrum master, and the development team.
- Scrum events: A number of time-boxed events that help create regularity, promote and provide feedback, foster self-adjustment, and promote an iterative and incremental life cycle. These events include Sprint Planning, Daily Scrum, Sprint Review, and Sprint Retrospective.
- Scrum artifacts: Items that represent work or added value and that provide transparency for the team's work progress and achievements. The Scrum artifacts are the product backlog, the Sprint backlog, and the increment, which is the software that needs to be delivered for the Sprint.
Scrum does not prescribe any development methodologies or task management processes. How to design and develop our code and how to manage our tasks is left up to us. There are certain practices that most Scrum teams use, like test-driven development or story-point estimating, but these are not mandated by the Scrum framework. We will see how our requirements management methodology output fits within Scrum in the subsequent sections.
Sprint planning
The Sprint planning event signals the start of a new Sprint. The development team, in conjunction with the product owner, select which features to move from the backlog into the To do column of the task board. This doesn't happen randomly. There are a number of rules for how and which features are moved into the To do list:
- Priority: Features are selected according to their priority, which is decided by the product owner. They are also selected so that they satisfy a theme or goal for that Sprint. This could be something like Enable blog sharing on social media or Recommend relevant content to blog reader. This is where our requirements model really comes in handy. We have already derived our features from capabilities. A capability can easily serve as a Sprint theme. This makes it easy to select features, as we already know which features we need to deliver a capability for. In addition, capabilities are directly related to goals, so our product owner can use that to help set the Sprint goal. All the analytical work we did in creating our requirements model is now paying dividends for our development process too.
- Load Capacity: The number of features moved to the To do column is limited by the development's team constraint of how much work they can handle in a Sprint. This is usually measured by a metric called velocity. Velocity is a measure of the amount of work a team can tackle during a single Sprint. Velocity is determined and refined after the completion of many Sprints. As part of the Sprint planning event, the development team will have to estimate the effort involved in implementing a feature and decide whether they can take it on as part of the upcoming Sprint.
- Fully-formedness: Only features with full contextual information and detailed scenarios (as described in Chapter 3, Writing Fantastic Features with the Gherkin Language, in the Writing a fully-formed feature section), can be moved to the To do column.
- UI guidelines: Many, if not most, of our features will involve direct interaction with an actor through a UI. There are many ways in which the functionality implemented in a feature can be invoked by and presented to an actor. This is why it is very important that such features are accompanied by screen mock-ups or wireframes that allow us to aim for specific UI layout and styling.
Important note:
The To do column of the task board is usually referred to as the Sprint backlog when using Scrum.
Sprint development cycle
The aim of a Sprint is to move all features from the To do column to the Accepted column within the Sprint's duration. During the Sprint, the development team will examine the features in the To do column and will come up with a set of tasks required to implement these features. These tasks are placed in the Planning column. Tasks associated with a feature are referenced with that feature's identifier. Some tasks will be associated with more than one feature. Multiple feature identifiers should then be used.
Tip:
Some tasks will be universal, that is, they will be required by all our features. Usually, these tasks are things like setting up a database, a cloud-server instance, or some other generic or infrastructure task. It's good practice to use a generic identifier for these tasks (I personally prefer the asterisk (*) symbol) so that these tasks can be given due attention and priority.
When developers start actively working on a task, they move it to the Doing column. When the task is complete, that is, the developer is assured the task is finished, the task is moved to the Complete column. The task is then peer-reviewed. If the peer review outcome is that modification is needed to the task, then it is moved back to the Planning or Doing columns (dependent on the level of modification required).
Tasks that are reviewed successfully are labeled as checked and remain in the Complete column until all the tasks required by a particular feature are Complete. We then verify that feature by executing its specification, that is, its feature file, with a BDD tool such as Cucumber, JBehave, and so on. Alternatively, we can verify the feature manually, simply by running our feature code and checking that it does what it says in our specification.
If the feature is verified it is then moved to the Done column. Once in the Done column, it is the development team's responsibility to ensure the feature is deployed to the staging area where our stakeholders can use it and give us their feedback. Since our feature has been already verified against the specification, and the specification has been agreed with the stakeholders, the feedback we should be getting at that stage should be limited to minor usability issues. In most cases, the stakeholder should be happy with the feature, in which case we move it into the Accepted column.
If the feature is not verified, that is, our Cucumber run fails, then we need to determine the cause of failure. The feature will stay in the To do column and we may add new tasks to the Planning column in order to address the cause of the verification failure.
If the feature is verified but the stakeholder refuses to accept it, there are three probable causes:
- Some system behavior doesn't match the stakeholder's expectation. This should be a rare occurrence. It means our specification is wrong. We have probably violated some basic principles or applied some anti-patterns (very likely the Vague Outcomes one) when writing our feature. We need to go back to our specification and fix it. The feature will go back to the To do column.
- There is some usability issue. This is the most common cause of non-acceptance. Our specification is basically accurate, but we may need to enhance or expand it. If the issue is simply UI-related, for example, layout or styling, then we leave our feature in the Done column and we create a new task under Planning in order to fix the issue. If the issue is one of usability affecting behavior, for example, non-accessible color schemes, or a lack of keyboard shortcuts, then we put the feature back in the To do column and we change the specification to include the desired behavior.
- There is a bug in our system. Our specification is accurate but there may be a bad code line or a badly designed component that causes our system to behave inconsistently under certain circumstances. We leave our feature in the Done column and we create a new task under Planning in order to fix the bug.
The workflow algorithm described in this section can be illustrated by the following flowchart:

Fig. 7.2 – Sprint development workflow
The preceding diagram is just a visual representation of everything mentioned so far in this section.
Our task board during the Sprint development will look something like this:
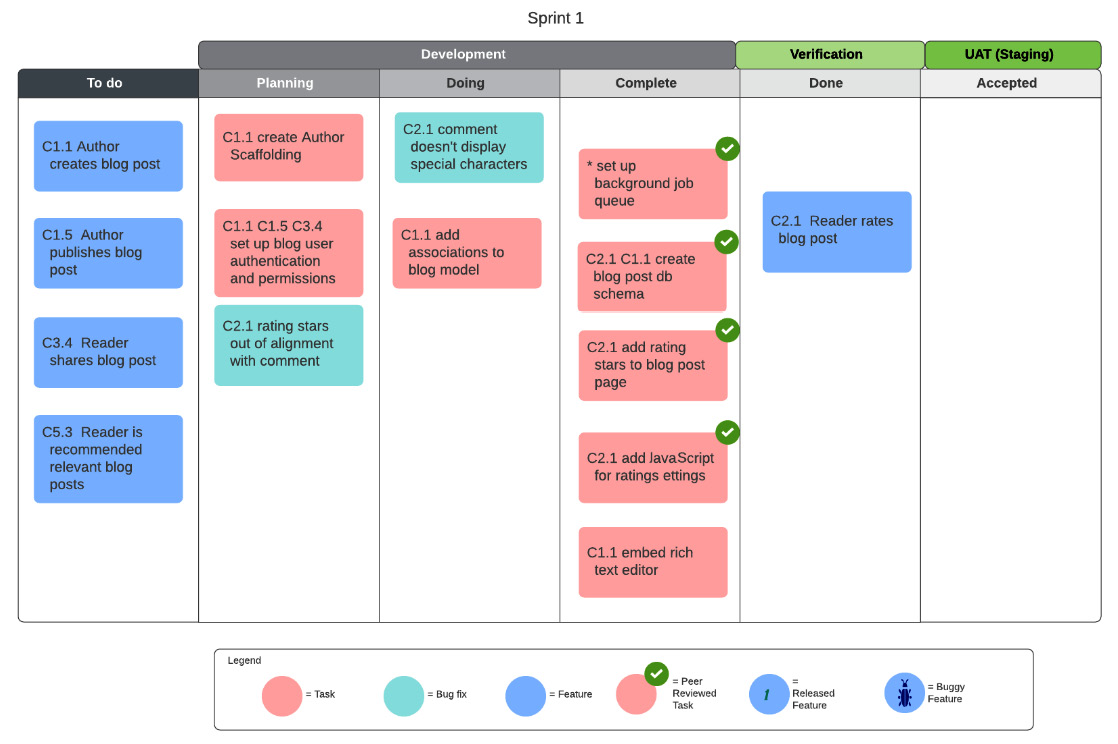
Fig. 7.3 – Task board during Sprint development
As you can see, features reside in the To do column and they are moved to the Done and Accepted columns as necessary. The development-type columns (Planning, Doing, Complete) are for development-related items only, such as tasks and bug fixes. This provides a clear and useful separation between the items incidental to development and items critical to the project and stakeholders, that is, the features.
End of Sprint
At the end of the Sprint period, our Sprint will be in one of two states.
Completed Sprint
In a completed Sprint, all features are in the Accepted column and all tasks/bugs are in the Complete column, as depicted in the following diagram:

Fig. 7.4 – Task board for a completed Sprint
This means that our Sprint has been successful. We can now reset the board, as follows:
- We remove items from the Complete column. Some people prefer to add an Archived column on their task board, into which they place all completed tasks and bugs. Many tools, like Trello, offer a built-in archiving functionality.
- We mark the features in the Accepted column with the Sprint number and move them back to our system backlog. The Sprint number is effectively a release number for our feature and helps us track when a feature has been delivered, as well as its context (the Sprint goal).
At the end of a completed Sprint, our task board should be empty again, waiting for the next Sprint.
Incomplete Sprint
If at the end of the Sprint, there is at least one feature in the To do or Done columns, as illustrated in the following board, then the Sprint is incomplete:

Fig. 7.5 – Task board for an incomplete Sprint
In this case, we do the following:
- Archive all cards in the Complete column.
- Mark the features in the Accepted column with the Sprint number and move them back to our system backlog.
- Move cards from the Doing column back to the To do column.
In our preceding example board, that would mean that after tidying up, our board would have three cards in the To do column: the C2.1 feature, task, and bug. Any features not completed in a Sprint are almost always scheduled for the next Sprint. This is reflected in our board management process.
Tip:
In the unlikely event that the product owner decides an unfinished feature will not be in the next Sprint, move the feature back in the backlog and mark the related tasks/bugs as "Dropped" before archiving them. That way, you'll be able to easily retrieve them in the future, if needed.
Next, let's see what happens when things change unexpectedly during our development cycle.
Dealing with change
One of the constant risks in every line of work is dealing with change. We can't control the way things change but we can be prepared and be adaptable to anything new coming our way. Scrum tries to control change by discouraging changes that distract from the Sprint goal or theme. Once the development team commits to a Sprint, then it should try to reach the Sprint goal, or – if it realizes it can't – it should abort the Sprint.
What that means with respect to the methodology presented in this book is that once all features in the To do column, that is, the Sprint backlog, have been agreed upon, then no new features should be added during the Sprint. We can, though, add new tasks mid-Sprint if that's when we realize that we need them in order to implement a feature that's currently in the Sprint To do column.
Inevitably in our development life cycle, we will get a number of Change Requests (CRs) from our client-facing stakeholders. CRs usually tend to cover three types of changes:
- Emergent bugs, that is, bugs discovered after a code release.
- Behavioral changes, when already agreed, accepted, and delivered features need to be modified.
- New behaviors, that is, new requirements.
Dealing with new requirements is something we've been addressing a lot in this book. You should know the drill by now:
- Analyze and map the requirements, as described in Chapter 4, Crafting Features Using Principles and Patterns, in the Discovering requirements section.
- Model the requirements, as detailed in Chapter 2, Impact Mapping and Behavior-Driven Development.
- Describe the new features, as explained in Chapter 3, Writing Fantastic Features with the Gherkin Language, and Chapter 4, Crafting Features Using Principles and Patterns.
- Finally, just add the new features to the system backlog.
For the rest of this section, we'll deal with the other two types of change.
Emergent bugs
So far, we have seen how to deal with bugs occurring within a Sprint, as part of a feature implementation. But what happens if someone finds a bug with an already released feature? An emergent bug is not immediately obvious after feature delivery but usually surfaces after a certain number of functionality repetitions, certain data/user loads, or when exercising some extreme scenarios. In such a case, the first thing to do is to mark the feature as buggy in our backlog. Again, adding labels or color-marking is a great, visual way of marking a card. We should also add some comments on that feature's card, describing the bug or referencing a bug tracking database.
Important note:
If the bug is deemed by the stakeholders as critical or high priority, and is caused by some scenario that we haven't captured in our feature, we must add that scenario to our feature. Any behavior that is significant in the business domain should be represented in our specification.
It is now up to the product owner to decide in which Sprint to fix that bug. They will have to re-prioritize that feature in the backlog and decide when to put it into the To do column during Sprint Planning. The development team will then treat that feature like any other feature in the To do column. The only difference is that the generated tasks will be focused on fixing that bug, instead of re-creating feature functionality from scratch.
The following diagram illustrates such an example:

Fig. 7.6 – Dealing with emergent bugs – start of Sprint
The task board in this image is being used to plan Sprint number 5. The product owner has decided that in this Sprint, we should be fixing a bug reported in relation to feature C7.9. That feature was delivered during Sprint 2, as per the card label. A bug was reported in relation to this feature, so it has been already been marked as defective (buggy) in the backlog. A reference to the bug details has been included in the card's details. The development team has analyzed the bug and decided it can be fixed by doing two things, which they have captured as two tasks. They have already made changes to the feature's affected scenarios, which are detailed in a link included in the card's details. They can now start working on these tasks and move them through the Doing to Complete columns. They can then verify the feature by running its executable steps. By the end of the Sprint, the task board should look like this:

Fig. 7.7 – Dealing with emergent bugs – end of Sprint
The bug has been fixed. Our feature is now in the Accepted column. It is no longer marked as buggy and its release number has changed to the current Sprint, that is, number 5. We can now move the feature back to the bottom of our backlog and make ourselves a deserved cup of tea.
Changes to existing behavior
Sometimes, it may turn out that some behavior that we specified and agreed with our stakeholders is based on false assumptions and needs to be changed after our feature has been accepted and released. In such a case, our stakeholders will request that we make a change to the feature. Dealing with such changes is not much different than dealing with emergent bugs. They both necessitate some changes to our feature, but each is presented in different contexts. In terms of task management, however, we deal with behavioral changes in exactly the same way we deal with bugs. The practical differences are as follows:
- We label our feature with a CR (or any other symbol that makes sense to our team), instead of a bug symbol.
- We describe the change requested (or link to it) in our feature's card details.
- We make any necessary modifications to our feature files.
Important note:
Be careful when analyzing CRs. Although some may seem to request changes to existing features, sometimes they will subtly lead to the creation of new features, or even capabilities. This is commonly known as scope creep or feature creep and can have negative consequences, so make sure you put any CRs thoroughly through the D3 process, so as to catch any potential extra features or capabilities that the CR necessitates.
We now know how to manage our development cycle using a feature-first methodology within Scrum. Let's take a look at how we can do the same using Kanban.
Working within Kanban
The Kanban method is another popular Agile approach. While Scrum is focused on an iterative and incremental development and delivery workflow, Kanban favors a more continuous flow. With Kanban, there are no required time-boxed events or iterations. System backlog cards are pulled into the To do columns as and when needed. There are some other things to note when working with Kanban:
- The Doing column has a card limit. Only a certain number of cards are allowed on it at any given time. This usually corresponds to the number of developers on the team, thus ensuring a developer is only working on one thing at any one time.
- The responsibility for managing the system backlog falls mainly to the Service Request Manager (SRM). This is an informal role similar to the Scrum's product owner, although the SRM is regarded more as a customer proxy, rather than someone who decides what the product should look and behave like.
- Kanban does not prescribe team roles such as Scrum master, product owner, and so on. Instead, individuals may be given the less formal roles of SRM and Service Delivery Manager. Other than that, everyone within the team has equal powers and responsibilities.
- In Scrum, any changes that violate the Sprint goal are prevented during the Sprint. Any out-of-Sprint changes need the approval of the product owner as well as the development team. In Kanban, any team member can add items to the task board at any time, as long as the Doing column limit is respected.
- Kanban does not prescribe a planning schedule or event. The team schedules planning meetings when it is deemed necessary.
- In Scrum, the task board is reset at the end of a Sprint. Completed and Accepted items are archived or moved. In Kanban, the board keeps constantly changing and evolving but never completely resets.
Overall, Kanban's continuous delivery approach simplifies the task board workflow. However, it makes the issue of planning code releases a bit more complicated. In Scrum, we release code at the end of the Sprint. Each release is tied to a Sprint goal or theme and releases are incremental, that is, they build on top of one another. This makes it easy to plan releases. For example, we may decide to release a beta version of our system at the end of Sprint 8. We then tag all code that has been released up to and including Sprint 8 as our beta release. We know, through the Sprint goals, what functionality and capabilities that release should deliver. Kanban's continuous – and seemingly random – delivery, however, means that release planning requires a little bit more consideration and effort. Fear not, though, as our feature-first approach makes our workflow much easier and risk-free.
Kanban planning
Although Kanban does not dictate formal planning meetings, it is advisable to have an informal planning session every 2 weeks or so. The activity and goal of this meeting should be similar to the Sprint Planning event, that is, to decide which features should be moved to the To do list. The criteria are almost the same as with Scrum:
- Priority: Features are selected according to their priority, which is decided by the team in consultation with the Service Request Manager. The requirements model, with its hierarchical view of goals, capabilities, and features, should inform our decisions as to which features to prioritize.
- Fully-formedness: Only features with full contextual information and detailed scenarios (as described in Chapter 3, Writing Fantastic Features with the Gherkin Language, in the Writing a fully-formed feature section), can be moved to the To do column.
- User Interface (UI) guidelines: Many, if not most of our features will involve direct interaction with an actor through a UI. There are many ways in which the functionality implemented in a feature can be invoked by and presented to an actor. This is why it is very important that such features are accompanied by screen mock-ups or wireframes that allow us to aim for a specific UI layout and styling.
One thing we don't need to account for – that we do in Scrum – is load capacity, that is, estimating how many features we can work on within a Sprint (obviously, as there are no Sprints in Kanban). However, it is a good idea to limit how many features we place in the To do column. Having too many features there may suggest we are too hasty in our analysis. A limited number of To do features also helps focus the team and provide some scope for the upcoming work.
Kanban development cycle
As with Scrum, the aim is to move all features from the To do column to the Accepted column. The team will examine the features in the To do column and will come up with a set of tasks required to implement these features. These tasks are placed in the Planning column and the team follows the same workflow illustrated in Fig. 7.2 – Sprint development workflow. The only differences are depicted in the following diagram:

Fig. 7.8 – Kanban task board
Let's check what happened on the board:
- The Doing column has a limit on it (5 in this example), which indicates the maximum number of items that can be on it at any one time.
- When a feature has been pushed to staging and has been Accepted, it's simply labeled as released. Labeling features with release versions is done at the discretion of the team.
- Once a task has been moved from the Doing column, we may drag another task for the same feature from the Planning column. If there are no other tasks for that feature, then we drag a task for a different feature.
Other than these, everything else flows the same way as with a Sprint development cycle. Of course, in Kanban, we don't have to worry about what to do at the beginning or end of the Sprint, as the Kanban development cycle is continuous and uninterrupted.
Dealing with change
In Kanban, changes can occur at any time. Unlike Scrum, we don't have to schedule the fixing of bugs or any requested changes for a specific iteration, that is, a Sprint. The two major kinds of change we'll have to deal with in our development cycle are emergent bugs and changes to existing features. We deal with both in a similar manner:
- We analyze and model any CRs following the methods detailed in Chapter 5, Discovering and Analyzing Requirements, in the Discovering requirements section.
- We label our feature with a CR or bug label, as appropriate.
- We describe the CR (or link to it) in our feature's card details.
- With a CR, we would almost certainly have to make changes to our feature's details, that is, in our feature files.
Overall, our task board workflow does not change dramatically between Scrum and Kanban. Scrum is great for regular and scoped software delivery. Kanban is more relaxed about delivery but tends to accommodate changes more easily.
Summary
In this chapter, we learned how to use the output of our requirements analysis and modeling process, that is, our features, to drive an agile development cycle using Scrum or Kanban. This is where the methods detailed in the previous chapters of this book start to pay big dividends. By knowing how to write features that are descriptive, robust, accurate, and finely scoped, we have ensured what we can use these features as complete, autonomous work units that can be completed within a Sprint. By having a requirements model that ties features to capabilities to stakeholder goals, we can easily classify and prioritize our features so we can address what our stakeholder needs most urgently and what adds the most value to them. By having step definitions for our features, that is, true executable specifications, we have an automated, consistent, and accurate way to measure when a feature is done.
We also learned how to apply JIT development with a feature-first approach. This approach cuts down waste and avoids the user-story hell phenomenon that plagues so many projects. We saw how this approach fits smoothly within the constraints of a Scrum or Kanban-based development cycle. In the next chapter, we will delve a little bit deeper into a short but essential part of our development process: verification. See you there!