
Chapter 4: Crafting Features Using Principles and Patterns
In the previous chapter, we learned how to write Features correctly. In this chapter, we will take it one step further. We will learn how to craft our Features. Creating something can be done by following an instruction set. Crafting something is different. It takes skill, deep knowledge of the materials and domain we're working with, and intuition derived from trial and error. In this chapter, we'll be crafting Features by applying principles and patterns in order to write high-quality, maintainable, and verifiable Features. In particular, we will cover the following:
- Behavior-Driven Development (BDD) principles
- Discerning patterns in our Features
- Patterns to avoid
After reading this chapter, you will be confident that you can write solid, future-proof Features by using the right mental models and discerning which patterns to apply and which to avoid.
Applying the BDD principles
The best way to ensure that we write good Features is to adhere to certain principles that will help us avoid mistakes and increase the quality of our Features. In this section, we will examine the four major mental models to help us write concise, descriptive, and well-scoped Features. Let's start at understanding that BDD is not about testing.
BDD isn't testing
BDD is about collaboration and shared understanding. By writing our features using a structured and ubiquitous language that can be understood by all stakeholders, we provide clarity and transparency. We allow and invite non-technical stakeholders to get involved in specifying our system's behavior. We make sure we all sing from the same hymn sheet, and that hymn sheet is our features, that is, our specifications. Yes, we also provide executable step definitions so that we can verify that our delivered code works as described in our features. But do not make the mistake of confusing this with testing. If you approach BDD with a testing mentality, you will start thinking as a tester, not as an actor in a specific feature. Having a testing mentality will, inevitably, lead to adding implementation details into your scenarios, thinking about 100% coverage and other such practices that will make your features unreadable and unusable. We will cover the effects of such bad practices later on when we look at anti-patterns.
The 80-20 rule
Also known as the Pareto principle, this is a probabilistic distribution rule originally applied to wealth distribution. According to the original application of the rule, 80% of the wealth of a society is held by 20% of its population. It was subsequently found that this rule also applies to other areas of human and natural activity. For instance, 80% of your company's revenue will be generated by 20% of your customers, 80% of your system's errors will be caused by 20% of your system's bugs, as Microsoft already discovered, (https://www.crn.com/news/security/18821726/microsofts-ceo-80-20-rule-applies-to-bugs-not-just-features.htm), and so on.
This rule applies to our features too. 80% of a feature's transpired behavior will be reflected in 20% of our scenarios. What does this mean? It means that when our feature is in actual use, chances are that 20% of the scenarios we have come up with will be invoked 80% of the time. The implication is that we shouldn't try to cover every eventuality with a scenario. In our sample Author uploads profile picture feature, we identified four basic behaviors and created four scenarios:
- Successful image upload
- Wrong type of image
- Image too large
- Resolution too low
With these scenarios, we've covered the most likely behaviors. When our actor tries to upload a file, it is almost certain that one of these behaviors will come into effect. By reading the feature and its scenarios, our stakeholder knows exactly how our system will behave 99% of the time when an author tries to upload a profile picture.
You may ask, "But what if the internet connection is very slow and the picture takes a long time to upload? Shouldn't we have a Scenario for this eventuality?" Yes, that may happen. But what are the chances of it happening? We've already prevented large files from being uploaded. If your internet takes a long time to upload a few MBs, then you have bigger problems to worry about than simply uploading your profile picture. Focus on the behaviors that are likely to occur instead of the behaviors that may occur. Focus on the behaviors that matter to stakeholders, not the ones that matter to you. Look out for behaviors that fall within your sphere of control, not outside it. Look out for probable scenarios instead of possible scenarios. 20% of the scenarios we can think of will be invoked 80% of the time. Don't worry about exceptional or unique circumstances.
System behavior is not system implementation
When we write our features, we are specifying behavior. We are saying this:
Feature writers sometimes tend to add statements to scenarios such as "Then the message is pushed to a queue" or "And a pop-up dialog with a warning icon is displayed." The truth is, the actor who is directly involved in this behavior couldn't care less about the message getting in a queue, a stack, or on a conveyor belt, for that matter. They just want the message successfully delivered. Similarly, most people who use computers don't really care about messages popping up with a yellow warning mark next to them. They care about having information conveyed to them in a clear, unambiguous manner. Whether this information is presented in a pop-up dialog with rounded edges or a flash message across their screen is not of great importance to them. The people using the system care about the behavior much more than the implementation of that behavior.
Tip
Most actors tend to care about the What, Where, and When of their interactions with the system, not the How. They want to know what the system does, when it does it, where it does it, and with what they need to respond. How the system does what it does is of little interest to them.
Our specifications describe our system's behavior from the actors' point of view. Our executable step definitions need to know about the implementation of this behavior. Our features are only concerned with the behavior itself.
Important note:
An exception to the preceding rule is where implementation does affect behavior. This is most notable in accessibility-related features. For instance, if we implement some behavior with mouse or gesture-only actions, then we are withholding this behavior from system users who don't use a mouse or a touchpad. If we implement displaying a message in certain color hues, then we may be affecting our system's behavior with respect to color-blind users. In such cases, it may be wise to add the implementation details in our scenario steps.
Wearing different hats
Within an organization, we all have specific roles and job titles. We are software engineers, architects, project managers, testers, and so on. We are used to seeing things from the perspective of our assigned role. We may all look at the same problem, but we each see different things. What is important to a software engineer will not have the same importance to an end user, for instance. To be able to write features correctly, we need to overcome this mental hurdle. When we're thinking about a feature, we must be able to discard our usual hat and wear the same hat as the actor involved in that feature. Only then will we be able to see what is important to that actor and be able to capture these important things in the Feature.
Discerning patterns in our features
Feature patterns are general, repeatable outlines or models of the way Feature is written or what it represents. Because patterns are repeated, we have learned to know the implications of applying (or not applying) specific patterns. Being able to discern patterns in our features means that we can anticipate potential problems and pre-empt them. It also means that we can choose to apply a pattern that is known to be beneficial, if conditions allow it. Let's examine the main feature patterns.
The CRUD Features pattern
CRUD stands for Create, Read, Update, Delete. It's a very common term in software engineering, used to denote generic read/write operations or behaviors. Let's imagine that we are developing a blogging system. We have outlined our impact map, as illustrated in the following figure:
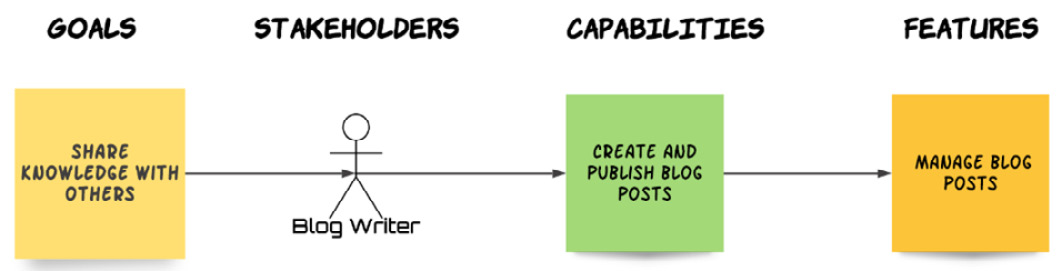
Fig. 4.1 – A CRUD Feature
Our main capability is CREATE AND PUBLISH BLOG POSTS. This clearly involves more than just creating a post and making it available to our users. Our blog writers will also need to make changes to their post, re-publish it, and even delete it, if the circumstances demand.
So, we decide that we'll deliver the capability by implementing a MANAGE BLOG POSTS feature. Our feature will have scenarios for creating, updating, and deleting a blog post. At first sight, this looks reasonable. However, let's think this through: we'll need to have three Happy Path Scenarios, one for each of our create, update, delete behaviors. We'll also have at least three more failure scenarios, one for each of these behaviors. We'll probably need to have a separate Publish post scenario to illustrate what happens after the post is created. The Edit behavior will also very likely behave differently depending on whether the edit occurs for a published or unpublished post. If you're keeping count, we have nine scenarios so far. We will also need to define the behavior when we try to publish a post with a title that belongs to another published post. Also, the behavior of deleting a post that is currently being read by other users will have to be captured. That's 11 scenarios and counting.
To cut a long story short, accumulating CRUD behaviors in the same feature can (and does) lead to large, convoluted Features that are difficult to read and understand. A much better practice is to separate our CRUD feature into distinct features for each CRUD behavior, as shown in the following diagram:
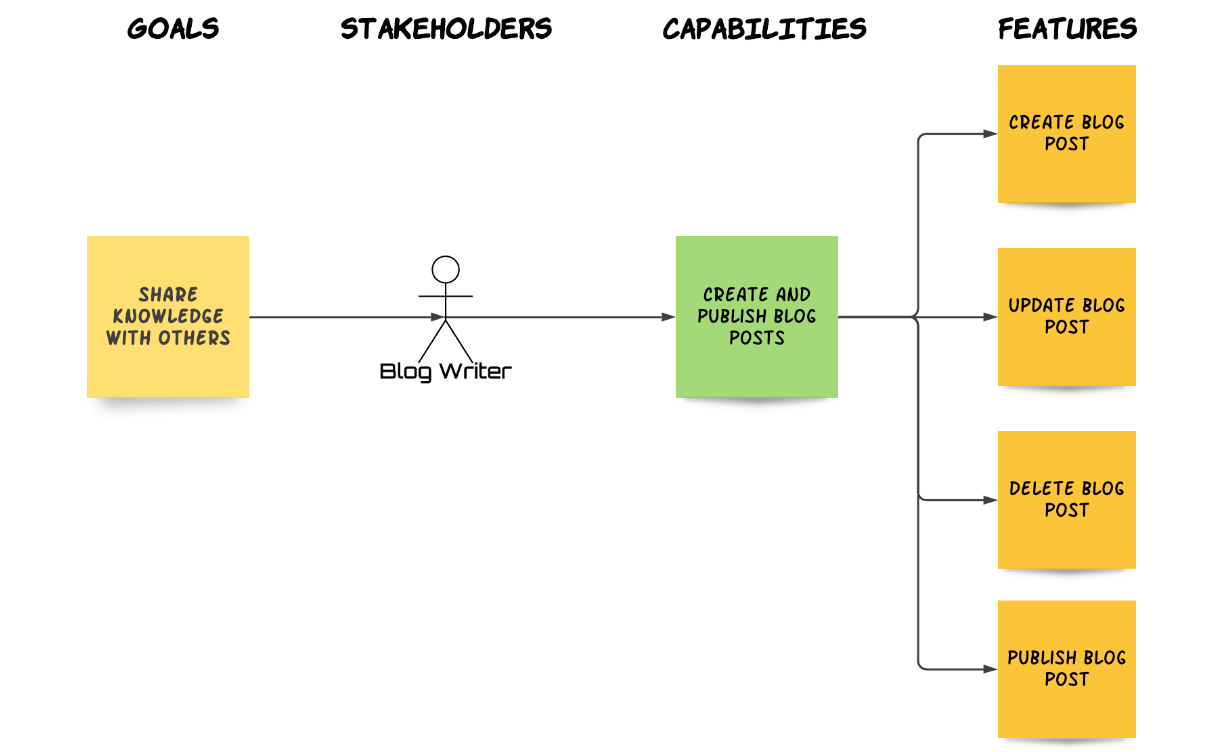
Fig. 4.2 – CRUD Feature simplified
By decomposing our CRUD behaviors, instead of one large, unreadable feature, we have four concise features with only a few scenarios each, which are far easier for our stakeholders to read and for us to manage.
The composite features pattern
Let's imagine that, while analyzing requirements for our blogging platform, we have created a Create User Profile feature. It involves the user writing a short biography (bio), adding a tagline, and uploading a photo, as depicted in the following mock-up provided by our stakeholders:

Fig. 4.3 – Create profile mock-up screen
We can readily identify at least three Happy Path Scenarios for our feature, as per the areas of required functionality:
- Scenario: Successfully write biography
- Scenario: Successfully write tagline
- Scenario: Successfully upload photo
Much as we described in the CRUD Features pattern, this can quickly escalate to dozens of scenarios, when we take into account different scenarios for each area of functionality (biography, photo, tagline). To solve the problem, we apply the same solution we did to the CRUD Features pattern: we break down the complex functionality into its sub-functionalities. So, we're going to replace the big, composite Create Profile feature with three new, smaller features:
- Write biography
- Set tagline
- Upload profile photo
By doing so, we have created features that are more readable and easily managed, while also ensuring that each feature focuses on very specific behaviors.
Important information
Composites and CRUD are sibling patterns. The main difference is that CRUD features group together dissimilar operations (create, update, and delete) within the same area of functionality (blog posts), while composite features group together similar operations within dissimilar sub-areas of functionality (biography, tags, and photo). Often, features will be composite and CRUD at the same time. In such cases, we need to break down the composite parts first. This will leave us with a set of new, smaller CRUD features for distinct functionality areas. Then, for each new feature, we will break down its CRUD operations into further new features, one for each CRUD operation in that distinct area.
The feature interpolation pattern
In Chapter 2, Impact Mapping and Behavior-Driven Development, we discussed Non-Functional Requirements (NFRs) and explained how we can model them in the same way as functional requirements, using the standard Goal-Capability-Feature Impact Map model. Many NFRs are cross-cutting, in that they affect a number of other features in our system. Such requirements may be represented as separate capabilities and features, or they can be interpolated within other features. Let's look at the example of the blogging system from the previous section, CRUD Features. After talking with the relevant stakeholders, we write a Create Blog Post feature like this:
Feature: Blog writer creates post
User Story: As a Writer, when I have some information worth sharing with my peers, I want to make it available to them, so that my peers are helped and my reputation increases
Impact: http://example.com/my-project-impacts-map
Background:
Given the user is logged in as a Writer
And the Writer goes to their MyPosts page
Scenario: Successful post creation
When the Writer chooses to create a post
And the Writer writes a title "iPhone SE review" for the post
And the Writer writes a body for the post
And the Writer chooses to save the post
Then the MyPosts page lists a post titled 'iPhone SE review'
Our marketing director now comes in and tells us that, according to their research, many users want to use our blogging system on all of their devices, such as desktop computers, laptops, tablets, and cellphones. Consequently, we need to provide the functionality for them to create blog posts from any device they are using. There are two ways we can model this requirement:
- Option 1: We create a specific capability, for example, using the system on different devices and deriving some features. In the example depicted in the following figure, we have our actor wanting to create, read, and rate blog posts on a variety of devices:

Fig. 4.4 – New Capability and Features for NFR
The problem with this approach should be obvious simply by looking at this impact map: duplication. We have already created the blog-creation feature when we analyzed the Create and Publish Blog Posts capability. The only difference between the Create Blog Post and Create Blog Post on Tablet features would be that the latter would have an extra scenario step, such as Given I am using an iPad, to reflect the multi-device capability we need to support. Clearly, this approach is wasteful and superfluous. Fear not, though; we can model our new requirement using a different approach, as follows.
- Option 2: We interpolate the new behavior into the existing Create Blog Post feature. This would be done simply by adding some extra conditional steps to reflect our multi-device constraint:
Feature: Blog writer creates post
User Story: As a Writer, when I have some information worth sharing with my peers, I want to make it available to them, so that my peers are helped and my reputation increases
Impact: http://example.com/my-project-impacts-map
Background:
Given the user is logged in as a Writer ### new step below:
And the Writer is using a:| device |
| MacBook |
| Windows laptop |
| iPhone |
| Android phone |
| Android tablet |
| iPad |
And the Writer goes to their MyPosts page
Scenario: Successful post creation
When the Writer chooses to create a post
And the Writer writes a title "iPhone SE review" for the post
And the Writer writes a body for the post
And the Writer chooses to save the post
Then the MyPosts page lists a post titled 'iPhone SE review'
As you can see, the only difference between the original feature and the re-written feature is that we added a new Background step with a data table to account for the different devices the Writer can create a blog post on. Our impact map is also greatly simplified, as illustrated in the following figure:
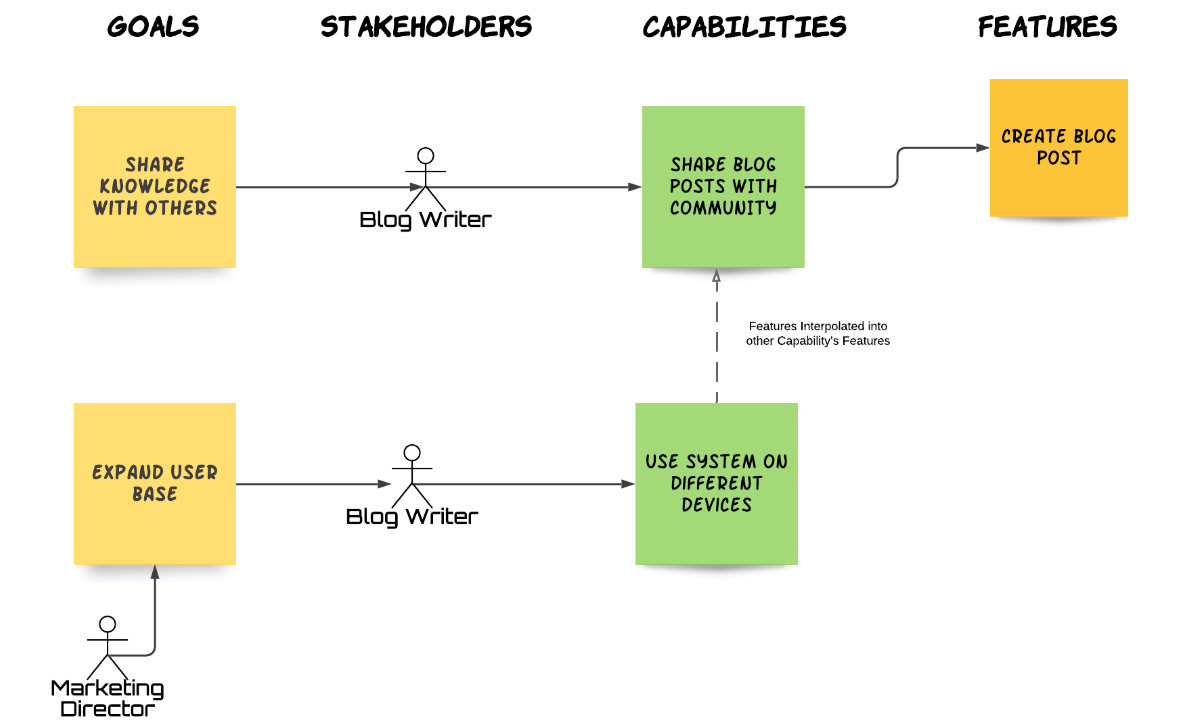
Fig. 4.5 – Interpolated Features
Interpolating features is a very effective way to model NFRs. By identifying the capability suggested by the NFR (and its associated stakeholders and goals), we captured the requirement and assessed its impact. At the same time, we didn't duplicate effort by creating new features and we didn't pollute our requirements model unnecessarily.
Now that we know which patterns help us improve our features, let's take a look at which patterns hinder them.
Patterns to avoid
Anti-patterns are patterns that are known to produce adverse effects, such as making features too large, difficult to understand, or hard to verify. These patterns are to be spotted early and avoided. This section presents some of the most common anti-patterns found in the wild.
Anti-pattern – thinking like developers
Let's look at a Scenario written for our system's Search for Books feature:
Given I am a Book Reviewer
When I go to 'http://example.com/search'
And I click on the Search button
And I see a search text box with the id #search_books
And I enter "adams + galaxy"
Then I'm redirected to the results page
And I see the 'The Hitchhiker's Guide to the Galaxy' by Douglas Adams
Here, we can easily tell that this scenario was written by a software developer or some other technical person, simply by looking at the amount of technical details described. Step 2 has a URL in it. Step 3 specifies an HTML element (button). Step 4 refers to a CSS ID. Step 5 specifies the plus operator. Step 6 mentions a redirection. The reason that this is problematic is that such technical details – while being obviously valuable to a software developer or tester – are totally irrelevant to the actor who'll be exercising this scenario. Our Book Reviewer doesn't care much about the URL they visit or the type and ID of HTML element they interact with, and they probably don't even know what a re-direction is.
Tip
Neglecting the Wearing Different Hats principle is the main cause of the thinking-like-developers anti-pattern.
Let's re-write this scenario from the Book Reviewer's perspective:
Given I am a Book Reviewer
When I go to the search page
And I search for 'adams' and 'galaxy'
Then I see 'The Hitchhiker's Guide to the Galaxy' by Douglas Adams
It's really that simple. This is all the Book Reviewer cares about when searching. Let's not confuse our readers with irrelevant technical details.
Anti-pattern – incidental details
Let's look at a Scenario for our user login behavior:
Given I am a Book Reviewer
When I go to the login page
And I enter 'Fred' as the username
And I enter 'mypassword' as the password
Then I see a message:
"""
Welcome Fred. Happy reading!"""
At first sight, nothing seems wrong with this scenario – that is, until we start thinking about the value each step adds to the Book Reviewer. Do they really need to know about a specific username or password? Also, what would happen if our Book Reviewer saw a message that said, "Hello Fred" instead of, "Welcome, Fred. Happy reading!"? I think it is safe to assume they wouldn't really mind either way.
Tip
In our scenarios, we only capture the behavior and details that are important to the actor involved. We don't capture specifics unless they reflect some essential business rule or constraint. Ignoring the system behavior is not system implementation principle will often cause this anti-pattern.
So, let's re-write our Scenario in a way that captures what our Book Reviewer really cares about:
Given I am a Book Reviewer
When I go to the login page
And I enter a valid username and password
Then I see a welcome message
By removing incidental details, we make our scenario not only more readable but also more resistant to change. The text of the welcome message and specific credentials will change often. The behavior depicted in our scenario, however, is much more likely to remain the same.
Anti-pattern – scenario flooding
In this anti-pattern, our Feature is flooded with dozens of scenarios. This makes our feature difficult to read, as most people find it difficult to read beyond a handful of scenarios in a feature. It can also make it longer to write step definitions (verification code) for that many scenarios. Too many scenarios indicates an overlapping of different functionalities in the same feature, or a pre-occupation with edge-case behaviors. The usual causes of this anti-pattern are the following:
- Ignoring the BDD isn't about testing principle. People who think of writing Features as a way of testing the system will usually go for 100% test coverage, and that leads to a huge number of scenarios, most of which aren't likely to be exercised often.
- Ignoring the 80-20 rule principle. People will often write down Scenario simply because they can think of it, rather than because it helps illustrate a specific behavior. We write scenarios to show our stakeholders how the system will behave under most working conditions, not to demonstrate how many edge cases we can think of.
- The feature is a CRUD or composite feature (see the The CRUD Features pattern section) that hasn't been simplified.
- The feature is actually a capability. Capabilities are much more coarsely grained and treating them as Features will produce a plethora of scenarios. If unsure, check Chapter 3, Writing Fantastic Features with the Gherkin Language, specifically the Capabilities versus Features section.
Having too many scenarios in our feature not only deters people from reading it but also makes it harder (and longer) to implement. Ideally, features should be implemented within 2 working weeks, which is the minimum duration of a Scrum sprint, as we'll discover in Chapter 7, Feature-First Development, specifically the Working with Scrum section. As a rule of thumb, more than nine scenarios in a feature should be a cause for concern and should prompt a re-evaluation of that Feature.
Anti-pattern – vague outcomes
Let's imagine we have just written the following Feature:
Given I am a Blog Author
And I am editing my blog post
When I change the existing title to a new title
And I save the changes
Then my post title has been updated
This makes perfect sense to us. After all, we know exactly how the system is supposed to work. But let's consider how this looks like from someone else's point of view. Someone who doesn't know what post title has been updated means. Does it mean that they can now see the new title on the current page? Do they need to go to a different page to see the updated title? That last step is just too vague to answer those questions. Even more importantly, the developer who writes the step definitions, that is, the code that verifies this step, may not know how to verify it. Ignorance breeds assumptions. So, they may just go and write some code that checks that the new title has been updated in the system database while ignoring the UI. This may lead to a disastrous situation where the scenario will be successfully verified when we run the step definitions, but the system will not behave as the user expects. The solution to this conundrum is to be specific about our scenario outcomes. Let's re-write our Scenario as follows:
Given I am a Blog Author
And I am editing my blog post
When I change the existing title to a new title
And I save the changes
Then I see a listing of my blog posts
And I see that my edited blog post now has a new title
We now have a specific outcome that leaves little room for ambiguity or misunderstanding. But we can make this even clearer:
Given I am a Blog Author
And I have a blog post titled 'Gone with the wind'
And I am editing this blog post
When I change the post title to 'Casablanca'
And I save the changes
Then I see a listing of my blog posts
And I see one of my blogs is titled 'Casablanca'
And none of my blogs is titled 'Gone with the wind'
We are now using specific examples to convey the full impact of the behavior we are describing in a clear, understandable manner.
Tip
Never neglect the Wearing Different Hats principle, as it is the main cause of the vague outcomes anti-pattern.
Anti-pattern – compound steps
Compound steps are Scenario steps that blend in more than one action within a single step. Let's look at this example of a compound step:
When I enable the 'per diem' and 'travel allowance' options
Now let's re-write it as two separate steps:
When I enable the 'per diem' option
And I enable the 'travel allowance' option
Having two separate steps makes our behavior much more obvious, as we are clarifying that we are referring to two distinct actions. It also helps implement step definitions as we are clearly delineating different parts of the UI we need to code against when verifying those steps.
Sometimes, compound steps are subtle and hard to detect, as here:
When I add a unique email
Here we have a step that looks like it comprises a single action. This is an illusion, though. When we add a unique email, in reality, we do two things:
- We come up with an email name.
- We check that the email is not taken by anyone else in our domain or organization; that is, we check whether it's a unique email.
The person who writes the step definition for this will also have to perform these two actions in order to verify this behavior. So, let's just help them out and write our step as follows:
When I add an email
And that email is unique
Not only did we make it easier to write step definitions, we opened the path to discover new scenarios, such as what happens when the email we add is not unique. Much better all around!
Summary
In this chapter, we learned how to apply good practices in order to produce high-quality Features. Features are at the heart of requirements management: they are our system's specifications, and they drive our whole development effort. This is why it is so important to be able to write non-brittle Features that are easy to read, fully describe our system's behavior, and are easy to verify. By now, you should be armed with the knowledge needed to write a Feature correctly, accurately, and legibly, and be able to futureproof it by knowing which principles to follow and which patterns to apply or to avoid.
So far, we have learned what a requirements model is, which entities constitute this model (goals, stakeholders, capabilities, and features), and how to create this model and correctly define and describe our entities. In the next chapter, we will take an in-depth look at how to analyze requirements in order to identify, define, and create our requirements model. So, put your analytical hat on and get ready to learn some interesting new methods and techniques.