
Chapter 9: The Requirements Life Cycle
In the last few chapters of this book, we have been delving into the nitty-gritty details of system backlogs, task boards, the development life cycle, and verification code. In this chapter, we'll take a high-level view of what we have learned so far. This includes looking at how it all fits together as an integrated, working, Agile methodology within the context of the requirements life cycle stages. In detail, we will be covering the following topics:
- Revisiting the requirements life cycle
- Applying the Agile requirements management workflow
By the end of this chapter, you will know how the different techniques and methods presented in this book fit within the canonical requirements management life cycle model. You will also better understand how they all flow together in a continuous, delineated, end-to-end methodology that enables us to convert raw requirements into working code.
Mapping the different stages of the requirements life cycle against relevant and pragmatic methods or techniques will give you a more holistic understanding of how these methods help with requirements management. This will also solidify the lessons of this book. Knowing how you can use these methods to elicit diverse requirements from our stakeholders, analyze them, model them, convert them to verifiable specifications, and deliver them in an agile manner, will cement your ability to manage building the correct software. This will ultimately help you deliver the system that your stakeholders want and deserve.
Revisiting the requirements management life cycle
In Chapter 1, The Requirements Domain, we talked about the requirements management life cycle, where I claimed that this book would provide methods and techniques that will help you implement every stage of it. It is now time to back this claim up and discuss how what you've learned in this book can be applied to each and every stage of the requirements life cycle. We shall illustrate this with an example project regarding a knowledge-sharing website. The initial requirements for this system are summarized as follows:
- Knowledge producers (authors, in this case) can share their knowledge as blog posts, recorded videos, or live sessions.
- Shared content will either be free or premium. Premium content can be purchased for a fee.
- Authors decide which content is free and which is premium, as well as the fee for premium content.
- A percentage of the fees that have been paid for premium content go to the website owners. The rest goes to the authors.
- Knowledge consumers can search for content based on topics, tags, or producers' names.
- Content must be able to be consumed on a diverse range of desktop and mobile devices.
Now, let's examine how our methodology fits within the requirements management life cycle, one stage at a time, by providing examples.
Validating requirements
Validation is about ensuring that the requirements fulfil a realistic and useful business need. Our methodology ensures that everything is traced back to a goal, so we immediately know the business need fulfilled by any given task we are working on. In Chapter 1, The Requirements Domain, in the Identifying goals section, we also examined how to validate business and domain goals in order to establish that they reflect realistic and useful business needs.
Example: The business makes it clear that content should be available on a number of different devices. We identify a list of devices and browsers that we intend to support. One of the business's account managers wants us to add support for the Internet Explorer browser since a client whose account he looks after is still using that browser. This seems like a reasonable requirement but doing some quick market research tells us that Internet Explorer's share is 6% and dropping. We already know from Chapter 1, The Requirements Domain, that a requirement must be ultimately tied to a goal that either increases and protects revenue or reduces and avoids costs. Supporting Internet Explorer will give us a potentially small increase in revenue and cost a large amount of money for supporting and maintaining compatibility with that browser. Overall, the business need for this requirement appears to be neither realistic nor useful to anyone apart from the director's personal reputation with a specific client.
Modeling requirements
Modeling is about having a structured and consistent way to describe and store requirements. We are doing exactly that by using Impact Mapping as our modeling tool and by having clear and precise definitions of the entities in our requirements model, as described in Chapter 1, The Requirements Domain, and Chapter 2, Impact Mapping and Behavior-Driven Development. Also, in Chapter 5, Discovering and Analyzing Requirements, we set out clear rules about how to define and derive those entities.
Example: In our knowledge-sharing website example, after applying the techniques from Chapter 5, Discovering and Analyzing Requirements, we'll end up with a standard requirements model. It will look something like the following diagram (displaying only a small part of the model for illustration purposes):
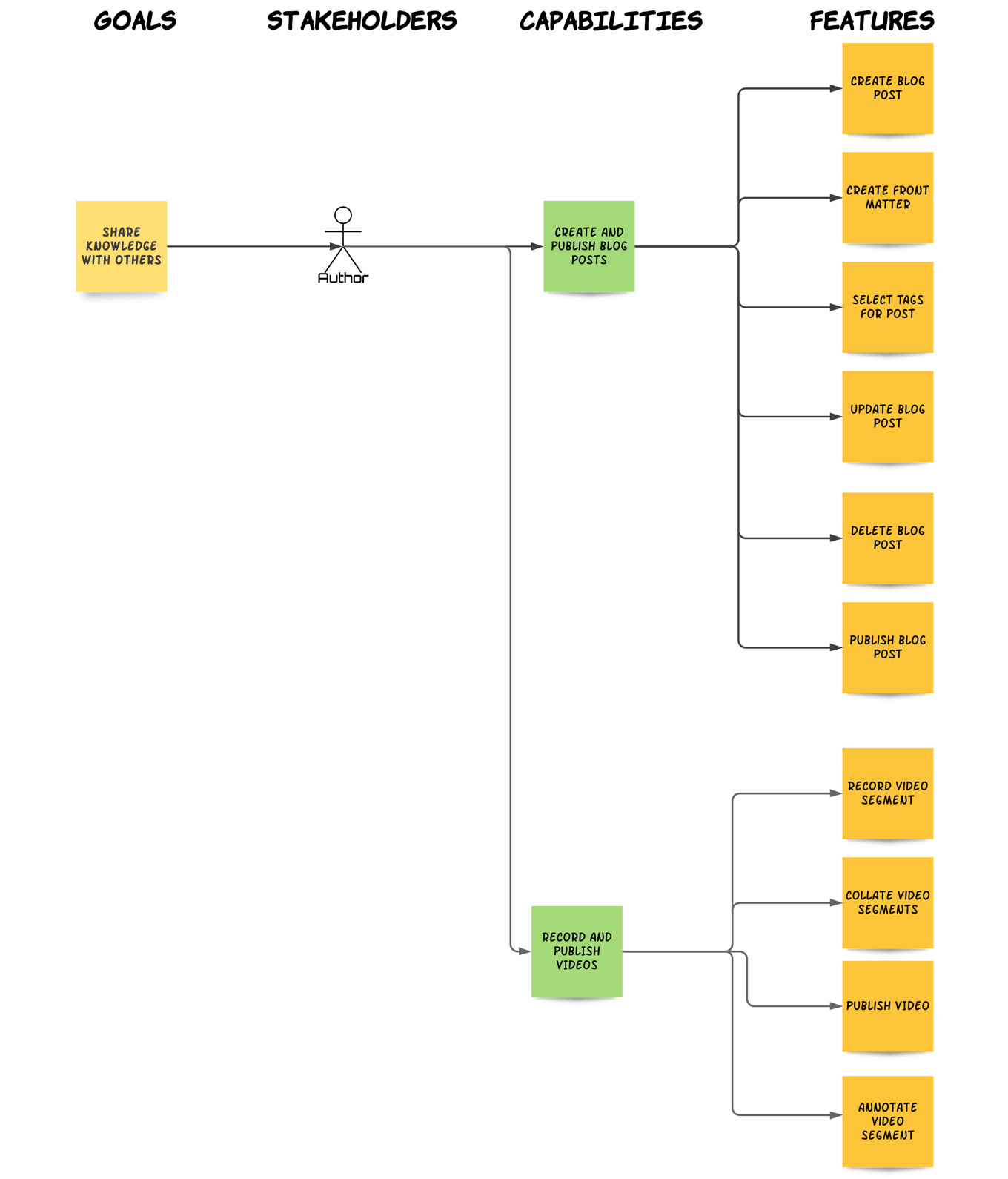
Fig. 9.1 – Example requirements model
Every requirements model has the same structure and contains the same type of entities. It therefore provides a structured and consistent way of modeling requirements.
Creating specifications
The specification stage is one of the most important ones as without a specification, we cannot deliver the correct system. This stage is where we translate the requirements into concrete and clear system behaviors; that is, our features. In Chapter 3, Writing Fantastic Features with the Gherkin Language, and Chapter 4, Crafting Features Using Principles and Patterns, we discussed how to write such concrete and clear system behaviors extensively. In Chapter 5, Discovering and Analyzing Requirements, we learned how to translate requirements into goals, capabilities, and features. One of this book's central themes is bridging the gap between requirements and specifications, which we do by applying the right analysis techniques (refer to Chapter 5, Discovering and Analyzing Requirements) and creating a hierarchical, delineated requirements model (Chapter 2, Impact Mapping and Behavior-Driven Development).
Example: We can pick an identified feature from our requirements model and specify its behavior in a feature file, which will look something like the following:
Feature: Author updates blog post
User Story: As an Author, I want to update a blog post,
so that I can correct any mistakes or inaccuracies
Impact: http://example.com/my-project/impacts-map
Background:
Given the user is logged in as an Author
And the Author goes to their Blog Posts
And the Author selects the "How to reduce memory footprint" blog post
And the Author chooses to edit the post
Scenario Outline: Successful word editing
When the Author moves into the editor part of the page
And the Author replaces the words <existing> word with the <new> word
And the Author saves the blog post
And the Author views the "How to reduce memory footprint" blog post
Then the Autor cannot see the <existing> words
Examples:
| existing | new |
| 100 | 1000 |
| ommit | omit |
Feature prescribes a clear system behavior that our development team can take away and implement as system code. We should also share our features with our stakeholders in a specification document.
Classifying requirements
Requirements can be classified according to the area of the system they affect, their complexity level, their risk level, and many other factors. The guide to the Business Analysis Body of Knowledge (BABOK – https://www.iiba.org/standards-and-resources/babok/) describes four types of requirements:
- Business requirements represent business objectives. These are our business and domain goals, as represented on the first level of the requirements model.
- Stakeholders requirements represent the requirements of individual stakeholders. They reflect the impact stakeholders need to have on our system in their quest to accomplish their goals. These are our capabilities and they comprise the second level of the requirements model.
- Solution requirements represent the requirements of a solution. These requirements form the basis on which the development team will develop the system. They are our features and they occupy the third level of the requirements model.
- Transition requirements are temporary requirements that are needed to facilitate a solution and they usually relate to data migration, data cleaning, or user training. In reality, no requirement is really transient as every requirement leaves a residue of value behind after it's fulfilled. So, transition requirements will be captured in the usual form of goal – capability – feature in our requirements model. For instance, we may have a Migrate data from legacy system capability, with a related Administrator batch imports user from old system feature. Although this feature may be executed only once, it will affect our system during its lifetime, so it must be dealt with like any other required behavior.
So, in summary, the methodology presented in this book provides us with an already structured and classified requirements model that is in line with industry standards.
Example: The requirements model for our knowledge-sharing site example (Figure 9.1) already presents the captured requirements, which are visually classified as follows:
- Business Requirements: Our customers can share knowledge with others.
- Stakeholder Requirements: Create and publish blog posts, record and publish videos.
- Solution Requirements: Create blog post, create front matter, tag post, record video segment, and many others.
Classifying requirements helps us understand and further process the requirements model well.
Documenting requirements
One of the great things about writing features with Gherkin is that features are self-documented. Using a simple, ubiquitous language that anyone can understand means that our system's behavior can easily by perceived simply by reading these features. Our requirements model also serves as a visual guide to our requirements, providing a classified and traceable tree of our analysis outcome. Furthermore, in Chapter 6, Organizing Requirements, in the Creating a Specification document section, we detailed the creation of a specifications document, which provides accumulated, annotated, and comprehensive documentation for our system. Providing ample and accessible requirements documentation is one of the greatest benefits our methodology offers.
Example: The Author updates blog post feature, which we created earlier in this chapter, describes in a non-technical, domain-specific language the system behavior for that particular functionality in a step-by-step manner. It can be easily read by businesspeople, as well as developers.
Prioritizing requirements
There are four general approaches to prioritizing requirements:
- By value: This is about the benefits a requirement gives to stakeholders. These could be of business or economic value. It is common to prioritize higher-value requirements first. Because our requirements model associates stakeholders with goals and capabilities, it is easy to select the stakeholders we want to please the most and choose the most high-value capabilities these stakeholders need. We can then drill down to each capability's feature and decide which ones to implement first.
- By cost: Cost prioritizing can be about implementing the requirements that need the least time, effort, or money first (the low-hanging fruit approach). It can also be about implementing requirements with the greatest return on investment (ROI). Our requirements model makes it easier to discern both cost and ROI. By following the methodology in this book – Chapter 3, Writing Fantastic Features with the Gherkin Language, and Chapter 4, Crafting Features Using Principles and Patterns, in particular – we should have a set of well-scoped features associated with each capability. This means that we shouldn't have to break down any features even further and that no one feature should take an extraordinary amount of time to implement. This is no replacement for proper estimation, but it should enable a relative, ball-park assessment of a capability's cost, simply based on the number of features required to deliver it. Also, since a capability is tied to a goal, we should be able to get a feel for the potential return of our cost investment. Business goals are always underlined by financial motives, such as increasing profit or protecting from losses, so these are the goals with the potentially highest ROI.
- By risk: Prioritizing based on risk is most commonly used on projects in new, controversial, or disruptive areas. The idea is that if the high-risk requirements fail to be delivered, then the project can be scaled down or even abandoned. Being able to trace a feature to a capability, and then to a goal, on our requirements model makes it easier to appreciate the inherent business risk of a feature we plan to implement. This should always be complemented by an assessment of the technical risk associated with the feature.
- By urgency: Some requirements are more time-sensitive than others. For instance, our client may need to demonstrate some capability at a trade show or exhibition.
Regardless of the prioritization method used, our requirements model's visual nature and hierarchical structure makes it much easier to prioritize requirements than the usual text-based methods.
Example: In our knowledge sharing example, we identified three capabilities that will help the author stakeholder achieve their goal. Let's suppose that the fee that's charged for having interactive sessions will be higher than the fee for watching video content, which will, in turn, be higher than the fee for reading blog posts. We can then prioritize these capabilities in terms of economic value, where Arrange Interactive Session will have the highest priority and Create and Publish Post will have the lowest one.
Now, let's suppose that the Arrange Interactive Session capability has 20 features associated with it (trust me, it takes a lot of functionalities to arrange online sessions). Let's also assume that we followed the advice given in Chapter 4, Crafting Features Using Principles and Patterns, by breaking down composite or CRUD features. We could then reasonably assume that Arrange Interactive Session was more costly than Create and Publish Post (which has six features). So, if we prioritized by cost, Create and Publish Post would have a higher priority than Arrange Interactive Session.
The structure, hierarchy, and visual simplicity of our requirements model makes classifying requirements much easier and less stressful.
Verifying requirements
Verification is about ensuring that our system functions in a way that fulfills our requirements. Because our analysis methodology results in executable specifications, we have an out-of-the-box way of verifying our system, as explained in Chapter 3, Writing Fantastic Features with the Gherkin Language, in the Features are executable specifications section. By using a BDD tool and the right approach to writing verification code (as detailed in Chapter 8, Automating Verification), we can ensure that we have an automated way of verifying our features. Since each feature is tied to a capability and, from there, to a stakeholder and goal, verified features equate to fulfilled stakeholder goals; that is, fully verified requirements.
Example: In the Creating specifications section, earlier in this chapter, we created a specification for the Author updates blog post Feature. To verify that feature, we would also have written some step definition code that executes the conditions specified in the Given steps, the actions in the When steps, and asserted that the outcomes in the Then steps did actually occur. We would then be reassured that our system does indeed behave the way we specified it would.
Dealing with change
This is about dealing with changes to requirements. How we achieve that relies largely on the delivery cycle we adopt. An incremental and iterative delivery cycle such as the one prescribed by the Scrum framework requires a slightly different approach to a continuous delivery cycle, such as the one prescribed by the Kanban method. Change management techniques for both of these cycles were detailed in Chapter 7, Feature-First Development. To summarize, the key things to apply in order to be change-resilient are as follows:
- Feature-First development: By focusing our development and delivery on the things that are constant (features), rather than transient (development tasks, bug fixes, and so on), we can isolate and discern what changes from how it changes and, therefore, deal with it more effectively.
- Tracked delivery: By keeping track of when features are deployed or delivered, such as sprint numbers or release versions, we can easily track changes and their effects on both our system behavior and the underlying code.
Let's examine this within the scope of our current example.
Example: Let's suppose we are developing our knowledge sharing system within Scrum. At the end of our first sprint, we have delivered two features: BL.1 and BL.2. Our Scrum Board will look as follows:
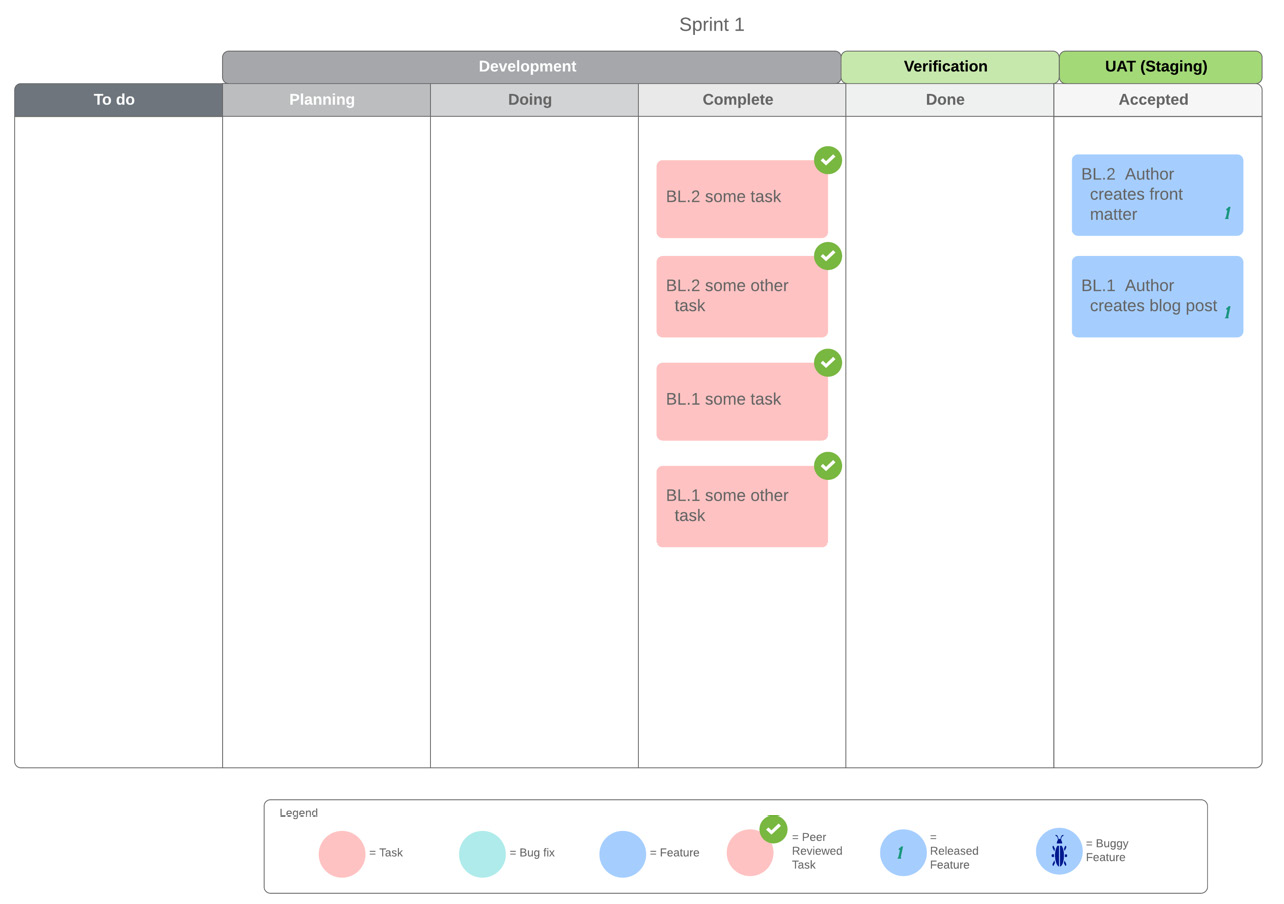
Fig. 9.2 – Knowledge sharing project – 1st sprint end
Our BL.1 and BL.2 features are labelled with the 1 (for 1st sprint) tag. Now, let's imagine that our stakeholders require a change in the behavior of BL.1. We need to add some new Steps or Scenarios to our Feature and drag the board card for BL.1 back into the sprint backlog (To do list) for the next sprint.
Let's also imagine that a small defect was discovered with our delivered BL.2 feature. It will have to be fixed, so we drag the board card for BL.2 back into the sprint backlog too.
When Sprint 2 starts, we create a task to implement the changes in BL.1 and a task to correct the defect in BL.2. Our Scrum board for Sprint 2 looks as follows:

Fig. 9.3 – Knowledge sharing project – 2nd sprint start
At the end of the Sprint, when our tasks are complete and our Features have been verified and accepted, we label the features as 2 (meaning they're released with the 2nd sprint). Our Scrum Board now looks as follows:

Fig. 9.4 – Knowledge sharing project – 2nd sprint end
By tracking and labelling feature releases, we can see how and when our features change over time. By including the feature release labels in our source version control system (git, for instance), we have an audit trail of our system changes, as well as the related code changes.
One of the biggest benefits of our requirements analysis and modeling methodology is that it ties in seamlessly with a Feature-First delivery and development cycle. This means that changes are analyzed and modeled like any other requirements, and that our system backlog and task board reflect these changes without clutter and ambiguity.
It's now time to look at how the methods and techniques displayed in this section come together in an integrated workflow.
Applying the Agile requirements management workflow
Throughout this book, we've learned about different techniques, processes, and methods for dealing with various stages of the analysis and development life cycle. We can now put them all together in an integrated workflow that will start by capturing raw requirements from the stakeholders and end by delivering working code that verifiably delivers what our stakeholders require.
Our workflow consists of four distinct phases:
- Elicitation and Analysis
- Discovery and Modeling
- Executable Specification
- Development and Verification
These phases will be repeated time and time again throughout our project's life cycle, for each set of requirements that comes to our attention and through each development cycle or iteration (sprint). They will also be applied concurrently, where some of our team members will be eliciting requirements from the stakeholders, while some other team members will be creating Scenarios for discovered Features, and someone else will be writing code to implement the most high-priority Features on our task board. Let's look at each phase more closely.
Elicitation and Analysis
When our project is about to start and throughout its development, requirements will be thrown at us from different directions and in different forms, such as conversational, textual, diagrammatic, or formal. Often, we will have to draw requirements out of stakeholders, deduce them from existing documentation, or infer them from a legacy system's behavior. The Elicitation and Analysis phase aims to draw out requirements from the stakeholders in a clear and specific manner, which will then allow us to map the raw requirements to well-defined and fine-scoped requirement domain entities; that is, goals, stakeholders, capabilities, and features, as described in Chapter 1, The Requirements Domain, and Chapter 2, Impact Mapping and Behavior-Driven Development.
The mental model we use during this phase is that of a separation funnel, as depicted in the following diagram:

Fig. 9.5 – The Elicitation and Analysis phase
Raw requirements come into the funnel from different sources and in different forms. We apply filtering techniques in order to separate values from waste and identify the requirement domain entities that these raw requirements encapsulate. These filtering techniques are Structured Conversation, D3, and Business Process Mapping, as explained in Chapter 5, Discovering and Analyzing Requirements. The outcome of this phase is a number of entities, such as goals, stakeholder, capabilities, and features.
Modeling and Discovery
The aim of this phase is to produce a requirements model using the entities identified in the Elicitation and Analysis phase. The requirements model is a tree-like structure that visually displays our requirement domain entities and their associations, as depicted in the following diagram:
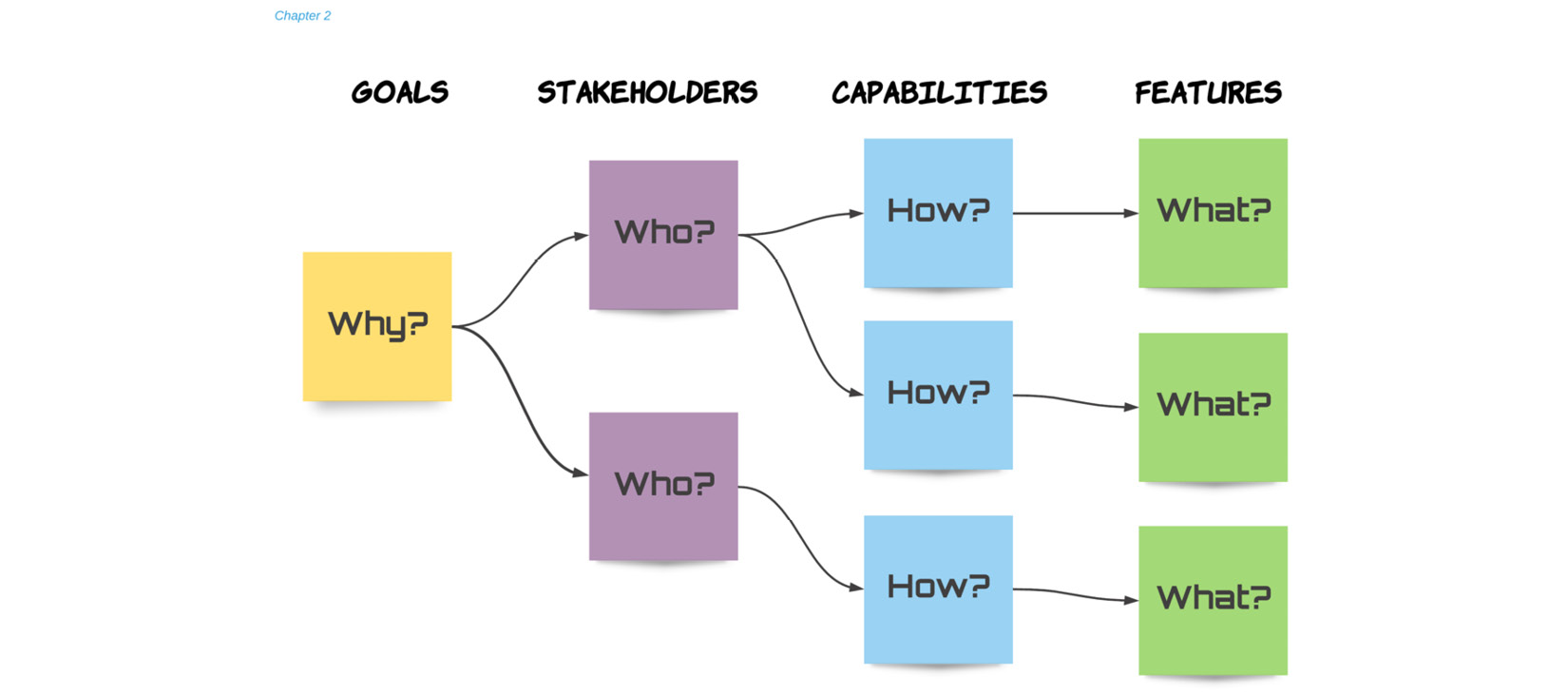
Fig. 9.6 – The Modeling and Discovery phase
The requirements model provides quick and easy traceability so that any team member can trace a feature to a capability, stakeholder, and goal. Not only does the requirements model ensure that everyone can see the big picture, but it also allows us to get proactive. Having a visual and hierarchical representation of the requirements, as discussed in Chapter 2, Impact Mapping and Behavior-Driven Development, makes it easier to discover new requirements or functionality. For instance, by knowing the goal that a capability helps accomplish, we may come up with new capabilities to accomplish the same goal. Similarly, knowing a capability, in the context of its relevant stakeholder and goals, enables us to discover the right functionality (features) needed to deliver the capability correctly. The requirements model is a uniquely valuable artifact and is at the heart of the methodology presented in this book.
Executable specification
Here, in the last level of our requirements model, our features form the input for the next phase. The executable specification phase is crucial to the successful delivery of our system. Our specifications are our fully-formed features; that is, our features are fleshed out with scenarios written in a ubiquitous language that's easily understood by our stakeholders. These features are stored in feature (.feature) files and they are the basis on which code development will proceed. Together with the system glossary, the stakeholder model, and other contextual information, they form the specifications document, which we can deliver to our stakeholders, as illustrated in the following diagram:
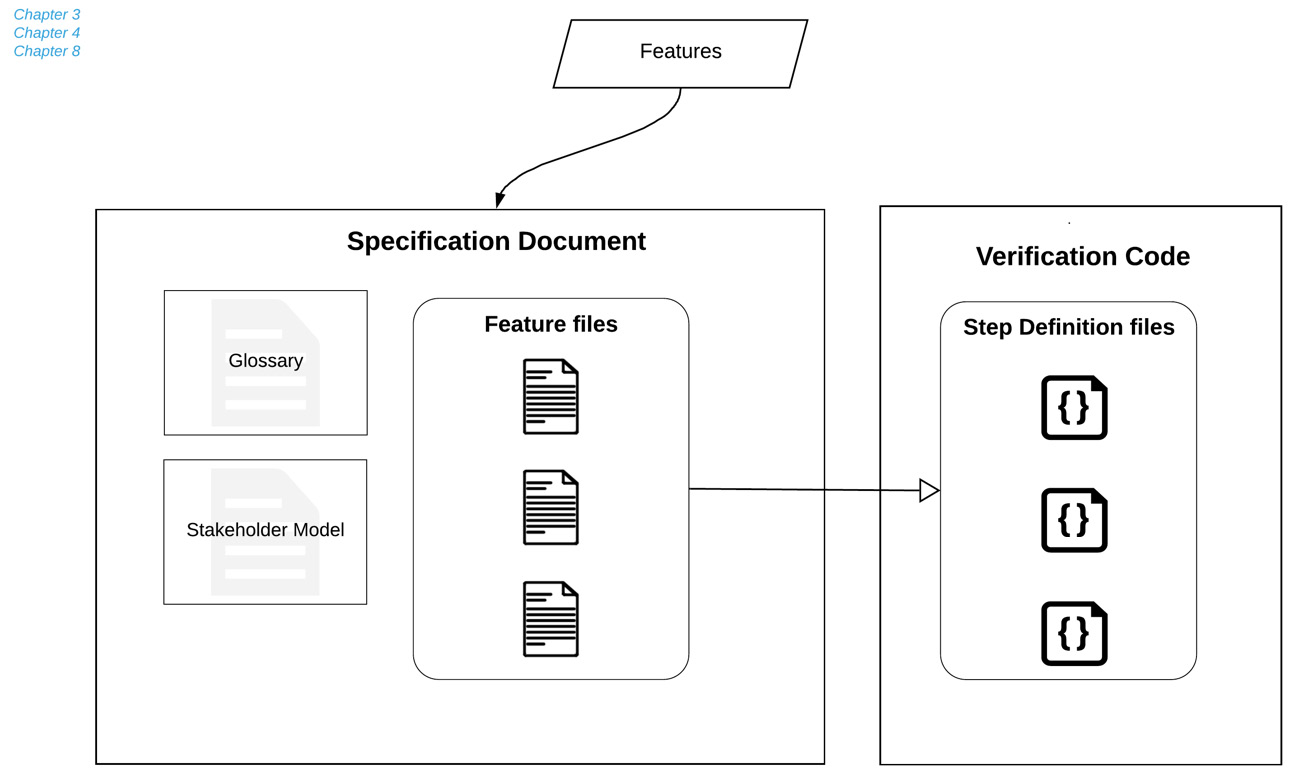
Fig. 9.7 – Executable specification
The specification document should contain everything the stakeholders need to know about our system. Chapter 3, Writing Fantastic Features with the Gherkin Language, and Chapter 4, Crafting Features Using Principles and Patterns, explain in great detail how to write features correctly.
In addition to fully describing our system's behavior, these features can also be executed; that is, they can be verified against our delivered system. We achieve this by creating step definitions; that is, verification code that matches the steps described in our feature scenarios with actions on our system's interface. Chapter 8, Automating Verification, details how to write solid step definitions. By having comprehensive features and matching step definitions to verify them, we have ourselves a truly executable specification.
Development, Validation, and Verification
No requirements management methodology would be useful if it didn't explain how to turn requirements into working and verified code. The fully-formed features that are created at the executable specification phase form the cornerstone of our development process. Our Feature-First approach means that our system backlog consists entirely of features. Our job, as system builders, ultimately comes down to that: implementing features. To do that, we will need to complete certain tasks, which we store and monitor under the Development column of our task board. Tasks are transient; we only do them in order to implement a feature. Once all feature tasks are complete, we can verify our feature by using a BDD tool to run our step definitions against a version of the system that includes that feature, as depicted in the following diagram:

Fig. 9.8 – Development, Validation, and Verification
Once verification is successful, we can deploy the feature on a staging server and get our users to validate the features and give us their feedback. Chapter 6, Organizing Requirements, and Chapter 7, Feature-First Development, go into great depth in order to explain this process, also taking into account different Agile development and delivery approaches.
Summary
This chapter brought together the techniques, methods, and processes we've examined so far in this book. A comprehensive requirements management methodology should address all the stages of the traditional life cycle. In the first section of this chapter, we explained how each requirements management stage was dealt with in this book. In the second section, we iterated how each lesson of this book can be brought together in an integrated workflow that allows us to start with raw requirements and end up with verified and working code, which is the main purpose of this book.
This chapter recapped, summarized, and enhanced everything we've learned about in this book. This should help you understand how different techniques and methods flow together in an integrated methodology that enables us to deliver working code from raw requirements.
In previous chapters, we addressed individual chunks of the requirements management puzzle. In this chapter, we took a step back and looked at the whole puzzle as one big, beautiful picture. By looking at the big picture we can better appreciate the importance of the individual pieces and how well they fit together in order to provide the desired outcome.
In the next chapter, we'll look at how to apply the first stages of our workflow to a fictional, yet realistic, use case. Stay tuned for the Camford University paper publishing system!
Further reading
- Kent J. McDonald, Beyond Requirements: Analysis with an Agile Mindset, Addison-Wesley Professional; 1st edition (29 Aug. 2015)
- Dean Leffingwell, Agile Software Requirements: Lean Requirements Practices for Teams, Programs, and the Enterprise, Addison Wesley; 1 edition (27 Dec. 2010)
- Dan Olsen, The Lean Product Playbook: How to Innovate with Minimum Viable Products and Rapid Customer Feedback, Wiley; 1st edition (June 2, 2015)