
The k-nearest neighbors algorithm is a simple machine-learning algorithm used for supervised classification. The main components of this algorithm are:
- A train dataset: This dataset is formed by instances with one or more attributes that define every instance and a special attribute that determines the example or label of the instance
- A distance metric: This metric is used to determine the distance (or similarity) between the instances of the train dataset and the new instances you want to classify
- A test dataset: This dataset is used to measure the behavior of the algorithm
When it has to classify an instance, it calculates the distance against this instance and all the instances of the train dataset. Then, it takes the k-nearest instances and looks at the tag of those instances. The tag with the most instances is the tag assigned to the input instance.
In this chapter, we are going to work with the Bank Marketing dataset of the UCI Machine Learning Repository, which you can download from http://archive.ics.uci.edu/ml/datasets/Bank+Marketing. To measure the distance between instances, we are going to use the Euclidean distance. With this metric, all the attributes of our instances must have numerical values. Some of the attributes of the Bank Marketing dataset are categorical (that is to say, they can take one of some predefined values), so we can't use the Euclidean distance directly with this dataset. It's possible to assign ordinal numbers to each categorical value; for example, for marital status, 0 would be single, 1 would be married, and 2 would be divorced. However, this would imply that the divorced person is closer to married than to single, which is disputable. To make all the categorical values equally distant, we create separate attributes such as married, single, and divorced, which have only two values: 0 (no) and 1 (yes).
Our dataset has 66 attributes and two possible tags: yes and no. We also divided the data in two subsets:
- The train dataset: With 39,129 instances
- The test dataset: With 2,059 instances
As we explained in Chapter 1, The First Step – Concurrency Design Principles, we first implemented a serial version of the algorithm. Then, we looked for the parts of the algorithm that could be parallelized, and we used the executor framework to execute the concurrent tasks. In the following sections, we explain the serial implementation of the k-nearest neighbors algorithm and two different concurrent versions. The first one has a concurrency with very fine-grained granularity, whereas the second one has coarse-grained granularity.
We have implemented the serial version of the algorithm in the KnnClassifier class. Internally, this class stores the train dataset and the number k (the number of examples that we will use to determine the tag of an instance):
public class KnnClassifier {
private List <? extends Sample> dataSet;
private int k;
public KnnClassifier(List <? extends Sample> dataSet, int k) {
this.dataSet=dataSet;
this.k=k;
}The KnnClassifier class only implements a method named classify that receives an Sample object with the instance we want to classify, and it returns a string with the tag assigned to that instance:
public String classify (Sample example) {This method has three main parts—first, we calculate the distances between the input example and all the examples of the train dataset:
Distance[] distances=new Distance[dataSet.size()];
int index=0;
for (Sample localExample : dataSet) {
distances[index]=new Distance();
distances[index].setIndex(index);
distances[index].setDistance (EuclideanDistanceCalculator.calculate(localExample, example));
index++;
}Then, we sort the examples from lower to higher distance, using the Arrays.sort() method:
Arrays.sort(distances);
Finally, we count the tag with most instances in the k-nearest examples:
Map<String, Integer> results = new HashMap<>();
for (int i = 0; i < k; i++) {
Sample localExample = dataSet.get(distances[i].getIndex());
String tag = localExample.getTag();
results.merge(tag, 1, (a, b) -> a+b);
}
return Collections.max(results.entrySet(), Map.Entry.comparingByValue()).getKey();
}To calculate the distance between two examples, we can use the Euclidean distance implemented in an auxiliary class. This is the code of that class:
public class EuclideanDistanceCalculator {
public static double calculate (Sample example1, Sample example2) {
double ret=0.0d;
double[] data1=example1.getExample();
double[] data2=example2.getExample();
if (data1.length!=data2.length) {
throw new IllegalArgumentException ("Vector doesn't have the same length");
}
for (int i=0; i<data1.length; i++) {
ret+=Math.pow(data1[i]-data2[i], 2);
}
return Math.sqrt(ret);
}
}We have also used the Distance class to store the distance between the Sample input and an instance of the train dataset. It only has two attributes: the index of the example of the train dataset and the distance to the input example. In addition, it implements the Comparable interface to use the Arrays.sort() method. Finally, the Sample class stores an instance. It only has an array of doubles and a string with the tag of that instance.
If you analyze the serial version of the k-nearest neighbors algorithm, you can find the following two points where you can parallelize the algorithm:
- The computation of the distances: Every loop iteration that calculates the distance between the input example and one of the examples of the train dataset is independent of the others
- The sort of the distances: Java 8 has included the
parallelSort()method in theArraysclass to sort arrays in a concurrent way
In the first concurrent version of the algorithm, we are going to create a task per distance between examples that we're going to calculate. We are also going to make it possible to produce a concurrent sort of array of distances. We have implemented this version of the algorithm in a class named KnnClassifierParrallelIndividual. It stores the train dataset, the k parameter, the ThreadPoolExecutor object to execute the parallel tasks, an attribute to store the number of worker-threads we want to have in the executor, and an attribute to store if we want to make a parallel sort.
We are going to create an executor with a fixed number of threads so that we can control the resources of the system that this executor is going to use. This number will be the number of processors available in the system we obtain with the availableProcessors() method of the Runtime class multiplied by the value of a parameter of the constructor named factor. Its value will be the number of threads you will have from the processor. We will always use the value 1, but you can test with other values and compare the results. This is the constructor of the classification:
public class KnnClassifierParallelIndividual {
private List<? extends Sample> dataSet;
private int k;
private ThreadPoolExecutor executor;
private int numThreads;
private boolean parallelSort;
public KnnClassifierParallelIndividual(List<? extends Sample> dataSet, int k, int factor, boolean parallelSort) {
this.dataSet=dataSet;
this.k=k;
numThreads=factor* (Runtime.getRuntime().availableProcessors());
executor=(ThreadPoolExecutor) Executors.newFixedThreadPool(numThreads);
this.parallelSort=parallelSort;
}To create the executor, we have used the Executors utility class and its newFixedThreadPool() method. This method receives the number of worker-threads you want to have in the executor. The executor will never have more worker-threads than the number you specified in the constructor. This method returns an ExecutorService object, but we cast it to a ThreadPoolExecutor object to have access to methods provided but the class and not included in the interface.
This class also implements the classify() method that receives an example and returns a string.
First, we create a task for every distance we need to calculate and send them to the executor. Then, the main thread has to wait for the end of the execution of those tasks. To control that finalization, we have used a synchronization mechanism provided by the Java concurrency API: the CountDownLatch class. This class allows a thread to wait until other threads have arrived at a determined point of their code. It's initialized with the number of threads you want to wait for. It implements two methods:
getDown(): This method decreases the number of threads you have to wait forawait(): This method suspends the thread that calls it until the counter reaches zero
In this case, we initialize the CountDownLatch class with the number of tasks we are going to execute in the executor. The main thread calls the await() method and calls the getDown() method for every task, when it finishes its calculation:
public String classify (Sample example) throws Exception {
Distance[] distances=new Distance[dataSet.size()];
CountDownLatch endController=new CountDownLatch(dataSet.size());
int index=0;
for (Sample localExample : dataSet) {
IndividualDistanceTask task=new IndividualDistanceTask(distances, index, localExample, example, endController);
executor.execute(task);
index++;
}
endController.await();Then, depending on the value of the parallelSort attribute, we call the Arrays.sort() or Arrays.parallelSort() methods.
if (parallelSort) {
Arrays.parallelSort(distances);
} else {
Arrays.sort(distances);
}Finally, we calculate the tag assigned to the input examples. This code is the same as in the serial version.
The KnnClassifierParallelIndividual class also includes a method to shutdown the executor calling its shutdown() method. It you don't call this method, your application will never end because threads created by the executor are still alive and waiting for the new tasks to do. Previously submitted tasks are executed, and newly submitted tasks are rejected. The method doesn't wait for the finalization of the executor, it returns immediately:
public void destroy() {
executor.shutdown();
}A critical part of this example is the IndividualDistanceTask class. This is the class that calculates the distance between the input example and an example of the train dataset as a concurrent task. It stores the full array of distances (we are going to establish the value of one of its positions only), the index of the example of the train dataset, both examples, and the CountDownLatch object used to control the end of the tasks. It implements the Runnable interface, so it can be executed in the executor. This is the constructor of the class:
public class IndividualDistanceTask implements Runnable {
private Distance[] distances;
private int index;
private Sample localExample;
private Sample example;
private CountDownLatch endController;
public IndividualDistanceTask(Distance[] distances, int index, Sample localExample,
Sample example, CountDownLatch endController) {
this.distances=distances;
this.index=index;
this.localExample=localExample;
this.example=example;
this.endController=endController;
}The run() method calculates the distance between the two examples using the EuclideanDistanceCalculator class explained before and stores the result in the corresponding position of the distances:
public void run() {
distances[index] = new Distance();
distances[index].setIndex(index);
distances[index].setDistance (EuclideanDistanceCalculator.calculate(localExample, example));
endController.countDown();
}The concurrent solution presented in the previous section may have a problem. You are executing too many tasks. If you stop to think, in this case, we have more than 29,000 train examples, so you're going to launch 29,000 tasks per example you want to classify. On the other hand, we have created an executor with a maximum of numThreads worker-threads, so another option is to launch only numThreads tasks and split the train dataset in numThreads groups. We executed the examples with a quad-core processor, so each task will calculate the distances between the input example and approximately 7,000 train examples.
We have implemented this solution in the KnnClassifierParallelGroup class. It's very similar to the KnnClassifierParallelIndividual class with two main differences. First, the first part of the classify() method. Now, we will only have numThreads tasks, and we have to split the train dataset in numThreads subsets:
public String classify(Sample example) throws Exception {
Distance distances[] = new Distance[dataSet.size()];
CountDownLatch endController = new CountDownLatch(numThreads);
int length = dataSet.size() / numThreads;
int startIndex = 0, endIndex = length;
for (int i = 0; i < numThreads; i++) {
GroupDistanceTask task = new GroupDistanceTask(distances, startIndex, endIndex, dataSet, example, endController);
startIndex = endIndex;
if (i < numThreads - 2) {
endIndex = endIndex + length;
} else {
endIndex = dataSet.size();
}
executor.execute(task);
}
endController.await();We calculate the number of samples per task in the length variable. Then, we assign to each thread the start and end indexes of the samples they have to process. For all the threads except the last one, we add the length value to the start index to calculate the end index. For the last one, the last index is the size of the dataset.
Second, this class uses GroupDistanceTask instead of IndividualDistanceTask. The main difference between those classes is that the first one processes a subset of the train dataset, so it stores the full train dataset and the first and last positions of the dataset it has to process:
public class GroupDistanceTask implements Runnable {
private Distance[] distances;
private int startIndex, endIndex;
private Sample example;
private List<? extends Sample> dataSet;
private CountDownLatch endController;
public GroupDistanceTask(Distance[] distances, int startIndex, int endIndex, List<? extends Sample> dataSet, Sample example, CountDownLatch endController) {
this.distances = distances;
this.startIndex = startIndex;
this.endIndex = endIndex;
this.example = example;
this.dataSet = dataSet;
this.endController = endController;
}The run() method processes a set of examples instead of only one example:
public void run() {
for (int index = startIndex; index < endIndex; index++) {
Sample localExample=dataSet.get(index);
distances[index] = new Distance();
distances[index].setIndex(index);
distances[index].setDistance(EuclideanDistanceCalculator
.calculate(localExample, example));
}
endController.countDown();
}Let's compare the different versions of the k-nearest neighbors algorithms we have implemented. We have the following five different versions:
- The serial version
- The fine-grained concurrent version with serial sorting
- The fine-grained concurrent version with concurrent sorting
- The coarse-grained concurrent version with serial sorting
- The coarse-grained concurrent version with concurrent sorting
To test the algorithm, we have used 2,059 test instances, which we take from the Bank Marketing dataset. We have classified all those examples using the five versions of the algorithm using the values of k as 10, 30, and 50, and measured their execution time. We have used the JMH framework (http://openjdk.java.net/projects/code-tools/jmh/) which allows you to implement microbenchmarks in Java. Using a framework for benchmarking is a better solution that simply measures time using the currentTimeMillis() or nanoTime() methods. These are the results:
|
Algorithm |
K |
Execution time (seconds) |
|---|---|---|
|
Serial |
10 |
100.296 |
|
30 |
99.218 | |
|
50 |
99.458 | |
|
Fine-grained serial sort |
10 |
108.150 |
|
30 |
105.196 | |
|
50 |
109.797 | |
|
Fine-grained concurrent sort |
10 |
84.663 |
|
30 |
85,392 | |
|
50 |
83.373 | |
|
Coarse-grained serial sort |
10 |
78.328 |
|
30 |
77.041 | |
|
50 |
76.549 | |
|
Coarse-grained concurrent sort |
10 |
54,017 |
|
30 |
53.473 | |
|
50 |
53.255 |
We can draw the following conclusions:
- The selected values of the K parameter (10, 30, and 50) don't affect the execution time of the algorithm. The five versions present similar results for the three values.
- As it was expected, the use of the concurrent sort with the
Arrays.parallelSort()method gives a great improvement in performance in the fine-grained and the coarse-grained concurrent versions of the algorithms. - The fine-grained version of the algorithm gives the same or slightly worse results than the serial algorithm. The overhead introduced by the creation and management of concurrent tasks provokes these results. We execute too many tasks.
- The coarse-grained version, on the other hand, offers a great improvement of performance, with serial or parallel sorting.
So, the best version of the algorithm is the coarse-grained solution using parallel sorting. If we compare it with the serial version calculating the speedup:
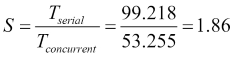
This example shows how a good election of a concurrent solution can give us a great improvement, and a bad election can give us a bad performance.