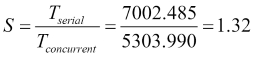Social networks are transforming our society and the way people relate to each other. Fackebook, Linkedin, Twitter, or Instagram have millions of users who use these networks to share life moments with their friends, make new professional contacts, promote their professional brand, meet new people, or simply know the latest trends in the world.
We can see a social network as a graph where users are the nodes of the graph and relations between users are the arcs of the graph. As occurs with graphs, there are social networks such as Facebook, where relations between users are undirected or bidirectional. If user A is connected with user B, user B is connected with A too. On the contrary, there are social networks such as Twitter where relations between users are directed. We say in this case that user A follows user B, but the contrary is not necessarily true.
In this section, we are going to implement an algorithm to calculate the common contacts for every pair of users in a social network with bidirectional relations between users. We are going to implement the algorithm described in http://stevekrenzel.com/finding-friends-with-mapreduce. The main steps of that algorithm are as follows.
Our data source will be a file where we store every user with their contacts:
A-B,C,D, B-A,C,D,E, C-A,B,D,E, D-A,B,C,E, E-B,C,D,
This means that user A has users B, C, and D as contacts. Take into account that the relations are bidirectional, so if B is a contact for A, A will be a contact for B too and both relations have to be represented in the file. So, we have elements with the following two parts:
- A user identifier
- The list of contacts for that user
In the next step, we generate a set of elements with three parts per every element. The three parts are:
- A user identifier
- The user identifier of a friend
- The list of contacts for that user
Thus, for user A, we will generate the following elements:
A-B-B,C,D A-C-B,C,D A-D-B,C,D
We follow the same process for all the elements. We are going to store the two user identifiers alphabetically sorted. Thus, for user B, we generate the following elements:
A-B-A,C,D,E B-C-A,C,D,E B-D-A,C,D,E B-E-A,C,D,E
Once we have generated all the new elements, we group them for the two user identifiers. For example, for the tuple A-B we will generate the following group:
A-B-(B,C,D),(A,C,D,E)
Finally, we calculate the intersection between the two lists. The resultant lists are the common contacts between the two users. For example, users A and B have in common the contacts C and D.
To test our algorithm, we have used two datasets:
- The test sample presented earlier.
- The social circles: the Facebook dataset that you can download from https://snap.stanford.edu/data/egonets-Facebook.html contains the contact information of 4,039 users from Facebook. We have transformed the original data into the data format used by our example.
As with other examples in the book, we have implemented the serial and concurrent versions of this example to verify that parallel streams improve the performance of our application. Both versions share some classes.
The Person class stores the information about every person in the social network that includes the following:
- It's user ID, stored in the ID attribute
- The list of contacts of that user, stored as a list of
Stringobjects in the contacts attribute
The class declares both attributes and the corresponding getXXX() and setXXX() methods. We also need a constructor to create the list and a method named addContact() to add a single contact to the list of contacts. The source code of this class is very simple, so it won't be included here.
The PersonPair class extends the Person class adding the attribute to store the second user identifier. We called this attribute otherId. This class declares the attribute and implements the corresponding getXXX() and setXXX() methods. We need an additional method named getFullId() that returns a string with the two user identifiers separated by a , character. The source code of this class is very simple, so it won't be included here.
The DataLoader class loads the file with the information of the users and their contacts and converts it into a list of Person objects. It implements only a static method named load() that receives the path of the file as a String object as a parameter and returns the list of Person objects.
As we mentioned earlier, the file has the following format:
User-C1,C2,C3...CN
Here, User is the identifier of the user, and C1, C2, C3….CN are the identifiers of the contacts of that user.
The source code of this class is very simple, so it won't be included here.
First, let's analyze the concurrent version of this algorithm.
The CommonPersonMapper class is an auxiliary class that will be used later. It will generate all the PersonPair objects you can generate from a Person object. This class implements the Function interface parameterized with the Person and List<PersonPair> classes.
It implements the apply() method defined in the Function interface. First, we initialize the List<PersonPair> object that we're going to return and obtain and sort the list of contacts for the person:
public class CommonPersonMapper implements Function<Person, List<PersonPair>> {
@Override
public List<PersonPair> apply(Person person) {
List<PersonPair> ret=new ArrayList<>();
List<String> contacts=person.getContacts();
Collections.sort(contacts);Then, we process the whole list of contacts creating the PersonPair object per contact. As we mentioned earlier, we store the two contacts sorted in alphabetical order. The lesser one in the ID field and the other in the otherId field:
for (String contact : contacts) {
PersonPair personExt=new PersonPair();
if (person.getId().compareTo(contact) < 0) {
personExt.setId(person.getId());
personExt.setOtherId(contact);
} else {
personExt.setId(contact);
personExt.setOtherId(person.getId());
}Finally, we add the list of contacts to the new object and the object to the list of results. Once we have processed all the contacts, we return the list of results:
personExt.setContacts(contacts);
ret.add(personExt);
}
return ret;
}
}The ConcurrentSocialNetwork is the main class of this example. It implements only a static method named bidirectionalCommonContacts(). This method receives the list of persons of the social network with their contacts and returns a list of PersonPair objects with the common contacts between every pair of users who are contacts.
Internally, we use two different streams to implement our algorithm. We use the first one to transform the input list of Person objects into a map. The keys of this map will be the two identifiers of every pair of users, and the value will be a list of PersonPair objects with the contacts of both users. So, these lists will always have two elements. We have the following code:
public class ConcurrentSocialNetwork {
public static List<PersonPair> bidirectionalCommonContacts(
List<Person> people) {
Map<String, List<PersonPair>> group = people.parallelStream()
.map(new CommonPersonMapper())
.flatMap(Collection::stream)
.collect(Collectors.groupingByConcurrent (PersonPair::getFullId));This stream has the following components:
- We create the stream using the
parallelStream()method of the input list. - Then, we use the
map()method and theCommonPersonMapperclass explained earlier to transform everyPersonobject in a list ofPersonPairobjects with all the possibilities for that object. - At this moment, we have a stream of
List<PersonPair>objects. We use theflatMap()method to convert that stream into a stream ofPersonPairobjects. - Finally, we use the
collect()method to generate the map using the collector returned by thegroupingByConcurrent()method using the value returned by thegetFullId()method as the keys for the map.
Then, we create a new collector using the of() method of the Collectors class. This collector will receive a Collection of string as input, use an AtomicReference<Collection<String>> as intermediate data structure, and return a Collection of string as the return type.
Collector<Collection<String>, AtomicReference<Collection<String>>, Collection<String>> intersecting = Collector.of(
() -> new AtomicReference<>(null), (acc, list) -> {
acc.updateAndGet(set -> set == null ? new ConcurrentLinkedQueue<>(list) : set).retainAll(list);
}, (acc1, acc2) -> {
if (acc1.get() == null)
return acc2;
if (acc2.get() == null)
return acc1;
acc1.get().retainAll(acc2.get());
return acc1;
}, (acc) -> acc.get() == null ? Collections.emptySet() : acc.get(), Collector.Characteristics.CONCURRENT, Collector.Characteristics.UNORDERED);The first parameter of the of() method is the supplier function. This supplier is called always when we need to create an intermediate structure of data. In serial streams, this method is called only once, but in concurrent streams, this method will be called once per thread.
() -> new AtomicReference<>(null),
In our case, we simply create a new AtomicReference to store the Collection<String> object.
The second parameter of the of() method is the accumulator function. This function receives an intermediate data structure and an input value as parameters:
(acc, list) -> {
acc.updateAndGet(set -> set == null ? new ConcurrentLinkedQueue<>(list) : set).retainAll(list);
},In our case, the acc parameter is an AtomicReference and the list parameter is a ConcurrentLinkedDeque. We use the updateAndGet() method of the AtomicReference. This method updates the current value and returns the new value. If the AtomicReference is null, we create a new ConcurrentLinkedDeque with the elements of the list. If the AtomicReference is not null, it will store a ConcurrentLinkedDeque. We use the retainAll() method to add all the elements of the list.
The third parameter of the of() method is the combiner function. This function is only called in parallel streams, and it receives two intermediate data structures as a parameter to generate only one.
(acc1, acc2) -> {
if (acc1.get() == null)
return acc2;
if (acc2.get() == null)
return acc1;
acc1.get().retainAll(acc2.get());
return acc1;
},In our case, if one of the parameters is null, we return the other. Otherwise, we use the retainAll() method in the acc1 parameter and returns the result.
The fourth parameter of the of() method is the finisher function. This function converts the final intermediate data structure in the data structure we want to return. In our case, the intermediate and final data structures are the same, so no conversion is needed.
(acc) -> acc.get() == null ? Collections.emptySet() : acc.get(),
Finally, we use the last parameter to indicate to the collector that the collector is concurrent, that is to say, the accumulator function can be called concurrently with the same result container from multiple threads, and unordered, that is to say, this operation will not preserve the original order of the elements.
As we have defined the collector now, we have to convert the map generated with the first stream into a list of PersonPair objects with the common contacts of each pair of users. We use the following code:
List<PersonPair> peopleCommonContacts = group.entrySet()
.parallelStream()
.map((entry) -> {
Collection<String> commonContacts =
entry.getValue()
.parallelStream()
.map(p -> p.getContacts())
.collect(intersecting);
PersonPair person = new PersonPair();
person.setId(entry.getKey().split(",")[0]);
person.setOtherId(entry.getKey().split (",")[1]);
person.setContacts(new ArrayList<String> (commonContacts));
return person;
}).collect(Collectors.toList());
return peopleCommonContacts;
}
}We use the entySet() method to process all the elements of the map. We create a parallelStream() method to process all the Entry objects and then use the map() method to convert every list of PersonPair objects into a unique PersonPair object with the common contacts.
For each entry, the key is the identifier of a pair of users concatenated with, as separator and the value is a list of two PersonPair objects. The first one contains the contacts of one user, and the other contains the contacts of the other user.
We create a stream for that list to generate the common contacts of both users with the following elements:
- We create the stream using the
parallelStream()method of the list - We use the
map()method to replace eachPersonPair()object for the list of contacts stored in it - Finally, we use our collector to generate
ConcurrentLinkedDequewith the common contacts
Finally, we create a new PersonPair object with the identifier of both users and the list of common contacts. We add that object to the list of results. When all the elements of the map have been processed, we can return the list of results.
The ConcurrentMain class implements the main() method to test our algorithm. As we mentioned earlier, we have tested it with the following two datasets:
- A very simple dataset to test the correctness of the algorithm
- A dataset based on real data from Facebook
This is the source code of this class:
public class ConcurrentMain {
public static void main(String[] args) {
Date start, end;
System.out.println("Concurrent Main Bidirectional - Test");
List<Person> people=DataLoader.load("data","test.txt");
start=new Date();
List<PersonPair> peopleCommonContacts= ConcurrentSocialNetwork.bidirectionalCommonContacts (people);
end=new Date();
peopleCommonContacts.forEach(p -> System.out.println (p.getFullId()+": "+getContacts(p.getContacts())));
System.out.println("Execution Time: "+(end.getTime()- start.getTime()));
System.out.println("Concurrent Main Bidirectional - Facebook");
people=DataLoader.load("data","facebook_contacts.txt");
start=new Date();
peopleCommonContacts= ConcurrentSocialNetwork.bidirectionalCommonContacts (people);
end=new Date();
peopleCommonContacts.forEach(p -> System.out.println (p.getFullId()+": "+getContacts(p.getContacts())));
System.out.println("Execution Time: "+(end.getTime()- start.getTime()));
}
private static String formatContacts(List<String> contacts) {
StringBuffer buffer=new StringBuffer();
for (String contact: contacts) {
buffer.append(contact+",");
}
return buffer.toString();
}
}As with other examples in this book, we have implemented a serial version of this example. This version is equal to the concurrent one making the following changes:
- Replace the
parallelStream()method by thestream()method - Replace the
ConcurrentLinkedDequedata structure by theArrayListdata structure - Replace the
groupingByConcurrent()method by thegroupingBy()method - Don't use the final parameter in the
of()method
We have executed both versions with both datasets using the JMH framework (http://openjdk.java.net/projects/code-tools/jmh/) that allows you to implement micro benchmarks in Java. Using a framework for benchmarking is a better solution that simply measures time using methods such as currentTimeMillis() or nanoTime(). We have executed them 10 times in a computer with a four-core processor and calculated the medium execution time of those 10 times. These are the results in milliseconds:
|
Example |
| |
|---|---|---|
|
Serial |
0.861 |
7002.485 |
|
Concurrent |
1.352 |
5303.990 |
We can draw the following conclusions:
- For the example dataset, the serial version obtains a better execution time. The reason for this result is that the example dataset has few elements.
- For the Facebook dataset, the concurrent version obtains a better execution time.
If we compare the concurrent and serial versions for the Facebook dataset, we obtain the following results: