According to Wikipedia (https://en.wikipedia.org/wiki/Information_retrieval), information retrieval is:
"The activity obtaining information resources relevant to an information need from a collection of information resources."
Usually, the information resources are a collection of documents and the information need is a set of words, which summarizes our need. To make a fast search over the document collection, we use a data structure named inverted index. It stores all the words of the document collection, and for each word, a list of the documents that contains that word. In Chapter 4, Getting Data from the Tasks – The Callable and Future Interfaces, you constructed an inverted index of a document collection constructed with the Wikipedia pages with information about movies to construct a set of 100,673 documents. We have converted each Wikipedia page in a text file. This inverted index is stored in a text file where each line contains the word, its document frequency, and all the documents in which the word appears with the tfxidf attribute of the word in the document. The documents are sorted by the value of the tfxidf attribute. For example, a line of the file looks like this:
velankanni:4,18005302.txt:10.13,20681361.txt:10.13,45672176.txt:10 .13,6592085.txt:10.13
This line contains the velankanni word with a DF of 4. It appears in the 18005302.txt document with a tfxidf value of 10.13, in the 20681361.txt document with a tfxidf value of 10.13, in the document 45672176.txt with a tfxidf value of 10.13, and in the 6592085.txt document with a tfxidf value of 10.13.
In this chapter, we will use the stream API to implement different versions of our search tool and obtain information about the inverted index.
As we mentioned earlier in this chapter, the reduce operation applies a summary operation to the elements of a stream to generate a single summary result. This single result can be of the same type as the elements of the stream of an other type. A simple example of the reduce operation is calculating the sum of a stream of numbers.
The stream API provides the reduce() method to implement reduction operations. This method has the following three different versions:
reduce(accumulator): This version applies theaccumulatorfunction to all the elements of the stream. There is no initial value in this case. It returns anOptionalobject with the final result of theaccumulatorfunction or an emptyOptionalobject if the stream is empty. Thisaccumulatorfunction must be anassociativefunction. It implements theBinaryOperatorinterface. Both parameters could be either the stream elements or the partial results returned by previous accumulator calls.reduce(identity, accumulator): This version must be used when the final result and the elements of the stream has the same type. The identity value must be an identity value for theaccumulatorfunction. That is to say, if you apply theaccumulatorfunction to the identity value and any valueV, it must return the same valueV: accumulator(identity,V)=V. That identity value is used as the first result for the accumulator function and is the returned value if the stream has no elements. As in the other version, the accumulator must be anassociativefunction that implements theBinaryOperatorinterface.reduce(identity, accumulator, combiner): This version must be used when the final result has a different type than the elements of the stream. The identity value must be an identity for thecombinerfunction, that is to say,combiner(identity,v)=v. Acombinerfunction must be compatible with theaccumulatorfunction, that is to say,combiner(u,accumulator(identity,v))=accumulator(u,v). Theaccumulatorfunction takes a partial result and the next element of the stream to generate a partial result, and the combiner takes two partial results to generate another partial result. Both functions must be associative, but in this case, theaccumulatorfunction is an implementation of theBiFunctioninterface and thecombinerfunction is an implementation of theBinaryOperatorinterface.
The reduce() method has a limitation. As we mentioned before, it must return a single value. You shouldn't use the reduce() method to generate a collection or a complex object. The first problem is performance. As the documentation of the stream API specifies, the accumulator function returns a new value every time it processes an element. If your accumulator function works with collections, every time it processes an element it creates a new collection, which is very inefficient. Another problem is that, if you work with parallel streams, all the threads will share the identity value. If this value is a mutable object, for example, a collection, all the threads will be working over the same collection. This does not comply with the philosophy of the reduce() operation. In addition, the combiner() method will always receive two identical collections (all the threads are working over only one collection), that also doesn't comply the philosophy of the reduce() operation.
If you want to make a reduction that generates a collection or a complex object, you have the following two options:
- Apply a mutable reduction with the
collect()method. Chapter 8, Processing Massive Datasets with Parallel Streams – The Map and Collect Model, explains in detail how to use this method in different situations. - Create the collection and use the
forEach()method to fill the collection with the required values.
In this example, we will use the reduce() method to obtain information about the inverted index and the forEach() method to reduce the index to the list of relevant documents for a query.
In our first approach, we will use all the documents associated with a word. The steps of this implementation of our search process are:
- We select in the inverted index the lines corresponding with the words of the query.
- We group all the document lists in a single list. If a document appears associated with two or more different words, we sum the
tfxidfvalue of those words in the document to obtain the finaltfxidfvalue of the document. If a document is only associated with one word, thetfxidfvalue of that word will be the finaltfxidfvalue for that document. - We sort the documents using its
tfxidfvalue, from high to low. - We show to the user the 100 documents with a higher value of
tfxidf.
We have implemented this version in the basicSearch()method of the ConcurrentSearch class. This is the source code of the method:
public static void basicSearch(String query[]) throws IOException {
Path path = Paths.get("index", "invertedIndex.txt");
HashSet<String> set = new HashSet<>(Arrays.asList(query));
QueryResult results = new QueryResult(new ConcurrentHashMap<>());
try (Stream<String> invertedIndex = Files.lines(path)) {
invertedIndex.parallel() .filter(line -> set.contains(Utils.getWord(line))) .flatMap(ConcurrentSearch::basicMapper) .forEach(results::append);
results .getAsList() .stream() .sorted() .limit(100) .forEach(System.out::println);
System.out.println("Basic Search Ok");
}
}We receive an array of string objects with the words of the query. First, we transform that array in a set. Then, we use a try-with-resources stream with the lines of the invertedIndex.txt file, which is the file that contains the inverted index. We use a try-with-resources so we don't have to worry about opening or closing the file. The aggregate operations of the stream will generate a QueryResult object with the relevant documents. We use the following methods to obtain that list:
parallel(): First, we obtain a parallel stream to improve the performance of the search process.filter(): We select the lines that associated the word in the set with the words in the query. TheUtils.getWord()method obtains the word of the line.flatMap(): We convert the stream of strings where each string is a line of the inverted index in a stream ofTokenobjects. Each token contains thetfxidfvalue of a word in a file. Of every line, we will generate as many tokens as files containing that word.forEach(): We generate theQueryResultobject adding every token with theadd()method of that class.
Once we have created the QueryResult object, we create other streams to obtain the final list of results using the following methods:
getAsList(): TheQueryResultobject returns a list with the relevant documentsstream(): To create a stream to process the listsorted(): To sort the list of documents by itstfxidfvaluelimit(): To get the first 100 resultsforEach(): To process the 100 results and write the information in the screen
Let's describe the auxiliary classes and methods used in the example.
This method converts a stream of strings into a stream of Token objects. As we will describe later in detail, a token stores the tfxidf value of a word in a document. This method receives a string with a line of the inverted index. It splits the line into the tokens and generates as many Token objects as documents containing the word. This method is implemented in the ConcurrentSearch class. This is the source code:
public static Stream<Token> basicMapper(String input) {
ConcurrentLinkedDeque<Token> list = new ConcurrentLinkedDeque();
String word = Utils.getWord(input);
Arrays .stream(input.split(","))
.skip(1) .parallel() .forEach(token -> list.add(new Token(word, token)));
return list.stream();
}First, we create a ConcurrentLinkedDeque object to store the Token objects. Then, we split the string using the split() method and use the stream() method of the Arrays class to generate a stream. Skip the first element (which contains the information of the word) and process the rest of the tokens in parallel. For each element, we create a new Token object (we pass to the constructor the word and the token that has the file:tfxidf format) and add it to the stream. Finally, we return a stream using the stream() method of the ConcurrenLinkedDeque object.
As we mentioned earlier, this class stores the tfxidf value of a word in a document. So, it has three attributes to store this information, as follows:
public class Token {
private final String word;
private final double tfxidf;
private final String file;The constructor receives two strings. The first one contains the word, and the second one contains the file and the tfxidf attribute in the file:tfxidf format, so we have to process it as follows:
public Token(String word, String token) {
this.word=word;
String[] parts=token.split(":");
this.file=parts[0];
this.tfxidf=Double.parseDouble(parts[1]);
}Finally, we have added methods to obtain (not to set) the values of the three attributes and to convert an object to a string, as follows:
@Override
public String toString() {
return word+":"+file+":"+tfxidf;
}This class stores the list of documents relevant to a query. Internally, it uses a map to store the information of the relevant documents. The key is the name of the file that stores the document, and the value is a Document object that also contains the name of the file and the total tfxidf value of that document to the query, as follows:
public class QueryResult {
private Map<String, Document> results;We use the constructor of the class to indicate the concrete implementation of the Map interface we will use. We use a ConcurrentHashMap to the concurrent version and a HashMap in the serial version:
public QueryResult(Map<String, Document> results) {
this.results=results;
}The class includes the append method that inserts a token in the map, as follows:
public void append(Token token) {
results.computeIfAbsent(token.getFile(), s -> new Document(s)).addTfxidf(token.getTfxidf());
}We use the computeIfAbsent() method to create a new Document object if there is no Document object associated with the file or to obtain the corresponding one if already exists and add the tfxidf value of the token to the total tfxidf value of the document using the addTfxidf() method.
Finally, we have included a method to obtain the map as a list, as follows:
public List<Document> getAsList() {
return new ArrayList<>(results.values());
}The Document class stores the name of the file as a string and the total tfxidf value as DoubleAdder. This class is a new feature of Java 8 and allows us to sum values to the variable from different threads without worrying about synchronization. It implements the Comparable interface to sort the documents by its tfxidf value, so the documents with biggest tfxidf will be first. Its source code is very simple, so it is not included.
The first approach creates a new Token object per word and file. We have noted that common words, for example, the, take a lot of documents associated and a lot of them have low values of tfxidf. We have changed our mapper method to take into account only 100 files per word, so the number of Token objects generated will be smaller.
We have implemented this version in the reducedSearch() method of the ConcurrentSearch class. This method is very similar to the basicSearch() method. It only changes the stream operations that generate the QueryResult object, as follows:
invertedIndex.parallel() .filter(line -> set.contains(Utils.getWord(line))) .flatMap(ConcurrentSearch::limitedMapper) .forEach(results::append);
Now, we use the limitedMapper() method as function in the flatMap() method.
This method is similar to the basicMapper() method, but, as we mentioned earlier, we only take into account the first 100 documents associated with every word. As the documents are sorted by its tfxidf value, we are using the 100 documents in which the word is more important, as follows:
public static Stream<Token> limitedMapper(String input) {
ConcurrentLinkedDeque<Token> list = new ConcurrentLinkedDeque();
String word = Utils.getWord(input);
Arrays.stream(input.split(",")) .skip(1) .limit(100) .parallel() .forEach(token -> {
list.add(new Token(word, token));
});
return list.stream();
}The only difference with the basicMapper() method is the limit(100) call that takes the first 100 elements of the stream.
While working with a search tool using a web search engine (for example, Google), when you make a search, it returns you the results of your search (the 10 most important) and for every result the title of the document and a fragment of the document where the words you have searched for appears.
Our third approach to the search tool is based on the second approach but by adding a third stream to generate an HTML file with the results of the search. For every result, we will show the title of the document and three lines where one of the words introduced in the query appears. To implement this, you need access to the files that appears in the inverted index. We have stored them in a folder named docs.
This third approach is implemented in the htmlSearch()method of the ConcurrentSearch class. The first part of the method to construct the QueryResult object with the 100 results is equal to the reducedSearch() method, as follows:
public static void htmlSearch(String query[], String fileName) throws IOException {
Path path = Paths.get("index", "invertedIndex.txt");
HashSet<String> set = new HashSet<>(Arrays.asList(query));
QueryResult results = new QueryResult(new ConcurrentHashMap<>());
try (Stream<String> invertedIndex = Files.lines(path)) {
invertedIndex.parallel() .filter(line -> set.contains(Utils.getWord(line))) .flatMap(ConcurrentSearch::limitedMapper) .forEach(results::append);Then, we create the file to write the output and the HTML headers in it:
path = Paths.get("output", fileName + "_results.html");
try (BufferedWriter fileWriter = Files.newBufferedWriter(path, StandardOpenOption.CREATE)) {
fileWriter.write("<HTML>");
fileWriter.write("<HEAD>");
fileWriter.write("<TITLE>");
fileWriter.write("Search Results with Streams");
fileWriter.write("</TITLE>");
fileWriter.write("</HEAD>");
fileWriter.write("<BODY>");
fileWriter.newLine();Then, we include the stream that generates the results in the HTML file:
results.getAsList()
.stream()
.sorted()
.limit(100)
.map(new ContentMapper(query)).forEach(l -> {
try {
fileWriter.write(l);
fileWriter.newLine();
} catch (IOException e) {
e.printStackTrace();
}
});
fileWriter.write("</BODY>");
fileWriter.write("</HTML>");
}We have used the following methods:
getAsList()to get the list of relevant documents for the query.stream()to generate a sequential stream. We can't parallelize this stream. If we try to do it, the results in the final file won't be sorted by thetfxidfvalue of the documents.sorted()to sort the results by itstfxidfattribute.map()to convert aResultobject into a string with the HTML code for each result using theContentMapperclass. We will explain the details of this class later.forEach()to write theStringobjects returned by themap()method in the file. The methods of theStreamobject can't throw a checked exception, so we have to include the try-catch block that will throw.
Let's see the details of the ContentMapper class.
The ContentMapper class is an implementation of the Function interface that converts a Result object in an HTML block with the title of the document and three lines that include one or more words of the query.
The class uses an internal attribute to store the query and implements a constructor to initialize that attribute, as follows:
public class ContentMapper implements Function<Document, String> {
private String query[];
public ContentMapper(String query[]) {
this.query = query;
}The title of the document is stored in the first line of the file. We use a try-with-resources instruction and the lines() method of the Files class to create and stream String objects with the lines of the file and take the first one with the findFirst() to obtain the line as a string:
public String apply(Document d) {
String result = "";
try (Stream<String> content = Files.lines(Paths.get("docs",d.getDocumentName()))) {
result = "<h2>" + d.getDocumentName() + ": "
+ content.findFirst().get()
+ ": " + d.getTfxidf() + "</h2>";
} catch (IOException e) {
e.printStackTrace();
throw new UncheckedIOException(e);
}Then, we use a similar structure, but in this case, we use the filter() method to get only the lines that contain one or more words of the query, the limit() method to take three of those lines. Then, we use the map() method to add the HTML tags for a paragraph (<p>) and the reduce() method to complete the HTML code with the selected lines:
try (Stream<String> content = Files.lines(Paths.get ("docs",d.getDocumentName()))) {
result += content
.filter(l -> Arrays.stream(query).anyMatch (l.toLowerCase()::contains))
.limit(3)
.map(l -> "<p>"+l+"</p>")
.reduce("",String::concat);
return result;
} catch (IOException e) {
e.printStackTrace();
throw new UncheckedIOException(e);
}
}The three previous solutions have a problem when they are executed in parallel. As we mentioned earlier, parallel streams are executed using the common Fork/Join pool provided by the Java concurrency API. In Chapter 6, Optimizing Divide and Conquer Solutions – The Fork/Join Framework, you learned that you shouldn't use I/O operations as read or write data in a file inside the tasks. This is because when a thread has blocked reading or writing data from or to a file, the framework doesn't use the work-stealing algorithm. As we use a file as the source of our streams, we are penalizing our concurrent solution.
One solution to this problem is to read the data to a data structure and then create our streams from that data structure. Obviously, the execution time of this approach will be smaller when we compare it with the other approaches, but we want to compare the serial and concurrent versions to see (as we expect) that the concurrent version gives us better performance than the serial version. The bad part of this approach is that you need to have your data structure in memory, so you will need a big amount of memory.
This fourth approach is implemented in the preloadSearch() method of the ConcurrentSearch class. This method receives the query as an Array of String and an object of the ConcurrentInvertedIndex class (we will see the details of this class later) with the data of the inverted index as parameters. This is the source code of this version:
public static void preloadSearch(String[] query, ConcurrentInvertedIndex invertedIndex) {
HashSet<String> set = new HashSet<>(Arrays.asList(query));
QueryResult results = new QueryResult(new ConcurrentHashMap<>());
invertedIndex.getIndex()
.parallelStream()
.filter(token -> set.contains(token.getWord()))
.forEach(results::append);
results
.getAsList()
.stream()
.sorted()
.limit(100)
.forEach(document -> System.out.println(document));
System.out.println("Preload Search Ok.");
}The ConcurrentInvertedIndex class has List<Token> to store all the Token objects read from the file. It has two methods, get() and set() for this list of elements.
As in other approaches, we use two streams: the first one to get a ConcurrentLinkedDeque of Result objects with the whole list of results and the second one to write the results in the console. The second one doesn't change over other versions, but the first one changes. We use the following methods in this stream:
getIndex(): First, we obtain the list ofTokenobjectsparallelStream(): Then, we create a parallel stream to process all the elements of the listfilter(): We select the token associated with the words in the queryforEach(): We process the list of tokens adding them to theQueryResultobject using theappend()method
The ConcurrentFileLoader class loads into memory the contents of the invertedIndex.txt file with the information of the inverted index. It provides a static method named load() that receives a path with the route of the file where the inverted index is stored and returns an ConcurrentInvertedIndex object. We have the following code:
public class ConcurrentFileLoader {
public ConcurrentInvertedIndex load(Path path) throws IOException {
ConcurrentInvertedIndex invertedIndex = new ConcurrentInvertedIndex();
ConcurrentLinkedDeque<Token> results=new ConcurrentLinkedDeque<>();We open the file using a try-with-resources structure and create a stream to process all the lines:
try (Stream<String> fileStream = Files.lines(path)) {
fileStream
.parallel()
.flatMap(ConcurrentSearch::limitedMapper)
.forEach(results::add);
}
invertedIndex.setIndex(new ArrayList<>(results));
return invertedIndex;
}
}We use the following methods in the stream:
parallel(): We convert the stream into a parallel oneflatMap(): We convert the line into a stream ofTokenobjects using thelimitedMapper()method of theConcurrentSearchclassforEach(): We process the list ofTokenobjects adding them to aConcurrentLinkedDequeobject using theadd()method
Finally, we convert the ConcurrentLinkedDeque object into ArrayList and set it in the InvertedIndex object using the setIndex() method.
To go further with this example, we're going to test another concurrent version. As we mentioned in the introduction of this chapter, parallel streams use the common Fork/Join pool introduced in Java 8. However, we can use a trick to use our own pool. If we execute our method as a task of the Fork/Join pool, all the operations of the stream will be executed in the same Fork/Join pool. To test this functionality, we have added the executorSearch() method to the ConcurrentSearch class. This method receives the query as an array of String objects as a parameter, the InvertedIndex object, and a ForkJoinPool object. This is the source code of this method:
public static void executorSearch(String[] query, ConcurrentInvertedIndex invertedIndex, ForkJoinPool pool) {
HashSet<String> set = new HashSet<>(Arrays.asList(query));
QueryResult results = new QueryResult(new ConcurrentHashMap<>());
pool.submit(() -> {
invertedIndex.getIndex()
.parallelStream()
.filter(token -> set.contains(token.getWord()))
.forEach(results::append);
results
.getAsList()
.stream()
.sorted()
.limit(100)
.forEach(document -> System.out.println(document));
}).join();
System.out.println("Executor Search Ok.");
}We execute the content of the method, with its two streams, as a task in the Fork/Join pool using the submit() method, and wait for its finalization using the join() method.
We have implemented some methods to get information about the inverted index using the reduce() method in the ConcurrentData class.
The first method calculates the number of words in a file. As we mentioned earlier in this chapter, the inverted index stores the files in which a word appears. If we want to know the words that appear in a file, we have to process all the inverted index. We have implemented two versions of this method. The first one is implemented in getWordsInFile1(). It receives the name of the file and the InvertedIndex object as parameters, as follows:
public static void getWordsInFile1(String fileName, ConcurrentInvertedIndex index) {
long value = index
.getIndex()
.parallelStream()
.filter(token -> fileName.equals(token.getFile()))
.count();
System.out.println("Words in File "+fileName+": "+value);
}In this case, we get the list of Token objects using the getIndex() method and create a parallel stream using the parallelStream() method. Then, we filter the tokens associated with the file using the filter() method, and finally, we count the number of words associated with that file using the count() method.
We have implemented another version of this method using the reduce() method instead of the count() method. It's the getWordsInFile2() method:
public static void getWordsInFile2(String fileName, ConcurrentInvertedIndex index) {
long value = index
.getIndex()
.parallelStream()
.filter(token -> fileName.equals(token.getFile()))
.mapToLong(token -> 1)
.reduce(0, Long::sum);
System.out.println("Words in File "+fileName+": "+value);
}The start of the sequence of operations is the same as the previous one. When we have obtained the stream of Token objects with the words of the file, we use the mapToInt() method to convert that stream into a stream of 1 and then the reduce() method to sum all the 1 numbers.
We have implemented the getAverageTfxidf() method that calculates the average tfxidf value of the words of a file in the collection. We have used here the reduce() method to show how it works. You can use other methods here with better performance:
public static void getAverageTfxidf(String fileName, ConcurrentInvertedIndex index) {
long wordCounter = index
.getIndex()
.parallelStream()
.filter(token -> fileName.equals(token.getFile()))
.mapToLong(token -> 1)
.reduce(0, Long::sum);
double tfxidf = index
.getIndex()
.parallelStream()
.filter(token -> fileName.equals(token.getFile()))
.reduce(0d, (n,t) -> n+t.getTfxidf(), (n1,n2) -> n1+n2);
System.out.println("Words in File "+fileName+": "+(tfxidf/wordCounter));
}We use two streams. The first one calculates the number of words in a file and has the same source code as the getWordsInFile2() method. The second one calculates the total tfxidf value of all the words in the file. We use the same methods to get the stream of Token objects with the words in the file and then we use the reduce method to sum the tfxidf value of all the words. We pass the following three parameters to the reduce() method:
O: This is passed as the identity value.(n,t) -> n+t.getTfxidf(): This is passed as theaccumulatorfunction. It receives adoublenumber and aTokenobject and calculates the sum of the number and thetfxidfattribute of the token.(n1,n2) -> n1+n2: This is passed as thecombinerfunction. It receives two numbers and calculates their sum.
We have also used the reduce() method to calculate the maximum and minimum tfxidf values of the inverted index in the maxTfxidf() and minTfxidf() methods:
public static void maxTfxidf(ConcurrentInvertedIndex index) {
Token token = index
.getIndex()
.parallelStream()
.reduce(new Token("", "xxx:0"), (t1, t2) -> {
if (t1.getTfxidf()>t2.getTfxidf()) {
return t1;
} else {
return t2;
}
});
System.out.println(token.toString());
}The method receives the ConcurrentInvertedIndex as a parameter. We use the getIndex() to obtain the list of Token objects. Then, we use the parallelStream() method to create a parallel stream over the list and the reduce() method to obtain the Token with the biggest tfxidf. In this case, we use the reduce() method with two parameters: an identity value and an accumulator function. The identity value is a Token object. We don't care about the word and the file name, but we initialize its tfxidf attribute with the value 0. Then, the accumulator function receives two Token objects as parameters. We compare the tfxidf attribute of both objects and return the one with greater value.
The minTfxidf() method is very similar, as follows:
public static void minTfxidf(ConcurrentInvertedIndex index) {
Token token = index
.getIndex()
.parallelStream()
.reduce(new Token("", "xxx:1000000"), (t1, t2) -> {
if (t1.getTfxidf()<t2.getTfxidf()) {
return t1;
} else {
return t2;
}
});
System.out.println(token.toString());
}The main difference is that in this case, the identity value is initialized with a very high value for the tfxidf attribute.
To test all the methods explained in the previous sections, we have implemented the ConcurrentMain class that implements the main() method to launch our tests. In these tests, we have used the following three queries:
query1, with the wordsjamesandbondquery2, with the wordsgone,with,the, andwindquery3, with the wordsrocky
We have tested the three queries with the three versions of our search process measuring the execution time of each test. All the tests have a code similar to this:
public class ConcurrentMain {
public static void main(String[] args) {
String query1[]={"james","bond"};
String query2[]={"gone","with","the","wind"};
String query3[]={"rocky"};
Date start, end;
bufferResults.append("Version 1, query 1, concurrent
");
start = new Date();
ConcurrentSearch.basicSearch(query1);
end = new Date();
bufferResults.append("Execution Time: "
+ (end.getTime() - start.getTime()) + "
");To load the inverted index from a file to an InvertedIndex object, you can use the following code:
ConcurrentInvertedIndex invertedIndex = new ConcurrentInvertedIndex();
ConcurrentFileLoader loader = new ConcurrentFileLoader();
invertedIndex = loader.load(Paths.get("index","invertedIndex.txt"));To create the Executor to use in the executorSearch() method, you can use the following code:
ForkJoinPool pool = new ForkJoinPool();
We have implemented a serial version of this example with the SerialSearch, SerialData, SerialInvertendIndex, SerialFileLoader, and SerialMain classes. To implement that version, we have made the following changes:
- Use sequential streams instead of parallel ones. You have to delete the use of the
parallel()method to convert the streams in parallel or replace the methodparallelStream()to create a parallel stream for thestream()method to create a sequential one. - In the
SerialFileLoaderclass, useArrayListinstead ofConcurrentLinkedDeque.
Let's compare the solutions of the serial and concurrent versions of all the methods we have implemented. We have executed them using the JMH framework (http://openjdk.java.net/projects/code-tools/jmh/), which allows you to implement micro benchmarks in Java. Using a framework for benchmarking is a better solution that simply measures time using methods such as currentTimeMillis() or nanoTime(). We have executed them 10 times in a computer with a four-core processor so a concurrent algorithm can become theoretically four times faster than a serial one. Take into account that we have implemented a special class to execute the JMH tests. You can find these classes in the com.javferna.packtpub.mastering.irsystem.benchmark package of the source code.
For the first query, with the words james and bond, these are the execution times obtained in milliseconds:
|
Serial |
Concurrent | |
|---|---|---|
|
Basic search |
3516.674 |
3301.334 |
|
Reduced search |
3458.351 |
3230.017 |
|
HTML search |
3298.996 |
3298.632 |
|
Preload search |
153.414 |
105.195 |
|
Executor search |
154.679 |
102.135 |
For the second query, with the words gone, with, the, and wind, these are the execution times obtained in milliseconds:
|
Serial |
Concurrent | |
|---|---|---|
|
Basic search |
3446.022 |
3441.002 |
|
Reduced search |
3249.930 |
3260.026 |
|
HTML search |
3299.625 |
3379.277 |
|
Preload search |
154.631 |
113.757 |
|
Executor search |
156.091 |
106.418 |
For the third query, with the words rocky, these are the execution times obtained in milliseconds:
|
Serial |
Concurrent | |
|---|---|---|
|
Basic search |
3271.308 |
3219.990 |
|
Reduced search |
3318.343 |
3279.247 |
|
HTML search |
3323.345 |
3333.624 |
|
Preload search |
151.416 |
97.092 |
|
Executor search |
155.033 |
103.907 |
Finally, these are the average execution times in milliseconds for the methods that return information about the inverted index:
|
Serial |
Concurrent | |
|---|---|---|
|
|
131.066 |
81.357 |
|
|
132.737 |
84.112 |
|
|
253.067 |
166.009 |
|
|
90.714 |
66.976 |
|
|
84.652 |
68.158 |
We can draw the following conclusions:
- When we read the inverted index to obtain the list of relevant documents, we obtain worse execution times. In this case, the execution times between the concurrent and serial versions are very similar.
- When we work with a preload version of the inverted index, concurrent versions of the algorithms give us better performance in all cases.
- For the methods that give us information about the inverted index, concurrent versions of the algorithms always give us better performance.
We can compare the parallel and sequential streams for the three queries in this end using the speed-up:

Finally, in our third approach, we generate an HTML web page with the results of the queries. These are the first results with the query james bond:
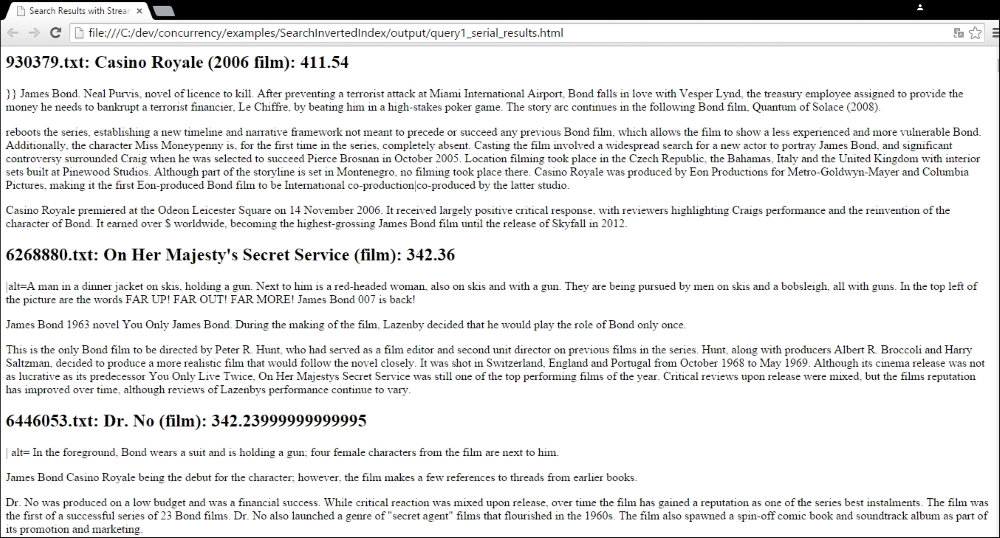
For the query gone with the wind, these are the first results:
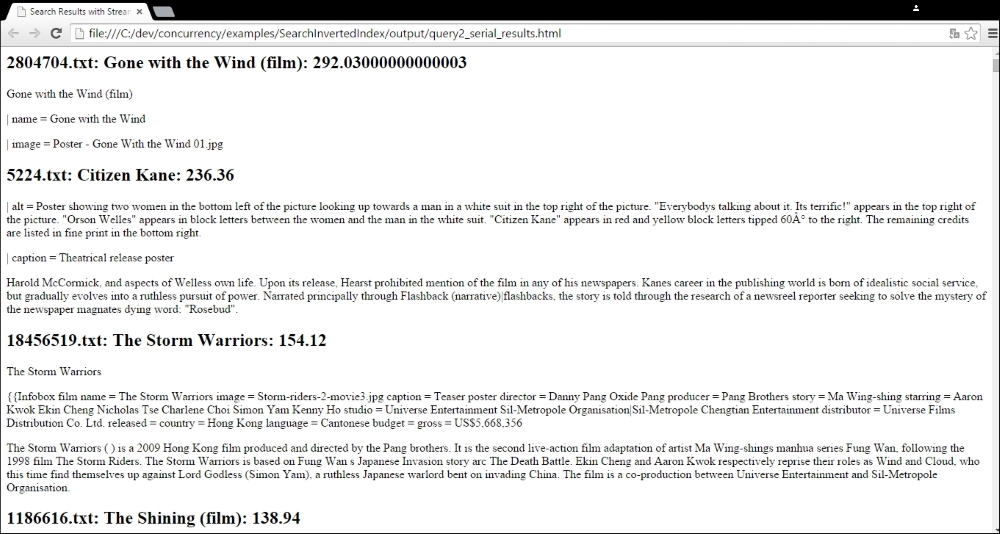
Finally, these are the first results for the query rocky: