
Synchronization of tasks is the coordination between those tasks to get the desired results. In concurrent applications, we can have two kinds of synchronizations:
- Process synchronization: We use this kind of synchronization when we want to control the order of execution of the tasks. For example, a task must wait for the finalization of other tasks before it starts its execution.
- Data synchronization: We use this kind of synchronization when two or more tasks access the same memory object. In this case, you have to protect the access in the write operations to that object. If you don't do this, you can have a data race condition where the final results of a program vary from one execution to another.
The Java concurrency API provides mechanisms that allow you to implement both types of synchronization. The most basic synchronization mechanism provided by the Java language is the synchronized keyword. This keyword can be applied to a method or to a block of code. In the first case, only one thread can execute the method at a time. In the second case, you have to specify a reference to an object. In this case, only one block of code protected by an object can be executed at the same time.
Java also provide other synchronization mechanisms:
- The
Lockinterface and its implementation classes: This mechanism allows you to implement a critical section to guarantee that only one thread will execute that block of code. - The
Semaphoreclass that implements the well-known semaphore synchronization mechanism introduced by Edsger Dijkstra. CountDownLatchallows you to implement a situation where one or more threads wait for the finalization of other threads.CyclicBarrierallows you to synchronize different tasks in a common point.Phaserallows you to implement concurrent tasks divided into phases. We made a detailed description of this mechanism in Chapter 5, Running Tasks Divided into Phases – The Phaser Class.Exchangerallows you to implement a point of data interchange between two tasks.CompletableFuture, a new feature of Java 8, extends theFuturemechanism of the executor tasks to generate the result of a task in an asynchronous way. You can specify tasks to be executed after the result is generated, so you can control the order of the execution of the tasks.
In the following section, we will show you how to use these mechanisms, giving special attention to the CompletableFuture mechanism introduced in the Java 8 version.
We have implemented a class named the CommonTask class. This class will sleep the calling thread during a random period of time between 0 and 10 seconds. This is its source code:
public class CommonTask {
public static void doTask() {
long duration = ThreadLocalRandom.current().nextLong(10);
System.out.printf("%s-%s: Working %d seconds
",new Date(),Thread.currentThread().getName(),duration);
try {
TimeUnit.SECONDS.sleep(duration);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}All the tasks we're going to implement in the following sections will use this class to simulate its execution time.
One of the most basic synchronization mechanisms is the Lock interface and its implementation classes. The basic implementation class is the ReentrantLock class. You can use this class to implement a critical section in an easy way. For example, the following task gets a lock in the first line of its code using the lock() method and releases it in the last line using the unlock() method. Only one task can execute the code between these two sentences at the same time.
public class LockTask implements Runnable {
private static ReentrantLock lock = new ReentrantLock();
private String name;
public LockTask(String name) {
this.name=name;
}
@Override
public void run() {
try {
lock.lock();
System.out.println("Task: " + name + "; Date: " + new Date() + ": Running the task");
CommonTask.doTask();
System.out.println("Task: " + name + "; Date: " + new Date() + ": The execution has finished");
} finally {
lock.unlock();
}
}
}You can check this if, for example, you execute ten tasks in an executor using the following code:
public class LockMain {
public static void main(String[] args) {
ThreadPoolExecutor executor=(ThreadPoolExecutor) Executors.newCachedThreadPool();
for (int i=0; i<10; i++) {
executor.execute(new LockTask("Task "+i));
}
executor.shutdown();
try {
executor.awaitTermination(1, TimeUnit.DAYS);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}In the following image, you can see the result of an execution of this example. You can see how only one task is executed at a time.
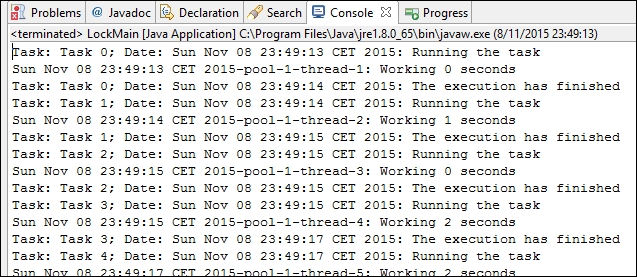
The semaphore mechanism was introduced by Edsger Dijkstra in 1962 and is used to control the access to one or more shared resources. This mechanism is based on an internal counter and two methods named wait() and signal().When a thread calls the wait() method, if the internal counter has a value bigger than 0, then the semaphore decrements the internal counter and the thread gets access to the shared resource. If the internal counter has a value of 0, the thread is blocked until some thread calls the signal() method. When a thread calls the signal() method, the semaphore looks to see whether there are some threads waiting in the waiting state (they have called the wait() method). If there are no threads waiting, it increments the internal counter. If there are threads waiting for the semaphore, it gets one of those threads, which will return for the wait() method and access the shared resource. The other threads that were waiting continue waiting for their turn.
In Java, semaphores are implemented in the Semaphore class. The wait() method is called acquire() and the signal() method is called release(). For example, in this example, we have used this task where a Semaphore class is protecting its code:
public class SemaphoreTask implements Runnable{
private Semaphore semaphore;
public SemaphoreTask(Semaphore semaphore) {
this.semaphore=semaphore;
}
@Override
public void run() {
try {
semaphore.acquire();
CommonTask.doTask();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
}
}
}In the main program, we execute ten tasks that share a Semaphore class initialized with two shared resources, so we will have two tasks running at the same time.
public static void main(String[] args) {
Semaphore semaphore=new Semaphore(2);
ThreadPoolExecutor executor=(ThreadPoolExecutor) Executors.newCachedThreadPool();
for (int i=0; i<10; i++) {
executor.execute(new SemaphoreTask(semaphore));
}
executor.shutdown();
try {
executor.awaitTermination(1, TimeUnit.DAYS);
} catch (InterruptedException e) {
e.printStackTrace();
}
}The following screenshot shows the results of an execution of this example. You can see how two tasks are running at the same time:
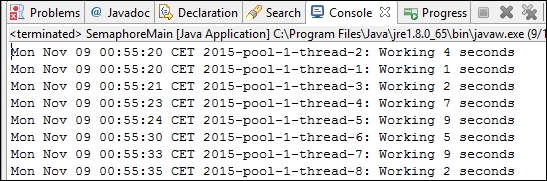
This class provides a mechanism to wait for the finalization of one or more concurrent tasks. It has an internal counter that must be initialized with the number of tasks we are going to wait for. Then, the await() method sleeps the calling thread until the internal counter arrives at zero and the countDown() method decrements that internal counter.
For example, in this task we use the countDown() method to decrement the internal counter of the CountDownLatch object it receives as a parameter in its constructor.
public class CountDownTask implements Runnable {
private CountDownLatch countDownLatch;
public CountDownTask(CountDownLatch countDownLatch) {
this.countDownLatch=countDownLatch;
}
@Override
public void run() {
CommonTask.doTask();
countDownLatch.countDown();
}
}Then, in the main() method, we execute the tasks in an executor and wait for their finalization using the await() method of CountDownLatch. The object is initialized with the number of tasks we want to wait for.
public static void main(String[] args) {
CountDownLatch countDownLatch=new CountDownLatch(10);
ThreadPoolExecutor executor=(ThreadPoolExecutor) Executors.newCachedThreadPool();
System.out.println("Main: Launching tasks");
for (int i=0; i<10; i++) {
executor.execute(new CountDownTask(countDownLatch));
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.
executor.shutdown();
}The following screenshot shows the results of an execution of this example:
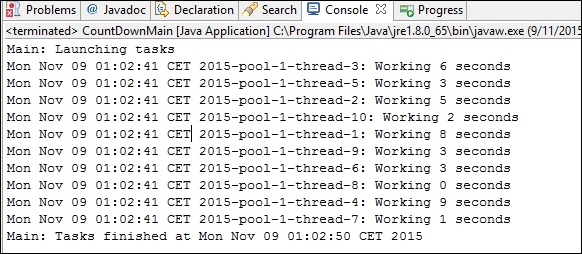
This class allows you to synchronize some tasks in a common point. All tasks will wait in that point until all have arrived. Internally, it also manages an internal counter with the tasks that haven't arrived at that point yet. When a task arrives at the determined point, it has to execute the await() method to wait for the rest of the tasks. When all the tasks have arrived, the CyclicBarrier object wakes them up so they continue with their execution.
This class allows you to execute another task when all the parties have arrived. To configure this, you have to specify a runnable object in the constructor of the object.
For example, we have implemented the following Runnable that uses a CyclicBarrier object to wait for other tasks:
public class BarrierTask implements Runnable {
private CyclicBarrier barrier;
public BarrierTask(CyclicBarrier barrier) {
this.barrier=barrier;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+": Phase 1");
CommonTask.doTask();
try {
barrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+": Phase 2");
}
}We have also implemented another Runnable object that will be executed by CyclicBarrier when all the tasks have executed the await() method.
public class FinishBarrierTask implements Runnable {
@Override
public void run() {
System.out.println("FinishBarrierTask: All the tasks have finished");
}
}Finally, in the main() method, we execute ten tasks in an executor. You can see how CyclicBarrier is initialized with the number of tasks we want to synchronize and with an object of the FinishBarrierTask object:
public static void main(String[] args) {
CyclicBarrier barrier=new CyclicBarrier(10,new FinishBarrierTask());
ThreadPoolExecutor executor=(ThreadPoolExecutor) Executors.newCachedThreadPool();
for (int i=0; i<10; i++) {
executor.execute(new BarrierTask(barrier));
}
executor.shutdown();
try {
executor.awaitTermination(1, TimeUnit.DAYS);
} catch (InterruptedException e) {
e.printStackTrace();
}
}The following screenshot shows the results of an execution of this example:
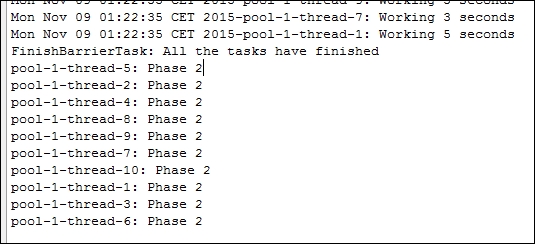
You can see how when all the tasks arrive at the point where the await() method is called, FinishBarrierTask is executed and then all the tasks continue with their execution.
This is a new synchronization mechanism introduced in the Java 8 concurrency API. It extends the Future mechanism, giving it more power and flexibility. It allows you to implement an event-driving model linking tasks that will only be executed when others have finished. As with the Future interface, CompletableFuture must be parameterized with the type of the result that will be returned by the operation. As with a Future object, the CompletableFuture class represents a result of an asynchronous computation, but the result of CompletableFuture can be established by any thread. It has the complete() method to establish the result when the computation ends normally, and the method completeExceptionally() when the computation ends with an exception. If two or more threads call the complete() or completeExceptionally() methods over the same CompletableFuture, only the first call will take effect.
First, you can create CompletableFuture using its constructor. In this case, you have to establish the result of the task using the complete() method as we explained before. But you can also create one using the runAsync() or supplyAsync() methods. The runAsync() method executes a Runnable object and returns CompletableFuture<Void> so that computation can't return any result. The supplyAsync() method executes an implementation of the Supplier interface parametrized with the type that will be returned by this computation. The Supplier interface provides the get() method. In that method, we have to include the code of the task and return the result generated by it. In this case, the result of CompletableFuture will be the result of the Supplier interface.
This class provides a lot of methods that allow you to organize the order of execution of tasks implementing an event-driving model where one task doesn't start its execution until a previous one has finished. These are some of those methods:
thenApplyAsync(): This method receives as a parameter an implementation of theFunctioninterface that can be represented as a lambda expression. This function will be executed when the callingCompletableFuturehas been completed. This method will returnCompletableFutureto get the result of theFunction.thenComposeAsync(): This method is analogous tothenApplyAsync, but is useful when the supplied function returnsCompletableFuturetoo.thenAcceptAsync(): This method is similar to the previous one but the parameter is an implementation of theConsumerinterface that can be also specified as a lambda expression; in this case, the computation won't return a result.thenRunAsync(): This method is equivalent to the previous one but in this case receives aRunnableobject as a parameter.thenCombineAsync(): This method receives two parameters. The first one is anotherCompletableFutureinstance. The other is an implementation of theBiFunctioninterfaces that can be specified as a lambda function. ThisBiFunctionwill be executed when bothCompletableFuture(the calling one and the parameter) have been completed. This method will returnCompletableFutureto get the result of theBiFunction.runAfterBothAsync(): This method receives two parameters. The first one is anotherCompletableFuture. The other is an implementation of theRunnableinterface that will be executed when bothCompletableFuture(the calling one and the parameter) have been completed.runAfterEitherAsync(): This method is equivalent to the previous one, but the Runnable task is executed when one of theCompletableFutureobjects is completed.allOf(): This method receives as a parameter a variable list ofCompletableFutureobjects. It will return aCompletableFuture<Void>object that will return its result when all theCompletableFutureobjects have been completed.anyOf(): This method is equivalent to the previous one, but the returnedCompletableFuturereturns its result when one of theCompletableFutureis completed.
Finally, if you want to obtain the result returned by CompletableFuture, you can use the get() or join() methods. Both methods block the calling thread until CompletableFuture has been completed and then returns its result. The main difference between both methods is that get() throws ExecutionException, which is a checked exception, but join() throws RuntimeException (which is an unchecked exception). Thus, it's easier to use join() inside non-throwing lambdas (like Supplier, Consumer, or Runnable).
Most of the methods explained before have the Async suffix. This means that these methods will be executed in a concurrent way using the ForkJoinPool.commonPool instance. Those methods that have versions without the Async suffix will be executed in a serial way (that is to say, in the same thread where CompletableFuture is executed) and with the Async suffix and an executor instance as an additional parameter. In this case, CompletableFuture will be executed asynchronously in the executor passed as a parameter.
In this example, you will learn how to use the CompletableFuture class to implement the execution of some asynchronous tasks in a concurrent way. We will use our collection of 20,000 products of Amazon to implement the following tree of tasks:
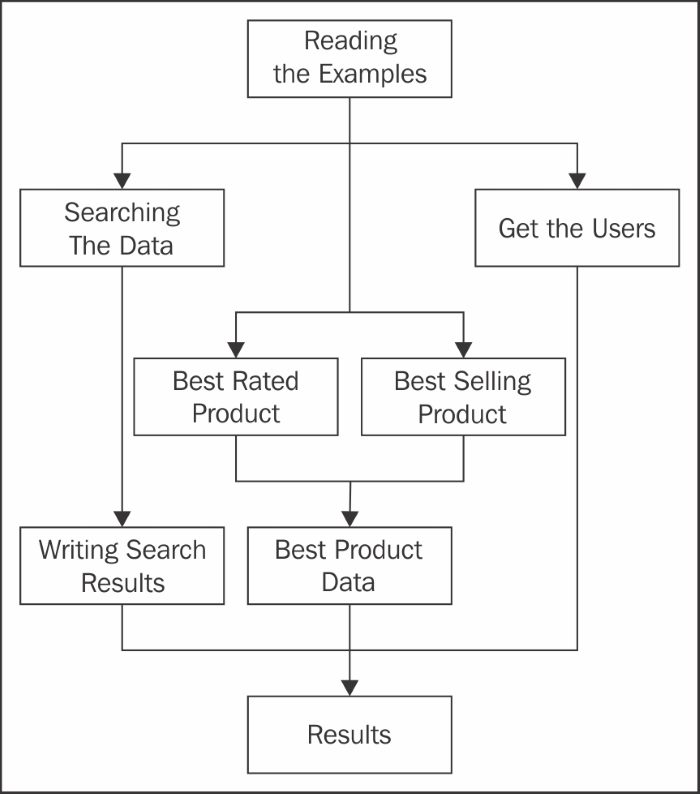
First, we're going to use the examples. Then, we will execute four concurrent tasks. The first one will make a search of products. When the search finishes, we will write the results to a file. The second one will obtain the best-rated product. The third one will obtain the best-selling product. When these both finish, we will concatenate their information using another task. Finally, the fourth task will get a list with the users who have purchased a product. The main() program will wait for the finalization of all the tasks and then will write the results.
Let's see the details of the implementation.
In this example, we will use some auxiliary tasks. The first one is LoadTask, which will load the product information from the disk and will return a list of Product objects.
public class LoadTask implements Supplier<List<Product>> {
private Path path;
public LoadTask (Path path) {
this.path=path;
}
@Override
public List<Product> get() {
List<Product> productList=null;
try {
productList = Files.walk(path, FileVisitOption.FOLLOW_LINKS).parallel()
.filter(f -> f.toString().endsWith(".txt")) .map(ProductLoader::load).collect (Collectors.toList());
} catch (IOException e) {
e.printStackTrace();
}
return productList;
}
}It implements the Supplier interface to be executed as CompletableFuture. Inside, it uses a stream to process and parse all the files obtaining a list of products.
The second task is SearchTask, which will implement the search in the list of Product objects, looking for the ones that contain a word in the title. This task is an implementation of the Function interface.
public class SearchTask implements Function<List<Product>, List<Product>> {
private String query;
public SearchTask(String query) {
this.query=query;
}
@Override
public List<Product> apply(List<Product> products) {
System.out.println(new Date()+": CompletableTask: start");
List<Product> ret = products.stream()
.filter(product -> product.getTitle() .toLowerCase().contains(query))
.collect(Collectors.toList());
System.out.println(new Date()+": CompletableTask: end: "+ret.size());
return ret;
}
}It receives List<Product> with the information of all the products a return List<Product> with the products that meet the criteria. Internally, it creates the stream on the input list, filters it, and collects the result to another list.
Finally, the WriteTask is going to write the products obtained in the search task in a File. In our case, we generate an HTML file, but feel free to write this information in the format you want. This task implements the Consumer interface, so its code must be something like the follow:
public class WriteTask implements Consumer<List<Product>> {
@Override
public void accept(List<Product> products) {
// implementation is omitted
}
}We have organized the execution of the tasks in the main() method. First, we execute the LoadTask using the supplyAsync() method of the CompletableFuture class.
public class CompletableMain {
public static void main(String[] args) {
Path file = Paths.get("data","category");
System.out.println(new Date() + ": Main: Loading products");
LoadTask loadTask = new LoadTask(file);
CompletableFuture<List<Product>> loadFuture = CompletableFuture
.supplyAsync(loadTask);Then, with the resultant CompletableFuture, we use thenApplyAsync() to execute the search task when the load task has been completed.
System.out.println(new Date() + ": Main: Then apply for search");
CompletableFuture<List<Product>> completableSearch = loadFuture
.thenApplyAsync(new SearchTask("love"));Once the search task has been completed, we want to write the results of the execution in a file. As this task won't return a result, we use the thenAcceptAsync() method:
CompletableFuture<Void> completableWrite = completableSearch
.thenAcceptAsync(new WriteTask());
completableWrite.exceptionally(ex -> {
System.out.println(new Date() + ": Main: Exception "
+ ex.getMessage());
return null;
});We have used the exceptionally() method to specify what we want to do if the write task throws an exception.
Then, we use the thenApplyAsync() method over the completableFuture object to execute the task to get the list of users who purchased a product. We specify this task as a lambda expression. Take into account that this task will be executed in parallel with the search task.
System.out.println(new Date() + ": Main: Then apply for users");
CompletableFuture<List<String>> completableUsers = loadFuture
.thenApplyAsync(resultList -> {
System.out.println(new Date()
+ ": Main: Completable users: start");
List<String> users = resultList.stream()
.flatMap(p -> p.getReviews().stream())
.map(review -> review.getUser())
.distinct()
.collect(Collectors.toList());
System.out.println(new Date()
+ ": Main: Completable users: end");
return users;
});In parallel with these tasks, we also executed the tasks using the thenApplyAsync() method to find the best-rated product and the best-selling product. We have defined these tasks using a lambda expression too.
System.out.println(new Date()
+ ": Main: Then apply for best rated product....");
CompletableFuture<Product> completableProduct = loadFuture
.thenApplyAsync(resultList -> {
Product maxProduct = null;
double maxScore = 0.0;
System.out.println(new Date()
+ ": Main: Completable product: start");
for (Product product : resultList) {
if (!product.getReviews().isEmpty()) {
double score = product.getReviews().stream()
.mapToDouble(review -> review.getValue())
.average().getAsDouble();
if (score > maxScore) {
maxProduct = product;
maxScore = score;
}
}
}
System.out.println(new Date()
+ ": Main: Completable product: end");
return maxProduct;
});
System.out.println(new Date()
+ ": Main: Then apply for best selling product....");
CompletableFuture<Product> completableBestSellingProduct = loadFuture
.thenApplyAsync(resultList -> {
System.out.println(new Date() + ": Main: Completable best selling: start");
Product bestProduct = resultList
.stream()
.min(Comparator.comparingLong (Product::getSalesrank))
.orElse(null);
System.out.println(new Date()
+ ": Main: Completable best selling: end");
return bestProduct;
});As we mentioned before, we want to concatenate the results of the last two tasks. We can do this using the thenCombineAsync() method to specify a task that will be executed after both tasks have been completed.
CompletableFuture<String> completableProductResult = completableBestSellingProduct
.thenCombineAsync(
completableProduct, (bestSellingProduct, bestRatedProduct) -> {
System.out.println(new Date() + ": Main: Completable product result: start");
String ret = "The best selling product is " + bestSellingProduct.getTitle() + "
";
ret += "The best rated product is "
+ bestRatedProduct.getTitle();
System.out.println(new Date() + ": Main: Completable product result: end");
return ret;
});Finally, we wait for the end of the final tasks using the allOf() and join() methods and write the results using the get() method to obtain them.
System.out.println(new Date() + ": Main: Waiting for results");
CompletableFuture<Void> finalCompletableFuture = CompletableFuture
.allOf(completableProductResult, completableUsers,
completableWrite);
finalCompletableFuture.join();
try {
System.out.println("Number of loaded products: "
+ loadFuture.get().size());
System.out.println("Number of found products: "
+ completableSearch.get().size());
System.out.println("Number of users: "
+ completableUsers.get().size());
System.out.println("Best rated product: "
+ completableProduct.get().getTitle());
System.out.println("Best selling product: "
+ completableBestSellingProduct.get() .getTitle());
System.out.println("Product result: "+completableProductResult.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}In the following screenshot, you can see the results of an execution of this example:
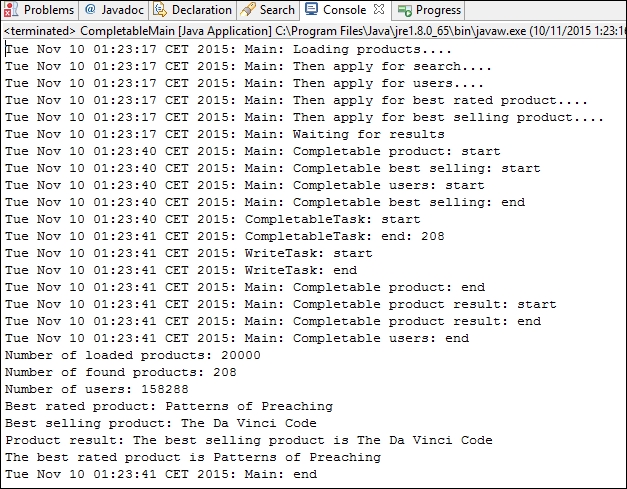
First, the main() method executes all the configuration and waits for the finalization of the tasks. The execution of the tasks follows the order we have configured.