
We have imported our database our mock data into our RethinkDB instance. Now it's time to run a use case query and make use of it. But before we do so, we need to figure out one data alteration. We have made a mistake while generating mock data (on purpose actually) we have a $ sign before ctc. Hence, it becomes tough to perform salary-level queries.
Before we move ahead, we need to figure out this problem, and basically get rid of the $ sign and update the ctc value to an integer instead of a string.
In order to do this, we need to perform the following operation:
- Traverse through each document in the database
- Split the ctc string into two parts, containing
$and the other value - Update the
ctcvalue in the document with a new data type and value
Since we require the chaining of queries, I have written a small snippet in Node.js to achieve the previous scenario as follows:
var rethinkdb = require('rethinkdb');
var connection = null;
rethinkdb.connect({host : 'localhost', port : 28015},function(err,conn) {
if(err) {
throw new Error('Connection error');
}
connection = conn;
rethinkdb.db("company").table("employees")
.run(connection,function(err,cursor) {
if(err) {
throw new Error(err);
}
cursor.each(function(err,data) {
data.ctc = parseInt(data.ctc.split("$")[1]);
rethinkdb.db("company").table("employees")
.get(data.id)
.update({ctc : data.ctc})
.run(connection,function(err,response) {
if(err) {
throw new Error(err);
}
console.log(response);
});
});
});
});
As you can see in the preceding code, we first fetch all the documents and traverse them using cursor, one document at a time. We use the split() method as a $ separator and convert the outcome, which is salary, into an integer using the parseInt() method. We update each document at a time using the id value of the document:

After selecting all the documents again, we can see an updated ctc value as an integer, as shown in the following figure:
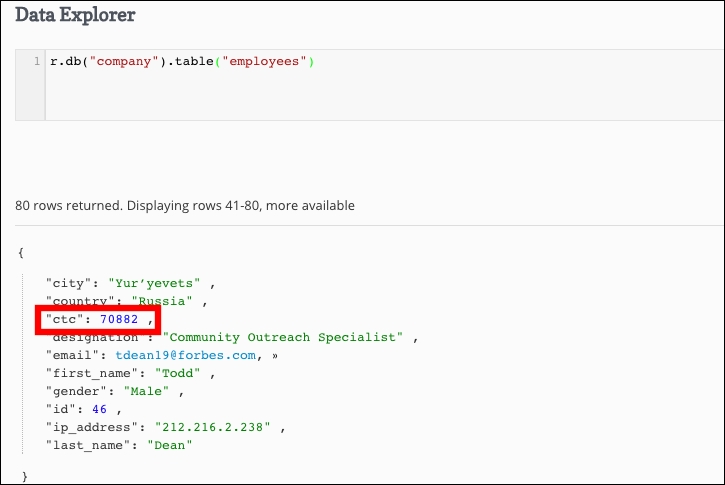
This is one of the practical examples where we perform some data manipulation before moving ahead with complex queries. Similarly, you can look for errors such as blank spaces in a specific field or duplicate elements in your record.
We can use distinct() to find out whether there is any duplicate element present in the table. Say you have 1,000 rows and there are 10 duplicates. In order to determine that, we just need to find out the unique rows (of course excluding the ID key, as that's unique by nature).
Here is the query for the same:
r.db("company").table('employees').without('id').distinct().count()
As shown in the following screenshot, this query returns the count of unique rows, which should be 1,000 if there are no duplicates:

This implies that our records contain no duplicate documents.
We can write a query to find all the countries we have in our record and also use distinct again by just selecting the country field. Here is the query:
r.db("company").table('employees')("country").distinct()
As shown in this image, we have 124 countries in our records:

In this use case, we need to evaluate all the records and find the top 10 employees with the highest to lowest pay. Here is the query for the same:
r.db("company").table("employees").orderBy(r.desc("ctc")).limit(10)
Here we are using orderBy, which by default orders the record in ascending order. To get the highest pay at the first document, we need to use descending ordering; we did it using the desc() ReQL command.
As shown in the following image, the query returns 10 rows:
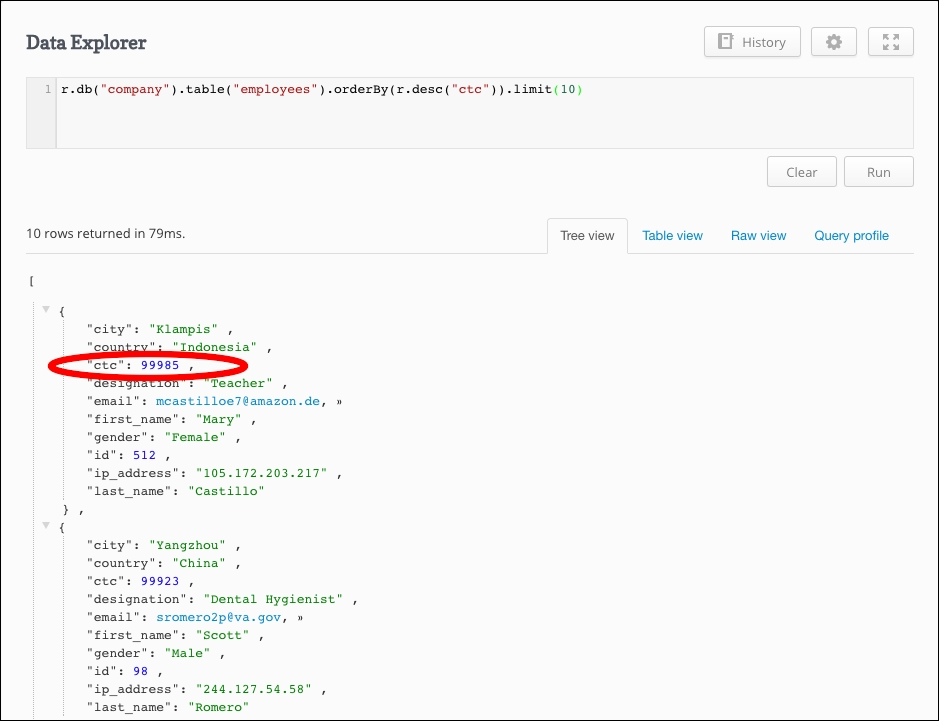
You can modify the same query by just by limiting the number of users to one to get the highest-paid employee.
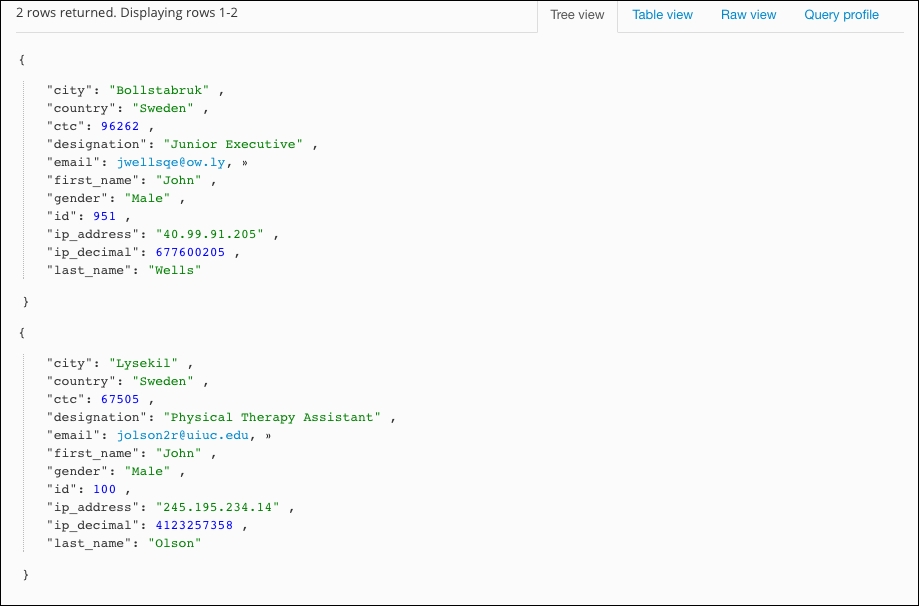
To extract such records from our table, we need to again perform a filter on the "first_name" and "country" fields. Here is the query to return those records:
r.db("company").table('employees').filter({"first_name" : "John","country" : "Sweden"})
We are just performing a basic filter and comparing both fields. ReQL queries are really easy for solving such queries due to their chaining feature. After executing the preceding query, we show the following output:
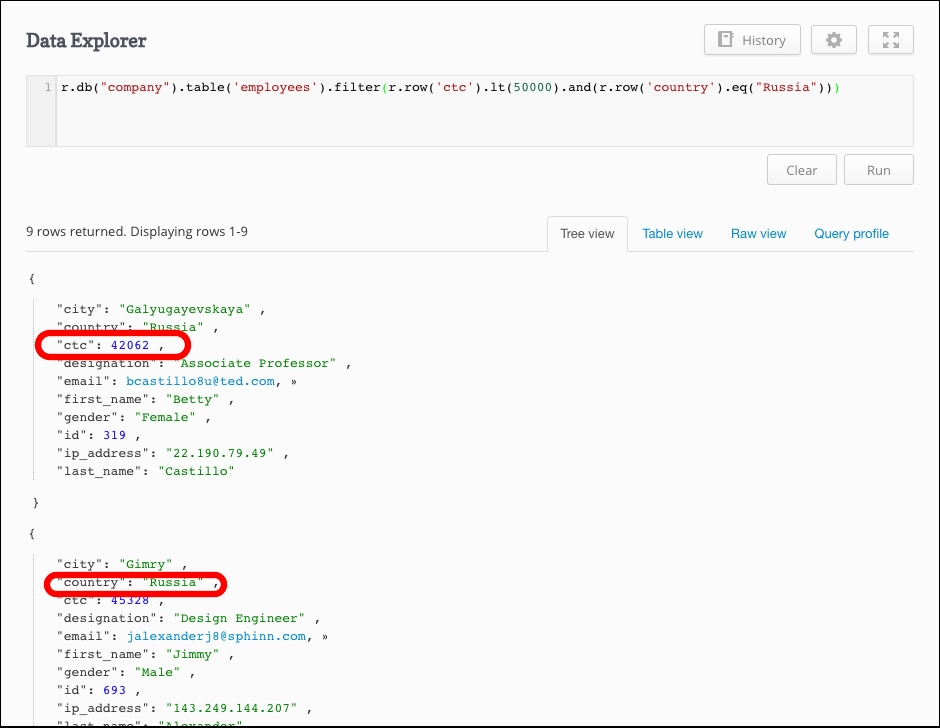
We need to traverse through each document and filter on the basis of the ctc and country fields. Here is the query for the same:
r.db("company").table('employees').filter(r.row('ctc').lt(50000).and(r.row('country').eq("Russia")))")))
We are using the and ReQL command, which is equivalent to the boolean operator. Here is the output for the previous query:
Constant contact is a popular e-mail service for mass mailers. In our randomly generated mock data, there are some employees' e-mails ending with a constant contact address. In this use case, we are going to use a regular expression to filter out employees with a constant contact e-mail. Here is the query for the same:
r.db("company").table('employees').filter(r.row('email').match("constantcontact.com$"))
The following are the e-mail addresses that end with the constant string; hence, we had put a $ sign at the end of the expression in the match ReQL method:

This is one of the more complicated use cases that we are going to deal with. As you noticed in the mock data, we have randomly generated IP addresses that lie in classes B, C, D, and so on. Here we need to find out the employees who are using a class C IP address, that is, address ranging between 192.0.1.1 and 223.255.254.254.
Although it seems easy to find the difference between these numbers, technically it is quite difficult. As you can see, an IP address consists of four digits separated by a dot operator. IP addresses are written using a base 256 encoding.
In order to efficiently find the IP addresses ranging between the class C IP range, we need to convert the IP from base 256 to decimal, that is, base 10.
To convert it, we need to use following formula. Consider 192.168.1.1 as the IP:
192 * (256)^3 + 168 * (256)^2 + 1 * (256)^1 + 1 * 256^0 = decimal value of IP
Upon getting the data decimal value of the IP, we can easily use the between ReQL method to find the documents ranging in class C.
Since we don't have the decimal value of IP in our documents, we first need to calculate and create a new field in each document containing the decimal value of IP.
Here is how we do it in Node.js:
var rethinkdb = require('rethinkdb');
var connection = null;
rethinkdb.connect({host : 'localhost', port : 28015},function(err,conn) {
if(err) {
throw new Error('Connection error');
}
connection = conn;
rethinkdb.db("company").table("employees").run(connection,function(err,cursor) {
if(err) {
throw new Error(err);
}
cursor.each(function(err,data) {
let ip = data.ip_address.split(".");
let decimalIp = 0;
for(let ipCounter = 0; ipCounter < ip.length; ipCounter++) {
let power = 3 - ipCounter;
let ipElement = parseInt(ip[ipCounter]);
decimalIp += ipElement * Math.pow(256,power);
}
data.ip_decimal = decimalIp;
// updating the document
rethinkdb.db("company").table("employees")
.get(data.id)
.run(connection,function(err,response) {
if(err) { console.log(
.update(data)
err);}
console.log(response);
});
});
});
});
In the preceding code, we traverse over each document and convert the IP address into a decimal format. After that, we create a new field and update the document.
Here is the updated document in the employees table:
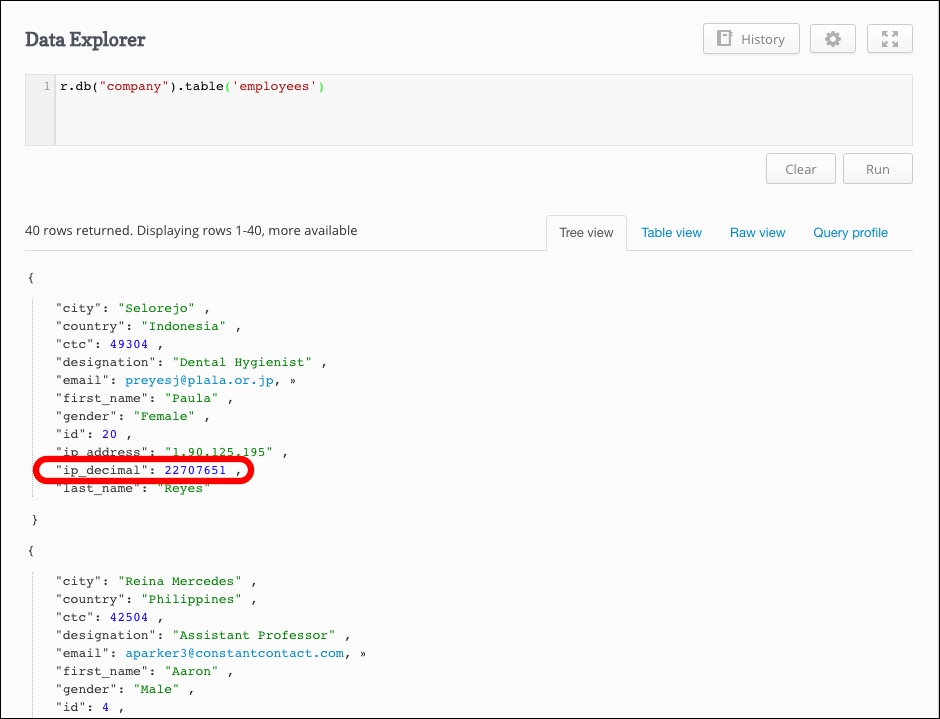
We have the data in place. Before making a query, we need to create this field as an index because the between method of ReQL works on indexes only. That's no big deal! Here is a query to do so:.
r.db("company").table('employees').indexCreate('ip_decimal')
Once the index is created, we can query the table to return us, employees using the class C address. I have converted the starting and ending addresses of Class C into decimal using the same preceding formula:
|
Base 256 IP address |
Base 10 (decimal) IP address |
|
|
|
|
|
|
Here is the query to fetch the employees using the IP in that range:
r.db("company").table('employees').between(3221225729,3758096126,{index : 'ip_decimal'})
In the next image, we pass the start and end IP addresses and use the ip_decimal field as an index:

Here is the last record for the same, containing the last IP address:
