
In the past decade, many companies have started to deploy objected-oriented (OO) technology in their software development efforts. Object-oriented analysis (OOA), object-oriented design (OOD), and object-oriented languages and programming (OOP) have gained wide acceptance in many software organizations. OO metrics have been proposed in the literature and there have been increased discussions in recent years. In this chapter we discuss the major OO metrics in the literature, and give examples of metrics and data from commercial software projects. We attempt to discuss the metrics from several perspectives including design and complexity, productivity, and quality management. In the last part of the chapter, we discuss the lessons learned from the assessments of a good number of the OO projects over the past decade.
Class, object, method, message, instance variable, and inheritance are the basic concepts of the OO technology. OO metrics are mainly measures of how these constructs are used in the design and development process. Therefore, a short review of definitions is in order.
A class is a template from which objects can be created. It defines the structure and capabilities of an object instance. The class definition includes the state data and the behaviors (methods) for the instances of that class. The class can be thought of as a factory that creates instances as needed. For example, an Account class may have methods to allow deposits and withdrawals, using a balance instance variable to hold the current balance. This definition defines how an Account works, but it is not an actual account.
An abstract class is a class that has no instances, created to facilitate sharing of state data and services among similar, more specialized subclasses.
A concrete class is a class that has instances. For example, there might be a Savings Account class with a number of instances in a bank application.
An object is an instantiation of a class. It is anything that models things in the real world. These things can be physical entities such as cars, or events such as a concert, or abstractions such as a general-purpose account. An object has state (data) and behavior (methods or services), as defined for the class of objects it belongs to.
A method is a class service behavior. It operates on data in response to a message and is defined as part of the declaration of a class. Methods reflect how a problem is broken into segments and the capabilities other classes expect of a given class.
Message: Objects communicate via messages. To request a service from another object, an object sends it a message. This is the only means to get information from an object, because its data is not directly accessible (this is called encapsulation).
Instance variable is a place to store and refer to an object’s state data. In traditional programming, this would be a data variable. In OO paradigm, data is made up of instance variables of an object.
Inheritance: Similar classes of objects can be organized into categories called class hierarchies. The lower-level classes (called subclasses) can use the services of all the higher classes in their hierarchy. This is called inheritance. Inheritance is simply a way of reusing services and data. As an example, Savings accounts are types of general Account, and IRA accounts are types of Savings accounts. The Savings account inherits the capability to handle deposits from the Account class. The number of subclasses in the class hierarchy is called hierarchy nesting or depth of inheritance tree (DIT).
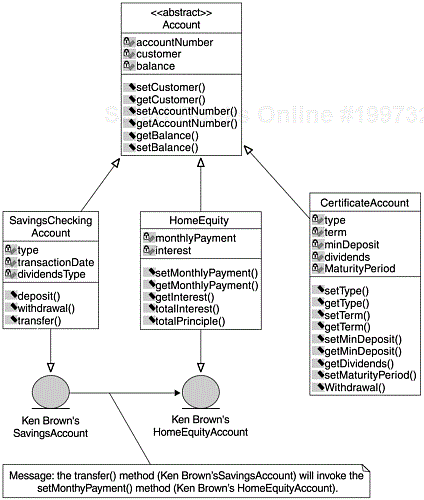
Figure 12.1 provides a pictorial description of the OO structures and key concepts. For example, “Account”, “SavingsCheckingAccount”, “HomeEquity”, and “CertificateAccount” are all classes. “Account” is also an abstract class; the other classes are its subclasses, which are concrete classes. “Ken Brown’sSavingsAccount” and “Ken Brown’s HomeEquity Account” are objects. The “Account” class has three subclasses or children. “AccountNumber” is an instance variable, also called an attribute, and getBalance() is a method of the “Account” class. All instance variables and methods for the “Account” class are also the instance variables and methods of its subclasses through inheritance. The object “Ken Brown’sSavingsAccount” sends a message to the object “Ken Brown’s HomeEquity Account”, via the “transfer()” method and thereby invokes the “setMonthlyPayment()” method. Therefore, the class “SavingsCheckingAccount” is coupled to the class “HomeEquity” through the message.
Classes and methods are the basic constructs for OO technology. The amount of function provided by an OO software can be estimated based on the number of identified classes and methods or its variants. Therefore, it is natural that the basic OO metrics are related to classes and methods, and the size (logical lines of code, or LOC) or function points of the classes and methods. For design and complexity measures, the metrics would have to deal with specific OO characteristics such as inheritance, instance variable, and coupling.
Based on his experience in OO software development, Lorenz (1993) proposed eleven metrics as OO design metrics. He also provided the rules of thumb for some of the metrics, which we summarized in Table 12.1..
As the table shows, some of these metrics are guidelines for OO design and development rather than metrics in the sense of quantitative measurements. Although most of these eleven metrics are related to OO design and implementation, metric 8 is a statement of good programming practices, metric 9 is a quality indicator, and metric 11 is a metric for validating the OO development process.
With regard to average method size, a large number may indicate poor OO designs and therefore function-oriented coding. For average number of methods per class, a large number is desirable from the standpoint of code reuse because subclasses tend to inherit a larger number of methods from superclasses. However, if the number of methods per object class gets too large, extensibility will suffer. A larger number of methods per object class is also likely to complicate testing as a result to increased complexity. Too many methods in a single class, not counting inherited methods, is also a warning that too much responsibility is being placed in one type of object. There are probably other undiscovered classes. On this point, similar reasoning can be applied to instance variables—a large number of instance variables indicates that one class is doing more than it should. In other words, the design may need refinement.
Inheritance tree depth is likely to be more favorable than breadth in terms of reusability via inheritance. Deeper inheritance trees would seem to promote greater method sharing than would broad trees. On the other hand, a deep inheritance tree may be more difficult to test than a broad one and comprehensibility may be diminished. Deep class hierarchy may be the result of overzealous object creation, almost the opposite concern of having too many methods or instance variables in one class.
The pertinent question therefore is, what should the optimum value be for OO metrics such as the several just discussed? There may not be one correct answer, but the rules of thumb by Lorenz as shown in Table 12.1. are very useful. They were derived based on experiences from industry OO projects. They provide a threshold for comparison and interpretation.
Table 12.1.. OO Metrics and Rules of Thumb Recommended by Lorenz (1993)
|
Metric |
Rules of Thumb and Comments |
|---|---|
|
Source: Lorenz, 1993. | |
|
1. Average Method Size (LOC) |
Should be less than 8 LOC for Smalltalk and 24 LOC for C++ |
|
2. Average Number of Methods per Class |
Should be less than 20. Bigger averages indicate too much responsibility in too few classes. |
|
3. Average Number of Instance Variables per Class |
Should be less than 6. More instance variables indicate that one class is doing more than it should. |
|
4. Class Hierarchy Nesting Level (Depth of Inheritance Tree, DIT) |
Should be less than 6, starting from the framework classes or the root class. |
|
5. Number of Subsystem/Subsystem Relationships |
Should be less than the number in metric 6. |
|
6. Number of Class/Class Relationships in Each Subsystem |
Should be relatively high. This item relates to high cohesion of classes in the same subsystem. If one or more classes in a subsystem don’t interact with many of the other classes, they might be better placed in another subsystem. |
|
7. Instance Variable Usage |
If groups of methods in a class use different sets of instance variables, look closely to see if the class should be split into multiple classes along those “service” lines. |
|
8. Average Number of Comment Lines (per Method) |
Should be greater than 1. |
|
9. Number of Problem Reports per Class |
Should be low (no specifics provided). |
|
10. Number of Times Class Is Reused |
If a class is not being reused in different applications (especially an abstract class), it might need to be redesigned. |
|
11. Number of Classes and Methods Thrown Away |
Should occur at a steady rate throughout most of the development process. If this is not occurring, one is probably doing an incremental development instead of performing true iterative OO design and development. |
In 1994 Lorenz and Kidd (1994) expanded their metrics work by publishing a suite of recommended OO metrics with multiple metrics for each of the following categories: method size, method internals, class size, class inheritance, method inheritance, class internals, and class externals. They also showed the frequency distribution of the number of classes for five projects, in the histogram form, along the values of some of the metrics. No numeric parameters of these metrics (e.g., mean or median) were provided, however.
In early 1993, IBM Object Oriented Technology Council (OOTC) (1993) published a white paper on OO metrics with recommendations to the product divisions. The list included more that thirty metrics, each with a relative importance rating of high, medium, or low. All proposed metrics by Lorenz in 1993 (Table 12.1.), with the exception of metrics 5 and 6, were in the IBM OOTC list with a high importance rating. Almost all of the OOTC metrics were included in Lorenz and Kidd’s (1994) comprehensive suite. This commonality was not a coincidence because both Lorenz and Kidd were formerly affiliated with IBM and Lorenz was formerly the technical lead of IBM’s OOTC. As one would expect, Lorenz’s OO metrics rules of thumb were the same as IBM OOTC’s. The OOTC also recommended that the average depth of hierarchy be less than 4 for C++ projects. In terms of project size, the OOTC classified projects with fewer than 200 classes as small, projects with 200 to 500 classes as medium, and projects with more than 500 classes as large.
Table 12.2 shows selected metrics for six OO projects developed at the IBM Rochester software development laboratory. Project A was for the lower layer of a large operating system that interacts with hardware microcode; Project B was the development of an operating system itself; Project C was for the software that drives the input and output (IO) devices of a computer system; Project D was for a Visualage application; Project E was for a software for a development environment, which was a joint project with an external alliance; and Project F was for a software that provides graphical operations for a subsystem of an operating system. Based on OOTC’s project size categorization, Projects A, B, and C were very large projects, Projects E and F were medium-sized projects, and Project D was a small project.
Compared with the rules of thumb per Lorenz (1993) and IBM OOTC (1993), Project E had a much higher average number of methods per class, a larger class in terms of LOC, and a larger maximum depth of inheritance tree. Project E was a joint project with an external alliance and when code drops were delivered, acceptance testing was conducted by IBM. Our defect tracking during acceptance testing did show a high defect volume and a significantly higher defect rate, even when compared to other projects that were developed in procedural programming. This supports the observation that a deep inheritance tree may be more difficult to test than a broad one and comprehensibility may be diminished, thereby allowing more opportunities for error injection.
Table 12.2. Some OO Metrics for Six Projects
|
Metric |
Project A (C++) |
Project B (C++) |
Project C (C++) |
Project D (IBM Smalltalk) |
Project E (OTI Smalltalk) |
Project F (Digitalk of Smalltalk) |
Rules of Thumb |
|---|---|---|---|---|---|---|---|
|
(S)* = Smalltalk; (C)* = C++ | |||||||
|
Number of Classes |
5,741 |
2,513 |
3,000 |
100 |
566 |
492 |
na |
|
Methods per Class |
8 |
3 |
7 |
17 |
36 |
21 |
<20 |
|
LOC per Method |
21 |
19 |
15 |
5.3 |
5.2 |
5.7 |
<8(S)* <24(C)* |
|
LOC per Class |
207 |
60 |
100 |
97 |
188 |
117 |
<160(S)* <480(C)* |
|
Max Depth of Inheritance Tree (DIT) |
6 |
na |
5 |
6 |
8 |
na |
<6 |
|
Avg DIT |
na |
na |
3 |
4.8 |
2.8 |
na |
<4 (C)* |
The metric values for the other projects all fell below the rule-of-thumb thresholds. The average methods per class for projects A, B, and C were far below the threshold of 20, with project B’s value especially low. A smaller number of methods per class may mean larger overheads in class interfaces and a negative impact on the software’s performance. Not coincidentally, all three projects were not initially meeting their performance targets, and had to undergo significant performance tuning before the products were ready to ship. The performance challenges of these three projects apparently could not be entirely attributed to this aspect of the class design because there were other known factors, but the data demonstrated a good correlation. Indeed, our experience is that performance is a major concern that needs early action for most OO projects. The positive lesson learned from the performance tuning work of these projects is that performance tuning and improvement are easier in OO development than in procedural programming.
In 1994 Chidamber and Kemerer proposed six OO design and complexity metrics, which later became the commonly referred to CK metrics suite:
Weighted Methods per Class (WMC): WMC is the sum of the complexities of the methods, whereas complexity is measured by cyclomatic complexity. If one considers all methods of a class to be of equal complexity, then WMC is simply the number of methods defined in each class. Measuring the cyclomatic complexity is difficult to implement because not all methods are assessable in the class hierarchy due to inheritance. Therefore, in empirical studies, WMC is often just the number of methods in a class, and the average of WMC is the average number of methods per class.
Depth of Inheritance Tree (DIT): This is the length of the maximum path of a class hierarchy from the node to the root of the inheritance tree.
Number of Children of a Class (NOC): This is the number of immediate successors (subclasses) of a class in the hierarchy.
Coupling Between Object Classes (CBO): An object class is coupled to another one if it invokes another one’s member functions or instance variables (see the example in Figure 12.1). CBO is the number of classes to which a given class is coupled.
Response for a Class (RFC): This is the number of methods that can be executed in response to a message received by an object of that class. The larger the number of methods that can be invoked from a class through messages, the greater the complexity of the class. It captures the size of the response set of a class. The response set of a class is all the methods called by local methods. RFC is the number of local methods plus the number of methods called by local methods.
Lack of Cohesion on Methods (LCOM): The cohesion of a class is indicated by how closely the local methods are related to the local instance variables in the class. High cohesion indicates good class subdivision. The LCOM metric measures the dissimilarity of methods in a class by the usage of instance variables. LCOM is measured as the number of disjoint sets of local methods. Lack of cohesion increases complexity and opportunities for error during the development process.
Chidamber and Kemerer (1994) applied these six metrics in an empirical study of two companies, one using C++ and one using Smalltalk. Site A, a software vendor, provided data on 634 classes from two C++ libraries. Site B, a semiconductor manufacturer, provided data on 1,459 Smalltalk classes. The summary statistics are shown in Table 12.3.
The median weighted methods per class (WMC) for both sites were well below the threshold value for the average number of methods (20) as discussed earlier. The DIT maximums exceeded the threshold of 6, but the medians seemed low, especially for the C++ site. The classes for both sites had low NOCs—with medians equal to zero, and 73% of site A and 68% of site B had zero children. Indeed the low values of DIT and NOC led the authors to the observation that the designers might not be taking advantage of reuse of methods through inheritance. Striking differences in CBOs and RFCs were shown between the C++ and Smalltalk sites, with the median values for the Smalltalk site much higher. The contrast reflects the differences in the lan-guages with regard to OO implementation. Smalltalk has a higher emphasis on pure OO message passing and a stronger adherence to object-oriented principles (Henderson-Sellers, 1995). Last, the distribution of lack of cohesion on methods was very different for the two sites. Overall, this empirical study shows the feasibility of collecting metrics in realistic environments and it highlights the lack of use of inheritance. The authors also suggested that the distribution of the metric values be used for the identification of design outliers (i.e., classes with extreme values).
Table 12.3. Median Values of CK Metrics for Two Companies
|
Site A (C++) |
Site B (Smalltalk) | |
|---|---|---|
|
Source: Chidamber and Kemerer, 1993, 1994; Henderson-Sellers, 1995. | ||
|
WMC (Weighted Methods per Class) |
5 |
10 |
|
DIT (Depth of Inheritance Tree) |
1(Max. = 8) |
3 (Max = 10) |
|
NOC (Number of Children) |
0 |
0 |
|
RFC (Response for a Class) |
6 |
29 |
|
CBO (Coupling Between Object Classes) |
0 |
9 |
|
LCOM (Lack of Cohesion on Methods) |
0 (Range: 0–200) |
2 (Range: 0–17) |
To evaluate whether the CK metrics are useful for predicting the probability of detecting faulty classes, Basili and colleagues (1996) designed and conducted an empirical study over four months at the University of Maryland. The study participants were the students of a C++ OO software analysis and design class. The study involved 8 student teams and 180 OO classes. The independent variables were the six CK metrics and the independent variables were the faulty classes and number of faults detected during testing. The LCOM metric was operationalized as the number of pairs of member functions without shared instance variables, minus the number of pairs of member functions with shared instance variables. When the above subtraction is negative, the metric was set to zero. The hypotheses linked high values of the CK metrics to higher probability of faulty classes. Key findings of the study are as follows:
The six CK metrics were relatively independent.
The lack of use of inheritance was confirmed because of the low values in the DITs and NOCs.
The LCOM lacked discrimination power in predicting faulty classes.
DITs, RFCs, NOCs, and CBOs were significantly correlated with faulty classes in multivariate statistical analysis.
These OO metrics were superior to code metrics (e.g., maximum level of statement nesting in a class, number of function declaration, and number of function calls) in predicting faulty classes.
This validation study provides positive confirmation of the value of the CK metrics. The authors, however, caution that several factors may limit the generalizability of results. These factors include: small project sizes, limited conceptual complexity, and student participants.
In 1997 Chidamber, Darcy, and Kemerer (1997) applied the CK metrics suite to three financial application software programs and assessed the usefulness of the metrics from a managerial perspective. The three software systems were all developed by one company. They are used by financial traders to assist them in buying, selling, recording, and analysis of various financial instruments such as stocks, bonds, options, derivatives, and foreign exchange positions. The summary statistics of the CK metrics of these application software are in Table 12.4.
One of the first observed results was the generally small values for the depth of inheritance tree (DIT) and number of children (NOC) metrics in all three systems, indicating that developers were not taking advantage of the inheritance reuse feature of the OO design. This result is consistent with the earlier findings of an empirical study by two of the authors on two separate software systems (Chidamber and Kemerer, 1994). Second, the authors found that three of the metrics, weighted methods per class (WMC), response for a class (RFC), and coupling between classes (CBO) were highly correlated, with correlation coefficients above the .85 level. In statistical interpretation, this implies that for the three software systems in the study, all three metrics were measuring something similar. This finding was in stark contrast to the findings by the validation study by Basilli and colleagues (1995), in which all six CK metrics were found to be relatively independent. This multi-collinearity versus independence among several of the CK metrics apparently needs more empirical studies to clarify.
We noted that the metrics values from these three systems are more dissimilar than similar, especially with regard to the maximum values. This is also true when including the two empirical data sets in Table 12.3. Therefore, it seems that many more empirical studies need to be accumulated before preferable threshold values of the CK metrics can be determined. The authors also made the observation that the threshold values of these metrics cannot be determined a priori and should be derived and used locally from each of the data sets. They decided to use the “80-20” principle in the sense of using the 80th percentile and 20th percentile of the distributions to determine the cutoff points for a “high” or “low” value for a metric. The authors also recommended that the values reported in their study not be accepted as rules, but rather practitioners should analyze local data and set thresholds appropriately.
Table 12.4. Summary Statistics of the CK Metrics for Three Financial Software Systems
|
Source: Chidamber et al., 1997. | |||
|---|---|---|---|
|
Software A (45 Classes) |
Median |
Mean |
Maximum |
|
WMC (Weighted Methods per Class) |
6 |
9.27 |
63 |
|
DIT (Depth of Inheritance Tree) |
0 |
0.04 |
2 |
|
NOC (Number of Children) |
0 |
0.07 |
2 |
|
RFC (Response for a Class) |
7 |
13.82 |
102 |
|
CBO (Coupling Between Object Classes) |
2 |
4.51 |
39 |
|
LCOM (Lack of Cohesion on Methods) |
0 |
6.96 |
90 |
|
Software B (27 classes) |
Median |
Mean |
Maximum |
|
WMC (Weighted Methods per Class) |
22 |
20.22 |
31 |
|
DIT (Depth of Inheritance Tree) |
1 |
1.11 |
2 |
|
NOC (Number of Children) |
0 |
0.07 |
2 |
|
RFC (Response for a Class) |
33 |
38.44 |
93 |
|
CBO (Coupling Between Object Classes) |
7 |
8.63 |
22 |
|
LCOM (Lack of Cohesion on Methods) |
0 |
29.37 |
387 |
|
Software C (25 Classes) |
Median |
Mean |
Maximum |
|
WMC (Weighted Methods per Class) |
5 |
6.48 |
22 |
|
DIT (Depth of Inheritance Tree) |
2 |
1.96 |
3 |
|
NOC (Number of Children) |
0 |
0.92 |
11 |
|
RFC (Response for a Class) |
7 |
9.8 |
42 |
|
CBO (Coupling Between Object classes) |
0 |
1.28 |
8 |
|
LCOM (Lack of Cohesion on Methods) |
0 |
4.08 |
83 |
The authors’ major objective was to explore the effects of the CK metrics on managerial variables such as productivity, effort to make classes reusable, and design effort. Each managerial variable was evaluated using data from a different project. Productivity was defined as size divided by the number of hours required (lines of code per person hour), and was assessed using data from software A. Assessment of the effort to make classes reusable was based on data from software B. Some classes in software B were reused on another project and the rework effort was recorded and measured in the number of hours spent by the next project staff to modify each class for use in the next project. Assessment on design effort was based on data from software C. Design effort was defined as the amount of time spent in hours to specify the high-level design of each class. Multivariate statistical techniques were employed with class as the unit of analysis and with each managerial variable as the independent variable. The CK metrics were the independent variables; other relevant variables, such as size and specific developers who had superior performance, were included in the models to serve as control variables so that the net effect of the CK metrics could be estimated. The findings indicated that of the six CK metrics, high levels of CBOs (coupling between object classes) and LCOMs (lack of cohesion on methods) were associated with lower productivity, higher effort to make classes reusable, and greater design effort. In other words, high values of CBO and LCOM were not good with regard to the managerial variables. Specifically, the final regression equation for the productivity evaluation was as follows:
The equation indicates that controlling for the size of the classes and the effect of a star performer (STAFF_4), the productivity for classes with high CBO (coupling between object classes) and LCOM (lack of cohesion on methods) values was much lower (again, the authors used the 80th percentile as the cutoff point to define high values). Because productivity was defined as lines of code per person hour, the regression equation indicates that the productivity was 76.57 lines of code per hour lower (than other classes) for classes with high CBO values, and 33.96 lines of code per hour lower for classes with high LCOM values. The effects were very significant! As a side note, it is interesting to note that the productivity of the classes developed by the star performer (STAFF_4) was 48.11 lines of code per hour higher!
This finding is significant because it reflects the strength of the underlying concepts of coupling and cohesion. In practical use, the metrics can be used to flag out-lying classes for special attention.
Rosenberg, Stapko, and Gallo (1999) discuss the metrics used for OO projects at the NASA Software Assurance Technology Center (SATC). They recommend the six CK metrics plus three traditional metrics, namely, cyclomatic complexity, lines of code, and comment percentage based on SATC experience. The authors also used these metrics to flag classes with potential problems. Any class that met at least two of the following criteria was flagged for further investigation:
Response for Class (RFC) > 100
Response for Class > 5 times the number of methods in the class
Coupling between Objects (CBO) > 5
Weighted Methods per Class (WMC) > 100
Number of Methods > 40
Considerable research and discussions on OO metrics have taken place in recent years, for example, Li and Henry (1993), Henderson-Sellers (1996), De Champeaux (1997), Briand (1999), Kemerer (1999), Card and Scalzo (1999), and Babsiya and Davis (2002). With regard to the direction of OO metrics research, there seems to be agreement that it is far more important to focus on empirical validation (or refuta-tion) of the proposed metrics than to propose new ones, and on their relationships with managerial variables such as productivity, quality, and project management.
As stated in the preface, productivity metrics are outside the scope of this book. Software productivity is a complex subject that deserves a much more complete treatment than a brief discussion in a book that focuses on quality and quality metrics. For non-OO projects, much research has been done in assessing and measuring productivity and there are a number of well-known books in the literature. For example, see Jones’s work (1986, 1991, 1993, 2000). For productivity metrics for OO projects, relatively few research has been conducted and published. Because this chapter is on OO metrics in general, we include a brief discussion on productivity metrics.
Metrics like lines of code per hour, function points per person-month (PM), number of classes per person-year (PY) or person-month, number of methods per PM, average person-days per class, or even hours per class and average number of classes per developer have been proposed or reported in the literature for OO productivity (Card and Scalzo, 1999; Chidamer et al., 1997; IBM OOTC, 1993; Lorenz and Kidd, 1994). Despite the differences in units of measurement, these metrics all measure the same concept of productivity, which is the number of units of output per unit of effort. In OO development, the unit of output is class or method and the common units of effort are PY and PM. Among the many variants of productivity metric, number of classes per PY and number of classes per PM are perhaps the most frequently used.
Let us look at some actual data. For the five IBM projects discussed earlier, data on project size in terms of number of classes were available (Table 12.2). We also tracked the total PYs for each project, from design, through development, to the completion of testing. We did not have effort data for Project E because it was a joint project with an external alliance. The number of classes per PY thus calculated for these projects are shown in Table 12.5. The numbers ranged from 2.8 classes per PM to 6 classes per PM. The average of the projects was 4.4 classes per PM, with a standard deviation of 1.1. The dispersion of the distribution was small in view of the fact that these were separate projects with different development teams, albeit all developed in the same organization. The high number of classes per PM for Project B may be related to the small number of methods per class (3 methods per class) for the project, as discussed earlier. It is also significant to note that the differences between the C++ projects and the Smalltalk projects were small.
Lorenz and Kidd (1994) show data on average number of person-days per class for four Smalltalk projects and two C++ projects, in a histogram format. From the histograms, we estimate the person-days per class for the four Smalltalk projects were 7, 6, 2, and 8, and for the two C++ projects, they were about 23 and 35. The Smalltalk data seem to be close to that of the IBM projects, amounting to about 4 classes per PM. The C++ projects amounted to about one PM or more per class.
Table 12.5. Productivity in Terms of Number of Classes per PY for Five OO Projects
|
Project A C++ |
Project B C++ |
Project C C++ |
Project D IBM Smalltalk |
Project E OTI Smalltalk |
Project F Digitalk Smalltalk | |
|---|---|---|---|---|---|---|
|
Number of Classes |
5,741 |
2,513 |
3,000 |
100 |
566 |
492 |
|
PY |
100 |
35 |
90 |
2 |
na |
10 |
|
Classes per PY |
57.4 |
71.8 |
33.3 |
50 |
na |
49.2 |
|
Classes per PM |
4.8 |
6 |
2.8 |
4.2 |
na |
4.1 |
|
Methods per PM |
8 |
18 |
20 |
71 |
na |
86 |
Lorenz and Kidd (1994) list the pertinent factors affecting the differences, including user interface versus model class, abstract versus concrete class, key versus support class, framework versus framework-client class, and immature versus mature classes. For example, they observe that key classes, classes that embody the “essence” of the business domain, normally take more time to develop and require more interactions with domain experts. Framework classes are powerful but are not easy to develop, and require more effort. Mature classes typically have more methods but required less development time. Therefore, without a good understanding of the projects and a consistent operational definition, it is difficult to make valid comparisons across projects or organizations.
It should be noted that all the IBM projects discussed here were systems software, either part of an operating system, or related to an operating system or a development environment. The architecture and subsystem design were firmly in place. Therefore, the classes of these projects may belong more to the mature class category. Data on classes shown in the tables include all classes, regardless of whether they were abstract or concrete, and key or support classes.
In a recent assessment of OO productivity, we looked at data from two OO projects developed at two IBM sites, which were developing middleware software related to business frameworks and Web servers. Their productivity numbers are shown in Table 12.6. The productivity numbers for these two projects were much lower than those discussed earlier. These numbers certainly reflected the difficulty in designing and implementing framework-related classes, versus the more mature classes related to operating systems. The effort data in the table include the end-to-end effort from architecture to design, development, and test. If we confined the measurement to development and test and excluded the effort related to design and architecture, then the metrics value would increase to the following:
Web server: 2.6 classes per PM, 4.5 methods per PM
Framework: 1.9 classes per PM, 14.8 methods per PM
Table 12.6. Productivity Metrics for Two OO Projects
|
Classes (C++) |
Methods (C++) |
Total PMs |
Classes per PM |
Methods per PM | |
|---|---|---|---|---|---|
|
Web Server |
598 |
1,029 |
318 |
1.9 |
3.2 |
|
Framework |
3,215 |
24,670 |
2,608 |
1.2 |
9.5 |
The IBM OOTC’s rule of thumb for effort estimate (at the early design stage of a project) is one to three PM per business class (or key class) (West, 1999). In Lorenz and Kidd’s (1994) definition, a key class is a class that is central to the business domain being automated. A key class is one that would cause great difficulties in developing and maintaining a system if it did not exist. Since the ratio between key classes and support classes, or total classes in the entire project is not known, it is difficult to correlate this 1 to 3 PM per key class guideline to the numbers discussed above.
In summary, we attempt to evaluate some empirical OO productivity data, in terms of number of classes per PM. With the preceding discussion, we have the following tentative values as a stake in the ground for OO project effort estimation:
For project estimate at the early design phase, 1 to 3 PM per business class (or one-third of a class to one class per PM)
For framework-related projects, about 1.5 classes per PM
For mature class projects for systems software, about 4 classes per PM
Further studies and accumulation of empirical findings are definitely needed to establish robustness for such OO productivity metrics. A drawback of OO metrics is that there are no conversion rules to lines of code metrics and to function point metrics. As such, comparisons between OO projects described by OO metrics and projects outside the OO paradigm cannot be made. According to Jones (2002), function point metrics works well with OO projects. Among the clients of the Software Productivity Research, Inc. (SPR), those who are interested in comparing OO productivity and quality level to procedural projects all use function point metrics (Jones, 2002). The function point could eventually be the link between OO and non-OO metrics. Because there are variations in the function and responsibility of classes and methods, there are studies that started to use the number of function points as a weighting factor when measuring the number of classes and methods.
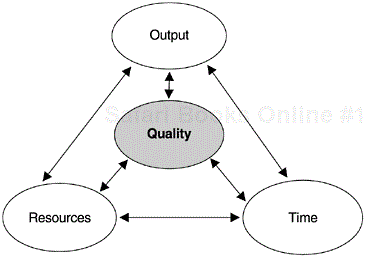
Finally, as a side note, regardless of whether it is classes per PM for OO projects or LOC per PY and function points per PM for procedural languages, these productivity metrics are two dimensional: output and effort. The productivity concept in software, especially at the project level, however, is three-dimensional: output (size or function of deliverables), effort, and time. This is because the tradeoff between time and effort is not linear, and therefore the dimension of time must be addressed. If quality is included as yet another variable, the productivity concept would be four-dimensional. Assuming quality is held constant or quality criteria can be established as part of the requirements for the deliverable, we can avoid the confusion of mixing productivity and quality, and productivity remains a three-dimensional concept. As shown in Figure 12.2, if one holds any of the two dimensions constant, a change in the third dimension is a statement of productivity. For example, if effort (resources) and development time are fixed, then the more output (function) a project produces, the more productive is the project team. Likewise, if resources and output (required functions) are fixed, then the faster the team delivers, the more productive it is.
It appears then that the two-dimensional metrics are really not adequate to measure software productivity. Based on a large body of empirical data, Putnam and Myers (1992) derived the software productivity index (PI), which takes all three dimensions of productivity into account. For the output dimension, the PI equation still uses LOC and therefore the index is subject to all shortcomings associated with LOC, which are well documented in the literature (Jones, 1986, 1991, 1993, 2000). The index is still more robust comparing to the two-dimensional metrics because (1) it includes time in its calculation, (2) there is a coefficient in the formula to calibrate for the effects of project size, and (3) after the calculation is done based on the equation, a categorization process is used to translate the raw number of productivity parameters (which is a huge number) to the final productivity index (PI), and therefore the impact of the variations in LOC data is reduced. Putnam and associates also provided the values of PI by types of software based on a large body of empirical data on industry projects. Therefore, the calculated PI value of a project can be compared to the industry average according to type of software.
For procedural programming, function point productivity metrics are regarded as better than the LOC-based productivity metrics. However, the time dimension still needs to be addressed. This is the same case for the OO productivity metrics. Applying Putnam’s PI approach to the function point and OO metrics will likely produce better and more adequate productivity metrics. This, however, requires more research with a large body of empirical data in order to establish appropriate equations that are equivalent to the LOC-based PI equation.
In procedural programming, quality is measured by defects per thousand LOC (KLOC), defects per function point, mean time to failure, and many other metrics and models such as those discussed in several previous chapters. The corresponding measure for defects per KLOC and defects per function point in OO is defects per class. In search of empirical data related to OO defect rates, we noted that data about OO quality is even more rare than productivity data. Table 12.7 shows the data that we tracked for some of the projects we discuss in this chapter.
Testing defect rates for these projects ranged from 0.21 defects per class to 0.69 per class and from 2.6 defects per KLOC (new and changed code) to 8.2 defects per KLOC. In our long history of defect tracking, defect rates during testing when the products were under development ranges from 4 defects per KLOC to about 9 defects per KLOC for procedural programming. The defect rates of these OO projects compare favorably with our history. With one year in the field, the defect rates of these products ranged from 0.01 defects per class to 0.05 defects per class and from 0.05 defects per KLOC to 0.78 defects per KLOC. Again, these figures, except the defects/KLOC for Project B, compare well with our history.
With regard to quality management, the OO design and complexity metrics can be used to flag the classes with potential problems for special attention, as is the practice at the NASA SATC. It appears that researchers have started focusing on the empirical validation of the proposed metrics and relating those metrics to managerial variables. This is certainly the right direction to strengthen the practical values of OO metrics. In terms of metrics and models for in-process quality management when the project is under development, we contend that most of the metrics discussed in this book are relevant to OO projects, for example, defect removal effectiveness, the inspection self-assessment checklist (Table 9.1), the software reliability growth models (Chapters 8 and 9), and the many metrics for testing (Chapter 10). Based on our experience, the metrics for testing apply equally well to OO projects. We recommend the following:
Table 12.7. Testing Defect Rate and Field Defect Rates for Some OO Projects
|
Project B (C++) |
Project C (C++) |
Project D (Smalltalk) |
Project F (Smalltalk) | |
|---|---|---|---|---|
|
Testing Defect Rate | ||||
|
Defects/Class |
0.21 |
0.82 |
0.27 |
0.69 |
|
Defects/KLOC |
3.1 |
8.2 |
2.6 |
5.9 |
|
Field Defect Rate (1 Year After Delivery) | ||||
|
Defects/Class |
0.05 |
na |
0.04 |
0.01 |
|
Defects/KLOC |
0.78 |
na |
0.41 |
0.05 |
Test progress S curve
Testing defect arrivals over time
Testing defect backlog over time
Number of critical problems over time
Number of system crashes and hangs over time as a measure of system stability
The effort/outcome paradigm for interpreting in-process metrics and for in-process quality management
Furthermore, for some simple OO metrics discussed in this chapter, when we put them into the context of in-process tracking and analysis (for example, trend charts), they can be very useful in-process metrics for project and quality management. We illustrate this point below with the examples of a small project.
Project MMD was a small, independent project developed in Smalltalk with OO methodology and iterative development process over a period of 19 weeks (Hanks, 1998). The software provided functions to drive multimedia devices (e.g., audio and video equipment) and contained 40 classes with about 3,200 lines of code. The team consisted of four members—two developers for analysis, design, and cod-ing, and two testers for testing, tracking, and other tasks required for the product to be ready to ship. With good in-process tracking and clear understanding of roles and responsibilities, the team conducted weekly status meetings to keep the project moving. Throughout the development process, four major iterations were completed. Figure 12.3 shows the trends of several design and code metrics over time. They all met the threshold values recommended by Lorenz (1993). Figure 12.4 shows the number of classes and classes discarded over time (i.e., metric number 11 in Table 12.1.). The trend charts reflect the several iterations and the fact that iterative development process was used.
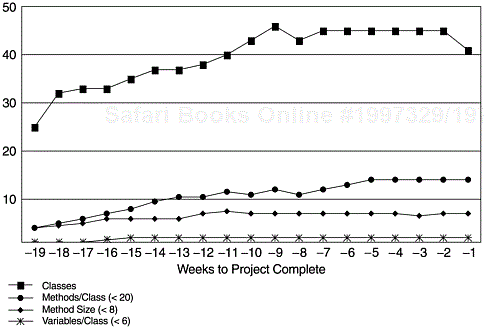

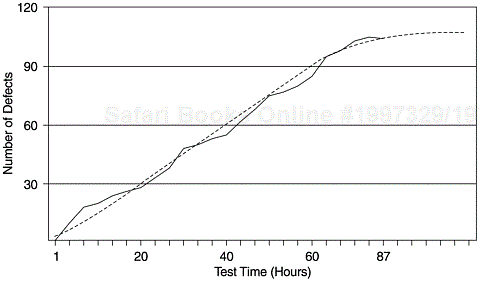
Figure 12.5 shows the relationship between defect arrivals and testing time, with a fitted curve based on the delayed S reliability growth model. This curve fitting confirms the applicability of reliability growth models to data from OO projects. In fact, we contend that this match may be even better than data from procedural software projects, because in OO environment, with the class structure, the more difficult bugs tend to be detected and “flushed” out earlier in the testing process.
Finally, if we use this project as another data point for productivity estimates, with 40 classes and 76 person-weeks (4 x 19 weeks) and assuming 4.33 person-weeks per person-month (PM), we get 2.3 classes per PM. This number falls between the numbers for the framework-related projects (1.2 and 1.9 classes per PM) and the mature systems software projects (about 4 classes per PM).
At IBM Rochester, the deployment of OO technology in software development began in the early 1990s. More than ten years later, numerous projects are now developed with this technology. We conducted assessments of selected projects throughout the past decade and the following is a summary of lessons learned. Organizations with OO deployment experience may have made similar observations or learned additional lessons.
To transition from structural design and procedural programming to OO design and programming, it is crucial to allow time for the learning curve. Formal classroom education is needed. A curriculum customized to the organization or specific projects and timely delivery are major considerations in a training program. The most effective curriculum spreads out class time with on-the-job training. Consultants or trainers should be industry experts or experienced in-house experts with full-time training jobs, so that classroom education as well as consulting and trouble shooting when the project is under way can be provided. The education should include the entire design and development life cycle (requirements, analysis, design, coding, and testing) and not focus only on language and programming. Based on experience, it takes six months to complete OO skills training based on the model that classroom education is spread out with on-the-job training: three months in calendar time to complete initial training followed by three months of advanced training. After training, it takes three months to become capable, that is, to acquire the working knowledge to do OO design and development. It takes another nine to twelve months to become proficient in OO technology, provided that the developers have been working on a project.
Like any software projects, domain-specific knowledge and skills and software engineering skills are equally important. For OO software engineering, if we dichotomize domain knowledge and OO skills and cross-tabulate the two variables, we get the four skills categories shown in Figure 12.6.
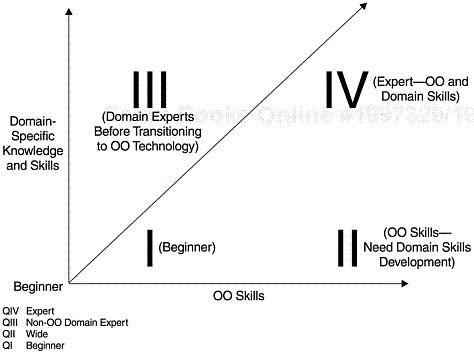
For developers who are not experienced in OO skills and domain knowledge (e.g., a banking application software, or an operating system architecture and design), the progression in skills would be from category I to II to IV. For experienced developers with rich domain-specific knowledge who are transitioning to OO technology, the transition path would be from category III to IV. For an OO development project, at any phase in the development process, there should be OO experts (category IV skills) leading the projects and providing on-the-job guidance to those who are less experienced. The composition of skills categories and the percentage of OO experts can vary across the development cycle. The percentage of OO skills over the phases of the development cycle can be distributed as shown in Figure 12.7 so that the project has enough OO experts to enhance its success, and at the same time has the capacity for skills development. In the figure, the line curve approximates the staffing curve of a project, and the phases are characterized by different distribution of the analysis, design, code, and test (ADCT) activities.

A consistent process architecture in an organization is important so each new project does not require reinvention of the wheel. Consistency is also the basis for systematic improvements. If at all possible, use a mature tool set and a stable development environment, and have peer support for the language that is being used. Many good tools exist in the industry. But the robustness of the tools and the integration of tools to provide cohesive development environments are even more important. Tools and development environment are as important as the languages and specific OO methods to be used for the project. Developing your own tools should be considered only as a last resort. At the same time, it is very advantageous if the development team knows its compiler well because changes may be needed for performance tuning.
Good project management is ever more important due to the iterative nature of the OO development process. We recommend monthly goals or mini-milestones be set with the project schedule, and explicit and frequent checkpoints be conducted. The use of metrics to show the status and trends of the project progress, such as those shown in Figures 12.3 through 12.5, enhances the focus of the team. As illustrated in the example illustrated with these figures, metrics are applicable to large projects as well as small ones. The measurements should be decided at the outset and the team should ensure that everyone knows the measurements and that measurements are collected regularly. Status reporting is another area that must be watched because developers might regard status reporting as dead time. It is not rare that teams disclose the information that they are going to fail to meet a target only when they have actually failed.
Inevitably, some large software projects involve multiteam and multilocation development. Our experience suggests that, because of the iterative nature of the OO process, such projects require more coordination and better communication than projects using the conventional approach.
Directly related to the iterative nature of the OO development process are two major items on the top of the project management list: (1) beware of analysis and design without code—the so called analysis/paralysis phenomenon, and (2) beware of prototypes that never end. Prototypes play an important role in OO development and are often used in building a fully functional user interface or in showing a proof of feasibility of the project. Seeing is believing; prototypes usually command high visibility from customers, project managers, and particularly executives of the organization. However, there is a big gap between the completion of prototypes and the completion of the design and development of the project. To fill the gap, rigorous work on the overall architecture, design (internal as well as external), scaling, and implementation needs to happen. Technical leaders need to provide the leadership to bridge the gap and project management needs to plan and drive the necessary activities and milestones after successful prototypes were achieved. We have seen OO projects that kept on prototyping and iterating, that mistook the success of prototypes as success of the project, and that significantly underestimated the design and development work after prototypes and therefore failed to meet product delivery targets. Warning signs include hearing conversation among developers like the following: “What have you been up to in the past several months?” “I have been working on our prototype project.”
Good reusable classes are hard to build. To encourage reuse, some projects purchased libraries of reusable classes, some projects created internal programs (e.g., a reuse council), and some projects took both approaches. But they resulted in only a slight increase in reuse, and there were few submissions to the reuse program. This was a clear contrast to the original anticipation associated with the OO technology and process. This low level of reuse is consistent with the findings in the literature (Kemerer, 1999) with regard to inheritance and reuse.
Our lesson learned is that OO technology is not automatically equal to code reuse. To have tangible results, the team has to design for it, and must continually work at it. Class reuse issues may not even be able to be adequately addressed at the project level. From the perspective of product development, there is an inherent conflict of interest between development cycle time and the building of reusable classes. It is more effective to have a reuse strategy in place at the organization level so that issues related to the management system, interproject coordination, libraries for reusable classes, possible incentive program, and so on, can be dealt with on a long-term basis.
Performance is a major concern in most, if not all, OO projects during development, especially new projects. It is not uncommon that initial measures of performance cause serious distress. We did see projects fail due to performance problems. Performance problems can be attributed to several factors related to experience and technology:
An inexperienced team may be overzealous in class creation, leading to overmodularization.
Dynamic memory allocations may not be used appropriately.
OO compiler technology may not yet be optimized for performance.
With regard to the compiler factor, its contribution to performance problems should be lesser now than in the early days of OO technology. Although the compiler technology has improved, it remains a concern to OO development experts. A recent assessment of an OO project that had to be rewritten due to performance problems confirms that compiler optimization (or the lack thereof) remains a critical factor.
On the positive side, our experience indicates that performance tuning in OO structure is not too difficult to achieve, especially if it is done early. In most cases, performance problems were overcome when the project was complete. The lesson with regard to performance: It is a concern to be taken seriously, and early performance measurement and tuning are crucial.
Assessments by developers were that in OO development, bugs are easier to find and fix. Our data also indicate that more often than not, defect rates for OO projects are indeed lower during the testing phases as well as when the products are in the field. The data on OO quality for a few projects that were discussed earlier in this chapter do support these observations. Type checking abilities of OO compilers, the practice of object coherence checking, the class structure in OO designs, the focus on analysis and design in the OO development process, and design tools are among the many positive factors for quality.
This chapter discusses design and complexity metrics, productivity metrics, and metrics for measuring quality and for in-process tracking and management for OO projects. On design and complexity metrics, it highlights the Lorenz metrics and the CF metrics suite. We found the rules of thumb for some of Lorenz’s metrics useful for interpreting actual project data. We also provide actual project data in the discussions and attempt to put the metrics and the threshold values into proper context. With regard to productivity, we put the stakes in the ground by showing the productivity numbers of several types of OO class. Certainly a lot more empirical data has to be accumulated before consistent guidelines for OO productivity can be derived. But starting the process is important. We also show examples of simple OO metrics for in-process project and quality management. We assert that in addition to specific OO metrics, many metrics and models for quality management while the project is under development discussed here, are as applicable to OO projects as to conventional projects.
In the last section we offer the lessons learned from OO development projects with respect to education, training and OO skills, tools and development environment, project management, reuse, performance, and quality.