
Chapter 6. Special Index and Collection Types
This chapter covers the special collections and index types MongoDB has available, including:
Capped collections for queue-like data
TTL indexes for caches
Full-text indexes for simple string searching
Geospatial indexes for 2D and spherical geometries
GridFS for storing large files
Capped Collections
“Normal” collections in MongoDB are created dynamically and automatically grow in size to fit additional data. MongoDB also supports a different type of collection, called a capped collection, which is created in advance and is fixed in size (see Figure 6-1). Having fixed-size collections brings up an interesting question: what happens when we try to insert into a capped collection that is already full? The answer is that capped collections behave like circular queues: if we’re out of space, the oldest document will be deleted, and the new one will take its place (see Figure 6-2). This means that capped collections automatically age-out the oldest documents as new documents are inserted.
Certain operations are not allowed on capped collections. Documents cannot be removed or deleted (aside from the automatic age-out described earlier), and updates that would cause documents to grow in size are disallowed. By preventing these two operations, we guarantee that documents in a capped collection are stored in insertion order and that there is no need to maintain a free list for space from removed documents.
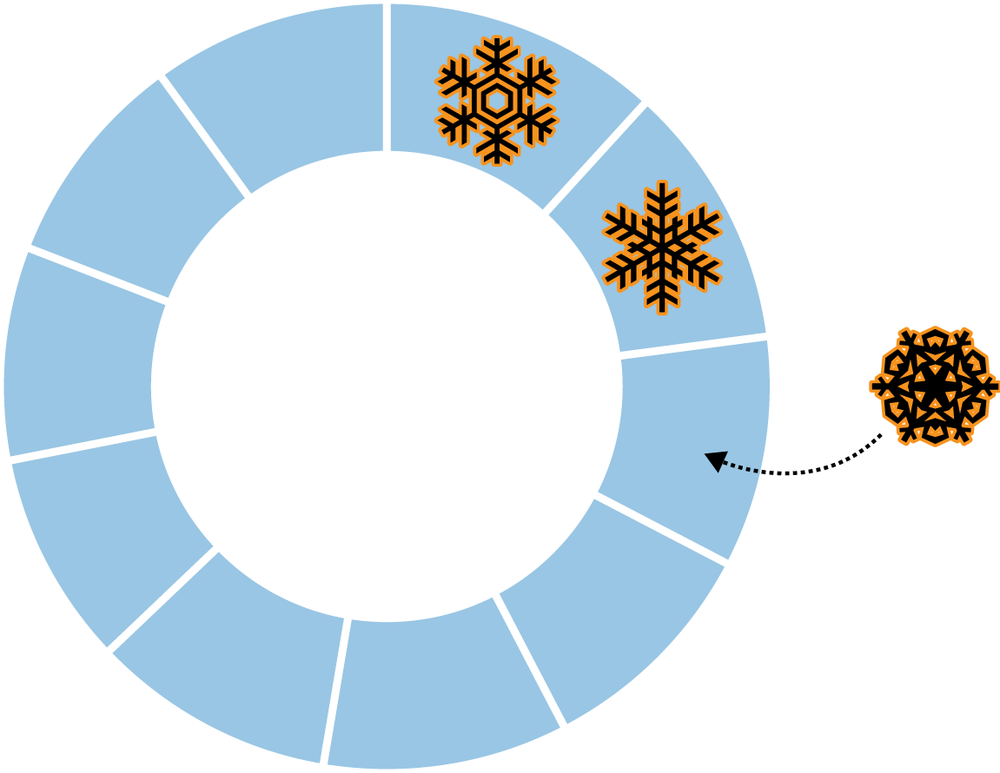

Capped collections have a different access pattern than most MongoDB collections: data is written sequentially over a fixed section of disk. This makes them tend to perform writes quickly on spinning disk, especially if they can be given their own disk (so as not to be “interrupted” by other collections’ random writes).
Note
Capped collections cannot be sharded.
Capped collections tend to be useful for logging, although they lack flexibility: you cannot control when data ages out, other than setting a size when you create the collection.
Creating Capped Collections
Unlike normal collections, capped collections must be explicitly
created before they are used. To create a capped collection, use the
create command. From the shell, this
can be done using createCollection:
>db.createCollection("my_collection",{"capped":true,"size":100000});{"ok":true}
The previous command creates a capped collection, my_collection, that is a fixed size of 100,000 bytes.
createCollection can also
specify a limit on the number of documents in a capped collection in
addition to the limit size:
>db.createCollection("my_collection2",...{"capped":true,"size":100000,"max":100});{"ok":true}
You could use this to keep, say, the latest 10 news articles or limit a user to 1,000 documents.
Once a capped collection has been created, it cannot be changed (it must be dropped and recreated if you wish to change its properties). Thus, you should think carefully about the size of a large collection before creating it.
Note
When limiting the number of documents in a capped collection,
you must specify a size limit as well. Age-out will be based on
whichever limit is reached first: it cannot hold more than "max" documents nor take up more than
"size" space.
Another option for creating a capped collection is to convert an
existing, regular collection into a capped collection. This can be done
using the convertToCapped command—in the following example, we
convert the test collection to a capped collection
of 10,000 bytes:
>db.runCommand({"convertToCapped":"test","size":10000});{"ok":true}
There is no way to “uncap” a capped collection (other than dropping it).
Sorting Au Naturel
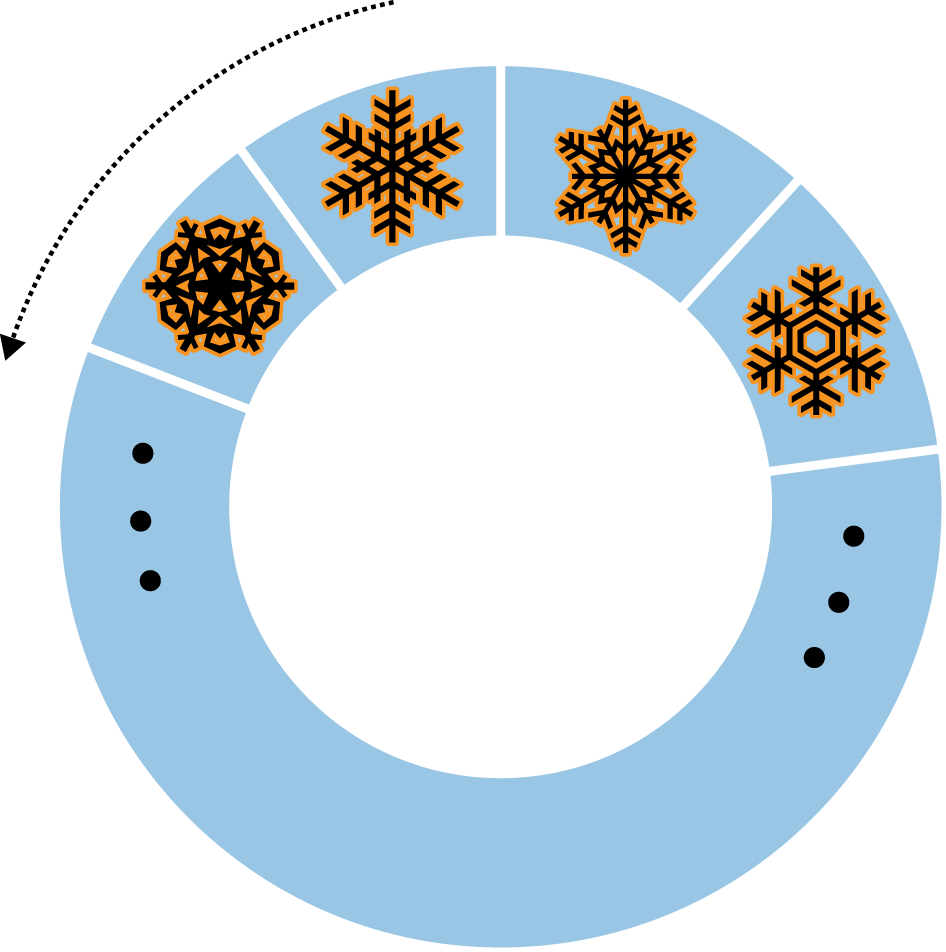
There is a special type of sort that you can do with capped collections, called a natural sort. A natural sort returns the documents in the order that they appear on disk (see Figure 6-3).
For most collections, this isn’t a very useful sort because documents move around. However, documents in a capped collection are always kept in insertion order so that natural order is the same as insertion order. Thus, a natural sort gives you documents from oldest to newest. You can also sort from newest to oldest (see Figure 6-4):
>db.my_collection.find().sort({"$natural":-1})

Tailable Cursors
Tailable cursors are a special type of cursor that are not closed when their results are exhausted. They were inspired by the tail -f command and, similar to the command, will continue fetching output for as long as possible. Because the cursors do not die when they run out of results, they can continue to fetch new results as documents are added to the collection. Tailable cursors can be used only on capped collections, since insert order is not tracked for normal collections.
Tailable cursors are often used for processing documents as they are inserted onto a “work queue” (the capped collection). Because tailable cursors will time out after 10 minutes of no results, it is important to include logic to re-query the collection if they die. The mongo shell does not allow you to use tailable cursors, but using one in PHP looks something like the following:
$cursor=$collection->find()->tailable();while(true){if(!$cursor->hasNext()){if($cursor->dead()){break;}sleep(1);}else{while($cursor->hasNext()){do_stuff($cursor->getNext());}}}
The cursor will process results or wait for more results to arrive until the cursor dies (it will time out if there are no inserts for 10 minutes or someone kills the query operation).
No-_id Collections
By default, every collection has an "_id" index. However, you can create
collections without "_id" indexes by
setting the autoIndexId option to false when calling
createCollection. This is not
recommended but can give you a slight speed boost on an insert-only
collection.
Warning
If you create a collection without an "_id" index, you will never be able
replicate the mongod it lives on.
Replication requires the "_id"
index on every collection (it is important that replication can
uniquely identify each document in a collection).
Capped collections prior to version 2.2 did not have an "_id" index unless
autoIndexId was explicitly set to true. If you are
working with an “old” capped collection, ensure that your application is
populating the "_id" field (most
drivers will do this automatically) and then create the "_id" index using ensureIndex.
Remember to make the "_id"
index unique. Do a practice run before creating the index in production,
as unlike other indexes, the "_id"
index cannot be dropped once created. Thus, you must get it right the
first time! If you do not, you cannot change it without dropping the
collection and recreating it.
Time-To-Live Indexes
As mentioned in the previous section, capped collections give you limited control over when their contents are overwritten. If you need a more flexible age-out system, time-to-live (TTL) indexes allow you to set a timeout for each document. When a document reaches a preconfigured age, it will be deleted. This type of index is useful for caching problems like session storage.
You can create a TTL index by specifying the
expireAfterSeconds option in the second argument to
ensureIndex:
>// 24-hour timeout>db.foo.ensureIndex({"lastUpdated":1},{"expireAfterSeconds":60*60*24})
This creates a TTL index on the "lastUpdated" field. If a document’s
"lastUpdated" field exists and is a date, the document
will be removed once the server time is
expireAfterSeconds seconds ahead of the document’s
time.
To prevent an active session from being removed, you can update the
"lastUpdated" field to the current time whenever there
is activity. Once "lastUpdated" is 24 hours old, the
document will be removed.
MongoDB sweeps the TTL index once per minute, so you should not
depend on to-the-second granularity. You can change the
expireAfterSeconds using the collMod command:
>db.runCommand({"collMod":"someapp.cache","index":{"keyPattern":{"lastUpdated":1},"expireAfterSeconds":3600}});
You can have multiple TTL indexes on a given collection. They cannot be compound indexes but can be used like “normal” indexes for the purposes of sorting and query optimization.
Full-Text Indexes
MongoDB has a special type of index for searching for text within documents. In previous chapters, we’ve queried for strings using exact matches and regular expressions, but these techniques have some limitations. Searching a large block of text for a regular expression is slow and it’s tough to take linguistic issues into account (e.g., that “entry” should match “entries”). Full-text indexes give you the ability to search text quickly, as well as provide built-in support for multi-language stemming and stop words.
While all indexes are expensive to create, full-text indexes are particularly heavyweight. Creating a full-text index on a busy collection can overload MongoDB, so adding this type of index should always be done offline or at a time when performance does not matter. You should be wary of creating full-text indexes that will not fit in RAM (unless you have SSDs). See Chapter 18 for more information on creating indexes with minimal impact on your application.
Full-text search will also incur more severe performance penalties on writes than “normal” indexes, since all strings must be split, stemmed, and stored in a few places. Thus, you will tend to see poorer write performance on full-text-indexed collections than on others. It will also slow down data movement if you are sharding: all text must be reindexed when it is migrated to a new shard.
As of this writing, full text indexes are an “experimental” feature,
so you must enable them specifically. You can either start MongoDB with
the --setParameter textSearchEnabled=true option or set
it at runtime by running the setParameter command:
>db.adminCommand({"setParameter":1,"textSearchEnabled":true})
Suppose we use the unofficial Hacker News JSON API to load some recent stories into MongoDB.
To run a search over the text, we first need to create a "text" index:
>db.hn.ensureIndex({"title":"text"})
Now, to use the index, we must use the text command (as of this writing, full text indexes cannot be used with “normal” queries):
test>db.runCommand({"text":"hn","search":"ask hn"}){"queryDebugString":"ask|hn||||||","language":"english","results":[{"score":2.25,"obj":{"_id":ObjectId("50dcab296803fa7e4f000011"),"title":"Ask HN: Most valuable skills you have?","url":"/comments/4974230","id":4974230,"commentCount":37,"points":31,"postedAgo":"2 hours ago","postedBy":"bavidar"}},{"score":0.5625,"obj":{"_id":ObjectId("50dcab296803fa7e4f000001"),"title":"Show HN: How I turned an old book...","url":"http://www.howacarworks.com/about","id":4974055,"commentCount":44,"points":95,"postedAgo":"2 hours ago","postedBy":"AlexMuir"}},{"score":0.5555555555555556,"obj":{"_id":ObjectId("50dcab296803fa7e4f000010"),"title":"Show HN: ShotBlocker - iOS Screenshot detector...","url":"https://github.com/clayallsopp/ShotBlocker","id":4973909,"commentCount":10,"points":17,"postedAgo":"3 hours ago","postedBy":"10char"}}],"stats":{"nscanned":4,"nscannedObjects":0,"n":3,"timeMicros":89},"ok":1}
The matching documents are returned in order of decreasing
relevance: “Ask HN” is first, then two “Show HN” partial matches. The
"score" field before each object
describes how closely the result matched the query.
As you can see from the results, the search is case insensitive, at
least for characters in [a-zA-Z].
Full-text indexes use toLower to
lowercase words, which is locale-dependant, so users of other languages
may find MongoDB unpredictably case sensitive, depending on how toLower behaves on their character set. Better
collation support is in the works.
Full text indexes only index string data: other data types are ignored and not included in the index. Only one full-text index is allowed per collection, but it may contain multiple fields:
>db.blobs.ensureIndex({"title":"text","desc":"text","author":"text"})
This is not like “nomal” multikey indexes where there is an ordering on the keys: each field is given equal consideration. You can control the relative importance MongoDB attaches to each field by specifying a weight:
>db.hn.ensureIndex({"title":"text","desc":"text","author":"text"},...{"weights":{"title":3,"author":2}})
The default weight is 1, and you may use weights from 1 to 1
billion. The weights above would weight "title" fields the most, followed by "author" and then "desc" (not specified in the weight list, so
given a default weight of 1).
You cannot change field weights after index creation (without dropping the index and recreating it), so you may want to play with weights on a sample data set before creating the index on your production data.
For some collections, you may not know which fields a document will
contain. You can create a full-text index on all string fields in a
document by creating an index on "$**":
this not only indexes all top-level string fields, but also searches
embedded documents and arrays for string fields:
>db.blobs.ensureIndex({"$**":"text"})
You can also give "$**" a
weight:
>db.hn.ensureIndex({"whatever":"text"},...{"weights":{"title":3,"author":1,"$**":2}})
"whatever" can be anything since
it is not used. As the weights specify that you’re indexing all fields,
MongoDB does not require you to give a field list.
Search Syntax
By default, MongoDB queries for an OR of all the words: “ask OR hn”. This is the most efficient way to perform a full text query, but you can also do exact phrase searches and NOT. To search for the exact phrase “ask hn”, you can query for that by including the query in quotes:
>db.runCommand({text:"hn",search:""ask hn""}){"queryDebugString":"ask|hn||||ask hn||","language":"english","results":[{"score":2.25,"obj":{"_id":ObjectId("50dcab296803fa7e4f000011"),"title":"Ask HN: Most valuable skills you have?","url":"/comments/4974230","id":4974230,"commentCount":37,"points":31,"postedAgo":"2 hours ago","postedBy":"bavidar"}}],"stats":{"nscanned":4,"nscannedObjects":0,"n":1,"nfound":1,"timeMicros":20392},"ok":1}
This is slower than the OR-type match, since MongoDB first performs an OR match and then post-processes the documents to ensure that they are AND matches, as well.
You can also make part of a query literal and part not:
>db.runCommand({text:"hn",search:""ask hn" ipod"})
This will search for exactly "ask hn" and,
optionally, "ipod".
You can also search for not including a
certain string by using "-":
>db.runCommand({text:"hn",search:"-startup vc"})
This will return results that match “vc” and don’t include the word “startup”.
Full-Text Search Optimization
There are a couple ways to optimize full text searches. If you can first narrow your search results by other criteria, you can create a compound index with a prefix of the other criteria and then the full-text fields:
>db.blog.ensureIndex({"date":1,"post":"text"})
This is referred to as partitioning the
full-text index, as it breaks it into several smaller trees based on
"date" (in the example above). This
makes full-text searches for a certain date much faster.
You can also use a postfix of other criteria to cover queries with
the index. For example, if we were only returning the "author" and "post" fields, we could create a compound
index on both:
>db.blog.ensureIndex({"post":"text","author":1})
These prefix and postfix forms can be combined:
>db.blog.ensureIndex({"date":1,"post":"text","author":1})
Creating a full-text index automatically enables the
usePowerOf2Sizes option on the collection, which
controls how space is allocated. Do not disable this option, since it
should improve writes speed.
Searching in Other Languages
When a document is inserted (or the index is first created),
MongoDB looks at the indexes fields and stems
each word, reducing it to an essential unit. However, different
languages stem words in different ways, so you must specify what
language the index or document is. Thus, text-type indexes allow a
"default_language" option to be
specified, which defaults to "english" but can be set to a number of other
languages (see the online documentation for an up-to-date
list).
For example, to create a French-language index, we could say:
>db.users.ensureIndex({"profil":"text","intérêts":"text"},...{"default_language":"french"})
Then French would be used for stemming, unless otherwise
specified. You can, on a per-document basis, specify another stemming
language by having a "language" field
that describes the document’s language:
>db.users.insert({"username":"swedishChef",..."profile":"Bork de bork",language:"swedish"})
Geospatial Indexing
MongoDB has a few types of geospatial indexes. The most commonly
used ones are 2dsphere, for
surface-of-the-earth-type maps, and 2d,
for flat maps (and time series data).
2dsphere allows you to specify
points, lines, and polygons in GeoJSON format. A point is given by
a two-element array, representing [longitude,
latitude]:
{"name":"New York City","loc":{"type":"Point","coordinates":[50,2]}}
A line is given by an array of points:
{"name":"Hudson River","loc":{"type":"Line","coordinates":[[0,1],[0,2],[1,2]]}}
A polygon is specified the same way a line is (an array of points),
but with a different "type":
{"name":"New England","loc":{"type":"Polygon","coordinates":[[0,1],[0,2],[1,2]]}}
The "loc" field can be called
anything, but the field names within its subobject are specified by
GeoJSON and cannot be changed.
You can create a geospatial index using the "2dsphere" type with ensureIndex:
>db.world.ensureIndex({"loc":"2dsphere"})
Types of Geospatial Queries
There are several types of geospatial query that you can perform:
intersection, within, and nearness. To query, specify what you’re
looking for as a GeoJSON object that looks like {"$geometry" : geoJsonDesc}.
For example, you can find documents that intersect the query’s
location using the "$geoIntersects"
operator:
>vareastVillage={..."type":"Polygon",..."coordinates":[...[-73.9917900,40.7264100],...[-73.9917900,40.7321400],...[-73.9829300,40.7321400],...[-73.9829300,40.7264100]...]}>db.open.street.map.find(...{"loc":{"$geoIntersects":{"$geometry":eastVillage}}})
This would find all point-, line-, and polygon-containing documents that had a point in the East Village.
You can use "$within" to query
for things that are completely contained in an area, for instance: “What
restaurants are in the East Village?”
>db.open.street.map.find({"loc":{"$within":{"$geometry":eastVillage}}})
Unlike our first query, this would not return things that merely pass through the East Village (such as streets) or partially overlap it (such as a polygon describing Manhattan).
Finally, you can query for nearby locations with "$near":
>db.open.street.map.find({"loc":{"$near":{"$geometry":eastVillage}}})
Note that $near is the only
geospatial operator that implies a sort: results from "$near" are always returned in distance from
closest to farthest.
One interesting thing about geospatial queries is that you do not
need a geospatial index to use "$geoIntersects" or "$within" ("$near" requires an index). However, having an
index on your geo field will speed up queries significantly, so it’s
usually recommended.
Compound Geospatial Indexes
As with other types of indexes, you can combine geospatial indexes with other fields to optimize more complex queries. A possible query mentioned above was: “What restaurants are in the East Village?” Using only a geospatial index, we could narrow the field to everything in the East Village, but narrowing it down to only “restaurants” or “pizza” would require another field in the index:
>db.open.street.map.ensureIndex({"tags":1,"location":"2dsphere"})
Then we can quickly find a pizza place in the East Village:
>db.open.street.map.find({"loc":{"$within":{"$geometry":eastVillage}},..."tags":"pizza"})
We can have the “vanilla” index field either before or after the
"2dsphere" field, depending on
whether we’d like to filter by the vanilla field or the location first.
Choose whichever will filter out more results as the first index
term.
2D Indexes
For non-spherical maps (video game maps, time series data, etc.)
you can use a "2d" index, instead of
"2dsphere":
>db.hyrule.ensureIndex({"tile":"2d"})
"2d" indexes assume a perfectly
flat surface, instead of a sphere. Thus, "2d" indexes should not be used with spheres
unless you don’t mind massive distortion around the poles.
Documents should use a two-element array for their 2d indexed field (which is
not a GeoJSON document, as of this writing). A
sample document might look like this:
{"name":"Water Temple","tile":[32,22]}
"2d" indexes can only index
points. You can store an array of points, but it will be stored as
exactly that: an array of points, not a line. This is an important
distinction for "$within" queries, in
particular. If you store a street as an array of points, the document
will match $within if one of those
points is within the given shape. However, the line created by those
points might not be wholly contained in the shape.
By default, geospatial indexing assumes that your values are going
to range from -180 to 180. If you are expecting larger or smaller
bounds, you can specify what the minimum and maximum values will be as
options to ensureIndex:
>db.star.trek.ensureIndex({"light-years":"2d"},{"min":-1000,"max":1000})
This will create a spatial index calibrated for a 2,000 × 2,000 square.
"2d" predates "2dsphere", so querying is a bit simpler. You
can only use "$near" or "$within", and neither have a "$geometry" subobject. You just specify the
coordinates:
>db.hyrule.find({"tile":{"$near":[20,21]}})
This finds all of the documents in the hyrule collection, in order by distance from the point (20, 21). A default limit of 100 documents is applied if no limit is specified. If you don’t need that many results, you should set a limit to conserve server resources. For example, the following code returns the 10 documents nearest to (20, 21):
>db.hyrule.find({"tile":{"$near":[20,21]}}).limit(10)
"$within" can query for all
points within a rectangle, circle, or polygon. To use a rectangle, use
the "$box" option:
>db.hyrule.find({"tile":{"$within":{"$box":[[10,20],[15,30]]}}})
"$box" takes a two-element
array: the first element specifies the coordinates of the lower-left
corner; the second element the upper right.
Similarly, you can find all points within a circle with "$center", which takes an array with the
center point and then a radius:
>db.hyrule.find({"tile":{"$within":{"$center":[[12,25],5]}}})
Finally, you can specify a polygon as an array of points.
>db.hyrule.find(...{"tile":{"$within":{"$polygon":[[0,20],[10,0],[-10,0]]}}})
This example would locate all documents containing points within the given triangle. The final point in the list will be “connected to” the first point to form the polygon.
Storing Files with GridFS
GridFS is a mechanism for storing large binary files in MongoDB. There are several reasons why you might consider using GridFS for file storage:
Using GridFS can simplify your stack. If you’re already using MongoDB, you might be able to use GridFS instead of a separate tool for file storage.
GridFS will leverage any existing replication or autosharding that you’ve set up for MongoDB, so getting failover and scale-out for file storage is easier.
GridFS can alleviate some of the issues that certain filesystems can exhibit when being used to store user uploads. For example, GridFS does not have issues with storing large numbers of files in the same directory.
You can get great disk locality with GridFS, because MongoDB allocates data files in 2 GB chunks.
There are some downsides, too:
Slower performance: accessing files from MongoDB will not be as fast as going directly through the filesystem.
You can only modify documents by deleting them and resaving the whole thing. MongoDB stores files as multiple documents so it cannot lock all of the chunks in a file at the same time.
GridFS is generally best when you have large files you’ll be accessing in a sequential fashion that won’t be changing much.
Getting Started with GridFS: mongofiles
The easiest way to try out GridFS is by using the mongofiles utility. mongofiles is included with all MongoDB
distributions and can be used to upload, download, list, search for, or
delete files in GridFS.
As with any of the other command-line tools, run mongofiles --help to see the options available
for mongofiles.
The following session shows how to use mongofiles to upload a file from the
filesystem to GridFS, list all of the files in GridFS, and download a
file that we’ve previously uploaded:
$echo"Hello, world">foo.txt$./mongofilesputfoo.txtconnectedto:127.0.0.1addedfile:{_id:ObjectId('4c0d2a6c3052c25545139b88'),filename:"foo.txt",length:13,chunkSize:262144,uploadDate:newDate(1275931244818),md5:"a7966bf58e23583c9a5a4059383ff850"}done!$./mongofileslistconnectedto:127.0.0.1foo.txt13$rmfoo.txt$./mongofilesgetfoo.txtconnectedto:127.0.0.1donewriteto:foo.txt$catfoo.txtHello,world
In the previous example, we perform three basic operations using
mongofiles: put, list,
and get. The put operation takes a file in the filesystem
and adds it to GridFS; list will list
any files that have been added to GridFS; and get does the inverse of put: it takes a file from GridFS and writes it
to the filesystem. mongofiles also
supports two other operations: search
for finding files in GridFS by filename and delete for removing a file from GridFS.
Working with GridFS from the MongoDB Drivers
All the client libraries have GridFS APIs. For example, with
PyMongo (the Python driver for MongoDB) you can perform the same series
of operations as we did with mongofiles:
>>>frompymongoimportConnection>>>importgridfs>>>db=Connection().test>>>fs=gridfs.GridFS(db)>>>file_id=fs.put("Hello, world",filename="foo.txt")>>>fs.list()[u'foo.txt']>>>fs.get(file_id).read()'Hello, world'
The API for working with GridFS from PyMongo is very similar to
that of mongofiles: we can easily
perform the basic put, get, and list operations. Almost all the MongoDB drivers follow this basic pattern
for working with GridFS, while often exposing more advanced
functionality as well. For driver-specific information on GridFS, please
check out the documentation for the specific driver you’re using.
Under the Hood
GridFS is a lightweight specification for storing files that is built on top of normal MongoDB documents. The MongoDB server actually does almost nothing to “special-case” the handling of GridFS requests; all the work is handled by the client-side drivers and tools.
The basic idea behind GridFS is that we can store large files by splitting them up into chunks and storing each chunk as a separate document. Because MongoDB supports storing binary data in documents, we can keep storage overhead for chunks to a minimum. In addition to storing each chunk of a file, we store a single document that groups the chunks together and contains metadata about the file.
The chunks for GridFS are stored in their own collection. By default chunks will use the collection fs.chunks, but this can be overridden. Within the chunks collection the structure of the individual documents is pretty simple:
{"_id":ObjectId("..."),"n":0,"data":BinData("..."),"files_id":ObjectId("...")}
Like any other MongoDB document, the chunk has its own unique
"_id". In addition, it has a couple
of other keys:
"files_id"The
"_id"of the file document that contains the metadata for the file this chunk is from."n"The chunk’s position in the file, relative to the other chunks.
"data"The bytes in this chunk of the file.
The metadata for each file is stored in a separate collection, which defaults to fs.files. Each document in the files collection represents a single file in GridFS and can contain any custom metadata that should be associated with that file. In addition to any user-defined keys, there are a couple of keys that are mandated by the GridFS specification:
"_id"A unique id for the file—this is what will be stored in each chunk as the value for the
"files_id"key."length"The total number of bytes making up the content of the file.
"chunkSize"The size of each chunk comprising the file, in bytes. The default is 256K, but this can be adjusted if needed.
"uploadDate"A timestamp representing when this file was stored in GridFS.
"md5"An md5 checksum of this file’s contents, generated on the server side.
Of all of the required keys, perhaps the most interesting (or
least self-explanatory) is "md5". The
value for "md5" is generated by the
MongoDB server using the filemd5
command, which computes the md5 checksum of the uploaded chunks. This
means that users can check the value of the "md5" key to ensure that a file was uploaded
correctly.
As mentioned above, you are not limited to the required fields in fs.files: feel free to keep any other file metadata in this collection as well. You might want to keep information such as download count, MIME type, or user rating with a file’s metadata.
Once you understand the underlying GridFS specification, it
becomes trivial to implement features that the driver you’re using might
not provide helpers for. For example, you can use the distinct command to get a list of unique
filenames stored in GridFS:
>db.fs.files.distinct("filename")["foo.txt","bar.txt","baz.txt"]
This allows your application a great deal of flexibility in loading and collecting information about files.