
Appendix B. MongoDB Internals
It is not necessary to understand MongoDB’s internals to use it effectively, but it may be of interest to developers who wish to work on tools, contribute, or simply understand what’s happening under the hood. This appendix covers some of the basics. The MongoDB source code is available at https://github.com/mongodb/mongo.
BSON
Documents in MongoDB are an abstract concept—the concrete representation of a document varies depending on the driver/language being used. Because documents are used extensively for communication in MongoDB, there also needs to be a representation of documents that is shared by all drivers, tools, and processes in the MongoDB ecosystem. That representation is called Binary JSON, or BSON (no one knows where the J went).
BSON is a lightweight binary format capable of representing any MongoDB document as a string of bytes. The database understands BSON, and BSON is the format in which documents are saved to disk.
When a driver is given a document to insert, use as a query, and so on, it will encode that document to BSON before sending it to the server. Likewise, documents being returned to the client from the server are sent as BSON strings. This BSON data is decoded by the driver to its native document representation before being returned to the client.
The BSON format has three primary goals:
- Efficiency
BSON is designed to represent data efficiently, without using much extra space. In the worst case BSON is slightly less efficient than JSON; and in the best case (e.g., when storing binary data or large numerics), it is much more efficient.
- Traversability
In some cases, BSON does sacrifice space efficiency to make the format easier to traverse. For example, string values are prefixed with a length rather than relying on a terminator to signify the end of a string. This traversability is useful when the MongoDB server needs to introspect documents.
- Performance
Finally, BSON is designed to be fast to encode to and decode from. It uses C-style representations for types, which are fast to work with in most programming languages.
For the exact BSON specification, see http://www.bsonspec.org.
Wire Protocol
Drivers access the MongoDB server using a lightweight TCP/IP wire protocol. The protocol is documented on the MongoDB wiki but basically consists of a thin wrapper around BSON data. For example, an insert message consists of 20 bytes of header data (which includes a code telling the server to perform an insert and the message length), the collection name to insert into, and a list of BSON documents to insert.
Data Files
Inside of the MongoDB data directory, which is /data/db/ by default, there are separate files for each database. Each database has a single .ns file and several data files, which have monotonically increasing numeric extensions. So, the database foo would be stored in the files foo.ns, foo.0, foo.1, foo.2, and so on.
The numeric data files for a database will double in size for each new file, up to a maximum file size of 2 GB. This behavior allows small databases to not waste too much space on disk, while keeping large databases in mostly contiguous regions on disk.
MongoDB also preallocates data files to ensure consistent
performance. (This behavior can be disabled using the
--noprealloc option.) Preallocation happens in the
background and is initiated every time that a data file is filled. This
means that the MongoDB server will always attempt to keep an extra, empty
data file for each database to avoid blocking on file allocation.
Namespaces and Extents
Within its data files, each database is organized into namespaces, each storing a specific collection’s data. The documents for each collection have their own namespace, as does each index. Metadata for namespaces is stored in the database’s .ns file.
The data for each namespace is grouped on disk into sections of the data files, called extents. In Figure B-1 the foo database has three data files, the third of which has been preallocated and is empty. The first two data files have been divided up into extents belonging to several different namespaces.
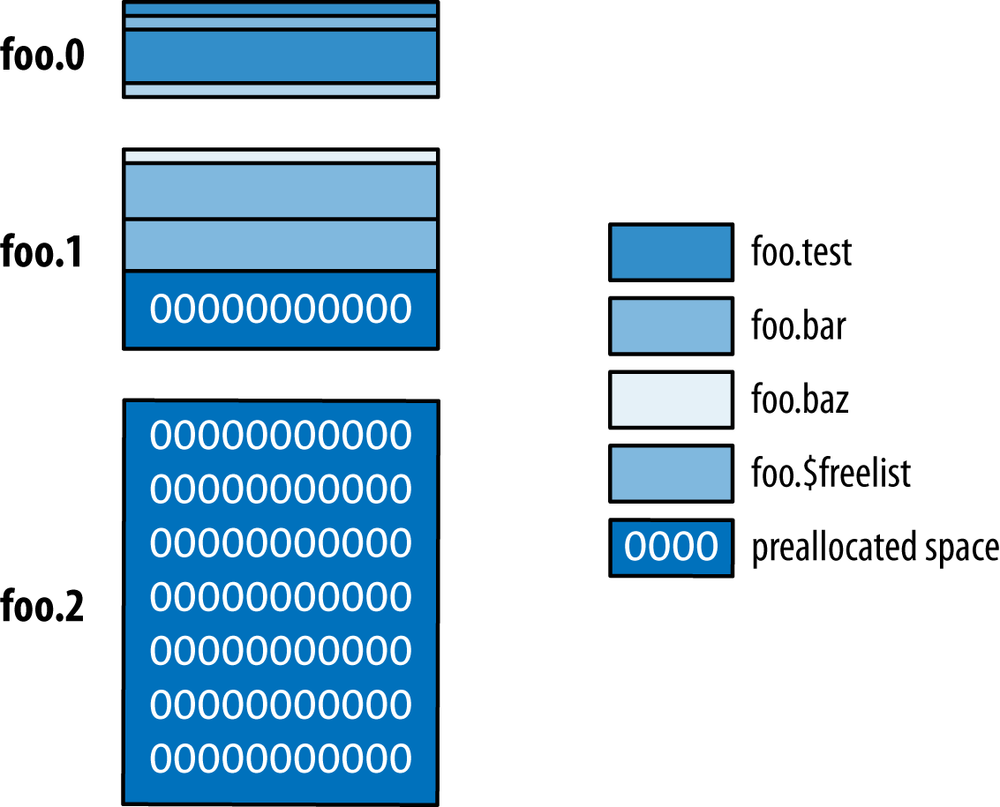
Figure B-1 shows us several interesting things about namespaces and extents. Each namespace can have several different extents, which are not (necessarily) contiguous on disk. Like data files for a database, extents for a namespace grow in size with each new allocation. This is done to balance wasted space used by a namespace versus the desire to keep data for a namespace mostly contiguous on disk. The figure also shows a special namespace, $freelist, which keeps track of extents that are no longer in use (e.g., extents from a dropped collection or index). When a namespace allocates a new extent, it will first search the freelist to see whether an appropriately sized extent is available.
Memory-Mapped Storage Engine
The default storage engine (and only supported storage engine at the time of this writing) for MongoDB is a memory-mapped engine. When the server starts up, it memory maps all its data files. It is then the responsibility of the operating system to manage flushing data to disk and paging data in and out. This storage engine has several important properties:
MongoDB’s code for managing memory is small and clean because most of that work is pushed to the operating system.
The virtual size of a MongoDB server process is often very large, exceeding the size of the entire data set. This is OK because the operating system will handle keeping the amount of data resident in memory contained.
32-bit MongoDB servers are limited to a total of about 2 GB of data per
mongod. This is because all of the data must be addressable using only 32 bits.