
12
Final Considerations
While looking through the Internet history on the latest system he was able to compromise, he discovered accounts with Dropbox, Google, and Amazon. The accounts led him to a fair amount of data stored with these providers. Additionally, he was able to retrieve the cached passwords for the accounts, which meant he was able to directly access the accounts from other systems. The Amazon account led to a system that was running, presumably for business purposes, and that was another account that he might be able to use. Amazing that he was able to turn up so many accounts from this one system with data stored off-site. These were just the sorts of finds that kept him going. The best part about using these sites is that they were all encrypted, which meant it wasn't easy to determine what was being sent without direct access to the endpoint.
One area that I have deliberately steered away from until now, though it has tremendous impact on network traffic capture and analysis, is encryption. One reason to I've stayed away from discussing it is that if you run across encrypted network traffic, it can be difficult, if not impossible, to get at what is inside the messages. At best, you may be left with the metadata that you get out of the conversation from the headers. You can get the IP information and the TCP information but none of the application information, which may be the most important data you are looking for. Because of the challenge associated with encryption, it's important to understand it, its capabilities, and its limitations. Encryption has become a fact of life, not only from the standpoint of host analysis with whole disk encryption, but also because as more and more sensitive data is stored with service providers, network encryption is far more prevalent.
Cloud computing, despite its ambiguous name, has become another fact of life. More businesses are moving to service providers to not only take care of data storage but also handle applications. The workforce is increasingly mobile and geographically dispersed, which means workers need to be able to access business data from wherever they are. Service providers can make this possible, by allowing businesses to outsource a lot of the hard and expensive stuff while empowering their workers. This creates issues when it comes to forensic investigations because it requires working with the service provider to acquire data rather than acquiring it directly. Unlike a local business where you can go in, seize the computer, and then get an image of a drive, or where you could install a network sensor to capture packets, service providers have a far more complex setup and also won't provide you with permission to just monitor their network.
If you watch TV or movies, especially the so-called police procedurals, you will likely have heard of the dark net or the dark web. These terms are commonly and colloquially used to refer to sites that are not reachable by way just firing up a web browser like Chrome, Edge, Internet Explorer, Safari, or Firefox and heading out to the Internet in the way you are used to. Instead, you would use a TOR browser to gain access to these hidden sites or reconfigure your current browser to use the TOR network. You can also browse regular websites without being identified because of the way traffic is passed around to get to its destination. This is another way that life of a forensic investigator can be challenged over the course of a network investigation. Understanding how this works will help you to know where you may be able to look next.
Encryption
Almost as long as there has been sensitive data in need of protection, people have been finding ways to hide that information. They do this by taking information and altering it such that someone would need to understand how it was altered in order to read the original message. The process of altering a message using a piece of information that should only be known by the sender and recipient, rendering the original information unreadable is called encryption. Restoring encrypted information to the original message, commonly called plaintext, is called decryption. Once a message is encrypted, it is called ciphertext. We normally think of encryption as something that requires a computer, but in fact, we were taking plaintext and creating ciphertext out of it centuries before we had computers.
One method of encryption that doesn't require a computer is sometimes referred to as the Caesar cipher, and sometimes it's just called a rotation cipher. The way it works is you write out the alphabet and then write it out a second time but shifted some number of letters. You can see this in the following example. To encrypt a message, you find the letter in the plaintext in the top alphabet, then locate the letter directly below it and that becomes your ciphertext. You repeat the process for all letters in your message until you have a completely encoded message.
The word “hello,” for example, becomes “lipps.” To restore the original word, find the letters in the cyphertext in the lower alphabet and replace them with the letters directly above them in the upper alphabet. Of course, you don't have to write your alphabet out in order to perform this encryption and decryption, but it does help to be able to see what is going on and makes wrapping around the end of the alphabet a little easier. All we are doing is rotating the letters by 3. If you see an A, you skip ahead three letters to get D and that's your ciphertext letter. You reverse the process by skipping back 3 letters.
Encryption is a complicated business, and not least of all because of the mathematics involved in doing modern encryption. Protecting information is not as simple as converting it to a ciphertext; if that were the case, we'd still be using a rotation cipher. The problem is that as fast as people can come up with schemes to encrypt information, other people are working just as fast to figure out how to decrypt that information. As a result, a lot goes into encryption and we're going to talk about the different ways encryption happens and how the information gets to be protected.
Keys
When it comes to encryption, the key has always been the key. Even if we are talking about a simple rotation cipher, you still need to know how many characters to rotate before you can start to do the decryption. Using a simple rotation cipher, you should be able to do something like a frequency analysis if you have enough text to look at. A frequency analysis will let you determine the most used characters in the message. This will let you map what you have found to a normal frequency distribution of letters. Once you have the frequency of letter occurrences, you can start the process of reversing the encryption. The most frequently used letter in the English language is e. After that, it depends on whose analysis you want to believe. It could be t or a. According to Robert Lewand, who did a frequency analysis for his book Cryptological Mathematics (The Mathematical Association of America, 2000), the letter e is used more than 12% of the time. This is followed by the letter a, which is used slightly more than 8% of the time.
Once you have determined the letter mapping, you can get to what is referred to as the key. The key is the piece of information that is needed to decipher a piece of encrypted text. In the case of the rotation cipher, the key could be thought of as 3. This means that the alphabet is rotated three positions. In modern encryption, the key is quite a bit more complex and larger, because modern encryption makes use of complex math and the key is used to feed the equations that do the encryption and decryption.
Based on this simple example, though, you can see how important it is to protect the key. Once the key is known, no matter how complex or how simple it is, the encrypted data can be decrypted. Protecting the key is one of the biggest challenges in modern cryptography. If you and I were to try to communicate sensitive information, we would need a key. How do we come up with a key that both of us know so we can encrypt and decrypt the information? Do I call you and tell you what the key is? No, because someone could overhear it—all they need is the ciphertext and they can convert it to plaintext.
The phone mechanism for transmission is entirely simplistic, especially considering keys are very long and often not even readable, which means they need to be converted to something that is readable. This is typically hexadecimal, which can make the key more manageable, but if there is any mistake at all in telling you what the key is, you are not going to be able to decrypt what I send you.
Fortunately, a number of researchers and cryptographers came up, roughly at the same time, with a way of sharing keys that protects the key. The method that is most well-known—in part because some of the other teams were working under government intelligence secrecy and weren't allowed to publish like Whitfield Diffie and Martin Hellman—is the Diffie-Hellman key exchange protocol. Diffie and Hellman came up with a way of allowing both sides to independently derive the key that would be used. They do this by starting at a common point and sharing a piece of information that is fed into an algorithm with another piece of information they create themselves.
Let's say, by way of an entirely unrealistic example, that we wanted to create an animal that could carry our information. We both agree to start with a tiger. You choose to cross your tiger with a wolf, creating a wolf-tiger. I choose to cross my tiger with an elephant, creating an elephant-tiger. I send you my elephant-tiger and you send me your wolf-tiger. As soon as I add in my elephant to your wolf-tiger, I get a wolf-tiger-elephant. You take my elephant-tiger and add in your wolf and you also get a wolf-tiger-elephant.
Imagine a mathematical process that equates to this really bad genetic process and you have a sense of how Diffie-Hellman works at creating a key that we can both use, and that has not been transmitted. The assumption is that taking the wolf-tiger and determining that both a wolf and a tiger went into it is a very expensive process. If someone could extract the wolf-tiger into its component pieces and the elephant-tiger into its component pieces, that someone would know what went into creating the key, and since the mathematical process to create the key is well-known, that person could create the key that you and I are using to encrypt information. Because you have the key, you can decrypt the data.
Now, hold onto the idea of keys and the knowledge that keys are used to encrypt and decrypt data. We are going to talk about different ways that those keys can be used.
Symmetric
The process where you and I are using the same key to encrypt and decrypt information is called symmetric encryption. The same key is used on both ends of the communication. If you have done any exchanges on the Internet that have been encrypted, you are using symmetric encryption, whether you realize it or not. You may even be familiar with the names of the encryption ciphers. DES, 3DES, and AES are all encryption ciphers that use symmetric encryption.
Symmetric key encryption tends to be faster than asymmetric and takes less computing power. Additionally, key sizes tend to be smaller. Don't be fooled by this, though. You can't compare key lengths and assume that a cipher with a larger key is necessarily stronger. The strength of an encryption process is related to the algorithm and the algorithm determines the size of the key based on how it works. As an example, AES is a block cipher. This means that it takes in chunks of data in 128-bit blocks. That's 16 ASCII characters, to give you a sense. Your data is chunked into blocks of 128 bits and sent into the algorithm. If what you send isn't a multiple of 128 bits, your data will be padded out to make sure that it's a multiple so the block size doesn't have to be compromised or adjusted.
Using symmetric key encryption, one algorithm is used to encrypt while another is used to decrypt and both sides use the same key, which means that protection of the key is important, as indicated previously. Because both sides need to use the same key, there needs to be a way of either uniquely deriving the same key on both sides, or a way to get the key from one side to the other. One of the challenges of symmetric key algorithms is that after prolonged use, the key may be prone to attack because an attacker can acquire a large amount of ciphertext that he can analyze to attempt to derive the key that can be used for decryption. The solution to this is to rekey periodically, meaning replace the key you were using with a different key. However, that does bring up the issue of how do both sides know when to rekey and how do they both get the new key?
Asymmetric
Unlike symmetric encryption, asymmetric uses two separate keys. One of the keys is used to encrypt while the other is used to decrypt. A common implementation of asymmetric encryption is sometimes called public key encryption, because the two keys are referred to as the public key and the private key. Not surprisingly, the public key is available for public use while the private key is the one you keep protected. This is by design. The more people who have your public key, the more people who can send encrypted messages to you. If I don't have your public key, I can't encrypt a message. On the other side of that coin, even if I have your public key, I can't decrypt any message that has been encrypted with your public key. The public key is only good for encrypting messages because the private key is required to decrypt them.
In the case of asymmetric keys, the two keys, which are just numbers after all, are related mathematically. You can think of them as two halves of a whole because they are linked. The way asymmetric algorithms work is to take advantage of the mathematical relationship between the two numbers. Without getting too deep into the math, unless you feel like doing some research, it's sufficient for our purposes here to know that the two keys are related and the algorithms make use of the two keys to encrypt and decrypt messages.
The whole system works because you have a public key or you have the ability to obtain a public key. There are two primary systems for key management. One is centralized and the other is decentralized. The centralized approach uses a certificate authority to generate the keys and validate that the owner of the keys is who that entity (it could be a system or a person) claims to be. The keys are stored in a data object called a certificate and use of the keys is typically protected by password because, unlike symmetric keys, these keys will stick around for a long time. While you do want your public key getting out, you do not want your private key to be accessed or used by anyone but you. As a result, since the key is just a chunk of data that is stored in a file, you password protect access to the key so that anyone wanting to use your private key needs to know the password.
The second approach is decentralized. Pretty Good Privacy (PGP) and Gnu Privacy Guard (GPG) both use this approach. Unlike the certificate authority, PGP and GPG rely on the users to validate one another's identities. Public keys are stored on key servers and a key server can be anywhere and available to anyone since the idea is to make public keys accessible. Until you are able to get my public key, you are unable to encrypt a message to me.
This all sounds awesome, right? Asymmetric keys tend to be considerably longer than symmetric keys, though that's not always the case. However, they are also processor-intensive and the algorithms used to encrypt and decrypt tend to be slow. As a result, they are not great for real-time communication or even near-real-time communication. Asymmetric encryption is good for e-mail where it doesn't much matter how fast or slow it is, because we aren't as worried about additional milliseconds for encryption and decryption as we would be for data that was constantly flowing.
We now have two different algorithms. One is slow and not great for real-time communication, while the other is fast but suffers from the need to rekey to protect itself. What if we were able to use them together?
Hybrid
What you will commonly see in communication systems that require encryption is a hybrid approach. Using a hybrid approach, we use symmetric encryption for the actual communication but we use asymmetric encryption to send the symmetric key. This allows us to use the faster communication of a symmetric cipher while also providing the protection that the asymmetric encryption offers. It also solves the problem of key sharing because with asymmetric encryption, I am entirely okay with you getting access to my public key. You and everyone else can have it. We don't need to protect it at all like we do with the symmetric key. As a result, we can use that encryption to send symmetric keys back and forth and they should be well-protected, assuming the private keys of both parties are protected.
When it comes to real-time communications, or even near-real-time, both parties will generate a symmetric key and then send that key to the other side. This symmetric key is called the session key because it is used to encrypt and decrypt messages during the course of the communication session between the two parties. Since the messages using the symmetric key are still flowing over open networks, which is why we're encrypting to begin with, we still have the issue of rekeying. When the session is established, a rekeying timer may be set. At some point, when the timer triggers, the session keys will be regenerated and shared using the asymmetric encryption. This maintains the integrity of the communication stream.
Web-based communications, such as those with Amazon or any other website that uses encryption to protect your data, will use a hybrid cryptosystem. This means that servers you communicate with will have certificates associated with them.
SSL/TLS
To support the increasing desire for businesses to engage with consumers over the World Wide Web in the mid-1990s, Netscape, the company, developed the Secure Sockets Layer (SSL). The initial version wasn't considered ready to release so the first version that was available was version 2.0, released in 1995. By 1996, version 3.0 was out because of the security issues with version 2.0. Both versions of SSL have since become deprecated or even prohibited because of issues with the security they provide to the connection. As a result, the current standard for offering encryption between a client and a web server is Transport Layer Security (TLS). TLS was developed in 1999 and while it doesn't vary greatly from SSL 3.0, the changes were significant enough that the two mechanisms were not considered compatible.
SSL/TLS provides a way for the two ends of the conversation to first agree on encryption mechanisms, then decide on keys, and finally send encrypted communication back and forth. Since the different versions of SSL are considered unusable due to issues in the way they work, we'll talk about TLS and how it functions.
To determine how the two ends are going to communicate, they need to agree on several things, not least of which are the keys they will use. To do this, they need to perform a handshake. This is separate from the three-way handshake that happens with TCP. Since TLS runs over TCP, the three-way handshake has to happen first. The first stage of the TLS handshake happens as soon as the three-way TCP handshake has completed. It starts with a ClientHello, which includes the TLS versions supported as well as the cipher suites that it can support. You can see a list of cipher suites supported by www.microsoft.com in Listing 12-1, which shows the variety that are available, as determined by the program SSLScan.
The very first line, which is one of the preferred cipher suites, indicates that the key exchange would happen with the elliptic curve Diffie-Hellman key exchange, using RSA as the asymmetric key algorithm. They are also specifying AES for the symmetric key algorithm with a 256-bit key. With AES, the server is offering to use Galois/Counter Mode (GCM) as the form of block cipher. Finally, the server is offering Secure Hash Algorithm for data integrity checks using a 384-bit hash result. When the client sends its ClientHello to the server, it would send a list of cipher suites similar to what you see in Listing 12-1. The list may not be nearly as long as that one but it would present choices to the server.
The server would follow up by selecting the cipher suite it preferred from the list provided by the client. It would send its selection back to the client in a ServerHello message. In addition to the selection of the cipher suite, the server would send its certificate. The certificate would include its public key that could be used to encrypt messages to send back to the server. The server would have to have a certificate. Without a certificate, it couldn't be configured to use TLS. The same would have been true with SSL. The challenge at this point is that the client can encrypt messages to the server but the server can't encrypt messages to the client. The server could ask the client if it had a certificate, in which case, the server could use the public key from the certificate to encrypt the message back to the client. Barring the certificate, they would have to use Diffie-Hellman to derive the symmetric key that will be used going forward.
Once the client has received the preferred cipher suite from the server, it either chooses to agree with it or it suggests another cipher suite. This would not be typical. Instead, it would normally begin the key exchange process, sending a message to the server indicating that. Both sides would go through the Diffie-Hellman exchange, ending up with a key at the end that could be used during the communication session. In Figure 12.1, you can see a packet capture in Wireshark demonstrating the handshake taking place between the browser on my system and a web server on the other end.
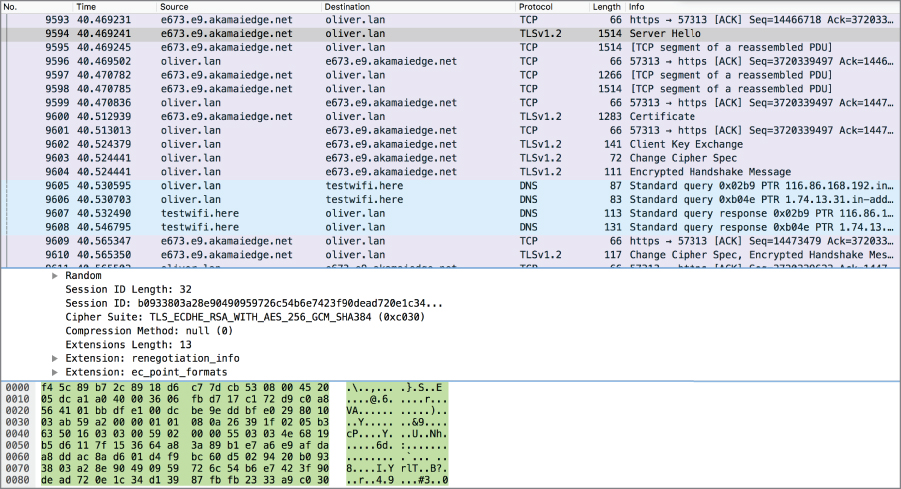
Figure 12.1: TLS handshake in Wireshark.
Partway down the packet capture is a message (frame number 9603) that is labeled ChangeCipherSpec. This is a message used to indicate to the other side that the negotiated cipher suite and keys will be used going forward. In short, it says this is the last message you will receive before receiving nothing but encrypted messages. You will notice that both sides send the ChangeCipherSpec message in frames 9603 and 9610. These messages indicate that all subsequent messages will be encrypted. After that, everything you see captured will be Application Data or just fragments of packets. You'll get nothing in the Info column from Wireshark other than TCP-related data because that's the last thing it can see in the packet. Everything beyond the TCP header is encrypted.
Certificates
We've been talking about certificates without providing a lot of information about them. The certificate is a data structure that has been defined by the X.509 standard. X.509 falls underneath the X.500 directory protocol suite. X.500 is a way of structuring information about organizations and individuals within the organization. A simplified implementation of X.500 is the Lightweight Directory Access Protocol (LDAP), which is how Microsoft accesses information stored for its domains including resources like users, printers and even encryption keys. Other companies also use LDAP. As part of the directory, each entry could have encryption information. The certificate is organized with fields providing information about the owner of the certificate; a certificate could have the Organizational Unit or Common Name fields, for example.
Additionally, the certificate will include information about its issuance: the organization that issued the certificate, the date it was issued and the date it expires, the algorithm that was used to sign the certificate, and a number of other fields that not only describe the certificate but also provide important information to judge its validity.
If you are using a web browser, you can look at certificates that have been provided by the web server you have connected to over HTTPS. Figure 12.2 is an example of a certificate, as shown in Google Chrome. Different browsers will present the information in different ways, but ultimately, what you see is all included in the certificate.

Figure 12.2: Amazon's web server certificate.
In Figure 12.2, you can see not only the name of the website, www.amazon.com, but also the organization that provided the certificate to Amazon, Symantec. Toward the bottom, you can see the algorithm that was used to sign the certificate. Signing the certificate involves a known and trusted entity, in this case Symantec, indicating that the certificate is valid and the entity that has the certificate, Amazon's web server, is known to Symantec. If you trust Symantec to do its job correctly and well, and Symantec trusts Amazon and that the web server named www.amazon.com is the correct website, then by the transitive property, you trust Amazon's website.
Certificates work by not only providing a means for encryption to happen but also by providing a way for users to trust the sites they are going to. If a known and trusted authority like the Symantec certificate authority has issued a certificate, it must be to the right place, as indicated in the certificate. If all that is true, you can trust the site and not worry that data sent to it will get into the wrong hands.
One of the ways that you indicate that you trust a certificate authority is by having the certificate for that authority installed on your system. When certificates are issued, they come with a chain. At the very top is the certificate authority. This is called the root certificate. The root certificate is the only certificate in the chain of certificates you will see that is self-signed because there is nothing above it. The way you prove that the certificate you are looking at is trustworthy is to check it against the certificate you have installed for the certificate authority. If the certificate authority has signed the certificate and it's a valid signature, meaning it was definitely signed by the certificate you have installed for the certificate authority, then the certificate is considered valid, meaning it's trustworthy. It does mean that you have to have the certificate for the certificate authority installed. Most of the well-known root certificates for certificate authorities like Verisign, Symantec, Google, and others are installed for you by the operating system or browser vendor. If there are other certificate authorities you know about and can verify that they are legitimate, you can install their certificate for yourself. Once you have done this, all certificates issued by that authority would be, again by the transitive property, trusted by you.
A chain of certificates, which may be several deep depending on how many intermediate systems were also involved in generating your certificate, is called a chain of trust. The trust anchor—the entity that all trust is tied to—is the root certificate, which belongs to the certificate authority. If you trust the certificate authority, all of the cascading certificates would also be considered trustworthy. In the case of PGP, which is not used in web communications but which also uses certificates, it would not be a certificate authority but instead would be a number of users that sign the certificate, providing its validity. If you know Milo Bloom and you trust him to sign certificates for others, and you see that Milo has signed the certificate of Michael Binkley, you, by extension, trust that the certificate of Michael Binkley is legitimate and really belongs to Michael Binkley.
Cipher Suites
We talked briefly about cipher suites earlier in this section. It is worth going into a little more detail rather than just passing quickly over a single example. The cipher suite is a defined collection of the following components of the entire encryption process. These components are used through TLS 1.2.
- Authentication
- Encryption
- Message authentication code (MAC)
- Key exchange
All of these components represent different algorithms. The authentication piece could use either RSA or DSA, which are both examples of asymmetric encryption algorithms. RSA is a proprietary algorithm developed by the men it is named for—Ron Rivest, Adi Shamir, and Leonard Adleman. DSA, on the other hand, is the Digital Signature Algorithm and is an open standard endorsed by the National Institute of Standards and Technology (NIST). Both of these are used to verify identities in certificates. If you are presented a certificate, you can use that certificate to verify an identity because of the trust relationship discussed earlier. If a certificate authority you trust says a certificate belongs to www.amazon.com, it belongs to www.amazon.com.
Over the course of a communication stream between a client and server the encryption would use a symmetric algorithm like AES, IDEA, DES, or another symmetric algorithm. Taking an entire communication stream and encrypting it is sometimes called bulk encryption. When negotiating the bulk encryption to be used, one of the elements would be the key length. Some algorithms, like AES, include the ability to support multiple key lengths, so it's important that both ends understand the length of the key to use. It's no good having one side generate a 128-bit key and encrypting with that when the other side is using a 256-bit key. If the keys don't match exactly, the process of communication won't work.
The message authentication code (MAC) is typically a message digest or hashing algorithm. As an example, the Secure Hash Algorithm (SHA) can be used to take variable length input and generate a fixed-length value from that. This value can then be used to compare against as a way of ensuring messages were not tampered with. If I send an encrypted message to you and a hash value, no one would be able to intercept that and send you a different message or even a modified version of the original message because the hash values would not match. Since a cryptographic hash like SHA cannot be reversed (they are considered one-way functions), meaning you can't take a hash value and derive the original message from it, an attacker would have no way of generating a message that matched the hash value without a lot of time and effort. If he did generate a second value that matched the hash, it would be considered a collision, which is something these hashing algorithms are designed to avoid. Longer hashing algorithms like the 384-bit SHA384 would be considerably harder to get a collision in than the much smaller MD5, which only uses 128-bits, or even SHA-1, which uses 160-bits.
Finally, the key exchange algorithm that would be used has to be selected. Diffie-Hellman would be a common approach to exchange keys in the open, meaning without encryption to protect them. Diffie-Hellman doesn't exchange keys directly. Instead, it allows both sides of a communication stream to generate the key to be used independently. Both sides end up with exactly the same key without ever actually exchanging the key itself.
All of these individual components are essential to the successful encryption of messages. TLS is the primary protocol in use for transmitting encrypted messages over network communications. Other protocols, including SMTP, POP3, and FTP might make use of TLS to transmit encrypted messages. The more people who use the Internet and the more malicious users there are, the more formerly cleartext protocols need encryption over the top in order to protect the users of those protocols.
SSLScan, SSLStrip, and Encryption Attacks
There are two open source programs that you should be aware of. You saw the first earlier in this section in a very limited capacity. SSLScan can be used to obtain information about the cipher suites that are in use by any server that supports SSL or TLS. In addition, SSLScan can determine whether a server is vulnerable to the HeartBleed bug that had the potential to take an encrypted communication stream and offer a way to decrypt it, exposing the information in the clear. Listing 12-1 shows partial output from SSLScan, run from a Kali Linux system, checking the Microsoft website, www.microsoft.com. You can see from the output that the underlying library, OpenSSL, isn't a version that supports SSLv2, which was deprecated and prohibited in 2011. As a result, there were no checks done against SSLv2. You'll also note that SSLScan did run checks to see if the server was vulnerable to the HeartBleed bug.
You can use SSLScan to determine the capabilities that are supported by a server. This doesn't get you to the point where you can see any data, however. For that, you need a tool like sslstrip. This is a program that takes advantage of weaknesses in some of the versions of SSL to decrypt messages. It does, however, require that the program can get all of the messages from a communication stream in order to be able to do what it does. This requires some understanding of manipulating networks using Linux. The following steps are required to get sslstrip to work and have the potential to see decrypted information:
- Install sslstrip, which may be available in the package repository for your Linux distribution
- Enable forwarding of packets on your Linux system (
sudo sysctl -w net.ipv4.ip_forward=1). - Use an ARP spoofing attack (Ettercap, arpspoof) to get all of the messages on your network to come to your machine. If you don't enable forwarding, the communication stream between the endpoints will break because you will be getting messages destined for someone else and they will never reply.
- Configure a port forwarding rule using iptables to make sure messages to port 443 are sent to a port you want sslstrip to listen on (e.g.,
iptables -t nat -A PREROUTING -p tcp --dport 443 -j REDIRECT --to-ports 5000 - Start sslstrip, telling it which port to listen on. This may look something like
sslstrip -l 5000 or sslstrip --listen=5000, which is the same command expressed a different way. This needs to be the port you redirected traffic to in your iptables rule. - Sit and wait for sslstrip to do what it does.
This is referred to as a man in the middle (MiTM) attack and it's a common approach to going after encrypted messages. If you are unable to sit in the middle of the communication stream, you will be unable to gather enough information to determine how the encryption is happening. Without any of that information, you are going to be utterly blind. Once you are sitting in the middle gathering information, though, you may be able to make some changes.
One way of implementing a man in the middle attack, though it will generate authentication errors because you can't pretend to be someone you are not without being caught, is to terminate one end of the communication stream and re-originate it on the other side. This means that when a client attempts to communicate, you pretend to be the server and respond as such. On the other side, you pretend to be the client, originating messages to the server. This is not nearly as easy as it sounds and it is prone to error, especially because any certificate you send to the client pretending to be Amazon simply won't pass the sniff test. Of course, certificate errors have gotten to be so common that users may simply click through any error they receive.
Another attack is called a bid down attack. If you can, again, get in the middle, you may be able to get the server and client to agree to a lower strength cipher suite. The lower strength may allow you to go after the ciphertext and decrypt it. Weaker encryption may be susceptible to different attacks that can lead to decryption. This is because either the encryption algorithm has already been chosen or because the key strength is so low that it may be susceptible to something like a brute force attack. Smaller key sizes mean far fewer possible keys that can be used. A 40-bit key, for instance, only has the potential for 2^40 possible keys. This is considerably fewer, by several orders of magnitude, than a 128-bit key, which has 2^128 possible values.
Encryption protocols, algorithms, and ciphers are constantly under attack. The longer they're around, the more time people have to really look at them to identify potential weaknesses. Additionally, the longer they are in use, the more computing power comes into play. Computers today are vastly more powerful than the ones 20 years ago when the AES algorithm was being selected from the many prospective algorithms under consideration. This means that attacks that require faster processors are feasible now when they would have been unthinkable then. This is why key sizes keep increasing, as do the sizes of the hash value used for message authentication. Bigger keys and hash values make for many more possibilities, which increases the computation needed to go after them.
Cloud Computing
Cloud computing is an ambiguous term. It covers, as they say, all manner of sins. The term originates from the fact that large, open networks like the Internet are commonly depicted as clouds on network diagrams. Clouds are used because they are amorphous, insubstantial, and almost entirely opaque. You can't see inside a cloud from the outside, and you also may not to be able to see inside the cloud if you are in it. Objects that pass into the cloud can pass out the other side entirely unaltered, and we just don't know what happens inside.
When you take the idea of a cloud as a stand in for the Internet and you add in service providers and accessibility through the Internet, you get cloud computing. However, even with that bit of clarity, the term cloud computing is still vague and not especially transparent. The reason for this is there are multiple types of cloud computing. Ultimately, what cloud computing means is that a computing service is being provided somewhere in a network, often using web-based technologies, rather than locally on individual systems. Because these are the ones that are most important for our purposes, we're going to talk about Infrastructure as a Service (IaaS), Storage as a Service (StaaS), and Software as a Service (SaaS).
Infrastructure as a Service
Imagine that you have a way to make a computer very, very small. So small that you can then stuff a lot of them into a single piece of hardware that you would normally think of as a computer system. Imagine that you can install Windows or Linux on every single one of those computers and then you can get access to every one of those operating systems individually. You have a way to dump a lot of systems into a single container, such that every one of your “tiny” systems believes it is running on a regular piece of computer hardware.
All of these smaller systems are crammed into one piece of hardware by virtual machines. A virtual machine looks to an operating system like actual, physical hardware. In fact, the OS is interacting with software and a set of extensions within the central processing unit (CPU) of the computer system. This makes it possible to run a number of virtual computers within a single computer system. One reason this is possible is because current CPUs are so powerful that they are often idle. Even running multiple operating systems with all of their associated programs and services, modern CPUs are not highly stressed. Virtual machines make efficient use of modern, fast, powerful hardware by allowing much more to run on a single computer system and CPU.
Why do we bother doing this? Well, computer hardware is comparatively expensive. If you can run half a dozen systems on every piece of computer hardware and save the extra hardware expenditure, lots of companies can save a lot of money. Why would a company want to buy separate machines for a web server, a mail server, a database server, and a file server when they can buy a single machine? Additionally, every computer system purchased costs power, floor space, cooling, and maintenance. The fewer computer systems needed, the more money the company saves. You can see why virtualization would be popular for companies that can make use of it. Managing virtual systems isn't free, however. It does require systems powerful enough to run all of the services the company needs and the software, called hypervisors, needed to run the virtual machines. That software needs management and maintenance, which means paying someone who knows how to run it.
What does all of this have to do with Infrastructure as a Service (IaaS)? There are companies that can offer up access to virtual machines at a moment's notice. Some of this started with companies like Amazon that had an excess of capacity and the infrastructure in place to manage these services on behalf of customers. However, this is just an extension of the outsourcing that has long been going on. Companies have been buying outsourced computing power for decades. Even virtual machines have been around for decades. Finally, the cheaper computing power and easier delivery came together to allow companies like Amazon, Google, and many others to offer virtual infrastructure to companies.
One significant advantage to going with one of these providers is that they have all of the deployment, configuration, and management automated. You can very quickly set up an entire infrastructure for anything you need, including complex web applications, in a very short period of time without all of the hardware expenditures that would otherwise be necessary. You can see how this would be appealing to a lot of companies. This would be especially true of smaller companies that get quick and easy access to a lot of computational power without having to put up a lot of money up front.
Where there have been companies that would put up hardware for you and allow you access to it or even allow you to put up your own hardware at their facilities, management could be done physically unless you had remote management configured. In the case of IaaS providers, everything is done through a web interface. As an example, Figure 12.3 shows that you can quickly set up a number of virtual machines that can support web applications, mobile application back ends, or other requirements you may have.
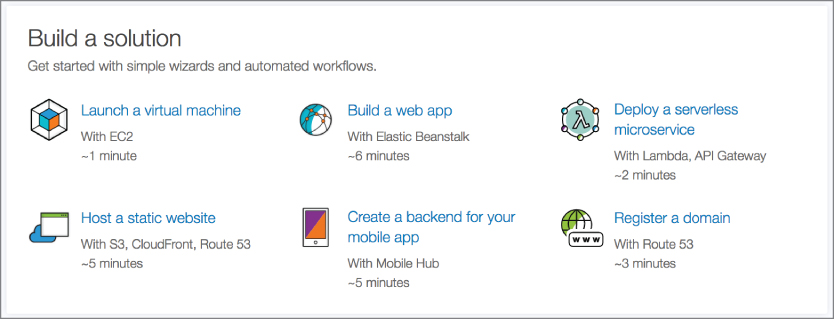
Figure 12.3: Amazon EC2 workflows.
Even if all you want to do is just set up a single virtual machine, that process is very simple and you can have a choice of a number of operating systems that will already be installed on the system you get access to. You aren't being given just a hunk of bare metal that you need to do a lot with to make it useful. You are being presented with a working, completely configured operating system in a matter of minutes. In Figure 12.4, you can see a small sample of the number of operating systems that are available. The figure shows the Ubuntu Server, but other flavors of Linux server are available as well.

Figure 12.4: Amazon EC2 virtual machine choices.
Of course, Amazon is not the only company in this business. Google, Microsoft, and several others offer this. What this means, though, is that when a company stands up a set of systems using any of the service providers, any data that is being managed by those servers is stored not on the company's systems but instead on storage owned and managed by the service provider. What it also means is that every interaction with this infrastructure happens over the network. This is no longer just the local network. Management and application traffic all happens over the same set of wires, where normally they are separated when companies use their own networks.
Storage as a Service
Not everyone needs entire computing systems. Sometimes all you need is a place to store some things for a while, or even permanently. When a service provider puts together what is needed to service customers' infrastructure needs, one thing it has to do is make sure it has a lot of storage capacity. Virtual machine capacity and storage capacity are not directly related since different virtual machines have different storage needs. It's not as simple as 10 virtual machines will need 10 terabytes of storage. One of the virtual machines may need only 10 gigabytes of storage while another may want 20 terabytes. This is why service providers that offer up infrastructure services will also have storage capacity as well.
Where formerly we made use of File Transfer Protocol (FTP) servers to share information across the network, these days we are more likely to use storage devices that are accessible through a web interface. You are probably even familiar with many of the storage services that individuals and companies are likely to use. Google's is Drive, Microsoft has OneDrive, Apple has iCloud, and there are also companies that do nothing but offer storage like Dropbox, Box.Com, and others. Access to all of these is through a web interface or maybe a mobile application that uses the same web-based protocols that your browser uses to access the web interface. You may also be able to get a service that presents the cloud storage as just another folder on your computer. This is true of services from Dropbox, Box, Microsoft, Google, and Apple and perhaps others as well.
In most cases, you will find that the web interface looks more or less like any other file browser that you would see, whether it's the Windows File Explorer or the Mac Finder or any of the different file managers that are available for Linux. You can see an example in Figure 12.5 from Microsoft OneDrive. There is a list of files and folders, just as you would see in any other file browser.
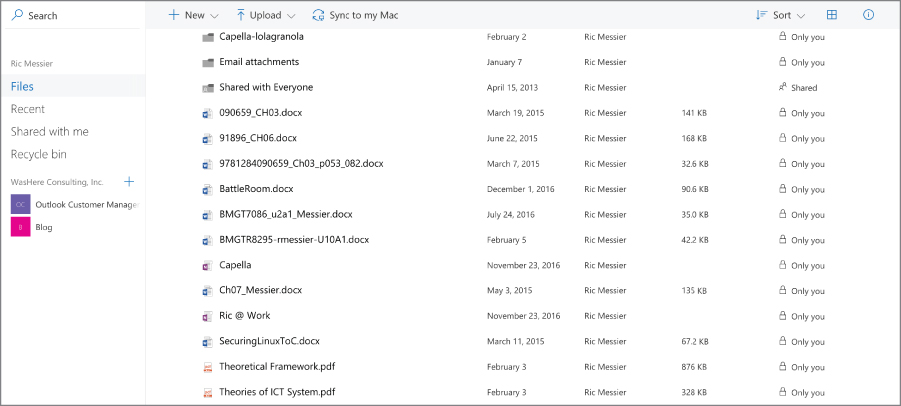
Figure 12.5: Microsoft OneDrive interface.
One thing you don't see from the image in Figure 12.5, though, is the address bar and the fact that the communication is secured. You can't see that the communication is encrypted using AES with 256-bit keys. The certificate in use has a 2048-bit public key that is used, as noted earlier, to protect the 256-bit session key. This is Microsoft and it has the infrastructure to be able to support strong encryption on communications with its services. Not all providers will have that capability, but since it's really easy to do even basic encryption, especially over a web interface, it would be rare to find a storage service provider that didn't encrypt its network transmissions.
Software as a Service
Over the course of decades, the information technology industry has gone from centralized with mainframes to decentralized with personal computers, back to centralized with so-called thin clients, then back to decentralized as computing power and storage got to be cheap. We are now back to centralized again. As infrastructure became easy to do with service providers, along with even more powerful processors and much cheaper storage, it was cost efficient to start providing access to common software and services through a web interface.
There is a significant advantage to providing software through a service provider. As companies become geographically more dispersed, picking up talent where the talent lives, they need to be able to provide their employees access to business data and applications. This is where Software as a Service (SaaS) becomes so beneficial. Previously, remote employees required virtual private networks (VPNs) to get access to corporate facilities. The VPN provided an encrypted tunnel to protect business data. If you access data by way of HTTP and encrypt it with TLS, the effect is the same. The web interface becomes the presentation layer and all protocol interactions happen either over HTTP to the user or over whatever protocol is necessary on the back end.
You may be familiar with a lot of these SaaS solutions. Some companies have developed their business around them. If a company needs a contact management or customer relationship management solution, it may well be using Salesforce.com. This is an application that stores contacts and all information related to engagement with those contacts. Storing information with an application service provider helps any employee gain access to that information remotely. It also relieves the problems of syncing data for anyone who may be making changes offline. Since the access is always online, there are no issues with syncing. All changes are made live and you can have multiple people working within the data set at any point. Previous solutions relied on a central database that everyone synchronized their data with. They may have worked online or they may not have.
Other solutions are tied directly to the storage solutions just mentioned. With the ability to store and share documents online, companies like Microsoft and Google offer office productivity suites entirely online. You no longer need Word and Excel installed locally. You can just open them up in a web browser. Word looks and behaves very similarly to the one you would have installed locally. Figure 12.6 shows the page where you can select from different templates in Word to create a new document. This is the same as current versions of native Word (the application designed to run locally). An advantage to online versions of these applications is the ability to share the document. Rather than having to e-mail it out every time it changes or editing from a file share or any other way of handling this task previously, every change is made in real time. If you are editing a document and someone opens it up, they can see the changes you have just made. They can also edit simultaneously.
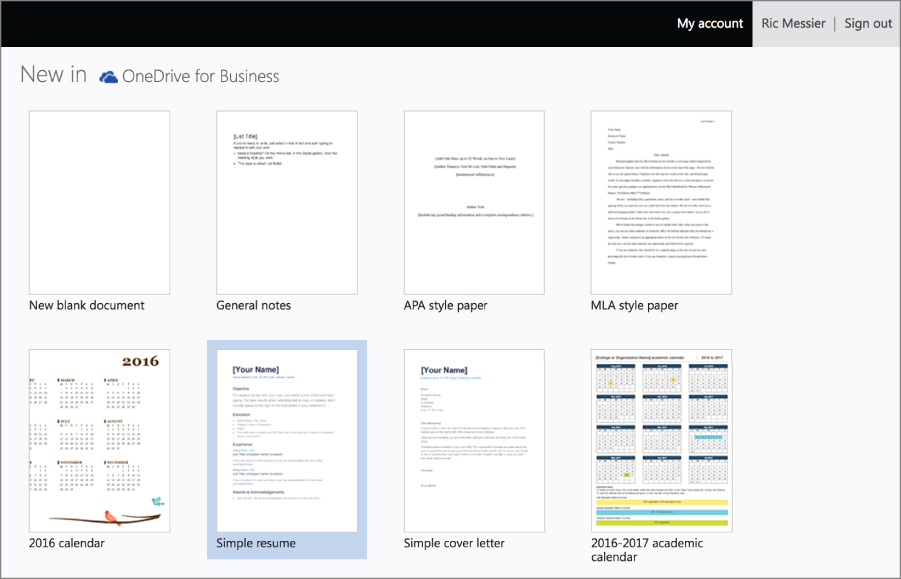
Figure 12.6: Microsoft Word new document.
With a solution like this, layered on top of a storage solution, you are gaining access to the documents stored in the storage solution. You are able to make edits and changes to those documents, leaving the documents local to the storage provider. Everything is done over the network, rather than leaving any artifact on the local system. Solutions like this have a number of benefits. One of them is that people can work wherever they are, on whatever system they have access to. Since there are no local artifacts other than Internet history and potential memory artifacts, most of the artifacts will be either network-based or they will reside with the service provider.
Other Factors
Data in cloud-based solutions, regardless of what the solution is, resides with the service provider. Even in the case of IaaS, where the only thing the service provider is providing is remote access to virtual machines and the underlying storage, gaining access to the artifacts quite likely requires going to the service provider. As an investigator, you could, of course, gain the same remote access to the service that the customer has but you would be probing live systems and, in the process, potentially altering that data. In order to get raw data (files, logs, etc), you would need to go to the service provider, with appropriate legal documentation, and ask for the information. This is a very common approach. To get a sense of how common, you can review the transparency reports from service providers like Google or Microsoft. Google's transparency history graph is shown in Figure 12.7. In the first half of 2016, which is the last set of data available at the time of this writing, Google received nearly 45,000 requests.
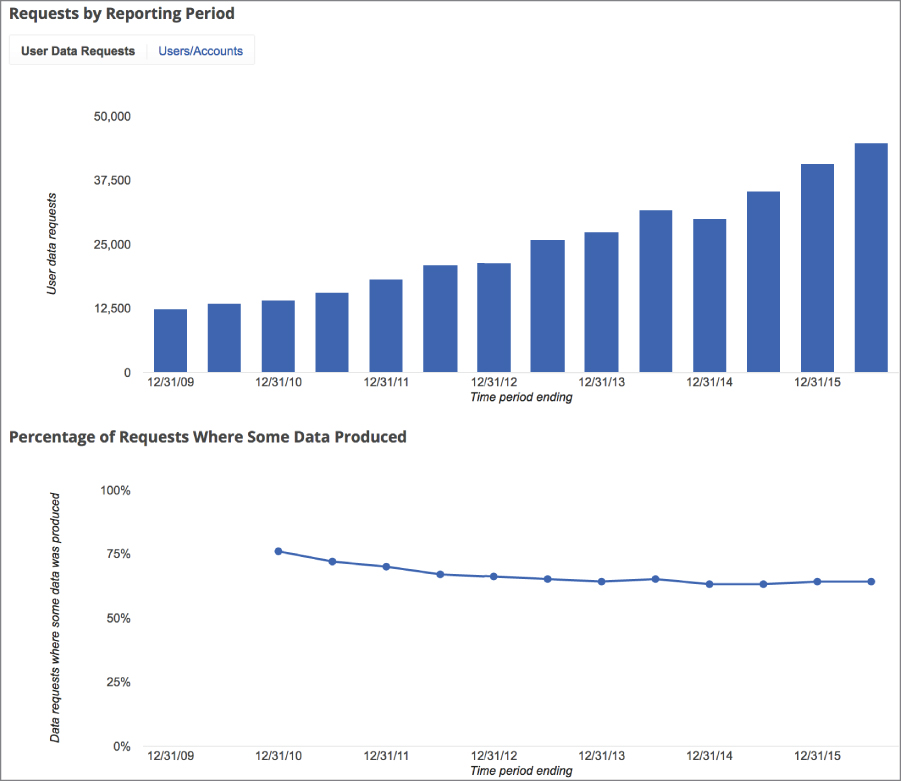
Figure 12.7: Google transparency report.
The bottom chart shows that Google is able to provide data in roughly 75% of the cases. What is not clear from any of this is why exactly Google was not able to provide data in the other 25% of cases. Microsoft sees similar numbers in terms of legal requests. In Microsoft's case, it provides more specific graphs. You can see in Figure 12.8 what it disclosed from the more than 35,000 requests it received in the first half of 2016. The number of requests received is based on everything they get from around the world. Just over 5,000 of those requests came from the United States, and nearly 5,000 requests came from the United Kingdom. What you can see clearly from the pie chart is that the majority of cases only provide subscriber information. What isn't clear from the graph is whether that was all that was asked for.
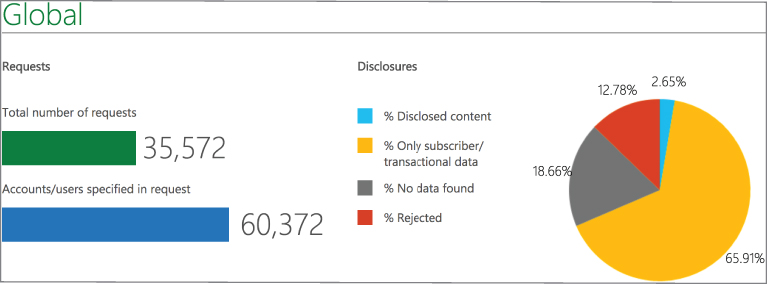
Figure 12.8: Microsoft transparency report.
This brings up the importance of network investigations. We need to be able to perform investigations on the network events as they happen, even if the events represent interaction with service providers, rather than relying on the ability to have quick and easy access to all data files and relevant information. Being able to at least observe interactions with these service providers, even if we may not be able to see what is being transacted, at least gives us information about when users were gaining access and what services they were gaining access to. In most cases, unless you have something sitting in between the user and the outside of the network, you are going to have a hard time seeing the actual content of the data because it will be encrypted. Larger service providers will have their encryption house well in order, but there are constantly attacks on encryption, resulting in regular changes to what is allowed and what isn't.
Even when you can see how users are engaging with service providers, they may be using Asynchronous JavaScript and XML (AJAX). What AJAX provides is the ability for the server to reach out to the client without the client requesting a page. The way HTTP was initially developed, it assumed clients would make requests of servers that would respond. As applications delivered over HTTP have become far more complex, a reverse route was needed, which meant the server could autonomously send data to the client, which would be displayed to the user. When AJAX is used to communicate to the client or even for the client to send data to the server without the user's involvement, it may be done in small chunks rather than entire documents at a time. You may get a single packet containing a handful of characters that are sent to the server. This may then require a lot of work to piece everything together.
There is a slim possibility of getting data from a proxy server in this case, but it's not common. SSL/TLS are supposed to guarantee end-to-end encryption, which means that the browser should send a CONNECT message to the proxy server. This essentially turns the connection into a raw TCP connection rather than an HTTP connection. However, it is possible for the proxy to see the message by allowing it to sit in the middle of the request, providing encryption to the proxy and then again from the proxy to the end server. Some proxies will allow this behavior, but there is the potential for it to cause problems with the browser. The browser will want to verify the certificate, but the certificate can't match if the browser is trying to compare names in the certificate with the name of the server being requested.
As more and more services go to the web, one of the drivers continues to be the use of smartphones. People are transacting business less on traditional computers like desktops and laptops and more on mobile devices like smartphones or tablets. Either way, the use of these small form-factor devices is driving more uptake of web-based communications. As mobile applications are developed, it's far easier to just use web protocols since the access to those are built into the programming libraries used to develop them. Because it's easy, available, and well-understood, it makes sense to use it. Also, no additional infrastructure is required to support these mobile applications. A company can just make use of its existing web infrastructure to support these applications. In the end, they are exposing functionality that is already available in the primary web application.
The Onion Router (TOR)
There's one last topic to cover: dark nets. They are overlays to other networks, like the Internet. While you gain access to them over the Internet, meaning you can get to it from your cable modem, DSL connection or mobile device, the services require that you access them using services that lie over the top of those you would normally access through the Internet. One common dark net is The Onion Router (TOR). TOR was developed by United States Naval Research Laboratory employees in the mid-'90s and was conceived as an anonymity project. Tor (no longer an acronym) sits on top of the Internet but provides services to users in a way that the user sees no difference from normal Internet access. What is different is what happens on the other end of the connection.
In normal Internet use, if you want to gain access to a service, you would send a request to figure out the address of that service. You probably know a hostname and your application knows a port to connect to, whether it's a mail client or a web browser, but what you need is an IP address. Your computer sends out a request to a DNS server to get the IP address from the hostname you provide. Your computer then sends out a request to the server. All along the way, you are leaving bread crumbs—your IP address is leaving a trail that can be followed, because you left it with the DNS server you are trying to talk to in order to get to a website. Additionally, your IP address has traveled through multiple routers to get to the DNS server and then to the web server. Those routers have dutifully sent your request along and then the response back to you, based on the IP addresses in the IP headers.
In the case of Tor, your requests are sent through a peer-to-peer network. The network itself is Tor. Your request is routed through the Tor network and eventually exits looking as though it came from someone else entirely. This is how you obtain anonymity. No request to an end server ever appears to originate from you. Instead, it comes from the network and some departure node. You also need to have an entry node to match the departure node. This means that when you connect to the Tor network, you aren't just throwing messages out to the Internet. You are communicating directly with what is, in essence, an application-layer router. You can see the initial connection to the entry node (rv1131.blu.de) to the Tor network in Figure 12.9. (This is a TLS connection.)

Figure 12.9: Wireshark capture of Tor communication.
The application I used to get access is the Tor Browser. The Tor Browser is just a browser, like Google Chrome or Microsoft Edge. However, underneath the browser interface is the ability to gain access to the Tor network. The browser takes care of all of the exchanges with the network and all of the encryption necessary to make it work. The Tor Browser is available from the Tor Project directly for Windows, Mac OS X, Linux, and Android. This allows you to connect to the network and then configure your own applications to make use of that network.
While you can use Tor as your browser and it will work with websites just as other browsers do, Tor also provides more than just anonymity to clients. Additionally, there are servers that are only accessible within the Tor network and it's really these servers and services that comprise the “dark web.” Over the years, there have been a number of sites selling products and services through the Tor network. One of the most notorious was Silk Road, which was a site dealing drugs through the Tor network. It was shut down in 2013. Many other sites that have previously been available are now defunct.
A disadvantage to Tor is that while it provides anonymity for people who have legitimate need for it, it can also be a hiding place for criminals and criminal activity. Although there are projects focused on rooting out the criminal activity, it does become a bit like whack-a-mole, much like other attempts to deter criminal activity. Tor makes it hard to identify where people are because of the way the network operates. It is intentionally that way. Since anonymity is the point, you can see why criminals would be drawn to a service like Tor. This is not at all to say that Tor is is the only place where criminals operate, because there are plenty of criminal activities on the open Internet. It's also not to say that only criminals utilize the Tor network. There are often attempts to self-police the service. You can see in Figure 12.10 that the search engine Ahmia searches for hidden services on the Tor network but also that it doesn't tolerate abuse. It keeps a blacklist of services and encourages users to report abuse so that abusive services can be blocked.

Figure 12.10: Ahmia search site.
It is important to recognize that Tor uses common web ports. You can see this when you look closely at a packet capture. This means that Tor traffic can't easily be blocked. It looks and behaves just like regular web traffic. If you were to see a packet capture of someone using Tor, it may be very difficult to distinguish between the Tor traffic and another capture of web traffic.
One piece of data you can use to determine if you're seeing Tor traffic is the name of the host on the other end of the connection, though this is not always the case. rv113.1blu.de doesn't look much like a common Internet address to be communicating with. Looking a little further, as shown in Listing 12-3, it appears that the domain name 1blu.de belongs to an individual rather than a business or an organization.
This also is not necessarily suspicious, since anyone can get a domain name and set up a website. This sort of digging may be needed in order to determine whether someone is using a Tor browser or just a regular browser to connect to websites over the Internet. One thing you would note from a Tor connection is the duration of the connection and the amount of traffic transmitted. Over the course of a few minutes, I visited a few websites and the Wireshark capture showed that the host I was exchanging information with never changed. This doesn't mean that it never changes, but it certainly doesn't based on individual transactions over a period of a few minutes.
Summary
One of the biggest challenges associated with network investigations is encryption. Over the course of the book, I've mostly skirted the issue, demonstrating a lot of network traffic that takes place in the clear. It would be disingenuous to pretend that encrypted traffic doesn't happen. This has a profound effect on forensics because it is difficult, if not impossible, to obtain decrypts of the ciphertext that has been transmitted. Even if you are able to obtain a complete packet capture, encryption mechanisms are designed to not be reverse engineered. You can see the key exchange happening but you can't get the key. It is never transmitted. You might have the public key used to transmit the data, but that's insufficient for decryption. Without the private key, the public key is meaningless. Encryption will make your life very difficult. However, what you will always get, even when the data is encrypted, is the metadata, which is the source and destination of the traffic as well as the timing of the connection. While the time isn't transmitted as part of the packets, you do know when packets arrived relative to the start of the capture. This means you know when the network communication took place, assuming the timestamp on the file is accurate, which is a reason to ensure all of your systems are synchronized to a reliable time server.
Cloud-based services are available over the Internet, typically offered by a service provider, and you will encounter them very commonly in investigations. Whether the individual or organization is using a service provider for virtual machine access (IaaS) or just to host files (StaaS) or maybe even entire applications (SaaS), you will be able to see users gaining access to these services. Unfortunately, this is another area where you are likely to be foiled by encryption. Most service providers will offer their services using TLS, because these cloud-based services are offered using web-based technologies for the most part. Doing encryption through a website is simple and well-known. It's also cheap. Even strong encryption is no problem, so finding a service provider that is still offering services without encryption is going to be a challenge.
Savvy users, concerned with their privacy, may be using Tor as a way of communication. The Tor network provides services just as the open Internet does. Users can get e-mail over the Tor network and they can do peer-to-peer communication just as they could with Google Hangouts, Skype, Yammer, Slack, and other messaging applications. The communication happens, completely encrypted and anonymous, across the Tor network. Using the Tor network, you are anonymous because your address is hidden by the network. It's important to remember that Tor is just an overlay on top of the Internet—it is a logical construct rather than a physical one. All of the systems that are on the Tor network exist, by definition, on the Internet. Tor is just the way they have all connected themselves using the Tor program.