
Up to now we have looked at network management in a fairly theoretical way, with the discussion centering on:
MIBs, agents, and managers
Enterprise and SP networks
Connection management at layers 2 and 3
NMS/EMS layers
Network migration to layer 3
MPLS
Scalability
Development skills needed for producing high-grade NMS
Operational skills needed for running networks and using NMS
In this chapter we look at a real NMS product—Hewlett-Packard's OpenView Network Node Manager—and describe some of its principal features. No endorsement of HP OpenView is intended. It is selected purely because it is relatively well-known and also to illustrate the concepts described in this and previous chapters. This product is special in that it is in widespread use by both enterprises and service providers. The headings under which we study it are:
MIB support features, such as loading new MIBs for third-party NEs
MPLS support
Policy support
Reliability features, such as support for failover
Integration with other software, for example, data export/import, trouble ticketing, and workflow
Programmability, for example, adding additional software for new features such as provisioning
In this chapter we leave the design and development domains, and look more closely at the way organizations actually use real network management products. A good description of this and many other SNMP management features can be found in [EssentialSNMP]. Following these sections is a description of the typical business processes and workflows in enterprises and how these are facilitated using NMS.
HP OpenView [HPOpenView] is a broad family of network and system management products. This reflects the fact that network management needs in general are sophisticated and wide-ranging, and no single product can generally satisfy any more than a small subset of the overall user requirements. Central to the function of NNM is the management station—the command and control center. This is the computer (UNIX or Windows) that performs the bulk of the data:
Collection of information from NEs via SNMP notifications/polling
Processing and archiving in a database
Distribution to registered applications
For large networks, there can be more than one management station, and these can exchange information with one another. A management station can also delegate NE data acquisition to collection stations. The latter connect to NEs and collect status and configuration data, which is then passed to the management station. Typically, HP suggests that a single management station can handle 5,000 managed objects. Up to 60,000 objects can be managed if collection stations are deployed along with the management station [HPNNMScale2002]. This type of distribution helps to reduce the load on the NMS. In its default-installed state, NNM provides the following main features:
As these are quite generic NMS facilities, each of them is discussed in general terms in the following sections. Each section is then followed by an NNM-specific description. These facilities are all based on manually retrieving or asynchronously receiving data from the network. Pushing data onto the network can be achieved only by using special-purpose, third-party, add-on software. In this sense, NNM is a platform on which additional software can be layered in order to achieve full-featured network management. This again reflects that network management is complex and requires a range of software applications that go together to make up an overall solution. As networks grow, they can be effectively managed only using advanced software.
An interesting aspect of managing modern networks is that there is no single solution to all the network management needs. This is similar to the fact that there is no single desktop software application that satisfies all possible needs (word processing, email, Web browsing, spreadsheet, etc.). Desktop user workflows and business processes are generally too complex and varied for it to be feasible to produce one application capable of handling them all. Instead, a range of software packages are deployed and used. In the same way, the many commercial network management tools go together to make up a continuum of packages. This then forms the basis for the management solution. Substantial teams of people are needed in vendor organizations to service the ongoing (and changing) needs of large enterprise customers.
Before looking at NNM, we take a brief detour into the important area of mediation.
Once we start to look at the way NMS are used in practice, the area of mediation becomes relevant. This is another type of layering, similar to the ones we have mentioned in previous chapters. Mediation software exists to protect application layer software from proprietary configuration data. Figure 5-1 illustrates a multivendor network operating in conjunction with a mediation layer that feeds network-originated data into a set of NMS applications. Raw data is processed by the mediation layer and passed up to the applications for further processing.
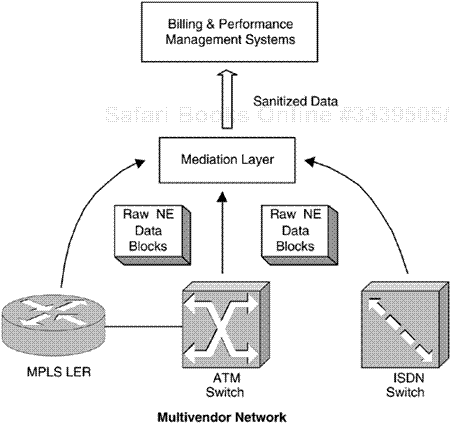
An example of one of these applications is billing—the A (accounting) in FCAPS. The NEs in Figure 5-1 generate data relevant to billing, such as:
The number of ATM-encapsulated IP packets received by the MPLS LER
The number of ATM cells received by the ATM switch
The number of ATM cells forwarded onto an ATM virtual circuit
The number of voice calls made using the ISDN switch
Typically, the NEs generate billing data in a proprietary format, and this must be transferred from the network into the mediation layer. The processed data emitted by the mediation software is presented in a standard format such as Billing Automatic Message Accounting Format (BAF) that can be handled using a standard commercial off-the-shelf (COTS) accounting package.
Discovery is a useful NMS feature by which NEs are automatically detected (or learned) and recorded. It fits into the C (configuration) part of the FCAPS areas. Automatic discovery frees the user from the potentially error-prone and tedious task of manually entering and maintaining the details of the deployed NEs. Large service providers tend to deploy NMS from the point in time that they start to build their networks (smaller service providers may wait for some revenues before adding an NMS). So, the burden of data entry may not be so great for large service providers; that is, they add an NE to the network and simultaneously add all the necessary details to the NMS. Once the deployed NEs are known and stored in a persistent repository, they can be managed. Discovery typically follows three main stages:
Initial discovery of previously unknown NEs
Incremental discovery of some change that has occurred to previously discovered data—for example, new cards (hardware) are added to a switch or additional protocols (software) are configured
Discovery of removal, where a device is taken out of the network and is then automatically removed from the NMS
Initial discovery occurs when a device is encountered about which nothing is known by the NMS. Its details are read by the discovery application and recorded in the database. Examples of such details are:
IP address of the SNMP agent on the device
IP address of the device interfaces
Device type; for example, for multiservice switches, this might be some combination of SONET/SDH, DWDM, ATM, MPLS, Frame Relay, and so on
Inventory details, such as configured software and cards deployed in the device
Protocols and technologies running on the device, such as ATM PNNI, MPLS, X.25, IS-IS, and so on
Links to other devices
Virtual connections, traffic profiles, route objects, and so on
NE software configuration is equally as important as the hardware details. An example is the set of ATM and MPLS virtual circuits we saw in Chapter 4, “Solving the Network Management Problem,” in Figure 4-9. These circuits facilitated the exchange of a range of traffic types between the two geographically distant sites.
The results of discovery are extremely useful, but even automated, it can be a time-consuming and expensive operation requiring SNMP (not all NEs support SNMP, e.g., many optical devices use the OSI management protocols for historical/technical reasons) messaging, and much database activity. Discovery provides the information needed for the other functional areas of management (such as provisioning, fault handling, performance analysis, and billing), but it should try not to do this at the expense of the overall solution. A balance is needed between supporting all the FCAPS features and the computational discovery effort required in trying to maintain parity between the actual network and the list of discovered entities.
A network-mapping feature further processes the discovered NEs and attempts to understand and depict the logical (and sometimes geographical) interconnections between them. Knowing the interconnections allows for a more comprehensive understanding of the network operation.
NNM provides an automatic discovery mechanism. This reflects the fact that many deployments of NNM are in enterprise networks with a wide range of layer 2 (switches, bridges, repeaters, etc.) and layer 3 devices. The discovery process uses SNMP-based polling and ICMP requests (over UDP and IPX) to build a picture of the network. For networks connected to the Internet, a seed file must be provided in order to avoid trying to discover NEs outside the organizational boundary.
The discovery process populates an IP topology database using a series of tables such as:
Network-level connectivity
Segments
Nodes
Interfaces
This grouping allows NNM to create logical maps of the NEs and to graphically indicate operational status using a color, such as green for up, red for down, and so on. An icon representing a network can be expanded to show the constituent nodes. Similarly, nodes can be viewed in terms of their interfaces. In other words, containment relationships are depicted clearly and intuitively.
Updates to the topology database occur continuously as a result of information received from managed nodes. These are nodes that are specially designated by the network operator for regular polling. Both status and configuration changes are recorded for such nodes. On the other hand, the operator must explicitly initiate on-demand, polling of unmanaged nodes. These are nodes deemed to be either relatively unchanging or not as important (from a management perspective) as their managed counterparts. This reduction in the number of managed nodes assists in improving scalability of both the network and the NMS.
Monitoring is the process of recording temporal changes in the status of managed objects such as:
Nodes
Interfaces
Links
Virtual connections (e.g., ATM PVCs, LSPs)
Ethernet VLANs
Status changes can be simple transitions such as link/interface up or down, or more complex, such as when an LSP path is being signaled through the network. In the latter case, a complex and dynamic state transition is occurring. Many such status changes can have an important bearing on the service received by the associated end user. An example is when an interface that is part of an ATM PVC goes down. The interface is no longer able to handle traffic. Such a status change may be service-affecting if there is no backup connection. For this reason, monitoring functions are an important part of an NMS, and the faster they record changes, the better.
The same process that carries out discovery also executes NNM monitoring. This is convenient because both discovery and monitoring can use the same set of objects—lists of NEs, interfaces, links, connections, and so on. Status changes are reflected back into the topology.
Notification processing is an important part of network fault management—this is the F (fault) part of the FCAPS areas—arguably the most critical part of any NMS because faults generally reflect problems in the network. Network problems can in turn affect end users. Notifications are the means by which SNMP agents asynchronously communicate problems with their NMS. From a scalability perspective, notifications provide a cue for remedial action from the NMS in response to some change in the network. This reduces the need for polling by the NMS. A number of issues arise in relation to SNMP notifications:
Notifications are not acknowledged by the NMS (unless they are informs).
Notifications are transported using the UDP protocol and hence are unreliable.
Faulty NEs can generate many notifications.
Aggregated services that become faulty can result in notification storms.
New hardware being added to (or reconfigured in) a network can produce notification storms.
When an NMS receives an SNMP trap over an unreliable transport, it never acknowledges it. This is in the interests of scalability and keeping the management protocol as lightweight as possible. It also helps avoid exacerbating situations such as network congestion. When an agent detects a problem, it sends a best-effort notification message and delegates resolution of the underlying problem to the NMS. Networks are often designed to leave an absolute minimum of about 25 percent bandwidth free to allow for routing, signaling, and management protocols to continue to operate at all times. If this is adhered to, then in theory agent notifications should always get through to the NMS. This enables the latter to carry out some meaningful remedial action.
Faulty NEs can generate large numbers of notifications; for example, if a node interface is flapping up and down, then each status transition results in a new notification. The NMS user should quickly try to resolve this by downing the associated link or resolving the underlying problem with the interface.
Aggregated services, such as layer 2 VPNs (as we saw in Chapter 3, “The Network Management Problem,” Figure 3-2), may have thousands of underlying connections. If a major fault occurs, such as a fiber cut, then the originating node for each affected connection may legitimately emit a notification. This can result in a great many notifications, particularly for the increasingly dense next-generation NEs (described in Chapter 3). If the NEs are aware they are participating in a VPN, then it should be possible to intelligently reduce the number of notifications, as discussed next.
Managed objects that are constituents of an aggregated service (such as all the virtual circuits in a layer 2 VPN) can be logically grouped by an NMS. This allows the network operator to view the service as a whole rather than as a collection of objects. The NEs are not generally aware of such a grouping. This means that the associated NEs cannot act in concert in the event of faults. This can lead to problems like notification storms.
A MIB table that expressed membership of aggregated services like VPNs could help prevent such notification storms. MIB indexes of members (e.g., virtual circuits) could be entered in the table, and the NEs could then negotiate overall service status before issuing notifications. This would have the effect of pushing more intelligence into the network and reducing the burden on the NMS. Given the trend towards increasingly dense NEs with more complex component objects (such as layer 2 and layer 3 VPNs), this type of issue may become more important.
NNM uses the term event to describe NE notifications as well as messages from other sources (e.g., external applications). NNM provides an alarm browser for all such events. Important (service-affecting) events can then be configured to show up as alarms so that operator intervention is prompted.
NNM distinguishes between SNMP notifications and events. The lifecycle for a notification is as follows:
An NE sends a notification.
The notification is received by NNM and logged.
NNM then distributes the notification to applications that registered for it.
NNM allows notifications to be paired so that notification A indicates a problem (e.g., link down) and notification B indicates problem rectification (e.g., link up). Not all notifications are symmetric like this; for example, if an LSR receives an MPLS-encapsulated packet with an invalid (or unknown) label—this is called a label fault—then there is no correction for this. It is a once-off, hopefully transient type of error. Paired notifications assist a network operator because they reflect those situations when the network self-heals. Likewise, when the corrective notification does not occur, then the fault remains active.
NNM also supports event correlation in which a given notification is processed before it is forwarded to one of the applications. This helps in situations where the same notification keeps recurring. As mentioned in the previous chapter, a very useful NE facility would be one that allows for notifications to be staggered or paced in order to avoid flooding the network with unnecessary traffic. This is particularly relevant during network reconfigurations. Some MIBs support notification throttling (RFC 1224) by using a sliding window of a specific duration (in seconds) and limiting the number of notifications allowed in this window.
Reporting is one of the most important features of an NMS. Data is retrieved from the network and presented in a specified report format. This can include:
Deployed NEs
NE configuration
Interfaces
Links
Virtual connections
The data gathered is presented in a manner useful to the operator.
NNM reporting is GUI-based and accessible through a browser. The main options are:
Report configuration: Create, delete, and modify reports
Report presentation: View reports
NNM reports can be:
Scheduled daily/monthly
Configured/viewed using a standard browser
Automatically emailed to a recipient
NNM comes configured with standard reports that can be used immediately or extended. Examples of such reports are:
Accounting
Availability
Congestion, for example, FR PVCs
Historical details
Inventory
Performance
Real-time details
Thresholds
Trend analysis
Utilization
These provide a useful foundation for creating additional reports if required.
NMS provide a persistent repository, typically, a commercial database product such as Informix, Oracle, or Ingres. It is this database that the NMS tries to keep synchronized with the network state. This is also the database used by remote management clients. By storing most of the managed data centrally, the outlying components of the NMS can be made as thin as required, even hosted on standard COTS applications such as Web browsers. It also facilitates data security to a degree because the database can be hosted in a secure location with access granted only to authorized clients.
Once a network topology has been discovered and stored in the database, the user can execute management operations against it such as:
Viewing the configuration of a given node
Provisioning an ATM virtual connection between two nodes
Viewing the active faults on a node interface
The database is therefore a key component of the NMS. All of the FCAPS applications use it. Commercial database products are often complex, sophisticated software products in their own right.
Backup and restore are important functions in any network environment. In the case of network management, both firmware and NE configuration are high value items. The firmware version on a given NE is subject to change as new features and technologies are added. It is important to be able to back up the existing version of firmware, allowing for it to be reapplied if required. One application for this would be firmware redistribution as part of disaster recovery, such as a lightning strike.
Configuring NEs is also an increasingly nontrivial task as more and more technologies and protocols are packed into devices. Once the NEs have been configured and are operational, it is important to be able to back up the settings—often called a configuration database. As for the firmware case, the configuration details can then be restored if necessary. In providing the backup and restore capabilities, equipment vendors can use protocols such as File Transfer Protocol (FTP) and Trivial File Transfer Protocol (TFTP).
NNM provides a backup facility that allows a snapshot to be taken of the topology and maps. These are frozen during the time it takes to copy the data into a backup directory. After this, normal service ensues. At no point during this process do the alarm handling and data collection procedures stop.
Standard Java-enabled Web browsers can play an increasingly important role in network management because they are COTS products. This reduces the investment required for producing clientside NMS solutions because almost no development is required for the client application framework. The browser provides the execution environment for client applications. A Java-based client application can be executed using the browser to download a Java applet. The use of Java has a number of additional merits:
Java is object-oriented.
Java provides built-in security.
Java is a multiplatform programming language.
Java supports field-replaceable packages.
The needs of network management solution developers are well served by the object-oriented features of Java [JavaDev]. The multiple views of UML fit easily into a Java environment, and some development tools (e.g., Telelogic Tau and Rational Rose) can generate Java code.
Security is an increasingly important issue in network management as the incidence of attacks increase [CERTWeb], so it is with good reason that security increasingly concerns the operators of all types of networks. All levels of network management infrastructure have to be protected from the NEs/EMS, all the way up to the business-management layer. Multiplatform support is also important, because two of the main competing platforms are:
The many different versions of UNIX, such as SunOS, Solaris, and HP-UX
Windows NT/2000
Java allows for full compatibility across these platforms: Code written for NT should run unmodified on the others. This can help reduce development and testing time.
As NEs deploy increasingly advanced features, it is often necessary to upgrade deployed NMS components. Java provides an elegant means for doing this by the use of packages. These are logical Java code and data entities that can be signed for security and swapped in and out of systems as required. Packages also provide many advantages for developers, such as encapsulation and interfaces.
The Java-based Web interface in NNM allows the user to connect to the NNM management station. It is also possible to offload the server processes from the management station. This permits the remote viewing of:
Topology
Alarms
Node status
MIBs
Maps
Graphs
The Java interface exports much of the management station function onto desktop systems equipped with little more than standard browsers. This is a very powerful use of COTS software and illustrates the merit of thin clients based on standard browsers. It allows for easy remote access to NNM. Remote operation provides several advantages:
Clients can be geographically remote.
Scalability is improved because client applications execute remotely, offloading NMS servers.
Geographic distribution means that network administrators do not have to be located close to the management station. They can dial in and access the functions and features. This raises an important issue of security. Network topology details are sensitive matters from the perspective of security, infrastructure protection, and commercial advantage.
Offloading management station functions is useful for freeing central resources. This can facilitate deployment of more advanced third-party software features on the central server.
MIBs are the cornerstone of SNMP-based NMS. They provide details concerning the network managed objects and form the basis for the NMS data model. In an ideal world, the MIBs would be sufficiently flexible to provide the bulk of the data model, but (as discussed in Chapter 3) for the current generation of MIBs, this is generally not the case. NMS should provide a number of baseline features for MIB support, including the ability to:
Load new MIBs in addition to the existing set
Support multiple versions of the same MIB
Unload MIBs no longer in use
Browse and analyze MIBs
When new devices are added to networks, their associated MIBs must be loaded into the NMS in order to provide managed-object access. It should be a relatively simple matter of adding new MIB files to the existing set. The new MIB files should be automatically compiled by the NMS and verified for correctness. Following the addition of the files, the associated managed objects should then become visible to the NMS. This latter would almost certainly be a manual configuration step, but the inclusion of marked objects could help in automating it, as described next.
Mandatory managed objects in a MIB should be clearly indicated and marked for easy inclusion in an NMS. These MIB objects reflect the core management features supported by a host NEs, and ease of inclusion facilitates importing new NEs into existing managed networks. (This point was made in the preface).
If the mandatory objects are marked (or tagged), then this can also facilitate automatic parsing. A sample marking could be a simple MIB comment like “--M” placed just before the mandatory object with “--/M” just after it. Coupled with default object values, this serves to improve the device manageability. The MPLS MIBs already include this with MODULE-COMPLIANCE clauses. RFC 2580 provides useful SMIv2 conformance guidelines; for example, related objects can be indicated using the OBJECT-GROUP macro.
It was mentioned in Chapter 1, “Large Enterprise Networks,” that not all NEs deployed in a network will necessarily host the same firmware version. In some cases, later firmware revisions may require extra memory or even special-purpose hardware. This reflects the ongoing problem of feature cram as NEs become more complex. Denser NEs require more RAM, flash, and more powerful processors to support higher levels of intelligence. So, it is a fact of life that a given network operator may not have a common firmware revision on all its NEs. Since the MIB set is generally compiled into the executable firmware image, it follows that there may then be numerous versions of the same MIB deployed in the network. This adds up to a broader range of managed network objects. The NMS must be able to support all deployed MIB versions. Providing this support can be difficult, particularly when (as is often the case) there exist substantial differences between the various MIB versions. MIB authors (and implementers) can greatly reduce the burden on NMS developers and users by following guidelines such as those in RFC 2578. Examples of the latter include the DESCRIPTION clause and not using reserved keywords (some MIB compilers may not complain about reserved keywords),
Where entire MIBs have been deprecated or the associated managed objects are no longer in use, it is useful to be able to retire them from the NMS. This helps to free up resources and can take the form of unloading the relevant MIB files—the reverse process of manually loading MIB files.
NNM supports the loading of both standard and third-party MIBs. This helps in extending NNM to support additional and modified existing NEs. As long as all MIB objects have unique object identifiers, it is also possible to support different versions of the same MIB. Unwanted MIBs can be unloaded as required. NNM also allows operators to browse and graph managed objects from any loaded MIB. This can be done either in real time or historically.
MPLS operates at the network level; that is, the managed objects relevant to MPLS involve more than one node. MPLS nodes have a number of managed objects, the status of which can change over time:
Interfaces can be up or down.
Routing protocols, such as OSPF, IS-IS, and BGP4, can be operational or disabled.
Signaling protocols, such as RSVP-TE and LDP, can be operational or disabled.
Forwarding table entries can be active or inactive.
LSPs can be up or down.
There are other MPLS objects that do not change because they are static in nature:
EROs
Resource blocks
Cross-connects
All of these are highly relevant to managing MPLS; for example, LSPs may span any number of MPLS nodes and can be built using EROs, resource blocks, and cross-connects. Providing MPLS support requires software for managing these and other objects.
Chapter 3 introduced PBNM in the context of automatic traffic engineering and explained some of its advantages. In general network management terms, policies can be used to automatically solve recurring problems, such as certain types of failures or other important events. A simple example is traffic thresholds. The user can set a threshold on an interface for the number of packets received. If the threshold is exceeded, then a notification is generated and the NMS can divert some of the traffic. A simple rule is defined to achieve this based on the setting and crossing of a traffic threshold.
Apart from some fairly basic policies (such as issuing emails in response to certain events), NNM requires third-party products to implement policy handling. Policy-based applications provide features such as
Application prioritization, that is, certain key applications are assigned a specified level of service according to business priority.
Enterprisewide policy distribution, for example, access to servers and NEs.
Service-level mappings, such as those provided by technologies like IEEE 802.1p and IP DiffServ, can be used to deliver consistent quality of service across the network.
User-based security policies similar to the user-based security model of SNMPv3.
CIM/DEN, LDAP, SNMP, and so on.
An example of a third-party application providing such features is Avaya CajunRules Policy Manager. We mention this product for reference only in order to assist further research into this important area.
System reliability is an estimate of the probability of failure. There are a number of ways of improving reliability using backup facilities. In the case of NMS, this can take the form of protecting the central database. Failure of the database is usually fatal, and for this reason, many database vendors provide a failover capability. The user can deploy a backup version of the database that runs in parallel with the primary system. Failure of the primary results in a full switchover to the secondary.
Supporting the wide variety of NEs in enterprise networks requires a rich mix of NMS and operational skills. Our primary concern in this chapter is the NMS, and in this section we briefly review the function of some ancillary systems to which it may be attached. These can include software applications that handle:
Data export of network topology/inventory data for business asset analysis—. for leaseback arrangements, departmental billing, and so on.
Data export to software-based modeling packages—. traffic analysis, network design, and capacity planning.
Alarm generation—. trouble tickets, audible/visual, email, mobile telephony text message, pager, phone, and so on.
Performance analysis—. the number of packets, frames, and cells transported in a given period by a node, interface, link, or connection.
Billing—. reports generated using call detail records and other data, such as connection type, class of service, and bandwidth consumed.
Security—. distribution of keys, user account names and passwords, digital certificates, encryption settings, authentication, and so on.
Workflow—. unsignaled virtual connections, such as ATM PVCs, require manual (or software-assisted) creation. A workflow system external to the NMS may provide this facility by handling task delegation, tracking, and completion.
Business asset analysis can be used for depreciation studies, lifecycle management, and department billing. NEs are expensive items that need to be recorded, managed, and maintained from initial deployment through decommissioning. Issues like upgrade and replacement have an important bearing on the network operator.
Specialized software applications can be used to carry out offline traffic analysis. A snapshot of the discovered topology can be exported into a modeling package, and the user can execute what-if scenarios, for example, increasing the bandwidth on a given link. The effects of any such changes can be viewed offline before making a change in the network. Modeling packages may also allow new topology details to be exported back into the NMS.
Alarms generated by the network can be routed via the NMS to trouble ticket applications. This allows for recording and directing any remedial work required to clear the fault. Another method of alarm annunciation is the simple audible variety, such as sounding a bell or a computer speaker. Visual indication can be a GUI topology object color change. Routing a message to an email recipient (or a short text message to a mobile phone or pager) can be used to indicate text-based fault indication. It is even feasible that a voice phone call could be initiated by the NMS to indicate a particularly serious fault.
Performance analysis can be facilitated by a combination of special reports and third-party applications. Many NEs generate performance data records (PDR) that provide utilization details for:
Ports, links, and virtual circuit utilization
Protocols
Networking technologies
Mediation software can process PDRs to produce data ready for export to reporting. This is similar to billing. Billing is already a critical SP business requirement, particularly as IP service billing becomes increasingly important [IPDR-ORG]. Enterprises also need billing as SLAs become more common.
Many NEs generate call detail records (CDR) that are preprocessed by mediation software prior to export to billing. The raw NE data blocks in Figure 5-1 are generally CDRs and/or PDRs.
Security is an issue of grave concern to the owners and operators of all large networks. The distributed nature of managed networks provides possible targets for attack:
SNMP agents can be flooded with request messages (denial of service).
NMS hosts can be attacked by various means, such as by viruses or hackers.
The network joining the NEs and the NMS can be broken or spied upon.
The data passing between the network and the NMS can be stolen, modified, or destroyed.
Security is required at all levels of a managed network, and this may require additional specialized software, such as directories for secure storage of relevant data.
Networks generally do not remain static, and changes need to be applied in a controlled manner. Workflow systems can help achieve this by tracking and managing the tasks required for running a network. This is discussed in more detail later in the chapter.
Many third-party applications can be integrated into NNM: This is one of its great strengths. This includes Microsoft Systems Management Server (SMS), which can be launched via the pull-down NNM menus. The reason for integrating applications in this way is to assist in solving operational problems. Clearly, it is a matter for the network operator to decide if such close integration is required. For example, if an enterprise application starts to misbehave by continuously sending out network messages (e.g., an NMS auto-discovery application), then the operator could locate the offending machine and then launch SMS to remotely remove the application.
The facility of adding software to an NMS can greatly extend its usefulness. This can include anything from MPLS/ATM/SONET provisioning to special-purpose NE monitoring. Open source NMS are a relatively new phenomenon and represent what might be called the ultimate in end-user configurability—actually changing the base software itself. Network management requirements are unique to every network, so programmability is an important addition.
NNM allows for user-software to be added to enhance the base functions. Examples of this can be in any of the FCAPS areas. NNM allows for geographical map-level integration between itself and third-party applications. In this, a user can select an NNM map node (such as a router) and launch third-party software to carry out operations on that device. This can include reporting, alarm and event processing, and other applications. The merit of the integration is the value added to NNM and the ease with which the third-party software can be accessed from the operational context.
Enterprises deploy an increasingly wide variety of NEs as their network requirements and business processes evolve. In this section we look at the workflows and business processes surrounding the way these networks are managed and operated.
Enterprise network customers are generally the employees of the organization except in cases where e-commerce applications and extranets exist. In such cases, the enterprise network boundary stretches outside the traditional limits and allows specially authorized and protected traffic inside, such as an extranet VPN. Beyond these capabilities, the everyday management of enterprise networks broadly follows a model of:
NE deployment, upgrades, management, and (proactive) support.
Trouble ticket-based (reactive) workflows; typically, an NE breaks or needs service (e.g., a VLAN link becomes congested), and an IT engineer fixes it in conjunction with details entered in the trouble ticketing system. The lifecycle of the problem is recorded in the ticketing system. Using an NMS helps in recording the details of the repair work.
General policing—minimizing traffic-generating file downloads from the Internet (and other hazardous activities) and implementing policies such as virus protection.
Connecting the network to other networks, such as SP networks and remote sites.
Some of the NE types deployed by enterprises include:
Switches—ATM, Frame Relay, MPLS, X.25, and Ethernet
IP Routers
PABXs/soft switches
SANs
Servers
Wireless devices (base stations, access points, and exchanges)
The types of issues that crop up in managing enterprise networks with devices like these are:
Fault analysis and rectification
Rebalancing traffic after adding new hardware
Billing
Performance analysis
Security
Creating virtual connections
To illustrate a typical problem, imagine that an enterprise PC has been inadvertently disconnected from a VLAN during a network reconfiguration. The result is an inability to log into the network, access email and the Web, other such problems. This can be quickly fixed with no measurable loss of revenue (apart from wasted time).
An enterprise uses its network to carry out its day-to-day activities rather than as a means of generating revenue. However, network downtime can be very costly. Also costly is the maintenance of multiple incompatible management systems. Consolidation of these is a useful enterprise network management goal.
Increasingly, NMS are required to assist in rapidly bringing up, keeping up, and downing large networks. One application of this is when a network is rebalanced after a significant hardware addition occurs, such as a new multiservice switch. The operator wants to execute this as smoothly as possible, and this may involve:
Managing VLANs
Tearing down existing virtual circuits
Re-creating the virtual circuits on the new switch
Generating CLI scripts or SNMP messages to move the connections to the new device
Suppressing faults during the changeover
Major reconfiguration actions such as these can be recorded by the NMS and stored as command files. These can be reused at a later time when similar operations are required.
It is sometimes said that the network is the database for any NMS. As we've seen, all NMS attempt to maintain parity between their database and the one stored in the network. Saying that the network is the database reflects the fact that the following may all be stored on the NEs and accessed at will via an NMS:
NE configuration details
Firmware
Performance details
Billing details
Security settings
NE Faults
The merit of this is that all such device-resident data is completely up to date because it exists in the network. The problem with retrieving this data is that there is so much of it. Getting the requisite data from the network for processing by an NMS requires expensive and possibly lengthy device retrievals. As we've seen, most NMS struggle to close the gap between their snapshot of the network and the real picture.
When data is discovered from the network, it is important that it is accurately reflected in the NMS. This can lead to anomalous results when NEs support multiple personalities, such as for MPLS SIN. As discussed earlier, SIN provides support for both MPLS and ATM at port level on the same NE. Should this node be described as an MPLS or an ATM entity? Whatever solution is found, the NMS should respect the data stored in the network, because in this context, the network is the true database.
An important point about managed networks is the definition of the boundary. This is the point outside of which the NMS has no jurisdiction. NNM must have some idea about this in order to avoid trying to discover nodes unnecessarily. This can arise when a given network is connected to the Internet and the operator wants discovery to stop its data collection at the last node before the Internet.
The network boundary problem is also seen in multiservice networks that contain numerous clouds of different technologies, including:
ATM switches
MPLS switches
Frame Relay switches
IP routers
As for the Internet case, this may require careful administrative actions, such as specifying a seed file in NNM. In essence, this sets a boundary address for management beyond which it is not permitted (or meaningful) to operate.
One last point about this is that even when the boundary has been carefully and correctly designated, the traffic introduced by network management may be too high.[1] In this case, it is important to be able to pace the management operations to suit the available bandwidth.
The theory and practice of network management are separate and distinct. Effective network management requires a broad range of software tools. Two approaches can be taken: Build one all-encompassing system or divide and conquer via a number of packages. The latter is the philosophy adopted in NNM and reflects the fact that computing power is increasingly inexpensive. Specialized software can be employed for areas such as mediation, billing, and performance analysis. The cost of ownership and development can be significantly lowered by the use of standard COTS packages. Java-based software can facilitate the use of standard browsers for (thin client-based) network management. Discovery, mapping, and monitoring are often inextricably interwoven, and along with fault management, these are the big “readers” from the network. They are the means by which the NMS attempts to keep pace with changes in the network.
Minimizing the gap between the network situation and that perceived by the NMS is crucial and provides a baseline for defining the quality of a given NMS. Provisioning both writes to and reads from the network as it executes the user's commands. Fault management can perhaps be considered the most crucial of all NMS facilities. The workflows associated with enterprise and SP networks share some similarities, but the financial cost of downtime may be more keenly felt in the latter. We briefly explored the reasons why it is often said that the network is the database. All NMS have a boundary, particularly those that encompass more than one service or technology.
[1] This is a little like Heisenberg's Uncertainty Principle. By managing a network, its characteristics are modified. Each action that pushes data into the network instantaneously reduces the bandwidth and changes the dynamics of the affected NEs.