
This chapter discusses the major protocols that can be captured, decoded, and reviewed using protocol analysis during a network baselining exercise. The protocol types chosen for review in this chapter include most of the major protocols encompassed within the local area network (LAN) and wide area network (WAN) environment in today's enterprise internetwork infrastructure.
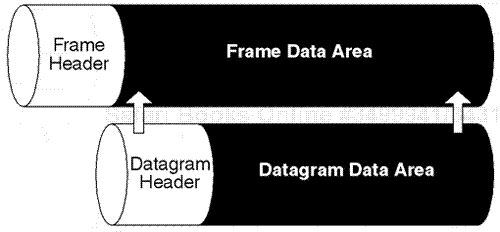
When performing a network baseline project, it is necessary to completely investigate and decode the packets received during a protocol analysis session. Each captured packet contains a specific set of protocol layers encapsulated inside the physical frame header.
For instance, an Ethernet frame could contain the Internet Protocol (IP) or Internetwork Packet Exchange (IPX) protocol at the network layer within a particular packet. Other protocol layers could also be used such as the transport layer, which could include the encapsulation of protocols such as Transmission Control Protocol(TCP) orSequence Packet Exchange(SPX). The protocol-layering systems usually change depending on the network operating system(NOS) and the applied protocol suite.
Another example is that in a Windows NT transmission it is common to capture packets that use a physical frame header, which would then encapsulate the IP protocol at the network layer, the TCP protocol at the transport layer, along with the NetBIOS protocol at the session layer, and Server Message Block (SMB) at the application layer. This is just one example of a particular protocol-layering sequence.
Protocol information for individual packets can be clearly displayed within the layers of each packet by viewing a protocol analyzer summary and detail display window. The display of the protocols depends on the type of network analyzer being used during the session. An analyst must be able to monitor the internals of a packet to understand the type of protocol layering involved, and how the protocol layering relates to the interaction of the network communication session being investigated.
Every protocol suite involved in a network transmission is affected by the NOS design, which is invoked by the vendor providing the workstation-to-server communication scheme for the particular LAN or WAN environment. For instance, the Novell protocol suite differs from the Windows NT protocol suite.
It is also important to understand that each protocol suite has specific layers that are used for certain processes. Each specific layer within a protocol suite is mentioned as a separate protocol within its own right. Each individual protocol has field categories specific to the protocol type.
During a baseline analysis session, an analyst must keep a technical notebook to carefully reference any key information identified in the baseline session. This process does take time, but proves extremely valuable to the development of an analyst's required technical skill set.
The following sections of this chapter present the key protocol-layering mechanisms used for each protocol, along with techniques for analyzing the protocol suite. This chapter covers most of the major protocols within the internetwork environment.
Some of the protocols presented may have varying fields related to internal operations, which may change depending on update releases of the NOS or variations of software patches provided by vendors. The material presented in this chapter is based on the base specifications for each one of the protocol types as engaged by a particular protocol suite.
Some general analysis techniques should be noted before moving forward with this chapter. When investigating a packet within a protocol analysis session, it is important to understand the particular protocol-layering mechanism. After a data trace capture has been completed and saved, the analyst must display the internal data in both a summary and detailed screen view. Next the analyst can invoke the "paging through the trace" process, as mentioned earlier in this book, and just take notes on the type of physical header used and any other types of protocols used for encapsulation. The analyst should carefully note the network layer protocol, along with the type of transport protocol, if engaged, and whether connections are being maintained. Next, note the type of application protocol involved.
An analyst must understand the type of protocol-layering schemes working between workstations and file servers. It will be helpful to carefully analyze individual packets to truly understand the application process flow and the internetwork operations involved in such.
Some NOS and software application development engineering teams choose to use certain NOSs expressly to engage the protocol layers inherent in the operating system's design.
As noted earlier, with the Windows NT protocol suite, the NOS inherently uses IP at the network layer and TCP at the transport layer. Because of this alone, many application developers have chosen the Windows NT operating system as a protocol suite because it is compliant and form-fits their particular application dataflow requirements. In certain cases, the application developers may also invoke different fields within protocol layer operations that will cause the application layer, transport layer, or other layers of the protocol suite to produce various custom operations for an application.
The only way to understand this process is to fully analyze the protocol- layering scheme at the start of an upper-layer review analysis session.
As noted earlier in this book, it is important to take detailed notes on the protocol-layering scheme. Most protocol analyzers used for network baselining can usually display the protocol-layering schemes in the summary level and show all active layers. If the protocol analyzer being used does not have this feature, the individual packets may have to be decoded at a detailed level, and the actual internals of the packets investigated.
This chapter now focuses on each one of the major protocol suites, along with a review of the key layers of the protocol suites and associated technical fields. Certain specialized techniques relate to specific protocol suites.
The Novell protocol suite is well known throughout the global networking industry. The Novell protocol suite was introduced in the mid-1980s when the original Novell NetWare NOS was unleashed. The Novell NetWare operating system achieved immediate success. The NetWare NOS was designed specifically to fit small-to-medium internetworks from an original design standpoint. The popularity of Novell NetWare NOS grew, because it adequately supported general node-to-node communications for local area networking processes. It also was very user friendly in terms of access for general application deployment throughout the internetworking environment. Companies of all sizes found the Novell NOS to form-fit their requirements for distributed communications between PCs in both the LAN and WAN infrastructures.
The Novell protocol suite was originally designed and based on the implementation of an application layer protocol called NetWare Core Protocol (NCP). This protocol was designed to operate inherently between a workstation and a server for access. The NCP was also designed to work internally with a network layer protocol process that engaged a protocol called Internetwork Packet Exchange (IPX). The transport layer protocol that was engaged for connection-based processes was called Sequence Packet Exchange (SPX). Certain components of the Novell protocol suite were somewhat similar in design to layers of the Xerox protocols. The Novell NetWare protocol IPX is comparable to the Xerox Networking Systems (XNS) protocol for network layer operations, for example. The Novell SPX protocol is similar to Xerox's Sequence Packet Protocol (SPP) for the transport layer protocol design.
When the Novell NetWare operating system was originally unleashed, the applied protocol suite included five main protocols for general communication. The IPX protocol was intended for general network layer communications, the SPX protocol was intended for general transport layer communications, and NCP was intended for access and update for workstation to file server communication calls. Novell also implemented a routing protocol-layering system. Novell Routing Information Protocol (RIP) is a Novell version of the Transmission Control Protocol/Internet Protocol(TCP/IP) RIP version, but Novell RIP is based on a 60-second update. Novell NetWare was also designed with a protocol to advertise the services of NetWare servers for updates every 60 seconds through a protocol called Service Advertising Protocol (SAP). The Novell SAP updates allow different Novell servers to maintain a database of all available Novell services. The NetWare protocol suite was enhanced after the original release to allow for a more robust application layer protocol process through a derivative of NCP called NetWare Core Protocol Burst(NCPB) (see Figure 7.1).
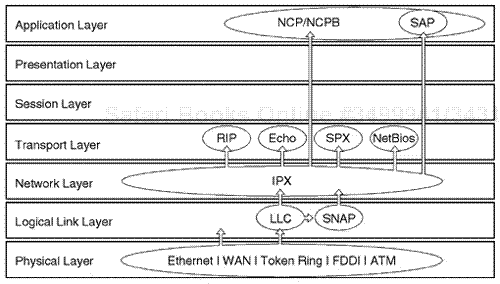
The following sections detail some of the main protocol-layering schemes used in the Novell protocol suite.
IPX was designed to allow for network layer communications to occur. There is no connection actually maintained within the IPX protocol. It does not actually guarantee a final delivery of any data across an internetwork channel. However, it does allow for two nodes to initiate communication and for communication to commence. It does not maintain a connection for the actual protocol sequencing.
The IPX protocol does allow for setting up of the communication channel between two NetWare nodes and the transfer of data in relation to a unit of measure. The IPX protocol is not normally used for extensive broadcasting, but there is currently a derivative of standard IPX called IPX WAN broadcast processes, which does allow for a higher broadcast sequencing cycle (see Figure 7.2).
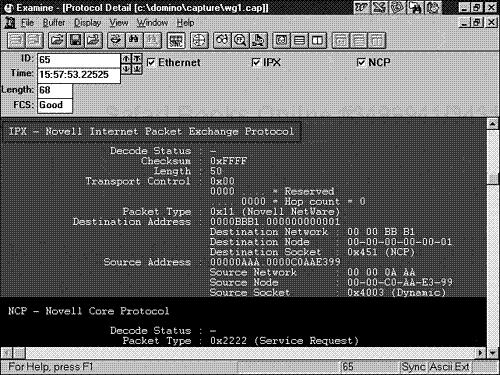
The IPX packet has the following specific field configurations:
Checksum field. . This field is normally used for an algorithm check to occur in communications of two nodes using an IPX transmission. The field is based on an algorithm check that engages a cyclical redundancy check (CRC). The field is 2 bytes long.
Length field. . This field represents the length of the IPX protocol layer, plus any other protocol layers encapsulated within IPX, along with any data within the IPX encapsulation cycle. This field is 2 bytes long and again identifies the total length of the IPX header, plus other protocols and data involved.
Transport Control field. . This field is used by the IPX header to identify how many hops or IPX-based networks have been traversed across a network-generated transmission cycle. This is also called the Novell hop-count field. The Transport Control field is based on a 1-byte length configuration.
Packet Type field. . This 1-byte field identifies the next upper-layer protocol that will be encapsulated inside the IPX packet.
Source and Destination Network fields. . These fields are normally 4 bytes long and indicate the source or destination Novell network number assigned for the IPX transmission.
Source and Destination node. . These fields indicate the Novell device communicating, such as a workstation or a server. This field normally includes a physical address such as a Media Access Control(MAC) address used for higher-layer identification. This is a 6-byte field.
Source or Destination socket. . The source or destination socket within the IPX header indicates the actual type of upper-layer protocol process within the Novell protocol stream being communicated to for operation. In this type of call, there can be an identification, such as a NetWare server or an actual NetWare application process, or types of custom socket as designed by an application developer. This field is a 2-byte field that allows for an identification of a protocol communication area and is somewhat similar to a port in the TCP nomenclature (see Figure 7.3).
The SPX protocol is normally used in a Novell transmission environment that requires maintenance of a connection. The SPX protocol is engaged by the Novell NOS or an application developer for the express purpose of maintaining a connection in a Novell internetworking environment. SPX is a transport layer protocol.
The connection is maintained by engaging certain fields such as the Connection Control field, the Sequencing and Acknowledgment Number fields, and the Allocation field. Two devices within the Novell internetworking environment, considered network nodes, can communicate back and forth using the SPX protocol layer to encapsulate data for transmission while also maintaining a connection sequence process.
The actual connection sequence can be continuous with data flowing on an ongoing basis, or the SPX layer can be used just for a polling and acknowledgment cycle (to maintain a connection, for example).
The NetWare protocol suite has two versions of active SPX: SPXI and SPXII. The SPXII version protocol allows for a packet larger than 576 bytes to be used for a Protocol Data Unit(PDU) inside the SPX header and also allows for variances in operation as related to the allocation and windowing design within the SPX protocol header.
The SPX protocol is specialized, because some fields allow for polling on event cycles, as required. An internal end-to-end acknowledgment and sequence process can be maintained through endpoint monitoring. The SPX process engages an examination between two NetWare nodes of the sequence acknowledgment and allocation-based fields. The following fields are considered active as SPX configuration fields and are important for analysis (see Figure 7.4).
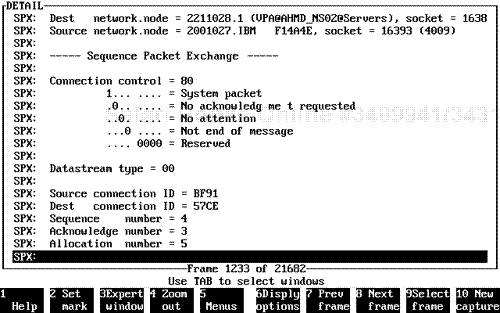
Connection Control field. . This field is used to identify the type of connection active between two specific NetWare nodes. Certain active connection processes can be identified, such as system, acknowledgment process active, connection active, attention active, and process inactive or process ending. This is a 1-byte field.
Data Stream Type field. . This field is identified in an SPX header, and is intended to internally flag to the upper-layer application sequence the type of data encapsulated within the SPX header. If there is an end-of-the-message cycle, this field configuration is also active. This field is 1 byte long.
Source and Destination ID field. . This particular field identifies the main virtual assignment from the NetWare NOS of the SPX virtual assignment for the transport connection process. This is somewhat similar to a TCP port assignment. The source and destination ID is a virtual assignment applied upon connection when using the SPX protocol for transport between two NetWare nodes. A virtual source and destination ID is assigned to each Novell node endpoint (relevant to the internal process using SPX for a connection-based cycle). This field is 2 bytes long.
Sequence Number field. . This field indicates the sequence of the SPX transmission between two NetWare nodes. The sequence number alternates upon transmission between two nodes on an ongoing basis. The sequence number increases depending on the sequence of data being transmitted in relation to the connection being maintained. This field is 2 bytes long.
Acknowledgment Number field. . This field is engaged in direct correlation with the Sequence Number field, but in converse correlation of the sequence number used between two NetWare nodes utilizing SPX for communication. The Acknowledgment Number field updates upon dynamic assignment in reverse order with the Sequence Number field between two nodes communicating with the SPX-based connection. Note that the bidirectional dataflow between the two devices is consistently updated within the acknowledgment number sequence on an ongoing basis. The acknowledgment number and the sequence number work together to maintain the connection sequencing between the two NetWare nodes communicating via SPX.
Allocation Number field. . This field indicates the number of Novell receive buffers available for transmit and receive as to available count between the source and destination virtual SPX ID assignments. This is somewhat similar to a TCP windowing scheme for inside the TCP operation for available window size. The Allocation Number field operates somewhat differently in the Novell environment, and is based on the allocation as related to receive buffers between the two NetWare endpoints communicating with SPX for connection.
Data field. . This optional field includes the PDU, and if active is variable in length. If the field is not active, the SPX protocol usually includes application layer protocols as encapsulated inside the SPX header. An SPX packet can carry pure data, and data can be encapsulated; the size of this field varies in length depending on the data size or requirements in this particular field (see Figure 7.5).

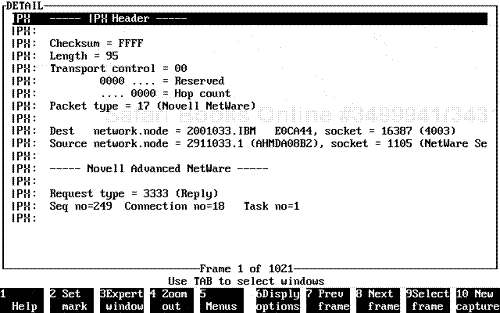
The Network Core Protocol was the first application layer protocol that was developed and used by the Novell operating system development team. The protocol was key to the success of Novell NetWare, because its main purpose was to allow a workstation to call on a server for a particular type of access (such as a connection, login, or file access). The server uses the same protocol to respond to the respective requesting Novell NetWare workstation node.
This particular protocol is very clear and easy to investigate via protocol analysis. Tips on analyzing NCP are offered later in this chapter.
The following is a description of the key internal field configurations for NCP. Note that the NCP is based on a request-and-reply sequence for standard NCP. The NCPB protocol uses a different type of request-and-reply mechanism.
The focus now turns to the standard NCP basic mechanism operation. The communication mechanism used is a standard Request sequence, in which a workstation performs an NCP Request and a NetWare server then provides an NCP Reply on a per-packet basis.
The following list identifies the NCP Request sequence configuration fields, along with the NCP Reply sequence configuration fields (see Figure 7.6).
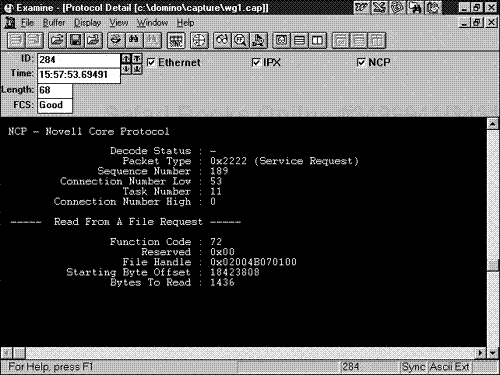
Request Type. . This field is normally used by NCP clients, such as a workstation, to request information from a Novell server. This field is normally noted as a Code 2222 for standard NCP request operations (a file access or file read sequence call to a server, for example).
This field can also be active for other key request types such as a Code 1111, which requests NCP to create a service connection. Code 5555 requests a connection breakdown. If burst mode is active, which would only be active and used in NCPB, Code 7777 applies. This is a 2-byte field that indicates the request type.
Sequence Number. . This field allows for the sequencing of a transfer related to NCP to be referenced on a cyclical basis between a workstation and a server. The sequence number updates upon each transmission. Each outbound request from a workstation that is replied to is eventually followed by another sequence number that normally increments by one. This may vary depending on the type of transmission involved in the overall data cycle. Normally, the sequence number is tracked and is incremental depending on the number of requests from a workstation. This is a 1-byte field.
Connection Number Low. . This field is used to identify the type of connection number assigned to the NetWare node as compared with the NetWare NOS task-tracking connections. This can be cross-reviewed in the Novell monitoring screens. The key is that the connection number will be assigned to low if the NOS is configured for connections under a certain node count level. This is a 1-byte field.
Connection Number High. . This field identifies the type of connection if the node count is exceeded based on a NOS-specific identification separation level. Certain operating systems in the NetWare environment allow for a higher number of connections, depending on the high count of connection. The Connection High field is used to identify the connection number, which is also going to be similar to the connection number low assigned by the NOS for the Novell workstation node. This is a 1-byte field.
Task Number. . This particular field identifies the actual I/O cycle task assigned by the Novell NetWare operating system to the particular workstation node. Note that the task number will change, depending on the requirement of the operating system (which assigns different tasks on an ongoing dynamic cycle). This is a dynamic field and is not consistently tracked in network analysis because it changes so rapidly, depending on the I/O cycle of the server. This is a 1-byte field.
Function. . This field is extremely important to network analysis and includes the actual function of the NCP request sequence. Note that the Function field changes based on the request type chosen, such as open a file, close a file, or create a connection. The NCP function is the actual NCP vector for the type of workstation NCP request being performed on the server. The field indicates the request type identification. The function identifies the actual action being requested by the workstation node. This is a 1-byte field and directly affects the following two fields: Subfunction and Subfunction Structure Length.
Subfunction. . This field acts as a subvector off the main Function field and identifies a subfunction such as "read all files with a modify flag active." In other words, this is a subfunction of the main function called on by the NetWare workstation node. This is a 1-byte field.
Subfunction Structure Length. . This field further identifies any more specific operations related to the main function or subfunction that are required by the workstation endpoint communicating with the NetWare server. This is a 2-byte field and allows for varied communication as related to custom structuring for the function request.
Data (variable). . This field is a variable-length field and may include actual data if encapsulating data is active in the NCP reply process. This is usually not active on a request cycle and is normally only active on a Reply sequence. This is a valid field format, however, for the NCP request header (see Figure 7.7).
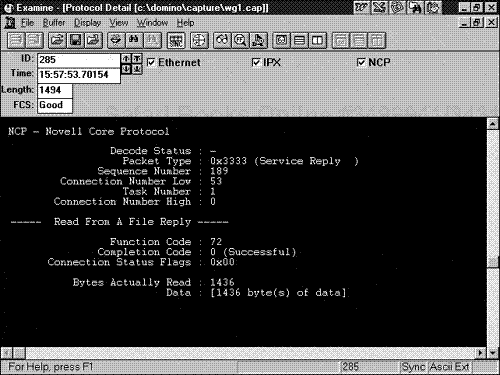
NetWare Core Protocol Reply. . This field indicates the type of reply from the NetWare server and response provided back to the NetWare work- station node. The server normally replies with a Code 3333 if all functions are active and the NCP reply is responding to a direct correlated NCP request Code 2222. If the NCPB mode is active a Code 7777 is used, which would not directly correlate to standard NCP. If a particular server operation cannot respond to a NetWare inbound request Code 2222 and the server is busy related to task I/O or other server functions discussed later in this chapter, an NCP reply Code 9999 may be provided. This indicates that the request is being processed and the server may be busy. If all active communications are normal, this field is normally decoded as a standard Code 3333 mode reply. This is a 2-byte field.
Sequence Number. . This field indicates the server-based sequence NCP reply to an inbound NCP request from a workstation. If a workstation NCP Request sequence number is noted as 128, an NCP reply with sequence 128 should also be provided for the Request sequence number 128. On the next inbound request of 129 from a workstation, the server should reply to active sequence number 129 and so forth. This will directly correlate to inbound requests from certain workstations, based on the actual task assigned for the server I/O cycle. This is a 1-byte field.
Connection Number Low. . This field is used to maintain the connection-sequencing operation upon reverse dataflow between a workstation and a server. The actual connection number is assigned based on the assignment level within the NOS. This will also directly correlate to the main operating system function. This is normally a 1-byte field.
Connection Number High. . This field is active if the connection between the workstation and the server is being maintained is above a certain operating system level based on a certain deployment for license at the account. This is normally a higher number than, for instance, 285 on active communications. This is a 1-byte field.
Task Number. . This field identifies the dynamic I/O cycle task assigned between the workstation and the server for communication on a Reply sequence mode. This is a 1-byte field.
Completion Code. . This is an extremely important field for analysis. This field indicates how a server is responding related to an exact function response to the main function request from a workstation. If a workstation requests information on a basic 2222 request, with a function read, and the server NCP reply completion code is responded with a "file not found," this completion code is considered an FF or a "failure to find" the file. If the file is found, the completion code would be normal and this field would be considered actively noted as OK in the code response. This field can be monitored, and it is designed on a 1-byte field and directly correlates to the workstation NCP request inbound and is considered the actual server NCP reply to the function request from the inbound workstation.
Connection Status. . This field normally indicates the response from the NetWare server as to the connection and whether the communication cycle between the workstation and the server is considered active within the operating system connection mode. This field is a 1-byte field.
Data. . This field is extremely important to upper-layer protocol analysis. By using a protocol analyzer properly in a network baseline session and turning on the hexadecimal and ASCII displays, it is possible to investigate this field from the NCP header to examine the exact type of data encapsulated in NCP. Data can be sent back and forth upon transmissions, depending on application design, and the NCP reply carries the data. This field indicates the size of the data and is variable size (see Figure 7.8).
The following protocol descriptions are summary reviews of other protocols used in the NetWare protocol suite enterprise processing environment. The following descriptions do not include actual field breakouts because of the extensive nature of the particular protocol type. Appendix B,"Reference Material, lists other manuscripts that detail the actual fields related to the following protocol types. If an analyst requires more information on a NetWare decode, the vendor should be contacted for any public documents available for review. It is always recommended that a protocol analyst have the most common public documents related to reference or white paper information on a protocol type. Protocol type fields can change, based on NOS release functions that are also modified on different versions of operating systems. Protocol operations can also vary when patches are provided for an operating system and the protocol suites used within the operating system type.
The standard NCP layer was basically designed for a small-to-medium-sized internetwork operation. In a standard NCP operation, a workstation may request a file open and a file read, and upon a file transfer from the server to the workstation would reply with one packet. For each other portion of the file required, the workstation would have to provide a request and another reply would then be provided by the server. This would be an ongoing reverse cycle that is considered somewhat chatty for large internetwork structures.
Because of this, and the increasing count of network nodes throughout many global network environments, the Novell NetWare development team provided a modification to NetWare Core Protocol: the NetWare Core Protocol Burst(NCPB).
The NCPB mode sequence allows a workstation to provide a request for a sequence of the data required, and the server to reply with multiple replies in a particular sequence.
This allows for a complete stream of communication to be sent back and forth in multiple sequences in a less-chatty operation, in which there is a constant request for every reply required from a server.
Basically, the complete stream transmission for NCP operations is provided with multiple sequences that includes multiple cycles of replies from the server that match a single request from a workstation.
Specifically, NCPB allows a workstation to request certain information from a file server, and the server can then reply with multiple replies for the single request. The workstation then requests any additional information related to the sequence, and the server continues to provide multiple packets for reply. An analyst can decode NCPB by just reviewing the server request type and the server reply type, which will always be active as a Code 7777. Also incorporated into the NCP operating system burst mode operation is the capability for the IPX packet to be engaged with a Large Internetwork Packet Exchange (LIPX) header that increases the standard IPX header length by more than 576 bytes. This allows for a larger PDU to be used in certain topology environments that allow for larger packet sizes, such as Token Ring and FDDI. In most cases when NCPB and LIPX are engaged, packet sizes can be engaged up to the maximum transmission unit of the applied topology.
The burst mode configuration field format allows for an extensive field breakout that includes a Request and Reply sequence, tracking of sequencing acknowledgment numbers, actual the actual transmission of sequence numbers, burst length, and burst offset fields. For large PDU transmission requirements, fragmentation fields allow for length offset and breakouts as related to fragmentation transmission. After the file has been opened and requested, different timing parameters can even be tracked, on a consecutive basis, such as delay times, sequence numbers, and acknowledgment numbers.
The Novell protocol suite was originally configured to allow for a routing information protocol to be used for each Novell router, or any servers acting as routers, to update on a consistent basis. Any key information could be updated as to server location, device location, and the amount of time or length to actually reach that location. The Novell RIP is a distance vector routing protocol that is somewhat similar to standard Internet Protocol–based RIP. The main difference in Novell RIP is that the RIP updates are provided on a 60-second cycle rather than the 30-second update used in the IP environment. The RIP protocol operation can be activated on the NetWare server and NetWare-specific routers, such as multiprotocol routers.
The fields within the NetWare RIP that are important to decode and analyze are specific information fields that identify the location of the device within the Novell internetwork and the actual length of time to reach that device as related to a specific metric.
The Novell RIP packet configuration format includes a network address for devices running RIP. A Novell device running RIP can broadcast a RIP sequence that identifies the routing table within the particular device. In this case, each available Novell server and router can usually be identified within the Novell RIP update. The RIP update table is presented in the RIP packets transmitted from the Novell device generating a RIP broadcast. Novell RIP updates include the Novell router location and ID. Also included is the time away as related to delay to reach the router in a metric called TICK, set for 1/18 of a second in timing for each TICK. An analyst can closely examine Novell RIP sequences, which should occur on 60-second updates on an ongoing basis between key servers and routers (see Figure 7.9).

The Novell SAP has been around since early versions of the NetWare operating system. It allows a server to advertise its available services to other key Novell servers, routers, and other devices throughout a Novell internetwork. The normal update sequence occurs on a 60-second interval. The Novell server advertises its current Novell services to other internal Novell servers of which it is aware. That awareness is based on the current SAP table, which is consistently maintained.
An outbound Service Advertising Update includes the Novell servers available, along with detailed information about the server type, server location, and the server process location as related to transmission.
The Novell SAP packet header relies on an IPX encapsulation technique to be transmitted across Novell bridges and routers throughout an infrastructure involving Novell devices. The SAP packets normally include a request and reply format. This is because, at times, a server must locate another server. Therefore, a Novell SAP request can be generated by a server, and then another Novell server can reply directly with a Novell Service Advertising reply from the device attempting to be located in the Novell internetwork. In this case, a server may request information on another server, and then other servers within the Novell internetwork can reply (see Figure 7.10).

This is considered a very chatty protocol on large Novell internetworks, which have server node counts of 50 and more. In smaller Novell internetworks this is a very useful protocol because it allows the Novell server environment to maintain a hooked operation in which each server is available and also aware of the location of other servers throughout the Novell internetwork.
In large Novell internetworks with multiple Novell servers, the server location and mapping scheme usually involves an implementation of NetWare Directory Services (NDS). NDS allows a NetWare workstation or other NetWare nodes to log in to a complete Novell internetwork and essentially eliminates the consistent requirement for Novell SAP processes. Also, the implementation of NetWare Link State Protocol (NLSP) has allowed for a more consecutive and nonintrusive process with less-frequent updates (see Figure 7.11).
In the 1990s, Novell introduced a protocol that could update standard NetWare servers and routers as to the state of a particular device, its service offered, and the location within the Novell internetwork. NLSP is based on a link-state routing update operation rather than a distance vector approach (which is normally used in the Novell SAP or RIP cycles). The NLSP is much less intensive to the overall network operation traffic cycle with regard to constant transmission. The only updates provided to a router or server running NLSP in the Novell environment are based on a changed-state occurrence or on timing intervals based on an hourly sequence, which is less intensive than the standard Novell RIP and SAP 60-second sequence.
The NLSP also addresses larger internetworks by providing longer routing address fields, allowing for more than 127 Novell networks. The NLSP uses more than 128 network hop counts rather than the standard Novell RIP limitation of 16 network hops.
The following are analysis techniques that can be used to examining certain Novell protocol suite layers encountered during a network analysis session. As previously noted, the overall fields have been presented as to their configuration and operation. The following are notes on actual analysis techniques for the protocol layer type.
The IPX protocol is extremely valuable for analysis because it includes the Novell nomenclature for the internetworking addressing schemes on the packet being investigated. When using a protocol analyzer and investigating a Novell NetWare IPX layer within a packet, the Novell source and destination network number are clearly noted, along with the Novell network node. These two fields alone are important to identifying the actual source node or device transmitting a packet within the Novell internetwork. A protocol analyst should always closely monitor these fields when investigating a Novell error packet or any type of Novell communication, such as file access. These fields identify the source network and node, along with the final destination network and node.
Also contained within the IPX header is the Transport Control field, or Hop Count field. By closely analyzing this field with a protocol analyzer, an analyst can identify how many hops the packet has traveled before it was captured. By analyzing this field, an analyst may be able to identify any routing loops or improper routes that may be present.
The Addressing and Hop Count fields enable an analyst to identify vector address situations, along with path routes taken in a network analysis session.
The Protocol Type field shows the next protocol layer up in the packet sequence, which can also be analyzed by moving through the packet detail process.
When analyzing the Sequence Packet Protocol in a Novell connection sequence, an analyst can closely examine a Novell source and destination virtual ID when the two nodes are maintaining a connection. By monitoring the connection-based sequence, an analyst can determine whether the NetWare connection is maintained on a consistent basis. If the connection is broken, the SPX header of the field shows this.
The other key factor is that if the communication is consistent and ongoing, and a connection is maintained in a normal way, the SPX field shows this as well.
If several devices on a Novell internetwork have problems and a user complains about connection drops, an analyst can just filter on the SPX communication for the user's ID if it is found that SPX is used for connection maintenance. By consistently filtering on the SPX communication and monitoring the summary view of the SPX communication between the two source and destination IDs, it may be possible to follow the connection Sequencing Acknowledgment and Allocation fields in the SPX header to identify a connection break. It may then be possible to vector into the connection break sequence and investigate any ASCII or hex data that was active or any other upper-layer protocol in process when a connection break occurred. This may also enable an analyst to identify high timing in interpacket delta time differences in between the sequences where the SPX connection breaks. An analyst may also be able to identify timing delays on the internetwork. Either way, by closely monitoring the SPX fields and monitoring the Sequence Acknowledgment and Allocation field between two NetWare nodes, an analyst can use the summary screen to follow the NetWare connection sequence.
By following the connection communication cycle, an analyst can determine whether the connection process is operating normally.
When examining NCP, an analyst should closely focus on the outbound requests from a workstation and the subsequent reply from the server. In most cases, the NCP indicates what the workstation is requesting and how the server replies in relation to the function request. The upper-layer protocol communication fields of the NCP are usually clearly displayed in most protocol analyzers. At times, if there is a problem with a server responding to a request, the NCP reply indicates the type of failure (a file not found, a bindery error, a server operating system error, for example).
Analysis of the NCP layer is extremely important for investigation of how workstations are requesting information from servers and how servers are replying.
The key to analyzing NCP in most cases is to use a summary view in a network protocol analyzer. Just focus on the NCP requests from certain devices to the server and how the server responds.
In problem situations that identify a specific device on the network having a problem, an analyst should filter on the device by using a physical or network layer Novell IPX layer filter to watch the two devices communicate.
NCP is active, depending on the encapsulation and operation of the IPX header. By monitoring the NCP communication inbound and outbound sequences from the server as related to a specific station, an analyst can follow the NCP communication sequence between the Novell workstation and server.
For example, a workstation may attempt to connect to a server, and the server provides the connection. The workstation may then attempt to log in to the server, and the server provides the login function. The workstation then may request authentication, and the server may reply with "authentication failed" because of an improper password. By examining NCP, an analyst can actually see this failure code come back from the server in the NCP reply in the authentication sequence request-reply operation. The process of protocol analysis is key in investigating and locating this type of problem. In this particular case, the problem could be as simple as an incorrect password. The main lesson here is that by examining NCP in a focused analysis and by using proper filtering schemes, actual NCP problems can be identified (workstation connection problems, login problems, file access problems, for example).
When examining any session via network baseline process, it is important to keep a close eye on NCP frame communication between workstations and NetWare servers by examining NCP at the summary and detail level with a protocol analyzer.
SAP is a simple protocol used by Novell servers to periodically update services available related to Novell resource service types. It is important to filter on Novell SAP sequences and monitor the services available from servers. By decoding SAP transmissions, an analyst can locate servers, identify server functions, and the delay of the server as related to its position within the internetwork. It is also important to watch the frequency of Novell SAPs to investigate whether too many NetWare servers are being broadcast as available in a NetWare area that does not require access to the servers. In large Novell internetworks, SAP updates can cause high traffic levels. In such a case, it may be necessary to put filters on a router or a switch via a network Layer 3 filtering within certain internetwork environments.
RIP analysis process is focused on the area of analyzing standard 60-second Novell RIP updates along with any outbound RIP requests from a router trying to locate another router within a Novell internetwork. When analyzing the packets, it is important to examine the address of certain routers, the number of hops away for the router, and the amount of time away related to the TICK field for the 1/18-of-a-second process.
A protocol analyzer can be positioned on a Novell internetwork to capture RIP updates by setting a protocol display filter wide-open trace, or presetting a pattern match filter with certain protocol analyzers just to investigate Novell RIP sequence timing and Novell internal RIP sequence information data.
As noted, Novell recently identified the requirement to reduce the amount of broadcast traffic associated with standard SAP and RIP operations. The standard RIP updates are keyed on 60-second standard intervals. This is because of standard distance vector implementation of Novell's version of RIP. The new NLSP allows for a link-state routing protocol implementation.
NLSP produces less network overhead traffic and timing by reducing the overall routing update frequency. This in turn reduces the overall amount of processing required for NetWare-based servers related to routing operations. The updates are sent in hourly intervals and only during router and server operational changes. The NLSP protocol also addresses internetwork size concerns by allowing routing between 127 hop counts rather than the standard RIP limitation of 16 network hop counts. The NLSP processes can also be more easily managed by host management platforms.
NLSP updates should be closely monitored with an analyzer. The key is to monitor the standard NLSP updates of the linked routers and to watch for out-of-normal time sequencing.
Many Novell communication processes require exact analysis techniques and a specific analysis view from a baseline perspective. The following sections describe these unique processes.
When file servers in a Novell environment are operating at a high inbound I/O task level or are incorrectly designed with regard to hardware/software configuration, or if too many users are applied for connection or too high of an application balance is applied to the server, a server may operate in a busy mode. The NetWare operating system has an inherent technique for a server to provide an outbound communication packet in responses to NetWare work-station requests with this type of occurrence. In standard NCP, a reply of a Code 9999 in the NCP reply packet indicates a NetWare busy operation. In a situation where the NCPB mode is active, a NetWare busy flag can be flagged in the field header of the format of an NCP flag format for the NCPB operation.
In this type of circumstance, an analyst can just review certain upper-layer protocol traces in the NetWare baseline session to find this type of situation, or in certain cases an analysis can preset filters to determine whether servers are busy in the NetWare environment.
When performing a large baseline study in a situation in which there are critical NetWare file servers, it is sometimes beneficial to filter on the NetWare servers through physical MAC addresses or network layer IPX addresses.
In doing so, after the address filter has been applied, another pattern-match data filter can be applied against the NCP reply field indicating whether a server is busy. In an NCP environment, an extra pattern match would be required matching the pattern of Code 9999 being engaged in the reply on an outbound server transmission for the hex offset of an NCP reply sequence. Upon capturing any packets matching the pattern, these sequences would be identified as busy packets by just reviewing a summary level of the screen. If NCPB mode is active, server busy conditions can be identified by closely examining the NCPB flag fields as related to the busy flag hex offset in the pattern of data. With NCPB busy flags, a capture and display protocol analyzer filter can also be set to examine the same occurrence (see Figure 7.12).
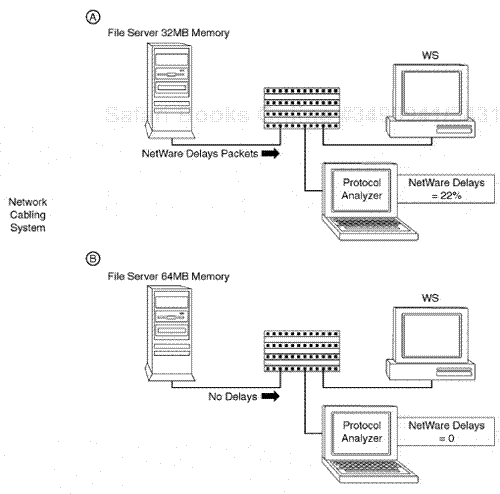
The key factor here is that by closely examining NetWare servers for NetWare busy packets, it may be possible to identify NetWare servers that have inadequate resources as related to memory, hardware, or other possible software configuration issues. When a server is busy, it is usually because the server has software or hardware configuration issues. The application layer may be overbalanced, and there may be too high of an application load or too high of a user count assigned to the server. In this case the server can be investigated based on the analysis results.
NCP or NCPB mode busy indications from a server that exceed 200 to 300 per hour indicate a server inundated with requests which cannot be replied to by the NOS I/O task handler. This again can be because of internal problems within the server or an overbalance of user connections or applications.
A network analysis session sometimes indicates file access errors. The normal process is this: A file is requested by using a search command. After the file has been located, it is either opened for the either writing or reading. The file is eventually closed.
In certain circumstances in NCP or NCPB, a workstation attempts to locate a file on a server but fails.
This can be because of file misplacement or misconfiguration of Novell mapping in the Novell workstation and server infrastructure. Problems also arise when workstation path statements are incorrect as related to Novell server drive mapping configurations for the workstation image. For either condition, the key factor is that by properly using a network protocol analyzer and analyzing NCP or NCPB, file access errors can be captured.
Some of the key access errors clearly seen are identified in the NCP Reply sequences in standard NCP or in standard NCP burst replies from the server. The area to closely examine is the Function field for the NetWare request, along with the NCP reply from the server. If replies are found showing that files are not found or file access fails, subfunctions of the NCP request and reply fields should be investigated for data relating to the cause (see Figure 7.13).
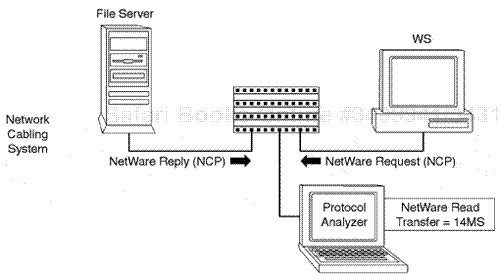
In certain circumstances, the reply command may indicate whether the file could not be accessed because of improper attributes based on a search attribute request or file access parameters in the request that are not valid. In some cases, a file may not even be located on the server being searched. In any case, it is important to always examine NetWare file access communication by closing studying the inbound workstation NCP request and then closely examining the outbound server NCP reply. The detail area of the NCP or NCPB header is where the information is indicated upon reply from the server. This type of information should be carefully noted in a technical analysis log when encountered by an analyst.
Prior to the release of the newer NetWare 4.x and 5.x operating systems, some of the older Novell operating systems contained a bindery configuration. The NetWare bindery allows for the general linking of the database of resources important to the NetWare operating system—that is, for linked files for which the server provides resources to the user community. If a bindery is corrupt, an NCP reply is provided on the network packet transmission with a completion code indicating a bindery error.
This is just encapsulated in the NCP as an NCP reply with bindery error. A network analyst can use a protocol analyzer to capture NetWare bindery errors by just applying a pattern match for the bindery error after capture during the initial session.
After the initial session has been captured, the hex offset along with the Bindery Error Type field should be identified and a pattern match can be set up for a precapture filter to further investigate the frequency of occurrence.
If bindery errors occur at a rate of more than 1% of all absolute traffic, there is a critical problem in the NetWare bindery. In this case, the bindery may have to be repaired or the NOS may need to be reloaded. In a NovellNDS environment, this is not an issue because of the infrastructure change of the overall design of an NDS container and the general operation without an active bindery.
A Novell internetwork may have many different login request processes. In a standard NCP operation, a workstation just logs in to one server may request information from one server about another server via a specific NCP call, and eventually links to other servers throughout the internetwork. In a NetWare NDS design, a workstation logs in to the complete internetwork of servers.
The following login process occurs in a standard NetWare core protocol environment.
The workstation attempts to locate the nearest server on the internetwork and attempts an initial connection. The workstation negotiates a packet size and buffer size with the server and establishes initial connection. The workstation may destroy connection from the primary initial server, which was found from the "get nearest server" command, and then connect to the preferred server for login processes to access certain information on the client/server cycle. Next, a workstation usually attempts to locate and download the LOGIN.EXE file from a primary server and establish user privileges associated with the file.
A protocol analysis approach can be used to examine a Novell login process. In some circumstances, based on certain login shells or certain menuing systems used, the NetWare access login cycle can be examined in detail. By creating a connection with a server, negotiating file server information, along with buffer size, packet size, and the actual connection to the initial server, it is possible to actually watch a NetWare workstation establish the initial connection. It is easy for the analyst to also examine the summary login mode. An analyst can determine how a workstation establishes a login process through authentication of the login key and eventual password process to negotiate access to the server. The analyst can monitor a workstation connecting to the main system drive in the NetWare server for connection and eventual connection to other applications.
During examination of the login process, an analyst might identify abnormal occurrences. Login sequences should be fluent. If there are excessive instances of "files not found" or "login files cannot be located" errors, or other information related in NCP shows connection or login sequence as not fluent, it is possible to identify the cause. In certain cases, the cause can be menuing systems or mapping of the workstation. In other cases, the server may be improperly configured.
NetWare login analysis is critical. Many users complain of delays when they log in to the internetwork. One of the key rules of a NetWare analysis is to limit NetWare login sequences to a minimal level (to the most minimal level for I/O). By using protocol analysis and network baselining, it is possible to investigate how long a NetWare login sequence takes. A normal sequence contains less than 1,000 frames. If 3,000 or more frames are identified, it is possible anomalies exist in the NetWare login sequence.
In certain situations, the server may indicate specific conditions such as "access to server denied" or an error message generated from the ATTACH.EXE process. Other circumstances also indicate errors (a workstation attempting to log in to a server, the server responding with "unauthorized workstation," for example). Other common errors include "cannot route to a key file server" and "bad local network address." These are just samples of errors that might be encountered in a protocol analysis session when investigating NetWare login sequencing.
Investigation of a NetWare login sequence requires an understanding of the standard authentication and analysis processes. The NetWare login cycle includes a process in which the workstation invokes an encrypted private key unique to the user and should be valid to the specific user. There is also the RSA public key (the Rivest Shamir and Adleman process) that it used for the authentication services to validate user information. This key is part of the normal requester in the RSA process.
The authenticator is a special credential operation created and engaged by a client, including a specific session information that is utilizing a user's complete name, workstation address, or validity period. A signature is considered a background authentication credential, which is engaged within the combination of multiple packets such as the authenticator and encrypted private key.
The final proof is the encryption technique used in a LAN or WAN in a Novell environment, which is constructed by using the message, signature, and user's private key in a random number generator to ensure that each message is unique. When conducting a network analysis session, different levels of security must be considered.
A client requests authentication by invoking the DOS requester from the client endpoint. The operating system then returns an encrypted key. The server key can only be decrypted with the proper password. The user then provides a valid password to decrypt the key. The client receives an encryption link called a signature, using the authenticator and the private key, and the key is then removed from memory. The signature is used as a background authentication review, and the client then requests access using a proof. The proof is then sent across the network to prevent it from being captured. Every proof from a workstation has a different proof because of the random number generation process. The user in then authenticated. After the proof has been received and validated by the server, the access to the Novell server is pending the completion of the second layer of authentication, which is considered the final detailed level, if required. The second level is not always used, depending on the level of security assigned.
The NetWare Directory Service is inherent to NetWare 4.x and 5.x releases, and allows a workstation to log in to a complete Novell internetwork of servers. It is based on an object-oriented database and allows for NetWare resources to be designed into an hierarchical tree.
The NDS tree is distributed throughout the complete enterprise server internetwork from one centralized approach. This differs completely from the bindery system that preceded the NDS operation. In an NDS operation, the user logs in to the complete internetwork and all the servers within the Novell enterprise environment. This login capability allows for an enhanced security process for the login cycle. In NDS, a full computing environment can be accessed by one user from one single point within the internetwork.
Some synchronization concerns apply in large NDS trees because all servers must be constantly aware of each other in terms of NetWare server location, function, and access points to allow for the NDS tree to be designed.
The NDS tree structure is comprised of a main container and subordinate leaf objects. The top level of the tree container is called the root. From that point, there is an organization (O), a country (C) and an organizational unit (OU). The tree is designed on a partitioned segmentation strategy.
The NDS tree can be split into many different segments, and databases can be distributed and replicated throughout the Novell server environment. By distributing the segments and the databases throughout the NDS tree, it is possible to have a more fault-tolerant and smoother internetwork design.
Partitioning allows an administrator to take pieces of the NDS tree and distribute them to various servers. Note that the main root is considered the key portion of the tree. The backup copies of the NDS tree off the main root can be considered replicas and can be transmitted across multiple trees and customized by the NetWare administrator.
There are four types of NDS replicas. A read/write copy of the original partition is considered the master. A read/write copy that is a copy of the partition. A partition may have multiple read/write copies. If changes are made to one of the replicas, these changes must be communicated to all servers that have a copy of this replica. A read-only is one that can be viewed but cannot be modified, and a subordinate reference is a replica that is created by the NDS and is sent to other portions of the tree for just pure fault redundancy. The parent replica does not reside in this reference and this is considered a subordinate reference for redundancy only.
The replication strategy in an NDS server-to-server environment is extensive. The process allows a main server with a master replica to go down the list of the NetWare environment and produce replicas by copying the affected partitions. The replication traffic can actually be viewed through functional programs in the NetWare environment, such as DS Trace.
The key is that by also using a network analysis tool, such as a protocol analyzer during a network baseline session, the NDS tree updates can be examined. This can be achieved by examining NDS updates, such as location pointers to where the updates are traveling.
In large internetworks, too many replicas designed against the master replica may cause excessive traffic as well as excessive updates of objects between the NDS tree. This could also put a severe load on the network.
NetWare administrators must always be concerned as to whether they are creating the proper number of replicas and what the effect is on the overall internetwork.
When performing network analysis, it is important to review the NDS tree operation via protocol analysis. One of the key areas to be examined is NDS replica distribution. When the subordinate references are created in their pyramid design and transmitted throughout the internetwork, a network analyzer can be used to examine the frequency and the traffic impact of the sync procedures in relation to the replicas on the internetwork traffic level. As more NetWare servers become involved and the NetWare NDS tree becomes more complex, larger NDS synchronization patterns will be clearly present in Network analysis sessions. The use of a protocol analyzer is extremely valuable in these cases. The sync procedure should be closely analyzed to ensure that the NDS tree is properly configured and the replicas are being properly distributed in an efficient manner without extensive traffic load.
Also, the standard NCP traffic alarm log with interactive NDS traffic can show an analyst how often a synchronization occurs.
For further information on NDS operation, see Appendix B.
When analyzing the NetWare environment, it is important to keep in mind that the protocol analyzer platforms available facilitate a clear view of NCP, and in most sequences, NCPB. Investigation of the network and transport layer protocols such as IPX, SPXI and SPXII, are also simple from a standard analysis standpoint.
The key factor in analysis is to monitor workstations communicating to servers. It is important to be able to determine whether the connection, login, and file access processes are fluent. Another important factor is whether file access on an ongoing basis is consistent and shows fluent communication. The main point here is that NetWare workstations should be able to connect to servers, log in to servers, and access files on a consistent basis.
NDS traffic should be minimal and should allow for smooth login processes. Any problems seen in the NetWare environment will most likely be identified through a close analysis of the NCP upper-layer protocol layers on request and reply analysis, along with NCPB Request and Reply sequence analysis.
TCP/IP is a architecture that was designed for the large enterprise internetwork. The TCP/IP suite was originally designed in the early 1970s as a protocol that would allow for broad communication across diverse computing environments, such as mini-computers and LAN operating system file servers. The protocol was primarily designed to enhance interaction of communication between application and resource data node points spread across a large global enterprise infrastructure. TCP/IP directly relates to the discussion of the key network layer protocol, Internet Protocol(IP), and the transport-based connection protocol, Transmission Control Protocol(TCP).
Quite often, the entire group of protocols that rely on TCP and IP, which involves many protocols, is referred to as the TCP/IP suite. This is because all the key process application protocols, which include protocols such as File Transfer Protocol (FTP) and Telnet, rely on the IP and TCP layer for a network communication to be developed for a transfer of data and for a connection process to be maintained. Most of the process application protocols, which are discussed briefly in this chapter, rely on and preside on the TCP/IP.
Note also that TCP/IP was developed and engineered to accommodate the original development of the Internet. The Internet is a medium spread across the worldwide global infrastructure that interconnects many computing environments, including government and corporations.
The TCP/IP suite was developed in late 1969 and was directed by the U.S. Defense Department through an agency called the Defense Advanced Research Project Agency (DARPA). DARPA developed the TCP/IP protocol through an initial network called the Advanced Research Project Agency Network (ARPAnet). The original direction of the ARPAnet internetwork was to develop a large interconnection based on packet-switching technology. ARPAnet was tested for initial evaluation in four key locations: the University of Utah, the University of California at Santa Barbara, Stanford Research Institute, and the University of California at Los Angeles. The original configuration was based on a design for the IP host configuration in the testing of TCP/IP, which was based on a Honeywell platform. In the late 1970s, the National Science Foundation (NSF) decided to augment the development effort and named a production system the Computer Science Network (CSNET).
As things progressed, eventually DARPA decided there should be a clear division of the two organizations to divide the ARPAnet into MILitary NETwork (MILNET) for military traffic and the ARPAnet for nonmilitary traffic.
Eventually the ARPAnet network was redefined into a network called National Science Foundation Network (NSFnet), which was maintained by the Office of Advanced Science and Computing (OASC). This was done to allow for further development of the TCP/IP protocol.
The TCP/IP protocol was actually defined for standards in 1973 by the RFC standards. The model was defined under the Department of Defense (DOD) model.
The DOD model compares to the Open System Interconnection (OSI) model in the following way. There are four specific DOD layers rather than seven OSI layers. The DOD model includes the network interface layer, the Internet layer, the host-to-host layer, and the application processing layer.
The network layer involves the physical data link processes of key devices that communicate throughout the physical infrastructure, such as the physical layer, the NIC area, and other physical entities such as connectors, firmware, and hardware.
The Internet layer directly relates to the IP protocol itself and is involved with the movement of a unit of data in the encapsulation data of other upper-layer protocols. The IP layer allows for the identification of addressing schemes for internetwork routing and for the transfer of units of data between two IP nodes.
The host-to-host layer is involved with the final delivery of data between two specific devices that are considered IP nodes. The point of connection between the two devices is a port. Two protocols are used at the host-to-host layer: TCP or the User Datagram Protocol (UDP). The TCP protocol uses a connection-based process and is much more reliable and stable. The TCP layer involves a high amount of end-to-end node packet interaction that is separate from data transmission (to maintain true connectivity and stability). The UDP protocol involves less overhead and only communicates between the endpoints via UDP ports when data is being sent and does not maintain a connection.
The highest layer in the TCP/IP protocol model is the application layer. This layer involves several protocols such as FTP, Telnet, Simple Mail Transfer Protocol (SMTP), Trivial File Transfer Protocol (TFTP), SMNP, and other key protocols (see Figure 7.14).
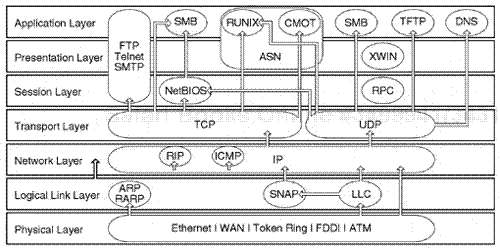
This discussion focuses on the IP, TCP, and UDP layers, as well as other surrounding protocols required for analysis, such as ARP and Internet Control Message Protocol (ICMP), which is an error-based reporting protocol in the IP node environment. The following section considers the TCP protocol layers.
Prior to presenting an in-depth discussion of the IP, TCP, and UDP, this section first discusses some additional protocols considered important for general analysis when a solid physical DOD model is required underneath the process application protocol layer.
Note that any application that uses a process application protocol in the TCP/IP environment requires a solid transfer of data across all IP-based gateways and reliable port transfer of data at the transport level. Specifically, the IP layer must be stable and the transport layer must be also reliable at the TCP and UDP levels, regardless of whether a connection is being maintained. The endpoint host port access must be available via TCP and UDP. The IP and TCP layers require the physical layer to be solid.
With that said, other protocols below the process application layer are also involved in the TCP/IP protocol suite; the following sections discuss these.
This protocol is used when a TCP node requires access to a physical address of a device that will be used for general access to resources, routing, or switching communication transfer across the internetwork. It is also sometimes necessary to locate a specific physical device on the network, such as a server, which is required for communication. In this particular case, a device in an IP network can be configured with a known IP address but without knowledge to the physical location or physical device address to locate the device. In some cases, the sought device may be on the other side of a router or a switch. ARP has been developed to allow for this type of situation.
A TCP/IP host node can transmit a packet to another host node with an identification of the IP address that it is trying to locate. The target hardware address field will be empty. Upon transmission, the device transmits its source IP address and its source hardware address, along with its target IP address and a target hardware address as unknown (see Figure 7.15).

Any device that intercepts the ARP, such as a router, a switch, or a server directly correlated to the target IP address, can respond with the IP address so the source device can transmit to the physical address for physical layer communications to commence (see Figure 7.16).

In the case of a router, a router intercepts an ARP and establishes an investigation process in which the router operation process reviews the ARP cache table within the router to cross-map and return the target hardware address to the source IP device for communications. This type of reply, when received by the original device, allows the original device to continue communication.
There is also a process called Reverse Address Resolution Protocol (RARP). This same process can be used in a reverse cycle. The source node typically knows its own IP address and may know certain physical addresses of other hosts. However, it may not have the required target IP address. In this situation, an RARP can be used to obtain a remote IP address.
Proxy ARP is another protocol that can be used in the address mapping process. Gateways and routers in an IP environment use proxy ARP. Proxy ARP allows routers and switches to provide the actual hardware address or destination nodes of devices on another side of a router to a source node performing an ARP request with an IP address that is not on the same logical network. Basically, the router or the switch assumes a proxy mask mode of the actual target device.
The Internet addressing scheme is extremely involved and is detailed in many different texts, some of which are mentioned in Appendix B. Many different IP addressing schemes can be used and there are many different ways to assign IP addresses. Various devices can engage technologies, such as Dynamic Host Control Protocol (DHCP) and Boot Protocol (BOOTP), for device IP address assignment; any DHCP or BOOTP packet transmissions should be referenced for exact protocol analysis investigation with a protocol analyzer during a network baseline session.
For the purposes of this discussion, the current IP addressing schemes are based on either IP version 4 or IP version 6. The overall concept of an IP addressing scheme is based on a logical 32-bit address assigned to an IP physical node within the network. The Internet address is required for the IP datagram to be used for communication from one IP host to another IP host. Different classes of IP addresses are available: Class A, Class B, Class C, Class D, and Class E. The IP version 4 addressing scheme is briefly discussed in the following subsections (see Figure 7.17).
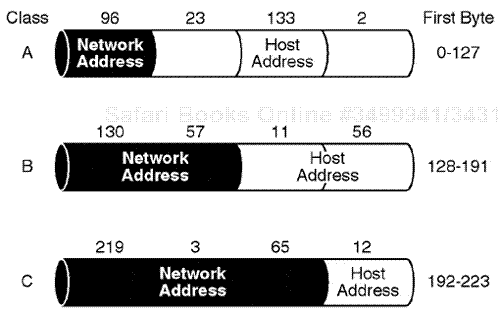
Class A is the highest area in the IP addressing design. There are 128 class A network addresses. Each of the 128 networks can address up to approximately 16 million hosts. In a Class A network, the first byte is the network address, and the last three bytes are the host address. The first bit must be set to zero, making the first byte in the range of 0 to 127. As displayed earlier, 73.34.103.4 is a Class A address.
Class A addresses are designed for very large networks. They are identified through the first 8 bits: 0 through 7. This area identifies the network. Again, the first byte 0 is reserved. Bits 1 to 7 actually identify the network. The remaining 24 bits identify the host. There are only 128 Class A network addresses available; 0 and 127 are reserved.
Class B is in the second highest area in the IP addressing design. The first byte must be in range of the 128 to 191 area. The first two bytes are used for the network area assignment, and the last two bytes are for the host. An example of a Class B address is 134.64.23.5.
Class B addresses are more common. The first two bits have a binary value of 10, which is standard. The next 14 bits identify the network. The next remaining 16 bits in the total 32-bit address configuration identify the host. A total of 16,384 Class B addresses are possible, but the addresses for 0 and 16,383 are reserved.
Class C addresses are the bottom area in the IP address design. The first byte is always in the 192 to 223 area. The network is assigned in the first three bytes, and the host is assigned by the last byte. An example of a Class C address is 209.43.12.4.
Class C addresses are generally used for smaller networks. The first byte begins with a binary 110. The next 21 bits identify the network address, and the remaining 8 bits identify the host. A total of 2,097,152 Class C addresses are possible.
Class E addresses begin with a binary 1111 and are reserved for future use.
The scope of this book does not include subnet discussions or version 6 IP addressing. (For more information on IP addressing, refer to Appendix B.)
The IP is an extremely robust protocol that allows two devices to communicate across an internetwork. It is based on the design of one device that communicates with the IP to another device that communicates with the IP. These two devices are IP nodes or hosts. The IP nodes transfer data in a packet called a datagram. This datagram an IP message unit for a unit of measure transfer of data. The IP datagram provides for a unit of measure of up to 65K in size. This is an extremely large unit of measure for a transfer of data. Because of this fact, IP allows for inherent fragmentation within the overall configuration fields assigned to the general communication process.
Although guidelines apply to the transfer of data, they are not 100% reliable because there is no connection maintained. The overall tiered service allows for a data transfer process to occur. The transfer of data is effected between two IP nodes through an initial connection between the two nodes, which is established but not maintained. This is considered a connectionless protocol and provides only for a unit of data transfer. Guidelines within the IP fields apply, and these allow for the transfer of data to occur between nodes in an organized way. Fields are used for specialized processing, such as a Service Type field. In a Service Type field, type of service routing can be engaged for high-performance routing in certain routing algorithms, such as Open Shortest Path First (OSPF), that work with Type of Service (TOS) routing. Fragmentation is also possible for large datagram transfers of up to 65K; these can be broken up into multiple packets and tracked on transfer from node to node. Again, there is no reliable connection mechanism, but the fragmentation can be tracked through the identification flag and certain flag fields. An IP packet can also avoid excessive routing through an internetwork because of the Time-To-Live (TTL) field, which assigns a TTL interval or hop count to the field process. This is also an inherent design within the IP system (see Figure 7.18).
IP Version, 4 bits. . This field identifies the current version of IP used. IP software modules check this field to ensure version.
IP Header Length, 4 bits. . This field identifies the length of the IP header. This field is measured in 2-bit words.
IP Service Type, 8 bits. . This field identifies how the IP packet can be processed by a destination host. The Service Type field is divided into five internal fields:
3 bits, Priority Area (0 normal, to 7 critical).
1 bit, Requests Low Delay Processing.
1 bit, Requests High Throughput Processing.
1 bit, Requests High Reliability Processing.
Bits 6 and 7 are not used.
IP Total Length, 16 bits. . This field identifies the total length of the current IP packet. The length includes the IP header and Data field. The largest size of an IP datagram is approximately 65535 bytes.
IP Identification, 16 bits. . This field is engaged for fragmentation control. Each network topology may limit the size of a maximum transmission unit (MTU). The IP software will then have to fragment packets. When fragmentation occurs, packets must be divided and reassembled when transmitted. It is considered standard for IP routers to handle packets of at least 576 bytes. This field identifies the unique datagram when fragmentation process is active.
IP Flags, 34 bits. . This field assists with controlling the fragmentation process. The first bit is a "do not fragment" identifier. If active, this bit indicates that the IP datagram should not be fragmented. The second bit is a "more fragments" identifier field. When nonactive, this indicates that the IP packet holds the last fragment of a IP transmission.
IP Fragment Offset, 13 bits. . This field is used when fragmentation occurs. The destination node requires this field for reassembly because packets may not flow in order. This field identifies the current offset area for data that is internal in the packet as related to the total datagram. The value is set from zero to the highest offset.
IP TTL, 8 bits. . This field is important for protocol analysis and it identifies how long in actual time an IP packet can flow on a network. Time is measured in seconds. The IP software puts an internal starting value in this field. Any IP-based host or router that processes an IP packet on an internetwork transfer must decrease the TTL value by at least one second. All IP hosts and routers must also decrease the TTL of the IP packet by the actual time in a second count for internal processing time when routing across the channel. If the IP field is ever found to drop to zero in value by an IP router or host, the IP device discards the IP packet. This prevents an IP packet from traveling in network loops (see Figure 7.19).
IP Protocol, 8 bits. . This field indicates the next upper- or higher-layer protocol, which is further encapsulated after the IP Data field.
IP Header Checksum, 16 bits. . This field uses a basic algorithm to perform a verification on the IP header but not on the IP Data field.
IP Source and Destination IP Address, 32 bits each. . This field includes the IP address of the endpoint host in an IP packet.
IP Options, variable length. . This field is not required and considered optimal. The field can be used for testing. The options field contain an IP code, IP option class, and IP option number. This field can be used for special operations. Examples include routing and time-stamp adjustments.
IP Data, variable length. . This field carries actual data. The padding of zero bits may be used to ensure that the final size of the IP datagram reaches at least a 32-bit word (see Figure 7.20).

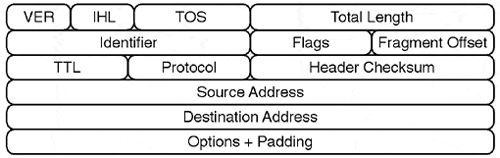
The UDP is a transport layer protocol and is the simplest version of a transport mechanism that allows for an open port communication between two IP host nodes. The basic design is two devices in an IP network are considered hosts and communicate to each other across the IP network. Each host is assigned an IP address and communicates through the IP datagram services. The IP datagram encapsulates a transport-based protocol that assigns a port communication area to each endpoint. Each endpoint will have a port area assigned for communications. These ports are assigned through either UDP or TCP at the transport layer.
In the case of UDP, the ports are just assigned and based on the application port access at the process application layer. UDP does allow for integrity checks on the Data field if the checksum is valid. UDP is not a connection-based protocol and has no inherent connection-based process (see Figure 7.21).

The following is a description of the UDP field configurations:
UDP Source Port, 16 bits. . This field contains the UDP-assigned source port identifier in a host.
UDP Designation Port, 16 bits. . This field contains the UDP-assigned destination port identifier in a host.
UDP Message Length, 16 bits. . This field contains the length of the UDP header plus and any assigned upper-layer protocols and the Data field length.
UDP Checksum, 16 bits. . This field provides a checksum verification process for UDP header and any attached data. This field is considered as optional because of overhead processing concerns. At times it is invoked for integrity checks to occur on the data, because the IP datagram does not check data.
UDP Data, variable. . This field contains any data encapsulated in the UDP headers.
TCP is a protocol used for operation at the transport layer. As its name implies, the protocol operates at the transport layer and allows for extensive control over communications. Two ports are assigned to each endpoint IP host through an involved synchronized process, in which the port is opened for communication. The TCP process and internal mechanism operation allows for a TCP port to be assigned and a connection to then be maintained. This process relies on the IP datagram to provide an overall unit of measure and transfer across the internetwork as related to IP addressing schemes. The TCP mechanism, just as UDP, assigns a port. But the port, once assigned, is maintained through a consecutive connection process, which engages sequence and acknowledgment numbers on consecutive communication (see Figure 7.22).
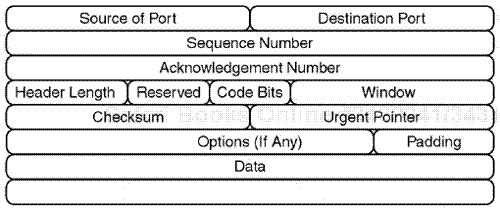
The TCP also has an inherent capability for a window size to be advertised. The TCP window size is advertised in bytes and allocates the amount of data available at the endpoint of each TCP/IP node connection within the host data area for the TCP port allocation assignment as related to TCP stream transfer.
TCP is based on a stream transfer process. The stream transfer allows for a stream of data to be transferred in segments across the IP datagram transfer channel. The segments sent in a TCP stream rely on each one of the IP datagrams or packets within the IP datagram process for transfer. The TCP connection is actually maintained through the acknowledgment and sequence number ports. The availability of TCP ports on each end are advertised through the TCP window mechanism.
A source TCP host node starts a TCP connection by communicating with another TCP destination host node by sending a TCP packet with an initial sequence number. This TCP packet identifies the start of communication and the start of a three-way handshake. On the other endpoint of the TCP communication process, the TCP destination host node responds by providing an immediate response to the initial sequence number by providing a TCP packet transmission an acknowledgment, and also assigns its own initial sequence number for the bidirectional transfer of data. When the TCP source node receives this packet, it then understands that the TCP destination node communicates on an active session in a bidirectional TCP open state and sends a TCP packet with an acknowledgment to the initial sequence number from the destination node. This is considered the third packet of transmission or third IP datagram with the internal TCP three-way handshake active.
On the fourth packet transmission, the original node that started the TCP transmission begins to send regular sequence numbers rather than initial sequence numbers. These sequence numbers are consistently updated when transfer of data or data length is actually sent within each packet. The packets flow back and forth in a bidirectional process (see Figure 7.23).

Each TCP node advertises its TCP window size, depending on bytes available in the port area for TCP communication that the process application protocol is using. This process continues to flow in both directions (see Figure 7.24).

When one device sends a TCP sequence number and a certain number of data segments, it waits for an acknowledgment from the other endpoint. If the receiving endpoint responds with an acknowledgment (as receiving and processing some of the segments sent by the source node), the source node continues to send segments. If for some reason the destination endpoint does not acknowledge the segments as being received, the source end node throttles back the TCP stream transmission and does not continue to send segments. This is based on a mechanisms called Positive Acknowledgment and Retransmission (PAR).
In TCP communication, the protocol requires that each set of segments has some acknowledgment or else a TCP retransmission occurs, and data is again requested. This is a PAR operation and is considered a positive factor in maintaining a connection.
As long as everything is working in a normal fashion, TCP communications flow in a normal manner. There will always be a certain number of sequence numbers and data being sent out and window sizes being advertised on each transmission from endpoint to endpoint.
As the TCP communication starts, it can be viewed from a protocol analysis standpoint. The initial sequence numbers can be viewed by setting a SYN flag inside the header of the TCP. After the three-way handshake occurs, a TCP open state exists. Eventually, if the TCP open communications have completed and all the required data has been communicated through the TCP packets, eventually a TCP connection will be requested for finish or breakdown of normal communications from one endpoint. This is usually the source device that started the communication. If an abnormal communication break occurs, it is a TCP reset. But again, on normal TCP breakdown of communication, a finish request by one endpoint is provided and the destination node replies with a "finish." This is the normal process of TCP stream communication from a TCP open state to a TCP closed stated (see Figure 7.25).
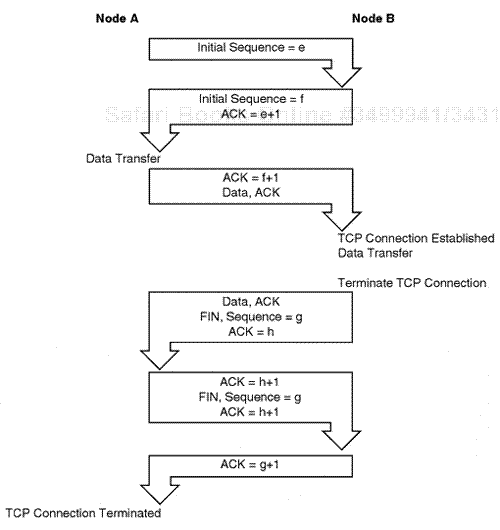
The following list describes the TCP fields that should be reviewed during a network baseline session:
TCP Source field and the Destination Port field, 16 bits. . These fields identify the TCP port numbers that are assigned to endpoint hosts. These fields can associate certain application programs at end nodes. Note that a TCP port in a TCP host can be used by multiple endpoint IP hosts.
TCP Sequence Number field, 32 bits. . This field indicates the position of the TCP data stream in sequence of dataflow. If the indication is an initial sequence number, the field indicates the start or open state of a TCP communication session.
TCP Acknowledgment Number field, 32 bits. . This field displays the sequence number of the sender in the last transmission plus the data received in bytes.
TCP Header Length field, 4 bits. . This field indicates the length of the TCP layer header.
TCP Code Bits field, 6 bits. . This field indicates how the TCP packet sent should be handled by a TCP router and the TCP destination host node. The following TCP flag code bits apply:
URG = Urgent
ACK = Acknowledge active
PSH = Push TCP data in buffers to maximum process
RST = The TCP port state of connection should be reset
SYN = This Flag starts the TCP open state in sequence
FIN = The TCP data stream is about to close and end
TCP Window Size field, 16 bits. . A TCP endpoint host uses this field to notify the other endpoint host of available window buffer size in bytes available as to receive the next TCP transmission.
TCP Checksum field, 16 bits. . This TCP field is used for a CRC algorithm as to calculate the value of both the TCP header and data fields to ensure for maximum reliability.
TCP Urgent Pointer field, 16 bits. . The urgent pointer field displays the end of any urgent dataflow.
TCP Options field and Data fields, variable. . This field area usually holds data. This Options field may point to other upper-layer protocols and may also invoke data padding. The maximum segment size (MSS) of a PDU that a TCP packet can handle can also be noted in this field on the initial open state (see Figure 7.26).

The Internet Control Message Protocol (ICMP) is an inherent error-based protocol designed into the operation of an IP stack for most IP node configurations. Whether an IP host is an endpoint host, an IP router, or any specific device using an IP-based protocol stack, the device can usually communicate via an internal ICMP.
The ICMP provides a method by which devices using the IP for datagram services can send messages and assist in the control of the IP process when there is an error-based process in an IP environment. It is normal technique for an analyst to filter on the ICMP when analyzing an IP-based network for possible errors. Different ICMP messages can be generated by hosts and other devices in an IP-based network when an IP-based error occurs (see Figure 7.27).
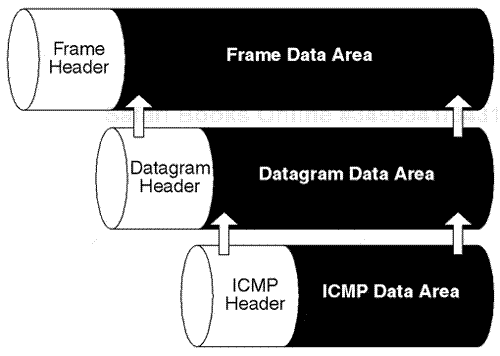
For example, one of the ICMP errors considered common is an ICMP redirect, which indicates that a packet is being redirected to another gateway, router, or switch.
Another example is an ICMP destination unreachable error, which indicates that a network, host, protocol, or application port is not available for access (see Figure 7.28).

These types of occurrences are described in more detail later in this chapter in the section titled "ICMP Analysis."
The following list shows the key message types used in ICMP packet transmission:
Type 3. . An IP Destination Unreachable
Type 4. . Source Quench (Busy IP Host)
Type 5. . Redirect Required
Type 8. . Echo Requests & Type (0) Echo Reply (Pings)
Type 11. . IP (TTL) field - Time To Live Exceeded
See Figure 7.29.
Type 12. . IP Parameter Problem
Type 13. . IP Timestamp Request & Type (14) Reply
Type 15. . IP Data Information Request Type (16) Reply
Type 17. . IP Address Mask Request & Type (18) Reply
ICMP field internals:
ICMP Type field
ICMP Code field
ICMP Checksum field
ICMP Datagram Address field
ICMP Data field
ICMP Type field, 8 bits. . This field indicates the ICMP data message type and issue.
ICMP Code field, 8 bits. . This ICMP field provides a set of information about the ICMP Type field. This Code field further defines the message type. For example, an ICMP message type of destination unreachable has a code that indicates whether the host, network, or a specific protocol is unreachable.
Code identifiers:
0 DU/Network Unreachable
1 DU/Host Unreachable
2 DU/Protocol Unreachable
3 DU/Port Unreachable
4 IP Fragmentation Required
5 IP Source Route Failed
6 IP Destination Network Unknown
7 IP Destination Host Unknown
8 IP Source Host Identified
9IP Prohibited Communication to Destination Network
10 IP Prohibited Communication to Destination Host
11 Type of Service (TOS) Cannot Be Used For Network Area
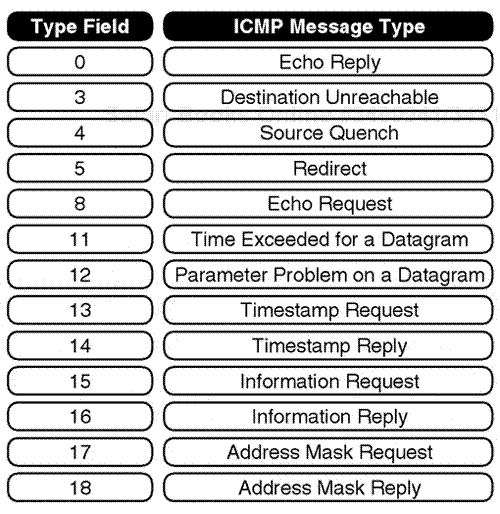
See Figure 7.30

The ICMP message code subvalue type fields:
ICMP Checksum field, 16 bits. . This ICMP field allows for the check sum process for an ICMP packet.
CMP Datagram Address and ICMP fields, variable. . This field contains the specific address of the first 64 bits of original packet involved in ICMP issue. The original IP datagram involved in IP error occurrence is tagged or padded on the end of the ICMP message data. This field also contains ICMP data (see Figure 7.31).

A range of application protocols in the networking industry rely on the TCP/IP stack for general communications. Specifically, certain applications and applied upper-layer protocols require the use of a transport protocol, such as TCP or UDP, and always require the underlying network layer protocol IP to be present for general transmission. These protocols are considered part of the TCP/IP suite.
The scope of this text does not cover a full discussion of these protocols, because there are other sources available, some of which are mentioned in Appendix B. These other sources can give a more detailed description of these protocol types and their interaction on the internetwork.
The following list describes other TCP/IP that are part of the TCP suite (application as well as other layer protocols):
File Transfer Protocol (FTP). . This is an application layer protocol used above the TCP and IP layers for a guaranteed reliable mode of accurate file access and transfer.
Trivial File Transfer Protocol (TFTP). . The access and transfer of files between TCP/IP network nodes. The TFTP requires less overhead than standard FTP, but also provides for less overhead.
The Telnet Protocol. . This is an application layer protocol used above the TCP and IP layers for transmitting characters in an oriented terminal mode based on keyboard screen data between IP networking nodes.
Simple Mail Transfer Protocol (SMTP). . This is an application layer protocol used above the TCP and IP layers for a guaranteed mail transfer process for TCP/IP nodes requiring mail transfer.
Remote UNIX (RUNIX) protocol. . A remote UNIX host–based communication protocol for UNIX calls made on the TCP/IP layers.
Domain Name Service (DNS). . A database query protocol for obtaining network addresses in an enterprise TCP/IP environment.
TCP/IP Common Management (CMOT). . An information-based management protocol used over TCP/IP.
X Window Protocols. . This is an application layer protocol used above the TCP and IP layers for complex screen remote draw calls.
Network Basic I/O System (NetBIOS). . This protocol is mainly considered part of the IBM and SNA protocol suite. It is used in the TCP/IP suite for connection setup protocol process for naming station addresses, datagram sending processes session setup, maintenance, and session data processing.
Routing Information Protocol (RIP). . This is a distance vector routing protocol and is based on 30-second standard updates. The IP-based RIP is used for updating routing information as to enterprise network and device location information required across IP-related routers, gateways, and host systems.
Subnetwork Access Protocol (SNAP). . This is standard encapsulation protocol used for protocol node-to-node device stack interpretation. The SNAP protocol is used as a protocol-handling vehicle—that is, as an enveloping protocol.
Logical Link Control (LLC). . This is also standard encapsulation protocol used for protocol node-to-node stack interpretation. This protocol is also considered a main part of the IBM and SNA protocol suite and offers polling capabilities. The LLC protocol can also be used for connection setup and maintenance by higher-layer protocols and applications. LLC is seen quite frequently in TCP/IP dataflow (see Figure 7.32).
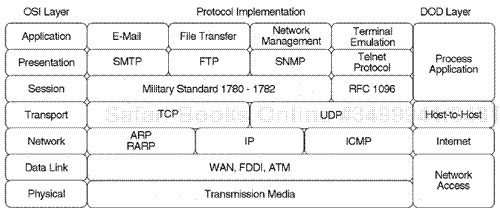
The TCP/IP environment is very complex. To become a master in protocol analysis of this environment involves extensive study and research of the TCP/IP Request for Comments (RFCs).
This section discusses some of the key analysis techniques that an analyst can use when examining the TCP/IP suite. The discussion starts with a general review of analyzing the IP layer or IP.
When reviewing the IP, keep mind that the key focus of the protocol is to provide an internetwork addressing scheme, along with a measure of length of transfer between two points in an IP-based network. A packet could not traverse an IP-based network gateway or router, unless an IP address was available for an IP address check to transfer a packet across one IP segment to another.
The IP Addressing field clearly identifies the source IP address network and the source host from which the network transmission originates from or is being transmitted to for process. In this case, the source and destination IP addresses are extremely important, especially with the subnetting schemes in place on today's IP-based networks. The key factor is that the IP Addressing fields are the main focal point of the analysis.
An analyst should examine the IP header of any problem type packet by examining the TOS field. If all the flags are inactive, no specialized routing is being used for TOS. If any of the fields are active, perhaps a specific type of service is being assigned to the packet; this may lead the analyst to understand the specific communication design being invoked by the application developer or the IP protocol stack or operation within the specific device.
The next valuable field is the Protocol Type field. Note, however, that most protocol analyzers just display the next protocol being encapsulated in the packet internal view and the Protocol Type field most likely correlates directly to that review.
Another important area is the TTL field. The TTL area of the IP header may enable an analyst to identify issues related to routing loops or delays. The TTL field indicates the amount of time that a packet has spent in an IP-based network or the number of hops traversed. This could show long delays or indicate a routing loop in an IP-based network. The TTL field is usually set upon generation at a default of 64 or 128 second to live or travel across an IP internetwork. Depending on which IP version is invoked, this field can vary in terms of seconds to live on an internetwork. If a TTL packet shows a low TTL of two to three seconds, the packet has traversed a high number of network hops or has spent too much time inside the router.
Remember that the TTL packet is decreased by one for each second that it spends within an internetwork IP path of a routing device, and must also be decreased by one for each device or logical hop that it traverses.
When examining the TCP and UDP layers, specific techniques must be used with a protocol analyzer to examine the overall fluency of endpoint-host– to–endpoint host for IP communications. When IP communication commence, both endpoints in a host-to-host transport layer process provide a TCP or UDP port as assigned for general communications. Because of this, an analyst should focus on any problem based in a TCP communication analysis session by investigating what ports are open in the source and destination end-host points for general communication between the two IP nodes. In most cases, a workstation and a server have certain host layer ports open for general application transfers.
When examining the UDP, keep in mind that the UDP provides only the function of assigning and allowing access to a port for TCP-based communications. An analyst should closely study the UDP-assigned ports and be aware of what ports are assigned for communication. Also, the Checksum field should be investigated to see whether it is active. If the field is active, data is being verified for integrity. In some cases, this may cause minor latency when the application process has to investigate the data for communications. Most application programs deactivate the field; however, if the Checksum field is active, it was most designed to be active because the process application protocol does not provide for an integrity check on data. This is the reason the field is provided for use, because it will actually check the data via an algorithm between two IP nodes communicating via a UDP port. An analyst should also note the length field in the UDP header.
When analyzing TCP/IP, many different areas must be examined. The first area to focus on when examining general TCP communications is the fluency of the TCP open-to-closed state communication process. An initial TCP communication between two devices can be investigated by filtering on the two devices from a physical or network layer standpoint. Specifically, the analyst can start the session by filtering on the physical MAC address or the IP address for the two communicating devices. If a connection-based problem exists, the following process enables an analyst to examine the overall cycle.
The analyst should investigate the initial sequence of a TCP open communication process. It is important to look for a TCP three-way handshake to occur on a consecutive basis. This should consist of two packets that are initially communicated with initial sequence numbers, and then a third packet without an initial sequence number (which is the end of the three-way handshake). Dataflow should then commence on a consecutive basis in a bidirectional manner. There should be low latency between the two endpoints when communicating back and forth in a transitional phase.
One of the most important areas to examine in this communication is how well the TCP window handles the dataflow from endpoint to endpoint. If the TCP window is initially communicated and advertised at 8K, it should remain open at 8K and should provide communication availability within the 8K-range window. If the 8K window is ever transitioned down to a lower level, such as 1000 bytes or 0 bytes available, this could indicate a possible disconnect or reset is about to occur in TCP communications. It is important for an analyst to keep an eye on the TCP window and the overall float size of the TCP window range.
If the TCP window range is initially advertised at 8K, the TCP window should not float any more than 2000 bytes on each endpoint for adequate handling of a TCP window operation. If there is an excessive float, say from 8K to 1K or 0, this could very well indicate that a larger TCP window size is needed on each endpoint.
The next area that should be investigated in TCP communications is the Flags field for a reset if there is an abnormal breakdown in communications. If this does occur, it is an abnormal operation.
The other area that should be focused on is the TCP finish state. Upon break of a normal TCP open to a closed state communication, a finish bit should be set from one endpoint, and the other endpoint should send another finish bit. This would indicate a normal finish or smooth TCP closed state operation. If a smooth TCP closed state is not achieved and a TCP reset or abrupt TCP close occurs, overall communication flow suffers.
It is also important to note whether sequence and acknowledgment numbers are incrementing in a normal fashion when flowing back and forth during general communications of the TCP open state to closed state. The bidirectional communication process should show the payload of data adding to the sequence and acknowledgment numbers on sequence cycle reverse directions upon transfer. The positive acknowledgment and retransmission mechanism effects should not have to take upon active occurrence unless extensive delays occur. If there are a high number of retransmissions from one point to another, the analyst should examine the delta time to see whether any delays in the internetwork are causing the PAR transmission of the TCP mechanism to take effect.
These are some of the most helpful hints that will assist an analyst to understand the general TCP communications from one endpoint to another. If there is an extensive delay process and the PAR communication appears to take over the overall operation effects of the TCP communications, this may indicate continuous retransmissions and an eventual TCP reset. This type of event indicates an immediate problem that could be related to network delays or inherent slow operations within one of the IP nodes.
In summary, closely examine all the areas noted in a network analysis session, and ensure that focused notes are taken during the TCP/IP analysis session.
The ICMP is an error-based protocol. Because of this fact alone, ICMP dataflow is a main focal point when starting an analysis session on an IP-based network. The inherent operation of the IP-based protocol allows for the ICMP-based errors to be generated upon an actual error occurrence within a device or when actual communication between two devices is affected by an IP-based problem in the overall internetwork. With that said, several ICMP-based errors can be captured by an analyst when correctly and effectively using a protocol analysis approach during network baselining.
Again, if a network is heavily based on the IP, an ICMP error test should be performed when investigating the error levels of the network. This is more of an error level focus on the IP and can be considered an upper-layer protocol analysis technique. At the same time, it is an effective way to examine the IP configuration stability and reliability of IP nodes throughout an internetwork.
The discussion now turns to a brief description of each ICMP-based error protocol generation type.
The ICMP Echo Request and Reply sequence is one of the most common ICMP types and is called ping. This type allows for the generation capability of an IP node to send out an IP request to another IP node for an IP address to respond back. If the IP device responds back through an ICMP reply, the ICMP request was responded to in a normal manner and the ping is considered active and working. This means that the device was located and in effect "pinged" and operating. If an analyst detects a high numbers of ICMP pings during an analysis session, which is considered a passive network baseline, a network management process is most likely under effect or operation during that given time.
Typically, network management systems use follow inherent approach of using pings to investigate device status or operation on umbrella-based management systems, such as HP OpenView and other hub-based management systems such as the Bay Network Optivity and Cabletron's Spectrum. These are just samples of network management programs that can invoke the ping. Pings are also invoked by actual network management or support personnel to test network delay or propagation sequence. In such a case, this would be a static invoked process for a specific purpose. In most cases, the network analyst is aware of the ping cycle.
As noted, the IP can send a datagram up to 65K in size. Because datagrams can be sent which are much larger than the normal physical topology MTU of approximately 1500 bytes for Ethernet, or approximately 4K bytes for Token Ring, most packets will be fragmented based on datagram size. In other words, the sent datagram will be sent in multiple packets. In this case, fragmentation fields are required to traverse different routers, switches, or topology points in a physical blended or uniform topology internetwork architecture.
With this in mind, there is an ICMP error type called "ICMP Fragmentation Required." This type of IP error message is typically generated from an IP-based host, router, or gateway that encounters a packet attempting to be transmitted across a routing or switched channel without fragmentation active when it is required. This is common, for instance, when a Token Ring packet is generated from a Token Ring interface on a router over to an Ethernet interface, and the router interface on the Ethernet side intercepts the packet with a bit set upon the source node that says the fragmentation is not going to be used. In this case, the router turns the packet back to the original source device, saying that the ICMP fragmentation bit is required to traverse, because of the change in topology MTU from Token Ring to Ethernet. An analyst should closely monitor for these types of situations, because they identify topology MTU mismatches and configurations on switches, routers, and hosts in an IP-based internetwork.
An incorrect IP address mask error can be an indication that the subnet mask applied to an IP address is incorrect. If an analyst captures an ICMP address mask request packet, this can indicate that an IP address was assigned with the incorrect address as it relates to the interface or device for the IP addressing scheme at the facility. Various configurations can be applied in the subnet masks as they relate to various address schemes active in enterprise internetworks. To verify this symptom as a problem also requires investigation of the IP addressing scheme at the site. In this case, you should note these errors and the devices that generate the address mask request. In this particular case, it could be possible that the default gateway or the settings of the IP addressing scheme in the source device generating the packet prior to the address mask request is causing the problem. It is also possible that the router or switch IP addressing scheme is not compatible with the IP addressing scheme at the site.
ICMP redirect messages communicate a misconfiguration in an IP routing scheme or the default gateway setting in an IP addressing scheme in an IP-based internetwork. Specifically, an ICMP redirect is a packet generated from a IP gateway or router device when it receives a packet that should be sent in another direction.
The process is as follows: A source device generates a packet to a destination device. If an IP-based gateway or router intercepts the packet and sees that the packet should not be sent through its channel, it sends an ICMP redirect message. As the redirect message is generated outbound, an analyst can capture the message. The message usually indicates the original IP transmission by tagging on the IP header from the original transmission. It shows the original source and destination device at the bottom of the detail area of the packet. This shows how the original transmission was intended to flow. The top of the packet contains an IP header in the normal IP encapsulation mode showing the device retransmitting the packet to the original device. Then, in the middle is an ICMP redirect area that shows the IP router or gateway that should be used for processing the packet through for general transfer.
By investigating this packet, an analyst can see the original IP header transmission from the source to the destination device and can also see the intercepting device returning the packet and identifying within the middle of the ICMP packet, along with the proper router or gateway path to take for route. Upon capture of this type of event, an analyst should investigate the source device for a proper default gateway setting, and should also investigate the site router tables and router configurations within the device returning the packet. There may also be an incorrect setting in that particular router or switch or host, if a host is providing routing via two NICs within a server channel. Such circumstances may indicate that a close review of the routing environment should be performed by the analyst to investigate an IP configuration routing issue. Packets excessively redirected may cause delays on the internetwork, and may prevent ports and hosts from being reached upon transfer for IP communications. Specifically, by intercepting redirects and properly troubleshooting the redirects to cause, it is very likely that connectivity and latency problems will be resolved in an IP-based network.
The IP header contains a TTL field, which determines the amount of time in seconds that a packet can live in an IP network, and the number of hops that the packet can traverse. The normal default for an IP node upon an IP stack configuration is 64 seconds to live.
If a packet is generated and traverses from a site in New York across a WAN to California, for example, the following scenario could unfold. If a packet leaves New York with 64 seconds to live and traverses the Chicago router, and the Chicago router has a 30-second delay, the packet would have approximately 33 seconds to live. This would account for a 1-second drop for the hop in Chicago plus a 30-second drop for the delay in the Chicago router. If the packet reaches the Salt Lake City router and there is a 40-second delay, the Salt Lake City router would discard the packet because there is no more time to live. In this case, an "ICMP time to live exceeded" packet would have to be sent back to the source device in New York.
An analyst using a WAN analyzer in the Chicago or New York headquarters where the packet originated can capture the TTL expired packet sent from the Salt Lake City router. In this case, the packet would show the original transmission tagged at the bottom of the ICMP analysis packet and it would show the device returning the packet. By investigating the TTL Expired field and understanding the route of the packet, the analyst may be able to identify which router or which area of the internetwork has the highest delay. This is an important investigative process during network analysis. An analyst should thoroughly troubleshoot any TTL expired packets, because they most likely indicate a delay on the internetwork or a misconfiguration of a router or switch device in a large enterprise design.
An "ICMP destination unreachable" packet indicates that an IP node is returning a transmission onto the internetwork because its destination was not reached.
There are several classifications of destination unreachable:
ICMP destination unreachable network unreachable
ICMP destination unreachable host unreachable
ICMP destination unreachable protocol unreachable
ICMP destination unreachable port unreachable
With all four of these types identified, it can clearly be seen that if a packet is intercepted with this type of event, the packet should be closely reviewed. The packet usually shows the original IP packet source transmission from the source to destination device that was attempted, and the type of protocol, network, or host, that was sought. The vector of the internal ICMP field showing the network, host, protocol, or port unreachable determines which action should be taken.
If a network is unreachable, it most likely that the packet is being returned from a router or switch, and that the network cannot be found or identified because it is not built within the static or dynamic router of the router. Another possibility is the fact that the route is incorrect, or the network is down and not available.
If a host is unreachable, this usually indicates that the host is inactive, nonresponsive, or not functioning on a network. It could also indicate that the host is not a legal address on an IP-based network, or is improperly configured. This can also indicate that the source device is improperly calling on the wrong host.
A port unreachable message could indicate that an application is inactive within a host. This is a very common occurrence in a network analysis session. When an analyst captures ICMP destination unreachable port unreachable conditions, the application type for the port assignment should be investigated. The port should be clearly noted and the device returning the error should be closely noted. Most likely this will be a server with a certain application running with a port that was inactive or too busy at the time to respond. If the problem is intermittent, it could be because of the application load on the port of the host being too heavy, and the port temporarily not being accessible. If this is a consistent error, the application may not be running, or the port may be incorrectly assigned and the application may be misconfigured. It is also possible that the server or NOS operation may be misconfigured.
A protocol unreachable condition usually indicates that a particular protocol is not active at a router, switch, or host device. This requires further investigation of the device reporting the error.
TCP/IP analysis requires a truly investigative technique via protocol analysis during a network baselining exercise. To truly identify the cause of problems requires exact troubleshooting and cause analysis techniques based on protocol analysis results. It is also recommended that the analyst thoroughly study the TCP/IP suite through the RFCs and other documents cited in Appendix B. Extensive knowledge of TCP/IP is helpful when analyzing TCP/IP-based environments.
The IBM protocol suite, which was derived directly from the industry migration cycle of the IBM networking architecture, includes two main protocols that are predominant in the IBM networking environment: Systems Networking Architecture protocol (SNA), and NetBIOS.
Many other protocols could be considered part of the IBM SNA protocol suite. Some of these protocols are independent of the IBM protocol model and are used in other protocol suites for specific operations. The independent protocols within the suite are mentioned briefly in the following list.
Systems Networking Architecture (SNA). . A high-layer data communication protocol for access to the IBM host data resources.
Server Message Block (SMB). . The SMB protocol was engaged for use in the IBM OS2 LAN Server networking process for calls from a workstation to a LAN server NOS. The SMB protocol is used as an application layer protocol for the LAN server environment, as required for connection, login, and file access.
Remote Program Load (RPL). . The RPL protocol is used as a diskless workstation protocol for IBM Token Ring PROMS.
Network Basic I/O System (NetBIOS). . This protocol allows for engaging name-mapping processes and data-sending processes. The NetBIOS is also used to establish and maintain session services. The NetBIOS protocol is also engaged as a connection setup protocol for named station addresses.
IBM Network Management protocol (IBMNM). . The IBMNM protocol is also used for functional address communication at Token Ring physical layer.
Bridge Protocol Data Unit (BPDU). . The BPDU is engaged for launching updates in spanning-tree algorithm (STA)–based communication. The BPDU protocol is also used for identifying an STA topology change in the STA root tree in communication for bridges.
Logical Link Control (LLC). . This protocol is popular for encapsulation. LLC is also used as a connection setup and maintenance process to maintain polling in certain computing environments. LLC is engaged for connection setup between workstations and different IBM-based hosts and servers and works well with various higher-layer protocols (see Figure 7.33).
The protocols in the preceding list are among the most common protocols seen within the SNA and IBM environments. These protocols can be used individually for specific purposes. When running a network baseline session, it may become necessary to engage a network protocol analyzer to individually decode these protocols for a specific purpose.
The two most common IBM-based protocols encountered are SNA and NetBIOS. Based on the predominance of these two protocols as related to the overall protocol suite, the following sections describe these two protocols in the context of network analysis.
The SNA protocol was developed within the IBM networking environment. SNA is the protocol responsible for most of the key network communications for endpoints within an IBM enterprise environment. The SNA protocol was originally designed and structured for the IBM host environment. In today's LAN and WAN internetworking infrastructures, a user sometimes requires access to applications that reside on an IBM host environment. The SNA protocol can be used for access when communicating to a host. In most cases, there is a shell or terminal emulator running on the PC workstation on a LAN when this type of communication takes place. On certain topologies, this type of communication is more prevalent than in others, such as the Token Ring environment as opposed to an Ethernet environment. This is because of the natural transition of the IBM host environment, which was present within local area environments that eventually grew from a Token Ring infrastructure.
Keeping that in mind, sometimes an analyst must analyze SNA during a baseline session. The following is a description of each one of the SNA protocol layers. In consideration of the context of this book, the descriptions have been limited to the protocol layers. For more detail regarding SNA operations or SNA protocol layer field configuration issues, refer to the sources cited in Appendix B.
The SNA protocol suite is based on a seven-layer internetwork communication process model that includes the following layers (see Figure 7.34):
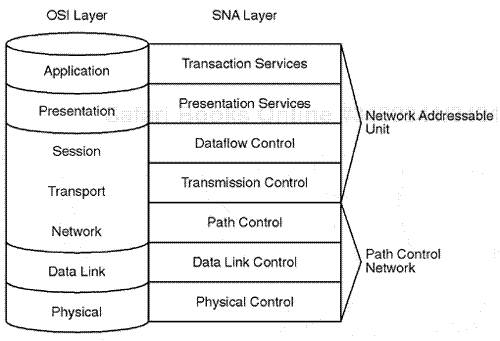
Physical control/data link control layer
Path control layer
Transmission control layer
Dataflow control layer
Presentation services/transaction services layer
The SNA physical and data link layers work in an interoperable fashion to ensure that the communication from the local or WAN medium as communicated to an IBM host can be processed as a normal data stream to the physical channel of the IBM host SNA environment. In some ways, these layers are somewhat similar in terms of the standard OSI model for physical and data link control. The physical connection is the main focus of the physical layer, along with the packet assembler and dissembler process. After the packet has been received off the medium and the physical medium-dependent code is interpreted, the packet is then sent up to the data link layer in SNA. In this layer, the transfer process is handled by the data link controller of SNA.
The data link control layer is responsible for the node-to-node, endpoint-to-endpoint SNA device communications for data transfer. This layer ensures a reliable data transfer sequence.
The SNA path control layer is somewhat similar to the network layer as it relates to the OSI model. The SNA path control layer provides for an SNA packet to be transferred between one path to another. Note, however, that the protocol itself is not designed for a high amount of internetwork routing in terms of today's LAN infrastructures. Another key function of the path control layer is to ensure that each of the two node points involved in an SNA conversation is properly connected through to assist the transport processes. Because of this capability, it is quite common to see the path control layer compared to a transport connection layer in the OSI model. The path control layer is responsible for the compatibility connection sequence function of one node to talk to another node across an SNA internetwork. The route configured between the two SNA nodes, such as a workstation running an emulation program and an SNA host, is a virtual route. The function of actual routing between the two nodes across the SNA internetwork is achieved through the SNA transmission control layer.
The SNA transmission control layer operates in a session mode sequence, such as the session layer protocol in the OSI model. The flow control between two SNA nodes is established and a session is considered active at this layer. If there is a need for any data to be encrypted for security purposes and to be reinterpreted through decryption, that process occurs at this layer. The request and response headers of the SNA packet format are also interpreted at the SNA transmission control layer.
The SNA dataflow control layer also operates as an area that is responsible for maintaining a session between the workstation emulator and the SNA host. The process of investigating the integrity of the data from endpoint-to-endpoint communications occurs at this layer. The dataflow layer receives each request and provides each response inbound and outbound of each SNA endpoint channel. It is also the responsibility of the dataflow layer to reassemble dataflow sequences for any fragmented messages in the overall communication sequences. The request and response units within the SNA dataflow communication must occasionally send portions of the message. The dataflow layer ensures that the portions of the message are assembled upon reception at each endpoint and broken down for transmission through a dissembler process for generation outbound upon an internetwork transfer. This is one of the key responsibilities of the dataflow layer.
When the SNA host session is considered physically stable, meaning that the path is established, the transmission control layer has ensured that the nodes are maintaining flow control, and the response sequences are being properly assembled and dissembled. The presentation services and transaction services next come into play. In these layers, the host environment and endpoint environment communicate through certain transactions called back and forth from node to node for each specific application call. When the data is ready to be presented to an application layer process, the presentation services become effective for program-to-program communication. This is where higher-layer application processes and database-interrelation processes take place.
The following is an example of a general scenario of a workstation-to-host communication process. When using a protocol analysis tool such as protocol analyzer during a network baseline session, an analyst can capture the session by either filtering on the workstation running the SNA emulation program, or by filtering on the host channel on the LAN connection, such as a LAN-based SNA TIC connection from an IBM host connection.
An SNA packet would be assembled with key information that can be interpreted on the protocol analyzer. This information may include a key area within the packets called the Data Link Control header for SNA. This header is normally encapsulated inside of a physical frame and captured on the LAN, such as Token Ring frame (see Figure 7.35).
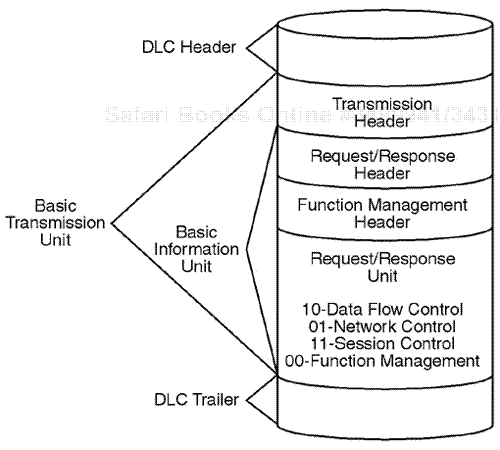
The Token Ring frame includes a Routing Information field, for example, and then pad a protocol called the LLC. The LLC header normally encapsulates the source service access point and destination service access points. Contained within the SNA portion of the Token Ring frame is an SNA transmission header that includes the format, identification, and the required destination and source addresses for the SNA session. Flags are present and identify header information for general communication, which is key to the path control and transmission control layer areas. The request and response header contain bytes of information important for general communication. If any function management data is present within the SNA header, it includes the pointers for a particular function to engage a specific network operation, such as starting an initial connection and performing an authentication process to log on to the host. The SNA dataflow layer is involved in this area, along with the transaction and presentation services. If the data control process is finally going to be set up and locked in for general communications, a request and response unit and a session layer control process is involved. In this case, the SNA transmission control layer and SNA dataflow layer would be key in the communication sequence. If a network control process is required to perform receive/request or response unit cycles as identified, this area carries key information such as testing and network management processes for SNA network management functions.
Relative to the high-level processes for general SNA communications, keep in mind that the SNA architecture design is based on logical units (LUs), physical units, (PUs), and system services control points (SSCPs). The LUs are defined as end-to-end node-to-node communication points across the SNA internetwork. A PU is a device that can have a hardware or software logical configuration, through which communication can be directed for input and output. The SSCP is an area within the SNA internetwork where a host system usually resides, and software and hardware processes are working together to allow for the SNA process to take place. When investigating an SNA packet, it is important to decode the transmission header and the request and response notation, and the management function header, if required. Notations in the frame may indicate certain information related to dataflow control, network control, or session control. The Connection Control field is important to analysis and general decoding sessions. If the connection is going to be maintained on a consistent basis, the LLC is usually consistently engaged as a polling sequence protocol, or in some cases, NetBIOS session services may be involved.
NetBIOS is a communication protocol based on a connection-oriented process, and was originally developed for IBM's PC LAN broadband network. The development cycle was overseen by IBM and Sytec, Inc. Originally NetBIOS was designed to function on read-only memory on the NIC. In today's environments, NetBIOS is loaded within the network card driver area and built in to the firmware and hardware operations of many network interface channels involved in SNA communications.
Other protocols are compatible and work quite frequently with SNA and NetBIOS, such as SMB and other key protocols. Within the NetBIOS communication cycle, four key functions take place.
Name services
Session services
Datagram services
Miscellaneous functions
The name service allows for the naming processes to take place upon the initiation of the NetBIOS session. The name consists of a number of characterizations, usually within the 16-characterization category. This is where a device attempts to map a logical name to a process for the SNA communication cycle. Three individual calls usually occur during this sequence. They are Add Name, Delete Name, or Add Group Name.
The NetBIOS session service is a process in which a session is usually established through the SNA transmission control and dataflow layer sequences. At times, however, the NetBIOS session is used for straight data transfer, because it allows for a more reliable link than standard NetBIOS datagram services. Data messages are usually variable in length. NetBIOS session services include the following:
Call
Listen
Hang up
Send
Receive
Session status
NetBIOS datagram services allow for a transfer of data, but in a somewhat unreliable manner. This is somewhat similar to the unreliable transfer noted for UDP in the TCP/IP suite. Datagram services allow for fast transfer of a unit of data between two SNA established endpoints for communication. The transmission control layer and dataflow layers are involved, but the actual maintenance is not as critical.
Datagram services are used for the following functions:
Send datagram
Send broadcast datagram
Receive datagram
Receive broadcast datagram
Other functions in the NetBIOS protocol are also used and fall into a category called miscellaneous functions. These include the following:
Reset
Cancel
Remote program
Load
Adaptor link status
Unlink
The NetBIOS communication sequences vary depending on implementation and the requirements of the application or NOS environment. Some of the key NetBIOS calls that can be interpreted with a protocol analysis tool are noted in the following table. Note that the various protocol analyzers may provide a different display sequence or name for the actual NetBIOS call. Table 7.1 lists some examples.
Table 7.1. Some of the More Generic Call Names
Because of the lack of predominance of SNA and NetBIOS protocols in today's networking environments, this text presents only a limited discussion regarding analysis of the SNA protocol suite. When analyzing the SNA protocol suite, it is important to start with a proper filtering approach on the SNA host and on the workstation providing terminal emulation to the SNA host. First, capture the inbound and outbound communications from the SNA host environment. An analyst will note certain processes within an SNA connection that should be examined. Usually a workstation calls with a link control query setup that can be captured with a protocol analyzer. In certain situations, after the SNA session has been established, a request and response sequence occurs in reverse order, which can be captured and examined to understand the overall function calls of the SNA host. Standard communications occur and involve logical assignment of SNA exchange IDs or physical and logical unit setup processes in general communication. These also can be examined using a protocol analysis approach. Sometimes an SNA host shows itself as extremely busy on a LAN environment. This may be the result of a generated outbound "Receiver Not Ready" frame that can be captured from a LAN configuration. Excessive upper-layer communications related to an application flowing between a workstation emulator and an SNA host may indicate the presence of delays through a high number of segment continue packets. In this event, it is quite possible that the SNA configuration and channel configuration need to be redesigned to allow for more fluent communication to handle the amount of inbound LAN traffic at a certain data rate.
NetBIOS can be used as a reliable connection-based protocol sequence and will still allow for sending data as through the session control or through datagram control sequences. The type of NetBIOS protocol sequence being engaged must be closely examined. An analyst should be able to quickly identify naming services, session services, and datagram services, and decipher the various cycles as related to the SNA communication cycle. During a protocol analysis session, an analyst should watch for the SNA communication to establish a proper connection sequence from an initial standpoint. The connection sequence involves the path control layer and the transmission control layer. After the session has been established and data is available for transfer, the transmission control and dataflow layers will most likely be involved in every transmission. Whenever the application is called upon or a sequence for the application process is engaged, the transaction and presentation services can also be analyzed.
An analyst should keep a close focus on the request and response headers in the SNA communication cycle for these types of sequences, and eventually look for a proper breakdown of normal communication sequences, when the teardown is valid for the SNA session.
The Windows NT protocol suite is comprised of various protocols that were derived from other internetworking protocol suites in the enterprise environment. The Windows NT protocol directly involves the SMB protocol, which was originally developed within the context of the IBM OS2 LAN Server infrastructure, along with the NetBIOS protocol, which is heavily used in the SNA protocol suite. For the network and transport layer protocol communication processes, IP is used for the network layer communications, and TCP is used for general transport connectivity.
The NT protocol suite is designed around the Windows NT peer-to-peer networking services, along with the capability of a Windows NT Workstation, a Windows 98 station, or a Windows 2000 station to communicate to an NT Server. In this type of configuration, the workstation establishes physical communications to an NT-based server through a physical topology frame such as an Ethernet or a Token Ring frame. After this type of communication has been established, the IP is used for datagram transfer of units of data across an internetwork channel. The IP address is significant because it provides the capability to route or transfer data across a bridge, a routed or a switched channel in an internetwork. This is the way in which a Windows NT Workstation can communicate to a server on another segment.
After the data communication session has been started, the session is maintained through engagement of TCP. Standard TCP mechanisms for TCP open state to closed state occur, such as described in the TCP analysis section of this book. A TCP windowing advertisement is used in a consistent process along with TCP sequence and acknowledgment processes.
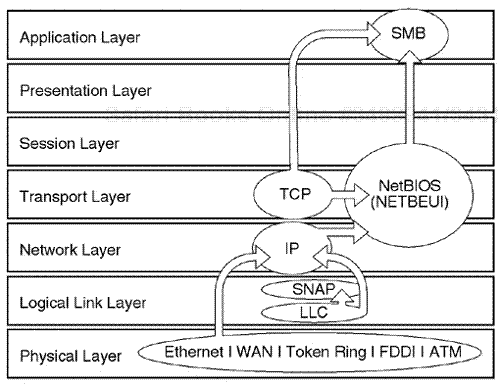
The Windows NT operating system then invokes the SMB protocol. The SMB protocol is extremely important, because it is used for calling on the server in the NT NOS process. The NT NOS process involves a high number of calls through application programming interface (API) calls to an SMB processing level, which engages certain areas in the NT operating system as communicating to the SMB protocol functions. This includes sequencing in areas of the SMB protocol sequence calls as related to the NOS, which include communication to areas within the operating system, as follows:
Redirector
Transport driver interface (TDI)
Other protocols within the suite
The following is a brief description of the Windows NT protocol suite processes engaged when taking into account the interaction between the layers. Note that when performing a network baseline session, an analyst may need to capture certain packets between a workstation and a server in an NT protocol analysis session. Not all protocol layers may be active, depending on the function of the particular protocol call, such as a workstation connecting to a server, logging on to a server, or transferring data to an application in an NT Server.
With sequences in which a workstation is just maintaining a connection with an NT Server, for example, the only layers that may be active would be the physical topology layer, the IP layer, and the TCP layer. If actual data is being transferred, the NetBIOS session layer may also be active. In other cases, there may be circumstances during which the NT server is being called on by an NT Workstation for a specific file to be opened and accessed. In this case, the SMB protocol may be active in the packet.
The following is a list of the protocols in the Windows NT protocol suite.
IP. . Network layer datagram and addressing services for delivery of data
TCP. . Transport-based connection-based protocol operation and reliable end-to-end communication over IP datagrams
NetBIOS. . Session layer operations for connection setup protocol processes and for naming station address processes
NetBEUI. . Comparable to NetBIOS, but nonroutable
Server Message Block (SMB). . Used for Windows NT Workstation–to–NT Server application layer protocol calls in a LAN and WAN environment.
The following is a description of the overall protocol layer interaction scheme designed around the Windows NT protocol suite access from a workstation to a server in an NT protocol operation.
To truly understand all the protocol analysis events that need to be performed to tune or troubleshoot a Windows NT environment, an analyst must also understand the architecture of the internetwork composite. When examining the NT server-to-client operation, the analyst must take into account how the Windows NT protocol suite matches up against the OSI model.
It should always be noted that the OSI model may apply, but the Windows NT protocol suite is mapped differently across the model. The Windows NT client model includes an area of operation for the general NOS communication directly through the protocol chain to a redirector process. The redirector process then allows for creation of I/O calls through SMB. The SMB protocol then communicates to a subnet protocol stack that includes Layers 3, 4, and 5 (transport, session transport, and network layer protocol stacks). Communication then inherently directs to the network drivers, which involves the NDIS specification and communication with the key network adaptor. The network driver normally provided by Microsoft uses the Network Driver Interface Specification (NDIS) interface. This particular interface allows multiple protocol stacks to communicate across the network infrastructure with single or multiple NIC adaptors inside the server or workstation. The NDIS drivers are widely used and are usually internal to the NT distribution software. Note that the NDIS drivers normally operate within the NOS at protocol layer points two and three (see Figure 7.37).

The driver implementation of the NDIS drivers is usually built within the NIC configuration process. The NDIS driver is actually used in a mode where a wrapper data link library(DLL) is implemented around the NDIS interface.
Multiple protocols such as NetBEUI, TCP/IP with streams, and IPX/SPX communicate with the NDIS interface. These are normally in the area of the network transport and session layer.
They then communicate up to a TDI, which communicates to the redirector area of the NOS.
Note that in between the redirector and the TDI, key interaction of I/O occurs and SMB interacts with session, transport and network layer protocol operations.
NDIS allows for the true separation of physical networks from transport protocols. NDIS also allows for different protocol stacks to interactively work on a single NIC adaptor. NDIS also allows for full 32-byte accessing multiprocessing.
Note that the protocol stacks that reside between Layers 3, 4, and 5 are sometimes referred to as the subnet protocol area. The protocol stacks normally used are IP and TCP, or IPX and SPX with NW Link IPX compatible protocol in Windows NT or NetBEUI. These protocols cover the spectrum of the subnet area Layers 3, 4, and 5.
The Windows NT Server does not just support the NDIS interface, but also supports the Open Data-link Interface (ODI). The ODI is more inherent to the general Novell and Apple computer environment.
The NDIS specification was developed by Microsoft and is the main internal native driver mechanism used with the Microsoft protocols as related to the OSI model. If the ODI architecture is used, the NDIS drivers would correspond to a portion of data in the data link layer and are written to work with the link support layer (LSL). The LSL is a key element of the ODI specification; it allows for the NIC adaptor to be virtually viewed across the logical plane of the network process. In the Windows NT Server environment, the streams interface can be used to encapsulate communication protocols to allow for a uniform transport interface. Streams is an interface that was developed by AT&T in the UNIX environment and allows for a common interface between applications, by providing a package around key network and transport layer protocols, and involves a stream tail and stream head.
All network drivers have an internal capability to operate with a hardware operation of a particular NIC. Key NIC hardware registers are under the control of the driver, such as status registers, memory access, and I/O operation. It is important that the Windows NT Workstation or Server be installed with the correct driver to match the NIC card. It is inherent to the Windows NT Server and NT Workstation operations to engage the capability to bind the NIC card to the NIC driver. Note that Windows NT Workstation and Server software normally includes most of the popular NIC drivers. If the NIC driver is not available, the appropriate vendor must be contacted. Windows NT NIC drivers are written to the NDIS 3.0 specification, which is compliant with the NetBEUI, SPX, IPX, and TCP/IP protocol suites. NDIS drivers are not restricted to 640KB of memory as a typical DOS environment allows. The other major improvement is that the NDIS driver in 3.0 allows for the elimination of the protocol manager, which did engage overhead. Instead of using a protocol manager, Windows NT uses an internal Registry, which is a database within the server, and allows a software module (NDIS Wrapper) to surround the NIC driver. The main internal subnet protocols inherent to the NT Server native mode for Layers 3, 4, and 5 are Layer 3 = IPX and IP; Layer 4 = SPX and TCP; Layer 5 = NetBIOS; Layer Span 3 to 5 = NetBEUI (see Figure 7.38).
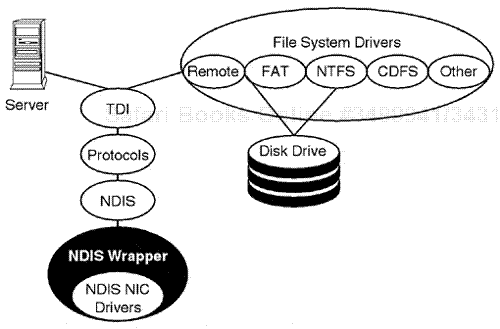
The original implementation of IP was configured to allow for true network layer connectionless service to occur along reliable non-connection-based communication of an IP datagram. The IP datagram process allows for internetwork dataflow to occur and provides for a true unit of measure for data. This is also the same for the standard Network layer IPX protocol in the Novell environment. The key to network layer protocols is that data is packaged for internetwork transfer and internetwork addressing fields. In reference to the transport layer at Layer 4, note that the TCP, UDP, or SPX protocol, allows for some sort of connection to be maintained.
The inherent difference is the capability in the operation of each transport layer protocol. The most popular implementation is to use TCP; it has a full internal capability for data windowing, true connection-based operation, and sequenced and acknowledgment communications, which are considered the most reliable on top of the standard IP datagram service communications. In reference to the session layer or cross-layer 3/4/5 communication processes that are inherent methods to NT, two particular implementations are possible: NetBIOS and NetBEUI. The original implementation of the NetBIOS specification allowed for approximately 17 internal commands for connection-based functions to occur that allowed for the creation, maintenance, and disconnect of certain network client-to-server communications.
The basic NetBIOS commands were originally developed and then extended and so called the NetBEUI. In the late 1980s and early 1990s, NetBIOS and NetBEUI were widely released. The NetBEUI protocol allows for an actual cross-layer transport and session protocol operation to occur; and NetBIOS refers more to the session layer for engaging programming command activity that interacts with the APIs. By separating the transport protocol from the application layer processes of API, it is possible to have the NetBIOS API call support on protocols other than NetBEUI. Specifically, NetBIOS can communicate on top of TCP and IP, which is usually the most popular protocol stack implemented in the Windows NT environment. The NetBEUI protocol is not routable, but does span network Layers 3, 4, and 5. This presents a problem on large internetworks that require packets to be routed across bridges and routers. The NetBEUI protocol is adequate for small LANs that do not require a large amount of interconnections to other networks through bridges or routers. NetBIOS and NetBEUI both allow for establishing naming connections and assignments to provide for protocol calls and session establishment. This process assists with the Windows NT peer-to-peer networking capabilities (see Figure 7.39).
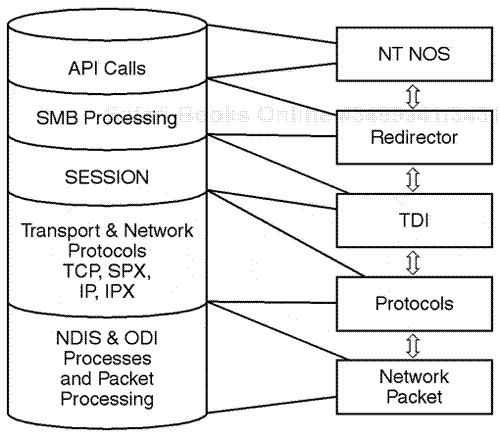
In the event that multiple networks are required and interconnection between networks is necessary for communications, NetBIOS should be used on top of the TCP/IP stacks for most implementations. If NetWare interaction is going to be a factor, the NWLink IPX-to-SPX communication can also be used. The Windows NT implementation in NetBEUI/NetBIOS contains extensions over the original NetBEUI designed by Microsoft, IBM, and Intel, and is referred to an the Windows NT NetBIOS frame processes. If the client uses the NetBEUI protocol in its original form, it spans Layers 3, 4, and 5. If NetBIOS operates at the session level, it normally communicates with TCP/IP or the IPX/SPX components of the NWLink design. NetBIOS originally had a limit of connections per active workstation on the network. The new NetBIOS frame implementation removes the limit of connections and permits the NT Server to interact with more stations.
It is important to understand that the TCP/IP suite is also a benefit because it allows Windows NT Servers and client workstations to interact more heavily with the Internet, and allows for applications to be inherently loaded across particular devices with protocols such as FTP, Telnet, NFS, X Window, and other key protocols. Windows NT can also communicate with IBM mainframes via the Datalink Control(DLC) protocol, and also allows for LLC interaction. It is also possible that the Windows socket interface, WinSock, will be used in TCP as part of the standard BSD UNIX operation for general communications. Both NetBIOS and WinSock are implemented as DLLs in the Windows environment. One of the key factors that has to be considered is that the Windows NT subnet layer design is intended to allow for communication on the internetwork via the TDI. The TDI interacts above the subnet layer and communicates to the redirector services.
The TDI resides between Layers 4 and 5 and above, and communicates as a uniform interface for network hardware communications to the redirector services. The TDI is critical for transport layer protocol communication to APIs. The redirector is a component operation that resides in the TDI area of the NOS design. The redirector allows the actual communication coming through the protocol to the transport chain and the TDI to be communicated up to the NOS application operations. The redirector component communicates with the TDI by utilizing an I/O request/response director that communicates with an I/O manager. The I/O manager calls upon certain driver entry points within the redirector to create SMB protocol commands that can be communicated through the TDI down through the transport layer, into the network layer, and across the internetwork to the other key clients and communication. Specifically, between the redirector and TDI, the resulting SMB commands are used interactively to create and process key operating system calls. Most Windows NT file server and print-sharing operations are performed by the SMB protocol operation in this particular area. The main SMB protocol calls are the following:
High-level, connection-based process services
Obtaining directory entries
Reading and writing blocks of data for host file access
Overall file access
Manipulating database operations
Name-registering services across the internetwork
After the redirector, the last area that needs to be considered is the API. The API is the I/O communication area where the NOS is actually operating in an interactive mode with the redirector to create the SMB calls on the network.
The API operation depends on the implementation of the protocol chain within the server and client. In reference to the general NOS calls on the redirector, note that certain internal operations called "named pipes" and "mail-slot application" programming interfaces are engaged to perform the open, read, and write processes for file access and resource access across the internetwork. On the Windows NT Servers, the named pipes APIs are based on OS2 APIs in the original form, and allow for security operations. In the OS2 environment, they are called "first-class" mail slots. In the NT environment, they are called "second-class" mail slots and are used as connectionless message deliver process API calls upon the redirector. Specifically, mail-slot messages are developed and generated between the server and the client to allow for identification of computer services and notification messages. NT clients can call on the name-pipe operation. The name-pipe operation allows for true client identification. This enables the server to service a workstation request based on its security ID(SID) to match the request to allow for proper authentication. Generally, the NOS within the NT operating system is used in a full multitasking interaction and communicates to the redirector, which then uses an I/O manager to create the SMB protocol calls through the TDI. The TDI then communicates through the session, transport, and network layer protocol chain of the subnet area, which then uses the NDIS driver (or other driver components in composite) to create a packet sent across the network (see Figure 7.40).

The following section discusses the actual protocol layer interaction and fields used on the Windows NT network for analysis.
The Windows NT protocol suite includes the standard topology frame that will be used, such as Ethernet or Token Ring. The next process that will engaged is the IP for datagram services, and the transmission control for connection-based processes. If session data is going to be transferred back and forth in pure form, the NetBIOS session layer is engaged. The final focus is that the SMB protocol is used for application access. Earlier in this chapter, during the TCP analysis and SNA/IBM analysis discussions, the other key protocols such as IP, TCP, and NetBIOS were examined in detail. For the purposes of bringing forward a discussion of the SMB protocol, this book now presents the key configuration fields that may be interpreted with a protocol analysis tool when analyzing a Windows NT protocol session and reviewing the SMB protocol. Note that certain analyzers may display the SMB protocols in different sequences that may cause the function names to be displayed differently than as noted here. The following descriptions are the most common terms for the SMB protocol and are used in most network analysis tools.
The SMB protocol is an application layer protocol that was developed in the IBM PC LAN program operational release that interactively uses NetBIOS API protocol calls for the session layer for final interaction across an internetwork.
The internal functions of the SMB protocol are used to communicate with remote workstation clients to the NT Server, and from client to client for interaction in an internetwork configuration. The Windows NT NOS calls on the redirector, which then communicates to the TDI and intercepts certain calls based on the I/O manager creation of SMB protocol commands. The SMB protocol is also common in the OS2, LanMan, and VINES protocol environments. The protocol may be used for connection-based operations, connection maintenance, and file call operations. Complete file search modes are supported in multiple levels of the file access via different transaction calls (see Figure 7.41).
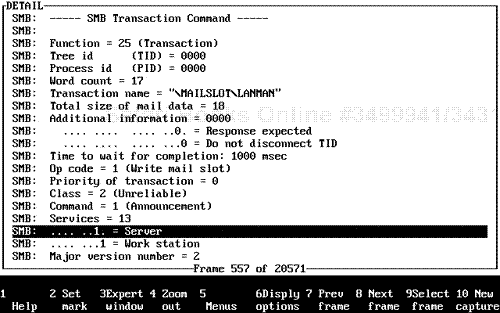
A list of SMB functions and their description follows.
SMB Function, 1 byte. . The Function field can be used for any protocol call from a server/client to a complete main operation process on the remote server/client. The Function field is considered the primary operation field of the SMB call.
SMB Tree ID, 2 bytes. . The Tree ID is the vector pointer related to disk access on the server/client request command and the associated remote server/client reply command.
SMB Process ID, 2 bytes. . This is the internal process ID between the server/client to a remote server/client connection.
SMB Multiplex ID, 2 bytes. . This is the internal subvector of the process ID related to the connection between the server/client and the applied remote server/client.
SMB Word Count, 1 byte. . This is the specific focus related to the word subvector of the protocol model.
SMB Transaction, variable. . This field is used for unique protocol operational event calls between a server/client and remote server/client. The actual transaction event will be unique, depending on whether there is a server/client broadcast occurring, a file search occurring, or a file operation occurring.
SMB protocol commands are divided into four categories:
Session control. . SMB control operations allow for the connection and disconnection of key services between the server and the redirector and allow for the interactive communication between these two processes.
File commands. . SMB file operations and commands allow for the access of certain key files and directories across the internetwork between client to server and client to client.
Print commands. . SMB print processes allow for communication of key print operations across the internetwork infrastructure.
Message commands. . SMB messages will allow for transmitting and receiving key I/O information for the NOS-to-client-to-server communications, along with broadcast messages that are critical for internetwork control.
The following is a brief breakdown of the standard SMB protocol commands:
SMB Start Setup and More and Tree Request/Response. . This protocol call establishes the initial connection between the redirector process and the shared resources of a server or client. This command is unique because it normally engages the packet-size negotiation for a buffer and also includes the authentication for the account name and the password for the NT domain name, including the native operating system and the native manager version. The Tree connection process allows for the connection sequence to occur for the server/client.
SMB Tree Disconnector Break Connection. . This protocol call disconnects the connection between the redirector and the applied shared resources of the NOS and the NT server/client.
SMB Logon and Logoff Request Reply Sequences. . This protocol call is normally used for the logon and logoff processes between server/client and server/client nodes.
SMB Negotiate Protocol. . This function is used to establish a communication dialect between server/client and server/client multiple nodes. Normally the network program, network version, and the applied DOS versions will be communicated on the negotiation protocol sequence. After the negotiation protocol response has been received, the security mode, Maximum Size of Host Transmit buffer, and virtual circuit assignments occur. The session key is established, along with authentication and the date of negotiation.
SMB Transaction Functions. . When the protocol call is a function-equals transaction, the SMB sequence can include unique transactions such as: MAIL SLOT BROWSE, MAIL SLOT NET/NET LOGON, and NAMED/PIPE. The named-pipe and mail-slot operation commands are used for unique communication for file system operations to communicate with APIs between server/client and server/client. The mail-slot commands are used in a connection second-class mode to locate on the network server/client, and send broadcast and notification messages processes. Transaction commands are unique common sequences; many more transactions can be called in the subvector through the function-equals transaction protocol call.
SMB Get Attributes for Disk File Access and More. . This call allows the file attributes from the remote server/client to be accessed as required.
SMB Rename a File and More. . This command requests a server/client to rename a file as required.
SMB Delete a File and More. . This command requests a server/client to forward an instruction to delete a file as required.
SMB Commit a File and More. . This command allows the server/client to send a write command through SMB for all buffers related to a hard disk operation.
SMB Create a Directory and More. . This command allows a server/client to engage a "Make Directory" command.
SMB Delete a Directory and More. . This command allows the server/client to engage a "Remove Directory" operation across a particular structure.
SMB Open a File and More. . This command allows the server/client to engage an "Open File" operation through assigning a file handle. The "SMB Open and More" file command is the initial open sequence for the function in SMB actual file access. This is where the function would be labeled as an "Open and More" request sequence, and the file and path names would be identified. All key file attributes would be identified within the subvectors of the file path name within the "Open and More" command. Also, the creation date along with the "Read and More" command may be attached. Upon the response of an SMB "Open and More" response sequence, the final attribute assignments will be identified along with the file handle and the current file size. This may also include an SMB "Read and More" response with data bytes read attached to the packet.
SMB Create a File and More. . This command allows the server/client to engage an initial creation process on a file.
SMB Close a File and More. . This command allows the server/client to close a particular file.
SMB Set Attributes in File and More. . This command allows the server/client to set a specific set of attributes.
SMB Lock a Byte in Block and More. . This command allows the server/client to lock a set of data blocks in a file.
SMB Unlock a Byte in Block and More. . This command allows the server/client to unlock a set of data blocks in a file.
SMB Create a Special File and More. . This command allows a server/client to create a special filename and pass it to the redirector process.
SMB Create a New File and More. . This command allows the server/client to generate a new file if the assigned file name does not currently exist.
SMB Check a Directory and More. . This command allows the server/client to engage an investigation on a directory structure.
SMB Read a Byte in Block and More. . This command allows the server/client to request a read on a specific block of data.
SMB Write a Byte in Block and More. . This command allows the server/client to write a specific block of data to a file.
SMB End of Data Process and More. . This command allows the server/client to terminate a certain node connection as required.
SMB Get a Set of Disk Attributes and More. . This command allows the server/client to request hard disk storage statistics on a particular server/client.
SMB Search for Directory/File and More. . This command requests the server/client to engage file search operations.
SMB Return Print Cue and More. . This command requests server/client to reengage a print cue operation.
SMB Create a Spool File and More. . This command requests the server/client to start a file for printing.
SMB Spool Byte Block and More. . This command requests the server/client to write a block of data to a print spool file.
SMB Close Spool File and More. . This command requests the server/ client to close a specific file that's cued for printing.
SMB Get a Machine Name and More. . This command allows a server/client machine name to be requested and mapped to a user.
SMB Forward Client Name and More. . This command allows the server/client to intercept a message from a user/client name and add a name to its name table.
SMB Send Broadcast Message and More. . This command allows the server/client to send an SMB message to all servers/clients that can intercept on the network.
SMB Send Single Block Message and More. . This command allows the server/client to transmit a single block of data with up to 128 characters between two clients.
SMB Start Send of Multi-Block Message and More. . This command allows a server/client to send a multiple-block message.
SMB End of Send of Multi-Block Message and More. . This command allows a server/client to end a multiple-block transmission message process.
SMB Send Text of Multi-Block Message and More. . This command allows for sending text messages of up to 1600 characters.
SMB Cancel Forward Process and More. . This command allows a server/client to delete a name from its naming table.
The following is a brief overview of the protocol operational sequencing as normally seen on an NT-based internetwork and the protocol-tracking events between the IP, TCP, NetBIOS protocol, and SMB protocol.
This is just one example of the protocol layering that can occur with these protocol types. The physical layer is normally engaged for general connection processes. Specifically, if Token Ring is used, ring insertion occurs; or if Ethernet is used, the station is active on the network. The connection process between two clients, or a client and server, occurs through the NetBIOS naming services, where a Check Name process occurs, followed by a Find Name for the actual host. After the Find Name has been recognized through the NetBIOS sequencing, the NetBIOS protocol moves to a Session Initialize process, and then a Session Confirm returns from the remote host. After the two clients or client and server have been connected through a NetBIOS session, SMB is engaged for a Negotiate Protocol sequence and a Negotiate Protocol response. The next process that takes place is an SMB Set Up Account and then a Connect Confirm on the setup process. The next process, the SMB transaction sequence, is followed by multiple transactions, that may include file searches, file opens, and writes and applied reads, as required. This is where true application transfer occurs; and applications may be called upon between clients and servers. Eventually a logoff process occurs through an SMB sequence, and a disconnect in the SMB engagement takes place. At that point, the NetBIOS session eventually breaks in normal fashion, completing the protocol event sequence on the internetwork.
When analyzing the Windows NT protocol suite, it is important to keep a close focus on the overall topology frame sequence to ensure that the physical layer is solid.
After the physical layer has been determined to be solid and operating, the next area to examine is the IP addressing scheme. As long as the IP addressing scheme is properly operating, any other areas of the IP datagram should next be investigated, such as TTL, for proper fluency and routing across the internetwork channels involved in the Windows NT analysis session.
The TCP layer should be examined for connectivity, positive acknowledgment and retransmission sequencing, as well as window sequencing and true connection maintenance.
If the connection layer appears to be solid, the NetBIOS layer will most likely show true transfer of data and the maximum amount of data transferred between the workstation and server based on the session established between the NT Workstation and the NT Server.
When the server is being called upon for general I/O sequences such as searching for files, finding a file, opening and accessing files within the NT Server, for any process ranging from connection, to logon, to application access, the SMB protocol sequence is active. After the application has been opened, it may decide to invoke transmission of data straight through the NetBIOS session layer or possibly through encapsulation within the SMB protocols.
The results seen in a network analysis session can be affected by the application development team data processes implemented and the implementation of Windows NT against the application in a specific internetworking environment.
In closing, an important note to remember during a Windows NT analysis session is to closely examine the IP, TCP, NetBIOS, and SMB layers for general fluency and overall communications. It is important that the complete protocol stack operation be working in a solid manner. Any improper conditions could indicate that other areas of the internetwork may have problems such as the physical network, or the routing layer network, or even that a switching-based problem exists.
If the application layer has a problem, the protocol communication at the SMB layer will most likely indicate SMB errors or other problems that relate to inherent problems in SMB protocol sequencing. This may indicate NOS- compliancy issues with certain workstation shells such as incompatible service packs or other conditions.
Keep an open mind when analyzing Windows NT, because the protocol suite uses an abstract design that engages many protocol suites that must work together in an interoperable fashion. This is an important fact to remember when performing a network baseline session in an SMB environment.
The DEC protocol suite is an extremely complex protocol that was derived for terminals to communicate to the DEC mini-host environment. An analyst should keep this in mind when encountering the DEC protocol suite during a protocol analysis baseline session.
In the LAN environment, certain protocols may be active for certain communication sequences that apply. A physical frame is usually encountered and in most cases the physical frame is Ethernet, because DEC is heavily deployed against the Ethernet topology. In an analysis capture, a physical frame is the outside physical header and trailer portion of the packet, such as outlined in the Ethernet frame specifics.
The next area that would be encountered in a network analysis session includes a data link encapsulation protocol such as LLC or SNAP.
For the packet to be routed from one DECnet node to another, the DECnet routing protocol is usually active and clearly shows the source and destination network areas for the DECnet internetwork along with the DEC nodes active for communication.
If a connection is being maintained and stability is required, Network Services Protocol(NSP) is usually active. From there, a process application protocol is present in the packet that is active for the LAN workstation's communication sequence as related to the DEC host environment.
In today's environment, it is common to see other protocols present above NSP protocol, such as X Window or SMB, when communicating to a host environment.
Protocols that were extremely predominant in the early days of the DEC mini-computing environment, such as Local Area Transport(LAT) protocol, are not as active in today's networking environments. It is more common to see protocols such as SMB at the application layer, because of the low amount of overhead required when calling upon a host environment. The LAT protocol and other protocols used at the DEC application access level, such as Data Access Protocol (DAP) are extremely redundant protocols and require more overhead and general communications.
The following is a description of some of the DEC protocol sequencing layer interaction processes that can occur, along with some of the DEC protocol types. Also presented are hints on analyzing the DEC protocol environment.
The DEC protocol suite centers on the DECnet protocols developed in the early 1970s by Digital Equipment Corporation.
First, DEC introduced DECnet Phase I protocol, which was based on PDP systems. Next, DECnet Phase II was introduced, which offered host support for DECnet. VAX process DECnet Phase III was introduced in the 1980s, which added cross-network routing along with network management. The DECnet Phase IV protocol suite was next introduced, which included support for Ethernet LAN and WAN technologies. Next, DEC introduced DECnet Phase V. The LAN and WAN DECnet architecture includes a physical and data process link layer, followed by a key routing layer. Above the routing layer is an end node–to–end node communication layer. The next layer is the session control layer. A network application layer is also present and interoperates with a network management layer. The DECnet phase operations is at the top layer.
The following list describes the major protocols engaged in the DECnet computing protocol suite model:
DECnet Routing Protocol (DRP). . This DRP acts as network layer protocol and assists with routing across DEC areas. DRP's intent is to initiate and maintain cross-area router links in a DEC internetwork. DRP is responsible for routing packets from source DEC nodes through DEC area routers that separate DEC areas, and to destination DEC endpoint hosts.
DEC Network Services Protocol (NSP). . The NSP ensures that a reliable message process can occur at the transport layer for overall transmission. NSP creates a virtual connection. The main functions of NSP are to establish, process, and destroy DEC links and to provide error and dataflow control. The overall transport process is engaged.
DEC Data Access Protocol (DAP). . The DAP allows for remote file access in a DEC environment. The DAP provides a command and reply protocol that allows a DEC workstation to initiate a process to create a files on host. The DAP allows for file access, opening, reading, writes, and closing cycles.
DEC Network Information and Control Exchange (NICE). . The NICE protocol is a DEC command/reply protocol that allows network management processes in a LAN and WAN session.
DEC Server Message Block (SMB). . This is the application layer protocol described earlier in this a book as developed for the LAN server environment. The SMB protocol can also be used in the DEC environment for remote file access use.
DEC Command Terminal (CTERM). . This DEC protocol is engaged for communication with DEC terminals in DEC LAN and WAN environments. It works with the DEC Foundation Services protocol.
DEC Foundation Services (FOUND). . The Found protocol is engaged when communication require a terminal-handling service on a LAN or WAN session. DEC FOUND can be engaged for initiating and disconnecting logical DEC connections that occur with DEC-based workstations and applications. FOUND works with the CTERM protocol.
DEC Session Control Protocol (SCP). . The SCP performs a session operation and is engaged to establish and maintain a virtual connection with DEC NSP sequencing.
DEC Maintenance Operations Protocol (MOP). . The DEC MOP is engaged for DEC network maintenance services for device-to-device tracking. MOP can be used for diskless workstation downloading and remote sequence loads.
DEC Local Area Transport (LAT) Protocol. . The LAT protocol is designed for terminal I/O process flow between devices in DEC areas that require endpoint-to-endpoint source communication. LAT can function as an interface protocol for a DECnet mini-host to general LAN domain link communication (see Figure 7.42).

The following items are important to analyze in the DECnet protocol suite:
Physical stability analysis. . It is critical that the physical layer supporting DECnet protocol communication be healthy. An analyst should always verify the physical frame carrying the DEC protocols.
DEC LAT error analysis. . The DEC LAT protocol may exhibit error information that a protocol analyzers can capture. DEC LAT errors are noted when they occur in the LAT decode layer. WAN analysts can locate DEC LAT errors by paging through the data trace. Any DEC node and area addresses must be noted when analyzing the DEC protocol suite.
DECnet Routing Protocol analysis. . The DRP protocol includes information such as addressing for nodes and DEC areas and the hop count between areas and costs to DEC networks. It is important to examine the DRP header internals for protocol errors such as excessive hop counts or high costs in route.
DEC connection analysis. . An analyst should examine connection integrity in the NSP and SCP layers in a DECnet environment. A connection should be set up, communication take place, and the session breakdown occur normally.
DEC polling analysis. . The DECnet nodes will notify each node of the node location and continue updates with Hello Timer packets. A protocol analyzer can capture errors in the Hello Timer values if the Hello Timer values are not correct and updates occur out of sequence, DEC devices may encounter routing errors. It may be possible to reconfigure the timer values if they are incorrect (see Figure 7.43).
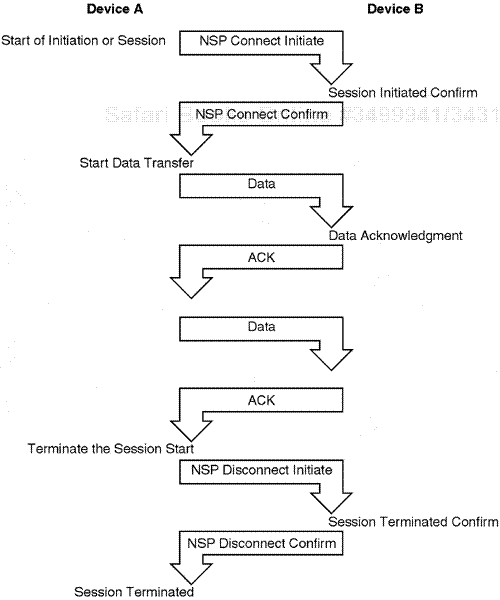
To fully understand and examine the decodes of any DECnet protocol in the suite requires a close review of the specific protocol. The references listed in his book enable an analyst to further research the DECnet protocols (see Appendix B).
The AppleTalk protocol suite is usually encountered in internetworking environments that use a heavy amount of Apple Macintosh workstations. The AppleTalk protocol is common for network-based industry applications such as art design and other innovative applications that are popular in the Apple computer and Macintosh computing environment. The AppleTalk node-to-node communication processes can be based on peer-to-peer transfers.
The following discussion provides a brief history of the AppleTalk protocol, along with a description of the AppleTalk protocol types.
We have also presented a set of AppleTalk Analysis techniques. We have limited the discussion of AppleTalk protocols to general areas. The AppleTalk protocol suite varies in actual implementations, because of the current market presence of many other protocols such as Windows NT that are more predominant in industry site configurations. In fact, there are really only two main implementations, Phase I and Phase II. In the 1980s, Apple unleashed the original AppleTalk protocol, Phase I. The AppleTalk Phase I protocol was designed for Macintosh peer-to-peer LAN-based communications. In the late 1980s Apple unleashed Phase II. The AppleTalk Phase II operation offers expanded support for internetworking. The AppleTalk zone mapping system is increased to 255 zones. Phase II supports Token Ring overlay implementations.
The AppleTalk internetwork addressing scheme encompasses nodes, network zones, and ports. A workstation corresponds to an AppleTalk node. The AppleTalk network is grouped into a zone. An AppleTalk router device is called a port.
The physical layers of an AppleTalk network usually rely on the topology for support. Most of the time, AppleTalk is resident over topologies such as Token Ring, Ethernet, or the LocalTalk. The AppleTalk-based networking involves the engagement of a set of sequenced protocols that rely on the physical frame of a particular topology for communication, such as Ethernet or Token Ring. The AppleTalk data link layer usually engages an encapsulation protocol such as LLC or an AppleTalk protocol for the data link layer, such as Link Access Protocol (LAP). The AppleTalk protocol has subcomponent layers such as TokenTalk, LAP, EtherTalk LAP, and LocalTalk LAP layers.
After the network layer protocol communication sequencing has been established between an AppleTalk workstation and an operating system server, the DDP is usually active for decoding. This is the network layer protocol that allows for investigation of the AppleTalk node network layer addressing scheme and processing of an AppleTalk packet across an AppleTalk router or switch.
At the OSI transport layer, the AppleTalk Routing Table Maintenance Protocol (RTMP), AppleTalk Echo Protocol, AppleTalk Transaction Protocol, and Name Binding Protocol are active. For AppleTalk nodes to map addressing and cross-links to devices on the network, other protocols are critical at the network and transport layer such as Zone Information Protocol (ZIP) and Name Binding Protocol(NBP).
The AppleTalk protocol engages session layer operating by suing AppleTalk Data Stream Protocol, ZIP, the AppleTalk Session Protocol, and the Printer Access Protocol (PAP).
The AppleTalk architecture engages presentation services through AppleTalk Filing Protocol and Postscript. After the application process has been engaged, the required application-based protocols in the AppleTalk environment, such as AppleTalk Filing Protocol (AFP) or other custom protocols such as SMB, can even be used for sequencing above the AppleTalk network layer. The AppleTalk architecture also allows for application calls through AppleShare File Server and the AppleShare Print Server Protocols.
DDP. . A network layer protocol engaged to activate addressing for transfer across AppleTalk zones and used to transfer data between AppleTalk nodes on an internetwork. The DDP layer includes information on addressing and hop counts traversed.
LAP. . The LAP protocol is used as a main logical link for an AppleTalk node to link upper-layer protocols with the physical medium.
SNAP. . This encapsulation protocol is engaged to package ULP protocols for protocol stack link configuration.
AEP. . The AEP protocol engages the capability to link Echo or Ping process for AppleTalk nodes for identification and timing links.
ZIP. . The ZIP protocol is engaged to provide a process to cross-map NBP binding to the AppleTalk network routing links to zones.
NBP. . The NBP protocol translates an AppleTalk name to specific zone for data sockets.
RTMP. . This protocol assists with AppleTalk routing updates between AppleTalk routers. RTMP can also be used as a route discovery protocol for routers.
PAP. . The PAP protocol is engaged to link printer dataflow in a route of stream mode to print devices.
ASP. . The ASP protocol is engaged at the session layer and is used for AppleTalk session establishment, connection, maintenance, dataflow, and disconnects.
AppleTalk Data Stream Protocol (ADSP). . The ADSP protocol provides for a connection-linked socket to provide for a data stream to process between AppleTalk nodes.
AppleTalk Data Stream Protocol (ATP). . The ATP protocol is used to provide a transaction of data between two specific sockets in AppleTalk endpoint nodes.
AFP. . The AFP protocol engages a file access and file mode transfer cycle at the application level (see Figure 7.44).

An analyst should engage a focused view when analyzing the AppleTalk protocol suite. The interaction of the protocol suite is complex. It is important to keep a focused view on the ZIP communication. The ZIP is involved in the communication of the internal zones in an AppleTalk internetwork environment. The ZIP is used to translate between the AppleTalk network numbers and zone names. Any ZIP packets should be examined for proper addressing between nodes. An analyst should also review the NBP protocol. The NBP is used as a name relational transfer mapping process across the AppleTalk internetwork to link devices to names and zones. This protocol allows AppleTalk network stations to refer to different types of services through a cycle of mapping AppleTalk character names. Most processes within an AppleTalk internetwork are named and have NBP designations. NBP packets can be captured and decoded to examine the addressing information. When an AppleTalk node user cannot locate a particular service, there can be various misconfigurations present within a device. By analyzing NBP, an analyst can locate misconfigurations. The RTMP is a key protocol to examine for problems with routing lengths and wait times in the AppleTalk layers. An analyst should closely review and RTMP updates for proper routing convergence. By analyzing RTMP, an analyst may locate routers that have configuration concerns. RTMP holds key information on wait time, routing length, routing hops, and router location.
The AFP contains key information on AppleTalk resources for file access to AppleTalk nodes. An analyst can decode AFP to examine node request for certain file pointers and file accessed method required. An analyst can review AFP to examine and evaluate file access fluency (see Figure 7.45).
If there are connectivity issues, an analyst can review the ASP. The ASP protocol can be checked for proper device connection initiation, connection, transmission, and breakdown (see Figure 7.46).

For more details as to information on the AppleTalk protocols contained within the suite, refer to the sources cited in Appendix B.
In today's networking environment, the Banyan protocol suite is not predominantly deployed across large LAN and WAN internetworks. This protocol, however, was extremely popular throughout the 1980s and early 1990s, especially in large government infrastructures throughout the world. This was because of the stability available through reliable interconnection of large server environments spread across diverse global infrastructures. The Banyan Virtual Networking System(VINES) protocol suite was introduced by Banyan Systems, Inc. The Banyan VINES network architecture includes a set of protocols drawn from the Xerox XNS suite and the TCP/IP. The Banyan suite also includes protocols from the SNA environment.
The server infrastructure within a Banyan environment has the capability for a strong interconnection via the StreetTalk processes for server-to-server communications. When investigating the Banyan protocol suite, it not unusual to encounter other protocols common to other protocol suites. Many of the protocol layers within the Banyan protocol suite are somewhat similar to other industry protocols.
When decoding a Banyan packet, a physical layer protocol topology frame header is present from the local area topology where the Banyan protocol suite is captured in a network baseline session.
After the physical layer protocol has been investigated in a packet, a data link protocol is present for encapsulation, such as the LLC or SNAP. The data link layer engages VINES fragmentation protocol(VFRP).
In most cases, the VINES Internet Protocol (VIP) is engaged, which is very common to standard IP operations. The VIP, Vines Routing Update Table Protocol (VRTP), and ARP operate at the network layer.
When a transport layer connection is required for maintenance, in most cases the Sequence Packet Protocol (SPP) is engaged. The VINES Internet Control Protocol(VICP) works mainly at the transport layer along with SPP and other TCP/IP-related protocols, and AppleTalk-related routing protocols.
An analyst encounters application protocol layers engaged on top of the VINES protocol suite, such as SMB protocol or other application layer protocols for workstation-to-server calls in a Banyan environment.
Some of the other key Banyan application layer protocols that may be encapsulated for general communications are the Matchmaker Protocol, FTP, and the VINES StreetTalk protocol for server synchronization.
The following list describes the Banyan VINES suite protocols:
VIP. . The VIP is used for network layer operations and data-transfer services.
VRTP. . The VRTP is used in the VINES internetwork environment to maintain routing information between routers.
VICP. . The VICP is engaged to broadcast errors and network topology changes to VINES nodes active with VIP.
VINES Interprocess Communication Protocol (VIPC). . The VIPC is a transport layer protocol used for providing connection services.
SPP. . The SPP transport level protocol is engaged to establish a virtual connection, process data transfer, and maintain a connection operation.
VFRP. . The VFRP allows for breakdown decoding and reassembly of the network layer packets for transmission to the data link layer, the physical layer, and any higher layers.
VINES MAIL Protocol. . The MAIL protocol is engaged for transmission of messages in the VINES email system.
SMB. . The SMB protocol is also used in the VINES suite for application file access.
VINES MATCHMAKER. . The MATCHMAKER protocol is used by the VINES upper layers for operating node program-to-program communication. MATCHMAKER also supports RPC calls. The MATCHMAKER packet-tagging techniques allow for linking functions: File, FTP, Server, Echo, Router, Background, Talk, and Network Management (see Figure 7.47).
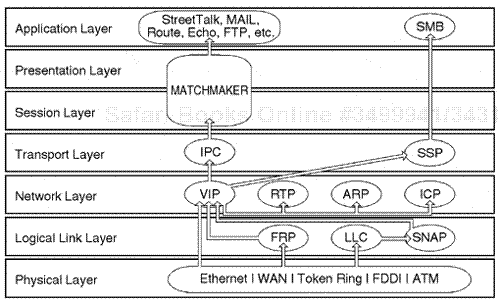
Certain VINES protocols have specific functions. The following is a combined synopsis of their interaction.
The VFP allows the main VINES protocols to communicate with different hardware in the internetworking environment, for example. The VFRP protocol interacts with the VIP to determine the required packet size for hardware connections. At the network layer process area, the VIP, the VRTP, the VARP, and the VIPC work together to ensure node-to-node communication. The VIP works with the VRTP to establish connection between source and destination VINES nodes. The VRTP protocol is responsible for updating all the VINES servers and routing nodes with information relating to routing metrics. The VINES Address Resolution Protocol (VARP) works to assign the required addressing schemes. The VIPC is important, because it interrelates most of the key information between nodes as far as general integrity of communication between client nodes. This VIPC protocol tracks any errors in communication between nodes, and can specifically be analyzed for error data. At the transport layer, the SPP is used to set up and maintain a virtual connection between any two specific VINES nodes in an internetwork. The higher-layer application protocols such as the Remote Procedure Call(RPC) protocol and SMB are next engaged.
The first focus in a Banyan VINES analysis session should be a physical layer review. The physical layers must have true integrity. Errors at the physical layer can cause higher-layer communication errors in the VINES process. It is important that a VINES analyst examine the workstation-to-server connections and operation of the server routing update tables and server addressing environments. By determining that VIP packets communication fields are proper, an analyst can verify the key network health points in a VINES internetwork. The VIP layer includes addressing information to ensure that the nodes and servers can be identified. It is important that all addressing be verified in a VINES environment.
The VRTP packets contain information related to server internal addressing, and are used to maintain address information throughout a VINES internetwork. The VINES network communication is based on a cross-site WAN update scheme whereby servers update other servers in the internetwork regarding the services with which they are associated. The StreetTalk naming system is based on a database synchronization between each server. It is important that each server update other servers on changes to the addressing environment.
The VINES RTMP packets contain address information regarding VINES network numbers and subnetwork numbers. As noted, RTMP packets are engaged for routing updates as to key routing information for VINES-based routers. An analyst can capture VRTP packets and decode for information on site routers. The analyst should evaluate the VRTP updating sequence for updates to occur every 90 seconds. When performing a baseline study of a large enterprise WAN internetwork for VINES, the StreetTalk database should be checked on all key host and any interchannel packet communication for server-to-server sync process must be examined.
The VINES IP has metric values on transport hops between VINES nodes, which require examination. The VINES IP header includes most of the information for examining addressing from network and subnet information as noted. An analyst should examine the IP header to determine what address communication is occurring. If two nodes are having a communication problem, the analyst should use the protocol analyzer to filter on the nodes. Next an analyst should perform analysis and decode the IP headers, and record the internal information such as the network number, subnet number, protocol type, and Transport Control fields. The VINES StreetTalk database should update approximately every 12 hours. The StreetTalk database can be analyzed with proper filters applied on the protocol analyzer.
To truly understand the VINES protocol suite may require further research of the VINES protocol (see Figure 7.48). Appendix B lists references to the VINES material.
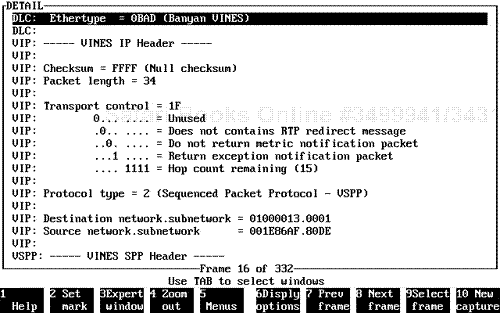
When performing a network baseline, a key process is to examine how the overall internetwork routers in the enterprise environment communicate to each other in a stable and reliable manner. An enterprise facility that incorporates more than one network segment will use a router or a switch to separate the segments.
In most networking environments, there are no longer simple networks, but rather internetworks comprised of many segments, which may require routers to separate the different logical segments. Many of the routers found in today's environment can communicate to each other and update each other regarding device location and routing vectors as related to location of various networks and devices throughout the complete enterprise configuration. Routing protocols are used for two main reasons. One reason is to determine internetwork routes, and the second reason is to provide a transfer of information between different networks. The actual determination of internetwork routes is based on a complex set of measurements within the specific routing protocol. Routers communicate with other routers by using specific algorithms for determining the optimal internetwork routes between multiple networks. Routers maintain a subset of routing tables, to store all the key information to be used in obtaining the correct addressing for different routes between the different routers.
A group of measurements and categories, called "routing metrics," are used to determine some of the routing parameters; these usually vary from router type to type. For example, a Bay router works different from a Cisco router. All routers normally maintain complex routing tables with all the key information on the other routers on the internetwork. The routers share this information periodically by updating each other through some sort of routing information protocol. The routers communicate with each other and continue to keep the updates current between the different routers. Consequently, when a node on one network wants to transfer information to a node on another network, if the complete routing table is current, the source node can obtain the most efficient route. At times, certain routing algorithms may not be efficient, and this can cause the updates from table to table in routers and file servers not to be performed on a proper time sequence. This can temporarily cause a routing loop, which is not an unusual occurrence on large internetworks that do not support some of the complex routing algorithms that may be required (see Figure 7.49).

It is important for all the network routers housed within a specific location to communicate to each other in a proper way. If all network routers are contained within one location, this is considered an "interior" location. If Company A from one location wants to communicate to Company B at another location, it is likely that they will be separated by routers that use an "exterior"-based routing communication cycle for updates.
When interior routers communicate to each other, such as the routers within Company A, they use an interior routing–based protocol. When routers communicate across different interior-based routing systems, they use an exterior-based routing protocol (see Figure 7.50).

Routing technologies also vary when taking into account the types of protocols that can be used to update various routers for internetwork segment location and device location. These routing update protocol sequence processes are usually broken into two types: distance vector protocols and link-state-based routing protocols.
When enabling a routing protocol configuration within a facility, it is first important to determine the difference between an interior and exterior system.
Routing algorithms within internal-based system routers can be designed to allow for changes in network size and network delays, including bottlenecks and even lows or peaks in network bandwidth utilization factors. Some routers have groups of complex routing algorithm configurations, and other basic algorithms are in some standard basic routers. Most routers should be able to maintain either a dynamic or a static routing information table. Dynamic routing is used when routers are updating each other because of general information changes and operation changes on the particular networks involved. Static changes are usually modified by the network design group and can be configured so that the router operates in a standard way in certain areas. Many routers can support static and dynamic routing.
Any protocol should have a centralized algorithm that enables routers to always maintain tables of the precalculated, most efficient routes within standard internetwork layouts. There should also be distributive algorithms in order for internetwork routes and time changes on the network to be calculated on a dynamic basis.
Most routers should be able to provide a multipath approach to allow traffic to flow in multiple areas throughout a large internetwork. The term "collapsed backbone" refers to the situation in which the external networks throughout an internetwork actually join within the backplane of a large comprehensive router; that router then serves as a complete backbone between the networks.
Many routers today function efficiently with complex internetworks. These routers can identify performance issues in an internetwork traffic flow and provide reliability when delays and high-bandwidth utilization occur. Most routers should be able to calculate whether a packet needs to be communicated in a different route. These routers should be able to make a decision dynamically on whether an alternative route would be more efficient in relation to load or communication cost factors.
At times, routers also may need to adjust their packet size on the network to accommodate communication load factors throughout an internetwork. In today's complex internetworks, router technology needs to take into account bandwidth utilization to allow for this type of transfer.
Interior-based routing-based protocols can have a dynamic or a static route, depending on the type of routing protocol engaged. One of the more common routing protocols for interior-based routing updates is RIP. This protocol was originally developed to operate in the BSDI version of UNIX and was standardized in the late 1980s in different RFCs.
The RIP has been enhanced and there are now two versions: Version 1 RIP and Version 2 RIP. Version 2 now supports variable-length subnet masking, which allows for interoperability across different routing schemes in a more enhanced fashion for addressing flexibility.
The RIP usually updates on a very frequent basis and advertises the distance to a device based on routing hops and the vector based on thenetwork point-to-point path.
Each router involved in a RIP updating sequence, or RIP communication sequences between two routers, updates on specific intervals. Most RIP update intervals are set for 30 seconds, which is considered standard. Certain RIP intervals are set for 60 seconds, which is custom for specific RIP protocol variances such as Novell RIP.
The only concern with regard to RIP is that the shortest path first or time metric to a certain network is ignored. There are no internal calculations within a RIP-based routing protocol of what the shortest path is to a device. This can be of concern when a RIP calculation is being performed.
If a device is located two hops away through a set of Fast Ethernet channel networks rather than hop away through a shared Ethernet channel, for example, the RIP takes the shortest hop, which would be the shared Ethernet channel. In this case the shared channel would actually be a slower channel for general communications, but the convergence of the route would occur in this manner. When RIP determines a final route through the distance vector process, this is called "convergence."
Other protocols in an interior-based system, such as OSPF and Extended Interior Gateway Routing Protocol (EIGRP), which is proprietary to the Cisco environment, use a link-state-based protocol that is more sensitive to overall internetwork delays.
In a link-state-based protocol system, the changes in routing environments are based on the status of the physical speed of the linked internetwork of routers in the networking environment. When the router is originally launched or refreshed, it will usually participate in the routing protocol sequence through a Hello sequence or Update sequence of its state to other routers in the internetwork. Updates are usually sent on hourly intervals and are somewhat custom configured, depending on the enterprise design.
If the state of a router changes, the advertisement is performed via a link-state advertisement chain update. This is important because the router can create and maintain a consistent database in a link-state-based routing designs such as OSPF or EIGRP. Link-state protocols can evaluate the corresponding shortest path first and time metric to a specific router. Each router can use link state changes to pass information to neighboring routers to update the complete internetwork interior-based router scheme.
The link-state database is maintained in a consistent basis, which differs somewhat from the routing information table base in a RIP-based scheme. There are constant calculations against the path of the destination to each network, which does engage some overhead against the current hardware router system performing the hardware configuration for the routing environment.
In most cases, however, this is a standalone router and does not cause any load. The key factor to remember regarding link-state-based protocols is that if an interface on a router goes down, this information is usually propagated across the complete internetwork at once.
If there is a redundant path configuration available, routing convergence takes place and a recalculation of the shortest path first to the new route is established. Because of these calculations, a small load may be imposed on the routers involved, but this not considered a negative situation.
In most link-state-based routing environments, the network has the inherent capability to allow for contiguous networks to be recognized and identified through variable-length subnet masking. It is also possible to summarize all the routing updates within one routing table update. The rule of thumb ranges from 50 to 150 interface routers per area to be designed within a particular area.
Other routing protocols are available today, depending on the exterior or interior requirement.
When performing network baselining, it is important to understand that an analyst must capture routing protocol updates when investigating the sequencing between two routers to investigate the routes that may be static or advertised on the routers. If there is a problem with a router or switch on a network during a network baseline, an analyst may encounter an abnormal transmission in the routing update packets sent from one router to another. In this type of situation, the validity of certain routing tables may be abnormally refreshed, and route validity changes could occur frequently within the interior-based routing system. An analyst should be able to quickly capture routing updates from certain routers, and identify whether sequences are normal.
When examining a RIP-based router such as a Novell server or standard IP-based router running 30-second RIP, for example, the RIP update sequences should occur in this time interval. If for some reason the updates occur every 1 to 2 seconds, this is an abnormal condition in a distance vector system based on standard RIP.
Another example would be if in a link-state-based routing system, an abnormal change was detected and an link state advertisement (LSA) was being sent every two to three minutes; this would also be abnormal because link-state changes are normally sent on half-hour or hourly sequences.
With these facts in mind, note also that the RIP updates or any type of routing protocol update, such as OSPF, will be communicated inside the physical topology frame and must be investigated through packet analysis via a protocol analysis session.
Two other terms need to be defined: intradomain domain (within the same area or domain) and interdomain (in different areas or domains).
As a final note regarding baseline techniques, it is important for an analyst to be able to decode the different routing algorithms present within the internal packets of the routing protocols captured with a protocol analyzer. A protocol analyzer can pick up the routing protocols and enable the analyst to decode the fields for the respective routing protocols. At times, it is an advantage to be able to capture a particular packet between two networks, and display the packet to obtain information on how the packet was transferred from one network to the other. Key information probably will be found in the packet's Routing Protocol fields relating to how long the time transfer took between the two networks. Also encoded in the protocol packet is information on the number of delays between the network and the respective hops between the complete internetwork traffic cycle.
Novell RIP packets encode the time required to traverse a network in terms of units called TICKS, for example. Data in the RIP packets also encode the number of networks passed through on the transfer from Network A to Network F in the Hops fields in the packet. This type of information is critical during actual troubleshooting of internetwork traffic route issues.
Again, the focus here is that routing protocols provide for a determination of internetwork routes, and the actual transfer of information between those particular networks. An analyst can decode routing information packets to obtain key information about internetwork traffic flow. The discussion now turns to a general description of some of the key routing protocols available for intercommunication between interior- and exterior-based routing schemes.
Following are descriptions of some key routing protocols in the internetworking environment. The routing protocols should not be confused with the protocols used to route data at the network layer, such as IP. Routing protocols are internetwork protocols used in certain internetworking environments to allow for communication and calculation of routes between respective routers connecting networks. These protocols include protocols such as the RIP, OSPF, and other routing protocols that are proprietary used by certain router manufacturers, such as the Cisco's EIGRP from Cisco Systems Inc.
The key routing protocols are as follows:
Interior Gateway Protocol (IGP)
Exterior Gateway Protocol (EGP)
Routing Information Protocol (RIP)
Open Shortest Path First (OSPF)
OSI ES-to-IS and IS-to-IS Protocols
Cisco's Extended Interior Gateway Routing Protocol (EIGRP)
In the IP networking environment, the term gateway can describe routers. Some routers are used to move packets between networks under the same network management control on the Internet, and are termed core routers or interior routers. The protocol used to route between the interior routers within a specific network management scheme is the IGP.
Exterior Gateway Routing Protocols are used for routing between the interior routers on one independent internetwork to other exterior routers on another independent internetwork. EGP is a dynamic protocol that allows for this transfer. EGP updates based on the number of networks that can be reached, and is also used at a regular interval for updating those routers. The information within EGP packets varies depending on the subset of the protocol.
The RIP was developed in the Berkeley and Xerox development environment. This protocol has been used in a large subset of high-end computing environments. Most of these major computing protocol subsets use a derivative of RIP, but not in exact form. RIP is normally used in interior-based routing systems. RIP is based on a distance vector scheme. The RIP is intended to efficiently route packets. RIP was intended for smaller networks. RIP has a 16-hop count limit. Large networks frequently must exceed the 16-hop count limit. RIP uses a simplistic algorithm for metrics and for updating multiple routes. At times, RIP may have problems and effect incorrect updates in the routing tables for large networks. When router resets occur in a RIP environment on large internetworks, incorrect routing tables may be the result. Update mismatches can occur when tables are not updated for 60 seconds, which is the standard RIP update interval. Newer routing protocols are more robust in complex internetworks, but RIP remains an efficient protocol for most of the more standard-size internetworks.
OSPF was developed by the Proteon Corp., along with major educational institutions. This protocol was developed as a link-state routing protocol, used mainly in interior-based routing systems, and is extremely dynamic for routing algorithms between large internetworks. The OSPF protocol is regarded as one of the popular protocols for use in large internetworks. The OSPF routing protocol takes advantage of some of the strengths of RIP. It conforms to the basic structure within the RIP environment, but it also addresses some high-end techniques applied to the protocol algorithm. Instead of updating routers throughout an internetwork on the standard every 30 to 60 seconds, for example, the OSPF routing protocol updates on-the-fly when there are problems between any routers. This feature eliminates most occurrences of routing loops. In an OSPF scheme, routers can recover quickly and update the internetwork-linked routers.
Another advantage of OSPF is that it allows for multiple path routing dynamics and can route on-the-fly to the most efficient route. This protocol also works with higher-end applications to decide routes on the dynamics of a particular application process. The OSPF protocol includes a feature called TOS routing, in which an application can dictate to the IP TOS and allow the internetwork routing protocol (OSPF) to dictate a packet and give it priority on its route and identification path. This capability to work with upper-layer applications allows OSPF to dynamically route between destinations in a large internetwork on an application's request. OSPF can also engage load-balancing techniques to carefully calculate ways to balance traffic over multiple routes on an internetwork. This is an essential capability if low delay factors are to be achieved throughout the internetwork.
The International Standards Organization has developed a group of different routing protocols to communicate across OSI protocol environments. The protocols are based on end systems (ES) and intermediate systems(IS). End systems are devices that do not route; intermediate systems are routing devices. These devices can exist in areas called routing domains. It is possible for an ES to route to an IS in the same area through the ES–to–IS version protocol. An IS version can route to another IS device in the same area through the IS-to-IS version protocol. IS-to-IS is a derivative of DECnet Phase V routing. If an ES or IS device needs to communicate across areas, the Interdomain Routing Protocol (IDRP) is used. There are Level 1 and Level 2 routers. Level 1 routers can talk to Level 2 routers, and normally, Level 2 routers communicate only with other Level 2 routers. This provides an organized approach for internetwork routing.
EIGRP is a proprietary protocol developed by Cisco Systems. EIRGP is intended for large internetworking environments. The internal configurations for a router using EIGRP can be extensively customized. EIGRP has a large group of settings for custom environments. Its metric settings allow for custom multipath setups with auto-switching on-the-fly to other routes when failures in a route occur. A feature called holddown is used to prevent a router from automatically reestablishing routes on a bad link. Routing loops can be prevented by a feature called split-horizon, which stops redundant updates on bad routes.
This chapter has presented some of the major protocols along with the key routing protocols that can be examined with a network protocol analyzer. The key to understanding protocol analysis at the upper layers is to maintain a set of network baseline mechanisms, as previously discussed in this book.
To become proficient at analyzing specific protocols, an analyst must keep a library of current reference material on each protocol suite. An analyst should always have a set of reading or reference materials from NOS vendors and application vendors available when examining any key protocol environments such as Novell, NT, or TCP/IP.
It is important to remain current on updates and changes to any configurations of the fields of the protocols, because these parameters change quite frequently upon new releases of operating systems, new applications, and internetwork change requirements.
This is an extremely dynamic industry and an analyst must have sufficient reference material available to analyze the protocol suites that may flow on top of the various topologies of an internetwork.
This book now moves to a description of each one of the major topologies in the physical network area of LAN and WAN environments. Each topology is discussed in terms of its architecture and the proper analysis and baseline techniques related to each topology environment. To truly baseline any large enterprise environment, an analyst must understand the physical topology and the upper-layer protocols being investigated. It is a mandatory for an analyst to thoroughly use an analyzer across the complete spectrum of site protocols in a network baseline study to properly evaluate an internetwork infrastructure from an enterprise standpoint.
A client in the financial industry contacted the LAN Scope analysis team to monitor an application that was experiencing extensive corruption of its database records for financial information. The client, a financial brokerage institution, provided investment capability for clients in the areas of mutual funds, general stock and bond operations, and other financial instruments.
The application in question was an investment-based application, which kept customer records online for the financial institution. The information included personal data on customers as well as their financial history with the financial institution. Complete tracking information was utilized in this application against all financial transactions involved with the client. This was considered a major business application because it impacted the general business flow of the company.
In the past, this type of information was maintained on the mainframe in a mini-host environment and was considered 100% stable. A recent rollout and push to move the application against the LAN as a mandate was instituted, which prompted some concerns about the stability of the application along with its rollout across the internetwork infrastructure.
There were concerns about using the LAN, but again it was a mandate to deploy the application across the LAN based on the distributed access of remote offices supporting the client infrastructure throughout the world.
At the time LAN Scope was contacted, the application was in an early rollout phase, with only approximately 100 users. More than 1,200 users at multiple locations were targeted for the final rollout stages of this application. The main concern was that users were experiencing intermittent corruption in certain database areas that appeared to show anomalies, and therefore the application was not 100% accurate. Fortunately, this application was in a predeployment testing phase and not considered production at the time, (see Figure CS6.1).
The application was only being used at the headquarters facility and was in a test phase. In other words, the information was also being directly input into the mini- and mainframe host environment via terminal servers, so that the client records could be verified upon corruption to any of the data files.
The output from the host environment was periodically checked against the LAN records in the database using an automated test program provided by the new application vendor. Periodic nonconsecutive information was located in output reports for comparison of the databases that showed the anomalies in data results between the host processor area and the new LAN-based application area.
Based on this concern, it was necessary to immediately troubleshoot why the corruption was taking place. The LAN Scope analysis team was requested to perform this exercise.
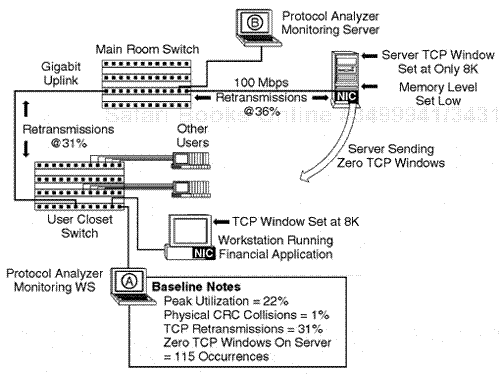
Figure CS6.1. Monitoring an application which was experiencing extensive corruption of it's database records for financial information.
LAN Scope conducted an entrance briefing with the client and the vendor of the application, during which we reviewed the topology, architecture, and application event cycles involved. We utilized application characterization processes after we performed a rapid baseline on the application characterization areas of the topology where the application movement was taking place. After we had completed the baseline notes, it was clear that the overall utilization levels were not of concern, the protocol percentages appeared to be normal, and the physical error rates related to the physical Ethernet topology were nominal.
The overall architecture was extremely robust and based on Fast Ethernet, with gigabit uplinks throughout the facility. With this noted, we also detected an extremely high level of TCP/IP, noted at 95%. This application was based on a network and transport layer of utilizing IP for general datagram transfer and TCP for transport connectivity stabilization. The application layer was built on a custom design of engaging a custom application engine.
With this noted, the LAN Scope analysis team focused on decoding the actual application events, looking for any stability problems related to connectivity. We noted during our initial application characterization phases that the application showed a high number of connectivity-based errors in the connection layer statistics of our network analyzer.
A high number of TCP window-size exceeded errors were noted. This type of error indicates that a TCP window stream has been affected by a TCP window not being available to handle communications. This type of event is an extreme problem when a connection state is considered active and open in a TCP port transmission.
As explained previously, TCP operates in the following manner. A connection is established between two endpoints across an internetwork. Each end is considered a TCP host endpoint for communications. The TCP connection starts with a three-way transmission process, which is considered a handshake, and a TCP port is considered open and active on the two endpoints. When the port is open, a size of available TCP buffering capability on each end is advertised through what is called a TCP window. This can be translated to exact data in bytes. This is the area in each endpoint, or workstation, or server being reviewed in this manner, that is available for TCP stream transmission between the two points. This area allocates in bytes and its availability and size is also directly tied to memory and resources in the PC (and operating system.)
The default TCP window being advertised for this particular application was noted at 8K between the workstation and the server. This is exactly related to the number of bytes available. The TCP communication which occurs back and forth is always updated by sequence and acknowledgment numbers to update each TCP end transmission. The process is also noted as engaging with a TCP open state to a TCP closed state. When a TCP session is opened, an initial sequence number is identified; and when a TCP closed state ends, a finish request is brought from one node to another and confirmed by the other end. If a TCP reset occurs abnormally, it can indicate a breakdown in TCP communications. If critical data is being sent back and forth, and a TCP reset occurs, it is very possible that the TCP transport connection could experience loss of data and thus create a direct loss of data input to any application utilizing TCP at the upper layers for transport. This could then cause database corruption.
The LAN Scope analysis team noted that during a database transmission and final record lock on a transmission of a particular client's financial records, that TCP connection errors and TCP window-size exceeded errors were both common. The exceeded errors indicated that one endpoint had a TCP window size that was exceeded and was not available any further for receiving or transmitting TCP information to the other endpoint. In this case, we noted that the event took place consistently in the LAN file server in the main computer room that handled the database application for the financial record-keeping process. This particular file server had only an 8K TCP window configured. The file server configuration was noted as having a robust level of memory, a high-speed Ethernet full duplex, along with a high-speed channel access design. The overall CPU processing levels appeared to less than 25%.
The main concern here was that the overall Ethernet channel and general network layer communications appeared to be stable. The application appeared to be operating in a fluent manner. There were no application errors from the vendor noted in the application process.
From our review, it appeared as though the transport layer was of concern, because of the network analysis results being received during the session. Again, one analyzer was positioned at the user area where the investment records were being entered from a user platform on a workstation. The user was then connected to a half-duplex Ethernet channel link through a port on the switch on the user floor. An uplink was then provided via a Gigabit Ethernet channel to the main computer room where the server was connected to a full-duplex Ethernet channel operating in a normal manner. All Ethernet statistics on the switched port showed low utilization, along with our baseline statistics. The only areas that appeared to be affected were the transport layer or connection-based layer statistics on our network analyzer.
Upon decoding all the symptoms, we immediately noticed that the server was dropping from an 8K window to a zero window after approximately two to three minutes of general transmissions. This appeared to take place on high user access when 20 to 30 users connected using the application. Upon lower user counts, it appeared as if the TCP window floated between 8K and 2K. When the 20-user threshold was applied, it appeared as though the server's TCP window's handling capability would be exceeded in the server, and connection breaks were frequent, noted as TCP resets on any ports active on the server. The server also would continue to have a TCP window-size exceeded error on any ports that were considered open at the time. Specifically, ports that were already open would not be able to float between the 8K and 2K range, and would float from 8K to 0 bytes available. Any new ports would not be properly synchronized through a TCP open state and would almost immediately be reset and would not allow transmission to start.
We immediately brought our findings to the MIS team for review. The MIS team, the application vendor, and the LAN Scope analysis team sat down to develop a synopsis, based on this information.
Our immediate findings were that we would require an upgrade of the TCP window size on the server of a minimum of 32K, just to handle the main users in the facility.
For predictive analysis as to the application rollout, future studies were required for application characterization and placement of users throughout the facility.
It was quite possible that this application would require a multiserver environment for different locations, based on the user-count levels. Because of the robust transfer of the application related to packet size and requirements on TCP port handling, it was likely that servers would be required in a distributive fashion based on 64K TCP window size, along with much higher memory levels of 1 and 2 gigabytes of memory, just to handle application dataflow.
To resolve the issue at this site for further testing and verification, we had the MIS team upgrade the server's TCP window via a Registry change in Windows NT to 32K. We also had a memory upgrade applied of 1/2 gigabytes to the LAN server, and the application was retested.
The LAN Scope analysis team immediately found that the TCP window was no longer being exceeded, and the 100+ users deployed were able to connect continuously to the server without causing a situation in which the server could not handle multiple TCP ports open without incident. There were no reset concerns and no further TCP resets took place. All ports were opened with a proper open state and a proper finish state for general TCP communications.
This allowed the initial application testing phase of the migration to continue at the facility and to be fine-tuned. Also the database records were shown and verified on multiple cycles against the host's mini-computer output and were shown to be consistent and accurate on an ongoing basis at the LAN server. This application was tested for another three to four months before we were requested to perform application modeling and rollout requirements for other locations for the financial institution.
We considered this initial process an excellent testing cycle, using network baselining and application characterization combined to troubleshoot the TCP port connectivity issues. The TCP has an extremely robust communication-handling capability for transferring data. One of the requirements to support TCP handling capabilities is a focused approach to characterizing application rollouts and also adjusting certain TCP parameters that may be required. In the early phases of TCP rollouts in the early 1970s, the TCP parameters for protocol stacks were released in such a way that TCP parameters could be modified easily to allow an accurate configuration.
When TCP became an industry standard, many different parameters could be adjusted for TCP port operation. As more and more operating systems became prevalent, certain TCP configuration parameters were considered hard-configured and were not allowed to be modified. This was because some stability was required on TCP stack uniformity. The only concern here is that many applications today require TCP for transport modifications and require different configuration flavors as related to TCP parameters. Many of the operating system vendors have had to move forward and offer parameter-change capabilities in the protocol stack of their operating system or workstation design. In recent years, the NOS and applications vendors have noted this concern and have redesigned their TCP configurations to be more flexible for application vendors and MIS teams that require TCP handling capability.
This exercise was positive because the implementation of proper network baselining methodology, along with application characterization and troubleshooting processes, identified the TCP-based issues and assisted the site MIS team to produce a successful application rollout.
One of LAN Scope's clients was experiencing a problem with a new application, and requested that the LAN Scope analysis team review the application process. Our client indicated to us that the application was running on a file server that had recently been upgraded to a Novell NetWare 4.x release, and that he thought the problem was possibly more related to the operating system release rather than the application.
The LAN Scope analysis team began this cause-isolation analysis exercise with an entrance briefing, during which we reviewed the network topology and the problematic symptom history. We also reviewed the migration history of the server as well as future migration plans for the server.
The application implemented on the server was an accounting-based application. The MIS team stated that the application had been used in other server environments at other locations without incident, and did not think that the application was causing the problems being experienced.
The specific symptom being experienced was users being disconnected frequently from the server, which was utilizing a Novell 4.x release and maintaining an SPXII connectivity between the workstation and the server when utilizing the application.
A high number of printing processes was associated with this particular accounting process and the SPXII protocol was required for connectivity stability by the application vendor.
Other parameters noted were that the file server utilized for this application was based on a robust hardware platform, but it was also noted that the server had not received any upgrades for internal hardware design prior to the 4.x implementation. It was noted, however, that the server did receive a connection upgrade from a 100Mbps half duplex to a full-duplex connection in the main computer room Ethernet-switched environment (see Figure CS7.1).
The LAN Scope analysis team took these facts into consideration upon performing our network analysis exercises. Our first exercise was to use the process of rapid baselining, during which we closely monitored certain points of workstation usage throughout the facility against the server. Next, we engaged a vector point of analyzing the main server in the computer room environment. We made this decision because the number of symptomatic complaints against this particular server were so widespread, along with the fact that the servers running this application at other sites did not have problems.
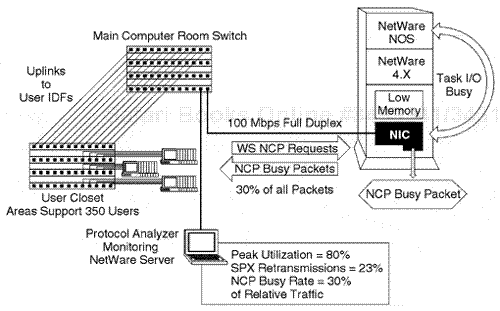
We also requested information regarding comparable configurations on the other servers for hardware and software, NOS release, and other parameters that were supporting the application. We wanted to get a complete picture of the server environments that were not experiencing the application problem and wanted to compare them to the unique server that was exhibiting application problems.
We started in the main computer room and closely monitored the server through a port-mirroring process on the Ethernet switch. We closely monitored the server for general utilization levels on the Ethernet channel. We noted that utilization levels on the 100Mbps full-duplex ports were extremely high, ranging between 50% to 60% for an average, and peaking in the 70% to 80% range. This was of concern on such a high-speed channel. We noted that there were more than 350 users connecting to the application throughout the enterprise infrastructure.
The general protocol statistics showed a high number of inbound broadcast frames from other Ethernet areas within the domain. Overall the traffic levels were extremely high against the server. We examined the physical Ethernet level, which did not show any major problems.
We next moved to upper-layer protocol analysis decoding and utilized specialized filtering against the server. It is quite common in the Novell environment—whether in standard Network Core Protocol or in NCPB—for a Novell NetWare server that when experiencing heavy I/O task load at the server application processing level to be able to generate outbound to the network a transmission frame for responses to workstations that indicate when the server is busy.
Specifically, when a NetWare request comes inbound to a NetWare 3.x NCP-based standard server or a 4.x-based NCPB server environment, there is a field set where the server can reply back and say that the operating system is too busy to respond at this time. This is referred to as a NetWare Core Protocol "delay" or NetWare Core Protocol "busy" flag, which also can be indicated in the NetWare Core Protocol burst response fields. In standard NetWare Core Protocol, an inbound request is noted as a 2222, and a normal reply is noted as a 3333. If a 9999 is sent on an outbound standard NetWare Core Protocol reply from the server, this indicates that the server is busy. A NetWare Core Protocol burst response is set at 7777 with a busy flag set, responding to the workstation.
Normally a workstation mechanism shell allows for a back off of outbound transmission when this process reply is received from a server. Depending on the workstation image configurations, which may vary within a facility, however, it is possible that continued transmissions will take place. Other parameters can also be modified in the IPX and SPX levels at the workstation shell or image area and will cause a workstation to continue to retransmit.
If the server is continuously busy and the transport level is based on SPX and the connection is maintained consistently, this impacts the server with inundated requests for the information to be returned. Depending on a modification of IPX and SPX retry timers, workstations can eventually time out. The normal process is that a NetWare workstation connects to a server and then logs on to the server environment. When application file access is required, an open event for certain files may occur, and the information should flow back and forth.
In standard NetWare Core Protocol, each request is provided with a reply interpacket transfer for the overall complete file transfer cycle. In NCPB, one request is sent out and multiple replies can be brought down from the server in a sequence mode, and then another request can be brought forward. This is a less-intensive process, because it allows the workstation to only request for certain sequences of the total transfer, and for the server to provide multiple replies. This type of situation can cause a maximum traffic level to also be impacted against the Ethernet channel.
In this particular case in this site environment, the Ethernet channel was not of concern. Both standard NetWare Core Protocol and NCPB could be fully applied to the Ethernet channel. The main concern here was that the overall internal server platform, once closely reviewed, was a major issue. In our baseline analysis exercises, we continued to monitor the NetWare Core Protocol operations via upper-layer protocol decoding. We found that the NetWare Core Protocol busy frames were responsible for more than 30% of all replies out of the server, even in the NCPB operation design. The client had recently implemented the 4.x release against the server without taking into account various memory and hardware platform upgrades that were performed at other sites on servers that were housing this application.
It was clear from reviewing information from the other servers that differences did exist. This server had approximately 25% less memory than the other servers that received the upgrade and also had a much older general platform design on processor and other bus configurations.
Based on these concerns, along with other NetWare modification parameters that were not consistent, we requested that a server build be applied to this facility that was comparable with the other facilities. The MIS team immediately concurred with our recommendations because we were able to display the output of our trace analysis results, showing a high number of NCP busy packets being generated by the server. With these clear results at hand, the client immediately applied a new hardware configuration against this facility. The new hardware configuration for the server allowed higher memory and CPU modifications as for an immediate implementation that was considered 100% compatible with the application and comparable to the other site locations.
We reanalyzed the issue and found that the NCP busy rate dropped from 30% of all frames to only 2% to 3% of frames upon extremely heavy access. The overall user community stopped complaining about the issue, and the help desk calls were brought down to a minimal level.
Overall, the accounting application was now operating in a much more positive fashion.
In this particular case, the findings were that the Novell 4.x release was applied on a server that was not properly resourced for the upgrade. By performing rapid network baselining and by investigating the NetWare ULPs following a technique to pattern match on the NetWare Core Protocol outbound busy frames based on our previous experience, we quickly resolved this concern.
The LAN Scope analysis team was requested to perform a baseline analysis exercises for large pharmaceutical company that was in the process of rolling out multiple NT Servers as an overall migration change from Novell NetWare to NT. Recently the site had only been using 2 NT-based servers and just completed a rollout of approximate 25 additional servers across their enterprise infrastructure. The servers were carefully implemented in a proper NT rollout with primary domain and backup domain controllers properly placed, and the NT trust configuration properly designed. This was based on the entrance briefing notes that we received.
We also noted in the entrance briefing that there were a high number of symptomatic problems in which users were experiencing slow performance and sluggish traffic levels after the NT rollout. Prior to the rollout, most of the users were still accessing the applications in the environment, which were basic office suite applications in a Novell operating system environment. The users stated immediately that they thought the new NT environment was not performing properly.
The NT environment up to the rollout was based on only one to two servers being tested in one area of the enterprise internetwork. The complete site node configuration interacting with the new NT server environment involved an immediate move from approximately 100 users to more than 2,000 users. This rapid change of user access having problems was of immediate concern (see Figure CS8.1).
In our entrance briefing meeting, the LAN Scope analysis team reviewed the internetwork configuration, the topology configuration, architecture, and the application environment overlay. We reviewed the symptomatic history and the recent migrations at the site. We also looked at any planned migrations for the near future.
Because the problems occurred immediately upon rollout and there were no problems logged in the test environment, we intuitively had concerns based on our previous experience in the NT environment with other clients.

We deployed our protocol analyzers in two to three user areas that were experiencing performance problems in user IDF closets. We ran through standard baseline characterization, and noted average to peak utilizations to be in check; however, with peak transitions occurring in the 80% level for brief, but bursty periods of 1.2 to 2 seconds. This was noted on different switched Ethernet channel areas and shared Ethernet areas throughout the facility. All the standard Ethernet characterizations for utilization, protocol percentages, and Ethernet error rates all appeared to be within check. It was just that certain protocol percentages in broadcast form that appeared to be bursty as related to the TCP/IP, NetBIOS, and SMB protocol stack normally engaged for Windows NT.
Upon final decode in various site IDF closet session areas, it appeared that most of the bursty transitions pointed to a definite concern with SMB broadcast levels. After completing standard utilization, protocol percentage, and physical error rates, our focus was upper-layer protocol decoding. In the broadcast percentage statistics of our protocol analyzers for all the areas tested, we noted that SMB showed bursty protocol sequences and intermittent transitional burst transfers of 22% broadcast that quickly coincided with utilization peaks of 70% plus in the areas being sampled. We stopped all our network analyzers and synchronized time sequences and parameters for display view. We turned on network utilization within the data-trace review along with relative time, and upper-layer protocol data viewing on SMB.
We noted that all peak saturation levels that we were concerned about, and that would be considered transitional and high in the broadcast level, had SMB protocol as active. In this case, we also noticed immediately that SMB vector type was noted as a SMB Mailslot Browse, which we were familiar with from previous exercises. Upon Windows NT implementations in peer-to-peer NOS environments, it is normal to have file and print share services as active, which will cause periodic SMB Mailslot Browse commands to occur. This type of browse or broadcast is usually necessary for peer-to-peer networking.
In this particular environment, based on the primary and backup domain controller layout and file and print share application configurations, browsing services were not required. Peer-to-peer networking was not engaged and the browse services were extremely high. The rollout increase from 100 users to more than 2,000 users generated a higher SMB browse broadcast frame process on a consecutive basis that was not in direct parallel with the requirements for this particular network.
What was actually occurring in the facility was that extremely high SMB broadcast levels had been induced in different Ethernet physical shared areas and switched areas throughout the facility. Because the facility was not yet engaging broadcast Layer 3 filtering in any area, and the site MIS team also was not aware of the SMB broadcast level, what was occurring was an effect of an outbound local and wide area network storm sequence of SMB broadcasts that were not expected. These traffic levels were negatively impacting other areas of the network such as standard data transfers and usage for other business applications throughout the facility.
This type of SMB broadcast was immediately pinpointed as the cause of the problem that was affecting performance throughout the facility.
We immediately requested that the file and print share services were turned off for the devices and workstations where peer-to-peer networking services were not required, and only left on in the server environments where it was required. The NT support team at the site closely reviewed the situation and immediately understood what parameters were required for change control to modify this configuration and adjust the SMB broadcast levels to a minimum for SMB Mailslot Browse operations.
Upon implementation of the changes, the LAN Scope analysis team was asked to re-analyze the issue. We moved through the site to analyze different Ethernet areas and found that the broadcast levels had dropped from 26% to 3% for SMB.
We immediately noted that we had a success measurement vector that compared with the previous sampling session during the troubleshooting phase. We provided our findings to the site and we requested that the application environment be closely monitored and reviewed by the help desk and also that the user community be interviewed.
We noted that performance appeared to be enhanced throughout the facility upon immediate implementation of the change. It took several days before all the issues were communicated in a clear fashion, because of perception issues that were already present about possible slow performance in the new Windows NT Server environment. After the MIS team had communicated a change-control modification to the user community, the user community felt more comfortable with the new NT environment. General access of the NT environment continued in a positive fashion, and the issues were resolved through the baselining exercises that LAN Scope performed for this client.
This type of occurrence is still common in NT implementations, because this operating system has strong inherent capabilities that can be applied in a variety of ways, depending on specific requirements of the client. Even though this is a simple problem, this type of concern is a problem that could likely occur in critical NOS environments that are using heavy Windows NT infrastructure.
Network baselining was extremely useful in this particular exercise, along with the process of investigating upper-layer protocols related to the Windows NT protocol stack, which utilizes a heavy amount of SMB transaction calls for general access across the workstation and server platforms.
A large advertising firm based on the West Coast contacted LAN Scope regarding a routing problem. They were using a high number of applications that were based on AppleTalk and Novell server operating system environments. Most of the application data was housed on various Novell file servers within the infrastructure, even though different AppleTalk networks were segmented and connected throughout the facility.
The advertising firm, located in the suburbs of Los Angeles, had a four-office location design against the enterprise internetwork architecture. Each independent office had different advertising departments, such as Development, Design, Sales, and so forth placed in each one of the offices. The offices were considered similar in operation but as distributed to location, depending upon advertising sales requirements.
The different location offices were connected through Novell multiprotocol routers for an initial configuration throughout the facility. Most of the Novell NetWare file servers at the facility had been in place since the mid-1980s, but had been upgraded for hardware, software, and NOS release. Much of the server environment was still based on 3.x in many of the different Novell areas (see Figure CS9.1).
Based on the inherent operation of the business and the migration cycle of the network, there were many different servers implemented in distributed fashion throughout the four facilities. Also, the Novell servers were not controlled by any centralized MIS department. Each location had its own MIS administrator, and they worked with each for general connectivity and transfer of information related to advertising design, sales models, and so forth.
Eventually the total Novell server environment climbed to more than 60 Novell file servers for the complete company and the wide area sites in the Los Angeles suburbs were still connected through a Novell internal routing process in the Novell multiprotocol router design. Because of the number of Novell file servers across the four sites, there were many different user requirements at each location to access various servers to obtain advertising design files, sales information, or client history files.
Specifically, there was a tremendous amount of interaction across the four sites between users in the workstation environment, which totaled about 800 users and 60 file servers at the four sites. This was also taking place without the servers being centralized for a particular design.
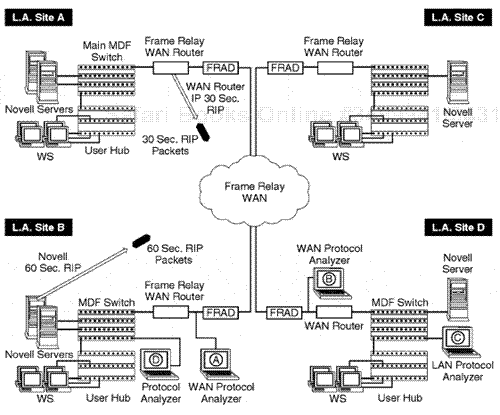
All the Novell file servers were running SAP on 60-second intervals to update services to other Novell file servers. In this particular layout, they were also running Novell RIP on standard 60-second updates from the original Novell 2.x and 3.x design. The Novell multiprotocol routers were also participating in the Novell RIP updates for general communication.
Stabilization was in place in the facility, and most of the workstations throughout the facility were able to locate different Novell file services or applications running on different file servers, because the Novell SAP and RIP processes were provided clear 60-second updates as to all the distance vector routing protocol tables in the various servers. RIP in a Novell configuration is based on a 60-second update and is based on a distance vector routing protocol sequence. As explained later in this book, the distance vector routing protocols allow for an understanding of the link vector to a particular service or router or device stored in a routing table of a router, and the actual time or metric or distance to that device. In the Novell metrics, the distance vector routing protocol is applied on a 60-second update. What this means is that each one of the file servers and the routers throughout the facility was sending routing updates on 60-second intervals to ensure that each routing table in all the cross-site routers or servers had information related to other servers or routing services through the facilities so that all devices could be located by different workstations or servers as required. Overall, the internetwork in terms of the Novell infrastructure could be considered "hooked" or consistently updated for all services and routing channels available.
Recently the site had a requirement to increase their WAN bandwidth because the T1 circuits were showing extremely high utilization, at the 80% to 90% level. Performance on the WAN was also being perceived as negative by the user community. This problem started to occur over a one-year period during a consistent growth period, when the number of advertising designers increased from 100 to 300.
The MIS team immediately worked on a plan to migrate the facility to a WAN infrastructure based on Frame Relay, which allowed for a Committed Information and Burst Channel rate to be implemented across the facility, and to remove the meshed T1 point-to-point architecture between the four offices in the remote Los Angeles location. The implementation was effected through a router and WAN vendor in a positive fashion. WAN routers were implemented at each site and the Novell multiprotocol routers were removed. The four sites were interconnected through the new WAN routing scheme. The routers were considered to be a robust platform and had an extremely high throughput rate that would allow for a much higher performance level. Also the bandwidth levels were actually doubled by the Frame Relay intersystem switching cloud design between the facilities provided by the WAN vendor.
As soon as the wide area implementation was completed, connectivity problems started to be exhibited that were not present in the preceding design. Specifically, there was an immediate problem with certain workstations finding certain file servers or services that were previously available.
Even though the WAN levels appeared to show a positive bandwidth increase on the platform configuration, the main concern was that designers could not connect to file servers or get critical files, along with the sales team not being able to transmit important information. These problems were immediately present upon implementation of the new WAN platform, which was cut-over in just one business weekend.
The LAN Scope analysis team was immediately contacted to troubleshoot this issue. We arrived on-site with an emergency troubleshooting focus. We conducted a quick entrance briefing with the client, reviewed the previous topology and architecture configurations, as well as the migrations that took place with the WAN. Because this was a client of ours, and we understood the internetwork intimately, we immediately proceeded with troubleshooting exercises. We placed a WAN analyzer between two of the key locations where two of the WAN router channels were implemented. We also placed LAN analyzers against the LAN areas within those particular environments, which were based on Token Ring and Ethernet architecture. Several file servers were closely monitored by the LAN analyzers. The WAN channel was monitored via our two WAN protocol analyzers.
Our immediate focus was to examine utilization levelson the WAN medium, to verify the bandwidth concerns. WAN utilization levels appeared to be in check, with utilization below 30% between all sites, which was extremely low compared to the vendor reports for the previous T1 circuits. We examined protocol percentage levels and noted normal percentages as expected for AppleTalk and Novell NetWare. Our main concern was that the TCP/IP RIP appeared to be prevalent, which was not noticed before in previous analysis sessions.
We moved into our upper-layer protocol process to examine the routing updates between the new routers that had been implemented. We noticed that RIP updates were occurring on a consistent basis between the two routers. We also noticed that certain RIP updates were also seen on the LAN, on a consistent basis.
Upon further investigation of our analysis data, we finally observed that the statistical screen of our network analyzer showed a high number of routes confirmed and route cancelled errors, where routes were being recycled on the new WAN routers. We also saw a high number of NCP "file server not found" errors in the upper-layer NetWare Core Protocol decoding process.
With this type of occurrence, we further analyzed the NetWare Routing Information updates and noticed that they were occurring on 60-second intervals. The routing updates were also examined on the routing channels between the WAN routers. The new WAN routers that were being sampled showed a 30-second update sequence.
From these findings, we closely reviewed the configuration and found a condition to be present at this facility that we had handled before at other sites. The Novell implementation of Routing Information Protocol is based on a standard 60-second update. The new routers that were implemented against the WAN were based on a 30-second update. The new WAN router and the Novell file servers at each one of the four remote sites were intermittently canceling the routes by flushing the routing tables in the routing update configuration against the new standard IP RIP on the new router platforms for the WAN. This caused an intermittent condition in which certain routes would be unavailable and also made specific devices unable to be located in the router tables. This problem would be prevalent when certain workstations would have a default router point to the WAN router to find a remote server that housed an application or key sales information for the facility.
Based on this finding, we recommended to the MIS team that they adjust the new routers throughout the infrastructure to a 60-second RIP forced update. The other option was to modify the servers to IP-based 30-second RIP updates. With this implementation being of concern because of different patch upgrades and NOS upgrades required throughout the facility in the future, the client decided to back off the WAN routing scheme from an IP-based routing scheme to a Novell-compliant RIP scheme of 60-second intervals. They thought this was a simpler modification and contacted the WAN vendor.
The WAN vendor applied the configuration to the WAN router protocol scheme for a 60-second update. This allowed for a more consecutive routing information distance vector update between all of the Novell servers running RIP and the new WAN routers between the four sites.
We immediately reapplied a post baseline review of the facility, and found that all servers were being located and all key services and applications could be accessed from all four location offices. With this finding, we immediately identified that the Novell and IP RIP incompatibility had been the issue, and provided a final report to the client.
Our technical synopsis was that the WAN routing scheme, although implemented on a standard IP-based 30-second RIP update scheme was normal, but it was not 100% compatible with the current configuration of the Novell SAP and RIP scheme.
The final finding was that the modifications had to be applied either to the Novell server environment or the new router environment. The fact was that modifying the Novell server environment was more complex than modifying the router environment, until the future Novell migration cycles were completed, such as NetWare 4.x and NLSP implementations that were planned.
This baselining exercise was successful because we performed a standard baseline to verify the WAN channels and used upper-layer protocol analysis against the Routing Information Protocol updates and general upper-layer Novell protocol communication for server location vectoring. The baseline analysis process allowed for an immediate cause analysis of this particular issue.