
With the onset of the new millennium, networking has entered a new era. Network stability, reliability, and performance is a must. It is our mission. We, as network analysts, have a clear charter. We must use our inherent and finely developed skills of abstract-geared network astronomy to systematically view network point-to-point dataflow and then to analyze complex network communication sequencing. In this process, we must extract accurate metrics to surgically expose "real-world" issues that affect our network's operation and performance. We must then closely review the extracted issues to develop a concise technical synopsis supported by a clear-cut recommendation.
We then face the task of inserting the results in a final report that accurately displays a network baseline study. The final network baseline study report must accurately reflect a network's current state of operation. Therefore, we must ensure that statistical measurements which characterize the data workload applied to our network infrastructure, reflect our findings and recommendations. This methodology, which enables us to utilize metric reflection to extract relevant issues, is critical for the process of building a true proactive and reactive view of the network design integrity, network operational health, and final end-node–to–end-node performance. Figure 1.1 represents a high-level concept of network baselining.
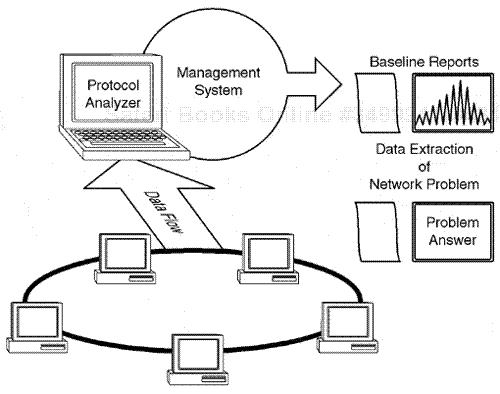
The galaxy of network infrastructure that we have created is now multi-symmetrical. The endpoints, which communicate throughout the galaxy, are not always visible to the average eye. Our networks have evolved to internetworks. Many complex topologies and protocols now interconnect for the express purpose of transmitting data from one point to another and gaining access to remote resources on different end systems. In a perfect world, our goal is to transmit the most data in the fastest amount of time with absolute fluency. This concept can be thought of as flawless network communications.
We must use a specific methodology to plan our vector for a focused network baselining workflow process. This methodology must include a structured data-acquisition plan via protocol analysis. After the data-acquisition plan is in place, we must then use a structured workflow-analysis, data-gathering engine to ensure that we gather all essential information. At that same time, we must be dynamic enough to cross-examine all the required metrics that dictate changes in our data-gathering process. We can obtain the metrics that we use from a view via a network management system or a network protocol analyzer. As we capture the metrics, we must review the data closely through exact protocol analysis specifically to extract problematic and exception-based dataflow to identify issues. To develop a defined technical synopsis, we may then adjust our final data-acquisition process to actually verify issues. This process may require us to closely adjust our focused viewpoint of the network galaxy dataflow with our protocol analysis scope and tools via measurement processes, such as filtering and triggering. After we have truly isolated a network-affected issue and the applied cause, only then can we start to draw possible conclusions or to offer recommendations.
We must always keep in mind that the goal of network baselining is to use quantitative statistical measurements to expressly identify key network issues relevant to our mission.
Now that we have defined network baselining, let's move forward with the dynamics of data capturing and obtaining a true network baseline. Network baselining has always been my goal, and has now become a reality as well as a requirement in our global networking industry.
Every day on an internetwork, many scenarios that require on-the-fly decisions by a network analyst surface. When faced with a network problem, the analyst's immediate impulse is to react. Even in the quiet moments and days, when standard technical tasks are planned and the network is stable, an analyst ponders ways to enhance the network's overall performance and operational features. This is the time when the analyst considers adding new products or features to a network to make it more effective.
Network optimization refers to using the art of network baselining to obtain network metrics to enhance the network's capability to reach a higher altitude of dataflow energy (DFE).Maximum dataflow energy (MDFE) is defined as sending the maximum amount of data in the fastest amount of time with optimal fluent protocol cycles (see Figure 1.2). A plateau of MDFE can be defined as "perfect network communications."

Many reasons compel us to optimize a network through the art of network baselining. One main reason is reactive problem analysis. Many of us face day-to-day troubleshooting issues that require an immediate response. Throughout this book, the discussion identifies specific ways to use protocol analysis and network monitoring tools to resolve critical network problems and to attack this monkey on our back that we constantly encounter.
Network baselining, for example, enables us to isolate certain low-level topology and medium-based errors that may be causing intermittent problems that affect our network's stability. By using protocol analysis to locate the devices that cause these errors when the error generation cycle is dormant, we can partially optimize our network.
Another reason to perform proactive network analysis is to ensure that our network is always operating in a stable and reliable fashion. Considering the number of reactive network problems that we must face on a daily basis, this may seem an impossible task. The path to achieving the goal of using consistent proactive network sampling in our daily schedule is always impeded by the time and resource restraints that result from constantly handling daily network problems. We can actually use network baselining and optimization techniques to reduce the occurrence of reactive problem situations and move into a proactive stance.
By using daily trend analysis of certain metric statistics, for example, we might locate network workstation logon-sequence inefficiencies. By using specific techniques, such as filtering of a user via protocol analysis, we may be able to extract data that shows clients redundantly generating protocol calls on certain server-based files while accessing servers. If we capture this event, we may also find that the protocol-redundant events actually increase the user's startup time (that is, the time it takes the user to log on to the network). Next, by cross-threading our analysis process and checking other key measurements, such as peak utilization, we may also find that this event negatively affects endpoint connection integrity by increasing the use of a complete network area and causes further problems in other application access modes in a certain network user domain.
Another reason to use baselining techniques for optimization is to monitor network modifications and new product implementations. As network analysts in today's networking world, we must rapidly implement many changes on our networks. Some of these changes or implementations are planned cyclical migrations, while other changes are required on a dynamic and immediate basis to accommodate unpredicted network operational cycles or business application changes.
Later in this book, you learn actual techniques that enable you to wrap a working methodology based on protocol analysis around a network modification and implementation cycle process to ensure that network configuration changes and product deployment occur in a smooth and solid process.
During the course of network migration planning and implementation, it is important to recognize the benefits of network baselining—specifically, that network baselining enables us to predict how a new migration process being implemented may impact a network. It is also critical that we verify whether the change to configuration or product implementation is properly deployed against our network infrastructure. We must use protocol analysis in a pre- and post- mode to ensure that we actually realize the predicted effect or benefit of the change or product implementation cycle. Again, it is vital that other operational areas of our network environment not be negatively impacted when the change or product implementation is activated in our network.
Network baselining enables us to use key analysis methods in a network migration cycle to optimize a network.
By properly using protocol analysis to focus on endpoint-to-endpoint dataflow and to monitor reactive, proactive, and network change implementation cycles, we can ensure network stability and reliability. After we have become consistent and technically competent in the required protocol analysis techniques, the overall network that we support will benefit from our own internal technical skills. By studying the technical measurement and data-decoding techniques presented in this book, you will significantly enhance your network support skills. As analysts, it is imperative that we develop a real network baselining methodology that inherently focuses on constantly optimizing our complete internetwork.
Finally, one of the most important goals of network baselining is to predict the effects of application deployment on an internetwork. Today, application deployment is the key activity that drives the network design, implementation, and support cycles of the MIS community. Network analysts know with certainty that the complete internetwork infrastructure exists primarily to employ critical business applications. Applications are the entities that drive the need for a strong foundation within local and wide area network (LAN and WAN) infrastructures. It is crucial to understand the importance of the application entity to the business and to ensure that steps be taken to accurately measure the impact of applications on a network infrastructure.
It is critical to ensure that the network infrastructure can accommodate the required applications of our business. Again, we must never forget that the entire reason for network infrastructure is to support business applications.
Network baselining involves a set of complex analytical steps that comprise part of a complete methodology.
As noted, this methodology requires that we understand how to plan for data acquisition, perform actual data acquisition via protocol analysis, and report on our complete data-acquisition cycle. After we have completed this process, it all comes down to ensuring that we can support the flow of critical business applications. Having said that, we can now discuss network baselining goals. (You will learn how to achieve these goals later in this book.)
Foremost, the network must be stable, reliable, and must perform. We must ensure that business applications perform in a positive manner. We must also predict and gauge the impact of applications on the network to ensure that the internetwork can support the application component. We must maximize all our network technologies, and we must ensure that our network communication channels are available and can handle the capacity required for the business dataflow. All network devices and endpoints throughout the galaxy of our network infrastructure must be interoperable.
To gain the full return on our investment, networking technology must operate at peak performance. After all, networks comprise the critical infrastructure that makes global networking possible.
With these facts clearly in mind, the discussion now turns to the technical knowledge required to obtain and effectively use network metrics. To determine a network baseline, we must develop a skill set in key analytical measurement areas, such as protocol analysis dissection and decoding, as well as a process methodology.
It is a new day. We have many new network implementations planned. We have a schedule. Let's keep it. No, let's not. Why don't we take a quick break? Let's review the implementation plan. How many of the projects scheduled are really required? Do we need to perform all the steps we have outlined? Did we verify whether the actual products offered by our vendors are real requirements? Did our vendors and integrators draft the vector for our next implementation cycle or did we pave our own network migration path.
Many new implementations are painstakingly thought out, but many are not. That's okay, it's reality. But we have to take a break. Let's grab the wheel. Let's take the opportunity to own our network implementation cycle. It's where we live. Is the network so complex that we can't take a minute, a day, or a week to actually review the required implementation? It would be helpful to our mission. To truly manage new network implementation, we should use the art of network baselining. By using network baselining, we can review our implementation cycles. We can verify network implementations by using pre- and post-protocol analysis sessions. A definite component of network baselining is using protocol analysis and certain network metrics as gauges to properly plan and evaluate the success of network implementations.
These network implementations include such things as new products that we might introduce into our internetworks on daily cycles. We might also deploy new products, such as workstations, servers, new routers, and so on. We might also make changes to such things as the workstation software image, network interface card (NIC) drivers, and switch firmware. Network baselining enables us to verify these types of implementations. Many new products have specifications and benefits designed to be brought forward through actual implementation.
Did we realize the expected benefit? That is the question. Protocol analysis enables us to measure an area of our network as it relates to new product implementation. Measurements can be taken prior to deploying the product on the network in a pre-protocol analysis mode, and a comparative measurement can be taken after the implementation in a post-protocol analysis mode.
If we schedule a new server to replace a current server, for example, we must qualify the actual benefit of implementing the new server. Let's say, for this example, that the new server is required to generate higher effective throughput and faster response time than the current server (as related to housing and serving a critical business application). In this case, it would be beneficial if prior to deployment we were to engage a protocol analyzer in a pre-measurement mode to examine the current server's interpacket response time in handling inbound and outbound file Read and Reply sequencing. We would also benefit from checking the server's effective file throughput(EFT) and channel performance when multiple end nodes actually access the business application. For the purposes of this discussion, these are key measurements that enable us to view end-to-end data transfer performance criteria. (You learn how to measure delta response time (DRT) and EFT later in this book.)
After the new server is implemented, it would then be beneficial from a post-protocol analysis standpoint if we were to closely monitor the new server for the same measurements. It may be very clear that the new server does in fact generate a higher effective throughput and a faster DRT when our user base accesses the critical business application. We can only see this, however, through the process of pre- and post-protocol analysis. Figure 1.3 shows the use of pre- and post-protocol analysis to thoroughly review the impact of a new implementation or change on a network.
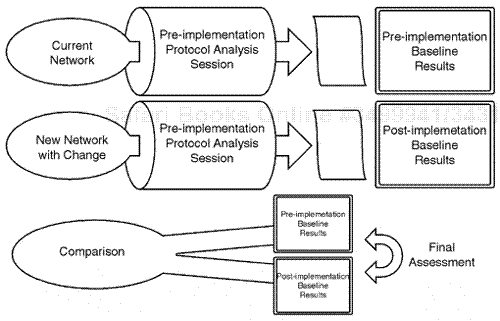
These performance components, although inherent through many network management systems and high-end application monitoring systems, are only truly seen in an intricate and exact way through accurate pre- and post-protocol analysis. This book presents the actual methodologies and specific critical statistical measurement steps required to view this particular area of network implementation so vital to our network infrastructure and performance.
Circumstances may arise, for example, when we face a technical task that calls for a configuration change to accommodate our network operation, or for the implementation of a new product. Because of the real-world rapid work cycles in MIS, we may not always have time to conduct a preplanned protocol analysis session for statistical measurement prior to a change. It should always be possible, however, to use protocol analysis after a change in configuration to benchmark the effect of the change on the network environment. The important point here is that protocol analysis, when engaged properly against our network, enables us to view the product implementation and configuration change in a focused process mode. (Otherwise, we would make a limited rudimentary benchmark assessment of the network environment by just logging daily operations or by monitoring the end user's perception, perhaps by reviewing a daily help desk log.)
Keep in mind that network protocol analysis via structured techniques enables us to use statistical quantitative measurements to view our network implementations on a proactive and reactive basis. Many devices, products, and applications, along with software modules related to operating systems, are implemented on our network on a daily, weekly, or monthly basis. Many of these implementations are scheduled. From my many years of field experience, it is clear to me that many of these implementations and changes are not monitored closely throughout their implementation cycle. Is this because we do not have the time? Or is this because we do not have the necessary structured processes within our technical workflow model? Or perhaps we have not focused on the value of protocol analysis as an overall enhanced insurance related to our overall network operation and stability. The final message is simple: It is critical that we use protocol analysis and statistical measurements through structured network baselining processes when implementing a new network product or when changing a network configuration.
We must remember this important fact in our future project management!
"Hey, I got a call from the help desk to troubleshoot a performance issue. I have a busy day implementing a new router. I'll hand the ticket to the Level 1 user support team; they will close out the issue. It will be a non-factor tomorrow. Fewer problems, fewer headaches, right?"
"Well, let's see, what if the same problem comes back tomorrow. That will not be viewed positively. We can mask the occurrence in this week's support meetings; and if it comes back next week, then we'll call in the top guns."
As an industry consultant who specializes in network baselining, these situations mean more business. We're going to get another call for emergency protocol analysis.
In today's network environment, in the fast climate of MIS support and operations, however, it is critical that networks be supported in a reactive and rapid fashion. To do this, we must take responsibility for a network reactive situation and must establish an understanding of the term mean time to repair (MTTR). MTTR refers to the time required to resolve or repair a network problem. The term MTTR is used consistently in the glass-house support world of mainframe computers as a measure of uptime factors in computing.
We must minimize the amount of time required to resolve critical network issues in LAN and WAN environments. Just as this was part of the mainframe environment and also related to mini-network support, it is also a real factor in today's network environment (as related to internetwork support for critical business applications).
Consider, for example, the CIO who puts his business reputation on the line, guaranteeing that the internetwork will support a new critical business application. Well, we (as network analysts) have to watch his back. It's our job. Better yet, it's our mission, because it's real life and because we care. So what's the deal?
We can use network protocol analysis to react to problems and also for extraction analysis. This statement is a clear fact. By using protocol analysis and properly deploying network analysis tools, we can analyze and troubleshoot most critical network issues and then find and propose specific recommendations at a rapid pace.
To accomplish this, we must use an exact methodology. The methodology must implement rapid network baselining to move quickly through statistical measurement processes. After we have moved through the statistical measurement processes and have developed a benchmark, we can then move forward with exact problem extraction using protocol analysis techniques. You can read about these techniques throughout this book. The key element to understand, however, is this: Workload characterization statistical measurement via network baselining is the front-end process to actual problem extraction!
Too often, we turn to conventional methods of problem determination to troubleshoot a network problem (because those methods seem familiar and easy). We must learn to rapidly measure our network infrastructure through baselining techniques, however, to extract data that clearly points to an exact cause of a network problem. This is the only way we can truly step to the plate when attempting to hit a home run on reactive problem and extraction analysis. Figure 1.4 represents the high-level concept of using protocol analyzers and associated management systems to rapidly troubleshoot network problems.
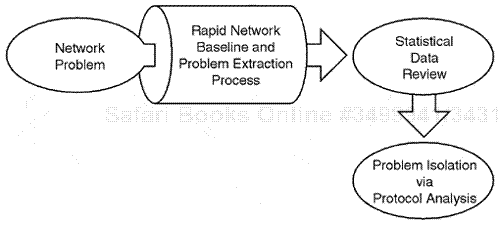
Throughout this book, you learn how to use a protocol analyzer to resolve critical network problems. Simply put, however, you must follow a sequenced process in which you use workload characterization measurements to review key statistics, such as utilization, protocol percentages, error rates per topology, and so on, before actually reviewing the analyzer trace data to extract the problem. After you have extracted the problem, many other techniques enable you to analyze the data to determine the exact cause of the problem. These techniques also entail a structured and regimented methodology; however, they also demand a free-form dynamic mental process whereby you actually thread data to the network problem to prove the exact cause. This book presents other processes that are required to document the data items extracted via protocol analysis. To ensure that the final baseline report correctly represents how certain statistics and actual data points to the cause of a network problem, it is important that you use these documentation processes. More technical material appears later in this book (on both network documentation and key items to document in a network baseline report).
It is critical to use network baselining to review and document certain statistics on an ongoing basis (even when faced with emergency problems on a network). When troubleshooting, network baselining enables you to determine the exact problem. By using the network baselining methodology, you can develop an "on-target" technical synopsis of a problem's actual cause and can then make clear-cut recommendations to solve that problem!
In the network support world, rarely do we have time to think proactively. When we do find an opening in our schedule, sometimes it's nice just to focus on reading the current issue of a network magazine. As important as keeping current with the literature is, perhaps (if we can push ourselves) it may be better to take any extra time to think about what proactive internetwork analysis can do to ensure our network stability, reliability, and to enhance performance.
Is it possible to actually use our internetwork analysis tools in a proactive way for our network operation? Are the network analysis tools properly deployed? Let's take a look and see. Have we set up the network analysis and monitoring tools and adjusted them in such a way that the configurations and thresholds meet our unique network dataflow? Are they set on default? Or are they set in such a way that enables us to determine whether issues that affect our network stability occur on a daily basis?
Is it time to determine whether some of the network tools that we have implemented are properly integrated? Are they interoperable? Have we created a network management and analysis tool umbrella that truly cross-links and extracts the critical statistical metrics and data from certain tools that are valuable for our viewing capability? Have we tied our tools together in a proper manner and allowed them to intersect at a common area so that we can actually see the required statistics and data from a centralized viewpoint? Are the tools configured so that we can extract the required data for final baseline reporting?
Do we understand that the tools we have deployed are extremely powerful? Do we thoroughly understand these tools and use them to their maximum? We face these questions and challenges on a day-to-day basis.
A good time to become proactive is when all network operations are stable. By focusing on centralized internetwork analysis in a proactive stance, we may have a unique opportunity to get a strong handle on our network's current operation. By doing so, we can help to ensure the network's future stability, reliability, and performance. Remember that time may not be available in the future for this important process.
To move forward into a proactive stance, we must first review our network analysis tools. We must understand how they operate, and how they are configured, both internally as individual tools and tied together and applied against our unique network design. When we understand these facts, we then have the option of moving forward, using the tools in their default operation or possibly using a modified or adjusted setup of the tools that may provide for a better fit with our network. In other words, if we are at a point where we understand how the tools are configured and adjusted, it is then key that we move forward with any final adjustments required to enhance their effectiveness for our internetwork and our dataflow operation.
Most network monitoring and protocol analysis tools have a standard (or so-called default) configuration. In the default configuration, the tools may only be set up to gather and display certain types of statistics and data. Each network has a different design. An analyst can adjust certain parameters on most tools and thereby gather additional information and possibly display the results in a unique way. We must configure and adjust any tool we use for our internetwork operation in such a way that the tool relates specifically to our actual dataflow.
In summary, it may be necessary to modify the tools to form-fit our environment. This may require us to actually review the tool's configuration design, review the tool's thresholds that set alarms or display data, and adjust the tools to ensure that they can properly measure the actual dataflow within our unique network infrastructure.
After we have optimally implemented all the different monitoring and analysis tools, we must consider whether any overlap in features or operation exists among the tools. Some of the tools may include network management systems, application modeling tools, protocol analyzers, and predictive analysis tools.
The discussion here focuses mainly on the operational cross-threading of different tools. This relates importantly to proactive monitoring and data-analysis extraction. When we understand whether any overlap in features exists, in which the different tools represent common data types or statistics, we can then identify the overlap metrics that are more powerful in certain tools and less useful in other tools. Next, we can eliminate any non-required output from certain tools. By so doing, we can focus in a more proactive fashion and use the tools to their maximum potential, not becoming overloaded with redundant similar statistics and data from many different tool sources. Figure 1.5 shows the process of using protocol analyzers and high-level network management systems to produce structured baseline reports that include statistical measurements and data related to the network baseline process.
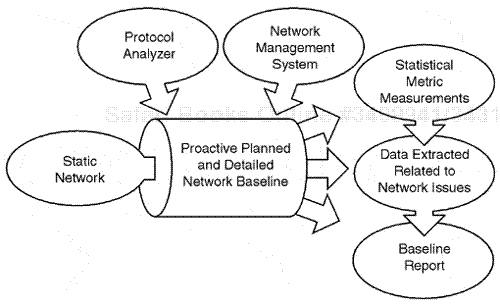
The final area to focus on in proactive analysis is network baseline reporting. We can have all the data and statistics in the world, but if we cannot accurately pull the required data from the tools and use the information to create a simple focused report on real network issues, the tools are useless. We have to learn how to drill down through all the statistics and data and find the relevant information. Next, we must extract the required proof to support our findings. Then we have to apply the information to a simple and focused documentation process to create a network baseline report.
Throughout this book, you learn key requirements of network baselining. We discuss in detail the monitoring and analysis tools most effective in today's networks. You learn how to use these tools to measure the network, using specific techniques that involve a real, working methodology. The art of data extraction will become your most valuable skill. Finally, you learn how to apply the gathered data to a real reporting process to create a network baseline.
At this point, you should understand the need to use proactive internetwork analysis. Proactive internetwork analysis is the most positive step you can take to ensure that your reactive problem cycle is minimal and that the application environment impacts on your network infrastructure in a positive manner. As discussed earlier, you should be prepared to use proactive internetwork analysis for new pre- and post-analysis implementation cycles.
We must never forget a critical thread throughout proactive internetwork analysis: Quantitative and statistical measurements are only real if an analyst can surgically remove the required data to present important issues to the appropriate technical and management personnel!
We must also never forget that our internetwork dataflow is the core of our business infrastructure. As we move forward, we must keep in mind that key parties must be able to view this data and make critical business decisions. Although some of these parties may be technical personnel, some may not be. Either way, we must create both critical exception reports and complete network baseline reports. Some of these reports may be reactive, but many may be proactive. Overall, by correctly using proactive internetwork analysis techniques, we can create a vanguard of energetic information to help us to ensure that reactive issues do not come to the surface.
Our job is to use the art of proactive internetwork analysis to extract the important information required to ensure that the network is both reliable and can support the business.
As mentioned earlier, application deployment is now one of the more critical technical cycles related to network infrastructure that we must face on a day-to-day basis (in terms of network design, implementation, and support). After all, application deployment across the infrastructure is the primary reason for a network's being. Early in networking, it was common for network users to launch a business application from one central file server. As networking moved forward during the late 1980s and throughout the 1990s, many network applications were structured with a centralized server design but were deployed in abstract fashion across internetwork architectures. This became more of a factor in client/server-based network deployment architectures. This natural evolution of application deployment has made network support that much more complex.
When applications are deployed in a centralized server process, it is much easier to track application usage through server and network operating system management processes. When the deployment of server applications became more abstract, it was due to the cross-pollination of application modules throughout internetwork infrastructures. As application component modules were spread across multiple points, such as client workstations and multiple servers, the support issues became even more complex.
Specifically, to actually troubleshoot or analyze networking issues related to application performance or application usage in a decentralized network design, we must deploy and use a troubleshooting process across many different areas of our internetwork infrastructure.
Because many applications require custom protocol flow sequencing through more than one server in today's networking architectures, we must deploy application modules across many different endpoints of our internetwork galaxy.
In many instances, application usage requires a launch from a specific client endpoint, and then an initial connection to a specific server. After the initial connection has been established, the dataflow may sequence and chain and process associated dataflow threads through multiple servers within an internetwork infrastructure. As this occurs, it is quite a complex task to actually track this type of dataflow. The only way to do so from an accurate technical standpoint is by using strategic protocol analysis techniques. This specifically means using protocol analysis dataflow capture techniques at multiple network area intersection points. This requires a skill set that includes an in-depth understanding of the methodology of network protocol analysis positioning for the express purpose of application characterization.
Throughout specific sections of this book, such as in the chapters on network baselining and the subchapters on application characterization and modeling, we identify the technical steps required to truly study today's application environment.
You learn how to use network analysis data-acquisition planning, network analyzer positioning, and application decoding and modeling techniques required to accurately characterize the applications deployed across today's internetworking environment. Figure 1.6 shows the use of protocol analysis and application monitoring tools to determine how an application will impact our internetwork infrastructure.
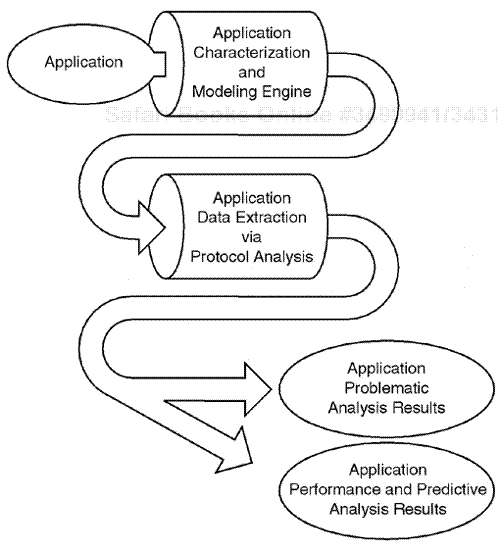
Techniques discussed include how to capture an application and review the events that occur within an application's process. Among these events may be sequences, such as a user connection, logon, application file access, application printing or scanning, and other specifics related to a certain application. You learn how to track the application's process through a technique called frame marking. The frame-marking techniques presented in this book teach you how to capture application data in such a way that you can go back into the traces at a later time and extract specific symptomatic problems and statistics related to the application (and relevant for certain analysis exercises).
One of the specific focus areas is measuring how applications impact the specific network area on which they are deployed. This requires using such analysis techniques as marking time sequences and data-transfer blocks for cumulative data. After reviewing these techniques, the discussion turns to how to investigate the dataflow for the specific chain and threading sequences through multiple devices and servers. The only way you can accomplish this is by applying the precise art of application characterization analysis.
Determining how applications impact the network is one of the most critical reasons in today's internetwork infrastructures to engage the art of protocol analysis and to present network baselining as a high-level umbrella process. It is essential to ensure that we are properly designing, implementing, and supporting today's business applications on our networks!
Chapter 2, "Baselining Goals," presents specifics on some of the key goals of network baselining.