
6
Coding with Streams
Streams are one of the most important components and patterns of Node.js. There is a motto in the community that goes, "stream all the things!", and this alone should be enough to describe the role of streams in Node.js. Dominic Tarr, a top contributor to the Node.js community, defines streams as "Node's best and most misunderstood idea." There are different reasons that make Node.js streams so attractive; again, it's not just related to technical properties, such as performance or efficiency, but it's more about their elegance and the way they fit perfectly into the Node.js philosophy.
This chapter aims to provide a complete understanding of Node.js streams. The first half of this chapter serves as an introduction to the main ideas, the terminology, and the libraries behind Node.js streams. In the second half, we will cover more advanced topics and, most importantly, we will explore useful streaming patterns that can make your code more elegant and effective in many circumstances.
In this chapter, you will learn about the following topics:
- Why streams are so important in Node.js
- Understanding, using, and creating streams
- Streams as a programming paradigm: leveraging their power in many different contexts and not just for I/O
- Streaming patterns and connecting streams together in different configurations
Without further ado, let's discover together why streams are one of the cornerstones of Node.js.
Discovering the importance of streams
In an event-based platform such as Node.js, the most efficient way to handle I/O is in real time, consuming the input as soon as it is available and sending the output as soon as the application produces it.
In this section, we will give you an initial introduction to Node.js streams and their strengths. Please bear in mind that this is only an overview, as a more detailed analysis on how to use and compose streams will follow later in this chapter.
Buffering versus streaming
Almost all the asynchronous APIs that we've seen so far in this book work using buffer mode. For an input operation, buffer mode causes all the data coming from a resource to be collected into a buffer until the operation is completed; it is then passed back to the caller as one single blob of data. The following diagram shows a visual example of this paradigm:

Figure 6.1: Buffering
In Figure 6.1, we can see that, at time t1, some data is received from the resource and saved into the buffer. At time t2, another data chunk is received—the final one—which completes the read operation, so that, at t3, the entire buffer is sent to the consumer.
On the other side, streams allow us to process the data as soon as it arrives from the resource. This is shown in the following diagram:
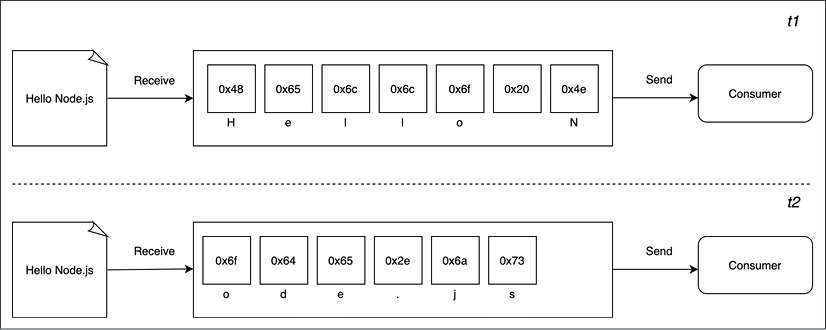
Figure 6.2: Streaming
This time, Figure 6.2 shows you that as soon as each new chunk of data is received from the resource, it is immediately passed to the consumer, who now has the chance to process it straight away, without waiting for all the data to be collected in the buffer.
But what are the differences between these two approaches? Purely from an efficiency perspective, streams can be more efficient in terms of both space (memory usage) and time (computation clock time). However, Node.js streams have another important advantage: composability. Let's now see what impact these properties have on the way we design and write our applications.
Spatial efficiency
First of all, streams allow us to do things that would not be possible by buffering data and processing it all at once. For example, consider the case in which we have to read a very big file, let's say, in the order of hundreds of megabytes or even gigabytes. Clearly, using an API that returns a big buffer when the file is completely read is not a good idea. Imagine reading a few of these big files concurrently; our application would easily run out of memory. Besides that, buffers in V8 are limited in size. You cannot allocate more than a few gigabytes of data, so we may hit a wall way before running out of physical memory.
The actual maximum size of a buffer changes across platforms and versions of Node.js. If you are curious to find out what's the limit in bytes in a given platform, you can run this code:
import buffer from 'buffer'
console.log(buffer.constansts.MAX_LENGTH)
Gzipping using a buffered API
To make a concrete example, let's consider a simple command-line application that compresses a file using the GZIP format. Using a buffered API, such an application will look like the following in Node.js (error handling is omitted for brevity):
import { promises as fs } from 'fs'
import { gzip } from 'zlib'
import { promisify } from 'util'
const gzipPromise = promisify(gzip)
const filename = process.argv[2]
async function main () {
const data = await fs.readFile(filename)
const gzippedData = await gzipPromise(data)
await fs.writeFile(`${filename}.gz`, gzippedData)
console.log('File successfully compressed')
}
main()
Now, we can try to put the preceding code in a file named gzip-buffer.js and then run it with the following command:
node gzip-buffer.js <path to file>
If we choose a file that is big enough (for instance, about 8 GB), we will most likely receive an error message saying that the file that we are trying to read is bigger than the maximum allowed buffer size:
RangeError [ERR_FS_FILE_TOO_LARGE]: File size (8130792448) is greater than possible Buffer: 2147483647 bytes
That's exactly what we expected, and it's a symptom of the fact that we are using the wrong approach.
Gzipping using streams
The simplest way we have to fix our Gzip application and make it work with big files is to use a streaming API. Let's see how this can be achieved. Let's write a new module with the following code:
// gzip-stream.js
import { createReadStream, createWriteStream } from 'fs'
import { createGzip } from 'zlib'
const filename = process.argv[2]
createReadStream(filename)
.pipe(createGzip())
.pipe(createWriteStream(`${filename}.gz`))
.on('finish', () => console.log('File successfully compressed'))
"Is that it?" you may ask. Yes! As we said, streams are amazing because of their interface and composability, thus allowing clean, elegant, and concise code. We will see this in a while in more detail, but for now, the important thing to realize is that the program will run smoothly against files of any size and with constant memory utilization. Try it yourself (but consider that compressing a big file may take a while).
Note that, in the previous example, we omitted error handling for brevity. We will discuss the nuances of proper error handling with streams later in this chapter. Until then, be aware that most examples will be lacking proper error handling.
Time efficiency
Let's now consider the case of an application that compresses a file and uploads it to a remote HTTP server, which, in turn, decompresses it and saves it on the filesystem. If the client component of our application was implemented using a buffered API, the upload would start only when the entire file had been read and compressed. On the other hand, the decompression would start on the server only when all the data had been received. A better solution to achieve the same result involves the use of streams. On the client machine, streams allow us to compress and send the data chunks as soon as they are read from the filesystem, whereas on the server, they allow us to decompress every chunk as soon as it is received from the remote peer. Let's demonstrate this by building the application that we mentioned earlier, starting from the server side.
Let's create a module named gzip-receive.js containing the following code:
import { createServer } from 'http'
import { createWriteStream } from 'fs'
import { createGunzip } from 'zlib'
import { basename, join } from 'path'
const server = createServer((req, res) => {
const filename = basename(req.headers['x-filename'])
const destFilename = join('received_files', filename)
console.log(`File request received: ${filename}`)
req
.pipe(createGunzip())
.pipe(createWriteStream(destFilename))
.on('finish', () => {
res.writeHead(201, { 'Content-Type': 'text/plain' })
res.end('OK
')
console.log(`File saved: ${destFilename}`)
})
})
server.listen(3000, () => console.log('Listening on http://localhost:3000'))
In the preceding example, req is a stream object that is used by the server to receive the request data in chunks from the network. Thanks to Node.js streams, every chunk of data is decompressed and saved to disk as soon as it is received.
You might have noticed that, in our server application, we are using basename() to remove any possible path from the name of the received file. This is a security best practice as we want to make sure that the received file is saved exactly within our received_files folder. Without basename(), a malicious user could craft a request that could effectively override system files and inject malicious code into the server machine. Imagine, for instance, what happens if filename is set to /usr/bin/node? In such a case, the attacker could effectively replace our Node.js interpreter with any arbitrary file.
The client side of our application will go into a module named gzip-send.js, and it looks as follows:
import { request } from 'http'
import { createGzip } from 'zlib'
import { createReadStream } from 'fs'
import { basename } from 'path'
const filename = process.argv[2]
const serverHost = process.argv[3]
const httpRequestOptions = {
hostname: serverHost,
port: 3000,
path: '/',
method: 'PUT',
headers: {
'Content-Type': 'application/octet-stream',
'Content-Encoding': 'gzip',
'X-Filename': basename(filename)
}
}
const req = request(httpRequestOptions, (res) => {
console.log(`Server response: ${res.statusCode}`)
})
createReadStream(filename)
.pipe(createGzip())
.pipe(req)
.on('finish', () => {
console.log('File successfully sent')
})
In the preceding code, we are again using streams to read the data from the file, and then compressing and sending each chunk as soon as it is read from the filesystem.
Now, to try out the application, let's first start the server using the following command:
node gzip-receive.js
Then, we can launch the client by specifying the file to send and the address of the server (for example, localhost):
node gzip-send.js <path to file> localhost
If we choose a file big enough, we can appreciate how the data flows from the client to the server. But why exactly is this paradigm—where we have flowing data—more efficient compared to using a buffered API? Figure 6.3 should make this concept easier to grasp:

Figure 6.3: Buffering and streaming compared
When a file is processed, it goes through a number of sequential stages:
- [Client] Read from the filesystem
- [Client] Compress the data
- [Client] Send it to the server
- [Server] Receive from the client
- [Server] Decompress the data
- [Server] Write the data to disk
To complete the processing, we have to go through each stage like in an assembly line, in sequence, until the end. In Figure 6.3, we can see that, using a buffered API, the process is entirely sequential. To compress the data, we first have to wait for the entire file to be read, then, to send the data, we have to wait for the entire file to be both read and compressed, and so on.
Using streams, the assembly line is kicked off as soon as we receive the first chunk of data, without waiting for the entire file to be read. But more amazingly, when the next chunk of data is available, there is no need to wait for the previous set of tasks to be completed; instead, another assembly line is launched in parallel. This works perfectly because each task that we execute is asynchronous, so it can be parallelized by Node.js. The only constraint is that the order in which the chunks arrive in each stage must be preserved. The internal implementation of Node.js streams takes care of maintaining the order for us.
As we can see from Figure 6.3, the result of using streams is that the entire process takes less time, because we waste no time waiting for all the data to be read and processed all at once.
Composability
The code we have seen so far has already given us an overview of how streams can be composed thanks to the pipe() method, which allows us to connect the different processing units, each being responsible for one single functionality, in perfect Node.js style. This is possible because streams have a uniform interface, and they can understand each other in terms of API. The only prerequisite is that the next stream in the pipeline has to support the data type produced by the previous stream, which can be either binary, text, or even objects, as we will see later in this chapter.
To take a look at another demonstration of the power of this property, we can try to add an encryption layer to the gzip-send/gzip-receive application that we built previously.
In order to do this, we will need to apply some small changes to both our client and server.
Adding client-side encryption
// ...
import { createCipheriv, randomBytes } from 'crypto' // (1)
const filename = process.argv[2]
const serverHost = process.argv[3]
const secret = Buffer.from(process.argv[4], 'hex') // (2)
const iv = randomBytes(16) // (3)
// ...
Let's review what we changed here:
- First of all, we import the
createCipheriv()Transformstream and therandomBytes()function from thecryptomodule. - We get the server's encryption secret from the command line. We expect the string to be passed as a hexadecimal string, so we read this value and load it in memory using a buffer set to
hexmode. - Finally, we generate a random sequence of bytes that we will be using as an initialization vector for the file encryption.
Now, we can update the piece of code responsible for creating the HTTP request:
const httpRequestOptions = {
hostname: serverHost,
headers: {
'Content-Type': 'application/octet-stream',
'Content-Encoding': 'gzip',
'X-Filename': basename(filename),
'X-Initialization-Vector': iv.toString('hex') // (1)
}
}
// ...
const req = request(httpRequestOptions, (res) => {
console.log(`Server response: ${res.statusCode}`)
})
createReadStream(filename)
.pipe(createGzip())
.pipe(createCipheriv('aes192', secret, iv)) // (2)
.pipe(req)
// ...
The main changes here are:
- We pass the initialization vector to the server as an HTTP header.
- We encrypt the data, just after the Gzip phase.
That's all for the client side.
Adding server-side decryption
Let's now refactor the server. The first thing that we need to do is import some utility functions from the core crypto module, which we can use to generate a random encryption key (the secret):
// ...
import { createDecipheriv, randomBytes } from 'crypto'
const secret = randomBytes(24)
console.log(`Generated secret: ${secret.toString('hex')}`)
The generated secret is printed to the console as a hex string so that we can share that with our clients.
Now, we need to update the file reception logic:
const server = createServer((req, res) => {
const filename = basename(req.headers['x-filename'])
const iv = Buffer.from(
req.headers['x-initialization-vector'], 'hex') // (1)
const destFilename = join('received_files', filename)
console.log(`File request received: ${filename}`)
req
.pipe(createDecipheriv('aes192', secret, iv)) // (2)
.pipe(createGunzip())
.pipe(createWriteStream(destFilename))
// ...
Here, we are applying two changes:
- We have to read the encryption initialization vector (nodejsdp.link/iv) sent by the client.
- The first step of our streaming pipeline is now responsible for decrypting the incoming data using the
createDecipherivTransformstream from thecryptomodule.
With very little effort (just a few lines of code), we added an encryption layer to our application; we simply had to use some already available Transform streams (createCipheriv and createDecipheriv) and included them in the stream processing pipelines for the client and the server. In a similar way, we can add and combine other streams, as if we were playing with Lego bricks.
The main advantage of this approach is reusability, but as we can see from the code so far, streams also enable cleaner and more modular code. For these reasons, streams are often used not just to deal with pure I/O, but also as a means to simplify and modularize the code.
Now that we have introduced streams, we are ready to explore, in a more structured way, the different types of streams available in Node.js.
Getting started with streams
In the previous section, we learned why streams are so powerful, but also that they are everywhere in Node.js, starting from its core modules. For example, we have seen that the fs module has createReadStream() for reading from a file and createWriteStream() for writing to a file, the HTTP request and response objects are essentially streams, the zlib module allows us to compress and decompress data using a streaming interface and, finally, even the crypto module exposes some useful streaming primitives like createCipheriv and createDecipheriv.
Now that we know why streams are so important, let's take a step back and start to explore them in more detail.
Anatomy of streams
Every stream in Node.js is an implementation of one of the four base abstract classes available in the stream core module:
ReadableWritableDuplexTransform
Each stream class is also an instance of EventEmitter. Streams, in fact, can produce several types of event, such as end when a Readable stream has finished reading, finish when a Writable stream has completed writing, or error when something goes wrong.
One reason why streams are so flexible is the fact that they can handle not just binary data, but almost any JavaScript value. In fact, they support two operating modes:
- Binary mode: To stream data in the form of chunks, such as buffers or strings
- Object mode: To stream data as a sequence of discrete objects (allowing us to use almost any JavaScript value)
These two operating modes allow us to use streams not just for I/O, but also as a tool to elegantly compose processing units in a functional fashion, as we will see later in this chapter.
Let's start our deep dive of Node.js streams by introducing the class of Readable streams.
Readable streams
A Readable stream represents a source of data. In Node.js, it's implemented using the Readable abstract class, which is available in the stream module.
Reading from a stream
There are two approaches to receive the data from a Readable stream: non-flowing (or paused) and flowing. Let's analyze these modes in more detail.
The non-flowing mode
The non-flowing or paused mode is the default pattern for reading from a Readable stream. It involves attaching a listener to the stream for the readable event, which signals the availability of new data to read. Then, in a loop, we read the data continuously until the internal buffer is emptied. This can be done using the read() method, which synchronously reads from the internal buffer and returns a Buffer object representing the chunk of data. The read() method has the following signature:
readable.read([size])
Using this approach, the data is imperatively pulled from the stream on demand.
To show how this works, let's create a new module named read-stdin.js, which implements a simple program that reads from the standard input (which is also a Readable stream) and echoes everything back to the standard output:
process.stdin
.on('readable', () => {
let chunk
console.log('New data available')
while ((chunk = process.stdin.read()) !== null) {
console.log(
`Chunk read (${chunk.length} bytes): "${chunk.toString()}"`
)
}
})
.on('end', () => console.log('End of stream'))
The read() method is a synchronous operation that pulls a data chunk from the internal buffers of the Readable stream. The returned chunk is, by default, a Buffer object if the stream is working in binary mode.
In a Readable stream working in binary mode, we can read strings instead of buffers by calling setEncoding(encoding) on the stream, and providing a valid encoding format (for example, utf8). This approach is recommended when streaming UTF-8 text data as the stream will properly handle multibyte characters, doing the necessary buffering to make sure that no character ends up being split into separate chunks. In other words, every chunk produced by the stream will be a valid UTF-8 sequence of bytes.
Note that you can call setEncoding() as many times as you want on a Readable stream, even after you've started consuming the data from the stream. The encoding will be switched dynamically on the next available chunk. Streams are inherently binary; encoding is just a view over the binary data that is emitted by the stream.
The data is read solely from within the Readable listener, which is invoked as soon as new data is available. The read() method returns null when there is no more data available in the internal buffers; in such a case, we have to wait for another readable event to be fired, telling us that we can read again, or wait for the end event that signals the end of the stream. When a stream is working in binary mode, we can also specify that we are interested in reading a specific amount of data by passing a size value to the read() method. This is particularly useful when implementing network protocols or when parsing specific data formats.
Now, we are ready to run the read-stdin.js module and experiment with it. Let's type some characters into the console and then press Enter to see the data echoed back into the standard output. To terminate the stream and hence generate a graceful end event, we need to insert an EOF (end-of-file) character (using Ctrl + Z on Windows or Ctrl + D on Linux and macOS).
We can also try to connect our program with other processes. This is possible using the pipe operator (|), which redirects the standard output of a program to the standard input of another. For example, we can run a command such as the following:
cat <path to a file> | node read-stdin.js
This is an amazing demonstration of how the streaming paradigm is a universal interface that enables our programs to communicate, regardless of the language they are written in.
Flowing mode
Another way to read from a stream is by attaching a listener to the data event. This will switch the stream into using flowing mode, where the data is not pulled using read(), but instead is pushed to the data listener as soon as it arrives. For example, the read-stdin.js application that we created earlier will look like this using flowing mode:
process.stdin
.on('data', (chunk) => {
console.log('New data available')
console.log(
`Chunk read (${chunk.length} bytes): "${chunk.toString()}"`
)
})
.on('end', () => console.log('End of stream'))
Flowing mode offers less flexibility to control the flow of data compared to non-flowing mode. The default operating mode for streams is non-flowing, so to enable flowing mode, it's necessary to attach a listener to the data event or explicitly invoke the resume() method. To temporarily stop the stream from emitting data events, we can invoke the pause() method, causing any incoming data to be cached in the internal buffer. Calling pause() will switch the stream back to non-flowing mode.
Async iterators
Readable streams are also async iterators; therefore, we could rewrite our read-stdin.js example as follows:
async function main () {
for await (const chunk of process.stdin) {
console.log('New data available')
console.log(
`Chunk read (${chunk.length} bytes): "${chunk.toString()}"`
)
}
console.log('End of stream')
}
main()
We will discuss async iterators in greater detail in Chapter 9, Behavioral Design Patterns, so don't worry too much about the syntax in the preceding example for now. What's important to know is that if you need to write a function that consumes an entire Readable stream and returns a Promise, this syntax could come in very handy.
Implementing Readable streams
Now that we know how to read from a stream, the next step is to learn how to implement a new custom Readable stream. To do this, it's necessary to create a new class by inheriting the prototype Readable from the stream module. The concrete stream must provide an implementation of the _read() method, which has the following signature:
readable._read(size)
The internals of the Readable class will call the _read() method, which, in turn, will start to fill the internal buffer using push():
readable.push(chunk)
Please note that read() is a method called by the stream consumers, while _read() is a method to be implemented by a stream subclass and should never be called directly. The underscore usually indicates that the method is not public and should not be called directly.
To demonstrate how to implement new Readable streams, we can try to implement a stream that generates random strings. Let's create a new module called random-stream.js that contains the code of our random string generator:
import { Readable } from 'stream'
import Chance from 'chance'
const chance = new Chance()
export class RandomStream extends Readable {
constructor (options) {
super(options)
this.emittedBytes = 0
}
_read (size) {
const chunk = chance.string({ length: size }) // (1)
this.push(chunk, 'utf8') // (2)
this.emittedBytes += chunk.length
if (chance.bool({ likelihood: 5 })) { // (3)
this.push(null)
}
}
}
At the top of the file, we load our dependencies. There is nothing special there, except that we are loading an npm module called chance (nodejsdp.link/chance), which is a library for generating all sorts of random values, from numbers to strings to entire sentences.
The next step is to create a new class called RandomStream, which specifies Readable as its parent. In the preceding code, invoking super(options) in the RandomStream constructor will call the constructor of the parent class, allowing us to initialize the stream's internal state.
If you have a constructor that only invokes super(options), you can remove it as you will inherit the parent constructor. Just be careful to remember to call super(options) every time you need to write a custom constructor.
The possible parameters that can be passed through the options object include the following:
- The
encodingargument, which is used to convert buffers into strings (defaults tonull) - A flag to enable object mode (
objectMode, defaults tofalse) - The upper limit of the data stored in the internal buffer, after which no more reading from the source should be done (
highWaterMark, defaults to16KB)
Okay, now let's explain the _read() method:
- The method generates a random string of length equal to
sizeusingchance. - It pushes the string into the internal buffer. Note that since we are pushing strings, we also need to specify the encoding,
utf8(this is not necessary if the chunk is simply a binaryBuffer). - It terminates the stream randomly, with a likelihood of 5 percent, by pushing
nullinto the internal buffer to indicate anEOFsituation or, in other words, the end of the stream.
Note that the size argument in the _read() function is an advisory parameter. It's good to honor it and push only the amount of data that was requested by the caller, even though it is not mandatory to do so.
When we invoke push(), we should check whether it returns false. When that happens, it means that the internal buffer of the receiving stream has reached the highWaterMark limit and we should stop adding more data to it. This is called backpressure, and we will be discussing it in more detail in the next section of this chapter.
That's it for RandomStream, we are now ready to use it. Let's see how to instantiate a RandomStream object and pull some data from it:
// index.js
import { RandomStream } from './random-stream.js'
const randomStream = new RandomStream()
randomStream
.on('data', (chunk) => {
console.log(`Chunk received (${chunk.length} bytes): ${chunk.toString()}`)
})
.on('end', () => {
console.log(`Produced ${randomStream.emittedBytes} bytes of random data`)
})
Now, everything is ready for us to try our new custom stream. Simply execute the index.js module as usual and watch a random set of strings flowing on the screen.
Simplified construction
For simple custom streams, we can avoid creating a custom class by using the Readable stream's simplified construction approach. With this approach, we only need to invoke new Readable(options) and pass a method named read() in the set of options. The read() method here has exactly the same semantic as the _read() method that we saw in the class extension approach. Let's rewrite our RandomStream using the simplified constructor approach:
import { Readable } from 'stream'
import Chance from 'chance'
const chance = new Chance()
let emittedBytes = 0
const randomStream = new Readable({
read (size) {
const chunk = chance.string({ length: size })
this.push(chunk, 'utf8')
emittedBytes += chunk.length
if (chance.bool({ likelihood: 5 })) {
this.push(null)
}
}
})
// now use randomStream instance directly ...
This approach can be particularly useful when you don't need to manage a complicated state and allows you to take advantage of a more succinct syntax. In the previous example, we created a single instance of our custom stream. If we want to adopt the simplified constructor approach but we need to create multiple instances of the custom stream, we can wrap the initialization logic in a factory function that we can invoke multiple times to create those instances.
Readable streams from iterables
You can easily create Readable stream instances from arrays or other iterable objects (that is, generators, iterators, and async iterators) using the Readable.from() helper.
In order to get accustomed with this helper, let's look at a simple example where we convert data from an array into a Readable stream:
import { Readable } from 'stream'
const mountains = [
{ name: 'Everest', height: 8848 },
{ name: 'K2', height: 8611 },
{ name: 'Kangchenjunga', height: 8586 },
{ name: 'Lhotse', height: 8516 },
{ name: 'Makalu', height: 8481 }
]
const mountainsStream = Readable.from(mountains)
mountainsStream.on('data', (mountain) => {
console.log(`${mountain.name.padStart(14)} ${mountain.height}m`)
})
As we can see from this code, the Readable.from() method is quite simple to use: the first argument is an iterable instance (in our case, the mountains array). Readable.from() accepts an additional optional argument that can be used to specify stream options like objectMode.
Note that we didn't have to explicitly set objectMode to true. By default, Readable.from() will set objectMode to true, unless this is explicitly opted out by setting it to false. Stream options can be passed as a second argument to the function.
Running the previous code will produce the following output:
Everest 8848m
K2 8611m
Kangchenjunga 8586m
Lhotse 8516m
Makalu 8481m
Try not to instantiate large arrays in memory. Imagine if, in the previous example, we wanted to list all the mountains in the world. There are about 1 million mountains, so if we were to load all of them in an array upfront, we would allocate a quite significant amount of memory. Even if we then consume the data in the array through a Readable stream, all the data has already been preloaded, so we are effectively voiding the memory efficiency of streams. It's always preferable to load and consume the data in chunks, and you could do so by using native streams such as fs.createReadStream, by building a custom stream, or by using Readable.from with lazy iterables such as generators, iterators, or async iterators. We will see some examples of the latter approach in Chapter 9, Behavioral Design Patterns.
Writable streams
A Writable stream represents a data destination. Imagine, for instance, a file on the filesystem, a database table, a socket, the standard error, or the standard output interface. In Node.js, it's implemented using the Writable abstract class, which is available in the stream module.
Writing to a stream
Pushing some data down a Writable stream is a straightforward business; all we have to do is use the write() method, which has the following signature:
writable.write(chunk, [encoding], [callback])
The encoding argument is optional and can be specified if chunk is a string (it defaults to utf8, and it's ignored if chunk is a buffer). The callback function, on the other hand, is called when the chunk is flushed into the underlying resource and is optional as well.
To signal that no more data will be written to the stream, we have to use the end() method:
writable.end([chunk], [encoding], [callback])
We can provide a final chunk of data through the end() method; in this case, the callback function is equivalent to registering a listener to the finish event, which is fired when all the data written in the stream has been flushed into the underlying resource.
Now, let's show how this works by creating a small HTTP server that outputs a random sequence of strings:
// entropy-server.js
import { createServer } from 'http'
import Chance from 'chance'
const chance = new Chance()
const server = createServer((req, res) => {
res.writeHead(200, { 'Content-Type': 'text/plain' }) // (1)
while (chance.bool({ likelihood: 95 })) { // (2)
res.write(`${chance.string()}
`) // (3)
}
res.end('
') // (4)
res.on('finish', () => console.log('All data sent')) // (5)
})
server.listen(8080, () => {
console.log('listening on http://localhost:8080')
})
The HTTP server that we created writes into the res object, which is an instance of http.ServerResponse and also a Writable stream. What happens is explained as follows:
- We first write the head of the HTTP response. Note that
writeHead()is not a part of theWritableinterface; in fact, it's an auxiliary method exposed by thehttp.ServerResponseclass and is specific to the HTTP protocol. - We start a loop that terminates with a likelihood of 5% (we instruct
chance.bool()to returntrue95% of the time). - Inside the loop, we write a random string into the stream.
- Once we are out of the loop, we call
end()on the stream, indicating that no more data will be written. Also, we provide a final string containing two new line characters to be written into the stream before ending it. - Finally, we register a listener for the
finishevent, which will be fired when all the data has been flushed into the underlying socket.
To test the server, we can open a browser at the address http://localhost:8080 or use curl from the terminal as follows:
curl localhost:8080
At this point, the server should start sending random strings to the HTTP client that you chose (please bear in mind that some browsers might buffer the data, and the streaming behavior might not be apparent).
Backpressure
Similar to a liquid flowing in a real piping system, Node.js streams can also suffer from bottlenecks, where data is written faster than the stream can consume it. The mechanism to cope with this problem involves buffering the incoming data; however, if the stream doesn't give any feedback to the writer, we may incur a situation where more and more data is accumulated in the internal buffer, leading to undesired levels of memory usage.
To prevent this from happening, writable.write() will return false when the internal buffer exceeds the highWaterMark limit. In Writable streams, the highWaterMark property is the limit of the internal buffer size, beyond which the write() method starts returning false, indicating that the application should now stop writing. When the buffer is emptied, the drain event is emitted, communicating that it's safe to start writing again. This mechanism is called backpressure.
Backpressure is an advisory mechanism. Even if write() returns false, we could ignore this signal and continue writing, making the buffer grow indefinitely. The stream won't be blocked automatically when the highWaterMark threshold is reached; therefore, it is recommended to always be mindful and respect the backpressure.
The mechanism described in this section is similarly applicable to Readable streams. In fact, backpressure exists in Readable streams too, and it's triggered when the push() method, which is invoked inside _read(), returns false. However, that's a problem specific to stream implementers, so we usually have to deal with it less frequently.
We can quickly demonstrate how to take into account the backpressure of a Writable stream by modifying the entropy-server.js module that we created previously:
// ...
const server = createServer((req, res) => {
res.writeHead(200, { 'Content-Type': 'text/plain' })
function generateMore () { // (1)
while (chance.bool({ likelihood: 95 })) {
const randomChunk = chance.string({ // (2)
length: (16 * 1024) - 1
})
const shouldContinue = res.write(`${randomChunk}
`) // (3)
if (!shouldContinue) {
console.log('back-pressure')
return res.once('drain', generateMore)
}
}
res.end('
')
}
generateMore()
res.on('finish', () => console.log('All data sent'))
})
// ...
The most important steps of the previous code can be summarized as follows:
- We wrapped the main logic in a function called
generateMore(). - To increase the chances of receiving some backpressure, we increased the size of the data chunk to 16 KB minus 1 byte, which is very close to the default
highWaterMarklimit. - After writing a chunk of data, we check the return value of
res.write(). If we receivefalse, it means that the internal buffer is full and we should stop sending more data. When this happens, we exit the function and register another cycle of writes usinggenerateMore()for when thedrainevent is emitted.
If we now try to run the server again, and then generate a client request with curl, there is a high probability that there will be some backpressure, as the server produces data at a very high rate, faster than the underlying socket can handle.
Implementing Writable streams
We can implement a new Writable stream by inheriting the class Writable and providing an implementation for the _write() method. Let's try to do it immediately while discussing the details along the way.
Let's build a Writable stream that receives objects in the following format:
{
path: <path to a file>
content: <string or buffer>
}
For each one of these objects, our stream has to save the content property into a file created at the given path. We can immediately see that the inputs of our stream are objects, and not strings or buffers. This means that our stream has to work in object mode.
Let's call the module to-file-stream.js:
import { Writable } from 'stream'
import { promises as fs } from 'fs'
import { dirname } from 'path'
import mkdirp from 'mkdirp-promise'
export class ToFileStream extends Writable {
constructor (options) {
super({ ...options, objectMode: true })
}
_write (chunk, encoding, cb) {
mkdirp(dirname(chunk.path))
.then(() => fs.writeFile(chunk.path, chunk.content))
.then(() => cb())
.catch(cb)
}
}
We created a new class for our new stream, which extends Writable from the stream module.
We had to invoke the parent constructor to initialize its internal state; we also needed to make sure that the options object specifies that the stream works in object mode (objectMode: true). Other options accepted by Writable are as follows:
highWaterMark(the default is 16 KB): This controls the backpressure limit.decodeStrings(defaults totrue): This enables the automatic decoding of strings into binary buffers before passing them to the_write()method. This option is ignored in object mode.
Finally, we provided an implementation for the _write() method. As you can see, the method accepts a data chunk and an encoding (which makes sense only if we are in binary mode and the stream option decodeStrings is set to false). Also, the method accepts a callback function (cb), which needs to be invoked when the operation completes; it's not necessary to pass the result of the operation but, if needed, we can still pass an error that will cause the stream to emit an error event.
Now, to try the stream that we just built, we can create a new module and perform some write operations against the stream:
import { join } from 'path'
import { ToFileStream } from './to-file-stream.js'
const tfs = new ToFileStream()
tfs.write({
path: join('files', 'file1.txt'), content: 'Hello' })
tfs.write({
path: join('files', 'file2.txt'), content: 'Node.js' })
tfs.write({
path: join('files', 'file3.txt'), content: 'streams' })
tfs.end(() => console.log('All files created'))
Here, we created and used our first custom Writable stream. Run the new module as usual and check its output. You will see that after the execution, three new files will be created within a new folder called files.
Simplified construction
As we saw for Readable streams, Writable streams also offer a simplified construction mechanism. If we were to rewrite our ToFileStream using the simplified construction for Writable streams, it would look like this:
// ...
const tfs = new Writable({
objectMode: true,
write (chunk, encoding, cb) {
mkdirp(dirname(chunk.path))
.then(() => fs.writeFile(chunk.path, chunk.content))
.then(() => cb())
.catch(cb)
}
})
// ...
With this approach, we are simply using the Writable constructor and passing a write() function that implements the custom logic of our Writable instance. Note that with this approach, the write() function doesn't have an underscore in the name. We can also pass other construction options like objectMode.
Duplex streams
A Duplex stream is a stream that is both Readable and Writable. It is useful when we want to describe an entity that is both a data source and a data destination, such as network sockets, for example. Duplex streams inherit the methods of both stream.Readable and stream.Writable, so this is nothing new to us. This means that we can read() or write() data, or listen for both readable and drain events.
To create a custom Duplex stream, we have to provide an implementation for both _read() and _write(). The options object passed to the Duplex() constructor is internally forwarded to both the Readable and Writable constructors. The options are the same as those we already discussed in the previous sections, with the addition of a new one called allowHalfOpen (defaults to true) that, if set to false, will cause both parts (Readable and Writable) of the stream to end if only one of them does.
If we need to have a Duplex stream working in object mode on one side and binary mode on the other, we can use the options readableObjectMode and writableObjectMode independently.
Transform streams
Transform streams are a special kind of Duplex stream that are specifically designed to handle data transformations. Just to give you a few concrete examples, the functions zlib.createGzip() and crypto.createCipheriv() that we discussed at the beginning of this chapter create Transform streams for compression and encryption, respectively.
In a simple Duplex stream, there is no immediate relationship between the data read from the stream and the data written into it (at least, the stream is agnostic to such a relationship). Think about a TCP socket, which just sends and receives data to and from the remote peer; the socket is not aware of any relationship between the input and output. Figure 6.4 illustrates the data flow in a Duplex stream:

Figure 6.4: Duplex stream schematic representation
On the other hand, Transform streams apply some kind of transformation to each chunk of data that they receive from their Writable side, and then make the transformed data available on their Readable side. Figure 6.5 shows how the data flows in a Transform stream:

Figure 6.5: Transform stream schematic representation
From the outside, the interface of a Transform stream is exactly like that of a Duplex stream. However, when we want to build a new Duplex stream, we have to provide both the _read() and _write() methods, while for implementing a new Transform stream, we have to fill in another pair of methods: _transform() and _flush().
Let's see how to create a new Transform stream with an example.
Implementing Transform streams
Let's implement a Transform stream that replaces all the occurrences of a given string. To do this, we have to create a new module named replaceStream.js. Let's jump directly to the implementation:
import { Transform } from 'stream'
export class ReplaceStream extends Transform {
constructor (searchStr, replaceStr, options) {
super({ ...options })
this.searchStr = searchStr
this.replaceStr = replaceStr
this.tail = ''
}
_transform (chunk, encoding, callback) {
const pieces = (this.tail + chunk).split(this.searchStr) // (1)
const lastPiece = pieces[pieces.length - 1] // (2)
const tailLen = this.searchStr.length - 1
this.tail = lastPiece.slice(-tailLen)
pieces[pieces.length - 1] = lastPiece.slice(0, -tailLen)
this.push(pieces.join(this.replaceStr)) // (3)
callback()
}
_flush (callback) {
this.push(this.tail)
callback()
}
}
In this example, we created a new class extending the Transform base class. The constructor of the class accepts three arguments: searchStr, replaceStr, and options. As you can imagine, they allow us to define the text to match and the string to use as a replacement, plus an options object for advanced configuration of the underlying Transform stream. We also initialize an internal tail variable, which will be used later by the _transform() method.
Now, let's analyze the _transform() method, which is the core of our new class. The _transform() method has practically the same signature as the _write() method of the Writable stream, but instead of writing data into an underlying resource, it pushes it into the internal read buffer using this.push(), exactly as we would do in the _read() method of a Readable stream. This shows how the two sides of a Transform stream are connected.
The _transform() method of ReplaceStream implements the core of our algorithm. To search for and replace a string in a buffer is an easy task; however, it's a totally different story when the data is streaming, and possible matches might be distributed across multiple chunks. The procedure followed by the code can be explained as follows:
- Our algorithm splits the data in memory (
taildata and the currentchunk) usingsearchStras a separator. - Then, it takes the last item of the array generated by the operation and extracts the last
searchString.length - 1characters. The result is saved in thetailvariable and will be prepended to the next chunk of data. - Finally, all the pieces resulting from
split()are joined together usingreplaceStras a separator and pushed into the internal buffer.
When the stream ends, we might still have some content in the tail variable not pushed into the internal buffer. That's exactly what the _flush() method is for; it is invoked just before the stream is ended, and this is where we have one final chance to finalize the stream or push any remaining data before completely ending the stream.
The _flush() method only takes in a callback, which we have to make sure to invoke when all the operations are complete, causing the stream to be terminated. With this, we have completed our ReplaceStream class.
Now, it's time to try the new stream. Let's create a script that writes some data into the stream and then reads the transformed result:
import { ReplaceStream } from './replace-stream.js'
const replaceStream = new ReplaceStream('World', 'Node.js')
replaceStream.on('data', chunk => console.log(chunk.toString()))
replaceStream.write('Hello W')
replaceStream.write('orld!')
replaceStream.end()
To make life a little bit harder for our stream, we spread the search term (which is World) across two different chunks, then, using the flowing mode, we read from the same stream, logging each transformed chunk. Running the preceding program should produce the following output:
Hel
lo Node.js
!
Please note that the preceding output is broken into multiple lines because we are using console.log() to print it out. This allows us to demonstrate that our implementation is able to replace string matches correctly, even when the matching text spans multiple chunks of data.
Simplified construction
Unsurprisingly, even Transform streams support simplified construction. At this point, we should have developed an instinct for how this API might look, so let's get our hands dirty straight away and rewrite the previous example using this approach:
const searchStr = 'World'
const replaceStr = 'Node.js'
let tail = ''
const replaceStream = new Transform({
defaultEncoding: 'utf8',
transform (chunk, encoding, cb) {
const pieces = (tail + chunk).split(searchStr)
const lastPiece = pieces[pieces.length - 1]
const tailLen = searchStr.length - 1
tail = lastPiece.slice(-tailLen)
pieces[pieces.length - 1] = lastPiece.slice(0, -tailLen)
this.push(pieces.join(replaceStr))
cb()
},
flush (cb) {
this.push(tail)
cb()
}
})
// now write to replaceStream ...
As expected, simplified construction works by directly instantiating a new Transform object and passing our specific transformation logic through the transform() and flush() functions directly through the options object. Note that transform() and flush() don't have a prepended underscore here.
Filtering and aggregating data with Transform streams
As we mentioned in the previous section, Transform streams are the perfect building blocks for implementing data transformation pipelines. In the previous section, we illustrated an example of a Transform stream that can replace words in a stream of text. But Transform streams can be used to implement other types of data transformation as well. For instance, it's quite common to use Transform streams to implement data filtering and data aggregation.
Just to make a practical example, let's imagine we are asked by a Fortune 500 company to analyze a big file containing all the sales for the year 2020. The company wants us to use data.csv, a sales report in CSV format, to calculate the total profit for the sales made in Italy.
For simplicity, let's imagine the sales data that is stored in the CSV file contains three fields per line: item type, country of sale, and profit. So, such a file could look like this:
type,country,profit
Household,Namibia,597290.92
Baby Food,Iceland,808579.10
Meat,Russia,277305.60
Meat,Italy,413270.00
Cereal,Malta,174965.25
Meat,Indonesia,145402.40
Household,Italy,728880.54
[... many more lines]
Now, it's clear that we have to find all the records that have "Italy" as country and, in the process, sum up the profit value of the matching lines into a single number.
In order to process a CSV file in a streaming fashion, we can use the excellent csv-parse module (nodejsdp.link/csv-parse).
If we assume for a moment that we have already implemented our custom streams to filter and aggregate the data, a possible solution to this task might look like this:
import { createReadStream } from 'fs'
import parse from 'csv-parse'
import { FilterByCountry } from './filter-by-country.js'
import { SumProfit } from './sum-profit.js'
const csvParser = parse({ columns: true })
createReadStream('data.csv') // (1)
.pipe(csvParser) // (2)
.pipe(new FilterByCountry('Italy')) // (3)
.pipe(new SumProfit()) // (4)
.pipe(process.stdout) // (5)
The streaming pipeline proposed here consists of five steps:
- We read the source CSV file as a stream.
- We use the
csv-parselibrary to parse every line of the document as a CSV record. For every line, this stream will emit an object containing the propertiestype,country, andprofit. - We filter all the records by country, retaining only the records that match the country "Italy." All the records that don't match "Italy" are dropped, which means that they will not be passed to the other steps in the pipeline. Note that this is one of the custom
Transformstreams that we have to implement. - For every record, we accumulate the profit. This stream will eventually emit one single string, which represents the value of the total profit for products sold in Italy. This value will be emitted by the stream only when all the data from the original file has been completely processed. Note that this is the second custom
Transformstream that we have to implement to complete this project. - Finally, the data emitted from the previous step is displayed in the standard output.
Now, let's implement the FilterByCountry stream:
import { Transform } from 'stream'
export class FilterByCountry extends Transform {
constructor (country, options = {}) {
options.objectMode = true
super(options)
this.country = country
}
_transform (record, enc, cb) {
if (record.country === this.country) {
this.push(record)
}
cb()
}
}
FilterByCountry is a custom Transform stream. We can see that the constructor accepts an argument called country, which allows us to specify the country name we want to filter on. In the constructor, we also set the stream to run in objectMode because we know it will be used to process objects (records from the CSV file).
In the _transform method, we check if the country of the current record matches the country specified at construction time. If it's a match, then we pass the record on to the next stage of the pipeline by calling this.push(). Regardless of whether the record matches or not, we need to invoke cb() to indicate that the current record has been successfully processed and that the stream is ready to receive another record.
Pattern: Transform filter
Invoke this.push() in a conditional way to allow only some data to reach the next stage of the pipeline.
Finally, let's implement the SumProfit filter:
import { Transform } from 'stream'
export class SumProfit extends Transform {
constructor (options = {}) {
options.objectMode = true
super(options)
this.total = 0
}
_transform (record, enc, cb) {
this.total += Number.parseFloat(record.profit)
cb()
}
_flush (cb) {
this.push(this.total.toString())
cb()
}
}
This stream needs to run in objectMode as well, because it will receive objects representing records from the CSV file. Note that, in the constructor, we also initialize an instance variable called total and we set its value to 0.
In the _transform() method, we process every record and use the current profit value to increase the total. It's important to note that this time, we are not calling this.push(). This means that no value is emitted while the data is flowing through the stream. We still need to call cb(), though, to indicate that the current record has been processed and the stream is ready to receive another one.
In order to emit the final result when all the data has been processed, we have to define a custom flush behavior using the _flush() method. Here, we finally call this.push() to emit a string representation of the resulting total value. Remember that _flush() is automatically invoked before the stream is closed.
Pattern: Streaming aggregation
Use _transform() to process the data and accumulate the partial result, then call this.push() only in the _flush() method to emit the result when all the data has been processed.
This completes our example. Now, you can grab the CSV file from the code repository and execute this program to see what the total profit for Italy is. No surprise it's going to be a lot of money since we are talking about the profit of a Fortune 500 company!
PassThrough streams
There is a fifth type of stream that is worth mentioning: PassThrough. This type of stream is a special type of Transform that outputs every data chunk without applying any transformation.
PassThrough is possibly the most underrated type of stream, but there are actually several circumstances in which it can be a very valuable tool in our toolbelt. For instance, PassThrough streams can be useful for observability or to implement late piping and lazy stream patterns.
Observability
If we want to observe how much data is flowing through one or more streams, we could do so by attaching a data event listener to a PassThrough instance and then piping this instance in a given point of a stream pipeline. Let's a see a simplified example to be able to appreciate this concept:
import { PassThrough } from 'stream'
let bytesWritten = 0
const monitor = new PassThrough()
monitor.on('data', (chunk) => {
bytesWritten += chunk.length
})
monitor.on('finish', () => {
console.log(`${bytesWritten} bytes written`)
})
monitor.write('Hello!')
monitor.end()
In this example, we are creating a new instance of PassThrough and using the data event to count how many bytes are flowing through the stream. We also use the finish event to dump the total amount to the console. Finally we write some data directly into the stream using write() and end(). This is just an illustrative example; in a more realistic scenario, we would be piping our monitor instance in a given point of a stream pipeline. For instance, if we wanted to monitor how many bytes are written to disk in our first file compression example of this chapter, we could easily achieve that by doing something like this:
createReadStream(filename)
.pipe(createGzip())
.pipe(monitor)
.pipe(createWriteStream(`${filename}.gz`))
The beauty of this approach is that we didn't have to touch any of the other existing streams in the pipeline, so if we need to observe other parts of the pipeline (for instance, imagine we want to know the number of bytes of the uncompressed data), we can move monitor around with very little effort.
Note that you could implement an alternative version of the monitor stream by using a custom transform stream instead. In such a case, you would have to make sure that the received chunks are pushed without any modification or delay, which is something that a PassThrough stream would do automatically for you. Both approaches are equally valid, so pick the approach that feels more natural to you.
Late piping
In some circumstances, we might have to use APIs that accept a stream as an input parameter. This is generally not a big deal because we already know how to create and use streams. However, it may get a little bit more complicated if the data we want to read or write through the stream is available after we've called the given API.
To visualize this scenario in more concrete terms, let's imagine that we have to use an API that gives us the following function to upload a file to a data storage service:
function upload (filename, contentStream) {
// ...
}
This function is effectively a simplified version of what is commonly available in the SDK of file storage services like Amazon Simple Storage Service (S3) or Azure Blob Storage service. Often, those libraries will provide the user with a more flexible function that can receive the content data in different formats (for example, a string, a buffer, or a Readable stream).
Now, if we want to upload a file from the filesystem, this is a trivial operation, and we can do something like this:
import { createReadStream } from 'fs'
upload('a-picture.jpg', createReadStream('/path/to/a-picture.jpg'))
But what if we want to do some processing to the file stream before the upload. For instance, let's say we want to compress or encrypt the data? Also, what if we have to do this transformation asynchronously after the upload function has been called?
In such cases, we can provide a PassThrough stream to the upload() function, which will effectively act as a placeholder. The internal implementation of upload() will immediately try to consume data from it, but there will be no data available in the stream until we actually write to it. Also, the stream won't be considered complete until we close it, so the upload() function will have to wait for data to flow through the PassThrough instance to initiate the upload.
Let's see a possible command-line script that uses this approach to upload a file from the filesystem and also compresses it using the Brotli compression. We are going to assume that the third-party upload() function is provided in a file called upload.js:
import { createReadStream } from 'fs'
import { createBrotliCompress } from 'zlib'
import { PassThrough } from 'stream'
import { basename } from 'path'
import { upload } from './upload.js'
const filepath = process.argv[2] // (1)
const filename = basename(filepath)
const contentStream = new PassThrough() // (2)
upload(`${filename}.br`, contentStream) // (3)
.then((response) => {
console.log(`Server response: ${response.data}`)
})
.catch((err) => {
console.error(err)
process.exit(1)
})
createReadStream(filepath) // (4)
.pipe(createBrotliCompress())
.pipe(contentStream)
In this book's repository, you will find a complete implementation of this example that allows you to upload files to an HTTP server that you can run locally.
Let's review what's happening in the previous example:
- We get the path to the file we want to upload from the first command-line argument and use
basenameto extrapolate the filename from the given path. - We create a placeholder for our content stream as a
PassThroughinstance. - Now, we invoke the
uploadfunction by passing our filename (with the added.brsuffix, indicating that it is using the Brotli compression) and the placeholder content stream. - Finally, we create a pipeline by chaining a filesystem
Readablestream, a Brotli compressionTransformstream, and finally our content stream as the destination.
When this code is executed, the upload will start as soon as we invoke the upload() function (possibly establishing a connection to the remote server), but the data will start to flow only later, when our pipeline is initialized. Note that our pipeline will also close the contentStream when the processing completes, which will indicate to the upload() function that all the content has been fully consumed.
Pattern
Use a PassThrough stream when you need to provide a placeholder for data that will be read or written in the future.
We can also use this pattern to transform the interface of the upload() function. Instead of accepting a Readable stream as input, we can make it return a Writeable stream, which can then be used to provide the data we want to upload:
function createUploadStream (filename) {
// ...
// returns a writable stream that can be used to upload data
}
If we were tasked to implement this function, we could achieve that in a very elegant way by using a PassThrough instance, as in the following example implementation:
function createUploadStream (filename) {
const connector = new PassThrough()
upload(filename, connector)
return connector
}
In the preceding code, we are using a PassThrough stream as a connector. This stream becomes a perfect abstraction for a case where the consumer of the library can write data at any later stage.
The createUploadStream() function can then be used as follows:
const upload = createUploadStream('a-file.txt')
upload.write('Hello World')
upload.end()
This book's repository also contains an HTTP upload example that adopts this alternative pattern.
Lazy streams
Sometimes, we need to create a large number of streams at the same time, for example, to pass them to a function for further processing. A typical example is when using archiver (nodejsdp.link/archiver), a package for creating archives such as TAR and ZIP. The archiver package allows you to create an archive from a set of streams, representing the files to add. The problem is that if we want to pass a large number of streams, such as from files on the filesystem, we would likely get an EMFILE, too many open files error. This is because functions like createReadStream() from the fs module will actually open a file descriptor every time a new stream is created, even before you start to read from those streams.
In more generic terms, creating a stream instance might initialize expensive operations straight away (for example, open a file or a socket, initialize a connection to a database, and so on), even before we actually start to use such a stream. This might not be desirable if you are creating a large number of stream instances for later consumption.
In these cases, you might want to delay the expensive initialization until you actually need to consume data from the stream.
It is possible to achieve this by using a library like lazystream (nodejsdp.link/lazystream). This library allows you to effectively create proxies for actual stream instances, where the proxied instance is not created until some piece of code is actually starting to consume data from the proxy.
In the following example, lazystream allows us to create a lazy Readable stream for the special Unix file /dev/urandom:
import lazystream from 'lazystream'
const lazyURandom = new lazystream.Readable(function (options) {
return fs.createReadStream('/dev/urandom')
})
The function we pass as a parameter to new lazystream.Readable() is effectively a factory function that generates the proxied stream when necessary.
Behind the scenes, lazystream is implemented using a PassThrough stream that, only when its _read() method is invoked for the first time, creates the proxied instance by invoking the factory function, and pipes the generated stream into the PassThrough itself. The code that consumes the stream is totally agnostic of the proxying that is happening here, and it will consume the data as if it was flowing directly from the PassThrough stream. lazystream implements a similar utility to create lazy Writable streams as well.
Creating lazy Readable and Writable streams from scratch could be an interesting exercise that is left to you. If you get stuck, have a look at the source code of lazystream for inspiration on how to implement this pattern.
In the next section, we will discuss the .pipe() method in greater detail and also see other ways to connect different streams to form a processing pipeline.
Connecting streams using pipes
The concept of Unix pipes was invented by Douglas Mcllroy. This enabled the output of a program to be connected to the input of the next. Take a look at the following command:
echo Hello World! | sed s/World/Node.js/g
In the preceding command, echo will write Hello World! to its standard output, which is then redirected to the standard input of the sed command (thanks to the pipe | operator). Then, sed replaces any occurrence of World with Node.js and prints the result to its standard output (which, this time, is the console).
In a similar way, Node.js streams can be connected using the pipe() method of the Readable stream, which has the following interface:
readable.pipe(writable, [options])
Very intuitively, the pipe() method takes the data that is emitted from the readable stream and pumps it into the provided writable stream. Also, the writable stream is ended automatically when the readable stream emits an end event (unless we specify {end: false} as options). The pipe() method returns the writable stream passed in the first argument, allowing us to create chained invocations if such a stream is also Readable (such as a Duplex or Transform stream).
Piping two streams together will create suction, which allows the data to flow automatically to the writable stream, so there is no need to call read() or write(), but most importantly, there is no need to control the backpressure anymore, because it's automatically taken care of.
To provide a quick example, we can create a new module that takes a text stream from the standard input, applies the replace transformation discussed earlier when we built our custom ReplaceStream, and then pushes the data back to the standard output:
// replace.js
import { ReplaceStream } from './replace-stream.js'
process.stdin
.pipe(new ReplaceStream(process.argv[2], process.argv[3]))
.pipe(process.stdout)
The preceding program pipes the data that comes from the standard input into an instance of ReplaceStream and then back to the standard output. Now, to try this small application, we can leverage a Unix pipe to redirect some data into its standard input, as shown in the following example:
echo Hello World! | node replace.js World Node.js
This should produce the following output:
Hello Node.js!
This simple example demonstrates that streams (and in particular, text streams) are a universal interface and that pipes are the way to compose and interconnect all these interfaces almost magically.
Pipes and error handling
The error events are not propagated automatically through the pipeline when using pipe(). Take, for example, this code fragment:
stream1
.pipe(stream2)
.on('error', () => {})
In the preceding pipeline, we will catch only the errors coming from stream2, which is the stream that we attached the listener to. This means that, if we want to catch any error generated from stream1, we have to attach another error listener directly to it, which will make our example look like this:
stream1
.on('error', () => {})
.pipe(stream2)
.on('error', () => {})
This is clearly not ideal, especially when dealing with pipelines with a significant number of steps. To make this worse, in the event of an error, the failing stream is only unpiped from the pipeline. The failing stream is not properly destroyed, which might leave dangling resources (for example, file descriptors, connections, and so on) and leak memory. A more robust (yet inelegant) implementation of the preceding snippet might look like this:
function handleError (err) {
console.error(err)
stream1.destroy()
stream2.destroy()
}
stream1
.on('error', handleError)
.pipe(stream2)
.on('error', handleError)
In this example, we registered a handler for the error event for both stream1 and stream2. When an error happens, our handleError() function is invoked, and we can log the error and destroy every stream in the pipeline. This allows us to ensure that all the allocated resources are properly released, and the error is handled gracefully.
Better error handling with pipeline()
Handling errors manually in a pipeline is not just cumbersome, but also error-prone—definitely something we should avoid if we can!
Luckily, the core stream package offers us an excellent utility function that can make building pipelines a much safer and more enjoyable practice, which is the pipeline() helper function.
In a nutshell, you can use the pipeline() function as follows:
pipeline(stream1, stream2, stream3, ... , cb)
This helper pipes every stream passed in the arguments list to the next one. For each stream, it will also register a proper error and close listeners. This way, all the streams are properly destroyed when the pipeline completes successfully or when it's interrupted by an error. The last argument is an optional callback that will be called when the stream finishes. If it finishes because of an error, the callback will be invoked with the given error as the first argument.
In order to build up some practice with this helper, let's write a simple command-line script that implements the following pipeline:
- Reads a Gzip data stream from the standard input
- Decompresses the data
- Makes all the text uppercase
- Gzips the resulting data
- Sends the data back to the standard output
Let's call this module uppercasify-gzipped.js:
import { createGzip, createGunzip } from 'zlib' // (1)
import { Transform, pipeline } from 'stream'
const uppercasify = new Transform({ // (2)
transform (chunk, enc, cb) {
this.push(chunk.toString().toUpperCase())
cb()
}
})
pipeline( // (3)
process.stdin,
createGunzip(),
uppercasify,
createGzip(),
process.stdout,
(err) => { // (4)
if (err) {
console.error(err)
process.exit(1)
}
}
)
In this example:
- We are importing the necessary dependencies from
zliband thestreammodules. - We create a simple
Transformstream that makes every chunk uppercase. - We define our pipeline, where we list all the stream instances in order.
- We add a callback to monitor the completion of the stream. In the event of an error, we print the error in the standard error interface, and we exit with error code
1.
The pipeline will start automatically by consuming data from the standard input and producing data for the standard output.
We could test our script with the following command:
echo 'Hello World!' | gzip | node uppercasify-gzipped.js | gunzip
This should produce the following output:
HELLO WORLD!
If we try to remove the gzip step from the preceding sequence of commands, our script will fail with an error similar to the following:
Error: unexpected end of file
at Zlib.zlibOnError [as onerror] (zlib.js:180:17) {
errno: -5,
code: 'Z_BUF_ERROR'
}
This error is raised by the stream created with the createGunzip() function, which is responsible for decompressing the data. If the data is not actually gzipped, the decompression algorithm won't be able to process the data and it will fail. In such a case, pipeline() will take care of cleaning up after the error and destroy all the streams in the pipeline.
The pipeline() function can be easily promisified by using the promisify() helper from the core util module.
Now that we have built a solid understanding of Node.js streams, we are ready to move into some more involved stream patterns like control flow and advanced piping patterns.
Asynchronous control flow patterns with streams
Going through the examples that we have presented so far, it should be clear that streams can be useful not only to handle I/O, but also as an elegant programming pattern that can be used to process any kind of data. But the advantages do not end at its simple appearance; streams can also be leveraged to turn "asynchronous control flow" into "flow control," as we will see in this section.
Sequential execution
By default, streams will handle data in sequence. For example, the _transform() function of a Transform stream will never be invoked with the next chunk of data until the previous invocation completes by calling callback(). This is an important property of streams, crucial for processing each chunk in the right order, but it can also be exploited to turn streams into an elegant alternative to the traditional control flow patterns.
Some code is always better than too much explanation, so let's work on an example to demonstrate how we can use streams to execute asynchronous tasks in sequence. Let's create a function that concatenates a set of files received as input, making sure to honor the order in which they are provided. Let's create a new module called concat-files.js and define its contents as follows:
import { createWriteStream, createReadStream } from 'fs'
import { Readable, Transform } from 'stream'
export function concatFiles (dest, files) {
return new Promise((resolve, reject) => {
const destStream = createWriteStream(dest)
Readable.from(files) // (1)
.pipe(new Transform({ // (2)
objectMode: true,
transform (filename, enc, done) {
const src = createReadStream(filename)
src.pipe(destStream, { end: false })
src.on('error', done)
src.on('end', done) // (3)
}
}))
.on('error', reject)
.on('finish', () => { // (4)
destStream.end()
resolve()
})
})
}
The preceding function implements a sequential iteration over the files array by transforming it into a stream. The algorithm can be explained as follows:
- First, we use
Readable.from()to create aReadablestream from thefilesarray. This stream operates in object mode (the default setting for streams created withReadable.from()) and it will emit filenames: every chunk is a string indicating the path to a file. The order of the chunks respects the order of the files in thefilesarray. - Next, we create a custom
Transformstream to handle each file in the sequence. Since we are receiving strings, we set the optionobjectModetotrue. In our transformation logic, for each file, we create aReadablestream to read the file content and pipe it intodestStream(aWritablestream for the destination file). We make sure not to closedestStreamafter the source file finishes reading by specifying{ end: false }in thepipe()options. - When all the contents of the source file have been piped into
destStream, we invoke thedonefunction to communicate the completion of the current processing, which is necessary to trigger the processing of the next file. - When all the files have been processed, the
finishevent is fired; we can finally enddestStreamand invoke thecb()function ofconcatFiles(), which signals the completion of the whole operation.
We can now try to use the little module we just created. Let's do that in a new file, called concat.js:
import { concatFiles } from './concat-files.js'
async function main () {
try {
await concatFiles(process.argv[2], process.argv.slice(3))
} catch (err) {
console.error(err)
process.exit(1)
}
console.log('All files concatenated successfully')
}
main()
We can now run the preceding program by passing the destination file as the first command-line argument, followed by a list of files to concatenate; for example:
node concat.js all-together.txt file1.txt file2.txt
This should create a new file called all-together.txt containing, in order, the contents of file1.txt and file2.txt.
With the concatFiles() function, we were able to obtain an asynchronous sequential iteration using only streams. This is an elegant and compact solution that enriches our toolbelt, along with the techniques we already explored in Chapter 4, Asynchronous Control Flow Patterns with Callbacks, and Chapter 5, Asynchronous Control Flow Patterns with Promises and Async/Await.
Pattern
Use a stream, or combination of streams, to easily iterate over a set of asynchronous tasks in sequence.
In the next section, we will discover how to use Node.js streams to implement unordered parallel task execution.
Unordered parallel execution
We just saw that streams process each data chunk in sequence, but sometimes, this can be a bottleneck as we would not make the most of the concurrency of Node.js. If we have to execute a slow asynchronous operation for every data chunk, it can be advantageous to parallelize the execution and speed up the overall process. Of course, this pattern can only be applied if there is no relationship between each chunk of data, which might happen frequently for object streams, but very rarely for binary streams.
Caution
Unordered parallel streams cannot be used when the order in which the data is processed is important.
To parallelize the execution of a Transform stream, we can apply the same patterns that we learned in Chapter 4, Asynchronous Control Flow Patterns with Callbacks, but with some adaptations to get them working with streams. Let's see how this works.
Implementing an unordered parallel stream
Let's immediately demonstrate how to implement an unordered parallel stream with an example. Let's create a module called parallel-stream.js and define a generic Transform stream that executes a given transform function in parallel:
import { Transform } from 'stream'
export class ParallelStream extends Transform {
constructor (userTransform, opts) { // (1)
super({ objectMode: true, ...opts })
this.userTransform = userTransform
this.running = 0
this.terminateCb = null
}
_transform (chunk, enc, done) { // (2)
this.running++
this.userTransform(
chunk,
enc,
this.push.bind(this),
this._onComplete.bind(this)
)
done()
}
_flush (done) { // (3)
if (this.running > 0) {
this.terminateCb = done
} else {
done()
}
}
_onComplete (err) { // (4)
this.running--
if (err) {
return this.emit('error', err)
}
if (this.running === 0) {
this.terminateCb && this.terminateCb()
}
}
}
Let's analyze this new class step by step:
- As you can see, the constructor accepts a
userTransform()function, which is then saved as an instance variable. We invoke the parent constructor and for convenience, we enable the object mode by default. - Next, it is the
_transform()method's turn. In this method, we execute theuserTransform()function and then increment the count of running tasks. Finally, we notify theTransformstream that the current transformation step is complete by invokingdone(). The trick for triggering the processing of another item in parallel is exactly this. We are not waiting for theuserTransform()function to complete before invokingdone(); instead, we do it immediately. On the other hand, we provide a special callback touserTransform(), which is thethis._onComplete()method. This allows us to get notified when the execution ofuserTransform()completes. - The
_flush()method is invoked just before the stream terminates, so if there are still tasks running, we can put the release of thefinishevent on hold by not invoking thedone()callback immediately. Instead, we assign it to thethis.terminateCallbackvariable. - To understand how the stream is then properly terminated, we have to look into the
_onComplete()method. This last method is invoked every time an asynchronous task completes. It checks whether there are any more tasks running and, if there are none, it invokes thethis.terminateCallback()function, which will cause the stream to end, releasing thefinishevent that was put on hold in the_flush()method.
The ParallelStream class we just built allows us to easily create a Transform stream that executes its tasks in parallel, but there is a caveat: it does not preserve the order of the items as they are received. In fact, asynchronous operations can complete and push data at any time, regardless of when they are started. We immediately understand that this property does not play well with binary streams where the order of data usually matters, but it can surely be useful with some types of object streams.
Implementing a URL status monitoring application
Now, let's apply our ParallelStream to a concrete example. Let's imagine that we want to build a simple service to monitor the status of a big list of URLs. Let's imagine all these URLs are contained in a single file and are newline separated.
Streams can offer a very efficient and elegant solution to this problem, especially if we use our ParallelStream class to parallelize the checking of the URLs.
Let's build this simple application immediately in a new module called check-urls.js:
import { pipeline } from 'stream'
import { createReadStream, createWriteStream } from 'fs'
import split from 'split'
import superagent from 'superagent'
import { ParallelStream } from './parallel-stream.js'
pipeline(
createReadStream(process.argv[2]), // (1)
split(), // (2)
new ParallelStream( // (3)
async (url, enc, push, done) => {
if (!url) {
return done()
}
try {
await superagent.head(url, { timeout: 5 * 1000 })
push(`${url} is up
`)
} catch (err) {
push(`${url} is down
`)
}
done()
}
),
createWriteStream('results.txt'), // (4)
(err) => {
if (err) {
console.error(err)
process.exit(1)
}
console.log('All urls have been checked')
}
)
As we can see, with streams, our code looks very elegant and straightforward: everything is contained in a single streaming pipeline. Let's see how it works:
- First, we create a
Readablestream from the file given as input. - We pipe the contents of the input file through
split(nodejsdp.link/split), aTransformstream that ensures each line is emitted in a different chunk. - Then, it's time to use our
ParallelStreamto check the URL. We do this by sending aheadrequest and waiting for a response. When the operation completes, we push the result down the stream. - Finally, all the results are piped into a file,
results.txt.
Now, we can run the check-urls.js module with a command such as this:
node check-urls.js urls.txt
Here, the file urls.txt contains a list of URLs (one per line); for example:
https://mario.fyi
https://loige.co
http://thiswillbedownforsure.com
When the command finishes running, we will see that a file, results.txt, was created. This contains the results of the operation; for example:
http://thiswillbedownforsure.com is down
https://mario.fyi is up
https://loige.co is up
There is a good probability that the order in which the results are written is different from the order in which the URLs were specified in the input file. This is clear evidence that our stream executes its tasks in parallel, and it does not enforce any order between the various data chunks in the stream.
For the sake of curiosity, we might want to try replacing ParallelStream with a normal Transform stream and compare the behavior and performance of the two (you might want to do this as an exercise). Using Transform directly is way slower, because each URL is checked in sequence, but on the other hand the order of the results in the file results.txt is preserved.
In the next section, we will see how to extend this pattern to limit the number of parallel tasks running at a given time.
Unordered limited parallel execution
If we try to run the check-urls.js application against a file that contains thousands or millions of URLs, we will surely run into issues. Our application will create an uncontrolled number of connections all at once, sending a considerable amount of data in parallel, and potentially undermining the stability of the application and the availability of the entire system. As we already know, the solution to keep the load and resource usage under control is to limit the concurrency of the parallel tasks.
Let's see how this works with streams by creating a limited-parallel-stream.js module, which is an adaptation of parallel-stream.js we created in the previous section.
Let's see what it looks like, starting from its constructor (we will highlight the changed parts):
export class LimitedParallelStream extends Transform {
constructor (concurrency, userTransform, opts) {
super({ ...opts, objectMode: true })
this.concurrency = concurrency
this.userTransform = userTransform
this.running = 0
this.continueCb = null
this.terminateCb = null
}
// ...
We need a concurrency limit to be taken as input, and this time, we are going to save two callbacks, one for any pending _transform method (continueCb—more on this next) and another one for the callback of the _flush method (terminateCb).
Next is the _transform() method:
_transform (chunk, enc, done) {
this.running++
this.userTransform(
chunk,
enc,
this.push.bind(this),
this._onComplete.bind(this)
)
if (this.running < this.concurrency) {
done()
} else {
this.continueCb = done
}
}
This time, in the _transform() method, we have to check whether we have any free execution slots before we can invoke done() and trigger the processing of the next item. If we have already reached the maximum number of concurrently running streams, we can simply save the done() callback in the continueCb variable so that it can be invoked as soon as a task finishes.
The _flush() method remains exactly the same as in the ParallelStream class, so let's move directly to implementing the _onComplete() method:
_onComplete (err) {
this.running--
if (err) {
return this.emit('error', err)
}
const tmpCb = this.continueCb
this.continueCb = null
tmpCb && tmpCb()
if (this.running === 0) {
this.terminateCb && this.terminateCb()
}
}
Every time a task completes, we invoke any saved continueCb() that will cause the stream to unblock, triggering the processing of the next item.
That's it for the LimitedParallelStream class. We can now use it in the check-urls.js module in place of ParallelStream and have the concurrency of our tasks limited to the value that we set.
Ordered parallel execution
The parallel streams that we created previously may shuffle the order of the emitted data, but there are situations where this is not acceptable. Sometimes, in fact, it is necessary to have each chunk emitted in the same order in which it was received. However, not all hope is lost: we can still run the transform function in parallel; all we have to do is to sort the data emitted by each task so that it follows the same order in which the data was received.
This technique involves the use of a buffer to reorder the chunks while they are emitted by each running task. For brevity, we are not going to provide an implementation of such a stream, as it's quite verbose for the scope of this book. What we are going to do instead is reuse one of the available packages on npm built for this specific purpose, that is, parallel-transform (nodejsdp.link/parallel-transform).
We can quickly check the behavior of an ordered parallel execution by modifying our existing check-urls module. Let's say that we want our results to be written in the same order as the URLs in the input file, while executing our checks in parallel. We can do this using parallel-transform:
//...
import parallelTransform from 'parallel-transform'
pipeline(
createReadStream(process.argv[2]),
split(),
parallelTransform(4, async function (url, done) {
if (!url) {
return done()
}
console.log(url)
try {
await request.head(url, { timeout: 5 * 1000 })
this.push(`${url} is up
`)
} catch (err) {
this.push(`${url} is down
`)
}
done()
}),
createWriteStream('results.txt'),
(err) => {
if (err) {
console.error(err)
process.exit(1)
}
console.log('All urls have been checked')
}
)
In the example here, parallelTransform() creates a Transform stream in object mode that executes our transformation logic with a maximum concurrency of 4. If we try to run this new version of check-urls.js, we will now see that the results.txt file lists the results in the same order as the URLs appear in the input file. It is important to see that, even though the order of the output is the same as the input, the asynchronous tasks still run in parallel and can possibly complete in any order.
When using the ordered parallel execution pattern, we need to be aware of slow items blocking the pipeline or growing the memory indefinitely. In fact, if there is an item that requires a very long time to complete, depending on the implementation of the pattern, it will either cause the buffer containing the pending ordered results to grow indefinitely or the entire processing to block until the slow item completes. With the first strategy, we are optimizing for performance, while with the second, we get predictable memory usage. parallel-transform implementation opts for predictable memory utilization and maintains an internal buffer that will not grow more than the specified maximum concurrency.
With this, we conclude our analysis of the asynchronous control flow patterns with streams. Next, we are going to focus on some piping patterns.
Piping patterns
As in real-life plumbing, Node.js streams can also be piped together by following different patterns. We can, in fact, merge the flow of two different streams into one, split the flow of one stream into two or more pipes, or redirect the flow based on a condition. In this section, we are going to explore the most important plumbing patterns that can be applied to Node.js streams.
Combining streams
In this chapter, we have stressed the fact that streams provide a simple infrastructure to modularize and reuse our code, but there is one last piece missing in this puzzle: what if we want to modularize and reuse an entire pipeline? What if we want to combine multiple streams so that they look like one from the outside? The following figure shows what this means:

Figure 6.6: Combining streams
From Figure 6.6, we should already get a hint of how this works:
- When we write into the combined stream, we are actually writing into the first stream of the pipeline.
- When we read from the combined stream, we are actually reading from the last stream of the pipeline.
A combined stream is usually a Duplex stream, which is built by connecting the first stream to its Writable side and the last stream to its Readable side.
To create a Duplex stream out of two different streams, one Writable and one Readable, we can use an npm module such as duplexer2 (nodejsdp.link/duplexer2) or duplexify (nodejsdp.link/duplexify).
But that's not enough. In fact, another important characteristic of a combined stream is that it has to capture and propagate all the errors that are emitted from any stream inside the pipeline. As we already mentioned, any error event is not automatically propagated down the pipeline when we use pipe(), and we should explicitly attach an error listener to each stream. We saw that we could use the pipeline() helper function to overcome the limitations of pipe() with error management, but the issue with both pipe() and the pipeline() helper is that the two functions return only the last stream of the pipeline, so we only get the (last) Readable component and not the (first) Writable component.
We can verify this very easily with the following snippet of code:
import { createReadStream, createWriteStream } from 'fs'
import { Transform, pipeline } from 'stream'
import { strict as assert } from 'assert'
const streamA = createReadStream('package.json')
const streamB = new Transform({
transform (chunk, enc, done) {
this.push(chunk.toString().toUpperCase())
done()
}
})
const streamC = createWriteStream('package-uppercase.json')
const pipelineReturn = pipeline(
streamA,
streamB,
streamC,
() => {
// handle errors here
})
assert.strictEqual(streamC, pipelineReturn) // valid
const pipeReturn = streamA.pipe(streamB).pipe(streamC)
assert.strictEqual(streamC, pipeReturn) // valid
From the preceding code, it should be clear that with just pipe() or pipeline(), it would not be trivial to construct a combined stream.
To recap, a combined stream has two major advantages:
- We can redistribute it as a black box by hiding its internal pipeline.
- We have simplified error management, as we don't have to attach an error listener to each stream in the pipeline, but just to the combined stream itself.
Combining streams is a pretty common practice, so if we don't have any particular need, we might just want to reuse an existing library such as pumpify (nodejsdp.link/pumpify).
This library offers a very simple interface. In fact, all you have to do to obtain a combined stream is to call pumpify(), passing all the streams you want in your pipeline. This is very similar to the signature of pipeline(), except that there's no callback:
const combinedStream = pumpify(streamA, streamB, streamC)
When we do something like this, pumpify will create a pipeline out of our streams, return a new combined stream that abstracts away the complexity of our pipeline, and provide the advantages discussed previously.
If you are curious to see what it takes to build a library like pumpify, you should check its source code on GitHub (nodejsdp.link/pumpify-gh). One interesting fact is that, internally, pumpify uses pump (nodejsdp.link/pump), a module that was born before the Node.js pipeline() helper. pump is effectively the module that inspired the development of pipeline(). If you compare their source code, you will find out that, unsurprisingly, the two modules have a lot in common.
Implementing a combined stream
To illustrate a simple example of combining streams, let's consider the case of the following two Transform streams:
- One that both compresses and encrypts the data
- One that both decrypts and decompresses the data
Using a library such as pumpify, we can easily build these streams (in a file called combined-streams.js) by combining some of the streams that we already have available from the core libraries:
import { createGzip, createGunzip } from 'zlib'
import {
createCipheriv,
createDecipheriv,
scryptSync
} from 'crypto'
import pumpify from 'pumpify'
function createKey (password) {
return scryptSync(password, 'salt', 24)
}
export function createCompressAndEncrypt (password, iv) {
const key = createKey(password)
const combinedStream = pumpify(
createGzip(),
createCipheriv('aes192', key, iv)
)
combinedStream.iv = iv
return combinedStream
}
export function createDecryptAndDecompress (password, iv) {
const key = createKey(password)
return pumpify(
createDecipheriv('aes192', key, iv),
createGunzip()
)
}
We can now use these combined streams as if they were black boxes, for example, to create a small application that archives a file by compressing and encrypting it. Let's do that in a new module named archive.js:
import { createReadStream, createWriteStream } from 'fs'
import { pipeline } from 'stream'
import { randomBytes } from 'crypto'
import { createCompressAndEncrypt } from './combined-streams.js'
const [,, password, source] = process.argv
const iv = randomBytes(16)
const destination = `${source}.gz.enc`
pipeline(
createReadStream(source),
createCompressAndEncrypt(password, iv),
createWriteStream(destination),
(err) => {
if (err) {
console.error(err)
process.exit(1)
}
console.log(`${destination} created with iv: ${iv.toString('hex')}`)
}
)
Note how we don't have to worry about how many steps there are within archiveFile. In fact, we just treat it as a single stream within our current pipeline. This makes our combined stream easily reusable in other contexts.
Now, to run the archive module, simply specify a password and a file in the command-line arguments:
node archive.js mypassword /path/to/a/file.txt
This command will create a file called /path/to/a/file.txt.gz.enc and it will print the generated initialization vector to the console.
Now, as an exercise, you could use the createDecryptAndDecompress() function to create a similar script that takes a password, an initialization vector, and an archived file and unarchives it.
In real-life applications, it is generally preferable to include the initialization vector as part of the encrypted data, rather than requiring the user to pass it around. One way to implement this is by having the first 16 bytes emitted by the archive stream to be representing the initialization vector. The unarchive utility would need to be updated accordingly to consume the first 16 bytes before starting to process the data in a streaming fashion. This approach would add some additional complexity, which is outside the scope of this example, therefore we opted for a simpler solution. Once you feel comfortable with streams, we encourage you to try to implement as an exercise a solution where the initialization vector doesn't have to be passed around by the user.
With this example, we have clearly demonstrated how important it is to combine streams. From one side, it allows us to create reusable compositions of streams, and from the other, it simplifies the error management of a pipeline.
Forking streams
We can perform a fork of a stream by piping a single Readable stream into multiple Writable streams. This is useful when we want to send the same data to different destinations; for example, two different sockets or two different files. It can also be used when we want to perform different transformations on the same data, or when we want to split the data based on some criteria. If you are familiar with the Unix command tee (nodejsdp.link/tee), this is exactly the same concept applied to Node.js streams!
Figure 6.7 gives us a graphical representation of this pattern:
Figure 6.7: Forking a stream
Forking a stream in Node.js is quite easy, but there are a few caveats to keep in mind. Let's start by discussing this pattern with an example. It will be easier to appreciate the caveats of this pattern once we have an example at hand.
Implementing a multiple checksum generator
Let's create a small utility that outputs both the sha1 and md5 hashes of a given file. Let's call this new module generate-hashes.js:
import { createReadStream, createWriteStream } from 'fs'
import { createHash } from 'crypto'
const filename = process.argv[2]
const sha1Stream = createHash('sha1').setEncoding('hex')
const md5Stream = createHash('md5').setEncoding('hex')
const inputStream = createReadStream(filename)
inputStream
.pipe(sha1Stream)
.pipe(createWriteStream(`${filename}.sha1`))
inputStream
.pipe(md5Stream)
.pipe(createWriteStream(`${filename}.md5`))
Very simple, right? The inputStream variable is piped into sha1Stream on one side and md5Stream on the other. There are a few things to note that happen behind the scenes:
- Both
md5Streamandsha1Streamwill be ended automatically wheninputStreamends, unless we specify{ end: false }as an option when invokingpipe(). - The two forks of the stream will receive the same data chunks, so we must be very careful when performing side-effect operations on the data, as that would affect every stream that we are sending data to.
- Backpressure will work out of the box; the flow coming from
inputStreamwill go as fast as the slowest branch of the fork. In other words, if one destination pauses the source stream to handle backpressure for a long time, all the other destinations will be waiting as well. Also, one destination blocking indefinitely will block the entire pipeline! - If we pipe to an additional stream after we've started consuming the data at source (async piping), the new stream will only receive new chunks of data. In those cases, we can use a
PassThroughinstance as a placeholder to collect all the data from the moment we start consuming the stream. Then, thePassThroughstream can be read at any future time without the risk of losing any data. Just be aware that this approach might generate backpressure and block the entire pipeline, as discussed in the previous point.
Merging streams
Merging is the opposite operation to forking and involves piping a set of Readable streams into a single Writable stream, as shown in Figure 6.8:

Figure 6.8: Merging streams
Merging multiple streams into one is, in general, a simple operation; however, we have to pay attention to the way we handle the end event, as piping using the default options (whereby { end: true }) causes the destination stream to end as soon as one of the sources ends. This can often lead to an error, as the other active sources continue to write to an already terminated stream.
The solution to this problem is to use the option { end: false } when piping multiple sources to a single destination and then invoke end() on the destination only when all the sources have completed reading.
Merging text files
To make a simple example, let's implement a small program that takes an output path and an arbitrary number of text files, and then merges the lines of every file into the destination file. Our new module is going to be called merge-lines.js. Let's define its contents, starting from some initialization steps:
import { createReadStream, createWriteStream } from 'fs'
import split from 'split'
const dest = process.argv[2]
const sources = process.argv.slice(3)
In the preceding code, we are just loading all the dependencies and initializing the variables that contain the name of the destination (dest) file and all the source files (sources).
Next, we will create the destination stream:
const destStream = createWriteStream(dest)
Now, it's time to initialize the source streams:
let endCount = 0
for (const source of sources) {
const sourceStream = createReadStream(source, { highWaterMark: 16 })
sourceStream.on('end', () => {
if (++endCount === sources.length) {
destStream.end()
console.log(`${dest} created`)
}
})
sourceStream
.pipe(split((line) => line + '
'))
.pipe(destStream, { end: false })
}
In the preceding code, we created a Readable stream for every source file. Then, for each source stream, we attached an end listener, which will terminate the destination stream only when all the files have been read completely. Finally, we piped every source stream to split(), a Transform stream that makes sure that we produce a chunk for every line of text, and finally, we piped the results to our destination stream. This is when the real merge happens. We are piping multiple source streams into one single destination.
We can now execute this code with the following command:
node merge-lines.js <destination> <source1> <source2> <source3> ...
If you run this code with large enough files, you will notice that the destination file will contain lines that are randomly intermingled from all the source files (a low highWaterMark of 16 bytes makes this property even more apparent). This kind of behavior can be acceptable in some types of object streams and some text streams split by line (as in our current example), but it is often undesirable when dealing with most binary streams.
There is one variation of the pattern that allows us to merge streams in order; it consists of consuming the source streams one after the other. When the previous one ends, the next one starts emitting chunks (it is like concatenating the output of all the sources). As always, on npm, we can find some packages that also deal with this situation. One of them is multistream (https://npmjs.org/package/multistream).
Multiplexing and demultiplexing
There is a particular variation of the merge stream pattern in which we don't really want to just join multiple streams together but, instead, use a shared channel to deliver the data of a set of streams. This is a conceptually different operation because the source streams remain logically separated inside the shared channel, which allows us to split the stream again once the data reaches the other end of the shared channel. Figure 6.9 clarifies this situation:

Figure 6.9: Multiplexing and demultiplexing streams
The operation of combining multiple streams (in this case, also known as channels) to allow transmission over a single stream is called multiplexing, while the opposite operation, namely reconstructing the original streams from the data received from a shared stream, is called demultiplexing. The devices that perform these operations are called multiplexer (or mux) and demultiplexer (or demux), respectively. This is a widely studied area in computer science and telecommunications in general, as it is one of the foundations of almost any type of communication media such as telephony, radio, TV, and, of course, the Internet itself. For the scope of this book, we will not go too far with the explanations, as this is a vast topic.
What we want to demonstrate in this section is how it's possible to use a shared Node.js stream to transmit multiple logically separated streams that are then separated again at the other end of the shared stream.
Building a remote logger
Let's use an example to drive our discussion. We want a small program that starts a child process and redirects both its standard output and standard error to a remote server, which, in turn, saves the two streams in two separate files. So, in this case, the shared medium is a TCP connection, while the two channels to be multiplexed are the stdout and stderr of a child process. We will leverage a technique called packet switching, the same technique that is used by protocols such as IP, TCP, and UDP. Packet switching involves wrapping the data into packets, allowing us to specify various meta information that's useful for multiplexing, routing, controlling the flow, checking for corrupted data, and so on. The protocol that we are implementing in our example is very minimalist. We wrap our data into simple packets, as illustrated in Figure 6.10:

Figure 6.10: Bytes structure of the data packet for our remote logger
As shown in Figure 6.10, the packet contains the actual data, but also a header (Channel ID + Data length), which will make it possible to differentiate the data of each stream and enable the demultiplexer to route the packet to the right channel.
Client side – multiplexing
Let's start to build our application from the client side. With a lot of creativity, we will call the module client.js. This represents the part of the application that is responsible for starting a child process and multiplexing its streams.
So, let's start by defining the module. First, we need some dependencies:
import { fork } from 'child_process'
import { connect } from 'net'
Now, let's implement a function that performs the multiplexing of a list of sources:
function multiplexChannels (sources, destination) {
let openChannels = sources.length
for (let i = 0; i < sources.length; i++) {
sources[i]
.on('readable', function () { // (1)
let chunk
while ((chunk = this.read()) !== null) {
const outBuff = Buffer.alloc(1 + 4 + chunk.length) // (2)
outBuff.writeUInt8(i, 0)
outBuff.writeUInt32BE(chunk.length, 1)
chunk.copy(outBuff, 5)
console.log(`Sending packet to channel: ${i}`)
destination.write(outBuff) // (3)
}
})
.on('end', () => { // (4)
if (--openChannels === 0) {
destination.end()
}
})
}
}
The multiplexChannels() function takes in, as input, the source streams to be multiplexed and the destination channel, and then it performs the following steps:
- For each source stream, it registers a listener for the
readableevent, where we read the data from the stream using the non-flowing mode. - When a chunk is read, we wrap it into a packet that contains, in order, 1 byte (
UInt8) for the channel ID, 4 bytes (UInt32BE) for the packet size, and then the actual data. - When the packet is ready, we write it into the destination stream.
- Finally, we register a listener for the
endevent so that we can terminate the destination stream when all the source streams have ended.
Our protocol is to be able to multiplex up to 256 different source streams because we only have 1 byte to identify the channel.
Now, the last part of our client becomes very easy:
const socket = connect(3000, () => { // (1)
const child = fork( // (2)
process.argv[2],
process.argv.slice(3),
{ silent: true }
)
multiplexChannels([child.stdout, child.stderr], socket) // (3)
})
In this last code fragment, we perform the following operations:
- We create a new TCP client connection to the address
localhost:3000. - We start the child process by using the first command-line argument as the path, while we provide the rest of the
process.argvarray as arguments for the child process. We specify the option{silent: true}so that the child process does not inheritstdoutandstderrof the parent. - Finally, we take
stdoutandstderrof the child process and we multiplex them into the socket'sWritablestream using themutiplexChannels()function.
Server side – demultiplexing
Now, we can take care of creating the server side of the application (server.js), where we demultiplex the streams from the remote connection and pipe them into two different files.
Let's start by creating a function called demultiplexChannel():
import { createWriteStream } from 'fs'
import { createServer } from 'net'
function demultiplexChannel (source, destinations) {
let currentChannel = null
let currentLength = null
source
.on('readable', () => { // (1)
let chunk
if (currentChannel === null) { // (2)
chunk = source.read(1)
currentChannel = chunk && chunk.readUInt8(0)
}
if (currentLength === null) { // (3)
chunk = source.read(4)
currentLength = chunk && chunk.readUInt32BE(0)
if (currentLength === null) {
return null
}
}
chunk = source.read(currentLength) // (4)
if (chunk === null) {
return null
}
console.log(`Received packet from: ${currentChannel}`)
destinations[currentChannel].write(chunk) // (5)
currentChannel = null
currentLength = null
})
.on('end', () => { // (6)
destinations.forEach(destination => destination.end())
console.log('Source channel closed')
})
}
The preceding code might look complicated, but it is not. Thanks to the features of Node.js Readable streams, we can easily implement the demultiplexing of our little protocol as follows:
- We start reading from the stream using the non-flowing mode.
- First, if we have not read the channel ID yet, we try to read 1 byte from the stream and then transform it into a number.
- The next step is to read the length of the data. We need 4 bytes for that, so it's possible (even if unlikely) that we don't have enough data in the internal buffer, which will cause the
this.read()invocation to returnnull. In such a case, we simply interrupt the parsing and retry at the nextreadableevent. - When we can finally also read the data size, we know how much data to pull from the internal buffer, so we try to read it all.
- When we read all the data, we can write it to the right destination channel, making sure that we reset the
currentChannelandcurrentLengthvariables (these will be used to parse the next packet). - Lastly, we make sure to end all the destination channels when the source channel ends.
Now that we can demultiplex the source stream, let's put our new function to work:
const server = createServer((socket) => {
const stdoutStream = createWriteStream('stdout.log')
const stderrStream = createWriteStream('stderr.log')
demultiplexChannel(socket, [stdoutStream, stderrStream])
})
server.listen(3000, () => console.log('Server started'))
In the preceding code, we first start a TCP server on port 3000; then, for each connection that we receive, we create two Writable streams pointing to two different files: one for the standard output and the other for the standard error. These are our destination channels. Finally, we use demultiplexChannel() to demultiplex the socket stream into stdoutStream and stderrStream.
Running the mux/demux application
Now, we are ready to try our new mux/demux application, but first, let's create a small Node.js program to produce some sample output; let's call it generate-data.js:
console.log('out1')
console.log('out2')
console.error('err1')
console.log('out3')
console.error('err2')
Okay; now, we are ready to try our remote logging application. First, let's start the server:
node server.js
Then, we'll start the client by providing the file that we want to start as a child process:
node client.js generateData.js
The client will run almost immediately, but at the end of the process, the standard input and standard output of the generate-data.js application will have traveled through one single TCP connection and then, on the server, be demultiplexed into two separate files.
Please make a note that, as we are using child_process.fork() (nodejsdp.link/fork), our client will only be able to launch other Node.js modules.
Multiplexing and demultiplexing object streams
The example that we have just shown demonstrates how to multiplex and demultiplex a binary/text stream, but it's worth mentioning that the same rules apply to object streams. The biggest difference is that when using objects, we already have a way to transmit the data using atomic messages (the objects), so multiplexing would be as easy as setting a channelID property in each object. Demultiplexing would simply involve reading the channelID property and routing each object toward the right destination stream.
Another pattern involving only demultiplexing is routing the data coming from a source depending on some condition. With this pattern, we can implement complex flows, such as the one shown in Figure 6.11:
Figure 6.11: Demultiplexing an object stream
The demultiplexer used in the system in Figure 6.11 takes a stream of objects representing animals and distributes each of them to the right destination stream based on the class of the animal: reptiles, amphibians, or mammals.
Using the same principle, we can also implement an if...else statement for streams. For some inspiration, take a look at the ternary-stream package (nodejsdp.link/ternary-stream), which allows us to do exactly that.
Summary
In this chapter, we have shed some light on Node.js streams and some of their most common use cases. We learned why streams are so acclaimed by the Node.js community and we mastered their basic functionality, enabling us to discover more and navigate comfortably in this new world. We analyzed some advanced patterns and started to understand how to connect streams in different configurations, grasping the importance of interoperability, which is what makes streams so versatile and powerful.
If we can't do something with one stream, we can probably do it by connecting other streams together, and this works great with the one thing per module philosophy. At this point, it should be clear that streams are not just a good to know feature of Node.js; they are an essential part—a crucial pattern to handle binary data, strings, and objects. It's not by chance that we dedicated an entire chapter to them.
In the next few chapters, we will focus on the traditional object-oriented design patterns. But don't be fooled; even though JavaScript is, to some extent, an object-oriented language, in Node.js, the functional or hybrid approach is often preferred. Get rid of every prejudice before reading the next chapters.
Exercises
- 6.1 Data compression efficiency: Write a command-line script that takes a file as input and compresses it using the different algorithms available in the
zlibmodule (Brotli, Deflate, Gzip). You want to produce a summary table that compares the algorithm's compression time and compression efficiency on the given file. Hint: This could be a good use case for the fork pattern, but remember that we made some important performance considerations when we discussed it earlier in this chapter. - 6.2 Stream data processing: On Kaggle, you can find a lot of interesting data sets, such as the London Crime Data (nodejsdp.link/london-crime). You can download the data in CSV format and build a stream processing script that analyzes the data and tries to answer the following questions:
- Did the number of crimes go up or down over the years?
- What are the most dangerous areas of London?
- What is the most common crime per area?
- What is the least common crime?
Hint: You can use a combination of
Transformstreams andPassThroughstreams to parse and observe the data as it is flowing. Then, you can build in-memory aggregations for the data, which can help you answer the preceding questions. Also, you don't need to do everything in one pipeline; you could build very specialized pipelines (for example, one per question) and use the fork pattern to distribute the parsed data across them. - 6.3 File share over TCP: Build a client and a server to transfer files over TCP. Extra points if you add a layer of encryption on top of that and if you can transfer multiple files at once. Once you have your implementation ready, give the client code and your IP address to a friend or a colleague, then ask them to send you some files! Hint: You could use mux/demux to receive multiple files at once.
- 6.4 Animations with Readable streams: Did you know you can create amazing terminal animations with just
Readablestreams? Well, to understand what we are talking about here, try to runcurl parrot.livein your terminal and see what happens! If you think that this is cool, why don't you try to create something similar? Hint: If you need some help with figuring out how to implement this, you can check out the actual source code ofparrot.liveby simply accessing its URL through your browser.