
1
The Node.js Platform
Some principles and design patterns literally define the developer experience with the Node.js platform and its ecosystem. The most peculiar one is probably its asynchronous nature, which makes heavy use of asynchronous constructs such as callbacks and promises. In this introductory chapter, we will explore where Node.js gets its asynchronous behavior from. This is not just good-to-know theoretical information: knowing how Node.js works at its core will give you a strong foundation for understanding the reasoning behind more complex topics and patterns that we will cover later in the book.
Another important aspect that characterizes Node.js is its philosophy. Approaching Node.js is, in fact, far more than simply learning a new technology: it's also embracing a culture and a community. You will see how this greatly influences the way we design our applications and components, and the way they interact with those created by the community.
In this chapter, you will learn about the following:
- The Node.js philosophy or the "Node way"
- The reactor pattern—the mechanism at the heart of the Node.js asynchronous event-driven architecture
- What it means to run JavaScript on the server compared to the browser
The Node.js philosophy
Every programming platform has its own philosophy, a set of principles and guidelines that are generally accepted by the community, or an ideology for doing things that influence both the evolution of the platform and how applications are developed and designed. Some of these principles arise from the technology itself, some of them are enabled by its ecosystem, some are just trends in the community, and others are evolutions of ideologies borrowed from other platforms. In Node.js, some of these principles come directly from its creator—Ryan Dahl—while others come from the people who contribute to the core or from charismatic figures in the community, and, finally, some are inherited from the larger JavaScript movement.
None of these rules are imposed and they should always be applied with common sense; however, they can prove to be tremendously useful when we are looking for a source of inspiration while designing our software.
You can find an extensive list of software development philosophies on Wikipedia at nodejsdp.link/dev-philosophies.
Small core
The Node.js core—understood as the Node.js runtime and built-in modules—has its foundations built on a few principles. One of these is having the smallest possible set of functionalities, while leaving the rest to the so-called userland (or userspace), which is the ecosystem of modules living outside the core. This principle has an enormous impact on the Node.js culture, as it gives freedom to the community to experiment and iterate quickly on a broader set of solutions within the scope of the userland modules, instead of having one slowly evolving solution that is built into the more tightly controlled and stable core. Keeping the core set of functionalities to the bare minimum, then, is not only convenient in terms of maintainability, but also in terms of the positive cultural impact that it brings to the evolution of the entire ecosystem.
Small modules
Node.js uses the concept of a module as the fundamental means for structuring the code of a program. It is the building block for creating applications and reusable libraries. In Node.js, one of the most evangelized principles is designing small modules (and packages), not only in terms of raw code size, but, most importantly, in terms of scope.
This principle has its roots in the Unix philosophy, and particularly in two of its precepts, which are as follows:
- "Small is beautiful."
- "Make each program do one thing well."
Node.js has brought these concepts to a whole new level. Along with the help of its module managers—with npm and yarn being the most popular—Node.js helps to solve the dependency hell problem by making sure that two (or more) packages depending on different versions of the same package will use their own installations of such a package, thus avoiding conflicts. This aspect allows packages to depend on a high number of small, well-focused dependencies without the risk of creating conflicts. While this can be considered unpractical or even totally unfeasible in other platforms, in Node.js, this practice is the norm. This enables extreme levels of reusability; they are so extreme, in fact, that sometimes we can find packages comprising of a single module containing just a couple of lines of code—for example, a regular expression for matching emails such as nodejsdp.link/email-regex.
Besides the clear advantage in terms of reusability, a small module is also:
- Easier to understand and use
- Simpler to test and maintain
- Small in size and perfect for use in the browser
Having smaller and more focused modules empowers everyone to share or reuse even the smallest piece of code; it's the Don't Repeat Yourself (DRY) principle applied at a whole new level.
Small surface area
In addition to being small in size and scope, a desirable characteristic of Node.js modules is exposing a minimal set of functionalities to the outside world. This has the effect of producing an API that is clearer to use and less susceptible to erroneous usage. In fact, most of the time the user of a component is only interested in a very limited and focused set of features, without needing to extend its functionality or tap into more advanced aspects.
In Node.js, a very common pattern for defining modules is to expose only one functionality, such as a function or a class, for the simple fact that it provides a single, unmistakably clear entry point.
Another characteristic of many Node.js modules is the fact that they are created to be used, rather than extended. Locking down the internals of a module by forbidding any possibility of an extension might sound inflexible, but it actually has the advantage of reducing use cases, simplifying implementation, facilitating maintenance, and increasing usability. In practice, this means preferring to expose functions instead of classes, and being careful not to expose any internals to the outside world.
Simplicity and pragmatism
Have you ever heard of the Keep It Simple, Stupid (KISS) principle? Richard P. Gabriel, a prominent computer scientist, coined the term "worse is better" to describe the model whereby less and simpler functionality is a good design choice for software. In his essay The Rise of "Worse is Better" he says:
"The design must be simple, both in implementation and interface. It is more important for the implementation to be simple than the interface. Simplicity is the most important consideration in a design."
Designing simple, as opposed to perfect, fully featured software is a good practice for several reasons: it takes less effort to implement, it allows shipping faster with fewer resources, it's easier to adapt, and, finally, it's easier to maintain and understand. The positive effects of these factors encourage community contributions and allow the software itself to grow and improve.
In Node.js, the adoption of this principle is also facilitated by JavaScript, which is a very pragmatic language. In fact, it's common to see simple classes, functions, and closures replacing complex class hierarchies. Pure object-oriented designs often try to replicate the real world using the mathematical terms of a computer system without considering the imperfection and complexity of the real world itself. Instead, the truth is that our software is always an approximation of reality, and we will probably have more success by trying to get something working sooner and with reasonable complexity, instead of trying to create near-perfect software with huge effort and tons of code to maintain.
Throughout this book, you will see this principle in action many times. For example, a considerable number of traditional design patterns, such as Singleton or Decorator, can have a trivial, even if sometimes not bulletproof, implementation, and you will see how an uncomplicated, practical approach is (most of the time) preferred to a pure, flawless design.
Next, we will take a look inside the Node.js core to reveal its internal patterns and event-driven architecture.
How Node.js works
In this section, you will gain an understanding of how Node.js works internally and be introduced to the reactor pattern, which is the heart of the asynchronous nature of Node.js. We will go through the main concepts behind the pattern, such as the single-threaded architecture and the non-blocking I/O, and you will see how this creates the foundation for the entire Node.js platform.
I/O is slow
I/O (short for input/output) is definitely the slowest among the fundamental operations of a computer. Accessing the RAM is in the order of nanoseconds (10E-9 seconds), while accessing data on the disk or the network is in the order of milliseconds (10E-3 seconds). The same applies to the bandwidth. RAM has a transfer rate consistently in the order of GB/s, while the disk or network varies from MB/s to optimistically GB/s. I/O is usually not expensive in terms of CPU, but it adds a delay between the moment the request is sent to the device and the moment the operation completes. On top of that, we have to consider the human factor. In fact, in many circumstances, the input of an application comes from a real person—a mouse click, for example—so the speed and frequency of I/O doesn't only depend on technical aspects, and it can be many orders of magnitude slower than the disk or network.
Blocking I/O
In traditional blocking I/O programming, the function call corresponding to an I/O request will block the execution of the thread until the operation completes. This can range from a few milliseconds, in the case of disk access, to minutes or even more, in the case of data being generated from user actions, such as pressing a key. The following pseudocode shows a typical blocking thread performed against a socket:
// blocks the thread until the data is available
data = socket.read()
// data is available
print(data)
It is trivial to notice that a web server that is implemented using blocking I/O will not be able to handle multiple connections in the same thread. This is because each I/O operation on a socket will block the processing of any other connection. The traditional approach to solving this problem is to use a separate thread (or process) to handle each concurrent connection.
This way, a thread blocked on an I/O operation will not impact the availability of the other connections, because they are handled in separate threads.
The following illustrates this scenario:
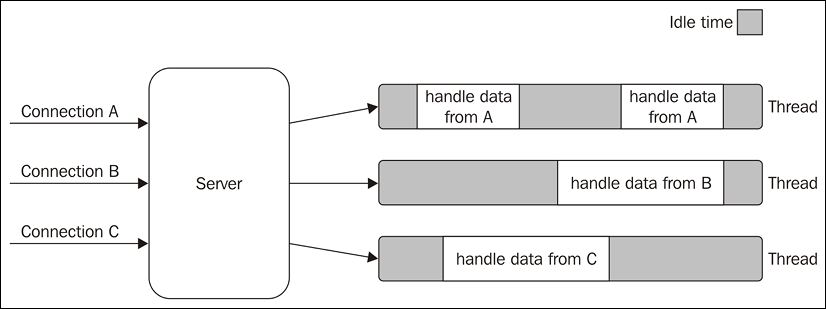
Figure 1.1: Using multiple threads to process multiple connections
Figure 1.1 lays emphasis on the amount of time each thread is idle and waiting for new data to be received from the associated connection. Now, if we also consider that any type of I/O can possibly block a request—for example, while interacting with databases or with the filesystem—we will soon realize how many times a thread has to block in order to wait for the result of an I/O operation. Unfortunately, a thread is not cheap in terms of system resources—it consumes memory and causes context switches—so having a long-running thread for each connection and not using it for most of the time means wasting precious memory and CPU cycles.
Non-blocking I/O
In addition to blocking I/O, most modern operating systems support another mechanism to access resources, called non-blocking I/O. In this operating mode, the system call always returns immediately without waiting for the data to be read or written. If no results are available at the moment of the call, the function will simply return a predefined constant, indicating that there is no data available to return at that moment.
For example, in Unix operating systems, the fcntl() function is used to manipulate an existing file descriptor (which in Unix represents the reference used to access a local file or a network socket) to change its operating mode to non-blocking (with the O_NONBLOCK flag). Once the resource is in non-blocking mode, any read operation will fail with the return code EAGAIN if the resource doesn't have any data ready to be read.
The most basic pattern for dealing with this type of non-blocking I/O is to actively poll the resource within a loop until some actual data is returned. This is called busy-waiting. The following pseudocode shows you how it's possible to read from multiple resources using non-blocking I/O and an active polling loop:
resources = [socketA, socketB, fileA]
while (!resources.isEmpty()) {
for (resource of resources) {
// try to read
data = resource.read()
if (data === NO_DATA_AVAILABLE) {
// there is no data to read at the moment
continue
}
if (data === RESOURCE_CLOSED) {
// the resource was closed, remove it from the list
resources.remove(i)
} else {
//some data was received, process it
consumeData(data)
}
}
}
As you can see, with this simple technique, it is possible to handle different resources in the same thread, but it's still not efficient. In fact, in the preceding example, the loop will only consume precious CPU for iterating over resources that are unavailable most of the time. Polling algorithms usually result in a huge amount of wasted CPU time.
Event demultiplexing
Busy-waiting is definitely not an ideal technique for processing non-blocking resources, but luckily, most modern operating systems provide a native mechanism to handle concurrent non-blocking resources in an efficient way. We are talking about the synchronous event demultiplexer (also known as the event notification interface).
If you are unfamiliar with the term, in telecommunications, multiplexing refers to the method by which multiple signals are combined into one so that they can be easily transmitted over a medium with limited capacity.
Demultiplexing refers to the opposite operation, whereby the signal is split again into its original components. Both terms are used in other areas (for example, video processing) to describe the general operation of combining different things into one and vice versa.
The synchronous event demultiplexer that we were talking about watches multiple resources and returns a new event (or set of events) when a read or write operation executed over one of those resources completes. The advantage here is that the synchronous event demultiplexer is, of course, synchronous, so it blocks until there are new events to process. The following is the pseudocode of an algorithm that uses a generic synchronous event demultiplexer to read from two different resources:
watchedList.add(socketA, FOR_READ) // (1)
watchedList.add(fileB, FOR_READ)
while (events = demultiplexer.watch(watchedList)) { // (2)
// event loop
for (event of events) { // (3)
// This read will never block and will always return data
data = event.resource.read()
if (data === RESOURCE_CLOSED) {
// the resource was closed, remove it from the watched list
demultiplexer.unwatch(event.resource)
} else {
// some actual data was received, process it
consumeData(data)
}
}
}
Let's see what happens in the preceding pseudocode:
- The resources are added to a data structure, associating each one of them with a specific operation (in our example, a
read). - The demultiplexer is set up with the group of resources to be watched. The call to
demultiplexer.watch()is synchronous and blocks until any of the watched resources are ready forread. When this occurs, the event demultiplexer returns from the call and a new set of events is available to be processed. - Each event returned by the event demultiplexer is processed. At this point, the resource associated with each event is guaranteed to be ready to read and to not block during the operation. When all the events are processed, the flow will block again on the event demultiplexer until new events are again available to be processed. This is called the event loop.
It's interesting to see that, with this pattern, we can now handle several I/O operations inside a single thread, without using the busy-waiting technique. It should now be clearer why we are talking about demultiplexing; using just a single thread, we can deal with multiple resources. Figure 1.2 will help you visualize what's happening in a web server that uses a synchronous event demultiplexer and a single thread to handle multiple concurrent connections:
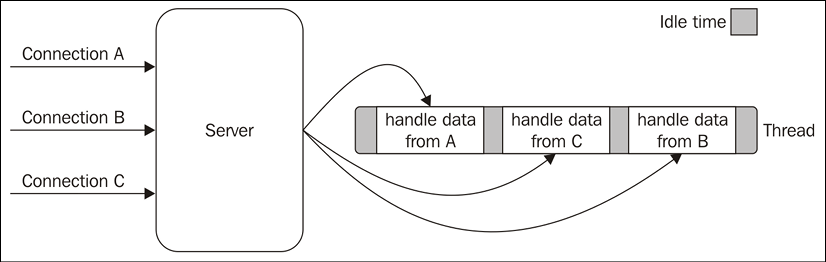
Figure 1.2: Using a single thread to process multiple connections
As this shows, using only one thread does not impair our ability to run multiple I/O-bound tasks concurrently. The tasks are spread over time, instead of being spread across multiple threads. This has the clear advantage of minimizing the total idle time of the thread, as is clearly shown in Figure 1.2.
But this is not the only reason for choosing this I/O model. In fact, having a single thread also has a beneficial impact on the way programmers approach concurrency in general. Throughout the book, you will see how the absence of in-process race conditions and multiple threads to synchronize allows us to use much simpler concurrency strategies.
The reactor pattern
We can now introduce the reactor pattern, which is a specialization of the algorithms presented in the previous sections. The main idea behind the reactor pattern is to have a handler associated with each I/O operation. A handler in Node.js is represented by a callback (or cb for short) function.
The handler will be invoked as soon as an event is produced and processed by the event loop. The structure of the reactor pattern is shown in Figure 1.3:
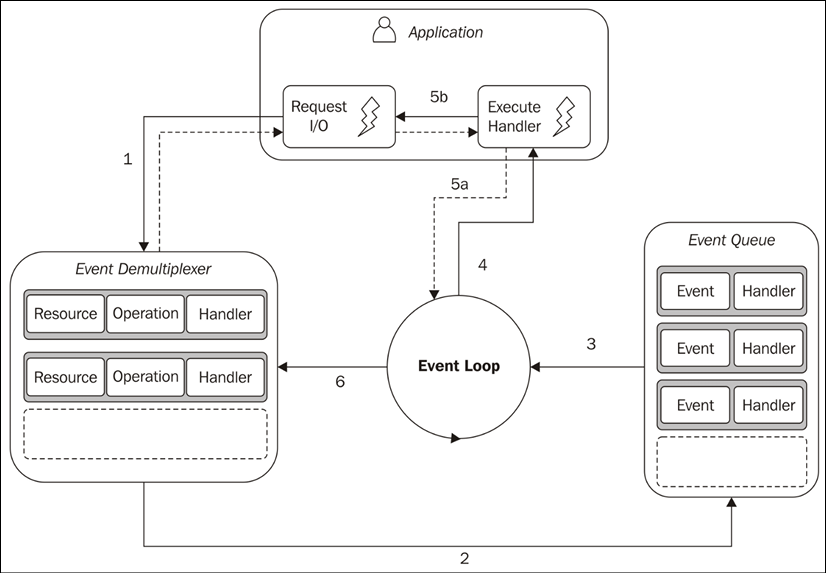
Figure 1.3: The reactor pattern
This is what happens in an application using the reactor pattern:
- The application generates a new I/O operation by submitting a request to the Event Demultiplexer. The application also specifies a handler, which will be invoked when the operation completes. Submitting a new request to the Event Demultiplexer is a non-blocking call and it immediately returns control to the application.
- When a set of I/O operations completes, the Event Demultiplexer pushes a set of corresponding events into the Event Queue.
- At this point, the Event Loop iterates over the items of the Event Queue.
- For each event, the associated handler is invoked.
- The handler, which is part of the application code, gives back control to the Event Loop when its execution completes (5a). While the handler executes, it can request new asynchronous operations (5b), causing new items to be added to the Event Demultiplexer (1).
- When all the items in the Event Queue are processed, the Event Loop blocks again on the Event Demultiplexer, which then triggers another cycle when a new event is available.
The asynchronous behavior has now become clear. The application expresses interest in accessing a resource at one point in time (without blocking) and provides a handler, which will then be invoked at another point in time when the operation completes.
A Node.js application will exit when there are no more pending operations in the event demultiplexer, and no more events to be processed inside the event queue.
We can now define the pattern at the heart of Node.js:
The reactor pattern
Handles I/O by blocking until new events are available from a set of observed resources, and then reacts by dispatching each event to an associated handler.
Libuv, the I/O engine of Node.js
Each operating system has its own interface for the event demultiplexer: epoll on Linux, kqueue on macOS, and the I/O completion port (IOCP) API on Windows. On top of that, each I/O operation can behave quite differently depending on the type of resource, even within the same operating system. In Unix operating systems, for example, regular filesystem files do not support non-blocking operations, so in order to simulate non-blocking behavior, it is necessary to use a separate thread outside the event loop.
All these inconsistencies across and within the different operating systems required a higher-level abstraction to be built for the event demultiplexer. This is exactly why the Node.js core team created a native library called libuv, with the objective to make Node.js compatible with all the major operating systems and normalize the non-blocking behavior of the different types of resource. Libuv represents the low-level I/O engine of Node.js and is probably the most important component that Node.js is built on.
Other than abstracting the underlying system calls, libuv also implements the reactor pattern, thus providing an API for creating event loops, managing the event queue, running asynchronous I/O operations, and queuing other types of task.
A great resource to learn more about libuv is the free online book created by Nikhil Marathe, which is available at nodejsdp.link/uvbook.
The recipe for Node.js
The reactor pattern and libuv are the basic building blocks of Node.js, but we need three more components to build the full platform:
- A set of bindings responsible for wrapping and exposing libuv and other low-level functionalities to JavaScript.
- V8, the JavaScript engine originally developed by Google for the Chrome browser. This is one of the reasons why Node.js is so fast and efficient. V8 is acclaimed for its revolutionary design, its speed, and for its efficient memory management.
- A core JavaScript library that implements the high-level Node.js API.
This is the recipe for creating Node.js, and the following image represents its final architecture:
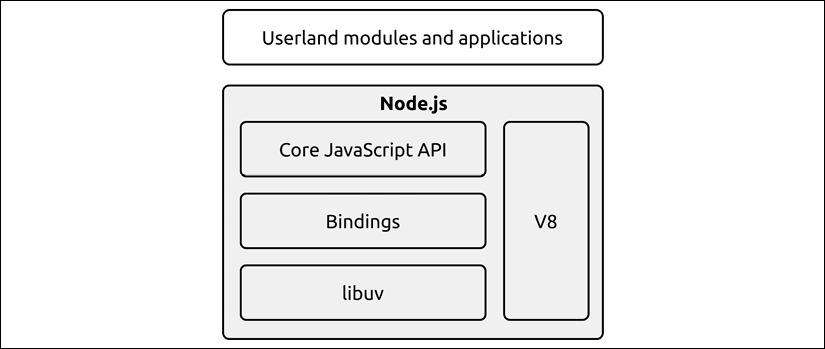
Figure 1.4: The Node.js internal components
This concludes our journey through the internal mechanisms of Node.js. Next, we'll take a look at some important aspects to take into consideration when working with JavaScript in Node.js.
JavaScript in Node.js
One important consequence of the architecture we have just analyzed is that the JavaScript we use in Node.js is somewhat different from the JavaScript we use in the browser.
The most obvious difference is that in Node.js we don't have a DOM and we don't have a window or a document. On the other hand, Node.js has access to a set of services offered by the underlying operating system that are not available in the browser. In fact, the browser has to implement a set of safety measures to make sure that the underlying system is not compromised by a rogue web application. The browser provides a higher-level abstraction over the operating system resources, which makes it easier to control and contain the code that runs in it, which will also inevitably limit its capabilities. In turn, in Node.js we can virtually have access to all the services exposed by the operating system.
In this overview, we'll take a look at some key facts to keep in mind when using JavaScript in Node.js.
Run the latest JavaScript with confidence
One of the main pain points of using JavaScript in the browser is that our code will likely run on a variety of devices and browsers. Dealing with different browsers means dealing with JavaScript runtimes that may miss some of the newest features of both the language or the web platform. Luckily, today this problem can be somewhat mitigated by the use of transpilers and polyfills. Nonetheless, this brings its own set of disadvantages and not everything can be polyfilled.
All these inconveniences don't apply when developing applications on Node.js. In fact, our Node.js applications will most likely run on a system and a Node.js runtime that are well known in advance. This makes a huge difference as it allows us to target our code for a specific JavaScript and Node.js version, with the absolute guarantee that we won't have any surprises when we run it on production.
This factor, in combination with the fact that Node.js ships with very recent versions of V8, means that we can use with confidence most of the features of the latest ECMAScript specification (ES for short; this is the standard on which the JavaScript language is based) without the need for any extra transpilation step.
Please bear in mind, though, that if we are developing a library meant to be used by third parties, we still have to take into account that our code may run on different versions of Node.js. The general pattern in this case is to target the oldest active long-term support (LTS) release and specify the engines section in our package.json, so that the package manager will warn the user if they are trying to install a package that is not compatible with their version of Node.js.
You can find out more about the Node.js release cycles at nodejsdp.link/node-releases. Also, you can find the reference for the engines section of package.json at nodejsdp.link/package-engines. Finally, you can get an idea of what ES feature is supported by each Node.js version at nodejsdp.link/node-green.
The module system
From its inception, Node.js shipped with a module system, even when JavaScript still had no official support for any form of it. The original Node.js module system is called CommonJS and it uses the require keyword to import functions, variables, and classes exported by built-in modules or other modules located on the device's filesystem.
CommonJS was a revolution for the JavaScript world in general, as it started to get popular even in the client-side world, where it is used in combination with a module bundler (such as Webpack or Rollup) to produce code bundles that are easily executable by the browser. CommonJS was a necessary component for Node.js to allow developers to create large and better organized applications on a par with other server-side platforms.
Today, JavaScript has the so-called ES modules syntax (the import keyword may be more familiar) from which Node.js inherits just the syntax, as the underlying implementation is somewhat different from that of the browser. In fact, while the browser mainly deals with remote modules, Node.js, at least for now, can only deal with modules located on the local filesystem.
We'll talk about modules in more detail in the next chapter.
Full access to operating system services
As we already mentioned, even if Node.js uses JavaScript, it doesn't run inside the boundaries of a browser. This allows Node.js to have bindings for all the major services offered by the underlying operating system.
For example, we can access any file on the filesystem (subject to any operating system-level permission) thanks to the fs module, or we can write applications that use low-level TCP or UDP sockets thanks to the net and dgram modules. We can create HTTP(S) servers (with the http and https modules) or use the standard encryption and hashing algorithms of OpenSSL (with the crypto module). We can also access some of the V8 internals (the v8 module) or run code in a different V8 context (with the vm module).
We can also run other processes (with the child_process module) or retrieve our own application's process information using the process global variable. In particular, from the process global variable, we can get a list of the environment variables assigned to the process (with process.env) or the command-line arguments passed to the application at the moment of its launch (with process.argv).
Throughout the book, you'll have the opportunity to use many of the modules described here, but for a complete reference, you can check the official Node.js documentation at nodejsdp.link/node-docs.
Running native code
One of the most powerful capabilities offered by Node.js is certainly the possibility to create userland modules that can bind to native code. This gives to the platform a tremendous advantage as it allows us to reuse existing or new components written in C/C++. Node.js officially provides great support for implementing native modules thanks to the N-API interface.
But what's the advantage? First of all, it allows us to reuse with little effort a vast amount of existing open source libraries, and most importantly, it allows a company to reuse its own C/C++ legacy code without the need to migrate it.
Another important consideration is that native code is still necessary to access low-level features such as communicating with hardware drivers or with hardware ports (for example, USB or serial). In fact, thanks to its ability to link to native code, Node.js has become popular in the world of the Internet of things (IoT) and homemade robotics.
Finally, even though V8 is very (very) fast at executing JavaScript, it still has a performance penalty to pay compared to executing native code. In everyday computing, this is rarely an issue, but for CPU-intensive applications, such as those with a lot of data processing and manipulation, delegating the work to native code can make tons of sense.
We should also mention that, nowadays, most JavaScript virtual machines (VMs) (and also Node.js) support WebAssembly (Wasm), a low-level instruction format that allows us to compile languages other than JavaScript (such as C++ or Rust) into a format that is "understandable" by JavaScript VMs. This brings many of the advantages we have mentioned, without the need to directly interface with native code.
You can learn more about Wasm on the official website of the project at nodejsdp.link/webassembly.
Summary
In this chapter, you have seen how the Node.js platform is built upon a few important principles that shape both its internal architecture and the code we write. You have learned that Node.js has a minimal core, and that embracing the "Node way" means writing modules that are smaller, simpler, and that expose only the minimum functionality necessary.
Next, you discovered the reactor pattern, which is the pulsating heart of Node.js, and dissected the internal architecture of the platform runtime to reveal its three pillars: V8, libuv, and the core JavaScript library.
Finally, we analyzed some of the main characteristics of using JavaScript in Node.js compared to the browser.
Besides the obvious technical advantages enabled by its internal architecture, Node.js is attracting so much interest because of the principles you have just discovered and the community orbiting around it. For many, grasping the essence of this world feels like returning to the origins, to a more humane way of programming in both size and complexity, and that's why developers end up falling in love with Node.js.
In the next chapter, we will go deep into one of the most fundamental and important topics of Node.js, its module system.