
So far in this book, we've created a Node.js-based application stack comprising two Node.js microservices, a pair of MySQL databases, and a Redis instance. In the previous chapter, we learned how to use Docker to easily launch those services, intending to do so on a cloud hosting platform. Docker is widely used for deploying services such as ours, and there are lots of options available to us for deploying Docker on the public internet.
Because Amazon Web Services (AWS) is a mature feature-filled cloud hosting platform, we've chosen to deploy there. There are many options available for hosting Notes on AWS. The most direct path from our work in Chapter 11, Deploying Node.js Microservices with Docker, is to create a Docker Swarm cluster on AWS. That enables us to directly reuse the Docker compose file we created.
Docker Swarm is one of the available Docker orchestration systems. These systems manage a set of Docker containers on one or more Docker host systems. In other words, building a swarm requires provisioning one or more server systems, installing Docker Engine on each, and enabling swarm mode. Docker Swarm is built into Docker Engine, and it's a matter of a few commands to join those servers together in a swarm. We can then deploy Docker-based services to the swarm, and the swarm distributes the containers among the server systems, monitoring each container, restarting any that crash, and so on.
Docker Swarm can be used in any situation with multiple Docker host systems. It is not tied to AWS because we can rent suitable servers from any of hundreds of web hosting providers around the world. It's sufficiently lightweight that you can even experiment with Docker Swarm using virtual machine (VM) instances (Multipass, VirtualBox, and so on) on a laptop.
In this chapter, we will use a set of AWS Elastic Compute Cloud (EC2) instances. EC2 is the AWS equivalent of a virtual private server (VPS) that we would rent from a web hosting provider. The EC2 instances will be deployed within an AWS virtual private cloud (VPC), along with a network infrastructure on which we'll implement the deployment architecture we outlined earlier.
Let's talk a little about the cost since AWS can be costly. AWS offers what's called the Free Tier, where, for certain services, the cost is zero as long as you stay below a certain threshold. In this chapter, we'll strive to stay within the free tier, except that we will have three EC2 instances deployed for a while, which is beyond the free tier for EC2 usage. If you are sensitive to the cost, it is possible to minimize it by destroying the EC2 instances when not needed. We'll discuss how to do this later.
The following topics will be covered in this chapter:
- Signing up with AWS and configuring the AWS command-line interface (CLI)
- An overview of the AWS infrastructure to be deployed
- Using Terraform to create an AWS infrastructure
- Setting up a Docker Swarm cluster on AWS EC2
- Setting up Elastic Container Registry (ECR) repositories for Notes Docker images
- Creating a Docker stack file for deployment to Docker Swarm
- Provisioning EC2 instances for a full Docker Swarm
- Deploying the Notes stack file to the swarm
You will be learning a lot in this chapter, starting with how to get started with the AWS Management Console, setting up Identity and Access Management (IAM) users on AWS, and how to set up the AWS command-line tools. Since the AWS platform is so vast, it is important to get an overview of what it entails and the facilities we will use in this chapter. Then, we will learn about Terraform, a leading tool for configuring services on all kinds of cloud platforms. We will learn how to use it to configure AWS resources such as the VPC, the associated networking infrastructure, and how to configure EC2 instances. We'll next learn about Docker Swarm, the orchestration system built into Docker, how to set up a swarm, and how to deploy applications in a swarm.
For that purpose, we'll learn about Docker image registries, the AWS Elastic Container Registry (ECR), how to push images to a Docker registry, and how to use images from a private registry in a Docker application stack. Finally, we'll learn about creating a Docker stack file, which lets you describe Docker services to deploy in a swarm.
Let's get started.
Signing up with AWS and configuring the AWS CLI
To use AWS services you must, of course, have an AWS account. The AWS account is how we authenticate ourselves to AWS and is how AWS charges us for services.
The Amazon Free Tier is a way to experience AWS services at zero cost: https://aws.amazon.com/free/.
Documentation is available at https://docs.aws.amazon.com.
AWS has two kinds of accounts that we can use, as follows:
- The root account is what's created when we sign up for an AWS account. The root account has full access to AWS services.
- An IAM user account is a less privileged account you can create within your root account. The owner of a root account creates IAM accounts, assigning the scope of permissions to each IAM account.
It is bad form to use the root account directly since the root account has complete access to AWS resources. If the account credentials for your root account were to be leaked to the public, significant damage could be done to your business. If the credentials for an IAM user account were leaked, the damage is limited to the resources controlled by that user account as well as by the privileges assigned to that account. Furthermore, IAM user credentials can be revoked at any time, and then new credentials generated, preventing anyone who is holding the leaked credentials from doing any further damage. Another security measure is to enable multi-factor authentication (MFA) for all accounts.
If you have not already done so, proceed to the AWS website at one of the preceding links and sign up for an account. Remember that the account created that way is your AWS root account.
Our first step is to familiarize ourselves with the AWS Management Console.
Finding your way around the AWS account
Because there are so many services on the AWS platform, it can seem like a maze of twisty little passages, all alike. However, with a little orientation, we can find our way around.
First, look at the navigation bar at the top of the window. On the right, there are three dropdowns. The first has your account name and has account-related choices. The second lets you select which AWS region is your default. AWS has divided its infrastructure into regions, which essentially means the area of the world where AWS data centers are located. The third connects you with AWS Support.
On the left is a dropdown marked Services. This shows you the list of all AWS services. Since the Services list is unwieldy, AWS gives you a search box. Simply type in the name of the service, and it will show up. The AWS Management Console home page also has this search box.
While we are finding our way around, let's record the account number for the root account. We'll need this information later. In the Account dropdown, select My Account. The account ID is there, along with your account name.
It is recommended to set up MFA on your AWS root account. MFA simply means to authenticate a person in multiple ways. For example, a service might use a code number sent via a text message as a second authentication method, alongside asking for a password. The theory is that the service is more certain of who we are if it verifies both that we've entered a correct password and that we're carrying the same cell phone we had carried on other days.
To set up MFA on your root account, go to the My Security Credentials dashboard. A link to that dashboard can be found in the AWS Management Console menu bar. This brings you to a page controlling all forms of authentication with AWS. From there, you follow the directions on the AWS website. There are several possible tools for implementing MFA. The simplest tool is to use the Google Authenticator application on your smartphone. Once you set up MFA, every login to the root account will require a code to be entered from the authenticator app.
So far, we have dealt with the online AWS Management Console. Our real goal is to use command-line tools, and to do that, we need the AWS CLI installed and configured on our laptop. Let's take care of that next.
Setting up the AWS CLI using AWS authentication credentials
The AWS CLI tool is a download available through the AWS website. Under the covers, it uses the AWS application programming interface (API), and it also requires that we download and install authentication tokens.
Once you have an account, we can prepare the AWS CLI tool.
Instructions to install the AWS CLI can be found here: https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2.html.
Instructions to configure the AWS CLI can be found here: https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html.
Once you have installed the AWS CLI tool on your laptop, we must configure what is known as a profile.
AWS supplies an AWS API that supports a broad range of tools for manipulating the AWS infrastructure. The AWS CLI tools use that API, as do third-party tools such as Terraform. Using the API requires access tokens, so of course, both the AWS CLI and Terraform require those same tokens.
To get the AWS API access tokens, go to the My Security Credentials dashboard and click on the Access Keys tab.
There will be a button marked Create New Access Key. Click on this and you will be shown two security tokens, the Access Key ID and the Secret Access Key. You will be given a chance to download a comma-separated values (CSV) file containing these keys. The CSV file looks like this:
$ cat ~/Downloads/accessKeys.csv
Access key ID,Secret access key
AKIAZKY7BHGBVWEKCU7H,41WctREbazP9fULN1C5CrQ0L92iSO27fiVGJKU2A
You will receive a file that looks like this. These are the security tokens that identify your account. Don't worry, as no secrets are being leaked in this case. Those particular credentials have been revoked. The good news is that you can revoke these credentials at any time and download new credentials.
Now that we have the credentials file, we can configure an AWS CLI profile.
The aws configure command, as the name implies, takes care of configuring your AWS CLI environment. This asks a series of questions, the first two of which are those keys. The interaction looks like this:
$ aws configure --profile root-user
AWS Access Key ID [****************E3GA]: ... ENTER ACCESS KEY
AWS Secret Access Key [****************J9cp]: ... ENTER SECRET KEY
Default region name [us-west-2]:
Default output format [json]:
For the first two prompts, paste in the keys you downloaded. The Region name prompt selects the default Amazon AWS data center in which your service will be provisioned. AWS has facilities all around the world, and each locale has a code name such as us-west-2 (located in Oregon). The last prompt asks how you wish the AWS CLI to present information to you.
For the region code, in the AWS console, take a look at the Region dropdown. This shows you the available regions, describing locales, and the region code for each. For the purpose of this project, it is good to use an AWS region located near you. For production deployment, it is best to use the region closest to your audience. It is possible to configure a deployment that works across multiple regions so that you can serve clients in multiple areas, but that implementation is way beyond what we'll cover in this book.
By using the --profile option, we ensured that this created a named profile. If we had left off that option, we would have instead created a profile named default. For any of the aws commands, the --profile option selects which profile to use. As the name suggests, the default profile is the one used if we leave off the --profile option.
A better choice is to be explicit at all times in which an AWS identity is being used. Some guides suggest to not create a default AWS profile at all, but instead to always use the --profile option to be certain of always using the correct AWS profile.
An easy way to verify that AWS is configured is to run the following commands:
$ aws s3 ls
Unable to locate credentials. You can configure credentials by running "aws configure".
$ aws s3 ls --profile root-user
$ export AWS_PROFILE=root-user
$ aws s3 ls
The AWS Simple Storage Service (S3) is a cloud file-storage system, and we are running these commands solely to verify the correct installation of the credentials. The ls command lists any files you have stored in S3. We don't care about the files that may or may not be in an S3 bucket, but whether this executes without error.
The first command shows us that execution with no --profile option, and no default profile, produces an error. If there were a default AWS profile, that would have been used. However, we did not create a default profile, so therefore no profile was available and we got an error. The second shows the same command with an explicitly named profile. The third shows the AWS_PROFILE environment variable being used to name the profile to be deployed.
Using the environment variables supported by the AWS CLI tool, such as AWS_PROFILE, lets us skip using command-line options such as --profile while still being explicit about which profile to use.
As we said earlier, it is important that we interact with AWS via an IAM user, and therefore we must learn how to create an IAM user account. Let's do that next.
Creating an IAM user account, groups, and roles
We could do everything in this chapter using our root account but, as we said, that's bad form. Instead, it is recommended to create a second user—an IAM user—and give it only the permissions required by that user.
To get to the IAM dashboard, click on Services in the navigation bar, and enter IAM. IAM stands for Identity and Access Management. Also, the My Security Credentials dashboard is part of the IAM service, so we are probably already in the IAM area.
The first task is to create a role. In AWS, roles are used to associate privileges with a user account. You can create roles with extremely limited privileges or an extremely broad range of privileges.
In the IAM dashboard, you'll find a navigation menu on the left. It has sections for users, groups, roles, and other identity management topics. Click on the Roles choice. Then, in the Roles area, click on Create Role. Perform the following steps:
- Under Type of trusted identity, select Another AWS account. Enter the account ID, which you will have recorded earlier while familiarizing yourself with the AWS account. Then, click on Next.
- On the next page, we select the permissions for this role. For our purpose, select AdministratorAccess, a privilege that grants full access to the AWS account. Then, click on Next.
- On the next page, you can add tags to the role. We don't need to do this, so click Next.
- On the last page, we give a name to the role. Enter admin because this role has administrator permissions. Click on Create Role.
You'll see that the role, admin, is now listed in the Role dashboard. Click on admin and you will be taken to a page where you can customize the role further. On this page, notice the characteristic named Role ARN. Record this Amazon Resource Name (ARN) for future reference.
ARNs are identifiers used within AWS. You can reliably use this ARN in any area of AWS where we can specify a role. ARNs are used with almost every AWS resource.
Next, we have to create an administrator group. In IAM, users are assigned to groups as a way of passing roles and other attributes to a group of IAM user accounts. To do this, perform the following steps:
- In the left-hand navigation menu, click on Group, and then, in the group dashboard, click on Create Group.
- For the group name, enter Administrators.
- Skip the Attach Policy page, click Next Step, and then, on the Review page, simply click Create Group.
- This creates a group with no permissions and directs you back to the group dashboard.
- Click on the Administrators group, and you'll be taken to the overview page. Record the ARN for the group.
- Click on Permissions to open that tab, and then click on the Inline policies section header. We will be creating an inline policy, so click on the Click here link.
- Click on Custom Policy, and you'll be taken to the policy editor.
- For the policy name, enter AssumeAdminRole. Below that is an area where we enter a block of JavaScript Object Notation (JSON) code describing the policy. Once that's done, click the Apply Policy button.
The policy document to use is as follows:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::ACCOUNT-ID:role/admin"
}
]
}
This describes the policy created for the Administrators group. It gives that group the rights we specified in the admin role earlier. The Resource tag is where we enter the ARN for the admin group that was created earlier. Make sure to put the entire ARN into this field.
Navigate back to the Groups area, and click on Create Group again. We'll create a group, NotesDeveloper, for use by developers assigned to the Notes project. It will give those user accounts some additional privileges. Perform the following steps:
- Enter NotesDeveloper as the group name. Then, click Next.
- For the Attach Policy page, there is a long list of policies to consider; for example, AmazonRDSFullAccess, AmazonEC2FullAccess, IAMFullAccess, AmazonEC2ContainerRegistryFullAccess, AmazonS3FullAccess, AdministratorAccess, and AmazonElasticFileSystemFullAccess.
- Then, click Next, and if everything looks right on the Review page, click Create Group.
These policies cover the services required to finish this chapter. AWS error messages that stipulate that the user is not privileged enough to access that feature do a good job of telling you the required privilege. If it is a privilege the user needs, then come back to this group and add the privilege.
In the left-hand navigation, click on Users and then on Create User. This starts the steps involved in creating an IAM user, described as follows:
- For the username, enter notes-app, since this user will manage all resources related to the Notes application. For Access type, click on both Programmatic access and AWS management console access since we will be using both. The first grants the ability to use the AWS CLI tools, while the second covers the AWS console. Then, click on Next.
- For permissions, select Add User to Group and then select both the Administrators and NotesDeveloper groups. This adds the user to the groups you select. Then, click on Next.
- There is nothing more to do, so keep clicking Next until you get to the Review page. If you're satisfied, click on Create user.
You'll be taken to a page that declares Success. On this page, AWS makes available access tokens (a.k.a. security credentials) that can be used with this account. Download these credentials before you do anything else. You can always revoke the credentials and generate new access tokens at any time.
Your newly created user is now listed in the Users section. Click on that entry, because we have a couple of data items to record. The first is obviously the ARN for the user account. The second is a Uniform Resource Locator (URL) you can use to sign in to AWS as this user. For that URL, click on the Security Credentials tab and the sign-in link will be there.
It is recommended to also set up MFA for the IAM account. The My Security Credentials choice in the AWS taskbar gets you to the screen containing the button to set up MFA. Refer back a few pages to our discussion of setting up MFA for the root account.
To test the new user account, sign out and then go to the sign-in URL. Enter the username and password for the account, and then sign in.
Before finishing this section, return to the command line and run the following command:
$ aws configure --profile notes-app
... Fill in configuration
This will create another AWS CLI profile, this time for the notes-app IAM user.
Using the AWS CLI, we can list the users in our account, as follows:
$ aws iam list-users --profile root-user
{
"Users": [ {
"Path": "/",
"UserName": "notes-app",
"UserId": "AIDARNEXAMPLEYM35LE",
"Arn": "arn:aws:iam::USER-ID:user/notes-app",
"CreateDate": "2020-03-08T02:19:39+00:00",
"PasswordLastUsed": "2020-04-05T15:34:28+00:00"
}
]
}
This is another way to verify that the AWS CLI is correctly installed. This command queries the user information from AWS, and if it executes without error then you've configured the CLI correctly.
AWS CLI commands follow a similar structure, where there is a series of sub-commands followed by options. In this case, the sub-commands are aws, iam, and list-users. The AWS website has extensive online documentation for the AWS CLI tool.
Creating an EC2 key pair
Since we'll be using EC2 instances in this exercise, we need an EC2 key pair. This is an encrypted certificate that serves the same purpose as the normal Secure Shell (SSH) key we use for passwordless login to a server. In fact, the key-pair file serves the same purpose, allowing passwordless login with SSH to EC2 instances. Perform the following steps:
- Log in to the AWS Management Console and then select the region you're using.
- Next, navigate to the EC2 dashboard—for example, by entering EC2 in the search box.
- In the navigation sidebar, there is a section labeled Network & Security, containing a link for Key pair.
- Click on that link. In the upper-right corner is a button marked Create key pair. Click on this button, and you will be taken to the following screen:
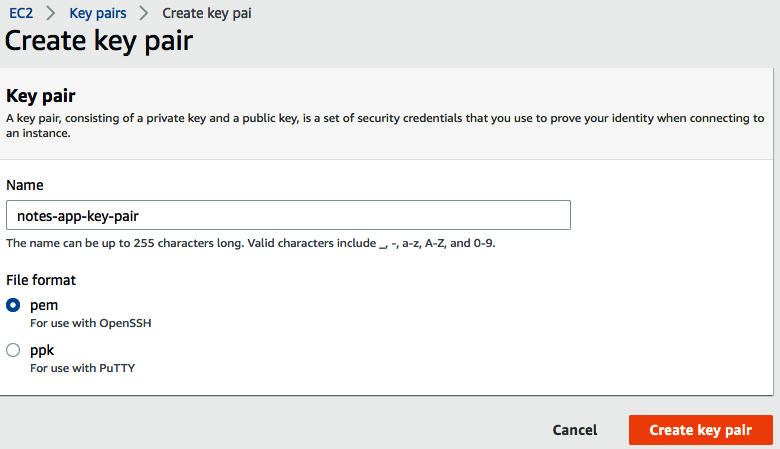
- Enter the desired name for the key pair. Depending on the SSH client you're using, use either a pem (used for the ssh command) or a ppk (used for PuTTY) formatted key-pair file.
- Click on Create key pair and you'll be returned to the dashboard, and the key-pair file will download in your browser.
- After the key-pair file is downloaded, it is required to make it read-only, which you can do by using the following command:
$ chmod 400 /path/to/keypairfile.pem
Substitute here the pathname where your browser downloaded the file.
For now, just make sure this file is correctly stored somewhere. When we deploy EC2 instances, we'll talk more about how to use it.
We have familiarized ourselves with the AWS Management Console, and created for ourselves an IAM user account. We have proved that we can log in to the console using the sign-in URL. While doing that, we copied down the AWS access credentials for the account.
We have completed the setup of the AWS command-line tools and user accounts. The next step is to set up Terraform.
An overview of the AWS infrastructure to be deployed
AWS is a complex platform with dozens of services available to us. This project will touch on only the part required to deploy Notes as a Docker swarm on EC2 instances. In this section, let's talk about the infrastructure and AWS services we'll put to use.
An AWS VPC is what it sounds like—namely, a service within AWS where you build your own private cloud service infrastructure. The AWS team designed the VPC service to look like something that you would construct in your own data center, but implemented on the AWS infrastructure. This means that the VPC is a container to which everything else we'll discuss is attached.
The AWS infrastructure is spread across the globe into what AWS calls regions. For example, us-west-1 refers to Northern California, us-west-2 refers to Oregon, and eu-central-1 refers to Frankfurt. For production deployment, it is recommended to use a region nearer your customers, but for experimentation, it is good to use the region closest to you. Within each region, AWS further subdivides its infrastructure into availability zones (a.k.a. AZs). An AZ might correspond to a specific building at an AWS data center site, but AWS often recommends that we deploy infrastructure to multiple AZs for reliability. In case one AZ goes down, the service can continue in the AZs that are running.
When we allocate a VPC, we specify an address range for resources deployed within the VPC. The address range is specified with a Classless Inter-Domain Routing (CIDR) specifier. These are written as 10.3.0.0/16 or 10.3.20.0/24, which means any Internet Protocol version 4 (IPv4) address starting with 10.3 and 10.3.20, respectively.
Every device we attach to a VPC will be attached to a subnet, a virtual object similar to an Ethernet segment. Each subnet will be assigned a CIDR from the main range. A VPC assigned the 10.3.0.0/16 CIDR might have a subnet with a CIDR of 10.3.20.0/24. Devices attached to the subnet will have an IP address assigned within the range indicated by the CIDR for the subnet.
EC2 is AWS's answer to a VPS that you might rent from any web hosting provider. An EC2 instance is a virtual computer in the same sense that Multipass or VirtualBox lets you create a virtual computer on your laptop. Each EC2 instance is assigned a central processing unit (CPU), memory, disk capacity, and at least one network interface. Hence, an EC2 instance is attached to a subnet and is assigned an IP address from the subnet's assigned range.
By default, a device attached to a subnet has no internet access. The internet gateway and network address translation (NAT) gateway resources on AWS play a critical role in connecting resources attached to a VPC via the internet. Both are what is known as an internet router, meaning that both handle the routing of internet traffic from one network to another. Because a VPC contains a VPN, these gateways handle traffic between that network and the public internet, as follows:
- Internet gateway: This handles two-way routing, allowing a resource allocated in a VPC to be reachable from the public internet. An internet gateway allows external traffic to enter the VPC, and it also allows resources in the VPC to access resources on the public internet.
- NAT gateway: This handles one-way routing, meaning that resources on the VPC will be able to access resources on the public internet, but does not allow external traffic to enter the VPC. To understand the NAT gateway, think about a common home Wi-Fi router because they also contain a NAT gateway. Such a gateway will manage a local IP address range such as 192.168.0.0/16, while the internet service provider (ISP) might assign a public IP address such as 107.123.42.231 to the connection. Local IP addresses, such as 192.168.1.45, will be assigned to devices connecting to the NAT gateway. Those local IP addresses do not appear in packets sent to the public internet. Instead, the NAT gateway translates the IP addresses to the public IP address of the gateway, and then when reply packets arrive, it translates the IP address to that of the local device. NAT translates IP addresses from the local network to the IP address of the NAT gateway.
In practical terms, this determines the difference between a private subnet and a public subnet. A public subnet has a routing table that sends traffic for the public internet to an internet gateway, whereas a private subnet sends its public internet traffic to a NAT gateway.
Routing tables describe how to route internet traffic. Inside any internet router, such as an internet gateway or a NAT gateway, is a function that determines how to handle internet packets destined for a location other than the local subnet. The routing function matches the destination address against routing table entries, and each routing table entry says where to forward matching packets.
Attached to each device deployed in a VPC is a security group. A security group is a firewall controlling what kind of internet traffic can enter or leave that device. For example, an EC2 instance might have a web server supporting HTTP (port 80) and HTTPS (port 443) traffic, and the administrator might also require SSH access (port 22) to the instance. The security group would be configured to allow traffic from any IP address on ports 80 and 443 and to allow traffic on port 22 from IP address ranges used by the administrator.
A network access control list (ACL) is another kind of firewall that's attached to subnets. It, too, describes which traffic is allowed to enter or leave the subnet. The security groups and network ACLs are part of the security protections provided by AWS.
If a device connected to a VPC does not seem to work correctly, there might be an error in the configuration of these parts. It's necessary to check the security group attached to the device, and to the NAT gateway or internet gateway, and that the device is connected to the expected subnet, the routing table for the subnet, and any network ACLs.
Using Terraform to create an AWS infrastructure
Terraform is an open source tool for configuring a cloud hosting infrastructure. It uses a declarative language to describe the configuration of cloud services. Through a long list of plugins, called providers, it has support for a variety of cloud services. In this chapter, we'll use Terraform to describe AWS infrastructure deployments.
Alternatively, you will find the Terraform CLI available in many package management systems.
Once installed, you can view the Terraform help with the following command:
$ terraform help
Usage: terraform [-version] [-help] <command> [args]
The available commands for execution are listed below.
The most common, useful commands are shown first, followed by
less common or more advanced commands. If you're just getting
started with Terraform, stick with the common commands. For the
other commands, please read the help and docs before usage.
Common commands:
apply Builds or changes infrastructure
console Interactive console for Terraform interpolations
destroy Destroy Terraform-managed infrastructure
...
init Initialize a Terraform working directory
output Read an output from a state file
plan Generate and show an execution plan
providers Prints a tree of the providers used in the configuration
...
Terraform files have a .tf extension and use a fairly simple, easy-to-understand declarative syntax. Terraform doesn't care which filenames you use or the order in which you create the files. It simply reads all the files with a .tf extension and looks for resources to deploy. These files do not contain executable code, but declarations. Terraform reads these files, constructs a graph of dependencies, and works out how to implement the declarations on the cloud infrastructure being used.
An example declaration is as follows:
variable "base_cidr_block" { default = "10.1.0.0/16" }
resource "aws_vpc" "main" {
cidr_block = var.base_cidr_block
}
The first word, resource or variable, is the block type, and in this case, we are declaring a resource and a variable. Within the curly braces are the arguments to the block, and it is helpful to think of these as attributes.
Blocks have labels—in this case, the labels are aws_vpc and main. We can refer to this specific resource elsewhere by joining the labels together as aws_vpc.main. The name, aws_vpc, comes from the AWS provider and refers to VPC elements. In many cases, a block—be it a resource or another kind—will support attributes that can be accessed. For example, the CIDR for this VPC can be accessed as aws_vpc.main.cidr_block.
The general structure is as follows:
<BLOCK TYPE> "<BLOCK LABEL>" "<BLOCK LABEL>" {
# Block body
<IDENTIFIER> = <EXPRESSION> # Argument
}
The block types include resource, which declares something related to the cloud infrastructure, variable, which declares a named value, output, which declares a result from a module, and a few others.
The structure of the block labels varies depending on the block type. For resource blocks, the first block label refers to the kind of resource, while the second is a name for the specific instance of that resource.
The type of arguments also varies depending on the block type. The Terraform documentation has an extensive reference to every variant.
A Terraform module is a directory containing Terraform scripts. When the terraform command is run in a directory, it reads every script in that directory to build a tree of objects.
Within modules, we are dealing with a variety of values. We've already discussed resources, variables, and outputs. A resource is essentially a value that is an object related to something on the cloud hosting platform being used. A variable can be thought of as an input to a module because there are multiple ways to provide a value for a variable. The output values are, as the name implies, the output from a module. Outputs can be printed on the console when a module is executed, or saved to a file and then used by other modules. The code relating to this can be seen in the following snippet:
variable "aws_region" {
default = "us-west-2"
type = "string"
description = "Where in the AWS world the service will be hosted"
}
output "vpc_arn" { value = aws_vpc.notes.arn }
This is what the variable and output declarations look like. Every value has a data type. For variables, we can attach a description to aid in their documentation. The declaration uses the word default rather than value because there are multiple ways (such as Terraform command-line arguments) to specify a value for a variable. Terraform users can override the default value in several ways, such as the --var or --var-file command-line options.
Another type of value is local. Locals exist only within a module because they are neither input values (variables) nor output values, as illustrated in the following code snippet:
locals {
vpc_cidr = "10.1.0.0/16"
cidr_subnet1 = cidrsubnet(local.vpc_cidr, 8, 1)
cidr_subnet2 = cidrsubnet(local.vpc_cidr, 8, 2)
cidr_subnet3 = cidrsubnet(local.vpc_cidr, 8, 3)
cidr_subnet4 = cidrsubnet(local.vpc_cidr, 8, 4)
}
In this case, we've defined several locals related to the CIDR of subnets to be created within a VPC. The cidrsubnet function is used to calculate subnet masks such as 10.1.1.0/24.
Another important feature of Terraform is the provider plugin. Each cloud system supported by Terraform requires a plugin module that defines the specifics of using Terraform with that platform.
One effect of the provider plugins is that Terraform makes no attempt to be platform-independent. Instead, all declarable resources for a given platform are unique to that platform. You cannot directly reuse Terraform scripts for AWS on another system such as Azure because the resource objects are all different. What you can reuse is the knowledge of how Terraform approaches the declaration of cloud resources.
Another task is to look for a Terraform extension for your programming editor. Some of them have support for Terraform, with syntax coloring, checking for simple errors, and even code completion.
That's enough theory, though. To really learn this, we need to start using Terraform. In the next section, we'll begin by implementing the VPC structure within which we'll deploy the Notes application stack.
Configuring an AWS VPC with Terraform
An AWS VPC is what it sounds like—namely, a service within AWS to hold cloud services that you've defined. The AWS team designed the VPC service to look something like what you would construct in your own data center, but implemented on the AWS infrastructure.
In this section, we will construct a VPC consisting of a public subnet and a private subnet, an internet gateway, and security group definitions.
In the project work area, create a directory, terraform-swarm, that is a sibling to the notes and users directories.
In that directory, create a file named main.tf containing the following:
provider "aws" {
profile = "notes-app"
region = var.aws_region
}
This says to use the AWS provider plugin. It also configures this script to execute using the named AWS profile. Clearly, the AWS provider plugin requires AWS credential tokens in order to use the AWS API. It knows how to access the credentials file set up by aws configure.
As shown here, the AWS plugin will look for the AWS credentials file in its default location, and use the notes-app profile name.
In addition, we have specified which AWS region to use. The reference, var.aws_region, is a Terraform variable. We use variables for any value that can legitimately vary. Variables can be easily customized to any value in several ways.
To support the variables, we create a file named variables.tf, starting with this:
variable "aws_region" { default = "us-west-2" }
The default attribute sets a default value for the variable. As we saw earlier, the declaration can also specify the data type for a variable, and a description.
With this, we can now run our first Terraform command, as follows:
$ terraform init
Initializing the backend...
Initializing provider plugins...
- Checking for available provider plugins...
- Downloading plugin for provider "aws" (hashicorp/aws) 2.56.0...
The following providers do not have any version constraints in configuration, so the latest version was installed.
...
* provider.aws: version = "~> 2.56"
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see any changes that are required for your infrastructure. All Terraform commands should now work.
This initializes the current directory as a Terraform workspace. You'll see that it creates a directory, .terraform, and a file named terraform.tfstate containing data collected by Terraform. The .tfstate files are what is known as state files. These are in JSON format and store the data Terraform collects from the platform (in this case, AWS) regarding what has been deployed. State files must not be committed to source code repositories because it is possible for sensitive data to end up in those files. Therefore, a .gitignore file listing the state files is recommended.
The instructions say we should run terraform plan, but before we do that, let's declare a few more things.
To declare the VPC and its related infrastructure, let's create a file named vpc.tf. Start with the following command:
resource "aws_vpc" "notes" {
cidr_block = var.vpc_cidr
enable_dns_support = var.enable_dns_support
enable_dns_hostnames = var.enable_dns_hostnames
tags = {
Name = var.vpc_name
}
}
This declares the VPC. This will be the container for the infrastructure we're creating.
The cidr_block attribute determines the IPv4 address space that will be used for this VPC. The CIDR notation is an internet standard, and an example would be 10.0.0.0/16. That CIDR would cover any IP address starting with the 10.0 octets.
The enable_dns_support and enable_dns_hostnames attributes determine whether Domain Name System (DNS) names will be generated for certain resources attached to the VPC. DNS names can assist with one resource finding other resources at runtime.
The tags attribute is used for attaching name/value pairs to resources. The name tag is used by AWS to have a display name for the resource. Every AWS resource has a computer-generated, user-unfriendly name with a long coded string and, of course, we humans need user-friendly names for things. The name tag is useful in that regard, and the AWS Management Console will respond by using this name in the dashboards.
In variables.tf, add this to support these resource declarations:
variable "enable_dns_support" { default = true }
variable "enable_dns_hostnames" { default = true }
variable "project_name" { default = "notes" }
variable "vpc_name" { default = "notes-vpc" }
variable "vpc_cidr" { default = "10.0.0.0/16" }
These values will be used throughout the project. For example, var.project_name will be widely used as the basis for creating name tags for deployed resources.
Add the following to vpc.tf:
data "aws_availability_zones" "available" {
state = "available"
}
Where resource blocks declare something on the hosting platform (in this case, AWS), data blocks retrieve data from the hosting platform. In this case, we are retrieving a list of AZs for the currently selected region. We'll use this later when declaring certain resources.
Configuring the AWS gateway and subnet resources
Remember that a public subnet is associated with an internet gateway, and a private subnet is associated with a NAT gateway. The difference determines what type of internet access devices attached to each subnet have.
Create a file named gw.tf containing the following:
resource "aws_internet_gateway" "igw" {
vpc_id = aws_vpc.notes.id
tags = {
Name = "${var.project_name}-IGW"
}
}
resource "aws_eip" "gw" {
vpc = true
depends_on = [ aws_internet_gateway.igw ]
tags = {
Name = "${var.project_name}-EIP"
}
}
resource "aws_nat_gateway" "gw" {
subnet_id = aws_subnet.public1.id
allocation_id = aws_eip.gw.id
tags = {
Name = "${var.project_name}-NAT"
}
}
This declares the internet gateway and the NAT gateway. Remember that internet gateways are used with public subnets, and NAT gateways are used with private subnets.
An Elastic IP (EIP) resource is how a public internet IP address is assigned. Any device that is to be visible to the public must be on a public subnet and have an EIP. Because the NAT gateway faces the public internet, it must have an assigned public IP address and an EIP.
For the subnets, create a file named subnets.tf containing the following:
resource "aws_subnet" "public1" {
vpc_id = aws_vpc.notes.id
cidr_block = var.public1_cidr
availability_zone = data.aws_availability_zones.available.names[0]
tags = {
Name = "${var.project_name}-net-public1"
}
}
resource "aws_subnet" "private1" {
vpc_id = aws_vpc.notes.id
cidr_block = var.private1_cidr
availability_zone = data.aws_availability_zones.available.names[0]
tags = {
Name = "${var.project_name}-net-private1"
}
}
This declares the public and private subnets. Notice that these subnets are assigned to a specific AZ. It would be easy to expand this to support more subnets by adding subnets named public2, public3, private2, private3, and so on. If you do so, it would be helpful to spread these subnets across AZs. Deployment is recommended in multiple AZs so that if one AZ goes down, the application is still running in the AZ that's still up and running.
This notation with [0] is what it looks like—an array. The value, data.aws_availability_zones.available.names, is an array, and adding [0] does access the first element of that array, just as you'd expect. Arrays are just one of the data structures offered by Terraform.
Each subnet has its own CIDR (IP address range), and to support this, we need these CIDR assignments listed in variables.tf, as follows:
variable "vpc_cidr" { default = "10.0.0.0/16" }
variable "public1_cidr" { default = "10.0.1.0/24" }
variable "private1_cidr" { default = "10.0.3.0/24" }
These are the CIDRs corresponding to the resources declared earlier.
For these pieces to work together, we need appropriate routing tables to be configured. Create a file named routing.tf containing the following:
resource "aws_route" "route-public" {
route_table_id = aws_vpc.notes.main_route_table_id
destination_cidr_block = "0.0.0.0/0"
gateway_id = aws_internet_gateway.igw.id
}
resource "aws_route_table" "private" {
vpc_id = aws_vpc.notes.id
route {
cidr_block = "0.0.0.0/0"
nat_gateway_id = aws_nat_gateway.gw.id
}
tags = {
Name = "${var.project_name}-rt-private"
}
}
resource "aws_route_table_association" "public1" {
subnet_id = aws_subnet.public1.id
route_table_id = aws_vpc.notes.main_route_table_id
}
resource "aws_route_table_association" "private1" {
subnet_id = aws_subnet.private1.id
route_table_id = aws_route_table.private.id
}
To configure the routing table for the public subnets, we modify the routing table connected to the main routing table for the VPC. What we're doing here is adding a rule to that table, saying that public internet traffic is to be sent to the internet gateway. We also have a route table association declaring that the public subnet uses this route table.
For aws_route_table.private, the routing table for private subnets, the declaration says to send public internet traffic to the NAT gateway. In the route table associations, this table is used for the private subnet.
Earlier, we said the difference between a public and private subnet is whether public internet traffic is sent to the internet gateway or the NAT gateway. These declarations are how that's implemented.
In this section, we've declared the VPC, subnets, gateways, and routing tables—in other words, the infrastructure within which we'll deploy our Docker Swarm.
Before attaching the EC2 instances in which the swarm will live, let's deploy this to AWS and explore what gets set up.
Deploying the infrastructure to AWS using Terraform
We have now declared the bones of the AWS infrastructure we'll need. This is the VPC, the subnets, and routing tables. Let's deploy this to AWS and use the AWS console to explore what was created.
Earlier, we ran terraform init to initialize Terraform in our working directory. When we did so, it suggested that we run the following command:
$ terraform plan
Refreshing Terraform state in-memory prior to plan...
The refreshed state will be used to calculate this plan, but will not be
persisted to local or remote state storage.
data.aws_availability_zones.available: Refreshing state...
------------------------------------------------------------------------
An execution plan has been generated and is shown below.
Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# aws_eip.gw will be created
+ resource "aws_eip" "gw" {
+ allocation_id = (known after apply)
+ association_id = (known after apply)
+ customer_owned_ip = (known after apply)
+ domain = (known after apply)
+ id = (known after apply)
+ instance = (known after apply)
+ network_interface = (known after apply)
+ private_dns = (known after apply)
+ private_ip = (known after apply)
+ public_dns = (known after apply)
+ public_ip = (known after apply)
+ public_ipv4_pool = (known after apply)
+ tags = {
+ "Name" = "notes-EIP"
}
+ vpc = true
}
...
This command scans the Terraform files in the current directory and first determines that everything has the correct syntax, that all the values are known, and so forth. If any problems are encountered, it stops right away with error messages such as the following:
Error: Reference to undeclared resource
on outputs.tf line 8, in output "subnet_public2_id":
8: output "subnet_public2_id" { value = aws_subnet.public2.id }
A managed resource "aws_subnet" "public2" has not been declared in the root
module.
Terraform's error messages are usually self-explanatory. In this case, the cause was a decision to use only one public and one private subnet. This code was left over from there being two of each. Therefore, this error referred to stale code that was easy to remove.
The other thing terraform plan does is construct a graph of all the declarations and print out a listing. This gives you an idea of what Terraform intends to deploy on to the chosen cloud platform. It is therefore your opportunity to examine the intended infrastructure and make sure it is what you want to use.
Once you're satisfied, run the following command:
$ terraform apply
data.aws_availability_zones.available: Refreshing state...
An execution plan has been generated and is shown below.
Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
...
Plan: 10 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
...
Apply complete! Resources: 10 added, 0 changed, 0 destroyed.
Outputs:
aws_region = us-west-2
igw_id = igw-006eb101f8cb423d4
private1_cidr = 10.0.3.0/24
public1_cidr = 10.0.1.0/24
subnet_private1_id = subnet-0a9044daea298d1b2
subnet_public1_id = subnet-07e6f8ed6cc6f8397
vpc_arn = arn:aws:ec2:us-west-2:098106984154:vpc/vpc-074b2dfa7b353486f
vpc_cidr = 10.0.0.0/16
vpc_id = vpc-074b2dfa7b353486f
vpc_name = notes-vpc
With terraform apply, the report shows the difference between the actual deployed state and the desired state as reflected by the Terraform files. In this case, there is no deployed state, so therefore everything that is in the files will be deployed. In other cases, you might have deployed a system and have made a change, in which case Terraform will work out which changes have to be deployed based on the changes you've made. Once it calculates that, Terraform asks for permission to proceed. Finally, if we have said yes, it will proceed and launch the desired infrastructure.
Once finished, it tells you what happened. One result is the values of the output commands in the scripts. These are both printed on the console and are saved in the backend state file.
To see what was created, let's head to the AWS console and navigate to the VPC area, as follows:

Compare the VPC ID in the screenshot with the one shown in the Terraform output, and you'll see that they match. What's shown here is the main routing table, and the CIDR, and other settings we made in our scripts. Every AWS account has a default VPC that's presumably meant for experiments. It is a better form to create a VPC for each project so that resources for each project are separate from other projects.
The sidebar contains links for further dashboards for subnets, route tables, and other things, and an example dashboard can be seen in the following screenshot:

For example, this is the NAT gateway dashboard showing the one created for this project.
Another way to explore is with the AWS CLI tool. Just because we have Terraform doesn't mean we are prevented from using the CLI. Have a look at the following code block:
$ aws ec2 describe-vpcs --vpc-ids vpc-074b2dfa7b353486f
{
"Vpcs": [ {
"CidrBlock": "10.0.0.0/16",
"DhcpOptionsId": "dopt-e0c05d98",
"State": "available",
"VpcId": "vpc-074b2dfa7b353486f",
"OwnerId": "098106984154",
"InstanceTenancy": "default",
"CidrBlockAssociationSet": [ {
"AssociationId": "vpc-cidr-assoc-0f827bcc4fbb9fd62",
"CidrBlock": "10.0.0.0/16",
"CidrBlockState": {
"State": "associated"
}
} ],
"IsDefault": false,
"Tags": [ {
"Key": "Name",
"Value": "notes-vpc"
} ]
} ]
}
This lists the parameters for the VPC that was created.
Remember to either configure the AWS_PROFILE environment variable or use --profile on the command line.
To list data on the subnets, run the following command:
$ aws ec2 describe-subnets --filters "Name=vpc-id,Values=vpc-074b2dfa7b353486f"
{
"Subnets": [
{ ... },
{ ... }
]
}
To focus on the subnets for a given VPC, we use the --filters option, passing in the filter named vpc-id and the VPC ID for which to filter.
For documentation relating to the EC2 sub-commands, refer to https://docs.aws.amazon.com/cli/latest/reference/ec2/index.html.
The AWS CLI tool has an extensive list of sub-commands and options. These are enough to almost guarantee getting lost, so read carefully.
In this section, we learned how to use Terraform to set up the VPC and related infrastructure resources, and we also learned how to navigate both the AWS console and the AWS CLI to explore what had been created.
Our next step is to set up an initial Docker Swarm cluster by deploying an EC2 instance to AWS.
Setting up a Docker Swarm cluster on AWS EC2
What we have set up is essentially a blank slate. AWS has a long list of offerings that could be deployed to the VPC that we've created. What we're looking to do in this section is to set up a single EC2 instance to install Docker, and set up a single-node Docker Swarm cluster. We'll use this to familiarize ourselves with Docker Swarm. In the remainder of the chapter, we'll build more servers to create a larger swarm cluster for full deployment of Notes.
A Docker Swarm cluster is simply a group of servers running Docker that have been joined together into a common pool. The code for the Docker Swarm orchestrator is bundled with the Docker Engine server but it is disabled by default. To create a swarm, we simply enable swarm mode by running docker swarm init and then run a docker swarm join command on each system we want to be part of the cluster. From there, the Docker Swarm code automatically takes care of a long list of tasks. The features for Docker Swarm include the following:
- Horizontal scaling: When deploying a Docker service to a swarm, you tell it the desired number of instances as well as the memory and CPU requirements. The swarm takes that and computes the best distribution of tasks to nodes in the swarm.
- Maintaining the desired state: From the services deployed to a swarm, the swarm calculates the desired state of the system and tracks its current actual state. Suppose one of the nodes crashes—the swarm will then readjust the running tasks to replace the ones that vaporized because of the crashed server.
- Multi-host networking: The overlay network driver automatically distributes network connections across the network of machines in the swarm.
- Secure by default: Swarm mode uses strong Transport Layer Security (TLS) encryption for all communication between nodes.
- Rolling updates: You can deploy an update to a service in such a manner where the swarm intelligently brings down existing service containers, replacing them with updated newer containers.
We will use this section to not only learn how to set up a Docker Swarm but to also learn something about how Docker orchestration works.
To get started, we'll set up a single-node swarm on a single EC2 instance in order to learn some basics, before we move on to deploying a multi-node swarm and deploying the full Notes stack.
Deploying a single-node Docker Swarm on a single EC2 instance
For a quick introduction to Docker Swarm, let's start by installing Docker on a single EC2 node. We can kick the tires by trying a few commands and exploring the resulting system.
This will involve deploying Ubuntu 20.04 on an EC2 instance, configuring it to have the latest Docker Engine, and initializing swarm mode.
Adding an EC2 instance and configuring Docker
To launch an EC2 instance, we must first select which operating system to install. There are thousands of operating system configurations available. Each of these configurations is identified by an AMI code, where AMI stands for Amazon Machine Image.
To find your desired AMI, navigate to the EC2 dashboard on the AWS console. Then, click on the Launch Instance button, which starts a wizard-like interface to launch an instance. You can, if you like, go through the whole wizard since that is one way to learn about EC2 instances. We can search the AMIs via the first page of that wizard, where there is a search box.
For this exercise, we will use Ubuntu 20.04, so enter Ubuntu and then scroll down to find the correct version, as illustrated in the following screenshot:

This is what the desired entry looks like. The AMI code starts with ami- and we see one version for x86 CPUs, and another for ARM (previously Advanced RISC Machine). ARM processors, by the way, are not just for your cell phone but are also used in servers. There is no need to launch an EC2 instance from here since we will instead do so with Terraform.
Another attribute to select is the instance size. AWS supports a long list of sizes that relate to the amount of memory, CPU cores, and disk space. For a chart of the available instance types, click on the Select button to proceed to the second page of the wizard, which shows a table of instance types and their attributes. For this exercise, we will use the t2.micro instance type because it is eligible for the free tier.
Create a file named ec2-public.tf containing the following:
resource "aws_instance" "public" {
ami = var.ami_id
instance_type = var.instance_type
subnet_id = aws_subnet.public1.id
key_name = var.key_pair
vpc_security_group_ids = [ aws_security_group.ec2-public-sg.id ]
associate_public_ip_address = true
tags = {
Name = "${var.project_name}-ec2-public"
}
depends_on = [ aws_vpc.notes, aws_internet_gateway.igw ]
user_data = join("
", [
"#!/bin/sh",
file("sh/docker_install.sh"),
"docker swarm init",
"sudo hostname ${var.project_name}-public"
])
}
In the Terraform AWS provider, the resource name for EC2 instances is aws_instance. Since this instance is attached to our public subnet, we'll call it aws_instance.public. Because it is a public EC2 instance, the associate_public_ip_address attribute is set to true.
The attributes include the AMI ID, the instance type, the ID for the subnet, and more. The key_name attribute refers to the name of an SSH key we'll use to log in to the EC2 instance. We'll discuss these key pairs later. The vpc_security_group_ids attribute is a reference to a security group we'll apply to the EC2 instance. The depends_on attribute causes Terraform to wait for the creation of the resources named in the array. The user_data attribute is a shell script that is executed inside the instance once it is created.
For the AMI, instance type, and key-pair data, add these entries to variables.tf, as follows:
variable "ami_id" { default = "ami-09dd2e08d601bff67" }
variable "instance_type" { default = "t2.micro" }
variable "key_pair" { default = "notes-app-key-pair" }
The AMI ID shown here is specifically for Ubuntu 20.04 in us-west-2. There will be other AMI IDs in other regions. The key_pair name shown here should be the key-pair name you selected when creating your key pair earlier.
It is not necessary to add the key-pair file to this directory, nor to reference the file you downloaded in these scripts. Instead, you simply give the name of the key pair. In our example, we named it notes-app-key-pair, and downloaded notes-app-key-pair.pem.
The user_data feature is very useful since it lets us customize an instance after creation. We're using this to automate the Docker setup on the instances. This field is to receive a string containing a shell script that will execute once the instance is launched. Rather than insert that script inline with the Terraform code, we have created a set of files that are shell script snippets. The Terraform file function reads the named file, returning it as a string. The Terraform join function takes an array of strings, concatenating them together with the delimiter character in between. Between the two we construct a shell script. The shell script first installs Docker Engine, then initializes Docker Swarm mode, and finally changes the hostname to help us remember that this is the public EC2 instance.
Create a directory named sh in which we'll create shell scripts, and in that directory create a file named docker_install.sh. To this file, add the following:
sudo apt-get update
sudo apt-get upgrade -y
sudo apt-get -y install apt-transport-https
ca-certificates curl gnupg-agent software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg
| sudo apt-key add -
sudo apt-key fingerprint 0EBFCD88
sudo add-apt-repository
"deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt-get update
sudo apt-get upgrade -y
sudo apt-get install -y docker-ce docker-ce-cli containerd.io
sudo groupadd docker
sudo usermod -aG docker ubuntu
sudo systemctl enable docker
This script is derived from the official instructions for installing Docker Engine Community Edition (CE) on Ubuntu. The first portion is support for apt-get to download packages from HTTPS repositories. It then configures the Docker package repository into Ubuntu, after which it installs Docker and related tools. Finally, it ensures that the docker group is created and ensures that the ubuntu user ID is a member of that group. The Ubuntu AMI defaults to this user ID, ubuntu, to be the one used by the EC2 administrator.
For this EC2 instance, we also run docker swarm init to initialize the Docker Swarm. For other EC2 instances, we do not run this command. The method used for initializing the user_data attribute lets us easily have a custom configuration script for each EC2 instance. For the other instances, we'll only run docker_install.sh, whereas for this instance, we'll also initialize the swarm.
Back in ec2-public.tf, we have two more things to do, and then we can launch the EC2 instance. Have a look at the following code block:
resource "aws_security_group" "ec2-public-sg" {
name = "${var.project_name}-public-security-group"
description = "allow inbound access to the EC2 instance"
vpc_id = aws_vpc.notes.id
ingress {
protocol = "TCP"
from_port = 22
to_port = 22
cidr_blocks = [ "0.0.0.0/0" ]
}
ingress {
protocol = "TCP"
from_port = 80
to_port = 80
cidr_blocks = [ "0.0.0.0/0" ]
}
egress {
protocol = "-1"
from_port = 0
to_port = 0
cidr_blocks = [ "0.0.0.0/0" ]
}
}
This is the security group declaration for the public EC2 instance. Remember that a security group describes the rules of a firewall that is attached to many kinds of AWS objects. This security group was already referenced in declaring aws_instance.public.
The main feature of security groups is the ingress and egress rules. As the words imply, ingress rules describe the network traffic allowed to enter the resource, and egress rules describe what's allowed to be sent by the resource. If you have to look up those words in a dictionary, you're not alone.
We have two ingress rules, and the first allows traffic on port 22, which covers SSH traffic. The second allows traffic on port 80, covering HTTP. We'll add more Docker rules later when they're needed.
The egress rule allows the EC2 instance to send any traffic to any machine on the internet.
These ingress rules are obviously very strict and limit the attack surface any miscreants can exploit.
The final task is to add these output declarations to ec2-public.tf, as follows:
output "ec2-public-arn" { value = aws_instance.public.arn }
output "ec2-public-dns" { value = aws_instance.public.public_dns }
output "ec2-public-ip" { value = aws_instance.public.public_ip }
output "ec2-private-dns" { value = aws_instance.public.private_dns }
output "ec2-private-ip" { value = aws_instance.public.private_ip }
This will let us know the public IP address and public DNS name. If we're interested, the outputs also tell us the private IP address and DNS name.
Launching the EC2 instance on AWS
We have added to the Terraform declarations for creating an EC2 instance.
We're now ready to deploy this to AWS and see what we can do with it. We already know what to do, so let's run the following command:
$ terraform plan
...
Plan: 2 to add, 0 to change, 0 to destroy.
If the VPC infrastructure were already running, you would get output similar to this. The addition is two new objects, aws_instance.public and aws_security_group.ec2-public-sg. This looks good, so we proceed to deployment, as follows:
$ terraform apply
...
Plan: 2 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
...
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
Outputs:
aws_region = us-west-2
ec2-private-dns = ip-10-0-1-55.us-west-2.compute.internal
ec2-private-ip = 10.0.1.55
ec2-public-arn = arn:aws:ec2:us-west-2:098106984154:instance/i-0046b28d65a4f555d
ec2-public-dns = ec2-54-213-6-249.us-west-2.compute.amazonaws.com
ec2-public-ip = 54.213.6.249
igw_id = igw-006eb101f8cb423d4
private1_cidr = 10.0.3.0/24
public1_cidr = 10.0.1.0/24
subnet_private1_id = subnet-0a9044daea298d1b2
subnet_public1_id = subnet-07e6f8ed6cc6f8397
vpc_arn = arn:aws:ec2:us-west-2:098106984154:vpc/vpc-074b2dfa7b353486f
vpc_cidr = 10.0.0.0/16
vpc_id = vpc-074b2dfa7b353486f
vpc_name = notes-vpc
This built our EC2 instance, and we have the IP address and domain name. Because the initialization script will have required a couple of minutes to run, it is good to wait for a short time before proceeding to test the system.
The ec2-public-ip value is the public IP address for the EC2 instance. In the following examples, we will put the text PUBLIC-IP-ADDRESS, and you must of course substitute the IP address your EC2 instance is assigned.
We can log in to the EC2 instance like so:
$ ssh -i ~/Downloads/notes-app-key-pair.pem ubuntu@PUBLIC-IP-ADDRESS
The authenticity of host '54.213.6.249 (54.213.6.249)' can't be established.
ECDSA key fingerprint is SHA256:DOGsiDjWZ6rkj1+AiMcqqy/naAku5b4VJUgZqtlwPg8.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '54.213.6.249' (ECDSA) to the list of known hosts.
Welcome to Ubuntu 20.04 LTS (GNU/Linux 5.4.0-1009-aws x86_64)
...
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
ubuntu@notes-public:~$ hostname
notes-public
On a Linux or macOS system where we're using SSH, the command is as shown here. The -i option lets us specify the Privacy Enhanced Mail (PEM) file that was provided by AWS for the key pair. If on Windows using PuTTY, you'd instead tell it which PuTTY Private Key (PPK) file to use, and the connection parameters will otherwise be similar to this.
This lands us at the command-line prompt of the EC2 instance. We see that it is Ubuntu 20.04, and the hostname is set to notes-public, as reflected in Command Prompt and the output of the hostname command. This means that our initialization script ran because the hostname was the last configuration task it performed.
Handling the AWS EC2 key-pair file
Earlier, we said to safely store the key-pair file somewhere on your computer. In the previous section, we showed how to use the PEM file with SSH to log in to the EC2 instance. Namely, we use the PEM file like so:
$ ssh -i /path/to/key-pair.pem USER-ID@HOST-IP
It can be inconvenient to remember to add the -i flag every time we use SSH. To avoid having to use this option, run this command:
$ ssh-add /path/to/key-pair.pem
As the command name implies, this adds the authentication file to SSH. This has to be rerun on every reboot of the computer, but it conveniently lets us access EC2 instances without remembering to specify this option.
Testing the initial Docker Swarm
We have an EC2 instance and it should already be configured with Docker, and we can easily verify that this is the case as follows:
ubuntu@notes-public:~$ docker run hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
0e03bdcc26d7: Pull complete
...
The setup script was also supposed to have initialized this EC2 instance as a Docker Swarm node, and the following command verifies whether that happened:
ubuntu@notes-public:~$ docker info
...
Swarm: active
NodeID: qfb1ljmw2fgp4ij18klowr8dp
Is Manager: true
ClusterID: 14p4sdfsdyoa8el0v9cqirm23
...
The docker info command, as the name implies, prints out a lot of information about the current Docker instance. In this case, the output includes verification that it is in Docker Swarm mode and that this is a Docker Swarm manager instance.
Let's try a couple of swarm commands, as follows:
ubuntu@notes-public:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
qfb1ljmw2fgp4ij18klowr8dp * notes-public Ready Active Leader 19.03.9
ubuntu@notes-public:~$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
The docker node command is for managing the nodes in a swarm. In this case, there is only one node—this one, and it is shown as not only a manager but as the swarm leader. It's easy to be the leader when you're the only node in the cluster, it seems.
The docker service command is for managing the services deployed in the swarm. In this context, a service is roughly the same as an entry in the services section of a Docker compose file. In other words, a service is not the running container but is an object describing the configuration for launching one or more instances of a given container.
To see what this means, let's start an nginx service, as follows:
ubuntu@notes-public:~$ docker service create --name nginx --replicas 1 -p 80:80 nginx
ephvpfgjwxgdwx7ab87e7nc9e
overall progress: 1 out of 1 tasks
1/1: running
verify: Service converged
ubuntu@notes-public:~$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
ephvpfgjwxgd nginx replicated 1/1 nginx:latest *:80->80/tcp
ubuntu@notes-public:~$ docker service ps nginx
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
ag8b45t69am1 nginx.1 nginx:latest notes-public Running Running 15 seconds ago
We started one service using the nginx image. We said to deploy one replica and to expose port 80. We chose the nginx image because it has a simple default HTML file that we can easily view, as illustrated in the following screenshot:

Simply paste the IP address of the EC2 instance into the browser location bar, and we're greeted with that default HTML.
We also see by using docker node ls and docker service ps that there is one instance of the service. Since this is a swarm, let's increase the number of nginx instances, as follows:
ubuntu@notes-public:~$ docker service update --replicas 3 nginx
nginx
overall progress: 3 out of 3 tasks
1/3: running
2/3: running
3/3: running
verify: Service converged
ubuntu@notes-public:~$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
ephvpfgjwxgd nginx replicated 3/3 nginx:latest *:80->80/tcp
ubuntu@notes-public:~$ docker service ps nginx
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
ag8b45t69am1 nginx.1 nginx:latest notes-public Running Running 9 minutes ago
ojvbs4n2iriy nginx.2 nginx:latest notes-public Running Running 13 seconds ago
fqwwk8c4tqck nginx.3 nginx:latest notes-public Running Running 13 seconds ago
Once a service is deployed, we can modify the deployment using the docker service update command. In this case, we told it to increase the number of instances using the --replicas option, and we now have three instances of the nginx container all running on the notes-public node.
We can also run the normal docker ps command to see the actual containers, as illustrated in the following code block:
ubuntu@notes-public:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6dc274c30fea nginx:latest "nginx -g 'daemon of…" About a minute ago Up About a minute 80/tcp nginx.2.ojvbs4n2iriyjifeh0ljlyvhp
4b51455fb2bf nginx:latest "nginx -g 'daemon of…" About a minute ago Up About a minute 80/tcp nginx.3.fqwwk8c4tqckspcrrzbs0qyii
e7ed31f9471f nginx:latest "nginx -g 'daemon of…" 10 minutes ago Up 10 minutes 80/tcp nginx.1.ag8b45t69am1gzh0b65gfnq14
This verifies that the nginx service with three replicas is actually three nginx containers.
In this section, we were able to launch an EC2 instance and set up a single-node Docker swarm in which we launched a service, which gave us the opportunity to familiarize ourselves with what this can do.
While we're here, there is another thing to learn—namely, how to set up the remote control of Docker hosts.
Setting up remote control access to a Docker Swarm hosted on EC2
A feature that's not well documented in Docker is the ability to control Docker nodes remotely. This will let us, from our laptop, run Docker commands on a server. By extension, this means that we will be able to manage the Docker Swarm from our laptop.
One method for remotely controlling a Docker instance is to expose the Docker Transmission Control Protocol (TCP) port. Be aware that miscreants are known to scan an internet infrastructure for Docker ports to hijack. The following technique does not expose the Docker port but instead uses SSH.
The following setup is for Linux and macOS, relying on features of SSH. To do this on Windows would rely on installing OpenSSH. From October 2018, OpenSSH became available for Windows, and the following commands may work in PowerShell (failing that, you can run these commands from a Multipass or Windows Subsystem for Linux (WSL) 2 instance on Windows):
ubuntu@notes-public:~$ logout
Connection to PUBLIC-IP-ADDRESS closed.
Exit the shell on the EC2 instance so that you're at the command line on your laptop.
Run the following command:
$ ssh-add ~/Downloads/notes-app-key-pair.pem
Identity added: /Users/david/Downloads/notes-app-key-pair.pem (/Users/david/Downloads/notes-app-key-pair.pem)
We discussed this command earlier, noting that it lets us log in to EC2 instances without having to use the -i option to specify the PEM file. This is more than a simple convenience when it comes to remotely accessing Docker hosts. The following steps are dependent on having added the PEM file to SSH, as shown here.
To verify you've done this correctly, use this command:
$ ssh ubuntu@PUBLIC-IP-ADDRESS
Normally with an EC2 instance, we would use the -i option, as shown earlier. But after running ssh-add, the -i option is no longer required.
That enables us to create the following environment variable:
$ export DOCKER_HOST=ssh://ubuntu@PUBLIC-IP-ADDRESS
$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
ephvpfgjwxgd nginx replicated 3/3 nginx:latest *:80->80/tcp
The DOCKER_HOST environment variable enables the remote control of Docker hosts. It relies on a passwordless SSH login to the remote host. Once you have that, it's simply a matter of setting the environment variable and you've got remote control of the Docker host, and in this case, because the host is a swarm manager, a remote swarm.
But this gets even better by using the Docker context feature. A context is a configuration required to access a remote node or swarm. Have a look at the following code snippet:
$ unset DOCKER_HOST
We begin by deleting the environment variable because we'll replace it with something better, as follows:
$ docker context create ec2 --docker host=ssh://ubuntu@PUBLIC-IP-ADDRESS
ec2
Successfully created context "ec2"
$ docker --context ec2 service ls
ID NAME MODE REPLICAS IMAGE PORTS
ephvpfgjwxgd nginx replicated 3/3 nginx:latest *:80->80/tcp
$ docker context use ec2
ec2
Current context is now "ec2"
$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
ephvpfgjwxgd nginx replicated 3/3 nginx:latest *:80->80/tcp
We create a context using docker context create, specifying the same SSH URL we used in the DOCKER_HOST variable. We can then use it either with the --context option or by using docker context use to switch between contexts.
With this feature, we can easily maintain configurations for multiple remote servers and switch between them with a simple command.
For example, the Docker instance on our laptop is the default context. Therefore, we might find ourselves doing this:
$ docker context use default
... run docker commands against Docker on the laptop
$ docker context use ec2
... run docker commands against Docker on the AWS EC2 machines
There are times when we must be cognizant of which is the current Docker context and when to use which context. This will be useful in the next section when we learn how to push the images to AWS ECR.
We've learned a lot in this section, so before heading to the next task, let's clean up our AWS infrastructure. There's no need to keep this EC2 instance running since we used it solely for a quick familiarization tour. We can easily delete this instance while leaving the rest of the infrastructure configured. The most effective way to so is by renaming ec2-public.tf to ec2-public.tf-disable, and to rerun terraform apply, as illustrated in the following code block:
$ mv ec2-public.tf ec2-public.tf-disable
$ terraform apply
...
Plan: 0 to add, 0 to change, 2 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
...
The effect of changing the name of one of the Terraform files is that Terraform will not scan those files for objects to deploy. Therefore, when Terraform maps out the state we want Terraform to deploy, it will notice that the deployed EC2 instance and security group are not listed in the local files, and it will, therefore, destroy those objects. In other words, this lets us undeploy some infrastructure with very little fuss.
This tactic can be useful for minimizing costs by turning off unneeded facilities. You can easily redeploy the EC2 instances by renaming the file back to ec2-public.tf and rerunning terraform apply.
In this section, we familiarized ourselves with Docker Swarm by deploying a single-node swarm on an EC2 instance on AWS. We first added suitable declarations to our Terraform files. We then deployed the EC2 instance on AWS. Following deployment, we set about verifying that, indeed, Docker Swarm was already installed and initialized on the server and that we could easily deploy Docker services on the swarm. We then learned how to set up remote control of the swarm from our laptop.
Taken together, this proved that we can easily deploy Docker-based services to EC2 instances on AWS. In the next section, let's continue preparing for a production-ready deployment by setting up a build process to push Docker images to image repositories.
Setting up ECR repositories for Notes Docker images
We have created Docker images to encapsulate the services making up the Notes application. So far, we've used those images to instantiate Docker containers on our laptop. To deploy containers on the AWS infrastructure will require the images to be hosted in a Docker image repository.
This requires a build procedure by which the svc-notes and svc-userauth images are correctly pushed to the container repository on the AWS infrastructure. We will go over the commands required and create a few shell scripts to record those commands.
A site such as Docker Hub is what's known as a Docker Registry. Registries are web services that store Docker images by hosting Docker image repositories. When we used the redis or mysql/mysql-server images earlier, we were using Docker image repositories located on the Docker Hub Registry.
The AWS team offers a Docker image registry, ECR. An ECR instance is available for each account in each AWS region. All we have to do is log in to the registry, create repositories, and push images to the repositories.
Because it is important to not run Docker build commands on the Swarm infrastructure, execute this command:
$ docker context use default
This command switches the Docker context to the local system.
To hold the scripts and other files related to managing AWS ECR repositories, create a directory named ecr as a sibling to notes, users, and terraform-swarm.
There are several commands required for a build process to create Docker images, tag them, and push them to a remote repository. To simplify things, let's create a few shell scripts, as well as PowerShell scripts, to record those commands.
The first task is to connect with the AWS ECR service. To this end, create a file named login.sh containing the following:
aws ecr get-login-password --profile $AWS_PROFILE --region $AWS_REGION
| docker login --username AWS
--password-stdin $AWS_USER.dkr.ecr.$AWS_REGION.amazonaws.com
This command, and others, are available in the ECR dashboard. If you navigate to that dashboard and then create a repository there, a button labeled View Push Command is available. This and other useful commands are listed there, but we have substituted a few variable names to make this configurable.
If you are instead using Windows PowerShell, AWS recommends the following:
(Get-ECRLoginCommand).Password | docker login --username AWS --password-stdin ACCOUNT-ID.dkr.ecr.REGION-NAME.amazonaws.com
This relies on the AWS Tools for PowerShell package (see https://aws.amazon.com/powershell/), which appears to offer some powerful tools that are useful with AWS services. In testing, however, this command was not found to work very well.
Instead, the following command was found to work much better, which you can put in a file named login.ps1:
aws ecr get-login-password --region %AWS_REGION% | docker login --username AWS --password-stdin %AWS_USER%.dkr.ecr.%AWS_REGION%.amazonaws.com
This is the same command as is used for Unix-like systems, but with Windows-style references to environment variables.
Several environment variables are being used, but just what are those variables being used and how do we set them?
Using environment variables for AWS CLI commands
Look carefully and you will see that some environment variables are being used. The AWS CLI commands know about those environment variables and will use them instead of command-line options. The environment variables we're using are the following:
- AWS_PROFILE: The AWS profile to use with this project.
- AWS_REGION: The AWS region to deploy the project to.
- AWS_USER: The numeric user ID for the account being used. This ID is available on the IAM dashboard page for the account.
The AWS command-line tools will use those environment variables in place of the command-line options. Earlier, we discussed using the AWS_PROFILE variable instead of the --profile option. The same holds true for other command-line options.
This means that we need an easy way to set those variables. These Bash commands can be recorded in a shell script like this, which you could store as env-us-west-2:
export AWS_REGION=us-west-2
export AWS_PROFILE=notes-app
export AWS_USER=09E1X6A8MPLE
This script is, of course, following the syntax of the Bash shell. For other command environments, you must transliterate it appropriately. To set these variables in the Bash shell, run the following command:
$ chmod +x env-us-west-2
$ . ./env-us-west-2
For other command environments, again transliterate appropriately. For example, in Windows and in PowerShell, the variables can be set with these commands:
$env:AWS_USER = "09E1X6A8MPLE"
$env:AWS_PROFILE = "notes-app"
$env:AWS_REGION = "us-west-2"
These should be the same values, just in a syntax recognized by Windows.
We have defined the environment variables being used. Let's now get back to defining the process to build Docker images and push them to the ECR.
Defining a process to build Docker images and push them to the AWS ECR
We were exploring a build procedure for pushing Docker containers to ECR repositories until we started talking about environment variables. Let's return to the task at hand, which is to easily build Docker images, create ECR repositories, and push the images to the ECR.
As mentioned at the beginning of this section, make sure to switch to the default Docker context. We must do so because it is a policy with Docker Swarm to not use the swarm hosts for building Docker images.
To build the images, let's add a file named build.sh containing the following:
( cd ../notes && npm run docker-build )
( cd ../users && npm run docker-build )
This handles running docker build commands for both the Notes and user authentication services. It is expected to be executed in the ecr directory and takes care of executing commands in both the notes and users directories.
Let's now create and delete a pair of registries to hold our images. We have two images to upload to the ECR, and therefore we create two registries.
Create a file named create.sh containing the following:
aws ecr create-repository --repository-name svc-notes --image-scanning-configuration scanOnPush=true
aws ecr create-repository --repository-name svc-userauth --image-scanning-configuration scanOnPush=true
Also, create a companion file named delete.sh containing the following:
aws ecr delete-repository --force --repository-name svc-notes
aws ecr delete-repository --force --repository-name svc-userauth
Between these scripts, we can create and delete the ECR repositories for our Docker images. These scripts are directly usable on Windows; simply change the filenames to create.ps1 and delete.ps1.
In aws ecr delete-repository, the --force option means to delete the repositories even if they contain images.
With the scripts we've written so far, they are executed in the following order:
$ sh login.sh
Login Succeeded
$ sh create.sh
{
"repository": {
"repositoryArn": "arn:aws:ecr:us-
REGION-2:09E1X6A8MPLE:repository/svc-notes",
"registryId": "098106984154",
"repositoryName": "svc-notes",
"repositoryUri": "09E1X6A8MPLE.dkr.ecr.us-
REGION-2.amazonaws.com/svc-notes",
"createdAt": "2020-06-07T12:34:03-07:00",
"imageTagMutability": "MUTABLE",
"imageScanningConfiguration": {
"scanOnPush": true
}
}
}
{
"repository": {
"repositoryArn": "arn:aws:ecr:us-
REGION-2:09E1X6A8MPLE:repository/svc-userauth",
"registryId": "098106984154",
"repositoryName": "svc-userauth",
"repositoryUri": "09E1X6A8MPLE.dkr.ecr.us-
REGION-2.amazonaws.com/svc-userauth",
"createdAt": "2020-06-07T12:34:05-07:00",
"imageTagMutability": "MUTABLE",
"imageScanningConfiguration": {
"scanOnPush": true
}
}
}
The aws ecr create-repository command outputs these descriptors for the image repositories. The important piece of data to note is the repositoryUri value. This will be used later in the Docker stack file to name the image to be retrieved.
The create.sh script only needs to be executed once.
Beyond creating the repositories, the workflow is as follows:
- Build the images, for which we've already created a script named build.sh.
- Tag the images with the ECR repository Uniform Resource Identifier (URI).
- Push the images to the ECR repository.
For the latter two steps, we still have some scripts to create.
Create a file named tag.sh containing the following:
docker tag svc-notes:latest $AWS_USER.dkr.ecr.$AWS_REGION.amazonaws.com/svc-notes:latest
docker tag svc-userauth:latest $AWS_USER.dkr.ecr.$AWS_REGION.amazonaws.com/svc-userauth:latest
The docker tag command we have here takes svc-notes:latest, or svc-userauth:latest, and adds what's called a target image to the local image storage area. The target image name we've used is the same as what will be stored in the ECR repository.
For Windows, you should create a file named tag.ps1 using the same commands, but with Windows-style environment variable references.
Then, create a file named push.sh containing the following:
docker push $AWS_USER.dkr.ecr.$AWS_REGION.amazonaws.com/svc-notes:latest
docker push $AWS_USER.dkr.ecr.$AWS_REGION.amazonaws.com/svc-userauth:latest
The docker push command causes the target image to be sent to the ECR repository. And again, for Windows, create a file named push.ps1 containing the same commands but with Windows-style environment variable references.
In both the tag and push scripts, we are using the repository URI value, but have plugged in the two environment variables. This will make it generalized in case we deploy Notes to another AWS region.
We have the workflow implemented as scripts, so let's see now how it is run, as follows:
$ sh -x build.sh
+ cd ../notes
+ npm run docker-build
> [email protected] docker-build /Users/David/Chapter12/notes
> docker build -t svc-notes .
Sending build context to Docker daemon 84.12MB
Step 1/25 : FROM node:14
---> a5a6a9c32877
Step 2/25 : RUN apt-get update -y && apt-get -y install curl python build-essential git ca-certificates
---> Using cache
---> 7cf57f90c8b8
Step 3/25 : ENV DEBUG="notes:*,messages:*"
---> Using cache
---> 291652c87cce
...
Successfully built e2f6ec294016
Successfully tagged svc-notes:latest
+ cd ../users
+ npm run docker-build
> [email protected] docker-build /Users/David/Chapter12/users
> docker build -t svc-userauth .
Sending build context to Docker daemon 11.14MB
...
Successfully built 294b9a83ada3
Successfully tagged svc-userauth:latest
This builds the Docker images. When we run docker build, it stores the built image in an area on our laptop where Docker maintains images. We can inspect that area using the docker images command, like this:
$ docker images svc-userauth
REPOSITORY TAG IMAGE ID CREATED SIZE
svc-userauth latest b74f92629ed1 3 hours ago 1.11GB
The docker build command automatically adds the tag, latest, if we do not specify a tag.
Then, to push the images to the ECR repositories, we execute these commands:
$ sh tag.sh
$ sh push.sh
The push refers to repository [09E1X6A8MPLE.dkr.ecr.us-west-2.amazonaws.com/svc-notes]
6005576570e9: Pushing 18.94kB
cac3b3d9d486: Pushing 7.014MB/96.89MB
107afd8db3a4: Pushing 14.85kB
df143eb62095: Pushing 17.41kB
6b61442be5f8: Pushing 3.717MB
0c719438462a: Waiting
8c98a57451eb: Waiting
...
latest: digest: sha256:1ea31c507e9714704396f01f5cdad62525d9694e5b09e2e7b08c3cb2ebd6d6ff size: 4722
The push refers to repository [09E1X6A8MPLE.dkr.ecr.us-west-2.amazonaws.com/svc-userauth]
343a794bb161: Pushing 9.12MB/65.13MB
51f07622ae50: Pushed
b12bef22bccb: Pushed
...
Since the images are rather large, it will take a long time to upload them to the AWS ECR. We should add a task to the backlog to explore ways to trim Docker image sizes. In any case, expect this to take a while.
After a period of time, the images will be uploaded to the ECR repositories, and you can inspect the results on the ECR dashboard.
Once the Docker images are pushed to the AWS ECR repository, we no longer need to stay with the default Docker context. You will be free to run the following command at any time:
$ docker context use ec2
Remember that swarm hosts are not to be used for building Docker images. At the beginning of this section, we switched to the default context so that builds would occur on our laptop.
In this section, we learned how to set up a build procedure to push our Docker images to repositories on the AWS ECR service. This included using some interesting tools that simplify building complex build procedures in package.json scripts.
Our next step is learning how to use Docker compose files to describe deployment on Docker Swarm.
Creating a Docker stack file for deployment to Docker Swarm
In the previous sections, we learned how to set up an AWS infrastructure using Terraform. We've designed a VPC that will house the Notes application stack, we experimented with a single-node Docker Swarm cluster built on a single EC2 instance, and we set up a procedure to push the Docker images to the ECR.
Our next task is to prepare a Docker stack file for deployment to the swarm. A stack file is nearly identical to the Docker compose file we used in Chapter 11, Deploying Node.js Microservices with Docker. Compose files are used with normal Docker hosts, but stack files are used with swarms. To make it a stack file, we add some new tags and change a few things, including the networking implementation.
Earlier, we kicked the tires of Docker Swarm with the docker service create command to launch a service on a swarm. While that was easy, it does not constitute code that can be committed to a source repository, nor is it an automated process.
In swarm mode, a service is a definition of the tasks to execute on swarm nodes. Each service consists of a number of tasks, with this number depending on the replica settings. Each task is a container that has been deployed to a node in the swarm. There are, of course, other configuration parameters, such as network ports, volume connections, and environment variables.
The Docker platform allows the use of the compose file for deploying services to a swarm. When used this way, the compose file is referred to as a stack file. There is a set of docker stack commands for handling the stack file, as follows:
- On a regular Docker host, the docker-compose.yml file is called a compose file. We use the docker-compose command on a compose file.
- On a Docker swarm, the docker-compose.yml file is called a stack file. We use the docker stack command on a stack file.
Remember that a compose file has a services tag, and each entry in that tag is a container configuration to deploy. When used as a stack file, each services tag entry is, of course, a service in the sense just described. This means that just as there was a lot of similarity between the docker run command and container definitions in the compose file, there is a degree of similarity between the docker service create command and the service entries in the stack file.
One important consideration is a policy that builds must not happen on Swarm host machines. Instead, these machines must be used solely for deploying and executing containers. This means that any build tag in a service listed in a stack file is ignored. Instead, there is a deploy tag that has parameters for the deployment in the swarm, and the deploy tag is ignored when the file is used with Compose. Put more simply, we can have the same file serve both as a compose file (with the docker compose command) and as a stack file (with the docker stack command), with the following conditions:
- When used as a compose file, the build tag is used and the deploy tag is ignored.
- When used as a stack file, the build tag is ignored and the deploy tag is used.
Another consequence of this policy is the necessity of switching the Docker context as appropriate. We have already discussed this issue—that we use the default Docker context to build images on our laptop and we use the EC2 context when interacting with the swarm on the AWS EC2 instances.
To get started, create a directory named compose-stack that's a sibling to compose-local, notes, terraform-swarm, and the other directories. Then, copy compose-local/docker-compose.yml into compose-stack. This way, we can start from something we know is working well.
This means that we'll create a Docker stack file from our compose file. There are several steps involved, which we'll cover over the next several sections. This includes adding deploy tags, configuring networking for the swarm, controlling the placement of services in the swarm, storing secrets in the swarm, and other tasks.
Creating a Docker stack file from the Notes Docker compose file
With that theory under our belts, let's now take a look at the existing Docker compose file and see how to make it useful for deployment to a swarm.
Since we will require some advanced docker-compose.yml features, update the version number to the following:
version: '3.8'
For the Compose file we started with, version '3' was adequate, but to accomplish the tasks in this chapter the higher version number is required, to enable newer features.
Fortunately, most of this is straightforward and will require very little code.
For the deployment parameters, simply add a deploy tag to each service. Most of the options for this tag have perfectly reasonable defaults. To start with, let's add this to every service, as follows:
deploy:
replicas: 1
This tells Docker that we want one instance of each service. Later, we will experiment with adding more service instances. We will add other parameters later, such as placement constraints. Later, we will want to experiment with multiple replicas for both svc-notes and svc-userauth. It is tempting to put CPU and memory limits on the service, but this isn't necessary.
It is nice to learn that with swarm mode, we can simply change the replicas setting to change the number of instances.
The next thing to take care of is the image name. While the build tag is present, remember that it is ignored. For the Redis and database containers, we are already using images from Docker Hub, but for svc-notes and svc-userauth, we are building our own containers. This is why, earlier in this chapter, we set up a procedure for pushing the images to ECR repositories. We can now reference those images from the stack file. This means that we must make the following change:
services:
...
svc-userauth:
build: ../users
image: 098E0X9AMPLE.dkr.ecr.us-REGION-2.amazonaws.com/svc-userauth
...
svc-notes:
build: ../notes
image: 098E0X9AMPLE.dkr.ecr.us-REGION-2.amazonaws.com/svc-notes
...
If we use this with docker-compose, it will perform the build in the named directories, and then tag the resulting image with the tag in the image field. In this case, the deploy tag will be ignored as well. However, if we use this with docker stack deploy, the build tag will be ignored, and the images will be downloaded from the repositories listed in the image tag. In this case, the deploy tag will be used.
When running the compose file on our laptop, we used bridge networking. This works fine for a single host, but with swarm mode, we need another network mode that handles multi-host deployments. The Docker documentation clearly says to use the overlay driver in swarm mode, and the bridge driver for a single-host deployment.
To use overlay networking, change the networks tag to the following:
networks:
frontnet:
# driver: bridge
driver: overlay
authnet:
# driver: bridge
driver: overlay
svcnet:
# driver: bridge
driver: overlay
To support switching between using this for a swarm, or for a single-host deployment, we can leave the bridge network setting available but commented out. We would then change whether overlay or bridge networking is active by changing which is commented, depending on the context.
The overlay network driver sets up a virtual network across the swarm nodes. This network supports communication between the containers and also facilitates access to the externally published ports.
The overlay network configures the containers in a swarm to have a domain name automatically assigned that matches the service name. As with the bridge network we used before, containers find each other via the domain name. For a service deployed with multiple instances, the overlay network ensures that requests to that container can be routed to any of its instances. If a connection is made to a container but there is no instance of that container on the same host, the overlay network routes the request to an instance on another host. This is a simple approach to service discovery, by using domain names, but extending it across multiple hosts in a swarm.
That took care of the easy tasks for converting the compose file to a stack file. There are a few other tasks that will require more attention, however.
Placing containers across the swarm
We haven't done it yet, but we will add multiple EC2 instances to the swarm. By default, swarm mode distributes tasks (containers) evenly across the swarm nodes. However, we have two considerations that should force some containers to be deployed on specific Docker hosts—namely, the following:
- We have two database containers and need to arrange persistent storage for the data files. This means that the databases must be deployed to the same instance every time so that it can use the same data directory.
- The public EC2 instance, named notes-public, will be part of the swarm. To maintain the security model, most of the services should not be deployed on this instance but on the instances that will be attached to the private subnet. Therefore, we should strictly control which containers deploy to notes-public.
Swarm mode lets us declare the placement requirements for any service. There are several ways to implement this, such as matching against the hostname, or against labels that can be assigned to each node.
The documentation for the docker stack create command includes a further explanation of deployment parameters: https://docs.docker.com/engine/reference/commandline/service_create.
Add this deploy tag to the db-userauth service declaration:
services:
...
db-userauth:
..
deploy:
replicas: 1
placement:
constraints:
# - "node.hostname==notes-private-db1"
- "node.labels.type==db"
...
The placement tag governs where the containers are deployed. Rather than Docker evenly distributing the containers, we can influence the placement with the fields in this tag. In this case, we have two examples, such as deploying a container to a specific node based on the hostname or selecting a node based on the labels attached to the node.
To set a label on a Docker swarm node, we run the following command:
$ docker node update --label-add type=public notes-public
This command attaches a label named type, with the value public, to the node named notes-public. We use this to set labels, and, as you can see, the label can have any name and any value. The labels can then be used, along with other attributes, as influence over the placement of containers on swarm nodes.
For the rest of the stack file, add the following placement constraints:
services:
...
svc-userauth:
...
deploy:
replicas: 1
placement:
constraints:
- "node.labels.type==svc"
...
db-notes:
...
deploy:
replicas: 1
placement:
constraints:
- "node.labels.type==db"
...
svc-notes:
...
deploy:
replicas: 1
placement:
constraints:
- "node.labels.type==public"
...
redis:
...
deploy:
replicas: 1
placement:
constraints:
- "node.labels.type!=public"
...
This gives us three labels to assign to our EC2 instances: db, svc, and public. These constraints will cause the databases to be placed on nodes where the type label is db, the user authentication service is on the node of type svc, the Notes service is on the public node, and the Redis service is on any node that is not the public node.
The reasoning stems from the security model we designed. The containers deployed on the private network should be more secure behind more layers of protection. This placement leaves the Notes container as the only one on the public EC2 instance. The other containers are split between the db and svc nodes. We'll see later how these labels will be assigned to the EC2 instances we'll create.
Configuring secrets in Docker Swarm
With Notes, as is true for many kinds of applications, there are some secrets we must protect. Primarily, this is the Twitter authentication tokens, and we've claimed it could be a company-ending event if those tokens were to leak to the public. Maybe that's overstating the danger, but leaked credentials could be bad. Therefore, we must take measures to ensure that those secrets do not get committed to a source repository as part of any source code, nor should they be recorded in any other file.
For example, the Terraform state file records all information about the infrastructure, and the Terraform team makes no effort to detect any secrets and suppress recording them. It's up to us to make sure the Terraform state file does not get committed to source code control as a result.
Docker Swarm supports a very interesting method for securely storing secrets and for making them available in a secure manner in containers.
The process starts with the following command:
$ printf 'vuTghgEXAMPLE...' | docker secret create TWITTER_CONSUMER_KEY -
$ printf 'tOtJqaEXAMPLE...' | docker secret create TWITTER_CONSUMER_SECRET -
This is how we store a secret in a Docker swarm. The docker secret create command first takes the name of the secret, and then a specifier for a file containing the text for the secret. This means we can either store the data for the secret in a file or—as in this case—we use - to specify that the data comes from the standard input. In this case, we are using the printf command, which is available for macOS and Linux, to send the value into the standard input.
Docker Swarm securely records the secrets as encrypted data. Once you've given a secret to Docker, you cannot inspect the value of that secret.
In compose-stack/docker-compose.yml, add this declaration at the end:
secrets:
TWITTER_CONSUMER_KEY:
external: true
TWITTER_CONSUMER_SECRET:
external: true
This lets Docker know that this stack requires the value of those two secrets.
The declaration for svc-notes also needs the following command:
services:
...
svc-notes:
...
secrets:
- TWITTER_CONSUMER_KEY
- TWITTER_CONSUMER_SECRET
..
environment:
...
TWITTER_CONSUMER_KEY_FILE: /var/run/secrets/TWITTER_CONSUMER_KEY
TWITTER_CONSUMER_SECRET_FILE:
/var/run/secrets/TWITTER_CONSUMER_SECRET
...
This notifies the swarm that the Notes service requires the two secrets. In response, the swarm will make the data for the secrets available in the filesystem of the container as /var/run/secrets/TWITTER_CONSUMER_KEY and /var/run/secrets/TWITTER_CONSUMER_SECRET. They are stored as in-memory files and are relatively secure.
To summarize, the steps required are as follows:
- Use docker secret create to register the secret data with the swarm.
- In the stack file, declare secrets in a top-level secrets tag.
- In services that require the secrets, declare a secrets tag that lists the secrets required by this service.
- In the environments tag for the service, create an environment variable pointing to the secrets file.
The Docker team has a suggested convention for configuration of environment variables. You could supply the configuration setting directly in an environment variable, such as TWITTER_CONSUMER_KEY. However, if the configuration setting is in a file, then the filename should be given in a different environment variable whose name has _FILE appended. For example, we would use TWITTER_CONSUMER_KEY or TWITTER_CONSUMER_KEY_FILE, depending on whether the value is directly supplied or in a file.
This then means that we must rewrite Notes to support reading these values from the files, in addition to the existing environment variables.
To support reading from files, add this import to the top of notes/routes/users.mjs:
import fs from 'fs-extra';
Then, we'll find the code corresponding to these environment variables further down the file. We should rewrite that section as follows:
const twittercallback = process.env.TWITTER_CALLBACK_HOST
? process.env.TWITTER_CALLBACK_HOST
: "http://localhost:3000";
export var twitterLogin = false;
let consumer_key;
let consumer_secret;
if (typeof process.env.TWITTER_CONSUMER_KEY !== 'undefined'
&& process.env.TWITTER_CONSUMER_KEY !== ''
&& typeof process.env.TWITTER_CONSUMER_SECRET !== 'undefined'
&& process.env.TWITTER_CONSUMER_SECRET !== '') {
consumer_key = process.env.TWITTER_CONSUMER_KEY;
consumer_secret = process.env.TWITTER_CONSUMER_SECRET;
twitterLogin = true;
} else if (typeof process.env.TWITTER_CONSUMER_KEY_FILE !== 'undefined'
&& process.env.TWITTER_CONSUMER_KEY_FILE !== ''
&& typeof process.env.TWITTER_CONSUMER_SECRET_FILE !== 'undefined'
&& process.env.TWITTER_CONSUMER_SECRET_FILE !== '') {
consumer_key =
fs.readFileSync(process.env.TWITTER_CONSUMER_KEY_FILE, 'utf8');
consumer_secret =
fs.readFileSync(process.env.TWITTER_CONSUMER_SECRET_FILE, 'utf8');
twitterLogin = true;
}
if (twitterLogin) {
passport.use(new TwitterStrategy({
consumerKey: consumer_key,
consumerSecret: consumer_secret,
callbackURL: `${twittercallback}/users/auth/twitter/callback`
},
async function(token, tokenSecret, profile, done) {
try {
done(null, await usersModel.findOrCreate({
id: profile.username, username: profile.username, password:
"",
provider: profile.provider, familyName: profile.displayName,
givenName: "", middleName: "",
photos: profile.photos, emails: profile.emails
}));
} catch(err) { done(err); }
}));
}
This is similar to the code we've already used but organized a little differently. It first tries to read the Twitter tokens from the environment. Failing that, it tries to read them from the named files. Because this code is executing in the global context, we must read the files using readFileSync.
If the tokens are available from either source, the twitterLogin variable is set, and then we enable the support for TwitterStrategy. Otherwise, Twitter support is disabled. We had already organized the views templates so that if twitterLogin is false, the Twitter login buttons do not appear.
All of this is what we did in Chapter 8, Authenticating Users with a Microservice, but with the addition of reading the tokens from a file.
Persisting data in a Docker swarm
The data persistence strategy we used in Chapter 11, Deploying Node.js Microservices with Docker, required the database files to be stored in a volume. The directory for the volume lives outside the container and survives when we destroy and recreate the container.
That strategy relied on there being a single Docker host for running containers. The volume data is stored in a directory in the host filesystem. But in swarm mode, volumes do not work in a compatible fashion.
With Docker Swarm, unless we use placement criteria, containers can deploy to any swarm node. The default behavior for a named volume in Docker is that the data is stored on the current Docker host. If the container is redeployed, then the volume is destroyed on the one host and a new one is created on the new host. Clearly, that means that the data in that volume is not persistent.
What's recommended in the documentation is to use placement criteria to force such containers to deploy to specific hosts. For example, the criteria we discussed earlier deploy the databases to a node with the type label equal to db.
In the next section, we will make sure that there is exactly one such node in the swarm. To ensure that the database data directories are at a known location, let's change the declarations for the db-userauth and db-notes containers, as follows:
services:
..
db-userauth:
...
volumes:
# - db-userauth-data:/var/lib/mysql
- type: bind
source: /data/users
target: /var/lib/mysql
...
db-notes:
...
volumes:
# - db-notes-data:/var/lib/mysql
- type: bind
source: /data/notes
target: /var/lib/mysql
...
# volumes:
# db-userauth-data:
# db-notes-data:
...
In docker-local/docker-compose.yml, we used the named volumes, db-userauth-data and db-notes-data. The top-level volumes tag is required when doing this. In docker-swarm/docker-compose.yml, we've commented all of that out. Instead, we are using a bind mount, to mount specific host directories in the /var/lib/mysql directory of each database.
Therefore, the database data directories will be in /data/users and /data/notes, respectively.
This result is fairly good, in that we can destroy and recreate the database containers at will and the data directories will persist. However, this is only as persistent as the EC2 instance this is deployed to. The data directories will vaporize as soon as we execute terraform destroy.
That's obviously not good enough for a production deployment, but it is good enough for a test deployment such as this.
It is preferable to use a volume instead of the bind mount we just implemented. Docker volumes have a number of advantages, but to make good use of a volume requires finding the right volume driver for your needs. Two examples are as follows:
- In the Docker documentation, at https://docs.docker.com/storage/volumes/, there is an example of mounting a Network File System (NFS) volume in a Docker container. AWS offers an NFS service—the Elastic Filesystem (EFS) service—that could be used, but this may not be the best choice for a database container.
- The REX-Ray project (https://github.com/rexray/rexray) aims to advance the state of the art for persistent data storage in various containerization systems, including Docker.
Another option is to completely skip running our own database containers and instead use the Relational Database Service (RDS). RDS is an AWS service offering several Structured Query Language (SQL) database solutions, including MySQL. It offers a lot of flexibility and scalability, at a price. To use this, you would eliminate the db-notes and db-userauth containers, provision RDS instances, and then update the SEQUELIZE_CONNECT configuration in svc-notes and svc-userauth to use the database host, username, and password you configured in the RDS instances.
For our current requirements, this setup, with a bind mount to a directory on the EC2 host, will suffice. These other options are here for your further exploration.
In this section, we converted our Docker compose file to be useful as a stack file. While doing this, we discussed the need to influence which swarm host has which containers. The most critical thing is ensuring that the database containers are deployed to a host where we can easily persist the data—for example, by running a database backup every so often to external storage. We also discussed storing secrets in a secure manner so that they may be used safely by the containers.
At this point, we cannot test the stack file that we've created because we do not have a suitable swarm to deploy to. Our next step is writing the Terraform configuration to provision the EC2 instances. That will give us the Docker swarm that lets us test the stack file.
Provisioning EC2 instances for a full Docker swarm
So far in this chapter, we have used Terraform to create the required infrastructure on AWS, and then we set up a single-node Docker swarm on an EC2 instance to learn about Docker Swarm. After that, we pushed the Docker images to ECR, and we have set up a Docker stack file for deployment to a swarm. We are ready to set up the EC2 instances required for deploying a full swarm.
Docker Swarm is able to handle Docker deployments to large numbers of host systems. Of course, the Notes application only has delusions of grandeur and doesn't need that many hosts. We'll be able to do everything with three or four EC2 instances. We have declared one so far, and will declare two more that will live on the private subnet. But from this humble beginning, it would be easy to expand to more hosts.
Our goal in this section is to create an infrastructure for deploying Notes on EC2 using Docker Swarm. This will include the following:
- Configuring additional EC2 instances on the private subnet, installing Docker on those instances, and joining them together in a multi-host Docker Swarm
- Creating semi-automated scripting, thereby making it easy to deploy and configure the EC2 instances for the swarm
- Using an nginx container on the public EC2 instance as a proxy in front of the Notes container
That's quite a lot of things to take care of, so let's get started.
Configuring EC2 instances and connecting to the swarm
We have one EC2 instance declared for the public subnet, and it is necessary to add two more for the private subnet. The security model we discussed earlier focused on keeping as much as possible in a private secure network infrastructure. On AWS, that means putting as much as possible on the private subnet.
Earlier, you may have renamed ec2-public.tf to ec2-public.tf-disable. If so, you should now change back the filename to ec2-public.tf. Remember that this tactic is useful for minimizing AWS resource usage when it is not needed.
Create a new file in the terraform-swarm directory named ec2-private.tf, as follows:
resource "aws_instance" "private-db1" {
ami = var.ami_id
// instance_type = var.instance_type
instance_type = "t2.medium"
subnet_id = aws_subnet.private1.id
key_name = var.key_pair
vpc_security_group_ids = [ aws_security_group.ec2-private-sg.id ]
associate_public_ip_address = false
root_block_device {
volume_size = 50
}
tags = {
Name = "${var.project_name}-ec2-private-db1"
}
depends_on = [ aws_vpc.notes, aws_internet_gateway.igw ]
user_data = join("
", [
"#!/bin/sh",
file("sh/docker_install.sh"),
"mkdir -p /data/notes /data/users",
"sudo hostname ${var.project_name}-private-db1"
])
}
resource "aws_instance" "private-svc1" {
ami = var.ami_id
instance_type = var.instance_type
subnet_id = aws_subnet.private1.id
key_name = var.key_pair
vpc_security_group_ids = [ aws_security_group.ec2-private-sg.id ]
associate_public_ip_address = false
tags = {
Name = "${var.project_name}-ec2-private-svc1"
}
depends_on = [ aws_vpc.notes, aws_internet_gateway.igw ]
user_data = join("
", [
"#!/bin/sh",
file("sh/docker_install.sh"),
"sudo hostname ${var.project_name}-private-svc1"
])
}
This declares two EC2 instances that are attached to the private subnet. There's no difference between these instances other than the name. Because they're on the private subnet, they are not assigned a public IP address.
Because we use the private-db1 instance for databases, we have allocated 50 gigabytes (GB) for the root device. The root_block_device block is for customizing the root disk of an EC2 instance. Among the available settings, volume_size sets its size, in GB.
Another difference in private-db1 is the instance_type, which we've hardcoded to t2.medium. The issue is about deploying two database containers to this server. A t2.micro instance has 1 GB of memory, and the two databases were observed to overwhelm this server. If you want the adventure of debugging that situation, change this value to be var.instance_type, which defaults to t2.micro, then read the section at the end of the chapter about debugging what happens.
Notice that for the user_data script, we only send in the script to install Docker Support, and not the script to initialize a swarm. The swarm was initialized in the public EC2 instance. The other instances must instead join the swarm using the docker swarm join command. Later, we will go over initializing the swarm, and see how that's accomplished. For the public-db1 instance, we also create the /data/notes and /data/users directories, which will hold the database data directories.
Add the following code to ec2-private.tf:
resource "aws_security_group" "ec2-private-sg" {
name = "${var.project_name}-private-sg"
description = "allow inbound access to the EC2 instance"
vpc_id = aws_vpc.notes.id
ingress {
protocol = "-1"
from_port = 0
to_port = 0
cidr_blocks = [ aws_vpc.notes.cidr_block ]
}
ingress {
description = "Docker swarm (udp)"
protocol = "UDP"
from_port = 0
to_port = 0
cidr_blocks = [ aws_vpc.notes.cidr_block ]
}
egress {
protocol = "-1"
from_port = 0
to_port = 0
cidr_blocks = [ "0.0.0.0/0" ]
}
}
This is the security group for these EC2 instances. It allows any traffic from inside the VPC to enter the EC2 instances. This is the sort of security group we'd create when in a hurry and should tighten up the ingress rules, since this is very lax.
Likewise, the ec2-public-sg security group needs to be equally lax. We'll find that there is a long list of IP ports used by Docker Swarm and that the swarm will fail to operate unless those ports can communicate. For our immediate purposes, the easiest option is to allow any traffic, and we'll leave a note in the backlog to address this issue in Chapter 14, Security in Node.js Applications.
In ec2-public.tf, edit the ec2-public-sg security group to be the following:
resource "aws_security_group" "ec2-public-sg" {
name = "${var.project_name}-public-sg"
description = "allow inbound access to the EC2 instance"
vpc_id = aws_vpc.notes.id
ingress {
protocol = "-1"
from_port = 0
to_port = 0
cidr_blocks = [ "0.0.0.0/0" ]
}
ingress {
description = "Docker swarm (udp)"
protocol = "UDP"
from_port = 0
to_port = 0
cidr_blocks = [ aws_vpc.notes.cidr_block ]
}
egress {
protocol = "-1"
from_port = 0
to_port = 0
cidr_blocks = [ "0.0.0.0/0" ]
}
}
This is literally not a best practice since it allows any network traffic from any IP address to reach the public EC2 instance. However, it does give us the freedom to develop the code without worrying about protocols at this moment. We will address this later and implement the best security practice. Have a look at the following code snippet:
output "ec2-private-db1-arn" { value = aws_instance.private-db1.arn }
output "ec2-private-db1-dns" { value = aws_instance.private-db1.private_dns }
output "ec2-private-db1-ip" { value = aws_instance.private-db1.private_ip }
output "ec2-private-svc1-arn" { value = aws_instance.private-svc1.arn }
output "ec2-private-svc1-dns" { value = aws_instance.private-svc1.private_dns }
output "ec2-private-svc1-ip" { value = aws_instance.private-svc1.private_ip }
This outputs the useful attributes of the EC2 instances.
In this section, we declared EC2 instances for deployment on the private subnet. Each will have Docker initialized. However, we still need to do what we can to automate the setup of the swarm.
Implementing semi-automatic initialization of the Docker Swarm
Ideally, when we run terraform apply, the infrastructure is automatically set up and ready to go. Automated setup reduces the overhead of running and maintaining the AWS infrastructure. We'll get as close to that goal as possible.
For this purpose, let's revisit the declaration of aws_instance.public in ec2-public.tf. Let's rewrite it as follows:
resource "aws_instance" "public" {
ami = var.ami_id
instance_type = var.instance_type
subnet_id = aws_subnet.public1.id
key_name = var.key_pair
vpc_security_group_ids = [ aws_security_group.ec2-public-sg.id ]
associate_public_ip_address = true
tags = {
Name = "${var.project_name}-ec2-public"
}
depends_on = [
aws_vpc.notes, aws_internet_gateway.igw,
aws_instance.private-db1, aws_instance.private-svc1
]
user_data = join("
", [
"#!/bin/sh",
file("sh/docker_install.sh"),
"docker swarm init",
"sudo hostname ${var.project_name}-public",
"docker node update --label-add type=public ${var.project_name}
-public",
templatefile("sh/swarm-setup.sh", {
instances = [ {
dns = aws_instance.private-db1.private_dns,
type = "db",
name = "${var.project_name}-private-db1"
}, {
dns = aws_instance.private-svc1.private_dns,
type = "svc",
name = "${var.project_name}-private-svc1"
} ]
})
])
}
This is largely the same as before, but with two changes. The first is to add references to the private EC2 instances to the depends_on attribute. This will delay the construction of the public EC2 instance until after the other two are running.
The other change is to extend the shell script attached to the user_data attribute. The first addition to that script is to set the type label on the notes-public node. That label is used with service placement.
The last change is a script with which we'll set up the swarm. Instead of setting up the swarm in the user_data script directly, it will generate a script that we will use in creating the swarm. In the sh directory, create a file named swarm-setup.sh containing the following:
cat >/home/ubuntu/swarm-setup.sh <<EOF
#!/bin/sh
### Capture the file name for the PEM from the command line
PEM=$1
join="`docker swarm join-token manager | sed 1,2d | sed 2d`"
%{ for instance in instances ~}
ssh -i $PEM ${instance.dns} $join
docker node update --label-add type=${instance.type} ${instance.name}
%{ endfor ~}
EOF
This generates a shell script that will be used to initialize the swarm. Because the setup relies on executing commands on the other EC2 instances, the PEM file for the AWS key pair must be present on the notes-public instance. However, it is not possible to send the key-pair file to the notes-public instance when running terraform apply. Therefore, we use the pattern of generating a shell script, which will be run later.
The pattern being followed is shown in the following code snippet:
cat >/path/to/file <<EOF
... text to output
EOF
The part between <<EOF and EOF is supplied as the standard input to the cat command. The result is, therefore, for /home/ubuntu/swarm-setup.sh to end up with the text between those markers. An additional detail is that a number of variable references are escaped, as in PEM=$1. This is necessary so that those variables are not evaluated while setting up this script but are present in the generated script.
This script is processed using the templatefile function so that we can use template commands. Primarily, that is the %{for .. } loop with which we generate the commands for configuring each EC2 instance. You'll notice that there is an array of data for each instance, which is passed through the templatefile invocation.
Therefore, the swarm-setup.sh script will contain a copy of the following pair of commands for each EC2 instance:
ssh -i $PEM ${instance.dns} $join
docker node update --label-add type=${instance.type} ${instance.name}
The first line uses SSH to execute the swarm join command on the EC2 instance. For this to work, we need to supply the AWS key pair, which must be specified on the command file so that it becomes the PEM variable. The second line adds the type label with the named value to the named swarm node.
What is the $join variable? It has the output of running docker swarm join-token, so let's take a look at what it is.
Docker uses a swarm join token to facilitate connecting Docker hosts as a node in a swarm. The token contains cryptographically signed information that authenticates the attempt to join the swarm. We get the token by running the following command:
$ docker swarm join-token manager
To add a manager to this swarm, run the following command:
docker swarm join --token SWMTKN-1-1l161hnrjbmzg1r8a46e34dt21sl5n4357qrib29csi0jgi823-3g80csolwaioya580hjanwfsf 10.0.3.14:2377
The word manager here means that we are requesting a token to join as a manager node. To connect a node as a worker, simply replace manager with worker.
Once the EC2 instances are deployed, we could log in to notes-public, and then run this command to get the join token and run that command on each of the EC2 instances. The swarm-setup.sh script, however, handles this for us. All we have to do, once the EC2 hosts are deployed, is to log in to notes-public and run this script.
It runs the docker swarm join-token manager command, piping that user-friendly text through a couple of sed commands to extract out the important part. That leaves the join variable containing the text of the docker swarm join command, and then it uses SSH to execute that command on each of the instances.
In this section, we examined how to automate, as far as possible, the setup of the Docker swarm.
Let's now do it.
Preparing the Docker Swarm before deploying the Notes stack
When you make an omelet, it's best to cut up all the veggies and sausage, prepare the butter, and whip the milk and eggs into a mix before you heat up the pan. In other words, we prepare the ingredients before undertaking the critical action of preparing the dish. What we've done so far is to prepare all the elements of successfully deploying the Notes stack to AWS using Docker Swarm. It's now time to turn on the pan and see how well it works.
We have everything declared in the Terraform files, and we can deploy our complete system with the following command:
$ terraform apply
...
Plan: 5 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
...
This deploys the EC2 instances on AWS. Make sure to record all the output parameters. We're especially interested in the domain names and IP addresses for the three EC2 instances.
As before, the notes-public instance should have a Docker swarm initialized. We have added two more instances, notes-private-db1 and notes-private-svc1. Both will have Docker installed, but they are not joined to the swarm. Instead, we need to run the generated shell script for them to become nodes in the swarm, as follows:
$ scp ~/Downloads/notes-app-key-pair.pem ubuntu@PUBLIC-IP-ADDRESS:
The authenticity of host '52.39.219.109 (52.39.219.109)' can't be established.
ECDSA key fingerprint is SHA256:qdK5ZPn1EtmO1RWljb0dG3Nu2mDQHtmFwcw4fq9s6vM.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '52.39.219.109' (ECDSA) to the list of known hosts.
notes-app-key-pair.pem 100% 1670 29.2KB/s 00:00
$ ssh ubuntu@PUBLIC-IP-ADDRESS
Welcome to Ubuntu 20.04 LTS (GNU/Linux 5.4.0-1009-aws x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
...
We have already run ssh-add on our laptop, and therefore SSH and secure copy (SCP) commands can run without explicitly referencing the PEM file. However, the SSH on the notes-public EC2 instance does not have the PEM file. Therefore, to access the other EC2 instances, we need the PEM file to be available. Hence, we've used scp to copy it to the notes-public instance.
If you want to verify the fact that the instances are running and have Docker active, type the following command:
ubuntu@notes-public:~$ ssh -i ./notes-app-key-pair.pem
ubuntu@IP-FOR-EC2-INSTANCE docker run hello-world
In this case, we are testing the private EC2 instances from a shell running on the public EC2 instance. That means we must use the private IP addresses printed when we ran Terraform. This command verifies SSH connectivity to an EC2 instance and verifies its ability to download and execute a Docker image.
Next, we can run swarm-setup.sh. On the command line, we must give the filename for the PEM file as the first argument, as follows:
ubuntu@notes-public:~$ sh -x swarm-setup.sh ./notes-app-key-pair.pem
+ PEM=./notes-app-key-pair.pem
+ ssh -i ./notes-app-key-pair.pem ip-10-0-3-151.us-west-2.compute.internal docker swarm join --token SWMTKN-1-04shb3msc7a1ydqcqmtyhych60wwptkxwcqiexi1ou6fetx2kg-7robjlgber03xo44jwx1yofaw 10.0.1.111:2377
...
This node joined a swarm as a manager.
+ docker node update --label-add type=db notes-private-db1
notes-private-db1
+ ssh -i ./notes-app-key-pair.pem ip-10-0-3-204.us-west-2.compute.internal docker swarm join --token SWMTKN-1-04shb3msc7a1ydqcqmtyhych60wwptkxwcqiexi1ou6fetx2kg-7robjlgber03xo44jwx1yofaw 10.0.1.111:2377
...
This node joined a swarm as a manager.
+ docker node update --label-add type=svc notes-private-svc1
notes-private-svc1
We can see this using SSH to execute the docker swarm join command on each EC2 instance, causing these two systems to join the swarm, and to set the labels on the instances, as illustrated in the following code snippet:
ubuntu@notes-public:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
ct7d65v8lhw6hxx0k8uk3lw8m notes-private-db1 Ready Active Reachable 19.03.11
k1x2h83b0lrxnh38p3pypt91x notes-private-svc1 Ready Active Reachable 19.03.11
nikgvfe4aum51yu5obqqnnz5s * notes-public Ready Active Leader 19.03.11
Indeed, these systems are now part of the cluster.
The swarm is ready to go, and we no longer need to be logged in to notes-public. Exiting back to our laptop, we can create the Docker context to control the swarm remotely, as follows:
$ docker context create ec2 --docker host=ssh://ubuntu@PUBLIC-IP-ADDRESS
ec2
Successfully created context "ec2"
$ docker context use ec2
We've already seen how this works and that, having done this, we will be able to run Docker commands on our laptop; for example, have a look at the following code snippet:
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
ct7d65v8lhw6hxx0k8uk3lw8m notes-private-db1 Ready Active Reachable 19.03.11
k1x2h83b0lrxnh38p3pypt91x notes-private-svc1 Ready Active Reachable 19.03.11
nikgvfe4aum51yu5obqqnnz5s * notes-public Ready Active Leader 19.03.11
From our laptop, we can query the state of the remote swarm that's hosted on AWS. Of course, this isn't limited to querying the state; we can run any other Docker command.
We also need to run the following commands, now that the swarm is set up:
$ printf 'vuTghgEXAMPLE...' | docker secret create TWITTER_CONSUMER_KEY -
$ printf 'tOtJqaEXAMPLE...' | docker secret create TWITTER_CONSUMER_SECRET -
Remember that a newly created swarm does not have any secrets. To install the secrets requires these commands to be rerun.
If you wish to create a shell script to automate this process, consider the following:
scp $AWS_KEY_PAIR ubuntu@${NOTES_PUBLIC_IP}:
ssh -i $AWS_KEY_PAIR ubuntu@${NOTES_PUBLIC_IP} swarm-setup.sh `basename ${AWS_KEY_PAIR}`
docker context update --docker host=ssh://ubuntu@${NOTES_PUBLIC_IP} ec2
docker context use ec2
printf $TWITTER_CONSUMER_KEY | docker secret create TWITTER_CONSUMER_KEY -
printf $TWITTER_CONSUMER_SECRET | docker secret create TWITTER_CONSUMER_SECRET -
sh ../ecr/login.sh
This script executes the same commands we just went over to prepare the swarm on the EC2 hosts. It requires the environment variables to be set, as follows:
- AWS_KEY_PAIR: The filename for the PEM file
- NOTES_PUBLIC_IP: The IP address of the notes-public EC2 instance
- TWITTER_CONSUMER_KEY, TWITTER_CONSUMER_SECRET: The access tokens for Twitter authentication
In this section, we have deployed more EC2 instances and set up the Docker swarm. While the process was not completely automated, it's very close. All that's required, after using Terraform to deploy the infrastructure, is to execute a couple of commands to get logged in to notes-public where we run a script, and then go back to our laptop to set up remote access.
We have set up the EC2 instances and verified we have a working swarm. We still have the outstanding issue of verifying the Docker stack file created in the previous section. To do so, our next step is to deploy the Notes app on the swarm.
Deploying the Notes stack file to the swarm
We have prepared all the elements required to set up a Docker Swarm on the AWS EC2 infrastructure, we have run the scripts required to set up that infrastructure, and we have created the stack file required to deploy Notes to the swarm.
What's required next is to run docker stack deploy from our laptop, to deploy Notes on the swarm. This will give us the chance to test the stack file created earlier. You should still have the Docker context configured for the remote server, making it possible to remotely deploy the stack. However, there are four things to handle first, as follows:
- Install the secrets in the newly deployed swarm.
- Update the svc-notes environment configuration for the IP address of notes-public.
- Update the Twitter application for the IP address of notes-public.
- Log in to the ECR instance.
Let's take care of those things and then deploy the Notes stack.
Preparing to deploy the Notes stack to the swarm
We are ready to deploy the Notes stack to the swarm that we've launched. However, we have realized that we have a couple of tasks to take care of.
The environment variables for svc-notes configuration require a little adjustment. Have a look at the following code block:
services:
..
svc-notes:
..
environment:
# DEBUG: notes:*,express:*
REDIS_ENDPOINT: "redis"
TWITTER_CALLBACK_HOST: "http://ec2-18-237-70-108.us-west-
2.compute.amazonaws.com"
TWITTER_CONSUMER_KEY_FILE: /var/run/secrets/TWITTER_CONSUMER_KEY
TWITTER_CONSUMER_SECRET_FILE:
/var/run/secrets/TWITTER_CONSUMER_SECRET
SEQUELIZE_CONNECT: models/sequelize-docker-mysql.yaml
SEQUELIZE_DBHOST: db-notes
NOTES_MODEL: sequelize
...
Our primary requirement is to adjust the TWITTER_CALLBACK_HOST variable. The domain name for the notes-public instance changes every time we deploy the AWS infrastructure. Therefore, TWITTER_CALLBACK_HOST must be updated to match.
Similarly, we must go to the Twitter developers' dashboard and update the URLs in the application settings. As we already know, this is required every time we have hosted Notes on a different IP address or domain name. To use the Twitter login, we must change the list of URLs recognized by Twitter.
Updating TWITTER_CALLBACK_HOST and the Twitter application settings will let us log in to Notes using a Twitter account.
While here, we should review the other variables and ensure that they're correct as well.
The last preparatory step is to log in to the ECR repository. To do this, simply execute the following commands:
$ cd ../ecr
$ sh ./login.sh
This has to be rerun every so often since the tokens that are downloaded time out after a few hours.
We only need to run login.sh, and none of the other scripts in the ecr directory.
In this section, we prepared to run the deployment. We should now be ready to deploy Notes to the swarm, so let's do it.
Deploying the Notes stack to the swarm
We just did the final preparation for deploying the Notes stack to the swarm. Take a deep breath, yell out Smoke Test, and type the following command:
$ cd ../compose-stack
$ docker stack deploy --with-registry-auth --compose-file docker-compose.yml notes
...
Creating network notes_svcnet
Creating network notes_frontnet
Creating network notes_authnet
Creating service notes_svc-userauth
Creating service notes_db-notes
Creating service notes_svc-notes
Creating service notes_redis
Creating service notes_db-userauth
This deploys the services, and the swarm responds by attempting to launch each service. The --with-registry-auth option sends the Docker Registry authentication to the swarm so that it can download container images from the ECR repositories. This is why we had to log in to the ECR first.
Verifying the correct launch of the Notes application stack
It will be useful to monitor the startup process using these commands:
$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
l7up46slg32g notes_db-notes replicated 1/1 mysql/mysql-server:8.0
ufw7vwqjkokv notes_db-userauth replicated 1/1 mysql/mysql-server:8.0
45p6uszd9ixt notes_redis replicated 1/1 redis:5.0
smcju24hvdkj notes_svc-notes replicated 1/1 098106984154.dkr.ecr.us-west-2.amazonaws.com/svc-notes:latest *:80->3000/tcp
iws2ff265sqb notes_svc-userauth replicated 1/1 098106984154.dkr.ecr.us-west-2.amazonaws.com/svc-userauth:latest
$ docker service ps notes_svc-notes # And.. for other service names
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
nt5rmgv1cf0q notes_svc-notes.1 09E1X6A8MPLE.dkr.ecr.us-REGION-2.amazonaws.com/svc-notes:latest notes-public Running Running 18 seconds ago
The service ls command lists the services, with a high-level overview. Remember that the service is not the running container and, instead, the services are declared by entries in the services tag in the stack file. In our case, we declared one replica for each service, but we could have given a different amount. If so, the swarm will attempt to distribute that number of containers across the nodes in the swarm.
Notice that the pattern for service names is the name of the stack that was given in the docker stack deploy command, followed by the service name listed in the stack file. When running that command, we named the stack notes; so, the services are notes_db-notes, notes_svc-userauth, notes_redis, and so on.
The service ps command lists information about the tasks deployed for the service. Remember that a task is essentially the same as a running container. We see here that one instance of the svc-notes container has been deployed, as expected, on the notes-public host.
Sometimes, the notes_svc-notes service doesn't launch, and instead, we'll see the following message:
$ docker service ps notes_svc-notes
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
nt5rmgv1cf0q notes_svc-notes.1 0E8X0A9M4PLE.dkr.ecr.us-REGION-2.amazonaws.com/svc-notes:latest Running Pending 9 minutes ago "no suitable node (scheduling …"
The error, no suitable node, means that the swarm was not able to find a node that matches the placement criteria. In this case, the type=public label might not have been properly set.
The following command is helpful:
$ docker node inspect notes-public
[
{
...
"Spec": {
"Labels": {},
"Role": "manager",
"Availability": "active"
},
...
}
]
Notice that the Labels entry is empty. In such a case, you can add the label by running this command:
$ docker node update --label-add type=public notes-public
notes-public
As soon as this is run, the swarm will place the svc-notes service on the notes-public node.
If this happens, it may be useful to add the following command to the user_data script for aws_instance.public (in ec2-public.tf), just ahead of setting the type=public label:
"sleep 20",
It would appear that this provides a small window of opportunity to allow the swarm to establish itself.
Diagnosing a failure to launch the database services
Another possible deployment problem is that the database services might fail to launch, and the notes-public-db1 node might become Unavailable. Refer back to the docker node ls output and you will see a column marked Status. Normally, this column says Reachable, meaning that the swarm can reach and communicate with the swarm agent on that node. But with the deployment as it stands, this node might instead show an Unavailable status, and in the docker service ls output, the database services might never show as having deployed.
With remote access from our laptop, we can run the following command:
$ docker service ps notes_db-notes
The output will tell you the current status, such as any error in deploying the service. However, to investigate connectivity with the EC2 instances, we must log in to the notes-public instance as follows:
$ ssh ubuntu@PUBLIC-IP-ADDRESS
That gets us access to the public EC2 instance. From there, we can try to ping the notes-private-db1 instance, as follows:
ubuntu@notes-public:~$ ping PRIVATE-IP-ADDRESS
PING 10.0.3.141 (10.0.3.141) 56(84) bytes of data.
64 bytes from 10.0.3.141: icmp_seq=1 ttl=64 time=0.481 ms
^C
This should work, but the output from docker node ls may show the node as Unreachable. Ask yourself: what happens if a computer runs out of memory? Then, recognize that we've deployed two database instances to an EC2 instance that has only 1 GB of memory—the memory capacity of t2.micro EC2 instances as of the time of writing. Ask yourself whether it is possible that the services you've deployed to a given server have overwhelmed that server.
To test that theory, make the following change in ec2-private.tf:
resource "aws_instance" "private-db1" {
...
instance_type = "t2.medium" // var.instance_type
...
}
This changes the instance type from t2.micro to t2.medium, or even t2.large, thereby giving the server more memory.
To implement this change, run terraform apply to update the configuration. If the swarm does not automatically correct itself, then you may need to run terraform destroy and then run through the setup again, starting with terraform apply.
Once the notes-private-db1 instance has sufficient memory, the databases should successfully deploy.
In this section, we deployed the Notes application stack to the swarm cluster on AWS. We also talked a little about how to verify the fact that the stack deployed correctly, and how to handle some common problems.
Next, we have to test the deployed Notes stack to verify that it works on AWS.
Testing the deployed Notes application
Having set up everything required to deploy Notes to AWS using Docker Swarm, we have done so. That means our next step is to put Notes through its paces. We've done enough ad hoc testing on our laptop to have confidence it works, but the Docker swarm deployment might show up some issues.
In fact, the deployment we just made very likely has one or two problems. We can learn a lot about AWS and Docker Swarm by diagnosing those problems together.
The first test is obviously to open the Notes application in the browser. In the outputs from running terraform apply was a value labeled ec2-public-dns. This is the domain name for the notes-public EC2 instance. If we simply paste that domain name into our browser, the Notes application should appear.
However, we cannot do anything because there are no user IDs available to log in with.
Logging in with a regular account on Notes
Obviously, in order to test Notes, we must log in and add some notes, make some comments, and so forth. It will be instructive to log in to the user authentication service and use cli.mjs to add a user ID.
The user authentication service is on one of the private EC2 instances, and its port is purposely not exposed to the internet. We could change the configuration to expose its port and then run cli.mjs from our laptop, but that would be a security problem and we need to learn how to access the running containers anyway.
We can find out which node the service is deployed on by using the following command:
$ docker service ps notes_svc-userauth
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
b8jf5q8xlbs5 notes_svc-userauth.1 0E8X0A9M4PLE.dkr.ecr.us-REGION-2.amazonaws.com/svc-userauth:latest notes-private-svc1 Running Running 31 minutes ago
The notes_svc-userauth task has been deployed to notes-private-svc1, as expected.
To run cli.mjs, we must get shell access inside the container. Since it is deployed on a private instance, this means that we must first SSH to the notes-public instance; from there, SSH to the notes-private-svc1 instance; and from there, run the docker exec command to launch a shell in the running container, as illustrated in the following code block:
$ ssh ubuntu@PUBLIC-IP-ADDRESS
...
ubuntu@notes-public:~$ ssh -i notes-app-key-pair.pem ubuntu@PRIVATE-IP-ADDRESS
...
ubuntu@notes-private-svc1:~$ docker ps | grep userauth
e7398953b808 0E8X0A9M4PLE.dkr.ecr.us-REGION-2.amazonaws.com/svc-userauth:latest "docker-entrypoint.s…" 37 minutes ago Up 37 minutes 5858/tcp notes_svc-userauth.1.b8jf5q8xlbs5b8xk7qpkz9a3w
ubuntu@notes-private-svc1:~$ docker exec -it notes_svc-userauth.1.b8jf5q8xlbs5b8xk7qpkz9a3w bash
root@e7398953b808:/userauth#
We SSHd to the notes-public server and, from there, SSHd to the notes-private-svc1 server. On that server, we ran docker ps to find out the name of the running container. Notice that Docker generated a container name that includes a coded string, called a nonce, that guarantees the container name is unique. With that container name, we ran docker exec -it ... bash to get a root shell inside the container.
Once there, we can run the following command:
root@e7398953b808:/userauth# node cli.mjs add --family-name Einarsdottir --given-name Ashildr --email [email protected] --password w0rd me
Created {
id: 'me',
username: 'me',
provider: 'local',
familyName: 'Einarsdottir',
givenName: 'Ashildr',
middleName: null,
emails: [ '[email protected]' ],
photos: []
}
This verifies that the user authentication server works and that it can communicate with the database. To verify this even further, we can access the database instance, as follows:
ubuntu@notes-public:~$ ssh -i notes-app-key-pair.pem [email protected]
...
ubuntu@notes-private-db1:~$ docker exec -it notes_db-userauth.1.0b274ges82otektamyq059x7w mysql -u userauth -p --socket /tmp/mysql.sock
Enter password:
From there, we can explore the database and see that, indeed, Ashildr's user ID exists.
With this user ID set up, we can now use our browser to visit the Notes application and log in with that user ID.
Diagnosing an inability to log in with Twitter credentials
The next step will be to test logging in with Twitter credentials. Remember that earlier, we said to ensure that the TWITTER_CALLBACK_HOST variable has the domain name of the EC2 instance, and likewise that the Twitter application configuration does as well.
Even with those settings in place, we might run into a problem. Instead of logging in, we might get an error page with a stack trace, starting with the message: Failed to obtain request token.
There are a number of possible issues that can cause this error. For example, the error can occur if the Twitter authentication tokens are not deployed. However, if you followed the directions correctly, they will be deployed correctly.
In notes/appsupport.mjs, there is a function, basicErrorHandler, which will be invoked by this error. In that function, add this line of code:
debug('basicErrorHandler err= ', err);This will print the full error, including the originating error that caused the failure. You may see the following message printed: getaddrinfo EAI_AGAIN api.twitter.com. That may be puzzling because that domain name is certainly available. However, it might not be available inside the svc-notes container due to the DNS configuration.
From the notes-public instance, we will be able to ping that domain name, as follows:
ubuntu@notes-public:~$ ping api.twitter.com
PING tpop-api.twitter.com (104.244.42.2) 56(84) bytes of data.
64 bytes from 104.244.42.2: icmp_seq=1 ttl=38 time=22.1 ms
However, if we attempt this inside the svc-notes container, this might fail, as illustrated in the following code snippet:
ubuntu@notes-public:~$ docker exec -it notes_svc-notes.1.et3b1obkp9fup5tj7bdco3188 bash
root@c2d002681f61:/notesapp# ping api.twitter.com
... possible failure
Ideally, this will work from inside the container as well. If this fails inside the container, it means that the Notes service cannot reach Twitter to handle the OAuth dance required to log in with Twitter credentials.
The problem is that, in this case, Docker set up an incorrect DNS configuration, and the container was unable to make DNS queries for many domain names. In the Docker Compose documentation, it is suggested to use the following code in the service definition:
services:
...
svc-notes:
...
dns:
- 8.8.8.8
- 9.9.9.9
...
These two DNS servers are operated by Google, and indeed this solves the problem. Once this change has been made, you should be able to log in to Notes using Twitter credentials.
In this section, we tested the Notes application and discussed how to diagnose and remedy a couple of common problems. While doing so, we learned how to navigate our way around the EC2 instances and the Docker Swarm.
Let's now see what happens if we change the number of instances for our services.
Scaling the Notes instances
By now, we have deployed the Notes stack to the cluster on our EC2 instances. We have tested everything and know that we have a correctly functioning system deployed on AWS. Our next task is to increase the number of instances and see what happens.
To increase the instances for svc-notes, edit compose-swarm/docker-compose.yml as follows:
services:
...
svc-notes:
...
deploy:
replicas: 2
...
This increases the number of replicas. Because of the existing placement constraints, both instances will deploy to the node with a type label of public. To update the services, it's just a matter of rerunning the following command:
$ docker stack deploy --with-registry-auth --compose-file docker-compose.yml notes
Ignoring unsupported options: build, restart
...
Updating service notes_svc-userauth (id: wjugeeaje35v3fsgq9t0r8t98)
Updating service notes_db-notes (id: ldfmq3na5e3ofoyypub3ppth6)
Updating service notes_svc-notes (id: pl94hcjrwaa1qbr9pqahur5aj)
Updating service notes_redis (id: lrjne8uws8kqocmr0ml3kw2wu)
Updating service notes_db-userauth (id: lkbj8ax2cj2qzu7winx4kbju0)
Earlier, this command described its actions with the word Creating, and this time it used the word Updating. This means that the services are being updated with whatever new settings are in the stack file.
After a few minutes, you may see this:
$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
ldfmq3na5e3o notes_db-notes replicated 1/1 mysql/mysql-server:8.0
lkbj8ax2cj2q notes_db-userauth replicated 1/1 mysql/mysql-server:8.0
lrjne8uws8kq notes_redis replicated 1/1 redis:5.0
pl94hcjrwaa1 notes_svc-notes replicated 2/2 098106984154.dkr.ecr.us-west-2.amazonaws.com/svc-notes:latest *:80->3000/tcp
wjugeeaje35v notes_svc-userauth replicated 1/1 098106984154.dkr.ecr.us-west-2.amazonaws.com/svc-userauth:latest
And indeed, it shows two instances of the svc-notes service. The 2/2 notation says that two instances are currently running out of the two instances that were requested.
To view the details, run the following command:
$ docker service ps notes_svc-notes
...
As we saw earlier, this command lists to which swarm nodes the service has been deployed. In this case, we'll see that both instances are on notes-public, due to the placement constraints.
Another useful command is the following:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d46c6bba56d3 098106984154.dkr.ecr.us-west-2.amazonaws.com/svc-notes:latest "docker-entrypoint.s…" 7 minutes ago Up 7 minutes 3000/tcp notes_svc-notes.2.zo2mdxk9fuy33ixe0245y7uii
a93f1d5d8453 098106984154.dkr.ecr.us-west-2.amazonaws.com/svc-notes:latest "docker-entrypoint.s…" 15 minutes ago Up 15 minutes 3000/tcp notes_svc-notes.1.cc34q3yfeumx0b57y1mnpskar
Ultimately, each service deployed to a Docker swarm contains one or more running containers.
You'll notice that this shows svc-notes listening on port 3000. In the environment setup, we did not set the PORT variable, and therefore svc-notes will default to listening to port 3000. Refer back to the output for docker service ls, and you should see this: *:80->3000/tcp, meaning that there is mapping being handled in Docker from port 80 to port 3000.
That is due to the following setting in docker-swarm/docker-compose.yml:
services:
...
svc-notes:
...
ports:
- "80:3000"
...
This says to publish port 80 and to map it to port 3000 on the containers.
In the Docker documentation (https://docs.docker.com/network/overlay/#bypass-the-routing-mesh-for-a-swarm-service), we learned that services deployed in a swarm are reachable by the so-called routing mesh. Connecting to a published port routes the connection to one of the containers handling that service. As a result, Docker acts as a load balancer, distributing traffic among the service instances you configure.
In this section, we have—finally—deployed the Notes application stack to a cloud hosting environment we built on AWS EC2 instances. We created a Docker swarm, configured the swarm, created a stack file with which to deploy our services, and we deployed to that infrastructure. We then tested the deployed system and saw that it functioned well.
With that, we can wrap up this chapter.
Summary
This chapter is the culmination of a journey of learning Node.js application deployment. We developed an application existing solely on our laptop and added a number of useful features. With the goal of deploying that application on a public server to gain feedback, we worked on three types of deployment. In Chapter 10, Deploying Node.js Applications to Linux Servers, we learned how to launch persistent background tasks on Linux using PM2. In Chapter 11, Deploying Node.js Microservices with Docker, we learned how to dockerize the Notes application stack, and how to get it running with Docker.
In this chapter, we built on that and learned how to deploy our Docker containers on a Docker Swarm cluster. AWS is a powerful and comprehensive cloud hosting platform with a long list of possible services to use. We used EC2 instances in a VPC and the related infrastructure.
To facilitate this, we used Terraform, a popular tool for describing cloud deployments not just on AWS but on many other cloud platforms. Both AWS and Terraform are widely used in projects both big and small.
In the process, we learned a lot about AWS, and Terraform, and using Terraform to deploy infrastructure on AWS; how to set up a Docker Swarm cluster; and how to deploy a multi-container service on that infrastructure.
We began by creating an AWS account, setting up the AWS CLI tool on our laptop, and setting up Terraform. We then used Terraform to define a VPC and the network infrastructure within which to deploy EC2 instances. We learned how to use Terraform to automate most of the EC2 configuration details so that we can quickly initialize a Docker swarm.
We learned that a Docker compose file and a Docker stack file are very similar things. The latter is used with Docker Swarm and is a powerful tool for describing the deployment of Docker services.
In the next chapter, we will learn about both unit testing and functional testing. While a core principle of test-driven development is to write the tests before writing the application, we've done it the other way around and put the chapter about unit testing at the end of the book. That's not to say unit testing is unimportant, because it certainly is important.