
Chapter Eight
![]()
Query-Cycle Simulator
8.1 CHALLENGES IN EMPIRICAL EVALUATION OF P2P ALGORITHMS
Due to the decentralized nature and fast growth of today’s P2P networks, testing P2P algorithms in a real-world environment by simply deploying them on an existing P2P network and collecting data on their performance is a daunting task. In some cases, measurements are easier to carry out due to some easily accessible central control entity in the network that manages node joins and departures [71]. Also, some algorithms may be tested by deploying them on one or a few controlled nodes in the network (as in [74]). However, for a wide range of P2P-related algorithms and protocols, simply deploying and testing them on existing P2P networks is not possible. For example, most algorithms require each peer in the network to implement the algorithm. Today’s popular P2P networks [1] have hundreds of thousands of nodes. Performing a software update for each of these nodes in order to test each novel P2P algorithm is impractical. As another example, security protocols require testing under different threat scenarios such as an attack on the network by a coordinated group of malicious peers. Testing such protocols would require introducing malicious peers into the network, which is also not practical. Thus, P2P algorithms and protocols are tested by simulation, under network models that attempt to mimic typical node interconnections, traffic patterns, and other properties. Since algorithms and protocols are often sensitive to the traffic and network behavior, there is a clear need for accurate P2P network models.
Work in this area has been mainly done on the fly to test novel algorithms. Because of this, most P2P simulators have used simple models. For example, [2] assumes entirely random interactions among peers in a P2P network to test a P2P reputation management protocol. In simulating a distributed search algorithm, [28] simply use a uniformly random location of files and generation of queries by peers.
In this chapter, we present the Query-Cycle Simulator, a P2P file-sharing network simulator based on the query-cycle model described in Section 8.2, and discuss the issues that arise in the accurate modeling of a P2P network. We focus on modeling a file-sharing network such as Gnutella [1].
8.2 THE QUERY-CYCLE MODEL
We consider a typical P2P network: interconnected, file-sharing peers are able to issue queries for files, peers can respond to queries, and files can be transferredbetween two peers to conclude a search process. When a query is issued by a peer, it is propagated by broadcast with hop-count horizon throughout the network; peers that receive the query forward it and check if they are able to respond to it.
We suggest a simulation process that proceeds in query cycles. In each query cycle, a peer i in the network may be actively issuing a query, inactive, or even down and not responding to queries passing by. Upon issuing a query, a peer waits for incoming responses, selects a download source among those nodes that responded, and starts downloading the file. The query cycle finishes when all peers who have issued queries download a satisfactory response. Statistics may be collected at each peer, such as the number of downloads and uploads of the peer.
8.3 BASIC PROPERTIES
8.3.1 Network Topology
The P2P network is represented as an undirected graph G = (P, E), where P is the set of nodes, and E is the set of edges (i, j) describing the connections between nodes i, j ∈ P. The connections in the P2P network are symmetric and describe a peer’s neighbor set. That is, peer i’s neighbor set is defined as N(i) = {j | (i, j) ∈ E}. The network is initialized to contain some number of peers whose connections form a power-law topology, as described later in this chapter.
8.3.2 Joining the Network
A peer joins the P2P network by contacting a designated pong server to obtain some number of live IP addresses [1]. Before adding a node to its neighbor set, the peer must be permitted to make a direct connection. A connection request message R(i, j) is initiated by peer i requesting a direct connection to peer j. The request is sent directly to peer j, which then decides whether to accept the connection. If peer j accepts the connection, then both peers add one another to their neighbor sets. System bootstrap proceeds by having each peer attempt an initial number of connections γ that does not exceed some system-wide maximum number of connections t.
Bootstrapping and node discovery are still open issues in P2P systems. Schemes that distribute the IP addresses maintained by the pong servers to nodes in the network are evaluated in [10]. The details of bootstrapping are not an integral issue in our simulator as most of our experiments are done at a steady state.
8.3.3 Query Propagation
Query messages are propagated via flooding-based broadcast. A search query can be initiated by any node in the network by first broadcasting to all peers in its neighbor set. Each node, upon receiving a propagated search query, will examine its local file system for a match. Any matches are returned directly to the query initiator. The peer may then propagate the query to all its neighbors except for the node from which it received the query. Each query maintains a time-to-live (TTL) field to limit the scope of the query flooding. At query time, the issuing peer will set the TTL field to some default value, which is then decremented by one at each propagation. A node receiving a query with TTL = 0 will not forward the query.
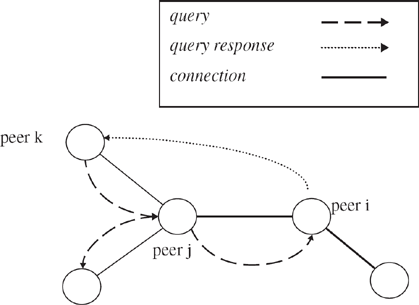
Figure 8.1 Query propagation.
Figure 8.1 illustrates how a query propagates through the P2P network. In the example, peer k initiates the search query, with TTL = 1, by broadcasting to all of its neighbors, in this case peer j. Peer j decides not to respond to the query and forwards the query to its neighbors, except to peer k. Upon receiving the query, peer i directly responds to peer k with a match. The query flooding terminates at peer i since the TTL is now 0.
8.4 PEER-LEVEL PROPERTIES
The system-level dynamics of a P2P network are highly dependent on local, peer- dependent properties, such as the activity level or file-sharing behavior of each peer. In [50], different convergence behavior and different characteristic path lengths are observed in simulating a novel P2P network topology construction algorithm under two different models, one assigning bandwidth capacities to nodes based on a Zipf distribution, the other one based on a real-world distribution measured in [64].
Since the system-level dynamics of a P2P network — and hence the systemlevel impact of a P2P algorithm — is dependent on local, peer-level parameters, it is essential to accurately model these parameters. We may classify these parameters into two types: content distribution parameters and peer behavior parameters.
Content distribution. We must accurately model the volume and type of content each peer carries. P2P networks are far from homogeneous in terms of type and volume of data shared; hence a model reflecting real-world P2P networks is required.
Peer behavior. We must also accurately model peer behavior, including how a peer submits and responds to queries, how it chooses which query response to download, and its uptime and session duration.
In the next two sections, we discuss how to accurately model the content distribution and peer behavior parameters, and we discuss open questions and empirical studies that would be useful to the accurate modeling of these parameters.
8.5 CONTENT DISTRIBUTION MODEL
The dynamics of P2P networks are highly dependent on the volume and variety of files each peer chooses to share. If few peers choose to share files, then queries are likely to be routed via many peers, and the load on the network referring to file uploads is likely to be highly imbalanced. If many peers choose to each share a wide variety of files, the network of peers who interact with one another is likely to be dense and unclustered, and query response times are likely to be quick.
Accurate assessment of the impact of intelligent query-routing algorithms and content-based topologies depends on the accurate modeling of the volume and variety each peer shares. Furthermore, accurate modeling of the content shared by peers in the network gives us greater insight into the file-sharing and communication patterns in the network, which is useful in many areas of P2P research.
8.5.1 Data Volume
In our model, each peer in the network shares a certain number of files.
Real-world observations. [64] has measured the probability distribution over the number of files shared by peers in Gnutella.
Model. We use this distribution to assign a number of shared files, Fi, to each peer i in the network. Currently, we use the absolute values from [64].
8.5.2 Content Type
In this section, we describe how we model the individual files each peer chooses to share. It is important to model this accurately because this will determine patterns of peers who interact with one other. A model in which the files peers share are chosen randomly is insufficient, as it will fail to produce clusters of peers that interact with on another, as has been observed [21]. Such properties affect the performance of many algorithms, including search algorithms [22] and reputation algorithms [41].
Real-world observations. In [21], it is observed that peers in a P2P network are in general interested in a subset of the total available content on the network. Furthermore, it is also observed in [21] that peers are often interested only in files from a few content categories. For example, in the domain of educational resources [26], users have a certain affinity toward learning materials related to the course of study they undertake.
It also has been observed in [46] that many document storage systems, including the WWW, exhibit Zipf distributions on the popularity of documents. This reflects the fact that some popular documents are very widely copied and held, while most documents are held by far fewer peers. The same can be said of content categories: there are some content categories (such as “Top 40 Hits” in the music domain”) that are very popular and widely held, while most other categories (such as “Acid Jazz”) are less widely held.
Model. We model the properties described above as follows. Briefly, peers are assumed to be interested in a subset of the total available content in the network; that is, each peer initially picks a number of content categories and shares files only in these categories. Furthermore, we assume that files with different popularities exist within each content category, governed by a Zipf distribution. Files are assigned to peers at initialization in the following manner. According to the probabilistic model described below, each peer i is assigned some content categories Ci. Then, peer i is given an interest level for each content category c ∈ Ci. Finally, peer i is assigned files F according to its content categories and interest levels in those categories. In this model, each distinct file fc, r may be uniquely identified by the content category c to which it belongs and its popularity ranking r within that category. The probabilistic model is based on empirical observations of file distributions in [64] and [46].
Assigning content categories. We assume n content categories C = {c1,…,cn}. Some content categories are more popular than others. That is, the files in some content categories are more widely held than the files in other categories. We model this popularity by a Zipf distribution: when a peer is initialized, it is set to be interested in content category ci ∈ C with probability p (Ci) given by ![]() . We require a peer to be interested in Cmin content categories, repeating the peer’s interest test until Cmin categories have been chosen. The set Ci is the set of content categories that interest peer i.
. We require a peer to be interested in Cmin content categories, repeating the peer’s interest test until Cmin categories have been chosen. The set Ci is the set of content categories that interest peer i.
Modeling interest level. A peer i interested in content categories Ci is probably not equally interested in all categories c ∈ Ci. Rather, peer i is more likely to be more interested in some categories than others. We model this by assigning an interest value wic to each content category c ∈ Ci of interest to peer i. This interest value is determined uniformly at random for each content category for each peer i. The fraction of files shared by peer i that are in category c is given by ![]() . The number of files shared by peer i that are in category c is given by Fic = p(c|i)Fi.
. The number of files shared by peer i that are in category c is given by Fic = p(c|i)Fi.
Note that the interest value is not correlated with the general popularity of content category c. This reflects the fact that, while a certain category may be of interest to many peers (e.g., Top 40 Hits), that category is not necessarily the main interest of those peers. Also note that since we assume a steady-state network, we assume that the interests of peers do not change over time.
Modeling files. We now wish to model the individual files held by each peer. Each distinct file may be uniquely identified by the tuple {c, r}, where c represents the content category to which the file belongs and r represents its popularity rank within content category c. We denote this file fc,r. Within each content category there are some files that are very popular, and some that are held by few people. We model this by a Zipf distribution as well. The fraction of files in content category c that are copies of file fc,r is given by

where Fc is the number of distinct files in category c. Notice that in order to evaluate p(fc,r |c), we need to model the number of distinct files in each content category (see below). The probability that a file f shared by peer i is a copy of file fc,r is given by the level of interest p(c|i) that peer i has in category c times the popularity p(fc,r |c) of file fc,r within category c p(fc,r |i) = p(c|i)p(fc,r |c). At initialization, we assign files to each peer i based on this distribution and the number of files Fci shared by peer i in each category. Each peer stores the {c, r} values for the files that it shares.
Modeling the number of distinct files per category. If there is maximum replication going on in the network, there are at maximum Fca files of content category c in the network, where Fca represents the number of files in category c shared by peer a, the peer who shares the most files in category c. On the other hand, if every file on the network is distinct, then there are p(c)F distinct files, where F is the total number of files on the network and p(c) is the fraction of files that are in category c. The truth probably lies somewhere in between, and we set Fc = dFca + (1 − d)p(c)F, where d is some number between 0 and 1. In our implementation, we set d = .25. Empirical evidence would be useful to determine an accurate choice of d.
8.6 PEER BEHAVIOR MODEL
In addition to content distribution, another primary factor in the systemwide dynamics of a P2P network is peer behavior, including peer uptime and session duration, peer activity levels, and how peers issue and respond to queries. These parameters affect the network in many ways. For example, frequently changing network participation (very short session durations, yet high uptimes of nodes) increases the administration overhead of topology construction protocols, which generally require communication among a number of peers to repair the network topology once a peer has left or joined, an important cost factor to consider in the design of such protocols. Second, node uptime represents the availability of storage space and computational power in the network. The pattern of node uptime in P2P networks is of interest for applications that wish to take advantage of these networks for large-scale computations, as in [41]. If the network consists of a large pool of nodes that participate only infrequently and are down most of the time, the nodes that remain in the network have to sustain a higher work and storage load.
Query activity level is another peer behavior that is of particular interest to P2P research, as the query behavior of peers (in conjunction with the network’s content distribution patterns) determines which peers interact with each other. These interaction patterns are of importance to the effective design of P2P algorithms ranging from search algorithms to file indexing protocols.
8.6.1 Uptime and Session Duration
Participating nodes frequently leave and rejoin a P2P network. We define a peer’s uptime to be the fraction of an observation period that a peer is participating in the network, issuing, responding to, and forwarding queries.
Real-world observations. Uptime and session duration of peers have been set in [64]. Observations on the MojoNation P2P network [71] have revealed that up to 84% enter the network one time, and for less than one hour. At the moment, we do not consider these peers in our simulations. They probably do not contribute to the shared data much, and they probably do not issue too many queries.
Model. We assume a pool of N peers, each peer with a certain probability of being online, assigned based on the uptime distribution in [64].
8.6.2 Query Activity
Peers in a P2P network issue queries to search for downloadable files that match their interests. A peer’s query activity determines the rate at which it issues queries when it is up.
Real-world observations. So far, we are not aware of measurements on query rates of peers in a P2P network. An empirical study on the distribution of query rates of real-world P2P networks would be straightforward and very useful to the accurate modeling of the network.
Model. In our model, nodes generate queries based on a Poisson process. The query rate λ of each node is set upon initialization and is picked uniformly at random from an interval {ratemin, ratemax}. In each query cycle, the equation ![]() gives the probability that a node issues x queries.
gives the probability that a node issues x queries.
8.6.3 Queries
In the query-cycle model, each active peer determines whether it generates a query according to the model above at each query cycle. If it generates a query, the specific query that peer i issues is given by the model described below.
Real-world observations. Peers in general query for files that exist on the network and are in the content category of their interest. The first is true in large and diverse P2P networks, the latter we claim to be true for the majority of queries a peer issues, albeit it is yet to be shown by empirical studies on the query behavior in P2P networks.
Model. In our model, a query qc,r represents a query for the file fc,r. We say that a peer only issues queries in the content categories in which it is interested. The probability that a peer i generates a query qc,r is given by its interest level in category c times the popularity of file r in c:
![]()
(We say here that the popularity p(qc,r |c) of a query qc,r is equal to the popularity p(fc,r |c) of its corresponding file fc,r.) We also suggest that a peer will not issue a query for a file that it already owns.
8.6.4 Query Responses
In this framework, modeling query responses is straightforward: if peer i receives a query qc,r, and it owns a copy of the corresponding file fc,r, it responds to the peer that has issued the query and offers to upload the file.
8.6.5 Downloads
In the query-cycle model, a cycle consists of each active peer issuing a query, waiting for the list of incoming responses, and downloading one of the responses. In our model, a peer randomly chooses a response to download. This may not accurately reflect reality. In fact, for a file-sharing system such as Gnutella, users tend to select peers with high bandwidth, hoping to be able to download a file fast. However, the Query-Cycle Simulator can easily be extended to bias source selection based on peer bandwidth.
8.7 NETWORK PARAMETERS
Network parameters characterize the underlying transport network of a P2P network and the transport network-related properties of peers.
8.7.1 Topology
Peers form an overlay network on top of a transport network. Upon joining the network, peers establish links to a number of peers in the network. When leaving, peers disband these links. Query and control messages are passed along the interconnection links between peers.
Real-world observations. Freely evolving P2P networks have been shown to exhibit power-law network characteristics [63]. Hence we organize peers into a power-law network. Upon joining the network, peers connect to a node i with probability ![]() , where N is the set of nodes currently in the network and di is the node degree of peer i. Thus, joining nodes have a higher probability of connecting to nodes which maintain a higher number of network connections, which yields a network with power-law characteristics [52].
, where N is the set of nodes currently in the network and di is the node degree of peer i. Thus, joining nodes have a higher probability of connecting to nodes which maintain a higher number of network connections, which yields a network with power-law characteristics [52].
Model. The topology of a P2P network is to be considered in several ways when designing P2P algorithms. First, the pattern of where new peers usually join the network can be important for designing topology construction protocols. For example, the fact that P2P networks exhibit a power-law topology shows that some peers in the network have a higher probability of being contacted when a new peer joins the network, challenging topology construction protocols with an inherent imbalance. Second, depending on the search method deployed in the network, the topology may determine the scope of a peer in the network (Gnutella uses a broadcast search with a hop-count horizon of 7 hops). Peers in the “center” of the network, — highly connected peers in a power-law network — will be able to see a larger fraction of the query traffic in the network. Malicious peers trying to attack the network by responding to queries with decoy files may try to locate and connect to highly connected peers in the network to increase their chances of responding to many queries, a threat scenario to be considered for reputation algorithms.
8.7.2 Bandwidth
We currently have a simple understanding of a peer’s bandwidth in our simulations: bandwidth at a peer is consumed only while uploading or downloading files.
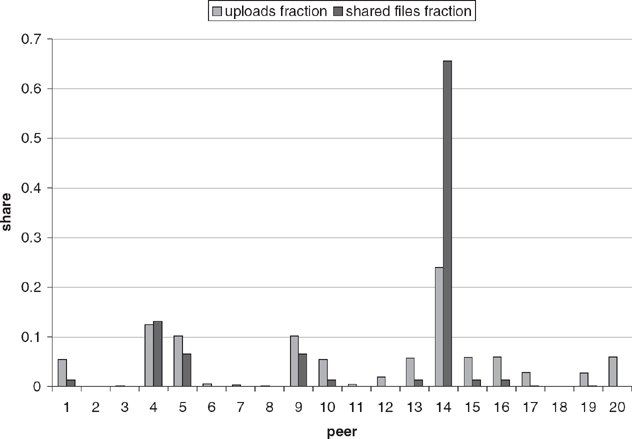
Figure 8.2 Share of uploads and files in a P2P network.
Bandwidth is assigned to a peer upon the creation of the peer based on measurements in [64]. Upon up- or downloading a file, peers always try to use their full bandwidth (the actual transfer rate is limited by the peer with less bandwidth). If a peer has several up- and downloads going on, the available bandwidth is split up equally.
8.8 DISCUSSION
Figure 8.2 depicts the load share in a sample network of 20 peers that was simulated based on the considerations above. One graph shows the number of uploads at a particular peer versus the total number of uploads in the system after 300 query cycles; the other graph shows the number of files shared by a peer versus the total number of files shared by all peers. Although the distribution of files is highly imbalanced — a property observed in real-world P2P networks [64] — all peers participate in responding to queries, since even peers with only a few files have a fair likelihood of responding to queries for very popular files. This is a property that can also be observed on real-world P2P networks and provides a first indication that our model is accurate.
We use this simulator to test the algorithms in the next chapters.