
We discussed ES6 arrow functions and the syntax in detail in the last chapter. However, an important aspect of arrow functions is that they behave differently from normal functions. The difference is subtle but important. Arrow functions do not have their own value of this. The value of this in an arrow function is inherited from the enclosing (lexical) scope.
Functions have a special variable this that refers to the object via which the method was invoked. As the value of this is dynamically given based on the function invocation, it is sometimes called dynamic this. A function is executed in two scopes-lexical and dynamic. A lexical scope is a scope that surrounds the function scope, and the dynamic scope is the scope that called the function (usually an object)
In JavaScript, traditional functions play several roles. They are non-method functions (aka subroutines or functions), methods (part of an object), and constructors. When functions do the duty of a subroutine, there is a small problem due to dynamic this. As subroutines are not called on an object, the value of this is undefined in a strict mode and set to the global scope otherwise. This makes writing callbacks difficult. Consider the following example:
var greeter = {
default: "Hello ",
greet: function (names){
names.forEach(function(name) {
console.log(this.default + name); //Cannot read property
'default' of undefined
})
}
}
console.log(greeter.greet(['world', 'heaven']))
We are passing a subroutine to the forEach() function on the names array. This subroutine has an undefined value of this, and unfortunately, it does not have access to this of the outer method greet. Clearly, this subroutine needs a lexical this,derive this from the surrounding scope of the greet method. Traditionally, to fix this limitation, we assign the lexical this into a variable, which is then accessible to the subroutine via closure.
We can fix the earlier example as follows:
var greeter = {
default: "Hello ",
greet: function (names){
let that = this
names.forEach(function(name) {
console.log(that.default + name);
})
}
}
console.log(greeter.greet(['world', 'heaven']))
This is a reasonable hack to simulate lexical this. However, the problem with such hacks is that it creates too much noise for the person writing or reviewing this code. First, you have to understand the quirk of the behavior of this. Even if you understand this behavior well, you will need to continuously remain on the lookout for such hacks in your code.
Arrow functions have lexical this and do not require such a hack. They are more suited as subroutines because of this. We can covert the preceding example to use lexical this using the arrow function:
var greeter = {
default: "Hello ",
greet: function (names){
names.forEach(name=> {
console.log(this.default + name); //lexical 'this'
available for this subroutine
})
}
}
console.log(greeter.greet(['world', 'heaven']))
You can see that you have this array-like arguments object looking so much like an array object. How can you reliably tell the difference between the two? Additionally, typeof returns an object when used with arrays. Therefore, how can you tell the difference between an object and an array?
The silver bullet is the Object object's toString() method. It gives you the internal class name used to create a given object:
> Object.prototype.toString.call({});
"[object Object]"
> Object.prototype.toString.call([]);
"[object Array]"
You have to call the original toString() method as defined in the prototype of the Object constructor. Otherwise, if you call the Array function's toString(), it will give you a different result, as it's been overridden for the specific purposes of the array objects:
> [1, 2, 3].toString();
"1,2,3"
The preceding code is same as:
> Array.prototype.toString.call([1, 2, 3]);
"1,2,3"
Let's have some more fun with toString(). Make a handy reference to save typing:
> var toStr = Object.prototype.toString;
The following example shows how we can differentiate between an array and the array-like object arguments:
> (function () {
return toStr.call(arguments);
}());
"[object Arguments]"
You can even inspect DOM elements:
> toStr.call(document.body);
"[object HTMLBodyElement]"
Your journey through the built-in objects in JavaScript continues, and the next three are fairly straightforward. They are Boolean, number, and string. They merely wrap the primitive data types.
You already know a lot about Booleans from Chapter 2, Primitive Data Types, Arrays, Loops, and Conditions. Now, let's meet the Boolean() constructor:
> var b = new Boolean();
It's important to note that this creates a new object, b, and not a primitive Boolean value. To get the primitive value, you can call the valueOf() method (inherited from Object class and customized):
> var b = new Boolean();
> typeof b;
"object"
> typeof b.valueOf();
"boolean"
> b.valueOf();
false
Overall, objects created with the Boolean() constructor are not too useful, as they don't provide any methods or properties other than the inherited ones.
The Boolean() function, when called as a normal function without new, converts non-Booleans to Booleans (which is like using a double negation !!value):
> Boolean("test");
true
> Boolean("");
false
> Boolean({});
true
Apart from the six false values, everything else is true in JavaScript, including all objects. This also means that all Boolean objects created with new Boolean() are also true, as they are objects:
> Boolean(new Boolean(false));
true
This can be confusing, and since Boolean objects don't offer any special methods, it's best to just stick with regular primitive Boolean values.
Similar to Boolean(), the Number() function can be used as:
- A
constructorfunction (withnew) to create objects. - A normal function in order to try to convert any value to a number. This is similar to the use of
parseInt()orparseFloat():> var n = Number('12.12'), > n; 12.12 > typeof n; "number" > var n = new Number('12.12'), > typeof n; "object"
As functions are objects, they can also have properties. The Number() function has constant built-in properties that you cannot modify:
> Number.MAX_VALUE;
1.7976931348623157e+308
> Number.MIN_VALUE;
5e-324
> Number.POSITIVE_INFINITY;
Infinity
> Number.NEGATIVE_INFINITY;
-Infinity
> Number.NaN;
NaN
The number objects provide three methods-toFixed(), toPrecision(), and toExponential()(see Appendix C, Built-in Objects, for more details):
> var n = new Number(123.456);
> n.toFixed(1);
"123.5"
Note that you can use these methods without explicitly creating a Number object first. In such cases, the Number object is created (and destroyed) for you behind the scenes:
> (12345).toExponential();
"1.2345e+4"
Like all objects, the Number object also provide the toString() method. When used with Number object, this method accepts an optional radix parameter (10 being the default):
> var n = new Number(255);
> n.toString();
"255"
> n.toString(10);
"255"
> n.toString(16);
"ff"
> (3).toString(2);
"11"
> (3).toString(10);
"3"
You can use the String() constructor function to create string objects. String objects provide convenient methods for text manipulation.
Here's an example that shows the difference between a String object and a primitive string data type:
> var primitive = 'Hello';
> typeof primitive;
"string"
> var obj = new String('world'),
> typeof obj;
"object"
A String object is similar to an array of characters. String objects have an indexed property for each character (introduced in ES5, but long supported in many browsers, except old IEs), and they also have a length property.
> obj[0];
"w"
> obj[4];
"d"
> obj.length;
5
To extract the primitive value from the String object, you can use the valueOf() or toString() method inherited from Object. You'll probably never need to do this, as toString() is called behind the scenes if you use an object in a primitive string context:
> obj.valueOf();
"world"
> obj.toString();
"world"
> obj + "";
"world"
The primitive strings are not objects, so they don't have any methods or properties. However, JavaScript also offers you the syntax to treat primitive strings as objects (just like you already saw with primitive numbers).
In the following example, String objects are being created (and then destroyed) behind the scenes every time you treat a primitive string as if it were an object:
> "potato".length;
6
> "tomato"[0];
"t"
> "potatoes"["potatoes".length - 1];
"s"
Here is one final example to illustrate the difference between a primitive string and a String object. In this example, we are converting them to Boolean. The empty string is a falsy value, but any string object is truthy (because all objects are truthy):
> Boolean("");
false
> Boolean(new String(""));
true
Similar to Number() and Boolean(), if you use the String() function without new, it converts the parameter to a primitive:
> String(1);
"1"
If you pass an object to String(), this object's toString() method will be called first:
> String({p: 1});
"[object Object]"
> String([1, 2, 3]);
"1,2,3"
> String([1, 2, 3]) === [1, 2, 3].toString();
true
Let's experiment with a few of the methods you can call on string objects (see Appendix C, Built-in Objects, for the complete list).
Start off by creating a string object:
> var s = new String("Couch potato");
The toUpperCase() and toLowerCase() methods transform the capitalization of the string:
> s.toUpperCase();
"COUCH POTATO"
> s.toLowerCase();
"couch potato"
The charAt() method tells you the character found at the position you specify, which is the same as using square brackets (treating a string as an array of characters):
> s.charAt(0);
"C"
> s[0];
"C"
If you pass a non-existent position to charAt(), you get an empty string:
> s.charAt(101);
""
The indexOf() method allows you to search within a string. If there is a match, the method returns the position at which the first match is found. The position count starts at 0, so the second character in Couch is o at position 1:
> s.indexOf('o'),
1
You can optionally specify where (at what position) to start the search. The following finds the second o, because indexOf() is instructed to start the search at position 2:
> s.indexOf('o', 2);
7
The lastIndexOf()starts the search from the end of the string (but the position of the match is still counted from the beginning):
> s.lastIndexOf('o'),
11
You can search , not only for characters, but also for strings, and the search is case sensitive:
> s.indexOf('Couch'),
0
If there is no match, the function returns position -1:
> s.indexOf('couch'),
-1
For a case-insensitive search, you can transform the string to lowercase first and then search:
> s.toLowerCase().indexOf('couch'.toLowerCase());
0
If you get 0, this means that the matching part of the string starts at position 0. This can cause confusion when you check with if, because if converts the position 0 to a Boolean false value. So, while this is syntactically correct, it is logically wrong:
if (s.indexOf('Couch')) {...}
The proper way to check whether a string contains another string is to compare the result of indexOf() to the number -1:
if (s.indexOf('Couch') !== -1) {...}
The slice()and substring() return a piece of the string when you specify the start and end positions:
> s.slice(1, 5);
"ouch"
> s.substring(1, 5);
"ouch"
Note that the second parameter you pass is the end position, not the length of the piece. The difference between these two methods is how they treat negative arguments. substring() treats them as zeros, while slice() adds them to the length of the string. So, if you pass parameters (1, -1) to both methods, it's the same as substring(1,0) and slice(1,s.length-1):
> s.slice(1, -1);
"ouch potat"
> s.substring(1, -1);
"C"
There's also the non-standard method substr(), but you should try to avoid it in favor of substring().
The split() method creates an array from the string using another string that you pass as a separator:
> s.split(" ");
["Couch", "potato"]
The split() method is the opposite of the join() method, which creates a string from an array:
> s.split(' ').join(' '),
"Couch potato"
The concat() glues strings together, in the same way in which the + operator does for primitive strings:
> s.concat("es");
"Couch potatoes"
Note that while some of the preceding methods discussed return new primitive strings, none of them modify the source string. After all the method calls listed previously, the initial string is still the same:
> s.valueOf();
"Couch potato"
You have seen how to use indexOf() and lastIndexOf() to search within strings, but there are more powerful methods (search(), match(), and replace()) that take regular expressions as parameters. You'll see these later in the RegExp() constructor function.
At this point, you're done with all of the data wrapper objects, so let's move on to the utility objects Math, Date, and RegExp.
Math is a little different from the other built-in global objects you have seen previously. It's not a function, and, therefore, cannot be used with new to create objects. Math is a built-in global object that provides a number of methods and properties for mathematical operations.
The Math object's properties are constants, so you can't change their values. Their names are all in uppercase to emphasize the difference between them and a normal property (similar to the constant properties of the Number() constructor). Let's see a few of these constant properties:
- The constant PI:
> Math.PI; 3.141592653589793 - Square root of 2:
> Math.SQRT2; 1.4142135623730951 - Euler's constant:
> Math.E; 2.718281828459045 - Natural logarithm of 2:
> Math.LN2; 0.6931471805599453 - Natural logarithm of 10:
> Math.LN10; 2.302585092994046
Now, you know how to impress your friends the next time they (for whatever reason) start wondering, "What was the value of e? I can't remember." Just type Math.E in the console and you have the answer.
Let's take a look at some of the methods the Math object provides (the full list is in Appendix C, Built-in Objects).
Generating random numbers:
> Math.random();
0.3649461670235814
The random() function returns a number between 0 and 1, so if you want a number between, let's say, 0 and 100, you can use the following line of code:
> 100 * Math.random();
For numbers between any two values, use the formula ((max-min) * Math.random())+min. For example, a random number between 2 and 10 can be obtained using the formula as follows:
> 8 * Math.random() + 2;
9.175650496668485
If you only need an integer, you can use one of the following rounding methods:
floor()to round downceil()to round upround()to round to the nearest
For example, to get either 0 or 1, you can use the following line of code:
> Math.round(Math.random());
If you need the lowest or the highest among a set of numbers, you have the min() and max() methods. So, if you have a form on a page that asks for a valid month, you can make sure that you always work with sane data (a value between 1 and 12):
> Math.min(Math.max(1, input), 12);
The Math object also provides the ability to perform mathematical operations for which you don't have a designated operator. This means that you can raise to a power using pow(), find the square root using sqrt(), and perform all the trigonometric operations-sin(), cos(), atan(), and so on.
For example, to calculate 2 to the power of 8, you can use the following line of code:
> Math.pow(2, 8);
256
To calculate the square root of 9, you can use the following line of code:
> Math.sqrt(9);
3
Date() is a constructor function that creates date objects. You can create a new object by passing:
- Nothing (defaults to today's date)
- A date-like string
- Separate values for day, month, time, and so on
- A timestamp
Here is an object instantiated with today's date/time (using the browser's timezone):
> new Date();
Wed Feb 27 2013 23:49:28 GMT-0800 (PST)
The console displays the result of the toString() method called on the Date object, so you get this long string Wed Feb 27 2013 23:49:28 GMT-0800 (PST) as a representation of the date object.
Here are a few examples of using strings to initialize a Date object. Note how many different formats you can use to specify the date:
> new Date('2015 11 12'),
Thu Nov 12 2015 00:00:00 GMT-0800 (PST)
> new Date('1 1 2016'),
Fri Jan 01 2016 00:00:00 GMT-0800 (PST)
> new Date('1 mar 2016 5:30'),
Tue Mar 01 2016 05:30:00 GMT-0800 (PST)
The Date constructor can figure out a date from different strings, but this is not really a reliable way of defining a precise date, for example, when passing user input to the constructor. A better way is to pass numeric values to the Date() constructor representing:
- Year
- Month - 0 (January) to 11 (December)
- Day - 1 to 31
- Hour - 0 to 23
- Minutes - 0 to 59
- Seconds - 0 to 59
- Milliseconds - 0 to 999
Let's look at some examples.
Passing all the parameters by writing the following line of code:
> new Date(2015, 0, 1, 17, 05, 03, 120);
Tue Jan 01 2015 17:05:03 GMT-0800 (PST)
Passing date and hour by writing the following line of code:
> new Date(2015, 0, 1, 17);
Tue Jan 01 2015 17:00:00 GMT-0800 (PST)
Watch out for the fact that the month starts from 0, so 1 is February:
> new Date(2016, 1, 28);
Sun Feb 28 2016 00:00:00 GMT-0800 (PST)
If you pass a value greater than the one allowed, your date overflows forward. As there's no February 30 in 2016, this means it has to be March 1 (2016 is a leap year):
> new Date(2016, 1, 29);
Mon Feb 29 2016 00:00:00 GMT-0800 (PST)
> new Date(2016, 1, 30);
Tue Mar 01 2016 00:00:00 GMT-0800 (PST)
Similarly, December 32 becomes January 1 of the next year:
> new Date(2012, 11, 31);
Mon Dec 31 2012 00:00:00 GMT-0800 (PST)
> new Date(2012, 11, 32);
Tue Jan 01 2013 00:00:00 GMT-0800 (PST)
Finally, a date object can be initialized with a timestamp (the number of milliseconds since the UNIX epoch, where 0 milliseconds is January 1, 1970):
> new Date(1357027200000);
Tue Jan 01 2013 00:00:00 GMT-0800 (PST)
If you call Date() without new, you get a string representing the current date, whether or not you pass any parameters. The following example gives the current time (current when this example was run):
> Date();
Wed Feb 27 2013 23:51:46 GMT-0800 (PST)
> Date(1, 2, 3, "it doesn't matter");
Wed Feb 27 2013 23:51:52 GMT-0800 (PST)
> typeof Date();
"string"
> typeof new Date();
"object"
Once you've created a date object, there are lots of methods you can call on that object. Most of the methods can be divided into set*() and get*() methods, for example, getMonth(), setMonth(), getHours(), setHours(), and so on. Let's see some examples.
Creating a date object by writing the following code:
> var d = new Date(2015, 1, 1);
> d.toString();
Sun Feb 01 2015 00:00:00 GMT-0800 (PST)
Setting the month to March (months start from 0):
> d.setMonth(2);
1425196800000
> d.toString();
Sun Mar 01 2015 00:00:00 GMT-0800 (PST)
Getting the month by writing the following code:
> d.getMonth();
2
In addition to all the methods of date objects, there are also two methods (plus one more added in ES5) that are properties of the Date() function/object. These do not need a date object; they work just like the Math object methods. In class-based languages, such methods would be called static because they don't require an instance.
The Date.parse() method takes a string and returns a timestamp:
> Date.parse('Jan 11, 2018'),
1515657600000
The Date.UTC() method takes all the parameters for year, month, day, and so on, and produces a timestamp in Universal Time (UT):
> Date.UTC(2018, 0, 11);
1515628800000
As the new Date() constructor can accept timestamps, you can pass the result of Date.UTC() to it. Using the following example, you can see how UTC() works with Universal Time, while new Date() works with local time:
> new Date(Date.UTC(2018, 0, 11));
Wed Jan 10 2018 16:00:00 GMT-0800 (PST)
> new Date(2018, 0, 11);
Thu Jan 11 2018 00:00:00 GMT-0800 (PST)
The ES5 addition to the Date constructor is the now()method, which returns the current timestamp. It provides a more convenient way to get the timestamp instead of using the getTime() method on a Date object as you would in ES3:
> Date.now();
1362038353044
> Date.now() === new Date().getTime();
true
You can think of the internal representation of the date being an integer timestamp and all other methods being sugar on top of it. So, it makes sense that valueOf() is a timestamp:
> new Date().valueOf();
1362418306432
Also, dates cast to integers with the + operator:
> +new Date();
1362418318311
Let's look at one final example of working with Date objects. I was curious about which day my birthday falls on in 2016:
> var d = new Date(2016, 5, 20);
> d.getDay();
1
Starting the count from 0 (Sunday), 1 means Monday. Is that so?
> d.toDateString();
"Mon Jun 20 2016"
ok, good to know, but Monday is not necessarily the best day for a party. So, how about a loop that shows how many times June 20 is a Friday from year 2016 to year 3016, or better yet, let's see the distribution of all the days of the week. After all, with all the progress in DNA hacking, we're all going to be alive and kicking in 3016.
First, let's initialize an array with seven elements, one for each day of the week. These will be used as counters. Then, as a loop goes up to 3016, let's increment the counters:
var stats = [0, 0, 0, 0, 0, 0, 0];
Here is the loop:
for (var i = 2016; i < 3016; i++) {
stats[new Date(i, 5, 20).getDay()]++;
}
Here is the result:
> stats;
[140, 146, 140, 145, 142, 142, 145]
142 Fridays and 145 Saturdays. Woo-hoo!
Regular expressions provide a powerful way to search and manipulate text. Different languages have different implementations (think dialects) of the regular expression syntax. JavaScript uses the Perl 5 syntax.
Instead of saying regular expression, people often shorten it to regex or regexp.
A regular expression consists of:
- A pattern you use to match text
- Zero or more modifiers (also called flags) that provide more instructions on how the pattern should be used
The pattern can be as simple as literal text to be matched verbatim, but that's rare, and in such cases you're better off using indexOf(). Most of the time, the pattern is more complex and could be difficult to understand. Mastering regular expressions' patterns is a large topic, which won't be discussed in full detail here. Instead, you'll see what JavaScript provides in terms of syntax, objects, and methods in order to support the use of regular expressions. You can also refer to Appendix D, Regular Expressions, to help you when you're writing patterns.
JavaScript provides the RegExp() constructor, which allows you to create regular expression objects:
> var re = new RegExp("j.*t");
There is also the more convenient regexp literal notation:
> var re = /j.*t/;
In the preceding example, j.*t is the regular expression pattern. It means " matches any string that starts with j, ends with t, and has zero or more characters in between ". The asterisk (*) means " zero or more of the preceding, " and the dot (.) means " any character ". The pattern needs to be quoted when passed to a RegExp() constructor.
Regular expression objects have the following properties:
global: If this property isfalse, which is the default, the search stops when the first match is found. Set this totrueif you want all matches.ignoreCase: When the match is case insensitive, this property defaults tofalse(meaning the default is a case-sensitive match).multiline: Search matches that may span over more than one line default tofalse.lastIndex: The position at which to start the search; this defaults to0.source: This contains theRegExppattern.
None of these properties, except for lastIndex, can be changed once the object has been created.
The first three items in the preceding list represent the regex modifiers. If you create a regex object using the constructor, you can pass any combination of the following characters as a second parameter:
gforglobaliforignoreCasemformultiline
These letters can be in any order. If a letter is passed, the corresponding modifier property is set to true. In the following example, all modifiers are set to true:
> var re = new RegExp('j.*t', 'gmi'),
Let's verify:
> re.global;
true
Once set, the modifier cannot be changed:
> re.global = false;
> re.global;
true
To set any modifiers using the regex literal, you add them after the closing slash:
> var re = /j.*t/ig;
> re.global;
true
Regex objects provide two methods you can use to find matches-test() and exec(). They both accept a string parameter. The test() method returns a Boolean (true when there's a match, false otherwise), while exec() returns an array of matched strings. Obviously, exec() is doing more work, so use test() only if you really need to do something with the matches. People often use regular expressions to validate data. In this case, test() should be enough.
In the following example, there is no match because of the capital J:
> /j.*t/.test("Javascript");
false
A case-insensitive test gives a positive result:
> /j.*t/i.test("Javascript");
true
The same test using exec() returns an array, and you can access the first element as shown here:
> /j.*t/i.exec("Javascript")[0];
"Javascript"
Previously in this chapter, you learned about string objects and how you can use the indexOf() and lastIndexOf() methods to search within text. Using these methods, you can only specify literal string patterns to search. A more powerful solution would be to use regular expressions to find text. String objects offer you this ability.
String objects provide the following methods that accept regular expression objects as parameters:
match(): Returns an array of matchessearch(): Returns the position of the first matchreplace(): Allows you to substitute matched text with another stringsplit(): Accepts a regexp when splitting a string into array elements
Let's look at some examples of using the search()and match() methods. First, you create a string object:
> var s = new String('HelloJavaScriptWorld'),
Using match(), you get an array containing only the first match:
> s.match(/a/);
["a"]
Using the g modifier, you perform a global search, so the result array contains two elements:
> s.match(/a/g);
["a", "a"]
A case-insensitive match is as follows:
> s.match(/j.*a/i);
["Java"]
The search() method gives you the position of the matching string:
> s.search(/j.*a/i);
5
The replace() method allows you to replace the matched text with some other string. The following example removes all capital letters (it replaces them with blank strings):
> s.replace(/[A-Z]/g, ''),
"elloavacriptorld"
If you omit the g modifier, you're only going to replace the first match:
> s.replace(/[A-Z]/, ''),
"elloJavaScriptWorld"
When a match is found, if you want to include the matched text in the replacement string, you can access it using $&. Here's how to add an underscore before the match while keeping the match:
> s.replace(/[A-Z]/g, "_$&");
"_Hello_Java_Script_World"
When the regular expression contains groups (denoted by parentheses), the matches of each group are available as $1 for the first group, $2 the second, and so on:
> s.replace(/([A-Z])/g, "_$1");
"_Hello_Java_Script_World"
Imagine you have a registration form on your web page that asks for an e-mail address, username, and password. The user enters their e-mail IDs, and then, your JavaScript kicks in and suggests the username, taking it from the e-mail address:
> var email = "[email protected]"; > var username = email.replace(/(.*)@.*/, "$1"); > username; "stoyan"
When specifying the replacement, you can also pass a function that returns a string. This gives you the ability to implement any special logic you may need before specifying the replacements:
> function replaceCallback(match) {
return "_" + match.toLowerCase();
}
> s.replace(/[A-Z]/g, replaceCallback);
"_hello_java_script_world"
The callback function receives a number of parameters (the previous example ignores all but the first one):
- The first parameter is the
match - The last is the string being searched
- The one before last is the position of the
match - The rest of the parameters contain any strings matched by any groups in your regex pattern
Let's test this. First, let's create a variable to store the entire arguments array passed to the callback function:
> var glob;
Next, define a regular expression that has three groups and matches e-mail addresses in the format [email protected]:
> var re = /(.*)@(.*).(.*)/;
Finally, let's define a callback function that stores the arguments in glob and then returns the replacement:
var callback = function () {
glob = arguments;
return arguments[1] + ' at ' +
arguments[2] + ' dot ' + arguments[3];
};
Now, perform a test:
> "[email protected]".replace(re, callback); "stoyan at phpied dot com"
Here's what the callback function received as arguments:
> glob;
["[email protected]", "stoyan", "phpied", "com", 0,
"[email protected]"]
You already know about the split() method, which creates an array from an input string and a delimiter string. Let's take a string of comma-separated values and split it:
> var csv = 'one, two,three ,four';
> csv.split(','),
["one", " two", "three ", "four"]
Because the input string happens to have random inconsistent spaces before and after the commas, the array result has spaces too. With a regular expression, you can fix this using s*, which means zero or more spaces:
> csv.split(/s*,s*/);
["one", "two", "three", "four"]
One last thing to note is that the four methods that you have just seen (split(), match(), search(), and replace()) can also take strings as opposed to regular expressions. In this case, the string argument is used to produce a new regex as if it were passed to new RegExp().
An example of passing a string to replace is shown as follows:
> "test".replace('t', 'r'),
"rest"
The preceding lines of code are the same as the following one:
> "test".replace(new RegExp('t'), 'r'),
"rest"
When you pass a string, you cannot set modifiers the way you do with a normal constructor or regex literal. There's a common source of errors when using a string instead of a regular expression object for string replacements, and it's due to the fact that the g modifier is false by default. The outcome is that only the first string is replaced, which is inconsistent with most other languages and a little confusing. Here is an example:
> "pool".replace('o', '*'),
"p*ol"
Most likely, you want to replace all occurrences:
> "pool".replace(/o/g, '*'),
"p**l"
Errors happen, and it's good to have the mechanisms in place so that your code can realize that there has been an error condition and can recover from it in a graceful manner. JavaScript provides the try, catch, and finally statements to help you deal with errors. If an error occurs, an error object is thrown. Error objects are created using one of these built-in constructors-EvalError, RangeError, ReferenceError, SyntaxError, TypeError, and URIError. All these constructors inherit from Error.
Let's just cause an error and see what happens. What's a simple way to cause an error? Just call a function that doesn't exist. Type this into the console:
> iDontExist();
You'll get something like the following:
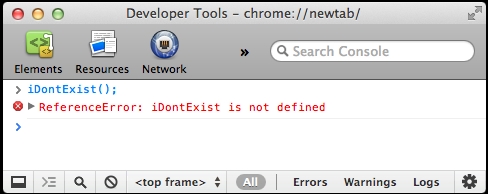
The display of errors can vary greatly between browsers and other host environments. In fact, most recent browsers tend to hide the errors from the users. However, you cannot assume that all of your users have disabled the display of errors, and it is your responsibility to ensure an error-free experience for them. The previous error propagated to the user, because the code didn't try to trap (catch) this error. The code didn't expect the error and was not prepared to handle it. Fortunately, it's trivial to trap the error. All you need is the try statement followed by a catch statement.
This code hides the error from the user:
try {
iDontExist();
} catch (e) {
// do nothing
}
Here you have:
- The
trystatement followed by a block of code. - The
catchstatement followed by a variable name in parentheses and another block of code.
There can be an optional finally statement (not used in this example) followed by a block of code, which is executed regardless of whether there was an error or not.
In the previous example, the code block that follows the catch statement didn't do anything. However, this is the place where you put the code that can help recover from the error, or at least give feedback to the user that your application is aware that there was a special condition.
The variable e in the parentheses after the catch statement contains an error object. Like any other object, it contains properties and methods. Unfortunately, different browsers implement these methods and properties differently, but there are two properties that are consistently implemented-e.name and e.message.
Let's try this code now:
try {
iDontExist();
} catch (e) {
alert(e.name + ': ' + e.message);
} finally {
alert('Finally!'),
}
This will present an alert() showing e.name and e.message and then another alert() saying Finally!.
In Firefox and Chrome, the first alert will say ReferenceError: iDontExist is not defined. In Internet Explorer, it will be TypeError: Object expected. This tells us two things:
- The
e.namemethod contains the name of the constructor that was used to create the error object - As the error objects are not consistent across host environments (browsers), it would be somewhat tricky to have your code act differently depending on the type of error (the value of
e.name)
You can also create error objects yourself using new Error() or any of the other error constructors and then let the JavaScript engine know that there's an erroneous condition using the throw statement.
For example, imagine a scenario where you call the maybeExists() function and after that make calculations. You want to trap all errors in a consistent way, no matter whether the error is that maybeExists() doesn't exist or that your calculations found a problem. Consider the following code:
try {
var total = maybeExists();
if (total === 0) {
throw new Error('Division by zero!'),
} else {
alert(50 / total);
}
} catch (e) {
alert(e.name + ': ' + e.message);
} finally {
alert('Finally!'),
}
This code will alert different messages depending on whether or not maybeExists() is defined and the values it returns:
- If
maybeExists()doesn't exist, you get ReferenceError: maybeExists() is not defined in Firefox and TypeError: Object expected in IE - If
maybeExists()returns0, you get Error: Division by zero! - If
maybeExists()returns2, you get an alert that says 25
In all cases, there will be a second alert that says Finally!.
Instead of throwing a generic error, thrownewError('Divisionbyzero!'), you can be more specific if you choose to, for example, throw thrownewRangeError('Divisionbyzero!'). Alternatively, you don't need a constructor; you can simply throw a normal object:
throw {
name: "MyError",
message: "OMG! Something terrible has happened"
}
This gives you cross-browser control over the error name.