
This chapter introduces the important concept of asynchronous programming and how JavaScript is an ideal language to utilize it. The other topic that we will cover in this chapter is meta programming with proxies. These two concepts are introduced in ES6.
In this chapter, our primary focus is to understand asynchronous programming, before we jump into the language - specific constructs, let's spend time in understanding the concept first.
The first model-the synchronous model-is where it all began. This is the simplest model of programming. Each task is executed one at a time, and only after the first task completes execution can, the next task start. When you program in this model, we expect that all tasks before the current task are complete and there is no error. Take a look at the following figure:

The single threaded asynchronous model is a familiar model we all know. However, this model can be wasteful and optimized. For any nontrivial programs composed of several different tasks, this model can be slow. Consider the following hypothetical scenario as an example:
var result = database.query("SELECT * FROM table");
console.log("After reading from the database");
With the synchronous model in mind, two tasks are executed one after the other. This means that the second statement will only be executed once the first has completed execution. Assuming the first statement is a costly one and takes 10 seconds (it is normal to take even more time to read from a remote database), the second statement will be blocked.
This is a serious problem when you need to write high - performance and scalable systems. There is another problem that manifests when you are writing programs where you need to write interfaces for human interactions like we do on websites that run on a browser. While you are performing a task that may take some time, you cannot block the user. They may be entering something in an input field while the costly task is running; it would be a terrible experience if we block user input while we are busy doing a costly operation. In such scenarios, the costly tasks need to be run in the background while we can happily take input from the user.
To solve this, one solution is to split each task into its own thread of control. This is called the multi-threaded or threaded model. Consider the following figure:

The difference is how the tasks are split. In the threaded model, each task is performed in its own thread of control. Usually, threads are managed by the operating system and can be run in parallel on different CPU cores or on a single core with appropriate thread scheduling done by the CPU. With modern CPUs, the threaded model can be extremely optimal in performance. Several languages support this popular model. Although a popular model, the threaded model can be complex to implement in practice. The threads need to communicate and coordinate with each other. Inter-thread communication can get tricky very quickly. There are variations of the threaded model where the state is immutable. In such cases, the model becomes simpler as each thread is responsible for immutable state and there is no need to manage state between threads.
The third model is what interests us the most. In this model, tasks are interleaved in a single thread of control. Consider the following figure:
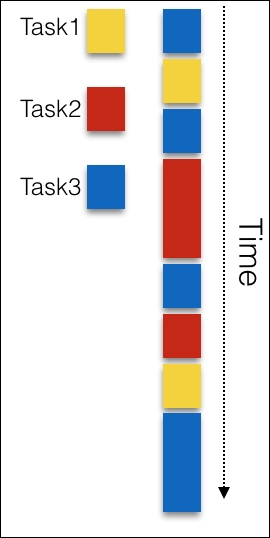
The asynchronous model is simpler because you have only one thread. When you are executing one task, you are sure that only that task is being executed. This model doesn't require complex mechanism for inter-thread coordination and, hence, is more predictable. There is one more difference between the threaded and the asynchronous models; in the threaded model, you don't have a way to control the thread execution as the thread scheduling is mostly done by the operating system. However, in the asynchronous model, there is no such challenge.
In which scenarios can the asynchronous model outperform the synchronous model? If we are simply splitting tasks into smaller chunks, intuitively, even the smaller chunks will take quite an amount of time when you add them up in the end.
There is a significant factor we have not yet considered. When you execute a task, you will end up waiting on something-a disk read, a database query, or a network call; these are blocking operations. When you enter a blocked mode, your task simply waits in the synchronous model. Take a look at the following figure:
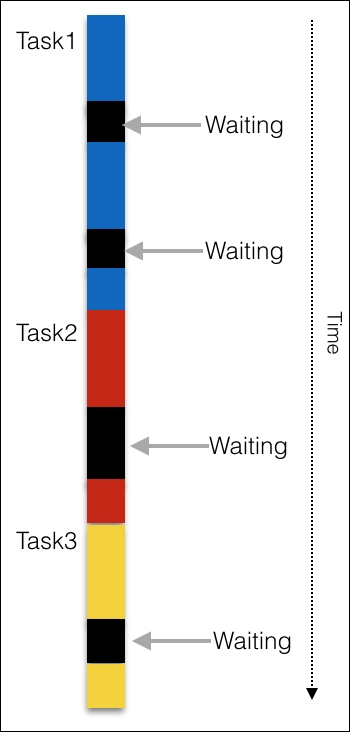
In the preceding diagram, the black blocks are where a task is waiting on something. What are the typical operations that can cause such a block? A task is performed in a CPU and RAM. A typical CPU and RAM can handle data transfer orders of magnitude faster than a typical disc read or a network call.
Tip
Please refer to a comparison (https://gist.github.com/jboner/2841832) of latencies between CPU, internal memory, and discs.
When your tasks wait on an I/O (Input/Output) from such sources, the latency is unpredictable. For a synchronous program that does a lot of I/O, this is a recipe for bad performance.
The most important difference between the synchronous and asynchronous models is the way they handle blocking operations. In the asynchronous model, a program, when faced with a task that encounters a block, executes another task without waiting for the blocking operation to finish. In a program where there are potential blocks, an asynchronous program outperforms an equivalent synchronous program because less time is spent on waiting. A slightly inaccurate visualization of such a model would be as seen in the following figure:

With this conceptual background of the asynchronous model with us, we can look at language - specific constructs to support this model.