
Tuning OpenACC loop execution
Saber Feki*; Malek Smaoui
†
* KAUST Supercomputing Laboratory, King Abdullah University of Science and Technology, Thuwal, Saudi Arabia
† Computer, Electrical, Mathematical Sciences and Engineering Division, King Abdullah University of Science and Technology, Thuwal, Saudi Arabia
Abstract
The purpose of this chapter is to help OpenACC developer who is already familiar with the basic and essential directives to further improve his code performance by adding more descriptive clauses to OpenACC loop constructs.
At the end of this chapter the reader will:
• Have a better understanding of the purpose of the OpenACC loop construct and its associated clauses illustrated with use cases
• Use the acquired knowledge in practice to further improve the performance of OpenACC accelerated codes
Keywords
OpenACC; Loop construct; Loop clauses; Use cases; Performance tuning
The purpose of this chapter is to help OpenACC developer who is already familiar with the basic and essential directives to further improve his code performance by adding more descriptive clauses to OpenACC loop constructs.
At the end of this chapter the reader will:
• Have a better understanding of the purpose of the OpenACC loop construct and its associated clauses illustrated with use cases
• Use the acquired knowledge in practice to further improve the performance of OpenACC accelerated codes
Whether you strive for scientific discovery or for professional achievement or may be working towards a degree, you certainly want to make the most of your resources. For instance, as a code developer/writer/programmer, you want to get the best of the computation devices available to you, whether it is Central Processing Unit (CPU) or accelerator. However, it is also known that such objective requires investing time and effort, which themselves are valuable resources—in both learning and applying the necessary skills. OpenACC design is based on a compromise between productivity and performance. Being a directive based paradigm, it is easier to learn and use compared to other code acceleration paradigms like CUDA for instance. So, make your life easy: start with the highest-level Application Programming Interface (API) (like OpenACC), then, eventually, delve down into lower-level APIs to achieve higher performance or to use a specific functionality.
If you are reading this chapter, you should already know how to run compute-intensive/parallelizable portions of your code on an accelerator using OpenACC. In other words, you should be familiar with the OpenACC kernels and the OpenACC parallel constructs which allow you to define a parallel execution section. If done properly, i.e., you managed data movements wisely with the OpenACC data constructs, you should have already seen significant performance improvement over native CPU code. But, it also means that you are striving for even better performance. Fortunately, simple as it is, OpenACC allows you to further improve your code performance, in a short time, while still using a high-level API.
For that purpose, and as it is very likely that the code portions that will be running on the accelerator are loops, you can apply the OpenACC loop construct to the loop which immediately follows, in order to provide hints to the compiler with more details about the parallelization and distribution of iterations. This implies that the loop already has to be part of a code section that will be executing on the accelerator. However, although perfectly legitimate, a bare loop construct is probably not very much useful (even risky). It is only through the multitude of associated clauses that you get to describe what type of parallelism should be used for executing the loop, and define any necessary reduction operations.
The Loop Construct
Referring to OpenACC standard version 2.5, the general syntax of the loop construct is (Figs. 1 and 2):


– In Fortran
where [clause-list] is one or a combination of clauses and their arguments properly selected from the following list (Fig. 3).
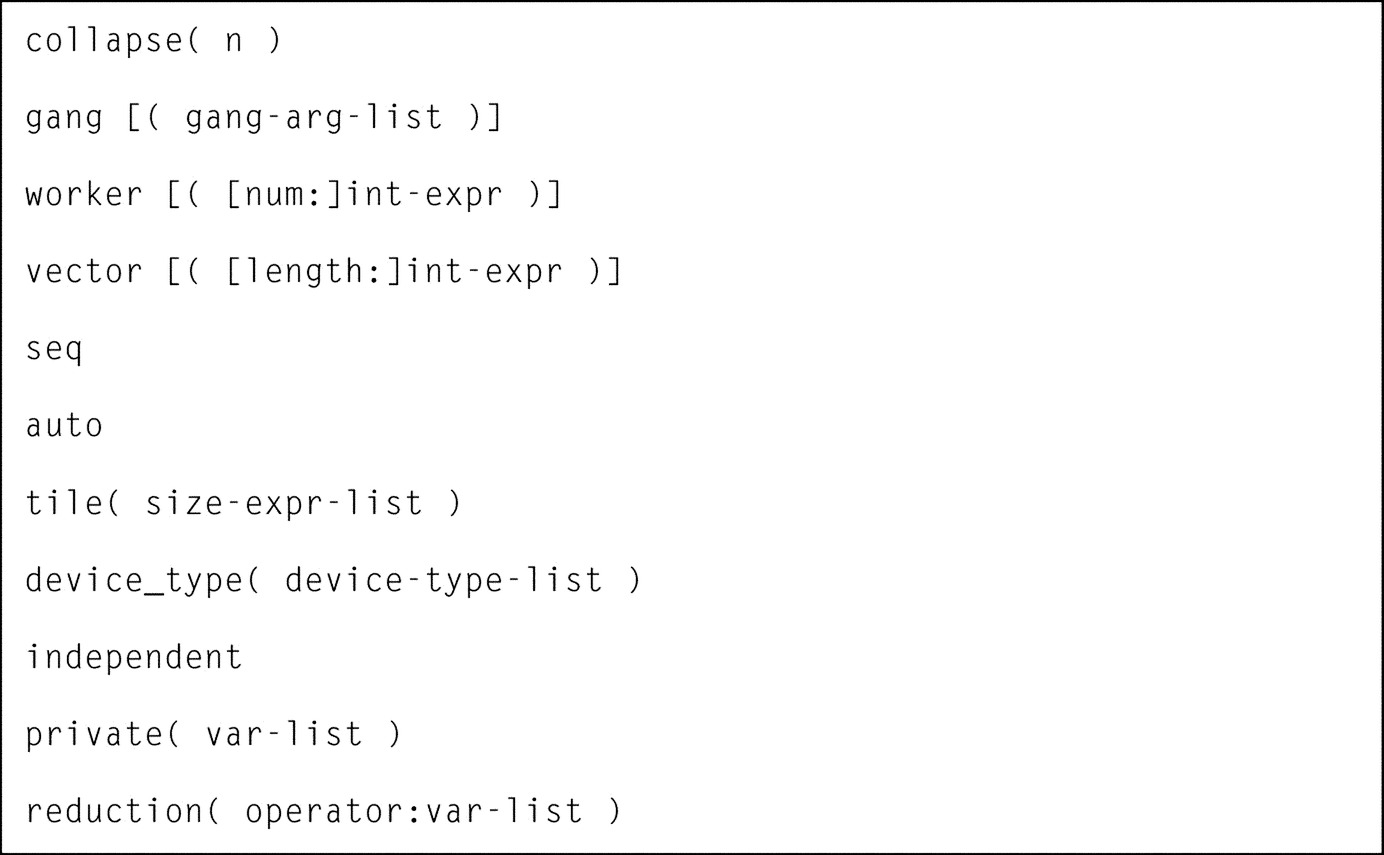
Throughout the rest of this chapter, the significance of most of these clauses and corresponding arguments will be explained and their usage illustrated using both a simple code example.
The first code is a naïve sequential implementation of the matrix-matrix multiplication operation, preceded by an initialization loop. You will find that, though pretty simple, it is a tangible example where the use of the loop construct is quite valuable (Fig. 4).

You may have noticed that the operands a and b are initialized with artificial values as this is just an illustrative example. In a more useful/purposeful code, these operands would be input to the program or would be result of previous calculations. It is why only the computation loops are considered for acceleration (and performance measurement).
Compiling this code using the Portland Group (PGI) compiler version 15.10 gives the following output while using the compiler flags “-acc -fast ta=nvidia -Minfo= accel”:
A quick analysis of this output reveals that the compiler decided to parallelize the two outermost loops (counters i and j). It also detected a data-dependency carried by the innermost loop and decided to execute this loop sequentially (Fig. 5).

Basic Loop Optimization Clauses
The auto Clause
With the auto clause, you can specify that the compiler is responsible for analyzing the loop and determining whether its iterations are data-independent and, consequently decide whether to apply parallelism to this loop or whether to run the loop sequentially. When the parent compute construct is a kernels construct, the compiler treats a loop construct with no independent or seq clause as if it has the auto clause.
The above example could be simply annotated with a loop construct either bare or with the auto clause before each of the nested loops, as follows (Fig. 6):

Since the compiler is still sole decider of the parallelization strategy, the compilation output does not change from previously and evidently neither does the code performance.
The above description of the auto clause, along with the example, might lead you to think that this clause is useless. Well, this clause is probably more useful when the parent compute clause is parallel and the explanation can be found right in the next section as it requires understanding of the more influential clause: independent.
The independent Clause
The independent clause allows you to indicate that the iterations of the loop are data-independent with respect to each other. As a result, the compiler will generate code that computes these iterations using independent asynchronous threads.
If you examine the loops in our previous example code, you will see that the computation of a single element of the product matrix does not depend on values of other elements of the same matrix. So, the two outermost computation loops are independent, which confirms the compiler’s previous analysis. However, for the innermost loop, each iteration requires the value of c[i][j] from the previous one: that is a data-dependency that excludes the use of the independent clause.
Note that you must exercise caution when considering this clause. First, if you happen to miss a data-dependency in a specific loop and annotate it with the independent clause, your program will most probably give you incorrect and inconsistent results. Then, there is also the case where the independent clause is implied on all loop constructs, unless explicitly overridden using the auto or the seq clauses, and that is when the parent compute construct is a parallel construct. And here rises the importance of the auto clause: using the loop construct with the auto clause is always safer than keeping it bare.
The seq Clause
If for some reason (most often a data-dependency), a loop has to execute sequentially, you need only annotate it with the loop construct along with the seq clause. This clause will override any automatic parallelization or vectorization that might be attempted by the compiler. Let’s note that compilers tend to operate on the safe side when it comes to data-dependency detection: false-positives are much more frequent than false-negatives. In other words, the seq clause is absolutely needed in the very rare cases where the compiler parallelizes a loop containing a data dependency, which would produce erroneous numerical results.
For it is quite straight forward, the compiler has already found out which loops were independent and which required sequential execution in our matrix-matrix multiplication example. So, the following annotation is only for the sake of illustrating the use of the independent and seq clauses but does not have any further influence on the extent of parallelization (Fig. 7).

The reduction Clause
Some data-dependencies can be overcome with reductions. If you are not already familiar with reductions, then the best way to proceed is via example and it happens that our matrix-matrix multiplication example is perfect for that purpose. The innermost computation loop consists in gradually accumulating the sum of the a[i][k] times b[k][j] multiplications performed at each iteration. The multiplication operations are independent through the iterations and thus could be performed in parallel, whereas the sum operations are what prevents parallelization of the whole loop. So, if the result of the multiplications could be individually saved to temporary variables, then it becomes possible to parallelize them. The sums are then performed with those temporary variables as operands after their values become available. This sounds like quite a bit of code modification and also extra storage that needs to be allocated. Fortunately, the compiler can do that automatically when hinted about this reduction operation via the reduction clause.
More generally, the reduction clause requires specifying arguments: a reduction operator and one or more scalar variables. For each reduction variable, a private copy is created and initialized for that operator according to the table in Fig. 8. While executing, threads will store partial results in their corresponding private copies of the variable. When all the threads finish the loop execution, the partial results are combined using the specified reduction operator along with the original value of the variable. The global result becomes available at the end of the parallel or kernels region if the loop has gang parallelism, and at the end of the loop otherwise.
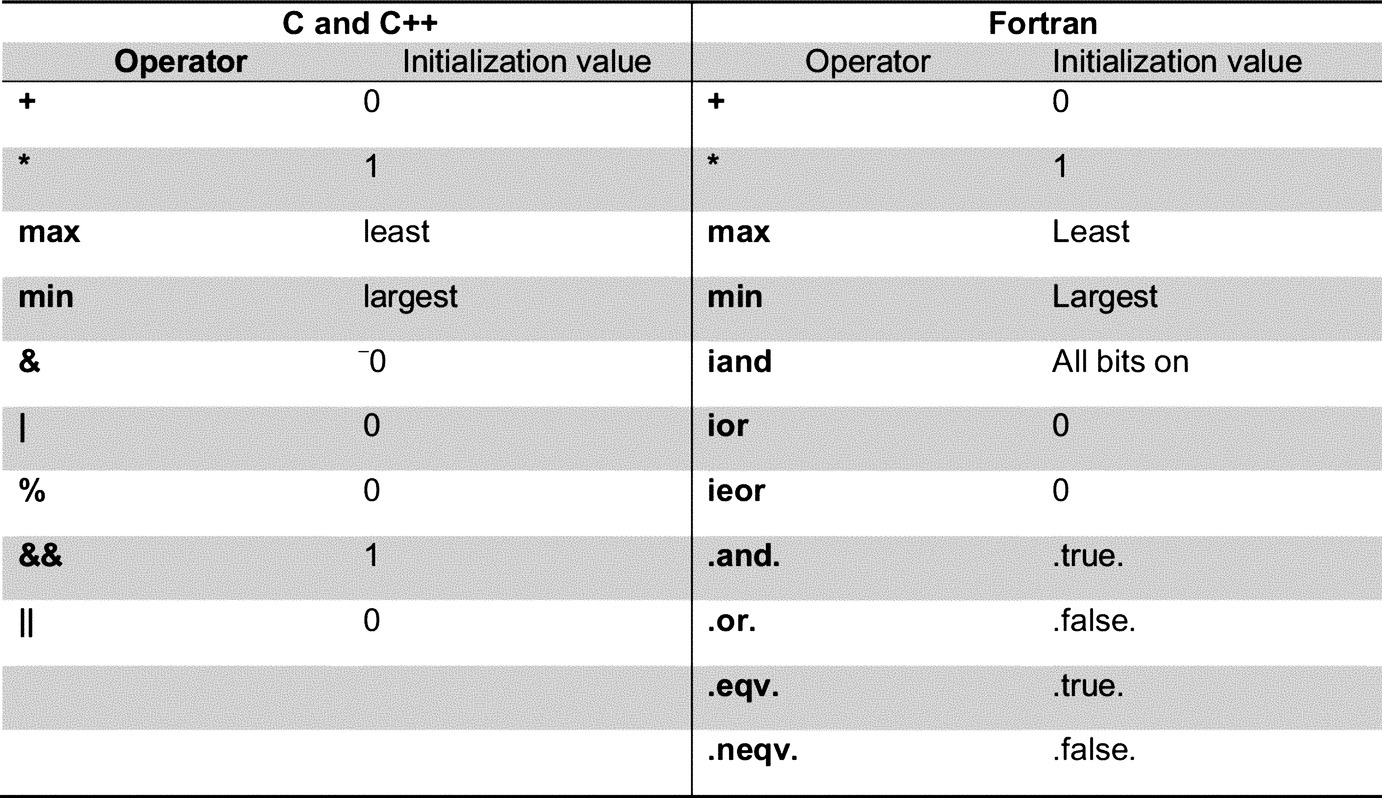
In our example, the reduction result supposedly should go in c[i][j]. However, the variable argument to the reduction clause is required to be scalar. Thus, a slight code modification is entailed, where a temporary scalar variable tmp replaces c[i][j] within the loop annotated with the reduction clause. Then, a simple assignment outside the loop stores the computation result in its final destination (Fig. 9).

The compilation output after the reduction is as follows (Fig. 10):

You can note the difference with the previous compilation output regarding the innermost loop parallelization.
On a side note, the PGI compiler is capable of detecting the reduction without even referring to a loop directive with a reduction clause, as long as a scalar variable is used instead of the matrix element c[i][j].
The collapse Clause
So far, you’ve seen that the OpenACC loop construct is associated with the immediately following loop. One directive is required for each nested loop. This tends to be cumbersome especially if multiple nested loops are to be treated in the same way. The collapse clause comes in handy in such a case. The argument to the collapse clause is a constant positive integer, which specifies how many tightly nested loops are associated with the loop construct. Consequently, you can describe the scheduling of the iterations of these loops using a single loop construct according to the rest of its clauses (other than the collapse).
In our example, we replace the two first loop directives with a single one that comes with a collapse(2) clause (Fig. 11).

The corresponding compilation output is as follows (Fig. 12):

Another case where the collapse clause is of great benefit is when the loop count in any of some tightly nested loops is relatively small compared to the available number of threads in the device. By creating a single iteration space across all the nested loops, the iteration count tends to increase thus allowing the compiler to extract more parallelism. Our example, however, is not a good illustration of this case.
Advanced Loop Optimization Clauses
The gang, worker, and vector Clauses
A typical accelerator architecture exhibits multiple levels of parallelism. For example, NVIDIA GPUs consists of multiple streaming multiprocessors, each of which can schedule multiple blocks of warps, which are 32-wide Single Instruction Multiple Data (SIMD) threads. On the other hand, Intel Xeon Phi, has a large number of x86_64 cores, each of which can execute up to four threads of 512-bits-wide SIMD instructions.
In line with these common architectural considerations, OpenACC has been equipped with the gang, worker, and vector clauses to allow you to map the loop iterations to the target device using up to three levels of parallelism. Please note that these clauses can also be associated with the parallel or kernels constructs parent to a loop construct. This chapter does not discuss this specific case and rather focuses on their usage while accompanying a loop construct.
The first level of parallelism can be specified using the gang clause, which suggests that the iterations of the associated loop or loops are to be executed in parallel across multiple gangs. Furthermore, you can add an integer argument to state the number of gangs to be scheduled on the device.
The second level of parallelism can be described using a worker clause to indicate that the iterations of the associated loops are to be executed in parallel across the workers within a gang. You can optionally add an integer argument to specify how many workers per gang to use to execute the iterations of this loop.
The third level of parallelism can be expressed using the vector clause, which specifies that the iterations of the associated loop or loops are to be executed with vector or SIMD processing. Similarly, you can an optional integer argument to determine the vector length. Typical vector lengths for Graphic Processing Unit (GPU) targets are multiple of the warp size, i.e., 32 in the latest generations.
If you do not specify these clauses and/or their arguments, the compiler will use its heuristics to make the best mappings.
On NVIDIA GPUs, a possible mapping could be gang to thread blocks, worker to warps, and vector to threads. Alternatively, you can omit the worker clause and map gang to thread blocks and vector to threads within a block.
In our example, we further annotate the outer loop construct with the gang clause and the subsequent nested loop with the vector clause. Then, the optional integer argument for both clauses is tuned to achieve better performance with the best combination of number of thread blocks and number of threads per block. While our example is tuned manually, it is possible to obtain the best values using some available auto-tuning tools (Fig. 13).

The corresponding compilation output is as follows (Fig. 14):

You can clearly see that the compiler took into consideration the hint provided with the additional clauses and their corresponding arguments.
The tile Clause
The tile clause causes each loop in the loop nest to be split into two loops: an outer tile loop and an inner element loop. Then, the tile loops will be reordered to be outside all the element loops, and the element loops will all be inside the tile loops. For instance, if you have two nested loops as follows (Fig. 15):
Splitting these loops into tiles of size tileX by tileY results in the following code (for simplicity, we shall assume that sizeX and sizeY are respectively multiples of tileX and sizeY but even if it is not the case, tiling is still possible with few tiles not reaching tileX by tileY size) (Fig. 16):

Generally, you would use the tile clause to take advantage of data locality which in many cases is an important factor contributing in the improvement of the code performance. Tiling is an operation that can be parameterized where the parameters are obviously the tile sizes. Consequently, the tile clause takes as argument a list of one or more constant positive integer tile sizes. If there are n tile sizes in the list, the loop construct must be immediately followed by n tightly nested loops. Alternatively, you can use an asterisk instead to let the compiler select an appropriate value.
The first two nested loops in our example are tiled using the tile clause with two integer arguments that have been tuned for better performance of the kernel. The third nested loop could not be tiled, as it is not tightly nested with the two other loops (Fig. 17).

The corresponding compilation output is as follows (Fig. 18):
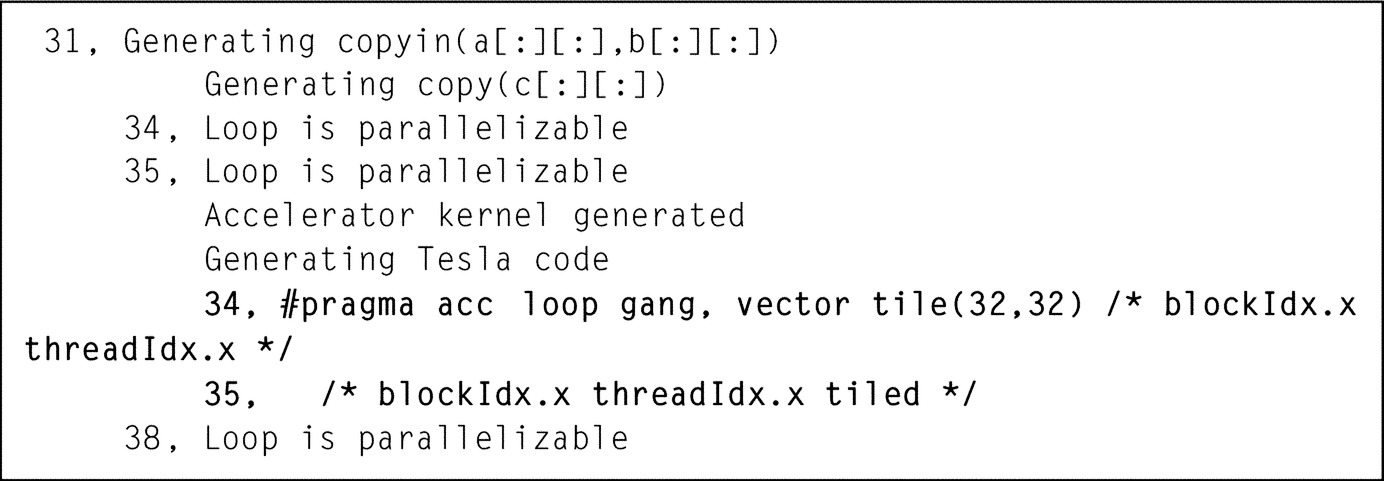
The compiler output clearly reflects the effect of the tile clause and its corresponding argument. When using two asterisks (*,*) instead of (32,32) arguments, the compiler chose tile arguments (32,4) instead and resulted in a longer execution time.
Performance Results
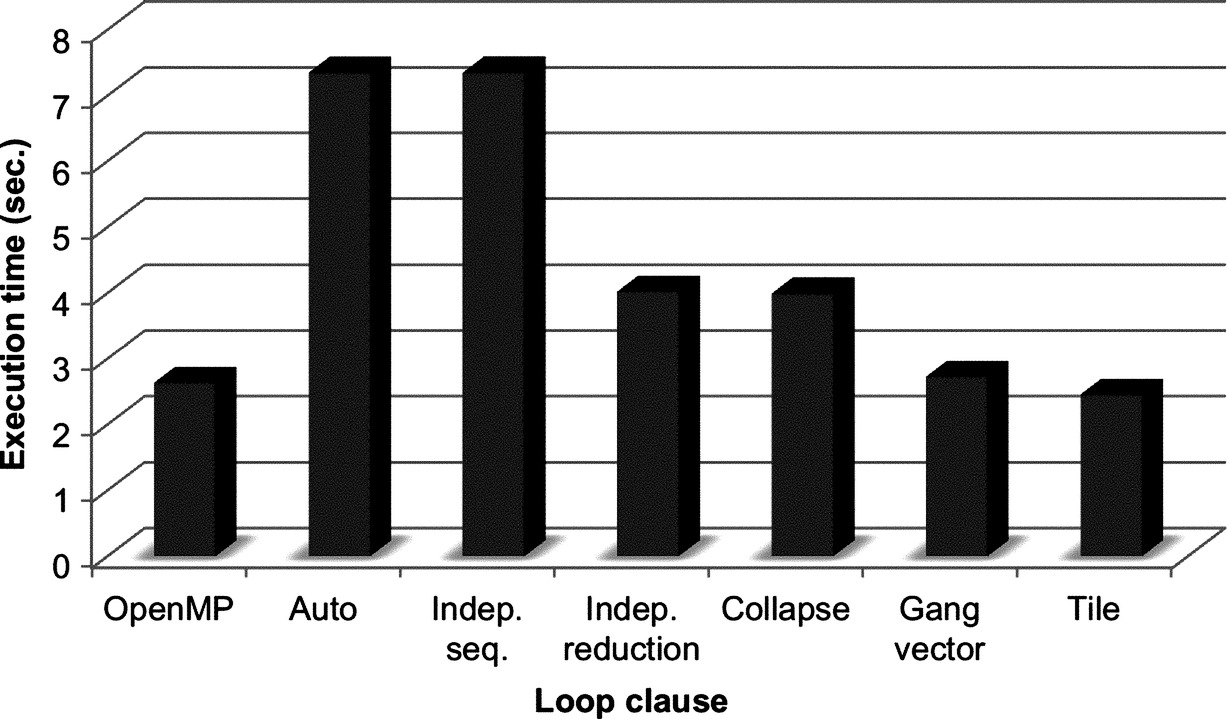
In Fig. 19, you will find the performance results obtained using OpenMP and OpenACC with the different loop clauses described in this chapter. Please note that some time and effort were invested to fine-tune the argument values where it applied. These results are provided to illustrate the performance benefit that you could get from tuning your code but may not be the best ever possible.
The test bed used for performance evaluation consists of a dual socket system hosting NVIDIA Kepler K20c GPU card. Each CPU socket contains an eight-core Sandy Bridge Intel(R) Xeon(R) CPU E5-2650, running at a clock speed of 2.00 GHz.
You can perceive a first good performance advantage when the third nested loop is parallelized using the reduction clause with the necessary code modification. A second significant performance gain is obtained by fine-tuning the execution of the loops using either the gang and vector clauses or the tile clause with careful choice of their corresponding optional parameters. The tuned OpenACC accelerated code running on the GPU was almost twice as fast as its OpenMP counterpart running on the multicore CPU.
Conclusion
The OpenACC standard allow for a multitude of options to annotate the loop construct in order to provide hints to the compiler about the type of parallelism that should be used for executing the loop and define any necessary reduction operations. Some of the clauses described in this chapter have special use cases; others are more common and applicable to the majority of codes. Further tuning of some integer arguments in some of the clauses is typically good to get better performance of the accelerated kernel on the target hardware. You can refer to some research work that has been conducted for auto-tuning these parameters. Even though this chapter focuses on explaining the different clauses that can be used with the loop construct, developer may use a combination of many of these in their kernels. Fig. 17 illustrates this aspect by using both tile and reduction clauses for example.