
The customer is a large, progressive credit union with a growing personal and business client base approaching 100,000 members. They offer a full set of services including banking, loans, mortgages, retirement funds, brokerage, and financial planning.
The customer relationship group in the credit union maintains their customer information in a commercial customer relationship management (CRM) system. They would like to track various pieces of information about their clients over time, but the CRM system maintains only a snapshot of the current status of their clients. Data is uploaded from the CRM system once per month into a data warehouse. The CRM system does not indicate what data has changed, and the data in the data warehouse is simply overwritten.
The credit union also receives monthly feeds of all the customer transactions for the preceding month from a central service provider. However, the CRM system and the financial transaction system feed are independent. The transactions contain an account number and a transaction date that could be used to determine the value of the client attributes at the time of the transaction, but this is of little analytic value because the data warehouse contains CRM data for only one period. No existing facility enables users to easily generate analytic reports that combine data from both systems and provide a view of any point in history. It is not even possible to reprint a previous report with the same data after more than one month, because the data has been replaced.
The solution we are going to examine builds a data warehouse designed with the ability to correctly represent historical information. We will use Integration Services to manage the loading and updating of slowly changing dimension tables and Analysis Services to analyze the facts in the context of the time it was captured.
The high-level requirements to support the business objectives are as follows:
-
Ability to track client history. Some changes to a client’s information are interesting and useful for analysis, other changes are not. Credit rating is interesting in analysis, phone number changes are not. The credit union needs the ability to know the state of their clients at any point in time, so that any analysis carried out in the client’s context applies at that point in time. Any significant changes in a client’s state should not overwrite existing values but should be added to the client’s history. This means, for example, that when a client’s credit rating changes, the periods of time when the old ratings are in effect and when the new rating is in effect are treated independently. Conversely, if the client’s phone number changes, it makes no difference to any analysis, and there is no need to track old phone numbers.
-
Multidimensional transaction analysis. The solution must allow the users to analyze the transactions using the dimension values from the CRM system that were in effect at the time of the transaction, as well as by other dimensions such as the type of transaction (withdrawal, payroll deposit, and so on) and channel (ATM, Branch, Internet Banking, and so forth).
We will build a data warehouse based on a standard dimensional data model and periodically load the information from the CRM and other systems (see Figure 8-1). In common with most real-world solutions, many of the descriptive dimension attributes such as channel names or customers’ credit rating can change over time, but usually these changes to a record will not happen frequently.
The dimension tables and ETL processes will be designed to support these changes, including detecting when records have been updated and making appropriate adjustments to the data warehouse records. Because ETL processes to support SCDs can be complex to implement properly, we will take advantage of the Integration Services Slowly Changing Dimension transformation to correctly process inserts and updates to the dimension tables.
The solution will deliver the following benefits to the client:
-
The effectiveness of planning and forecasting activities will be improved by having access to accurate data for all time periods, including historical data that was previously unavailable.
-
The ability to track changes in customer attributes will provide accurate models of customer behavior that can be used to develop more profitable products and services.
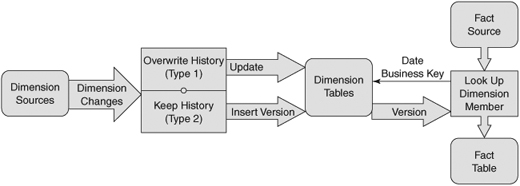
The data model for credit union transactions is for the most part fairly standard. The transactions can be analyzed by the channel, type of transaction, and source of the transaction, and by the customer responsible for the transaction with extensive attributes from the CRM system, including credit rating information, as shown in Figure 8-2.
The main modeling decision that we will need to make is how to handle the effect of dimension data changes in our data warehouse design. The key is to look carefully at the business requirements for each of the dimensions. The question that we need to answer for each dimension is “If a change to an attribute occurs, will users always want to analyze data using the latest value for that attribute, or when they look back at historical data, do they want to use the value that was in effect at that time?” The approach that we will take depends on the answer to this question.
If users always want to see the latest value for an attribute, we can just update the existing dimension record with the new value. This is known as a Type 1 SCD. This type of SCD is the easiest to implement because we don’t have to make any changes to our standard data model for dimension tables.
For example, the name attribute in the Channel dimension may change over time, but users really only want to see the latest names for the channels. When an update occurs in the source system, we can simply use the business key (which is a channel code in this case) to locate the record in the Channel dimension and replace the name (for example, replacing Internet with Internet Banking for the NET channel code, as shown in Table 8-1). When this dimension is used in a cube, only the latest name displays.

We know from the business requirements that the approach just described is not appropriate for all the attributes in the Customer dimension. When a customer’s credit rating changes, we cannot just replace the existing credit rating on the record. The reason for this is that when we look at the transactions in the cube, all the old transactions would be shown associated with the new credit rating rather than the credit rating that was in effect at the time of the transaction. What we need is a design that can accommodate the historical values for credit ratings. This type of dimension is known as a Type 2 SCD.
When the Customer dimension is initially loaded as shown in Table 8-2, it will have exactly one record for each business key (Customer Number in this case). If Emily Channing’s credit rating changes from High to Medium, for example, we will need to insert a new record that has the same business key (1000) but a new generated surrogate key (see Table 8-3).


Although the data model looks somewhat unorthodox because we have multiple records for the same customer number, we can reassure you that this design is a cornerstone of the dimensional approach and is used in most data warehouses of any significant size.
Some interesting questions arise now that we have multiple records for the same business key:
-
How will we identify the current or latest customer record?
-
More important, how will we make sure that users see the correct view of the information when looking at transactions?
The first question is fairly easy to handle. We have a few choices of how to approach this, such as adding a status column or date columns that represent the date range for which the dimension record is valid.
The second question is even easier to handle. The major reason that surrogate keys were introduced for dimensional models is to support SCDs that need to display historical information. Because we have used these surrogate keys in all our designs, there is actually nothing else we need to do as long as our ETL process is working correctly (and we will spend most of the technical solution stage explaining how this process should work). The following example helps illustrate this.
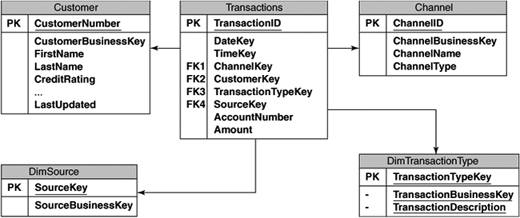
Suppose that Emily Channing’s credit rating was changed from High to Medium on 3/April/2006. Before that date, there was only one dimension record for customer number 1000, and it had a customer surrogate key of 1. All the transactions in the fact table for Emily Channing that were loaded up until that point are associated with a surrogate key of 1.
After we add the new dimension record for customer number 1000 with a surrogate key of 4, any new transactions after that date will use the latest customer record and have a customer key of 4, as shown in Table 8-4.
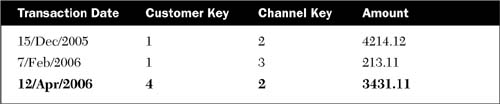
You can see how this would work using an SQL query that shows the sum of amounts grouped by credit rating. If we were to execute the following SQL, the result would be as shown in Table 8-5:
SELECT C.CreditRating, SUM(Amount) AS TotalAmount
FROM FactTransactions F
INNER JOIN DimCustomer C ON C.CustomerKey = F.CustomerKey
GROUP BY C.CreditRating

Another common example of a Type 2 SCD occurs in Sales databases. If we were to update the sales rep name attribute on a customer record, all transactions for that customer would be assigned to the new sales rep. Because this would undoubtedly affect the sales rep’s total bonus for the year, the business requirement would probably be to make sure that any transactions that occurred while the original sales rep was assigned to the customer are credited to that sales rep, and only the new transactions would be assigned to the new sales rep. This kind of situation occurs often enough that we can give you the following tip.
TIP:
Any Dimension Attribute That Affects Someone’s Bonus Is a Candidate for Type 2 SCD
This is a somewhat light-hearted statement but is usually born out in practice. During the modeling phase, it is common for users to claim that they are not interested in tracking attribute history. If that attribute affects how important metrics such as revenue or risk (as in the credit union example) are assigned, give the user concrete examples of what the ramifications would be.
When an Analysis Services cube is used to analyze the data, it will also take advantage of the join on the surrogate key and present the information correctly. So as you can see, Type 2 SCDs are a simple and powerful way to correctly represent historical information in a data warehouse.
The solution for the Credit Union data warehouse will focus on the ETL process required to handle SCDs and on the changes to the relational tables and Analysis Services dimensions required to support this.
We will start with the Channel dimension, which does not track historical information because any new values for attributes will overwrite existing values. (This is a Type 1 SCD.) There will not be any changes required for the Channel dimension table because we have followed the best practices of using a surrogate key and creating a unique key constraint on the business key.
The Slowly Changing Dimension transformation in Integration Services automates much of what used to be a fairly complex and time-consuming job for ETL designers. In the past, you would usually need to copy all the source records into a staging area, compare the staging table to the dimension table and insert any new records, compare all the attribute values that might have changed, and then retrieve and update the record using the business key.
To use the Slowly Changing Dimension transformation, you need to specify the source of the dimension records as well as the destination table in the data warehouse. The wizard also needs to know information such as which column is the business key and which columns may have changed values.
QUICK START: Using the Slowly Changing Dimension Transformation for Changing Dimensions
We will be using the Credit Union sample databases for this chapter, which already has the required dimension and fact tables. To begin, create a new Integration Services project and open the default package:
-
Drag a new Data Flow task onto the control flow area and double-click it.
-
Drag an OLE DB Source onto the data flow area and double-click it to bring up the Properties dialog. Specify a connection to the Credit Union Source database, select the Channel table, and click OK.
-
In the Data Flow Transformations section of the toolbar, find the Slowly Changing Dimension transformation and drag it onto the data flow area.
-
Drag the green arrow from the OLEDB source to the Slowly Changing Dimension transformation.
-
Double-click the Slowly Changing Dimension transformation to start the wizard. Click Next to skip the Welcome page.
-
Specify a connection to the Credit Union data warehouse and select Dim Channel as the dimension table. In the input columns table, map the ChannelCode source column to the ChannelBusinessKey column and select this column as the Business Key. Click Next.
-
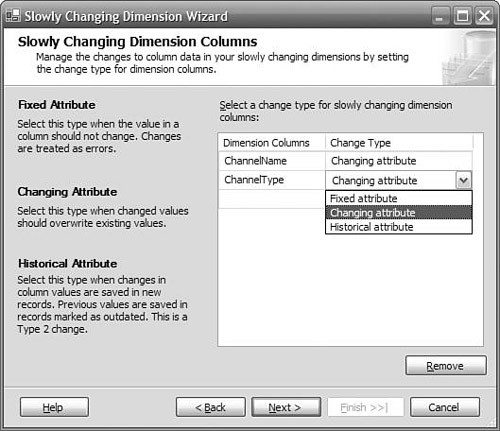
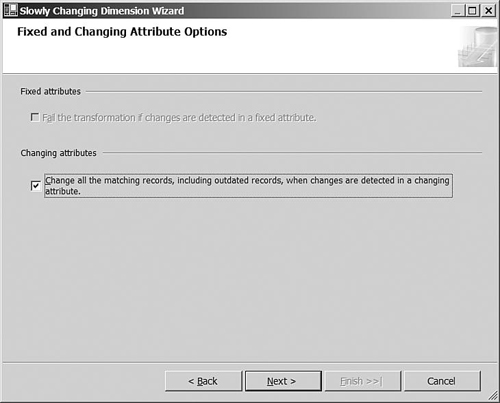
Specify ChannelName and ChannelType as Changing Attribute, as shown in Figure 8-3. Click Next and then Next again to skip the Fixed and Changing Attribute Options page.
-
Uncheck “Enable inferred member support” and click Next. Click Finish to complete the wizard.
The wizard will create two separate output destinations for new or updated records. Any new records that are not already in the dimension table (which is determined by looking up the record using the business key) are inserted into the table from the New Output data flow path. For dimension records that already exist, the Changing Attribute Updates Output path will execute an SQL command to retrieve the dimension record using the business key and update the changing attributes, which are ChannelName and ChannelType in our example. Because the SQL command uses the business key, it can take advantage of the clustered index that we recommended you create on all dimension tables, as described in Chapter 3, “Building a Data Warehouse.”
TIP:
Deleted Members
You might notice that the outputs from the SCD transformation do not cater for deleted records. Remember that you are trying to track history in the data warehouse. Even if a member is no longer used in new activities or transactions, it is still used by facts in your data warehouse. For this reason, you normally don’t want to delete any dimension rows from the data warehouse.
The next dimension that we will tackle is the Customer dimension. Even though some attributes, such as customer name, can be overwritten in the same way as channel, this dimension still needs to be able to preserve history because of the credit rating: Older facts still need to roll up under the correct credit rating, so we need to make some changes to the Customer dimension table.
When a customer record has an updated value for credit rating, we will be inserting a new dimension record that has the same business key but a new surrogate key. The first table change we need to make is to remove the unique key constraint for the Customer business key column, because each business key may now have multiple records. As discussed in the “Data Model” section, any new facts that are added will be using the new surrogate key and so they will automatically link to the correct credit rating.
However, when we are processing the facts, we only know the business key, so how do we know which one of the two dimension records to pick? The answer is to add some columns to the dimension table that enable us to indicate which one of the records is the latest dimension record, so that we can look up the correct surrogate key. One possible approach to this is to add a Status column that contains a value such as Current for the latest record and Expired for all the older records.
The problem with this approach is that it only tells you which record is the latest one. If at any point you need to reload all your historical facts (which should not happen if you have good backups), you need to know which dimension record is appropriate for each fact record. For example, a transaction from January 12, 1998, should use the dimension record that was in effect at that point.
In our Customer dimension, we will be using the approach of adding StartDate and EndDate columns to the table. These are simply DateTime columns, and only EndDate is nullable. When the dimension table is first loaded, all records will have the same initial StartDate and a null EndDate. When a changed dimension record is received, the existing record has its EndDate set to the date of the load, and a new record is created with a null EndDate and the StartDate set to the current load date, as shown in Table 8-6.

We can then see which dimension record is the “current” record for each business key by looking for all the records with null end dates. Also, we can reload historical facts by joining to the dimension table using the transaction date and selecting dimension records that fall into the correct range.
In Integration Services, the logic needed to detect changed attributes, to set the end date for the old record, and to add a new record is all provided for you by the same type of SCD transformation that we used for the Channel table. To implement the Customer load package, we can just follow the same steps as for the Channel table; but when the SCD wizard wants to know the type of changes that are required for Credit Rating, we can select Historical Attribute rather than Changing Attribute. This lets the wizard know that it will need to generate the steps that are required to support Type 2 dimension changes.
One thing to note is that we can still select Changing Attribute for the Customer Name column, which we always want to overwrite, even though the Credit Rating column has Historical Attribute. What will happen with this is that if the customer name changes, the Integration Services package will simply update the current dimension record with the correct customer name. However, if the credit rating changes, because it was marked as a Historical Attribute, the package will go through the steps required to expire the old record and create a new one with the changed credit rating.
By default, when a customer name or other field marked Changing Attribute changes, only the current dimension record is updated by the Integration Services package. This means that when you look at older facts records that link to expired dimension records, you will still see the old customer name. This is often not the behavior that you want—if an attribute is marked as Changing rather than Historical, the reason is usually that you always want to see the most current information for that attribute.
To make sure that the SCD transformation updates all the records for a changing attribute, when running the SCD wizard, you need to check the “Change all the matching records, including outdated records” check box in the Options page, as shown in Figure 8-4.
To understand how the SCD transformation for historical attributes actually works, it is helpful to load your dimension once and then go back and make a few changes to the source table to see what happens. For example, try updating a customer name on one record, changing a credit rating on another record, and adding a record with a new business key. When you run the Integration Services package, you can see the counts of records that flow to each of the steps, as shown in Figure 8-5.
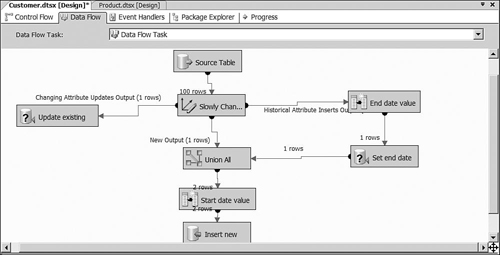
All the records in the source dimension table flow from the source to the SCD transformation and then are split up depending on their characteristics. If changing attributes such as Customer Name have changed, the record is sent to the Changing Attribute Updates Output to update the existing customer record. If a historical attribute has changed, the record is sent to the Historical Attribute Inserts Output, which will set a variable to determine the end date and then update the end date on the current record. The record is then sent on to the Union All transformation, which combines any new records from the source and sets a value for the start date. Finally, one record is inserted for the new source record, and another record is inserted for the new version of the record with changed historical attribute.
The packages that we have built so far have used all the records in the underlying source dimension tables as the input. This is easy to implement, and Integration Services provides good performance for most scenarios. However, if you have a large number of records in a source dimension that do not change often, it is inefficient to throw all the source records at the Slowly Changing Dimension transformation and let it figure out that almost none of them have been changed.
Ideally, you want to limit the list of source records to only those ones that have been added or changed since the last time you ran the load. This section describes some techniques that you can use to determine which records are affected if the source system supports them.
Applications often include a “Last Update Time” time stamp on any records that are updated through the application. This can prove helpful for determining which records should be loaded into the data warehouse. At the start of the load operation, you check the latest data warehouse load date and time and then load any source records with a Last Update Time since the last load.
This approach only works if the application strictly enforces the updating of the time stamp and no manual processes can bypass this process. If you are going to rely on a time stamp, it is worth spending extra time confirming the behavior with the owners of the source system. If there is any doubt at all, we recommend simply loading all records; otherwise, the “missing updates” will become a data quality issue for the data warehouse.
If an application database includes transaction sequence numbers such as automatically generated identity columns, these are an efficient method to detect additions to the fact tables. You can check for the highest sequence number in the fact table being loaded and then load any source facts with a higher transaction sequence number.
A trigger on the source table is a good way to capture changes because it doesn’t rely on developers to maintain time stamps or other indicators on the rows. They fire every time, regardless of which application loaded the data. Because every change is captured, even if your data source does not preserve history, your triggers can capture historical rows.
In the code for a trigger, you can insert the affected record into one of three tables depending on whether the operation is an insert, update, or delete. Or you can put all affected rows into one table with an operation type indicator.
Triggers can only be applied to data sources that are relational databases, not flat files or spreadsheets. Sometimes, the database administrator for the data source won’t let you add triggers for a variety of reasons, including application performance, so a trigger isn’t always an option.
The next area of the Credit Union solution that we need to look at is the fact records. Each transaction record from the source system has, as usual, the business key for dimension such as channel and customer. This is easy to handle for the Channel dimension because each business key maps to exactly one surrogate key, so it can be handled as described in Chapter 4, “Building a Data Integration Process,” using the Integration Services Lookup transformation.
The lookup for the Customer dimension is more challenging. Because there can be multiple records in the customer table for each business key, we need to implement some logic that can locate the correct customer record for each incoming fact. If all the facts that we load are always new (that is, we never have to reload historical facts), we can simply use a query that returns only the current, unexpired customer records as the source for the Lookup transformation, as shown in Figure 8-6.
SELECT CustomerKey, CustomerBusinessKey
FROM DimCustomer
WHERE EndDate IS NULL
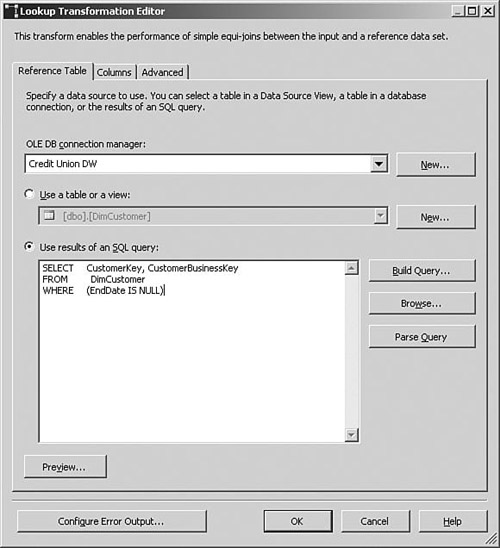
Because this will return a single record for each customer business key, we can use this as the lookup source to translate business keys to surrogate keys. However, it is more likely that we will want to support reloading historical facts. In this case, we need to check the transaction date on each fact record and figure out which customer record was applicable at that time. Because SQL is the best performing tool for big joins such as this, the approach usually involves copying the source fact records that you want to load into the temporary staging area and then joining to the dimension table to retrieve the surrogate key in the data source query, rather than in a lookup transform. An example data source query is shown below:
SELECT C.CustomerKey, F.Measure1, F.Measure2, ...
FROM FactStaging F
LEFT JOIN DimCustomer C
ON C.CustomerBusinessKey = F.CustomerBusinessKey
AND F.TransactionDate >= C.StartDate AND
(C.EndDate IS NULL OR F.TransactionDate < C.EndDate)
You need to explicitly check for null end dates in the join; otherwise, fact records for the latest time period will not be matched. You can see that we used a left-outer join to connect the dimension, so we will not lose any facts if the dimension member is missing. In a derived column transform, you can check to see if CustomerKey is null, and substitute a missing member key for CustomerKey.
In some CRM systems, you find a large number of attributes in a single table such as Customer. These attributes exist either because they came “out of the box” because the vendor wanted to cover as many situations as possible, or system owners kept adding attributes without much regard to an efficient data model. If you are trying to support a Type 2 changing dimension, a wide row can quickly inflate the space consumed by a dimension table. Not all dimensions will be a problem, but a dimension such as Customer can have millions of members and those members will have multiple rows. It is possible that each year each member will be updated several times, and each update will generate a new row.
Some of these attributes are only of interest for their current value. If they change, it is either to correct an error or the historical value isn’t relevant. The history of other attributes will be of interest, which is what makes a Type 2 SCD. If you find that you have only a few attributes where tracking history is important, and many attributes where replacing history is acceptable, you might want to split the physical dimension table into two parts, one for the Type 2 attributes and one for Type 1 attributes. In this way, you will be creating multiple versions of a much smaller row.
The approach that we have followed in earlier chapters for creating Analysis Services dimensions works pretty well for slowly changing dimensions, too. Returning to the example shown again in Table 8-7, if a user is looking at all time periods that include transactions from when Emily Channing had a High credit rating, as well as transactions where she had the updated Medium credit rating, the query will return the information that the user usually is expecting to see.

For example, if a user drags the Credit Rating attribute onto the rows, he will see totals for both High and Medium credit ratings correctly allocated to the relevant credit ratings. This is essentially the point of SCDs: The revenue earned from this customer when she had a High credit rating is shown correctly, regardless of the fact that she currently has a Medium credit rating.
If we use the Customer Business Key attribute (which contains the customer number from the source system) in a query, everything still works perfectly. Even though there are now two physical dimension records for customer number 1000 with different surrogate keys, the transactions for Emily Channing are correctly grouped together into a single row for customer number 1000 in the results.
Things get interesting when we drag the Customer attribute onto the rows. Remember that in our usual approach for dimensions, we remove the separate Customer Name attribute that the wizard creates, rename the Customer Key attribute to Customer, and use the customer name as the NameColumn property setting. So, we have a single Customer attribute that is based on the unique surrogate key (that is, Customer Key) and displays the customer name when it is used in a query.
Because we now have two records for Emily Channing with different surrogate keys, when we drag the Customer attribute onto the rows, we get two separate rows, as shown in Figure 8-7. All transactions from the original when she had a High credit rating are allocated to the first row, and all the later transactions are allocated to the last row. This is actually technically correct, but because the user can only see the customer name and not the surrogate key (nor would the user understand the surrogate key if he could see it), the user is likely to complain that the dimension contains duplicates.
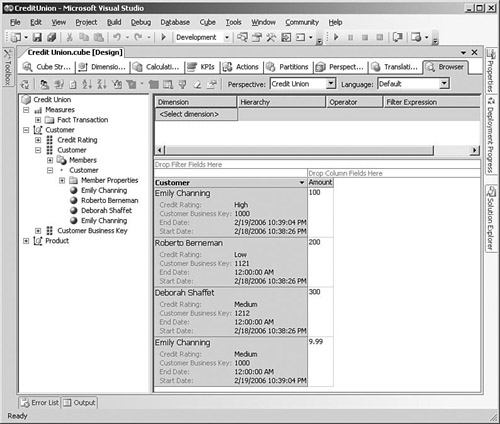
This might be exactly the behavior that the users want, especially because they can disambiguate the apparently duplicate records by showing the member properties for that attribute if their client tool supports it, which will show them the changes in member property values that are the reason for the separate rows. However, if this behavior is not what they want, you can fix the issue.
The first change to make to the dimension is to change the name of the Customer attribute that is based on the surrogate key to something else, such as Customer Key. You can then drag the CustomerBusinessKey column onto the list of dimension attributes to create a new attribute. Rename this new attribute to be Customer and specify the CustomerName field as the NameColumn property for this attribute. Now when the user drags the Customer attribute onto a query, the data will be grouped so that there is a single row for each unique customer number rather than separate rows for each surrogate key.
You can also hide the Customer Key attribute based on the surrogate key if you want by setting its AttributeHierarchyVisible property to false, although that means that the users won’t be able to use the member properties of this attribute to see the different states that the customers have gone through.
Deploying and operating this solution follows the usual model for Analysis Services, data warehouse, and Integration Services but with some additional steps to take the SCD loading and processing requirements into account.
One area that we need to pay particular attention to is the initial load of data for dimension tables. If you initially load all your dimension records with the current system date at that time, the SQL for surrogate key lookups will not work correctly for older fact records. The easiest solution to this is to use an old date, such as 1900/01/01, as the start date for all the dimension records when you initially load the dimension. That way, there will be one dimension record with an appropriate date range for each of the business keys in the fact table. Of course, you need to check that your facts themselves aren’t arriving with “special” dates that are even earlier—although these rarely represent the truth anyway, and so they should be replaced during the ETL process.
The daily processing for solutions using slowly changing dimensions is usually handled by a series of Integration Services packages to load the new and updated dimension data first followed by the fact data, and then reprocess Analysis Services objects as required.
To handle any changes or additions to the dimension tables, the Analysis Services processing will need to include running a Process Update on the dimensions. This is usually performed using an Analysis Services Processing Task in an Integration Services package that is executed after the new data has been loaded into the data warehouse. Process Update will read all the data in the dimension table and add any new members to the dimension (as well as update any changed attribute values for existing members).
TIP:
Use the Summary Pane to Select Multiple Dimensions for Processing
If you are working on fixing an issue with SCDs’ ETL and you need to reprocess several dimensions, you may have tried to select multiple dimensions at once in the free view in SQL Server Management Studio without any success. The trick is to click the Dimensions folder instead, which then shows the list of all dimensions in the Summary pane on the right, and then you can select multiple dimensions simultaneously in the Summary pane and right-click to select Process.
In an environment with specialized operations staff who perform daily tasks such as managing the overnight load process, there is often a requirement to create a role that only has permission to process some database objects but has no permissions to do anything else. You can create an Analysis Services role that has the Process permission for either the whole database or specific cubes or dimensions.
However, if you want to allow them to use the management tools such as SQL Server Management Studio, you also need to grant them the Read Definition permission, which means that they can see the metadata for all objects such as the data source connection string, which might not be what you want. A better choice is probably to grant them only the Process permission and then create an XMLA script that they can run that does the required job, as described in the following sidebar “Scripting Actions in SQL Server Management Studio.”
It’s important to regularly back up the data warehouse when SCDs are involved because you might not be able to rebuild the data warehouse from the source if the source is only a snapshot. However, even though this means that the data warehouse contains data no longer available anywhere else, you can still use the Simple recovery model rather than the Full recovery model because you are in complete control of when updates are made to the data warehouse, and can arrange your backup strategy to match. For example, you would typically back up the data warehouse as soon as a data load has been completed and checked to make sure that you could restore to that point in time. If you are not completely sure that there are no updates trickling in between batch loads and backups, you must use the Full recovery model; otherwise, you risk losing data.
In this chapter, we concentrated on the effects of changes to dimension data, but some solutions also need to support changes to the fact data.
Financial systems may restate the figures for historical time periods, or records in transaction systems occasionally need to be corrected. These applications may then retransmit the updated facts to the ETL process.
As we have seen for dimensions, there are a number of potential solutions depending on the business requirements. If each updated transaction has a unique key that can be used to locate the original record in the data warehouse, you could simply update the record in place. In this case, you need to reprocess any cubes (or specific partitions within a cube, as described in Chapter 11, “Very Large Data Warehouses”) that reference those time periods. This approach would not be appropriate for applications that need to show that an update has taken place, because the original information is lost.
If users need to be able to see original versus updated facts, for each update that is received, you could work out the difference for each measure between the original record and the updated record and then append a new record that has the (positive or negative) adjustment required with a flag that states that this is an update.
If users need to be able to see multiple versions of the data such as for financial restatements, you could add a Version dimension to the cube. This is somewhat complex to model, however, because if a user selects a specific version, the only information they will see will relate to that one version. One technique is to combine the Version dimension with the Date dimension so that each period can have multiple versions.
As you saw in Chapter 6, “Reporting,” Reporting Services enables administrators to store snapshots of reports at certain points in time, which can be retrieved by users. These snapshots are complete representations of the data required to display the report as it currently exists, even if the underlying data source is changed in the future.
This is a useful feature because we do not have to make any changes to the data warehouse to support it. For systems that have a high volume of fact changes and need to accurately reprint reports for historical periods, this might be the easiest approach.