
The stack is the first module of the calculator that we will design and implement. While we defined the module’s public interface in Chapter 2, we said very little about its implementation. We now need to decompose the stack into the functions and classes that provide the module’s functionality. Hence, this is where we begin. If you’re a little rusty on the mechanics of the stack data structure, now would be a great time to consult your favorite data structures and algorithms book. My personal favorite is the one by Cormen et al. [10].
3.1 Decomposition of the Stack Module
The first question to ask in decomposing the stack module is, “Into how many pieces should the stack be divided?” In object-oriented parlance, we ask, “How many objects do we need, and what are they?” In this case, the answer is fairly obvious: one, the stack itself. Essentially, the entire stack module is the manifestation of a single data structure, which can easily be encapsulated by a single class. The public interface for this class was already described in Chapter 2.
The second question one might ask is, “Do I even need to build a class at all or can I just use the Standard Template Library (STL) stack class directly?” This is actually a very good question. All design books preach that you should never write your own data structure when you can use one from a library, especially when the data structure can be found in the STL, which is guaranteed to be a part of a standards-conforming C++ distribution. Indeed, this is sage advice, and we should not rewrite the mechanics of the stack data structure. However, neither should we use the STL stack directly as the stack in our system. Instead, we will write our own stack class that encapsulates an STL container as a private member.
Suppose we chose to implement our stack module using an STL stack. Several reasons exist for preferring encapsulating an STL container (or a data structure from any vendor) vs. direct utilization. First, by wrapping the STL stack, we put in an interface guard for the rest of the calculator. That is, we are insulating the other calculator modules from potential changes to the underlying stack implementation by separating the stack’s interface from its implementation (remember encapsulation?). This precaution can be particularly important when using vendor software because this design decision localizes changes to the wrapper’s implementation rather than to the stack module’s interface. In the event that the vendor modifies its product’s interface (vendors are sneaky like that) or you decide to exchange one vendor’s product for another’s, these changes will only locally impact your stack module’s implementation and not affect the stack module’s callers. Even when the underlying implementation is standardized, such as the ISO standardized STL stack, the interface guard enables one to change the underlying implementation without impacting dependent modules. For example, what if you changed your mind and later decided to reimplement your stack class using, for example, a vector instead of a stack?
The second reason to wrap an STL container instead of using it directly is that this decision allows us to limit the interface to exactly match our requirements. In Chapter 2, we expended a significant amount of effort designing a limited, minimal interface for the stack module capable of satisfying all of pdCalc’s use cases. Often, an underlying implementation may provide more functionality than you actually wish to expose. If we were to choose the STL stack directly as our stack module, this problem would not be severe because the STL stack’s interface is, not surprisingly, very similar to the interface we have defined for the calculator’s stack. However, suppose we selected Acme Corporation’s RichStack class with its 67 public member functions to be used unwrapped as our stack module. A junior developer, who neglected to read the design spec, may unknowingly violate some implicit design contract of our stack module by calling a RichStack function that should not have been publicly exposed in the application’s context. While such abuse may be inconsistent with the module’s documented interface, one should never rely on other developers actually reading or obeying the documentation (sad, but true). If you can forcibly prevent a misuse from occurring via a language construct that the compiler can enforce (e.g., access limitation), do so.
The third reason to wrap an STL container is to expand or modify the functionality of an underlying data structure. For example, for pdCalc, we need to add two functions (getElements() and swapTop()) not present on the STL stack class and transform the error handling from standard exceptions to our custom error events. Thus, the wrapper class enables us to modify the STL’s standard container interface so that we can conform to our own internally designed interface rather than being bound by the functionality provided to us by the STL.
As one might expect, the encapsulation scenario described previously occurs quite frequently and has therefore been codified as a design pattern, the adapter (wrapper) pattern [11]. As described by Gamma et al., the adapter pattern is used to convert the interface of a class into another interface that clients expect. Often, the adapter provides some form of transformational capabilities, thereby also serving as a broker between otherwise incompatible classes.
In their original description of the pattern, the adapter is abstracted to allow a single message to wrap multiple distinct adaptees via polymorphism using an adapter class hierarchy. For the needs of pdCalc’s stack module, one simple concrete adapter class suffices. Remember, design patterns exist to assist in design and communication. Try not to get caught in the trap of implementing patterns exactly as they are prescribed in texts. Use the literature as a guide to help clarify your design, but, ultimately, prefer to implement the simplest solution that fits your application rather than the solution that most closely resembles the academic ideal.
A final question we should ask is, “Should my stack be generic (i.e., templated)?” The answer here is a resounding maybe. In theory, designing an abstract data structure to encapsulate any data type is sound practice. If the end goal of the data structure is to appear in a library or to be shared by multiple projects, the data structure should be generalized. However, in the context of a single project, I do not recommend making data structures generic, at least not at first. Generic code is harder to write, more difficult to maintain, and more difficult to test. Unless multiple type usage scenarios exist up front, I find writing generic code to not be worth the bother. I’ve finished too many projects where I spent extra time designing, implementing, and testing a generic data structure only to use it for one type. Realistically, if you have a nongeneric data structure and suddenly discover you do need to use it for a different type, the refactoring necessary is not usually more difficult than had the class been designed to be generic from the outset. Furthermore, the existing tests will be easily adapted to the generic interface providing a baseline for correctness established by a single type. We will, therefore, design our stack to be double specific.
3.2 The Stack Class
Only one stack should exist in the system.
The stack’s lifetime is the lifetime of the application.
Both the UI and the command dispatcher need to access the stack; neither should own the stack.
Stack access is not concurrent.
Anytime the first three criteria previously mentioned are met, the class is an excellent candidate for the singleton pattern [11].
3.2.1 The Singleton Pattern
The singleton pattern is used to create a class where only one instance should ever exist in the system. The singleton class is not owned by any of its consumers, but neither is the single instance of the class a global variable (some do, however, argue that the singleton pattern is global data in disguise). In order to not rely on the honor system, language mechanics are employed to ensure only a single instantiation can ever exist.
Additionally, in the singleton pattern, the lifetime of the instance is often from the time of first instantiation until program termination. Depending on the implementation, singletons can be created either to be thread safe or suitable for single-threaded applications only. An excellent discussion concerning different C++ singleton implementations can be found in Alexandrescu [5]. For our calculator, we’ll prefer the simplest implementation that satisfies our goals.
The static instance of the Singleton class is held at function scope instead of class scope to prevent uncontrollable instantiation order conflicts in the event that one singleton class’s constructor depends on another singleton. The details of C++’s instantiation ordering rules are beyond the scope of this book, but a detailed discussion in the context of singletons can be found in Alexandrescu [5].
Note that due to the lack of locking surrounding the access to the one instance, our model singleton is currently only suitable for a single-threaded environment. In this age of multicore processors, is such a limitation wise? For pdCalc, absolutely! Our simple calculator has no need for multithreading. Programming is hard. Multithreaded programming is much harder. Never turn a simpler design problem into a harder one unless it’s absolutely necessary.
On the first function call to the Instance() function , the instance variable is statically instantiated, and a reference to this object is returned. Because objects statically allocated at function scope remain in memory until program termination, the instance object is not destructed at the end of the Instance() function’s scope. On future calls to Instance(), instantiation of the instance variable is skipped (it’s already constructed and in memory from the previous function call), and a reference to the instance variable is simply returned. Note that while the underlying singleton instance is held statically, the foo() function itself is not static.
The inquisitive reader may now question, “Why bother holding an instance of the class at all? Why not instead simply make all data and all functions of the Singleton class static?” The reason is because the singleton pattern allows us to use the Singleton class where instance semantics are required. One particular important usage of these semantics is in the implementation of callbacks. For example, take Qt’s signals and slots mechanism (we’ll encounter signals and slots in Chapter 6), which can be loosely interpreted as a powerful callback system. In order to connect a signal in one class to a slot in another, we must provide pointers to both class instances. If we had implemented our singleton without a private instantiation of the Singleton class (i.e., utilizing only static data and static functions), using our Singleton class with Qt’s signals and slots would be impossible.
3.2.2 The Stack Module As a Singleton Class
The stack as a singleton
Because the focus of this book is on design, the implementation for each member function is not provided in the text unless the details are particularly instructive or highlight a key element of the design. As a reminder, the complete implementation for pdCalc can be downloaded from the GitHub repository. Occasionally, the repository source code will be a more sophisticated variant of the idealized interfaces appearing in the text. This will be the general format for the remainder of this book.
You probably noticed that, despite the STL providing a stack container, our Stack class was implemented using a deque; that’s odd. Let’s take a brief detour to discuss this relevant implementation detail. We spent a lot of time reviewing the importance of using the adapter pattern in the Stack’s design to hide the underlying data structure. One of the justifications for this decision was that it enabled the ability to seamlessly alter the underlying implementation without impacting classes dependent upon the Stack’s interface. The question is, “Why might the underlying implementation of the Stack change?”
In my first version of the Stack’s implementation, I selected the obvious choice for the underlying data structure, the STL stack. However, I quickly encountered an efficiency problem using the STL stack. Our Stack class’s interface provides a getElements() function that enables the user interface to view the contents of the calculator’s stack. Unfortunately, the STL stack’s interface provides no similar function. The only way to see an element other than the top element of an STL stack is to successively pop the stack until the element of interest is reached. Obviously, because we are only trying to see the elements of the stack and not alter the stack itself, we’ll need to immediately push all the entries back onto the stack. Interestingly enough, for our purposes, the STL stack turns out to be an unsuitable data structure to implement a stack! There must be a better solution.
Fortunately, the STL provides another data structure suitable for our task, the double-ended queue, or deque. The deque is an STL data structure that behaves similarly to a vector, except the deque permits pushing elements onto both its front and its back. Whereas the vector is optimized to grow while still providing a contiguity guarantee, the deque is optimized to grow and shrink rapidly by sacrificing contiguity. This feature is precisely the design trade-off necessary to implement a stack efficiently. In fact, the most common method to implement an STL stack is simply to wrap an STL deque (yes, just like our Stack, the STL’s stack is also an example of the adapter pattern). Fortuitously, the STL deque also admits nondestructive iteration, the additional missing requirement from the STL stack that we needed to implement our Stack’s getElements() method. It’s good that I used encapsulation to hide the Stack’s implementation from its interface. After realizing the limitations of visualizing an STL stack, I was able to change the Stack class’s implementation to use an STL deque with no impact on any of pdCalc’s other modules.
3.3 Adding Events
The final element necessary to build a Stack conforming to the stack interface from Chapter 2 is the implementation of events. Eventing is a form of weak coupling that enables one object, the notifier or publisher, to signal any number of other objects, the listeners or subscribers, that something interesting has occurred. The coupling is weak because neither the notifier nor the listener needs to know directly about the other’s interface. How events are implemented is both language and library dependent, and even within a given language, multiple options may exist. For example, in C#, events are part of the core language, and event handling is relatively easy. In C++, we are not so lucky and must implement our own eventing system or rely on a library providing this facility.
The C++ programmer has several published library options for handling events; prominent among these choices are boost and Qt. The boost library supports signals and slots, a statically typed mechanism for a publisher to signal events to subscribers via callbacks. Qt, on the other hand, provides both a full event system and a dynamically typed event callback mechanism, which, coincidentally, is also referred to as signals and slots. Both libraries are well documented, well tested, well respected, and available for open source and commercial use. Either library would be a viable option for implementing events in our calculator. However, for both instructive purposes and to minimize the dependency of our calculator’s backend on external libraries, we will instead implement our own eventing system. The appropriate decision to make when designing your own software is very situationally dependent, and you should examine the pros and cons of using a library vs. building custom event handling for your individual application. That said, the default position, unless you have a compelling reason to do otherwise, should be to use a library.
3.3.1 The Observer Pattern
Because eventing is such a commonly implemented C++ feature, you can rest assured that a design pattern describing eventing exists; this pattern is the observer. The observer pattern is a standard method for the abstract implementation of publishers and listeners. As the name of the pattern implies, here, the listeners are referred to as observers.
In the pattern as described by Gamma et al. [11], a concrete publisher implements an abstract publisher interface, and concrete observers implement an abstract observer interface. Notionally, the implementation is via public inheritance. Each publisher owns a container of its observers, and the publisher’s interface permits attaching and detaching observers. When an event occurs (is raised), the publisher iterates over its collection of observers and notifies each one that an event has occurred. Via virtual dispatch, each concrete observer handles this notify message according to its own implementation.
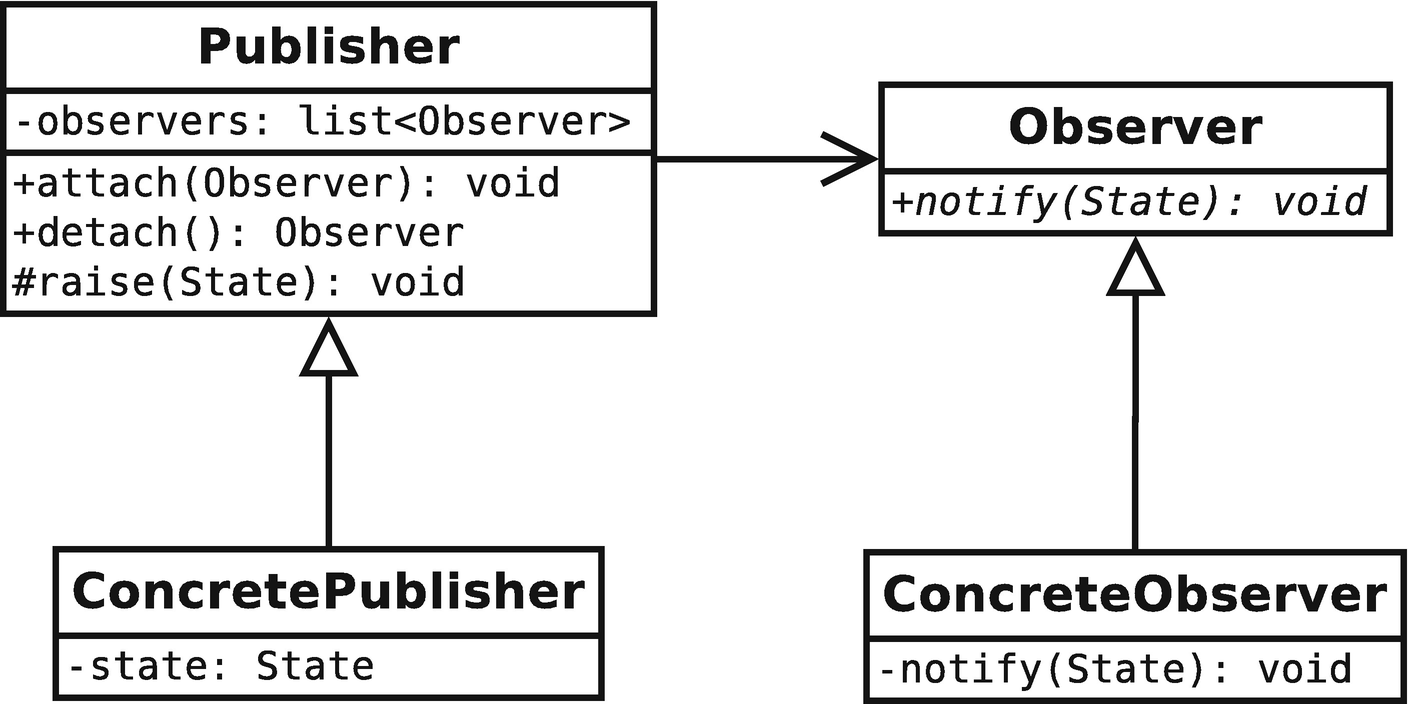
A simplified version of the class diagram for the observer pattern as it is implemented for pdCalc. The diagram illustrates push semantics for event data
Enhancing the Observer Pattern Implementation
In the actual implementation for our calculator, several additional features have been added beyond the abstraction depicted in Figure 3-1. First, in the figure, each publisher owns a single list of observers that are all notified when an event occurs. However, this implementation implies either that publishers have only one event or that publishers have multiple events, but no way of disambiguating which observers get called for each event. A better publisher implementation instead holds an associative array to lists of observers. In this manner, each publisher can have multiple distinct events, each of which only notifies observers interested in watching that particular event. While the key in the associative array can technically be any suitable data type that the designer chooses, I chose to use strings for the calculator. That is, the publisher distinguishes individual events by a name. This choice enhances readability and enables runtime flexibility to add events (vs., say, choosing enumeration values as keys).
Once the publisher class can contain multiple events, the programmer needs the ability to specify the event by name when attach() or detach() is called. These method signatures must therefore be modified appropriately from how they appear in Figure 3-1 to include an event name. For attachment, the method signature is completed by adding the name of the event. The caller simply calls the attach() method with the concrete observer instance and the name of the event to which this observer is attaching. Detaching an observer from a publisher, however, requires slightly more sophisticated mechanics. Since each event within a publisher can contain multiple observers, the programmer requires the ability to differentiate observers for detachment. Naturally, this requirement leads to naming observers as well, and the detach() function signature must be modified to accommodate both the observer’s and event’s names.
In order to facilitate detaching observers, observers on each event should be stored indirectly and referenced by their names. Thus, rather than storing an associative array of lists of observers, we instead choose to use an associative array of associative arrays of observers.
In modern C++, the programmer has a choice of using either a map or an unordered_map for a standard library implementation of an associative array. The canonical implementation of these two data structures are the red-black tree and the hash table, respectively. Since the ordering of the elements in the associative array is not important, I selected the unordered_map for pdCalc’s Publisher class. However, for the likely small number of observers subscribing to each event, either data structure would have been an equally valid choice.
To this point, we have not specified precisely how observers are stored in the publisher, only that they are somehow stored in associative arrays. Because observers are used polymorphically, language rules require them to be held by either pointer or reference. The question then becomes, should publishers own the observers or simply refer to observers owned by some other class? If we choose the reference route (by either reference or raw pointer), a class other than the publisher would be required to own the memory for the observers. This situation is problematic because it is not clear who should own the observers in any particular instance. Therefore, every developer would probably choose a different option, and the maintenance of the observers over the long term would descend into chaos. Even worse, if the owner of an observer released the observer’s memory without also detaching the observer from the publisher, triggering the publisher’s event would cause a crash because the publisher would hold an invalid reference to the observer. For these reasons, I prefer having the publisher own the memory for its observers.
Notice that the Publisher is exported from the Publisher partition of the utilities module. The Observer partition of the utilities module is imported to provide the definition of the Observer class. At first glance, you might wonder why the Observer module partition is imported instead of simply forward declaring the Observer class. After all, only the incomplete Observer type is used in declaring Observer smart pointers in Publisher’s declaration. However, the Publisher.m.cpp file contains both the partition interface unit and its implementation. Therefore, the full definition of the Observer class is needed in this file for the Publisher’s definition. Had the Publisher partition been split into separate interface and implementation files, the interface would have only needed a forward declaration of Observer.
The interface for the Observer class is quite a bit simpler than the interface for the Publisher class. However, because we have not yet described how to handle event data, we are not yet ready to design the Observer’s interface. We will address both event data and the Observer class’s interface in the “Handling Event Data” section.
In C++, the notion of owning an object implies the responsibility for deleting its memory when the object is no longer required. Prior to C++11, although anyone could implement his own smart pointer (and many did), the language itself expressed no standard semantics for pointer ownership (excepting auto_ptr, which was deprecated in C++11 and fully removed in C++17). Passing memory by native pointers was more of a trust issue. That is, if you “newed” a pointer and passed it via raw pointer to a library, you hoped the library deleted the memory when it was finished with it. Alternatively, the documentation for the library might inform you to delete the memory after certain operations were performed. Without a standard smart pointer, in the worst-case scenario, your program leaked memory. In the best-case scenario, you had to interface to a library using a nonstandard smart pointer.
C++11 corrected the problem of unknown pointer ownership by standardizing a set of smart pointers largely borrowed from the boost libraries. The unique_ptr finally allows programmers to implement unique ownership correctly (hence the deprecation of auto_ptr). Essentially, the unique_ptr ensures that only one instance of a pointer exists at any one time. For the language to enforce these rules, copy and nonmoving assignment for unique_ptrs are not implemented. Instead, move semantics are employed to ensure transfer of ownership (explicit function calls can also be used to manage the memory manually). Josuttis [13] provides an excellent detailed description of the mechanics of using the unique_ptr. An important point to remember is not to mix pointer types between unique_ptrs and raw pointers.
From a design perspective, the unique_ptr implies that we can write interfaces, using standard C++, that unequivocally express unique ownership semantics. As was seen in the discussion of the observer pattern, unique ownership semantics are important in any design where one class creates memory to be owned by another class. For example, in the calculator’s eventing system, while the publisher of an event should own its observers, a publisher will rarely have enough information to create its observers. It is therefore important to be able to create the memory for the observers in one location but be able to pass ownership of that memory to another location, the publisher. The unique_ptr provides that service. Because the observers are passed to the publisher via a unique_ptr, ownership is transferred to the publisher, and the observer’s memory is deleted by the smart pointer when the publisher no longer needs the observer. Alternatively, any class may reclaim an observer from the publisher. Since the detach() method returns the observer in a unique_ptr, the publisher clearly relinquishes ownership of the observer’s memory by transferring it back to the caller.
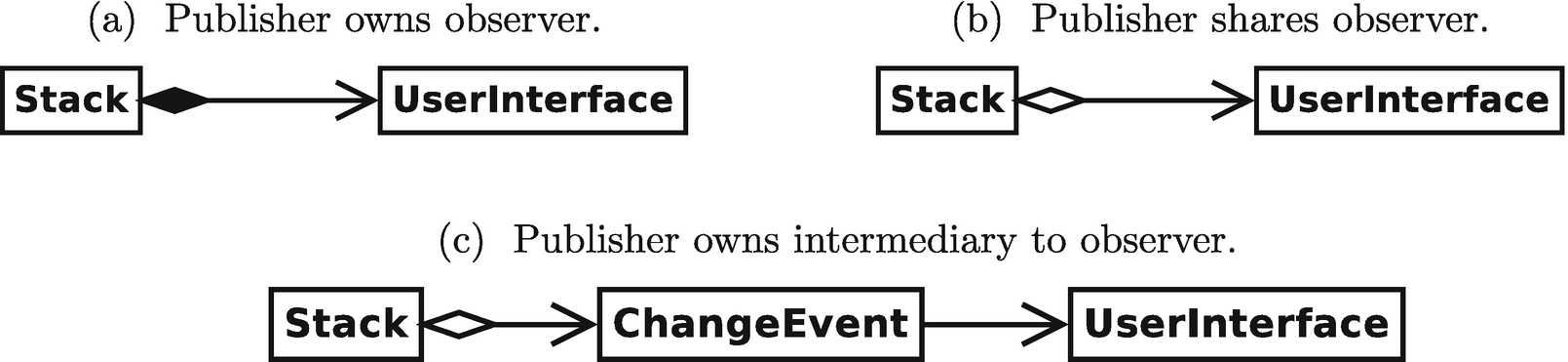
Different ownership strategies for the observer pattern
Modern C++ does admit yet another sensible alternative for the ownership semantics of the observer pattern: shared ownership. As we stated previously, it is unreasonable for the Stack to own the user interface. Some, however, might consider it equally unreasonable to create an extra ChangeEvent intermediary class instead of directly making the user interface an observer. The only middle ground option available seems to be for the Stack to refer to the user interface. Previously, though, we stated that having a publisher refer to its observers is unsafe because the observers could disappear from under the publisher leaving a dangling reference. What if we could solve this dangling reference problem?
Fortunately, modern C++ once again comes to the rescue with shared semantics (as depicted in Figure 3-2b). In this scenario, observers would be shared using a shared_ptr (see the sidebar on shared_ptrs), while the publisher would retain a reference to observers with a weak_ptr (a relative of the shared_ptr). weak_ptrs are designed specifically to mitigate the problem of dangling references to shared objects. This design for shared observer ownership by publishers is described by Meyers [24] in Item 20. Personally, I prefer the design that uses owning semantics and a lightweight, dedicated observer class.
Handling Event Data
In describing the observer pattern, we mentioned that two distinct paradigms exist for handling event data: pull and push semantics. In pull semantics, the observer is simply notified that an event has occurred. The observer then has the additional responsibility of acquiring any additional data that might be required. The implementation is quite simple. The observer maintains a reference to any object from which it might need to acquire state information, and the observer calls member functions to acquire this state in response to the event.
Pull semantics have several advantages. First, the observer can choose at the time of handling the event exactly what state it wants to acquire. Second, no unnecessary resources are consumed in passing potentially unused arguments to observers. Third, pull semantics are easy to implement because events do not need to carry data. However, pull semantics also have disadvantages. First, pull semantics increase coupling because observers need to hold references to and understand the state acquisition interfaces of publishers. Second, observers only have access to the public interfaces of publishers. This access restriction precludes observers from obtaining private data from publishers.
In contrast to pull semantics, push semantics are implemented by having the publisher send state data relevant to an event when that event is raised. Observers then receive this state data as the arguments to the notify callback. The interface enforces push semantics by making the notify function pure virtual in the abstract Observer base class.
Push semantics for event handling also have both advantages and disadvantages. The first advantage is that push semantics decrease coupling. Neither publishers nor observers need to know about one another’s interfaces. They need only obey the abstract eventing interface. Second, the publisher can send private information to the observers when it pushes state. Third, the publisher, as the object raising the event, can send precisely the data needed to handle the event. The main disadvantages of push semantics are that they are slightly more difficult to implement and potentially carry unnecessary overhead in situations where the observer does not require the state data that the publisher pushes. Finally, we note that a design that uses push semantics can always be trivially augmented with pull semantics for special cases by adding a callback reference to the pushed data. The reverse is not true since push semantics require dedicated infrastructure within the event handling mechanism.
Based on the trade-offs between push and pull semantics described previously, I chose to implement push semantics for the event handling for pdCalc. The main disadvantage of push semantics is the potential computational overhead of the implementation. However, since our application is not performance intensive, the decreased coupling this pattern exhibits and the argument control the publisher maintains outweigh the slight performance overhead. Our task now becomes designing an implementation for passing event data via push semantics.
In order to implement push semantics for event handling, one must standardize the interface for passing arguments from publisher to observer when an event is raised. Ideally, each publisher/observer pair would agree on the types of the arguments to be passed, and the publisher would call the appropriate member function on the observer when an event was raised. However, this ideal situation is effectively impossible within our publisher/observer class hierarchy because concrete publishers are not aware of the interfaces of concrete observers. Concrete publishers can only raise events generically by calling the raise() function in the Publisher base class. The raise() function , in turn, polymorphically notifies a concrete observer through the Observer base class’s virtual notify() function. We, therefore, seek a generic technique for passing customized data via the abstract raise/notify interface.
Essentially, our problem reduces to defining an interface to notify(T) such that T can contain any type of data, including the case where the data may be null. I present two similar techniques for accomplishing this task; only the second is implemented in pdCalc. The first technique is more of a “classical” solution based on a polymorphic design. It is the only design I presented in the first edition. The second solution is based on a more modern technique called type erasure. If you were willing to write a lot of boiler plate code, type erasure was possible before C++17. However, the any class, introduced in C++17, makes applying this technique for objects trivial. The technique is called type erasure because an object’s type is “erased” when passing it into the any class and only “recreated” by an any_cast when the object is extracted. Let’s examine each solution sequentially.
To apply the polymorphic solution to the event data problem, we create a parallel object hierarchy for event data and pass the event data from publisher to observer via this abstract state interface. The base class in this hierarchy, EventData, is an empty class that contains only a virtual destructor. Each event that requires arguments then subclasses this base class and implements whatever data handling scheme is deemed appropriate. When an event is raised, the publisher passes the data to the observer through an EventData base class pointer. Upon receipt of the data, the concrete observer downcasts the state data to the concrete data class and subsequently extracts the necessary data via the derived class’s concrete interface. While the concrete publisher and concrete observer do have to agree on the interface for the data object, neither concrete publisher nor concrete observer is required to know the interface of the other. Thus, we maintain loose coupling.
The type erasure solution to the event data problem is conceptually similar to the polymorphic approach, except we do not need an EventData base class. Instead, the standard any class replaces the abstract base class in the interface (see the sidebar discussing any, variant, and optional). Provided the concrete publisher and concrete observer implicitly agree on what is contained within this class, any object, including built-in types, can be passed as data. The agreement is enforced by the publisher passing a concrete type through an any object and the observer recreating the appropriate concrete type by any_casting the event data payload. As before, while an implicit agreement about the data must exist between concrete publisher and concrete observer, neither is required to know the interface of the other.
The C++17 standard library introduced three new, useful types: std::any, std::variant, and std::optional . any is designed to hold any type – the logical equivalent to a type-safe void pointer. It is a generic embodiment of type erasure for objects. variant provides a type-safe union. optional implements nullable types. Let’s look at a quick example of how each is used.
A more practical example using any to pass arbitrary data between events is shown in the main text.
Personally, I use unions infrequently. However, when a union is needed, I strongly prefer the standard library variant over the native language union.
I have spent many hours explaining to junior programmers that no, they did not just find a compiler bug but rather the compiler found their bug.
Ah, much better! Clearly, d converts to a bool, which returns true if d is nonnull. If you prefer a more verbose syntax, you can instead call the has_value() member function. Accessing the value of d can be performed by either dereferencing (i.e., *d) or through the value() member function. An optional is considered null if it is not initialized, initialized with an empty constructor (i.e., {}), or explicitly initialized with nullopt.
The preceding syntax is called a structured binding. Structured bindings, introduced in C++17, are a syntactic convenience to provide names to elements of an expression. Recall our original version of maybeReturnsDouble() that returned a pair<bool, double> indicating first if the double was defined and second the value of the double itself. Before structured bindings, we had a few options for using the return value: directly use pair’s first and second members (opaque and confusing), create new variables and assign them to pair’s first and second members (clear, but verbose), or use std::tie (now unnecessary). While the example shows a structured binding in the context of binding to accessible class members, structured bindings can also be used to bind to tuple-like objects and arrays. Additionally, structured bindings can be declared to be const or of reference type if the underlying element must be modifiable through the bound name. Although structured bindings do not fundamentally allow you to do anything you couldn’t before, they are really convenient and better express the programmer’s intent through a compact syntax. I find I use them a lot.
The StackErrorData class defines how the Stack’s event data is packaged and sent to classes observing the Stack. When an error occurs within the stack module, the Stack class raises an event and pushes information about that event to its observers. In this instance, the Stack creates an instance of StackErrorData specifying the type of error in the constructor. This enumerated type comprising the finite set of error conditions can be converted to a string using the message() function. The observers are then free to use or ignore this information when they are notified about the event’s occurrence. If you were paying attention, yes, I subtly just changed the signature for the error() interface.
Why choose one strategy over the other? Personally, I find the type erasure approach cleaner and simpler than the polymorphic approach; in many cases, it may also be more efficient. First, using the any class requires less code than requiring a polymorphic hierarchy. Second, using the any class is less restrictive. While the aforementioned example shows an instance using a StackErrorData class in both cases, any could be used to store a simple type like a double or string, completely obviating the need for a user-defined class. Finally, depending upon the implementation of any, the type erasure method may be more efficient than the polymorphic approach. Where the polymorphic approach always requires heap allocation using a shared_ptr, a high-quality implementation of any will avoid heap allocation for objects that fit in a small memory footprint. Of course, the polymorphic approach does have one distinct advantage. It should be used in cases where polymorphism is desired (e.g., in an interface that uses virtual functions instead of type casting) or where a forced, consistent interface is desired via an abstract interface. As previously stated, the polymorphic interface was implemented for the first edition of this book. Now that C++17 includes the any class in the standard library, the implementation of pdCalc in the second edition of this book implements the type erasure strategy.
Whereas unique_ptr enables the programmer to express, safely, unique ownership, shared_ptr enables the programmer to express, safely, shared ownership. Prior to the C++11 standard, C++ enabled data sharing by either raw pointer or reference. Because references for class data could only be initialized during construction, for late binding data, only raw pointers could be used. Therefore, often, two classes shared a single piece of data by each containing a raw pointer to a common object. The problem with that scenario is, of course, that it is unclear which object owns the shared object. In particular, this ambiguity implies uncertainty about when such a shared object can safely be deleted and which owning object ultimately should free the memory. shared_ptrs rectify this dilemma at the standard library level.
shared_ptr implements sharing semantics via reference counting. As new objects point to a shared_ptr, the internal reference count increases (enforced via constructors and assignment). When a shared_ptr goes out of scope, its destructor is called, which decrements the internal reference count. When the count goes to zero, the destruction of the final shared_ptr triggers reclamation of the underlying memory. As with unique_ptr, explicit member function calls can also be used to manage memory manually. Josuttis [13] provides an excellent detailed description of the mechanics of using shared_ptr. As with unique_ptr, one must be careful not to mix pointer types. The exception to this rule, of course, is mixed usage with weak_ptr. Additionally, reference counting carries both time and space overhead, so the reader should familiarize himself with these trade-offs before deploying shared pointers.
In terms of design considerations, the shared_ptr construct enables the programmer to share heap memory without directly tracking the ownership of the objects. Passing objects by value for polymorphic types is not an option, because for objects existing in a hierarchy, passing objects by value causes slicing. However, using raw pointers (or references) to pass event data is also problematic because the lifetime of these data objects cannot be known among the classes sharing them. Consider pdCalc’s need to use a shared_ptr when using the polymorphic event data strategy. Naturally, the publisher allocates the memory when it raises an event. Since an observer may wish to retain the memory after completion of event handling, the publisher cannot simply deallocate the memory after the event has been handled. Moreover, because multiple observers can be called for any given event, neither can the publisher transfer unique ownership of the data to any given observer. For event data in pdCalc, we saw that C++17 admits an alternative design using std::any. However, type erasure cannot always be substituted for shared ownership. Where shared ownership is desired, the shared_ptr standardized in C++11 offers the ideal semantics.
Maybe the interface is not exactly what you might have expected, particularly because the constructor to the Observer class uses a new feature of the C++ standard library introduced in C++17, the string_view. We’ll pause momentarily to discuss the string_view in the following sidebar. After that brief diversion, we’ll conclude the design of the Stack class’s interface by demonstrating how the Stack publishes events.
Before C++17, when referring to an immutable string (specifically, a sequence of characters), we typically used either a const char* or a const string&, depending on the underlying type. Why did we need a new container to refer to strings?
Using the aforementioned two types to refer to strings can be problematic. First, to use a const char*, we either need to know the underlying type is a char*, or we need to convert a string to a const char*. Additionally, const char*s do not store the length of the underlying string. Instead, it is assumed that the character sequence is null terminated (i.e., ends with '�'). Conversely, if we instead use a const string&, this works well if the underlying type was already a string, but if the underlying type was a const char*, we need to construct a temporary string unnecessarily. The string_view class addresses these problems.
The string_view class is essentially a container that holds a constant pointer to a character type and an integer specifying the length of the contiguous sequence of characters that comprise the string. The implications of its implementation lead to both its strengths and its caveats. Let’s start with the strengths.
The biggest strength of the string_view class is that it is very efficient and can point to most string types expressed in C++. Relative to a plain const char*, a string_view is safer because the string_view knows the length of the embedded string it represents. Being a class, a string_view also has a much richer interface (although one might argue const char*s have rich library support). Relative to a const string&, a string_view will never implicitly make a temporary copy of const char*, and because a string_view is nonowning, it has very efficient member functions for functionality like creating substrings. This efficiency arises because calls to string_view’s substr() function return a new string_view, which requires no construction of a new string, only the assignment of a character pointer (the new start) and an integer (the new length) to the same referenced original string.
string_views also have a few shortcomings. While it is beneficial that a string_view knows its own size, this is disadvantageous for library calls expecting a null terminated string. The easiest way to produce a null terminated string from a string_view is to construct a string and use its c_str() function. At this point, using a const string& would have been the better choice. Another two instances where a const string& is preferred over a string_view are where it is known that a string already exists and where an existing interface requires a string or const char*.
Finally, we must be careful in managing the lifetime of a string_view. Importantly, a string_view is nonowning and is hence only “viewing” a separately owned string. If a string is destroyed before a referring string_view, the string_view will be left in an invalid state (identically to a dangling pointer). Therefore, you must always ensure that the lifetime of a string is equal to or exceeds the lifetime of any string_views pointing to it.
In conclusion, string_view is a modern, nonowning improvement to passing strings by const char* and const string&. string_view should generally be preferred except in cases where we need a null terminated string, we need a string for a subsequent function call, or we already have a string. When using string_view, be careful about object lifetimes, ensuring that the underlying string storage outlives the string_view.
3.3.2 The Stack As an Event Publisher
The final step in constructing the Stack is simply to put all of the pieces together. Listing 3-1 shows the Stack as a singleton. In order to implement events, we simply modify this code to inherit from the Publisher base class. We now must ask ourselves, should this inheritance be public or private?
Typically, in object-oriented programming, one uses public inheritance to indicate the is-a relationship. That is, public inheritance expresses the relationship that a derived class is a type of or specialization of a base class. More precisely, the is-a relationship obeys the Liskov Substitution Principle (LSP) [37], which states that (via polymorphism) a function which takes a base class pointer (reference) as an argument must be able to accept a derived class pointer (reference) without knowing it. Succinctly, a derived class must be usable wherever a base class can be used, interchangeably. When people refer to inheritance, they are generally referring to public inheritance.
Private inheritance is used to express the implements-a relationship. Private inheritance, simply, is used to embed the implementation of one class into the private implementation of another. It does not obey the LSP, and in fact, the C++ language does not permit substitution of a derived class for a base class if the inheritance relationship is private. For completeness, the closely related protected inheritance is semantically the same as private inheritance. The only difference is that in private inheritance, the base class implementation becomes private in the derived class while in protected inheritance, the base class implementation becomes protected in the derived class.
Our question has now been refined to, “Is the Stack a Publisher or does the Stack implement a Publisher? The answer is yes and yes. That was unhelpful, so how do we choose?
In order to disambiguate whether we should use public or private inheritance in this instance, we must delve deeper into the usage of the Stack class. Public inheritance, or the is-a relationship, would indicate our intent to use the stack polymorphically as a publisher. However, this is not the case. While the Stack class is a publisher, it is not a publisher in the context that it could be substituted for a Publisher in an LSP sense. Therefore, we conclude that we should use private inheritance to indicate the intent to use the implementation of the Publisher within the Stack. Equivalently, we can state that the Stack provides the Publisher service. If you’ve been following along with the repository source code, you might have noticed a big hint that private inheritance was the answer. The Publisher class was implemented with a nonvirtual, protected destructor, making it unusable for public inheritance.
Readers familiar with object-oriented design may wonder why we didn’t ask the ubiquitous has-a question, which indicates ownership or the aggregation relationship. That is, why shouldn’t the Stack simply own a Publisher and reuse its implementation instead of privately inheriting from it? Many designers prefer almost exclusively to use aggregation in place of private inheritance arguing that when given an equivalent choice between these two, one should always prefer the language feature leading to looser coupling (inheritance is a stronger relationship than aggregation). This opinion has merit. Personally, though, I simply prefer to accept the technique that trades off stronger coupling for greater clarity. I believe that private inheritance more clearly states the design intent of implementing the Publisher service than does aggregation. This decision has no right or wrong answer. In your code, you should prefer the style that suits your tastes.
An additional consequence of privately inheriting from the Publisher class is that the attach() and detach() methods of the Publisher become private. However, they need to be part of the public interface for the Stack if any other class intends to subscribe to the Stack’s events. Thus, the implementer must choose to utilize either using statements or forwarding member functions to hoist attach() and detach() into the public interface of the Stack. Either approach is acceptable in this context, and the implementer is free to use their personal preference.
3.3.3 The Complete Stack Module Interface
As described in this chapter, the Stack is a singleton class (note the Instance() method) that implements the Publisher service (note the private inheritance of the Publisher class and the hoisting of the attach() and detach() methods into the public interface). The Stack class’s public section, in conjunction with the StackErrorData class, encompasses the complete interface of the stack module introduced in Table 2-2 in Chapter 2. While we have not yet described any concrete observers for the Stack, we have fully defined our event system for pdCalc, which is based on the tried and true observer pattern. At this point, we are ready to design pdCalc’s next component, the command dispatcher module.
3.4 A Quick Note on Testing
Before concluding our first chapter that introduced the source code for pdCalc, we should pause a moment and say a few words about testing. Testing is by no means a central exploratory topic of this book, and trying to cover both design and testing in depth would certainly break the cohesion of this text. Instead, the reader interested in a thorough exploration of developer testing is referred to the excellent book by Tarlinder [35]. Nonetheless, testing is an integral part of any high-quality implementation.
Alongside the source code for the calculator found on GitHub, I have also included all of my automated unit testing code. Because I chose to use Qt for the graphical user interface framework for pdCalc (see Chapter 6), the QtTest framework was a natural choice on which to build pdCalc’s unit test suite. Primarily, this choice does not add any additional library dependencies on the project, and the test framework is guaranteed to work on all platforms to which Qt has been ported. That said, any one of the many high-quality C++ unit test frameworks would have sufficed equally well.
Personally, I find unit testing to be indispensable when programming even small projects. First and foremost, unit tests provide a means to ensure your code functions as expected (verification). Second, unit testing enables you to see a module working correctly long before a user interface is developed. Early testing enables early bug detection, and a well-known fact of software engineering is that earlier bug detection leads to exponentially cheaper bug fixing costs. I also find that seeing modules fully working early in the development cycle is oddly motivational. Finally, unit tests also enable you to know that your code functions the same before and after code changes (regression testing). As iteration is an essential element of design and implementation, your code will change numerous times, even after you think you’ve completed it. Running comprehensive unit tests automatically at every build will ensure that new changes have not unpredictably broken any existing functioning units.
Because I value testing very highly (it’s one of the first lessons I try to teach to new professional developers), I strove to ensure completeness in the testing of pdCalc’s code. While I hope that the test code is of high quality, I admit that my testing nomenclature sometimes gets a little sloppy and, in some instances, I probably severely blurred the lines between unit, integration, and system testing. Nevertheless, all of the tests run very quickly, and they assured me that my code was verified throughout the code development portion of writing this book. However, despite my best intentions to write error-free code, and even after an irrational number of reviews of the source code, I am certain that bugs still exist in the final product. Please feel free to email me any and all errors that you find. I will make my best effort to incorporate corrections to the code in the GitHub repository and any future editions of this book, giving proper attribution to the first reader who reports any of my bugs to me.