
The command dispatcher is the centerpiece of the calculator. As the controller in the MVC framework, the command dispatcher is responsible for the entire business logic of the application. This chapter addresses not only the specific design of the command dispatcher module for the calculator but also, more broadly, the flexible design of a loosely coupled command infrastructure.
4.1 Decomposition of the Command Dispatcher
- 1.
Store a collection of known commands
- 2.
Receive and interpret requests for these commands
- 3.
Dispatch command requests (including the ability to undo and redo)
- 4.
Perform the actual operation (including updating the calculator’s state)
- 1.
CommandFactory: Creates available commands
- 2.
CommandInterpreter: Receives and interprets requests to execute commands
- 3.
CommandManager: Dispatches commands and manages undo and redo
- 4.
Command hierarchy: Executes commands
The CommandFactory, CommandInterpreter, and CommandManager classes are all components of the command dispatcher module. While the Command class hierarchy logically belongs to the command dispatcher module, as discussed in Chapter 2, the Command hierarchy of classes are contained in a separate command module because these classes must be independently exportable for plugin implementers. The remainder of this chapter is devoted to describing the design and salient implementation details for the aforementioned list of classes and class hierarchies.
4.2 The Command Class
At this stage in the decomposition, I find it more useful to switch to a bottom-up approach to design. In a strictly top-down approach, we would probably start with the CommandInterpreter, the class that receives and interprets command requests, and work our way down to the commands. However, in this bottom-up approach, we will begin by studying the design of the commands themselves. We begin with the abstraction known as the command pattern.
4.2.1 The Command Pattern
The command pattern is a simple, but very powerful, behavioral pattern that encapsulates a request in the form of an object. Structurally, the pattern is implemented as an abstract command base class that provides an interface for executing a request. Concrete commands simply implement the interface. In the most trivial case, the abstract interface consists solely of a command to execute the request that the command encapsulates. The class diagram for the trivial implementation is shown in Figure 4-1.
Essentially, the pattern does two things. First, it decouples the requester of a command from the dispatcher of the command. Second, it encapsulates the request for an action, which might otherwise be implemented by a function call, into an object. This object can carry state and possess an extended lifetime beyond the immediate lifetime of the request itself.
Practically, what do these two features give us? First, because the requester is decoupled from the dispatcher, the logic for executing a command does not need to reside in the same class or even the same module as the class responsible for executing the command. This obviously decreases coupling, but it also increases cohesion since a unique class can be created for each unique command the system must implement. Second, because requests are now encapsulated in command objects with a lifetime distinct from the lifetime of the action, commands can be both delayed in time (e.g., queuing
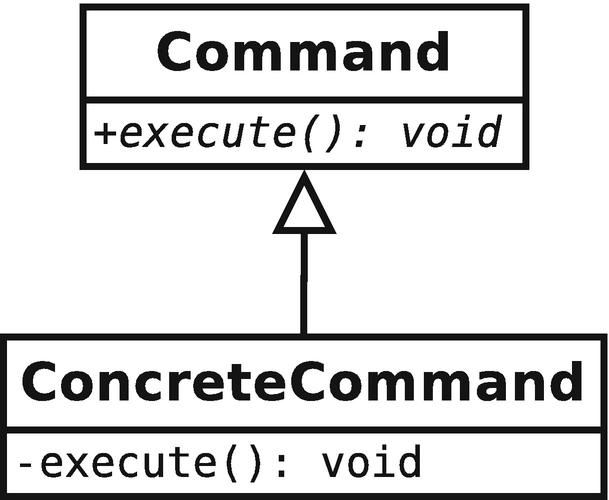
The simplest hierarchy for the command pattern
4.2.2 More on Implementing Undo/Redo
One of the requirements for pdCalc is to implement unlimited undo and redo operations. Most books state that undo can be implemented via the command pattern by merely augmenting the abstract command interface with an undo command. However, this simplistic treatment glosses over the actual details necessary to properly implement the undo feature.
Implementing undo and redo involves two distinct steps. First (and obviously), undo and redo must be implemented correctly in the concrete command classes. Second, a data structure must be implemented to track and store the command objects as they are dispatched. Naturally, this data structure must preserve the order in which the commands were executed and be capable of dispatching a request to undo, redo, or execute a new command. This undo/redo data structure is described in detail in Section 4.4. The implementation of undo and redo is discussed presently.
Implementing undo and redo operations themselves is usually straightforward. The redo operation is the same as the command’s execute function. Provided that the state of the system is the same before the first time a command is executed and after undo has been called, then implementing the redo command is essentially free. This, of course, immediately implies that implementing undo is really about reverting the state of the system to immediately before the command was first executed.
Undo can be implemented by two similar but slightly distinct mechanisms, each responsible for restoring the system’s state in different ways. The first mechanism does exactly what the name undo implies: it takes the current state of the system and literally reverses the process of the forward command. Mathematically, that is, undo is implemented as the inverse operation to execute. For example, if the forward operation were to take the square root of the number on the top of the stack, then the undo operation would be to take the square of the number on the top of the stack. The advantage of this method is that no extra state information needs to be stored in order to be able to implement undo. The disadvantage is that the method does not work for all possible commands. Let’s examine the converse of our previous example. That is, consider taking the square of the number on the stop of the stack. The undo operation would be to take the square root of the result of the squaring operation. However, was the original number the positive or negative root of the square? Without retaining additional state information, the inversion method breaks down.
The alternative to implementing undo as an inverse operation is to preserve the state of the system before the command is first executed and then implement the undo as a reversion to this prior state. Returning to our example of squaring a number, the forward operation would both compute the square and save the top number on the stack. The undo operation would then be implemented by dropping the result from the stack and pushing the saved state from before the forward operation was performed. This procedure is enabled by the command pattern since all commands are implemented as instantiations of concrete command classes that are permitted to carry state. An interesting feature of this method of implementing undo is that the operation itself need not have a mathematical inverse. Notice that in our example, the undo did not even need to know what the forward operation was. It simply needed to know how to replace the top element from the stack with the saved state.
Which mechanism to use in your application really depends on the distinct operations your application performs. When operations have no inverses, storing the state is the only option. When the inverse operation is overly expensive to compute, storing the state is usually the better implementation. When storage of the state is expensive, implementing undo via inversion is preferred, assuming an inverse operation exists. Of course, since each command is implemented as a separate class, a global decision for how undo is implemented need not be made for the entire system. The designer of a given command is free to choose the method most appropriate for that particular operation on a command-by-command basis. In some cases, even a hybrid approach (both storing and inverting separate parts of the operation) may be optimal. In the next section, we will examine the choices that I made for pdCalc.
4.2.3 The Command Pattern Applied to the Calculator
In order to execute, undo, and redo all of the operations in the calculator, we will implement the command pattern, and each calculator operation will be encapsulated by its own concrete class deriving from an abstract Command class. From the previous discussion concerning the command pattern, we can see that two decisions must be made in order to apply the pattern to the calculator. First, we must decide what operations must be supported by every command. This collection of operations will define the abstract interface of the Command base class. Second, we must choose a strategy for how undo will be supported. To be precise, this decision is always deferred to the implementer of a particular concrete command. However, by choosing either state reconstruction or command inversion up front, we can implement some infrastructure to simplify undo for command implementers. We’ll tackle these two issues consecutively.
The Command Interface
Choosing what public functions to include in the abstract Command class is identical to defining the interface for all commands in the calculator. Therefore, this decision must not be taken lightly. While each concrete command will perform a distinct function, all concrete commands must be substitutable for each other (recall the LSP). Because we want interfaces to be minimal but complete, we must determine the fewest number of functions that can abstractly express the operations needed for all commands.
Note the omission of the pdCalc namespace, as will generally be done throughout the text. Although explicitly listed earlier, I will also frequently omit from the text the module export line and the export keyword preceding a class name or namespace declaration if their presence can be implied from context.
In the preceding listing, the reader will immediately notice that the constructor is protected, both execute() and undo() are public and nonvirtual, and separate executeImpl() and undoImpl() virtual functions exist. The reason the constructor is protected is to signal to an implementer that the Command class cannot be directly instantiated. Of course, because the class contains pure virtual functions, the compiler prevents direct instantiation of the Command class, anyway. Making the constructor protected is, somewhat, superfluous. Defining the public interface using a combination of virtual and nonvirtual functions, on the other hand, deserves a more detailed explanation.
Defining the public interface for a class via a mixture of public nonvirtual functions and private virtual functions is a design principle known as the nonvirtual interface (NVI) pattern . The NVI pattern states that polymorphic interfaces should always be defined using nonvirtual public functions that forward calls to private virtual functions. The reasoning behind this pattern is quite simple. Since a base class with virtual functions acts as an interface class, clients should be accessing derived class functionality only through the base class’s interface via polymorphism. By making the public interface nonvirtual, the base class implementer reserves the ability to intercept virtual function calls before dispatch in order to add preconditions or postconditions to the execution of all derived class implementations. Making the virtual functions private forces consumers to use the nonvirtual interface. In the trivial case where no precondition or postcondition is needed, the implementation of the nonvirtual function reduces to a forwarding call to the virtual function. The additional verbosity of insisting on the NVI pattern even in the trivial case is warranted because it preserves design flexibility for future expansion at zero computational overhead since the forwarding function call can be inlined. A more in-depth rationale behind the NVI pattern is discussed in detail in Sutter [34].
Let’s now consider if either execute() or undo() requires preconditions or postconditions; we start with execute(). From a quick scan of the use cases in Chapter 2, we can see that many of the actions pdCalc must complete can only be performed if a set of preconditions are first satisfied. For example, to add two numbers, we must have two numbers on the stack. Clearly, addition has a precondition. From a design perspective, if we trap this precondition before the command is executed, we can handle precondition errors before they cause execution problems. We’ll definitely want to check preconditions as part of our base class execute() implementation before calling executeImpl().
What precondition or preconditions must be checked for all commands? Maybe, as with addition, all commands must have at least two numbers on the stack? Let’s examine another use case. Consider taking the sine of a number. This command only requires one number to be on the stack. Ah, preconditions are command specific. The correct answer to our question concerning the general handling of preconditions is to ask derived classes to check their own preconditions by having execute() first call a checkPreconditionsImpl() virtual function.
What about postconditions for execute()? It turns out that if the preconditions for each command are satisfied, then all of the commands are mathematically well defined. Great, no postcondition checks are necessary! Unfortunately, mathematical correctness is insufficient to ensure error-free computations with floating-point numbers. For example, floating-point addition can result in positive overflow when using the double-precision numbers required by pdCalc even when the addition is mathematically defined. Fortunately, however, our requirements from Chapter 1 stated that floating-point errors can be ignored. Therefore, we are technically excepted from needing to handle floating-point errors and do not need a postcondition check after all.
To keep the code relatively simple, I chose to adhere to the requirements and ignore floating-point exceptions in pdCalc. If I had instead wanted to be proactive in the design and trap floating-point errors, a checkPostconditions() function could have been used. Because floating-point errors are generic to all commands, the postcondition check could have been handled at the base class level.
Given that checkPreconditionsImpl() and executeImpl() must both be consecutively called and handled by the derived class, couldn’t we just lump both of these operations into one function call? We could, but that decision would lead to a suboptimal design. First, by lumping these two operations into one executeImpl() function call, we would lose cohesion by asking one function to perform two distinct operations. Second, by using a separate checkPreconditionsImpl() call, we could choose either to force derived class implementers to check for preconditions (by making checkPreconditionsImpl() pure virtual) or to provide, optionally, a default implementation for precondition checks. Finally, who is to say that checkPreconditionsImpl() and executeImpl() will dispatch to the same derived class? Remember, hierarchies can be multiple levels deep.
Analogously to the execute() function, one might assume that precondition checks are needed for undoing commands. However, it turns out that we never actually have to check for undo preconditions because they will always be true by construction. That is, since an undo command can only be called after an execute command has successfully completed, the precondition for undo() is guaranteed to be satisfied (assuming, of course, a correct implementation of execute()). As with forward execution, no postcondition checks are necessary for undo().
The analysis of preconditions and postconditions for execute() and undo() resulted in the addition of only one function to the virtual interface, checkPreconditionsImpl(). However, in order for the implementation of this function to be complete, we must determine the correct signature of this function. First, what should be the return value for the function? Either we could choose to make the return value void and handle failure of the precondition via an exception or make the return value a type that could indicate that the precondition was not met (e.g., a boolean returning false on precondition failure or an enumeration indicating the type of failure that occurred). For pdCalc, I chose to handle precondition failures via exceptions. This strategy enables a greater degree of flexibility because the error does not need to be handled by the immediate caller, the execute() function. Additionally, the exception can be designed to carry a customized, descriptive error message that can be extended by a derived command. This contrasts with using an enumerated type, which would have to be completely defined by the base class implementer.
The second item we must address in specifying the signature of checkPreconditionsImpl() is to choose whether the function should be pure virtual or have a default implementation. While it is true that most commands will require some precondition to be satisfied, this is not true of every command. For example, entering a new number onto the stack does not require a precondition. Therefore, checkPreconditionsImpl() should not be a pure virtual function. Instead, it is given a default implementation of doing nothing, which is equivalent to stating that preconditions are satisfied.
Because errors in commands are checked via the checkPreconditionsImpl() function, a proper implementation of any command should not throw an exception except from checkPreconditionsImpl() . Therefore, for added interface protection, each pure virtual function in the Command class should be marked noexcept. For brevity, I often skip this keyword in the text; however, noexcept does appear in the implementation. This specifier is really only important in the implementation of plugin commands, which are discussed in Chapter 7.
The next set of functions to be added to the Command class are functions for copying objects polymorphically. This set includes a protected copy constructor, a public nonvirtual clone() function, and a private cloneImpl() function. At this point in the design, the rationale for why commands must be copyable cannot be adequately justified. However, the reasoning will become clear when we examine the implementation of the CommandFactory. For continuity’s sake, however, we’ll discuss the implementation of the copy interface presently.
The preceding construction is illegal and will not compile. Because the Command class is abstract (and its copy constructor is protected), the compiler will not allow the creation of a Command object. However, not all hierarchies have abstract base classes, so one might be tempted to try this construction in those cases where it is legal. Beware. This construction would slice the hierarchy. That is, p2 would be constructed as a Command instance, not an Add instance, and any Add state from p would be lost in the copy.
The only interesting implementation feature here is the return type for the cloneImpl() function. Notice that the base class specifies the return type as Command*, while the derived class specifies the return type as Add*. This construction is called return type covariance, a rule which states that an overriding function in a derived class may return a type of greater specificity than the return type in the virtual interface. Covariance allows a cloning function to always return the specific type appropriate to the hierarchy level from which cloning was called. This feature is important for implementations that have public cloning functions and allow cloning calls to be made from all levels in the hierarchy.
I chose to round out the command interface with a help message function and a corresponding virtual implementation function. The intent of this help function is to enforce that individual command implementers provide brief documentation for the commands that can be queried through a help command in the user interface. The help function is not essential to the functionality of the commands, and its inclusion as part of the design is optional. However, it’s always nice to provide some internal documentation for command usage, even in a program as simplistic as a calculator.
If you look at the source code in Command.m.cpp, you will also see a virtual deallocate() function . This function is exclusively used for plugins, and its addition to the interface will be discussed in Chapter 7.
can never call anything but Derived’s foo().
Now, the compiler will flag the declaration as an error because the programmer explicitly declared that the derived function should override. Thus, the addition of the override keyword prevents a perplexing bug from occurring by allowing the programmer to disambiguate his intentions.
From a design perspective, the override keyword explicitly marks the function as being an override. While this may not seem important, it is quite useful when working on a large code base. When implementing a derived class whose base class is in another distinct part of the code, it is convenient to know which functions override base class functions and which do not without having to look at the base class’s declaration.
The Undo Strategy
Having defined the abstract interface for our commands, we next move on to designing the undo strategy. Technically, because the undo() command in our interface is a pure virtual, we could simply waive our hands and claim that the implementation of undo is each concrete command’s problem. However, this would be both inelegant and inefficient. Instead, we seek some functional commonality for all commands (or at least groupings of commands) that might enable us to implement undo at a higher level than at each leaf node in the command hierarchy.
As was previously discussed, undo can be implemented either via command inversion or state reconstruction (or some combination of the two). Command inversion was already shown to be problematic because the inverse problem is ill-posed (specifically, it has multiple solutions) for some commands. Let’s therefore examine state reconstruction as a generalized undo strategy for pdCalc.
We begin our analysis by considering a use case, the addition operation. Addition removes two elements from the stack, adds them together, and returns the result. A simple undo could be implemented by dropping the result from the stack and restoring the original operands, provided these operands were stored by the execute() command. Now, consider subtraction, or multiplication, or division. These commands can also be undone by dropping their result and restoring their operands. Could it be so simple to implement undo for all commands that we would simply need to store the top two values from the stack during execute() and implement undo by dropping the command’s result and restoring the stored operands? No. Consider sine, cosine, and tangent. They each take one operand from the stack and return a single result. Consider swap. It takes two operands from the stack and returns two results (the operands in the opposite order). A perfectly uniform strategy for undo cannot be implemented over all commands. That said, we shouldn’t just give up hope and return to implementing undo individually for every command.
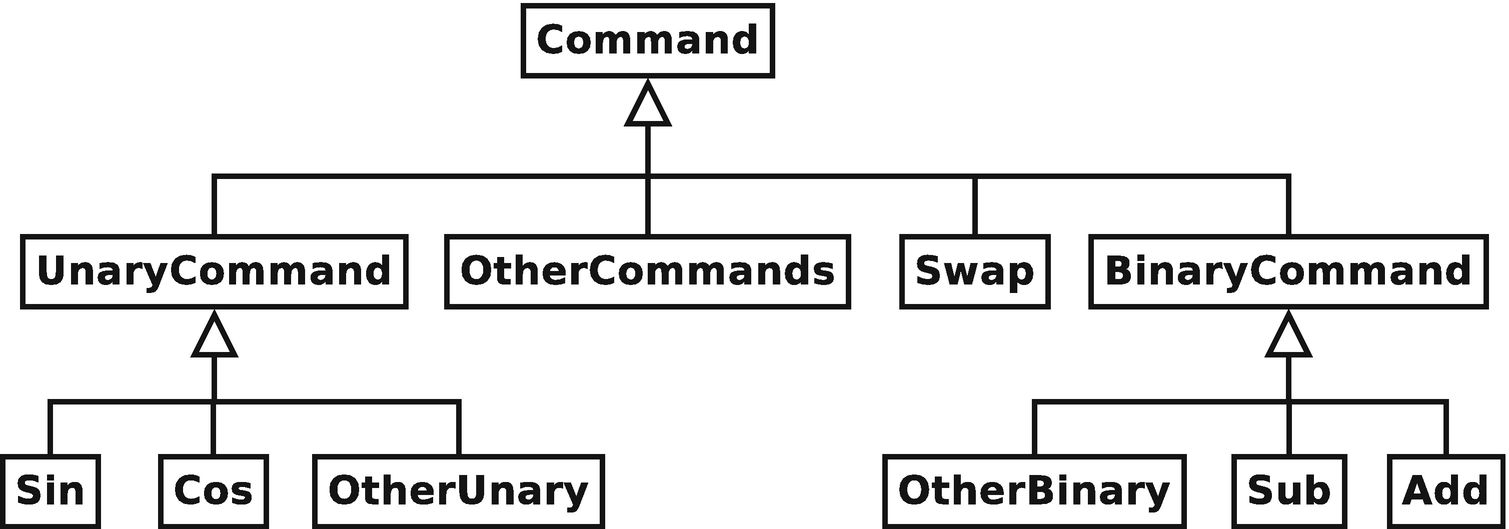
A multilevel hierarchy for the calculator’s command pattern
Our preceding use case analysis identified two significant subcategories of operations that implement undo uniformly for their respective members: binary commands (commands that take two operands and return one result) and unary commands (commands that take one operand and return one result). Thus, we can simplify our implementation significantly by generically handling undo for these two classes of commands. While commands not fitting into either the unary or binary command family will still be required to implement undo() individually, these two subcategories account for about 75% of the core commands of the calculator. Creating these two abstractions will save a significant amount of work.
Let’s examine the UnaryCommand class . By definition, all unary commands require one argument and return one value. For example, f (x) = sin(x) takes one number x from the stack and returns the result, f (x), onto the stack. As previously stated, the reason for considering all unary functions together as a family is because regardless of the function, all unary commands implement both forward execution and undo identically, differing only in the functional form of f. Additionally, they also all must minimally meet the same precondition. Namely, there must be at least one element on the stack.
Note that both the executeImpl() and undoImpl() functions are marked final, but the checkPreconditionsImpl() function is not. The entire reason for the UnaryCommand class to exist is to optimize the undo operation for all its descendants. Therefore, in order to be classified as a unary command, a derived class must accept UnaryCommand’s handling of undo and execute. We enforce this constraint by disabling the ability of derived classes to override undoImpl() and executeImpl() by using the final keyword. We’ll see a more detailed explanation of the final keyword in a sidebar later in this chapter. The checkPreconditionsImpl() function is different. While all unary commands share the common precondition that at least one element must be present on the stack, individual functions may require further preconditions. For example, consider the unary function arcsine, which requires its operand to be in the range [−1, 1]. The Arcsine class must be allowed to implement its own version of the checkPreconditionsImpl() function, which should call UnaryCommand’s checkPreconditionsImpl() before performing its own precondition check.
The top element is popped from the stack and stored in the UnaryCommand’s state for the purpose of undo. Remember, because we have already checked the precondition, we can be assured that unaryOperation() will complete without an error. As previously stated, commands with special preconditions will still need to implement checkPreconditionsImpl() , but they can at least delegate the unary precondition check upward to UnaryCommand’s checkPreconditionsImpl() function. In one fell swoop, we then dispatch the unary function operation to a further derived class and push its result back onto the stack.
The only peculiarity in UnaryCommand’s executeImpl() function is the boolean argument to the stack’s pop command. This boolean optionally suppresses the emission of a stack changed event. Because we know that the following push command to the stack will immediately alter the stack again, there is no need to issue two subsequent stack changed events. The suppression of this event permits the command implementer to lump the action of the command into one user apparent event. Although this boolean argument to Stack’s pop() was not part of the original design, this functionality can be added to the Stack class now as a convenience. Remember, design is iterative.
This function also has the expected obvious implementation. The result of the unary operation is dropped from the stack, and the previous top element, which was stored in the top_ member of the class during the execution of executeImpl(), is restored to the stack.
Clearly, the advantage of using the UnaryCommand as a base class instead of the highest-level Command class is that we have removed the need to implement undoImpl() and checkPreconditionsImpl(), and we replaced the implementation of executeImpl() with the slightly simpler unaryOperation(). Not only do we need less code overall, but because the implementations of undoImpl() and checkPreconditionsImpl() would be identical over all unary commands, we reduce code repetition as well, which is always a positive.
Binary commands are implemented in an analogous manner to unary commands. The only difference is that the function for executing the operation takes two commands as operands and correspondingly must store both of these values for undo. The complete definition for the BinaryCommand class can be found alongside the Command and UnaryCommand classes in the Command.m.cpp file found in the GitHub source code repository.
Concrete Commands
Defining the aforementioned Command, UnaryCommand, and BinaryCommand classes completed the abstract interface for using the command pattern in the calculator. Getting these interfaces correct encompasses the lion’s share of the design for commands. However, at this point, our calculator is yet to have a single concrete command (other than the partial Sine class implementation). This section will finally rectify that problem, and the core functionality of our calculator will begin to take shape.
The core commands of the calculator are all defined in the CoreCommands.m.cpp file. What are core commands? I have defined the core commands to be the set of commands that encompass the functionality distilled from the requirements listed in Chapter 1. A unique core command exists for each distinct action the calculator must perform. Why did I term these the core commands? They are the core commands because they are compiled and linked alongside the calculator and are therefore available immediately when the calculator loads. They are, in fact, an intrinsic part of the calculator. This is in contrast to plugin commands, which may be optionally loaded by the calculator dynamically during runtime. Plugin commands are discussed in detail in Chapter 7.
Interestingly enough, although the Command, UnaryCommand, and BinaryCommand classes were defined and exported from the command module, the core commands are all contained in the CoreCommands partition of the command dispatcher module. The CoreCommands are not exported from the command dispatcher module, except for testing. This design is justified because unlike the abstract command classes, the core commands, by definition, are those commands directly built into pdCalc, and the usage of these classes is entirely within the command dispatcher module itself.
The core commands listed by their immediate abstract base class
Command | UnaryCommand | BinaryCommand |
EnterCommand | Sine | Add |
SwapTopOfStack | Cosine | Subtract |
DropTopOfStack | Tangent | Multiply |
Duplicate | Arcsine | Divide |
ClearStack | Arccosine | Power |
Arctangent | Root | |
Negate |
In comparing the aforementioned list of core commands to the use cases from Chapter 2, one notes the conspicuous absence of undo and redo as commands even though they are both actions the user can request the calculator to perform. These two commands are special because they act on other commands in the system. For this reason, they are not implemented as commands in the command pattern sense. Instead, they are handled intrinsically by the yet-to-be-discussed CommandManager, which is the class responsible for requesting commands, executing commands, and requesting undo and redo actions. The undo and redo actions (as opposed to the undo and redo operations defined by each command) will be discussed in detail in Section 4.4.
The implementation of each core command, including the checking of preconditions, the forward operation, and the undo implementation, is relatively straightforward. Most of the command classes can be implemented in about 20 lines of code. The interested reader is referred to the repository source code if they wish to examine the details.
An Alternative to Deep Command Hierarchies
For completeness, we mention that because no classes further derive from BinaryCommandAlternative, we must handle help messages directly in the constructor rather than in a derived class. Additionally, as implemented, BinaryCommandAlternative only handles the binary precondition. However, additional preconditions could be handled in an analogous fashion to the handling of the binary operation. That is, the constructor could accept and store a lambda to execute the precondition test after the test for two stack arguments in checkPreconditionsImpl().
Obviously, unary commands could be handled similarly to binary commands through the creation of a UnaryCommandAlternative class. With enough templates, I’m quite certain you could even unify binary and unary commands into one class. Be forewarned, though. Too much cleverness, while impressive at the water cooler, does not usually lead to maintainable code. Keeping separate classes for binary commands and unary commands in this flattened command hierarchy probably strikes an appropriate balance between terseness and understandability.
The implementation difference between BinaryCommand’s executeImpl() and BinaryCommandAlternative’s executeImpl() is fairly small. However, we should not understate the magnitude of this change. The end result is a significant design difference in the implementation of the command pattern. Is one better than the other in the general case? I do not think such a statement can be made unequivocally; each design has trade-offs. The BinaryCommand strategy is the classic implementation of the command pattern, and most experienced developers will recognize it as such. The source code is very easy to read, maintain, and test. For every command, exactly one class is created that performs exactly one operation. The BinaryCommandAlternative, on the other hand, is very concise. Rather than having n classes for n operations, only one class exists, and each operation is defined by a lambda in the constructor. If paucity of code is your objective, this alternative style is hard to beat. However, because lambdas are, by definition, anonymous objects, some clarity is lost by not naming each binary operation in the system.
Which strategy is better for pdCalc, the deep command hierarchy or the shallow command hierarchy? Personally, I prefer the deep command hierarchy because of the clarity that naming each object brings. However, for such simple operations, like addition and subtraction, I think one could make a good argument that the reduced line count improves clarity more than what is lost through anonymity. Because of my personal preference, I implemented most of the commands using the deep hierarchy and the BinaryCommand class. Nonetheless, I did implement multiplication via the BinaryCommandAlternative to illustrate the implementation in practice. In a production system, I would highly recommend choosing one strategy or the other. Implementing both patterns in the same system is certainly more confusing than adopting one, even if the one chosen is deemed suboptimal.
Lambdas, standard function, and the final keyword are actually three independent modern C++ concepts. We’ll therefore address them separately.
Lambdas:
Lambdas (more formally, lambda expressions) can be thought of as anonymous function objects. The easiest way to reason about lambdas is to consider their function object equivalent. The syntax for defining a lambda is given by the following:
[capture-list](argument-list){function-body}
The preceding lambda syntax identically equates to a function object that stores the capture-list as member variables via a constructor and provides an operator() const member function with arguments provided by argument-list and a function body provided by function-body. The return type of the operator() is generally deduced from the function body, but it can be manually specified using the alternative function return type syntax (i.e., -> ret between the argument list and the function body), if desired. The type of the parameters to argument-list can either be specified or automatically deduced using auto. When the argument-list is automatically deduced, the function object equivalent to this generic lambda has a templated operator().
Given the equivalence between a lambda expression and a function object, lambdas do not actually provide new functionality to C++. Anything that can be done in C++11 with a lambda can be done in C++03 with a different syntax. What lambdas do provide, however, is a compelling, concise syntax for the declaration of inline, anonymous functions. Two very common use cases for lambdas are as predicates for STL algorithms and targets for asynchronous tasks. Some have even argued that the lambda syntax is so compelling that there is no longer a need to write for loops in high-level code since they can be replaced with a lambda and an algorithm. Personally, I find this point of view too extreme.
In the alternative design to binary commands, we saw yet another use for lambdas. They can be stored in objects and then called on demand to provide different options for implementing algorithms. In some respects, this paradigm encodes a microapplication of the strategy pattern. To avoid confusion with the command pattern, I specifically did not introduce the strategy pattern in the main text. The interested reader is referred to Gamma et al. [11] for details.
Standard function :
The function class is part of the C++ standard library. This class provides a generic wrapper around any callable target, converting this callable target into a function object. Essentially, any C++ construct that can be called like a function is a callable target. This includes functions, lambdas, and member functions.
Standard function provides two very useful features. First, it provides a generic facility for interfacing with any callable target. That is, in template programming, storing a callable target in a function object unifies the calling semantics on the target independent of the underlying type. Second, function enables the storage of otherwise difficult-to-store types, like lambda expressions. In the design of the BinaryCommandAlternative, we made use of the function class to store lambdas to implement small algorithms to overlay the strategy pattern onto the command pattern. Although not actually utilized in pdCalc, the generic nature of the function class actually enables the BinaryCommandAlternative constructor to accept callable targets other than lambdas.
The final keyword:
The final keyword , introduced in C++11, enables a class designer to declare either that a class cannot be inherited from or a virtual function may not be further overridden. For those programmers coming from either C# or Java, you’ll know that C++ is late to the game in finally (pun intended) adding this facility.
Before C++11, nasty hacks needed to be used to prevent further derivation of a class. Beginning with C++11, the final keyword enables the compiler to enforce this constraint. Prior to C++11, many C++ designers argued that the final keyword was unnecessary. A designer wanting a class to be noninheritable could just make the destructor nonvirtual, thereby implying that deriving from this class was outside the designer’s intent. Anyone who has seen code inheriting from STL containers will know how well developers tend to follow intent not enforced by the compiler. How often have you heard a fellow developer say, “Sure, that’s a bad idea, in general, but, don’t worry, it’s fine in my special case.” This oft uttered comment is almost inevitably followed by a week-long debugging session to track down obscure bugs.
Why might you want to prevent inheriting from a class or overriding a previously declared virtual function? Likely, because you have a situation where inheritance, while being well defined by the language, simply makes no sense, logically. A concrete example of this is pdCalc’s BinaryCommandAlternative class. While you could attempt to derive from it and override the executeImpl() member function (i.e., without the final keyword in place), the intent of the class is to terminate the hierarchy and provide the binary operation via a callable target. Inheriting from BinaryCommandAlternative is outside the scope of its design. Preventing derivation is therefore likely to prevent subtle semantic errors. Earlier in this chapter, when introducing the UnaryCommand class, we saw a situation where deriving from a class while simultaneously prohibiting the overriding of a subset of its virtual functions enforced the designer’s intended usage.
4.3 The Command Factory
Our calculator now has all of the commands required to meet its requirements. However, we have not yet defined the infrastructure necessary for storing commands and subsequently accessing them on demand. In this section, we’ll explore several design strategies for storing and retrieving commands.
4.3.1 The CommandFactory Class
Great, problem solved, right? Not really. How is this code called? Where does this code appear? What happens if new core commands are added (i.e., requirements change)? What if new commands are added dynamically (as in plugins)? What seems like an easy problem to solve is actually more complex than initially expected. Let’s explore possible design alternatives by answering the preceding questions.
First, we ask the question of how the code is called. Part of the calculator’s requirements is to have both a command line interface (CLI) and a graphical user interface (GUI). Clearly, the request to initialize a command will derive somewhere in the user interface in response to a user’s action. Let’s consider how the user interface would handle subtraction. Suppose that the GUI has a subtraction button, and when this button is clicked, a function is called to initialize and execute the subtraction command (we’ll ignore undo, momentarily). Now consider the CLI. When the subtraction token is recognized, a similar function is called. At first, one might expect that we could call the same function, provided it existed in the business logic layer instead of in the user interface layer. However, the mechanism for GUI callbacks makes this impossible because it would force an undesired dependency in the business logic layer on the GUI’s widget library (e.g., in Qt, a button callback is a slot in a class, which requires the callback’s class to be a Q_OBJECT). Alternatively, the GUI could deploy double indirection to dispatch each command (each button click would call a function which would call a function in the business logic layer). This scenario seems both inelegant and inefficient.
While the preceding strategy appears rather cumbersome, this initialization scheme has a structural deficit much deeper than inconvenience. In the model-view-controller architecture we have adopted for pdCalc, the views are not permitted direct access to the controller. Since the commands rightly belong to the controller, direct initialization of commands by the UI violates our foundational architecture.
How do we solve this new problem? Recall from Table 2-2 that the command dispatcher’s only public interface is the event handling function commandEntered (const string&). This realization actually answers the first two questions we originally posed: How is the initialization and execution code called and where does it reside? This code must be triggered indirectly via an event from the UI to the command dispatcher with the specific command encoded via a string. The code itself must reside in the command dispatcher. Note that this interface has the additional benefit of removing duplication between the CLI and the GUI in creating new commands. Now, both user interfaces can simply create commands by raising the commandEntered event and specifying the command by string. We’ll see how each user interface implements raising this event in Chapters 5 and 6, respectively.
From the aforementioned analysis, we are motivated to add a new class to the command dispatcher with the responsibility of owning and allocating commands. We’ll call this class the CommandFactory. For the moment, we’ll assume that another part of the command dispatcher (the CommandInterpreter class) receives the commandEntered() event and requests the appropriate command from the CommandFactory (via commandEntered()’s string argument), and yet another component of the command dispatcher (the CommandManager class) subsequently executes the command (and handles undo and redo). That is, we have decoupled the initialization and storage of commands from their dispatch and execution. The CommandManager and CommandInterpreter classes are the subjects of upcoming sections. For now, we’ll focus on command storage, initialization, and retrieval.
Our task now is to implement a function capable of instantiating any class derived from the Command class given only a string argument indicating its specific type. As one might expect, dissociating object creation from type is a common occurrence in design. Any such construct that provides this abstraction is generally known as a factory. Here, we introduce a particular embodiment, the factory function design pattern.
Before progressing, I should point out the semantic difference between a factory function and the factory method pattern, as defined by the Gang of Four [11]. As previously mentioned, a factory, generically, is a mechanism for separating the selection of the specific derived class in a hierarchy from the point of logical instantiation. Whereas the factory method pattern implements a factory via a separate class hierarchy, a factory function is simply a single function interface that implements the factory concept without a class hierarchy.
The aforementioned is a much more useful construct than direct instantiation using a class name or enumerated type because discovery of the value of t can be deferred to runtime. For example, typical usages of the factory function are for instantiating specific derived classes whose types are discovered from configuration files, input files, or dynamic user interactions (i.e., via a UI).
The interface employs a smart pointer return type to make explicit that the caller owns the memory for the newly constructed command.
The preceding interface is simple and effective, but it is limited by requiring a priori knowledge of every command in the system. In general, such a design would be highly undesirable and inconvenient for several reasons. First, adding a new core command to the system would require modifying the factory’s initialization function. Second, deploying runtime plugin commands would require a completely different implementation. Third, this strategy creates unwanted coupling between the instantiation of specific commands and their storage. Instead, we would prefer a design where the CommandFactory relies only on the abstract interface defined by the Command base class.
Here, we check whether or not the command is already in the factory. If it is, then we handle the error. If not, then we move the command argument into the factory, where the command becomes the prototype for the command name. Note that the use of unique_ptr indicates that registering a command transfers ownership of this prototype to the command factory. In practice, the core commands are all registered via a function in the CommandFactory.m.cpp file, and a similar function exists inside each plugin to register the plugin commands (we’ll see this interface when we examine the construction of plugins in Chapter 7). These function are called during initialization of the calculator and during plugin initialization, respectively. Optionally, the command factory can be augmented with a deregister command with the obvious implementation.
Now, if the command is found in the factory, a copy of the prototype is returned. If the command is not found, a nullptr is returned (alternatively, an exception could be thrown). The copy of the prototype is returned in a unique_ptr indicating that the caller now owns this copy of the command. Note the use of the clone() function from the Command class. The clone function was originally added to the Command class with the promise of future justification. As is now evident, we require the clone() function in order to copy Commands polymorphically for our implementation of the prototype pattern. Of course, had we not had the foresight to implement a cloning function for all commands at the time that the Command class was designed, it could easily be added now. Remember, you won’t get the design perfect on the first pass, so get used to the idea of iterative design.
The real alias, which can be found in Command.m.cpp, is slightly more complicated. Additionally, I used a function MakeCommandPtr() rather than the unique_ptr’s constructor to create CommandPtrs. The reasons for these differences will be explained in detail in Chapter 7.
Finally, the only other part of the interface from the repository code not already discussed that impacts the design is the choice to make the CommandFactory a singleton. The reason for this decision is simple. Regardless of how many different command interpreters exist in the system (interestingly enough, we’ll eventually see a case for having multiple command interpreters), the prototypes for functions never change. Therefore, making the CommandFactory a singleton centralizes the storage, allocation, and retrieval of all commands for the calculator.
- 1.
Uniform initialization is nonnarrowing:
- 2.
Uniform initialization (combined with initializer lists) permits initializing user-defined types with lists:
- 3.
Uniform initialization is never mistakenly parsed as a function:
Fortunately, the preceding situation does not arise often. However, when it does, you must understand the difference between uniform initialization and function style initialization.
From a design perspective, the main advantage of uniform initialization is that user-defined types may be designed to accept lists of identically typed values for construction. Therefore, containers, such as vectors, may be statically initialized with a list of values rather than default initialized followed by successive assignment. This modern C++ feature enables initialization of derived types to use the same syntax for initialization as built in array types, a syntactical feature missing in C++03.
4.3.2 Registering Core Commands
We have now defined the core commands of the calculator and a class for loading and serving the commands on demand. However, we have not discussed a method for loading the core commands into the CommandFactory. In order to function properly, the loading of all the core commands must only be performed once, and it must be performed before the calculator is used. Essentially, this defines an initialization requirement for the command dispatcher module. A finalization function is not needed since deregistering the core commands when exiting the program is unnecessary.
The best place to call an initialization operation for the command dispatcher is in the main() function of the calculator. Therefore, we simply create a global RegisterCoreCommands() function , implement it in the CommandFactory.m.cpp file, ensure the function is exported from the module, and call it from main(). The reason to create a global function instead of registering the core commands in the CommandFactory’s constructor is to avoid coupling the CommandFactory class with the derived classes of the command hierarchy. An alternative would have been to define the RegisterCoreCommands() in the CoreCommands.m.cpp file, but this would have required additional interface files, implementation files, and module exports. The registration function, of course, could have been called something like InitCommandDispatcher(), but I prefer a name that more specifically describes the functionality.
Implicitly, we have just extended the interface to the command dispatcher module (originally defined in Table 2-2), albeit fairly trivially. Should we have been able to anticipate this part of the interface in advance? Probably not. This interface update was necessitated by a design decision at a level significantly more detailed than the high-level decomposition of Chapter 2. I find slightly modifying a key interface during development to be an acceptable way of designing a program. A design strategy requiring immutability is simply too rigid to be practical. However, note that easy acceptance of a key interface modification during development is in contrast with the acceptance of a key interface modification after release, a decision that should only be made after significant consideration for how the change will affect clients already using your code.
4.4 The Command Manager
Having designed the command infrastructure and created a factory for the storage, initialization, and retrieval of commands in the system, we are now ready to design a class with responsibility for executing commands on demand and managing undo and redo. This class is called the CommandManager . Essentially, it manages the lifetime of commands by calling the execute() function on each command and subsequently retaining each command in a manner appropriate for implementing unlimited undo and redo. We’ll start by defining the interface for the CommandManager and conclude the section by discussing the strategy for implementing unlimited undo and redo.
4.4.1 The Interface
In the actual code listed in CommandManager.m.cpp, the interface additionally defines an enum class for selecting the undo/redo implementation strategy during construction. These strategies are discussed in the following section. I’ve included this option for illustrative purposes only. A production code would simply implement one undo/redo strategy and not make the underlying data structure customizable at construction.
4.4.2 Implementing Undo and Redo
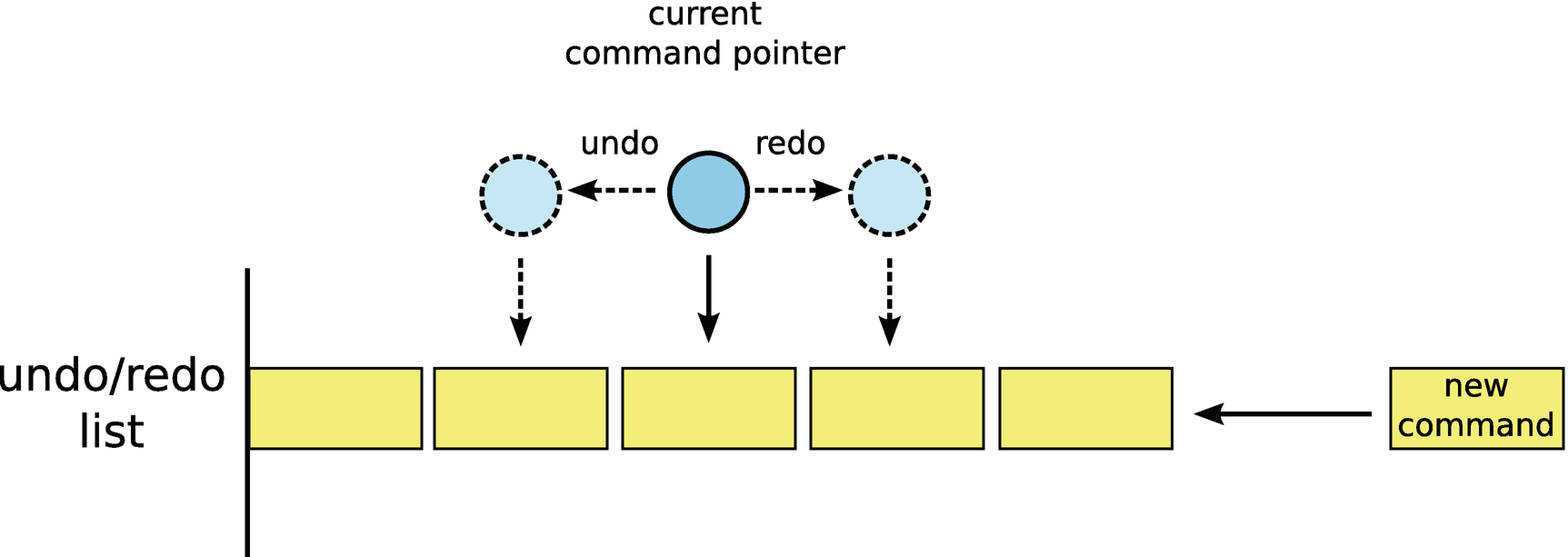
The undo/redo list strategy
Consider the data structure in Figure 4-3, which I have termed the list strategy. After a command is executed, it is added to a list (the implementation could be a list, vector, or other suitable ordered container), and a pointer (or index) is updated to point to the last command executed. Whenever undo is called, the command currently pointed to is undone, and the pointer moves to the left (the direction of earlier commands). When redo is called, the command pointer moves to the right (the direction of later commands), and the newly pointed to command is executed. Boundary conditions exist when the current command pointer reaches either the far left (no more commands exist to be undone) or far right (no more commands exist to be redone). These boundary conditions can be handled either by disabling the mechanism that enables the user to call the command (e.g., gray out the undo or redo button) or by simply ignoring an undo or redo command that would cause the pointer to overrun the boundary. Of course, every time a new command is executed, the entire list to the right of the current command pointer must be flushed before the new command is added to the undo/redo list. This flushing of the list is necessary to prevent the undo/redo list from becoming a tree with multiple redo branches.
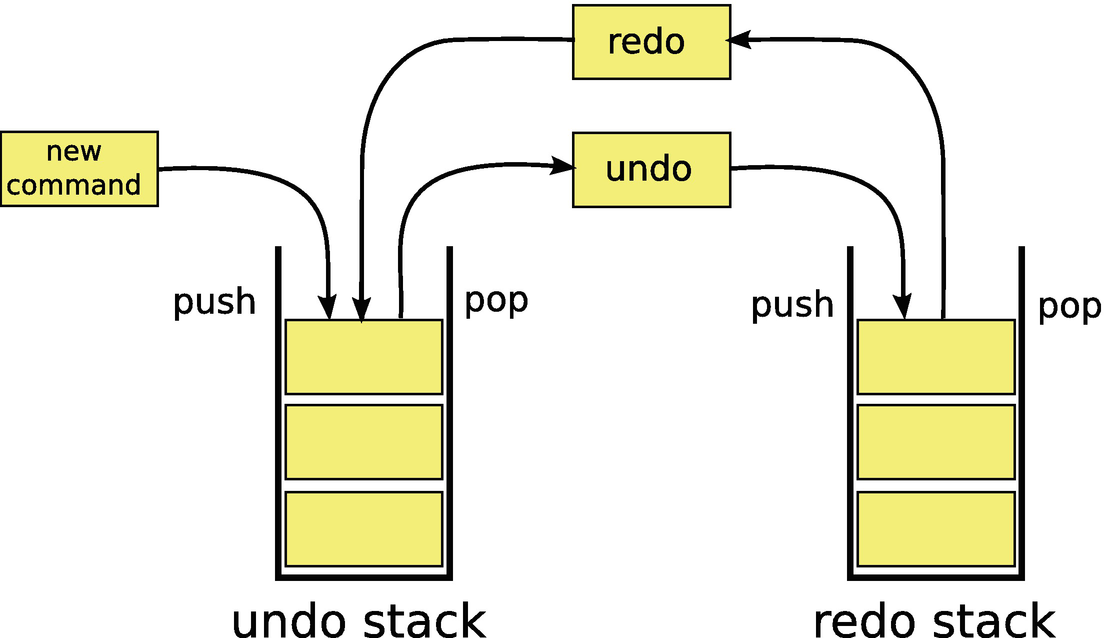
The undo/redo stack strategy
Practically, choosing between implementing undo and redo via either the stack or list strategy is largely a personal preference. The list strategy requires only one data container and less data movement. However, the stack strategy is slightly easier to implement because it requires no indexing or pointer shifting. That said, both strategies are fairly easy to implement and require very little code. Once you have implemented and tested either strategy, the CommandManager can easily be reused in future projects requiring undo and redo functionality, provided commands are implemented via the command pattern. For even more generality, the CommandManager could be templated on the abstract command class. For simplicity, I chose to implement the included CommandManager specifically for the abstract Command class previously discussed.
4.5 The Command Interpreter
The final component of the command dispatcher module is the CommandInterpreter class. As was previously stated, the CommandInterpreter class serves two primary roles. The first role is to serve as the primary interface to the command dispatcher module. The second role is to interpret each command, request the appropriate command from the CommandFactory, and pass each command to the CommandManager for execution. We address these two roles sequentially.
4.5.1 The Interface
Recall that the fundamental architecture of the calculator is based on the model-view-controller pattern and that the CommandInterpreter, as a component of the controller, is permitted to have direct access to both the model (stack) and view (user interface). Thus, the CommandInterpreter’s constructor takes a reference to an abstract UserInterface class, the details of which are discussed in Chapter 5. A direct reference to the stack is unneeded since the stack was implemented as a singleton. The actual implementation of the CommandInterpreter is deferred to a private implementation class, CommandInterpreterImpl. We’ll discuss this pattern of using a pointer to an implementation class, known as the pimpl idiom, in the next subsection.
An alternative design to the one previously mentioned would be to make the CommandInterpreter class an observer, directly. As discussed in Chapter 3, I prefer designs that use intermediary event observers. In Chapter 5, we’ll discuss the design and implementation of a CommandIssuedObserver proxy class to broker events between user interfaces and the CommandInterpreter class. Although the CommandIssuedObserver is described alongside the user interface, it actually belongs to the command dispatcher module.
The Pimpl Idiom
In the first version of this book, I extensively used the pimpl pattern in pdCalc’s implementation. However, when declaring classes in C++ module interfaces instead of in header files, I find that I use the pimpl pattern significantly less frequently. Despite my decreased usage of the pattern, because of its prominence in C++ code, the pimpl idiom is still worth discussing. Therefore, we’ll describe the pimpl pattern itself, why it was historically important, and where the pimpl pattern still makes sense in the presence of modules.
where u, v, w, v_, and m_ are now all be a part of class AImpl, which would be both declared and defined only in the implementation file associated with class A. To ensure AImpl cannot be accessed by any other classes, we declare this implementation class to be a private class wholly defined within A. Sutter and Alexandrescu [34] give a brief explanation of the advantages of the pimpl idiom. Assuming the use of a header/implementation file pair (as opposed to a module), one of the main advantages is that by moving the private interface of class A from A.h to A.cpp, we no longer need to recompile any code consuming class A when only A’s private interface changes. For large-scale software projects, the time savings during compilation can be significant.
For code that has even a moderately complex private interface, I tend to use the pimpl idiom regardless of its implications on compile times. The exception to my general rule is for code that is computationally intensive (i.e., code where the indirection overhead of the pimpl is significant). Assuming a legacy header implementation, in addition to the compilation benefits of not having to recompile files including A.h when only class AImpl changes, I find that the pimpl idiom adds significant clarity to the code. This clarity derives from the ability to hide helper functions and classes in implementation files rather than listing them in interface files. In this manner, interface files truly reflect only the bare essentials of the interface and thus prevent class bloat, at least at the visible interface level. For any other programmer simply consuming your class, the implementation details are visually hidden and therefore do not distract from your hopefully well-documented, limited, public interface. The pimpl idiom truly is the epitome of encapsulation.
Do Modules Obviate the Pimpl Idiom?
C++20 modules bring several design and implementation benefits to interfaces. Do these benefits obviate the need for the pimpl idiom? To answer this question, we need to enumerate the reasons the pimpl pattern is used and determine if modules deprecate the need for this idiom.
The first reason the pimpl pattern is used is to speed up compilations. In the classical header file inclusion model, the pimpl pattern decouples the dependency between a class’s private implementation and its public declaration. This decoupling implies that translation units dependent on a pimpl-ed class’s header file do not need to be recompiled when changes are only made to the private implementation class since those changes would appear in a separately compiled source file rather than in the pimpl-ed class’s header file. Modules partially solve this problem. To understand why, we’ll need to delve briefly into the module compilation model.
Suppose we have a function foo defined in foo.cpp that consumes class A. In the header inclusion model, A would be declared in A.h and defined in A.cpp; A.h would be included in foo.cpp. The header inclusion model essentially pastes the contents of A.h into foo.cpp when foo.cpp is compiled. Therefore, any changes in A.h force the recompiling of foo.cpp, which includes the recompilation of the entire contents of A.h since it was textually included into foo.cpp. This situation is problematic when A.h is large, and this situation is doubly problematic since this recompilation of the contents of A.h occurs for every consumer of this class. Of course, any changes in A.cpp do not cause the recompilation of its consumers because the consumers of A depend only on A.h, not on A.cpp. This compilation dependency is exactly why the pimpl-ing benefits us by moving implementation details of A from A.h to A.cpp.
The compilation model for modules is different than the header inclusion model. Modules are not textually included into their consumers; instead, they are imported. Modules do not require separate header and implementation files, and imports do not directly require visibility of declarations. Instead, importing modules relies on the compiler creating compiled module interfaces (CMIs), which is, unfortunately, a compiler-dependent process. For example, gcc caches CMIs automatically when modules are compiled, while clang relies on the build system manually defining a CMI precompilation step. Regardless, the module import mechanism provides a distinct advantage over the header inclusion model because the CMI is compiled once when the module is built, eliminating the need to recompile the definitions in a header file each time the header is included. Of course, the preceding explanation of the module’s compilation is slightly simplified, as modules can be split into module definition and module implementation files, and CMIs are both compiler version specific and even compilation option specific. Nonetheless, modules partially solve the first reason we use the pimpl idiom. If class A were defined in a module, ModuleA, instead of in A.h, any change to A’s definition would still require recompilation of A’s consumers. However, the recompilation of the former content of A.h would be precompiled once into a CMI rather than being textually included and recompiled with each consumer. Yes, each consumer would still need to be recompiled, but these compiles should be faster. Given ample tooling support, it is even possible that recompilation of consumers would be unnecessary if the build tool could detect the differences between public and private changes in a CMI.
Visibility versus accessibility
If A::bar(int) had instead been hidden in a private implementation class, the erroneous line in the preceding function foo() would have compiled with an implicit conversion of the number 7 from an int to a double.
The preceding example shows that we still must use the pimpl pattern to remove the name ambiguity for bar(). However, because modules can hide visibility without blocking reachability, we can construct our pimpl without a pointer indirection while still leaving AImpl hidden from consumers from an instantiation standpoint. This last fact brings us to our next dilemma.
Assuming the client does not have full source code access, the pimpl pattern enables us to hide implementation details from human eyes by moving these details from the human-readable interface, the header file, into the implementation file delivered to the client only as compiled binary code. Do modules permit hiding class implementation details from human eyes without resorting to the pimpl idiom? Unfortunately, no. Modules provide a language feature for enabling the compiler to hide visibility from consuming code, not from humans. While modules can be decomposed into separate module interface and module implementation units, the module interface unit must be human readable as the CMI cannot be used across compiler versions or settings reliably. That is, if a module’s interface must be exportable, the source code for its implementation must be distributable. This previous statement extends to the case where we define the implementation details of class A in its own module, AMod.Impl, and import AMod.Impl into AMod (without reexporting AMod.Impl). The lack of binary portability of the CMI implies that any module interface units imported by AMod must also be shipped with the module interface unit of AMod, just like nested header files. Additionally, analogous to a header file class declaration, a module interface unit–exported class declaration must contain sufficient information to instantiate an object. Therefore, types must be fully visible (even if not accessible), meaning that to hide code from human eyes, we must resort to the implementation of the pimpl pattern that uses pointer indirection rather than the more efficient method previously mentioned that utilizes class composition. Modules do not solve the human visibility problem solved by pimpl-ing private class implementation details.
Finally, my opinion is that the pimpl pattern stylistically simplifies interface code by minimizing the overall number of lines of code appearing in the visual representation of a class’s client interface. Many may not care about, or even acknowledge, this advantage of the pimpl idiom. This stylistic advantage applies to both header files and module interface units.
In summary, if you were using the pimpl pattern solely for its compilation efficiency benefits, modules, once matured, will likely obviate this usage of the pimpl idiom. If you were using the pimpl pattern to avoid collisions, modules may partially solve your problem. Finally, if you were using the pimpl idiom to remove implementation details from distributed interface source to avoid human visibility or just to clean up the interface, then modules do not help at all. The conclusion reached at the end of this section is that modules may partially obviate the pimpl idiom depending on your usage. While I still use the pimpl pattern, I do find I use it less frequently with modules than I do with header files.
4.5.2 Implementation Details
Lines 4–9 handle special commands. A special command is any command that is not entered in the command factory. In the preceding code, this includes entering a new number, undo, and redo. If a special command is not encountered, then it is assumed that the command can be found in the command factory; command factory requests are made on line 12. If nullptr is returned from the command factory, the error is handled in lines 25–26. Otherwise, the command is executed by the command manager. Note that the execution of commands is handled in a try/catch block. In this manner, we are able to trap errors caused by command precondition failures and report these errors in the user interface. The CommandManager’s implementation ensures that commands failing a precondition are not entered onto the undo stack.
The actual implementation of executeCommand() found in CommandInterpreter.cpp differs slightly from the preceding code. First, the actual implementation includes two additional special commands. The first of these additional special commands is help. The help command can be issued to print a brief explanatory message for all of the commands currently in the command factory. While the implementation generically prints the help information to the user interface, I only exposed the help command in the CLI (i.e., my GUI’s implementation does not have a help button). The second special command deals with the handling of stored procedures. Stored procedures are explained in Chapter 8. Additionally, I placed the try/catch block in its own function. This was done simply to shorten the executeCommand() function and separate the logic of command interpretation from command execution.
Depending on your familiarity with the evolution of the language’s syntax since C++17, two code statements in the implementation of executeCommand() may or may not have been new to you: an initializer in an if statement and the std::format() function. We’ll examine these two new features in the following sidebar.
Initialization in if statements was introduced in C++17, and the std::format() function was introduced in C++20. Let’s examine both of these new features.
If statement initializers :
std::format() :
Are you one of the people who never liked the overly verbose syntax of iostream string formatting and longed for a type-safe analog to sprintf() for C++? If you were, then std::format() will really excite you!
In the preceding example, I used numbered arguments to the format specifiers to enable reuse of the second argument, the precision value. Additionally, the example demonstrates how an argument can either be printed or used as a variable to a format specifier. Trust me when I say that the aforementioned only scratches the surface of the standard formatting.
Using format() allows you to format a single string. If you instead need a string builder, you can use format_to(). format_to() formats strings using the same syntax as format() except, instead of returning a formatted string, format_to() accepts an output iterator as its first argument and returns this same output iterator advanced by the formatted string. When the output iterator is a back_inserter<string>, then format_to() essentially replaces an ostringstream.
I must admit, I am not one of those people who were bothered by the overly verbose syntax of the iostream library. However, I have not used an ostream to format text since I started using the C++20 formatting library. I guess I actually was bothered by the previous syntax but didn’t even know it!
4.6 Revisiting Earlier Decisions
At this point, we have finished two of the main modules of our calculator: the stack and the command dispatcher. Let’s revisit our original design to discuss a significant subtle deviation that has arisen.
Recall from Chapter 2 that our original design handled errors by raising events in the stack and command dispatcher, and these events were to be handled by the user interface. The reason for this decision was for consistency. While the command dispatcher has a reference to the user interface, the stack does not. Therefore, we decided to simply let both modules notify the user interface of errors via events. The astute reader will notice, however, that the command dispatcher, as previously designed, never raises error events. Instead, it directly calls the user interface when errors occur. Have we not then broken the consistency that was intentionally designed into the system? No. Actually, we implicitly redesigned the error handling mechanism of the system during the design of the command dispatcher so that no error events are ever raised by either the stack or the command dispatcher. Let’s examine why.
As we just stated, it is obvious from its implementation that the command dispatcher does not raise error events, but what happened to stack events? We didn’t change the Stack class’s source code, so how did error events get eliminated? In the original design, the stack indirectly notified the user interface when errors occurred by raising events. The two possible stack error conditions were popping an empty stack and swapping the top two elements of an insufficiently sized stack. While designing the commands, I realized that if a command triggered either of these error conditions, the user interface would be notified, but the command dispatcher would not be (it is not an observer of stack events). In either error scenario, a command would have completed, albeit unsuccessfully, and been placed erroneously on the undo stack. I then realized that either the command dispatcher would have to trap stack errors and prevent erroneous placement onto the undo stack, or commands should not be permitted to make stack errors. As the final design demonstrates, I chose the easier and cleaner implementation of using preconditions before executing commands to prevent stack errors from occurring, thus implicitly suppressing stack errors.
The big question is, why didn’t I change the text describing the original design and the corresponding code to reflect the change in the error reporting? Simply stated, I wanted the reader to see that mistakes do occur. Design is an iterative process, and a book trying to teach design by example should embrace that fact rather than hide it. Designs should be somewhat fluid (but maybe with a high viscosity). It is much better to change a bad design decision early than to stick with it despite encountering evidence demonstrating flaws in the original design. The later a bad design is changed, the higher the cost will be to fix it, and the more pain the developers will incur while trying to implement a mistake. As for changing the code itself, I would have removed the superfluous code from the Stack class in a production system when I performed the refactor unless the Stack class was being designed for reuse in another program that handled errors via events. After all, as a generic design, the mechanism of reporting errors by raising events is not flawed. In hindsight, this mechanism was simply not right for pdCalc.