
Data analysis is the central phase of a data science process. It is similar to the construction phase in software development, where actual code is produced. The focus is on being able to handle large volumes of data to synthesize an actionable insight and knowledge. Data processing is the major phase where math and software engineering skills interplay to cope with all sorts of scalability issues (size, velocity, complexity, etc.). It isn’t enough to simply pile up various technologies in the hope that all will auto-magically align and deliver the intended outcome. Knowing the basic paradigms and mechanisms is indispensable. This is the main topic of this chapter: to introduce and exemplify pertinent concepts related to scalable data processing. Once you properly understand these concepts, then you will be in a much better position to comprehend why a particular choice of technologies would be the best way to go.
Augmented Descending Ball Project
Version 1.1
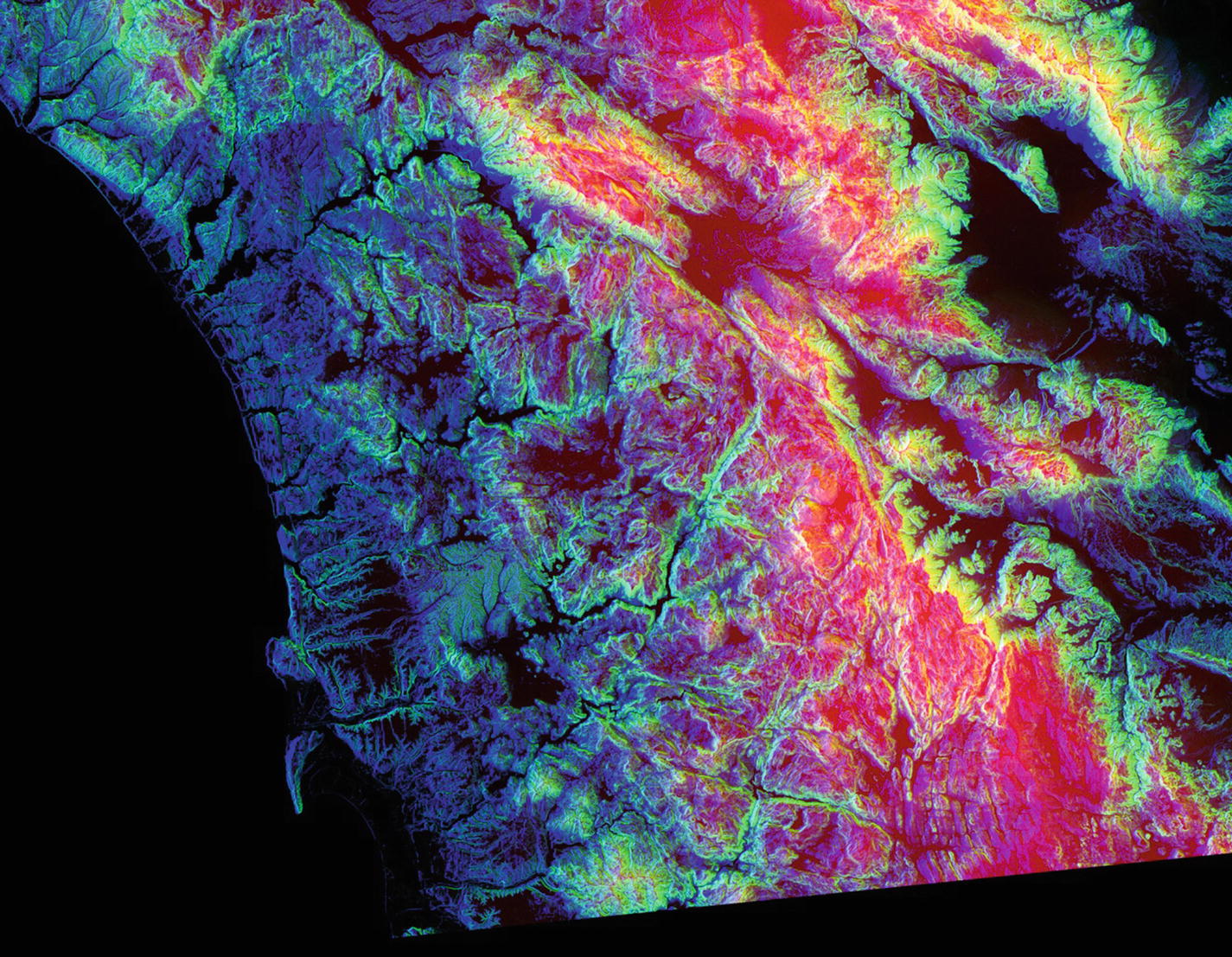
The satellite image of a coastline with encoded terrain data; each pixel’s red-green-blue components represent altitude, slope, and aspect, respectively. Higher color component values denote higher altitude, slope, and aspect.
Boundaries and Movement
An adjacent point with the lowest altitude is the lowest neighbor.
An adjacent point with the same altitude (if the others are at higher altitude) is the lowest neighbor, if the current point’s slope is greater than zero.
If there are multiple adjacent points satisfying the previous condition, then one of them is chosen in clockwise direction starting at south-west.
Path Finding Engine
Restructured Path Finding Module, Which Uses Object-Oriented Programming
The Simple Path Finder Class That Uses Recursion to Traverse the Terrain
Retrospective of Version 1.1
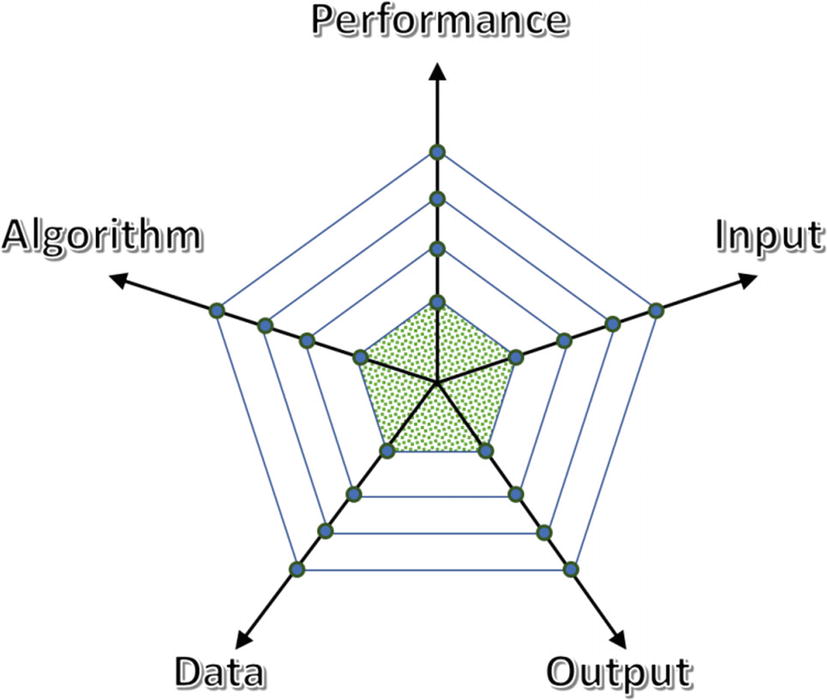
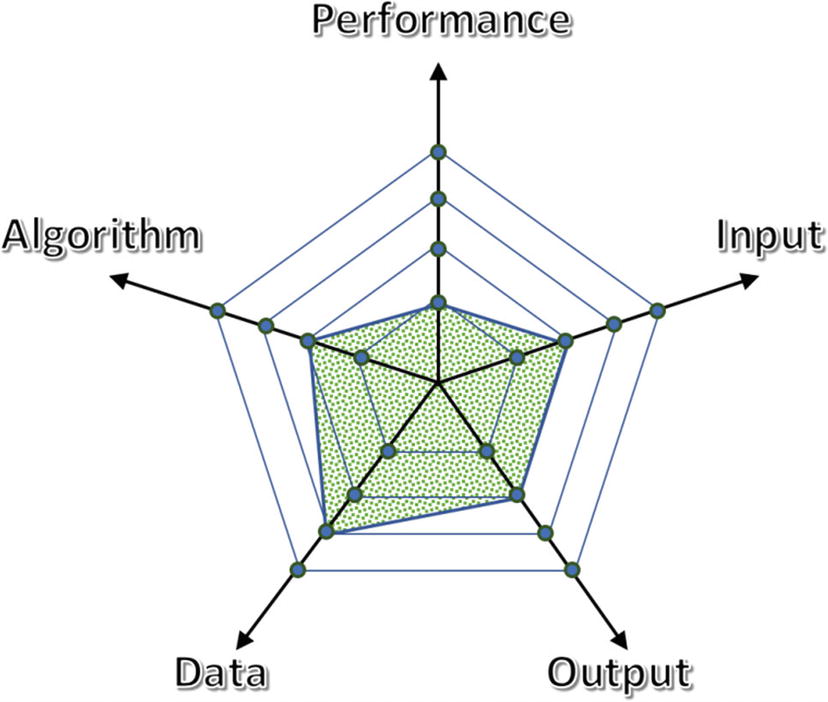
The shaded area represents the overall progress across all dimensions; dimensions may be arbitrarily chosen depending on the context
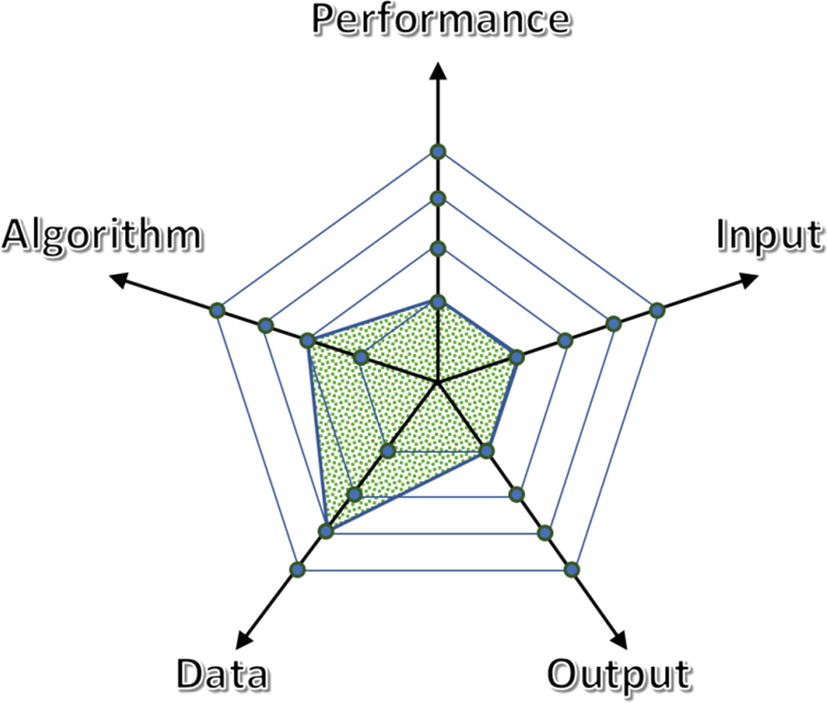
The new version has moved two units on the data axis (bigger size and enhanced structure) and one on the algorithm line
We have already seen that the input and output subsystems are deficient, so these require an improvement.
Retrospectives are regularly used in various Agile methods, too. They create opportunities for discussing lessons learned and potential improvements. Data science endeavors also require retrospectives. As you will see in the upcoming iterations, many times you will discover that there is a need for more exploration, preprocessing, and data-gathering cycles. The whole process is iterative and incremental.
Version 1.2
In this version we will move both the input and output subsystems by one unit; open the Terrain_Simulation_v1.2.ipubn notebook in the augmented_ball_descend source folder of this chapter. The idea is to allow the user to enter the starting position by directly specifying a point on the map. Furthermore, we would like to visualize the output on the map instead of just returning a set of points.
Enhancing the Input Subsystem
Removes the Default Title and Button for Closing the Interactive Session
Setup of an Interactive Session to Acquire the Starting Position from a User
Helper Class to Monitor User Actions
Caution
The previously implemented matplotlib interactive session only works with Jupyter Notebook (at the time of this writing). If you try to run the last code cell inside JupyterLab, you will receive the error Javascript Error: IPython is not defined. This is a fine example of the fact that you must occasionally solve problems completely unrelated to your main objectives.
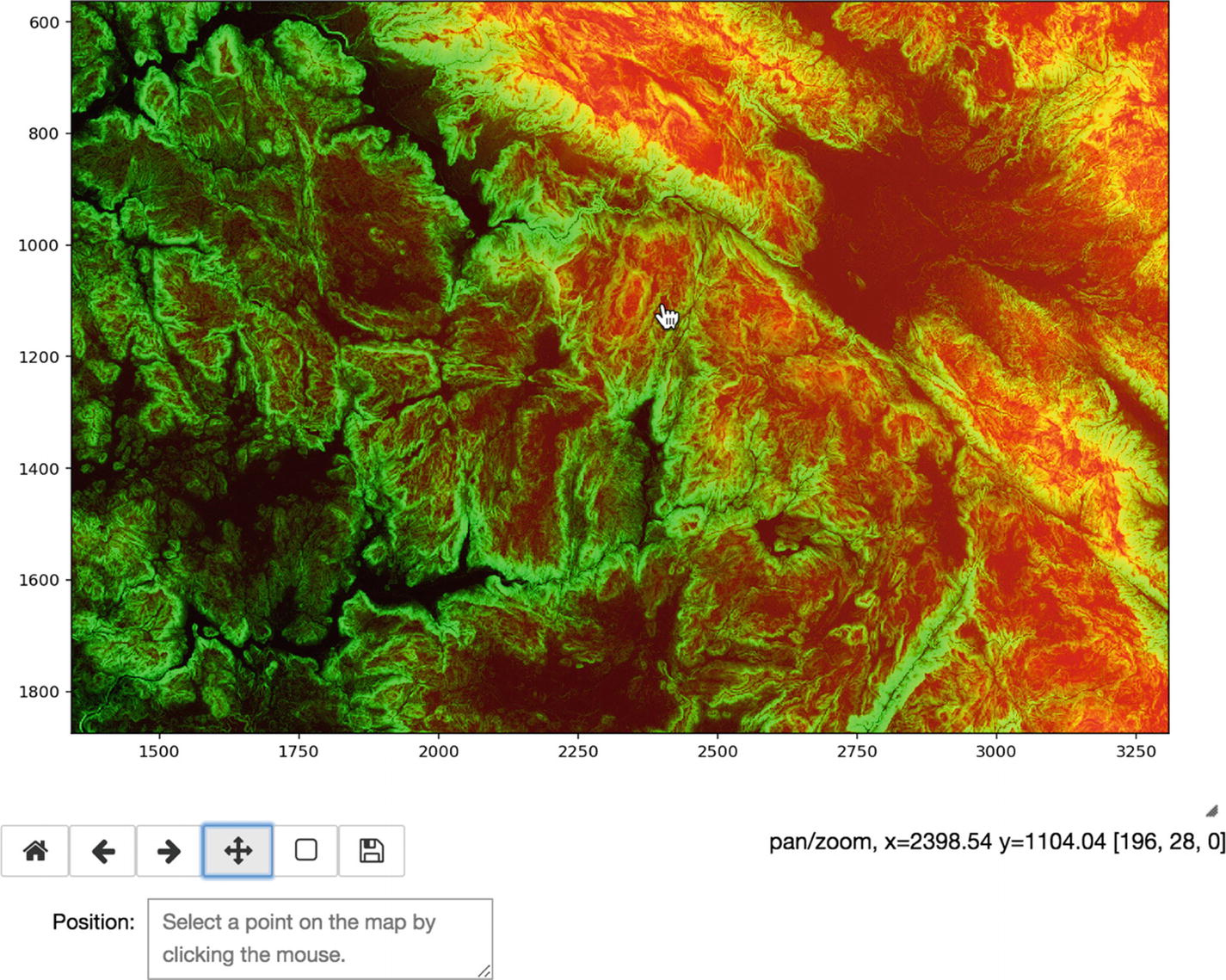
Part of the original image zoomed by a user to easily select a desired point (second button from the right)
You can see that the coordinates on axes reflect this zooming. The actual cursor position is printed on the right side together with data about the current altitude, slope, and aspect (this component is zeroed out so the whole picture is a combination of red and green). The small triangle above the coordinates is for resizing the whole UI. Once a point is selected, the session closes and its coordinates are displayed in the text area on the bottom. Compare this UI with the previous rudimentary slider-based input mechanism.
Enhancing the Output Subsystem
Handling the output will be an easier task. The system just needs to encode the path of a ball using the image’s blue color component (it will be set to 255). This new image may be reused for another run. Accordingly, the notebook will save the final image for later use. Of course, the raw coordinates may still be valuable, so the system should return those, too.
Implementation of the PathUtils Class, Currently Containing One Finalized Static Method
Notebook Cell That Uses the New Path Encoder Facility for Presenting Results
Retrospective of Version 1.2
A lot of effort has been invested into enhancing the user experience (both to gather input and to present a result). UI work commonly requires a considerable amount of time and care. Moreover, it demands highly specialized professionals, which again reminds us to look at data science as a discipline that requires team work. Neglecting this fact may lead to creating an unpopular data product. For example, it is a well-known fact in building recommender systems that user experience is as important as the fancy back-end system. Figure 5-5 shows the radar diagram for this version.
The input terrain data is coarsely grained, where 256 levels of altitude isn’t enough. Observe that our path finder can accept a higher-fidelity configuration without any change. So, one option is to look for images with higher color depth or abandon images altogether and rely on raw data.
The current algorithm to find neighbors is rudimentary. We all know from physics that a ball with high momentum can also roll up a slope. Furthermore, it will roll for some time even on a flat surface. Therefore, we may implement a new path finder that would better model the movement of a ball. One simple approach would be just to introduce a new state variable momentum. The ball’s momentum would increase at each spot with a positive slope toward a lower altitude, and its momentum would decrease at each spot after the lowest altitude is reached. On a flat surface, a ball would lose some small amount of its momentum at each iteration. Try to implement this as an additional exercise and see what happens.
The constraint of disallowing a ball to bounce back to a visited spot may also be a limiting factor. With an advanced model, you may allow such situations, especially if you introduce some randomness, too.
You should expect to need to improve performance soon after the publication of a useful, polished, and powerful data product. It cannot stay too long at its basic level.
Software architecture is the chief element for delivering nonfunctional requirements, including performance. This is why you must take care to structure your solution in a maintainable and evolvable manner with well-defined and connected components. Any optimization should be done on major pieces of the system, where the return on investment in performance tuning is most beneficial; measure performance (possibly with a profiler), consult the performance budget dictated by an architecture, and finally start making changes. If components are loosely coupled and expose clear APIs, you may be safe against ripple effects. Of course, covering your code with automated tests is something you should do by default. All these quality aspects will help you continue with rapid explorations, something you expect to be capable of by using Python and Jupyter Notebook technology. The secret is that your code base must also be in proper shape for magic to happen. Just think about the mess that would ensue if everything were piled up inside a single notebook, without information hiding and encapsulation (these were attained by using modules and object-oriented constructs).
Allow handling of arbitrarily large terrains. The current solution imposes an artificial limit on path size (the depth of recursion depends on stack size).
Allow calculating multiple paths at once (we will also need to update the UI to support this). We should also improve performance by using all available local and/or distributed hardware resources.
Version 1.3
- 1.
Implement your own proprietary solutions without reusing available open-source or commercial artifacts.
- 2.
Mostly reuse existing frameworks and spend time only on gluing things together.
- 3.
Combine the previous two options.
You would go with the first choice if you could not find a suitable framework to reuse. There is little chance that this will be the case in most situations. Therefore, it is always beneficial before any work to look around and see what is offered. Remember that any homemade software demands expertise to develop and fully maintain. The former is frequently a huge barrier to most developers and organizations. For example, a golden rule in security is to never invent your own encryption algorithm. Publicly exposing software is a potent way to ensure quality, since many users would report all sorts of issues and try it out in a multitude of scenarios.
At the opposite end of the spectrum is the eager reuse of software solutions. This option is again troublesome for several reasons. It is difficult to find for any complex problem an out-of-the-box solution. Even if you find one, it is usually arduous to overcome the limitations imposed by reused software; jumping out from a presupposed usage model is very costly. So, you must be confident that the model favoring a reused system will be right for you for a long period of time.
Often you will need to relax or alter the project’s initial set of requirements when considering a particular framework. If you don’t have such requirements, then you should first produce a proper project charter and gather such requirements. Consequently, be ready to revisit requirements with all pertinent stakeholders on the project. It isn’t uncommon in large organizations that requirements get ignored just because, somewhere down the road, a developer isn’t able to force a framework into a particular usage scenario.
When choosing frameworks, always consider many candidates. Each has its own strengths and weaknesses, so you will have to make a compromise based on the core objectives of your data product.
Every new framework requires some amount of familiarization and training. You also must ensure that your teammates are acquainted with the framework.
Always check the freshness of the framework and what kind of support you can get. There is nothing worse than bringing an obsolete library into your new product.
Every framework has a considerable impact on your design. Therefore, ensure that a later switch would not create a chain reaction (research the dependency inversion principle online).
Establishing the Baseline
To monitor progress, we need to specify the baseline. The current system has difficulties evaluating large terrains with long paths. For performance-testing purposes, we will create a degenerate terrain configuration to expose various running times (worst, average, and best case). We will produce a square surface whose spots are sorted according to altitude in ascending order and then augmented with “walls” of maximum altitude (like a maze). The worst-case performance can be measured by always starting from a lower-right corner. The best case would hit the top-left point. Randomly picking points and taking their average processing time would designate the average case. We can also make a terrain large enough to blow up the memory constraint (i.e., not being able to store it in memory).
Function to Produce a Maze-like Test Terrain (with Embedded Example)
Method That Calls find_path for Each Starting Position
Nonrecursive Simple Path Finder That Will, at Least Theoretically, Be Able to Process All Starting Positions
The nonrecursive version is capable of handling much longer paths, which shouldn’t surprise us when programming in Python (the recursive variant relies on tail recursion, which isn’t expensive in pure functional languages). Nevertheless, the running time of getting from point (1000, 1000) to the lowest point is already exorbitantly slow. There is no need to try with longer distances.
Performance Optimization
The bottleneck and critical parts of the code are identified; running your code under a profiler is mandatory.
The use cases that must be improved are evident; this defines the overall context of optimization. People often optimize for scenarios that will never occur in production.
The structure of your code base is of adequate quality and covered with tests to avoid regression and chaos.
Figure 5-6 shows a typical sequence of action between a user and our system; we will only focus on a specific user, but keep in mind that our service needs to support multiple users in parallel. From this use case we may conclude that many simulations will happen over the same terrain. All of those runs could execute in parallel, since the model is static (terrain data isn’t altered in any way). The story would be different for a dynamic setup.
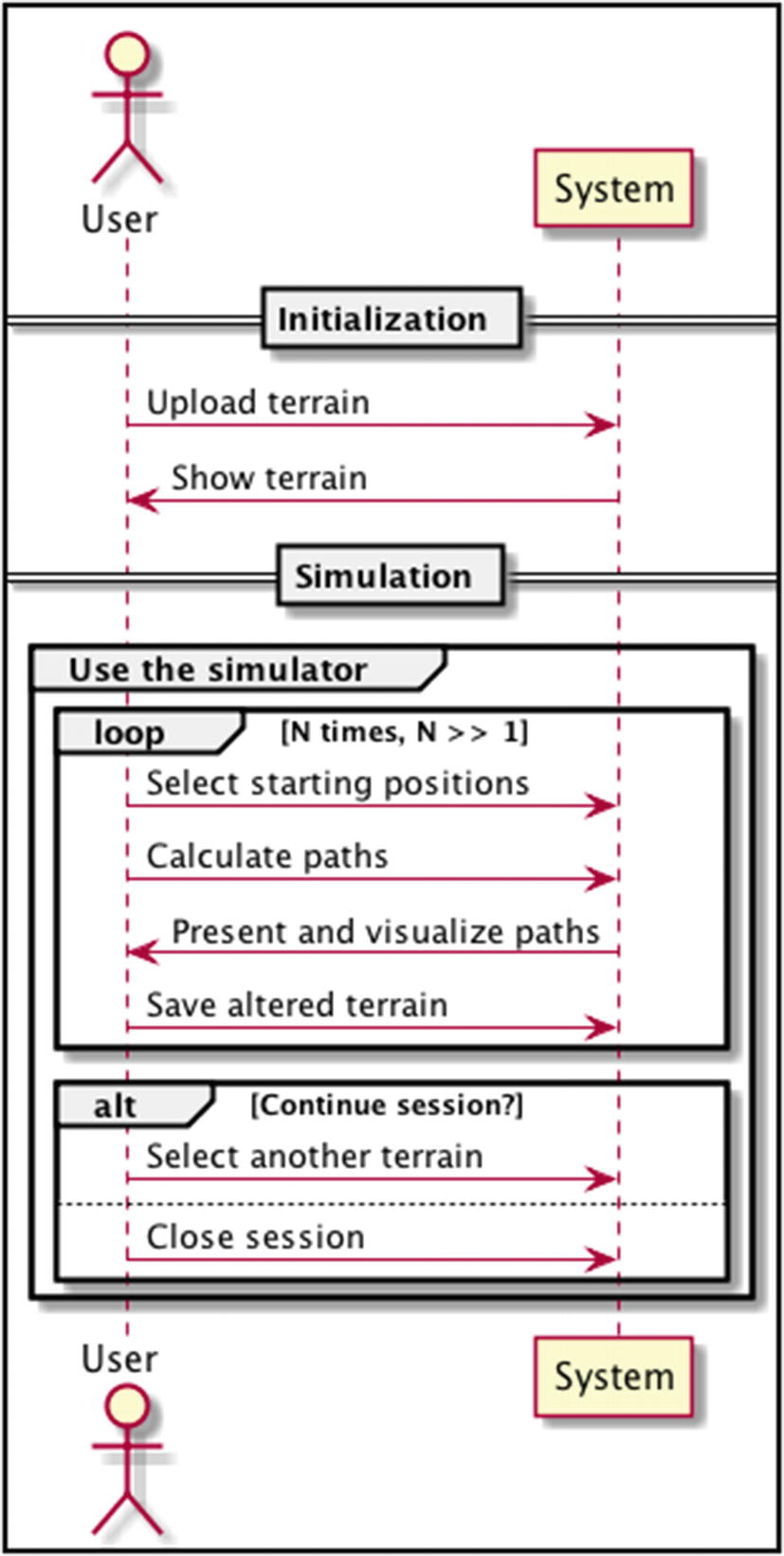
This sequence of interaction will happen independently for each user
We assume and optimize for a situation where the number of trials per terrain is large (>> 1). This may have a negative impact on extreme cases of 1 simulation per terrain. Again, this is a fine example of why you should be clear about your use cases.
Eliminate or reduce the number of calls to methods.
Speed up methods.
Combine the previous two options.
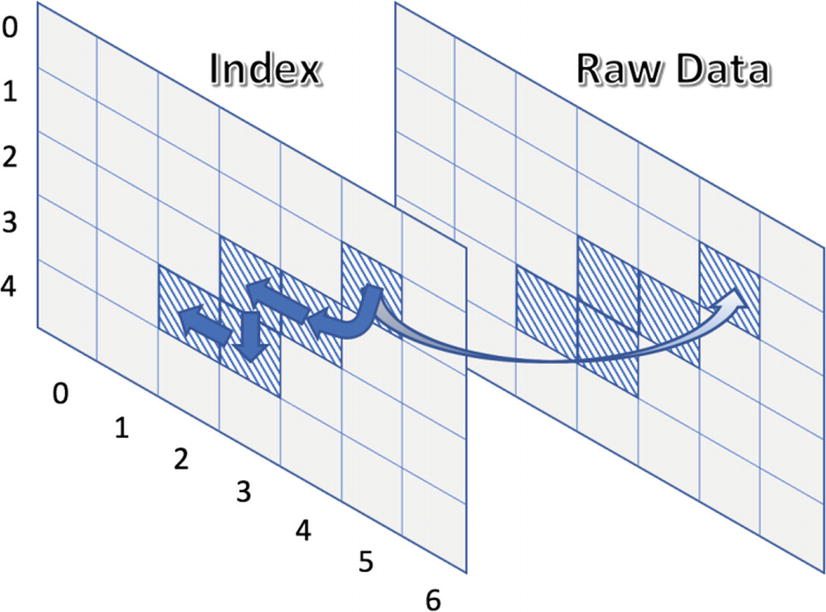
Here, the raw terrain data isn’t used at all during simulation
The next_neighbor method simply reads out next points based upon the current position. Preprocessing is performed by going over every point and storing its best neighbor (it may also be the current point if the ball cannot go anywhere else). For example, the index cell (1, 5) references the next neighbor, whose value is (2, 4). Reading the raw terrain data at (1, 5) yields that point’s altitude and slope.
The find_path method is called as many times as there are starting positions in the list. If we may parallelize find_path executions, then we may decrease the find_paths method’s execution time.
It must support both explicit and implicit parallelism. So, we are not looking solely for an abstraction over which we can reach out to many cores or machines. For example, Apache Spark exposes a straightforward model through the resilient distributed dataset abstraction but forces us to formulate problems in a specific way. For arbitrarily complex logic, we would need something more akin to generic frameworks, like multiprocessing in Python.
We don’t want to rewrite much of the existing code nor depart into another run-time environment. For example, a JVM-based technology isn’t preferable.
Preferably, we would like to retain the current APIs when working with new abstractions. This would also reduce learning time.
It turns out that there is an open-source framework that meets our aspirations. Numba (see http://numba.pydata.org ) is a just-in-time (JIT) compiler that translates Python functions with Numpy code into machine code. There is no special precompilation phase. All you need to do is annotate functions that you wish to accelerate. Numba integrates seamlessly with Dask and may even produce universal functions that behave like built-in Numpy functions. Being able to speed up arbitrary functions is very important when you have complex business logic with lots of conditionals. In this case, any crude parallelization scheme would become cumbersome to apply. Finally, with Numba you can optimize for GPUs, again something very crucial to gain top performance.
Performance-Tuned Path Finder Class That Uses Numba
So, execution time went down from 1min 46s to 8.82s! This is more than a 10× improvement. The good news is that there are tons of more possibilities to decrease the running time (indexing, mentioned earlier, is one of them).
Retrospective of Version 1.3
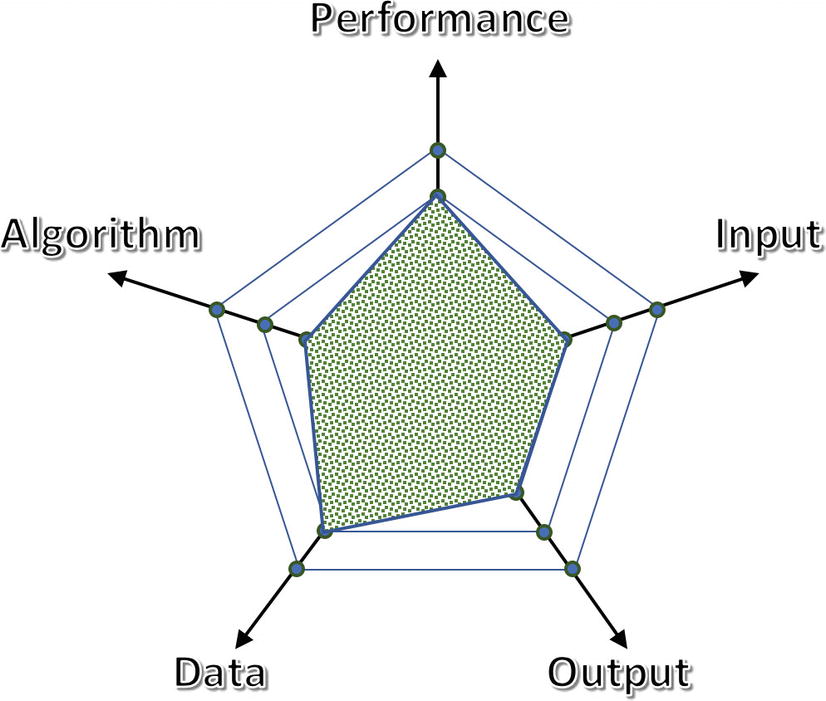
The performance is now satisfactory, which allows us to add new, complex features
Abstractions vs. Latent Features
Thus far, we have worked with software abstractions: frameworks, classes, data structures, etc. Abstractions are our principal mechanism to combat complexity. Working with entities on proper abstraction levels increases both efficacy and quality. These software abstractions have all been explicit, because we created them. In this section you will see that there is a totally different category of abstractions that emerges behind the scenes. We don’t even know what they represent, although we know everything about the process responsible for their creation. Often these artifacts are called latent features .
Latent features describe raw data in a more concise fashion; by using them, we can achieve high compression in many aspects. Besides dropping the sheer data size, more importantly, we can reduce the number of dimensions in the dataset. This directly brings down complexity, as many machine-learning algorithms work much better in lower dimensional space (we will talk about machine learning in Chapter 7).
There are two fundamental compression procedures: fully explainable and partially explainable. In Chapter 2 you witnessed the former, where the application of mathematical statistics produced a more compact data representation. In other words, we summarized the dataset while preserving all pertinent details regarding customer behavior. In this section, you will see an example of partially explainable compression procedures.
Interpretability of your solution is a very important topic nowadays (see reference [1] for a good recount). For example, many companies want to know how and why particular items were recommended to users by a recommender system. You cannot just respond that it was decided by a machine that leverages a well-known matrix factorization technique. Remember this side-effect of latent features when you start to design a new system.
Compressing the Ratings Matrix
Suppose that you are building a recommender system and store ratings of users for items inside matrix R. Each row represents one user and each column represents an item. For user u and item i you can easily find out the rating rui by looking at the corresponding cell of the matrix. Obviously, may cells will be empty, because users will rate only a miniscule number of items. With millions of users and items, this matrix may become enormous (even if you store it as a sparse matrix). Apparently, no commercial recommender system uses such raw matrices.
There is a theorem of linear algebra stating that any matrix Rmxn with rank k can be decomposed into three subordinate matrices Umxk, Skxk, and Vkxn, such that R = USVT. The columns of U and V are pairwise orthogonal, and the matrix S is diagonal (its elements are called singular values). Now, the magic is related to choosing the number of latent features d < k, so that we can abandon most of the elements in U, S, and V. Of course, the goal is to still be able to approximately reconstruct the original matrix R. The aim is to efficiently calculate predictions of ratings for users and items that haven’t been rated (we presume a multivalued rating scheme, such as number of stars).1
The singular values are ordered in descending order, and we kept the first five latent features. Sure, we no longer can faithfully reconstruct R in a lower dimensional space, but we may estimate its values quite correctly. Ratings anyhow contain noise, and our goal isn’t to figure out the known values. The mission is to predict unknown ratings, and for this purpose an approximation of R is good enough. The last line above shows the reduced vector for user 1. It is expressed with five latent features that somehow designate the “taste” of users. Without further deep analysis, we have no inkling what aspect of “taste” they denote.
This example only scratches the surface of recommender systems, but I hope that you have grasped the key idea.2 You will encounter latent features everywhere; the principal component analysis method and neural networks are all based upon them. In some sense, instead of doing feature engineering yourself, you leave this job to a machine.
Exercise 5-1. Random Path Finder
The SimplePathFinder class visits potential neighbors in a predefined order. Consequently, it will generate the same path every time (assuming no change in the starting position). This doesn’t quite mimic the real world and is also a boring behavior.
Create a new class RandomSimplePathFinder as a child of SimplePathFinder and override the next_neighbor method. It should randomly select the next point among equally good candidates, if there is more than one. Feel free to refactor the parent class(es), if you judge that would reduce duplication of code.
Exercise 5-2. Mores Reusable Interaction Monitor
The InteractionMonitor class accepts a text area to update its value property each time a user selects a new starting position. This was OK for our purpose but may be inadequate in other situations.
Improve this class by making it more reusable. One option is to receive a function (instead of that informational area) accepting one tuple argument that denotes the selected starting position. In this manner, users could have full control over the selection process. One good use case is selecting multiple points. These could be collected by your custom function until the desired number of points is reached. Afterward, your function would call the stop method on the InteractionMonitor instance.
Summary
This chapter has demonstrated how software engineering methods and concepts interplay with those related specifically to data science. You have witnessed how progression through multiple interrelated dimensions requires careful planning and realization. These dimensions were performance, input, output, data, and algorithms. Radar diagrams are very handy to keep you organized and to visually represent strengths and weaknesses of the current system. You should have implicitly picked up the main message: as soon as you start doing something advanced in any particular area, things get messy. This is the principal reason why methods that work at a small scale don’t necessarily work in large-scale situations.
There are tons of frameworks that we haven’t even mentioned, but all of them should be treated similarly to how we treated Numba in this chapter. The next two paragraphs briefly introduce a few notable frameworks, and in upcoming chapters you will encounter some very powerful frameworks, such as PyTorch for deep neural networks (in Chapter 12). We will also come back to Dask in Chapter 11.
Dask (see https://dask.org ) is a library for parallel computing in Python (consult references [1] and [2] for a superb overview). Dask parallelizes the numeric Python ecosystem, including Numpy, Pandas, and Scikit-Learn. You can utilize both the implicit and explicit parallelization capabilities of Dask. Furthermore, Dask manages data that cannot fit into memory as well as scales computation to run inside a distributed cluster. Dask introduces new abstractions that mimic the APIs of the underlying entities from the SciPy ecosystem. For example, with dask arrays you can handle multiple smaller Numpy arrays in the background while using the familiar Numpy API. There are some gotchas you need to be aware of. For example, don’t try to slice large dask arrays using the vindex method (implements fancy indexing over dask arrays). At any rate, combining Dask and Numba can give you a very powerful ensemble to scale your data science products.
Luigi (see https://github.com/spotify/luigi ) is a framework to build complex pipelines of batch jobs with built-in Hadoop support (this represents that harmonizing power between various frameworks). On the other hand, Apache Nifi (see https://nifi.apache.org ) is useful to produce scalable data pipelines. As you can see, these two frameworks attack different problems, although they may be orchestrated to work together depending on your needs.
References
- 1.
Steven Strogatz, “One Giant Step for a Chess-Playing Machine,” New York Times, https://www.nytimes.com/2018/12/26/science/chess-artificial-intelligence.html , Dec. 26, 2018.
- 2.
Matthew Rocklin, “Scaling Python with Dask,” Anaconda webinar recorded May 30, 2018, available at https://know.anaconda.com/Scaling-Python-Dask-on-demand-registration.html.
- 3.
Dask Tutorial,” https://github.com/dask/dask-tutorial .