
1 INTRODUCTION
WHY IS THIS CHAPTER WORTH READING?
This introductory chapter explains the importance of software testing, and covers what test design is, how we can put test design activities into the software development and testing life cycle, why tests should be designed, what factors affect test design and when test design should be done.
THE IMPORTANCE OF SOFTWARE TESTING
Software is a vital part of our everyday life. It helps in navigating to destinations, communicating with people, driving production, distributing energy resources, taking care of people’s health, and so much more. We use software for entertainment, for scientific research, for driving companies forward. There is embedded software in cars, trucks, locomotives, aeroplanes, mobile phones, electronic equipment and so on. Controlling and ensuring the quality of these software systems is vital. We need to check, that is test, software because things can always go wrong – humans make mistakes all the time. Despite this, the human aspects of producing quality software are indisputable even if artificial intelligence comes to the fore.
ISTQB certifies software testers worldwide; there are books, articles, documents, webinars, and blogs supporting the knowledge transfer of testing. In this book, we mainly draw on the terms of the ISTQB Glossary (2018a).
Let’s list a few goals that should be considered while testing software systems:
• ensuring the overall quality of the systems;
• customer satisfaction;
• reducing the risk of failures;
• cost-effective maintenance.
The most important goal of testing is to ensure good quality software by optimising the project costs in a way that all the parties involved gain confidence in the product – see Chapter 3. To be able to do this, a tester has to harvest information on system behaviour. One of the main reasons for gathering information is the execution of test cases. The test case is an essential notion in software testing: simply, ‘a test case is a set of preconditions, inputs, actions (where applicable), expected results and postconditions, developed on test conditions’ (ISTQB, 2018a). At this point the main questions are:
• How do we design the tests?
• Which test cases are the most appropriate for a given situation?
• How can test intensity be determined?
• How many test cases do we need?
• How can we validate the tests?
In answering these questions the process of test design is essential.
WHAT IS TEST DESIGN EXACTLY?
Test design is one of the most important prerequisites of quality. We design tests to support:
1. defining and improving quality-related processes and procedures (quality assurance);
2. evaluating the quality of the product with regards to customer expectations and needs (quality control);
3. finding defects in the product (testing).
Fortunately, or unfortunately, it is a creative process on its own, but also one that requires technical expertise.
More than the act of testing, the act of designing tests is one of the best bug preventers known. The thinking that must be done to create a useful test can discover and eliminate bugs before they are coded - indeed, test-design thinking can discover and eliminate bugs at every stage in the creation of software, from conception to specification, to design, coding and the rest.
(Beizer, 1990)
Test design depends on many factors. Figure 1.1 summarises the relevant entities of the traditional testing life cycle including test design activities.
Preceding test design activities – test planning and test analysis
In this subsection we describe the main activities that precede and influence test design.
Figure 1.1 Test design in the test software development life cycle (SDLC)
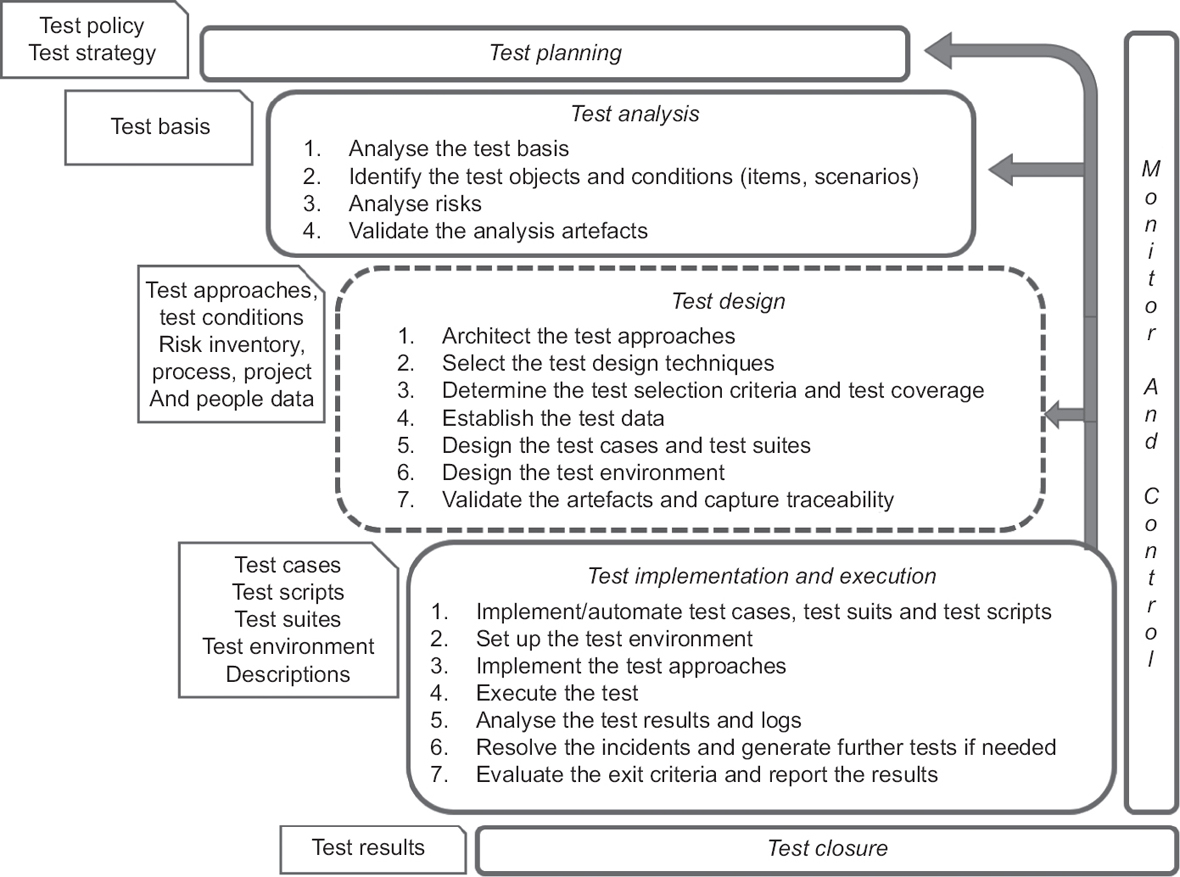
Test planning
The test planning process determines the scope, objective, approach, resources and schedule of the intended test activities. During test planning – amongst others – the test objectives, test items, features to be tested, the testing tasks, human and other resources, the degree of tester independence, the test environment, entry and exit criteria to be used, and any risks requiring contingency planning are identified.
The ISO/IEC/IEEE 29119-3 Standard for Software Testing – Test Documentation, recommends the necessary documents for use in defined stages of software testing.
A test policy document represents the testing philosophy of the company, selecting the frames that testing parties should adhere to and follow. It should apply to both new projects and maintenance work. The test strategy is defined as a set of guiding principles that influences the test design and regulates how testing is carried out.
The test approach defines how (in which way) testing is carried out, that is how to implement a test strategy. It can be proactive, that is the test process is initiated as early as possible to find and fix the faults before the build (preferable, if possible), or reactive, which means that the test design process begins after the implementation is finished. The test approach can be of different (not necessarily disjoint) types such as specification-based, structure-based, experience-based, model-based, risk-based, script-based, fault-based, failure-based, standard-compliant, test-first and so on, or a combination of them. For example, a risk-based approach is applied in almost all situations.
The proactive test-first approach starts with analysing the specifications, then applying risk analysis. Based on the result of this analysis one can select the appropriate techniques to design the test cases. The riskier code needs more techniques to be used in parallel. The test design can then be extended with structure-based testing, that is coverage analysis to create additional test cases for uncovered code.
Test monitoring and control
Test monitoring is an ongoing comparison of the actual and the planned progress. Test control involves the actions necessary to meet the objectives of the plan.
Although monitoring and control are activities that belong to the test manager, it is important to ensure that the appropriate data/metrics from the test design activities are collected, validated and communicated.
Test analysis
The test engineering activity in the fundamental test process begins mainly with test analysis. Test analysis is the process of looking at something that can be used to derive quality information for the software product. The test analysis process is based on appropriate project documents or knowledge, called the test basis, on which the tests are based.
The test analysis phase has three main steps before the review.
1. The first step is to analyse the test basis thoroughly. Possible test bases can take the form of business requirement documents, systems requirement documents, functional design specifications, technical specifications, user manuals, source codes and so on.
2. The second step is to identify the test objects (features, scenarios) and conditions by defining what should be tested.
A test condition is a statement about the test object, which can be true or false. Test conditions can be stated for any part of a component (or system) that could be verified by some tests, for example a function, transaction, feature, quality attribute or structural element.
A feature is an attribute of a component or system specified or implied by requirements documentation.
A test scenario is a business requirement to be tested, which may have one or more tests associated with it.
The advantages of using test scenarios are:
a. They help to achieve more complete test coverage.
b. They can be approved by various stakeholders.
c. They help to determine the end-to-end functionality of the test object.
Projects that follow Agile methodology – like Scrum or Kanban – usually do not use test scenarios: they apply user stories, sometimes use cases. We note that both are test objects, and a user story – which is an informal, natural language description of some system features – contains information about the test conditions.
A test object may consist of different test items. A test item is a specific element to be tested.
EXAMPLE FOR TEST OBJECT AND TEST ITEM
To clarify the notion, a test object can be login functionality, while a test item can be a username or password field in the login form. A test condition for this scenario can be an assertion for usernames such as ‘a username shall start with an alphabetical or numeric value’.
It is usually advisable to determine the test objects/conditions at different levels of detail. Initially, high-level objects/conditions have to be identified to define general targets for testing. Subsequently, in the design phase, the objects/conditions will be groomed towards specific targets. Applying this type of hierarchical approach can help to ensure that the coverage is sufficient for all high-level items.
3. The third step of the test analysis phase is risk analysis. For each elicited (mainly high level) test object the risk analysis process determines and records the following risk attributes:
a. the impact of malfunctioning (how important the appropriate functioning of the test is);
b. the likelihood of malfunctioning (how likely it is to fail).
Later, during test execution, the risk inventory supports the organisation of the tests in a way that the high-risk items are addressed with more intensive testing – see Chapter 3.
An effective risk analysis is a result of contributions from different stakeholders: managers, technical and business people, customer representatives and so on. Risk analysis is a continuous process.
We note that risk analysis is always necessary, not only in risk-based testing. The reason is that we should optimise the costs and effort of the whole test development process. Risk analysis performed during the test analysis phase refines the risks identified during test planning.
4. The last step of this phase is spent validating the identified artefacts, test objects, main scenarios and test conditions, and the risk inventory by applying reviews.
Present activity – test design
After the test analysis, the test design comes into the picture. The test design depends on a few factors:
• The result of risk and complexity analysis – see Chapter 3. This is the starting point of the test design techniques to be selected.
• The way the software development process is organised (for instance, V-model vs Agile).
• The knowledge and experience of the people involved.
• The available (sometimes limited) resources.
Based on these and other factors, the test design can be performed in seven steps (see Figure 1.1):
1. First, the test approaches are worked out, which means that it should be planned how the product quality together with the cost optimisation goals can be achieved via the approaches defined earlier, taking into consideration the elicited test conditions, code complexity and risks. Here we consider consistencies with standards, processes, flows, measures, user experience and so on.
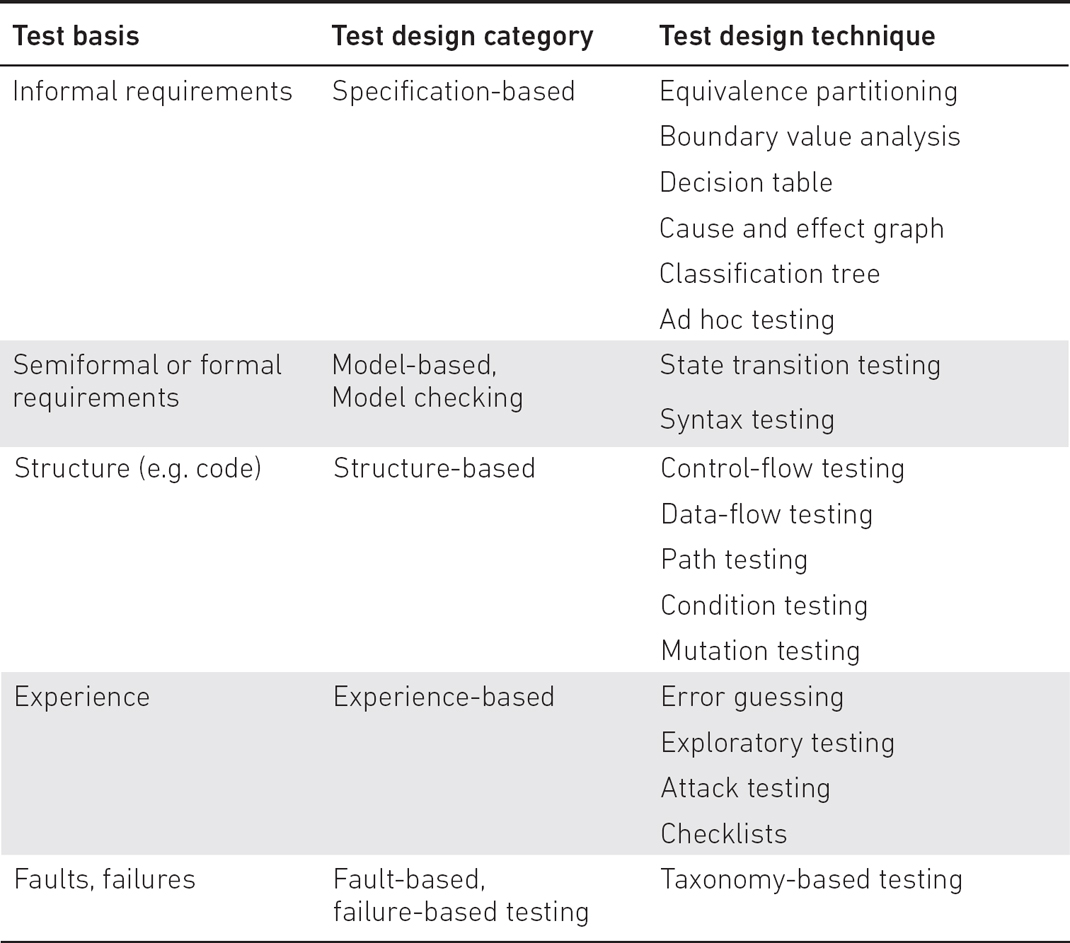
2. After planning the test approach, the test design techniques are selected that meet the testing objectives and the result of risk and complexity analysis. In general, it is advisable to select test design techniques understandable to other stakeholders. Real systems usually require using more than one test design technique together. Table 1.1 shows some test techniques related to different test design categories and test bases.
Table 1.1 Test bases, test design categories and test design techniques
3. The next step is to determine the test case selection criteria (for simplicity we refer to this as test selection criteria).
First, let’s consider the types of test cases. When a test case checks valid functionality then it is called a positive test case (or sometimes ‘happy path’); when a test case checks invalid functionality, then it is called a negative test case. Both positive and negative testing are equally important for quality software. Negative testing helps to find more defects, but it is done once positive testing is completed.
Usually, we distinguish high-level (abstract) and low-level (concrete) test cases. An abstract test case provides guidelines for the test selection using tables, lists and graphs. A concrete test case realises the abstract one by describing the preconditions, test steps, expected results, postconditions and by assigning concrete input values to it. Sometimes, the level of detail is forced by an outside authority (DO 178-C in avionics, for example). A good test case satisfies at least the following:
▪ Accurate: has a clear purpose.
▪ Effective: able to verify correctness or able to uncover faults depending on the test target.
▪ Economic: no unnecessary steps, cheap to use.
▪ Evolvable: easy to maintain.
▪ Exemplary: has low redundancy.
▪ Traceable: capable of being traced to requirements.
▪ Repeatable: can be used to perform the test several times.
▪ Reusable: can be ‘called’ from other test cases, avoiding duplication and therefore the room for human error.
A test case can be seen as an example for the specification. Examples are very useful measures of understanding anything. They can also be used to understand software specification, user stories and so on. In most cases, a test case is a good example. For example, if we test a login feature with test data, we can see that it is also an example for demonstrating some part of the login process.
Good test cases are understandable examples for any stakeholders. The project owner can validate the specification or user story; the developers can implement better code because of a deeper understanding. The tester is supported by the examples and gets feedback from the examples/test cases. Moreover, and this is also important, if test design has been done, we do not omit the test.
In agile testing, the Specification by Example (Adzic, 2011) uses this approach, that is the Agile team creates good examples, which can be considered as test cases and also as part of a specification. By applying examples, the problems in the specifications/user stories can be detected very early on.
The test selection criteria determine when to stop designing more test cases, or how many test cases have to be designed for a given situation. The test selection criterion for the equivalence partition method, for example, may result in designing a different number of test cases for each equivalence class.
It is possible to define different (‘weaker’ or ‘stronger’) test selection criteria for a given condition and design technique.
EXAMPLE FOR WEAK AND STRONG TEST SELECTION CRITERIA
Assume that during test design a technique was selected for a test condition where the input domain was partitioned into 100 disjoint subdomains. A ‘weak selection criterion’ with respect to the criterion and technique means for example choosing at most one item of test data from each subdomain. A ‘strong selection criterion’ means for example choosing test data on each of the borders between the subdomains, test data ‘close to’ the borders and test data from anywhere else in each subdomain.
There is an important notion closely related to test selection criteria, namely, the test data adequacy criteria.
While test selection criteria are defined concerning the test design, that is independently of the implementation, test data adequacy criteria are defined concerning program execution. Both test selection and test data adequacy criteria, however, provide a way to define a notion of ‘thoroughness’ for test case sets. By applying these criteria, we can check whether our test set is adequate and no additional testing is needed. We can call both test selection and test data adequacy criteria with regards to thoroughness.
The adequacy criteria define ‘what properties of a program must be exercised to constitute a thorough test’ (Goodenough and Gerhart, 1975). Satisfying a stronger adequacy criterion implies greater thoroughness in testing. The test data adequacy criteria validate whether the designed test cases are efficient concerning the testers’ expectations, and are applied after the test cases have been executed. Test data adequacy criteria focuses on validating the fulfilment of a specific code coverage and on the creation of additional test cases to detect specific types of defects.

THEORETICAL BACKGROUND
Let’s formalise these notions. Consider a program P written to meet a set of requirements R = {R1, R2,…,Rm}. Suppose now that a set of test cases T = {T1, T2,…,Tk} has been selected to test P to determine whether or not it meets all the requirements in R. The question arises naturally: is T good enough? Or in other words, is T adequate? Hence, adequacy is measured for a given test set designed to test P to determine whether or not P meets its requirements. This measurement is done against a given adequacy criterion C.
A test set is considered adequate concerning criterion C when it satisfies C. Let DC be a finite set of sub-criteria items belonging to criterion C, called coverage domain. We say that T covers DC if for each coverage item x in DC there is at least one test case t from T that tests x.
The test set T is considered adequate concerning C if it covers all items in the coverage domain. Similarly, T is considered inadequate concerning C if it covers only j items of DC where j < n and n is the number of the coverage items. The fraction j/n is a measure of the extent to which T is adequate concerning C. This ratio is also known as the coverage of DC concerning T, P and R. The coverage domain may depend on the program P under test or on the requirements R or both.
The examples below demonstrate test selection and test data adequacy criteria and the difference between them.
EXAMPLE FOR TEST SELECTION CRITERIA
Regarding the test design-related aspects of test selection criteria, consider the following requirements:
R1. Input two integers, say x and y from the standard input device
R2. If x and y are both negative, then print x + y to the standard output device
R3. If x and y are both positive, then print their greatest common divisor to the standard output device
R4. If x and y have opposite signs (one of them is positive and the other is negative), then print their product to the standard output device
R5. If x × y is zero then print zero to the standard output device.
After analysing the requirement set, R = {R1, R2, R3, R4, R5} one can see that R is consistent, does not contain redundancy and is deterministic. Let’s choose the test approach as a specification-based one. Suppose that the program P satisfies the requirement set R. Let’s specify a test selection criterion (TSC) as follows:
TSC: a test set T for the program P is considered adequate if for each requirement r in R there is at least one test case t in T such that t tests the correctness of P with respect to r.
In our case the coverage domain is R itself. With the test set T1 = {([-2, -3]; -5), ([2, 3]; 1)} (i.e. for input x = -2 and y = -3 the expected output is -5, for input x = 2 and x = 3 the expected output is 1) then T1 covers R1, R2 and R3, but does not cover R4 and R5. Hence, T1 is inadequate with respect to TSC and the coverage of T1 is 3/5 = 60%. The test set T2 = {([-2, -3]; -5), ([4, 2]; 2), ([2, -4]; -8), ([2, 0]; 0)} is adequate with regards to TSC, having 100% coverage. The appropriate test design technique for this scenario is called equivalence partitioning (see Chapter 5).
EXAMPLE FOR TEST DATA ADEQUACY CRITERIA
1. function coverage_demo
2. begin
3. int x, y;
4. input(x, y);
5. if x < 0 and y < 0 then
6. output(x+y);
7. else if x > 0 and y > 0 then
8. while x ≠ y
9. if x > y then
10. x = x-y
11. else y = y-x;
12. output(x);
13. else if sgn(x) * sgn(y) = -1 then
14. output(x * y);
15. else output(0);
16. end
In the pseudocode above the function coverage_demo is implemented. Line 3 contains the declarations, line 4 the input from the standard input device (requirement R1). Lines 5–6 contain the code for the requirement R2, lines 7–12 the Euclidean algorithm for requirement R3, lines 13–14 the code for requirement R4, and finally, line 15 contains the code for requirement R5.
Consider the following test data adequacy criterion (TAC):
TAC: a test set T for the program P (coverage_demo) is considered adequate if each statement in P is traversed at least once.
The coverage domain now is the set of all possible statements in P. Let the test set be T2 = {([-2, -3]; -5), ([4, 2]; 2), ([2, -4]; -8), ([2, 0]; 0)} as before. In the first test case ([-2, -3]; -5) the path 1-2-3-4-5-6-16 is executed. In the second test case ([4, 2]; 2) the path 1-2-3-4-5-7-8-9-10-8-12-16 is executed. In the third test case ([2, -4]; -8) the path 1-2-3-4-5-7-13-14-16 is executed, and in the fourth test case ([2, 0]; 0) the path 1-2-3-4-5-7-13-15-16 is executed. Hence, this test set is inadequate with regards to TAC. The coverage of T2 is 14/15 = 93% (the statement in line 11 is not covered).
Adequacy and full coverage can be achieved by T3 = {([-2, -3]; -5), ([2, 3]; 1), ([2, -4]; -8), ([2, 0]; 0)}.
Observe the difference between test selection and test data adequacy criteria. During test design we considered R3 as a simple requirement in the previous example, which can be covered by a single test case. On the other hand, the implementation (see lines 7–12) is more complex and may require more test cases.
Table 1.2 shows some coverage domains with test selection/test data adequacy criteria. Definition is an assignment statement, such as x = 1. Use occurs when the variable is read from memory, such as z = x + 1. Definition–Use pairs exist for a definition and a use of the same variable so that there is a program path between them where no other definition for that variable occurs.
It is important to note that some authors define test selection coverage as simply the same as code coverage. However, although test selection coverage and code coverage are both useful to assess the quality of the application code, code coverage is a term to describe which application code is exercised when the application is running, while test selection coverage relates to the percentage of the designed test cases with regard to the requirements in the selection criterion.
Table 1.2 Coverage domains with adequacy criteria
Coverage domain |
Adequacy criteria |
Boundary values |
Test selection: • One dimensional • Multidimensional |
State transitions |
Test selection: • Random • State coverage • Transition coverage • 0-switch coverage • 1-switch coverage • 2-switch coverage |
Test selection: • Random • One or some data pairs • All data pairs • N-wise (extension of pairwise) • All combinations Test data adequacy: • All Definition–Use pairs, etc. |
|
Control flow |
Test data adequacy: • Statement coverage • Decision coverage • Branch coverage • Path coverage |
Paths |
Test data adequacy: • Depth level N |
Decision points |
Test data adequacy: • Decision coverage • Simple condition coverage • Condition/decision coverage • Modified condition/decision coverage • Multiple condition coverage |
Please keep in mind that neither test selection nor test data adequacy criteria tell us anything about the quality of the software, only about the expected quality of the test cases. When deriving the test cases, be aware that one test case may exercise more than one test condition, and thus, there is the opportunity to optimise test case selection by combining multiple test coverage items in a single test case. At the end of this chapter, you can find a simple but complete example which explains these notions.
There is another important notion related to test selection. In a multivariate domain, we can apply different fault models to predict the consequences of faults. The single fault assumption relies on the statistic that failures are only rarely the product of two or more simultaneous faults. Here we assume that fault in a program occurs due to the value of just one variable. On the contrary, the multiple fault assumption means that more than one component leads to the cause of the problem. Here we assume that fault in the program occurs due to the values of more than one variable.
Single fault assumption also means that we test only one input domain with one test case, and if it fails, then we know the location of the fault. By applying multiple fault assumption we can design fewer test cases; however, in the case of a failure, we should make additional test cases for bug localisation. There is no rule for which method is better.
4. The next step is to establish the test data. Test data are used to execute the tests, and can be generated by testers or by any appropriate automation tool (produced systematically or by using randomisation models). Test data may be recorded for reuse (e.g. in automated regression testing) or may be thrown away after usage (e.g. in error guessing).
The time, cost and effectiveness of producing adequate test data are extremely important. Some data may be used for positive, others for negative testing. Typically, test data are created together with the test case they are intended to be used for. Test data can be generated manually, by copying from production or from legacy sources into the test environment, or by using automated test data generation tools. Test data creation takes many pre-steps or test environment configurations, which is very time-consuming. Note that concrete test cases may take a long time to create and may require a lot of maintenance.
5. Now we can finalise the test case design. A test case template contains a test case ID, a trace mapped to the respective test condition, test case name, test case description, precondition, postcondition, dependencies, test data, test steps, environment description, expected result, actual result, priority, status, expected average running time, comments and so on.
For some software, it may be difficult to compute the proper outcome of a test case. In these cases, test oracles (sources of information for determining whether a test has passed or failed) are useful. Test management tools are a great help to manage the test cases.
Where appropriate, the test cases should be recorded in the test case specification document. In this case, the traceability between the test basis, feature sets, test conditions, test coverage items and test cases should be explicitly described. It is advisable that the content of the test case specification document should be approved by the stakeholders.
A test suite (or test set) is a collection of test cases or test procedures that are used to test software in order to show that it fulfils the specified set of behaviours. It contains detailed instructions for each set of test cases and information on the system configuration. Test suites are executed in specific test cycles. In this book we use a simplified notation for a test case, for example TC = ([1, a, TRUE]; 99), where the test case TC has three input parameters 1, a, and TRUE, and expected value of 99. Sometimes, when the expected outcome is irrelevant with regard to a given example, we omit it from the test case. The notation TS = {([1, a, TRUE]; 17), ([2, b, FALSE]; 35)} means that the test suite TS contains two test cases. Sometimes we simply list the steps to perform in a test case. Unfortunately, the specification sometimes contains issues that have to be corrected. For example, it may contain solutions or implementation details. This is completely wrong. The customer should not tell you how to implement the functionality they need. It is the developer’s task to implement the user’s needs in the best way. The test design is similar, as designed test cases have to test the implementation-independent specification, therefore cannot contain any implementation-dependent element.
Example for a test containing implementation details:
▪ Click on the LOGIN button
▪ Write ‘smith’ into the ‘Login name’ box
▪ Write ‘aw12K@S’ into the ‘Password’ box
▪ Click on ‘OK’
There are many ways you could activate logging in and submitting a log-in request. Think mouse clicks, taps on screen, keyboard shortcuts, voice control and so on.
Here is the implementation-independent version:
Example for implementation-independent tests – CORRECT:
▪ Login as ‘smith’
▪ Password is ‘aw12K@S’
▪ Action: confirm
When the implementation is ready, and the tests are executed, coverage analysis reports the untested parts of the code.
Now it is high time to create additional test cases to cover the uncovered code. However, it is not test design; it is test generation.
6. The next step is to design the test environment. The test environment consists of items that support test execution: software, hardware and network configuration. The test environment design is based on entities like test data, network, storage, servers and middleware. The test environment management has organisational and procedural aspects: designing, building, provisioning and cleaning up test environments requires well-established organisation.
There is an emerging technology concentrating on unifying testing and operation, called TestOps. It can be seen as a ‘process of using a combination of engineering artefacts, test artefacts, and field artefacts and applying the process of software analytics to improve the V&V [verification and validation] strategy’ (Kurani, 2018). In other words, the testing and operation processes are integrated into a single entity aimed at producing the best software system as quickly and efficiently as possible. TestOps provides continuous feedback to the testing team to ensure that failed tests are identified and addressed as early as possible. TestOps allows organisations to deliver high-quality software quickly and cheaply.
We do not consider test environment design in this book. This is a different, but emerging, topic.
7. Finally, validate all the important artefacts produced during the test design including the control of the existence of the bi-directional traceability between the test basis, test conditions, test cases and procedures.
The following list summarises the important factors to be considered during test design:
▪ test approach;
▪ level of risks;
▪ test design technique;
▪ test selection criteria, and their coverage;
▪ fault assumption;
▪ type of test defensiveness;
▪ whether it is concrete or abstract.

The output of the design process aggregates descriptions of prioritised test scenarios, test cases, appropriate test data and the controlled test environment.
Subsequent activities – test implementation and execution, test closure
During the implementation and execution phase, the designed test cases are implemented and executed. After implementing the test cases the test scripts are developed. A test script (or test procedure specification) is a document specifying a sequence of actions and data needed to carry out a test. A script typically has steps that describe how to use the application (which items to select from a menu, which buttons to press, and in which order) to perform an action on the test object. In some sense, a test script is an extended test case with implementation details.
When test automation is determined to be a useful option, this stage also contains implementing the automation scripts. Test execution automation is useful when the project is long term and repeated regression testing provides a positive cost–benefit.
The next step is to set up the test environment. In greenfield projects (which lack constraints imposed by prior work), extra time should be allowed for experiencing and learning. Even in a stable environment, organising communication channels and communicating security issues and software evolutions are challenging and require time.
In some cases (performance testing, security testing, maintenance testing, etc.), the testing environment should be a clone of the production environment. Moreover, it is not enough to set up the environment; a plan should be in place for an update and reset when needed. In large-scale projects, several environments are present and need careful management and maintenance. Well-designed configuration management of the environment and testware is also important.
Next, the finalisation of the approach comes via test case implementation. At this point, everything is prepared for starting the execution, manually and/or automatically, which can be checked with the entry criteria. Some documents may help to localise the items that will be tested (test item transmittal documents or release notes).
The existence of the continuous integration environment is important for test execution (depending on the SDLC, and the type of project and product). The execution process is iterative, and in many cases, it is the longest step of the fundamental test process. Here, scripted techniques are often mixed with other dynamic techniques such as exploratory testing. The outcome of a test can usually be:
• Passed, if its actual result matches its expected result.
• Failed, if its actual result does not match its expected result.
• Blocked, if the test case cannot run because the preconditions for its execution are not fulfilled.
• Incomplete, if the test case did not complete its execution for various reasons.
• Inconclusive, if it produces a result that is not clear and requires further investigation and so on.
Once an issue is detected, it should be investigated whether it was really a result of a software defect. Logging the results is critical. Test logs are like gold dust and should be analysed thoroughly. The levels of logging depend on the test approach, the life cycle, regulatory rules, the project’s phase and so on. Logging information is especially useful in experience-based testing. In the case of failed tests, an incident management process begins. The analysis of the test results is extremely important since it serves as the basis of the feedback mechanisms. Testers have to gather all kinds of information during actual testing, which is then extracted and used to evaluate progress, data adequacy, coverage values, improvement possibilities and so on. For example, if the test design was not adequate, then some new tests must be designed. On the other hand, if code coverage was not appropriate, then new tests must be generated.
In extreme cases, the test management has to replan the test project to lower the quality risk. At this point there is important feedback for test design. In test evaluation and reporting, the test logs are checked against the clearly defined exit criteria (e.g. checking the test execution progress for high priority test cases, checking the status of all outstanding defects, etc.). Sometimes the exit criteria have to be modified with agreement from stakeholders. The result of the exit criteria evaluation is important information for all kinds of stakeholders; they want to know what happened during testing so that they can make the right decisions about the software project. A good test reporting tool is indispensable.
The test closure is a complete test report that gives a summary of the test project. It formally closes the project, collates all the test results, provides a detailed analysis, presents metrics to clients and assesses the risks with respect to the software as a whole.
We are not living in an ideal world. Nothing is perfect, including software. Developers make mistakes. The role of testers is to create tests, which reveal any mistakes made by the developers. The most secure way of doing this is to test the software for every possible input. However, this is impossible. Even for very simple code containing only two 32-bit integers, the number of test cases is 264. Assuming each test execution takes 1 microsecond, the total testing time would be 258 seconds, which is more than 1036 years and is incomparably more than the time elapsed from the Big Bang till now.
Well, even if exhaustive testing is not possible, there may be a general method or algorithm that generates reliable tests for every code. A reliable test set T has the property that either for each t ϵ T, t passes if and only if the code is correct or there is at least one test t for which the software fails.
Unfortunately, it has been proved by Howden (1976) that there is no such method or algorithm. The consequence is that testing is not able to detect each bug. The only thing we can expect is to be able to design our test cases so that:
• we can find as many bugs as we can, and
• spend as little time with testing and bug fixing as possible.
Software testing is a team responsibility. High-quality and efficient test cases can only be achieved when everyone involved in test design is aware of this.
Another alternative could be to apply ad hoc methods to tests without designing any tests. Companies who apply this trial-and-error approach, suffer from a buggy code base and low-quality products. Ad hoc testing is similar to ad hoc coding – the result can be catastrophic. By applying test design, we are able to:
• create efficient and reliable test cases;
• stop creating new test cases when the available ones are enough;
• automate test cases when needed;
• document the design as part of the testing activity;
• make test design documents alternative specifications understandable by stakeholders;
• maintain the test cases in accordance to some modifications, that is delete obsolete and design new test cases;
• select test cases to be re-executed after modifications.
Of course, test design is necessary but not sufficient for some of the points above. It is important to note that applying test design does not bound thinking and creativity. On the contrary, it offers a strong ground for test case quality and for creative thinking.
Designing tests has some advantages:
• possibility of reproducing a test;
• increase of faults found;
• long-term maintenance of the system and test automation support;
• an objective approach to the testing process.
However, it is not always necessary to apply test design. It is only to be applied if it adds value. Sometimes it is unimportant to systematically test a component implementing a less important ‘nice to have’ feature. For important functions, however, more care is needed. The test quality for these components is provided by an adequate test design.
In many organisations, the test base is often converted directly into a test case. But the tester will still implicitly use test design techniques during the conversion. Basic knowledge of the test design techniques and their principles still has added value.
A standardised way of working makes the tests more independent, separating the design from the execution. Note that test selection criteria enable tests to be designed more efficiently.
Test design and test execution can be automated. Test suites can automatically be generated by software using model-based testing, model checking or symbolic execution. Model-based testing tools generate test cases from a model, such as an activity diagram, Petri net, finite-state machine (see Chapter 6), timed automaton, Gherkin code (see Chapter 12) and so on. Model checking is a technique for automatically verifying the correctness of a program or automaton. It ensures, for example, that all the paths of a simple program are exercised. However, it requires that both the model of the system and the specification are formulated in a precise mathematical language (e.g. B, Z or Larch). By symbolic execution, we are able to generate tests directly from the code that will expose the bug when the software is running. These methods do not make the test design superfluous. On the contrary, these techniques necessitate a good test model, which can only be created if appropriate test design techniques are applied.
WHEN DO WE DESIGN TESTS?
Nowadays it is widely accepted that test execution has to be done as early as possible. Especially, ‘shift left’ testing (where the testing processes move to the left on the project timeline) requires integration testing earlier. Test design has to be done as early as possible as well, but before coding in all cases. Specifications, use cases and user stories are appropriate source documents for implementing the code. In addition, designed test cases can significantly improve the documents the developer will start with. Good test cases are in fact examples that lead the developer during implementation.
Early test design is a very effective defect prevention method. Lots of bugs are design errors. Test design before coding involves the validation of the specification, removing most of the design problems.
Early test design eliminates the problem of involving testers too late and lowers the problem of increased testing effort. Moreover, in most cases, the overall testing effort can be reduced.
IMPORTANT TEST DESIGN-RELATED CONSIDERATIONS
Test design techniques are like lighting up the landing strip. They help you to find the right way in order to pick the right data. In safety-critical systems test design techniques are recommended by standards (e.g. DO 178C in aerospace systems, BS EN 50128 in the railway industry).
This section deals with the effect of test data selection and mutation testing on the test design. Test data is not random – it must be chosen systematically. Regarding test data selection we will use two important hypotheses in this book. These are explained in the following two subsections.
Competent programmer hypothesis
The first hypothesis is the competent programmer hypothesis (CPH), which was identified by DeMillo et al. (1978), who observed that ‘Programmers have one great advantage that is almost never exploited: they create programs that are close to being correct.’ Developers do not implement software randomly. They start from a specification, and the software will be very similar to their expectations, hence, close to the specification.
CPH makes test design possible. If the implemented code could be anything then we should test the application to differentiate it from an infinite number of alternatives. This would need an infinite number of test cases. Fortunately, based on CPH we only have to test the application to separate it from the alternative specifications that are very close to the one being implemented.
To demonstrate CPH, let’s consider our example for test selection criteria in the ‘Present activity – test design’ section above, where the requirements are the following:
R1. Input two integers, say x and y from the standard input device
R2. If x and y are both negative, then print x + y to the standard output device
R3. If x and y are both positive, then print their greatest common divisor to the standard output device
R4. If x and y have opposite signs (one of them is positive and the other is negative), then print their product to the standard output device
R5. If x × y is zero then print zero to the standard output device.
The test set T2 = { ([-2, -3]; -5), ([4, 2]; 2), ([2, -4]; -8), ([2, 0]; 0) } is adequate. However, an alternative specification can be the following:
R1. Input two integers, say x and y from the standard input device
R2. If x and y are both negative, then print x + y to the standard output device
R3. If x and y are both positive and less than 100,000, then print their greatest common divisor to the standard output device, otherwise print the smaller value to the standard output device
R4. If x and y have opposite signs (one of them is positive and the other is negative), then print their product to the standard output device
R5. If x·y is zero then print zero to the standard output device.
Assume that the developer implemented this specification. In this case, T2 would not be adequate as all test cases would pass, yet the code is wrong. What’s more, any positive pair of test input below 100,000 would not be reliable. Assuming that the implementation can be anything we easily modify the specification again so that selecting any number of positive test input pairs would not be reliable.
Fortunately, because of the competent programmer hypothesis, it is unrealistic to implement the modified R3, since this requirement is far from the original, and the probability that a developer swaps them is minimal.
Coupling effect
The second hypothesis we will use in this book is the coupling effect, which states that a test data set that detects all simple faults in a program will also detect more complex faults. Here a simple fault means a fault that can be fixed by making a single change to a source statement. On the other hand, a complex fault is a fault that cannot be fixed by making a single change to a source statement. To reveal these complex faults, we suggest applying the Delta Debugging methodology, which automates debugging by systematically narrowing down the places where failures can occur (Zeller, 1999).
Test design defensiveness
The last notion that influences the test data selection and test design is its type of defensiveness. A defensive test design considers all possible input for designing the tests. Defensive testing designs test cases both for normal and abnormal preconditions. For instance, an invoked system should always test that the input file exists or not, is empty or not, contains the right data in the right order or not and so on.
Contract-based test design assumes that the preconditions stated in some ‘contract’ always hold and guarantee the fulfilments of some postconditions. In the previous example, we do not have to test the appropriateness of the input each time the system is called. Based on the contract, we assume that everything is OK with the input (i.e. preconditions are fulfilled), however, if security is an issue, then the defensive testing (and design) remains the only possibility.
Black and white-box mutation testing
Another important aspect of test design is mutation testing. In mutation testing, we are not directly concerned with testing the program. Rather we introduce faults into the code to see the reliability of our test design. Therefore, mutation testing is actually not testing, but ‘testing the tests’. The method is to slightly modify the original code, creating a mutant of it. We can make several mutants and a reliable test data set has to ‘kill’ all of them. A test kills a mutant if the original code and the mutant behave differently. For example, if the code is y = x2 and the mutant is y = 2x, then a test case x = 2 will not kill the mutant while x = 3 will.
The main problem with mutation testing is with cases of equivalent mutants. They are the false positives, that is equivalent mutants keep the program’s semantics unchanged, thus, cannot be detected by any test. Unfortunately, the decision whether two pieces of code are equivalent or not is an undecidable problem in general.
Mutation testing was introduced in the late 1970s by DeMillo et al. (1978) and Hamlet (1977). An excellent survey containing 250+ references on this topic is published by Jia and Harman (2011).
Mutation testing is applicable when the code is ready. The question is how to test our test cases when we have no code and thus white-box methods are out of the question.
Fortunately, a black-box solution can be introduced as well. Let’s assume that we have two specifications that are slightly different. The question is whether we can have a unique test set, which would test both specifications reliably. The answer is obviously no. To see why, let the task be implementing Specification A. Let Specification B be another specification, which is not equivalent to Specification A. Assume, on the contrary, that we have a unique perfect test set for both. Assume that the developer accidentally implemented Specification B bug free. In this case, no test will fail, though the code is not equivalent with Specification A, hence, some behaviour of A is not tested, which is a contradiction.
We can therefore slightly modify our specification and check whether there are any test cases that would be different for the test sets in the two versions. If there are, then the different test case(s) separate(s) the modified specification from the original one. Hence, we can create alternative specifications to prove that every test case we designed is necessary and there are no missing test cases. On the other hand, if an alternative specification consists of the same test cases, then some test is missing. Unfortunately, this process is very costly, and thus not always appropriate in practice.
SUMMARY
In this chapter we gave a general overview of software testing. We discussed its importance and the role of test design in the full testing life cycle. Among other notions, we explained test selection and test adequacy criteria, test coverage, test cases, a test suite and some related concepts, including the competent programmer hypothesis, coupling effect, test design defensiveness and black-box mutation testing.