
“Don't call us, we'll call you” (Hollywood Principle)
—Richard E. Sweet, The Mesa Programming Environment, 1985
When you start combining multiple UML state machines into systems, you'll quickly learn that the problem is not so much in coding the state machines—Part I of this book showed that this is actually a nonissue. The next main challenge is to generate events, queue the events, and write all the code around state machines to make them execute and communicate with one another in a timely fashion and without creating concurrency hazards.
Obviously, you can develop all this “housekeeping”1 Published estimates claim that anywhere from 60 to 90 percent of an application is common “housekeeping” code that can be reused if properly structured [Douglass 99]. code from scratch for each event-driven system at hand. But you could also reuse an event queue, an event dispatcher, or a time event generator across many projects. Ultimately, however, you can do much better than merely reusing specific elements as building blocks—you can achieve even greater leverage by reusing the whole infrastructure surrounding state machines. Such a reusable infrastructure is called a framework.
In this chapter I introduce the concepts associated with event-driven, real-time application frameworks. Most of the discussion is general and applicable to a wide range of event-driven frameworks. However, at times when I need to give more specific examples, I refer to the QF real-time framework, which is part of the QP platform and has been specifically designed for real-time embedded (RTE) systems. I begin with explaining why most event-driven infrastructures naturally take the form of a framework rather than a toolkit. Next, I present an overview of various CPU management policies and their relationship to the real-time framework design. In particular, I describe the modern active object computing model. Next, I discuss event management, memory management, and time management policies. I conclude with error- and exception-handling policies for a real-time framework.
Event-driven systems require a distinctly different way of thinking than traditional sequential programs. When a sequential program needs some incoming event, it waits in-line until the event arrives. The program remains in control all the time and because of this, while waiting for one kind of event, the sequential program cannot respond (at least for the time being) to other events.
In contrast, most event-driven applications are structured according to the Hollywood principle, which essentially means “Don't call us, we'll call you.” So, an event-driven application is not in control while waiting for an event; in fact, it's not even active. Only once the event arrives, the event-driven application is called to process the event and then it quickly relinquishes the control again. This arrangement allows an event-driven program to wait for many events in parallel, so the system remains responsive to all events it needs to handle.
This scheme implies that in an event-driven system the control resides within the event-driven infrastructure, rather than in the application code. In other words, the control is inverted compared to a traditional sequential program. Indeed, as Ralph Johnson and Brian Foote observe [Johnson+ 88], this inversion of control gives the event-driven infrastructure all the defining characteristics of a framework.
“One important characteristic of a framework is that the methods defined by the user to tailor the framework will often be called from within the framework itself, rather than from the user's application code. The framework often plays the role of the main program in coordinating and sequencing application activity. This inversion of control gives frameworks the power to serve as extensible skeletons. The methods supplied by the user tailor the generic algorithms defined in the framework for a particular application.”—Ralph Johnson and Brian Foote
Inversion of control is key part of what makes a framework different from a toolkit. A toolkit, such as a traditional real-time operating system (RTOS), is essentially a set of predefined functions that you can call. When you use a toolkit, you write the main body of the application and call the various functions from the toolkit. When you use a framework, you reuse the main body and provide the application code that it calls, so the control resides in the framework rather than in your code.
Inversion of control is a common phenomenon in virtually all event-driven architectures because it recognizes the plain fact that the events are controlling the application, not the other way around. That's why most event-driven infrastructures naturally take the form of a framework rather than a toolkit.
An event-driven framework can work with a number of execution models, that is, particular policies of managing the central processor unit (CPU). In this section, I briefly examine the basic traditional CPU management policies and point out how they relate to the real-time framework design.
A traditional sequential program controls the CPU at all times.2 Except when the CPU processes asynchronous interrupts, but the interrupts always return control to the point of preemption. Functions called directly or indirectly from the main program issue requests for external input and then wait for it; when input arrives, control resumes within the function that made the call. The location of the program counter, the tree of function calls on the stack, and local stack variables define the program state at any given time.
In the embedded space, the traditional sequential system corresponds to the background loop in the simple foreground/background architecture (a.k.a. super-loop or main+ISRs). As the name suggests, the foreground/background architecture consists of two main parts: the interrupt service routines (ISRs) that handle external interrupts in a timely fashion (foreground) and an infinite main loop that calls various functions (background). Figure 6.1 shows a typical flow of control within a background loop. This particular example depicts the control flow in the Quickstart application described in Section 1.9 in Chapter 1. The dashed boxes represent function calls. The heavy lines indicate the most frequently executed paths through the code.

The major advantage of the traditional sequential control is that it closely matches the way the conventional procedural languages work. C and C++, for example, are exactly designed to represent the flow of control in the rich set of control statements, function call tree, and local stack variables. The main disadvantage is that a sequential system is unresponsive while waiting, which is actually most of the time. Asynchronous events cannot be easily handled within the background loop because the loop must explicitly poll for inputs. Flexible control systems, communication software, or user interfaces are hard to build using this style [Rumbaugh+ 91].
Due to the explicit polling for events scattered throughout the background code, the traditional sequential architecture is not compatible with the event-driven paradigm. However, it can be adapted to implement a single event-loop, as described in Section 6.2.3. The simple sequential control flow is also an important stepping stone for understanding other, more advanced CPU management policies.
Multitasking is the process of scheduling and switching the CPU among several sequential programs called tasks or threads. Multitasking is like foreground/background with multiple backgrounds [Labrosse 02]. Tasks share the same address space3 By sharing a common address space, tasks (threads) are much lighter than heavyweight processes, which execute in separate address spaces and contain one or more lightweight threads. and, just like the backgrounds, are typically structured as endless loops. In a multitasking system, control resides concurrently in all the tasks comprising the application.
A specific software component of a multitasking system, called the kernel, is responsible for managing the tasks in such a way as to create an illusion that each task has a dedicated CPU all to itself, even though the computer has typically only one CPU. The kernel achieves this by frequently switching the CPU from one task to the next in the process called context switching. As shown in Figure 6.2, each task is assigned its own stack area in memory and its own data structure, called a task control block (TCB). Context switching consists of saving the CPU registers into the current task's stack and restoring the registers from the next task's stack. Some additional bookkeeping information is also updated in the TCBs. Context switches are generally transparent to the tasks and are activated from asynchronous interrupts (in case of a preemptive kernel) as well as synchronously from explicit calls to the kernel.

The multitasking kernel works hard behind the scenes to preserve the same state for each task as the state maintained automatically by a simple sequential program. As you can see in Figure 6.2, for each task the context-switching mechanism preserves the CPU registers, including the program counter as well as the whole private stack with the tree of nested function calls and local stack variables.
A big advantage of multitasking is better CPU utilization because when some tasks are waiting for events, other tasks can continue execution, so fewer CPU cycles are wasted on polling for events. The kernel enables the efficient waiting for events by providing special mechanisms for blocking tasks, such as semaphores, event flags, message mailboxes, message queues, timed blocking, and many others. A blocked task is simply switched away to memory and does not consume any CPU cycles.
Multiple tasks can wait on multiple events in parallel, so a multitasking system as a whole appears to be more responsive than a single background loop. The responsiveness of the system depends on how a kernel determines which task to run next. Understanding of these mechanisms is important for any real-time system, including a real-time framework.
Most kernels allow assigning static priorities to tasks according to their urgency. Figure 6.3 shows execution profiles of the two most popular priority-based kernel types. Panel (A) shows a nonpreemptive kernel that gets control only through explicit calls from the tasks to the kernel. Panel (B) shows a preemptive kernel that additionally gets control upon exit from every ISR. The following explanation section illuminates the interesting points (see also [Labrosse 02]).

(1a) A low-priority task under a nonpreemptive kernel is executing. Interrupts are enabled. A higher-priority task is blocked waiting for an event.
(2a) An interrupt occurs and the hardware suspends the current task and jumps to the ISR.
(3a) ISR executes and, among other things, makes the high-priority task ready to run.
(4a) The interrupt returns by executing a special interrupt-return instruction, which resumes the originally preempted task (the low-priority task) at the machine instruction following the interrupted instruction.
(5a) The low-priority task executes until it makes an explicit blocking call to the kernel or an explicit yield, just to give the kernel a chance to run.
(6a) The kernel runs and determines that the high-priority task is ready to run, so it performs a context switch to that task. The time delay between making the high-priority task ready to run in step (2a) and actually starting the task is called the task-level response.
The task-level response of a nonpreemptive kernel is nondeterministic because it depends on when other tasks voluntarily call the kernel. In other words, tasks must collaborate to share the CPU. Therefore, this form of multitasking is called cooperative multitasking. The upside is a much easer sharing of resources among the tasks. The kernel has an opportunity to perform a context switch only in explicitly known calls to the kernel, so tasks can safely access shared resources between any two kernel calls. In contrast, the execution profile of a preemptive kernel is as follows:
(1b) A low-priority task under a preemptive kernel is executing. Interrupts are enabled. A higher-priority task is blocked waiting for an event.
(2b) An interrupt occurs and the hardware suspends the current task and jumps to the ISR. Suspending a task typically involves saving at least part of the CPU register file to the current task's stack.
(4b) Before the interrupt returns, the preemptive kernel is called to determine which task to return to. The kernel finds out that the high-priority task is ready to run. Therefore, the kernel first completes the context save for the current task (the low-priority task) and then performs a context switch to the high-priority task. The tricky part of this process is to arrange the new stack frame and the CPU registers so that they look exactly as though the high-priority task was the one preempted by the interrupt.
(5b) The kernel executes the special interrupt-return instruction. Because of the careful preparations made in the previous step, the interrupt returns to the high-priority task. The low-priority task remains preempted.
(6b) The high-priority task executes until it blocks via a call to the kernel.
(7b) The kernel determines that the low-priority task is still preempted and needs to run. The tricky part of resuming the low-priority task is to fake an interrupt stack frame and an interrupt CPU context to resume the low-priority task that has been preempted by an interrupt, even though the kernel is invoked via a regular function call.
Note
A preemptive kernel must actually make every context switch look like an interrupt return, even though some context switches occur from regular function calls to the kernel and don't involve asynchronous interrupts.
A preemptive kernel can guarantee a deterministic task-level response of the highest-priority tasks because the lower-priority tasks can always be preempted4 Using some kernel blocking mechanisms can lead to the situation in which a ready-to-run higher-priority task cannot preempt a lower-priority task. This condition is called priority inversion. and so it does not matter that they even exist. But this determinism comes at a huge price of increased complexity in sharing resources. A preemptive kernel can perform a context switch at any point of the task's code as long as the scheduler is not locked and interrupts are enabled. Any unexpected context switch might lead to corruption of shared memory or other shared resources, and kernels provide a special mechanism (such as mutexes or monitors) to guarantee a mutually exclusive access to shared resources. Unfortunately, programmers typically vastly underestimate the risks and skills needed to use these mechanisms safely and therefore underestimate the true costs of their use.
In summary, perhaps the most important benefit of multitasking is partitioning of the original problem into smaller, more manageable pieces (the tasks). In this respect, multitasking is a very powerful divide-and-conquer strategy. Multitasking kernels carefully preserve the private stack contents of each task so that tasks are as close as possible to simple sequential programs and thus map well to the traditional languages like C or C++.
Ultimately, however, when it comes to handling events, tasks have the same fundamental limitations as the simple sequential programs. A blocked task waiting for an event is unresponsive to all other events. Also, the whole intervening code around a blocking call is typically designed to handle only the one event that it explicitly waits for. To get a picture of what a task control flow might look like, you can simply replace the heavy polling loops in Figure 6.1 with blocking calls. Adding new events to such code is hard and typically requires deep changes to the whole task structure.
Due to the explicit blocking calls scattered throughout the task code, which the kernel encourages by providing a rich assortment of blocking mechanisms, the traditional multitasking architecture is not compatible with the event-driven paradigm. However, it can be adapted (actually simplified) for executing concurrent active objects, as I describe in the upcoming Section 6.3. Especially valuable in this respect is the thread-safe intertask communication mechanism based on message queues that most kernels or RTOSs provide. Message queues can typically be easily customized for sending events to active objects.
A traditional event-driven system is clearly divided into the event-driven infrastructure and the application (see Figure 6.4). The event-driven infrastructure consists of an event loop, an event dispatcher, and an event queue. The application consists of event-handler functions that all share common data.
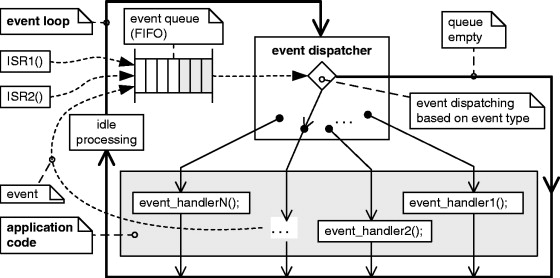
All events in the system originating from asynchronous interrupts or from the event-handler functions are always inserted first into the event queue. The control resides within the event dispatcher that polls the event queue in the infinite event loop. For every event extracted from the queue the dispatcher calls the event-handler function associated with this event type. All event-handler functions contain essentially linear code that returns to the main event loop as quickly as possible. In particular, the event-handler functions don't poll for events and don't access the event queue. All the polling and event queuing is centralized and encapsulated within the dispatcher.
To keep the system responsive, the dispatcher must be able to check for events continuously and frequently. This implies that the event-handler functions must execute quickly. An errant event-handler function can halt the entire application, so care must be taken to avoid any “blocking” code or simply long-running code. The application cannot preserve its state using the program counter and stack because the stack contents disappear when the event-handler functions return control to the event loop. The application must rely on static variables to maintain state.
The event-loop architecture automatically guarantees that every event-handler function runs to completion, because the dispatcher can dispatch a new event only after the last event-handler function returns to the event loop. The need for an event queue is the direct consequence of the run-to-completion event processing. Queuing prevents losing events that arrive while the event-handler functions are running to completion and the dispatcher is unable to accept new events. The event queue is an essential part of the design.
The traditional event-driven architecture is immensely popular in event-driven graphical user interface (GUI) frameworks such as MFC, OWL, Delphi, Tcl/Tk, X-Windows, SunView, or, more recently, Java/AWT/Swing, ActionScript, Qt, .NET, and many, many others. The countless variations of the technique have mostly to do with the creative ways of associating events with event-handler functions, but all of them are ultimately based on the prevalent event-action paradigm, in which event types are mapped to the code that is supposed to be executed in response.
However, as explained in Chapter 2, the system response to an event depends as much on the event type as on the application context (state) in which the event arrives. The prevalent event-action paradigm recognizes only the dependency on the event type and leaves the handling of the context to largely ad hoc techniques. State machines provide very strong support for handling the context (state), but unfortunately, the event-action paradigm is incompatible with state machines because a single event-handler function contains pieces of many states. (That's exactly why event-handler functions become convoluted and brittle as they grow and evolve.) The complementary relation between the event-action paradigm and state machines is best visible in the state-table representation of a state machine (see Table 3.1 in Chapter 3), in which an event-handler function corresponds to the vertical cut through all the states in the state table along a given event column.
To summarize, the traditional event-driven architecture permits more flexible patterns of control than any sequential system [Rumbaugh+ 91]. Also, compared to any traditional sequential technique, an event-driven scheme uses the CPU more efficiently and tends to consume less stack space, which are all very desirable characteristics for embedded systems. However, the traditional event-driven architecture is not quite suitable for real-time frameworks. The remaining problems are at least threefold:
1 Responsiveness. The single event queue does not permit any reasonable prioritization of work. Every event, regardless of priority, must wait for processing until all events that precede it in the queue are handled.
2 No support for managing the context of the application. The prevalent event-action paradigm neglects the application context in responding to events, so application programmers improvise and end up creating “spaghetti” code. Unfortunately, the event-action paradigm is incompatible with state machines.
3 Global data. In the traditional event architecture all event-handler functions access the same global data. This hinders partitioning of the problem and can create concurrency hazards for any form of multitasking.
The active object computing model addresses most problems of the traditional event-driven architecture, retaining its good characteristics. As described in the sidebar “From Actors to Active Objects,” the term active object comes from the UML and denotes “an object having its own thread of control” [OMG 07]. The essential idea of this model is to use multiple event-driven systems in a multitasking environment.
From Actors to Active Objects
The concept of autonomous software objects communicating by message passing dates back to the late 1970s, when Carl Hewitt and colleagues [Hewitt 73] developed a notion of an actor. In the 1980s, actors were all the rage within the distributed artificial intelligence community, much as agents are today. In the 1990s, methodologies like ROOM [Selic+ 94] adapted actors for real-time computing. More recently, the UML specification has introduced the concept of an active object that is essentially synonymous with the notion of a ROOM actor [OMG 07].
In the UML specification, an active object is “an object having its own thread of control” [OMG 07] that processes events in a run-to-completion fashion and that communicates with other active objects by asynchronously exchanging events. The UML specification further proposes the UML variant of state machines with which to model the behavior of event-driven active objects.
Active objects are most commonly implemented with real-time frameworks. Such frameworks have been in extensive use for many years and have proven themselves in a very wide range of real-time embedded (RTE) applications. Today, virtually every design automation tool that supports code synthesis for RTE systems incorporates a variant of a real-time framework. For instance, Real-time Object-Oriented Modeling (ROOM) calls its framework the “ROOM virtual machine” [Selic+ 94]. The VisualSTATE tool from IAR Systems calls it a “VisualSTATE engine” [IAR 00]. The UML-compliant design automation tool Rhapsody from Telelogic calls it “Object Execution Framework (OXF)” [Douglass 99].
Figure 6.5 shows a minimal active object system. The application consists of multiple active objects, each encapsulating a thread of control (event loop), a private event queue, and a state machine.

The active object's event loop, shown in Figure 6.5(B), is a simplified version of the event loop from Figure 6.4. The simplified loop gets rid of the dispatcher and directly extracts events from the event queue, which efficiently blocks the loop as long as the queue is empty. For every event obtained from the queue, the event loop calls the dispatch() function associated with the active object. The dispatch() function performs both the dispatching and processing of the event, similarly to the event-handler functions in the traditional event-driven architecture.
The event queues, event loops, and the event processor for state machines are all generic and as such are part of a generic real-time framework. The application consists of the specific state machine implementations, which the framework invokes indirectly through the dispatch()5 The dispatch() operation is understood here generically and denotes any state machine implementation method, such as any of the techniques described in Chapters 3 or 4. state machine operation.
Figure 6.6 shows the relationship between the application, the real-time framework, and the real-time kernel or RTOS. I use the QF real-time framework as an example, but the general structure is typical for any other framework of this type. The design is layered, with an RTOS at the bottom providing the foundation for multitasking and basic services like message queues and deterministic memory partitions for storing events. Based on these services, the QF real-time framework supplies the QActive class for derivation of active objects. The QActive class in turn derives from the QHsm base class, which means that active objects are state machines and inherit the dispatch() operation defined in the QHsm base class (see Chapter 4). Additionally, QActive contains a thread of execution and an event queue, typically based on the message queue of the underlying RTOS. An application extends the real-time framework by deriving active objects from the QActive base class and deriving events with parameters from the QEvent class.
Note
Most frameworks rely heavily on the object-oriented concepts of classes and inheritance as the key technique for extending and customizing the framework. If you program in C and the concepts are new to you, refer to the sidebar “Single Inheritance in C” in Chapter 1. In Chapter 7 you'll see that the QF real-time framework and the applications derived from it can be quite naturally implemented in standard, portable C.
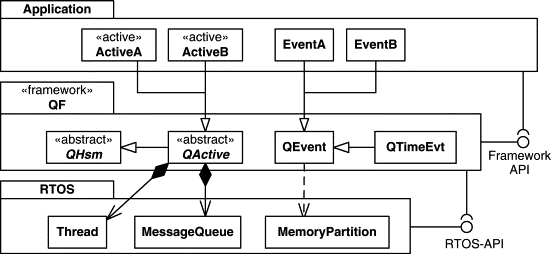
The application uses the QF communication and timing services through the framework API (indicated by the ball-and-socket UML notation); however, the application typically should not need to directly access the RTOS API. Thus, a real-time framework can serve as an RTOS abstraction layer. The framework effectively insulates applications from the underlying RTOS. Changing the RTOS on which the framework is built requires porting the framework but does not affect applications. I'll demonstrate this aspect in Chapter 8, where I discuss porting QF.
As shown in Figure 6.5(A), active objects receive events exclusively through their event queues. All events are delivered asynchronously, meaning that an event producer merely posts an event to the event queue of the recipient active object but doesn't wait in line for the actual processing of the event.
The system makes no distinction between external events generated from interrupts and internal events originating from active objects. As shown in Figure 6.5(A), an active object can post events to any other active object, including to self. All events are treated uniformly, regardless of their origin.
Each active object processes events in run-to-completion (RTC) fashion, which is guaranteed by the structure of the active object's event loop. As shown in Figure 6.5(B), the dispatch() operation must necessarily complete and return to the event loop before the next event from the queue can be extracted. RTC event processing is the essential requirement for proper execution of state machines.
In the case of active objects, where each object has its own thread of execution, it is very important to clearly distinguish the notion of RTC from the concept of thread preemption [OMG 07]. In particular, RTC does not mean that the active object thread has to monopolize the CPU until the RTC step is complete. Under a preemptive multitasking kernel, an RTC step can be preempted by another thread executing on the same CPU. This is determined by the scheduling policy of the underlying multitasking kernel, not by the active object computing model. When the suspended thread is assigned CPU time again, it resumes its event processing from the point of preemption and, eventually, completes its event processing. As long as the preempting and the preempted threads don't share any resources, there are no concurrency hazards.
Perhaps the most important characteristic of active objects, from which active objects actually derive their name, is their strict encapsulation. Encapsulation means that active objects don't share data or any other resources. Figure 6.5(A) illustrates this aspect by a thick, opaque encapsulation shell around each active object and by showing the internal state machines in gray, since they are really not supposed to be visible from the outside.
As described in the previous section, no sharing of any resources (encapsulation) allows active objects to freely preempt each other without the risk of corrupting memory or other resources. The only allowed means of communication with the external world and among active objects is asynchronous event exchange. The event exchange and queuing are controlled entirely by the real-time framework, perhaps with the help of the underlying multitasking kernel, and are guaranteed to be thread-safe.
Even though encapsulation has been traditionally associated with object-oriented programming (OOP), it actually predates OOP and does not require object-oriented languages or any fancy tools. Encapsulation is not an abstract, theoretical concept but simply a disciplined way of designing systems based on the concept of information hiding. Experienced software developers have learned to be extremely wary of shared (global) data and various mutual exclusion mechanisms (such as semaphores). Instead, they bind the data to the tasks and allow the tasks to communicate only via message passing. For example, the embedded systems veteran, Jack Ganssle, offers the following advice [Ganssle 98].
“Novice users all too often miss the importance of the sophisticated messaging mechanisms that are a standard part of all commercial operating systems. Queues and mailboxes let tasks communicate safely… the operating system's communications resources let you cleanly pass a message without fear of its corruption by other tasks. Properly implemented code lets you generate the real-time analogy of object-oriented programming's (OOP) first tenet: encapsulation. Keep all of the task's data local, bound to the code itself and hidden from the rest of the system.”—Jack Ganssle
Although it is certainly true that the operating system mechanisms, such as message queues, critical sections, semaphores, or condition variables, can serve in the construction of a real-time framework, application programmers do not need to directly use these often troublesome mechanisms. Encapsulation lets programmers implement the internal structure of active objects without concern for multitasking. For example, application programmers don't need to know how to correctly use a semaphore or even know what it is. Still, as long as active objects are encapsulated, an active object system can execute safely, taking full advantage of all the benefits of multitasking, such as optimal responsiveness to events and good CPU utilization.
In Chapter 9 I will show you how to organize the application source code so that the internal structure of active objects is hidden and inaccessible to the rest of the application.
Event-driven systems are in general more difficult to implement with standard languages, such as C or C++, than procedure-driven systems [Rumbaugh+ 91]. The main difficulty comes from the fact that an event-driven application must return control after handling each event, so the code is fragmented and expected sequences of events aren't readily visible.
For example, Figure 6.7(A) shows a snippet of a sequential pseudocode, whereas panel (B) shows the corresponding flowchart. The boldface statements in the code and heavy lines in the flowchart represent waiting for events (either polling or efficient blocking). Both the sequential code and the flowchart show the expected sequence of events (A, B…B, C) very clearly. Moreover, the sequential processing allows passing data from one processing stage to the next in temporary stack variables. Traditional programming languages and traditional multitasking kernels strongly support this style of programming that relies heavily on stack-intensive nested function calls and sophisticated flow of control (e.g., loops).

In contrast, the traditional event-driven code representing essentially the same behavior consists of three event-handler functions onA(), onB(), and onC(), and it is not at all clear that the expected sequence of calls should be onA(), onB()…onB(), onC(). This information is hidden inside the event-hander functions. Moreover, the functions must use static variables to pass data from one function to the next, because the stack context disappears when each function returns to the event loop. This programming style is harder to implement with standard languages because you get virtually no support for handling the execution context stored in static variables.
And this is where state machines beautifully complement the traditional programming languages. State machines are exactly designed to represent the execution context (state and extended-state variables) in static data. As you can see in Figure 6.7(C), the state machine clearly shows the expected event sequence, so this program structure becomes visible again. But unlike the sequential code, a state machine does not rely on the stack and the program counter to preserve the context from one state to the next. State machines are inherently event-driven.
Note
You can think of state machines, and specifically of the hierarchical event processor implementation described in Chapter 4, as an essential extension of the C and C++ programming languages to better support event-driven programming.
As opposed to the traditional event-driven architecture, the active object computing model is compatible with state machines. The active object event loop specifically eliminates the event dispatcher (Figure 6.5(B)) because demultiplexing events based on the event signal is not a generic operation but instead always depends on the internal state of an active object. Therefore, event dispatching must be left to the specific active object's state machine.
In the most common implementations of the active object computing model, active objects map to threads of a traditional preemptive RTOS or OS. For example, the real-time framework inside the Telelogic Rhapsody design automation tool provides standard bindings to VxWorks, QNX, and Linux, to name a few [Telelogic 07]. In this standard configuration the active object computing model can take full advantage of the underlying RTOS capabilities. In particular, if the kernel is preemptive, the active object system achieves exactly the same optimal task-level response as traditional tasks.
Consider how the preemptive kernel scenario depicted in Figure 6.3(B) plays out in an active object system. The scenario begins with a low-priority active object executing its RTC step and a high-priority active object efficiently blocked on its empty event queue.
At point (2b) in Figure 6.3(B), an interrupt preempts the low-priority active object. The ISR executes and, among other things, posts an event to the high-priority active object (3b). The preemptive kernel called upon the exit from the ISR (4b) detects that the high-priority active object is ready to run, so it switches context to that active object (5b). The interrupt returns to the high-priority active object that extracts the just-posted event from its queue and processes the event to completion (6b). When the high-priority active object blocks again on its event queue, the kernel notices that the low-priority active object is still preempted. The kernel switches context to the low-priority active object (7b) and lets it run to completion.
Note that even though the high-priority active object preempted the low-priority one in the middle of the event processing, the RTC principle hasn't been violated. The low-priority active object resumed its RTC step exactly at the point of preemption and completed it eventually, before engaging in processing another event.
Note
In Chapter 8, I show how to adapt the QF real-time framework to work with a typical preemptive kernel (μC/OS-II) as well as a standard POSIX operating system (e.g., Linux, QNX, Solaris).
The active object computing model can also work with nonpreemptive kernels. In fact, one particular cooperative kernel matches the active object computing model exceptionally well and can be implemented in an absolutely portable manner. For lack of a better name, I will call this kernel plain vanilla or just vanilla. I explain first how the vanilla kernel works and later I compare its execution profile with the profile of a traditional nonpreemptive kernel from Figure 6.3(A). Chapter 7 describes the QF implementation of the vanilla kernel.
Note
The vanilla kernel is so simple that many commercial real-time frameworks don't even call it a kernel. Instead this configuration is simply referred to as without an RTOS.6 For example, the Interrupt Driven Framework (IDF) inside the Telelogic Rhapsody design automation tool executes “without an RTOS.” However, if you want to understand what it means to execute active objects “without an RTOS” and what execution profile you can expect in this case, you need to realize that a simple cooperative vanilla kernel is indeed involved.
Figure 6.8 shows the architecture of the simple cooperative vanilla kernel. The most important element of the design is the scheduler, which is the part of a kernel responsible for determining which task to run next. The vanilla scheduler operates in a single loop. The scheduler constantly monitors all event queues of the active objects. Each event queue is assigned a unique priority, which is the priority of the active object that owns this queue. The scheduler always picks the highest-priority not-empty queue.
Note
The vanilla scheduler uses the event queues of active objects as priority queues and thus embodies the standard priority queue algorithm [Cormen+ 01]. Chapter 7 shows how the QF real-time framework implements the vanilla scheduler with a bitmask and a lookup table.
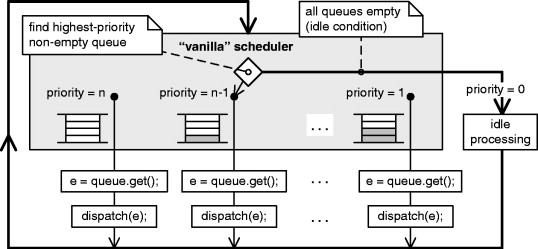
After finding the queue, the vanilla kernel extracts the event from the queue and dispatches it to the active object that owns this queue. Note that the queue get() operation cannot block because at this point the queue is guaranteed to be not empty. Of course, the vanilla kernel applies all the necessary safeguards to protect the internal state of the scheduler and the event queues from corruption by asynchronous interrupts, which can post events to the queues at any time.
The dispatch() operation always runs to completion and returns to the main loop. The scheduler takes over and the cycle repeats. As usual in event-driven systems, the main event loop and the event queues are all part of the vanilla kernel or the framework. The application code is not supposed to poll or block.
The vanilla scheduler very easily detects the condition when all event queues are empty. This situation is called the idle condition of the system. In this case, the scheduler performs idle processing, which can be customized by the application.
Note
In an embedded system, the idle processing is the ideal place to put the CPU into a low-power sleep mode. The power-saving hardware wakes up the CPU upon an interrupt, which is exactly right because at this point only an interrupt can provide new event(s) to the system.
Now consider how the scenario depicted in Figure 6.3(A) plays out under the vanilla kernel. The scenario begins with a low-priority active object executing its RTC step (dispatch() function) and a high-priority active object having its event queue empty. At point (2a) an interrupt preempts the low-priority active object. The ISR executes and, among other things, posts an event to the high-priority active object (3a). The interrupt returns and resumes the originally preempted low-priority active object (4a). The low-priority object runs to completion and returns to the main loop. At this point, the vanilla scheduler has a chance to run and picks the highest-priority nonempty queue, which is the queue of the high-priority active object (6a). The vanilla kernel calls the dispatch() function of the high-priority active object, which runs to completion.
As you can see, the task-level response of the vanilla kernel is exactly the same as any other nonpreemptive kernel. Even so, the vanilla kernel achieves this responsiveness without per-task stacks or complex context switching. The active objects naturally collaborate to share the CPU and implicitly yield to each other at the end of every RTC step. The implementation is completely portable and suitable for low-end embedded systems.
Because typically the RTC steps are quite short, the kernel can often achieve adequate task-level response even on a low-end CPU. Due to the simplicity, portability, and minimal overhead, I highly recommend the vanilla kernel as your first choice. Only if this type of kernel cannot meet your timing requirements should you move up to a preemptive kernel.
Note
The vanilla kernel also permits executing multiple active objects inside a single thread of a bigger multitasking system. In this case, the vanilla scheduler should efficiently block when all event queues are empty instead of wasting CPU cycles for polling the event queues. Posting an event to any of the active object queues should unblock the kernel. Of course, this requires integrating the vanilla kernel with the underlying multitasking system.
Finally, if your task-level response requirements mandate a preemptive kernel, you can consider a super-simple, run-to-completion preemptive kernel that matches perfectly the active object computing model [Samek+ 06]. A preemptive RTC kernel implements in software exactly the same deterministic scheduling policy for tasks as most prioritized interrupt controllers implement in hardware for interrupts.
Prioritized interrupt controllers, such as the venerable Intel 8259A, the Motorola 68K and derivatives, the interrupt controllers in ARM-based MCUs by various vendors, the NVIC in the ARMv7 architecture (e.g., Cortex-M3), the M16C from Renesas, and many others allow prioritized nesting of interrupts on a single stack.
In an RTC kernel tasks and interrupts are nearly symmetrical: both tasks and ISRs are one-shot, RTC functions (Figure 6.9(A)). In fact, an RTC kernel views interrupts very much like tasks of “super-high” priority, except that interrupts are prioritized in hardware by the interrupt controller, whereas tasks are prioritized in software by the kernel (Figure 6.9(B)).
Note
In all traditional kernels, tasks are generally structured as endless loops. An RTC kernel breaks with this arrangement entirely. Under an RTC kernel, tasks are one-shot functions that run to completion and return, very much like ISRs managed by a prioritized interrupt controller.

By requiring that all tasks run to completion and enforcing fixed-priority scheduling, an RTC kernel can use the machine's natural stack protocol. Whenever a task is preempted by a higher-priority task (perhaps as a result of the currently running task posting an event to a higher-priority task), the RTC kernel uses a regular C-function call to build the higher-priority task context on top of the preempted-task stack context. Whenever an interrupt preempts a task, the kernel uses the already established interrupt stack frame on top of which to build the higher-priority task context, again using a regular C-function call. This simple form of context management is adequate because every task, just like every ISR, runs to completion. Because the preempting task must also run to completion, the lower-priority stack context will never be needed until the preempting task (and any higher-priority task that might preempt it) has completed—at which time the preempted task will naturally be at the top of the stack, ready to be resumed. This simple mechanism works for exactly the same reason that a prioritized hardware-interrupt system works [Samek+ 06].
Note
Such a close match between the active object computing model and prioritized, nested interrupt handling implemented directly in hardware suggests that active objects are in fact quite a basic concept. In particular, the RTC processing style and no need for blocking in active objects map better to actual processor architectures and incur less overhead than traditional blocking kernels. In this respect, traditional blocking tasks must be viewed as a higher-level, more heavyweight concept than active objects.
One obvious consequence of the stack-use policy, and the most severe limitation of an RTC kernel, is that tasks cannot block. The kernel cannot leave a high-priority task context on the stack and at the same time resume a lower-priority task. The lower-priority task context simply won't be accessible on top of the stack unless the higher-priority task completes. But as I keep repeating ad nauseam throughout this book, event-driven programming is all about writing nonblocking code. Event-driven active objects don't have a need for blocking.
In exchange for not being able to block, an RTC kernel offers many advantages over traditional blocking kernels. By nesting all task contexts in a single stack, the RTC kernel can be super-simple because it doesn't need to manage multiple stacks and all their associated bookkeeping. The result is not just significantly less RAM required for the stacks and task control blocks but a faster context switch and, overall, less CPU overhead. At the same time, an RTC kernel is as deterministic and responsive as any other fully preemptive priority-based kernel. In Chapter 10, I describe an RTC kernel called QK, which is part of the QP platform. QK is a tiny preemptive, priority-based RTC kernel specifically designed to provide preemptive multitasking support to the QF real-time framework.
If you are using a traditional preemptive kernel or RTOS for executing event-driven systems, chances are that you're overpaying in terms of CPU and memory overhead. You can achieve the same execution profile and determinism with a much simpler RTC kernel. The only real reason for using a traditional RTOS is compatibility with existing software. For example, traditional device drivers, communication stacks (such as TCP/IP, USB, CAN, etc.), and other legacy subsystems are often written with the blocking paradigm. A traditional blocking RTOS can support both active object and traditional blocking code, which the RTOS executes outside the real-time framework.
One of the main responsibilities of every real-time framework is to efficiently deliver events from producers to consumers. The event delivery is generally asynchronous, meaning that the producers of events only insert them into event queues but do not wait for the actual processing of the events.
In addition, any part of the system can usually produce events, not necessarily only the active objects. For example, ISRs, device drivers, or legacy code running outside the framework can produce events. On the other hand, only active objects can consume events, because only active objects have event queues.
Note
A framework can also provide “raw” thread-safe event queues without active objects behind them. Such “raw” thread-safe queues can consume events as well, but they never block and are intended to deliver events to ISRs, that is, provide a communication mechanism from the task level to the ISR level.
Real-time frameworks typically support two types of event delivery mechanism (see Figure 6.10):
1 The simple mechanism of direct event posting, when the producer of an event directly posts the event to the event queue of the consumer active object.
2 A more sophisticated publish-subscribe event delivery mechanism, where a producer “publishes” an event to the framework, and the framework then delivers the event to all active objects that had “subscribed” to this event. The publish-subscribe mechanism provides lower coupling between event producers and consumers.

The simplest mechanism lets producers post events directly to the event queue of the recipient active object. This method requires minimal participation from the framework. The framework merely provides a public operation (a function in the framework API), which allows any producer to post an event directly to the given active object. For example, the QF real-time framework provides the operation QActive_postFIFO(), which is the operation of the QActive class (see Figure 6.6). Of course the framework is responsible for implementing this function in a thread-safe manner. Figure 6.10 illustrates this form of communication as thick, solid arrows connecting event producers and the consumer active objects.
Direct event posting is a “push-style” communication mechanism, in which recipients receive unsolicited events whether they want them or not. Direct event posting is ideal in situations where a group of active objects, or an active object and an ISR, form a subsystem delivering a particular service, such as a communication stack, GPS capability, digital camera subsystem in a mobile phone, or the like. This style of event passing requires that the event producers intimately “know” the recipients. The “knowledge” that a sender needs is more than merely having a pointer to the recipient active object; the sender must also know the kind of events the particular object might be interested in. This intimate knowledge, distributed among the participating application components, makes the coupling among the components quite strong and inflexible at runtime. For example, it might be difficult to add new active objects to the subsystem, because existing event producers won't know about the newcomers and won't send them events.
The publish–subscribe model is a popular way of decoupling the event producers from the event consumers. Publish-subscribe is a “pull-style” communication mechanism in which recipients receive only solicited events. The properties of the publish-subscribe model are:
• Producers and consumers of events don't need to know each other (loose coupling).
• The events exchanged via this mechanism must be publicly known and must have the same semantics to all parties.
• A mediator7 The publish-subscribe event delivery is closely related to the Observer and Mediator design patterns [GoF 95]. is required to accept published events and to deliver them to interested subscribers.
• Many-to-many interactions (object-to-object) are replaced with one-to-many (object-to-mediator) interactions.
The publish-subscribe event delivery is shown in Figure 6.10 as a “software bus” into which active objects “plug in” through the specified interface. Active objects interested in certain events subscribe to one or more event signals by the framework. Event producers make event publication requests to the framework. Such requests can originate asynchronously from many sources, not necessarily just active objects—for example, from interrupts or device drivers. The framework manages all these interactions by supplying the following services:
• Provide an API for active objects to subscribe and unsubscribe to particular event signals. For example, the QF real-time framework provides functions
QActive_subscribe(), QActive_unsubscribe(), andQActive_unsubscribeAll().• Provide a generally accessible interface for publishing events. For example, QF provides
QF_publish()function.• Define and implement a thread-safe event delivery policy (including multicasting events when an event is subscribed by multiple active objects).
One obvious implication of publish-subscribe is that the framework must store the subscriber information, whereas it must allow associating more than one subscriber active object with an event signal. The framework must also allow modifying the subscriber information at runtime (dynamic subscribe and unsubscribe). The QF real-time framework supports dynamic subscriptions and cancellations of subscriptions.
In any event-driven system, events are frequently produced and consumed, so by nature they are highly dynamic. One of the most critical aspects of every real-time framework is managing the memory used by events, because obviously this memory must be frequently reused as new events are constantly produced. The main challenge for the framework is to guarantee that the event memory is not reused until all active objects have finished their RTC processing of the event. In fact, as described in Section 4.7.10 in Chapter 4, corrupting the current event while it is still in use constitutes a violation of the RTC semantics and is one of the hardest bugs to resolve.
Section 4.7.10 offered the general solution, which is to use event queues. Indeed, as shown in Figure 6.11, entire events can be copied into an event queue and then copied out of the queue again before they can be processed. Many RTOSs support this style of event exchange through message queues. For example, the VxWorks RTOS provides functions msgQSend() to copy a chunk of memory (message) into a message queue, and msgQReceive() to copy the entire message out of the queue to the provided memory buffer.

Copying entire events addresses all the potential problems with corrupting event memory prematurely, but the approach is terribly expensive in both space and time. In terms of space requirements, a message queue must typically be oversized so that all locations in the queue are able to accept the largest expected event. Additionally, every event producer needs an oversized memory buffer and every event consumer needs another oversized buffer to hold copies of the events. In terms of CPU overhead, each event passed through the queue requires making at least two copies of the data (see Figure 6.11). Moreover, the queue is inaccessible while the lengthy copy operations take place, which can negatively impact responsiveness of the system. Of course, the high overheads of copying events only multiply when multicasting events is required.
To mitigate the costs of message queues, some authors advise sending just pointers to larger chunks of data over a message queue and then let the recipient directly access the data via the provided pointer [Li+ 03]. You should be very careful with this approach. Due to the asynchronous nature of a message queue, the sender typically cannot know when the event actually gets processed, and the sender all too easily can prematurely corrupt the memory buffer by trying to reuse it for the next event. This is, of course, the classic concurrency problem caused by a shared memory buffer. Introducing such direct sharing of memory defeats the purpose of the message queue as a safe mechanism for passing messages (events) from producers to consumers.
The brute-force approach of copying entire events into message queues is the best a traditional RTOS can do, because an RTOS does not control the events after they leave the queue. A real-time framework, on the other hand, can be far more efficient because, due to inversion of control, the framework actually manages the whole life cycle of an event.
As shown in Figures 6.5(B), 6.8, and 6.9(A) earlier in this chapter, a real-time framework is in charge of extracting an event from the active object's event queue and then dispatching the event for RTC processing. After the RTC step completes, the framework regains control of the event. At this point, the framework “knows” that the event has been processed and so the framework can automatically recycle the event. Figure 6.12 shows the garbage collection step (event recycling) added to the active object life cycle.

A real-time framework can also easily control the allocation of events. The framework can simply provide an API function that application code must call to allocate new events. The QF framework, for example, provides the macro Q_NEW() for this purpose.
With the addition of the event creation and automatic garbage collection steps, the framework controls the life cycle of an event from cradle to grave. This in turn permits the framework to implement controlled, thread-safe sharing of event memory, which from the application standpoint is undistinguishable from true event copying. Such memory management is called zero-copy event delivery.
Figure 6.13 illustrates the zero-copy event delivery mechanism. The life cycle of an event begins when the framework allocates the event from an event pool and returns a pointer to this memory to the event producer, such as the ISR in Figure 6.13(1). The producer then fills the event parameters, writing directly to the provided event pointer. Next, the event producer posts just the pointer to the event to the queue of the recipient active object (Figure 6.13(2)).
Note
In the “zero-copy” event delivery scheme, event queues hold only pointers or references to events, not the entire events.

At some later time, the active object comes around to process the event. The active object reads the event data via the pointer extracted from the queue. Eventually, the framework automatically recycles the event in the garbage collection step. Note that the event is never copied. At the same time the framework makes sure that the event is not recycled prematurely. Of course, the framework must also guarantee that all these operations are performed in a thread-safe manner.
Not all events in the system have parameters or changing parameters. For example, the TIME_TICK event or the PLAYER_TRIGGER button-press event in the “Fly ‘n’ Shoot” game from Chapter 1 don't really change. Such immutable event objects can be shared safely and can be allocated statically once, rather than being created and recycled every time. Figure 6.13(3) shows an example of a static event that does not come from an event pool.
The “zero-copy” event delivery mechanism can very easily accommodate such static events by simply not managing them at all. All static events must have a unique signature that indicates to the garbage collector to ignore such events. Conversely, events allocated dynamically must have a unique signature identifying them as dynamic events that the framework needs to manage. The applications use static and dynamic events in exactly the same way, except that static events are not allocated dynamically.
In the publish-subscribe mechanism, it is common for multiple active objects to subscribe to the same event signal. A real-time framework is then supposed to multicast identical copies of an event to all registered active objects simultaneously, much as a newspaper publisher sends out identical copies of a newspaper to all subscribers.
Of course, sending multiple identical copies of an event is not compatible with the zero-copy event delivery policy. However, making identical copies of the event is not really necessary because all subscribers can receive pointers to the same event. The problem is rather to know when the last active object has completed processing of a given event so that it can be recycled.
A simple expedient is to use the standard reference-counting algorithm (e.g., see [Preiss 99]), which works in this case as follows: Every dynamic event object maintains internally a counter of outstanding references to this event. The counter starts at zero when the event is created. Each insertion of the event to any event queue increments the reference count by one. Every attempt to garbage-collect the event decrements the reference count by one. The event is recycled only when its reference count drops to zero. Note that the reference counter is not decremented when the event is extracted from a queue but only later, inside the garbage collection step. This is because an event must be considered referenced as long as it is being processed, not just as long as it sits in a queue. Of course, the reference counting should only affect dynamic events and must be performed in a thread-safe manner.
Note
The garbage collection step is not equivalent to event recycling. The garbage collector function always decrements the reference counter of a dynamic event but actually recycles the event only when the counter reaches zero.
Reference counting allows more complex event exchange patterns than just multicasting. For example, a recipient of an event might choose to post the received event again, perhaps more than once. In any case, the reference-counting algorithm will correctly spare the event from recycling at the end of the first RTC step and will eventually recycle the event only when the last active object has finished processing the event.
The garbage collection step is part of the active object life cycle controlled by the real-time framework (Figure 6.12). The application has typically no need to recycle events explicitly. In fact, some automatic garbage collection systems, most notably Java, don't even expose a public API for recycling individual objects.
However, a real-time framework might decide to provide a way to explicitly garbage-collect an event object, but this is always intended for special purposes. For example, an event producer might start to build a dynamic event but eventually decide to bail out without posting or publishing the event. In this case the event producer must call the garbage collector explicitly to avoid leaking of the event.
The zero-copy event delivery mechanisms are designed to be transparent to the application-level code. Even so, applications must obey certain ownership rules with respect to dynamic events, similar to the rules of working with objects allocated dynamically with malloc() or the C++ operator new.
Figure 6.14 illustrates the concept of event ownership and possible transfers of ownership rights. All dynamic events are initially owned by the framework. An event producer might gain ownership of a new event only by calling the new_() operation. At this point, the producer gains the ownership rights with the permission to write to the event. The event producer might keep the event as long as it needs, but eventually the producer must transfer the ownership back to the framework. Typically the producer posts or publishes the event. As a special case, the producer might decide that the event is not good, in which case the producer must call the garbage collector explicitly. After any of these three operations, the producer loses ownership of the event and can no longer access it.

The consumer active object gains ownership of the current event ‘e’ when the framework calls the dispatch(e) operation. This time, the active object gains merely the read-only permission to the current event. The consumer active object is also allowed to post or publish the event any number of times. The ownership persists over the entire RTC step. The ownership ends, however, when the dispatch() operation returns to the framework. The active object cannot use the event in any way past the RTC step.
The dynamic, reference-counted events could, in principle, be allocated and freed with the standard malloc() and free() functions, respectively. However, as described in the sidebar “A Heap of Problems,” using the standard heap for frequent allocation and recycling of events causes simply too many problems for any high-performance system.
A HEAP OF PROBLEMS
If you have been in the embedded real-time software business for a while, you must have learned to be wary of
malloc()andfree()(or their C++ counterpartsnewanddelete) because embedded real-time systems are particularly intolerant of heap problems, which include the following pitfalls:
• Dynamically allocating and freeing memory can fragment the heap over time to the point that the program crashes because of an inability to allocate more RAM. The total remaining heap storage might be more than adequate, but no single piece satisfies a specific
malloc()request.• Heap-based memory management is wasteful. All heap management algorithms must maintain some form of header information for each block allocated. At the very least, this information includes the size of the block. For example, if the header causes a 4-byte overhead, a 4-byte allocation requires at least 8 bytes, so only 50 percent of the allocated memory is usable to the application. Because of these overheads and the aforementioned fragmentation, determining the minimum size of the heap is difficult. Even if you were to know the worst-case mix of objects simultaneously allocated on the heap (which you typically don't), the required heap storage is much more than a simple sum of the object sizes. As a result, the only practical way to make the heap more reliable is to massively oversize it.
• Both
malloc()andfree()can be (and often are) nondeterministic, meaning that they potentially can take a long (hard to quantify) time to execute, which conflicts squarely with real-time constraints. Although many RTOSs have heap management algorithms with bounded or even deterministic performance, they don't necessarily handle multiple small allocations efficiently.Unfortunately, the list of heap problems doesn't stop there. A new class of problems appears when you use heap in a multithreaded environment. The heap becomes a shared resource and consequently causes all the headaches associated with resource sharing, so the list goes on:
• Both
malloc()andfree()can be (and often are) nonreentrant; that is, they cannot be safely called simultaneously from multiple threads of execution.• The reentrancy problem can be remedied by protecting
malloc(), free(), realloc(), and so on internally with a mutex, which lets only one thread at a time access the shared heap. However, this scheme could cause excessive blocking of threads (especially if memory management is nondeterministic) and can significantly reduce parallelism. Mutexes can also be subject to priority inversion. Naturally, the heap management functions protected by a mutex are not available to ISRs because ISRs cannot block.Finally, all the problems listed previously come on top of the usual pitfalls associated with dynamic memory allocation. For completeness, I'll mention them here as well.
• If you destroy all pointers to an object and fail to free it or you simply leave objects lying about well past their useful lifetimes, you create a memory leak. If you leak enough memory, your storage allocation eventually fails.
• Conversely, if you free a heap object but the rest of the program still believes that pointers to the object remain valid, you have created dangling pointers. If you dereference such a dangling pointer to access the recycled object (which by that time might be already allocated to somebody else), your application can crash.
• Most of the heap-related problems are notoriously difficult to test. For example, a brief bout of testing often fails to uncover a storage leak that kills a program after a few hours or weeks of operation. Similarly, exceeding a real-time deadline because of nondeterminism can show up only when the heap reaches a certain fragmentation pattern. These types of problems are extremely difficult to reproduce.
However, simpler, higher-performance, and safer options exist to the general-purpose, variable-block-size heap. A well-known alternative, commonly supported by RTOSs, is a fixed-block-size heap, also known as a memory partition or memory pool. Memory pools are a much better choice for a real-time framework to manage dynamic event allocation than the general-purpose heap.
Unlike the conventional (variable-block-size) heap, a memory pool has guaranteed capacity. It is not subject to fragmentation, because all blocks are exactly the same size. Because all blocks have identical size, no header is associated with each block allocated, thus reducing the system overhead per block. Furthermore, allocation through a memory pool can be very fast and completely deterministic. This aspect allows the kernel to protect a memory pool with a critical section of code (briefly disabling interrupts) rather than a mutex. In the case of a memory pool, the access is so fast that interrupts need to be disabled only briefly (no longer than other critical sections in the system), which does not increase interrupt latency and allows access to a memory pool, even from ISRs.
Note
A memory pool is no different from any other multitasking kernel object. For example. accessing a semaphore also requires briefly turning off interrupts (after all, a semaphore is also a shared resource). The QF real-time framework provides a native implementation of a thread-safe memory pool.
The most obvious drawback of a memory pool is that it does not support variable-sized blocks. Consequently, the blocks have to be oversized to handle the biggest possible allocation. Such a policy is often too wasteful if the actual sizes of allocated objects (events, in this case) vary a lot. A good compromise is often to use not one but a few memory pools with blocks of different sizes. The QF real-time framework, for example, can manage up to three event pools with different block sizes (e.g., small, medium, and large, like shirt sizes).
When multiple memory pools are used, each dynamic event object must remember which pool it came from, so that the framework can recycle the event to the same pool. The QF real-time framework combines the pool ID and the reference count into one data member “dynamic_” of the QEvent structure (see Listings 4.2 and 4.3 in Chapter 4).
Time management available in traditional RTOSs includes delaying a calling task (sleep()) or timed blocking on various kernel objects (e.g., semaphores or event flags). These blocking mechanisms are not very useful in active object-based systems where blocking is not allowed. Instead, to be compatible with the active object computing model, time management must be based on the event-driven paradigm in which every interesting occurrence manifests itself as an event instance.
A real-time framework manages time through time events, often called timers. Time event is a UML term and denotes a point in time. At the specified time, the event occurs [OMG 07]. The basic usage model of these time events is as follows: An active object allocates one or more time event objects (provides the storage for them). When the active object needs to arrange for a timeout, it arms one of its time events to post itself at some time in the future.
Figure 6.15 shows the time event facility in the QF real-time framework. The QTimeEvt class derives from QEvent, which means that time events can be used in all the same contexts as regular events. Time events can be further specialized to add more information (event parameters).
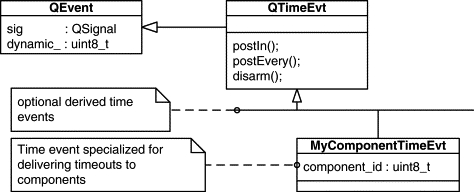
The time event provides public operations for that purpose: postIn() for a one-shot timeout and postEvery() for a periodic timeout event. Each timeout request has a different time event associated with it, so the application can make multiple parallel requests (from the same or different active objects). When the framework detects that the appropriate moment has arrived, the framework posts the requested time event directly into the recipient's event queue (direct event posting). The recipient then processes the time event just like any other event.
The application can explicitly disarm any time event (periodic or one-shot) at any time using the disarm() operation. After disarming (explicitly or implicitly, as in the case of the one-shot time event), the time event can be reused for one-shot or periodic timeouts. In addition, as long as the time event remains armed it can be rearmed with a different number of ticks through the rearm() operation. For one-shot time events, rearming is useful, for example, to implement watchdog timers that need to be periodically “tickled” to prevent them from ever timing out. Rearming might also be useful to adjust the phasing of periodic time events (often you need to extend or shorten one period).
Every real-time system, including traditional blocking kernels, requires a periodic time source called the system clock tick. The system clock tick is typically a periodic interrupt that occurs at a predetermined rate, typically between 10Hz and 100Hz. You can think of the system clock tick as the heartbeat of the system. The actual frequency of the system clock tick depends on the desired tick resolution of your application. The faster the tick rate, the more overhead the time management implies.
The system clock tick must call a special framework function to give the framework a chance to periodically update the armed time events. The QF real-time framework, for example, updates time events in the function QF_tick().
The delivery of time events in a real-time framework is subject to various delays, as is also the case with all real-time kernels or RTOSs [Labrosse 02]. Figure 6.16 shows in a somewhat exaggerated manner the various delays of a periodic time event programmed with one tick interval. As indicated by the varying time intervals in Figure 6.16, the time event delivery is always subject to jitter. The jitter gets worse as the priority of the recipient active object gets lower. In heavily loaded systems, the jitter might even exceed one clock tick period.8 This might be indicative of incorrect system design. In particular, a time event armed for just one tick might expire immediately because the system clock tick is asynchronous with respect to active object execution. To guarantee at least one tick timeout, you need to arm a time event for two clock ticks. Note too that time events are generally not lost due to event queuing. This is in contrast to clock ticks of a traditional RTOS, which can be lost during periods of heavy loading.

A real-time framework, just like any piece of system-level software, must implement a policy of handling erroneous conditions within the framework and—more important—within the application based on the framework. Of course, a framework could use the usual techniques, such as return error codes from the framework API calls, set error codes in the standard errno facility, or throw C++ exceptions. In fact, most operating systems and commercial RTOSs use these methods.
However, a real-time framework can do better than that. Due to inversion of control so typical in all event-driven systems, a real-time framework controls many more aspects of the application than a traditional operating system. A real-time framework is in a much better position to monitor the application to make sure that it is performing correctly, rather than the application to check error codes or catch exceptions originating from the framework. In other words, a real-time framework could use an error-handling policy that is consistent with the inversion of control between the framework and the application.
The Design by Contract9 Design by Contract is a registered trademark of Interactive Software Engineering. (DbC) approach, pioneered by Bertrand Meyer [Meyer 97], provides an excellent methodology for implementing a very robust error-handling policy within a real-time framework that makes the most of the control inversion. The DbC philosophy views a software system as a set of components whose collaboration is based on precisely defined specifications of mutual obligations—the contracts. The central idea of this method is to inherently embed the contracts in the code and validate them automatically at runtime.
In C or C++, the most important aspects of DbC (the contracts) can be implemented with assertions. The standard C-library macro assert() takes a Boolean argument and terminates the application if the argument evaluates to FALSE. A real-time framework can of course use a customized version of the macro, which would invoke an application-specific handler function when the assertion fails (see upcoming Section 6.7.3), but the general idea of asserting certain conditions at runtime is the same.
Assertions built into a real-time framework are consistent with inversion of control because through the assertions a real-time framework can enforce software contracts without relying on the application to check error codes or catch thrown exceptions.
The most important point to realize about software contracts (assertions in C/C++) is that they neither prevent errors nor really handle them, in the same way as contracts between people do not prevent fraud. For example, the QF real-time framework asserts that a published event signal is in the preconfigured range. Naturally, such an assertion neither handles nor prevents the application from publishing an event out of range. However, the assertion establishes a contract, which spells out that an attempt to publish an event out of range is an error. And sure enough, the framework will quite brutally abort the application that violates this contract. At first you might think that this must be backward. Contracts not only do nothing to prevent (let alone handle) errors, but they actually make things worse by turning every asserted condition, however benign, into a fatal error! However, when you really think about it, you must admit that publishing an event out of range is not really all right. It indicates that the application somehow lost consistency of event signals, which is a sure sign of a larger problem (a broken build, perhaps).
The DbC philosophy is the exact opposite of the popular defensive programming strategy, which denotes a programming style that aims at making operations more robust to errors, by accepting a wider range of inputs or allowing order of operations not necessarily consistent with the object's state. Defensive programming is often advertised as a better coding style, but unfortunately, it often hides bugs. To use the same example again, the QF framework could very easily make the publish() operation more “robust” simply by ignoring an event that is out of range. Defensive programming is not necessarily harder to implement than DbC. Rather, the problem with defensive programming is that it allows the code to “wonder around,” silently taking care of various invalid conditions. The DbC approach, in contrast, represents the point of view that either a program is in full control of what's going on or it isn't, whereas assertions define what it means that the program is in control. When any of these safeguards fails, the method prescribes that it is better to face up to the problem as soon as possible and put the system in a fail-safe state (whatever this might mean for a particular system) than to let a runaway program continue. This practice is especially advisable for safety-critical applications such as medical devices.
Due to their simplicity, assertions are sometimes viewed as too primitive error-checking mechanisms—something that's perhaps good enough for smaller programs but must be replaced with a “real” error handling in the industry-strength software. This view is inconsistent with the DbC philosophy, which regards contracts as the integral part of the software design. Software contracts embody important design decisions, namely declaring certain conditions as errors rather than exceptional conditions, and therefore embedding them in large-scale, mission-critical software is even more important than in quick-and-dirty solutions. As Bertrand Meyer [Meyer 97b] observes:
Another critical point to understand about the DbC philosophy is that the purpose of software contracts is to detect errors but not to handle exceptional conditions.
An error (known otherwise as a bug) means a persistent defect due to a design or implementation mistake (e.g., overrunning an array index or dereferencing a NULL pointer). Software contracts (assertions in C/C++) should be used to document such logically impossible situations to discover programming errors. If the “impossible” occurs, something fundamental is clearly wrong and you cannot trust the program anymore.
In contrast to an error, an exceptional condition is a specific circumstance that can legitimately arise during the system lifetime but is relatively rare and lies off the main execution path of your software. You need to design and implement a recovery strategy that handles the exceptional condition.
The distinction between errors and exceptional conditions is important because errors require the exact opposite programming strategy from dealing with exceptional conditions. The first priority in dealing with errors is to detect them as early as possible. Any attempt to handle a bug as an exceptional condition only increases the risks of damage that a runaway program can cause. It also tends to introduce immense complications to the code only camouflaging the bug. In the worst case, the attempts to “handle” a bug introduce new bugs.
A big often overlooked advantage of assertions is that they lead to considerable simplification of the software by flagging many situations as errors (that you don't need to handle) rather than exceptional conditions (that you do need to handle). Often, the application code is much simpler when it does not need to check and handle error codes returned by the framework but instead can rely on the framework policies enforced by assertions (see Section 6.1.6).
Listing 6.1 shows the simple, customizable, embedded systems-friendly assertions that I've found adequate for a wide range of projects, embedded or otherwise. These simple assertions are consistently used in all QP components, such as the QF real-time framework and the QEP event processor.
Listing 6.1. The qassert.h header file
(1)
#ifdef Q_NASSERT /* Q_NASSERT defined--assertion checking disabled */
#else /* Q_NASSERT not defined--assertion checking enabled */
/* callback invoked in case the condition passed to assertion fails */(2)
void Q_onAssert(char const Q_ROM * const Q_ROM_VAR file, int line);
static char const Q_ROM Q_ROM_VAR l_this_file [] = __FILE__;
/* general purpose assertion that ALWAYS evaluates the test_ argument */
The qassert.h header file shown in Listing 6.1 is similar to the standard <assert.h> header file, except (1) qassert.h allows customizing the error response, (2) it conserves memory by avoiding proliferation of multiple copies of the filename string, and (3) it provides additional macros for testing and documenting preconditions (Q_REQUIRE), postconditions (Q_ENSURE), and invariants (Q_INVARIANT). The names of these three latter macros are a direct loan from Eiffel, the programming language that natively supports DbC.
(1) Defining the macro
Q_NASSERTdisables assertions. When disabled, all assertion macros expand to empty statements that don't generate any code.(2) The function
Q_onAssert()prototyped in this line is invoked whenever an assertion fails. This function is application-specific and you need to define it somewhere in your program. In embedded systems,Q_onAssert()typically first disables interrupts to monopolize the CPU, then possibly attempts to put the system in a fail-safe state and eventually triggers a system reset. If possible, the function should also leave a “trail of bread crumbs” from the cause, perhaps by storing the filename and line number in a nonvolatile memory. In addition,Q_onAssert()is an ideal place to set a breakpoint during development and debugging.
Note
The macros
Q_ROMandQ_ROM_VARused in the signature ofQ_onAssert()are explained in Listing 4.14 in Chapter 4.
Compared to the standard assert(), the assertion macros defined in Listing 6.1 conserve memory (typically ROM) by using l_this_file[] string as the first argument to Q_onAssert() rather than the standard preprocessor macro __FILE__. This avoids proliferation of the multiple copies of the __FILE__ string for each use of the assert() macro (see [Maguire 93]).
(4) This macro
Q_DEFINE_THIS_MODULE()defines a static and constant stringl_this_file[]as the string provided in the argument. This macro provides an alternative toQ_DEFINE_THIS_FILE(so you use one or the other). The__FILE__macro often expands to the full path name of the translation unit, which might be too long to log.(5) The macro
Q_ASSERT()defines a general-purpose assertion. The empty block in theifstatement might seem strange, but you need both theifand theelsestatements to prevent unexpected danglingifproblems.(6) When assertions are disabled by defining
Q_NASSERT, the assertion macros don't generate any code; in particular, they don't test the expressions passed as arguments, so you should be careful to avoid any side effects required for normal program operation inside the expressions tested in assertions. The macroQ_ALLEGE()is a notable exception. This assertion macro always tests the condition, although when assertions are disabled it does not invoke theQ_onAssert()callback function.Q_ALLEGE()is useful in situations where avoiding side effects of the test would require introducing temporary variables on the stack—something you often want to minimize in embedded systems.(7) The macro
Q_ERROR()always fails. The use of this macro is equivalent toQ_ASSERT(0)but is more descriptive.(8-10) The macros
Q_REQUIRE(), Q_ENSURE(), andQ_INVARIANT()are intended for validating preconditions, postconditions, and invariants, respectively. They all map toQ_ASSERT(). Their different names serve only to better document the specific intent of the contract.(11) The macro
Q_ASSERT_COMPILE()validates a contract at compile time. The macro exploits the fact that the dimension of an array in C cannot be zero. Note that the macro does not actually allocate any storage, so there is no penalty in using it (see [Murphy 01]).
An exceptional condition is a specific situation in the lifetime of a system that calls for a special behavior. In a state-driven active object, a change in behavior corresponds to a change in state (state transition). Hence, in active object systems, the associated state machines are the most natural way to handle all conditions, including exceptional conditions.
Using state hierarchy can be very helpful to separate the “exceptional” behavior from the “normal” behavior. Such state-based exception handling is typically a combination of the Ultimate Hook and the Reminder state patterns (Chapter 5) and works as follows: A common superstate defines a high-level transition to the “exceptional” parts of the state machine. The submachine of this superstate implements the “normal” behavior. Whenever an action within the submachine encounters an exceptional condition, it posts a Reminder event to self to trigger the high-level transition to handle the exception. The exit actions executed upon the high-level transition perform the cleanup of the current context and cleanly enter the “exceptional” context.
State-based exception handling offers a safe and language-independent alternative to the built-in exception-handling mechanism of the underlying programming language. As described in Section 3.7.2 in Chapter 3, throwing and catching exceptions in C++ is risky in any state machine implementation because it conflicts with the fundamental RTC semantics of state machines. Stack unwinding inherent in propagating of thrown exceptions is also less relevant in event-driven systems than traditional sequential code because event-driven systems rely less on the stack and more on storing the state information in the static data. As Tom Cargill noticed in the seminal paper Exception handling: A false sense of security [Cargill 94]:
“Counter-intuitively, the hard part of coding exceptions is not the explicit throws and catches. The really hard part of using exceptions is to write all the intervening code in such a way that an arbitrary exception can propagate from its throw site to its handler, arriving safely and without damaging other parts of the program along the way.”—Tom Cargill
If you only can, consider leaving out the C++ throw-and-catch exception handling from your event-driven software. If you cannot avoid it, make sure to catch all exceptions before they can cause any damage.
The standard practice is to use assertions during development and testing but to disable them in the final product. The often-quoted opinion in this matter comes from C.A.R. Hoare, who considered disabling assertions in the final product like using a lifebelt during practice but then not bothering with it for the real thing.
The question of shipping with assertions really boils down to two issues. First is the overhead that assertions add to your code. Obviously, if the overhead is too big, you have no choice. But then you must ask yourself how you will build and test your application. It's much better to consider assertions as an integral part of the software and size the hardware adequately to accommodate them. As the prices of computer hardware rapidly drop while the capabilities increase, it simply makes sense to trade a small fraction of the raw CPU horsepower and some extra code memory for better system integrity. In practice, assertions often pay for themselves by eliminating reams of “error-handling” code that tries to camouflage bugs.
The other issue is the correct system response when an assertion fires in the field. This response must be obviously designed carefully and safety-critical systems might require some redundancy and recovery strategy. For many less critical applications a simple system reset turns out to be the least inconvenient action from the user's perspective—certainly less inconvenient than locking up the application and denying service. You should also try to leave some “bread crumbs” of information as to what went wrong. To this end, assertions provide a great starting point for debugging and ultimately fixing the root cause of the problem.
Traditional sequential systems communicate predominately by means of synchronous function calls. When module A wants to communicate with module B, module A calls a function in B. The communication is implicitly assumed to be reliable; that is, the programmer takes for granted that the function call mechanism will work, that the parameters will be passed to the callee, and that the return value will be delivered to the caller. The programmer does not conceive of any recovery strategy to handle a failure in the function call mechanism itself. But in fact, any function call can fail due to insufficient stack space. Consequently, the reliability of synchronous communication is in fact predicated on the implicit assumption of adequate stack resource.
Event-driven systems communicate predominately by asynchronous event exchange. When active object A wants to communicate with active object B, object A allocates an event and posts it to the event queue of object B. The programmer should be able to take for granted that the event delivery mechanism will work, that the event will be available, and that the event queue will accept the event. However, in fact, asynchronous communication can fail due to event pool depletion or insufficient queue depth. Consequently, the reliability of asynchronous communication is in fact predicated on the assumption of adequate event pool size and event queue depth. If those two resources are sized properly, the asynchronous event posting in the same address space should be as reliable as a synchronous function call.
Note
At this point, I limit the discussion to nondistributed systems executing in a single address space. Distributed systems connected with unreliable communication media pose quite different challenges. In this case neither synchronous communications such as remote procedure call (RPC) nor asynchronous communications via message passing can make strong guarantees.
I hope that this argument helps you realize that event pools and event queues should be treated on equal footing as the execution stacks in that depletion of any of these resources represents an error. In fact, event pools and queues fulfill in event-driven systems many responsibilities of the execution stacks in traditional multitasking systems. For example, parameters passed inside events play the same role as the parameters of function calls passed on the call stacks. Consequently, event-driven systems use less stack space than sequential systems but instead require event queues and event pools.
A real-time framework can use assertions to detect event pool and event queue overruns, in the same way that many commercial RTOSs detect stack overflows. For example, the QF real-time framework asserts internally that a requested dynamic event can always be allocated from one of the event pools. Similarly, the QF framework asserts that an event queue can always accept a posted event. It's up to the application implementer to adequately size all event pools and event queues in the system in the same exact way as it is the implementer's responsibility to adequately size the execution stacks for a multitasking kernel.
Note
Standard message queues available in traditional RTOSs allow many creative ways of circumventing the event delivery guarantee. For example, message queues allow losing events when the queue is full or blocking until the queue can accept the event. The QF real-time framework does not use these mechanisms. QF simply asserts that an event queue accepts every event without blocking.
A running application built of active objects is a highly structured affair where all important system interactions funnel through the real-time framework and the event processor executing the state machines. This arrangement offers a unique opportunity for applying software-tracing techniques. In a nutshell, software tracing is similar to peppering the code with printf() statements, which is called instrumenting the code, to log interesting discrete events for subsequent retrieval from the target system and analysis. Of course, a good software-tracing instrumentation can be much less intrusive and more powerful than the primitive printf().
By instrumenting just the real-time framework code you can gain an unprecedented wealth of information about the running system, far more detailed and comprehensive than any traditional RTOS can provide. (This is, of course, yet another benefit of control inversion.) The software trace data from the framework alone allows you to produce complete, time-stamped sequence diagrams and detailed state machine activity for all active objects in the system. This ability can form the foundation of the whole testing strategy for your application. In addition, individual active objects are natural entities for unit testing, which you can perform simply by injecting events into the active objects and collecting the trace data. Software tracing at the framework level makes all this comprehensive information available to you, even with no instrumentation added to the application-level code.
Most commercial real-time frameworks routinely use software tracing to provide visualization and animation of the state machines in the system. The QF real-time framework is also instrumented, and the software trace data can be extracted by means of the QS (Q-SPY) component, described in Chapter 11.
Event-driven programming requires a paradigm shift compared to traditional sequential programming. This paradigm shift leads to inversion of control between the event-driven application and the infrastructure on which it is based. The event-driven infrastructure can be generic and typically takes the form of a real-time framework. Using such a framework to implement your event-driven applications can spare you reinventing the wheel for each system you implement.
A real-time framework can employ a number of various CPU management policies, so it is important to understand the basic real-time concepts, starting from simple foreground/background systems through cooperative multitasking to fully preemptive multitasking. Traditionally, these execution models have been used with the blocking paradigm. Blocking means that the program frequently waits for events, either hanging in tight polling loops or getting efficiently blocked by a multitasking kernel. The blocking model is not compatible with the event-driven paradigm, but it can be adapted. The general strategy is to centralize and encapsulate all the blocking code inside the event-driven infrastructure (the framework) so that the application code never blocks.
The active object computing model combines multiple traditional event loops with a multitasking environment. In this model, applications are divided into multiple autonomous active objects, each encapsulating an execution thread (event loop), an event queue, and a state machine. Active objects communicate with one another asynchronously by posting events to each other's event queues. Within an active object, events are always processed in run-to-completion (RTC) fashion while a real-time framework handles all the details of thread-safe event exchange and queuing.
The active object computing model can work with a traditional preemptive RTOS, with just a basic cooperative vanilla kernel, or with the super-simple, preemptive, RTC kernel. In all these configurations, the active object model can take full advantage of the underlying CPU management policy, achieving optimal responsiveness and CPU utilization. As long as active objects are strictly encapsulated (i.e., they don't share resources), they can be programmed internally without concern for multitasking. In particular, the application programmer does not need to use or understand semaphores, mutexes, monitors, or other such troublesome mechanisms.
Most real-time frameworks support the simple direct event posting, and some frameworks also support the more sophisticated publish-subscribe event delivery mechanism. Direct event posting is a “push-style” communication in which the recipient active object gets unsolicited events, whether it wants them or not. Publish-subscribe is a “pull-style” communication in which active objects subscribe to event signals by the framework and then the framework delivers only the solicited events to the active objects. Publish-subscribe promotes loose coupling between event producers and event consumers.
Perhaps the biggest responsibility of a real-time framework is to guarantee thread-safe RTC event processing within active objects. This includes event management policies so that the current event is not corrupted over the entire RTC step. A simple but horrendously expensive method to protect events from corruption is to copy entire events into and out of event queues. A far more efficient way is for a framework to implement a zero-copy event delivery. Zero-copy really means that the framework controls thread-safe sharing of event memory, which at the application level is indistinguishable from true event copying. A real-time framework can do it because the framework actually controls the whole life cycle of events as well as active objects.
A real-time framework manages time through time events, also known as timers. Time events are time-delayed requests for posting events. The framework can handle many such requests in parallel. The framework uses the system clock tick to periodically gain control to manage the time events. The resolution of time events is one system clock tick, but it does not mean that the accuracy is also one clock tick due to various delays that cause jitter.
A real-time framework can use the traditional error-handling policies such as returning error-codes from framework API calls. However, a real-time framework can also use error management that takes advantage of the inversion of control between the framework and the application. Such techniques are based on assertions, or more generally on the Design by Contract (DbC) methodology. A framework can use assertions to constantly monitor the application. Among others, a framework can enforce guaranteed event delivery, which immensely simplifies event-driven application design.
Finally, a real-time framework can use software-tracing techniques to provide more detailed and comprehensive information about the running application than any traditional RTOS. The software-tracing instrumentation of the framework can form the backbone of a testing and debugging strategy for active-object systems.