
![]()
This chapter concerns the internals of .NET types, how value types and reference types are laid out in memory, what the JIT must do to invoke a virtual method, the intricacies of implementing a value type properly, and other details. Why would we trouble ourselves and spend a few dozen pages discussing these inner workings? How can these internal details affect our application’s performance? It turns out that value types and reference types differ in layout, allocation, equality, assignment, storage, and numerous other parameters—which makes proper type selection of paramount importance to application performance.
Consider a simple type called Point2D that represents a point in a small two-dimensional space. Each of the two coordinates can be represented by a short, for a total of four bytes for the entire object. Now suppose that you want to store in memory an array of ten million points. How much space would be required for them? The answer to this question depends greatly on whether Point2D is a reference type or a value type. If it is a reference type, an array of ten million points would actually store ten million references. On a 32-bit system, these ten million references consume almost 40 MB of memory. The objects themselves would consume at least the same amount. In fact, as we will see shortly, each Point2D instance would occupy at least 12 bytes of memory, bringing the total memory usage for an array of ten million points to a whopping 160MB! On the other hand, if Point2D is a value type, an array of ten million points would store ten million points – not a single extra byte wasted, for a total of 40MB, four times less than the reference type approach (see Figure 3-1). This difference in memory density is a critical reason to prefer value types in certain settings.
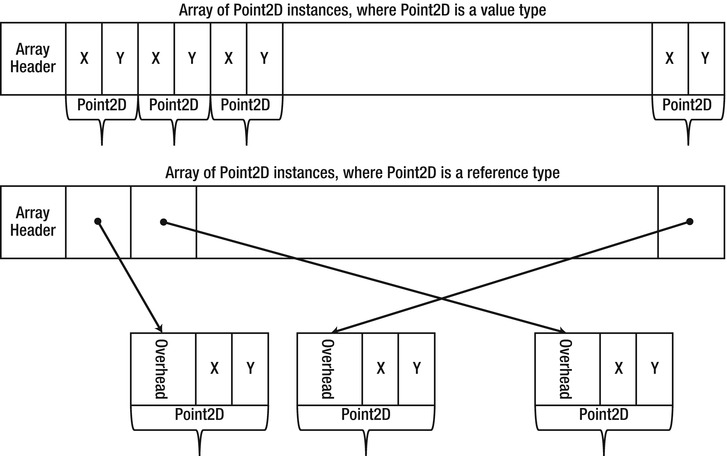
Figure 3-1 . An array of Point2D instances in the case Point2D is a reference type versus a value type
![]() Note There is another disadvantage to storing references to points instead of the actual point instances. If you want to traverse this huge array of points sequentially, it is much easier for the compiler and the hardware to access a contiguous array of Point2D instances than it is to access through references the heap objects, which are not guaranteed to be contiguous in memory. As we shall see in Chapter 5, CPU cache considerations can affect the application’s execution time up to an order of magnitude.
Note There is another disadvantage to storing references to points instead of the actual point instances. If you want to traverse this huge array of points sequentially, it is much easier for the compiler and the hardware to access a contiguous array of Point2D instances than it is to access through references the heap objects, which are not guaranteed to be contiguous in memory. As we shall see in Chapter 5, CPU cache considerations can affect the application’s execution time up to an order of magnitude.
It is inevitable to conclude that understanding the details of how the CLR lays out objects in memory and how reference types differ from value types is crucial for the performance of our applications. We begin by reviewing the fundamental differences between value types and reference types at the language level and then dive into the internal implementation details.
Semantic Differences between Reference Types and Value Types
Reference types in .NET include classes, delegates, interfaces, and arrays. string (System.String), which is one of the most ubiquitous types in .NET, is a reference type as well. Value types in .NET include structs and enums. The primitive types, such as int, float, decimal, are value types – but .NET developers are free to define additional value types using the struct keyword.
On the language level, reference types enjoy reference semantics, where the identity of the object is considered before its content, while value types enjoy value semantics, where objects don’t have an identity, are not accessed through references, and are treated according to their content. This affects several areas of the .NET languages, as Table 3-1 demonstrates.
Table 3-1. Semantic Differences Between Value Types and Reference Types
| Criteria | Reference Types | Value Types |
|---|---|---|
| Passing an object to a method | Only the reference is passed; changes propagate to all other references | The object’s contents are copied into the parameter (unless using the ref or out keywords); changes do not affect any code outside of the method |
| Assigning a variable to another variable | Only the reference is copied; two variables now contain references to the same object | The contents are copied; the two variables contain identical copies of unrelated data |
| Comparing two objects using operator== | The references are compared; two references are equal if they reference the same object | The contents are compared; two objects are equal if their content is identical on a field-by-field level |
These semantic differences are fundamental to the way we write code in any .NET language. However, they are only the tip of the iceberg in terms of how reference types and value types and their purposes differ. First, let’s consider the memory locations in which objects are stored, and how they are allocated and deallocated.
Storage, Allocation, and Deallocation
Reference types are allocated exclusively from the managed heap, an area of memory managed by the .NET garbage collector, which will be discussed in more detail in Chapter 4. Allocating an object from the managed heap involves incrementing a pointer, which is a fairly cheap operation in terms of performance. On a multi-processor system, if multiple processors are accessing the same heap, some synchronization is required, but the allocation is still extremely cheap compared to allocators in unmanaged environments, such as malloc.
The garbage collector reclaims memory in a non-deterministic fashion and makes no promises regarding its internal operation. As we shall see in Chapter 4, a full garbage collection process is extremely expensive, but the average garbage collection cost of a well-behaved application should be considerably smaller than that of a similar unmanaged counterpart.
![]() Note To be precise, there is an incarnation of reference types that can be allocated from the stack. Arrays of certain primitive types (such as arrays of integers) can be allocated from the stack using the unsafe context and the stackalloc keyword, or by embedding a fixed-size array into a custom struct, using the fixed keyword (discussed in Chapter 8). However, the objects created by the stackalloc and fixed keywords are not “real” arrays, and have a different memory layout than standard arrays allocated from the heap.
Note To be precise, there is an incarnation of reference types that can be allocated from the stack. Arrays of certain primitive types (such as arrays of integers) can be allocated from the stack using the unsafe context and the stackalloc keyword, or by embedding a fixed-size array into a custom struct, using the fixed keyword (discussed in Chapter 8). However, the objects created by the stackalloc and fixed keywords are not “real” arrays, and have a different memory layout than standard arrays allocated from the heap.
Stand-alone value types are usually allocated from the stack of the executing thread. However, value types can be embedded in reference types, in which case they are allocated on the heap, and can be boxed, transferring their storage to the heap (we will revisit boxing later in this chapter). Allocating a value type instance from the stack is a very cheap operation that involves modifying the stack pointer register (ESP on Intel x86), and has the additional advantage of allocating several objects at once. In fact, it is very common for a method’s prologue code to use just a single CPU instruction to allocate stack storage for all the local variables present in its outermost block.
Reclaiming stack memory is very efficient as well, and requires a reverse modification of the stack pointer register. Due to the way methods are compiled to machine code, often enough the compiler is not required to keep track of the size of a method’s local variables, and can destroy the entire stack frame in a standard set of three instructions, known as the function epilogue.
Below are the typical prologue and epilogue of a managed method compiled to 32-bit machine code (this is not actual production code produced by a JIT-compiler, which employs numerous optimizations discussed in Chapter 10). The method has four local variables, whose storage is allocated at once in the prologue and reclaimed at once in the epilogue:
int Calculation(int a, int b)
{
int x = a + b;
int y = a - b;
int z = b - a;
int w = 2 * b + 2 * a;
return x + y + z + w;
}
; parameters are passed on the stack in [esp+4] and [esp+8]
push ebp
mov ebp, esp
add esp, 16 ; allocates storage for four local variablesmov eax, dword ptr [ebp+8]
add eax, dword ptr [ebp+12]
mov dword ptr [ebp-4], eax
; ...similar manipulations for y, z, w
mov eax, dword ptr [ebp-4]
add eax, dword ptr [ebp-8]
add eax, dword ptr [ebp-12]
add eax, dword ptr [ebp-16] ; eax contains the return value
mov esp, ebp ; restores the stack frame, thus reclaiming the local storage spacepop ebp
ret 8 ; reclaims the storage for the two parameters
![]() Note The new keyword does not imply heap allocation in C# and other managed languages. You can allocate a value type on the stack using the new keyword as well. For example, the following line allocates a DateTime instance from the stack, initialized with the New Year’s Eve (System.DateTime is a value type): DateTime newYear = new DateTime(2011, 12, 31);
Note The new keyword does not imply heap allocation in C# and other managed languages. You can allocate a value type on the stack using the new keyword as well. For example, the following line allocates a DateTime instance from the stack, initialized with the New Year’s Eve (System.DateTime is a value type): DateTime newYear = new DateTime(2011, 12, 31);
What’s the Difference Between Stack and Heap?
Contrary to popular belief, there isn’t that much of a difference between stacks and heaps in a .NET process. Stacks and heaps are nothing more than ranges of addresses in virtual memory, and there is no inherent advantage in the range of addresses reserved to the stack of a particular thread compared to the range of addresses reserved for the managed heap. Accessing a memory location on the heap is neither faster nor slower than accessing a memory location on the stack. There are several considerations that might, in certain cases, support the claim that memory access to stack locations is faster, overall, than memory access to heap locations. Among them:
- On the stack, temporal allocation locality (allocations made close together in time) implies spatial locality (storage that is close together in space). In turn, when temporal allocation locality implies temporal access locality (objects allocated together are accessed together), the sequential stack storage tends to perform better with respect to CPU caches and operating system paging systems.
- Memory density on the stack tends to be higher than on the heap because of the reference type overhead (discussed later in this chapter). Higher memory density often leads to better performance, e.g., because more objects fit in the CPU cache.
- Thread stacks tend to be fairly small – the default maximum stack size on Windows is 1MB, and most threads tend to actually use only a few stack pages. On modern systems, the stacks of all application threads can fit into the CPU cache, making typical stack object access extremely fast. (Entire heaps, on the other hand, rarely fit into CPU caches.)
With that said, you should not be moving all your allocations to the stack! Thread stacks on Windows are limited, and it is easy to exhaust the stack by applying injudicious recursion and large stack allocations.
Having examined the superficial differences between value types and reference types, it’s time to turn to the underlying implementation details, which also explain the vast differences in memory density at which we hinted several times already. A small caveat before we begin: the details described below are internal implementation minutiae of the CLR, which are subject to change at any time without notice. We have done our best to ensure that this information is fresh and up to date with the .NET 4.5 release, but cannot guarantee that it will remain correct in the future.
We begin with reference types, whose memory layout is fairly complex and has significant effect on their runtime performance. For the purpose of our discussion, let’s consider a textbook example of an Employee reference type, which has several fields (instance and static), and a few methods as well:
public class Employee
{
private int _id;
private string _name;
private static CompanyPolicy _policy;
public virtual void Work() {
Console.WriteLine(“Zzzz...”);
}
public void TakeVacation(int days) {
Console.WriteLine(“Zzzz...”);
}
public static void SetCompanyPolicy(CompanyPolicy policy) {
_policy = policy;
}
}
Now consider an instance of the Employee reference type on the managed heap. Figure 3-2 describes the layout of the instance in a 32-bit .NET process:
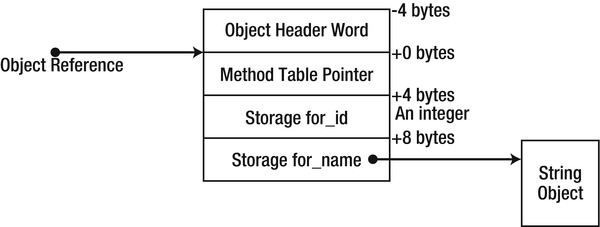
Figure 3-2 . The layout of an Employee instance on the managed heap, including the reference type overhead
The order of the _id and _name fields inside the object is not guaranteed (although it can be controlled, as we will see in the “Value Type Internals” section, using the StructLayout attribute). However, the object’s memory storage begins with a four byte field called object header word (or sync block index), followed by another four byte field called method table pointer (or type object pointer). These fields are not directly accessible from any .NET language – they serve the JIT and the CLR itself. The object reference (which, internally, is simply a memory address) points to the beginning of the method table pointer, so that the object header word is situated at a negative offset from the object’s address.
![]() Note On 32-bit systems, objects in the heap are aligned to the nearest four byte multiple. This implies that an object with only a single byte member would still occupy 12 bytes in the heap, due to alignment (in fact, even a class with no instance fields will occupy 12 bytes when instantiated). There are several differences where 64-bit systems are introduced. First, the method table pointer field (a pointer that it is) occupies 8 bytes of memory, and the object header word takes 8 bytes as well. Second, objects in the heap are aligned to the nearest eight byte multiple. This implies that an object with only a single byte member in a 64-bit heap would occupy a whopping 24 bytes of memory. This only serves to demonstrate more strongly the memory density overhead of reference types, in particular where small objects are created in bulk.
Note On 32-bit systems, objects in the heap are aligned to the nearest four byte multiple. This implies that an object with only a single byte member would still occupy 12 bytes in the heap, due to alignment (in fact, even a class with no instance fields will occupy 12 bytes when instantiated). There are several differences where 64-bit systems are introduced. First, the method table pointer field (a pointer that it is) occupies 8 bytes of memory, and the object header word takes 8 bytes as well. Second, objects in the heap are aligned to the nearest eight byte multiple. This implies that an object with only a single byte member in a 64-bit heap would occupy a whopping 24 bytes of memory. This only serves to demonstrate more strongly the memory density overhead of reference types, in particular where small objects are created in bulk.
The Method Table Pointer points to an internal CLR data structure called a method table (MT), which points in turn to another internal structure called EEClass (EE stands for Execution Engine). Together, the MT and EEClass contain the information required to dispatch virtual method calls, interface method calls, access static variables, determine the type of a runtime object, access the base type methods efficiently, and serve many additional purposes. The method table contains the frequently accessed information, which is required for the runtime operation of critical mechanisms such as virtual method dispatch, whereas the EEClass contains information that is less frequently accessed, but still used by some runtime mechanisms, such as Reflection. We can learn about the contents of both data structures using the !DumpMT and !DumpClass SOS commands and the Rotor (SSCLI) source code, bearing in mind that we are discussing internal implementation details that might differ significantly between CLR versions.
![]() Note SOS (Son of Strike) is a debugger extension DLL, which facilitates debugging managed applications using Windows debuggers. It is most commonly used with WinDbg, but can be loaded into Visual Studio using the Immediate Window. Its commands provide insight into CLR internals, which is why we are using it often in this chapter. For more information about SOS, consult the inline help (the !help command after loading the extension) and the MSDN documentation. An excellent treatment of SOS features in conjunction with debugging managed applications is in Mario Hewardt’s book, “Advanced .NET Debugging” (Addison-Wesley, 2009).
Note SOS (Son of Strike) is a debugger extension DLL, which facilitates debugging managed applications using Windows debuggers. It is most commonly used with WinDbg, but can be loaded into Visual Studio using the Immediate Window. Its commands provide insight into CLR internals, which is why we are using it often in this chapter. For more information about SOS, consult the inline help (the !help command after loading the extension) and the MSDN documentation. An excellent treatment of SOS features in conjunction with debugging managed applications is in Mario Hewardt’s book, “Advanced .NET Debugging” (Addison-Wesley, 2009).
The location of static fields is determined by the EEClass. Primitive fields (such as integers) are stored in dynamically allocated locations on the loader heap, while custom value types and reference types are stored as indirect references to a heap location (through an AppDomain-wide object array). To access a static field, it is not necessary to consult the method table or EEClass – the JIT compiler can hard-code the addresses of the static fields into the generated machine code. The array of references to static fields is pinned so that its address can’t change during a garbage collection (discussed in more detail in Chapter 4), and the primitive static fields reside in the method table which is not touched by the garbage collector either. This ensures that hard-coded addresses can be used to access these fields:
public static void SetCompanyPolicy(CompanyPolicy policy)
{
_policy = policy;
}
mov ecx, dword ptr [ebp+8] ;copy parameter to ECX
mov dword ptr [0x3543320], ecx ;copy ECX to the static field location in the global pinned array
The most obvious thing the method table contains is an array of code addresses, one for every method of the type, including any virtual methods inherited from its base types. For example, Figure 3-3 shows a possible method table layout for the Employee class above, assuming that it derives only from System.Object:
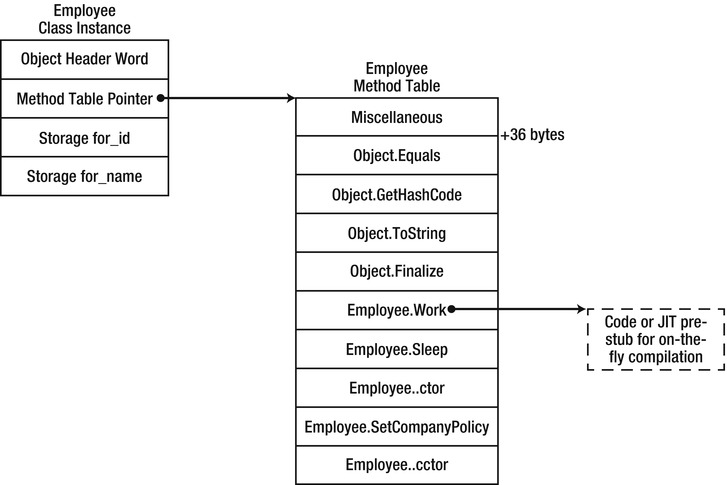
Figure 3-3 . The Employee class’ method table (partial view)
We can inspect method tables using the !DumpMT SOS command, given a method table pointer (which can be obtained from a live object reference by inspecting its first field, or by named lookup with the !Name2EE command). The -md switch will output the method descriptor table, containing the code addresses and method descriptors for each of the type’s methods. (The JIT column can have one of three values: PreJIT, meaning that the method was compiled using NGEN; JIT, meaning that the method was JIT-compiled at runtime; or NONE, meaning that the method was not yet compiled.)
0:000> r esi
esi=02774ec8
0:000> !do esi
Name: CompanyPolicy
MethodTable: 002a3828
EEClass: 002a1350
Size: 12(0xc) bytes
File: D:Development...App.exe
Fields:
None
0:000> dd esi L1
02774ec8 002a3828
0:000> !dumpmt -md 002a3828
EEClass: 002a1350
Module: 002a2e7c
Name: CompanyPolicy
mdToken: 02000002
File: D:Development...App.exe
BaseSize: 0xc
ComponentSize: 0x0
Slots in VTable: 5
Number of IFaces in IFaceMap: 0
--------------------------------------
MethodDesc Table
Entry MethodDe JIT Name
5b625450 5b3c3524 PreJIT System.Object.ToString()
5b6106b0 5b3c352c PreJIT System.Object.Equals(System.Object)
5b610270 5b3c354c PreJIT System.Object.GetHashCode()
5b610230 5b3c3560 PreJIT System.Object.Finalize()
002ac058 002a3820 NONE CompanyPolicy..ctor()
![]() Note Unlike C++ virtual function pointer tables, CLR method tables contain code addresses for all methods, including non-virtual ones. The order in which methods are laid out by the method table creator is unspecified. Currently, they are arranged in the following order: inherited virtual methods (including any possible overrides – discussed later), newly introduced virtual methods, non-virtual instance methods, and static methods.
Note Unlike C++ virtual function pointer tables, CLR method tables contain code addresses for all methods, including non-virtual ones. The order in which methods are laid out by the method table creator is unspecified. Currently, they are arranged in the following order: inherited virtual methods (including any possible overrides – discussed later), newly introduced virtual methods, non-virtual instance methods, and static methods.
The code addresses stored in the method table are generated on the fly – the JIT compiler compiles methods when they are first called, unless NGEN was used (discussed in Chapter 10). However, users of the method table need not be aware of this step thanks to a fairly common compiler trick. When the method table is first created, it is populated with pointers to special pre-JIT stubs, which contain a single CALL instruction dispatching the caller to a JIT routine that compiles the relevant method on the fly. After compilation completes, the stub is overwritten with a JMP instruction that transfers control to the newly compiled method. The entire data structure which stores the pre-JIT stub and some additional information about the method is called a method descriptor (MD) and can be examined by the !DumpMD SOS command.
Before a method has been JIT-compiled, its method descriptor contains the following information:
0:000> !dumpmd 003737a8
Method Name: Employee.Sleep()
Class: 003712fc
MethodTable: 003737c8
mdToken: 06000003
Module: 00372e7c
IsJitted: no
CodeAddr: ffffffff
Transparency: Critical
Here is an example of a pre-JIT stub that is responsible for updating the method descriptor:
0:000> !u 002ac035
Unmanaged code
002ac035 b002 mov al,2
002ac037 eb08 jmp 002ac041
002ac039 b005 mov al,5
002ac03b eb04 jmp 002ac041
002ac03d b008 mov al,8
002ac03f eb00 jmp 002ac041
002ac041 0fb6c0 movzx eax,al
002ac044 c1e002 shl eax,2
002ac047 05a0372a00 add eax,2A37A0h
002ac04c e98270ca66 jmp clr!ThePreStub (66f530d3)
After the method was JIT-compiled, its method descriptor changes to the following:
0:007> !dumpmd 003737a8
Method Name: Employee.Sleep()
Class: 003712fc
MethodTable: 003737c8
mdToken: 06000003
Module: 00372e7c
IsJitted: yes
CodeAddr: 00490140
Transparency: Critical
A real method table contains more information that we have previously disclosed. Understanding some of the additional fields is critical to the details of method dispatch discussed next; this is why we must take a longer look at the method table structure for an Employee instance. We assume additionally that the Employee class implements three interfaces: IComparable, IDisposable, and ICloneable.
In Figure 3-4, there are several additions to our previous understanding of method table layout. First, the method table header contains several interesting flags that allow dynamic discovery of its layout, such as the number of virtual methods and the number of interfaces the type implements. Second, the method table contains a pointer to its base class’s method table, a pointer to its module, and a pointer to its EEClass (which contains a back-reference to the method table). Third, the actual methods are preceded by a list of interface method tables that the type implements. This is why there is a pointer to the method list within the method table, at a constant offset of 40 bytes from the method table start.
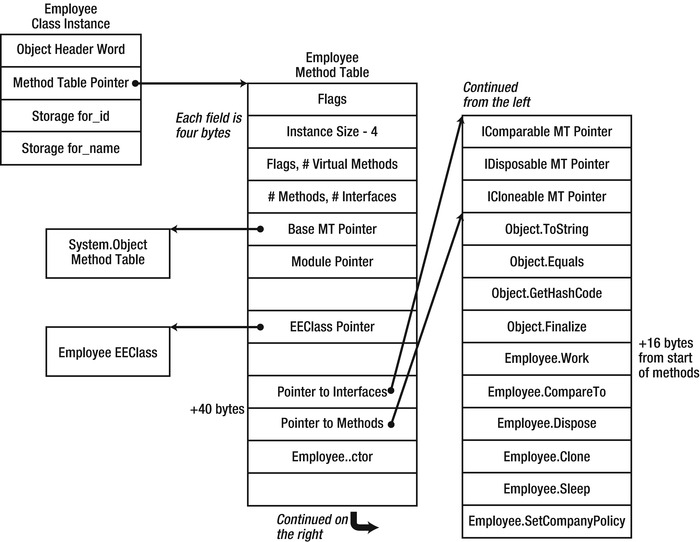
Figure 3-4 . Detailed view of the Employee method table, including internal pointers to interface list and method list used for virtual method invocation
![]() Note The additional dereference step required to reach the table of code addresses for the type’s methods allows this table to be stored separately from the method table object, in a different memory location. For example, if you inspect the method table for System.Object, you may find that its method code addresses are stored in a separate location. Furthermore, classes with many virtual methods will have several first-level table pointers, allowing partial reuse of method tables in derived classes.
Note The additional dereference step required to reach the table of code addresses for the type’s methods allows this table to be stored separately from the method table object, in a different memory location. For example, if you inspect the method table for System.Object, you may find that its method code addresses are stored in a separate location. Furthermore, classes with many virtual methods will have several first-level table pointers, allowing partial reuse of method tables in derived classes.
Invoking Methods on Reference Type Instances
Clearly, the method table can be used to invoke methods on arbitrary object instances. Suppose that the stack location EBP-64 contains the address of an Employee object with a method table layout as in the previous diagram. Then we can call the Work virtual method by using the following instruction sequence:
mov ecx, dword ptr [ebp-64]
mov eax, dword ptr [ecx] ; the method table pointer
mov eax, dword ptr [eax+40] ; the pointer to the actual methods inside the method table
call dword ptr [eax+16] ; Work is the fifth slot (fourth if zero-based)
The first instruction copies the reference from the stack to the ECX register, the second instruction dereferences the ECX register to obtain the object’s method table pointer, the third instruction fetches the internal pointer to the list of methods inside the method table (which is located at the constant offset of 40 bytes), and the fourth instruction dereferences the internal method table at offset 16 to obtain the code address of the Work method and calls it. To understand why it is necessary to use the method table for virtual method dispatching, we need to consider how runtime binding works – i.e., how polymorphism can be implemented through virtual methods.
Suppose that an additional class, Manager, were to derive from Employee and override its Work virtual method, as well as implement yet another interface:
public class Manager : Employee, ISerializable
{
private List<Employee> _reports;
public override void Work() ...
//...implementation of ISerializable omitted for brevity
}
The compiler might be required to dispatch a call to the Manager.Work method through an object reference that has only the Employee static type, as in the following code listing:
Employee employee = new Manager(...);
employee.Work();
In this particular case, the compiler might be able to deduce – using static flow analysis – that the Manager.Work method should be invoked (this doesn’t happen in the current C# and CLR implementations). In the general case, however, when presented with a statically typed Employee reference, the compiler needs to defer binding to runtime. In fact, the only way to bind to the right method is to determine at runtime the actual type of the object referenced by the employee variable, and dispatch the virtual method based on that type information. This is exactly what the method table enables the JIT compiler to do.
As depicted in Figure 3-5, the method table layout for the Manager class has the Work slot overridden with a different code address, and the method dispatch sequence would remain the same. Note that the offset of the overridden slot from the beginning of the method table is different because the Manager class implements an additional interface; however, the “Pointer to Methods” field is still at the same offset, and accommodates for this difference:
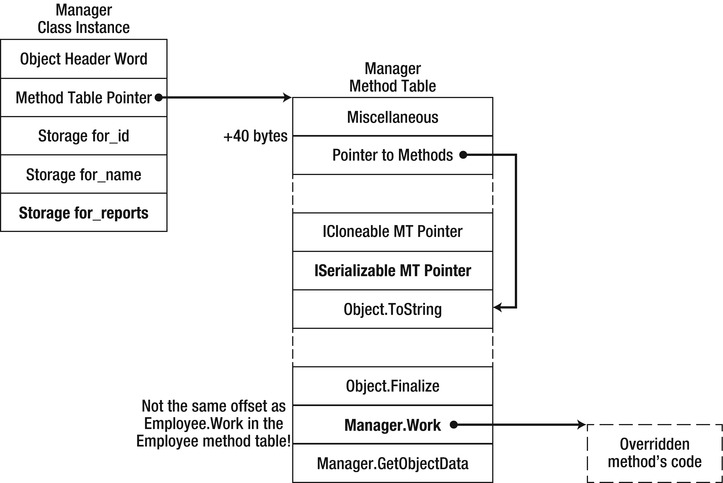
Figure 3-5 . Method table layout for the Manager method table.This method table contains an additional interface MT slot, which makes the “Pointer to Methods” offset larger
mov ecx, dword ptr [ebp-64]
mov eax, dword ptr [ecx]
mov eax, dword ptr [ecx+40] ;this accommodates for the Work method having a different
call dword ptr [eax+16] ;absolute offset from the beginning of the MT
![]() Note The object layout in which an overridden method’s offset from the beginning of the method table is not guaranteed to be the same in derived classes is new in CLR 4.0. Prior to CLR 4.0, the list of interfaces implemented by the type was stored at the end of the method table, after the code addresses; this meant that the offset of the Object.Equals address (and the rest of the code addresses) was constant in all derived classes. In turn, this meant that the virtual method dispatch sequence consisted of only three instructions instead of four (the third instruction in the sequence above was not necessary). Older articles and books may still reference the previous invocation sequence and object layout, serving as an additional demonstration for how internal CLR details can change between versions without any notice.
Note The object layout in which an overridden method’s offset from the beginning of the method table is not guaranteed to be the same in derived classes is new in CLR 4.0. Prior to CLR 4.0, the list of interfaces implemented by the type was stored at the end of the method table, after the code addresses; this meant that the offset of the Object.Equals address (and the rest of the code addresses) was constant in all derived classes. In turn, this meant that the virtual method dispatch sequence consisted of only three instructions instead of four (the third instruction in the sequence above was not necessary). Older articles and books may still reference the previous invocation sequence and object layout, serving as an additional demonstration for how internal CLR details can change between versions without any notice.
Dispatching Non-Virtual Methods
We can use a similar dispatch sequence to call non-virtual methods as well. However, for non-virtual methods, there is no need to use the method table for method dispatch: the code address of the invoked method (or at least its pre-JIT stub) is known when the JIT compiles the method dispatch. For example, if the stack location EBP-64 contains the address of an Employee object, as before, then the following instruction sequence will call the TakeVacation method with the parameter 5:
mov edx, 5 ;parameter passing through register – custom calling convention
mov ecx, dword ptr [ebp-64] ;still required because ECX contains ‘this’ by convention
call dword ptr [0x004a1260]
It is still required to load the object’s address into the ECX register – all instance methods expect to receive in ECX the implicit this parameter. However, there’s no longer any need to dereference the method table pointer and obtain the address from the method table. The JIT compiler still needs to be able to update the call site after performing the call; this is obtained by performing an indirect call through a memory location (0x004a1260 in this example) that initially points to the pre-JIT stub and is updated by the JIT compiler as soon as the method is compiled.
Unfortunately, the method dispatch sequence above suffers from a significant problem. It allows method calls on null object references to be dispatched successfully and possibly remain undetected until the instance method attempts to access an instance field or a virtual method, which would cause an access violation. In fact, this is the behavior for C++ instance method calls – the following code would execute unharmed in most C++ environments, but would certainly make C# developers shift uneasily in their chairs:
class Employee {
public: void Work() { } //empty non-virtual method
};
Employee* pEmployee = NULL;
pEmployee->Work(); //runs to completion
If you inspect the actual sequence used by the JIT compiler to invoke non-virtual instance methods, it would contain an additional instruction:
mov edx, 5 ;parameter passing through register – custom calling convention
mov ecx, dword ptr [ebp-64] ;still required because ECX contains ‘this’ by convention
cmp ecx, dword ptr [ecx]
call dword ptr [0x004a1260]
Recall that the CMP instruction subtracts its second operand from the first and sets CPU flags according to the result of the operation. The code above does not use the comparison result stored in the CPU flags, so how would the CMP instruction help prevent calling a method using a null object reference? Well, the CMP instruction attempts to access the memory address in the ECX register, which contains the object reference. If the object reference is null, this memory access would fail with an access violation, because accessing the address 0 is always illegal in Windows processes. This access violation is converted by the CLR to a NullReferenceException which is thrown at the invocation point; a much better choice than emitting a null check inside the method after it has already been called. Furthermore, the CMP instruction occupies only two bytes in memory, and has the advantage of being able to check for invalid addresses other than null.
![]() Note There is no need for a similar CMP instruction when invoking virtual methods; the null check is implicit because the standard virtual method invocation flow accesses the method table pointer, which makes sure the object pointer is valid. Even for virtual method calls you might not always see the CMP instruction being emitted; in recent CLR versions, the JIT compiler is smart enough to avoid redundant checks. For example, if the program flow has just returned from a virtual method invocation on an object — which contains the null check implicitly — then the JIT compiler might not emit the CMP instruction.
Note There is no need for a similar CMP instruction when invoking virtual methods; the null check is implicit because the standard virtual method invocation flow accesses the method table pointer, which makes sure the object pointer is valid. Even for virtual method calls you might not always see the CMP instruction being emitted; in recent CLR versions, the JIT compiler is smart enough to avoid redundant checks. For example, if the program flow has just returned from a virtual method invocation on an object — which contains the null check implicitly — then the JIT compiler might not emit the CMP instruction.
The reason we are so concerned with the precise implementation details of invoking virtual methods versus non-virtual methods is not the additional memory access or extra instruction that might or might not be required. The primary optimization precluded by virtual methods is method inlining, which is critical for modern high-performance applications. Inlining is a fairly simple compiler trick that trades code size for speed, whereby method calls to small or simple methods are replaced by the method’s body. For example, in the code below, it makes perfect sense to replace the call to the Add method by the single operation performed inside it:
int Add(int a, int b)
{
return a + b;
}
int c = Add(10, 12);
//assume that c is used later in the code
The non-optimized call sequence will have almost 10 instructions: three to set up parameters and dispatch the method, two to set up the method frame, one to add the numbers together, two to tear down the method frame, and one to return from the method. The optimized call sequence will have only one instruction – can you guess which one? One option is the ADD instruction, but in fact another optimization called constant-folding can be used to calculate at compile-time the result of the addition operation, and assign to the variable c the constant value 22.
The performance difference between inlined and non-inlined method calls can be vast, especially when the methods are as simple as the one above. Properties, for instance, make a great candidate for inlining, and compiler-generated automatic properties even more so because they don’t contain any logic other than directly accessing a field. However, virtual methods prevent inlining because inlining can occur only when the compiler knows at compile-time (in the case of the JIT compiler, at JIT-time) which method is about to be invoked. When the method to be invoked is determined at runtime by the type information embedded into the object, there is no way to generate correctly inlined code for a virtual method dispatch. If all methods were virtual by default, properties would have been virtual as well, and the accumulated cost from indirect method dispatches where inlining was otherwise possible would have been overwhelming.
You might be wondering about the effects of the sealed keyword on method dispatch, in light of how important inlining may be. For example, if the Manager class declares the Work method as sealed, invocations of Work on object references that have the Manager static type can proceed as a non-virtual instance method invocation:
public class Manager : Employee
{
public override sealed void Work() ...
}
Manager manager = ...; //could be an instance of Manager, could be a derived type
manager.Work(); //direct dispatch should be possible!
Nonetheless, at the time of writing, the sealed keyword has no effect on method dispatch on all the CLR versions we tested, even though knowledge that a class or method is sealed can be used to effectively remove the need for virtual method dispatch.
Dispatching Static and Interface Methods
For completeness, there are two additional types of methods we need to consider: static methods and interface methods. Dispatching static methods is fairly easy: there is no need to load an object reference, and simply calling the method (or its pre-JIT stub) would suffice. Because the invocation does not proceed through a method table, the JIT compiler uses the same trick as for non-virtual instance method: the method dispatch is indirect through a special memory location which is updated after the method is JIT compiled.
Interface methods, however, are a wholly different matter. It might appear that dispatching an interface method is not different from dispatching a virtual instance method. Indeed, interfaces enable a form of polymorphism reminiscent of classical virtual methods. Unfortunately, there is no guarantee that the interface implementations of a particular interface across several classes end up in the same slots in the method table. Consider the following code, where two classes implement the IComparable interface:
class Manager : Employee, IComparable {
public override void Work() ...
public void TakeVacation(int days) ...
public static void SetCompanyPolicy(...) ...
public int CompareTo(object other) ...
}
class BigNumber : IComparable {
public long Part1, Part2;
public int CompareTo(object other) ...
}
Clearly, the method table layout for these classes will be very different, and the slot number where the CompareTo method ends up will be different as well. Complex object hierarchies and multiple interface implementations make it evident that an additional dispatch step is required to identify where in the method table the interface methods were placed.
In prior CLR versions, this information was stored in a global (AppDomain-level) table indexed by an interface ID, generated when the interface is first loaded. The method table had a special entry (at offset 12) pointing into the proper location in the global interface table, and the global interface table entries pointed back into the method table, to the sub-table within it where the interface method pointers were stored. This allowed multi-step method dispatch, along the following lines:
mov ecx, dword ptr [ebp-64] ; object reference
mov eax, dword ptr [ecx] ; method table pointer
mov eax, dword ptr [eax+12] ; interface map pointer
mov eax, dword ptr [eax+48] ; compile time offset for this interface in the map
call dword ptr [eax] ; first method at EAX, second method at EAX+4, etc.
This looks complicated – and expensive! There are four memory accesses required to fetch the code address of the interface implementation and dispatch it, and for some interfaces this may be too high a cost. This is why you will never see the sequence above used by the production JIT compiler, even without optimizations enabled. The JIT uses several tricks to effectively inline interface methods, at least for the common case.
Hot-path analysis — when the JIT detects that the same interface implementation is often used, it replaces the specific call site with optimized code that may even inline the commonly used interface implementation:
mov ecx, dword ptr [ebp-64]
cmp dword ptr [ecx], 00385670 ; expected method table pointer
jne 00a188c0 ; cold path, shown below in pseudo-code
jmp 00a19548 ; hot path, could be inlined body here
cold path:
if (--wrongGuessesRemaining < 0) { ;starts at 100
back patch the call site to the code discussed below
} else {
standard interface dispatch as discussed above
}
Frequency analysis — when the JIT detects that its choice of hot path is no longer accurate for a particular call site (across a series of several dispatches), it replaces the former hot path guess with the new hot path, and continues to alternate between them every time it gets the guess wrong:
start: if (obj->MTP == expectedMTP) {
direct jump to expected implementation
} else {
expectedMTP = obj->MTP;
goto start;
}
For more details on interface method dispatch, consider reading Sasha Goldshtein’s article “JIT Optimizations” (http://www.codeproject.com/Articles/25801/JIT-Optimizations ) and Vance Morrison’s blog post (http://blogs.msdn.com/b/vancem/archive/2006/03/13/550529.aspx ). Interface method dispatch is a moving target and a ripe ground for optimization; future CLR versions might introduce further optimizations not discussed here.
Sync Blocks And The lock Keyword
The second header field embedded in each reference type instance is the object header word (or sync block index). Unlike the method table pointer, this field is used for a variety of purposes, including synchronization, GC book-keeping, finalization, and hash code storage. Several bits of this field determine exactly which information is stored in it at any instant in time.
The most complex purpose for which the object header word is used is synchronization using the CLR monitor mechanism, exposed to C# through the lock keyword. The gist is as follows: several threads may attempt to enter a region of code protected by the lock statement, but only one thread at a time may enter the region, achieving mutual exclusion:
class Counter
{
private int _i;
private object _syncObject = new object();
public int Increment()
{
lock (_syncObject)
{
return ++_i; //only one thread at a time can execute this statement
}
}
}
The lock keyword, however, is merely syntactic sugar that wraps the following construct, using the Monitor.Enter and Monitor.Exit methods:
class Counter
{
private int _i;
private object _syncObject = new object();
public int Increment()
{
bool acquired = false;
try
{
Monitor.Enter(_syncObject, ref acquired);
return ++_i;
}
finally
{
if (acquired) Monitor.Exit(_syncObject);
}
}
}
To ensure this mutual exclusion, a synchronization mechanism can be associated with every object. Because it is expensive to create a synchronization mechanism for every object on the outset, this association occurs lazily, when the object is used for synchronization for the first time. When required, the CLR allocates a structure called a sync block from a global array called the sync block table. The sync block contains a backwards reference to its owning object (although this is a weak reference that does not prevent the object from being collected), and, among other things, a synchronization mechanism called monitor, which is implemented internally using a Win32 event. The numeric index of the allocated sync block is stored in the object’s header word. Subsequent attempts to use the object for synchronization recognize the existing sync block index and use the associated monitor object for synchronization.
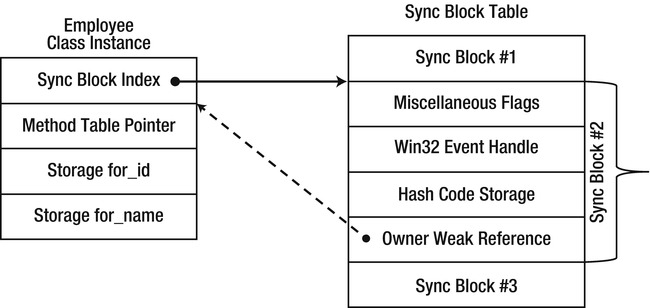
Figure 3-6 . A sync block associated with an object instance. The sync block index fields stores only the index into the sync block table, allowing the CLR to resize and move the table in memory without modifying the sync block index
After a sync block has been unused for a long period of time, the garbage collector reclaims it and detaches its owning object from it, setting the sync block index to an invalid index. Following this reclamation, the sync block can be associated with another object, which conserves expensive operating system resources required for synchronization mechanisms.
The !SyncBlk SOS command can be used to inspect sync blocks that are currently contended, i.e., sync blocks which are owned by a thread and waited for by another thread (possibly more than one waiter). As of CLR 2.0, there is an optimization that may lazily create a sync block only when there is contention for it. While there is no sync block, the CLR may use a thin lock to manage synchronization state. Below we explore some examples of this.
First, let’s take a look at the object header word of an object that hasn’t been used for synchronization yet, but whose hash code has already been accessed (later in this chapter we will discuss hash code storage in reference types). In the following example, EAX points to an Employee object whose hash code is 46104728:
0:000> dd eax-4 L2
023d438c 0ebf8098 002a3860
0:000> ? 0n46104728
Evaluate expression: 46104728 = 02bf8098
0:000> .formats 0ebf8098
Evaluate expression:
Hex: 0ebf8098
Binary: 00001110 10111111 10000000 10011000
0:000> .formats 02bf8098
Evaluate expression:
Hex: 02bf8098
Binary: 00000010 10111111 10000000 10011000
There is no sync block index here; only the hash code and two bits set to 1, one of them probably indicating that the object header word now stores the hash code. Next, we issue a Monitor.Enter call for the object from one thread to lock it, and inspect the object header word:
0:004> dd 02444390-4 L2
0244438c 08000001 00173868
0:000> .formats 08000001
Evaluate expression:
Hex: 08000001
Binary: 00001000 00000000 00000000 00000001
0:004> !syncblk
Index SyncBlock MonitorHeld Recursion Owning Thread Info SyncBlock Owner
1 0097db4c 3 1 0092c698 1790 0 02444390 Employee
The object was assigned the sync block #1, which is evident from the !SyncBlk command output (for more information about the columns in the command’s output, consult the SOS documentation). When another thread attempts to enter the lock statement with the same object, it enters a standard Win32 wait (albeit with message pumping if it’s a GUI thread). Below is the bottom of the stack of a thread waiting for a monitor:
0:004> kb
ChildEBP RetAddr Args to Child
04c0f404 75120bdd 00000001 04c0f454 00000001 ntdll!NtWaitForMultipleObjects+0x15
04c0f4a0 76c61a2c 04c0f454 04c0f4c8 00000000 KERNELBASE!WaitForMultipleObjectsEx+0x100
04c0f4e8 670f5579 00000001 7efde000 00000000 KERNEL32!WaitForMultipleObjectsExImplementation+0xe0
04c0f538 670f52b3 00000000 ffffffff 00000001 clr!WaitForMultipleObjectsEx_SO_TOLERANT+0x3c
04c0f5cc 670f53a5 00000001 0097db60 00000000 clr!Thread::DoAppropriateWaitWorker+0x22f
04c0f638 670f544b 00000001 0097db60 00000000 clr!Thread::DoAppropriateWait+0x65
04c0f684 66f5c28a ffffffff 00000001 00000000 clr!CLREventBase::WaitEx+0x128
04c0f698 670fd055 ffffffff 00000001 00000000 clr!CLREventBase::Wait+0x1a
04c0f724 670fd154 00939428 ffffffff f2e05698 clr!AwareLock::EnterEpilogHelper+0xac
04c0f764 670fd24f 00939428 00939428 00050172 clr!AwareLock::EnterEpilog+0x48
04c0f77c 670fce93 f2e05674 04c0f8b4 0097db4c clr!AwareLock::Enter+0x4a
04c0f7ec 670fd580 ffffffff f2e05968 04c0f8b4 clr!AwareLock::Contention+0x221
04c0f894 002e0259 02444390 00000000 00000000 clr!JITutil_MonReliableContention+0x8a
The synchronization object used is 25c, which is a handle to an event:
0:004> dd 04c0f454 L1
04c0f454 0000025c
0:004> !handle 25c f
Handle 25c
Type Event
Attributes 0
GrantedAccess 0x1f0003:
Delete,ReadControl,WriteDac,WriteOwner,Synch
QueryState,ModifyState
HandleCount 2
PointerCount 4
Name <none>
Object Specific Information
Event Type Auto Reset
Event is Waiting
And finally, if we inspect the raw sync block memory assigned to this object, the hash code and synchronization mechanism handle are clearly visible:
0:004> dd 0097db4c
0097db4c 00000003 00000001 0092c698 00000001
0097db5c 80000001 0000025c 0000000d 00000000
0097db6c 00000000 00000000 00000000 02bf8098
0097db7c 00000000 00000003 00000000 00000001
A final subtlety worth mentioning is that in the previous example, we forced the subsequent creation of a sync block by calling GetHashCode before locking the object. As of CLR 2.0, there is a special optimization aimed to conserve time and memory that does not create a sync block if the object has not been associated with a sync block before. Instead, the CLR uses a mechanism called thin lock. When an object is locked for the first time and there is no contention yet (i.e., no other thread has attempted to lock the object), the CLR stores in the object header word the managed thread ID of the object’s current owning thread. For example, here is the object header word of an object locked by the application’s main thread before there is any contention for the lock:
0:004> dd 02384390-4
0238438c 00000001 00423870 00000000 00000000
Here, the thread with managed thread ID 1 is the application’s main thread, as is evident from the output of the !Threads command:
0:004> !Threads
ThreadCount: 2
UnstartedThread: 0
BackgroundThread: 1
PendingThread: 0
DeadThread: 0
Hosted Runtime: no
Lock
ID OSID ThreadOBJ State GC Mode GC Alloc Context Domain Count Apt Exception
0 1 12f0 0033ce80 2a020 Preemptive 02385114:00000000 00334850 2 MTA
2 2 23bc 00348eb8 2b220 Preemptive 00000000:00000000 00334850 0 MTA (Finalizer)
Thin locks are also reported by the SOS !DumpObj command, which indicates the owner thread for an object whose header contains a thin lock. Similarly, the !DumpHeap -thinlock command can output all the thin locks currently present in the managed heap:
0:004> !dumpheap -thinlock
Address MT Size
02384390 00423870 12 ThinLock owner 1 (0033ce80) Recursive 0
02384758 5b70f98c 16 ThinLock owner 1 (0033ce80) Recursive 0
Found 2 objects.
0:004> !DumpObj 02384390
Name: Employee
MethodTable: 00423870
EEClass: 004213d4
Size: 12(0xc) bytes
File: D:Development...App.exe
Fields:
MT Field Offset Type VT Attr Value Name
00423970 4000001 4 CompanyPolicy 0 static 00000000 _policy
ThinLock owner 1 (0033ce80), Recursive 0
When another thread attempts to lock the object, it will spin for a short time waiting for the thin lock to be released (i.e., the owner thread information to disappear from the object header word). If, after a certain time threshold, the lock is not released, it is converted to a sync block, the sync block index is stored within the object header word, and from that point on, the threads block on the Win32 synchronization mechanism as usual.
Now that we have an idea how reference types are laid out in memory and what purpose the object header fields serve, it’s time to discuss value types. Value types have a much simpler memory layout, but it introduces limitations and boxing, an expensive process that compensates for the incompatibility of using a value type where a reference is required. The primary reason for using value types, as we have seen, is their excellent memory density and lack of overhead; every bit of performance matters when you develop your own value types.
For the purpose of our discussion, let’s commit to a simple value type we discussed at the onset of this chapter, Point2D, representing a point in two-dimensional space:
public struct Point2D
{
public int X;
public int Y;
}
The memory layout of a Point2D instance initialized with X=5, Y=7 is simply the following, with no additional “overhead” fields clutter:

Figure 3-7. Memory layout for a Point2D value type instance
In some rare cases, it may be desired to customize value type layout – one example is for interoperability purposes, when your value type instance is passed unchanged to unmanaged code. This customization is possible through the use of two attributes, StructLayout and FieldOffset. The StructLayout attribute can be used to specify that the object’s fields are to be laid out sequentially according to the type’s definition (this is the default), or explicitly according to the instructions provided by the FieldOffset attribute. This enables the creation of C-style unions, where fields may overlap. A crude example of this is the following value type, which can “convert” a floating-point number to the four bytes used by its representation:
[StructLayout(LayoutKind.Explicit)]
public struct FloatingPointExplorer
{
[FieldOffset(0)] public float F;
[FieldOffset(0)] public byte B1;
[FieldOffset(1)] public byte B2;
[FieldOffset(2)] public byte B3;
[FieldOffset(3)] public byte B4;
}
When you assign a floating-point value to the object’s F field, it concurrently modifies the values of B1-B4, and vice versa. Effectively, the F field and the B1-B4 fields overlap in memory, as demonstrated by Figure 3-8:
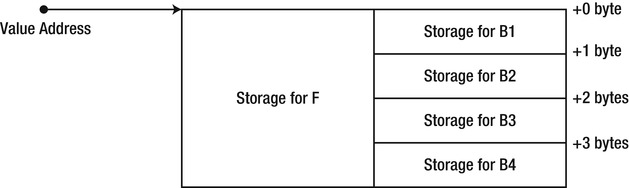
Figure 3-8 . Memory layout for a FloatingPointExplorer instance. Blocks aligned horizontally overlap in memory
Because value type instances do not have an object header word and a method table pointer, they cannot allow the same richness of semantics offered by reference types. We will now look at the limitations their simpler layout introduces, and what happens when developers attempt to use value types in settings intended for reference types.
First, consider the object header word. If a program attempts to use a value type instance for synchronization, it is most often a bug in the program (as we will see shortly), but should the runtime make it illegal and throw an exception? In the following code example, what should happen when the Increment method of the same Counter class instance is executed by two different threads?
class Counter
{
private int _i;
public int Increment()
{
lock (_i)
{
return ++_i;
}
}
}
As we attempt to verify what happens, we stumble upon an unexpected obstacle: the C# compiler would not allow using value types with the lock keyword. However, we are now seasoned in the inner workings of what the lock keyword does, and can attempt to code a workaround:
class Counter
{
private int _i;
public int Increment()
{
bool acquired=false;
try
{
Monitor.Enter(_i, ref acquired);
return ++_i;
}
finally
{
if (acquired) Monitor.Exit(_i);
}
}
}
By doing so, we introduced a bug into our program – it turns out that multiple threads will be able to enter the lock and modify _i at once, and furthermore the Monitor.Exit call will throw an exception (to understand the proper ways of synchronizing access to an integer variable, refer to Chapter 6). The problem is that the Monitor.Enter method accepts a System.Object parameter, which is a reference, and we are passing to it a value type – by value. Even if it were possible to pass the value unmodified where a reference is expected, the value passed to the Monitor.Enter method does not have the same identity as the value passed to the Monitor.Exit method; similarly, the value passed to the Monitor.Enter method on one thread does not have the same identity as the value passed to the Monitor.Enter method on another thread. If we pass around values (by value!) where references are expected, there is no way to obtain the correct locking semantics.
Another example of why value type semantics are not a good fit for object references arises when returning a value type from a method. Consider the following code:
object GetInt()
{
int i = 42;
return i;
}
object obj = GetInt();
The GetInt method returns a value type – which would typically be returned by value. However, the caller expects, from the method, to return an object reference. The method could return a direct pointer to the stack location where i is stored during the method’s execution. Unfortunately, it would be a reference to an invalid memory location, because the stack frame for the method is cleaned up before it returns. This demonstrates that the copy-by-value semantics value types have by default are not a good fit for when an object reference (into the managed heap) is expected.
Virtual Methods on Value Types
We haven’t considered the method table pointer yet, and already we have insurmountable problems when attempting to treat value types as first-class citizens. Now we turn to virtual methods and interface implementations. The CLR forbids inheritance relationships between value types, making it impossible to define new virtual methods on value types. This is fortunate, because if it were possible to define virtual methods on value types, invoking these methods would require a method table pointer which is not part of a value type instance. This is not a substantial limitation, because the copy-by-value semantics of reference types make them ill suited for polymorphism, which requires object references.
However, value types come equipped with virtual methods inherited from System.Object. There are several of them: Equals, GetHashCode, ToString, and Finalize. We will discuss only the first two here, but much of the discussion applies to the other virtual methods as well. Let’s start by inspecting their signatures:
public class Object
{
public virtual bool Equals(object obj) ...
public virtual int GetHashCode() ...
}
These virtual methods are implemented by every .NET type, including value types. It means that given an instance of a value type, we should be able to dispatch the virtual method successfully, even though it doesn’t have a method table pointer! This third example of how the value type memory layout affects our ability to do even simple operations with value type instances demands a mechanism that can “turn” value type instances into something that can more plausibly stand for an “authentic” object.
Whenever the language compiler detects a situation that requires treating a value type instance as a reference type, it emits the box IL instruction. The JIT compiler, in turn, interprets this instruction and emits a call to a method that allocates heap storage, copies the content of the value type instance to the heap, and wraps the value type contents with an object header – object header word and method table pointer. It is this “box” that is used whenever an object reference is required. Note that the box is detached from the original value type instance – changes made to one do not affect the other.
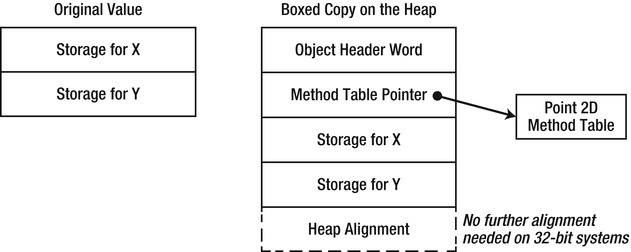
Figure 3-9. Original value and boxed copy on the heap. The boxed copy has the standard reference type “overhead” (object header word and method table pointer), and may require further heap alignment
.method private hidebysig static object GetInt() cil managed
{
.maxstack 8
L_0000: ldc.i4.s 0x2a
L_0002: box int32
L_0007: ret
}
Boxing is an expensive operation – it involves a memory allocation, a memory copy, and subsequently creates pressure on the garbage collector when it struggles to reclaim the temporary boxes. With the introduction of generics in CLR 2.0, there is hardly any need for boxing outside Reflection and other obscure scenarios. Nonetheless, boxing remains a significant performance problem in many applications; as we will see, “getting value types right” to prevent all kinds of boxing is not trivial without some further understanding of how method dispatch on value types operates.
Setting the performance problems aside, boxing provides a remedy to some of the problems we encountered earlier. For example, the GetInt method returns a reference to box on the heap which contains the value 42. This box will survive as long as there are references to it, and is not affected by the lifetime of local variables on the method’s stack. Similarly, when the Monitor.Enter method expects an object reference, it receives at runtime a reference to a box on the heap and uses that box for synchronization. Unfortunately, boxes created from the same value type instance at different points in code are not considered identical, so the box passed to Monitor.Exit is not the same box passed to Monitor.Enter, and the box passed to Monitor.Enter on one thread is not the same box passed to Monitor.Enter on another thread. This means that any use of value types for monitor-based synchronization is inherently wrong, regardless of the partial cure afforded by boxing.
The crux of the matter remains the virtual methods inherited from System.Object. As it turns out, value types do not derive from System.Object directly; instead, they derive from an intermediate type called System.ValueType.
![]() Note Confusingly, System.ValueType is a reference type – the CLR tells value types and reference types apart based on the following criterion: value types are types derived from System.ValueType. According to this criterion, System.ValueType is a reference type.
Note Confusingly, System.ValueType is a reference type – the CLR tells value types and reference types apart based on the following criterion: value types are types derived from System.ValueType. According to this criterion, System.ValueType is a reference type.
System.ValueType overrides the Equals and GetHashCode virtual methods inherited from System.Object, and does it for a good reason: value types have different default equality semantics from reference types and these defaults must be implemented somewhere. For example, the overridden Equals method in System.ValueType ensures that value types are compared based on their content, whereas the original Equals method in System.Object compares only the object references (identity).
Regardless of how System.ValueType implements these overridden virtual methods, consider the following scenario. You embed ten million Point2D objects in a List<Point2D> , and proceed to look up a single Point2D object in the list using the Contains method. In turn, Contains has no better alternative than to perform a linear search through ten million objects and compare them individually to the one you provided.
List<Point2D> polygon = new List<Point2D>();
//insert ten million points into the list
Point2D point = new Point2D { X = 5, Y = 7 };
bool contains = polygon.Contains(point);
Traversing a list of ten million points and comparing them one-by-one to another point takes a while, but it’s a relatively quick operation. The number of bytes accessed is approximately 80,000,000 (eight bytes for each Point2D object), and the comparison operations are very quick. Regrettably, comparing two Point2D objects requires calling the Equals virtual method:
Point2D a = ..., b = ...;
a.Equals(b);
There are two issues at stake here. First, Equals – even when overridden by System.ValueType – accepts a System.Object reference as its parameter. Treating a Point2D object as an object reference requires boxing, as we have already seen, so b would have to be boxed. Moreover, dispatching the Equals method call requires boxing a to obtain the method table pointer!
![]() Note The JIT compiler has a short-circuit behavior that could permit a direct method call to Equals, because value types are sealed and the virtual dispatch target is determined at compile-time by whether Point2D overrides Equals or not (this is enabled by the constrained IL prefix). Nevertheless, because System.ValueType is a reference type, the Equals method is free to treat its this implicit parameter as a reference type as well, whereas we are using a value type instance (Point2D a) to call Equals – and this requires boxing.
Note The JIT compiler has a short-circuit behavior that could permit a direct method call to Equals, because value types are sealed and the virtual dispatch target is determined at compile-time by whether Point2D overrides Equals or not (this is enabled by the constrained IL prefix). Nevertheless, because System.ValueType is a reference type, the Equals method is free to treat its this implicit parameter as a reference type as well, whereas we are using a value type instance (Point2D a) to call Equals – and this requires boxing.
To summarize, we have two boxing operations for each Equals call on Point2D instances. For the 10,000,000 Equals calls performed by the code above, we have 20,000,000 boxing operations, each allocating (on a 32-bit system) 16 bytes, for a total of 320,000,000 bytes of allocations and 160,000,000 bytes of memory copied into the heap. The cost of these allocations surpasses by far the time required to actually compare points in two-dimensional space.
Avoiding Boxing on Value Types with the Equals Method
What can we do to get rid of these boxing operations entirely? One idea is to override the Equals method and provide an implementation suitable for our value type:
public struct Point2D
{
public int X;
public int Y;
public override bool Equals(object obj)
{
if (!(obj is Point2D)) return false;
Point2D other = (Point2D)obj;
return X == other.X && Y == other.Y;
}
}
Using the JIT-compiler’s short-circuit behavior discussed previously, a.Equals(b) still requires boxing for b, because the method accepts an object reference, but no longer requires boxing for a. To get rid of the second boxing operation, we need to think outside the box (pun intended) and provide an overload of the Equals method:
public struct Point2D
{
public int X;
public int Y;
public override bool Equals(object obj) ... //as before
public bool Equals(Point2D other)
{
return X == other.X && Y == other.Y;
}
}
Whenever the compiler encounters a.Equals(b), it will definitely prefer the second overload to the first, because its parameter type matches more closely the argument type provided. While we’re at it, there are some more methods to overload – often enough, we compare objects using the == and != operators:
public struct Point2D
{
public int X;
public int Y;
public override bool Equals(object obj) ... // as before
public bool Equals(Point2D other) ... //as before
public static bool operator==(Point2D a, Point2D b)
{
return a.Equals(b);
}
public static bool operator!= (Point2D a, Point2D b)
{
return !(a == b);
}
}
This is almost enough. There is an edge case that has to do with the way the CLR implements generics, which still causes boxing when List<Point2D> calls Equals on two Point2D instances, with Point2D as a realization of its generic type parameter (T). We will discuss the exact details in Chapter 5; for now it suffices to say that Point2D needs to implement IEquatable<Point2D> , which allows clever behavior in List<T> and EqualityComparer<T> to dispatch the method call to the overloadedEquals method through the interface (at the cost of a virtual method call to the EqualityComparer<T>.Equals abstract method). The result is a 10-fold improvement in execution time and complete elimination of all memory allocations (introduced by boxing) when searching a list of 10,000,000 Point2D instances for a specific one!
public struct Point2D : IEquatable<Point2D>
{
public int X;
public int Y;
public bool Equals(Point2D other) ... //as before
}
This is a good time to reflect upon the subject of interface implementations on value types. As we have seen, a typical interface method dispatch requires the object’s method table pointer, which would solicit boxing where value types are concerned. Indeed, a conversion from a value type instance to an interface type variable requires boxing, because interface references can be treated as object references for all intents and purposes:
Point2D point = ...;
IEquatable<Point2D> equatable = point; //boxing occurs here
However, when making an interface call through a statically typed value type variable, no boxing will occur (this is the same short-circuiting enabled by the constrained IL prefix, discussed above):
Point2D point = ..., anotherPoint = ...;
point.Equals(anotherPoint); //no boxing occurs here, Point2D.Equals(Point2D) is invoked
Using value types through interfaces raises a potential concern if the value types are mutable, such as the Point2D we are churning through in this chapter. As always, modifying the boxed copy will not affect the original, which can lead to unexpected behavior:
Point2D point = new Point2D { X = 5, Y = 7 };
Point2D anotherPoint = new Point2D { X = 6, Y = 7 };
IEquatable<Point2D> equatable = point; //boxing occurs here
equatable.Equals(anotherPoint); //returns false
point.X = 6;
point.Equals(anotherPoint); //returns true
equatable.Equals(anotherPoint); //returns false, the box was not modified!
This is one ground for the common recommendation to make value types immutable, and allow modification only by making more copies. (Consider the System.DateTime API for an example of a well-designed immutable value type.)
The final nail in the coffin of ValueType.Equals is its actual implementation. Comparing two arbitrary value type instances according to their content is not trivial. Disassembling the method offers the following picture (slightly edited for brevity):
public override bool Equals(object obj)
{
if (obj == null) return false;
RuntimeType type = (RuntimeType) base.GetType();
RuntimeType type2 = (RuntimeType) obj.GetType();
if (type2 != type) return false;
object a = this;
if (CanCompareBits(this))
{
return FastEqualsCheck(a, obj);
}
FieldInfo[] fields = type.GetFields(BindingFlags.NonPublic | ← BindingFlags.Public | BindingFlags.Instance);
for (int i = 0; i < fields.Length; i++)
{
object obj3 = ((RtFieldInfo) fields[i]).InternalGetValue(a, false);
object obj4 = ((RtFieldInfo) fields[i]).InternalGetValue(obj, false);
if (obj3 == null && obj4 != null)
return false;
else if (!obj3.Equals(obj4))
return false;
}
return true;
}
In brief, if CanCompareBits returns true, the FastEqualsCheck is responsible for checking equality; otherwise, the method enters a Reflection-based loop where fields are fetched using the FieldInfo class and compared recursively by invoking Equals. Needless to say, the Reflection-based loop is where the performance battle is conceded completely; Reflection is an extremely expensive mechanism, and everything else pales compared to it. The definition of CanCompareBits and FastEqualsCheck is deferred to the CLR – they are “internal calls”, not implemented in IL – so we can’t disassemble them easily. However, from experimentation we discovered that CanCompareBits returns true if either of the following conditions hold:
- The value type contains only primitive types and does not override Equals
- The value type contains only value types for which (1) holds and does not override Equals
- The value type contains only value types for which (2) holds and does not override Equals
The FastEqualsCheck method is similarly a mystery, but effectively it executes a memcmp operation – comparing the memory of both value type instances (byte-by-byte). Unfortunately, both of these methods remain an internal implementation detail, and relying on them as a high-performance way to compare instances of your value types is an extremely bad idea.
The final method that remains and is important to override is GetHashCode. Before we can show a suitable implementation, let’s brush up our knowledge on what it is used for. Hash codes are used most often in conjunction with hash tables, a data structure that (under certain conditions) allows constant-time (O(1)) insertion, lookup, and deletion operations on arbitrary data. The common hash table classes in the .NET Framework include Dictionary<TKey,TValue> , Hashtable, and HashSet<T> . A typical hash table implementation consists of a dynamic-length array of buckets, each bucket containing a linked list of items. To place an item in the hash table, it first calculates a numeric value (by using the GetHashCode method), and then applies to it a hash function that specifies to which bucket the item is mapped. The item is inserted into its bucket’s linked list.
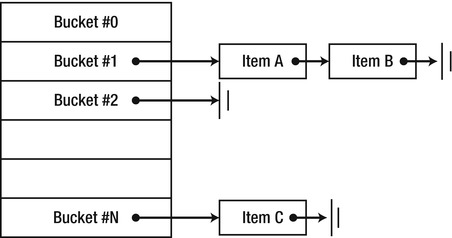
Figure 3-10. A hash table, consisting of an array of linked lists (buckets) in which items are stored. Some buckets may be empty; other buckets may contain a considerable number of items
The performance guarantees of hash tables rely strongly upon the hash function used by the hash table implementation, but require also several properties from the GetHashCode method:
- If two objects are equal, their hash codes are equal.
- If two objects are not equal, it should be unlikely that their hash codes are equal.
- GetHashCode should be fast (although often it is linear in the size of the object).
- An object’s hash code should not change.
![]() Caution Property (2) cannot state “if two objects are not equal, their hash codes are not equal” because of the pigeonhole principle: there can be types of which there are many more objects than there are integers, so unavoidably there will be many objects with the same hash code. Consider longs, for example; there are 264 different longs, but only 232 different integers, so there will be at least one integer value which is the hash code of 232 different longs!
Caution Property (2) cannot state “if two objects are not equal, their hash codes are not equal” because of the pigeonhole principle: there can be types of which there are many more objects than there are integers, so unavoidably there will be many objects with the same hash code. Consider longs, for example; there are 264 different longs, but only 232 different integers, so there will be at least one integer value which is the hash code of 232 different longs!
Formally, property (2) can be stated as follows to require a uniform distribution of hash codes: set an object A, and let S(A) be the set of all the objects B such that:
- B is not equal to A;
- The hash code of B is equal to the hash code of A.
Property (2) requires that the size of S(A) is roughly the same for every object A. (This assumes that the probability to see every object is the same – which is not necessarily true for actual types.)
Properties (1) and (2) emphasize the relationship between object equality and hash code equality. If we went to the trouble of overriding and overloading the virtual Equals method, there is no choice but to make sure that the GetHashCode implementation is aligned with it as well. It would seem that a typical implementation of GetHashCode would rely somehow on the object’s fields. For example, a good implementation of GetHashCode for an int is simply to return the integer’s value. For a Point2D object, we might consider some linear combination of the two coordinates, or combine some of the bits of the first coordinate with some other bits of the second coordinate. Designing a good hash code in general is a very difficult undertaking, which is beyond the scope of this book.
Lastly, consider property (4). The reasoning behind it is as follows: suppose you have the point (5, 5) and embed it in a hash table, and further suppose that its hash code was 10. If you modify the point to (6, 6) – and its hash code is also modified to 12 – then you will not be able to find in the hash table the point you inserted to it. But this is not a concern with value types, because you cannot modify the object you inserted into the hash table – the hash table stores a copy of it, which is inaccessible to your code.
What of reference types? With reference types, content-based equality becomes a concern. Suppose that we had the following implementation of Employee.GetHashCode:
public class Employee
{
public string Name { get; set; }
public override int GetHashCode()
{
return Name.GetHashCode();
}
}
This seems like a good idea; the hash code is based on the object’s contents, and we are utilizing String.GetHashCode so that we don’t have to implement a good hash code function for strings. However, consider what happens when we use an Employee object and change its name after it was inserted into the hash table:
HashSet<Employee> employees = new HashSet<Employee>();
Employee kate = new Employee { Name = “Kate Jones” };
employees.Add(kate);
kate.Name = “Kate Jones-Smith”;
employees.Contains(kate); //returns false!
The object’s hash code has changed because its contents have changed, and we can no longer find the object in the hash table. This is somewhat expected, perhaps, but the problem is that now we can’t remove Kate from the hash table at all, even though we have access to the original object!
The CLR provides a default GetHashCode implementation for reference types that rely on the object’s identity as their equality criterion. If two object references are equal if and only if they reference the same object, it would make sense to store the hash code somewhere in the object itself, such that it is never modified and is easily accessible. Indeed, when a reference type instance is created, the CLR can embed its hash code in the object heard word (as an optimization, this is done only the first time the hash code is accessed; after all, many objects are never used as hash table keys). To calculate the hash code, there’s no need to rely on a random number generation or consider the object’s contents; a simple counter would do.
![]() Note How can the hash code coexist in the object header word alongside the sync block index? As you recall, most objects never use their object header word to store a sync block index, because they are not used for synchronization. In the rare case that an object is linked to a sync block through the object header word storing its index, the hash code is copied to the sync block and stored there until the sync block is detached from the object. To determine whether the hash code or the sync block index is currently stored in the object header word, one of the field’s bits is used as a marker.
Note How can the hash code coexist in the object header word alongside the sync block index? As you recall, most objects never use their object header word to store a sync block index, because they are not used for synchronization. In the rare case that an object is linked to a sync block through the object header word storing its index, the hash code is copied to the sync block and stored there until the sync block is detached from the object. To determine whether the hash code or the sync block index is currently stored in the object header word, one of the field’s bits is used as a marker.
Reference types using the default Equals and GetHashCode implementation need not concern themselves with any of the four properties stressed above – they get them for free. However, if your reference type should choose to override the default equality behavior (this is what System.String does, for example), then you should consider making your reference type immutable if you use it as a key in a hash table.
Best Practices for Using Value Types
Below are some best practices that should guide you in the right direction when considering using a value type for a certain task:
- Use value types if your objects are small and you intend to create a great many of them.
- Use value types if you require high-density memory collections.
- Override Equals, overload Equals, implement IEquatable<T>, overload operator ==, and overload operator != on your value types.
- Override GetHashCode on your value types.
- Consider making your value types immutable.
Summary
In this chapter, we have unveiled the implementation details of reference types and value types, and how these details affect application performance. Value types exhibit superb memory density, which makes them a great candidate for large collections, but are not equipped with features required of objects such as polymorphism, synchronization support, and reference semantics. The CLR introduces two categories of types to provide a high-performance alternative to object orientation where it is required, but still demands a formidable effort from developers to implement value types correctly.