
![]()
High Availability
I’ve been in the SharePoint administrator role a few times and it is very like being a lifeguard or fireman. When nothing is going wrong, it looks like you’re not fully utilized. Managers want you do be busy doing something, working on specific projects. (This is to make them look busy, too.) Only when things go wrong is your real value to the organization fully appreciated—in a short and intense time you get to prove your worth to your manager and others. But I have actually seen administrators who generate a constant state of fake crises so they can look like they are constantly saving the day and putting out fires. This is done to make them look important.
The reality—with SharePoint and many other things—is that if you’re very good at your job you can make your system run so well you make it look effortless. The guys who are always averting disaster could apply themselves to proactively making the system more resilient so that it doesn’t keep threatening to fail all the time. This doesn’t always just mean adding more resources. More resources are more costly up front and in maintaining them. It’s also about optimizing the available resources. SharePoint should be constantly monitored—not just to get a notice that something has gone wrong, but also to anticipate disaster and avoid it—like steering away from the iceberg instead of hitting it so you can show how well you practiced your lifeboat drill.
High availability is all about SharePoint being there when your users need it to do something of value for your organization. Keeping it available is the key function of the person who owns the SharePoint infrastructure and servers. If you have done your business impact assessment, you will know the cost of unavailability. Accordingly, you have set your recovery time objectives (RTOs) and recovery point objectives (RPOs). You have also created a process for identifying when there is a disaster and making sure the right people can get into position to deal with it. You have divided your content into tiers so you can give the highest priority to the critical content when disaster strikes. Those tiers will also come into play when you are defining the availability you will need at the best price. The information in this chapter gives you what you need to assess the different options for availability with SharePoint. Topics covered in this chapter include:
- High availability measurement and targets (the nines)
- Resilience (making the system resistant to failure)
- Redundancy (having more than one element that provides the same functionality so there is not a single point of failure)
Together, they provide a framework for protecting the most valuable asset in the system: the information (see Figure 4-1).
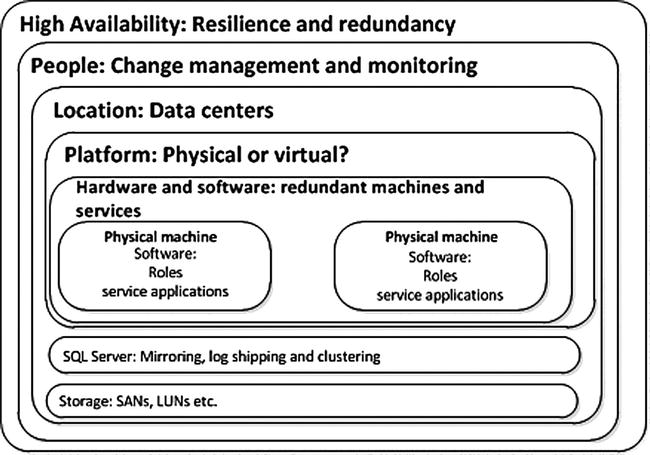
Figure 4-1. Availability is composed of interlocking elements
High Availability Overview
While disasters are by their definition destructive and unpredictable, it also makes sense to make your system as resilient as possible so that you can mitigate the impact or even stop the disaster in its tracks. As mentioned in Chapter 1, the Titanic had 16 watertight compartments and a double hull so that (it was believed) it could withstand an iceberg collision. In fact, other ships had survived collisions, so it was a sound and proven practice.
There are many steps you can take to toughen your SharePoint farm to make it more resilient, and they all have different considerations. Here are the main ones you’ll consider in this chapter:
- The platform: on premises vs. the cloud, virtual vs. physical
- The database layer availability options
- Storage options
- Change management
- Monitoring
- People
Redundancy is the method of having a standby ready to replace a malfunctioning part of the system. You’ll look at the options here on the following levels:
- Data centers
- Farms
- Hardware
- Applications
It is most important to look at high availability as something important to the organization as a whole. Your core business determines the impact of unavailability. For some, being available in real time all the time is crucial. These are organizations where information is their key asset and its value is very time sensitive. For example, if the news reports that there has been a coup in a particular country, you may want to sell your shares in a copper mine there quickly because you think the political instability will be bad for business. If you get the news of the coup late, and you can’t sell your shares fast enough, both of these things can cost you money. Communication-based organizations like ISPs and telecoms are relied on to be available all the time, too. Ringing your mother the day after her birthday is too late. Even online gaming companies depend on continuous access for their customers. Here are some examples of time-sensitive businesses:
- Online financial transaction processing
- Stock market software
- Online gaming
- ISPs
- Telephone companies
- News services
For some organizations the impact is not merely financial. Their downtime can have an effect on human life or the environment around us. Here the value is harder to quantify but no less important for that—indeed, it is often more important. The following are examples of organizations where lack of availability has a cost to life and not just livelihood:
- Oil companies
- Power companies
- Airlines
- Hospitals
You need to know from your business impact assessment the actual cost of SharePoint being unavailable for any length of time. It could range from no impact to catastrophic. For a ship, any percentage of time at the bottom of the sea is bad.
To know what availability your users need, you have to ask them. The most practical way is in a structured questionnaire because this helps secure definite metrics. First, collect the following in the questionnaire introduction section:
- Department name
- Date
- Process name
- Process description
Next, list each process or process stage, establish critical dates in the process when applicable (e.g., the day payroll is processed), and assign an impact timeline for each entry. This is identifies how long it takes to reach progressively higher levels of impact. Capturing dates also helps connect it to dependent processes. Table 4-1 shows a sample form for capturing the dates and impact levels.
Table 4-1. Critical Dates and the Impact Timeline

Notice the four columns under “Time Until Impact.” These are the four recommended levels to use in your evaluation.
- N (None): There is no impact on any work function. Examples of this include processes that are only utilized intermittently.
- M (Moderate): The process is causing minor or moderate disruption to the function of the department itself or to another department with a downstream dependency.
- S (Severe): The failure of the process results in the department or another department with a downstream dependency being unable to function.
- C (Critical): The failure of the process results in a disruption of the organization’s daily functioning.
The boxes on each row in the N, M, S, or C columns should be filled in with the length of time after a failure that it takes for the impact level to be reached. This gives the people planning for availability and disaster recovery more information to work with when calculating RTOs and RPOs.
In the next section of the questionnaire, ask users to provide a list of operational and financial impacts of this process failing under the headings for Impact, Time, and Severity Level. You should also include a section where you ask for a list of upstream and downstream dependencies on this process under the headings System/Process Name and Description.
Finally, ask the users for details for any (or multiple) workaround procedures for this process. For each workaround identified, the following information should be provided:
- Workaround name
- Description
- Date last tested or used
- Hardware required
- Additional personnel required
- Additional supplies required
- How long can it be used?
- How long will it take to implement this workaround?
- What percent of production can this alternative provide?
Combining all this information from the multiple teams/departments in your organization will give you a great deal of useful information. If your organization is very large this may be a daunting task, but it is necessary to secure the critical data users are producing, so resources should be assigned to complete this survey.
You will often see availability measured as a percentage of a year. For example, 99% availability is 365/100 = 3.65. This means the service provider is promising only 3.65 days downtime in a year, or 361.35 days uptime a year. In fact, 99% is referred to as “2 nines.” The ideal has been to aim for 5 nines, or 99.999% availability, which works out to only 5.26 minutes of downtime a year. Setting the amount of availability at 100% is unrealistic; it would be incredibly expensive, too. Your organization could run out of money before you get 100% availability. Does it matter that the system is 5 nines reliable but doesn’t save/earn the organization enough to justify this? Table 4-2 shows levels of the nines and the amount of maximum downtime per year for each level.
Table 4-2. Levels of Nines and the Corresponding Amount of Downtime
| % & (No. of 9s) | Downtime per Year |
|---|---|
| 90% (1) | 36.5 days (10% of 365) |
| 99% (2) | 3.65 days |
| 99.9% (3) | 8.76 hours |
| 99.99% (4) | 52.56 minutes |
| 99.999% (5) | 5.26 minutes |
| 99.9999% (6) | 31.5 seconds |
Even uptime or downtime is difficult to define. In SLAs, “planned outages” aren’t counted as downtime. However, it’s still an outage and the fact you may have known about it in advance doesn’t change that. If the outage affects users, it is still an outage. For example, Service Packs and patches take hours, potentially every month, to install; longer if the farm is large. How much downtime do they cause in a year? A SQL cluster failover will take up to 15 minutes to complete.
You can’t predict the future. As we know in Kildare, sheep happen(s). So 5 nines is nothing more than a bet or an insurance policy by the service provider. Their pricing strategy is based on probability to ensure profitability when an inevitable disaster happens.
How much a system has failed to perform its primary function is more important and more difficult to measure than availability. For example, if you are a streaming media company whose main product is a sports channel, and you guarantee 99.999% uptime, but the five minutes your system is down is the last five minutes of the Super Bowl, can you truly say you have met your users’ needs?
With SharePoint, the system has to be available when people need it the most; this is a measure of quality of service not quantity. It is also largely a matter of perception. The system could be down over a weekend and it might not be noticed until Monday morning (assuming your staff is in the same time zone). But every minute it is down Monday morning is bad for users’ perceptions of the system’s availability.
From my own experience the main cause of downtime is human error. The number one cause is routine maintenance tasks that went wrong, followed by lack of web server resources or SQL Server capacity. The way to prevent routine tasks from going wrong is to ensure there is sufficient oversight and attention to detail by the more senior staff. While is standard practice to automate and delegate routine tasks, there still has to be ownership and responsibility by those who have the greater levels of knowledge and experience. Sometimes, more senior staff are seen as too expensive, but the cost of breaking an SLA is higher than employing good people. Only occasionally does hardware failure causes the outage. Better change management practices will help reduce mistakes during maintenance tasks. Better monitoring and resource planning will reduce capacity issues.
“A stitch in time may save nine.”
—Gnomologia, Adagies and Proverbs, Wise Sentences and Witty Sayings,
Ancient and Modern, Foreign and British, Thomas Fuller, 1732
This expression, for those unfamiliar with it, means that one stitch in a piece of cloth to sew up a hole may prevent nine more if it tears. In other words, timely action can prevent more work later on, and who doesn’t like less work?
Resilience is your SharePoint system’s ability to withstand disaster. You can maximize resilience at multiple levels at the same time. The weakest point will ultimately be where the system breaks down, but remember that your goal is to minimize user impact and save the organization money, not to make the most resilient system possible for the sake of it. Also, a more complex system has more points of failure and is harder to administer.
Platform
Even before we look at the internal application redundancy options, the SharePoint platform itself presents us with a number of options that will have different resilience considerations. There is a big difference between how you will plan for resilience between SharePoint in the Cloud and a virtual on premises farm because of the way the servers are stored and maintained. Understanding the strengths and weaknesses of each platform decision specifically in relation to SharePoint is the first step in creating greater resilience.
On Premises vs. the Cloud
With great power there must also come—great responsibility!
—Stan Lee, Amazing Fantasy #15, August 1962 (the first Spider-Man story)
The primary difference from a resilience point of view between on premises and the cloud is that the owner of the SharePoint platform in your organization has little to no input into the physical infrastructure of your farm if it is built on a cloud solution like SPO, since the infrastructure is provided by an external provider. For example, if you build your own infrastructure, you can make decisions about the hard drives, cables, servers, NICs, power supply, and storage. Of course, this requires more knowledge and cost. Even if you build the servers and host them off-premises, the building, rack space, and some amount of the monitoring and perhaps backup or other operations are out of your full control. With this control comes responsibility, but as mentioned before, SLAs tend to be simplistic and focus on a percentage of time. SharePoint Online Standard offers 99.9% (http://download.microsoft.com/download/F/1/3/F133AF39-F878-4009-8C6A-B60144C32679/SharePointOnline%20Standard%20Service%20Description.doc).
This is qualified further with the following statement in the Service Continuity Management section:
SharePoint Online has set an RPO and RTO in the event of a disaster:
- 12-hour RPO: Microsoft protects an organization’s SharePoint Online data and has a copy of that data that is equal to or less than 12 hours old.
- 24-hour RTO: Organizations will be able to resume service within 24 hours after service disruption if a disaster incapacitates the primary data center.
SharePoint Online Enterprise offers a 1-hour RPO and a 6-hour RTO. I have referred to this information before but mention it here again in the context of how Microsoft is qualifying its initial 99.9% availability. The company says that with any disaster, no matter how many times you experience one in a year, you will lose up to 12 hours of data. Also, if the data center fails, you will have to wait 24 hours before it’s back online. That’s a long wait and a lot of loss. You have to decide if this amount of resilience is enough for your organization based on your BIA. If not, you should identify the content that could go in the cloud but separate out content that should not. This should then be given a more resilient platform on premises or with off-site hosting.
SharePoint Online takes a lot of the complexity of high availability out of your hands and puts it into Microsoft’s. This saves you resources, but it just ensures that downtime will not negatively impact your business beyond a point it can afford.
SharePoint Online is not the only option when it comes to SharePoint in the cloud. There are external hosting companies that will manage your servers for you or will host SharePoint on their servers in a standard multitenant model. Most of these options are becoming less relevant, however, with the advent of large cloud providers that offer some well-established and reliable options.
One of these options is to host your SharePoint servers with Amazon’s infrastructure called Amazon Web Services (AWS). The Amazon SLA offers 99.95% availability (http://aws.amazon.com/ec2-sla/). It also offers IaaS as opposed to SaaS, so you have more control over the infrastructure—although if there is an outage you are still at their mercy.
Not so much a resilience point, but from a disaster recovery point of view, the biggest difference is the amount of control the owners have when there is an outage. When your cloud provider has an outage, your SharePoint platform owners will feel helpless unless regular updates are provided by the infrastructure owners. In my opinion, cloud providers have trouble with this requirement: they want the power but are afraid of giving out information because it shows how responsible they were for the outage.
In my experience, the frequency of outages in the cloud that are caused by human error are just as high as on premise scenarios. For example, the Amazon outage in early 2011 was caused by a network engineer incorrectly shifting all the network traffic to a low-capacity network meant only for administration. This led to a cascade of problems that created among other things a “re-mirroring storm” and a brownout of the storage control plane. This article provides excellent perspective on what happened specifically, but it also teaches a lot about how one mistake can lead to a large outage, plus how to tackle and address it: http://aws.amazon.com/message/65648/.
The key learning point from this occurrence was that the users most affected were ones that had their entire infrastructure in the same Availability Zone. An AZ is roughly is the same as a data center but has more logical divisions than physical. There can be more than one AZ in a data center. Amazon has multiple AZs in one region. For example, the US East region has four Availability Zones: us-east-1a, us-east-1b, us-east-1c, us-east-1d. The Amazon EC2 SLA offers 99.95% availability, but only if you are running across multiple Availability Zones and not across an entire region. It really pays to know your infrastructure SLAs; don’t just trust to the provider to know these things.
If you did want to host SharePoint 2010 on AWS, what are the main considerations from an architecture perspective? Latency will be your main thing to watch. Amazon uses something called Elastic Block Storage (EBS) for storage and their hosting platform is called Elastic Compute Cloud (EC2). EC2 consists of Amazon Machine Images (AMIs), which are virtual machines (VMs) running in Amazons AZs. You should make sure your web front end (WFE) servers and SQL Server are in the same Availability Zone and using this ESB storage on EC2. For backup, you would use Simple Storage Service (S3), which is a cheap way to store large blocks of data. Your WFEs should also be configured to use Elastic Load Balancer (ELB) to provide redundancy. The main point I will make is that having your AMIs in the same AZ decreases your resilience, while spreading them across AZs even in the same region will increase latency beyond the point where it performs well and affects user experience. These AMIs are stateless and so have to be connected to EBS for storage. They are metered by the hour, so having them on 24 hours a day is expensive.
An interesting option may be to use AWS as a development platform. Performance is not so much an issue, and your costs are reduced as you can only run the AMIs for the eight or so hours your developers work per day.
My recommendation is to place tier 2 and 3 content in the cloud but keep tier 1 on premises. This way you are getting the flexibility and cost benefits of the cloud but you have full control over the most sensitive data. You’re keeping costs down by having the minimum amount of data in the expensive infrastructure for the critical content. This will also make disaster recovery planning simpler as you can focus upon the on-premises content first. But without knowledge of your particular circumstances, it’s difficult to make anything more than general recommendations.
SharePoint Online is a better option than AWS or other major cloud providers in most circumstances because of the ease of integrating your authentication with Windows. But even so, when trying to decide which option will suit your organization, the best option is always to test the waters with a pilot. Make sure the pilot has distinct measurable criteria for success. Check, for example, that moving to the cloud didn’t have any performance impact and all the users have the necessary browser and Windows version. Is there a large overhead in setting up ActiveSync between the users’ Windows accounts and SharePoint Online? What happens when this has to be done for all the users in your organization? Can users access from home? Will you require additional processes to manage granting of SharePoint Online accounts? Moving to a new platform is always disruptive, so make sure the rewards are worth the investment. Ensure that your SharePoint Online administrators know how to use the interface fully. Also, ensure that your developers are aware of the limitations involved in developing solutions for the online platform as the security is more restrictive. The final point I would make is that while Microsoft will facilitate synchronizing your Active Directory accounts with your SharePoint Online accounts, you must know the process of separating them again should you choose to. Once again, a pilot will provide a better understanding of the work involved in setting up SharePoint Online.
Virtualization adds more options for high availability. This is because it allows you to create failover clusters. These are groups of physical machines all running as part of your SharePoint farm such that the whole farm can continue to function if one part (node) fails. For example, Hyper-V, the virtualization software from Microsoft, uses Cluster Shared Volume (CSV). With CSV, multiple virtual machines can use the same logical unit number (LUN) (storage disk) yet failover (or move from node to node) independent of one another. CSV gives you flexibility for volumes in clustered storage; for example, it allows you to keep system files separate from data to optimize disk performance, even if both are contained within virtual hard disk (VHD) files.
Virtualization adds complexity and, as a result, requires more knowledge and experience to manage. However, because of clustering it will give you another layer of resilience and availability for your SharePoint Farm. The future is virtual, however, and so if you are trying to decide between two, I would recommend virtual. Fully virtual deployments have now been supported by Microsoft for SharePoint for a few years. A virtual platform allows you to allocate resources more dynamically and makes replication of machines simpler. For development and testing, virtualization has the great advantage of allowing you to roll back a machine to a previous point. I wouldn’t recommend doing this with a production system, but for testing a patch or code, it’s very helpful.
In your SharePoint farm the most difficult part to recreate is the user content. This is stored in SQL Server databases. As a result, your high availability focus should be on this content—not because it is the most vulnerable part of your platform, but because it will be the most costly to recover if users have to re-enter it.
As mentioned previously, bad capacity management is one of the main causes of unavailability. Once you have done your capacity planning projections, pre-grow your databases to that size. When they reach 75% of that capacity, revise the estimates and get more space. If content is growing beyond planned expectations, this in itself is symptomatic of a problem. If water is rushing into your ship, the solution is not to make your ship bigger! Without adequate quota usage or users placing large and unplanned amounts of content in SharePoint, your capacity usage will balloon faster than you can provide for it. Also, lack of quotas on logs can lead to more verbosity on diagnostic logging or auditing logs, which can fill up your databases very quickly.
Transaction logs are where most growth can occur in SQL Server. Every database that stores content has a corresponding log that tracks all changes to it. This is a way of maintaining as much data fidelity as possible. In SharePoint content databases where there are a lot of changes, these logs should be carefully managed. You should set the size of your transaction log files to a large value to avoid the automatic expansion of the transaction log files. If you do have automatic expansion turned on, configure it to use memory units instead of a percentage after you thoroughly evaluate the optimum memory size. Back up the transaction log files regularly to delete the inactive transactions in your transaction log. There is more on backing up in Chapter 6.
Also watch the size of site collection recycle bins, and make sure there are processes for the archiving or deleting unwanted content. The word “management” in a “content management system” means removing rubbish as well as making the ability to add content more efficient. Since meeting or exceeding capacity is a risk to availability, it should be tackled as such rather than seeing capacity as something that should be infinitely added. It’s true that overly draconian user quotas are counterproductive because they make users spend too much time removing content or not being able to use the system. For example, many companies have imposed 2GB mailbox limits on users when web mail products like Gmail allow 8GB. Exchange online now allows 25GB, which I think is more realistic but may be symptomatic of users storing and sharing too much via e-mail rather than using SharePoint. Transitioning to SharePoint for collaboration should make the rate of mailbox growth slow.
Once you have tackled the issue of capacity being used up unnecessarily, you can focus on ways to preserve the data. Here are the three main technical options that will make your SQL Server more resilient and hence more available: mirroring, log shipping, and clustering.
I’ve touched on mirroring before: a principal server has a mirror that maintains a current copy of its content. A third optional witness server in a third data center can monitor the principal, if it is unavailable. The mirror is made the principal by the witness server (see Figure 4-2). This is described as warm or even hot standby, depending on whether it takes minutes or seconds. SharePoint 2010 is mirroring-aware for all its databases as long as they are using the full recovery model. This is where setting the recovery model to FULL tells SQL Server to keep all committed transactions in the transaction log until a backup has been made.

Figure 4-2. The witness watches the principal and switches to the mirror if the principal is unavailable
Mirrors for databases can be specified in the SharePoint Administration UI via PowerShell or via the object model.
There are three types of mirroring, which have different benefits depending on your needs:
- High protection: This option is synchronous, which is like Twitter—constantly up to date but resource heavy. Failover is manual; there’s no witness server. There is also is a low tolerance for any poor latency or performance.
- High availability: This option is synchronous like high protection, but with the third witness server, which triggers the failover. Also not tolerant of any lag or interruptions between the principal and mirror servers.
- High performance: In this mode, SQL tells SharePoint that the write to the database is done before hearing back from the mirror that the write was done there too. For that reason this mode can be tolerant of high latency and poor bandwidth. This mode is referred to as asynchronous; it updates when it can, like friends meeting for an occasional dinner or your smartphone sync.
Simple mirroring like this is being deprecated. Mirroring is still supported in SharePoint 2010/2013 with SQL Server 2008, but is being deprecated because in SQL Server 2012 AlwaysOn is the favored “new” technology. This is the same in SQL Server 2014.
AlwaysOn combines availability for Windows Server and SQL Server and comes in two categories: failover cluster instances and availability groups. FCIs are simply one instance of SQL Server that has multiple nodes, perhaps in different subnets. SQL Server can then failover to another node if one fails. This is clustering as it was known before but better.
Availability groups are Mirroring 2.0. They allow for multiple mirrors that can all be active, which means you can run read-only operations against them. They can be grouped, which means they will failover together. This means having a listener that will failover the whole availability group if one database becomes unstable. SharePoint won’t even know it has happened. This is important because of the way Project works on SharePoint for example. Project has three databases for draft, archive, and published. If any one of these is giving trouble, SharePoint would have to failover to the mirror of them as a group because they are all interdependent.
Many factors come into play when making a decision about which option is right for your organization. Consider a simple example of a news organization with its servers in an office near a river. Several variables affect which option it adopts. The high protection option suits an organization with only two offices less than 30 miles apart, such as two offices in a large city. For example, London is approximately 27 miles across. If the organization needed high protection, it’s because they want to ensure that all information is captured; but there’s no requirement for automatic failover, so there is no witness server. Say this news agency has an office near the River Thames. In the event of the river overflowing, they could relocate to the other office. This could take a few hours; in the meantime, there would be no requirement to switch to the mirror system until all the staff were at the second location, when the switchover would be done manually.
The high availability option is the same, but here the witness server makes the switch. In this case, the staff doesn’t have to relocate because they are in a third location where the witness server is. In the event of a flood, the servers automatically switch.
The high performance option would suit the same news agency if their offices were more than 30 miles apart.
Mirroring has another secondary advantage when it comes to availability. Since maintenance mistakes are one of the main reasons for downtime (planned or unplanned), mirroring is a good way to patch SQL Server by patching the mirror first, then the principal. This prevents downtime because while you are patching the principal the users access the mirror. Then they are switched back to the principal. If there are issues with the mirror patch, there’s no service interruption. If you have a witness, patch that before the other two. Since a restarted machine has to “catch up,” patch when there are low amounts of activity on the server. If all goes well, downtime will be in seconds.
Here the transaction logs, which are the records of the changes to the database, are copied to a second database, but asynchronously, perhaps overnight. This is usually done to a distant data center perhaps in another country. For SharePoint Online, the logs are shipped from Dublin to Holland, which acts as a cold failover data center. As a result of the delay in moving the data and restoring it, log shipping is a disaster recovery option rather than high availability. However, it has the advantage of being simple and reliable and so is best utilized when used in conjunction with mirroring or your next option, clustering.
SQL Server clustering is a high-availability technology for SQL Server and is now part of AlwaysOn. Think of it as virtualization for SQL Server. It has a whole group of terminology all its own. A cluster involves the sharing of server resources between one or more nodes (servers) that have one or more shared disks grouped into logical units called resource groups. A resource group containing at least one IP address, network name, and disk resource is called a virtual server.
Each virtual server appears on the network as a complete system. When the virtual server contains SQL Server resources, clients connected to the virtual server access resources on its current host node. While the terms “active” and “passive” are often used here, they are not fixed roles, as all nodes in a cluster are interchangeable. Should the current host (sometimes designated as the primary) fail, the resource group will be transferred to another (secondary) node in the cluster. With clusters having more than two nodes or two instances, it’s important to set failover order by choosing the preferred node ownership order for each instance. The secondary will become the primary and host the virtual server. Active client connections will be broken during failover, but they can reconnect to the virtual server now hosted by the new node. The clients will have to reconnect manually, however, and work in progress will be lost during the failover. Most commercial applications now handle this reconnection task seamlessly.
The goal of clustering is to provide increased availability to clients by having a hot standby system with an automatic failover mechanism. SQL Server clustering is not a load-sharing or scale-out technology. During a failure, all clusters will experience a brief database server interruption. On large clusters with multiple nodes and instances, clients may experience degraded performance during a failure event but they will not lose database availability.
SQL clusters are either single or multiple instances. In the case of a single instance, one node in a cluster owns all resource groups at any one time and the other nodes are offline. Should the primary node fail, the resource groups will be transferred to the secondary node, which comes online. When the secondary node comes online, it will assume ownership of the resource groups, which typically consist of disks containing your database files and transaction logs. The secondary node comes and SQL Server will start up on the virtual server and roll uncommitted transactions in the transaction log backward or forward as it recovers the database.
This topology was formerly called active-passive. Single-instance clustering is most frequently used for mission-critical applications where the cost of downtime far outweighs the cost of the wasted hardware resources of the secondary node sitting idle while offline.
In the case of multiple instances, one virtual server in a cluster owns some of the resource groups and another virtual server owns other resource groups. At any one time, the virtual servers themselves can be hosted by a single node or different nodes and would appear to clients as named instances of a single server. In that case, they are named instances of a virtual server, hence the name “multiple instance.” With multiple-instance clustering, previously called active-active, the hardware requirements of each individual node are greater as each node may at any one time be hosting two (or more) virtual servers.
You should consider multiple-instance clusters to be more cost effective than single-instance clusters as there are no nodes offline or waiting. However, should one node host more than one virtual server, performance is typically degraded. Your best bet is to use multiple instances when you require high availability but not high performance.
Mirroring was the new kid on the block when it came to high availability with SharePoint 2010 and has now evolved to be part of AlwaysOn. Clustering is now also part of AlwaysOn but has been around for longer and has a number of advantages.
- Clustering technology is more established, which makes it better documented, supported, and known by SQL Server administrators.
- Mirroring means configuring within SharePoint, while clustering is more of a SQL Server–only availability option. This suits SQL and SharePoint administrators better.
- Clustering is always automatically self-correcting unlike mirroring, which has to have a witness server or be manually switched.
- Mirroring is resource heavy, while clustering claims to have no performance overhead.
With AlwaysOn, the two can be combined. Although it is complex it gives the best availability to the users. This is done using Windows Server Failover Clusters (WSFC). They allow you to combine multiple computer nodes. A Failover Cluster Instance is an instance of SQL Server that has been installed onto a WSFC as a clustered application. An AlwaysOn Availability Group is a group of one or more databases configured on a primary replica (or SQL Server instance) for high availability. This will typically include one or more further replicas that will service a copy of the highly available database(s). Partner databases may be either readable or standby and may also be asynchronous or synchronous. AlwaysOn relies on the WSFC core functionality to achieve the high availability that AlwaysOn offers.
AlwaysOn is a feature configured by using SQL Server Configuration Manager. A computer node must be a member of a WSFC before you will be able to enable AlwaysOn.
Another factor in picking either mirroring, clustering, or a combination of the two is the cost of storage, and that is the next topic.
Each PC, Mac, smartphone, tablet, and so forth has its own storage internally in the form of a hard drive. In recent years, large organizations have moved to having large storage devices that multiple server can connect to and use. The main type used now is a storage area network (SAN). This consists of blocks that can be efficiently allocated where needed and can store any type of content. An older type was network-attached storage (NAS). It is more like a server whose main function is storage and it also sits on the network. Direct-attached storage (DAS) is more like an external hard drive. Cheap and easy to set up, you just plug it into the server and you’re done.
Clustering comes with the requirement of shared storage; this means the nodes in the cluster have to be on the SAN. This is because all the servers in the cluster must be able to access the same data. This makes your SAN a single point of failure and so it’s good for HA but not DR. Clustering also does not support cheap DAS storage. Both require lots of storage so this is an important consideration. DAS storage costs much less because it’s attached directly to the SQL Server, either the principal or mirror. There’s no sharing between servers so it’s simpler and cheaper to implement. NAS differs from SAN in that it has its own file system, while SAN does not (see Figure 4-3). For database systems like SharePoint, SAN is better as it is simpler for the system to optimize the location and access to the data. NAS is better for storing and managing files.
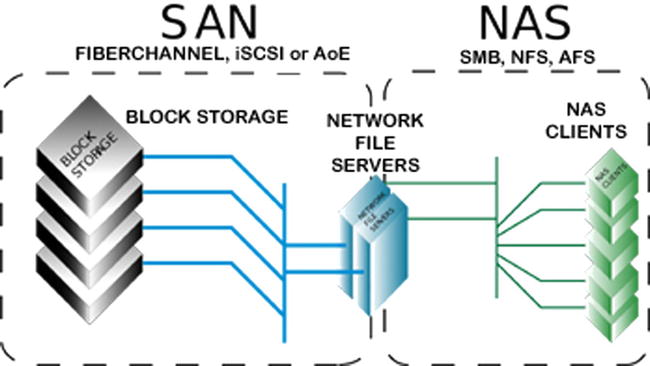
Figure 4-3. NAS has a file system, SAN does not
A final point about storage and high availability: SAN storage can in itself be mirrored. This means you could have a mirror of your cluster, but it costs millions of dollars and so would have to be justified.
Of the three options (mirroring, clustering, and log shipping), some organizations like Microsoft use a combination of all of them; so don’t think of them as separate choices especially with AlwaysOn. For tier 1, having all three in AlwaysOn is ideal. For tier 2 and 3, log shipping is sufficient in many cases, but of course it depends on what is in tier 2. In certain cases, you could have mirroring as well as it adds availability and makes maintenance easier while not being too expensive. To help you make the decision, here is a breakdown of the options.
Should I Choose Mirroring or Log Shipping?
Do both. Mirroring is mainly for HA and log shipping is for DR. If you have to choose one, I would choose log shipping because that’s your plan B if the farm becomes unavailable. Mirroring helps keep it going, but not if there is data corruption or a data center failure. One thing to note is that failovers can be complicated to manage when combining mirroring and log shipping. This is because your mirroring principal server is also your log-shipping primary server. However, during a mirroring failover, your primary role doesn’t automatically follow the principal role. You can either manage this manually (which I recommend) or you can automate. Playing around in SQL after a failover can be stressful, which makes automation a more attractive option.
Should I Choose Mirroring or Clustering?
I would choose clustering as it is a SQL-based technology and more resilient. But if money is a factor, mirroring is cheaper because of the expensive SAN storage. The main difference between clustering and mirroring is that the cluster works at the instance level and mirroring works at an individual database level. So in that sense, clustering protects more of your farm. Resource usage is also a factor: in clustering you can run active-active, which means that the second node in your cluster can be hosting another database instance (or two or three more) and be doing work. In mirroring, the mirror is passive until it becomes the primary, so it just sits there. Using AlwaysOn actually makes things even more complicated. I find the simpler a solution is, the less there is to go wrong.
So, your choice is mirroring or clustering for HA and log shipping for DR.
I should also mention that some service application databases can’t be log-shipped or asynchronously mirrored. For example, you have to rerun the search on the failover farm; you can’t replicate the search index although it can be backed up and restored with PowerShell. Also, some settings databases like Business Data Connectivity and the Application Registry Service can’t be mirrored; you just have to ensure they have the same settings by configuring them the same. But this is not a big issue with the Application Registry Service as it’s only used when upgrading the Business Data Catalog from MOSS 2007 to 2010. I will explain more about making Service Applications available later in the chapter.
“Am I responsible or are you,” a senior official asked his pilot, dubiously beginning a flight to Baghdad, “for seeing that this machine is not overloaded?”
“That will have to be decided at the inquest.”
—Jan Morris, Farewell the Trumpets: An Imperial Retreat (1978), p. 357.
Since most availability issues are caused by human error during maintenance, a practical change management process will help prevent mistakes. Change management is about ensuring that any need to change a live system goes through an agreed process. This means the following:
- Consistent review and approval criteria for change requests.
- Adequate communication between stakeholders regarding changes.
- Tracking and recording of requests to make historic analysis possible.
- A clear approval path for changes.
If your organization has proper change management processes that meet these needs, SharePoint should follow them, too. If not, a process needs to be set up.
The key reasons mistakes are made is the principle of least privilege is not followed. It means people have access rights higher than their training and knowledge allows. If a user can make a change without needing Site Collection Administrator rights or higher, it should not need a formal change request. Communication should be via a regular change board review meeting. A SharePoint list can be used to track the change requests and the approver. The point is that there must be a formal approval process, not just something ad hoc. Even “urgent” changes must meet review and approval criteria, be communicated to stakeholders, be recorded, and of course be properly approved by someone who understands the technology sufficiently to make a responsible decision. You don’t want that decided at the inquest.
While there are third-party tools for monitoring SharePoint such as IBM Tivoli and Microsoft’s own System Center Operations Manager (SCOM), there are built-in tools, too. These include:
- Health analysis problems and solutions
- Administrative reports
- IRM Policy Usage reports
- Health reports (slowest pages, most active users)
- Web Analytics reports
Custom reports can be built and deployed to Central Administration Monitoring using just Excel or even SQL Reporting Services. SharePoint’s logging service, which uses the Windows Unified Logging Service (ULS), includes a log viewer and PowerShell cmdlets for managing logs. Finally, the developer dashboard is a panel at the bottom of any page that gives a report in its behavior and performance.
The key point is that monitoring will be done well if the SharePoint farm owner has the appropriate training and experience. If you or the farm owner is not familiar with all of the above options, this knowledge gap should be filled. Monitoring is about averting disaster and keeping systems available. I will discuss this again in Chapter 7.
I mentioned the appropriate training is required for the stakeholders who will have ownership of SharePoint. Let’s discuss governance in relation to availability. The following roles should be filled when it comes to your SharePoint platform to make and keep it available:
- An architect to create the detailed design appropriate platform for your organization’s needs.
- An implementer to install and configure the platform.
- An infrastructure owner to maintain the hardware and software. This person will work in conjunction with the owners of Windows Active Directory, Networks, SQL Server, Storage, and any other dependent systems.
- A SharePoint application owner to manage the application itself.
- SharePoint site collection owners to manage site collection settings.
- Site owners to manage access to content.
- Content owners to manage content.
There should also be a backup person for each of these roles in case the main person is not available. I also recommend you invest in good people. Contractors can fill a gap but may disappear abruptly, taking their knowledge with them. If the expertise is hard to find, train someone internal. SharePoint is not that difficult. (How else would I be able to do it for 10 years?)
Having a fallback person for each role is the first step in approaching resilience from the point of view of having additional copies of other parts of your system, so if one fails, another can take over quickly with minimal loss of user access. Redundancy can be implemented on multiple levels that will benefit your SharePoint platform’s availability, and I will explain them next.
Redundancy
Redundancy is actually a subset of resilience but is sometimes seen as the main way to achieve it. Actually, when you think about it, surely it’s better to put in place measures that will prevent the failure of redundant parts of your platform. Hardware failure does happen, but it’s not as common as failures by people and processes.
Redundancy comes in two varieties depending on whether human intervention is required or not. With active redundancy, if a device goes down, the system automatically reroutes the work to another device. With passive redundancy, you maintain a standby system and manually switch over.
Here’s an example of redundancy to provide availability: at home I have two Wi-Fi networks, one that is connected to my high-speed cable Internet provider and another connected to a slower, cheaper mobile Internet provider. I rely on Internet availability to provide me with remote access to my clients, so it’s essential to my business. My Business Impact Analysis tells me if I can’t access my clients for more than a few hours, I won’t be able to do my work for them, hence I’ll cease making money. So I can’t just hope my Internet connection doesn’t go down. My process is that if is my high-speed Internet access goes down, I switch to the slower, cheaper option and still have Internet access. All my devices know the passwords of both Wi-Fi networks so the switch over is fast enough for me—only a few seconds. Initially, I had the two Wi-Fi networks switched on at once, but I found that sometimes devices connected to the slower one even when the faster one was available, so I was working unnecessarily with suboptimum performance. Now, I keep my second Wi-Fi switched off; I switch it on only if the first becomes unavailable. In other words, I initially had active redundancy, but I switched to passive redundancy as it gave me more control.
Redundancy should not be your only availability strategy with your SharePoint farm. Given enough time, a redundant system will be more resilient than one without any other form of resilience, but high-quality hardware, good change management, and monitoring are more important. Don’t make redundancy your only HA strategy. Keep in mind that redundancy is expensive and won’t on its own give you as much reliability as good system management.
With my home Wi-Fi, I have no control over my ISP. In fact, if the system goes down, I’m not even notified or given updates about work being done to fix it. The only way for me to work around this gap was to have a second provider. I could have started calling them the minute it went down, but we all know that is a waste of energy.
When adding redundancy to your SharePoint architecture, look at risk, impact, and conditions of failure. The three-tier model will help with prioritizing. In other words, the ship sinking is bad but the ship not having coffee is not so bad. Don’t give unimportant systems the same expensive redundancy as important ones.
Let’s look at the levels where you can have redundancy for your SharePoint farm.
A data center is a single geographical location where you host your SharePoint farm. This can also be your server room in your organization or even just under your desk. The point is it’s a single point of failure for your SharePoint platform. Having more than one with a redundant replica of your SharePoint farm in another data center is expensive but it can provide availability and disaster recovery. Bear in mind that once the second data center is more than 30 miles away, latency makes it a poor candidate for synchronous replication, so log shipping is a better option.
For change management, different SharePoint farms are used. There are usually three, but sometimes four or more. A typical setup looks like this:
- Development farm: Owned by developers. Virtual as this is cheaper and quicker to wipe or roll back. A simple architecture used for coding. Not necessarily on the network.
- Testing farm: Owned by developers. Closer in design to a production environment. On the network but only accessible by developers.
- Staging/Preproduction farm: Owned by infrastructure. Used for user acceptance testing (UAT) and stress testing. A copy of production. Also for infrastructure staff to test deployment and patches/service packs.
- Disaster Recovery farm: A copy of production. Sometimes the same farm as staging.
- Production farm: The live system in use by the main body of users to share content.
Note that multiple farms will give you more availability because they help prevent maintenance or development errors from breaking the production farm, because code and patches are not deployed straight to the live environment but are tested first. It also allows for UAT, which helps control changes being rushed into production to satisfy users.
Preventing hardware failure is a crucial skill for SharePoint Infrastructure owners. Here are some specific pointers for keeping your farm available:
Use the best hardware you can afford. Don’t use old or secondhand servers in your Production environment.
- Multiple servers are a relatively cheap way to do redundancy so buy redundant components. Scale out with multiple servers to avoid single points of failure.
- For all operating system and SharePoint application drives, use RAID 1.
- Follow vendor recommendations for maintenance and ensure the presence of redundant power through generators or batteries.
Within the SharePoint Application itself there are a number of configuration options that will give you redundancy and therefore availability.
Additional servers not only allow you to scale out and provide more resources, but SharePoint also allows you to have multiple servers with different roles. The main ones are the web front-end servers. These serve the pages to the users that are the UI for the application. I recommend a minimum of three for under 50k users. With each additional 25k users, add one more WFE. For application servers, I would suggest a minimum of two so that each service application is running on at least two servers. The second role is the application server. This runs services such as the user profile synchronization service, metadata management service, and the search service. Dedicating servers to the application server role allows you to assign resources more easily and manage the services more easily. For example, if you have a large amount of content to index, you may have multiple servers assigned to the search service role exclusively. Roles are logical terms because every server in the SharePoint farm has a particular service application once you install it. You then allocate instances of the service to servers to define their role in the farm.
Because the SharePoint application has grown to be able to do so much, its different functionalities have been split off into separate mini-applications (apps) in their own right and are now parts of the SharePoint platform. This means, for instance, that synchronizing user profile information with active directory SharePoint has a mini-app with its own settings pages, administrators, schedule, and three databases. Some apps are simple and can be made redundant by just having more than one instance on more than one application server, but some are more complex and require more careful planning.
SharePoint coordinates the multiple instances of the service applications by using timer jobs. They ensure that the system does the tasks it needs to do when they need to be done. For example, if the user profile service has to run every hour, the timer job will start either on the first available server running that instance or all the app servers. If the application server that is running the timer jobs failed, they will be restarted on another server when the next timer job is scheduled to run and the logs will record an error.
If users are in the middle of using a service application that doesn’t store its data in a database when it fails, they will lose some data. The two services that do this are the Access and Excel Services Applications. Here, your only option is to install the service app on multiple app servers. With other service apps, the data is stored in SQL Server so you have the option to use mirroring or clustering on those databases to keep the service app running.
There are some databases you can’t mirror. They are:
- The synchronization database for the User Profile service
- The database of the Application Registry service application
- The logging database of the Usage and Health Data Collection service application
- The staging database of the Web Analytics service application
If the databases are lost, they can only be restored from backup and reattached to the service application or new instances of the databases. This means you can’t perfectly mirror all of your databases, but the majority are redundant and resilient. They are:
- Search Administration, Crawl, and property databases of the Search service application
- Profiles and Social databases of the User Profile service
- Business Data Connectivity service application
- State service application
- Web Analytics service application
- Word Automation Services service application
- Microsoft SharePoint Foundation Subscription Settings service
- PerformancePoint services
Search requires more planning for availability as it has seven different components with different ways to make them available. They are:
- Query components
- Index partitions
- Property databases
- Crawl databases
- Crawl components
- The Search Administration component
- The Search Administration database
These are hosted on servers with specific search roles. They are:
- The crawl server, which hosts the crawl components and a search administration component
- The query server, which hosts query components and index partitions
- The database server, which hosts the crawl, query, and search administration databases
They interrelate in the following way:
- Crawl components crawl content sources and pass the indexed content to query components.
- Index partitions are groupings of query components. With them you can spread an index over more than one server.
- Property databases store metadata about the crawled content and are associated with an index partition.
- Crawl databases store schedules for crawls and data about what content sources to crawl.
- The Search Administration component monitors user actions and writes any search configuration changes to the Search Administration database, which stores general search configuration information.
Here is how you make each redundant:
- Crawl component: Run more than one on different crawl servers.
- Crawl database: Can be mirrored or clustered in SQL Server.
- Query component: Create mirrors on different query servers.
- Index partitions: Distribute multiple instances of the partition across multiple servers and link mirrored query components to the same index partition.
- Property database: Can be mirrored or clustered in SQL Server.
- Search Administration component: Have more than one search service application as there can only be one Search Administration component.
- Search administration database: Can be mirrored or clustered in SQL Server.
But how can users keep searching if part of your index partition is lost? You must have multiple instances of the same index partition propagated to multiple servers so that there is more than one copy of each part of the index connected to the same query component or its mirror. This way, the query component always has access to the entire index.
Summary
High availability is something achieved not just through meeting a percentage of uptime in a year. It is a proactive process of monitoring and change management to ensure the system does not go down. It is also about having high-quality hardware. Finally, it is about having redundancy at every level of your architecture from the data center down to the components of the individual service applications.