
Chapter 4 illustrated the role the operating system plays for applications that have a requirement for parallelism or multicore support. In it, we explained how the processes and kernel threads are the only execution units that the operating system schedules for processor execution. In Chapters 5 and 6, we explained how processes and threads are created and are used to gain access to Chip Multiprocessors (CMPs), but processes and threads are relatively low-level constructs. The question remains, "How do you approach application design when there is a concurrency requirement or when the design model has components that can operate in parallel?" In Chapter 7, we explored mechanisms that support Interprocess Communication (IPC): mutexes, semaphores, and synchronization. These are also low-level constructs that require intimate knowledge of operating-system-level Application Program Interfaces (APIs) and System Program Interfaces (SPIs) in order to program correctly.
So far we have discussed only scenarios that involved dual or quad core processors. But the trend in CMP production will soon replace dual and quad core processors. The UltraSparc T1, which we introduced in Chapter 2, has eight cores on a single chip with four hardware threads for each core. This makes it possible to have 32 processes or threads executing concurrently. Currently dual and quad core CMPs are the most commonly found configurations. However, dual and quad core configurations will soon be replaced by octa-core CMPs like the UltraSparc T1. So, how do you think about application design when 32 hardware threads are available? What if there are 64, 128, or 256 processors on a single CMP? How do you think about software decomposition as the numbers of available hardware threads approach the hundreds? This chapter turns to those questions by discussing:
A design approach for applications to run on multiple processor cores
The PADL and PBS approach to application design
Task-oriented software decompositions and declarative and predicate-oriented decompositions
Knowledge sources and multiagent architectures
Intel Thread Building Blocks (TBB) and the new C++ standard that supports concurrency
So, how do you approach process management or IPC in application design if you can have 100s or 1000s of concurrently executing processes or threads? Considerations of large numbers of concurrently executing tasks during application design can be daunting. And we use the term application design here loosely. It is a loaded term that means different things to different types and levels of software developers. It means one thing for system-level programmers and another for application-level programmers. Further, there are all sorts of classifications for software and computer applications. Consider a small excerpt taken from The Association of Computing Machinery (ACM) Computing Classification System (CCS) in Table 8-1
Table 8.1. Table 8-1
ACM Classification # | Software | Multiuser | Single User |
|---|---|---|---|
H.4.1 | Office automation | Groupware Project management Time management | Word processing Spreadsheets |
H.4.3 | Communication applications | Teleconferencing Videoconferencing Computer conferencing | Electronic mail Information browser |
D.2.2 | Software development tools | Software libraries Source code maintenance | Editors Compilers |
D.2.3 | Coding tools and techniques | Linkers | |
D.2.4 | Software reliability verification | ||
I.3.3 | Picture/image generation | Advance visualization Virtual environments | Digitizing and scanning Graphics packages |
I.3.4 | Graphics utilities | Virtual reality systems | Animation |
I.3.5 | 3D graphics | 3D rendering |
This classification breakdown looks at software categories from Sections H and D from the ACM's CCS. These categories are then further grouped by multiuser and single user. In multiuser applications, two or more users can access some feature(s) of a software application simultaneously. As can be seen from Table 8-1, multiuser applications come in all shapes and sizes ranging from intranet videoconferencing to Internet-based source code management applications. Many database servers, web servers, e-mail servers, and so on are good examples of multiuser applications. Further, while a single-user application doesn't have to worry about multiple users accessing some feature, the single-user application might be required to perform multiple tasks concurrently. Single-user multimedia applications that require synchronization of audio and video are good examples.
Also, look at the diversity of the applications in Table 8-1. Software developers in each of these domains may approach application design differently. One thing that most of the application classifications in Table 8-1 will definitely have in common in the future is that they will be running on medium- to large-scale CMPs. The classification in Table 8-1 is a small excerpt from a large taxonomy that the ACM has on software and computing classifications. In addition to being only a small excerpt, it is only a single view from the multiple views that can be found in the ACM CCS. Table 8-2 contains the CCS breakdown of computer applications by area. This breakdown is taken from Section J of the CCS.
Table 8.2. Table 8-2
(J.1) Administrative Data Processing | (J.2) Physical Sciences and Engineering |
|
|
(J.3) Life and Medical Sciences
| (J.4) Social and Behavioral Sciences
|
(J.6) Computer-Aided Engineering | |
|
|
As you consider software development approaches from the various areas shown in Table 8-2, it is clear that the phrase application design summons very different notions for different groups. If you add to the discussion multiprocessor computers and parallel programming techniques, then you have clarified at least the problem of which approach to take toward application design.
So, as you look at the applications in Table 8-1, it might be easier to visualize how to break up multiuser applications than it is to decompose single-user applications. However, decomposition complexity and task management are still issues once the number of available cores passes a certain threshold. Procedural bottom-up approaches to threading and multiprocessing become increasingly difficult as the number of available cores increases. As a developer, you will soon have cheap and widely available CMPs that can support any level of parallelism that you may need. But the question remains, "How do you approach multicore application design without getting overwhelmed by the available parallelism?"
It should be clear from the excerpt of classifications shown in Table 8-1 and the diversity of computer applications shown in Table 8-2 that there is no single tool, library, vendor solution, product, or cookbook recipe that will serve as the answer to that question. Instead, we share with you some of the approaches that we use as working software engineers. While our approaches are not meant to be one-size-fit-all, they are generic enough to be applied to many of the areas shown in Tables 8-1 and 8-2. They are for the most part platform- and vendor-neutral, or at the very least they assume ISO standard C++ implementations and POSIX-compliant operating environments. The techniques given in this chapter are not product or vendor driven. One reason for this is that no single vendor or product has produced a magic bullet solution, allowing all applications to exploit single chip multiprocessors.
Instead, as you have noticed, we focus on a paradigm shift for parallel programming that involves movement away from imperative task-oriented software decompositions to declarative and predicate-oriented decompositions. Our advice to you comes from a combination of our experience as software engineers and from many basic notions found in Object-Oriented software engineering and logic programming. You might be interested to know that the techniques, models, and approaches that we present in this chapter rely on the foundations of modal logic, its extensions and on situational calculus [Fagin et al., 1995]. Chapters 5, 6, and 7 include a discussion of low-level operating system primitives and POSIX APIs that are primarily used in conjunction with imperative approaches to parallel programming. Our intention is to show that these same low-level primitives can (and ultimately must) be used with declarative approaches to parallel programming.
Now, in this chapter, we explain how to approach the process of application design when there is a concurrency requirement in the original software development request or when parallelism is explicitly called for or implied by the solution decomposition. We introduce Parallel Application Design Layers (PADL). PADL is a five-layer analysis model that we use at CTEST Laboratories during the requirements analysis, software design, and decomposition activities of the Software Development Life Cycle (SDLC). We use PADL to place concurrency and parallelism considerations in the proper context. PADL is used during the initial problem and solution decomposition. We also use the PADL model to circumvent much of the complexity that results from bottom-up approaches to parallel programming. In this chapter, we present an architectural approach to parallelism rather than a task-oriented procedural approach. Although concurrently executing tasks represent the basic unit of work in applications that take advantage of CMPs, we place those tasks within declarative architectures and predicate-based software models. In this chapter, we approach application design with the fundamentals of the SDLC front and center.
We also briefly introduce Predicate Breakdown Structure (PBS) decomposition. The PBS of a software design presents a view of the software as a collection of assertions, propositions, and logical predicates. The PBS gives the declarative or predicate-based view of a software design. At CTEST Laboratories we use PADL and PBS as fundamental tools for application design when multithreading, multiprocessing, or parallel programming will be used. PADL and PBS are departures from procedural and bottom-up task-oriented methods, but they are tools that can be used in conjunction with interface classes, application frameworks, predicates, and algorithm templates to move the process of application design in a direction that will be able to exploit the availability of medium- and large-scale single chip multiprocessors.
As already noted, Parallel Application Design Layers (PADL) is a five-layer analysis model used in the design of software that requires some parallel programming. PADL is used to help organize the software decomposition effort. The PADL model is a refinement model. Starting with the top layer, each lower layer contains more detail and is one step closer to operating system and compiler primitives. PADL is meant to be used during the requirements analysis and software design activities of the SDLC. The industry standard description for an SDLC is contained in the IEEE Std 1074, Guide for Developing Software Life Cycle Processes. IEEE Std 1074 helps clarify what the minimum set of activities are.
Table 3-1 in Chapter 3 shows some of the common activities found in the SDLC, but it is not exhaustive.
The PADL model is used to help design or decompose patterns of work before the software is written. That's why we place an emphasis on its use during design and analysis activities of the SDLC. Figure 8-1 shows the five layers of PADL.
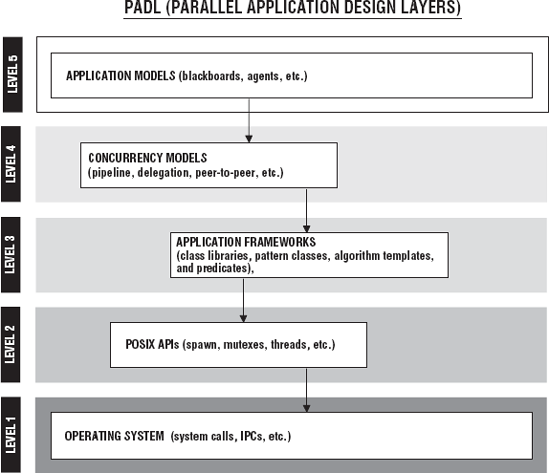
Layer 5 deals with application architecture selection. Selection of the application architecture is one of the most critical decisions because everything else follows the architecture, and once it is in place, it is expensive to change. The architecture allows certain functionality and features while preventing others. The architecture provides the basic infrastructure of the application.
Layer 4 in Figure 8-1 identifies concurrency models that will be used for the application. The architecture should be flexible enough to use the concurrency models that are needed, and the concurrency models should be flexible enough to support the architecture selected. Table 8-3 reviews the basic concurrency models and their definitions.
Table 8.3. Table 8-3
Description | |
|---|---|
Boss-worker model | A central process/thread (boss) creates the processes/threads (workers) and assigns each worker a task. The boss may wait until each worker completes its task. |
All the processes/threads have an equal working status; there are no leaders. A peer creates all the workers needed to perform the tasks but performs no delegation responsibilities. The peer can process requests from a single input stream shared by all the threads, or each thread may have its own input stream. | |
Pipeline | An assembly line approach to processing a stream of input in stages. Each stage is a thread that performs work on a unit of input. When the unit of input has been through all the stages, then the processing of the input has been completed. |
Producer-consumer model | A producer produces data to be consumed by the consumer thread. The data is stored in a block of memory shared by the producer and consumer threads. |
The pattern of work is initially expressed within the context of the architecture chosen in Layer 5. We discuss this shortly. The architecture is then fleshed out by one or more concurrency models in Layer 4.
It is important to note that Layer 4 and Layer 5 in Figure 8-1 are strictly conceptual models. Their primary purpose is to help describe and identify the concurrency structure a software application will have.
Layer 3 of the PADL starts to identify application frameworks, pattern class hierarchies, component/predicate libraries, and algorithm templates that are used to implement the concurrency models identified at Layer 4 of the analysis. Layer 3 introduces tangible software into the PADL model. Software libraries such at the Thread Building Blocks (TBB) library or STAPL would be identified in Layer 3.
Layer 2 represents the application's program interface to operating system. The components in Layer 3 ultimately talk to and cooperate with the OS API. In our case the POSIX API is used for the greatest cross-platform compatibility. Many of the components in Layer 3 are interface classes or wrappers for functionality found in Layer 2.
Finally, Layer 1 is the lowest level of detail that the software application can be decomposed into. At Layer 1 you are dealing with kernel execution units, signals, device drivers, and so on. The software at Layer 1 performs the actual work of the application interfaces presented in Layer 2. Layer 1 decomposition also encompasses compiler and linker switches.
Layers 4 and 5 are considered design layers. Layers 1-3 are the implementation layers. Layer 3 is usually reserved for application-level software development. Layers 1 and 2 are usually reserved system-level software development. Obviously, the barrier between Layer 2 and 3 can be (and often is) easily crossed. Once a PADL model analysis has been performed, the picture of the concurrency structure of an application is clear to all of those involved in the software development effort. The PADL analysis of an application provides the framework for the testing activities of the SDLC. The PADL analysis provides the necessary implementation and deployment targets of the SDLC for the application. At the top layers of the PADL are design concepts and models. At the lowest level of the PADL are operating system primitives. So, you have a complete picture of the concurrency of an application through the PADL model. The PADL model is meant to drive a declarative decomposition of the application because you proceed from architectures to operating system primitives not from the primitives to the architectures! But in order for PADL to ensure a declarative decomposition, it must restrict the architectures to software blueprints that have declarative, goal-oriented, or predicate-based semantics. The next sections take a closer look at how the PADL model moves you toward declarative approaches to parallel programming.
Consideration of the numbers of cores, threads, and processes is not part of the analysis in Layer 5. In fact, computers are not even visible at Layer 5. The application architectures considered in Layer 5 represent conceptual or logical structures that are platform, operating system, and computer independent. The value of these architectures is that they are known to support certain patterns of work. In the PADL model, we use two primary architectures:
Multiagent architectures
Blackboard architectures
It is important to note that here we are referring to the problem-solving structures and patterns of work as opposed to any specific tools or vendor products that are based on some of the ideas of multiagents and Blackboards. Our use of the terms agent and Blackboard is not to be confused with the many gimmicks that claim agent or Blackboard functionality. We use agents and Blackboards in their more formal sense. Multiagent architectures are classified in section I.2.11 of the ACM CCS, and Blackboard architectures are classified in D.2.11 of the ACM CCS. Both architectures are able to support a wide variety of concurrency models. They are well defined and well understood. Both architectures support the notion of PBS. We have chosen to use multiagent architectures to capture goal-oriented patterns of work and Blackboard architectures to capture state-oriented patterns of work. Although goals and states are sometimes used interchangeably and sometimes the goal is to reach a certain state, we differentiate between the two when using concurrency models. Goal-based decompositions and state transitions can help you in the direction of declarative models of parallel programming, and declarative models of parallel programming can help you cope with the transition to massively parallel chip multiprocessors. Multiagent architectures and Blackboard architectures can be understood using declarative semantics.
There was a lot of controversy over what constituted an object when object programming was initially introduced. There is a similar controversy over exactly what constitutes an agent. Many proponents define agents as autonomous continuously executing programs that act on behalf of a user. However, this definition can be applied to some Unix daemons or even some device drivers. Others add the requirements that the agent must have special knowledge of the user, must execute in an environment inhabited by other agents, and must function only within the specified environment. These requirements would exclude other programs considered to be agents by some. For instance, many e-mail agents act alone and may function in multiple environments. In addition to agent requirements, various groups in the agent community have introduced terms like softbot, knowbot, software broker, and smart object to describe agents. One commonly found definition defines an agent as "an entity that functions continuously and autonomously in an environment in which other processes take place and other agents exist."
Although it is tempting to accept this definition and move on, we cannot because it too easily describes other kinds of software constructions. A more formal source, the Foundation for Intelligent Physical Agents (FIFA) specification, defines the term agent as follows: "An Agent is the fundamental actor in a domain. It combines one or more service capabilities into a unified and integrated execution model which can include access to external software, human users and communication facilities."
While this definition has a more structured feel, it also needs further clarification because many servers (some Object-Oriented and some that are not) fit this definition. This definition as is would include too many types of programs and software constructs to be useful. In our PADL model we use the five-part definition of agents as stated by [Luger, 2002]:
Agents are autonomous or semi-autonomous. That is, each agent has certain responsibilities in problem solving with little or no knowledge either what other agents do or how they do it. Each agent does its own independent piece of the problem solving and either produces a result itself (does something) or reports its result back to others in the community of agents.
Agents are situated. Each agent is sensitive to its own surrounding environment and (usually) has no knowledge of the full domain of all agents.
Agents are interactional. That is, they form a collection of individuals that cooperate on a particular task. In this sense, they may be seen as a "society."
The society of agents is structured. In most views of agent-oriented problem solving, each individual, although having its own unique environment and skill set, will coordinate with other agents in the overall problem solving. Thus, a final solution will not only be seen as collective but also cooperative.
Although individual agents are seen as possessing sets of skills responsibilities, the overall cooperative result of the society of agents can be viewed as greater than the sum of its individual contributors.
We use the term multiagent architecture when referring to an agent-based architecture that consists of two or more agents that can execute concurrently if necessary. It should be clear from Luger's definition of agents that multiagent architecture can be used as an extremely flexible approach to patterns of work that require or can benefit from concurrency. Notice in this definition of agents that there is no mention of particular computer capabilities, numbers of processors, thread management, or so forth. There is also no limit on the number of agents involved. There are no complexity constraints on the patterns of work that a collection of agents can perform. If you begin with the blueprint that is consistent with a multiagent architecture, you should be able to handle concurrency of any size.
Decomposition is one of the primary challenges in software development. It is more of a challenge when the software development requires parallel programming. Our approach to this challenge is to find an appropriate model of the problem and appropriate solution model. Using PADL analysis, we select an application architecture based on the solution model. To see how this works, consider again the guess-what-code-I'm-thinking problem from Chapter 4.
Recall the game scenario from Chapter 4 goes as follows: I'm thinking of a six-character code. My code can contain any character more than once. However, my code can only contain any characters from the numbers 0-9 or characters a-z. Your job is to guess what code I have in mind. In the game the buzzer is set to go off after 5 minutes. If you guess what I'm thinking in 5 minutes you win. In that chapter, we determined that you have 4,496,388 possible codes to choose from.
Now, in this simple example, we want to make the game a little more challenging. You now have only 2 minutes to guess. In addition to this, instead of making up a code, I am handed the initial code by my trusted assistant. If my assistant determines that you have made more than N incorrect guesses within a 15-second interval, my assistant hands me a new code, and the new code is guaranteed to be among the guesses that you have already made.
Recall from Chapter 4 that you happened to have a file that contained all of the possible six-character codes. The total number of codes is determined by samples of size r that can be selected out of n objects. The formula that calculates the possibilities is as follows:
(n −1 + r)! / (n-1)!r!
In this case n is 36 counting (0-9, a-z) and r = 6. The original strategy was to the divide the file into four parts and have the parts searched in parallel. The thinking was that the longest search would be only the length of the time it took to search one-quarter of the file. But because you are given a new time constraint of 2 minutes, you now have to modify your strategy to divide the original file into eight parts and have the parts searched concurrently. Therefore, you should be able to guess correctly in the time that it takes to search one-eighth of the file. But you also make one other provision. If you are able to search all eight files, and still do not guess correctly and are not out of time, you divide the files into 64 and try again. If you fail and still have time, you divide the file into 128 and try again and so on.
If you carefully look at the code to be guessed, you see that if the assistant determines that some unusual number of guesses are being made within a 15-second interval, then the assistant changes the code to one that has already been guessed. It is not specified what the unusual number. So, your strategy is to try to make more guesses in a shorter period of time because the time constraint is tighter. Further, if you are able to go through all of the possibilities and still do not have the correct code, you assume that the code is being changed during the 2-minute interval, and, therefore, you attempt to increase the guesses at a rate faster than that at which the code can be changed.
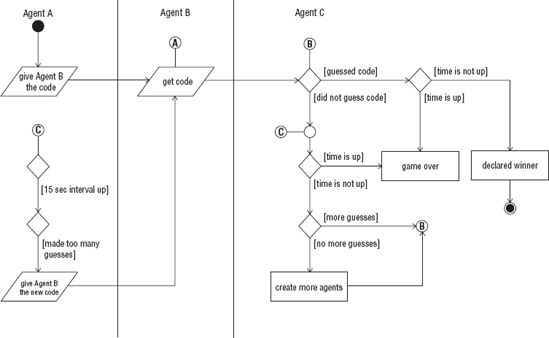
You can easily see from the statement of the problem that you are initially dealing with three agents. If you recast the game in terms of agents you have the following: Agent A gives the code to Agent B. Agent C tries to guess Agent B's code. If Agent C comes up with too many guesses in a 15-second interval, Agent A will give Agent B a new code that is guaranteed to be a code that Agent C has already presented. If Agent C is able to go through all of the possibilities and is still not declared the winner and if Agent C has more time left, that agent will make the same guesses only faster. Agent C realizes that in order to generate enough guesses to guarantee success within the given time limit will require help. So, Agent C recruits a team of agents to help him come up with guesses. For each pass through the total possibilities, Agent C recruits a bigger team of agents to help with the guesses.
Obviously, you could now start thinking in terms of agents mapped to either threads or processes. But we will resist this temptation. You do not want to think in terms of threads and processes at this level. In the PADL model approach, you work out a complete and correct logical statement of the application in Layers 5 and 4. So, before proceeding to Layer 4, if you are applying the PADL model to the game scenario, you refine the relationships and interactions of all of the agents involved. The assumption and conditions that the agents operated under would all be made clear. A complete picture of the multiagent interaction would be given. Figure 8-2 is a UML activity diagram that captures the interaction of the micro-multiagent society.
The Blackboard model is an approach to collaborative problem solving. The Blackboard is used to record, coordinate, and communicate the efforts of two or more software-based problem solvers. There are two primary types of components in the Blackboard model.
The Blackboard
The problem solvers
The Blackboard is a centralized object that each of the problem solvers has access to. The problem solvers may read the Blackboard and change the contents of the Blackboard. The contents of the Blackboard at any given time will vary. The initial content of the Blackboard will include the problem to be solved.
In addition to the problem to be solved, other information representing the initial state of the problem, problem constraints, goals, and objectives may be contained on the Blackboard. As the problem solvers are working toward the solution, intermediate results, hypotheses, and conclusions are recorded on the Blackboard. The intermediate results written by one problem solver on the Blackboard may act as catalyst for other problem solvers reading the Blackboard. Tentative solutions are posted to the Blackboard. If the solutions are determined not to be sufficient, these solutions are erased, and other solutions are pursued. The problem solvers use the Blackboard as opposed to direct communication to pass partial results and findings to each other. In some configurations, the Blackboard acts as a referee, informing the problem solvers when a solution has been reached or when to start work or stop work. The Blackboard is an active object, not simply a storage location. In some cases, the Blackboard determines which problem solvers to involve and what content to accept or reject. The Blackboard may also organize the incremental or intermediate results of the problem solvers. The Blackboard may translate or interpret the work from one set of problem solvers so that it can be used by another set of problem solvers.
The problem solver is a piece of software that typically has specialized knowledge or processing capabilities within some area or problem domain. The problem solver can be as simple a routine that converts from Celsius to Fahrenheit or as complex as a smart agent that handles medical diagnosis. In the Blackboard model, these problem solvers are called knowledge sources (KS). To solve a problem using Blackboards, you need two or more knowledge sources, and each knowledge source usually has a specific area of focus or specialty. The Blackboard is a natural fit for problems that can be divided into separate tasks that can be solved independently or semi-independently. In the basic Blackboard configuration each problem solver tackles a different part of the problem. Each problem solver only sees the part of the problem that it is familiar with. If the solutions to any parts of the problem are dependent on the solutions or partial solutions to other parts of the problem, then the Blackboard is used to coordinate the problem solvers and the integration of the partial solutions.
A Blackboard's problem solvers need not be homogeneous. Each problem solver may be implemented using different techniques. For instance, some problem solvers might be implemented using Object-Oriented techniques, while other solvers might be implemented as functions. Further the problem solvers may employ completely different problem-solving paradigms. For example, solver A might use a backward chaining approach to solving its problem, while solver B might use a counterpropagation approach. There is no requirement that the Blackboard's problem solvers be implemented using the same programming language.
The Blackboard model does not specify any particular structure or layout for the Blackboard. Neither does it suggest how the knowledge sources should be structured. In practice, the structure of a Blackboard is problem dependent. The implementation of the knowledge sources is also specific to the problem being solved. The Blackboard framework is a conceptual model describing relationships without describing the structures of the Blackboard and knowledge sources. The Blackboard model does not dictate the number or purpose of the knowledge sources. The Blackboard may be a single global object or a distributed object with components on multiple computers. Blackboard systems may even consist of multiple Blackboards, with each Blackboard dedicated to a part of the original problem. This makes the Blackboard an extremely flexible model for problem solving. The Blackboard model supports parallel programming and many of the concurrency models. The Blackboard can be segmented into separate parts, allowing concurrent access by multiple knowledge sources. The Blackboard easily supports Concurrent Read Exclusive Write (CREW), Exclusive Read Exclusive Write (EREW), and Multiple Instruction, Multiple Data (MIMD). The knowledge sources may execute simultaneously with each knowledge source working on its part of the problem.
Figure 8-3 shows two memory configurations for the Blackboard.
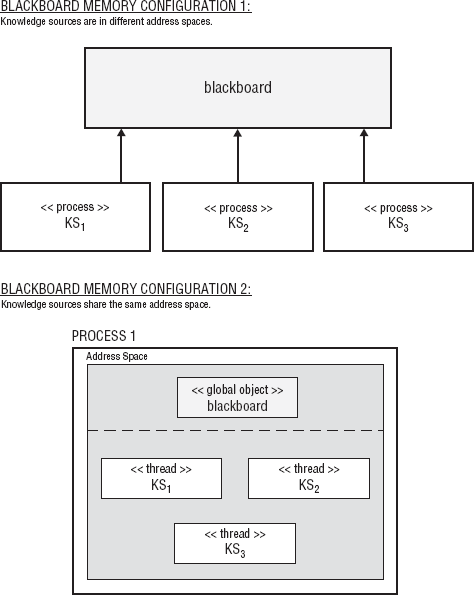
In both the cases in Figure 8-3, all knowledge sources have access to the Blackboard. This configuration provides for an extremely flexible model of problem solving.
As we have indicated, there is no one way to structure a Blackboard. However, most Blackboards have certain characteristics and attributes in common. The original contents of the Blackboard typically contain some kind of partitioning of the solution space for the problem that is to be solved. The solution space contains all the partial solutions and full solutions to a problem.
Say that you need a domain-specific information browser, that is, one that allows the user to search for information only on a narrow topic or range of specified topics (for example, anime, robots, YouTube, or so on). The user should be able to browse through the available information using a graphical interface or choose advanced search features. The advance search features should allow the user to simply type a question (as long as it pertains to the topic), and the browser should return a complete answer based on the information it has access to. It is assumed that most users will prefer the advanced search because it's faster.
In the innocent browser request above you see no mention made of multiple cores, concurrency threads, or processes. There is simply the assumption that the browser will have what the user perceives as an acceptable performance. You are immediately faced with, among other things, one of the primary challenges of software development (especially challenging for CMP deployments): decomposition. Decomposition begins with understanding the problem and then devising a solution that addresses the problem. In this case, browsing information using a graphical user interface is fairly well understood. On the other hand, allowing the user to type in a question and having software that can understand the user's question, search through information, find an appropriate answer, and then present it in a form that is acceptable is another challenge altogether. This problem involves determining what language the question is being asked in (perhaps, you can assume the local language). So, a quick run through of the problem yields the following challenges:
Is the question in a language that is known to the software?
Is the question concerning a topic that is available in the software's information?
Is the question clear and unambiguously stated?
Are there any unknown or misspelled words in the question? (How can it answer if so?)
How will the software deal with meaning in the question?
What about language grammar (syntax, semantics, morphology, pragmatics)?
After a moment of internal deliberation, you realize that to accept, understand, and appropriately respond in a timely manner (in a second or so) to a random question typed into an information browser is a challenging problem! With a little research you find out that natural language processing techniques are required. You stumble across partial solutions in computational linguistics and computational semantics. You now have a rough but somewhat complete picture of the problem.
To provide a solution to the problem, you realize that you need software components that include parsers, word experts, grammar analysis for syntax, semantics, pragmatics, and so on. As it turns out, the user's original question can be analyzed at several levels simultaneously. Determination of what language the question is asked in can be done at the same time as identification of unknown words or misspelled words. The syntax analysis that breaks down the question into its parts of speech can also be done at the same time. You also determine that once part of the syntax is figured out, the semantic analysis process can start. Likewise, once part of the question's semantics has been identified, identification of the pragmatics (context and meaning) can begin. You have now identified the parts. While there are some partial dependencies (for example, between syntax and semantics, and semantics and pragmatics), you can do most of the analysis of the user's question concurrently.
Looking at the PADL analysis model at Layer 5, it is clear that you can use both the multiagent and Blackboard architecture for the solution model. You choose the Blackboard architecture here because the semantic and pragmatic analysis can begin work with only partial solutions, and the Blackboard architecture is a good fit for incremental problem solving.
So, you place the original user's question on the Blackboard, and each of your knowledge sources has its specialties:
Checking a dictionary for unknown or misspelled words
Breaking down the question into parts of speech (nouns, verbs, interrogatives, and so on)
Understanding the morphology, that is, word forms (plural, present, past)
Semantic understanding of the meaning and use of words
Pragmatic analysis (the use of words in context)
The knowledge source that simply checks the question for unknown or misspelled words places its candidates on the Blackboard. As they arrive, the morphology knowledge sources make any corrections that could be due to plural forms, past tense, or abbreviations. They then place corrected words back on the Blackboard. While this is happening the syntax knowledge sources are breaking down the question with the corrected words into parts of speech and are placing phrases back up on the Blackboard as it goes. As soon as there is something that the semantics and pragmatics knowledge sources can work with, they read the Blackboard as well and begin to put up a potential meaning of the user's original question in a form that the search engine can use.
This is a cooperative kind of concurrent processing because the partial solutions can be used and interpreted on many levels by different knowledge sources. Each knowledge source writes a tentative hypothesis for what it is currently dealing with on the Blackboard. Something that the semantic knowledge source uncovers may help the syntax parser refine its work. Something that the syntax parser refines may clarify something for the pragmatics knowledge source and so on. The Blackboard represents a solution space that is divided into a hierarchy of partial solutions with proper forms of questions and answers at the highest level and parts of speech and word forms at the lowest level. If some part of the solution space matches something in the rules of grammar or usage of language, that piece of the solution is written to another part of the Blackboard as a partial solution. One KS might put a verb phrase on the Blackboard. Another may put a choice of contexts on the Blackboard. Once these two pieces of information have been put on the Blackboard, another KS may uses this information to aide in identifying the real subject or object of the question. All of this has to take place within the space of a few seconds.
From the original naïve statement of the question and answer browser request that did not really hint at concurrency, you have now produced a solution that needs to use parallel models of work in order to meet the assumed speed requirements. The Blackboard solution is well suited to concurrency with knowledge sources working with incomplete or staged information. Again, it is important to note that at this level you are not concerned with threads, numbers of cores, or processes.
The solution space is sometimes organized in a hierarchy. In the case of the question and answer processing example, valid question classifications would be at the top of the hierarchy, and the next level might consist of various views of the classifications. For example, with different forms for who, what, where, and when questions, each level describes a smaller perhaps less obvious aspect of a question classification (for example, is the verb transitive?). The knowledge sources may work on multiple levels within the hierarchy simultaneously. The solution space may also be organized as a graph where each node represents some part of the solution, and each edge represents the relationships between two partial solutions. The solution space may be represented as one or more matrices with each element of the matrix or matrices containing a solution or partial solution. The solution space representation is an important component of the Blackboard architecture. The nature of the problem will often determine how the solution space should be partitioned. This feature is critical in the PADL model because we use Layer 5 to describe the application architecture and the application architecture has to be flexible enough to map to the solution model. The structure of the Blackboard supports this flexibility.
In addition to a solution space component, Blackboards typically have one or more rule (heuristic) components. The rule component is used to determine which knowledge sources to deploy, and what solutions to accept or reject. The rule component can also be used to translate partial solutions from one level in the solution space hierarchy to another level. The rule component may also be used to prioritize the knowledge source approaches. The rule component supports concurrently among knowledge sources. This is the level where concurrency needs to be dealt with by using a declarative interpretation of parallel processing. Some knowledge sources might be going down blind alleys. The Blackboard deselects one set of knowledge sources in favor of another set. The Blackboard may use the rule component to suggest to the knowledge sources a more appropriate potential hypothesis based on the partial hypothesis already generated.
In addition to the solution space and rule component, the Blackboard often contains initial values, constraints values, and ancillary goals. In some cases, the Blackboard contains one or more event queues that are used to capture input from either the problem space or the knowledge sources. Figure 8-4 shows a logical layout for a basic Blackboard architecture.
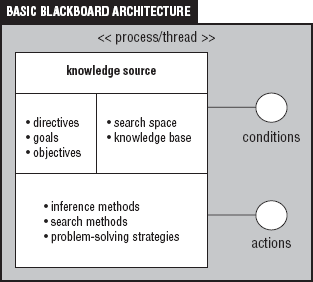
Figure 8-4 shows that the Blackboard has a number of segments. Each segment in Figure 8-4 has a variety of implementations. This suggests that Blackboards are more than global pieces of memory or traditional databases. While Figure 8-4 shows the common core components that most Blackboards have, the Blackboard architecture is not limited to these components. Other useful components for Blackboards include context models of the problem and domain models that can be used to aid the problem solvers (KS) with navigation through the solution space. The support that C++ has for Object-Oriented Design and Programming fits nicely with the flexibility requirements of the Blackboard model. Most Blackboard architectures can be modeled using classes in C++. Recall that classes can be used to model some person, place, thing, or idea. Blackboards are used to solve problems that involve persons, places, things, or ideas. So, using C++ classes to model the objects that Blackboards contain or the actual Blackboards is a natural fit. We take advantage of C++ container classes and the standard algorithms in our implementations of the Blackboard model.
Knowledge sources are represented as objects, procedures, sets of rules, logic assertions, and in some cases entire programs. Knowledge sources have a condition part and an action part. When the Blackboard contains some information that satisfies the condition part of some knowledge source, the action part of the knowledge source is activated. Robert Englemore and Tony Morgan clearly state the responsibilities of a knowledge source in their work Blackboard Systems:
Each knowledge source is responsible for knowing the conditions under which it can contribute to a solution. Each knowledge source has preconditions that indicate the condition on the Blackboard that must exist before the body of the knowledge source is activated. One can view a knowledge source as a large rule. The major difference between a rule and a knowledge source is the grain size of the knowledge each holds. The condition part of this large rule is called the knowledge source precondition, and the action part is called the knowledge source body. [Englemore, Morgan, 1998]
Here, Englemore and Morgan don't specify any of the details of the condition part or the action part of a knowledge source. They are logical constructs. The condition part could be as simple as the value of some boolean flag on the Blackboard or as complex as a specific sequence of events arriving in an event queue within a certain period of time. Likewise, the action part of a knowledge source can be a simple as a single statement performing an expression assignment or as involved as forward chain in an expert system. Again, this is a statement of how flexible the Blackboard model can be. The C++ class construct and the notion of an object are sufficient for our purposes. Each knowledge source will be an object (for sophisticated uses an object hierarchy). The action part of the knowledge source will be implemented by the object's methods. The condition part of the knowledge source will be captured as data members of the object. Once the object is in a certain state then the action parts of that object will be activated.
An important attribute of the knowledge source is its autonomy. Each knowledge source is a specialist and is largely independent from the other problem solvers. This presents one of the desired qualities for a parallel program. Ideally the tasks in a parallel program can operate concurrently without much interaction with other tasks. This is exactly the case in the Blackboard model. The knowledge sources act independently, and any major interaction is through the Blackboard. So, from the knowledge source's point of view, it is acting alone, getting additional information from the Blackboard, and recording its findings on the Blackboard. The activities of the other knowledge sources, their strategies, and structures are unknown. In the Blackboard model, the problem is partitioned into a number of autonomous or semi-autonomous program solvers. This is the advantage of the Blackboard model over other concurrency models. In the most flexible configuration, the knowledge sources are rational agents, meaning the agent is completely self-sufficient and able to act on its own with minimum interaction with the Blackboard. Rational agents in conjunction with Blackboards present the greatest opportunity for large scale parallelism or massively parallel CMPs. This use of rational agents as knowledge sources combines the two primary architectures from Layer 5 of PADL: multiagent architectures and Blackboard architectures. A full discussion of rational agents takes us beyond the scope of this book. However, we can say that rational agents fit into the category of agents that we discussed earlier in the chapter in the section "What Are Agents?" When knowledge sources are implemented as rational agents in large-scale systems, the rule and action components of the knowledge sources are learned using Inductive Logic Programming (ILP) techniques [Bergadano, Gunetti, 1996]. The ILP techniques provide a gateway to bottom-up declarative programming.
We move away from bottom-up procedural programming techniques and toward PADL in order to cope with complexity as the scale of available cores on CMP increases. However, bottom-up declarative programming using ILP or evolutionary programming techniques [Goertzel, Pennachin, 2007] is a legitimate part of the PADL analysis model. These approaches are used in Layer 3 where we are concerned with the availability and implementation of application frameworks, class libraries, algorithm templates, and so on.
Although there are many different types of software architectures that support parallelism, we use multiagent and Blackboard architectures in Layer 5 of PADL because of their general purpose nature and the range of concurrency models they support. Many different types of solutions that require concurrency can be expressed using multiagent or Blackboard architectures. Multiagent architectures and Blackboards are domain independent. They can be used in many different areas. Further, these architectures can be used for solutions of all sizes from small programs to large-scale, enterprise-wide solutions. While these architectures might be new to developers who are in the process of learning parallel or multithreaded programming techniques, they are well defined, and many useful resources that introduce the basic ideas of agents and Blackboards are available, see [Russell, Norvig, 2003], [Englemore, Morgan, 1988], [Goertzel, Pennachin, 2007], and [Fagin et al., 1996]. You will see that the selection of the architecture impacts software maintenance, testing, and debugging. Most successful software undergoes constant change. If that software has components that require concurrency and synchronization, then the natural evolution of the software can be extremely challenging if an appropriate application architecture was not selected from the start. The PADL analysis model presents two well-known and well-understood architectures that perform well under the conditions of software evolution. Ultimately, the concurrency of an application is going to be implemented by low-level operating system primitives like threads and processes. If the application architecture is clean, modular, scalable, and well understood, then the translation into manageable operating system primitives has a chance to succeed. On the other hand, selection of the wrong or a poor application architecture leads to brittle, error-prone software that cannot be readily changed, maintained, or evolved. While this is true of any kind of computer application, it is magnified when that software involves parallel programming, multithreading, or multiprocessing.
The applications architectures selected in Layer 5 have to flexible enough to support concurrency models selected in Layer 4. There can be more than one concurrency model needed in the application, so the architecture chosen should be able to accommodate multiple models. Layer 4 is also a design layer. We are not necessarily thinking in terms of threads or processes when we select concurrency models in Layer 4.
Whereas the architecture focuses on the language and concepts in the application domain, the concurrency model layer is concerned with picking known models of parallelism that will work. In the browser example used in the chapter so far, we have several highly specialized knowledge sources that are concurrently working on different parts of the user's question. This particular example uses a variation of the MIMD model of parallelism in combination with a peer-to-peer model. In this case, the peers communicated and cooperated through a shared Blackboard. Since each knowledge source has its own specialty and works on a different aspect of the question, we select the Multiple Instruction, Multiple Data (MIMD) concurrency model. In Chapter 7, we explained the Parallel Random-Access Machine (PRAM) and the Exclusive Read Exclusive Write (EREW), Concurrent Read Exclusive Write (CREW), Exclusive Read Concurrent Write (ERCW), and Concurrent Read Concurrent Write (CRCW) models for memory or critical section access. It is clear that in the example of the question and answer browser that you have either a CREW or CRCW requirement for the Blackboard.
The identification or selection of a MIMD/peer-to-peer model in conjunction with CREW/CRCW critical section access is important at this stage because it shapes and molds the use of threads and processes in Layers 2 and 3. This emphasizes the fact that the parallelism in the implementation model should naturally follow the concurrency in the solution model. If you allow implementation model and the solution model to drift or diverge too much, then you will not be able to guarantee that the software is correct. The simple game example discussed earlier in this chapter uses a multiagent application architecture. It uses the classic boss-worker concurrency model with a Single Instruction Multiple Data (SIMD) PRAM architecture and EREW access for the critical section. In the case of the game, the critical section is a shared queue that all of the agents used to get the names of the partial files to search. A shared queue was also used by the agents to report back to the main agent when a correct code was found. Table 8-4 shows the PADL analysis as it applies at this point to the two examples.
Table 8.4. Table 8-4
Architecture | Concurrency Model | PRAM Model | SIMD/MIMD | |
|---|---|---|---|---|
Guess-My-Code Agents | Multiagent | Peer-to-peer | CRCW or CREW | MIMD |
Question and Answer Browser | Blackboard | Boss-worker | EREW | SIMD |
While Table 8-4 does present a simplification of concurrency design choices for the two examples, it nevertheless gives a high-level evaluation of the concurrency infrastructure of the software. Once you've identified the concurrency models, you can plan for their strengths and weaknesses. For example, if you know that you are dealing with SIMD model, then vector optimization, loop unrolling, and pipelining all become serious contenders for implementation. You can take advantage of their strengths and plan for their weaknesses. On the other hand, if you know you're dealing with EREW critical sections, then you know ahead of time that you have potential bottleneck issues or indefinite postponement issues. One of the advantages of selecting well-known models is that you know what you're getting into before you start implementing the applications. Figure 8-5 shows a block diagram of the concurrency infrastructure of the two examples.
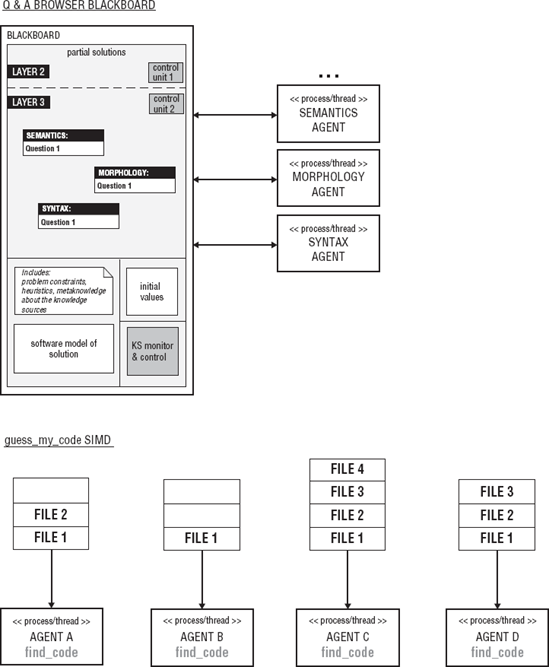
Figure 8-5 clarifies where the concurrency is in the applications. One of the major benefits of using a PADL model analysis is to identify the nature and location of concurrency in an application. Again, it is important to note that Layer 4 and 5 are conceptual design layers. We are not really concerned with threads, or processes in these layers. These layers function as a blueprint that specifies the concurrency architecture and infrastructure of the application. Layers 4 and 5 identify the primary agents, objects, components, and processes that will be involved in concurrency and where in the application the concurrency takes place. Layers 4 and 5 specify how the agents, objects, components, and processes are related in terms of concurrency models such as boss-worker, pipeline, SIMD, MIMD, and so on. After you have done the decomposition in Layers 4 and 5, you can begin to think about the implementation models in Layer 3. Figure 8-6 contains a general overview of how the PADL analysis is applied during decomposition.
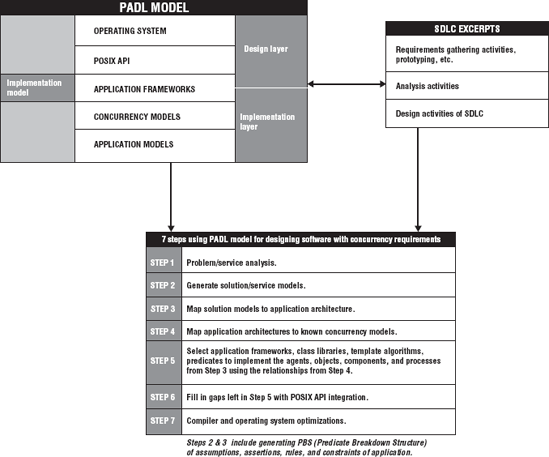
The concurrency infrastructure is identified from steps 1 through 4, as shown in the figure. Notice again that Layers 4 and 5 are design layers and that Layer 3 contains the implementation model for your application. Layer 3 plays a dual role because it is part of the design layer and the implementation layer. This is because application frameworks, pattern classes, class hierarchies, and template algorithms are useful during the design and are directly deployed at implementation. Once Layer 3 analysis is done, the application's concurrency infrastructure has a specific set of classes and template algorithms. We turn our attention to Layer 3 next.
Layer 3 analysis consists of selecting the application frameworks, pattern classes, class libraries, class hierarchies, algorithm templates, predicates, and container classes that are necessary to implement the agents, objects, components, predicates, and processes identified during the solution model decomposition, the application architecture selection and the concurrency model(s) identification. During Layer 3 analysis all of the primary design artifacts from Layers 4 and 5 are associated with specific Object-Oriented components, algorithms, and predicates. Once Layer 3 analysis is done, we have the clearest picture of the concurrency infrastructure and the concurrency implementation model of the application. Notice in Figure 8-6 that the items in Layer 3 are traceable back to the original statement of the problem. Since the entire PADL analysis takes place in the context of a well structured SDLC, the application that you deliver will be sound, scalable and maintainable by a software development group.
We mention development group here because the software development enterprise is a group effort. Useful software evolves over time and is changed and maintained by different individuals. Ad hoc approaches to parallel programming or multithreading hacks are virtually impossible to maintain in the long run. The work accomplished in Layers 3, 4, and 5 of the PADL analysis is the difference between software that has concurrency, allowing developers to actually manage and cope with the complexity, and software that just grows more complex and unmanageable and is finally decommissioned as the development group and the end users collapse under the strain.
Fortunately, the C++ environment has an impressive set of features, libraries, and techniques that can be deployed for model implementation. We emphasize the word model here because parallelism and concurrency are best managed in the context of models. The seven steps shown in Figure 8-6 move from models of the problem to models of the solution and finally to implementation models. If you use declarative models in your solutions, then you can reliably develop software that takes advantage of medium- to large-scale CMPs or massively parallel multicores. Although C++ does not have concurrency constructs, C++ does have excellent support for many categories of library. So, you can add support for parallel programming and multithreading to C++ through the use of libraries. There are three very important C++ component libraries that support parallel programming that we introduce in this chapter: the Parallel STL Library (STAPL), Intel Thread Building Blocks (TBB), and the new C++0x standard. Although there are many different efforts that have generated concurrency support using C++, we introduce these three because they will be soon be the most widely available and easily accessible C++ components that support concurrency, parallel programming, and multithreading.
As of this writing the new, standard for C++0x is on the verge of being adopted. The standard will probably be adopted in 2009, and the C++0x designation will become The C++09 Standard. C++03 adopted in 2003 is the current C++ standard. The C++0x standard includes some exciting updates to the language. Most of the improvements come in the form of new classes and libraries. The new C++ standard will have more support for parallel programming and multithreading through the addition of a concurrent programming library. This is very good news for C++ developers because prior to the new standard there was no guaranteed parallel programming facility in every C++ environment. The new standard will change this. Table 8-5 lists some of the new libraries that C++0x (C++09) will support.
Table 8.5. Table 8-5
Description | |
|---|---|
Message Passing Interface (MPI) library for use in distributed-memory and parallel application programming. | |
Includes interprocess mechanisms such as shared memory, memory mapped files, process shared mutexes, and condition variables. Also includes containers and allocators for processes. | |
-asio | A portable networking library that includes sockets, timers, and hostname resolution socket iostreams. |
The libraries in Table 8-5 contain some of the functionality that we discussed in Chapters 4, 5, 6, and 7, including threads, mutexes, condition variables, and Interprocess Communication (IPC) capabilities. The class libraries are essentially interface classes that wrap operating system APIs. They will be compatible with the POSIX thread management and process management facilities. Whereas the new standard provides an interface to most of the features in POSIX API, the holes can be filled by using other libraries, or providing your own interface classes to the POSIX API. Listing 8-1 shows a small part of the Boost C++ Libraries implementation of the new standard C++ thread class and some of the services that it offers developers. Boost has provided free peer-reviewed portable C++ source libraries that are compliant to the C++ Standard Library. Currently 10 of their libraries have been included in the C++ Standards Committee's Library Technical Report (TR1) and will become a part of future C++ Standards.
Example 8.1. Listing 8-1
//Listing 8-1 An implementation of the new C++0x thread class.
1 #ifndef BOOST_THREAD_THREAD_PTHREAD_HPP
2 #define BOOST_THREAD_THREAD_PTHREAD_HPP
3 // Copyright (C) 2001-2003
4 // William E. Kempf
5 // Copyright (C) 2007 Anthony Williams
6 //
7 // Distributed under the Boost Software License,
// Version 1.0. (See accompanying
8 // file LICENSE_1_0.txt or copy at http://www.boost.org/LICENSE_1_0.txt)
9
10 #include <boost/thread/detail/config.hpp>
11
12 #include <boost/utility.hpp>
13 #include <boost/function.hpp>
14 #include <boost/thread/mutex.hpp>
15 #include <boost/thread/condition_variable.hpp>
16 #include <list>
17 #include <memory>
1819 #include <pthread.h>
20 #include <boost/optional.hpp>
21 #include <boost/thread/detail/move.hpp>
22 #include <boost/shared_ptr.hpp>
23 #include "thread_data.hpp"
24 #include <stdlib.h>
25
26 #ifdef BOOST_MSVC
27 #pragma warning(push)
28 #pragma warning(disable:4251)
29 #endif
30
31 namespace boost
32 {
33 class thread;
34
35 namespace detail
36 {
37 class thread_id;
38 }
39
40 namespace this_thread
41 {
42 BOOST_THREAD_DECL detail::thread_id get_id();
43 }
44
45 namespace detail
46 {
47 class thread_id
48 {
49 private:
50 detail::thread_data_ptr thread_data;
51
52 thread_id(detail::thread_data_ptr thread_data_):
53 thread_data(thread_data_)
54 {}
55 friend class boost::thread;
56 friend thread_id this_thread::get_id();
57 public:
58 thread_id():
59 thread_data()
60 {}
61
62 bool operator==(const thread_id& y) const
63 {
64 return thread_data==y.thread_data;
65 }
66
67 bool operator!=(const thread_id& y) const68 {
69 return thread_data!=y.thread_data;
70 }
71
72 bool operator<(const thread_id& y) const
73 {
74 return thread_data<y.thread_data;
75 }
76
77 bool operator>(const thread_id& y) const
78 {
79 return y.thread_data<thread_data;
80 }
81
82 bool operator<=(const thread_id& y) const
83 {
84 return !(y.thread_data<thread_data);
85 }
86
87 bool operator>=(const thread_id& y) const
88 {
89 return !(thread_data<y.thread_data);
90 }
91
92 template<class charT, class traits>
93 friend std::basic_ostream<charT, traits>&
94 operator<<(std::basic_ostream<charT, traits>& os,
const thread_id& x)
95 {
96 if(x.thread_data)
97 {
98 return os<<x.thread_data;
99 }
100 else
101 {
102 return os<<"{Not-any-thread}";
103 }
104 }
105 };
106 }
107
108 struct xtime;
109 class BOOST_THREAD_DECL thread
110 {
111 private:
112 thread(thread&);
113 thread& operator=(thread&);
114
115 template<typename F>
116 struct thread_data:
117 detail::thread_data_base
118 {
119 F f;
120121 thread_data(F f_):
122 f(f_)
123 {}
124 thread_data(detail::thread_move_t<F> f_):
125 f(f_)
126 {}
127
128 void run()
129 {
130 f();
131 }
132 };
133
134 mutable boost::mutex thread_info_mutex;
135 detail::thread_data_ptr thread_info;
136
137 void start_thread();
138
139 explicit thread(detail::thread_data_ptr data);
140
141 detail::thread_data_ptr get_thread_info() const;
142
143 public:
144 thread();
145 ~thread();
146
147 template <class F>
148 explicit thread(F f):
149 thread_info(new thread_data<F>(f))
150 {
151 start_thread();
152 }
153 template <class F>
154 thread(detail::thread_move_t<F> f):
155 thread_info(new thread_data<F>(f))
156 {
157 start_thread();
158 }
159
160 thread(detail::thread_move_t<thread> x);
161 thread& operator=(detail::thread_move_t<thread> x);
162 operator detail::thread_move_t<thread>();
163 detail::thread_move_t<thread> move();
164
165 void swap(thread& x);
166
167 typedef detail::thread_id id;
168
169 id get_id() const;
170
171 bool joinable() const;
172 void join();
173 bool timed_join(const system_time& wait_until);174
175 template<typename TimeDuration>
176 inline bool timed_join(TimeDuration const& rel_time)
177 {
178 return timed_join(get_system_time()+rel_time);
179 }
180 void detach();
181
182 static unsigned hardware_concurrency();
183
184 // backwards compatibility
185 bool operator==(const thread& other) const;
186 bool operator!=(const thread& other) const;
187
188 static void sleep(const system_time& xt);
189 static void yield();
190
191 // extensions
192 void interrupt();
193 bool interruption_requested() const;
194 };
195
196 inline detail::thread_move_t<thread> move(thread& x)
197 {
198 return x.move();
199 }
200
201 inline detail::thread_move_t<thread>
move(detail::thread_move_t<thread> x)
202 {
203 return x;
204 }
205
206
207 template<typename F>
208 struct thread::thread_data<boost::reference_wrapper<F> >:
209 detail::thread_data_base
210 {
211 F& f;
212
213 thread_data(boost::reference_wrapper<F> f_):
214 f(f_)
215 {}
216
217 void run()
218 {
219 f();
220 }
221 };
222
223 namespace this_thread
224 {
225 class BOOST_THREAD_DECL disable_interruption226 {
227 disable_interruption(const disable_interruption&);
228 disable_interruption& operator=(const disable_interruption&);
229
230 bool interruption_was_enabled;
231 friend class restore_interruption;
232 public:
233 disable_interruption();
234 ~disable_interruption();
235 };
236
237 class BOOST_THREAD_DECL restore_interruption
238 {
239 restore_interruption(const restore_interruption&);
240 restore_interruption& operator=(const restore_interruption&);
241 public:
242 explicit restore_interruption(disable_interruption& d);
243 ~restore_interruption();
244 };
245
246 BOOST_THREAD_DECL thread::id get_id();
247
248 BOOST_THREAD_DECL void interruption_point();
249 BOOST_THREAD_DECL bool interruption_enabled();
250 BOOST_THREAD_DECL bool interruption_requested();
251
252 inline void yield()
253 {
254 thread::yield();
255 }
256
257 template<typename TimeDuration>
258 inline void sleep(TimeDuration const& rel_time)
259 {
260 thread::sleep(get_system_time()+rel_time);
261 }
262 }
263
264 namespace detail
265 {
266 struct thread_exit_function_base
267 {
268 virtual ~thread_exit_function_base()
269 {}
270 virtual void operator()() const=0;
271 };
272
273 template<typename F>
274 struct thread_exit_function:
275 thread_exit_function_base
276 {
277 F f;278
279 thread_exit_function(F f_):
280 f(f_)
281 {}
282
283 void operator()() const
284 {
285 f();
286 }
287 };
288
289 BOOST_THREAD_DECL void
add_thread_exit_function(thread_exit_function_base*);
290 }
291
292 namespace this_thread
293 {
294 template<typename F>
295 inline void at_thread_exit(F f)
296 {
297 detail::thread_exit_function_base*
const thread_exit_func=new detail::thread_exit_function<F>(f);
298 detail::add_thread_exit_function(thread_exit_func);
299 }
300 }
301
302 class BOOST_THREAD_DECL thread_group
303 {
304 public:
305 thread_group();
306 ~thread_group();
307
308 thread* create_thread(const function0<void>& threadfunc);
309 void add_thread(thread* thrd);
310 void remove_thread(thread* thrd);
311 void join_all();
312 void interrupt_all();
313 size_t size() const;
314
315 private:
316 thread_group(thread_group&);
317 void operator=(thread_group&);
318
319 std::list<thread*> m_threads;
320 mutex m_mutex;
321 };
322 } // namespace boost
323
324 #ifdef BOOST_MSVC
325 #pragma warning(pop)
326 #endif
327
328
329 #endifNotice on Line 302 of Listing 8-1 that the new thread class also supports thread groups. This provides much of the functionality of the POSIX pthread API. Notice on Line 19 that this implementation includes pthread.h. We covered the role of the operating system in Chapter 4 and explained that the operating system is the gatekeeper of the hardware and the multicores. Any class hierarchies, application frameworks, or pattern classes that present multithreading or multiprocessing capabilities are essentially providing interface classes to the operating system API. So, this is a welcome interface class because with standard C++ classes like the thread class shown in Listing 8-1 you get to move one step closer to declarative interpretations of parallel programming. These kinds of interface classes not only add declarative or Object-Oriented flavor to low-level operating system primitives, but they also simplify the interface. Consider Lines 308-311 and their POSIX API pthread counterparts. These methods replace direct calls to pthread calls such as pthread_create(), pthread_join(), using the attribute object to detach threads, thread cancellation functions, and so on. Interface classes as implemented in this type of library allow developers to maintain their Object-Oriented or declarative approach to application development.
In addition to thread interface classes, the C++0x standard will include mutex interface classes.
We explained the POSIX pthread_mutex() and its use in dealing with one of the primary synchronization challenges of multithreading. But pthread_mutex() is in Layer 2 of the PADL analysis. Ideally, you do not want to do most of the synchronization at Layer 2, and the important reason that you don't want to do the majority of your synchronization at Layer 2 is because the POSIX API has procedural semantics. To take advantage of the POSIX API services, you would have to provide interface classes. The new C++ standard comes to the rescue here by providing standard mutex classes. Listing 8-2 is Anthony William's implementation of the standard C++ mutex class. As you can see, the basic pthread mutex functionality of lock, unlock, destroy, timed lock, and so forth is encapsulated in the mutex class. Also, a timed mutex class is defined that encapsulates some of the functionality of a condition variable.
Example 8.2. Listing 8-2
//Listing 8-2 An implementation of the new standard C++0x mutex class. 1 #ifndef BOOST_THREAD_PTHREAD_MUTEX_HPP 2 #define BOOST_THREAD_PTHREAD_MUTEX_HPP 3 // (C) Copyright 2007 Anthony Williams 4 // Distributed under the Boost Software License, Version 1.0. (See 5 // accompanying file LICENSE_1_0.txt or copy at 6 // http://www.boost.org/LICENSE_1_0.txt) 7 8 #include <pthread.h> 9 #include <boost/utility.hpp> 10 #include <boost/thread/exceptions.hpp> 11 #include <boost/thread/locks.hpp> 12 #include <boost/thread/thread_time.hpp> 13 #include <boost/assert.hpp> 14 #ifndef WIN32 15 #include <unistd.h> 16 #endif 17 #include <errno.h> 18 #include "timespec.hpp" 19 #include "pthread_mutex_scoped_lock.hpp"
20
21 #ifdef _POSIX_TIMEOUTS
22 #if _POSIX_TIMEOUTS >= 0
23 #define BOOST_PTHREAD_HAS_TIMEDLOCK
24 #endif
25 #endif
26
27 namespace boost
28 {
29 class mutex:
30 boost::noncopyable31 {
32 private:
33 pthread_mutex_t m;
34 public:
35 mutex()
36 {
37 int const res=pthread_mutex_init(&m,NULL);
38 if(res)
39 {
40 throw thread_resource_error();
41 }
42 }
43 ~mutex()
44 {
45 BOOST_VERIFY(!pthread_mutex_destroy(&m));
46 }
47
48 void lock()
49 {
50 BOOST_VERIFY(!pthread_mutex_lock(&m));
51 }
52
53 void unlock()
54 {
55 BOOST_VERIFY(!pthread_mutex_unlock(&m));
56 }
57
58 bool try_lock()
59 {
60 int const res=pthread_mutex_trylock(&m);
61 BOOST_ASSERT(!res || res==EBUSY);
62 return !res;
63 }
64
65 typedef pthread_mutex_t* native_handle_type;
66 native_handle_type native_handle()
67 {
68 return &m;
69 }
70
71 typedef unique_lock<mutex> scoped_lock;
72 typedef scoped_lock scoped_try_lock;
73 };74
75 typedef mutex try_mutex;
76
77 class timed_mutex:
78 boost::noncopyable
79 {
80 private:
81 pthread_mutex_t m;
82 #ifndef BOOST_PTHREAD_HAS_TIMEDLOCK
83 pthread_cond_t cond;
84 bool is_locked;
85 #endif
86 public:
87 timed_mutex()
88 {
89 int const res=pthread_mutex_init(&m,NULL);
90 if(res)
91 {
92 throw thread_resource_error();
93 }
94 #ifndef BOOST_PTHREAD_HAS_TIMEDLOCK
95 int const res2=pthread_cond_init(&cond,NULL);
96 if(res2)
97 {
98 BOOST_VERIFY(!pthread_mutex_destroy(&m));
99 throw thread_resource_error();
100 }
101 is_locked=false;
102 #endif
103 }
104 ~timed_mutex()
105 {
106 BOOST_VERIFY(!pthread_mutex_destroy(&m));
107 #ifndef BOOST_PTHREAD_HAS_TIMEDLOCK
108 BOOST_VERIFY(!pthread_cond_destroy(&cond));
109 #endif
110 }
111
112 template<typename TimeDuration>
113 bool timed_lock(TimeDuration const & relative_time)
114 {
115 return timed_lock(get_system_time()+relative_time);
116 }
117
118 #ifdef BOOST_PTHREAD_HAS_TIMEDLOCK
119 void lock()
120 {
121 BOOST_VERIFY(!pthread_mutex_lock(&m));
122 }
123124 void unlock()
125 {
126 BOOST_VERIFY(!pthread_mutex_unlock(&m));
127 }
128
129 bool try_lock()
130 {
131 int const res=pthread_mutex_trylock(&m);
132 BOOST_ASSERT(!res || res==EBUSY);
133 return !res;
134 }
135 bool timed_lock(system_time const & abs_time)
136 {
137 struct timespec const timeout=detail::get_timespec(abs_time);
138 int const res=pthread_mutex_timedlock(&m,&timeout);
139 BOOST_ASSERT(!res || res==EBUSY);
140 return !res;
141 }
142 #else
143 void lock()
144 {
145 boost::pthread::pthread_mutex_scoped_lock const local_lock(&m);
146 while(is_locked)
147 {
148 BOOST_VERIFY(!pthread_cond_wait(&cond,&m));
149 }
150 is_locked=true;
151 }
152
153 void unlock()
154 {
155 boost::pthread::pthread_mutex_scoped_lock const local_lock(&m);
156 is_locked=false;
157 BOOST_VERIFY(!pthread_cond_signal(&cond));
158 }
159
160 bool try_lock()
161 {
162 boost::pthread::pthread_mutex_scoped_lock const local_lock(&m);
163 if(is_locked)
164 {
165 return false;
166 }
167 is_locked=true;
168 return true;
169 }
170
171 bool timed_lock(system_time const & abs_time)
172 {
173 struct timespec const timeout=detail::get_timespec(abs_time);
174 boost::pthread::pthread_mutex_scoped_lock const local_lock(&m);
175 while(is_locked)176 {
177 int const cond_res=pthread_cond_timedwait(&cond,&m,&timeout);
178 if(cond_res==ETIMEDOUT)
179 {
180 return false;
181 }
182 BOOST_ASSERT(!cond_res);
183 }
184 is_locked=true;
185 return true;
186 }
187 #endif
188
189 typedef unique_lock<timed_mutex> scoped_timed_lock;
190 typedef scoped_timed_lock scoped_try_lock;
191 typedef scoped_timed_lock scoped_lock;
192 };
193
194 }
195
196
197 #endifIf you look at Lines 77-110, you can see how the services that POSIX API functions such as pthread_mutex_init(), pthread_cond_init(), pthread_cond_destroy(), and pthread_mutex_destroy() are adapted in a timed_mutex interface class. We explained in Chapter 4 the importance of understanding the operating system's role even though the goal is to program at higher level. This implementation of a mutex class that will be available in the new C++ standard can serve to illustrate that point. This class does not perform all of the functionality that you might want in a mutex class. Further, this mutex class might be used in conjunction with other thread libraries such as the TBB. If there are any problems at runtime, you have to have some idea of where these classes intersect with the operating system. Both the C++ thread class and the TBB threading facilities may use the POSIX pthreads differently in subtle ways. So, you deploy higher-level classes in Layer 3 of the PADL model, but you must keep in mind that those classes are ultimately mapped to operating system APIs, in our case, the POSIX API.
The thread class in Listing 8-1 and the mutex class in Listing 8-2 are taken from the Boost C++ libraries found at www.boost.org. Boost provides free peer-reviewed portable C++ source libraries. The Boost group emphasizes libraries that work well with the C++ standard Library. Boost libraries are intended to be widely usable across a broad spectrum of applications. The Boost group aims to establish "existing practice" and provide reference implementations so that Boost libraries are suitable for eventual standardization. The concurrent programming libraries that we introduced in this chapter have Boost reference implementations and can be freely downloaded.
Another important component that can be used in level 3 PADL analysis is the Intel Threading Building Blocks (TBB). The TBB is a set of C++ components consisting of generic algorithm templates, container classes, and Object-Oriented synchronization components, as well as other miscellaneous components that are very useful in multithreaded programming. The TBB is a runtime-based parallel programming model for C++ code that uses threads. It is designed primary to write scalable applications that:
Specify tasks instead of threads
Emphasize data parallel programming
Take advantage of concurrent collections
Table 8-6 lists some of the primary template algorithms and containers that are available in the TBB library.
While the TBB intersects in a few areas (for example, mutexes), with the new concurrent programming library in the new C++ standard, it is largely complementary and provides a set of tools that can be used in the implementation Layer of PADL. Recall the seven steps from Figure 8-6. In Layer 4, we identified concurrency models. Layer 4 does not determine whether those concurrency models will be implemented by threads or processes. In fact, the concurrency models in Layer 4 can be implemented by clusters or other distributed computing models. The question and answer example that uses the Blackboard architecture does not indicate whether the knowledge sources should be implemented as threads or as processes. It also may be the case that one knowledge source may be implemented by a multiple threads or processes or even a combination of threads and processes. This can be necessary in order to meet the logical requirements of the knowledge source. To see how you might get to Layer 3 in the Blackboard example, you can take a closer look at the control strategies in the Blackboard architecture.
There are several layers of control in a Blackboard implementation where the knowledge sources may be activated concurrently. At the lowest layer, there are synchronization schemes that must protect the integrity of the Blackboard. Although the Blackboard is an application architecture from Layer 5 of PADL and the discussion at that level is conceptual, you can state that the Blackboard is a critical section because ultimately it is a shared modifiable resource. In fact Table 8-4 shows that CRCW or CREW concurrency models are called for in the use of the Blackboard applied to knowledge sources. In a parallel environment, the knowledge sources' read and write access must be coordinated and synchronized. This coordination and synchronization can involve file locking, semaphores, mutexes, and so on. This layer of control is not directly involved in the solution that the knowledge sources are working toward. This is a utility layer of control and should be independent of the problem to be solved by the Blackboard. In the architectural approach for this chapter's example, this layer of control will be implemented by interface classes like the mutex and semaphore classes that we introduced in Chapter 7. You can also take advantage of the concurrent containers that the TBB has to offer to partially meet your needs for CRCW or CREW. Parts of the Blackboard could be implemented using the concurrent_vector class from the TBB. The concurrent_vector allows safe simultaneous access, and it is easy to use and easily works with components from the standard C++ library. Listing 8-3 is an excerpt from the question and answer Blackboard example.
Example 8.3. Listing 8-3
//Listing 8-3 A Program that uses concurrent_vector and parallel_for from TBB.
1 using namespace std;
2 #include <iostream>
3 #include <vector>
4 #include <stdlib.h>
5 #include <ctype.h>
6 #include <algorithm>
7 #include <iterator>
8 #include <string>
9 #include "tbb/blocked_range.h"
10 #include "tbb/parallel_for.h"
11 #include "tbb/task_scheduler_init.h"
12 #include "tbb/concurrent_vector.h"
13 #include <sstream>
14 #include <fstream>
15
16 using namespace tbb;
17 concurrent_vector<string> Terms;
18 concurrent_vector<string> Question;
19
20
21 class lower_case{
22
23 public:
24 char operator()(char X){
25
26 return(tolower(X));
27 }
28
29 };
30
31
32
33 void changeIt(string &X)
34 {
35 transform(X.begin(),X.end(),X.begin(),lower_case());
36 }37
38
39
40 void tokenize(string &X)
41 {
42 stringstream Sin(X);
43 string Token;
44 while(!Sin.fail() && Sin.good())
45 {
46 Sin >> Token;
47 Terms.push_back(Token);
48 }
49 }
50
51
52 class parallel_lower_case{
53
54 public:
55
56 void operator() (const blocked_range<int> &X) const
57 {
58 for(int I = X.begin(); I != X.end(); I++)
59 {
60
61 changeIt(Terms[I]);
62
63 }
64
65 }
66
67 };
68
69 class valid_tokens{
70 public:
71 void operator() (const blocked_range<int> &X) const
72 {
73 for(int I = X.begin(); I != X.end(); I++)
74 {
75 tokenize(Question[I]);
76
77 }
78
79 }
80
81 };
82
83
84
85
86 int main(int argc,char *argv[])
87 {
88
89 task_scheduler_init Init;
90 ifstream Fin("question.txt");91 istream_iterator<string> Ftr(Fin);
92 istream_iterator<string> Eof;
93 copy(Ftr,Eof,back_inserter(Question));
94 Fin.close();
95 parallel_lower_case Lower;
96 valid_tokens Token;
97 parallel_for(blocked_range<int>(0,Question.size(),
(Question.size() /2)),Token);
98 parallel_for(blocked_range<int>(0,Terms.size(),
(Terms.size() /2)),Lower);
99 ostream_iterator<string> Out(cout,"
");
100 copy(Terms.begin(),Terms.end(),Out);
101
102
103 }Part of the processing of our knowledge sources required that the individual words in a question be tagged with their part of speech or flagged as unknown, misspelled, or so forth. The program in Listing 8-3 is for exposition only. We include it here to demonstrate how TBB components can be easily mapped from Layers 4 and 5 of the PADL. The Terms component declared on Line 17 is a TBB concurrent_vector<T>. This vector permits concurrent read access by multiple knowledge sources. This satisfies part of the CREW concurrency model. Likewise, part of the processing requires that the questions be broken up into individual words or tokens and that the tokens be converted to lowercase. The call to the TBB parallel_for algorithm on Line 97 breaks up each Question that is stored in the Question vector into individual tokens. This is done on Lines 40-49. The parallel_for() algorithm on Line 97 takes Token as a C++ function object. The parallel_for() on Line 98 converts the tokens in the Terms vector to lowercase. The parallel_for algorithm does a high-level loop unrolling. It can execute components of its function object in parallel. In this example, the function calls on Lines 61 and 75 are executed in parallel. Notice on Lines 93 and 100 that the TBB concurrent_vector<T> is used with ostream_iterator<string>, istream_iterator<string>, and the standard C++ copy() algorithm.
Here is Program Profile 8-1 for Listing 8-3.
The program in Listing 8-3 demonstrates how TBB components can be mapped from Layers 4 and 5 of the PADL. The Terms component is a TBB concurrent_vector<T>. This vector permits concurrent read access by multiple knowledge sources. The TBB parallel_for algorithm is used to break up each Question stored in the Question vector into individual tokens, takes Token as a C++ function object, and converts the tokens in the Terms vector to lowercase. The TBB concurrent_vector<T> is used with ostream_iterator<string>, istream_iterator<string>, and the standard C++ copy() algorithm.
c++ -o convert_it -I TBBIncludePath convert_it.cc -L TBBLibraryPath -ltbb
As noted, concurrent programming library facilities will appear in the new C++ standard, including a long awaited thread library and synchronization components. However, another important set of C++ components that will support parallel programming is the Standard Template Adaptive Parallel Library (STAPL). Whereas TBB and the upcoming concurrent programming library in C++ are designed to work with multicore and parallel computers, STAPL is designed to work on both shared and distributed memory parallel computers. The STAPL library design goals are consistent with our PADL analysis approach to designing parallel programs. STAPL is designed to allow developers to work at a high level of abstraction. It provides interface classes and interface algorithms that hide many of the details specific to parallel programming. Throughout this book, we have made a distinction between application-level developers and system-level developers. System-level development tends to work closer to the operating system APIs and SPIs. STAPL users are divided into three groups:
Users: These are the application developers who primarily use the STAPL components without having to do much extending or redefining.
Developers: These developers extend the toolset of STAPL usually within the context of specific domains or applications through adding new data structures and algorithms for the users.
Specialists: This group provides the users and the developers with additional programming frameworks for developing algorithms and applications.
Bjarne Stroustrup, the inventor of C++, is involved with the development of STAPL. This means that you can count on STAPL to be consistent with the philosophy of the C++ standard. STAPL consists of these primary components:
Views: Support the notion of iteration and object visitation for the pContainers.
pAlgorithms: Standard Template Library (STL) algorithms that support parallelism.
pRange: The pAlgorithms are executed over a range. The pRange allows for the Work Breakdown Structure (WBS) of the algorithm to be stated in a Task Dependency Graph.
Runtime: Runtime system that provides performance monitoring, communication primitives, scheduling for the subviews or tasks of the pRanges, and so on.
Figure 8-7 shows a block diagram of the structure of the STAPL library.
The standard C++ concurrent programming library will be complementary and compatible with STAPL.
The TBB is in part inspired by design concepts in STAPL, but STAPL is a higher-level framework that extends both the STL and TBB. Also notice in Figure 8-7 that the Runtime system can and will interface with the POSIX pthread API as well as with other operating thread and process APIs. You can see from looking at the structures of the new concurrent programming class library that will be part of C++0x, TBB, and STAPL that using interface classes and components that wrap lower-level operating system primitives is the most practical way to provide concurrency support to the C++ developer. Notice in Figure 8-7 that the user application code is at least two layers above the POSIX threads. If you look back at Figure 4-1 in Chapter 4, it shows the relationships for the developer's view of the operating system and frameworks such as STAPL. The complexity and special challenges of parallel programming as discussed in Chapter 3 require that the software developer have a clear understanding of the integration between class libraries, application frameworks, pattern classes, algorithm templates, and the concurrency and synchronization services that the operating system provides. PADL and PBS analysis (which is discussed later in the chapter) are performed in the context of a solid understanding of the relationships of all of the pieces involved.
More information about the STAPL library can be found at
http://parasol.tamu.edu/stapl.
The new standard C++ concurrent programming class libraries, TBB, and STAPL provide the bulk of the implementation domain independent components that you need in Layer 3 of the PADL analysis. Keep in mind that Layer 3 components consist of domain-specific application frameworks, class libraries, and so forth as well as domain-independent components.
If you look at the Blackboard example, the segmentation of the Blackboard into parts determines whether CREW or CRCW concurrency (determined in Layer 2 of PADL) is appropriate. The most flexible model of critical section access is CRCW. CRCW can be achieved depending on the structure of the Blackboard. For instance, if 16 knowledge sources are involved in a collaborative effort and each knowledge source accesses its own segment of the Blackboard, then these knowledge sources can concurrently read and write the Blackboard without data race problems. Looking at the communication model can also help determine what Layer 3 components will be used. Obviously, containers that support concurrency such as the TBB concurrent_vector<T> or concurrent_queue<T> or pContainers from STAPL can be used to implement some portions of the Blackboard that require CREW. With a little planning, these structures can also support CRCW.
One of the major reasons that we choose multiagent architectures and Blackboard architectures as our two fundamental application architectures for Layer 5 in PADL is that the patterns of work that can be captured by these architectures are extremely flexible and well understood. Here is an important point.
Before putting effort into the coordination and synchronization of concurrent threads or processes in your application, it is better to have a solid handle on the pattern of work at the domain and application level.
STAPL supports work at a higher level. The TBB is best used when the developer thinks in terms of tasks not threads. Here, we go a step further; think about the "story" of your application, how the actors and objects naturally interface. Work out the pattern of work at the model level in Layers 4 and 5. Understand the parallelism or concurrency in terms of a well-known architecture that supports concurrency (for example, Blackboards, multiagents).
To examine this further, take a closer look closer at the Blackboard control strategy for the example used in this chapter.
The layer of control in a Blackboard involves the selection of which knowledge sources to involve in the search for the solution and which aspects of the problem to focus on. This is a focus or attention layer. This layer of control focuses on a certain area of the problem and selects knowledge sources accordingly. Major issues to tackle in any kind of problem solving are where to start and what kind of information is needed to solve the problem. The focus/attention layer evaluates the initial conditions of the problem and then controls which knowledge sources to use and where they start. The available knowledge sources are known to the Blackboard, and typically the knowledge source accepts messages or parameters that dictate how it should proceed or where in the solution space it should begin the search. For parallel implementations, this layer determines the basic concurrency model for Layer 4 in PADL. Usually for Blackboards, this is the Multiple Programs Multiple Data (MPMD — a.k.a. MIMD) model because each knowledge source/problem solver has its own area of specialty. However, the nature of the problem might warrant the popular Single Program Multiple Data (SPMD or SIMD) model. If this model is used, the control layer spawns N number of the same knowledge source but pass different parameters to each.
The next layer of control involves determining what to do with the solution or partial solutions that are written to the Blackboard. This layer of control will determine whether the knowledge sources can stop work or whether the solution that was generated is acceptable, unacceptable, partially acceptable, and so on. This layer of control has complete visibility of the Blackboard and all the partial or tentative solutions. It guides the overall problem-solving strategies of the collective. As with the layout of the Blackboard and the structure of the knowledge sources, the Blackboard model suggests the existence of a control component but does not specify how it should be structured. Sometimes the control component is part of the Blackboard. Sometimes the control component is implemented by the knowledge sources. In some cases, the control component is implemented by modules external to the Blackboard. The control component can also be implemented by any combination of these. The knowledge sources collectively search for a solution to some problem. We want to emphasize a solution because many problems have more than one solution. Some of the solutions may be deeper in the search space than others. Some solutions may cost more to find than others. Some solutions may be deemed not good enough. The control component helps to manage the collective search strategies of the knowledge sources. The control component monitors the tentative or partial solutions to make sure that the knowledge sources are not pursuing an impractical search strategy. The control component looks out for any infinite loops, blind alleys, or recursive regression. Further, the control component is involved in selecting the best or the most appropriate knowledge sources for the problem. As the knowledge sources make progress toward a solution, the control component may relieve some knowledge sources while assigning others. The control strategy will be closely related to the search strategies used by the knowledge sources. It is important to remember that the knowledge sources may each use different search strategies and problem-solving techniques. Although they work with a common Blackboard, the knowledge sources or problem solvers are essentially autonomous and self-contained. Therefore, this layer of control has a two-way communication with the knowledge sources. Figure 8-8 shows possible control configurations and their layers in a Blackboard architecture.

Notice the relationships between the Blackboard and the knowledge sources in Figure 8-8. If this interface is properly and completely worked out at the design level, then mapping knowledge sources or agents to tasks, threads, or processes is easier. It is not practical to attempt to optimize threads or processes and coordinate communication or synchronization at the implementation level if things are murky at the design and domain level. On the other hand, if all of the relationships are completely clear at the design level, if the patterns of work are well understood, and if the details of actor/object interaction have been worked out, then mapping to threads or processes is straightforward.
The chances for a successful software deployment are greatly increased. The "story" of the application, that is, its beginning, middle, and ending, has to be clear to all the developers involved. This understanding starts with a PADL analysis and PBS of your software application.
A predicate is statement that is either true or false. A predicate makes a statement about some relationship between some person, place, thing, or idea. The Predicate Breakdown Structure (PBS) of an application breaks the application down into a set of statements that describe assertions and patterns of work of an application. The PBS of an application contains the rules, constraints, assertions, predicates, propositions, and axioms that apply to the agents, actors, and objects and their relationships within an application. The PBS captures the most declarative structure of an application or piece of software. This declarative structure is critical for software that has parallel programming or concurrency requirements. When it comes to parallel programming the old adage "Make it work, then make it fast" is a requirement for survival. The PBS helps you to understand what it truly means when you say the application works or that it's correct.
Throughout this book we've explained why if you think of multithreaded or multiprocessing programs from the bottom up as sequences of parallel instructions or parallel procedures, you will soon reach a limit because of the complexity of interactions between the instructions and procedures and the sheer number of cores that will eventually become available (that is, massively parallel CMPS). We have suggested that you need to begin the move away from thinking about parallel programming procedurally and move toward declarative programming techniques. There are many reasons why declarative interpretations of parallelism are beneficial. Today's systems are growing larger, more complex, and more integrated. Now adding to this mix are multicore capabilities of computers at the client side and server side. Imperative programming techniques buckle under this level of complexity. On the other hand, declarative techniques are scalable and have models that are designed to deal with complexity (for example, First-Order Logic analysis, model checking, Boolean algebra, and so on). Declarative interpretations describe what software systems are and what they mean as opposed to what they do and how it is done. Once you start thinking about hundreds or thousands of concurrently executing threads or processes, it is difficult to keep in mind what is going on in the system. This can make maintenance, testing, and debugging treacherous. Declarative interpretations make you consider what is true about the relationships between agents, actors, and objects in the system at any given time. Imperative approaches focus on what to do and when to do it. Declarative approaches focus on what is true or false and what conditions are necessary to cause some statement or predicate in the application to be true or false at any instant.
The PBS structure helps you capture the "meaning" of an application or piece of software. The meaning of a piece of software is important because if you understand the software, then you know how it can be scaled and evolved while at the same time keeping it reliable and correct. If you do not understand the software's meaning, then software maintenance and software evolution is hopeless. This is especially true for software that involves parallel programming. PADL analysis and PBS can be used to help make the shift away from imperative and sequential models of programming and toward declarative semantic design models.
You were able to write a guess-it application that used concurrently executing processes that were then broken down into currently executing threads in order to take enough guesses in the time limit to win the game. You could think about how many parallel threads or processes you would need to plow through 4 million codes in 2 minutes. You could also focus on what action the threads or processes would have to take. However, this would be more of an empirical approach to the problem. A PBS breakdown of the guess-what-code-I'm-thinking-of game would have a more goal look-and-feel. Example 8-1 is one PBS breakdown of the game.
Example 8.1. A PBS Breakdown of the Guess-What-Code Game
Breakdown 1: You've won the game if your guess is correct and in time.
Breakdown 2: Your guess is correct if it consists of a six-character code that contains only combinations of the characters (a-z, 0-9), considering duplication is allowed, and that code is the one my agent has handed me.
Breakdown 3: Your guess is in time if it is correct and it occurs within 2 minutes.
Breakdown 4: A brute force search through the codes will be successful if there are enough agents searching.
Breakdown 5: N agents are enough find the correct code from a sample of 4 million codes in 2 minutes.
Breakdown 6: 4 times N agents are required to find the correct code from a sample of 4 million codes in 2 minutes if the code is being changed every 15 seconds.
The PBS in Example 8-1 consists of the rules, statements, or predicates that make up the application.
These statements are either true or false. If you design code that correctly represents these statements, then the application will be correct and will work if the original statements are correct. On the other hand, if one or more of the statements are false, then the underlying code will also be in error. For example, Breakdown 5 states that N agents are enough. How do you know that N agents are enough? If you do your homework at this level, then later translations into concurrently executing instructions or threads are more productive and correct. How big should N be is the kind of information you want to discover during PADL analysis and the design activities of the SDLC. It should not be part of some trial-and-error process handled at the thread management level. Although the PBS presented in Example 8-1 is a simplification, it serves as a complete example of what we mean by PBS. Notice that Breakdown 6 deals with dynamically changing code and resubmission of the entire guess data set.
Once the PBS is complete and the development group is satisfied with the PBS of the application, then the PBS is used to help with the application architecture selection that is done in Layer 5 and the concurrency model identification that is done in Layer 4 of the PADL. In terms of the SDLC, the PBS is done during the requirements gathering, analysis, and design activities. Ideally, it is done before Layer 5 in PADL, but sometimes it is performed concurrently with Layer 5 analysis. In an actual PBS breakdown, the statements are refined and clarified until there is no ambiguity left in the statement of the applications solution or services. Further, because the PBS consists of propositions, predicates, and statements, theorem-proving approaches and model-checking techniques can be used to determine the correctness of the application prior to any code that is developed. This ability to check for correctness, meaning, and declarative semantics prior to code implementation becomes more critical as you move toward more complex systems and massively parallel multicore computers.
Domain components, that is, the agents, actors, and objects of the application domain, should be associated with C++ application frameworks, class hierarchies, domain classes, and so on at Layer 3 in the PADL model.
For every person, place, thing, or idea mentioned in the PBS, there should be a corresponding C++ component(s) that implements the concept and the relationships between the concepts. These components will be the domain components, and they will be directly visible in the application architecture. That's because the application architecture is primarily chosen because of its fit with the PBS. The correctness and completeness of the application can be seen and proved at this level. Once the domain classes are provided, they can be supported by components from the TBB, the C++ concurrent programming library, or frameworks such as STAPL. Using PADL and PBS helps produce applications that are correct, that can evolve and that can be maintained in an efficient manner.
In this chapter, we explained how to approach the process of application design when there is a concurrency requirement in the original software development request or when parallelism is explicitly called for or implied by the solution decomposition. We discussed two main approaches:
First, we introduced Parallel Application Design Layers (PADL), a five-layer analysis model that we use at CTEST Laboratories during the requirements analysis, software design, and decomposition activities of SDLC. We also use the PADL model to circumvent much of the complexity that results from bottom up approaches to parallel programming. Also in this chapter we presented a top-down architectural approach to parallelism rather than a bottom-up, task-oriented imperative approach. We also presented multiagent architectures and Blackboard architectures as two of the main and well understood paradigms for parallel programming at the application level. Most successful software undergoes constant change. If that software has components that require concurrency and synchronization, then the natural evolution of the software can be extremely challenging if an appropriate application architecture is not selected from the start. The PADL analysis model identifies multiagent and Blackboard architectures as two well-known and well-understood architectures that perform well under the conditions of software evolution. Ultimately, the concurrency of an application is going to be implemented by low-level operating system primitives like threads and processes. If the application architecture is clean, modular, scalable, and well understood, then the translation into manageable operating system primitives has a chance to succeed. On the other hand, selection of the wrong or a poor application architecture can lead to brittle, error-prone software that cannot be readily changed, maintained, or evolved. While this is true of any kind of computer application, it is magnified when that software involves parallel programming, multithreading, or multiprocessing.
We also introduced the notion of a Predicate Breakdown Structure (PBS) of an application idea. The PBS of an application breaks the application down into a set of statements that describe assertions and patterns of work of an application. The PBS of an application contains the rules, constraints, assertions, predicates, propositions, and axioms that apply to the agents, actors, and objects and their relationships within an application. The PBS captures the most declarative structure of an application or piece of software. This declarative structure is critical for software that has parallel programming or concurrency requirements. The PBS structure helps capture the "meaning" of an application or piece of software. The meaning of a piece of software is important because if you understand the software, then you know how it can be scaled and evolved, while at the same time keeping it reliable and correct. If you do not understand the software's meaning, then software maintenance and software evolution are impossible.
Today's systems are growing larger and more complex and more integrated. We are now adding to this mix multicore capabilities of computers at the client side and server side. Imperative programming techniques buckle under this level of complexity. On the other hand, declarative techniques are scalable and have models that are designed to deal with complexity Declarative interpretations describe what software systems are and what they mean as opposed to what they do and how it is done. They make you consider what is true about the relationships between agents, actors, and objects in the system at any given time. It is not practical to attempt to optimize thread or processes and coordinate communication or synchronization at the implementation level if things are murky at the design and domain level. On the other hand, if all of the relationships are completely clear at the design level and the patterns of work are well understood at the design level and the details of actor/object interaction has been worked out, then mapping to threads or processes will be straightforward. The chances for a successful software deployment are greatly increased. The story of the application has to be clear to all the developers involved. This understanding starts with a PADL analysis and PBS of your software application.
In the next chapter, we discuss modeling and documenting applications using UML notation for concurrent behavior. We have used UML class, sequence, and activity diagrams in the book so far. In the next chapter, we discuss some basic UML diagramming techniques for modeling classes, gradually covering concurrent notation and behavior between classes and ultimately the architecture of systems with parallelism.