
In this chapter, we will go slowly through the MOV and ADD instructions to lay the groundwork on how they work, especially in the way they handle parameters (operands), so that, in the following chapters, we can proceed at a faster pace as we encounter the rest of the ARM instruction set.
Before getting into the MOV and ADD instructions, we will discuss the representation of negative numbers and the concepts of shifting and rotating bits.
Negative Numbers
In the previous chapter, we discussed how computers represent positive integers as binary numbers, called unsigned integers, but what about negative numbers? Our first thought might be to make one bit represent whether the number is positive or negative. This is simple, but it turns out it requires extra logic to implement, since now the CPU must look at the sign bits, then decide whether to add or subtract and in which order.
It turns out there is a simple representation of negative numbers that works without any special cases or special logic; it is called two’s complement.
About Two’s Complement
The great mathematician John von Neumann, of the Manhattan Project, came up with the idea of the two’s complement representation for negative numbers, in 1945, when working on the Electronic Discrete Variable Automatic Computer (EDVAC) computer—one of the earliest electronic computers.
(all binary ones) we get 0x100.
Two’s complement is an interesting mathematical oddity for integers, which are limited to having a maximum value of one less than a power of two (which is all computer representations of integers).
3 in 1 byte is 0x03 or 0000 0011.
since we are limited to 1 byte or 8 bits.
Performing these computations by hand is educational, but practically a tool to do this would be handy.
About Gnome Programmer’s Calculator
Fortunately, we have computers to do the conversions and arithmetic for us, but when we see signed numbers in memory, we need to recognize what they are. The Gnome programmer’s calculator can calculate two’s complement for you. Figure 2-1 shows the Gnome calculator representing -3.
The Gnome programmer’s calculator uses 64-bit representations.
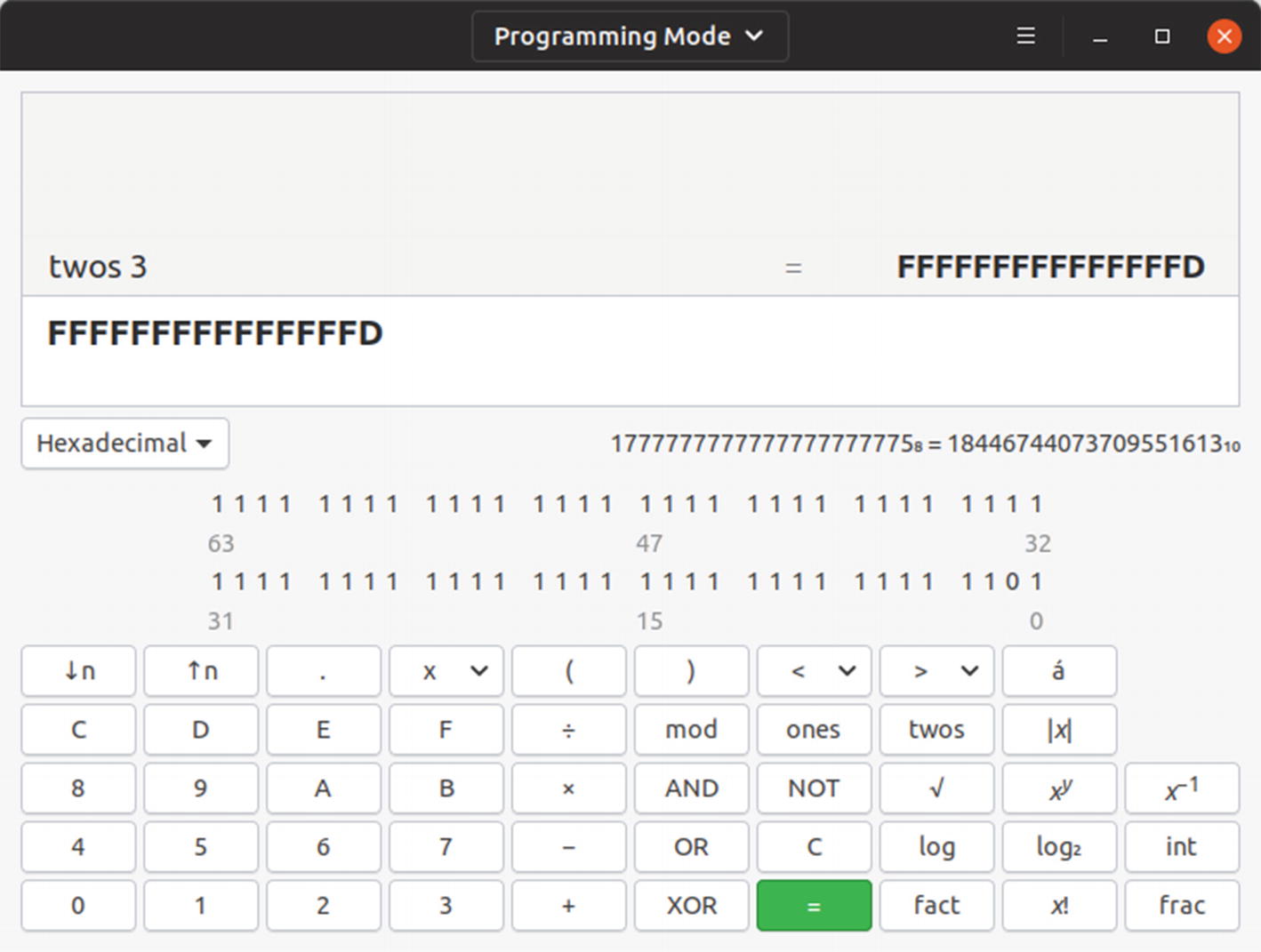
The Gnome programmer’s calculator calculating the two’s complement of 3
Two’s complement is the standard representation of negative integers; however, just reversing all the bits does have its uses.
About One’s Complement
If we don’t add 1, and just change all the 1s to 0s and vice versa, then this is called one’s complement. There are uses for the one’s complement form, and we will encounter it in how some instructions process their operands.
Now let’s return to the order the bytes that make up an integer are stored in memory.
Big vs. Little Endian

How integers are stored in memory in little- vs. big-endian format
The designers of the ARM processor didn’t want to take sides in the little- vs. big-endian debate, so they made the ARM processor support both.
About Bi-endian
The ARM CPU is called bi-endian, because it can do either. Most ARM-based computers use little-endian format. This includes all the systems we’ll cover in this book.
Now let’s look at why most ARM-based computers use little vs. big endian.
Pros of Little Endian
If we want the 1-byte representation of this number, we take the first byte; for the 16-bit representation, we take the first two bytes. The key point is that the memory address we use is the same in all cases, saving us an instruction cycle adjusting it.
When we are in the debugger, we will see more representations, and these will be pointed out again as we run into them.
Even though Linux uses little endian, many protocols like TCP/IP used on the Internet use big endian and so require a transformation when moving data from the computer to the outside world.
We’ve looked at how integers are represented and how addition works. It turns out that another useful simple manipulation is shifting the bits right or left and rotating them around inside a register.
Shifting and Rotating
Now if we shift 0x30 right by 4 bits, we undo what we just did and see how it is equivalent to dividing by 16.
When we shift and rotate, it turns out to be useful to include the carry flag. This means we can do a conditional logic based on the last bit shifted out of the register.
About Carry Flag
When instructions execute, they can optionally set some flags that contain useful information on what happened. Then other instructions can test these flags and process accordingly. One of these is the carry flag. This is normally used when performing addition of larger numbers. If you add two 64-bit numbers and the result is larger than 64 bits, the carry flag is set. We’ll see how to use this when we look at addition in detail later in this chapter.
Let’s look at how shifting is implemented in an ARM processor.
About the Barrel Shifter

The location of the barrel shifter to perform shifts as part of loading Operand2
Let’s get into the details of shifting and rotating.
Basics of Shifting and Rotating
Logical shift left
Logical shift right
Arithmetic shift right
Rotate right
Logical Shift Left
This is quite straightforward; as we shift the bits left by the indicated number of places, zeros come in from the right. The last bit shifted out ends up in the carry flag.
Logical Shift Right
Equally easy as logical shift left, here we shift the bits right, then zeros come in from the left, and the last bit shifted out ends up in the carry flag.
Arithmetic Shift Right
The problem with logical shift right is if it’s a negative number, having a zero come in from the left suddenly turns the number positive. If we want to preserve the sign bit, use arithmetic shift right. Here a 1 comes in from the left, if the number is negative, and a 0 if it is positive. This is then the correct form if you are shifting signed integers.
Rotate Right
Rotating is like shifting, except the bits don’t go off the end; instead they wrap around and reappear from the other side. So, rotate right shifts right, but the bits that leave on the right reappear on the left.
That concludes the theory part of the chapter; now we return to writing Assembly Language code by going into the details of loading values into the registers.
Loading Registers
In this section, we look at various ways to load registers with values contained in instructions or other registers. We’ll look at loading registers from memory in Chapter 5, “Thanks for the Memories.”
First, the ARM engineers worked hard to minimize the number of instructions required, and we’ll look at another technique they used to accomplish this.
Instruction Aliases
In Chapter 1, “Getting Started,” in our Hello World sample program, we used the MOV instruction to load the values we needed into registers. However, MOV isn’t an ARM Assembly instruction; it’s an alias. You’re telling the Assembler what you want to do; then the Assembler finds a real ARM instruction to do the job. If it can’t find an instruction to do what you specified, then you get an error.
(MOV X0, X1 actually translates to ORR X0, XZR, X1, and we’ll talk about the ORR instruction in Chapter 4, “Controlling Program Flow,” but the idea is the same.)
Remember that with ARM instructions being only 32 bits, we can’t waste any of them. Hence the ARM designers were careful to avoid redundancy. It would’ve been a waste of valuable bits to have such a MOV instruction.
Knowing all these tricks would make programs unreadable and put a lot of pressure on programmers to know all the clever tricks, the ARM designers used to reduce the number of real instructions in the processor. The solution is to have the GNU Assembler know all these tricks and do the translations for you.
In this book, we use instruction aliases to make our programs readable, but point out when they’re used to help understand what’s going on. If you use objdump, it might show the same alias you used, another alternate alias, or the real instruction. There is a “-M no-aliases” option for objdump where you can see the true underlying instruction.
Let’s get into the details and forms of the MOV instruction to load the registers.
MOV/MOVK/MOVN
- 1.
MOVK XD, #imm16{, LSL #shift}
- 2.
MOV XD, #imm16{, LSL #shift}
- 3.
MOV XD, XS
- 4.
MOV XD, operand2
- 5.
MOVN XD, operand2
We’ve seen examples of MOV, when putting a small number into a register. Here the immediate value can be any 16-bit quantity, and it will be placed in the lower 16 bits of the specified register unless an optional shift component is included. The shift values can only be the four values: 0, 16, 32, and 48. The shift value allows to put our 16-bit value in each of the four quarters of the 64-bit register.
We’ve listed the registers as X 64-bit registers here. But all these instructions can take W 32-bit registers. Remember that these are the same registers; you are just dealing with half of the register rather than the full register.
The first form is the move keep (MOVK) instruction.
About MOVK
Only four instructions are required, so not too painful, but a bit annoying.
This is our first example of adding a shift operator to the second operand. This saves us valuable instructions, since we don’t need to load the value and then shift it in a separate instruction and then combine it with the desired register in a third instruction.
The first MOV instruction is an alias and assembled as a MOVZ instruction, identical to the MOVK instruction, except it zeros the other 48 bits rather than keeping them. We could’ve used four MOVK instructions, but I like to start with a MOV instruction to guarantee we’ve initialized all the bits.
Register to Register MOV
copies register X2 into register X1.
For the remaining two forms of the MOV instruction, we need to study what is allowed as the second operand.
About Operand2
All the ARM’s data processing instructions have the option of taking a flexible Operand2 as one of their parameters. At this point, it won’t be clear why you want some of this functionality, but as we encounter more instructions, and start to build small programs, we’ll see how they help us. At the bit level, there is a lot of complexity here, but the people who designed the Assembler did a good job of providing syntax to hide a lot of this from us. Still, when doing Assembly programming, it’s good to always know what is going on under the covers.
- 1.
A register and a shift
- 2.
A register and an extension operation
- 3.
A small number and a shift
Due to the low number of bits for each instruction, the size of each component can differ. In the preceding MOVK case, the immediate is 16 bits and the shift is 2 bits. Rather than make the shift be 0, 1, 2, or 3 positions, instead these four values map to 0, 16, 32, or 48 bits. The possible values represent what the ARM designers felt were the most common use cases.
Register and Shift
These assemble to the same byte code. The intent is that it makes the code a little more readable, since it is clear you’re doing a shift or rotate operation and not just loading a register.
Register and Extension
Extension operators
Extension Operator | Description |
|---|---|
uxtb | Unsigned extend byte |
uxth | Unsigned extend halfword |
uxtw | Unsigned extend word |
sxtb | Sign-extend byte |
sxth | Sign-extend halfword |
sxtw | Sign-extend word |
If you are using the 32-bit W registers, then you would only use the byte and halfword variants of this.
The extension operators aren’t available for the MOV instruction, but we’ll see them shortly with the ADD instruction.
Small Number and Shift
The other form of operand2 consists of a small number and an optional shift amount. We saw this used with the preceding MOVK instruction. The size of this small number varies by instruction, and if a shift is allowed, there will be limited values. You can check the ARM Instruction Reference manual for the valid values for each instruction.
Fortunately, we don’t need to figure this all out. We just specify a number and the Assembler figures out how to represent it. Since there are only limited bits, not all 64-bit numbers can be represented, so if you specify something that can’t be dealt with, then the Assembler gives you an error message. You then need to use MOVK instructions as outlined previously.
MOV has the advantage that it can take an #imm16 operand, which can usually get us out of trouble. However, other instructions that must specify a third register, like the ADD instruction, don’t have this luxury.
when you run your program through the Assembler. This means the Assembler tried all its tricks and failed to represent the number. To load this, you need to use multiple MOV/MOVK instructions.
MOVN
This is the Move Not instruction. It works just like MOV, except it reverses all the 1s and 0s as it loads the register. This means it loads the register with the one’s complement form of what you specified. Another way to say it is that it applies a logical NOT operation to each bit in the word you are loading into the register.
- 1.
To calculate the one’s complement of something for you. This has its uses, but does it warrant its own opcode?
- 2.
Multiply by -1. We saw that with the shift operations, we can multiply or divide by powers of 2. This instruction gets us halfway to multiplying by -1. Remember that the negative of a number is the two’s complement of the number, or the one’s complement plus one. This means we can multiply by -1 by doing this instruction, then add one. Why would we do this rather than use the multiply (MUL) instruction? The same applies for shifting, why do that rather than using MUL? The answer is that the MUL instruction is quite slow and can take quite a few clock cycles to do its work. Shifting only takes one cycle and using MOVN and ADD, we can multiply by -1 in only two clock cycles. Multiplying by -1 is very common and now we can do it quickly.
- 3.
You get twice the number of values due to the extra bit—17 vs. 16. It turns out that all the numbers obtained by using a byte value and even shift are different for MOVN and MOV. This means that if the Assembler sees that the number you specified can’t be represented in a MOV instruction, then it tries to change it to an MOVN instruction and vice versa. So, you really have 17 bits of immediate data, rather than 16.
It still might not be able to represent your number, and you may still need to use multiple MOVK instructions.
MOV Examples
MOV examples
You can run the program after building it.
This program doesn’t do anything besides move various numbers into registers.
We will look at how to see what is going on in Chapter 3, “Tooling Up,” when we cover the GNU Debugger (GDB).
Disassembly of the MOV examples
Here we can see the true ARM 64-bit instructions that are produced by the Assembler. We’ve talked about how MOV instructions can be converted into ORR or MOVZ instructions.
We see the shift instructions were converted into UBFM, SBFM, and EXTR instructions. These are the underlying shift and rotate instructions. These instructions have more functionality than the aliases we are using, but we won’t need that advanced functionality and will stick with the straightforward alias versions.
Now that we’ve loaded numbers into our registers, let’s perform some arithmetic on them.
ADD/ADC
- 1.
ADD{S} Xd, Xs, Operand2
- 2.
ADC{S} Xd, Xs, Operand2
An example of MOVN and ADD
After running the program, it prints out 254. If you examine the bits, you will see this is the two’s complement form for -2 in 1 byte.
With the ARM processor, we can combine multiple ADD instructions to add arbitrarily large integers. The key to this is the carry flag.
Add with Carry
The new concepts in this section are what the {S} after the instruction means along with why we have both ADD and ADC. This will be our first use of a condition flag.
- 1.
We first add 7 + 8 and get 15.
- 2.
We put 5 in our sum and carry the 1 to the tens column.
- 3.
Now we add 1 + 7 + the carry from the ones column, so we add 1+7+1 and get 9 for the tens column.
This is the idea behind the carry flag. When an addition overflows, it sets the carry flag, so we can include that in the sum of the next part.
A carry is always 0 or 1, so we only need a 1-bit flag for this.
The ARM processor adds 64 bits at a time, so we only need the carry flag if we are dealing with numbers larger than what will fit into 64 bits. This means we can easily add 128-bit or even larger integers.
except that it sets various condition flags. We’ll cover all the flags when we cover conditional statements in Chapter 4, “Controlling Program Flow.” For now, we are interested in the carry flag that is designated C. If the result of an addition is too large, then the C flag is set to 1; otherwise it is set to 0.
The first ADDS adds the lower order 64 bits and sets the carry flag, if needed. It might set other flags, but we’ll worry about those later. The second instruction, ADDC, adds the higher-order words, plus the carry flag.
Example of 128-bit addition with ADD and ADC
we get 9 as expected.
Learning about MOV was difficult, because this was the first time we encountered both shifting and Operand2. With these behind us, learning about ADD was much easier. We still have some complicated topics to cover, but as we become more experienced with how to manipulate bits and bytes, the learning should become easier.
Covering addition wouldn’t be complete without covering its inverse: subtraction.
SUB/SBC
- 1.
SUB{S} Xd, Xs, Operand2
- 2.
SBC{S} Xd, Xs, Operand2
The operands are the same as those for addition, only now we are calculating Xs – Operand2. The carry flag is used to indicate when a borrow is necessary. SUBS will clear the carry flag if the result is negative and set it if positive; SBC then subtracts one if the carry flag is clear.
Summary
In this chapter, we learned how negative integers are represented in a computer. We went on to discuss big- vs. little-endian byte ordering. We then looked at the concept of shifting and rotating the bits in a register.
Next, we looked in detail at the MOV instruction that allows us to move data around the CPU registers or load constants from the MOV instruction into a register. We discovered the tricks of operand2 on how ARM represents a large range of values, given the limited number of bits it has at its disposal.
We covered the ADD and ADC instructions and discussed how to add both 64- and 128-bit numbers. Finally, we quickly covered the SUB and SBC instructions.
In Chapter 3, “Tooling Up,” we will look at better ways to build our programs and start debugging our programs with the GNU Debugger (gdb).
Exercises
- 1.
Compute the 8-bit two’s complement for -79 and -23.
- 2.
What are the negative decimal numbers represented by the bytes 0xF2 and 0x83?
- 3.
Write out the bytes in the little-endian representation of 0x12345678.
- 4.
Write out the bytes for 0x23 shifted left by 3 bits.
- 5.
Write out the bytes for 0x4300 shifted right by 5 bits.
- 6.
Write a program to add two 192-bit numbers. You will need to use the ADCS instruction for this. Remember you can set the flags from any instruction.
- 7.
Write a program that performs 128-bit subtraction. Convince yourself that the way it sets and interprets the carry flag is what you need in this situation. Use it to reverse the operations from the preceding 128-bit example.