
6. Functions and Functional Programming
Substantial programs are broken up into functions for better modularity and ease of maintenance. Python makes it easy to define functions but also incorporates a surprising number of features from functional programming languages. This chapter describes functions, scoping rules, closures, decorators, generators, coroutines, and other functional programming features. In addition, list comprehensions and generator expressions are described—both of which are powerful tools for declarative-style programming and data processing.
Functions
Functions are defined with the def statement:
![]()
The body of a function is simply a sequence of statements that execute when the function is called. You invoke a function by writing the function name followed by a tuple of function arguments, such as a = add(3,4). The order and number of arguments must match those given in the function definition. If a mismatch exists, a TypeError exception is raised.
You can attach default arguments to function parameters by assigning values in the function definition. For example:
![]()
When a function defines a parameter with a default value, that parameter and all the parameters that follow are optional. If values are not assigned to all the optional parameters in the function definition, a SyntaxError exception is raised.
Default parameter values are always set to the objects that were supplied as values when the function was defined. Here’s an example:

In addition, the use of mutable objects as default values may lead to unintended behavior:

Notice how the default argument retains modifications made from previous invocations. To prevent this, it is better to use None and add a check as follows:
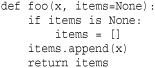
A function can accept a variable number of parameters if an asterisk (*) is added to the last parameter name:

In this case, all the remaining arguments are placed into the args variable as a tuple. To pass a tuple args to a function as if they were parameters, the *args syntax can be used in a function call as follows:
![]()
Function arguments can also be supplied by explicitly naming each parameter and specifying a value. These are known as keyword arguments. Here is an example:

With keyword arguments, the order of the parameters doesn’t matter. However, unless there are default values, you must explicitly name all of the required function parameters. If you omit any of the required parameters or if the name of a keyword doesn’t match any of the parameter names in the function definition, a TypeError exception is raised. Also, since any Python function can be called using the keyword calling style, it is generally a good idea to define functions with descriptive argument names.
Positional arguments and keyword arguments can appear in the same function call, provided that all the positional arguments appear first, values are provided for all non-optional arguments, and no argument value is defined more than once. Here’s an example:
![]()
If the last argument of a function definition begins with **, all the additional keyword arguments (those that don’t match any of the other parameter names) are placed in a dictionary and passed to the function. This can be a useful way to write functions that accept a large number of potentially open-ended configuration options that would be too unwieldy to list as parameters. Here’s an example:

You can combine extra keyword arguments with variable-length argument lists, as long as the ** parameter appears last:

![]()
Keyword arguments can also be passed to another function using the **kwargs syntax:
![]()
This use of *args and **kwargs is commonly used to write wrappers and proxies for other functions. For example, the callfunc() accepts any combination of arguments and simply passes them through to func().
Parameter Passing and Return Values
When a function is invoked, the function parameters are simply names that refer to the passed input objects. The underlying semantics of parameter passing doesn’t neatly fit into any single style, such as “pass by value” or “pass by reference,” that you might know about from other programming languages. For example, if you pass an immutable value, the argument effectively looks like it was passed by value. However, if a mutable object (such as a list or dictionary) is passed to a function where it’s then modified, those changes will be reflected in the original object. Here’s an example:
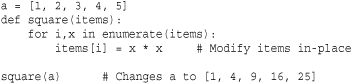
Functions that mutate their input values or change the state of other parts of the program behind the scenes like this are said to have side effects. As a general rule, this is a programming style that is best avoided because such functions can become a source of subtle programming errors as programs grow in size and complexity (for example, it’s not obvious from reading a function call if a function has side effects). Such functions interact poorly with programs involving threads and concurrency because side effects typically need to be protected by locks.
The return statement returns a value from a function. If no value is specified or you omit the return statement, the None object is returned. To return multiple values, place them in a tuple:

Multiple return values returned in a tuple can be assigned to individual variables:
x, y = factor(1243) # Return values placed in x and y.
or
(x, y) = factor(1243) # Alternate version. Same behavior.
Scoping Rules
Each time a function executes, a new local namespace is created. This namespace represents a local environment that contains the names of the function parameters, as well as the names of variables that are assigned inside the function body. When resolving names, the interpreter first searches the local namespace. If no match exists, it searches the global namespace. The global namespace for a function is always the module in which the function was defined. If the interpreter finds no match in the global namespace, it makes a final check in the built-in namespace. If this fails, a NameError exception is raised.
One peculiarity of namespaces is the manipulation of global variables within a function. For example, consider the following code:

When this code executes, a returns its value of 42, despite the appearance that we might be modifying the variable a inside the function foo. When variables are assigned inside a function, they’re always bound to the function’s local namespace; as a result, the variable a in the function body refers to an entirely new object containing the value 13, not the outer variable. To alter this behavior, use the global statement. global simply declares names as belonging to the global namespace, and it’s necessary only when global variables will be modified. It can be placed anywhere in a function body and used repeatedly. Here’s an example:

Python supports nested function definitions. Here’s an example:
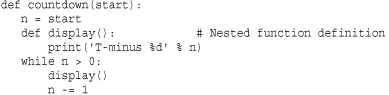
Variables in nested functions are bound using lexical scoping. That is, names are resolved by first checking the local scope and then all enclosing scopes of outer function definitions from the innermost scope to the outermost scope. If no match is found, the global and built-in namespaces are checked as before. Although names in enclosing scopes are accessible, Python 2 only allows variables to be reassigned in the innermost scope (local variables) and the global namespace (using global). Therefore, an inner function can’t reassign the value of a local variable defined in an outer function. For example, this code does not work:
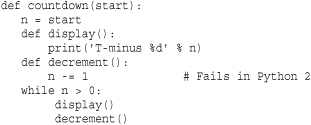
In Python 2, you can work around this by placing values you want to change in a list or dictionary. In Python 3, you can declare n as nonlocal as follows:

The nonlocal declaration does not bind a name to local variables defined inside arbitrary functions further down on the current call-stack (that is, dynamic scope). So, if you’re coming to Python from Perl, nonlocal is not the same as declaring a Perl local variable.
If a local variable is used before it’s assigned a value, an UnboundLocalError exception is raised. Here’s an example that illustrates one scenario of how this might occur:

In this function, the variable i is defined as a local variable (because it is being assigned inside the function and there is no global statement). However, the assignment i = i + 1 tries to read the value of i before its local value has been first assigned. Even though there is a global variable i in this example, it is not used to supply a value here. Variables are determined to be either local or global at the time of function definition and cannot suddenly change scope in the middle of a function. For example, in the preceding code, it is not the case that the i in the expression i + 1 refers to the global variable i, whereas the i in print(i) refers to the local variable i created in the previous statement.
Functions as Objects and Closures
Functions are first-class objects in Python. This means that they can be passed as arguments to other functions, placed in data structures, and returned by a function as a result. Here is an example of a function that accepts another function as input and calls it:
![]()
Here is an example of using the above function:

When a function is handled as data, it implicitly carries information related to the surrounding environment where the function was defined. This affects how free variables in the function are bound. As an example, consider this modified version foo.py that now contains a variable definition:

Now, observe the behavior of this example:

In this example, notice how the function helloworld() uses the value of x that’s defined in the same environment as where helloworld() was defined. Thus, even though there is also an x defined in foo.py and that’s where helloworld() is actually being called, that value of x is not the one that’s used when helloworld() executes.
When the statements that make up a function are packaged together with the environment in which they execute, the resulting object is known as a closure. The behavior of the previous example is explained by the fact that all functions have a _ _globals_ _ attribute that points to the global namespace in which the function was defined. This always corresponds to the enclosing module in which a function was defined. For the previous example, you get the following:

When nested functions are used, closures capture the entire environment needed for the inner function to execute. Here is an example:
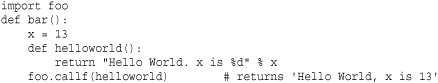
Closures and nested functions are especially useful if you want to write code based on the concept of lazy or delayed evaluation. Here is another example:

In this example, the page() function doesn’t actually carry out any interesting computation. Instead, it merely creates and returns a function get() that will fetch the contents of a web page when it is called. Thus, the computation carried out in get() is actually delayed until some later point in a program when get() is evaluated. For example:
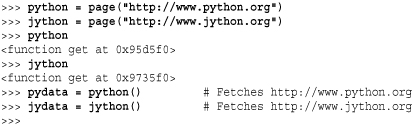
In this example, the two variables python and jython are actually two different versions of the get() function. Even though the page() function that created these values is no longer executing, both get() functions implicitly carry the values of the outer variables that were defined when the get() function was created. Thus, when get() executes, it calls urlopen(url) with the value of url that was originally supplied to page(). With a little inspection, you can view the contents of variables that are carried along in a closure. For example:

A closure can be a highly efficient way to preserve state across a series of function calls. For example, consider this code that runs a simple counter:

In this code, a closure is being used to store the internal counter value n. The inner function next() updates and returns the previous value of this counter variable each time it is called. Programmers not familiar with closures might be inclined to implement similar functionality using a class such as this:

However, if you increase the starting value of the countdown and perform a simple timing benchmark, you will find that that the version using closures runs much faster (almost a 50% speedup when tested on the author’s machine).
The fact that closures capture the environment of inner functions also make them useful for applications where you want to wrap existing functions in order to add extra capabilities. This is described next.
Decorators
A decorator is a function whose primary purpose is to wrap another function or class. The primary purpose of this wrapping is to transparently alter or enhance the behavior of the object being wrapped. Syntactically, decorators are denoted using the special @ symbol as follows:
![]()
The preceding code is shorthand for the following:
![]()
In the example, a function square() is defined. However, immediately after its definition, the function object itself is passed to the function trace(), which returns an object that replaces the original square. Now, let’s consider an implementation of trace that will clarify how this might be useful:
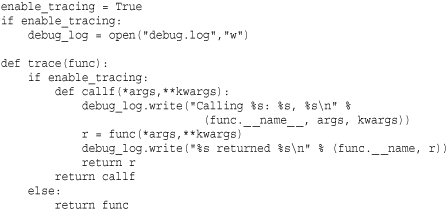
In this code, trace() creates a wrapper function that writes some debugging output and then calls the original function object. Thus, if you call square(), you will see the output of the write() methods in the wrapper. The function callf that is returned from trace() is a closure that serves as a replacement for the original function. A final interesting aspect of the implementation is that the tracing feature itself is only enabled through the use of a global variable enable_tracing as shown. If set to False, the trace() decorator simply returns the original function unmodified. Thus, when tracing is disabled, there is no added performance penalty associated with using the decorator.
When decorators are used, they must appear on their own line immediately prior to a function or class definition. More than one decorator can also be applied. Here’s an example:

In this case, the decorators are applied in the order listed. The result is the same as this:
![]()
A decorator can also accept arguments. Here’s an example:

If arguments are supplied, the semantics of the decorator are as follows:

In this case, the decorator function only accepts the arguments supplied with the @ specifier. It then returns a function that is called with the function as an argument. Here’s an example:

Decorators can also be applied to class definitions. For example:

For class decorators, you should always have the decorator function return a class object as a result. Code that expects to work with the original class definition may want to reference members of the class directly such as Bar.spam. This won’t work correctly if the decorator function foo() returns a function.
Decorators can interact strangely with other aspects of functions such as recursion, documentation strings, and function attributes. These issues are described later in this chapter.
Generators and yield
If a function uses the yield keyword, it defines an object known as a generator. A generator is a function that produces a sequence of values for use in iteration. Here’s an example:

If you call this function, you will find that none of its code starts executing. For example:
![]()
Instead, a generator object is returned. The generator object, in turn, executes the function whenever next() is called (or _ _next_ _() in Python 3). Here’s an example:

When next() is invoked, the generator function executes statements until it reaches a yield statement. The yield statement produces a result at which point execution of the function stops until next() is invoked again. Execution then resumes with the statement following yield.
You normally don’t call next() directly on a generator but use it with the for statement, sum(), or some other operation that consumes a sequence. For example:
![]()
A generator function signals completion by returning or raising StopIteration, at which point iteration stops. It is never legal for a generator to return a value other than None upon completion.
A subtle problem with generators concerns the case where a generator function is only partially consumed. For example, consider this code:
![]()
In this example, the for loop aborts by calling break, and the associated generator never runs to full completion. To handle this case, generator objects have a method close() that is used to signal a shutdown. When a generator is no longer used or deleted, close() is called. Normally it is not necessary to call close(), but you can also call it manually as shown here:

Inside the generator function, close() is signaled by a GeneratorExit exception occurring on the yield statement. You can optionally catch this exception to perform cleanup actions.

Although it is possible to catch GeneratorExit, it is illegal for a generator function to handle the exception and produce another output value using yield. Moreover, if a program is currently iterating on generator, you should not call close() asynchronously on that generator from a separate thread of execution or from a signal handler.
Coroutines and yield Expressions
Inside a function, the yield statement can also be used as an expression that appears on the right side of an assignment operator. For example:

A function that uses yield in this manner is known as a coroutine, and it executes in response to values being sent to it. Its behavior is also very similar to a generator. For example:

In this example, the initial call to next() is necessary so that the coroutine executes statements leading to the first yield expression. At this point, the coroutine suspends, waiting for a value to be sent to it using the send() method of the associated generator object r. The value passed to send() is returned by the (yield) expression in the coroutine. Upon receiving a value, a coroutine executes statements until the next yield statement is encountered.
The requirement of first calling next() on a coroutine is easily overlooked and a common source of errors. Therefore, it is recommended that coroutines be wrapped with a decorator that automatically takes care of this step.

Using this decorator, you would write and use coroutines using:

A coroutine will typically run indefinitely unless it is explicitly shut down or it exits on its own. To close the stream of input values, use the close() method like this:

Once closed, a StopIteration exception will be raised if further values are sent to a coroutine. The close() operation raises GeneratorExit inside the coroutine as described in the previous section on generators. For example:

Exceptions can be raised inside a coroutine using the throw(exctype [, value [, tb]]) method where exctype is an exception type, value is the exception value, and tb is a traceback object. For example:
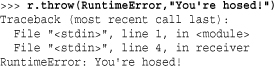
Exceptions raised in this manner will originate at the currently executing yield statement in the coroutine. A coroutine can elect to catch exceptions and handle them as appropriate. It is not safe to use throw() as an asynchronous signal to a coroutine—it should never be invoked from a separate execution thread or in a signal handler.
A coroutine may simultaneously receive and emit return values using yield if values are supplied in the yield expression. Here is an example that illustrates this:

In this case, we use the coroutine in the same way as before. However, now calls to send() also produce a result. For example:

Understanding the sequencing of this example is critical. The first next() call advances the coroutine to (yield result), which returns None, the initial value of result. On subsequent send() calls, the received value is placed in line and split into result. The value returned by send() is the value passed to the next yield statement encountered. In other words, the value returned by send() comes from the next yield expression, not the one responsible for receiving the value passed by send().
If a coroutine returns values, some care is required if exceptions raised with throw() are being handled. If you raise an exception in a coroutine using throw(), the value passed to the next yield in the coroutine will be returned as the result of throw(). If you need this value and forget to save it, it will be lost.
Using Generators and Coroutines
At first glance, it might not be obvious how to use generators and coroutines for practical problems. However, generators and coroutines can be particularly effective when applied to certain kinds of programming problems in systems, networking, and distributed computation. For example, generator functions are useful if you want to set up a processing pipeline, similar in nature to using a pipe in the UNIX shell. One example of this appeared in the Introduction. Here is another example involving a set of generator functions related to finding, opening, reading, and processing files:

Here is an example of using these functions to set up a processing pipeline:

In this example, the program is processing all lines in all "access-log*" files found within all subdirectories of a top-level directory "www". Each "access-log" is tested for file compression and opened using an appropriate file opener. Lines are concatenated together and processed through a filter that is looking for a substring "python". The entire program is being driven by the for statement at the end. Each iteration of this loop pulls a new value through the pipeline and consumes it. Moreover, the implementation is highly memory-efficient because no temporary lists or other large data structures are ever created.
Coroutines can be used to write programs based on data-flow processing. Programs organized in this way look like inverted pipelines. Instead of pulling values through a sequence of generator functions using a for loop, you send values into a collection of linked coroutines. Here is an example of coroutine functions written to mimic the generator functions shown previously:


Here is how you would link these coroutines to create a dataflow processing pipeline:

In this example, each coroutine sends data to another coroutine specified in the target argument to each coroutine. Unlike the generator example, execution is entirely driven by pushing data into the first coroutine find_files(). This coroutine, in turn, pushes data to the next stage. A critical aspect of this example is that the coroutine pipeline remains active indefinitely or until close() is explicitly called on it. Because of this, a program can continue to feed data into a coroutine for as long as necessary—for example, the two repeated calls to send() shown in the example.
Coroutines can be used to implement a form of concurrency. For example, a centralized task manager or event loop can schedule and send data into a large collection of hundreds or even thousands of coroutines that carry out various processing tasks. The fact that input data is “sent” to a coroutine also means that coroutines can often be easily mixed with programs that use message queues and message passing to communicate between program components. Further information on this can be found in Chapter 20, “Threads.”
List Comprehensions
A common operation involving functions is that of applying a function to all of the items of a list, creating a new list with the results. For example:

Because this type of operation is so common, it is has been turned into an operator known as a list comprehension. Here is a simple example:
![]()
The general syntax for a list comprehension is as follows:

This syntax is roughly equivalent to the following code:

To illustrate, here are some more examples:

The sequences supplied to a list comprehension don’t have to be the same length because they’re iterated over their contents using a nested set of for loops, as previously shown. The resulting list contains successive values of expressions. The if clause is optional; however, if it’s used, expression is evaluated and added to the result only if condition is true.
If a list comprehension is used to construct a list of tuples, the tuple values must be enclosed in parentheses. For example, [(x,y) for x in a for y in b] is legal syntax, whereas [x,y for x in a for y in b] is not.
Finally, it is important to note that in Python 2, the iteration variables defined within a list comprehension are evaluated within the current scope and remain defined after the list comprehension has executed. For example, in [x for x in a], the iteration variable x overwrites any previously defined value of x and is set to the value of the last item in a after the resulting list is created. Fortunately, this is not the case in Python 3 where the iteration variable remains private.
Generator Expressions
A generator expression is an object that carries out the same computation as a list comprehension, but which iteratively produces the result. The syntax is the same as for list comprehensions except that you use parentheses instead of square brackets. Here’s an example:

Unlike a list comprehension, a generator expression does not actually create a list or immediately evaluate the expression inside the parentheses. Instead, it creates a generator object that produces the values on demand via iteration. Here’s an example:

The difference between list and generator expressions is important, but subtle. With a list comprehension, Python actually creates a list that contains the resulting data. With a generator expression, Python creates a generator that merely knows how to produce data on demand. In certain applications, this can greatly improve performance and memory use. Here’s an example:

In this example, the generator expression that extracts lines and strips whitespace does not actually read the entire file into memory. The same is true of the expression that extracts comments. Instead, the lines of the file are actually read when the program starts iterating in the for loop that follows. During this iteration, the lines of the file are produced upon demand and filtered accordingly. In fact, at no time will the entire file be loaded into memory during this process. Therefore, this would be a highly efficient way to extract comments from a gigabyte-sized Python source file.
Unlike a list comprehension, a generator expression does not create an object that works like a sequence. It can’t be indexed, and none of the usual list operations will work (for example, append()). However, a generator expression can be converted into a list using the built-in list() function:
clist = list(comments)
Declarative Programming
List comprehensions and generator expressions are strongly tied to operations found in declarative languages. In fact, the origin of these features is loosely derived from ideas in mathematical set theory. For example, when you write a statement such as [x*x for x in a if x > 0], it’s somewhat similar to specifying a set such as { x2 | x εa, x > 0 }.
Instead of writing programs that manually iterate over data, you can use these declarative features to structure programs as a series of computations that simply operate on all of the data all at once. For example, suppose you had a file “portfolio.txt” containing stock portfolio data like this:

Here is a declarative-style program that calculates the total cost by summing up the second column multiplied by the third column:
![]()
In this program, we really aren’t concerned with the mechanics of looping line-by-line over the file. Instead, we just declare a sequence of calculations to perform on all of the data. Not only does this approach result in highly compact code, but it also tends to run faster than this more traditional version:

The declarative programming style is somewhat tied to the kinds of operations a programmer might perform in a UNIX shell. For instance, the preceding example using generator expressions is similar to the following one-line awk command:
![]()
The declarative style of list comprehensions and generator expressions can also be used to mimic the behavior of SQL select statements, commonly used when processing databases. For example, consider these examples that work on data that has been read in a list of dictionaries:

In fact, if you are using a module related to database access (see Chapter 17), you can often use list comprehensions and database queries together all at once. For example:
![]()
The lambda Operator
Anonymous functions in the form of an expression can be created using the lambda statement:
lambda args : expression
args is a comma-separated list of arguments, and expression is an expression involving those arguments. Here’s an example:
![]()
The code defined with lambda must be a valid expression. Multiple statements and other non-expression statements, such as for and while, cannot appear in a lambda statement. lambda expressions follow the same scoping rules as functions.
The primary use of lambda is in specifying short callback functions. For example, if you wanted to sort a list of names with case-insensitivity, you might write this:
names.sort(key=lambda n: n.lower())
Recursion
Recursive functions are easily defined. For example:
![]()
However, be aware that there is a limit on the depth of recursive function calls. The function sys.getrecursionlimit() returns the current maximum recursion depth, and the function sys.setrecursionlimit() can be used to change the value. The default value is 1000. Although it is possible to increase the value, programs are still limited by the stack size limits enforced by the host operating system. When the recursion depth is exceeded, a RuntimeError exception is raised. Python does not perform tail-recursion optimization that you often find in functional languages such as Scheme.
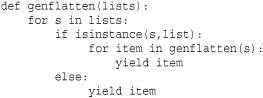
Recursion does not work as you might expect in generator functions and coroutines. For example, this code prints all items in a nested collection of lists:

However, if you change the print operation to a yield, it no longer works. This is because the recursive call to flatten() merely creates a new generator object without actually iterating over it. Here’s a recursive generator version that works:
Care should also be taken when mixing recursive functions and decorators. If a decorator is applied to a recursive function, all inner recursive calls now get routed through the decorated version. For example:

If the purpose of the decorator was related to some kind of system management such as synchronization or locking, recursion is something probably best avoided.
Documentation Strings
It is common practice for the first statement of function to be a documentation string describing its usage. For example:

The documentation string is stored in the _ _doc_ _ attribute of the function that is commonly used by IDEs to provide interactive help.
If you are using decorators, be aware that wrapping a function with a decorator can break the help features associated with documentation strings. For example, consider this code:

If a user requests help on this version of factorial(), he will get a rather cryptic explanation:

To fix this, write decorator functions so that they propagate the function name and documentation string. For example:

Because this is a common problem, the functools module provides a function wraps that can automatically copy these attributes. Not surprisingly, it is also a decorator:

The @wraps(func) decorator, defined in functools, propagates attributes from func to the wrapper function that is being defined.
Function Attributes
Functions can have arbitrary attributes attached to them. Here’s an example:

Function attributes are stored in a dictionary that is available as the _ _dict_ _ attribute of a function.
The primary use of function attributes is in highly specialized applications such as parser generators and application frameworks that would like to attach additional information to function objects.
As with documentation strings, care should be given if mixing function attributes with decorators. If a function is wrapped by a decorator, access to the attributes will actually take place on the decorator function, not the original implementation. This may or may not be what you want depending on the application. To propagate already defined function attributes to a decorator function, use the following template or the functools.wraps() decorator as shown in the previous section:

eval(), exec(), and compile()
The eval(str [,globals [,locals]]) function executes an expression string and returns the result. Here’s an example:
a = eval('3*math.sin(3.5+x) + 7.2')
Similarly, the exec(str [, globals [, locals]]) function executes a string containing arbitrary Python code. The code supplied to exec() is executed as if the code actually appeared in place of the exec operation. Here’s an example:
![]()
One caution with exec is that in Python 2, exec is actually defined as a statement. Thus, in legacy code, you might see statements invoking exec without the surrounding parentheses, such as exec "for i in a: print i". Although this still works in Python 2.6, it breaks in Python 3. Modern programs should use exec() as a function.
Both of these functions execute within the namespace of the caller (which is used to resolve any symbols that appear within a string or file). Optionally, eval() and exec() can accept one or two mapping objects that serve as the global and local namespaces for the code to be executed, respectively. Here’s an example:

If you omit one or both namespaces, the current values of the global and local namespaces are used. Also, due to issues related to nested scopes, the use of exec() inside of a function body may result in a SyntaxError exception if that function also contains nested function definitions or uses the lambda operator.
When a string is passed to exec() or eval() the parser first compiles it into bytecode. Because this process is expensive, it may be better to precompile the code and reuse the bytecode on subsequent calls if the code will be executed multiple times.
The compile(str,filename,kind) function compiles a string into bytecode in which str is a string containing the code to be compiled and filename is the file in which the string is defined (for use in traceback generation). The kind argument specifies the type of code being compiled—'single' for a single statement, 'exec' for a set of statements, or 'eval' for an expression. The code object returned by the compile() function can also be passed to the eval() function and exec() statement. Here’s an example:
