
Statistical Verification
The sporadic nature of race conditions sometimes defies strictly deterministic reproduction. However, many factors contribute to the occurrence of race conditions, including load, frequency, transactional volume, and timing. When explicit control eludes you, these factors become your friends.
Statistical verification works best at coarser granularities of testing, such as system and integration tests. It can be applied effectively at lower levels as well, but oftentimes, the exact conditions contributing to the race condition are harder to isolate and reproduce. At times, the integrated system produces interactions and timings that evade our ability to diagnose and reproduce. Additionally, coarser-granularity test beds may have a higher tolerance for the longer run times that can be associated with statistical verification.
There are several forms of statistical verification that can be useful. The simplest, running the test enough times to almost guarantee a failure, leverages the sporadic nature of race conditions. It helps if you have an understanding of the frequency of the failure. If you know a test fails 1% of the time, then running it 100 times gives you a reasonable likelihood of reproducing the failure. Does it give you a guarantee of failure? No. However, the likelihood of inducing a failure asymptotically approaches 100% the more times you run the test. Generally speaking, assuming the conditions are such that the per-run probability of failure, Pf, is constant, the total probability of failure, PF, over n runs is
PF = 1 – (1 – Pf)n
So with a 1% individual failure rate, it takes 300 iterations for a 95% likelihood of failure and over 450 iterations for a 99% chance, as shown in Figure 13-1.
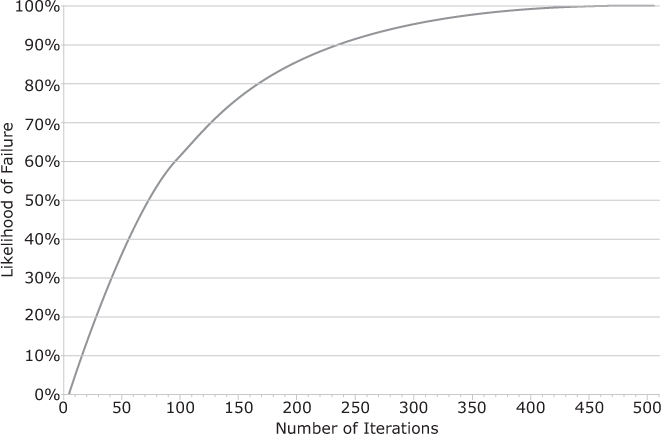
Figure 13-1: Cumulative likelihood of failure against number of iterations for a 1% individual failure rate
In many cases, race conditions only occur under concurrent loads. The likelihood of the race condition manifesting relates more to the number of concurrent participants than to the number of times through the code. Correlating failure rates against actor volumes provides a scientific approach to determining concurrent failure loads. This can provide surprising insights when graphed against system metrics (e.g., memory or page faults) or events (e.g., garbage collection, notifications, or logins). A well-instrumented system will give you application-specific usage metrics that you can use for correlation, as well as realistic event sequences that you can replay. In the absence of such analytical data, a trial and error approach can be applied.
The “monkey test” is a useful form of black box exploratory testing for concurrency issues. The name of this form of testing alludes to the Infinite Monkey Theorem, which visualizes a monkey randomly typing at a keyboard. As it pertains to concurrency testing, a framework that randomly injects inputs and signals into a system creates a very effective stress test of that system if run for enough time. In one system I worked on that involved a graph-structured network of autonomous agents (the system discussed earlier in Use Supervisory Control), randomly starting and stopping nodes in the network during operation revealed a wealth of concurrency bugs, including several that could be deterministically reproduced once understood.