
Introductory Concepts
Compressed RTP
Robust Header Compression
Considerations for RTP Applications
One area where RTP is often criticized is the size of its headers. Some argue that 12 octets of RTP header plus 28 octets of UDP/IPv4 header is excessive for, say, a 14-octet audio packet, and that a more efficient reduced header could be used instead. This is true to some extent, but the argument neglects the other uses of RTP in which the complete header is necessary, and it neglects the benefit to the community of having a single open standard for audio/video transport.
Header compression achieves a balance between these two worlds: When applied to a link layer, it can compress the entire 40-octet RTP/UDP/IP header into 2 octets, giving greater efficiency than a proprietary protocol over UDP/IP could achieve, with the benefits of a single standard. This chapter provides an introduction to the principles of header compression, and a closer look at two compression standards: Compressed RTP (CRTP) and Robust Header Compression (ROHC).
The use of header compression has a well-established history in the Internet community, since the definition of TCP/IP header compression in 19904 and its widespread implementation along with PPP for dial-up links. More recently, the standard for TCP/IP header compression has been revised and updated,25 and new standards for UDP/IP and RTP/UDP/IP header compression have been developed.26,27,37
A typical scenario for header compression comprises a host connected to the network via a low-speed dial-up modem or wireless link. The host and the first-hop router compress packets passing over the low-speed link, improving efficiency on that link without affecting the rest of the network. In almost all cases, there is a particular bottleneck link where it is desirable to use the bandwidth more efficiently, and there is no need for compression in the rest of the network. Header compression works transparently, on a per-link basis, so it is well suited to this scenario: The compressed link looks like any other IP link, and applications cannot detect the presence of header compression.
These features—per-link operation and application transparency—mean that header compression is usually implemented as part of the operating system (often as part of a PPP implementation). An application usually does not need to be aware of the presence of header compression, although in some circumstances, consideration for the behavior of header compression can increase performance significantly. These circumstances are discussed in the section titled Considerations for RTP Applications later in this chapter.
Compression relies on patterns in the packet headers: Many fields are constant or change in a predictable manner between consecutive packets belonging to the same packet stream. If we can recognize these patterns, we can compress those fields to an indication that “the header changed in the expected manner,” rather than explicitly sending them. Only header fields that change in an unpredictable manner need to be transmitted in every header.
An important principle in the design of header compression standards has been robustness. There are two aspects to this: robustness to packet loss, and robustness to misidentified streams. Network links—especially wireless links—can lose or corrupt packets, and the header compression scheme must be able to function in the presence of such damage. The most important requirement is that damage to the compressed bit stream not cause undetectable corruption in the uncompressed stream. If a packet is damaged, the following packets will either be decompressed correctly or discarded. The decompressor should never produce a corrupted packet.
The second robustness issue is that RTP flows are not self-identifying. The UDP header contains no field indicating that the data being transported is RTP, and there is no way for the compressor to determine unambiguously that a particular sequence of UDP packets contains RTP traffic. The compressor needs to be informed explicitly that a stream contains RTP, or it needs to be capable of making an educated guess on the basis of observations of packet sequences. Robust engineering requires that compression must not break anything if mistakenly applied to a non-RTP flow. A misinformed compressor is not expected to compress other types of UDP flows, but it must not damage them.
Together, the principles of pattern recognition and robustness allow the formulation of a general principle for header compression: The compressor will send occasional packets containing full headers, followed by incremental updates indicating which header fields changed in the expected manner and containing the “random” fields that cannot be compressed. The full headers provide robustness: Damage to the incremental packets may confuse the decompressor and prevent operation, but this will be corrected when the next full header arrives.
Finally, it is important that header compression be locally implementable. The aim is to develop a header compression scheme that operates over a single link without end-to-end support: If saving bandwidth is important, two systems can spend processor cycles to compress; otherwise, if processing is too expensive, uncompressed headers are sent. If two systems decide to compress headers on a single link, they should be able to do so in a manner that is invisible to all other systems. As a consequence, header compression should be implemented in the network protocol stack, not in the application. Applications are not expected to implement header compression themselves; an application designer should understand header compression and its consequences, but the implementation should be done as part of the protocol stack of the machines on either side of the link.
There are two standards for RTP header compression. The original Compressed RTP (CRTP) specification was designed for use with dial-up modems and is a straightforward extension of TCP header compression to work with RTP/UDP/IP. However, with the development of third-generation cellular technology, which uses voice-over-IP as its bearer, it was found that CRTP does not perform well in environments with high link delay and packet loss, so an alternative protocol—Robust Header Compression (ROHC)—was developed.
CRTP remains the protocol of choice for dial-up use because of its simplicity and good performance in that environment. ROHC is considerably more complex but performs much better in a wireless environment. The following sections discuss each standard in detail.
The standard for CRTP is specified in RFC 2508.26 It was designed for operation over low-speed serial links, such as dial-up modems, that exhibit low bit-error rates. CRTP is a direct out-growth of the Van Jacobson header compression algorithm used for TCP,4,25 having similar performance and limitations.
The principal gain of TCP header compression comes from the observation that half of the octets in the TCP/IP headers are constant between packets. These are sent once—in a full header packet—and then elided from the following update packets. The remaining gain comes from differential coding on the changing fields to reduce their size, and from eliminating the changing fields entirely for common cases by calculating the changes from the length of the packet.
RTP header compression uses many of the same techniques, extended by the observation that although several fields change in every packet, the difference from packet to packet is often constant and therefore the second-order difference is zero. The constant second-order difference allows the compressor to suppress the unvarying fields and the fields that change predictably from packet to packet.
Figure 11.1 shows the process in terms of just the RTP header fields. The shaded header fields are constant between packets—they have a first-order difference of zero—and do not need to be sent. The unshaded fields are varying fields; they have a nonzero first-order difference. However, their second-order difference is often constant and zero, making the varying fields predictable.

In Figure 11.1 all the fields except the M bit either are constant or have a zero second-order difference. Therefore, if the initial values for the predictable fields are known, only the change in the M bit needs to be communicated.
Compressed RTP starts by sending an initial packet containing full headers, thereby establishing the same state in the compressor and decompressor. This state is the initial context of the compressed stream. Subsequent packets contain reduced headers, which either indicate that the decompressor should use the existing context to predict the headers, or contain updates to the context that must be used for the future packets. Periodically a full header packet can be sent to ensure that any loss of synchronization between compressor and decompressor is corrected.
Full header packets comprise the uncompressed original packet, along with two additional pieces of information—a context identifier and a sequence number—as shown in Figure 11.2. The context identifier is an 8- or 16-bit field that uniquely identifies this particular stream. The sequence number is 4 bits and is used to detect packet loss on the link. The additional fields replace the IP and UDP length fields in the original packet, with no loss of data because the length fields are redundant with the link-layer frame length. The full header packet format is common to several compression schemes—including IPv4 and IPv6, TCP, and UDP header compression—hence the inclusion of the generation field, which is not used with RTP header compression.

The link-layer protocol indicates to the transport layer that this is a CRTP (rather than IP) full header packet. This information allows the transport layer to route the packets to the CRTP decompressor instead of treating them as normal IP packets. The means by which the link layer provides this indication depends on the type of link in use. Operation over PPP links is specified in RFC 2509.27
Context identifiers are managed by the compressor, which generates a new context whenever it sees a new stream that it believes it can compress. On receiving a new context identifier, the decompressor allocates storage for the context. Otherwise it uses the context identifier as an index into a table of stored context state. Context identifiers are not required to be allocated sequentially; an implementation that expects relatively few contexts should use a hash table to reduce the amount of storage space needed for the state, and one that expects many contexts should simply use an array with the context identifier as an index.
The context contains the following state information, which is initialized when a full header packet is received:
The full IP, UDP, and RTP headers, possibly including a CSRC list, for the last packet transferred.
The first-order difference for the IPv4 ID field, initialized to one when a full header packet is received. (This information is not needed when RTP-over-UDP/IPv6 is being compressed, because IPv6 does not have an ID field.)
The first-order difference for the RTP timestamp field, initialized to zero when a full header packet is received.
The last value of the four-bit CRTP sequence number, used to detect packet loss on the compressed link.
Given the context information, the receiver can decompress each consecutive packet it receives. No additional state is needed, although the state stored in the context may need to be updated with each packet.
After a full header packet has been sent to establish the context, the transition to Compressed RTP packets may occur. Each Compressed RTP packet indicates that the decompressor may predict the headers of the next packet on the basis of the stored context. Compressed RTP packets may update that context, allowing for common changes in the headers to be communicated without full header packet being sent. The format of a Compressed RTP packet is shown in Figure 11.3. In most cases, only the fields with solid outline are present, indicating that the next header may be directly predicted from the context. Other fields are present as needed, to update the context, and their presence is either inferred from the context or signaled directly within the compressed header.
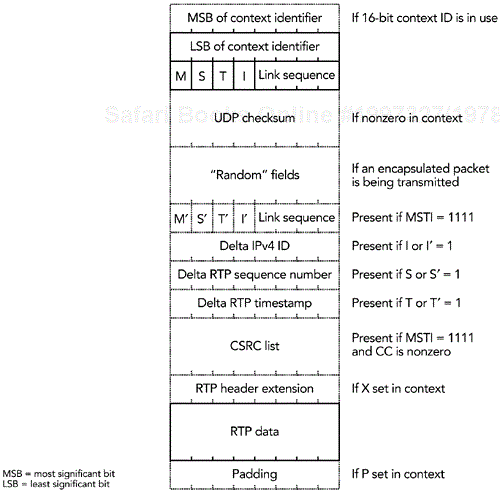
The compressor observes the characteristics of the stream and omits fields that are constant or that change in a predictable fashion. The compression algorithm will work on any stream of packets in which the bits in the position of the IPv4 ID, RTP sequence number, and RTP timestamp are predictable. In general, the compressor has no way of knowing whether a particular stream really is RTP; it must look for patterns in the headers and, if they are present, start compression. If the stream is not RTP, it is unlikely that the patterns will be present, so it will not be compressed (of course, if the stream is non-RTP but has the appropriate pattern, that the stream can be compressed). The compressor is expected to keep state to track which streams are compressible and which are not, to avoid wasting compression effort.
On receiving a Compressed RTP packet, the decompressor reconstructs the headers. You may reconstruct the IPv4 header by taking the header previously stored in the context, inferring the values of the header checksum and total length fields from the link-layer headers. If the I or I´ bit in the Compressed RTP packet is set, the IPv4 ID is incremented by the delta IPv4 ID field in the Compressed RTP packet, and the stored first-order difference in IPv4 ID in the context is updated. Otherwise the IPv4 ID is incremented by the first-order difference stored in the context.
If multiple IPv4 headers are present in the context—for example, because of IP-in-IP tunneling—their IPv4 ID fields are recovered from the Compressed RTP packet, where they are stored in order as the “random” fields. If IPv6 is being used, there are no packet ID or header checksum fields, so all fields are constant except the payload length, which may be inferred from the link-layer length.
You may reconstruct the UDP header by taking the header previously stored in the context and inferring the length field from the link-layer headers. If the checksum stored in the context is zero, it is assumed that the UDP checksum is not used. Otherwise the Compressed RTP packet will contain the new value of the checksum.
You may reconstruct the RTP header by taking the header previously stored in the context, modified as described here:
If all of M, S, T, and I are set to one, the packet contains a CC field and CSRC list, along with M´, S´, T´, and I´ fields. In this case, the M´, S´, T´, and I´ fields are used in predicting the marker bit, sequence number, timestamp, and IPv4 ID; and the CC field and CSRC list are updated on the basis of the Compressed RTP packet. Otherwise, the CC field and CSRC list are reconstructed on the basis of the previous packet.
The M bit is replaced by the M (or M´) bit in the Compressed RTP packet.
If the S or S´ bit in the Compressed RTP packet is set, the RTP sequence number is incremented by the delta RTP sequence field in the Compressed RTP packet. Otherwise the RTP sequence number is incremented by one.
If the T or T´ bit in the Compressed RTP packet is set, the RTP timestamp is incremented by the delta RTP timestamp field in the Compressed RTP packet, and the stored first-order difference in timestamp in the context is updated. Otherwise the RTP timestamp is incremented by the stored first-order difference from the context.
If the X bit is set in the context, the header extension is recovered from the Compressed RTP packet.
If the P bit is set in the context, the padding is recovered from the Compressed RTP packet.
The context is updated with the newly received headers, as well as any updates to first-order difference in IPv4 ID and RTP timestamp, and the link-layer sequence number. The reconstructed headers, along with the payload data, are then passed to the IP stack for processing in the usual manner.
Typically only the context identifier, link sequence number, M, S, T, and I fields are present, giving a 2-octet header (3 octets if 16-bit context identifiers are used). This compares well with the 40 octets of the uncompressed headers.
An RTP receiver detects packet loss by a discontinuity in the RTP sequence number; the RTP timestamp will also jump. When packet loss occurs upstream of the compressor, new delta values are sent to the decompressor to communicate these discontinuities. Although the compression efficiency is reduced, the packet stream is communicated accurately across the link.
Similarly, if packet loss occurs on the compressed link, the loss is detected by the link-layer sequence number in the Compressed RTP packets. The decompressor then sends a message back to the compressor, indicating that it should send a full header packet to repair the state. If the UDP checksum is present, the decompressor may also attempt to apply the deltas stored in the context twice, to see whether doing so generates a correct packet. The twice algorithm is possible only if the UDP checksum is included; otherwise the decompressor has no way of knowing whether the recovered packet is correct.
The need to request a full header packet to recover the context when loss occurs makes CRTP highly susceptible to packet loss on the compressed link. In particular, if the link round-trip time is high, it is possible that many packets are being received while the context recovery request is being delivered. As shown in Figure 11.4, the result is a loss multiplier effect, in which a single loss affects multiple packets until a full header packet is delivered. Thus, packet loss can seriously affect the performance of CRTP.

The other limiting factor of CRTP is packet reordering. If packets are reordered prior to the compressed link, the compressor is required to send packets containing both sequence number and timestamp updates to compensate. These packets are relatively large—commonly between two and four octets—and they have a significant effect on the compression ratio, at least doubling the size of the compressed headers.
Basic CRTP assumes that there is no reordering on the compressed link. Work is under way on an extension to make CRTP more robust in the face of packet loss and reordering.43 It is expected that these enhancements will make CRTP suitable for environments with low to moderate amounts of loss or reordering over the compressed link. The Robust Header Compression scheme described in the next section is designed for more extreme environments.
As noted earlier, CRTP does not work well over links with loss and long round-trip times, such as many cellular radio links. Each lost packet causes several subsequent packets to be lost because the context is out of sync during at least one link round-trip time.
In addition to reducing the quality of the media stream, the loss of multiple packets wastes bandwidth because some packets that have been sent are simply discarded, and because a full header packet must be sent to refresh the context. Robust Header Compression (ROHC)37 was designed to solve these problems, providing compression suitable for use with third-generation cellular systems. ROHC gets significantly better performance than CRTP over such links, at the expense of additional complexity of implementation.
Observation of the changes in header fields within a media stream shows that they fall into three categories:
Some fields are static, or mostly static. Examples include the RTP SSRC, UDP ports, and IP addresses. These fields can be sent once when the connection is established, and either they never change or they change very infrequently.
Some fields change in a predictable manner with each packet sent, except for occasional sudden changes. Examples include the RTP timestamp and sequence number, and (often) the IPv4 ID field. During periods when these fields are predictable, there is usually a constant relation between them. When sudden changes occur, often only a single field changes unpredictably.
Some fields are unpredictable, having essentially random values, and have to be communicated as is, with no compression. The main example is the UDP checksum.
ROHC operates by establishing mapping functions between the RTP sequence number and the other predictable fields, then reliably transferring the RTP sequence number and the unpredictable header fields. These mapping functions form part of the compression context, along with the values of static fields that are communicated at startup or when those fields change.
The main differences between ROHC and CRTP come from the way they handle the second category: fields that usually change in a predictable manner. In CRTP, the value of the field is implicit and the packet contains an indication that it changed in the predictable fashion. In ROHC, the value of a single key field—the RTP sequence number—is explicitly included in all packets, and an implicit mapping function is used to derive the other fields.
ROHC has three states of operation, depending on how much context has been transferred:
The system starts in initialization and refresh state, much like the full header mode of CRTP. This state conveys the necessary information to set up the context, enabling the system to enter first- or second-order compression state.
First-order compression state allows the system to efficiently communicate irregularities in the media stream—changes in the context—while still keeping much of the compression efficiency. In this state, only a compressed representation of the RTP sequence number, along with the context identifier, and a reduced representation of the changed fields are conveyed.
Second-order state is the highest compression level, when the entire header is predictable from the RTP sequence number and stored context. Only a compressed representation of the RTP sequence number and a (possibly implicit) context identifier are included in the packet, giving a header that can be as small as one octet.
If any unpredictable fields are present, such as the UDP checksum, then both first- and second-order compression schemes communicate those fields unchanged. As expected, the result is a significant reduction in the compression efficiency. For simplicity, this description omits further mention of these fields, although they will always be conveyed.
The compressor starts in initialization and refresh state, sending full headers to the decompressor. It will move to either first- or second-order state, sending compressed headers, after it is reasonably sure that the decompressor has correctly received enough information to set up the context.
The system can operate in one of three modes: unidirectional, bidirectional optimistic, and bidirectional reliable. Depending on the mode chosen, the compressor will transition from the initialization and refresh state to either first- or second-order compression state, according to a timeout or an acknowledgment:
Unidirectional mode. No feedback is possible, and the compressor transitions to first- or second-order state after a predetermined number of packets has been sent.
Bidirectional optimistic mode. The compressor transitions to the first- or second-order state after a predetermined number of packets has been sent, much as in unidirectional mode, or when an acknowledgment is received.
Bidirectional reliable mode. The compressor transitions to the first- or second-order state on receipt of an acknowledgment.
The choice of unidirectional or bidirectional feedback depends on the characteristics of the link between compressor and decompressor. Some network links may not support a (convenient) back channel for feedback messages, forcing unidirectional operation. In most cases, though, one of the bidirectional modes can be used, allowing the receiver to communicate its state to the sender.
The compressor starts by assuming unidirectional operation. The decompressor will choose to send feedback if the link supports it, depending on the loss patterns of the link. Receipt of feedback messages informs the compressor that bidirectional operation is desired. The choice between optimistic and reliable mode is made by the decompressor and depends on the capacity of the back channel and the loss characteristics of the link. Reliable mode sends more feedback but is more tolerant of loss.
Typically the system transitions from initialization and refresh state to the second-order state after context has been established. It then remains in second-order state until loss occurs, or until a context update is needed because of changes in the stream characteristics.
If loss occurs, the system's behavior depends on the mode of operation. If one of the bidirectional modes was chosen, the decompressor will send feedback causing the compressor to enter the first-order state and send updates to repair the context. This process corresponds to the sending of a context refresh message in CRTP, causing the compressor to generate a full header packet. If unidirectional mode is used, the compressor will periodically transition to lower states, to refresh the context at the decompressor.
The compressor will also transition to the first-order state when it is necessary to convey a change in the mapping for one of the predictable fields, or an update to one of the static fields. This process corresponds to the sending of a compressed packet containing an updated delta field or a full header packet in CRTP. Depending on the mode of operation, the change to first-order state may cause the decompressor to send feedback indicating that it has correctly received the new context.
If the compressed link is reliable, ROHC and CRTP have similar compression efficiency, although ROHC is somewhat more complex. For this reason, dial-up modem links do not typically use ROHC, because CRTP is less complex and yields comparable performance.
When there is packet loss on the compressed link, the performance of ROHC shows because of its flexibility in sending partial context updates, and its robust encoding of compressed values. The capability to send partial context updates allows ROHC to update the context in cases in which CRTP would have to send a full header packet. ROHC can also reduce the size of a context update when there is loss on the link. Both of these capabilities give improved performance, compared to CRTP.
The combination of robust encoding of compressed values and sequence number–driven operation is also a key factor. As noted earlier, the ROHC context contains a mapping between the RTP sequence number and the other predictable header fields. Second-order compressed packets convey the sequence number using a window-based least-significant bit (W-LSB) encoding, and the other fields are derived from this. It is largely the use of W-LSB encoding that gives ROHC its robustness to packet loss.
Standard LSB encoding transmits the k least-significant bits of the field value, instead of the complete field. On receiving these k bits, and given the previously transmitted value Vref, the decompressor can derive the original value of the field, provided that it is within a range known as the interpretation interval.
The interpretation interval is the 2k values surrounding Vref, offset by a parameter p so that it covers the range Vref – p to Vref + 2k – 1 – p. The parameter p is chosen on the basis of the characteristics of the field being transported and conveyed to the decompressor during initialization, forming part of the context. Possible choices include the following:
If the field value is expected to increase, p = –1.
If the field value is expected to increase or stay the same, p = 0.
If the field value is expected to vary slightly from a fixed value, p = 2(k–1) + 1.
If the field value is expected to undergo small negative changes and large positive changes—for example, the RTP timestamp of a video stream using B-frames—then p = 2(k–2) – 1.
As an example, consider the transport of sequence numbers, in which the last transmitted value Vref = 984 and k = 4 least-significant bits are sent as the encoded form. Assume also that p = –1, giving an interpretation interval ranging between 985 and 1,000, as shown in Figure 11.5. The next value sent is 985 (in binary: 1111011001), which is encoded as 9 (in binary: 1001, the 4 least-significant bits of the original value). On receiving the encoded value, the decompressor takes Vref and replaces the k least-signifi-cant bits with those received, restoring the original value.

LSB encoding will work provided that the encoded value is within the interpretation interval. If a single packet were lost in the preceding example and the next value received by the decoder were 10 (in binary: 1010), then the restored value would be 986, which is correct. If more than 2k packets were lost, however, the decoder would have no way of knowing the correct value to decode.
The window-based variant of LSB encoding, W-LSB, maintains the interpretation interval as a sliding window, advancing when the compressor is reasonably sure that the decompressor has received a particular value. Confidence that the window can advance is obtained by various means: In bidirectional optimistic mode, the decompressor sends acknowledgments; in bidirectional optimistic mode, the window advances after a period of time, unless the decompressor sends a negative acknowledgment; and in unidirectional mode, the window simply advances after a period of time.
The advantage of W-LSB encoding is that loss of a small number of packets within the window will not cause the decompressor to lose synchronization. This robustness allows an ROHC decompressor to continue operation without requesting feedback in cases when a CRTP decompressor would fail and need a context update. The result is that ROHC is much less susceptible to the loss multiplier effect than CRTP: A single packet loss on the link will cause a single loss at the output of a ROHC decompressor, whereas a CRTP decompressor must often to wait for a context update before it can continue decompression.
RTP header compression—whether by CRTP or ROHC—is transparent to the application. When header compression is in use, the compressed link becomes a more efficient conduit for RTP packets, but aside from increased performance, an application should not be able to tell that compression is being used.
Nevertheless, there are ways in which an application can aid the operation of the compressor. The main idea is regularity: An application that sends packets with regular timestamp increments, and with a constant payload type, will produce a stream of RTP packets that compresses well, whereas variation in the payload type or interpacket interval will reduce the compression efficiency. Common causes of variation in the interpacket timing include silence suppression with audio codecs, reverse predicted video frames, and interleaving:
Audio codecs that suppress packets during silent periods affect header compression in two ways: They cause the marker bit to be set, and they cause a jump in the RTP timestamp. These changes cause CRTP to send a packet containing an updated timestamp delta; ROHC will send a first-order packet containing the marker bit and a new timestamp mapping. Both approaches add at least one octet to the size of the compressed header. Despite this reduction in header compression efficiency, silence suppression almost always results in a net saving in bandwidth because some packets are not sent.
Reverse predicted video frames—for example, MPEG B-frames—have a timestamp less than that of the previous frame.12 As a result, CRTP sends multiple timestamp updates, seriously reducing compression efficiency. The effects on ROHC are less severe, although some reduction in compression efficiency occurs there also.
Interleaving is often implemented within the RTP payload headers, with the format designed so that the RTP timestamp increment is constant. In this case, interleaving does not affect header compression, and it may even be beneficial. For example, CRTP has a loss multiplier effect when operating on high-delay links, which is less of an issue for inter-leaved streams than for noninterleaved streams. In some cases, though, interleaving can result in packets that have RTP timestamps with nonconstant offsets. Thus, interleaving will reduce the compression efficiency and is best avoided.
The use of UDP checksums also affects compression efficiency. When enabled, the UDP checksum must be communicated along with each packet. This adds two octets to the compressed header, which, because fully compressed RTP/UDP/IP headers are two octets for CRTP and one octet for ROHC, is a significant increase.
The implication is that an application intended to improve compression efficiency should disable the checksum, but this may not necessarily be appropriate. Disabling the checksum improves the compression ratio, but it may make the stream susceptible to undetected packet corruption (depending on the link layer; some links include a checksum that makes the UDP checksum redundant). An application designer must decide whether the potential for receiving corrupt packets outweighs the gain due to improved compression. On a wired network it is often safe to turn off the checksum because bit errors are rare. However, wireless networks often have a relatively high bit-error rate, and applications that may be used over a wireless link might want to enable the checksum.
The final factor that may affect the operation of header compression is generation of the IPv4 ID field. Some systems increment the IPv4 ID by one for each packet sent, allowing for efficient compression. Others use a pseudorandom sequence of IPv4 ID values, making the sequence unpredictable in an attempt to avoid certain security problems. The use of unpredictable IPv4 ID values significantly reduces the compression efficiency because it is necessary to convey the two-octet IPv4 ID in every packet, rather than allowing it to be predicted. It is recommended that IP implementations increment the IPv4 ID by one when sending RTP packets, although it is recognized that the IP layer will not typically know the contents of the packets (an implementation might provide a call to inform the system that the IPv4 ID should increment uniformly for a particular socket).
The use of RTP header compression—whether CRTP or ROHC—can significantly improve performance when RTP is operating over low-speed network links. When the payload is small—say, low-rate audio, with packets several tens of octets in length—the efficiency to be gained from CRTP with 2-octet compressed headers, compared to 40-octet uncompressed headers, is significant. The use of ROHC can achieve even greater gains in some environments, at the expense of additional complexity.
Header compression is beginning to be widely deployed. ROHC is an essential part of third-generation cellular telephony systems, which use RTP as their voice bearer channel. CRTP is widely implemented in routers and is beginning to be deployed in end hosts.