
TCP/IP and the OSI Reference Model
Performance Characteristics of an IP Network
Measuring IP Network Performance
Effects of Transport Protocols
Requirements for Audio/Video Transport in Packet Networks
Before delving into details of RTP, you should understand the properties of IP networks such as the Internet, and how they affect voice and video communication. This chapter reviews the basics of the Internet architecture and outlines typical behavior of a network connection. This review is followed by a discussion of the transport requirements for audio and video, and how well these requirements are met by the network.
IP networks have unique characteristics that influence the design of applications and protocols for audio/video transport. Understanding these characteristics is vital if you are to appreciate the trade-offs involved in the design of RTP, and how they influence applications that use RTP.
When you're thinking about computer networks, it is important to understand the concepts and implications of protocol layering. The OSI reference model,93 illustrated in Figure 2.1, provides a useful basis for discussion and comparison of layered systems.

The model comprises a set of seven layers, each building on the services provided by the lower layer and, in turn, providing a more abstract service to the layer above. The functions of the layers are as listed here:
Physical layer. The lowest layer—the physical layer—includes the physical network connection devices and protocols, such as cables, plugs, switches, and electrical standards.
Data link layer. The data link layer builds on the physical connection; for example, it turns a twisted-pair cable into Ethernet. This layer provides framing for data transport units, defines how the link is shared among multiple connected devices, and supplies addressing for devices on each link.
Network layer. The network layer connects links, unifying them into a single network. It provides addressing and routing of messages through the network. It may also provide control of congestion in the switches, prioritization of certain messages, billing, and so on. A network layer device processes messages received from one link and dispatches them to another, using routing information exchanged with its peers at the far ends of those links.
Transport layer. The transport layer is the first end-to-end layer. It takes responsibility for delivery of messages from one system to another, using the services provided by the network layer. This responsibility includes providing reliability and flow control if they are needed by the session layer and not provided by the network layer.
Session layer. The session layer manages transport connections in a fashion meaningful to the application. Examples include the Hypertext Transport Protocol (HTTP) used to retrieve Web pages, the Simple Mail Transfer Protocol (SMTP) negotiation during an e-mail exchange, and the management of the control and data channels in the File Transfer Protocol (FTP).
Presentation layer. The presentation layer describes the format of the data conveyed by the lower layers. Examples include the HTML (Hypertext Markup Language) used to describe the presentation of Web pages, the MIME (Multipurpose Internet Mail Extensions) standards describing e-mail message formats, and more mundane issues, such as the difference between text and binary transfers in FTP.
Application layer. The applications themselves—Web browsers and e-mail clients, for example—compose the top layer of the system, the application layer.
At each layer in the model, there is a logical communication between that layer on one host and the equivalent layer on another. When an application on one system wants to talk to an application on another system, the communication proceeds down through the layers at the source, passes over the physical connection, and then goes up the protocol stack at the destination.
For example, a Web browser application renders an HTML presentation, which is delivered using an HTTP session, over a TCP transport connection, via an IP network, over an Ethernet data link, using twisted-pair physical cable. Each step can be viewed as the instantiation of a particular layer of the model, going down through the protocol stack. The result is the transfer of a Web page from application (Web server) to application (Web browser).
The process is not always that simple: There may not be a direct physical connection between source and destination, in which case the connection must partially ascend the protocol stack at an intermediate gateway system. How far does it need to ascend? That depends on what is being connected. Here are some examples:
The increasingly popular IEEE 802.11b wireless network uses base stations that connect one physical layer, typically wired Ethernet, to another—the wireless link—at the data link layer.
An IP router provides an example of a gateway in which multiple data links are connected at the network level.
Viewing a Web page on a mobile phone often requires the connection to ascend all the way to the presentation layer in the gateway, which converts from HTML to the Wireless Markup Language (WML) and relays the connection down to the different lower layers.
As the preceding discussion suggests, we can use the OSI reference model to describe the Internet. The fit is not perfect: The architecture of the Internet has evolved over time, in part pre-dating the OSI model, and often it exhibits much less strict layering than has been implied. Nevertheless, it is instructive to consider the relation of the Internet protocol suite to the OSI model, in particular the role taken by IP as a universal network layer.113
The lowest two layers of the OSI reference model can be related directly to the Internet, which works over a wide range of links such as dial-up modems, DSL, Ethernet, optical fiber, wireless, and satellite. Each of these links can be described in terms of the data link/physical layer split of the OSI model.
At the network layer, one particular protocol transforms a disparate set of private networks into the global Internet. This is the Internet Protocol (IP). The service provided by IP to the upper layers is simple: best-effort delivery of datagram packets to a named destination. Because this service is so simple, IP can run over a wide range of link layers, enabling the rapid spread of the Internet.
The simplicity comes with a price: IP does not guarantee any particular timeliness of delivery, or that a datagram will be delivered at all. Packets containing IP datagrams may be lost, reordered, delayed, or corrupted by the lower layers. IP does not attempt to correct these problems; rather it passes the datagrams to the upper layers exactly as they arrive. It does, however, provide the following services:
Fragmentation, in case the datagram is larger than the maximum transmission unit of the underlying link layer
A time-to-live field that prevents looped packets from circling forever
A type-of-service label that can be used to provide priority for certain classes of packets
An upper-layer protocol identifier to direct the packet to the correct transport layer
Addressing of the endpoints—including multicast to address a group of receivers—and routing of datagrams to the correct destination
The format of an IP header, showing how these services map onto a packet, is illustrated in Figure 2.2.

The Internet Protocol provides the abstraction of a single network, but this does not change the underlying nature of the system. Even though it appears to be a single network, in reality the Internet consists of many separate networks, connected by gateways—now more commonly called routers—and unified by the single service and address space of IP. Figure 2.3 shows how individual networks make up the larger Internet. The different Internet service providers choose how to run their own portions of the global network: Some have high-capacity networks, with little congestion and high reliability; others do not.
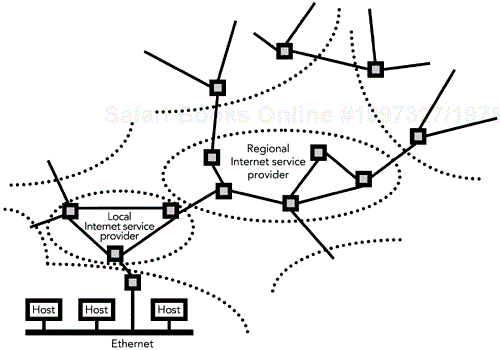
Within the maze of interconnected networks, the packets containing IP datagrams are individually routed to their destinations. Routers are not required to send a packet immediately; they may queue it for a short time if another packet is being transmitted on the outgoing link. They may also discard packets at times of congestion. The route taken by IP packets may change if the underlying network changes (for example, because of a link failure), possibly causing changes in delivery quality that can be observed by the upper-layer protocols.
Layered on top of IP in the Internet architecture are two common transport protocols: Transmission Control Protocol (TCP) and User Datagram Protocol (UDP). TCP adapts the raw IP service to provide reliable, ordered delivery between service ports on each host, and it varies its transmission rate to match the characteristics of the network. UDP, on the other hand, provides a service similar to the raw IP service, with only the addition of service ports. TCP and UDP are discussed in more detail later in this chapter.
Above these transport protocols sit the familiar session protocols of the Internet universe, such as HTTP for Web access and SMTP to deliver e-mail. The stack is completed by various presentation layers (HTML, MIME) and the applications themselves.
What should be clear from this discussion is that IP plays a key role in the system: It provides an abstraction layer, hiding the details of the underlying network links and topology from the applications, and insulating the lower layers from the needs of the applications. This architecture is known as the hourglass model, as illustrated in Figure 2.4.

The primary factor determining the performance of a system communicating across the Internet is the IP layer. The higher-layer protocols can adapt to, and compensate for, the behavior of the IP layer to a certain degree, but poor performance there will result in poor performance for the entire system. The next two sections discuss the performance of the IP layer in some detail, noting its unique properties and the potential problems and benefits it brings.
As is apparent from the hourglass model of the Internet architecture, an application is hidden from the details of the lower layers by the abstraction of IP. This means it's not possible to determine directly the types of networks across which an IP packet will have traveled—it could be anything from a 14.4-kilobit cellular radio connection to a multi-gigabit optical fiber—or the level of congestion of that network. The only means of discovering the performance of the network are observation and measurement.
So what do we need to measure, and how do we measure it? Luckily, the design of the IP layer means that the number of parameters is limited, and that number often can be further constrained by the needs of the application. The most important questions we can ask are these:
What is the probability that a packet will be lost in the network?
What is the probability that a packet will be corrupted in the network?
How long does a packet take to traverse the network? Is the transit time constant or variable?
What size of packet can be accommodated?
What is the maximum rate at which we can send packets?
The next section provides some sample measurements for the first four listed parameters. The maximum rate is closely tied to the probability that packets are lost in the network, as discussed in Chapter 10, Congestion Control.
What affects such measurements? The obvious factor is the location of the measurement stations. Measurements taken between two systems on a LAN will clearly show properties different from those of a transatlantic connection! But geography is not the only factor; the number of links traversed (often referred to as the number of hops), the number of providers crossed, and the times at which the measurements are taken all are factors. The Internet is a large, complex, and dynamic system, so care must be taken to ensure that any measurements are representative of the part of the network where an application is to be used.
We also have to consider what sort of network is being used, what other traffic is present, and how much other traffic is present. To date, the vast majority of network paths are fixed, wired (either copper or optical fiber) connections, and the vast majority of traffic (96% of bytes, 62% of flows, according to a recent estimate123) is TCP based. The implications of these traffic patterns are as follows:
Because the infrastructure is primarily wired and fixed, the links are very reliable, and loss is caused mostly by congestion in the routers.
TCP transport makes the assumption that packet loss is a signal that the bottleneck bandwidth has been reached, congestion is occurring, and it should reduce its sending rate. A TCP flow will increase its sending rate until loss is observed, and then back off, as a way of determining the maximum rate a particular connection can support. Of course, the result is a temporary overloading of the bottleneck link, which may affect other traffic.
If the composition of the network infrastructure or the traffic changes, other sources of loss may become important. For example, a large increase in the number of wireless users would likely increase the proportion of loss due to packet corruption and interference on the wireless links. In another example, if the proportion of multimedia traffic using transports other than TCP increased, and those transports did not react to loss in the same way as TCP does, the loss patterns would probably change because of variation in the dynamics of congestion control.
As we develop new applications that run on IP, we have to be aware of the changes we are bringing to the network, to ensure that we don't cause problems to other users. Chapter 10, Congestion Control, discusses this issue in more detail.
This section outlines some of the available data on IP network performance, including published results on average packet loss, patterns of loss, packet corruption and duplication, transit time, and the effects of multicast.
Several studies have measured network behavior over a wide range of conditions on the public Internet. For example, Paxson reports on the behavior of 20,000 transfers among 35 sites in 9 countries;124,95 Handley122 and Bolot67,66 report on the behavior of multicast sessions; and Yajnik, Moon, Kurose, and Towsley report on the temporal dependence in packet loss statistics.89,108,109 Other sources of data include the traffic archives maintained by CAIDA (the Cooperative Association for Internet Data Analysis),117 the NLANR (National Laboratory for Applied Network Research),119 and the ACM (Association for Computing Machinery).116
Various packet loss metrics can be studied. For example, the average loss rate gives a general measure of network congestion, while loss patterns and correlation give insights into the dynamics of the network.
The reported measurements of average packet loss rate show a range of conditions. For example, measurements of TCP/IP traffic taken by Paxson in 1994 and 1995 show that 30% to 70% of flows, depending on path taken and date, showed no packet loss, but of those flows that did show loss, the average loss ranged from 3% to 17% (these results are summarized in Table 2.1). Data from Bolot, using 64-kilobit PCM-encoded audio, shows similar patterns, with loss rates between 4% and 16% depending on time of day, although this data also dates from 1995. More recent results from Yajnik et al., taken using simulated audio traffic in 1997–1998, show lower loss rates of 1.38% to 11.03%. Handley's results—two sets of approximately 3.5 million packets of data and reception report statistics for multicast video sessions in May and September 1996—show loss averaged over five-second intervals varying between 0% and 100%, depending on receiver location and time of day. A sample for one particular receiver during a ten-hour period on May 29, 1996, plotted in Figure 2.5, shows the average loss rate, sampled over five-second intervals, varying between 0% and 20%.
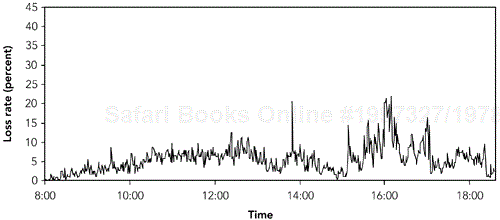
Table 2.1. Packet Loss Rates for Various Regions95
Fraction of Flows Showing No Loss | Average Loss Rate for Flows with Loss | |||
|---|---|---|---|---|
Region | Dec. 1994 | Dec. 1995 | Dec. 1994 | Dec. 1995 |
Within Europe | 48% | 58% | 5.3% | 5.9% |
Within U.S. | 66% | 69% | 3.6% | 4.4% |
U.S. to Europe | 40% | 31% | 9.8% | 16.9% |
Europe to U.S. | 35% | 52% | 4.9% | 6.0% |
The observed average loss rate is not necessarily constant, nor smoothly varying. The sample shows a loss rate that, in general, changes relatively smoothly, although at some points a sudden change occurs. Another example, from Yajnik et al., is shown in Figure 2.6. This case shows a much more dramatic change in loss rate: After a slow decline from 2.5% to 1% over the course of one hour, the loss rate jumps to 25% for 10 minutes before returning to normal—a process that repeats a few minutes later.

Figure 2.6. Loss Rate Distribution versus Time (Adapted from M. Yajnik, S. Moon, J. Kurose, and D. Towsley, “Measurement and Modeling of the Temporal Dependence in Packet Loss,” Technical Report 98-78, Department of Computer Science, University of Massachusetts, Amherst, 1998. © 1999 IEEE.)
How do these loss rates compare with current networks? The conventional wisdom at the time of this writing is that it's possible to engineer the network backbone such that packet loss never occurs, so one might expect recent data to illustrate this. To some extent this is true; however, even if it's possible to engineer part of the network to be loss free, that possibility does not imply that the entire network will behave in the same way. Many network paths show loss today, even if that loss represents a relatively small fraction of packets.
The Internet Weather Report,120 a monthly survey of the loss rate measured in a range of routes across the Internet, showed average packet loss rates within the United States ranging from 0% to 16%, depending on the ISP, as of May 2001. The monthly average loss rate is about 2% in the United States, but for the Internet as a whole, the average is slightly higher, at about 3%.
What should we learn from this? Even though some parts of the network are well engineered, others can show significant loss. Remember, as Table 2.1 shows, 70% of network paths within the United States had no packet loss in 1995, yet the average loss rate for the others was almost 5%, a rate that is sufficient to cause significant degradation in audio/video quality.
In addition to looking at changes in the average loss rate, it is instructive to consider the short-term patterns of loss. If we aim to correct for packet loss, it helps to know if lost packets are randomly distributed within a media flow, or if losses occur in bursts.
If packet losses are distributed uniformly in time, we should expect that the probability that a particular packet is lost is the same as the probability that the previous packet was lost. This would mean that packet losses are most often isolated events, a desirable outcome because a single loss is easier to recover from than a burst. Unfortunately, however, the probability that a particular packet is lost often increases if the previous packet was also lost. That is, losses tend to occur back-to-back. Measurements by Vern Paxson have shown, in some cases, a five- to tenfold increase in loss probability for a particular packet if the previous packet was lost, clearly implying that packet loss is not uniformly distributed in time.
Several other studies—for example, measurements collected by Bolot in 1995, by Handley and Yajnik et al. in 1996, and by me in 1999—have confirmed the observation that packet loss probabilities are not independent. In all cases, these studies show that the vast majority of losses are of single packets, constituting about 90% of loss events. The probability of longer bursts of loss decreases as illustrated in Figure 2.7; it is clear that longer bursts occur more frequently than they would if losses were independent.

Observed loss patterns also show significant periodicity in some cases. For example, Handley has reported bursts of loss occurring approximately every 30 seconds on measurements taken in 1996 (see Figure 2.8), and similar problems were reported in April 2001.121 Such reports are not universal, and many traces show no such effect. It is conjectured that the periodicity is due to the overloading of certain systems by routing updates, but this is not certain.

If packets can be lost in the network, can they be duplicated? Perhaps surprisingly, the answer is yes! It is possible for a source to send a single packet, yet for the receiver to get multiple copies of that packet. The most likely reason for duplication is faults in routing/switching elements within the network; duplication should not happen in normal operation.
How common is duplication? Paxson's measurements revealing the tendency of back-to-back packet losses also showed a small amount of packet duplication. In measuring 20,000 flows, he found 66 duplicate packets, but he also noted, “We have observed traces . . . in which more than 10% of the packets were replicated. The problem was traced to an improperly configured bridging device.”95 A trace that I took in August 1999 shows 131 duplicates from approximately 1.25 million packets.
Packet duplication should not cause problems, as long as applications are aware of the issue and discard duplicates (RTP contains a sequence number for this purpose). Frequent packet duplication wastes bandwidth and is a sign that the network contains badly configured or faulty equipment.
Packets can be corrupted, as well as lost or duplicated. Each IP packet contains a checksum that protects the integrity of the packet header, but the payload is not protected at the IP layer. However, the link layer may provide a checksum, and both TCP and UDP enable a checksum of the entire packet. In theory, these protocols will detect most corrupted packets and cause them to be dropped before they reach the application.
Few statistics on the frequency of packet corruption have been reported. Stone103 quotes Paxson's observation that approximately one in 7,500 packets failed their TCP or UDP checksum, indicating corruption of the packet. Other measurements in that work show average checksum failure rates ranging from one in 1,100 to one in 31,900 packets. Note that this result is for a wired network; wireless networks can be expected to have significantly different properties because corruption due to radio interference may be more severe than that due to noise in wires.
When the checksum fails, the packet is assumed to be corrupted and is discarded. The application does not see corrupted packets; they appear to be lost. Corruption is visible as a small increase in the measured loss rate.
In some cases it may be desirable for an application to receive corrupt packets, or to get an explicit indication that the packets are corrupted. UDP provides a means of disabling the checksum for these cases. Chapter 8, Error Concealment, and Chapter 10, Congestion Control, discuss this topic in more detail.
How long does it take packets to transit the network? The answer depends on the route taken, and although a short path does take less time to transit than a long one, we need to be careful of the definition of short.
The components that affect transit time include the speed of the links, the number of routers through which a packet must pass, and the amount of queuing delay imposed by each router. A path that is short in physical distance may be long in the number of hops a packet must make, and often the queuing delay in the routers at each hop is the major factor. In network terms a short path is most often the one with the least hops, even if it covers a longer physical distance. Satellite links are the obvious exception, where distance introduces a significant radio propagation delay. Some measures of average round-trip time, taken in May 2001, are provided in Table 2.2 for comparison. Studies of telephone conversations subject to various round-trip delays have shown that people don't notice delays of less than approximately 300 milliseconds (ms). Although this is clearly a subjective measurement, dependent on the person and the task, the key point is that the measured network round-trip times are mostly within this limit. (The trip from London to Sydney is the exception, but the significant increase here is probably due to a satellite hop in the path.)
Table 2.2. Sample Round-Trip Time Measurements
Source | Destination | Hop Count | Round-Trip Time (ms) |
|---|---|---|---|
Washington, DC | London | 20 | 94 |
Washington, DC | Berkeley, CA | 21 | 88 |
London | Berkeley, CA | 22 | 136 |
London | Sydney | 28 | 540 |
Measures of the delay in itself are not very interesting because they so clearly depend on the location of the source and the destination. Of more interest is how the network transit time varies from packet to packet: A network that delivers packets with constant delay is clearly easier for an application to work with than one in which the transit time can vary, especially if that application has to present time-sensitive media.
A crude measure of the variation in transit time (jitter) is the arrival rate of packets. For example, Figure 2.9 shows the measured arrival rate for a stream sent at a constant rate; clearly the arrival rate varies significantly, indicating that the transit time across the network is not constant.

A better measure, which doesn't assume constant rate, is to find the transit time by measuring the difference between arrival time and departure time for each packet. Unfortunately, measuring the absolute transit time is difficult because it requires accurate synchronization between the clocks at source and destination, which is not often possible. As a result, most traces of network transit time include the clock offset, and it becomes impossible to study anything other than the variation in delay (because it is not possible to determine how much of the offset is due to unsynchronized clocks and how much is due to the network).
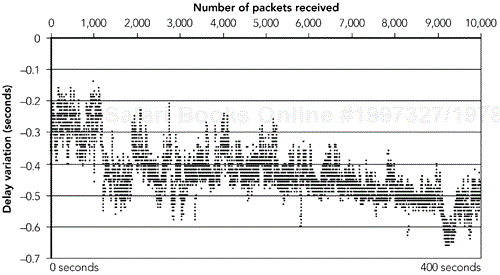
Some sample measurements of the variation in transit time, including the offset due to unsynchronized clocks, are presented in Figure 2.10 and Figure 2.11. I took these measurements in August 1999; similar measurements have been presented by Ramjee et al. (in 1994)96 and by Moon et al.90 Note the following:
The slow downward slope of the measurements is due to clock skew between the source and the destination. One machine's clock is running slightly faster than the other's, leading to a gradual change in the perceived transit time.
Several step changes in the average transit time, perhaps due to route changes in the network, can be observed.
The transit time is not constant; rather it shows significant variation throughout the session.

These are all problems that an application, or higher-layer protocol, must be prepared to handle and, if necessary, correct.
It is also possible for packets to be reordered within the network—for example, if the route changes and the new route is shorter. Paxson95 observed that a total 2% of TCP data packets were delivered out of order, but that the fraction of out-of-order packets varied significantly between traces, with one trace showing 15% of packets being delivered out of order.
Another characteristic that may be observed is “spikes” in the network transit time, such as those shown in Figure 2.12. It is unclear whether these spikes are due to buffering within the network or in the sending system, but they present an interesting challenge if one is attempting to smooth the arrival time of a sequence of packets.

Finally, the network transit time can show periodicity (as noted, for example, in Moon et al. 199889), although this appears to be a secondary effect. We expect this periodicity to have causes similar to those of the loss periodicity noted earlier, except that the events are less severe and cause queue buildup in the routers, rather than queue overflow and hence packet loss.
The IP layer can accept variably sized packets, up to 65,535 octets in length, or to a limit determined by the maximum transmission unit (MTU) of the links traversed. The MTU is the size of the largest packet that can be accommodated by a link. A common value is 1,500 octets, which is the largest packet an Ethernet can deliver. Many applications assume that they can send packets up to this size, but some links have a lower MTU. For example, it is not unusual for dial-up modem links to have an MTU of 576 octets.
In most cases the bottleneck link is adjacent to either sender or receiver. Virtually all backbone network links have an MTU of 1,500 octets or more.
IPv4 supports fragmentation, in which a large packet is split into smaller fragments when it exceeds the MTU of a link. It is generally a bad idea to rely on this, though, because the loss of any one fragment will make it impossible for the receiver to reconstruct the packet. The resulting loss multiplier effect is something we want to avoid.
In virtually all cases, audio packets fall within the network MTU. Video frames are larger, and applications should split them into multiple packets for transport so that each packet fits within the MTU of the network.
IP multicast enables a sender to transmit data to many receivers at the same time. It has the useful property that the network creates copies of the packet as needed, such that only one copy of the packet traverses each link. IP multicast provides for extremely efficient group communication, provided it is supported by the network, making the cost of sending data to a group of receivers independent of the size of the group.
Support for multicast is an optional, and relatively new, feature of IP networks. At the time of this writing, it is relatively widely deployed in research and educational environments and in the network backbone, but it is uncommon in many commercial settings and service providers.
Sending to a group means that more things can go wrong: Reception quality is no longer affected by a single path through the network, but by the path from the source to each individual receiver. The defining factor in the measurement of loss and delay characteristics for a multicast session is heterogeneity. Figure 2.13 illustrates this concept, showing the average loss rate seen at each receiver in a multicast session measured by me.

Multicast does not change the fundamental causes of loss or delay in the network. Rather it enables each receiver to experience those effects while the source transmits only a single copy of each packet. The heterogeneity of the network makes it difficult for the source to satisfy all receivers: Sending too fast for some and too slow for others is common. We will discuss these issues further in later chapters. For now it's sufficient to note that multicast adds yet more heterogeneity to the system.
The measurements that have been presented so far have been of the public, wide area, Internet. Many applications will operate in this environment, but a significant number will be used in private intranets, on wireless networks, or on networks that support enhanced quality of service. How do such considerations affect the performance of the IP layer?
Many private IP networks (often referred to as intranets) have characteristics very similar to those of the public Internet: The traffic mix is often very similar, and many intranets cover wide areas with varying link speeds and congestion levels. In such cases it is highly likely that the performance will be similar to that measured on the public Internet. If, however, the network is engineered specifically for real-time multimedia traffic, it is possible to avoid many of the problems that have been discussed and to build an IP network that has no packet loss and minimal jitter.
Some networks support enhanced quality of service (QoS) using, for example, integrated services/RSVP11 or differentiated services.24 The use of enhanced QoS may reduce the need for packet loss and/or jitter resilience in an application because it provides a strong guarantee that certain performance bounds are met. Note, however, that in many cases the guarantee provided by the QoS scheme is statistical in nature, and often it does not completely eliminate packet loss, or perhaps more commonly, variations in transit time.
Significant performance differences can be observed in wireless networks. For example, cellular networks can exhibit significant variability in their performance over short time frames, including noncongestive loss, bursts of loss, and high bit error rates. In addition, some cellular systems have high latency because they use interleaving at the data link layer to hide bursts of loss or corruption.
The primary effect of different network technologies is to increase the heterogeneity of the network. If you are designing an application to work over a restricted subset of these technologies, you may be able to leverage the facilities of the underlying network to improve the quality of the connection that your application sees. In other cases the underlying network may impose additional challenges on the designer of a robust application.
A wise application developer will choose a robust design so that when an application moves from the network where it was originally envisioned to a new network, it will still operate correctly. The challenge in designing audiovisual applications to operate over IP is making them reliable in the face of network problems and unexpected conditions.
Measuring, predicting, and modeling network behavior are complex problems with many subtleties. This discussion has only touched on the issues, but some important conclusions are evident.
The first point is that the network can and frequently does behave badly. An engineer who designs an application that expects all packets to arrive, and to do so in a timely manner, will have a surprise when that application is deployed on the Internet. Higher-layer protocols—such as TCP—can hide some of this badness, but there are always some aspects visible to the application.
Another important point to recognize is the heterogeneity in the network. Measurements taken at one point in the network will not represent what's happening at a different point, and even “unusual” events happen all the time. There were approximately 100 million systems on the Net at the end of 2000,118 so even an event that occurs to less than 1% of hosts will affect many hundreds of thousands of machines. As an application designer, you need to be aware of this heterogeneity and its possible effects.
Despite this heterogeneity, an attempt to summarize the discussion of loss and loss patterns reveals several “typical” characteristics:
Although some network paths may not exhibit loss, these paths are not usual in the public Internet. An application should be designed to cope with a small amount of packet loss—say, up to 5%.
Isolated packet losses compose most observed loss events.
The probability that a packet is lost is not uniform: Even though most losses are of isolated packets, bursts of consecutively lost packets are more common than can be explained by chance alone. Bursts of loss are typically short; an application that copes with two to three consecutively lost packets will suffice for most burst losses.
Rarely, long bursts of loss occur. Outages of a significant fraction of a second, or perhaps even longer, are not unknown.
Packet duplication is rare, but it can occur.
Similarly, in rare cases packets can be corrupted. The over-whelming majority of these are detected by the TCP or UDP checksum (if enabled), and the packet is discarded before it reaches the application.
The characteristics of transit time variation can be summarized as follows:
Transit time across the network is not uniform, and jitter is observed.
The vast majority of jitter is reasonably bounded, but the tail of the distribution can be long.
Although reordering is comparatively rare, packets can be reordered in transit. An application should not assume that the order in which packets are received corresponds to the order in which they were sent.
These are not universal rules, and for every one there is a network path that provides a counterexample.71 They do, however, provide some idea of what we need to be aware of when designing higher-layer protocols and applications.
Thus far, our consideration of network characteristics has focused on IP. Of course, programmers almost never use the raw IP service. Instead, they build their applications on top of one of the higher-layer transport protocols, typically either UDP or TCP. These protocols provide additional features beyond those provided by IP. How do these added features affect the behavior of the network as seen by the application?
The User Datagram Protocol (UDP) provides a minimal set of extensions to IP. The UDP header is shown in Figure 2.14. It comprises 64 bits of additional header representing source and destination port identifiers, a length field, and a checksum.

The source and destination ports identify the endpoints within the communicating hosts, allowing for multiplexing of different services onto different ports. Some services run on well-known ports; others use a port that is dynamically negotiated during call setup. The length field is redundant with that in the IP header. The checksum is used to detect corruption of the payload and is optional (it is set to zero for applications that have no use for a checksum).
Apart from the addition of ports and a checksum, UDP provides the raw IP service. It does not provide any enhanced reliability to the transport (although the checksum does allow for detection of payload errors that IP does not detect), nor does it affect the timing of packet delivery. An application using UDP provides data packets to the transport layer, which delivers them to a port on the destination machine (or to a group of machines if multicast is used). Those packets may be lost, delayed, or misordered in transit, exactly as observed for the raw IP service.
The most common transport protocol on the Internet is TCP. Although UDP provides only a small set of additions to the IP service, TCP adds a significant amount of additional functionality: It abstracts the unreliable packet delivery service of IP to provide reliable, sequential delivery of a byte stream between ports on the source and a single destination host.
An application using TCP provides a stream of data to the transport layer, which fragments it for transmission in appropriately sized packets, and at a rate suitable for the network. Packets are acknowledged by the receiver, and those that are lost in transit are retransmitted by the source. When data arrives, it is buffered at the receiver so that it can be delivered in order. This process is transparent to the application, which simply sees a “pipe” of data flowing across the network.
As long as the application provides sufficient data, the TCP transport layer will increase its sending rate until the network exhibits packet loss. Packet loss is treated as a signal that the bandwidth of the bottleneck link has been exceeded and the connection should reduce its sending rate to match. Accordingly, TCP reduces its sending rate when loss occurs. This process continues, with TCP continually probing the sustainable transmission rate across the network; the result is a sending rate such as that illustrated in Figure 2.15.

This combination of retransmission, buffering, and probing of available bandwidth has several effects:
TCP transport is reliable, and if the connection remains open, all data will eventually be delivered. If the connection fails, the endpoints are made aware of the failure. This is a contrast to UDP, which offers the sender no information about the delivery status of the data.
An application has little control over the timing of packet delivery because there is no fixed relation between the time at which the source sends data and the time at which that data is received. This variation differs from the variation in transit time exhibited by the raw IP service because the TCP layer must also account for retransmission and variation in the sending rate. The sender can tell if all outstanding data has been sent, which may enable it to estimate the average transmission rate.
Bandwidth probing may cause short-term overloading of the bottleneck link, resulting in packet loss. When this overloading causes loss to the TCP stream, that stream will reduce its rate; however, it may also cause loss to other streams in the process.
Of course, there are subtleties to the behavior of TCP, and much has been written on this subject. There are also some features that this discussion has not touched upon, such as push mode and urgent delivery, but these do not affect the basic behavior. What is important for our purpose is to note the fundamental difference between TCP and UDP: the trade-off between reliability (TCP) and timeliness (UDP).
So far, this chapter has explored the characteristics of IP networks in some detail, and has looked briefly at the behavior of the transport protocols layered above them. We can now relate this discussion to real-time audio and video transport, consider the requirements for delivery of media streams over an IP network, and determine how well the network meets those requirements.
When we describe media as real-time, we mean simply that the receiver is playing out the media stream as it is received, rather than simply storing the complete stream in a file for later play-back. In the ideal case, playout at the receiver is immediate and synchronous, although in practice some unavoidable transmission delay is imposed by the network.
The primary requirement that real-time media places on the transport protocol is for predictable variation in network transit time. Consider, for example, an IP telephony system transporting encoded voice in 20-millisecond frames: The source will transmit one packet every 20 milliseconds, and ideally we would like those to arrive with the same spacing so that the speech they contain can be played out immediately. Some variation in transit time can be accommodated by the insertion of additional buffering delay at the receiver, but this is possible only if that variation can be characterized and the receiver can adapt to match the variation (this process is described in detail in Chapter 6, Media Capture, Playout, and Timing).
A lesser requirement is reliable delivery of all packets by the network. Clearly, reliable delivery is desirable, but many audio and video applications can tolerate some loss: In our IP telephony example, loss of a single packet will result in a dropout of one-fiftieth of a second, which, with suitable error concealment, is barely noticeable. Because of the time-varying nature of media streams, some loss is usually acceptable because its effects are quickly corrected by the arrival of new data. The amount of loss that is acceptable depends on the application, the encoding method used, and the pattern of loss. Chapter 8, Error Concealment, and Chapter 9, Error Correction, discuss loss tolerance.
These requirements drive the choice of transport protocol. It should be clear that TCP/IP is not appropriate because it favors reliability over timeliness, and our applications require timely delivery. A UDP/IP-based transport should be suitable, provided that the variation in transit time of the network can be characterized and loss rates are acceptable.
The standard Real-time Transport Protocol (RTP) builds on UDP/IP, and provides timing recovery and loss detection, to enable the development of robust systems. RTP and associated standards will be discussed in extensive detail in the remainder of this book.
Despite TCP's limitations for real-time applications, some audio/video applications use it for their transport. Such applications attempt to estimate the average throughput of the TCP connection and adapt their send rate to match. This approach can be made to work when tight end-to-end delay bounds are not required and an application has several seconds worth of buffering to cope with the variation in delivery time caused by TCP retransmission and congestion control. It does not work reliably for interactive applications, which need short end-to-end delay, because the variation in transit time caused by TCP is too great.
The primary rationale for the use of TCP/IP transport is that many firewalls pass TCP connections but block UDP. This situation is changing rapidly, as RTP-based systems become more prevalent and firewalls smarter. I strongly recommend that new applications be based on RTP-over-UDP/IP. RTP provides for higher quality by enabling applications to adapt in a way that is appropriate for real-time media, and by promoting interoperability (because it is an open standard).
At this stage you may be wondering why anyone would consider a packet-based audio or video application over an IP network. Such a network clearly poses challenges to the reliable delivery of real-time media streams. Although these challenges are real, an IP network has some distinct advantages that lead to the potential for significant gains in efficiency and flexibility, which can outweigh the disadvantages.
The primary advantage of using IP as the bearer service for realtime audio and video is that it can provide a unified and converged network. The same network can be used for voice, music, and video as for e-mail, Web access, file and document transfers, games, and so on. The result can be significant savings in infrastructure, deployment, support, and management costs.
A unified packet network enables statistical multiplexing of traffic. For example, voice activity detection can be used to prevent packet voice applications from transmitting during silence periods, and traffic using TCP/IP as its transport will adapt to match the variation in available capacity. Provided that care is taken to design audio and video applications to tolerate the effects of this adaptation, the applications will not be adversely affected. Thus we can achieve much higher link utilization, which is important in resource-limited systems.
Another important benefit is provided by IP multicast, which allows inexpensive delivery of data to a potentially large group of receivers. IP multicast enables affordable Internet radio and television, and other group communication services, by making the cost of delivery independent of the size of the audience.
The final, and perhaps most compelling, case for audio and video over IP is that IP enables new services. Convergence allows rich interaction between real-time audio/video and other applications, enabling us to develop systems that would not previously have been possible.
The properties of an IP network are significantly different from those of traditional telephony, audio, or video distribution networks. When designing applications that work over IP, you need to be aware of these unique characteristics, and make your system robust to their effects.
The remainder of this book will describe an architecture for such systems, explaining RTP and its model for timing recovery and lip synchronization, error correction and concealment, congestion control, header compression, multiplexing and tunneling, and security.