
The Motivation for Multiplexing
Tunneling Multiplexed Compressed RTP
Other Approaches to Multiplexing
Multiplexing and tunneling provide an alternative to header compression, improving the efficiency of RTP by bundling multiple streams together inside a single transport connection. The aim is to amortize the size of the headers across multiple streams, reducing the per-stream overhead. This chapter discusses the motivation for multiplexing and outlines the mechanisms that can be used to multiplex RTP streams.
Header compression reduces the size of the headers of a single RTP stream, on a hop-by-hop basis. It provides very efficient transport but requires cooperation from the network (because header compression works hop-by-hop, rather than end-to-end). Header compression adds to the load on routers in terms of additional computation and flow-specific state, both of which may be unacceptable in systems that have to support many hundreds, or even thousands, of simultaneous RTP streams.
The traditional solution to the issues of computation and state within the network has been to push the complexity to the edge, simplifying the center of the network at the expense of additional complexity at the edges: the end-to-end argument. Application of this solution leads to the suggestion that headers should be reduced end-to-end if possible. You can reduce the header in this way by performing header compression end-to-end, thereby reducing the size of each header, or by placing multiple payloads within each packet to reduce the number of headers.
Applying RTP header compression end-to-end is possible, but unfortunately it provides little benefit. Even if the RTP headers were removed entirely, the UDP/IP headers would still be present. Thus a 28-octet overhead would remain for the typical IPv4 case, a size that is clearly unacceptable when the payload is, for example, a 14-octet audio frame. So there is only one possible end-to-end solution: Place multiple payloads within each packet, to amortize the overhead due to UDP/IP headers.
The multiple frames of payload data may come from a single stream or from multiple streams, as shown in Figure 12.1. Placing multiple frames of payload data from a single stream into each RTP packet is known is bundling. As explained in Chapter 4, RTP Data Transfer Protocol, bundling is an inherent part of RTP and needs no special support. It is very effective at reducing the header overhead, but it imposes additional delay on the media stream because a packet cannot be sent until all the bundled data is present.

The alternative, multiplexing, is the process by which multiple frames of payload data, from different streams, are placed into a single packet for transport. Multiplexing avoids the delay penalty inherent in bundling, and in some cases it can significantly improve efficiency. It is, however, not without problems, which may render it unsuitable in many cases:
Multiplexing requires many streams, with similar characteristics, to be present at the multiplex point. If frames have nonuniform arrival times, the multiplexing device will have to delay some frames, waiting for others to arrive. Other problems arise if frames have unpredictable sizes because the multiplexing device will not know in advance how many frames can be multiplexed. This may mean that partially multiplexed packets will be sent when the frames are not of convenient sizes to fully multiplex. The results are inefficient transport and variable latency, neither of which is desirable.
The quality-of-service mechanisms proposed for IP (Differentiated Services and Integrated Services) operate on the granularity of IP flows. Because a multiplex conveys several streams within a single IP layer flow, it is impossible to give those streams different quality of service. This limitation may restrict the usefulness of multiplexing in environments where QoS is used, because it requires all the flows to have identical QoS. On the other hand, if many flows require identical enhanced QoS, the multiplexing may help by reducing the number of flows that the QoS scheme must process.
Similarly, multiplexing means that all streams within the multiplex have the same degree of error resilience. This is not necessarily appropriate, because some streams may be considered more important than others and would benefit from additional protection.
Despite these issues, in some cases it may still be desirable to multiplex RTP streams. The most common example is the case in which a large number of essentially identical flows are being transferred between two points, something that occurs often when voice-over-IP is being used as a backbone “trunk” to replace conventional telephone lines.
Multiplexing is not directly supported within RTP. If multiplexing streams within RTP is desired, one of the extensions described in this chapter must be used.
The IETF Audio/Video Transport working group received numerous proposals for RTP multiplexing solutions. Many of these were driven by the needs of specific applications, and although they may have solved the needs of those applications, they generally failed to provide a complete solution. One of the few proposals to keep the semantics of RTP was Tunneling Multiplexed Compressed RTP (TCRTP), which was adopted as the recommended “best current practice” solution.52
The TCRTP specification describes how existing protocols can be combined to provide a multiplex. It does not define any new mechanisms. The combination of RTP header compression, the Layer Two Tunneling Procotol (L2TP),31 and PPP multiplexing39 provides the TCRTP system, with the protocol stack shown in Figure 12.2. Header compression is used to reduce the header overhead of a single RTP payload. Tunneling is used to transport compressed headers and payloads through a multiple-hop IP network without having to compress and decompress at each link. Multiplexing is used to reduce the overhead of tunnel headers by amortizing a single tunnel header over many RTP payloads.

The first stage of TCRTP is to compress the header, which it does in the usual way, negotiating the use of either CRTP or ROHC over a PPP link. The difference is that the PPP link is a virtual interface representing a tunnel rather than a real link. The tunnel is essentially invisible to the header compression, making its presence known only because of the loss and delay characteristics imposed. The concept is much as if the RTP implementation were running over a virtual private network (VPN) link, except that the aim is to provide more efficient transport, rather than more secure transport.
Compared to a single physical link, a tunnel typically has a longer round-trip time, may have a higher packet loss rate, and may reorder packets. As discussed in Chapter 11, Header Compression, links with these properties have adverse effects on CRTP header compression and may lead to poor performance. There are enhancements to CRTP under development that will reduce this problem.43 ROHC is not a good fit because it requires in-order delivery, which cannot be guaranteed with a tunnel.
The tunnel is created by means of L2TP providing a general encapsulation for PPP sessions over an IP network.31 This is a natural fit because both CRTP and ROHC are commonly mapped onto PPP connections, and L2TP allows any type of PPP session to be negotiated transparently. If the interface to the PPP layer is correctly implemented, the CRTP/ROHC implementation will be unaware that the PPP link is a virtual tunnel.
Unfortunately, when the overhead of a tunnel header is added to a single compressed RTP payload, there is very little bandwidth savings compared to uncompressed transport of RTP streams. Multiplexing is required to amortize the overhead of the tunnel header over many RTP payloads. The TCRTP specification proposes the use of PPP multiplexing39 for this purpose. PPP multiplexing combines consecutive PPP frames into a single frame for transport. It is negotiated as an option during PPP connection setup, and it supports multiplexing of variable sizes and types of PPP frames, as shown in Figure 12.3.

PPP adds framing to a point-to-point bit stream so that it can transport a sequence of upper-layer packets. At least four octets of framing are added to each upper-layer packet: a flag octet to signify the start of the PPP frame, followed by a protocol identifier, the mapped upper packet as payload data, and a two-octet check-sum (other framing headers may be present, depending on the options negotiated during channel setup). With several frames multiplexed into one, the PPP overhead is reduced from four octets per packet to two.
The need for TCRTP to include multiplexing becomes clear when the overhead of tunneling is considered. When PPP frames are tunneled over IP via L2TP, there is an overhead of 36 octets per frame (L2TP header compression46 may reduce this number to 20 octets per frame). This amount of overhead negates the gain from header compression, unless frames are multiplexed before they are tunneled.
TCRTP has the advantage of being invisible to the upper-layer protocols. An application generating RTP packets cannot tell whether those packets are multiplexed, and it should be possible to add a multiplex to an existing application without changing that application.
The versatility of multiplexing allows great flexibility in the use of TCRTP. For example, TCRTP may be implemented as a virtual network interface on a host to multiplex locally generated packets, or on a router to multiplex packets that happen to flow between two common intermediate points, or as part of a standalone gateway from PSTN (Public Switched Telephone Network) to IP, multiplexing voice calls in a telephony system.
Depending on the scenario, TCRTP may be implemented in many ways. One possible implementation is for the TCRTP stack to present itself to the rest of the system as a standard PPP network interface, which allows the negotiation of RTP header compression. Internally, it will implement PPP multiplexing and L2TP tunneling, but this implementation is transparent to the applications.
The transparency of the TCRTP interface depends primarily on the operating system. If the IP protocol implementation is only loosely coupled to the layer-two interface, it should be possible to add a new interface—TCRTP—relatively easily and transparently. If the IP layer is tightly coupled to the layer-two interface, as may occur in an embedded system in which the TCP/IP implementation is tuned to the characteristics of a particular link, then the process may be more difficult.
A more serious problem may be the interaction between layer-two interfaces and other parts of the network stack. TCRTP is a tunneling protocol, in which compressed RTP/UDP/IP is layered above multiplexed PPP and L2TP, and then layered above UDP/IP. If the operating system does not support the concept of tunnel interfaces, this layering of IP-over-something-over-IP can be problematic and require extensive work. It is also helpful if the system hides tunnel interfaces within the abstraction of a normal network interface because otherwise the different API for tunnel interfaces raises the possibility of application incompatibility with TCRTP.
Within a TCRTP interface, the degree of multiplexing must be carefully controlled to bound the delay, while ensuring that sufficient packets are included in the multiplex to keep the header overhead within acceptable limits. If too few packets are multiplexed together, the per-packet headers become large and negate the effects of the multiplex. We can avoid this problem by delaying sending multiplexed packets until they have accumulated sufficient data to make the header overhead acceptable; however, because interactive applications need a total end-to-end delay of less than approximately 150 milliseconds, the multiplex cannot afford to insert much delay.
Non-RTP traffic can be sent through a TCRTP tunnel but will cause a significant reduction in compression efficiency, so it is desirable to separate it from the RTP traffic. The destination address can be used to separate the two types of traffic if the implementations cooperate to ensure that only RTP packets are sent to a particular destination, or a more extensive examination of the packet headers can be used (for example, checking that the packets are UDP packets destined for a particular port range). Because RTP does not use a fixed port, there is no direct way of distinguishing an RTP flow from a non-RTP flow; so the multiplex cannot be certain that only RTP packets are transported, unless the applications generating those packets cooperate with the multiplex in some manner.
The bandwidth saved by the use of TCRTP depends on several factors, including the multiplexing gain, the expected packet loss rate within the tunnel, and the rate of change of fields within the multiplexed RTP and IP headers.
Multiplexing reduces the overhead due to the PPP and L2TP headers, and the reduction is greater as an increasing number of streams are multiplexed together into each PPP frame. Performance always increases as more flows are multiplexed together, although the incremental gain per flow is less as the total number of flows in the multiplex increases.
The packet loss rate, and the rate of change of the header fields, can have an adverse effect on the header compression efficiency. Packet loss will cause context invalidation, which will cause compression to switch to a less efficient mode of operation while the context is refreshed. The problem is particularly acute if standard CRTP is used; enhanced CRTP performs much better. Changes in the header fields may also cause the compression to transition to a less efficient mode of operation, sending first-order deltas instead of fully compressed second-order deltas. Little can be done about this, except to note that the section titled Considerations for RTP Applications, in Chapter 11, Header Compression, is also relevant to TCRTP.
The TCRTP specification includes a simple performance model, which attempts to predict the bandwidth used by a voice-over-IP stream (given enhanced CRTP compression), the packet size and duration, the average talk spurt length, the number of packets that can be multiplexed, and estimates of the overhead due to changes in the compressed RTP and IP headers. This model predicts that TCRTP will achieve a rate of 14.4 Kbps for a G.729 stream with 20-millisecond packets, three packets multiplexed into one, and an average talk spurt length of 1,500 milliseconds. This compares well with the 12 Kbps achieved by hop-by-hop CRTP, and the 25.4 Kbps of standard RTP with no header compression or multiplexing (all numbers include the layer-two overhead due to PPP-in-HDLC [High-level Data Link Control] framing).
Performance will, of course, depend heavily on the characteristics of the media and network, but it is believed that the relative performance seen in the example is not unrealistic. Provided that there is sufficient traffic to multiplex, TCRTP will perform significantly better than standard RTP but slightly worse than hop-by-hop header compression.
Multiplexing has been an area of some controversy, and considerable discussion, within the IETF. Although TCRTP is the recommended best current practice, there are other proposals that merit further discussion. These include Generic RTP Multiplexing (GeRM), which is one of the few alternatives to TCRTP that maintains RTP semantics, and several application-specific multiplexes.
Generic RTP Multiplexing (GeRM) was proposed at the IETF meeting in Chicago in August 1998 but was never developed into a complete protocol specification.45 GeRM uses the ideas of RTP header compression, but instead of compressing the headers between packets, it applies compression to multiple payloads multiplexed within a single packet. All compression state is reinitialized in each new packet, and as a result, GeRM can function effectively end-to-end.
Figure 12.4 shows the basic operation of GeRM. A single RTP packet is created, and multiple RTP packets—known as subpackets—are multiplexed inside it. Each GeRM packet has an outer RTP header that contains the header fields of the first subpacket, but the RTP payload type field is set to a value indicating that this is a GeRM packet.
The first subpacket header will compress completely except for the payload type field and length because the full RTP header and the subpacket header differ only in the payload type. The second subpacket header will then be encoded on the basis of predictable differences between the original RTP header for that subpacket and the original RTP header for the first subpacket. The third subpacket header is then encoded off of the original RTP header for the second subpacket, and so forth. Each subpacket header comprises a single mandatory octet, followed by several extension octets, as shown in Figure 12.5.
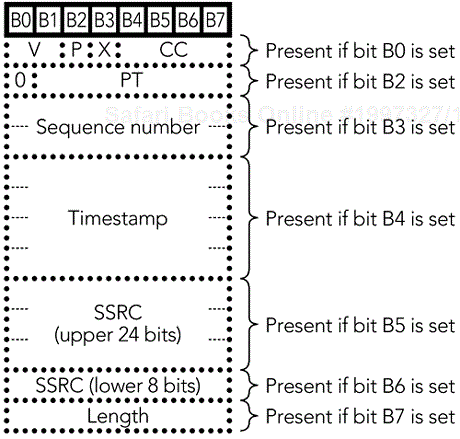
The meanings of the bits in the mandatory octet are as detailed here:
B0: Zero indicates that the first octet of the original RTP header remains unchanged from the original RTP header in the previous subpacket (or outer RTP header if there's no previous subpacket in this packet). That is, V, CC, and P are unchanged. One indicates that the first octet of the original RTP header immediately follows the GeRM header.
B1: This bit contains the marker bit from the subpacket's RTP header.
B2: Zero indicates that the payload type remains unchanged. One indicates that the payload type field follows the GeRM header and any first-octet header that may be present. Although PT is a seven-bit field, it is added as an eight-bit field. Bit 0 of this field is always zero.
B3: Zero indicates that the sequence number remains unchanged. One indicates that the 16-bit sequence number field follows the GeRM header and any first-octet or PT header that may be present.
B4: Zero indicates that the timestamp remains unchanged. One indicates that the 32-bit timestamp field follows the GeRM header and any first-octet, PT, or sequence number header that may be present.
B5: Zero indicates that the most significant 24 bits of the SSRC remain unchanged. One indicates that the most significant 24 bits of the SSRC follow the GeRM header and any first-octet, PT, sequence number, or timestamp field that may be present.
B6: Zero indicates that the least significant eight bits of the SSRC are one higher than the preceding SSRC. One indicates that the least significant eight bits of the SSRC follow the GeRM header and any first-octet, PT, sequence number, timestamp, or MSB SSRC header fields that may be present.
B7: Zero indicates that the subpacket length in bytes (ignoring the subpacket header) is unchanged from the previous subpacket. One indicates that the subpacket length (ignoring the subpacket header) follows all the other GeRM headers as an eight-bit unsigned integer length field. An eight-bit length field is sufficient because there is little to be gained by multiplexing larger packets.
Any CSRC fields present in the original RTP header then follow the GeRM headers. Following this is the RTP payload.
The bandwidth saving due to GeRM depends on the similarity of the headers between the multiplexed packets. Consider two scenarios: arbitrary packets and packets produced by cooperating applications.
If arbitrary RTP packets are to be multiplexed, the multiplexing gain is small. If there is no correlation between the packets, all the optional fields will be present and the subpacket header will be 14 octets in length. Compared to nonmultiplexed RTP, there is still a gain here because a 14-octet subheader is smaller than the 40-octet RTP/UDP/IP header that would otherwise be present, but the bandwidth saving is relatively small compared to the saving from standard header compression.
If the packets to be multiplexed are produced by cooperating applications, the savings due to GeRM may be much greater. In the simplest case, all the packets to be multiplexed have the same payload type, length, and CSRC list; so three octets are removed in all but the first subpacket header. If the applications generating the packets cooperate, they can collude to ensure that the sequence numbers and timestamps in the subpackets match, saving an additional six octets. Even more saving can be achieved if the applications generate packets with consecutive synchronization source identifiers, allowing the SSRC to be removed also.
Of course, such collusion between implementations is stretching the bounds of what is legal RTP. In particular, an application that generates nonrandom SSRC identifiers can cause serious problems in a session with standard RTP senders. Such nonrandom SSRC use is acceptable in two scenarios:
When RTP and GeRM are used to convey media data between two gateways. In this case the originators and receivers of the data are blissfully unaware that RTP and GeRM have been used to transfer data. An example might be a system that generates voice-over-IP packets as part of a gateway between two PSTN exchanges.
When the multiplexing device remaps the SSRC before inclusion in GeRM, with the demultiplexing device regenerating the original SSRC. In this case, the SSRC identifier mapping must be signaled out of band, but that may be possible as part of the call setup procedure.
At best, GeRM can produce packets with a two-octet header per multiplexed packet, which is a significant saving compared to nonmultiplexed RTP. GeRM will always reduce the header overheads, compared to nonmultiplexed RTP.
GeRM is not a standard protocol, and there are currently no plans to complete its specification. There are several reasons for this, primary among them being concern that the requirements for applications to collude in their production of RTP headers will limit the scope of the protocol and cause interoperability problems if GeRM is applied within a network. In addition, the bandwidth saving is relatively small unless such collusion occurs, which may make GeRM less attractive.
The concepts of GeRM are useful as an application-specific multiplex, between two gateways that source and sink multiple RTP streams using the same codec, and that are willing to collude in the generation of the RTP headers for those streams. The canonical example is IP-to-PSTN gateways, in which the IP network acts as a long-distance trunk circuit between two PSTN exchanges. GeRM allows such systems to maintain most RTP semantics, while providing a multiplex that is efficient and can be implemented solely at the application layer.
In addition to the general-purpose multiplexing protocols such as TCRTP and GeRM, various application-specific multiplexes have been proposed. The vast majority of these multiplexes have been targeted toward IP-to-PSTN gateways, in which the IP network acts as a long-distance trunk circuit between two PSTN exchanges. These gateways have many simultaneous voice connections between them, which can be multiplexed to improve the efficiency, enabling the use of low bit-rate voice codecs, and to improve scalability.
Such gateways often use a very restricted subset of the RTP protocol features. All the flows to be multiplexed commonly use the same payload format and codec, and it is likely that they do not employ silence suppression. Furthermore, each flow represents a single conversation, so there is no need for the mixer functionality of RTP. The result is that the CC, CSRC, M, P, and PT fields of the RTP header are redundant, and the sequence number and timestamp have a constant relation, allowing one of them to be elided. After these fields are removed, the only things left are the sequence number/timestamp and synchronization source (SSRC) identifier. Given such a limited use of RTP, there is a clear case for using an application-specific multiplex in these scenarios.
A telephony-specific multiplex may be defined as an operation on the RTP packets, transforming several RTP streams into a single multiplex with reduced headers. At its simplest, such a multiplex may concatenate packets with only the sequence number and a (possibly reduced) synchronization source into UDP packets, with out-of-band signaling being used to define the mapping between these reduced headers and the full RTP headers. Depending on the application, the multiplex may operate on real RTP packets, or it may be a logical operation with PSTN packets being directly converted into multiplexed packets. There are no standard solutions for such application-specific multiplexing.
As an alternative, it may be possible to define an RTP payload format for TDM (Time Division Multiplexing) payloads, which would allow direct transport of PSTN voice without first mapping it to RTP. The result is a “circuit emulation” format, defined to transport the complete circuit without caring for its contents.
In this case the RTP header will relate to the circuit. The SSRC, sequence number, and timestamp relate to the circuit, not to any of the individual conversations being carried on that circuit; the payload type identifies, for example, “T1 emulation”; the mixer functionality (CC and CSRC list) is not used, nor are the marker bit and padding. Figure 12.6 shows how the process might work, with each T1 frame forming a single RTP packet.

Of course, direct emulation of a T1 line gains little because the RTP overhead is large. However, it is entirely reasonable to include several consecutive T1 frames in each RTP packet, or to emulate a higher-rate circuit, both of which reduce the RTP overhead significantly.
The IETF has a Pseudo-Wire Edge-to-Edge Emulation working group, which is developing standards for circuit emulation, including PSTN (Public Switched Telephone Network), SONET (Synchronous Optical Network), and ATM (Asynchronous Transfer Mode) circuits. These standards are not yet complete, but an RTP payload format for circuit emulation is one of the proposed solutions.
The circuit emulation approach to IP-to-PSTN gateway design is a closer fit with the RTP philosophy than are application-specific multiplexing solutions. Circuit emulation is highly recommended as a solution for this particular application.
Multiplexing is not usually desirable. It forces all media streams to have a single transport, preventing the receiver from prioritizing them according to its needs, and making it difficult to apply error correction. In almost all cases, header compression provides a more appropriate and higher-performance solution.
Nevertheless, in some limited circumstances multiplexing can be useful, primarily when many essentially identical flows are being transported between two points, something that occurs often when voice-over-IP is being used as a backbone “trunk” to replace conventional telephone lines.