
8
Reliability Engineering for Services
8.1 WHAT TO EXPECT FROM THIS CHAPTER
Services are becoming an ever-larger part of the world economy. There will be an increasing number of service consumers across the globe. These consumers will expect that the services they purchase will be reliable. In this chapter, we will discuss what it means for a service to be reliable and some of the engineering techniques used to make them so. We cover always-on services and on-demand services but focus more on on-demand services because reliability for always-on services is equivalent to the reliability of the infrastructure used to deliver them.
8.2 INTRODUCTION
So far, we have worked with reliability engineering for systems, by which we meant tangible, physical objects designed and assembled to fulfill certain purposes. Now we turn to examination of those purposes and how to ensure that users of the systems receive the services they desire from those systems, or how well those systems fulfill their purpose(s) from the point of view of the users. In an important sense, this is an even more fundamental viewpoint because it finally encompasses the entire value chain from supplier to user, enabling the systems engineer to achieve a holistic view of system development from concept to user. While many publications concerning service reliability may be found in the literature (e.g., Refs. 3, 5, 9, and many others), the systematic study of service reliability as a distinct discipline was begun in Refs. 10, 11.
Service reliability engineering differs somewhat in details, but not in fundamental principles, from product reliability engineering. What is required, as is always the case with reliability engineering study, is a good understanding of the failure modes and failure mechanisms of the service. To achieve this understanding, it helps to begin by defining the concepts and primitives connected with services. We consider two types of services, those that are delivered by means of discrete transactions, and those that are intended to be “always on.”
8.2.1 On-Demand Services
An on-demand service comprises actions in which a server accomplishes some deed or takes some action in response to a request from a user or customer. Some examples of this kind of service are voice telephony, auto repair, retail sales, package delivery, business processes, etc. In an on-demand service, a user makes a request of a server (a caller dials digits, a car owner requests that a certain repair be accomplished, a customer buys a refrigerator, a sender contracts with the postal service to deliver a package, an insurance claim is filed, etc.), the server performs some actions to carry out the request (the telephone network sets up a (possibly virtual) connection to the called party, the car repair shop assigns a service technician who works on completing the repair, the retail store vends and delivers the refrigerator, the postal service forwards the package on to its destination, an insurance adjuster inspects the damaged property and makes a determination about payment, etc.), and the action has an identifiable completion upon which the server is dismissed and is able to accept new transaction requests. On-demand services are characterized by an interaction between a user and a server that is called a transaction. We think of the transaction as the basic unit of on-demand services. Informally, service reliability engineering for on-demand services is concerned with the delivery of successful transactions to all users throughout the useful life of the service. We consider the useful life of a service to be over (in general) when the service provider ceases offering the service or (for a particular service purchaser) when the service contract or agreement expires. We also consider the useful life of a service to be over when the service provider changes the requirements for the service. In that case, the service is changed, and it is different from the previous version; from a reliability engineering point of view, one should treat this as a new service.
Delivery of services to users is accomplished with the aid of certain equipment and processes. These “background” resources are the service delivery infrastructure (SDI). In a package delivery service, the SDI includes the service provider’s transportation network comprising vehicles, airplanes, routing software, etc., the customer interfaces such as service counters, local carriers, etc., and billing and payment mechanisms (over-the-counter, via the Internet, etc.). Understanding the SDI is important because it is the source of service failure mechanisms. In other words, we trace the failure mechanisms associated with each service failure mode back to events taking place in the SDI. This extra step is required in fault tree analysis (Chapter 6) for services. This approach underlies all the analyses in this chapter.
In addition, reliability engineering for a PC- or smartphone-based application is effectively accomplished using the concepts and methods of service reliability engineering. The user requests an action, such as bringing up an e-mail reader, starting a game, paying a bill by near-field communication, etc., to be performed by the PC or smartphone. The SDI in this case includes the hardware of the PC or smartphone and the software running on it; such applications may also require accessing resources over a remote network such as the Internet, and in these cases, the remote network becomes part of the SDI as well.
Service reliability can readily be understood, then, as the ability to continually deliver (the service provider’s concern) or carry out (the user’s concern) successful transactions in the service. Note how this is a consistent adaptation of the standard definition of reliability (the continued satisfactory operation of a system, according to its requirements, under specified conditions, for a specified period of time) to the particular properties of a service. Here is the formal definition:
Definition: Service reliability is the ability to deliver satisfactory transactions in the service, according to its requirements, under specified conditions, throughout the useful life of the service.
A transaction is considered satisfactory if it meets all the requirements of the service. As with systems or products, every requirement contains within it one or more failure modes, ways in which the requirement can be violated. This is completely analogous to the definition of reliability for systems that we have used so far. It incorporates the notion that the service has a set of requirements that are to be satisfied in order that (a transaction in) the service be deemed successful. This is analogous to the notion of successful operation of a system: all requirements for the system are met in successful operation. An instance of not meeting a requirement is a failure; reliability engineering for products or systems is the process by which we endeavor to make the product or system as free from failures as is economically reasonable. The same is true of services. Reliability engineering for services is the process by which we endeavor to make the service as free from failures as is economically reasonable. Accordingly, we gather in detail the knowledge available about service failures. In particular, this means we need to study service failure modes and failure mechanisms.
8.2.2 Always-On Services
In addition to services that are delivered by discrete transactions, many important services are of the nature that they are (supposed to be) always ready for use. Prominent examples are utilities: electric, natural gas, water, etc. Users expect that these will always be ready to use at any time. Always-on services may be accommodated in a transaction-based framework in two ways:
- The service may be thought of as a single transaction that began at a time in the past and is to continue into the indefinite future. In this interpretation, electricity service may be considered a single transaction that began when the current user first requested service to begin at his/her premises and ends when that user requests that service be discontinued at that premises. The primary concern for this user will be service continuity (Section 8.4.2.2), which concerns interruptions and instances of electricity being provided that is outside of the utilities’ requirements for voltage, frequency, etc.
- The service may be conceptualized as being delivered through transactions in which each transaction is a request by the premises owner to access the service; this would make each attempt to turn on a lamp, run a machine or appliance, etc., into a transaction, and the transaction-based reliability engineering models discussed in this chapter can be used without modification.
Either approach can yield useful results. The former approach is better adapted to the utility (service provider) view of the service, while the latter reflects more faithfully the user’s point of view. It is most likely that the service provider will be doing these analyses, and the user’s service fault tree analysis will rapidly reduce to the utility’s service continuity because when the utility service is accessible, the causes of a user’s individual transaction failures will be local to the user’s premises. Therefore, it usually suffices for the service provider to carry out the former analysis.
8.3 SERVICE FUNCTIONAL DECOMPOSITION
You can create a functional decomposition for a service in the same way that a functional decomposition can be created for products and systems. In most cases, the service will be provided through the use of some SDI—an arrangement of hardware and software owned by the service provider and used by the service consumer to access and use the service. A service functional decomposition comprises a sequence of operations that delivers the service. Those operations are carried out on a hardware and software platform, or SDI, which has to configure itself in certain defined ways to successfully deliver the service. The configuration of the underlying SDI is a key part of the service functional decomposition.
Example: The service we consider in this example is off-site backup of enterprise computer data “in the cloud.” This is an example of a cloud computing service. The service user contracts with a provider of memory space at a remote location to store certain files from various users at the remote location.
This may be thought of as an on-demand service (Section 8.2.1): in addition to scheduled times at which files may be transferred from users to the cloud storage location, users may asynchronously request files from the backup and/or send files to the backup. Users do this by running an application locally. We may construct a functional decomposition for this service as Figure 8.1.
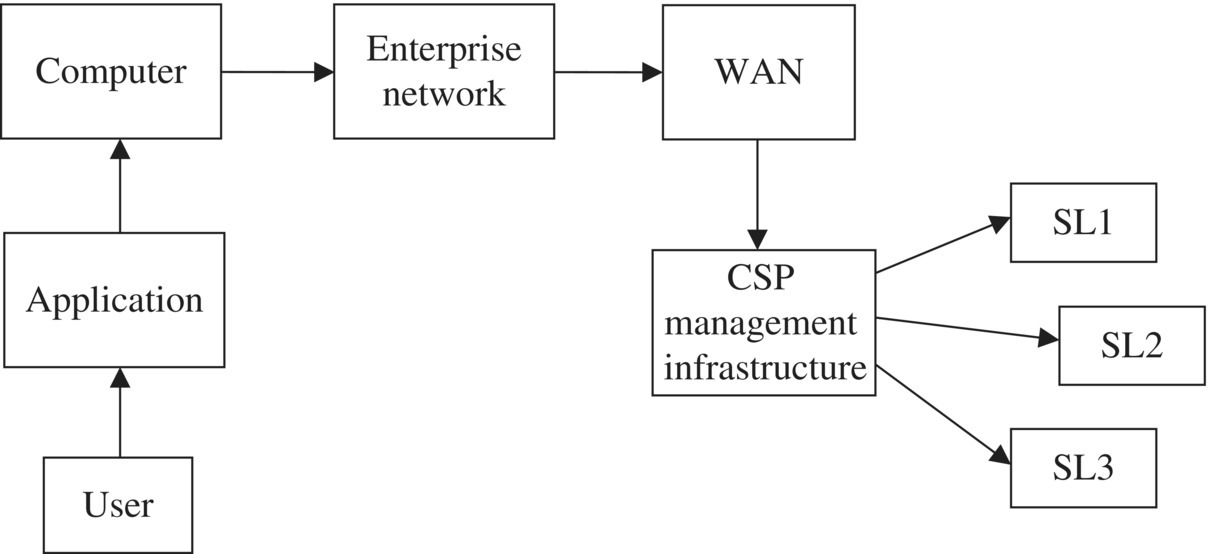
Figure 8.1 Cloud backup service functional decomposition.
The user invokes an application on her computer that forms a request to access some data stored remotely by the cloud service provider. The request travels through the user’s enterprise network and through a wide-area network to the service provider’s management infrastructure (computers, software, billing, etc.). The desired data are transmitted back to the user through the same means. More detail could be added to this service functional decomposition if necessary. For instance, it does not show the sequence of operations during any of the interactions depicted by the arrows (user with application, etc.). These interactions involve various requests and replies, usually mediated by some software residing in different parts of the platform. The decomposition presented in Figure 8.1 is adequate for a high-level reliability model in which there may exist some broad-based reliability estimates for each of the parts of the decomposition. If more detail is necessary or desired, the operations should be part of the decomposition also. Section 3.4.2.3 presents an example of a detailed service functional decomposition including the specific messages among the three entities in the diagram.
8.4 SERVICE FAILURE MODES AND FAILURE MECHANISMS
8.4.1 Introduction
Consistent with the considerations of Section 8.2.2, we will focus on reliability engineering for on-demand services for the remainder of this chapter.
Service failure modes derive from the service’s attribute requirements in exactly the same way system failure modes derive from the system’s attribute (functional, performance, physical, and safety) requirements. Any instance in which a requirement is not met is a failure, and a failure mode is an overt indication that this has taken place. For example, in voice telephony service, when one or the other party can no longer hear the other, a “cutoff call” has occurred. That these are rare events (except possibly in wireless telephony) speaks to the advanced state of development of telephony infrastructure in the developed world. This is an instance of a service failure, and the failure mode is the cutoff call. Many additional examples of service failure modes for telecom services are found in Ref. 10. Sufficiently complex services operate nearly 100% of the time in some degraded state for some transactions or users. For instance, folklore has it that about 5% of the routers in the Internet are failed at any given time. The robustness of IP helps ensure that these failures are hardly noticeable by users, although if demand increases enough, added congestion in the access network will be noticeable.
To facilitate the examination of service failure modes and failure mechanisms, it helps to analyze the concept of transaction in greater detail. As a transaction has an initiation phase, a proceeding phase, and an ending phase, we may classify service failure correspondingly as
- service accessibility failures,
- service continuity failures, and
- service release failures.
Service accessibility failures are any failures that are connected with the inability to set up or initiate a transaction. Service continuity failures are any failures connected with the ability to carry on a transaction to its completion, given that the transaction started correctly. Service release failures are any failures that are connected with the inability to dismiss a transaction that has completed its proceeding phase correctly. Some detailed examples in the context of telephony services are found in Ref. 10.
As with products or systems, reliability engineering requires that the failure mechanisms associated with each failure mode be understood. Here the study of service reliability requires an additional step. The key observation in service reliability engineering is that the service failure mechanisms are events in the SDI that cause transaction failures. This additional step is needed in service reliability engineering because services are intangible: an action can only fail if something required to carry out that action does not (by action or omission) complete the steps needed to further the action. In other words, service failures are caused by failures in the SDI, and the type of service failure seen is determined by the type of infrastructure failure. A good example of this is again drawn from telecom: infrastructure failures that occur while a call is being set up lead to service accessibility failures and infrastructure failures that occur during the stable phase of a call lead to service continuity failures.
Definition: Service accessibility is the ability to set up a transaction at a time desired by the user. Service continuity is the ability to carry on a transaction, without interruption and with satisfactory quality, until the desired completion of the transaction, given that it has been successfully initiated. Service release is the ability to successfully dismiss a transaction when it has been completed. This three-part breakdown is called the standard transaction decomposition.
Language tip: As usual, the same words are used for both the definition as given earlier and for the associated probabilities. So, for instance, we may speak of “service accessibility” both as the corpus of events associated with setting up or initiating transactions and as the probability of being able to successfully set up or initiate a transaction. Care should be taken to distinguish which meaning is intended if it is not clear from the context.
The service provider sets requirements for services using the same process of understanding customers’ needs and performing economic trade-offs that is used in setting requirements for tangible products and systems. When any requirement is not met in a particular transaction, that transaction is failed, and a service failure has occurred. Service failure modes are the overt signs that a service requirement is not met. It is helpful to classify service failure modes according to the standard transaction reliability analysis given earlier.
Requirements tip: Sometimes, what looks like a single service to a customer is a composite of two or more services from different service providers. For example, purchasing goods over the Internet from a specific seller involved two SDIs controlled by two different providers: the seller’s servers and associated software and the Internet service provider’s wide-area and access networks. The seller cannot set a requirement for any service failure modes without an understanding of the ISP’s performance and possibly some agreement with the ISP regarding carriage of the seller’s traffic. Under net neutrality rules, the ISP can make no special provision for the seller’s traffic, and any service reliability requirements from the seller need to be harmonized with the ISP’s service reliability performance. Should net neutrality rules be modified, service providers like Netflix may be free to write agreements concerning the contribution of the ISP to their service reliability. This book takes no position on net neutrality, noting only that systems engineers need to account for all segments and contributors to an SDI when crafting service reliability requirements.
8.4.2 Service Failure Modes
8.4.2.1 Service accessibility
Service accessibility failures are those occurring in the process of starting, or “setting up,” a transaction. Some examples of service accessibility failure modes are failure of a requested www page to load, excess delay in completing a telephone call (from receipt of dialed digits to the start of ringing at the far end) to the distant party (if the service provider has a requirement for delay), or failure of a home heating oil delivery to meet an appointed time. The typical service accessibility failure mode is excess delay: the customer makes a request to initiate a transaction, and service provider’s SDI does not respond in a timely manner (provided the service provider’s service accessibility requirement(s) contain a limit on the amount of time a transaction setup should take). A complete failure to set up a transaction would be an instance in which no matter how long the user were to wait, the transaction would not begin. An excess delay may look to an impatient user like a complete failure to set up a transaction, but the user’s balking probability must be taken into account. See Exercise 3.
In some cases, particularly for telecom and datacom services, service accessibility failures may be the result of congestion in the service provider’s network, even if all elements of the network are working properly. This is caused by an excess of demand above the network’s capacity.1 To the user, this looks like a failure, while to the service provider, this may be normal behavior. Here is an example of a service reliability requirement in action. The service provider may have established a service accessibility requirement that says “No more than 1.5% of transaction initiation attempts will experience a delay of greater than 3 seconds.”2 A user experiencing more than 3 seconds of delay may be one of those caught in the 1.5% when the service provider’s SDI is operating nominally. It is also possible that this requirement is not being met—more than 1.5% of users are experiencing delay over 3 seconds at that time. To discern which is the case, measurements need to be taken, data collected, and analyzed. We have discussed interpretation of requirements for products and systems in Chapter 5, but some additional ideas are needed when dealing with services. See Section 8.5.2.
8.4.2.2 Service continuity
Service continuity failures are those that take place during the time a transaction is being conducted, after it has been properly set up or initiated. Some examples of service continuity failures are failure to deliver a package that was properly accepted by the postal service and paid for by the user, excess distortion in the voice or video of a video teleconference call (if the service provider has a requirement limiting distortion), and delivery of a refrigerator model different from the one that was sold. It is sometimes useful to distinguish two types of service continuity failures. One type comprises those failures in which a transaction is interrupted and does not resume at all. The other comprises those transactions that carry on to completion but fail to adhere to one or more of the service provider’s quality requirements. The cutoff call is a good example of the first type. The parties are talking and suddenly “the connection disappears” and neither party hears the other. This condition persists indefinitely, that is, no matter how long the parties were to wait, the conversation would not be restored. An example of the second type is furnished by the video teleconference in which audio and/or video are distorted beyond the limits allowed for by the service provider’s requirements. The conference has not ceased entirely, but its quality fails to meet the relevant requirement(s). Hoeflin [6] refers to the latter type of service continuity failures as “service fulfillment failures.”
8.4.2.3 Service release
Service release failures are those connected with the release of the service provider’s resources after a transaction is complete. They also include any post-transaction actions that are connected with the specific transaction, such as billing, that affect the user’s perception of transaction success. Service release failures tend to occur less often than service accessibility or service continuity failures, but they do have economic consequences for the service provider who should, therefore, include them in a service reliability plan. Some examples of service release failures include an incorrect bill for a completed shipment, refusal of a videoconference to terminate after the terminate signal was given, etc.
8.4.3 Service Failure Mechanisms
As noted in Section 8.1, identifying the failure mechanisms connected with a service failure mode requires understanding what takes place in the service provider’s SDI to create the particular type of transaction under study. Failure of these actions to take place, or completion of the actions in an inadequate way, leads to transaction failures. Two important features of service failure mechanism analysis are
- It is essentially a fault tree analysis (Chapter 6) with the additional step of incorporating how elements and processes in the service provider’s SDI work together to deliver a transaction in the service.
- As we saw in the product/system case, the fault tree can be developed down to very detailed events. The analyst needs to determine the amount of detail that is included and how small the probability of an event should be for it to be omitted from the analysis.
We may classify service failure mechanisms following the standard transaction reliability analysis model of Section 8.4.1.
8.4.3.1 Service accessibility
Service accessibility failure mechanisms disrupt the process of setting up or initiating a transaction. Each service accessibility failure mode may be traced to one or more service accessibility failure mechanisms. Here are some examples.
- The US Postal Service’s online label printing and payment service: Suppose you are preparing a shipment and wish to pay for the shipment and print a shipping label with postage using this service. The most prominent service accessibility failure mode is inability to access the USPS web page for shipment preparation. Some associated failure mechanisms are:
- The USPS servers are experiencing a hardware outage, software failure, or a distributed denial of service (DDoS) attack.
- Some problem occurs in the transport of information from your PC to the USPS servers. This may include packet loss, network congestion, or a local problem such as a malfunctioning network interface.
- Cloud computing: You contract with a cloud computing service provider to back up your local files each night. One applicable service accessibility failure mode is “backup does not start as scheduled.” Some of the associated failure mechanisms are:
- The service provider’s servers are unavailable.
- The mechanism the service provider uses to assign content to different servers has failed.
- Failure in the communication process between your router and the service provider.
- Self-service gasoline fill-up: Many filling stations require you to swipe a credit card before you can dispense gasoline. A service accessibility failure mode here is pumping does not begin when the pump handle is actuated. Some associated service failure mechanisms are:
- Failure to register credit card information correctly, due to
- Failure of the credit card reader,
- Failure in the communication path between the pump and your bank,
- Failure of the bank’s servers due to hardware outage, software failure, or DDoS attack,
- Internal gasoline pump failure,
- External gasoline pump failure (e.g., dispenser handle failure).
- Failure to register credit card information correctly, due to
Note how, in these examples, more than one service provider is involved in a service failure mechanism: the immediate service provider (the cloud service provider, the filling station, etc.) or the background service provider (a telecom company, your bank, etc.) may be the source of the failure experienced by the user—who is indifferent to the source of the failure. As a business matter, the primary service provider’s service reliability planning must include its background partner(s) so that a unified service experience may be presented to users. Users who experience service failures should not be expected to diagnose the source of the problem, and their normal behavior will be to contact the primary service provider if they desire remediation of the problem.
In telecommunications and other services in which the SDI includes shared resources, transaction failures arise from competition for those shared resources. Some transaction requests will be denied because there is not enough capacity in the SDI to accept them all. It is usually not economically feasible to provide enough shared resources to handle every transaction request at all times, even when every element of the SDI is operating normally, so some degree of service inaccessibility is deliberately built into the service. The degree to which this prevails is a decision by the service provider based on their understanding of customer needs and behavior and unavoidable economic trade-offs. When elements of the SDI fail, this congestion, whose symptoms include increasing queuing delays and buffer overflows, increases even when the transaction request intensity stays the same. Any individual customer cannot tell, and should not be expected to tell, whether failure of her transaction request is due to “normal” congestion (the level of service inaccessibility specified in the requirement when all elements of the SDI are operating normally) or to “extra” congestion resulting from the failure of some element(s) of the SDI. Service designers should model service accessibility under normal and disrupted conditions in the SDI so that it is possible to understand the user experience and discern whether improvements (or cutbacks) in the SDI are warranted.
8.4.3.2 Service continuity
Service continuity failure mechanisms are those that disrupt a transaction once it has properly been initiated. Each service continuity failure mode may be traced to one or more service continuity failure mechanisms. The following are some examples:
- The US Postal Service’s online label printing and payment service: A prominent service continuity failure mode is an interrupted transaction. Some associated failure mechanisms are
- Packet loss or congestion in the WAN connecting you to the USPS server,
- USPS server failure,
- Failure in the credit card payment network.
- Cloud computing: One applicable service continuity failure mode is “backup does not complete.” Some associated failure mechanisms are
- The mechanism the service provider uses to assign content to different servers fails while the backup is in progress,
- Failure, occurring while backup is in progress, in the LAN or WAN between you and the service provider.
- Self-service gasoline fill-up: A service continuity failure mode here is pumping stops before the desired amount of gasoline is dispensed. Some associated service failure mechanisms are:
- Malfunctioning pump handle holding mechanism,
- Internal pump failure while dispensing is in progress.
8.4.3.3 Service release
Service release failures are any failures that cause inability to dismiss a transaction that has completed its proceeding phase correctly. Each service release failure mode may be traced to one or more service release failure mechanisms. Here are some examples.
- The US Postal Service’s online label printing and payment service: A service release failure mode is an incorrect amount billed by USPS to your credit card. Some associated failure mechanisms are
- Communication failure between the USPS and the credit card company,
- Interception and altering of the communication by a malicious actor.
- Cloud computing: An applicable service release failure mode is “backup application does not close when the backup is complete.” Some associated failure mechanisms are
- Lack of notification from the service provider that the backup was (or was not) successful,
- Failure in the communication process between your router and the service provider.
- Self-service gasoline fill-up: A service release failure mode here is “pump does not print receipt.” Some associated service failure mechanisms are
- Printer is out of paper,
- Printer electronics failure, and
- Customer keypad failure.
In each case, note how the causes of a user-perceived transaction failure can be traced back to some action or inaction in the SDI. You may say that it is enough to assign reliability requirements for all parts of the SDI, and this will control service transaction failures. However, using this approach ignores the vital information about how users perceive the reliability of the service. In addition, the user perspective allows you to decide how much reliability in the SDI is really needed—it is easy to over- or under-provision the SDI if you are not being guided by the needs and desires of the user community. A reasonable argument could be advanced, for instance, that the old Bell System requirement of switching system availability of at least 0.9999943 (expected downtime of 2 hours in 40 years of operation) was far tighter than necessary to achieve satisfactory POTS3 reliability given the many redundant paths through the PSTN4 for any pair of users. Only by understanding the user needs and desires for service reliability can the reliability requirements for the SDI and its components be developed in a rational way. The service reliability requirements need to drive the SDI reliability requirements so that neither overspending nor inadequate provisioning errors are made. See Section 8.7.
8.5 SERVICE RELIABILITY REQUIREMENTS
Service reliability requirements are categorized according to the standard transaction reliability analysis. The service provider uses their understanding of the needs and wants of their service customers, together with their understanding of their SDI’s behavior, to devise service reliability requirements that promote user satisfaction and are economically sensible.
8.5.1 Examples of Service Reliability Requirements
Reliability requirements for on-demand services may be organized according to the categories described in Section 8.4.2: accessibility, continuity, and release. Requirements may also be structured to apply to each individual transaction (Section 8.5.1.1) or to some aggregate of transactions, usually over a specified user population (Section 8.5.1.2). In each case, data collection and analysis to verify compliance with requirements are discussed in Section 8.5.2.
8.5.1.1 Per-transaction reliability requirements
Service reliability requirements may be structured to apply to individual transactions by specifying a proportion of transactions that may fail (or will succeed). Frequently, the proportion is expressed as a fraction of unsuccessful transactions per number of opportunities. In telecommunication and other fields where transactions are numerous and of relatively short duration, the proportion is often expressed as “defects per million (DPM) opportunities.” The proportion is a reliability effectiveness criterion whose achievement may be demonstrated by modeling (when designing the service) or data analysis (when validating achievement of the requirement after deployment). A related reliability figure of merit is the probability of success (or failure) per transaction.
For example, a service accessibility requirement may look like “the proportion of transactions that fail to initiate properly after a valid customer request shall be no more than 0.005% when all SDI elements are operating normally.” When expressed this way, with no conditions on sources of the requests, the requirement applies to any request from any service user. This means that even users accessing the worst (most congested) part of the SDI are to be treated as well as this requirement states. Some (many) users may experience service accessibility (much) better than this under normal conditions, but this formulation does not allow for different classes of service (e.g., better service reliability for a higher price) or for discernment of which parts of the SDI may be improved most efficiently (biggest return on service accessibility per dollar expended on improvement). Some of these objections may be handled by aggregating service users into various groupings.
8.5.1.2 Aggregated reliability requirements
In aggregated service reliability requirements, the requirement structure remains the same except that a requirement is written to pertain only to some specific group of users. For example, requirements may be written for users in a certain city, users purchasing a stated class of service, transactions occurring during a stated period of time, etc. Grouping allows focused improvement based on solid understanding of how service reliability may vary from group to group. It also allows for selling different classes of service—for example, video teleconferencing may be offered with standard definition video, or high-definition video for a higher price. Service accessibility and continuity requirements and service-level agreements may differ across different classes of service.
8.5.2 Interpretation of Service Reliability Requirements
Service reliability requirements are usually written as limits on some percentage of transactions that fail in each of the accessibility, continuity, and release categories. So expressed, the requirement is on a reliability effectiveness criterion. When designing a service, or analyzing data to determine compliance with a reliability requirement in the service, we compare the probability of a successful transaction with the value of the reliability effectiveness criterion. Requirements may also be written as a limit on the overall, or “omnibus,” transaction failure proportion (including accessibility, continuity, and release all in one measurement); in that case, the standard service reliability transaction analysis helps the service provider create a plan to meet the omnibus requirement by controlling each of the contributing factors. Many service providers express the percentage as a “DPM” measure, which is a percent multiplied by 104, because the number of transaction failures is usually small. Many service providers, especially in the telecom industry, are able to acquire data on every transaction through automated means, and when a census like this is available, comparison of results with requirements needs only a specification of a time period over which the requirement is to hold. However, when a census is not possible, a sample of transactions is taken, and realized service reliability is estimated from the sample. Comparing realized service reliability with requirements then is a problem of estimating a proportion. The statistical procedure for this is given in section 9.1 of Ref. 1. The following example illustrates the ideas in a telecommunications context.
Example: Suppose that a requirement for VoIP telephone service specifies that its reliability shall be no worse than 3.4 DPM. To demonstrate compliance with this requirement, we will test the hypothesis that the probability that a VoIP transaction fails (for any reason) does not exceed r = 3.4 × 10−6. A sample of 100,000 VoIP calls is taken, and the number of failed calls in the sample is 2. It would appear that the requirement is not being met. What is the strength of the evidence for this conclusion?
Solution: Let p0 denote the omnibus probability of transaction failure (i.e., including all the failure modes that the service provider counts when making the DPM determination) for all transactions in the population of VoIP calls comprehended by the service provider’s reliability management plan. We will test the null hypothesis H0: {p0 ≤ r = 3.4 × 10−6} (the requirement is met) against the alternative HA: {p0 > r} (performance is worse than the requirement). The appropriate statistical inference procedure is a test for proportions as described in section 10.3 of Ref. 1. The test statistic is the normalized sample proportion
– r /
(where
In Chapter 5, we approached demonstrations of this kind by estimating the proportion of (in this case) defective transactions, or, equivalently, estimating the probability that a transaction may fail. Either approach (that of Chapter 5 or that shown here) is suitable. The choice of which to use may depend on which is easier to communicate for the particular audience you face.
If a requirement applies to a stated aggregated population, data collection to verify achievement of that requirement should be limited to members of that population.
8.6 SERVICE-LEVEL AGREEMENTS
A service-level agreement is a statement by the service provider that some compensation will be paid to a service user in the event some service reliability requirement is violated by a stated margin. Each customer of the service provider has their own service-level agreement. A service-level agreement is a way for the service provider to make a service more attractive to potential purchasers.
A typical service-level agreement in telecommunications services may read “In the event that the service is unavailable for more than 30 minutes during a single calendar month, the service provider will rebate 5% of the service price5 for that month.” The agreement pertains to a specific service. A single service provider and a single service customer may have several service-level agreements in force, one for each service purchased by the customer from that service provider. As the service-level agreement is part of the contract between the service provider and a specific service customer, measurements need to be made for each service and each particular customer with whom the service provider has a service-level agreement. The provisions of the agreement are triggered when the measurements for that particular customer show the provisions are violated.
A key question for the service provider regarding service-level agreements is profitability. Before offering a service-level agreement, the service provider should have some idea of whether it will make or lose money on the agreement. Models based on the ideas in Chapter 4 may be constructed to study profitability of service-level agreements. See Exercise 4 for some ideas.
8.7 SDI RELIABILITY REQUIREMENTS
A basic principle of service reliability engineering is that the reliability of a service, in terms of its accessibility, continuity, and release properties, is determined by actions or omissions taking place in the SDI, so assignment of reliability requirements to elements of the SDI should be set so that when they are met, the service reliability requirements are met. This is a kind of reliability budgeting (Sections 2.8.4 and 4.7.3). It may be accomplished by formal means, as described in Section 4.7.3, or less formally when the precision of the input information available does not justify the expense and time required to complete a formal analysis. Here is an example of the latter case.
Example: In POTS, a dedicated circuit (“talking path”) comprising switching and transport elements is set up and held in place during the entire conversation between two parties. The primary cause of transaction interruptions in this service is failure of one (or more) of the elements in the talking path. Suppose a service continuity requirement for interruptions states that no more than 25 calls per 1,000,000 carried are to be interrupted. How should requirements be written for the switching and transport elements of the network so that this service reliability requirement will be met?
Solution: Interrupted transactions (“cutoff calls” in this service) occur when an element in the talking path for that call fails, so the prevalence of cutoff calls is determined by the frequency of failures in switching and transport systems. Let σ denote the number of failures per hour of switching systems and τ denote the number of failures per hour of transport systems (for simplicity, we will take σ and τ to apply to all types of switching and transport systems, respectively). If a talking path contains n switches and n + 1 transport systems (in which case we say its size is n), then the number of failures per hour in that talking path is nσ + (n + 1)τ (why?). Let r = 2.5 × 10−5, and the number of calls per hour be C. Furthermore, let the probability that a talking path contains n switches and n + 1 transport systems be pn, n = 1, 2, …, N, where N is the maximum talking path size allowed by other considerations, such as a loss plan. Then, based on expected values, we require
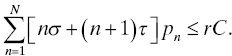
If the cost of achieving a failure rate of σ failures per hour in switching is kS(σ) and that for τ failures per hour in transport is kT(τ), then a sensible assignment based on minimized expected cost is achieved by solving the optimization problem
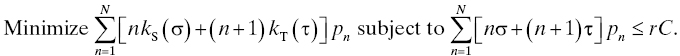
While this example pertains to an obsolete technology, and several simplifications were applied, it is intended to illustrate the important idea that service reliability comes from SDI reliability, and these should be considered together when designing a service. More precisely, service reliability requirements should be used to drive reliability requirements for elements of the SDI. The illustration given here is overly simplified but should provide useful guidance for more realistic studies of this kind.
An added feature that sometimes needs to be taken into account when partitioning or assigning service reliability requirements into the SDI is that achievement of a successful transaction may include an element of timing: certain actions need to happen in a specific order to enable a successful transaction (see the service functional decomposition example in Section 3.4.2.3). The reliability models shown in Chapters 3 and 4 cannot incorporate timing, so, for instance, if one wanted to analyze the VoIP service using SIP as shown in Section 3.4.2.3, a richer set of models would be needed. Situations like this are well adapted for modeling using stochastic Petri nets, which do allow for sequencing and timing of events. Description of stochastic Petri net modeling for reliability is beyond the scope of this book. Interested readers are referred to Refs. 2, 4, 12, or Ref. 8 for a good introduction.
8.8 DESIGN FOR RELIABILITY TECHNIQUES FOR SERVICES
The service functional decomposition (Section 8.3) is a good starting point for designing for reliability for services. It contains raw material for service fault tree analysis and service FME(C)A:
- How the SDI is configured to carry out the functions needed to support and deliver the service, and
- Messages that need to be sent and received correctly for a transaction in the service to be successful.
Once configuration of the SDI and appropriate assignment of reliability requirements (Section 8.7) are known, design for reliability techniques for hardware (Chapter 6) and software (Chapter 9) may be brought to bear. Should it be necessary to go into that level of detail, modeling for sequencing and timing of messages or other SDI events is introduced in Section 8.7.
This section discusses modifications or enhancements of fault tree analysis and FME(C)A for use with services. The main idea is that steps are added to the performance of fault tree analysis and FME(C)A that we have seen so far (Chapter 6) to account for the interface between the SDI and the service.
8.8.1 Service Fault Tree Analysis
Top events for fault trees for services can come from the listing of failure modes in the service, which, in turn, come from the service reliability requirements. This is the same pattern we follow for the fault tree analyses studied so far. It promotes a systematic approach for the development of a fault tree for a service. The top event will be some service reliability requirement violation whose causes are sought in the SDI or in the actions of the user. As with the fault trees developed for products and systems in Chapter 6, the Ishikawa, or fishbone, diagram can be a useful aid in developing the fault tree as well as for root cause analysis when diagnosing the SDI events or omissions contributing to service failures.
8.8.2 Service FME(C)A
FME(C)A is a bottom-up analysis that begins with an undesired event in some component of a system and develops the consequences of that event up to the point where a system failure follows. In applying FME(C)A to services, the system is the SDI. So a service FME(C)A begins with some undesirable event in the SDI (e.g., failure of a line card in an edge router). Additional steps are required at the end of the chain of consequences reasoning to determine the consequence(s) for the service. In all other respects, FME(C)A for services is the same as we have used before in Chapter 6.
8.9 CURRENT BEST PRACTICES IN SERVICE RELIABILITY ENGINEERING
8.9.1 Set Reliability Requirements for the Service
If you are a service provider, you will need to understand your customers’ experiences on all dimensions of the services you sell, including the reliability dimension. Reliability is a vital part of the value proposition for any service, and understanding and controlling reliability at the service level is best accomplished by assigning reliability requirements at the service level. Furthermore, those reliability requirements should be agnostic with respect to the technologies in the SDI. Most customers don’t know or care what technologies are used to provide their service. Their interaction with the service provider is strictly at the service level. Changes in the SDI should be invisible to service users. Service providers will of course advertise and sell the improved service reliability and performance that may result from improved SDI, but the fundamental point is still that what the user sees is the service, and properly managing that interface requires explicit statement of service reliability requirements.
8.9.2 Determine Infrastructure Reliability Requirements from Service Reliability Requirements
Behavior of the SDI determines the reliability of the services it supports. It makes no sense to independently assign reliability requirements for those services and for elements of the SDI because doing so risks conflicts and possible under- or over-provisioning of infrastructure elements. Either of these has economic consequences. Under-provisioning saves in initial capital expenditures at the cost of poorer service and damage to reputation. Over-provisioning causes capital expenditures that may be more than needed to assure adequate service reliability. These risks can be avoided by linking SDI reliability requirements to service reliability requirements as described in Section 8.7.
8.9.3 Monitor Achievement of Service Reliability Requirements
It is no less important to carry out this part of the Deming Cycle for a service as it is for any product or system. Monitoring service transactions does raise the unique issue of privacy, and responsible service providers will employ methods that respect user privacy. Some mathematical models [7, 13] have been developed that aid in this by enabling service-provider-generated transactions (e.g., ping packets used by an ISP to query and categorize network states and user experience) to at least approximately reflect what a user experiences without compromising privacy.
8.10 CHAPTER SUMMARY
This chapter brings to services the engineering principles needed to assure their reliability. Many technological systems are deployed precisely because they provide a service to some community of users. The chapter makes the key point that, in these cases, reliability requirements for the underlying technological systems (the SDI) should be derived from, and be consistent with, the service reliability requirements. Service reliability requirements come to the fore because the service is what the user purchases from the service provider and its characteristics are what will satisfy (or dissatisfy) the user/customer. Accordingly, the chapter begins with a discussion of on-demand and always-on services, and because reliability of an always-on service is equivalent to the reliability of its delivery infrastructure, the focus moves to on-demand services. The basic unit of on-demand services is the transaction, and we study service reliability requirements for accessibility, continuity, and release of transactions. Examples of service functional decomposition, service failure modes, and failure mechanisms are given, followed by development, interpretation, and verification of service reliability requirements. Techniques akin to reliability budgeting are described for rationally assigning reliability requirements to the SDI so that they are consistent with the reliability requirements for the services it supports. The chapter closes with a discussion of design for reliability for services.
8.11 EXERCISES
- Identify service failure modes and failure mechanisms for the following:
- Facsimile service (sending documents via telephone)
- Cloud computing service
- A smartphone weather forecasting app
- Package delivery service
Hint: define a transaction in each service first and use the service accessibility, service continuity, and service release formalism. Identify the SDI in each case.
- Discuss service reliability aspects of a PC application.
- Suppose each user in a specified population of service users has a random time B for which the user will abandon a transaction setup attempt if the delay in setting up the transaction exceeds B. B may vary from user to user and even from time to time for the same user. Let B have distribution F(t) = P{B ≤ t} and suppose it is the same for all users. Suppose the service provider’s delay in setting up a transaction is a random variable D having distribution function W(t). What is the proportion of users in that specified population who see transaction setups as failed? How should this phenomenon be accounted for in writing a service accessibility requirement?
- *A high-level model for service-level agreements. Service provider V contracts with a specific group of service customers for whom service accessibility is agreed to be at least 0.9995. The relevant service-level agreement states that if the service is inaccessible for more than 30 minutes in a 30-day month, V will rebate some portion of the price paid for the service for that month. V’s SDI suffers outages affecting these customers according to an alternating renewal process whose uptime distribution is exponential with a mean of 3000 hours and whose downtime distribution is exponential with a mean of 1 hour. What is the probability that V will have to pay a rebate in a given month? Assume that the SDI reliability process has been operating for a long time.
REFERENCES
- 1. Berry DA, Lindgren BW. Statistics: Theory and Methods. 2nd ed. Belmont: Duxbury Press (Wadsworth); 1996.
- 2. Ciardo G, Muppala J, Trivedi K. SPNP: stochastic Petri net package. Proceedings of the Third International Workshop on Petri Nets and Performance Models, 1989. December 11–13, 1989; Piscataway, NJ: IEEE; 1989. p 142–151.
- 3. Dai YS, Xie M, Poh KL, Liu GQ. A study of service reliability and availability for distributed systems. Reliab Eng Syst Saf 2003;79 (1):103–112.
- 4. Florin G, Fraize C, Natkin S. Stochastic Petri nets: properties, applications and tools. Microelectron Reliab 1991;31 (4):669–697.
- 5. Grassi V, Patella S. Reliability prediction for service-oriented computing environments. IEEE Internet Comput 2006;10 (3):43–49.
- 6. Hoeflin DA, Sherif MH. An integrated defect tracking model for product deployment in telecom services. Proceedings of the 10th IEEE Symposium on Computers and Communications. June 27–30, 2005; Piscataway, NJ: IEEE; 2005. p 927–932.
- 7. Melamed B, Whitt W. On arrivals that see time averages: a martingale approach. J Appl Probab 1990;27 (2):376–384.
- 8. Sahner RA, Trivedi K, Puliafito A. Performance and Reliability Analysis of Computer Systems: An Example-Based Approach Using the SHARPE Software Package. New York: Springer; 2012.
- 9. Tollefson G, Billinton R, Wacker G. Comprehensive bibliography on reliability worth and electrical service consumer interruption costs: 1980–90. IEEE Trans Power Syst 1991;6 (4):1508–1514.
- 10. Tortorella M. Service reliability theory and engineering, I: foundations. Qual Technol Quant Manage 2005;2 (1):1–16.
- 11. Tortorella M. Service reliability theory and engineering, II: models and examples. Qual Technol Quant Manage 2005;2 (1):17–37.
- 12. Volovoi V. Modeling of system reliability Petri nets with aging tokens. Reliab Eng Syst Saf 2004;84 (2):149–161.
- 13 Wolff RW. Poisson arrivals see time averages. Oper Res 1982;30 (2):223–231.