
Embedded security
J. Rosenberg Draper Laboratory, Cambridge, MA, United States
Abstract
This chapter is about security of embedded devices. Throughout this book, the effects of harsh environments in which we require many of our embedded devices to operate have been discussed in some detail. But even an embedded processor in a clean, warm, dry, stationary, and even physically safe situation is actually in an extremely harsh environment. That is because every processor everywhere can be subject to the harshness of cyber attacks. We know that even “air-gapped” systems can be attacked by the determined attacker as we saw happen with the famous Stuxnet attack. This chapter will discuss the nature of this type of harsh environment, what enables the cyber attacks we hear about every day, what are the principles we need to understand to work toward a much higher level of security, and we will present new developments that may change the game in our favor.
Keywords
Embedded systems; Security; Cyber attacks; Harsh environment; Internet of things
1 Important Security Concepts
We will now shift from these “motivating” discussions about how susceptible our embedded computing infrastructure is and the types of attacks that have been or could be perpetrated against them, and cover important security concepts that we will need for a common vocabulary and to have as a baseline when we delve into what might be done to improve our cybersecurity defensive posture.
1.1 Identification and Registration
Cybersecurity must begin with sufficiently strong identification and registration of any identities who will access the devices being secured or the networks those devices communicate with. If we get this wrong the security we build around all our embedded devices might as well be a house of cards.
National Institute of Standards and Technology (NIST) has established an Electronic Authentication Guide designated 800-63-2 [1] that defines technical requirements for each of four levels of assurance in the areas of identity proofing, registration, tokens, management processes, authentication protocols and related assertions. These four levels of authentication—simply designated Levels 1–4—are differentiated in terms of the consequences of the authentication errors and misuse of credentials at each successive level. Level 1 is the lowest assurance and Level 4 is the highest. The NIST guidance defines the required level of authentication assurance in terms of the likely consequences of an authentication error. As the consequences of an authentication error become more serious, the required level of assurance increases.
Electronic authentication, or E-authentication, begins with registration. The usual sequence for registration proceeds as follows. An Applicant applies to a Registration Authority (RA) to become a Subscriber of a Credential Service Provider (CSP). If approved, the Subscriber is issued a credential by the CSP which binds a token to an identifier (and possibly one or more attributes that the RA has verified). The token may be issued by the CSP, generated directly by the Subscriber, or provided by a third party. The CSP registers the token by creating a credential that binds the token to an identifier and possibly other attributes that the RA has verified. The token and credential may be used in subsequent authentication events.
The name specified in a credential may either be a verified name or an unverified name. If the RA has determined that the name is officially associated with a real person and the Subscriber is the person who is entitled to use that identity, the name is considered a verified name. If the RA has not verified the Subscriber's name, or the name is known to differ from the official name, the name is considered a pseudonym. The process used to verify a Subscriber's association with a name is called identity proofing, and is performed by an RA that registers Subscribers with the CSP.
At Level 1, identity proofing is not required so names in credentials and assertions are assumed to be pseudonyms. The name associated with the Subscriber is provided by the Applicant and accepted without verification. This is why there are thousands of Bill Gates in email systems because anyone can create any email name they want. Level 1 is never going to be acceptable for protecting embedded systems.
At Level 2, identity proofing is required, but the credential may assert the verified name or a pseudonym. In the case of a pseudonym, the CSP retains the name verified during registration. In addition, pseudonymous Level 2 credentials are distinguishable from Level 2 credentials that contain verified names. Level 2 credentials and assertions specify whether the name is a verified name or a pseudonym. This information assists relying parties (RPs) in making access control or authorization decisions.
In most cases, only verified names are specified in credentials and assertions at Levels 3 and 4. At Level 3 and above, the name associated with the Subscriber is always verified. At all levels, personally identifiable information collected as part of the registration process is also protected, and all privacy requirements are satisfied.
Fig. 1 shows the registration, credential issuance, maintenance activities, and the interactions between the Subscriber/Claimant, the RA and the CSP. The usual sequence of interactions is as follows:

Fig. 1
1. An individual Applicant applies to an RA through a registration process.
2. The RA identity proofs that Applicant.
3. On successful identity proofing, the RA sends the CSP a registration confirmation message.
4. A secret token and a corresponding credential are established between the CSP and the new Subscriber.
5. The CSP maintains the credential, its status, and the registration data collected for the lifetime of the credential (at a minimum).
6. The Subscriber maintains his or her token.
1.2 Authentication
In this chapter, the party to be authenticated is called a Claimant and the party verifying that identity is called a Verifier. When a Claimant successfully demonstrates possession and control of a token to a Verifier through an authentication protocol, the Verifier can verify that the Claimant is the Subscriber named in the corresponding credential. The Verifier passes on an assertion about the identity of the Subscriber to the relying party (RP). That assertion includes identity information about a Subscriber, such as the Subscriber name, an identifier assigned at registration, or other Subscriber attributes that were verified in the registration process (subject to the policies of the CSP and the needs of the application). Where the Verifier is also the RP, the assertion may be implicit. The RP can use the authenticated information provided by the Verifier to make access control or authorization decisions.
Authentication establishes confidence in the Claimant's identity, and in some cases in the Claimant's personal attributes (e.g., the Subscriber is a US citizen, is a student at a particular university, or is assigned a particular number or code by an agency or organization). Authentication does not determine the Claimant's authorizations or access privileges; this is a separate decision. RPs (e.g., government agencies) will use a Subscriber's authenticated identity and attributes with other factors to make access control or authorization decisions. The operational semantics of authentication varies according to the NIST levels as described next.
1.2.1 Level 1
Although there is no identity proofing requirement at this level, the authentication mechanism provides some assurance that the same Claimant who participated in previous transactions is accessing the protected transaction or data. It allows a wide range of available authentication technologies to be employed and permits the use of any of the token methods of Levels 2, 3, or 4. Successful authentication requires that the Claimant prove through a secure authentication protocol that he or she possesses and controls the token.
Plaintext passwords or secrets are not transmitted across a network at Level 1. However this level does not require cryptographic methods that block offline attacks by eavesdroppers. For example, simple password challenge-response protocols are allowed. In many cases an eavesdropper, having intercepted such a protocol exchange, will be able to find the password with a straightforward dictionary attack.
At Level 1, long-term shared authentication secrets may be revealed to Verifiers. At Level 1, assertions and assertion references require protection from manufacture/modification and reuse attacks.
1.2.2 Level 2
Level 2 provides single factor remote network authentication. At Level 2, identity proofing requirements are introduced, requiring presentation of identifying materials or information. A wide range of available authentication technologies can be employed at Level 2. For single factor authentication, Memorized Secret Tokens, Pre-Registered Knowledge Tokens, Look-up Secret Tokens, Out of Band Tokens, and Single Factor One-Time Password Devices are allowed at Level 2. Level 2 also permits any of the token methods of Levels 3 or 4. Successful authentication requires that the Claimant prove through a secure authentication protocol that he or she controls the token. Online guessing, replay, session hijacking, and eavesdropping attacks are resisted. Protocols are also required to be at least weakly resistant to man-in-the-middle (MITM) attacks. Long-term shared authentication secrets, if used, are never revealed to any other party except Verifiers operated by the CSP; however, session (temporary) shared secrets may be provided to independent Verifiers by the CSP. In addition to Level 1 requirements, assertions are resistant to disclosure, redirection, and capture and substitution attacks. Approved cryptographic techniques are required for all assertion protocols used at Level 2 and above.
1.2.3 Level 3
Level 3 provides multifactor remote network authentication. At least two authentication factors are required. At this level, identity proofing procedures require verification of identifying materials and information. Level 3 authentication is based on proof of possession of the allowed types of tokens through a cryptographic protocol. Multifactor Software Cryptographic Tokens are allowed at Level 3. Level 3 also permits any of the token methods of Level 4. Level 3 authentication requires cryptographic strength mechanisms that protect the primary authentication token against compromise by the protocol threats for all threats at Level 2 as well as verifier impersonation attacks. Various types of tokens may be used. Authentication requires that the Claimant prove, through a secure authentication protocol, that he or she controls the token. The Claimant unlocks the token with a password or biometric, or uses a secure multitoken authentication protocol to establish two-factor authentication (through proof of possession of a physical or software token in combination with some memorized secret knowledge). Long-term shared authentication secrets, if used, are never revealed to any party except the Claimant and Verifiers operated directly by the CSP; however, session (temporary) shared secrets may be provided to independent Verifiers by the CSP. In addition to Level 2 requirements, assertions are protected against repudiation by the Verifier.
1.2.4 Level 4
Level 4 is intended to provide the highest practical remote network authentication assurance. Level 4 authentication is based on proof of possession of a key through a cryptographic protocol. At this level, in-person identity proofing is required. Level 4 is similar to Level 3 except that only “hard” cryptographic tokens are allowed. The token is required to be a hardware cryptographic module validated at Federal Information Processing Standard (FIPS) 140–2 Level 2 or higher overall with at least FIPS 140–2 Level 3 physical security. Level 4 token requirements can be met by using the personal identity verification (PIV) authentication key of a FIPS 201 compliant PIV Card. Level 4 requires strong cryptographic authentication of all communicating parties and all sensitive data transfers between the parties. Either public key or symmetric key technology may be used. Authentication requires that the Claimant prove through a secure authentication protocol that he or she controls the token. All protocol threats at Level 3 are required to be prevented at Level 4. Protocols must also be strongly resistant to MITM attacks. Long-term shared authentication secrets, if used, are never revealed to any party except the Claimant and Verifiers operated directly by the CSP; however, session (temporary) shared secrets may be provided to independent Verifiers by the CSP. Approved cryptographic techniques are used for all operations. All sensitive data transfers are cryptographically authenticated using keys bound to the authentication process.
1.2.5 Multifactor authentication
The classic paradigm for authentication systems identifies three factors as the cornerstone of authentication:
• Something you know (e.g., a password)
• Something you have (e.g., an ID badge or a cryptographic key)
• Something you are (e.g., a fingerprint or other biometric data)
Multifactor authentication—as required in Levels 3 and 4 described earlier—refers to the use of more than one of the factors listed above. The strength of authentication systems is largely determined by the number of factors incorporated by the system. Single factor authentication (the vast majority of systems today) is almost always too weak to protect any type of important information or assets. Implementations that use two factors are considered to be stronger than those that use only one factor; systems that incorporate all three factors are stronger still (but become unwieldy quickly). The authors strongly suggest that developers of systems incorporate two-factor authentication from inception as people are beginning to accept the slight extra burden of it in order to have higher security.
The secrets contained in tokens commonly used in two-factor authentication are based on either public key pairs (asymmetric keys) or shared secrets. A public key and a related private key comprise a public key pair. The private key is stored on the token and is used by the Claimant to prove possession and control of the token. A Verifier, knowing the Claimant's public key through some credential (typically a public key certificate), can use an authentication protocol to verify the Claimant's identity, by proving that the Claimant has possession and control of the associated private key token. A common, easy to use, and very strong cryptographic key system for two-factor authentication (where a password is provided in addition to the code displayed on the token) made by RSA and others is the time-synchronized token. The working of this token is diagrammed in Fig. 2.
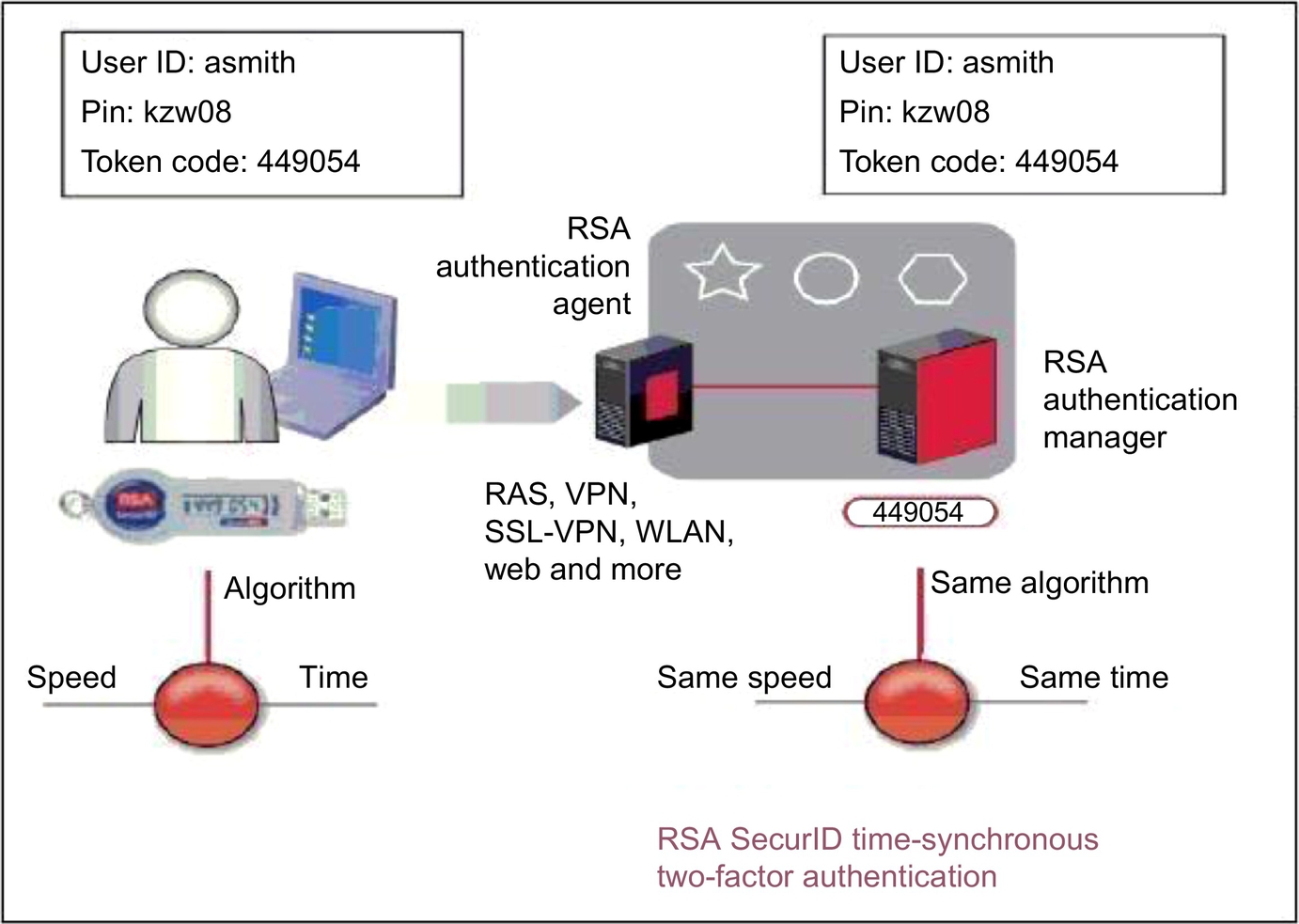
Fig. 2
EMC Corporation.
1.3 Authorization
Ultimately we are after access control which is control over exactly who can access the protected resources under specified circumstances. Access control depends on:
Identification (discussed in a previous section)
Subjects supplying identification information
Username, user ID, account number
Authentication (discussed in a previous section)
Verifying this identification information
Passphrase, PIN value, biometric, secure token, one-time password, password
Authorization
Using criteria to make a determination of operations that subjects can carry out on objects
Now that I know who you are, what am I going to allow you to do?
Accountability
Audit logs and monitoring to track subject activities with objects
Authentication and authorization are very different but together they represent a two-step process that determines whether an individual (or an application acting on behalf of an individual) is allowed to access a resource. Once authentication has sufficiently proven that the individual is who they claim to be, the system must establish whether this user is authorized to access the resource they are requesting and further, what actions this individual is allowed to perform on that resource.
Access control in computer systems and networks rely on access policies. The access control process can be divided into the following two phases: (1) policy definition phase where access is authorized, and (2) policy enforcement phase where access requests are approved or disapproved. Authorization is thus the function of the policy definition phase which precedes the policy enforcement phase where access requests are approved or disapproved based on the previously defined authorizations.
Most modern, multiuser operating systems include access control and thereby rely on authorization. Frequently it is such a multiuser system that acts as the gateway to embedded devices that depend on the general-purpose computer to protect them. Authorization is the responsibility of an authority, such as a department manager, within the application domain, but is often delegated to a custodian such as a system administrator. Authorizations are expressed as access policies in some types of “policy definition application,” e.g., in the form of an access control list (ACL) or a capability, on the basis of the “principle of least privilege”: consumers of services should only be authorized to access whatever they need to do their jobs. Older and single user operating systems often had weak or nonexistent authentication and access control systems.
An ACL with respect to a computer file system, is a list of permissions attached to an object. An ACL specifies which users or system processes are granted access to objects, as well as what operations are allowed on given objects. Each entry in a typical ACL specifies a subject and an operation. For instance, if a file object has an ACL that contains (Alice: read, write; Bob: read), this would give Alice permission to read and write the file and Bob to only read it.
Even when access is controlled through a combination of authentication and ACLs, the problems of maintaining the authorization data is not trivial, and often represents as much administrative burden as managing authentication credentials. It is often necessary to change or remove a user's authorization: this is done by changing or deleting the corresponding access rules on the system. Using atomic authorization is an alternative to per-system authorization management, where a trusted third party securely distributes authorization information.
SAML is an XML-based framework for creating and exchanging authentication and attribute information between trusted entities over the Internet. At the time of this writing, the latest specification is SAML v2.0, issued Mar. 15, 2005. SAML is used in large general-purpose computer systems and in embedded systems and the emerging Internet of things.
The building blocks of SAML include the Assertions XML schema which define the structure of the assertion; the SAML protocols which are used to request assertions and artifacts; and the Bindings that define the underlying communication protocols (such as HTTP or SOAP) and that can be used to transport the SAML assertions. The three components above define a SAML profile that corresponds to a particular use case.
SAML Assertions are encoded in a XML schema and can carry up to three types of statements:
• Authentication statements—Include information about the assertion issuer, the authenticated subject, validity period, and other authentication information. For example, an Authentication Assertion would state the subject “John” was authenticated using a password at 10:32 p.m. on Jun. 6, 2004.
• Attribute statements—Contain specific additional characteristics related to the Subscriber. For example, subject “John” is associated with attribute “Role” with value “Manager.”
• Authorization statements—Identify the resources the Subscriber has permission to access. These resources may include specific devices, files, and information on specific web servers. For example, subject “John” for action “Read” on “SCADA device 1002” given evidence “Role.”
Further exploration of SAML is best done in one of the many excellent detailed books on the subject.
1.4 Cryptography
[Some material here is derived from Securing Web Services with WS_Security written by this chapter's author and is used with permission.]
Once users are identified and registered and after they have authenticated themselves to a system they wish to access to which they have been provided access, the next important thing to consider is how they communicate with that system if their messages are confidential. Shared key technologies including shared key encryption—also called symmetric encryption—will be our critical tool for keeping messages confidential. In this section we will learn about the cryptography behind the algorithms, mechanisms for managing keys, and the relationship between shared key technologies and public key technologies, which are presented after shared key.
1.4.1 Shared key encryption
Several synonyms for shared key encryption are used. It is sometimes referred to as symmetric encryption or secret key encryption because the same key is used to both encrypt and decrypt a message and this key must be kept secret from all nonintended parties to keep the encrypted message secret. For clarity and simplicity, in this chapter we will use the term shared key encryption because sender and receiver share the same key, which is distinct from public key encryption where one key is made open and public to the entire world. The security principle we are driving for with shared key encryption is message confidentiality. By that we mean that no one other than the intended recipient will be able to read an encrypted message. Shared key encryption is explained pictorially in Fig. 3.

Fig. 3
In encryption, the key is the key so to speak. Since both sender and receiver must utilize the exact same key in shared key encryption, this solitary key must somehow be separately and confidentially exchanged so both parties have it prior to message exchange. Under other circumstances one might imagine you could send the key via US Mail or read it over the phone but neither of these would be consistent with the goals of computer-to-computer integration we are after. Typically key exchange must be done over the same channel that the encrypted messages will flow. Experience shows us that the best way to accomplish this is to encrypt the shared key using public key encryption before exchange. Public key encryption will be described after this discussion of shared key.
Only the key is secret. It has become clear from many years of experience that the algorithms themselves must be public and well scrutinized. The field of cryptography has unequivocal proof that this openness enhances confidence in the algorithm's security due to the extensive study and analysis by all the world's cryptographers of these public algorithms that ensues.
Without going into extensive mathematical derivations to prove it, we need you to take on faith the two most important things you need to know about shared key encryption:
(a) Shared key encryption is much faster than public key encryption, and
(b) Shared key encryption can operate on arbitrarily large plaintext messages which public key encryption cannot.
You cannot use public key encryption to encrypt large messages. You must use something comparable to public key encryption to get a shared key to the other endpoint from where the key was crafted. This is why you need to understand both technologies.
Shared key encryption uses cryptographic algorithms known as block ciphers. This means that the algorithm works by taking the starting plaintext message and first breaks it into fixed size blocks before encrypting each block. Two long-standing algorithms used throughout the software industry are Triple-Data Encryption Standard (3DES), and Advanced Encryption Standard (AES).
DES involves a lot of computationally fast and simple substitutions, permutations, XORs and shifting on a data block at a time to produce ciphertext from an input plaintext message. The design of DES is so clever that decryption uses exactly the same algorithm as encryption. The only difference is that the order in which the key parts are used in the algorithm is exactly reversed. DES was designed to be simple enough to build into high speed hardware. Many appliances used to accelerate Secure Sockets Layer (SSL), provide high speed virtual private networks (VPNs) and for other uses have been built with DES built in. However, in the past decade, weaknesses have been found in DES which has led to the creation of Triple-DES or 3DES.
3DES is a variant of DES that uses DES thrice in succession performing encrypt-decrypt-encrypt of the incoming message to compensate for DES' weakness. 3DES uses a key length of 192-bits. Like DES, 3DES is also frequently found in hardware devices for very high speed encryption.
AES is the most recently adopted shared key encryption standard. AES came out of a government-sponsored contest won by a cryptographer named Rijndael. It also works well in hardware and can have keys up to 256-bits long taking it out of the realm of being susceptible to a brute force attack with the current generation of computers.
A critical concept for shared key encryption is padding. The blocks that are input to the cipher must be of a fixed size so if the plaintext input is not already of the correct size it must be padded. But you can't just add random data or we would need to communicate to the receiver the correct real size of the data and that would be a dangerous clue to an attacker. You also can't just add zeros because the message itself might have leading or trailing zeros. So padding must include sentinel information that identifies the padding and must not give an attacker any critical information that might compromise the message. The name of the standard padding schemes accepted for use with these symmetric ciphers is PKCS#5 [2], and PKCS#7 [3].
As mentioned earlier, shared key technologies fail to solve the problem of scalable key distribution. While these algorithms are fast and can handle infinitely large messages, both ends of the communication need access to the same key and we need to get it to them securely which shared key cannot help with. Shared key cryptography also fails to solve the issue of repudiation. At times we are going to need to be able to prove that a certain identity created and attests to sending a message (or document) and no one else could have. They must not be able to deny having sent this exact document at this moment in time. Shared key cryptography provides no help here. Finally, shared key cryptography fails to solve the issue of data integrity. We know no one could have successfully intercepted our message and we have some assurance that no blocks of data in the message were substituted thanks to a process called cyclic block chaining that links each separately encrypted data block to the next, but we do not have assurance that the message sent and the one received are identical. To solve these issues, we need public key technologies.
1.4.2 Public key technologies
Public key technologies, including public key encryption, will be our tool for delivering integrity, nonrepudiation and authentication of messages. We will begin with an explanation of the concepts behind public key encryption. We will expand and apply this knowledge to build the basis for digital signatures. A discussion of public key technologies is not complete without discussion of public key infrastructure (PKI) and the issues of establishing trust.
Public key encryption
Public key encryption is also referred to as asymmetric encryption because there is not just one key used in both directions as with the symmetric encryption. In public key encryption there are two keys; whichever one is used to encrypt requires the other be used to decrypt. In this chapter we will stick with the term public key encryption to help establish context and contrast it to shared key encryption.
The keys in public key encryption are nonmatching but they are mathematically related. One key (it does not matter which) is used for encryption. That key is useless for decryption. Only the matching key can be used for decryption. This concept provides us with the critical facility we need for secure key exchange to establish and transport a shared key.
A diagram showing how basic public key encryption works is shown in Fig. 4.
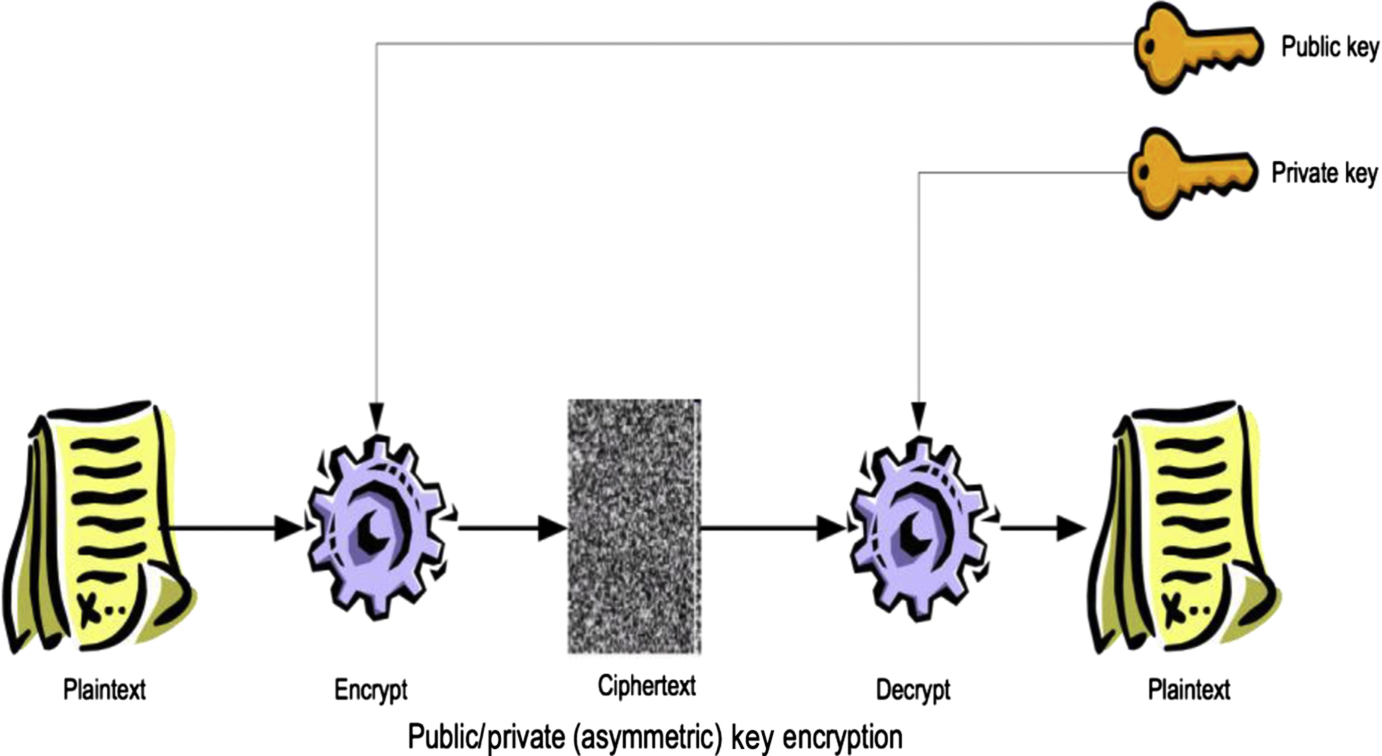
Fig. 4
A note about Kerberos before we continue with discussions of public key encryption. While it is true that Kerberos is an alternative for distributing shared keys, Kerberos only applies to a closed environment where all principals requiring keys share direct access to trusted key distribution centers (KDCs) and all principals share a key with that KDC. Microsoft Windows natively support Kerberos so within a closed Windows-only environment Kerberos is an option. No further discussion of Kerberos is contained in this chapter. We recommend public key systems for this function. Public key systems work with paired keys one of which (the private key) is kept strictly private and the other (the public key) is freely distributed; in particular the public key is made broadly accessible to the other party in secure communications.
Communicating parties each must generate a pair of keys. One of the keys, the private key, will never leave the possession of its creator. Each party to the communication passes their public key to the other party. The associated public key encryption algorithms are pure mathematical magic because whatever is encrypted with one half of the key pair can only be decrypted with its mate. Combining this simple fact with the strict rule that private keys remain private and only public keys can be distributed leads to a very interesting and powerful matrix of how public key encryption interrelates to confidentiality and identity. This matrix is shown in Table 1.
Table 1
How Public Key Encryption Interrelates to Confidentiality and Identity
| Public Key | Private Key | What This Means |
| Encrypt (w/ recipient's) | Decrypt (w/ recipient's) | Confidentiality (no one but intended recipient can read) |
| Decrypt (w/ sender's) | Encrypt (w/ sender's) | Signature (identity) (it could only have come from sender) |
For Alice to send a confidential message to Bob, Alice must obtain Bob's public key. That's easy since anyone can have Bob's public key at no risk to Bob; it is just for encrypting data. Alice takes Bob's public key and provides it to the standard encryption algorithm and encrypts her message to Bob. Because of the nature of the public-private key pair and the fact that Alice and Bob agree on a public, standard encryption algorithm (like RSA), Bob can use his private key to decrypt Alice's message. Most importantly, only Bob—because no one will ever get their hands on Bob's private key—can decrypt Alice's message. Alice just sent Bob a confidential message. Anyone intercepting it will get just scrambled data because they don't have Bob's private key.
Digital signatures will be described in just a moment but notice something interesting about doing things just the reverse of Alice's confidential message. If Alice encrypts a message with her private key, which only Alice could possess, and if Alice makes sure Bob has her public key, Bob can see that Alice and only Alice could have encrypted that message. In fact, since Alice's public key is in theory accessible to the entire world, anyone can tell that Alice and only Alice encrypted that message. The identity of the sender is established. That is the basic principle of digital signature.
Remember: encrypt with your private key and the whole world using your public key can tell it could be from you and only you (digital signature) or encrypt with a specific person's public key and they and only they, using their private key, can read your message (secret or confidential messages).
Public key encryption is based on the mathematics of factoring large numbers into their prime factors. This problem is thought to be computationally intractable if the numbers are large enough. But a limitation of public key encryption is that it can only be applied to small messages. To achieve our goal of distributing shared keys this is no problem—shared keys are not larger than the message size limitation of public key algorithms. To achieve our goal of digital signatures we will apply a neat trick and remain within this size limitation as we will discuss momentarily.
Digital signature basics
Digital signature is the tool we will use to achieve the message-level security principle of integrity. Digital signature involves a one-way mathematical function called hashing and using public key (asymmetric) encryption. The basic idea is to create a message digest and then to encrypt that. A message digest is a short representation for the full message. We need that because as we have just seen, asymmetric encryption is slow and is limited in the size message it can encrypt. A hash is a one-way mathematical function that creates a unique fixed size message digest from an arbitrary size text message. One-way means that you can never take the hash value and recreate the original message. Hash functions are designed to be very fast and are good at never creating the same result value from two different messages (they avoid collisions). Uniqueness is critical to make sure an attacker can never just replace one message with another and have the message digest come out the same anyway—that would pretty much ruin our goal of providing message integrity through digital signatures.
Here is the basic outline of digital signature:
1. Hash the entire plaintext message creating a fixed size (usually 20 bytes) message digest.
2. Encrypt this message digest using the signer's private key.
3. Send the original message and the encrypted message digest along with the signer's public key to any desired recipients.
4. Recipients use the signer's public key to decrypt the message digest. If the decryption is successful and the recipient trusts the signer's public key to be valid and the recipient trusts that the sender has protected their private key, then the recipient knows that it was the signer that sent this message.
5. Recipient uses the exact same hash function as the signer to create a message digest from the full, just-received plaintext message.
6. Recipient compares the just-created message digest to the one just decrypted and if they match message integrity has been proven.
These steps are shown in Figs. 5 and 6 where the hash algorithm being used is called Secure Hash Algorithm 1 (SHA-1).

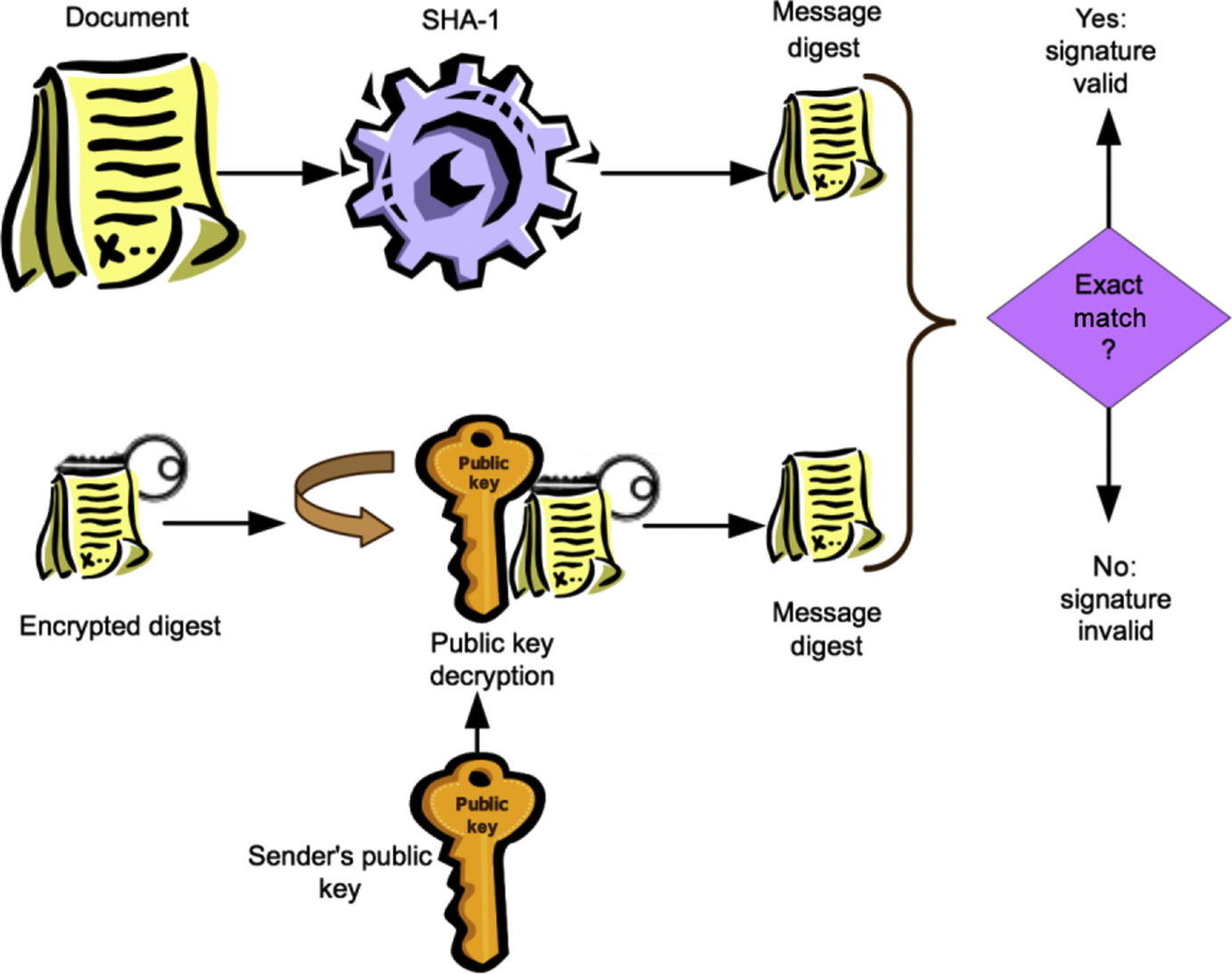
We know that public key encryption only works on small size messages. And we also know that if Alice encrypts a small message with her private key and sends the message to Bob, Bob can use Alice's public key to prove that the message could only have come from Alice. This identification of the sender is one half of what digital signature is all about. The other half relates to obtaining our goal of verifying the integrity of the message. By integrity we mean that we can tell if the message has changed by even one bit since it was sent. The key to integrity in our digital signature design was our use of the hash function to create a message digest.
Hashing the message to a message digest
A hash function is a one-way (nonreversable) function that takes an arbitrary plaintext message and creates a fixed size numerical output called a message digest that can be used as a proxy for our original message. We want this function to be very fast because we are going to need to run this function on both the sending and verifying ends of a communication. Most importantly we must be certain that it is virtually impossible for two messages to create the same output hash value or we will lose our integrity goal.
A large number of one-way hash functions that have excellent collision avoidance properties have been designed and deployed including MD4, MD5, and SHA-1. Weaknesses have been found in the first two and currently most security systems use SHA-1.
If we hash the entire plaintext message and then protect that hash value from being modified in any way and if the sender and the receiver use the exact same input message and hash algorithm, the integrity of the message can be checked and verified by the recipient without the huge expense of trying to encrypt the entire message. So let's discuss next how to protect the message digest.
Public key encryption of the message digest
Protecting the message digest simply involves encrypting the message digest with the private key of the sender, and to send the original message along with the encrypted message digest to the recipient. This public key encryption of the message digest (which is small so asymmetric encryption will work) gives us nonrepudiation because only the identity with the private key that did the encryption could have initiated the message. Protecting the message digest by encrypting it so no middleman attacker could have modified it gives us message integrity.
Signature verification
Signature verification is the process the message recipient must go through to achieve the message integrity and nonrepudiation goals. The recipient receives the original plaintext message and the encrypted message digest from the sender. Separately, or at this same time, the recipient will receive the public key of the sender. The original plaintext document is run through the same SHA-1 hash algorithm originally performed by the signer. This algorithm is identical on all platforms so the recipient has confidence that the exact same result will occur if the document has not been altered in any way. Separately, the encrypted digest is put through the public key decryption algorithm using the provided public key of the sender. The result of this operation is the decrypted message digest that was originally encrypted by the sender. The final step of the verification process is to do a bit-for-bit comparison of the message digest computed locally from the original document to the one just decrypted. If they are an exact match the signature is valid. We now know for sure that the private key that matches this public key is the one that encrypted the message digest which gives us nonrepudiation and we know that the message was sent unaltered so we have integrity. What we still need and we will discuss in a few moments is assurance that we know for sure the identity of the owner of the public key we just used.
Integrity without nonrepudiation
A very different approach to verifying message integrity when nonrepudiation is not a goal is via a message authentication code (MAC). This approach is like creating a cryptographic checksum. Combined with a hash, the acronym becomes HMAC.
Think of an HMAC as a key-dependent one-way hash function. Only someone with the identical key can verify the hash. We know that hashing is a very fast operation so these types of functions are very useful for guaranteeing authenticity when secrecy and nonrepudiation are not important but speed is. They are different from a straight hash because the hash value is encrypted and protected with a key. The algorithm is symmetric: the sender and the recipient possess a shared key.
1.4.3 Certificates, CAs, and CA hierarchies—public key infrastructure
In all of our discussions of public key encryption and its application to digital signatures, we oversimplified to the extreme when we said the public key is just sent to a recipient. We need more than just the public key itself if the public key is from someone we don't know well. We need identity information associated with the public key. We also need a way to know if someone we trust has verified this identity so that we can trust this entire transaction. Trust is what PKI is all about.
Digital certificates are containers for public keys
A digital certificate is a data structure that contains identity information along with an individual's public key and is signed by a certificate authority (CA). By signing the certificate the CA is vouching for the identity of the individual described in the certificate. Therefore RPs can trust the public key also contained in the same certificate.
Bob, the RP, must be certain that this is really Alice's key. He does this by checking the identity of the CA that signed this certificate (how does he trust them in the first place?) and by verifying both the identity and integrity of the certificate through the CA's attached signature. A validity date included in X.509 certificates helps insure against compromised (or out of date and invalid) keys.
The X.509 digital certificate trust model is a very general one. Each identity has a distinct name. The identity must be certified by the CA using some well-defined certification process they must describe and publish in a certification practice statement (CPS). The CA assigns a unique name to each user and issues a signed certificate containing the name and the user's public key.
Certificate authorities issue (and sign) digital certificates
The CA signs the certificate using a standard digital signature using the private key of the CA. Like any digital signature, this allows anyone with the CA's matching public key to verify that this certificate was indeed signed by the CA and is not fraudulent. The signature is an encrypted hash (called the thumbprint) of the contents of the certificate so standard signature verification guarantees integrity of the certificate data. That in turn allows you to believe the information contained in the certificate. Of course what we are really after is trust in the validity of the subject's (i.e., the sender/signer) public key that is contained in the certificate.
So far so good—if you trust the CA who signed this certificate, that is. The entire world may rely on such a signature so you can be sure the CA goes to extraordinary lengths to protect their private key including armed guards, copper clad enclosures and hardware protecting the private key that is heat and vibration sensitive. The matching public key of the CA is typically very widely distributed. In fact, the public keys for SSL certificates are found in all Web servers, in all Web browsers, and in the various trust store mechanisms many operating systems maintain to make sure RPs can always verify certificates signed by those CAs.
They key to trusting the signed certificate is what process the CA used to verify the identity of the subject prior to the issuance of the certificate. It might be based on my being an employee. It might require I produce my drivers license. Or it might be that I satisfy a set of shared secret questions drawn automatically from data bases that know about me such as telephone company, drivers license bureau, and credit bureau. In extreme cases where no doubt is tolerable (national security), a blood or DNA sample might have to be produced.
The CA can be thought of as a digital notary. One's identity is based on the assurance (honesty) of the notary. A certificate policy specifies the levels of assurance the CA has to provide and the CPS specifies the mechanisms and procedures to be used to achieve a level of assurance. Development of the CPS is the most time-consuming and essential component of establishing a CA. The planning and development of the certificate policies and procedures require the definition of requirements, such as key escrow, and processes such as certificate revocation.
A CA may be the guy down the hall, the HR department of your company, a local external company, a public CA, or the government. The CA must be trusted; or vouched for by someone who is.
Certificate revocation for dealing with public keys gone bad
Key escrow is an optional feature, but certificate revocation is an essential part of the certificate process to establish and maintain trust. Authentication of clients and servers requires a way to verify each certificate within the chain, as well as a way to determine if a certificate is valid or revoked. A certificate could be revoked if a key is compromised or lost due to modification of privileges, misuse, or termination. This is why it is essential that near real-time revocation of certificates is achieved. Currently two technologies are used for revocation: certificate revocation lists (CRLs) and online certificate status protocol (OCSP).
A CA must keep an up-to-date list of all certificates revoked in the CRL. It goes without saying that the CA must make it easy for registration authorities to revoke any given certificate (but prove that they have the right to). With CRLs, RPs have the burden of checking this list each time a certificate is presented. Best practices call for a certificate deployment point (CDP) URL to be embedded in the certificate. A CDP is a pointer to the location of the CRL on the Internet accessible programmatically by any RP's applications. CRLs are usually updated once per day because the process of generating them is nontrivial and time-consuming. When dealing with a compromised key or a rogue employee, once per day updates can potentially mean a huge loss could occur during that day especially when interactions are automated. Currently, almost no one checks revocation lists. While CRLs are created obediently by the sponsoring CAs and numerous tools can and do process them, there are so many unsolved problems with them that in this author's view, CRLs on the Internet are a technological failure.
OCSP was an attempt to create a much finer granularity protocol for essentially real-time revocation checking. But like CRLs, the information provided must be signed by the originating CA, which is a very expensive operation to perform in real-time. The best case on an unloaded system of moderate speed is 26 ms response time for a single OCSP request in our tests. In our view, this makes OCSP so limited in scope that it will continue to be only a bit player in revocation solutions.
1.4.4 SSL Transport Layer Security
The last topic under cryptography is about SSL. SSL is arguably the most widely used implementation of PKI ever deployed. It is important and relevant to a discussion of distributed networked embedded device security because it is so easy to use and so effective for some types of these deployments.
SSL security is most commonly used for browser-to-server security for e-commerce uses. SSL is effective at maintaining confidentiality of arbitrary transactions and will prove to be broadly useful for distributed networked embedded device security especially in early implementations.
There are four options when using http transport security:
1. SSL/TLS (one-way)
Secure Socket Layer (also known as Transport Layer Security). This is the same SSL that you use online when entering your credit card on a Web site. Using one-way SSL you get two benefits:
a. You are verifying the identity of the server, and
b. You are getting an encrypted session between the client and the server.
2. Basic Authentication (Basic Auth)
With Basic Authentication, a username and password is sent by the client for authentication. These credentials are sent in the clear so it is common practice to combine Basic Auth with one-way SSL.
3. Digest Authentication
Digest Authentication addresses the issue of the password being in the clear by using hashing technology (e.g., MD5 or SHA-1). Basically it involves the server passing a nonce (just a number or string chosen by the server) down to the client, which the client then combines with the password and hashes using the algorithm specified by the server. The server then receives the hash, runs the same hash algorithm on the password and nonce that it has. There are a couple of problems with Digest Authentication that make it seldom used. The main issue is that it is not supported in a standard way across Web servers and clients. The other issue is, for the server to participate, it must have access to a clear password, meaning the password must be stored in the clear. Many implementations will only store a hashed password making it impossible to participate in a digest protocol defined this way.
4. Client certificates (two-way SSL or mutually authenticated SSL)
This is one-way SSL as discussed earlier with the addition that the client must also provide an X.509 certificate. The protocol involves challenge and response by the server and the client in which information is digitally signed to prove the possession of the private key and therefore, identity based on the public key inside the certificate can be trusted. This is a powerful option but it adds a lot of complexity especially for Web applications with large numbers of clients because each client needs to be issued certificates in order to gain access. In some Web services scenarios—such as business-to-business—this may not be quite so onerous since the number of clients is typically small. However, one of the major complexity implications of using client certificates is that either.
a. X.509 certificates need to be issued by your company to each of the clients, meaning you need to get certificate management software and become a certificate authority, or
b. You need to work with a certificate authority's managed service. Also, unfortunately, configuring your Web server to accept client certificates is often not for the faint of heart, so you will need an experienced systems administrator to be successful.
When people talk about SSL transport layer security they will sometimes use the term “secure pipe” as a metaphor. What this means is that after the SSL endpoints have gone through their protocol (either one-way or two-way SSL) a cryptographic pathway has been created between the two endpoints (see Figs. 3–11). Web services that are based on HTTP as the transport will flow through this secure pipe making all messages sent back and forth confidential.
1.5 Other Ways to Keep Secrets
This section briefly describes four other ways to keep secrets. A one-time pad (OTP) is an encryption technique that cannot be cracked if used correctly. Steganography is the practice of concealing a file, message, image, or video within another file, message, image, or video. A one-way function is a function that is easy to compute on every input, but hard to invert given the image of a random input. Elliptic curve cryptography (ECC) depends on the ability to compute a point multiplication and the inability to compute the multiplicand given the original and product points.
1.5.1 One-time pad
In cryptography, the OTP is an encryption technique that cannot be cracked if used correctly. In this technique, a plaintext is paired with a random secret key (also referred to as a OTP). Then, each bit or character of the plaintext is encrypted by combining it with the corresponding bit or character from the pad using modular addition. If the key is truly random, is at least as long as the plaintext, is never reused in whole or in part, and is kept completely secret, then the resulting ciphertext will be impossible to decrypt or break. It has also been proven that any cipher with the perfect secrecy property must use keys with effectively the same requirements as OTP keys. However, practical problems have prevented OTPs from being widely used.
The “pad” part of the name comes from early implementations where the key material was distributed as a pad of paper, so that the top sheet could be easily torn off and destroyed after use. Here is how it works. Suppose Alice wishes to send the message “HELLO” to Bob. Assume two pads of paper containing identical random sequences of letters were somehow previously produced and securely issued to both. Alice chooses the appropriate unused page from the pad. The way to do this is normally arranged for in advance, as for instance “use the 12th sheet on 1 May,” or “use the next available sheet for the next message.” The material on the selected sheet is the key for this message. Each letter from the pad will be combined in a predetermined way with one letter of the message. (It is common, but not required, to assign each letter a numerical value, e.g., “A” is 0, “B” is 1, and so on.)
In this example, the technique is to combine the key and the message using modular addition. The numerical values of corresponding message and key letters are added together, modulo 26. So, if key material begins with “XMCKL” and the message is “HELLO,” then the coding would be done as follows:

If a number is larger than 26, then the remainder after subtraction of 26 is taken in modular arithmetic fashion. This simply means that if the computations “go past” Z, the sequence starts again at A.
The ciphertext to be sent to Bob is thus “EQNVZ.” Bob uses the matching key page and the same process, but in reverse, to obtain the plaintext. Here the key is subtracted from the ciphertext, again using modular arithmetic:

Similar to the above, if a number is negative then 26 is added to make the number zero or higher.
Thus Bob recovers Alice's plaintext, the message “HELLO.” Both Alice and Bob destroy the key sheet immediately after use, thus preventing reuse and an attack against the cipher. OTP has many challenges including being difficult to ensure that the key material is actually random, is used only once, never becomes known to the opposition, and is completely destroyed after use. The auxiliary parts of a software OTP implementation present real challenges: secure handling/transmission of plaintext, truly random keys, and one-time-only use of the key.
1.5.2 Steganography
Steganography is the practice of concealing a file, message, image, or video within another file, message, image, or video. Generally, the hidden messages appear to be (or be part of) something else: images, articles, shopping lists, or some other cover text. For example, the hidden message may be in invisible ink between the visible lines of a private letter. Some implementations of steganography that lack a shared secret are forms of security through obscurity, whereas key-dependent steganographic schemes adhere to Kerckhoffs's principle.1
The advantage of steganography over cryptography alone is that the intended secret message does not attract attention to itself as an object of scrutiny. Plainly visible encrypted messages—no matter how unbreakable—arouse interest, and may in themselves be incriminating in countries where encryption is illegal. Thus, whereas cryptography is the practice of protecting the contents of a message alone, steganography is concerned with concealing the fact that a secret message is being sent, as well as concealing the contents of the message.
Steganography includes the concealment of information within computer files. In digital steganography, electronic communications may include steganographic coding inside of a transport layer, such as a document file, image file, program or protocol. Media files are ideal for steganographic transmission because of their large size. For example, a sender might start with an innocuous image file and adjust the color of every 100th pixel to correspond to a letter in the alphabet, a change so subtle that someone not specifically looking for it is unlikely to notice it.
1.5.3 One-way functions
In computer science, a one-way function is a function that is easy to compute on every input, but hard to invert given the image of a random input. In applied contexts, the terms “easy” and “hard” are usually interpreted relative to some specific computing entity; typically “cheap enough for the legitimate users” and “prohibitively expensive for any malicious agents.” One-way functions, in this sense, are fundamental tools for cryptography, personal identification, authentication, and other data security applications. While the existence of one-way functions in this sense is also an open conjecture, there are several candidates that have withstood decades of intense scrutiny. Some of them are essential ingredients of most telecommunications, e-commerce, and e-banking systems around the world.
We have already discussed one type of one-way function called hash functions in the section on digital signatures. Other forms of one-way function include multiplication and factoring, the Rabin function, discrete exponential and logarithm, as well as others. Hash is easy, fast and very commonly used and we recommend staying with that unless a specific reason for a different form exists.
A cryptographic hash function is a hash function which is considered practically impossible to invert, that is, to recreate the input data from its hash value alone. These one-way hash functions have been called “the workhorses of modern cryptography.” The input data is often called the message, and the hash value is often called the message digest or simply the digest.
The ideal cryptographic hash function has four main properties:
1. It is easy to compute the hash value for any given message.
2. It is infeasible to generate a message from its hash.
3. It is infeasible to modify a message without changing the hash.
4. It is infeasible to find two different messages with the same hash.
Cryptographic hash functions have many information security applications, such as in digital signatures, and message authentication codes (MACs), as we have discussed. They can also be used as ordinary hash functions, to index data in hash tables, for fingerprinting, to detect duplicate data or uniquely identify files, and as checksums to detect accidental data corruption. Indeed, in information security contexts, cryptographic hash values are sometimes called (digital) fingerprints, checksums, or just hash values, even though all these terms stand for more general functions with rather different properties and purposes.
1.5.4 Elliptic curve cryptography
Public key cryptography is based on the intractability of certain mathematical problems. Early public key systems are secure assuming that it is difficult to factor a large integer composed of two or more large prime factors. For elliptic-curve-based protocols, it is assumed that finding the discrete logarithm of a random elliptic curve element with respect to a publicly known base point is infeasible: this is the “elliptic curve discrete logarithm problem” or ECDLP. The security of ECC depends on the ability to compute a point multiplication and the inability to compute the multiplicand given the original and product points. The size of the elliptic curve determines the difficulty of the problem.
The primary benefit promised by ECC is a smaller key size, reducing storage and transmission requirements, i.e., that an elliptic curve group could provide the same level of security afforded by an RSA-based system with a large modulus and correspondingly larger key: for example, a 256-bit ECC public key should provide comparable security to a 3072-bit RSA public key.
The US NIST has endorsed ECC in its Suite B set of recommended algorithms, specifically Elliptic Curve Diffie–Hellman (ECDH) for key exchange and Elliptic Curve Digital Signature Algorithm (ECDSA) for digital signature. The US National Security Agency (NSA) allows their use for protecting information classified up to top secret with 384-bit keys.
1.6 Discovering Root Cause
Root cause analysis (RCA) is a method of problem solving used for identifying the root causes of faults or problems. It is a standard part of thorough engineering in the face of issues much broader than cybersecurity but when a hack is successful against an embedded device, RCA is an important tool to developing a robust system that withstands attempts to cyber attack it. In RCA a factor is considered a root cause if removal thereof from the problem-fault-sequence prevents the final undesirable event from recurring; whereas a causal factor is one that affects an event's outcome, but is not a root cause. Though removing a causal factor can benefit an outcome, it does not prevent its recurrence within certainty.
Think of getting at the root cause of an exploited cybersecurity vulnerability like the difference between treating a symptom and curing a chronic medical condition. The truth is security professionals spend far too much time treating recurring symptoms without penetrating to the deeper roots of software and information technology (IT) issues so that problems can be solved at their source. Without utilizing the principles of RCA, sysadmins and operations managers may be kept too busy treating symptoms to ever bother digging down to find the roots of chronic conditions.
RCA has been used in many famous engineering disasters: the Tay Bridge collapse of 1879, the New London school explosion of 1937, and the Challenger space shuttle disaster of 1986 are a few examples. Builders, users, the public demanded that these types of incidents must never happen again. For that guarantee, it required RCA to be certain.
Now it is routinely used after major cyber attacks to determine what is needed to prevent a recurrence. One of the simplest and most common approaches to RCA—as it's practiced in every field and industry—is the “5-Why” approach developed by Sakichi Toyoda, the founder of Toyota Motor Corporation.
The 5-Why formula is incredibly simple: just keep asking why deeper and deeper like a 5-year-old child.
Formally or informally, this was the process used to ultimately understand how Stuxnet did the damage it did to just the centrifuges and just in one plant in the target country. It went like this:
Q Why did 2000 plutonium processing centrifuges at the nuclear processing site just get wheeled out to the dump?
A They self-destructed and were rendered useless and unfixable.
A Because their program said they should spin up very fast then slow down over and over during many months.
Q Why did they not follow their programming and boost speed over safe limits and slow down again over and over?
A Their program got corrupted before it was uploaded to the controller.
Q Why did the programmers who set up their programming not know the program being uploaded was corrupt?
A The design software itself had been corrupted and hid from the programmer what was actually in the uploaded code.
Q Why did the design software get corrupted?
A Because the entire Windows 7 machine was taken over by the worm.
Q Why was a worm able to take over the Windows 7 machine?
A Because an infected thumb drive was inserted into the machine.
1.6.1 Automatically determining root cause
Many attacks are multistage like Stuxnet. Each individual stage might not look like a major attack or even like a big problem. For example, there are legitimate reasons for a port scan so by itself just a port scan is not a reason for alarm. In fact, when monitoring software throws up an alarm at every port scan, a network operations center can be flooded with false negatives. But a port scan followed by an access to a behind-the-wall web page with no protecting password followed by a probe for the heart bleed bug is actually a multistage attack in the works.
A networking environment with a strong identity system and the ability to maintain reputation of an identity is able to keep track of the steps in what might become a multistage attack and is able to not sound an alarm too early but still to track the stages up to the point where it is clear that the individual (or application) is being nefarious and needs to be removed from the system before the last stage of their attack. This is especially important in a distributed environment with a large number of embedded devices because such an environment allows the perpetrator to move around from device to device thinking they are thwarting attempts to detect them.
1.7 Using Diversity for Security [4]
First, it is important that we acknowledge that software vulnerabilities exist. Second, we must also recognize that monocultures (where many devices and/or users are all running the same software, e.g., VxWorks or Linux) are highly vulnerable en masse. Diversity is a good way to acknowledge the first point and avoid the dangers of the second.
The principle that a moving target is harder to hit applies not only in conventional warfare but also in cybersecurity. Moving-target defenses change a system's attack surface with respect to time, space, or both. For instance, software diversity makes the software running on each individual system unique—and different from that of the attacker. Diversity can have a potentially large impact on security with little impact on runtime performance. That is not to say that software diversity is free or trivially easy to deploy, but it can be engineered to minimize impact on both developers and users. In addition, diversification costs can be placed up front (prior to execution) so there's no ongoing drag on performance.
The most prevalent form of software design diversity is N-version programming [5]. In an N-version system, developers write redundant software components to the same specification in the conventional manner. The premise behind design diversity is that separating methodology and programming teams will result in different faults in the different versions—although software will still fail, the hope is that different versions will fail at different times and in different ways.
Data diversity is the concept that diversity in the data space (as opposed to the design space) can potentially avoid event sequences that lead to failure. Applying data diversity changes the data that a program reads, causing the program to execute a different path and thereby possibly avoid a fault. Data diversity's advantage over design diversity is that it lends itself to automation and is thus scalable. Data diversity doesn't remove vulnerabilities, it only makes them harder to exploit.
A poor man's diversity of sorts is address space layout randomization (ASLR) [6]. Address space randomization hinders some types of security attacks by making it more difficult for an attacker to predict target addresses. For example, attackers trying to execute return-to-libc attacks must locate the code to be executed, while other attackers trying to execute shellcode injected on the stack have to find the stack first. In both cases, the system obscures related memory-addresses from the attackers. These values have to be guessed, and a mistaken guess is not usually recoverable due to the application crashing.
On the downside, for ASLR to be employed, the code must be compiled such that it is position-independent. Unfortunately, position-independent code increases register pressure on some processors and thus degrades performance. Furthermore, ASLR is highly susceptible to information leakage attacks; because all addresses in a segment are shifted by a constant amount, a single leaked code pointer lets attackers sidestep this defense.
The point in the development pipeline at which diversity is introduced matters for several reasons. Because software is predominantly distributed in binary form, diversification during compilation means that it occurs before software distribution and installation on end-user systems. So, software developers or distributors must pay for the computational resources necessary for diversification. Postponing diversification until the time at which the binaries are installed or updated on the end-user system distributes the diversification cost among users instead. However, post facto diversification via binary rewriting interferes with code signing because it changes the cryptographic hash. Signed code is used pervasively on mobile devices and increasingly on other embedded systems as a way to eliminate one source of cyber vulnerability. Finally, not all applications of diversity are possible with host-based solutions. Diversification makes tampering and piracy significantly harder and protects software updates against reverse engineering; these protections are ineffective if diversification is host based—users can simply disable the diversification engine running on their systems.
1.8 Defense in Depth
The idea behind defense in depth is to defend a system against any particular attack using several independent methods. It is a layering tactic, conceived by the NSA as a comprehensive approach to information and electronic security [7].
Defense in depth means there are overlapping systems designed to provide security even if one of them fails. An example from the enterprise systems domain is a firewall coupled with an intrusion-detection system (IDS). It can equally as effectively be applied in the embedded systems domain. Defense in depth bolsters security because there's no single point of failure and no assumed single vector for attacks.
Defense in depth was originally a military strategy that delays, rather than prevents, the advance of an attacker by yielding space in order to buy time. The placement of security protection mechanisms, procedures, and policies is intended to increase the dependability of an IT system where multiple layers of defense prevent espionage and direct attacks against critical systems. In terms of computer network defense, defense in depth measures should not only prevent security breaches, but also buy an organization time to detect and respond to an attack, thereby reducing and mitigating the consequences of a breach. Of course, key to this strategy working with an array of embedded systems “at the edge” of the network is that they can act as sensors and report back that they have detected an attack in process.
In the industrial control systems domain an increasing number of organizations are using modern networking to enhance productivity and reduce costs by increasing the integration of external, business, and control system networks; the ICA devices are being networked to each other and to the main systems of the organization. However, these integration strategies often lead to vulnerabilities that greatly reduce the cybersecurity posture of an organization and can expose mission-critical industrial control systems to cyber threats. Cyber-related vulnerabilities and risks are being created that did not exist when industrial control systems were isolated (but remember, the Stuxnet SCADA controllers were not connected to any network). A number of instances have illustrated the interdependence of industrial control systems, such as those in the power sector, including the 2003 North American blackout.
Simply deploying IT security technologies into a control system may not be a viable solution. Although modern industrial control systems often use the same underlying protocols that are used in IT and business networks, the very nature of control systems functionality (combined with operational and availability requirements) may make even proven security technologies inappropriate. Some sectors, such as energy, transportation, and chemical, have time sensitive requirements, so the latency and throughput issues associated with security software and hardware systems may introduce unacceptable delays and degrade or prevent acceptable system performance.
What this highlights is the need for security in depth within embedded systems and their frameworks. The same is true for IoT devices (to date more commonly thought of as consumer devices) and while an enterprise may have the ability to lock down, partition, and track the security of its network, it will be impossible for the average consumer or user to even come close. Many new companies are rapidly getting into the IoT market rushing products to market focused on functionality to grab a piece of market share and not giving any consideration to security. This is dangerous and it may mean a looming IoT cybersecurity disaster is on our horizon.
Industrial IoT—or IIoT—such as smart energy, intelligent transportation, factory automation, and industrial process control—like any other network, will require strong protection against malicious intrusions, including pervasive monitoring, wiretapping, MAC address spoofing, MITM attacks, and denial-of-service (DoS) attacks. Of the tens of billions of IoT-connected devices already in use today, few find themselves in physically secure locations. For better or worse, this is a natural consequence of mobility. Yet these same devices are often used to transmit confidential data.
As a specific minimal recommendation relative to defense in depth, it should be standard practice to have different security checks for actions like over-the-wire updates, Web-based management, and command authentication. Passwords or keys should never be stored as cleartext, they should follow the strongest standards for strong passwords and two-factor authentication should strongly be considered. Certainly security should not be an add-on or a simple firewall.
1.9 Least Privilege
The principle of least privilege (also known as the principle of minimal privilege or the principle of least authority) requires that in a particular abstraction layer of a computing environment, every module (such as a process, a user, or a program, depending on the subject) must be able to access only the information and resources that are necessary for its legitimate purpose [8].
The principle means giving a user account only those privileges which are essential to that user's work. For example, a backup user does not need to install software: hence, the backup user has rights only to run backup and backup-related applications. Any other privileges, such as installing new software, are blocked. The principle applies also to a user who usually does work in a normal user account, and opens a privileged, password protected account (i.e., a superuser) only when the situation absolutely demands it.
When applied to users, the terms least user access or least-privileged user account (LUA) are also used, referring to the concept that all user accounts at all times should run with as few privileges as possible, and also launch applications with as few privileges as possible. Software bugs may be exposed when applications do not work correctly without elevated privileges.
The principle of least privilege is widely recognized as an important design consideration in enhancing the protection of data and functionality from faults (fault tolerance) and malicious behavior (computer security).
From a security perspective the principle of least privilege means each part of a system has only the privileges that are needed for its function. This way even if an attacker gains access to one part, they have only limited access to the whole system.
No current OS fully abides by this approach although simpler OSs used in embedded systems have a much better chance of adhering to LP than full-fledged large system OSs like Unix derivatives.
Privilege escalation is a major component of many of the most damaging cyber attacks. Systems that have very little least privilege in their design and run several processes at highest privilege take on huge risk because if an attacker can successfully penetrate and take over such a process (or thread) it can now do anything. The attacker's malware can then read and write memory, can create or modify any existing file, and it can create and run any process. Through these and other means, an attacker can hide latent processes on the current system that may rise again later (called an advanced persistent threat (APT)) and it can spread its malice to machines to which the victim machine is connected. This was one of the strategies Stuxnet used to remain undetected.
1.10 Antitampering
Tampering involves the deliberate altering or adulteration of a product, package, or system. Why do adversaries do it? Three main goals of tampering are:
• To develop countermeasures. Those countermeasures might be to understand how to attack the device or if it is a weapon to develop a counter weapon that defeats or circumvents the capabilities of the device;
• To gain access to technology sooner than the adversary would have naturally developed it. Basically to steal the intellectual property employed in the device to advance the adversaries technological prowess; or
• To reverse engineer the device and in the process modify it to add features or capabilities to it.
Antitamper refers to technologies aimed at deterring and/or delaying unauthorized exploitation of critical information and technologies. Antitamper schemes range from simple “lock-it-up” to “deter-detect-react.”

Military weapons systems are frequent targets of tampering. Tampering may occur to take over a device in order to accomplish some malicious goals. This might be to take over a device so that its behavior or that of a device connected to the tampered one can be affected according to the purposes of the attacker. Tampering may occur by the end user of the product to change its behavior. Tampering with iPhones is common to accomplish what is called jail breaking the phone for the purpose of removing Apple's restrictions.
Tamper-resistant microprocessors are used to store and process private or sensitive information, such as private keys or electronic money credit. To prevent an attacker from retrieving or modifying the information, the chips are designed so that the information is not accessible through external means and can be accessed only by the embedded software. Examples of tamper-resistant chips include all secure cryptoprocessors, such as the IBM 4758 and chips used in smartcards, as well as the Clipper chip.
It is very difficult to make simple electronic devices secure against tampering, because numerous attacks are possible, including:
• physical attack of various forms (microprobing, drills, files, solvents, etc.)
• freezing the device
• applying out-of-spec voltages or power surges
• applying unusual clock signals
• inducing software errors using radiation (e.g., microwaves or ionizing radiation)
• measuring the precise time and power requirements of certain operations (see power analysis)
Tamper-resistant chips may be designed to zeroise their sensitive data (especially cryptographic keys) if they detect penetration of their security encapsulation or out-of-specification environmental parameters. A chip may even be rated for “cold zeroization”—the ability to zeroise itself even after its power supply has been crippled. In addition, the custom-made encapsulation methods used for chips used in some cryptographic products may be designed in such a manner that they are internally prestressed, so the chip will fracture if interfered with.
Nevertheless, the fact that an attacker may have the device in his possession for as long as he likes, and perhaps obtain numerous other samples for testing and practice, means that it is practically impossible to totally eliminate tampering by a sufficiently motivated opponent. Because of this, one of the most important elements in protecting a system is overall system design. In particular, tamper-resistant systems should “fail gracefully” by ensuring that compromise of one device does not compromise the entire system. In this manner, the attacker can be practically restricted to attacks that cost less than the expected return from compromising a single device. Since the most sophisticated attacks have been estimated to cost several hundred thousand dollars to carry out, carefully designed systems may be all but invulnerable in practice.
Digging deeper into the world of antitamper technologies (AT), there are four components to AT: tamper resistance, tamper detection, tamper response, and tamper evidence.
Tamper resistance is the ability to resist tamper attempts, and is achieved by specialized features such as the design security feature offered in some manufacturer's FPGAs. This AT technology encrypts an FPGA's configuration bitstream using AES encryption. To protect against copying, once an FPGA is configured, it is not possible to read back the unencrypted bitstream. FPGA manufacturers also optionally provide tamper-resistant coating solutions applied to the FPGA chip to further thwart physical tampering.
Tamper detection is the ability to make the system or user aware of the tamper event. In FPGAs, programming failures caused by not using the correct AES key may indicate a tamper event. On a system level, an attempt to open up a system box or casing may indicate a tamper event.
Tamper response is what happens after tempering is detected. The system must respond by taking countermeasures. For example, secured FPGAs do not allow programming when the incorrect encryption key is used. At a system level, a user can also implement “zeroization” as a response to tamper. Zeroization erases any critical technology information that is stored in the system.
Tamper evidence facilitates authorized personnel who are inspecting the system to identify whether the system has been tampered. In FPGAs with security enabled, multiple unsuccessful programming attempts may be evidence of tampering. Tamper-resistant coating solutions cause permanent silicon damage during physical tamper attempts on the FPGA silicon.
Finally, several steps can be employed to ensure security of the key storage within the FPGA:
• The key storage can be placed under layers of metal to resist physical attacks;
• Before the key is stored, it can be scrambled, so the stored key is not the actual key;
• The key bits can also be distributed among other logic making it exceedingly hard to find; and
• The volatile key can be erased via JTAG if a tamper event is detected.
2 Security and Network Architecture
Most embedded devices are part of a network and are therefore susceptible to a network-based attack. This section focuses on security concerns for, and network architecture concepts in support of, networked embedded devices.
2.1 IPsec
Internet protocol security (IPsec) is a protocol suite for secure Internet protocol (IP) communications that works by authenticating and encrypting each IP packet of a communication session. IPsec includes protocols for establishing mutual authentication between agents at the beginning of the session, and negotiation of cryptographic keys to be used during the session. IPsec can be used in protecting data flows between a pair of devices (device-to-device), between a pair of security gateways (network-to-network), or between a security gateway and a device (network-to-device).
IPsec supports network-level peer authentication, data origin authentication, data integrity, data confidentiality (encryption), and replay protection. It is an end-to-end security mechanism operating in the Internet Layer of the Internet Protocol Suite, while some other Internet security systems in widespread use, such as Transport Layer Security (TLS) and Secure Shell (SSH), operate in the upper layers at the Application layer. This is important because only IPsec protects all application traffic over an IP network.
IPsec can be implemented in two modes: a device-to-device (where either could be a host) transport mode, and a network tunneling mode as will be described next.
2.1.1 Transport mode
In transport mode, only the payload of the IP packet is usually encrypted and/or authenticated. The routing is intact, since the IP header is neither modified nor encrypted; however, when the authentication header is used, the IP addresses cannot be translated, as this always will invalidate the hash value. The transport and application layers are always secured by hash, so they cannot be modified in any way (e.g., by translating the port numbers).
2.1.2 Tunnel mode
In tunnel mode, the entire IP packet is encrypted and/or authenticated. It is then encapsulated into a new IP packet with a new IP header. Tunnel mode is used to create VPNs for network-to-network communications (e.g., between routers to link sites), device-to-network communications (e.g., remote user access) and device-to-device communications (e.g., private chat).
IPsec support is usually implemented in the operating system kernel. It was originally developed in conjunction with IPv6 and was originally required to be supported by all standards-compliant implementations of IPv6 but later it was made only a recommendation. IPsec is also optional for IPv4 implementations. The OpenBSD IPsec stack was the first implementation that was available under a permissive open-source license, and was therefore copied widely.
In 2013, as part of Snowden leaks, it was revealed that the US NSA had been actively working to “Insert vulnerabilities into commercial encryption systems, IT systems, networks, and endpoint communications devices used by targets” as part of the Bullrun program. There are allegations that IPsec was a targeted encryption system but no proof has been uncovered.
2.1.3 VPN
A VPN extends a private network across a public network, such as the Internet. It enables users to send and receive data across shared or public networks as if their computing devices were directly connected to the private network, and thus are benefiting from the functionality, security and management policies of the private network. A VPN is created by establishing a virtual point-to-point connection through the use of dedicated connections, virtual tunneling protocols, or traffic encryption.
A VPN spanning the Internet is similar to a wide area network (WAN). From a user perspective, the extended network resources are accessed in the same way as resources available within the private network. Traditional VPNs are characterized by a point-to-point topology, and they do not tend to support or connect broadcast domains. Therefore, communication, software, and networking, which are based on OSI layer 2 and broadcast packets, such as NetBIOS used in Windows networking, may not be fully supported or work exactly as they would on a local area network (LAN).
VPNs securely connect geographically separated offices of an organization, creating one cohesive network. VPN technology is also used by individual Internet users to secure their wireless transactions, to circumvent geo-restrictions and censorship, and to connect to proxy servers for the purpose of protecting personal identity and location. VPN is a security technology most appropriate for individual user connections as opposed to secure connections of an array of embedded devices. For secure tunneling to and from embedded devices, the IPsec tunneling mode described in the previous section is more appropriate.
2.1.4 TLS/SSL
TLS and its predecessor, SSL, are cryptographic protocols designed to provide communications security over a computer network. Several versions of the protocols are in widespread use in applications such as web browsing, email, Internet faxing, instant messaging, and voice-over-IP (VoIP). Major web sites (including Google, YouTube, Facebook, and many others) use TLS to secure all communications between their servers and web browsers.
The primary goal of the TLS protocol is to provide privacy and data integrity between two communicating computer applications. When secured by TLS, connections between a client (e.g., a web browser) and a server (e.g., wikipedia.org) will have one or more of the following properties:
• The connection is private because symmetric cryptography is used to encrypt the data transmitted. The keys for this symmetric encryption are generated uniquely for each connection and are based on a secret negotiated at the start of the session using RSA encryption of the shared symmetric keys as they are transported over the network. The server and client negotiate the details of which encryption algorithm and cryptographic keys to use before the first byte of data is transmitted. The negotiation of a shared secret is both secure (the negotiated secret is unavailable to eavesdroppers and cannot be obtained, even by an attacker who places himself in the middle of the connection) and reliable (no attacker can modify the communications during the negotiation without being detected).
• The identity of the communicating parties can be authenticated using public key cryptography. This authentication can be made optional, but is generally required for at least one of the parties (typically the server).
• The connection is reliable because each message transmitted includes a message integrity check using a message authentication code to prevent undetected loss or alteration of the data during transmission.
TLS supports many different methods for exchanging keys, encrypting data, and authenticating message integrity. As a result, secure configuration of TLS involves many configurable parameters, and not all choices provide all of the privacy-related properties described in the list above.
Attempts have been made to subvert aspects of the communications security that TLS seeks to provide and the protocol has been revised several times to address these security threats. Web browsers have also been revised by their developers to defend against potential security weaknesses after these were discovered.
TLS may be appropriate to use for embedded devices (VoIP, where it is used extensively, is an embedded device) but only if IPsec is considered first and eliminated for legitimate engineering reasons.
2.2 Firewalls
A firewall is a network security system that monitors and controls the incoming and outgoing network traffic based on predetermined security rules. A firewall typically establishes a barrier between a trusted, secure internal network and another outside network, such as the Internet, that is assumed to be not secure or trusted. Firewalls are often categorized as either network firewalls or host-based firewalls. Network firewalls are a software appliance running on general-purpose hardware or hardware-based firewall computer appliances that filter traffic between two or more networks. Host-based firewalls provide a layer of software on one host that controls network traffic in and out of that single machine. Routers that pass data between networks contain firewall components and can often perform basic routing functions as well. Firewall appliances may also offer other functionality to the internal network they protect such as acting as a DHCP or VPN server for that network.
First-generation firewalls were packet filtering firewalls which look at network addresses and ports within the packet and determine if that packet should be allowed or blocked. Packet filters act by inspecting the IP packets which are transferred between computers on the Internet. If a packet does not match the packet filter's set of filtering rules, the packet filter will drop (silently discard) the packet or reject it (discard it, and send “error responses” to the source). Conversely, if the packet matches one or more of the programmed filters, the packet is allowed to pass. This type of packet filtering pays no attention to whether a packet is part of an existing stream of traffic (i.e., it stores no information on connection “state”). Instead, it filters each packet based only on information contained in the packet itself (most commonly using a combination of the packet's source and destination address, its protocol, and, for TCP and UDP traffic, the port number). TCP and UDP protocols constitute most communication over the Internet, and because TCP and UDP traffic by convention use well known ports for particular types of traffic, a “stateless” packet filter can distinguish between, and thus control, those types of traffic (such as web browsing, remote printing, email transmission, file transfer), unless the machines on each side of the packet filter are both using the same nonstandard ports.
Second-generation firewalls perform the work of their first-generation predecessors but operate up to layer four (transport layer) of the OSI model. This is achieved by retaining packets until enough information is available to make a judgment about its state. Known as stateful packet inspection, it records all connections passing through it and determines whether a packet is the start of a new connection, a part of an existing connection, or not part of any connection. Though static rules are still used, these rules can now contain connection state as one of their test criteria. These stateful filtering firewalls are susceptible to certain types of DoS attacks which bombard the firewall with thousands of fake connection packets in an attempt to overwhelm it by filling its connection state memory.
Third-generation firewalls add application layer filtering to the previous generations capabilities. The key benefit of application layer filtering is that it can “understand” certain applications and protocols (such as file transfer protocol (FTP), domain name system (DNS), or hypertext transfer protocol (HTTP)). This is useful as it is able to detect if an unwanted protocol is attempting to bypass the firewall on an allowed port, or detect if a protocol is being abused in any harmful way.
Firewalls are best thought of as a perimeter defense. They are never enough by themselves but they are a critical first line of defense for critical systems and should not be ignored or omitted from consideration in system design. They apply to embedded systems, IoT and IIoT in many if not most situations because these devices are typically logically within an enterprise's network perimeter.
2.3 Intrusion Detection
An IDS is a device or software application that monitors network or system events for malicious activities or policy violations and produces reports to a management station. IDS come in a variety of “flavors” and approach the goal of detecting suspicious traffic in different ways. There are network based intrusion-detection systems (NIDS) and host based intrusion-detection systems (HIDS). NIDS is a network security system focusing on the attacks that come from the inside of the network (authorized users). Some systems may attempt to stop an intrusion attempt but this is neither required nor expected of a monitoring system. Intrusion detection and prevention systems (IDPS) are primarily focused on identifying possible incidents, logging information about them, and reporting attempts. In addition, organizations use IDPSes for other purposes, such as identifying problems with security policies, documenting existing threats and deterring individuals from violating security policies. IDPSes have become a necessary addition to the security infrastructure of nearly every organization.
IDPSes typically record information related to observed events, notify security administrators of important observed events and produce reports. Many IDPSes can also respond to a detected threat by attempting to prevent it from succeeding. They use several response techniques, which involve the IDPS stopping the attack itself, changing the security environment (e.g., reconfiguring a firewall) or changing the attack's content.
Though they both relate to network security, an IDS differs from a firewall in that a firewall looks outwardly for intrusions in order to stop them from happening. Firewalls limit access between networks to prevent intrusion and do not signal an attack from inside the network. An IDS evaluates a suspected intrusion once it has taken place and signals an alarm. An IDS also watches for attacks that originate from within a system. This is traditionally achieved by examining network communications, identifying heuristics and patterns (often known as signatures) of common computer attacks, and taking action to alert operators. A system that terminates connections is called an intrusion prevention system, and is another form of an application layer firewall.
2.3.1 Network intrusion-detection systems
NIDS are placed at a strategic point or points within the network to monitor traffic to and from all devices on the network. It performs an analysis of passing traffic on the entire subnet, and matches the traffic that is passed on the subnets to the library of known attacks. Once an attack is identified, or abnormal behavior is sensed, the alert can be sent to the administrator. An example of an NIDS would be installing it on the subnet where firewalls are located in order to see if someone is trying to break into the firewall. Ideally one would scan all inbound and outbound traffic, however doing so might create a bottleneck that would impair the overall speed of the network.
2.3.2 Host intrusion-detection systems
HIDS run on individual hosts or devices on the network. A HIDS monitors the inbound and outbound packets from the device only and will alert the user or administrator if suspicious activity is detected. It takes a snapshot of existing system files and matches it to the previous snapshot. If the critical system files were modified or deleted, an alert is sent to the administrator to investigate. An example of HIDS usage can be seen on mission critical machines, which are not expected to change their configurations.
2.3.3 Limitations
Noise can severely limit an IDS's effectiveness. Bad packets generated from software bugs, corrupt DNS data, and local packets that escaped can create a significantly high false-alarm rate. It is not uncommon for the number of real attacks to be far below the number of false-alarms. Number of real attacks is often so far below the number of false-alarms that the real attacks are often missed and ignored. Many attacks are geared for specific versions of software that are usually outdated. A constantly changing library of signatures is needed to mitigate threats. Outdated signature databases can leave the IDS vulnerable to newer strategies. For signature-based IDSes there will be lag between a new threat discovery and its signature being applied to the IDS. During this lag time the IDS will be unable to identify the threat. An IDS cannot compensate for a weak identification and authentication mechanisms or for weaknesses in network protocols. When an attacker gains access due to weak authentication mechanism then IDS cannot prevent the adversary from any malpractice. Encrypted packets are not processed by the intrusion detection software. Therefore, the encrypted packet can allow an intrusion to the network that is undiscovered until more significant network intrusions have occurred. Intrusion detection software provides information based on the network address that is associated with the IP packet that is sent into the network. This is beneficial if the network address contained in the IP packet is accurate. However, the address that is contained in the IP packet could be faked or scrambled. Due to the nature of NIDS systems, and the need for them to analyze protocols as they are captured, NIDS systems can be susceptible to same protocol based attacks that network hosts may be vulnerable. Invalid data and TCP/IP stack attacks may cause an NIDS to crash. Finally, hackers refer to enterprise networks that “think” they are fully protected with perimeter defenses like Firewalls and IDSs as “crunchy on the outside, chewy on the inside” because they know these are complex systems with the same percentage of bugs as any other large software system so if they can find a vulnerability in the perimeter systems they are in. Since these protection systems have to have high privilege access to the systems they are protecting, penetrating the security systems gives the attacker unfettered access to everything inside. Consequently, the systems doing the protecting have become the target of many determined attackers.
2.4 Antivirus Systems
While antivirus software was originally developed to detect and remove computer viruses, modern antivirus software can protect from malicious Browser Helper Objects (BHOs), browser hijackers, ransomware, keyloggers, backdoors, rootkits, trojan horses, worms, malicious LSPs, dialers, fraudtools, adware and spyware. Some products also include protection from other computer threats, such as infected and malicious URLs, spam, scam and phishing attacks, online identity (privacy), online banking attacks, social engineering techniques, APT and botnet DDoS attacks.
There are several methods antivirus engines use to identify malware. Signature-based detection is the most common method. To identify viruses and other malware, the antivirus engine compares the contents of a file to its database of known malware signatures. Heuristic-based detection is generally used together with signature-based detection. It detects malware based on characteristics typically used in known malware code. Behavioral-based detection is similar to heuristic-based detection and used also in IDS. The main difference is that, instead of characteristics hardcoded in the malware code itself, it is based on the behavioral fingerprint of the malware at runtime. This technique is able to detect (known or unknown) malware only after it has started malicious action. Sandbox detection is a particular behavioral-based detection technique that, instead of detecting the behavioral fingerprint at runtime, executes the programs in a virtual environment, logging actions the program performs. Depending on the actions logged, the antivirus engine can determine if the program is malicious or not. If not, then, the program is executed in the real environment. Albeit this technique has shown to be quite effective, given its heaviness and slowness, it is rarely used in end-user antivirus solutions. Data mining techniques are one of the latest approach applied in malware detection. Data mining and machine learning algorithms are used to try to classify the behavior of a file (as either malicious or benign) given a series of file features that are extracted from the file itself.
2.5 Security Information Management
Security information management (SIM) is an industry term related to information security referring to the collection of data (typically log files) into a central repository for trend analysis. SIM products generally are software agents running on the systems to be monitored, which then send the log information to a centralized server acting as a “security console.” The console typically displays reports, charts, and graphs of that information, often in real-time. Some software agents can incorporate local filters, to reduce and manipulate the data that they send to the server, although typically from a forensic point of view you would collect all audit and accounting logs to ensure you can recreate a security incident.
The security console is monitored by a human being, who reviews the consolidated information, and takes action in response to any alerts issued. The data that is sent to the server, to be correlated and analyzed, are normalized by the software agents into a common form, usually XML. Those data are then aggregated, in order to reduce their overall size.
The terminology can easily be mistaken as a reference to the whole aspect of protecting one's infrastructure from any computer security breach. Due to historic reasons of terminology evolution; SIM refers to just the part of information security which consists of discovery of “bad behavior” by using data collection techniques. The term commonly used to represent an entire security infrastructure that protects an environment is commonly called information security management (InfoSec).
2.6 Network-Based Attacks
In this section we will discuss two types of network-based attacks: DoS and MITM.
2.6.1 Denial of service (DoS)
In computing, a DoS attack is an attempt to make a machine or network resource unavailable to its intended users, such as to temporarily or indefinitely interrupt or suspend services of a host connected to the Internet. A distributed denial-of-service (DDoS) is where the attack source is more than one—and often thousands of-unique IP addresses [9].
Criminal perpetrators of DoS attacks often target sites or services hosted on high-profile web servers such as banks, credit card payment gateways; but motives of revenge, blackmail [10] or activism [11] can be behind other attacks.
DoS attacks can also lead to problems in the network “branches” around the actual computer being attacked. For example, the bandwidth of a router between the Internet and a LAN may be consumed by an attack, compromising not only the intended computer, but also the entire network or other computers on the LAN.
If the attack is conducted on a sufficiently large scale, entire geographical regions of Internet connectivity can be compromised without the attacker's knowledge or intent by incorrectly configured or flimsy network infrastructure equipment.
A DoS attack is characterized by an explicit attempt by attackers to prevent legitimate users of a service from using that service. There are two general forms of DoS attacks: those that crash services and those that flood services.
The most serious attacks are distributed and in many or most cases involve forging of IP sender addresses (IP address spoofing) so that the location of the attacking machines cannot easily be identified, nor can filtering be done based on the source address.
Types of DoS attacks
Internet control message protocol (ICMP) flood
A smurf attack relies on misconfigured network devices that allow packets to be sent to all computer hosts on a particular network via the broadcast address of the network, rather than a specific machine. The attacker will send large numbers of IP packets with the source address faked to appear to be the address of the victim. The network's bandwidth is quickly used up, preventing legitimate packets from getting through to their destination.
Ping flood is based on sending the victim an overwhelming number of ping packets, usually using the “ping” command from Unix-like hosts. It is very simple to launch, the primary requirement being access to greater bandwidth than the victim. Ping of death is based on sending the victim a malformed ping packet, which will lead to a system crash on a vulnerable system.
(S)SYN flood
A SYN flood occurs when a host sends a flood of TCP/SYN packets, often with a forged sender address. Each of these packets are handled like a connection request, causing the server to spawn a half-open connection, by sending back a TCP/SYN-ACK packet (acknowledge), and waiting for a packet in response from the sender address (response to the ACK packet). However, because the sender address is forged, the response never comes. These half-open connections saturate the number of available connections the server can make, keeping it from responding to legitimate requests until after the attack ends.
Distributed denial-of-service
A DDoS attack occurs when multiple systems flood the bandwidth or resources of a targeted system, usually one or more web servers. Such an attack is often the result of multiple compromised systems (e.g., a botnet) flooding the targeted system with traffic. A botnet is a network of zombie computers programmed to receive commands without the owner's knowledge. When a server is overloaded with connections, new connections can no longer be accepted. The major advantages to an attacker of using a distributed DoS attack are that multiple machines can generate more attack traffic than one machine, multiple attack machines are harder to turn off than one attack machine, and that the behavior of each attack machine can be stealthier, making it harder to track and shut down. These attacker advantages cause challenges for defense mechanisms. For example, merely purchasing more incoming bandwidth than the current volume of the attack might not help, because the attacker might be able to simply add more attack machines. This after all will end up completely crashing a website for periods of time.
Malware can carry DDoS attack mechanisms; one of the better-known examples of this was MyDoom. Its DoS mechanism was triggered on a specific date and time. This type of DDoS involved hardcoding the target IP address prior to release of the malware and no further interaction was necessary to launch the attack.
A system may also be compromised with a trojan, allowing the attacker to download a zombie agent, or the trojan may contain one. Attackers can also break into systems using automated tools that exploit flaws in programs that listen for connections from remote hosts. This scenario primarily concerns systems acting as servers on the web. Stacheldraht is a classic example of a DDoS tool. It utilizes a layered structure where the attacker uses a client program to connect to handlers, which are compromised systems that issue commands to the zombie agents, which in turn facilitate the DDoS attack. Agents are compromised via the handlers by the attacker, using automated routines to exploit vulnerabilities in programs that accept remote connections running on the targeted remote hosts. Each handler can control up to a thousand agents. In some cases a machine may become part of a DDoS attack with the owner's consent, for example, in Operation Payback, organized by the group Anonymous. These attacks can use different types of internet packets such as: TCP, UDP, ICMP, etc.
These collections of systems compromisers are known as botnets/rootservers. DDoS tools like Stacheldraht still use classic DoS attack methods centered on IP spoofing and amplification like smurf attacks and fraggle attacks (these are also known as bandwidth consumption attacks). SYN floods (also known as resource starvation attacks) may also be used. Newer tools can use DNS servers for DoS purposes. Unlike MyDoom's DDoS mechanism, botnets can be turned against any IP address. Script kiddies use them to deny the availability of well known websites to legitimate users. More sophisticated attackers use DDoS tools for the purposes of extortion—even against their business rivals.
DARPA (and the Pentagon) is so concerned about the continued vulnerability of all their systems—embedded devices in weapons systems, on board vessels, in communications devices, in Internet of Things devices being used in the military and intelligence communities, as well as their large enterprise systems—to DoS attacks that a new program called STAC (Space/Time Analysis for Cybersecurity) was created to research ways to determine susceptibility to DoS attacks in a given software system. As new defensive technologies make old classes of vulnerability difficult to exploit successfully, adversaries move to new classes of vulnerability. Vulnerabilities based on flawed implementations of algorithms have been popular targets for many years. However, once new defensive technologies make vulnerabilities based on flawed implementations less common and more difficult to exploit, adversaries will turn their attention to vulnerabilities inherent in the algorithms themselves.
2.6.2 Man-in-the-middle
In cryptography and computer security, a man-in-the-middle (often abbreviated to MITM) attack is an attack where the attacker secretly relays and possibly alters the communication between two parties who believe they are directly communicating with each other. MITM attacks can be thought about through a chess analogy. Mallory, who barely knows how to play chess, claims that she can play two grandmasters simultaneously and either win one game or draw both. She waits for the first grandmaster to make a move and then makes this same move against the second grandmaster. When the second grandmaster responds, Mallory makes the same play against the first. She plays the entire game this way and cannot lose using this strategy unless she runs into difficulty with time because of the slight delay between relaying moves. A MITM attack is a similar strategy and can be used against many cryptographic protocols. One example of MITM attacks is active eavesdropping, in which the attacker makes independent connections with the victims and relays messages between them to make them believe they are talking directly to each other over a private connection, when in fact the entire conversation is controlled by the attacker. The attacker must be able to intercept all relevant messages passing between the two victims and inject new ones. This is straightforward in many circumstances; for example, an attacker within reception range of an unencrypted Wi-Fi wireless access point, can insert himself as a MITM.
As an attack that aims at circumventing mutual authentication, or lack thereof, a MITM attack can succeed only when the attacker can impersonate each endpoint to their satisfaction as expected from the legitimate other end. Most cryptographic protocols include some form of endpoint authentication specifically to prevent MITM attacks. For example, TLS can authenticate one or both parties using a mutually trusted certification authority [citation needed].
Example of an attack is shown in Fig. 7.
Suppose Alice wishes to communicate with Bob. Meanwhile, Mallory wishes to intercept the conversation to eavesdrop and optionally deliver a false message to Bob.
First, Alice asks Bob for his public key. If Bob sends his public key to Alice, but Mallory is able to intercept it, a MITM attack can begin. Mallory sends a forged message to Alice that claims to be from Bob, but instead includes Mallory's public key.
Alice, believing this public key to be Bob's, encrypts her message with Mallory's key and sends the enciphered message back to Bob. Mallory again intercepts, deciphers the message using her private key, possibly alters it if she wants, and re-enciphers it using the public key Bob originally sent to Alice. When Bob receives the newly enciphered message, he believes it came from Alice.
Alice sends a message to Bob, which is intercepted by Mallory:
Mallory relays this message to Bob; Bob cannot tell it is not really from Alice:
Bob responds with his encryption key:
Mallory replaces Bob's key with her own, and relays this to Alice, claiming that it is Bob's key:
Alice encrypts a message with what she believes to be Bob's key, thinking that only Bob can read it:
However, because it was actually encrypted with Mallory's key, Mallory can decrypt it, read it, modify it (if desired), re-encrypt with Bob's key, and forward it to Bob:
Bob thinks that this message is a secure communication from Alice.
This example shows the need for Alice and Bob to have some way to ensure that they are truly using each other's public keys, rather than the public key of an attacker. Otherwise, such attacks are generally possible, in principle, against any message sent using public key technology. Fortunately, there are a variety of techniques that help defend against MITM attacks.
Defenses against the attack
All cryptographic systems that are secure against MITM attacks require an additional exchange or transmission of information over some kind of secure channel. Many key agreement methods have been developed, with different security requirements for the secure channel. Various defenses against MITM attacks use authentication techniques that include:
TLS is an example of implementing PKI over TCP. This is used to prevent a MITM attack over a secured HTTP connection on internet. The defense is that client and server exchange PKI certificates issued and verified by a common certificate authority. Mutual authentication is the main defense in a PKI scenario. In this case applications from both client and server mutually validate their certificates issued by a common root certificate authority. Similarly VPNs do mutual authentication before sending data over the created secure tunnel.
2.7 Introduction-Based Routing [12]
A central cause of the widespread corruption on the Internet is the ephemeral nature of the relationship between communicating parties. Whereas there is a concrete (fiduciary, organizational) relationship between an endpoint and its Internet service provider (ISP), and between the adjacent autonomous systems that the packets traverse, the Internet protocol (IP) hides these relationships so that all two communicating endpoints know is each other's IP address. In the physical economy, the supply chain is visible, and the resulting economic incentives reinforce good behavior. For example, when it was discovered that toothpaste exported from Asia contained diethylene glycol [13], public outrage pressurized the US government, which in turn pressurized the Chinese government, which (then) enforced product safety laws with the exporters. Without the exposed supply chain, consumers would have had no leverage with the exporters. Similarly, there is a supply chain behind every packet that traverses the Internet—but IP (in its current incarnation) hides it.
Introduction-based routing (IBR) is a way to limit misbehavior in a network by: (i) exposing the network supply chain, (ii) giving network elements authority over with whom they interact, and (iii) incorporating feedback, giving participants a basis for making their relationship choices. The ability to choose with whom one interacts creates economic incentives that (in the long run) discourage network elements from interacting with nodes that repeatedly misbehave. An IBR node's decisions concerning introductions are made by the node's policy, a software implementation of a strategy that maximizes the node's utility in a network that may contain corrupt participants.
To establish a new connection, a node must be introduced by a third party with connections to both the node and the neighbor-to-be. Since no node will be connected to every other (i.e., there is no universal introducer), forming a new connection may require multiple consecutive introductions. To bootstrap participation in the network, a node must have at least one a priori connection (a connection that does not require an introduction). The graph of nodes linked by a priori connections defines the network.
There are three parties to an introduction: the requester (the node requesting the introduction); the introducer (the node asked to make the introduction); and the target (the node to which the requester wishes to be introduced). If the introduction offer is accepted, a connection is established between the requester and target and the two nodes can exchange packets and/or request introductions to others. (These labels reflect roles in IBR, not inherent qualities of the nodes. A node may perform different roles at various points.)
A connection exists indefinitely until either party elects to close it. When a connection is closed, the requester and target provide feedback to the introducer regarding the state of the connection at the time of closing. If these nodes were introduced to the introducer, then the feedback is forwarded to those introducers after being processed. The feedback is binary—it is either positive (the other party was well-behaved) or negative. A connection closure is accompanied by messages between the two parties that signify the closure and notify the other party regarding the value of the feedback.
A key difference between IBRP and conventional routing protocols is that nodes have discretion regarding with which nodes they interact. There are two ways that a connection request can be refused. First, the introducer may respond to the introduction request with an introduction denied message. Second, the target may respond to the introduction offer with an introduction declined message. If the requester cannot find an introducer willing and able to make the introduction, then he will be unable to send packets to the target.
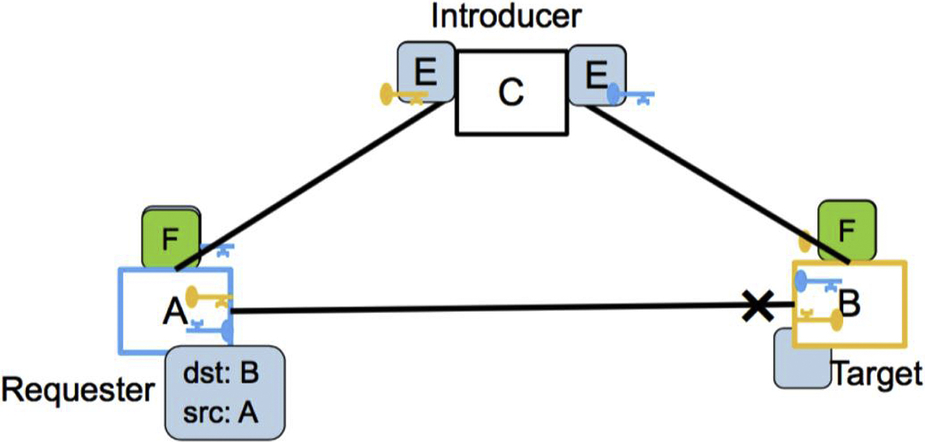
3 Software Vulnerability and Cyber Attacks
Having discussed the types of attacks that motivate us to drastically improve the security of our embedded devices, and delved into a critical set of security concepts it is important to understand, and applied those to network architectures, it is time to look at the role software is taking in our high vulnerability to cyber attacks. This will then set that stage for a discussion of how all of this relates to computer architecture and what we can do to thwart the exponentially increasing severity and rate of attacks.
3.1 Common Weakness Enumeration
The common weakness enumeration is a software community project that aims at creating a catalog of software weaknesses and vulnerabilities. The goal of the project is to better understand flaws in software and to create automated tools that can be used to identify, fix, and prevent those flaws. The top 25 most dangerous software errors is a list of the most widespread and critical errors that can lead to serious vulnerabilities in software. They are often easy to find, and easy to exploit. They are dangerous because they will frequently allow attackers to completely take over the software, steal data, or prevent the software from working at all.
3.2 Common Vulnerability and Exposures
The common vulnerabilities and exposures (CVE) system provides a reference-method for publicly known information-security vulnerabilities and exposures. The CVE is a dictionary of common names (i.e., CVE identifiers) for publicly known cybersecurity vulnerabilities. CVE's common identifiers make it easier to share data across separate network security databases and tools, and provide a baseline for evaluating the coverage of an organization's security tools. The CVE list steadily grows and as of early 2016 was over 75,000 entries.
3.3 Who Are the Attackers
Who are these attackers, how do they operate and what do they want?
3.3.1 Script kiddies
In programming culture a script kiddie or skiddie (also known as skid, script bunny, script kitty) is an unskilled individual who uses scripts or programs developed by others to attack computer systems and networks, and deface websites. It is generally assumed that script kiddies are juveniles who lack the ability to write sophisticated programs or exploits on their own, and that their objective is to try to impress their friends or gain credit in computer-enthusiast communities. However, the term does not relate to the actual age of the participant and they should not be underestimated: they can do real harm.
3.3.2 Vandals
Cyber vandals are individuals who damage information infrastructures purely for their own enjoyment and pleasure. Their primary motivation is not financial; it is the desire to prove that the feat could be accomplished. Once inside they leave their mark so there is no denying their presence. At first brush this may seem more of a prank than an attack aimed at destruction. The effect on business, however, is undeniable. These types of attacks generally fall into the category of DoS or Denial-of-service attack. The affected site must be shut down and repaired before it can resume normal operation. The messages left behind vary in tone: sometimes racial, sometimes profane, and sometimes political. Whatever the message, the effect is always disruptive.
3.3.3 Profiteers
Sophisticated hackers (individuals or small organized groups) are those who are after large profits through cyber attacks. A good example is the 22-year-old Ukrainian presumed to have been behind the Target POS attack that obtained 40 million consumer credit cards and which his group is selling on the black market in Eastern Europe. This group is selling batches of one million cards and going for anywhere from $20 to more than $100 per card.
3.4 How Do the Attackers Operate?
Attackers use a variety of approaches to ply their trade the most important to understand (and fear) is the zero-day. In this section we examine some of those approaches and use some illustrations to put these approaches into context.
3.4.1 Zero-day exploits
A zero-day (also known as zero-hour or 0-day) vulnerability is a previously undisclosed computer-software vulnerability that hackers can exploit to adversely affect computer programs, data, additional computers or a network. It is known as a “zero-day” because once the flaw becomes known, the software's author has zero days in which to plan and advise any mitigation against its exploitation (e.g., by advising workarounds or by issuing patches).
Attacks employing zero-day exploits are often attempted by attackers before or on the day that notice of the vulnerability is released to the public; sometimes before the author is aware or has developed and made available corrected code. Zero-day attacks are a severe threat to general-purpose and especially embedded systems.
Software vulnerabilities may be discovered by hackers, by security companies or researchers, by the software vendors themselves, or by users. If discovered by hackers, an exploit will be kept secret for as long as possible and will circulate only through the ranks of hackers, until software or security companies become aware of it or of the attacks targeting it. These types of attacks are defined by some as “less than zero-day” attacks.
3.4.2 The good guys vs the bad guys
If a vulnerability is discovered by “the good guys”—internet security software companies or software vendors—the tendency is to keep it under wraps until the software maker has a patch to fix it. In some cases, however, security researchers or software vendors may have to publicly announce the flaw because users could be able to avoid the problem, for instance by steering clear of a particular website or being sure to not open a certain email attachment. Or the vulnerability might be discovered by a user and wind up on a blog or otherwise be publicly disclosed.
In these cases, the race is on: good guys vs bad guys. Will the software vendor or a security company come up with a fix for the bug or will hackers learn how to exploit it before the vulnerability is patched?
Zero-day attacks targeting Microsoft software often hit right after Microsoft delivers its patches. Cybercriminals have found that they can take advantage of Microsoft's monthly security update cycle by timing new attacks just after Patch Tuesday—the second Tuesday of each month when Microsoft releases its fixes. These attacks will make Microsoft aware of the new vulnerabilities, but unless the vulnerabilities in question are extremely dangerous it will be a month before the software maker has a chance to respond. Security experts have coined the term “zero-day Wednesday” to describe that strategy.
3.4.3 Vulnerability timeline
A zero-day attack happens once that flaw, or software/hardware vulnerability is exploited, and attackers release malware before a developer has an opportunity to create a patch to fix the vulnerability, hence “zero-day.” Let's break down the steps of the window of vulnerability:
• A company's developers create software, but unbeknownst to them, it includes a vulnerability.
• The threat actor spots that vulnerability either before the developer does, or acts on it before the developer has a chance to fix it.
• The attacker writes and implements exploit code while the vulnerability is still open and available.
• After releasing the exploit, either the public recognizes it in the form of identity or information theft, or the developer catches it and creates a patch to staunch the cyber bleeding.
• Once a patch is written and used, the exploit is no longer called a zero-day exploit. These attacks are rarely discovered right away. In fact, it often takes not just days, but months, and sometimes years before a developer learns of the vulnerability that led to an attack.
3.4.4 RSA attack
In 2011 attackers breached EMC's RSA Security division and stole secrets related to RSA's widely used authentication system. The data theft had the potential of rendering the SecurID token authentication systems exposed—and affecting hundreds of thousands of RSA customers. SecurID is used in two-factor authentication for secure access to corporate assets, for remote employees to access corporate VPNs and secure mail programs, and to establish credentials to initiate encryption.
In the attack on RSA, the attacker sent “phishing” emails with the subject line “2011 Recruitment Plan” to two small groups of employees over the course of 2 days. Unfortunately, one was interested enough to retrieve one of these messages from his or her junk mail and open the attached Excel file. The spreadsheet contained malware that used a previously unknown, or “zero-day,” flaw in Adobe's Flash software to install a backdoor. RSA said that Adobe had since released a patch to fix that hole.
After installing a stealthy tool that allowed the hacker to control the machine from afar, he stole several account passwords belonging to the employee and used them to gain entry into other systems, where he could gain access to other employees with access to sensitive data.
Then came stage three: spiriting RSA files out of the company to a hacked machine at a hosting provider, and then on to the hacker himself.
Zero-day threats are getting quite prevalent. On any given day over the last 3 years, cybercriminals had access to at least 85 vulnerabilities targeting widely used software from Microsoft, Apple, Oracle, and Adobe. That estimate includes only vulnerabilities that were eventually reported. The true number of zero-day vulnerabilities available to cybercriminals could be much higher.
Vulnerabilities discovered by cybercriminals remain unknown to the public—including vendors of the vulnerable software—for an average of 310 days [14]. Not surprisingly, zero-day exploits are heavily used in targeted attacks. These secret weapons give attackers a crucial advantage over their targets, even those that have invested hundreds of thousands of dollars in traditional security products. Due to an abundance of zero-day vulnerabilities and increasingly mature global black market for exploits, these weapons are proliferating. Governments remain the top buyers of zero-day exploits, according to a recent Reuters article [15]. But anyone with enough money—as little as $5000 in some cases [16]—can purchase one.
3.4.5 Multistage attacks
The attack on Target's Point-of-Sale systems (an embedded device), with the goal of obtaining valid credit card numbers, was traced back to network credentials that were stolen from a third party vendor responsible for HVAC maintenance.
The central malware in the attack is Called BlackPOS, which is a specialized piece of malware designed to be installed on point-of-sale (POS) devices and record all data from credit and debit cards swiped through the infected system. A more advanced version of BlackPOS offers encryption support for stolen data and retails for $2300.
3.4.6 Advanced persistent threats
An APT is a set of stealthy and continuous computer hacking processes, often orchestrated by attackers targeting a specific entity. An APT usually targets organizations and/or nations for business or political motives. APT processes require a high degree of covertness over a long period of time. The “advanced” process signifies sophisticated techniques using malware (frequently zero-days) to exploit vulnerabilities in systems. The “persistent” process suggests that an external command and control system is continuously monitoring and extracting data from a specific target. The “threat” process indicates human involvement in orchestrating the attack.
It is important to understand how APTs work. Here are the six steps of an APT:
1. The cyber criminal, or threat actor, gains entry through an email, network, file, or application vulnerability and inserts malware into an organization's network. The network is considered compromised, but not breached.
2. The advanced malware probes for additional network access and vulnerabilities, or communicates with command-and-control (CnC) servers to receive additional instructions and/or malicious code.
3. The malware typically establishes additional points of compromise to ensure that the cyber attack can continue if one point is closed.
4. Once a threat actor determines that they have established reliable network access, they gather target data, such as account names and passwords. Even though passwords are often encrypted, encryption can be cracked. Once that happens, the threat actor can identify and access data.
5. The malware collects data on a staging server, and then exfiltrates the data off the network and under the full control of the threat actor. At this point, the network is considered breached.
6. Evidence of the cyber attack is removed, but the network remains compromised. The cybercriminal can return any time to continue the data breach.
3.4.7 Insiders
An insider attack is a malicious attack perpetrated on a network or computer system by a person with authorized system access. Insiders that perform attacks have a distinct advantage over external attackers because they have authorized access and also may be familiar with network architecture and system policies/procedures. In addition, there may be less security against insider attacks because many organizations focus on protection from outsiders.
Insider threats come from people who exploit legitimate access to an organization's cyberassets for unauthorized and malicious purposes or who unwittingly create vulnerabilities. They may be direct employees (from cleaners up to the C-suite), contractors, or third-party suppliers of data and computing services. (Edward Snowden, who famously stole sensitive information from the US NSA, worked for an NSA contractor.) With this legitimate access they can steal, disrupt, or corrupt computer systems and data without detection by ordinary perimeter-based security solutions—controls that focus on points of entry rather than what or who is already inside.
Over 50% of organizations report having encountered an insider cyberattack each year, with insider threat cases making up roughly 23% of all cybercrime incidents a percentage that has stayed consistent year over year, but the total number of attacks has increased significantly. The result is $2.9 trillion in employee fraud losses globally per year, with $40 billion in losses due to employee theft and fraud in the US annually alone. The damage and negative impact caused by insider threat incidents is reported to be higher than that of outsider or other cybercrime incidents.
Frequently multistage attacks begin to look like insiders. For example, Target where the HVAC contractors must be considered insiders with legitimate access but their devices were infected and that allowed access for the perpetrator to the POS network.
3.5 How Could We Stop the Attacks?
By examining two attacks we have previously discussed (Stuxnet, Target) in a little more detail, we can begin to shed light on how we might stop these types of attacks.
3.5.1 What would have stopped the Stuxnet attack against SCADA controllers?
What makes Stuxnet a watershed event in Cyber Warfare is the level of sophistication in the design of the worm. This indicates significant resources and expertise were needed to design and release it. The most significant indicators of a state-sponsored cyber threat are the exploitation of multiple zero-days to execute the attack, two different target platforms—Windows and Siemens—needed to execute the attack, and the specific domain knowledge of the target system that was required for the worm.
What is most telling about the designers of Stuxnet is the specific domain knowledge required to implement the attack against the Siemens Control System and its programming language, Step 7. While there are many groups versed in Windows libraries, how the Windows operating system works, C/C++, and reverse engineering, there is a much more limited set with the domain knowledge of this Siemens industrial control system, and an even smaller subset that has knowledge of both. This translates to significant resources to plan, assemble the team, design the exploits, have access to zero-days, test, get necessary intelligence on the target plant, put people in place with access, and then run the operation. Expert analysis estimates this would require a 1 to 2-year program with roughly $10–20 million in resources to pull off. Additionally, previous significant investments would have been made in developing the skill sets, technologies, zero-days, production engineering discipline, weaponization techniques and “concepts of operations” that would have been needed over a multiyear duration. This puts it almost exclusively in the realm of nation states, or extremely well-funded transnational terrorist groups.
Having made the case for state-sponsored cyber warfare, what is most surprising is that it got caught. Most state-sponsored offensive cyber operations do not get caught to be subsequently analyzed in the public domain for all to see the methods and zero-days employed. That's bad for business as it shows your adversaries your capabilities and methods while disclosing zero-days that are no longer zero-days. Second, while the targeting was narrow in one sense—a particular Siemens ICS—it was very broad in another sense—almost all Windows machines were vulnerable and would get infected if they came in contact with the worm. Not surprisingly, the worm has infected hundreds of thousands of machines over many countries. This is not normal modus operandi for state-sponsored cyber operations, not only because it means the attack will almost certainly be discovered, but also because of potential blowback. Blowback can come from the worm itself by infecting machines in the sponsoring nation's critical infrastructure, or political blowback from launching this type of visible attack. Since we have heard the admission that the US was involved, the entire approach taken is both surprising and troubling. Did the US want this to be discovered, analyzed and potentially copied? If so, why?
Stopping the next Stuxnet would take equivalent resources expended on the attack itself. Many holes need to be filled, some by the manufacturers of the ICA devices such as Siemens. Windows needs to be bolstered to detect anomalous behavior. Application such as the Step 7 application need to do a better job of detecting if they have been modified. Better monitoring of the behavior of the SCADA controller going outside normal operating ranges is needed. And perhaps most of all, help is needed from the processors in all our computers to help block the vectors of attack used by Stuxnet. More on this in just a bit.
3.5.2 What would have stopped the target attack against POS systems?
Six months before the data heist, Target spent $1.6 million on a sophisticated anti-malware system called FireEye that actually caught the hack and could have automatically eradicated the malware without any human interaction. But that feature was turned off, as it's believed the newly purchased, and tested system, was still mistrusted by Target's security personnel.
The same security system is employed by the CIA, the Pentagon and other spy agencies around the world, and has an interesting way of catching malware attacks in real-time instead of reacting to known malware only, as antivirus programs do. The system creates a parallel computer network on virtual machines that capture any data that comes from the web to Target, while attackers actually believe they are inside their intended victim.
FireEye captured the first malware code on Nov. 30 and issued an alert that was ignored. After using credentials from an HVAC company working for Target, hackers uploaded as many as five versions of the malware, which was disguised with a name related to a component in a data center management product—BladeLogic. FireEye was able to catch each one of them and escalate the warning alerts. But Target did not react to any of these notifications.
Even the Symantec Endpoint Protection antivirus program used by Target detected the malware around Thanksgiving issuing appropriate warnings, that were also ignored. Later, the assessment was that the malware utilized was unsophisticated. Target also has a team of security experts in Bangalore, that continuously monitors Target's network. The team got the alert on Nov. 30, and passed it on to the security team in Minneapolis. But that too was ignored. A defense-in-depth approach that used processors in the POS systems at each check-out station in each store would have stopped the attack. In an upcoming section we will discuss the architectural flaws in the processors that we now know how to fix.
3.6 Buffer Overflow Attacks
Buffer overflow attacks are by far the most common way network-based intrusions begin. According to Verizon's 2014 vulnerability report 70% of the exploited vulnerabilities were memory misuse (see Fig. 8) which almost always means buffer overflow. Therefore it is critical we understand how these attacks work and how the vulnerabilities enable them. Later we will talk about some new approaches to completely stop them from occurring at all.
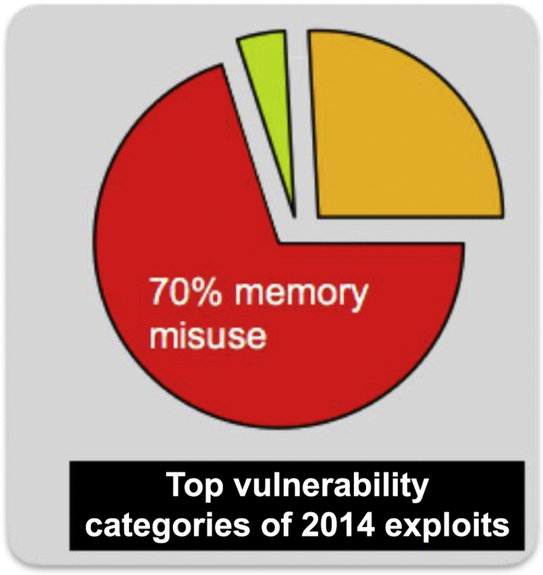
Fig. 8
Since many buffer overflow attacks focus on the computer's stack, we need to review how a stack works.
3.6.1 Use of the stack
The stack is a region in a program's memory space that is only accessible from the top. There are two operations, push and pop, to a stack. A push stores a new data item on top of the stack, a pop removes the top item (see Fig. 9). Every process has its own memory space (at least in a decent OS), among them a stack region and a heap region. The stack is used heavily to store local variables and the return address of called functions.

Given that we have a function
void foo(const char* input) {
char buf[10];
printf("Hello World ");
}
When this function is called from another function, for example main:
int main(int argc, char* argv[]) {
foo(argv[1]);
return 0;
}
the following happens: The calling function main() pushes the return address, that is the address of the statement immediately after the call to foo(), in this case the return(0) statement, onto the stack. Then the called function foo() pushes zeroes on the stack to store its local variable buf[] which requires space for 10 characters to be allocated. The stack thus will look like depicted in Fig. 10.
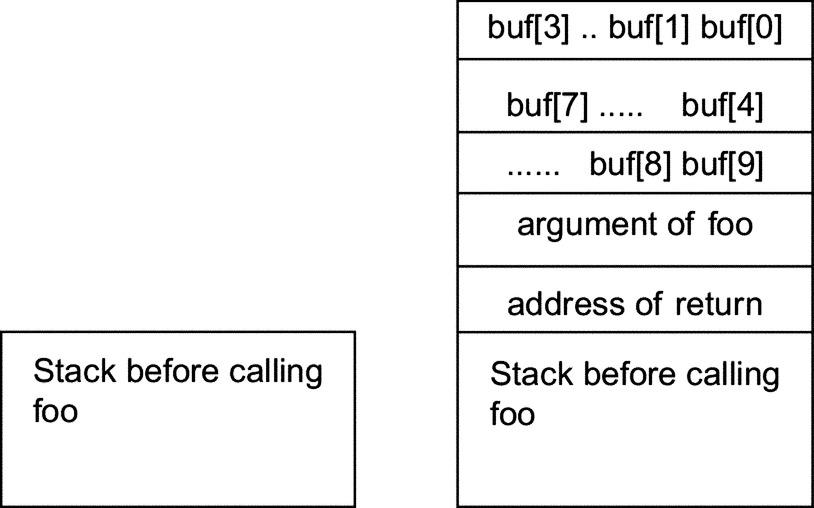
Now let's look at how an attacker might exploit a bug in a program with a buffer allocated on the stack. We will use an example program created by Howard and LeBlanc in Writing Secure Code, 2nd edition.
| /* StackOverrun.c This program shows an example of how a stack-based buffer overrun can be used to execute arbitrary code. Its objective is to find an input string that executes the function bar. */ #pragma check_stack(off) #include < string.h > #include < stdio.h > void foo(const char* input) { char buf[10]; printf(“My stack looks like: %p %p %p %p %p % p "); strcpy(buf, input); printf("%s ", buf); printf("Now the stack looks like: %p %p %p %p %p %p "); } void bar(void) { printf(“Augh! I’ve been hacked! "); } int main(int argc, char* argv[]) { //This is some cheating to make life easier on us printf("Address of foo = %p ", foo); printf("Address of bar = %p ", bar); if (argc != 2) { printf("Please supply a string as an argument! "); return -1; } foo(argv[1]); return 0; } | This is a simple C-program. Function main uses command line input. Recall that argc is the number of arguments including the call to the function itself. Thus, if we put : stackoverrun Hello then argc is two, argv[0] is “stackoverrun” and argv[1] is “Hello.” The main function calls function foo. foo gets the second word from the commandline as its input. As we look at foo, foo first prints the stack. This is done with a printf statement. The arguments to printf are taken directly from the stack. The “%p” format means that the argument is printed out as a pointer. The call to strcpy is the one that is dangerous. strcpy will just copy character for character until it finds a “0” character in the source string. Since the argument we give to the call can be much longer, this can mess up the stack. Unfortunately, commercial-grade software is full of these calls without checking for the length of the input. When the stack is messed up, the return address from foo will be overwritten. In other words, instead of going back to the next instruction after foo in main (that would be the return statement), the next instruction executed after foo finishes will be whatever is in the stack where the return address used to be. In this program, there is another function, called bar. The program logic prevents bar from ever running. However, by giving it the right input to main, we can get bar to run and if we do, we will have successfully executed a buffer overflow attack. |
| Prompt>stackoverrun.exe Hello Address of foo = 00401000 Address of bar = 00401050 My stack looks like: 00000000 00000A28 7FFDF000 0012FEE4 004010BB 0032154D Hello Now the stack looks like: 6C6C6548 0000006F 7FFDF000 0012FEE4 004010BB 0032154D | To the left is the result of running the stackoverrun program with the input “Hello.” The output gives us two pictures of the stack, one before the calling of strcpy in foo, the other afterwards. The return address from foo is printed in bold in both versions of the stack. We can stress-test the application by feeding it different input. If the input is too long, see below, we get bad program behavior. In the example below, the stack is overwritten with ASCI characters 31 and 32, standing for 1 and 2 respectively. The type of error message will depend on the operating system and the programs installed. Now it is only a matter of patience to find input that does something that we want, in this case, to execute bar. |
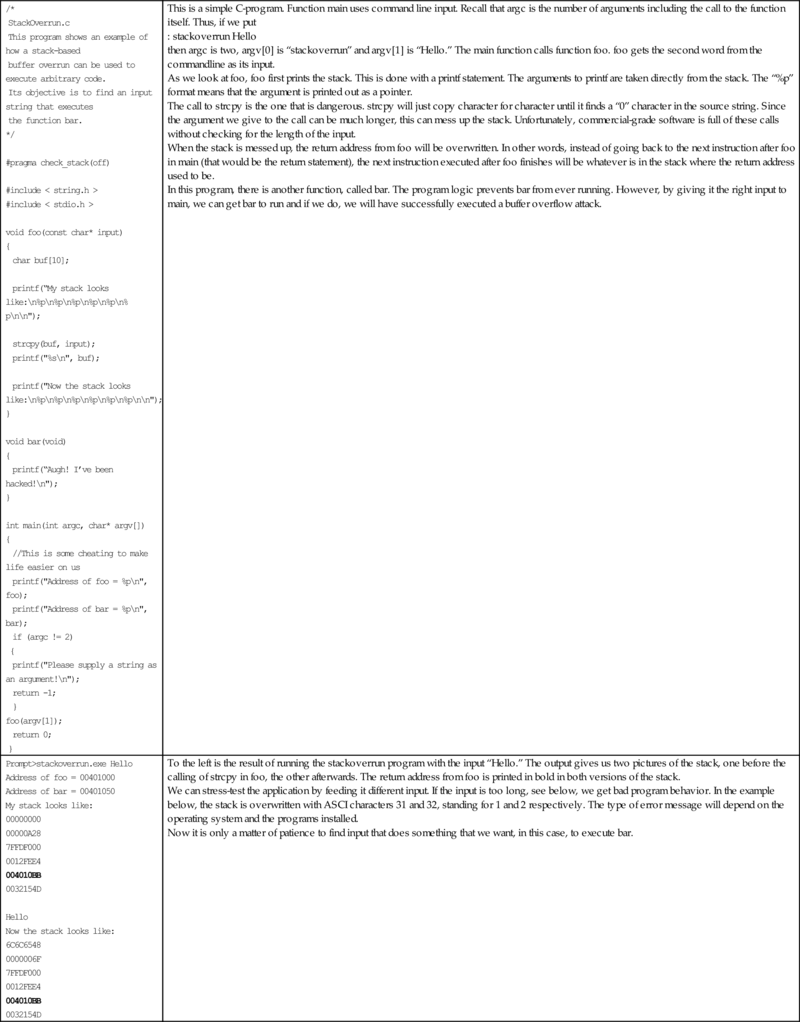
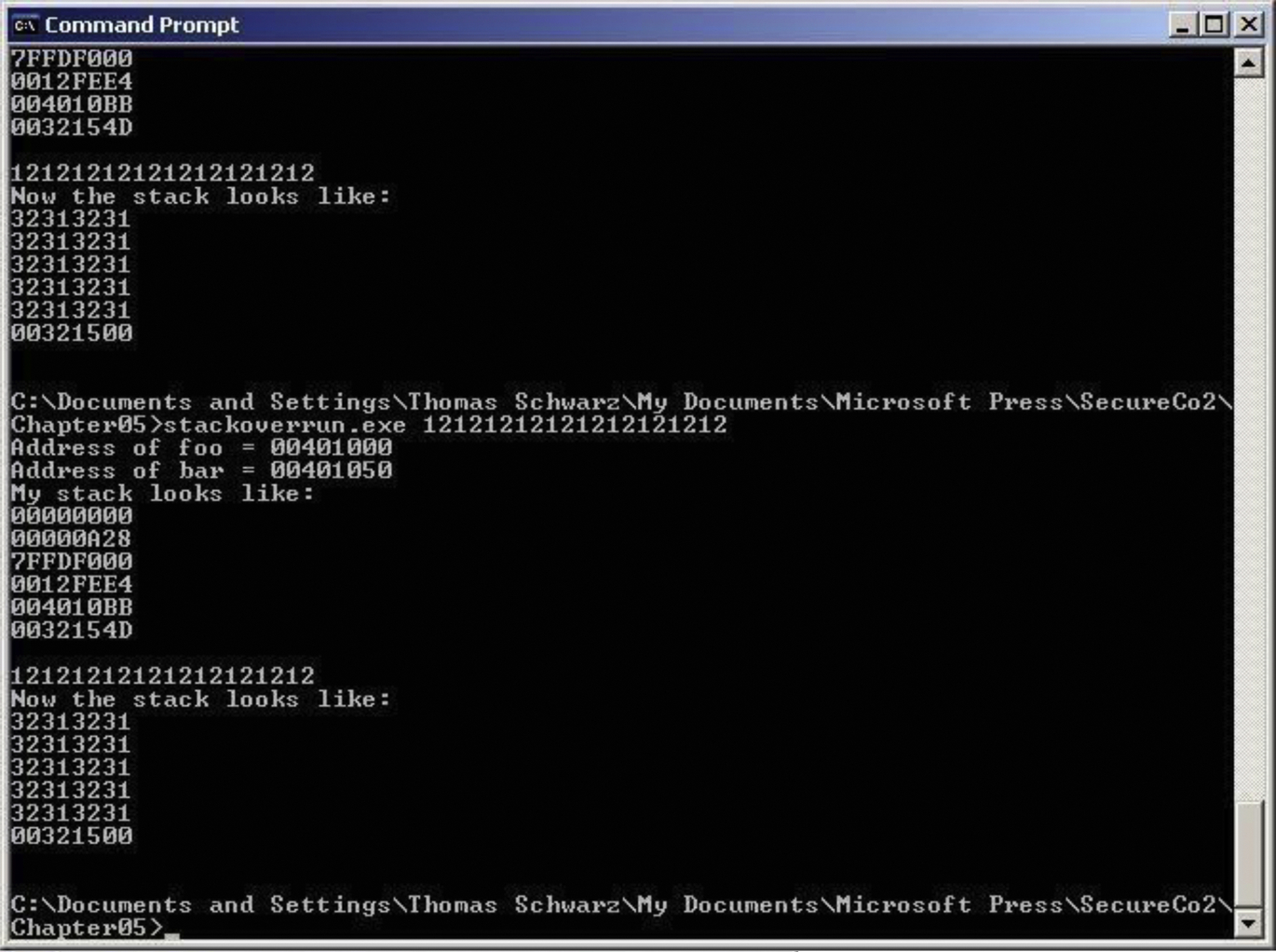

To make use of this, we need to feed the correct input to the program. In this example, we want to overwrite the second last line with the address of bar. To make navigation easier on us, we input a long list of different ASCI characters.
The line should be 00 40 10 50. Unfortunately, the character “10” is not printable. So to get around this we use a small perl script:

The first line concatenates the filler string with the right hex-characters.
Executing the Perl script yields the desired result:
Function bar is called and prints out to the screen.
If you use a different compiler, e.g., on a Unix system, the stack will look quite different. This is because compilers have freedom in how to structure the stack, and also, because they try to prevent exactly this type of problem.
3.6.2 Real stack overflow attacks
A real attack would try to place the address of the top of the stack in lieu of the return address, followed by some horrible lines of assembly code, such as a call to another tool. If the subverted program runs with high privileges, then the tool will run with the same privilege level. Even better for the attacker, the whole process takes only the transmission of a little script program.
3.6.3 Heap overflow attacks
Programs use dynamically allocated memory as well as the stack. A vulnerable program uses a call to something like strcpy to copy input into a buffer, allocated on the heap. The right type of input, longer than the buffer, will now overwrite data on the heap. The program will not always crash, but it will also not behave as advertised. A hacker noticing this behavior then tries various inputs until they find a way to corrupt the stack. Once the stack is corrupted, the attacker can get arbitrary code snippets executed.
3.6.4 Stack protection
It is not very difficult to rewrite the compiler so that stack smashing is thwarted. One simple approach is called Stack Guard [17]. Stack Guard writes a Canary word between the local variables and the return address on the stack, before a function is called, and checks it just before the function returns. This simple technique prevents stack overflow attacks at the cost of slight overhead in execution time and memory needs. The attacker needs to overwrite the canary word in order to overwrite the return address. Since the canary words vary, this overwrite can be detected with high probability.
Stack Guard prevents stack buffer overflow attacks that have not yet been discovered at the cost of recompiling the function. Unfortunately, the same method does not quite work for heap overflow attacks, though it can make the work of the hacker more complicated.
3.6.5 Writing secure code
Ultimately, the best defense is to not write code that is exploitable. Only safe string function calls should be used, strcpy and sprintf do not belong in code. Some programming languages enforce more secure code, but typically still allow unsafe constructs.
One lesson to draw for the programmer (or her manager) is that user input is far too dangerous to be left to users. Thus, all input should be treated as evil and corrupting unless proven otherwise. Second, a programmer needs to set up trusted and untrusted environments, and data needs to be checked whenever it crosses the boundary. The checking is easiest if there is a choke point for input. One should also consider the use of an input validator. Finally, run applications at the least possible privilege level.
In terms of dangerousness of attack, after buffer overflows, return-oriented programming attacks come in second. These attacks are related to and frequently require a buffer overrun to occur first. Their popularity is growing rapidly with the hacker class.
3.7 Return-Oriented Programming Attacks
Return-oriented programming (ROP) is an advanced version of a stack smashing attack. Generally, these types of attacks arise when an adversary manipulates the call stack by taking advantage of a bug in the program, often a buffer overrun. In a buffer overrun, as discussed in the previous section, a function that does not perform proper bounds checking before storing user-provided data into memory, accepts more input data than it can store properly. If the data is being written onto the stack, the excess data may overflow the space allocated to the function's variables (e.g., “DATA” in the stack diagram in Fig. 11) and overwrite the return address. This address will later be used by the function to redirect control flow back to the caller. If it has been overwritten, control flow will be diverted to the location specified by the new return address.

In a standard buffer overrun attack, the attacker would simply write attack code (the “payload”) onto the stack and then overwrite the return address with the location of these newly written instructions. Until the late 1990s, major operating systems did not offer any protection against these attacks; Microsoft Windows provided no buffer-overrun protections until 2004. Eventually, operating systems began to combat the exploitation of buffer overflow bugs by marking the memory where data is written as nonexecutable, a technique known as data execution prevention. With data execution prevention enabled, the machine would refuse to execute any code located in user-writable areas of memory, preventing the attacker from placing payload on the stack and jumping to it via a return address overwrite. Hardware support for data execution prevention later became available to strengthen this protection.
3.7.1 Return-into-library technique
The widespread implementation of data execution prevention made traditional stack-based buffer overflow vulnerabilities difficult or impossible to exploit in the manner described above. Instead, an attacker was restricted to code already in memory marked executable, such as the program code itself and any linked shared libraries. Since shared libraries, such as libc, often contain subroutines for performing system calls and other functionality potentially useful to an attacker, they are the most likely candidates for finding code to assemble an attack.
In a return-into-library attack, an attacker hijacks program control flow by exploiting a buffer overrun vulnerability, exactly as discussed above. Instead of attempting to write an attack payload onto the stack however, the attacker instead chooses an available library function and overwrites the return address with the location of the desired function. Further stack locations are then overwritten, obeying applicable calling conventions, to carefully pass the proper parameters to the function so it performs functionality useful to the attacker.
3.7.2 Borrowed code chunks
The next ROP evolution came in the form of an attack that used chunks of library functions, instead of entire functions themselves, to exploit buffer overrun vulnerabilities on machines with defenses against simpler attacks. This technique looks for functions that contain instruction sequences that pop values from the stack into registers. Careful selection of these code sequences allows an attacker to put suitable values into the proper registers to perform a function call under the new calling convention. The rest of the attack proceeds as a return-into-library attack.
3.7.3 Attacks
Return-oriented programming builds on the borrowed code chunks approach and extends it to provide Turing-complete functionality to the attacker, including loops and conditional branches. Put another way, return-oriented programming provides a fully functional “language” that an attacker can use to make a compromised machine perform any operation desired. Hovav Shacham published the technique in 2007 [18] and demonstrated how all the important programming constructs can be simulated using return-oriented programming against a target application linked with the C standard library and containing an exploitable buffer overrun vulnerability.
A return-oriented programming attack is superior to the other attack types discussed both in expressive power and in resistance to defensive measures. None of the counter-exploitation techniques mentioned above, including removing potentially dangerous functions from shared libraries altogether, are effective against a return-oriented programming attack. The import of this cannot be overstated. These attacks are extremely powerful and dangerous and can be employed against any computer running any modern processor.
3.7.4 x86 architecture
Although return-oriented programming attacks can be performed on a variety of architectures, Shacham's paper, as well as follow-up work, focuses on the Intel x86 architecture because of its variable-length CISC instruction set. Return-oriented programming on the x86 takes advantage of the fact that the instruction set is very “dense,” that is, any random sequence of bytes is likely to be interpretable as some valid set of x86 instructions.
It is therefore possible to search for an opcode that alters control flow, most notably the return instruction (0xC3) and then look backwards in the binary for preceding bytes that form possibly useful instructions. These sets of instruction, called “gadgets,” can then be chained by overwriting the return address, via a buffer overrun exploit, with the address of the first instruction of the first gadget. The first address of subsequent gadgets is then written successively onto the stack. At the conclusion of the first gadget, a return instruction will be executed, which will pop the address of the next gadget off the stack and jump to it. At the conclusion of that gadget, the chain continues with the third, and so on. By chaining the small instruction sequences, an attacker is able to produce arbitrary program behavior from pre-existing library code. Shacham asserts that given any sufficiently large quantity of code (including, but not limited to, the C standard library), sufficient gadgets will exist for Turing-complete functionality—i.e., anything the attacker wants to have the processor do.
Hacker groups have developed a tool to help automate the process of locating gadgets and constructing an attack against a binary. This tool, known as ROPgadget [19], searches through a binary looking for potentially useful gadgets, and attempts to assemble them into an attack payload that spawns a shell to accept arbitrary commands from the attacker.
3.7.5 Defenses
A number of techniques have been proposed to subvert attacks based on return-oriented programming. Most rely on randomizing the location of program and library code, so that an attacker cannot accurately predict the location of instructions that might be useful in gadgets and therefore cannot mount a successful return-oriented programming attack chain. One fairly common implementation of this technique, ASLR, loads shared libraries into a different memory location at each program load. Although widely deployed by modern operating systems, ASLR is vulnerable to information leakage attacks and other approaches to determine the address of any known library function in memory. If an attacker can successfully determine the location of one known instruction, the position of all others can be inferred and a return-oriented programming attack can be constructed.
Another defense will be shown shortly but requires the adoption of a new type of processor, an inherently secure processor.
3.8 Code Injection Attacks
Code injection is a dangerous attack that exploits a bug caused by processing invalid data. Injection is used by an attacker to introduce (or “inject”) code into a vulnerable computer program and change the course of execution. The result of successful code injection is often disastrous (for instance: code injection is used by some computer worms to propagate).
Injection flaws occur when an application sends untrusted data to an interpreter. Injection flaws are very prevalent, particularly in legacy code. They are often found in SQL, LDAP, Xpath, or NoSQL queries; OS commands; XML parsers, SMTP headers, program arguments, etc. Injection flaws are easy to discover when examining code, but frequently hard to discover via testing. Scanners and fuzzers can help attackers find injection flaws.
Injection can result in data loss or corruption, lack of accountability, or denial of access. Injection can sometimes lead to complete host takeover.
Code injection techniques are popular in system hacking or cracking to gain information, privilege escalation or unauthorized access to a system. Code injection can be used malevolently for many purposes, including:
• Arbitrarily modify values in a database through a type of code injection called SQL injection. The impact of this can range from website defacement to serious compromise of sensitive data.
• Install malware or execute malevolent code on a server, by injecting server scripting code (such as PHP or ASP).
• Privilege escalation to root permissions by exploiting Shell Injection vulnerabilities in a setuid root binary on UNIX, or Local System by exploiting a service on Windows.
• Attacking web users with HTML/Script injection (cross-site scripting).
To build embedded systems or the large computer systems that control them in such a way as to prevent code injection the important thing is to detect and isolate managed and unmanaged code injections by:
• Runtime image hash validation. Capture a hash of a part or complete image of the executable loaded into memory, and compare it with stored and expected hash.
• Enforce at the processor (hardware) level a rule that no data coming from outside the processor can ever be instructions to execute. On some processors such as x86, a bit such as the NX bit allows data to be stored in special memory sections that are marked as nonexecutable. The processor is made aware that no code exists in that part of memory, and refuses to execute anything found in there.
3.9 Side-Channel Attacks
In cryptography, a side-channel attack is any attack based on information gained from the physical implementation of a cryptosystem, rather than brute force or theoretical weaknesses in the algorithms (compare cryptanalysis). For example, timing information, power consumption, electromagnetic leaks or even sound can provide an extra source of information, which can be exploited to break the system. Some side-channel attacks require technical knowledge of the internal operation of the system on which the cryptography is implemented, although others such as differential power analysis (DPA) are effective as black-box attacks. Many powerful side-channel attacks are based on statistical methods pioneered by Paul Kocher [20].
3.9.1 Examples
A timing attack watches data movement into and out of the CPU or memory on the hardware running the cryptosystem or algorithm. Simply by observing variations in how long it takes to perform cryptographic operations, it might be possible to determine the entire secret key. Such attacks involve statistical analysis of timing measurements and have been demonstrated across networks [21].
A power-analysis attack can provide even more detailed information by observing the power consumption of a hardware device such as CPU or cryptographic circuit. These attacks are roughly categorized into simple power analysis (SPA) and DPA.
Fluctuations in current also generate radio waves, enabling attacks that analyze measurements of electromagnetic emanations. These attacks typically involve similar statistical techniques as power-analysis attacks.
Power consumption of devices causes heating, which is offset by cooling effects. Temperature changes create thermally induced mechanical stress. This stress can create low level acoustic (i.e., noise) emissions from operating CPUs (about 10 kHz in some cases). Recent research by Shamir et al. has suggested that information about the operation of cryptosystems and algorithms can be obtained in this way as well. This is an acoustic attack; if the surface of the CPU chip, or in some cases the CPU package, can be observed, infrared images can also provide information about the code being executed on the CPU, known as a thermal-imaging attack.
3.9.2 Countermeasures
Because side-channel attacks rely on the relationship between information emitted (leaked) through a side channel and the secret data, countermeasures fall into two main categories: (1) eliminate or reduce the release of such information and (2) eliminate the relationship between the leaked information and the secret data, that is, make the leaked information unrelated, or rather uncorrelated, to the secret data, typically through some form of randomization of the ciphertext that transforms the data in a way that can be undone after the cryptographic operation (e.g., decryption) is completed.
Under the first category, displays with special shielding to lessen electromagnetic emissions, reducing susceptibility to TEMPEST attacks, are now commercially available. Power line conditioning and filtering can help deter power-monitoring attacks, although such measures must be used cautiously, since even very small correlations can remain and compromise security. Physical enclosures can reduce the risk of surreptitious installation of microphones (to counter acoustic attacks) and other micromonitoring devices (against CPU power-draw or thermal-imaging attacks).
Another countermeasure (still in the first category) is to jam the emitted channel with noise. For instance, a random delay can be added to deter timing attacks, although adversaries can compensate for these delays by averaging multiple measurements together (or, more generally, using more measurements in the analysis). As the amount of noise in the side channel increases, the adversary needs to collect more measurements.
In the case of timing attacks against targets whose computation times are quantized into discrete clock cycle counts, an effective countermeasure is to design the software to be isochronous that is to run in an exactly constant amount of time, independently of secret values. This makes timing attacks impossible. Such countermeasures can be difficult to implement in practice, since even individual instructions can have variable timing on some CPUs.
One partial countermeasure against simple power attacks, but not differential power-analysis attacks, is to design the software so that it is “PC-secure” in the “program counter security model.” In a PC-secure program, the execution path does not depend on secret values. In other words, all conditional branches depend only on public information. (This is a more restrictive condition than isochronous code, but a less restrictive condition than branch-free code.) Even though multiply operations draw more power than NOP on practically all CPUs, using a constant execution path prevents such operation-dependent power differences (differences in power from choosing one branch over another) from leaking any secret information. On architectures where the instruction execution time is not data-dependent, a PC-secure program is also immune to timing attacks.
Another way in which code can be nonisochronous is that modern CPUs have a memory cache: accessing infrequently used information incurs a large timing penalty, revealing some information about the frequency of use of memory blocks. Cryptographic code designed to resist cache attacks attempts to use memory in only a predictable fashion (such as accessing only the input, outputs and program data, and doing so according to a fixed pattern). For example, data-dependent look-up tables must be avoided because the cache could reveal which part of the look-up table was accessed.
4 Security and Operating System Architecture
Privilege escalation is the act of exploiting a bug to gain elevated access to resources that are normally protected from an application or user. The result is that an application with more privileges than intended by the application developer or system administrator can perform unauthorized actions. Privileges mean what a user is permitted to do. Common privileges include viewing and editing files, or modifying system files.
Privilege escalation means a user receives privileges they are not entitled to. These privileges can be used to delete files, view private information, or install unwanted programs such as viruses. It usually occurs when a system has a bug that allows security to be bypassed or, alternatively, has flawed design assumptions about how it will be used.
This type of privilege escalation occurs when the user or process is able to obtain a higher level of access than an administrator or system developer intended, possibly by performing kernel-level operations.
4.1 Least Privilege
The principle means giving a user account only those privileges which are essential to that user's work. For example, a backup user does not need to install software: hence, the backup user has rights only to run backup and backup-related applications. Any other privileges, such as installing new software, are blocked. The principle applies also to a personal computer user who usually does work in a normal user account, and opens a privileged, password protected account (i.e., a superuser) only when the situation absolutely demands it.
When applied to users, the terms least user access or LUA are also used, referring to the concept that all user accounts at all times should run with as few privileges as possible, and also launch applications with as few privileges as possible. Software bugs may be exposed when applications do not work correctly without elevated privileges.
The principle of least privilege is widely recognized as an important design consideration in enhancing the protection of data and functionality from faults (fault tolerance) and malicious behavior (computer security).
Benefits of the principle include:
• Better system stability. When code is limited in the scope of changes it can make to a system, it is easier to test its possible actions and interactions with other applications. In practice for example, applications running with restricted rights will not have access to perform operations that could crash a machine, or adversely affect other applications running on the same system.
• Better system security. When code is limited in the system-wide actions it may perform, vulnerabilities in one application cannot be used to exploit the rest of the machine. For example, Microsoft states “Running in standard user mode gives customers increased protection against inadvertent system-level damage caused by ‘shatter attacks’ and malware, such as root kits, spyware, and undetectable viruses.”
• Ease of deployment. In general, the fewer privileges an application requires the easier it is to deploy within a larger environment. This usually results from the first two benefits, applications that install device drivers or require elevated security privileges typically have additional steps involved in their deployment, for example on Windows a solution with no device drivers can be run directly with no installation, while device drivers must be installed separately using the Windows installer service in order to grant the driver elevated privileges.
In practice, true least privilege is neither definable nor possible to enforce. Currently, there is no method that allows evaluation of a process to define the least amount of privileges it will need to perform its function. This is because it is not possible to know all the values of variables it may process, addresses it will need, or the precise time such things will be required. Currently, the closest practical approach is to eliminate privileges that can be manually evaluated as unnecessary. The resulting set of privileges still exceeds the true minimum required privileges for the process.
Another limitation is the granularity of control that the operating environment has over privileges for an individual process [4]. In practice, it is rarely possible to control a process's access to memory, processing time, I/O device addresses or modes with the precision needed to facilitate only the precise set of privileges a process will require.
4.2 Defense in Depth
Defense in depth (also known as castle approach) is an information assurance (IA) concept in which multiple layers of security controls (defense) are placed throughout an IT system. Its intent is to provide redundancy in the event a security control fails or a vulnerability is exploited that can cover aspects of personnel, procedural, technical and physical for the duration of the system's life cycle.
The idea behind the defense in depth approach is to defend a system against any particular attack using several independent methods. It is a layering tactic, conceived by the NSA as a comprehensive approach to information and electronic security.
Defense in depth is originally a military strategy that seeks to delay rather than prevent the advance of an attacker by yielding space to buy time. The placement of protection mechanisms, procedures and policies is intended to increase the dependability of an IT system, where multiple layers of defense prevent espionage and direct attacks against critical systems. In terms of computer network defense, defense in depth measures should not only prevent security breaches but also buy an organization time to detect and respond to an attack and so reduce and mitigate the consequences of a breach.
Defense in multiple places. Given that adversaries can attack a target from multiple points using either insiders or outsiders, an organization needs to deploy protection mechanisms at multiple locations to resist all classes of attacks. As a minimum, these defensive “focus areas” should include:
4.2.1 Information assurance
Defense in depth focus areas
• Defend the networks and infrastructure—Protect the local and wide area communications networks (e.g., from DoS attacks)
• Provide confidentiality and integrity protection for data transmitted over these networks (e.g., use encryption and traffic flow security measures to resist passive monitoring)
• Defend the enclave boundaries (e.g., deploy Firewalls and intrusion detection to resist active network attacks)
• Defend the computing environment (e.g., provide access controls on hosts and servers to resist insider, close-in, and distribution attacks).
Layered defenses. Even the best available IA products have inherent weaknesses. So, it is only a matter of time before an adversary will find an exploitable vulnerability. An effective countermeasure is to deploy multiple defense mechanisms between the adversary and his target. Each of these mechanisms must present unique obstacles to the adversary. Further, each should include both “protection” and “detection” measures. These help to increase risk (of detection) for the adversary while reducing his chances of success or making successful penetrations unaffordable. Deploying nested Firewalls (each coupled with intrusion detection) at outer and inner network boundaries is an example of a layered defense. The inner Firewalls may support more granular access control and data filtering.
Specify the security robustness (strength and assurance) of each IA component as a function of the value of what's it is protecting and the threat at the point of application. For example, it's often more effective and operationally suitable to deploy stronger mechanisms at the network boundaries than at the user desktop.
Deploy robust key management and PKI that support all of the incorporated IA technologies and that are highly resistant to attack. This latter point recognizes that these infrastructures are lucrative targets.
Deploy infrastructures to detect intrusions and to analyze and correlate the results and react accordingly. These infrastructures should help the “Operations” staff to answer questions such as: Am I under attack? Who is the source? What is the target? Who else is under attack? What are my options?
4.3 Secure Operating Systems
Increasingly, security experts are recommending not using an operating system specifically designed for embedded systems because so much more scrutiny has been given to mainstream operating systems, developers are more familiar with them and as embedded devices become more capable and prevalent it is more important they are running secure operating systems.
For years, embedded systems used purpose-built operating systems and software. The software had minimal functionality and limited access to the outside world, all of which minimized its vulnerability footprint. In recent years, embedded system vendors have been using more general-purpose operating systems such as Linux and Microsoft Windows XP Embedded, shifting away from the traditional purpose-built systems such as Wind River VxWorks. General-purpose operating systems can cost less to license, they can leverage open source software, and they can make software development cheaper and faster because software engineers already know how to program for Linux and Windows. The result is that many embedded systems bring to your network the same operating systems and also the same vulnerabilities as desktop workstations and servers. These systems are flooding the workplace. Smartphones, handheld medical devices, security systems, and environmental and process-control systems all have an IP address, and all represent a threat that must be managed.
4.3.1 HardenedBSD
HardenedBSD is a forked project from FreeBSD that brings low level security enhancements to the FreeBSD project, by aiming “to continuously implement kernel and userland hardening features, such as ASLR, mprotect hardening, position independent executable (PIE) support, and PTrace hardening, among other features.” Together with TrustedBSD, the HardenedBSD project resembles Trusted Solaris, a precursor which provided further security enhancements to the Solaris operating system. These early enhancements found their way into security features across a number of different operating systems, mostly Unix-like ones.
4.3.2 Qubes OS
Qubes OS is a Linux distribution based around the Xen hypervisor that allows to group programs into a number of isolated sandboxes (virtual machines) to provide security. Windows for programs running within these sandboxes (“security domains”) can be color coded for easy recognition. The security domains are configurable, they can be transient (changes to the file system will not be preserved), and their network connection can be routed through special virtual machines (e.g., one that only provides Tor networking). The operating system provides secure mechanisms for copy and paste and for copying files between the security domains.
4.3.3 SELinux
Security-Enhanced Linux (SELinux) is a Linux kernel security module that provides a mechanism for supporting access control security policies, including United States Department of Defense-style mandatory access controls (MAC).
SELinux is a set of kernel modifications and user-space tools that have been added to various Linux distributions. Its architecture strives to separate enforcement of security decisions from the security policy itself and streamlines the volume of software charged with security policy enforcement. The key concepts underlying SELinux can be traced to several earlier projects by the US NSA.
The US NSA, the original primary developer of SELinux, released the first version to the open source development community under the GNU GPL on Dec. 22, 2000. The software merged into the mainline Linux kernel 2.6.0-test3, released on Aug. 8, 2003. Other significant contributors include Red Hat, Network Associates, Secure Computing Corporation, Tresys Technology, and Trusted Computer Solutions. Experimental ports of the FLASK/TE implementation have been made available via the TrustedBSD Project for the FreeBSD and Darwin operating systems.
NSA Security-Enhanced Linux is a set of patches to the Linux kernel and some utilities to incorporate a strong, flexible mandatory access control (MAC) architecture into the major subsystems of the kernel. It provides an enhanced mechanism to enforce the separation of information based on confidentiality and integrity requirements, which allows threats of tampering and bypassing of application security mechanisms to be addressed and enables the confinement of damage that can be caused by malicious or flawed applications. It includes a set of sample security policy configuration files designed to meet common, general-purpose security goals.
SELinux was designed to demonstrate the value of mandatory access controls to the Linux community and how such controls could be added to Linux. Originally, the patches that make up SELinux had to be explicitly applied to the Linux kernel source; SELinux has been merged into the Linux kernel mainline in the 2.6 series of the Linux kernel.
4.3.4 Secure the boot and execution
Embedded systems are vulnerable at boot time. In fact, it is common for hobbyists to re-flash consumer hardware, but it's an undesirable liability for systems that are part of critical infrastructure. Many devices allow updates via web interfaces or other remote access, creating a serious security threat if abused.
Securing the boot image is an important step to securing a device. Trusted boot images are cryptographically signed with an identifier that the hardware recognizes as the only acceptable signature for execution. Support in the processor hardware makes this easier to adopt.
Trusted execution ensures on an ongoing basis that only properly signed applications/libraries/drivers are accepted for execution on the device. This blocks malware from being installed on the device.
4.3.5 UEFI
The UEFI 2.2 specification adds a protocol known as secure boot, which can secure the boot process by preventing the loading of drivers or OS loaders that are not signed with an acceptable digital signature. When secure boot is enabled, it is initially placed in “setup” mode, which allows a public key known as the “Platform key” (PK) to be written to the firmware. Once the key is written, secure boot enters “User” mode, where only drivers and loaders signed with the PK can be loaded by the firmware. Additional “Key Exchange Keys” (KEK) can be added to a database stored in memory to allow other certificates to be used, but they must still have a connection to the private portion of the PK. Secure boot can also be placed in “Custom” mode, where additional public keys can be added to the system that do not match the private key.
Unlike BIOS, UEFI does not rely on a boot sector, defining instead a boot manager as part of the UEFI specification. When a computer is powered on, the boot manager checks the boot configuration and, based on its settings, loads and executes the specified operating system loader or operating system kernel. The boot configuration is a set of global-scope variables stored in NVRAM, including the boot variables that indicate the paths to operating system loaders or kernels, which as a component class of UEFI applications are stored as files on the firmware-accessible EFI system partition (ESP).
Operating system loaders can be automatically detected by a UEFI implementation, which enables easy booting from removable devices such as USB flash drives. This automated detection relies on a standardized file path to the operating system loader, with the path depending on the computer architecture. The format of the file path is defined as < EFI_SYSTEM_PARTITION >/BOOT/BOOT<MACHINE_TYPE_SHORT_NAME >.EFI; for example, the file path to the loader on an x86-64 system is /efi/BOOT/BOOTX64.EFI.
Booting UEFI systems from GPT-partitioned disks is commonly called UEFI-GPT booting. It is also common for a UEFI implementation to include a menu-based user interface to the boot manager, allowing the user to manually select the desired operating system (or system utility) from a list of available boot options.
4.3.6 Coreboot
The coreboot project began in the winter of 1999 in the Advanced Computing Laboratory at Los Alamos National Laboratory (LANL), with the goal of creating a BIOS that would start fast and handle errors intelligently. It is licensed under the terms of the GNU General Public License (GPL). Main contributors include LANL, SiS, AMD, Coresystems and Linux Networx, Inc, as well as motherboard vendors MSI, Gigabyte and Tyan, which offer coreboot alongside their standard BIOS or provide specifications of the hardware interfaces for some of their motherboards. However, Tyan seems to have ceased support of coreboot [citation needed]. Google partly sponsors the coreboot project. CME Group, a cluster of futures exchanges, began supporting the coreboot project in 2009.
Coreboot has been accepted in seven consecutive years (2007–14) for the Google Summer of Code. Other than the first three models, all Chromebooks run Coreboot. Code from Das U-Boot has been assimilated to enable support for processors based on the ARM instruction set.
Coreboot typically loads a Linux kernel, but it can load any other stand-alone ELF executable, such as iPXE, gPXE, or Etherboot that can boot a Linux kernel over a network, or SeaBIOS that can load a Linux kernel, Microsoft Windows 2000 and later, and BSDs (previously, Windows 2000/XP and OpenBSD support was provided by ADLO). Coreboot can also load a kernel from any supported device, such as Myrinet, Quadrics, or SCI cluster interconnects. Booting other kernels directly is also possible, such as a Plan 9 kernel. Instead of loading a kernel directly, coreboot can pass control to a dedicated boot loader, such as a coreboot-capable version of GNU GRUB 2.
Coreboot is written primarily in C, with a small amount of assembly code. Choosing C as the primary programming language enabled easier code audits, which result in improved security. The source code is released under the GNU GPL version 2 license.
Coreboot performs the absolute minimal amount of hardware initialization and then passes control to the operating system. As a result, there is no coreboot code running once the operating system has taken control; in particular, system management mode (SMM) is not activated. A feature of coreboot is that the x86 version runs in 32-bit mode after executing only ten instructions (almost all other x86 BIOSes run exclusively in 16-bit mode). This is similar to the modern UEFI firmware, which is used on newer PC hardware.
By itself, coreboot does not provide BIOS call services. The SeaBIOS payload can be used to provide BIOS calls and thus allow coreboot to load operating systems that require those services, such as Windows 2000/XP/Vista/7 and BSDs. However, most modern operating systems access hardware in another manner and only use BIOS calls during early initialization and as a fallback mechanism.
4.3.7 Trusted platform module
The Trusted Platform Module offers facilities for the secure generation of cryptographic keys, and limitation of their use, in addition to a random number generator. It also includes capabilities such as remote attestation and sealed storage.
Remote attestation creates a nearly unforgeable hash-key summary of the hardware and software configuration. The program encrypting the data determines the extent of the summary of the software. This allows a third party to verify that the software has not been changed.
Binding encrypts data using the TPM endorsement key, a unique RSA key burned into the chip during its production, or another trusted key descended from it.
Sealing encrypts data in similar manner to binding, but in addition specifies a state in which the TPM must be in order for the data to be decrypted (unsealed).
Software can use a Trusted Platform Module to authenticate hardware devices. Since each TPM chip has a unique and secret RSA key burned in as it is produced, it is capable of performing platform authentication and as such is a key part of secure boot.
Generally, pushing the security down to the hardware level in conjunction with software provides more protection than a software-only solution. However even where a TPM is used, a key would still be vulnerable while a software application that has obtained it from the TPM is using it to perform encryption/decryption operations, as has been illustrated in the case of a cold boot attack. This problem is eliminated if key(s) used in the TPM are not accessible on a bus or to external programs and all encryption/decryption is done in the TPM.
4.3.8 Platform integrity
The primary scope of a TPM (in combination with other TCG implementations) is to assure the integrity of a platform. In this context “integrity” means “behave as intended” and a “platform” is generically any computer platform—not limited to PCs or just Windows: Start the power-on boot process from a trusted condition and extend this trust until the OS has fully booted and applications are running.
Together with the BIOS, the TPM forms a Root of Trust: The TPM contains several platform configuration registers (PCR) that allow a secure storage and reporting of security relevant metrics. These metrics can be used to detect changes to previous configurations and derive decisions how to proceed. A good example can be found in Microsoft's BitLocker Drive Encryption (see below).
The BIOS and the OS have the primary responsibility to utilize the TPM to assure platform integrity. Only then can applications and users running on that platform rely on its security characteristics such as secure I/O “what you see is what you get,” uncompromised keyboard entries, memory and storage operations.
Disk encryption
Full disk encryption applications, such as TrueCrypt, SecureDoc, the dm-crypt feature of modern Linux kernels, and the BitLocker Drive Encryption feature of some Windows operating systems, can use this technology to protect the keys used to encrypt the computer's hard disks and provide integrity authentication for a trusted boot pathway (e.g., BIOS, boot sector, etc.). A number of third-party full disk encryption products also support the TPM chip.
Password protection
Access to keys, data or systems is often protected and requires authentication by presenting a password. If the authentication mechanism is implemented in software only, the access typically is prone to “dictionary attacks.” Since the TPM is implemented in a dedicated hardware module, a dictionary attack prevention mechanism was built-in, which effectively prevents guessing or automated dictionary attacks, while still allowing the user a sufficient and reasonable number of tries. With this hardware based dictionary attack prevention, the user can opt for shorter or weaker passwords which are more memorable. Without this level of protection, only passwords with high complexity would provide sufficient protection.