
1
Introducing SAFe® and DevOps
Developing products in many organizations—especially ones that work on software-based systems or complex systems involving both hardware and software and further enabled by networking technologies, known as cyber-physical systems—has changed over the past 10 to 20 years. Factors such as changes in technology, movement to geographically distributed or remote development, the push for faster time-to-market (TTM), understanding the customer needs, and pressures to reduce the occurrence and severity of production failures are opportunities, challenges, or a mixture of both that these organizations face.
To address these challenges and take advantage of the opportunities, mindsets derived from Lean manufacturing began to emerge and evolve. These mindsets, combined with practices from emerging frameworks, began to allow organizations to move past the challenges and improve business outcomes.
In this chapter, we’re going to highlight the historical challenges and popular mindsets and approaches that have allowed many organizations to overcome these obstacles. These challenges, approaches, and frameworks are described in the following topics:
- Challenges organizations face in product development
- An introduction to Agile
- An introduction to DevOps
- Scaling DevOps with SAFe®
Challenges organizations face in product development
Product development today is enabled by a marriage of technology and society. Every product is a combination of hardware and software that is further enhanced by a connection to the internet. New product enhancements are only a software release away. We truly live in the age of software and digital.
It is against this backdrop that we look at challenges in product development and find that not only have these challenges not changed but the challenges also grow even more daunting thanks to the reliance on technology and software. Some of these classic challenges are presented here:
- TTM pressures
- Understanding customer wants
- Security and compliance
- Ensuring quality
- Competition
These challenges don’t appear in isolation. Sometimes several challenges appear, or they appear all at once. Let’s examine how these challenges, alone or together, impede product development.
TTM pressures
TTM is the measure of the length of time it takes for a new product or new product feature to launch from an initial idea. It is usually seen as a measure of how innovative a company is.
A growing trend is that the length of TTM has decreased in recent years. Advances in technology have increased the pace of innovation. This increased pace of innovation has forced product development cycles to decrease from yearly cycles to 6-month or quarterly cycles. This trend will continue to happen and will force organizations to consider whether they can deliver features more frequently.
Understanding customer wants
Henry Ford is quoted as saying, “If I had asked people what they wanted, they would have said faster horses.” It often seems as if that statement is true today. Often, in the beginning, customers have no idea which features they want with a product. If a product requires long development cycles, the customer preferences may change, often to the point that what ultimately gets delivered is not what the customer needs or wants.
Often, what spurs a change in customer wants or requirements could be features offered by similar products provided by competitors. The added pressure from competitors provides a challenge: understand the desires of your customer and release a product or feature that meets those desires before your competition does.
Security and compliance
One challenge that organizations face doesn’t come from the marketplace. Products using software face growing threats from hackers and other bad actors that seek to take advantage of vulnerabilities in the software. Damages, if they are able to exploit these vulnerabilities, range from reputation to money in the form of ransomware payment or litigation.
In addition, because of the threats of these bad actors, regulations intended to ensure privacy and security have been enacted. Products may have to comply with region-specific (for example, the General Data Protection Regulation (GDPR)) or industry-specific (for example, the Health Insurance Portability and Accountability Act (HIPAA)) regulatory standards so that a customer’s confidential data is not exposed.
Ensuring quality
One thing that is important for organizations is maintaining quality while doing product development. Organizations that do not apply rigor in ensuring that products are developed with built-in quality soon find themselves open to other challenges. Rework means longer lead times and delays in bringing products to market. Customer experience with buggy software or a low-quality product may drive them to competitors’ products. Inadequate attention to quality may also allow security vulnerabilities to go unnoticed, allowing exploits to occur.
Vigilance toward maintaining quality during product development is ideally done by creating, setting up, and executing tests at all levels throughout development. Testing could even be done in pre-production and production environments and automated as much as possible. An approval/inspection-based approach only defers the discovery of problems until it may be too late or too costly to fix them.
Competition
Some of the challenges previously mentioned talked about the part that competition plays. The truth of the matter is that your competitors face the same challenges that you do. If your competition has found a way to master these challenges, they have a distinct advantage in the market.
But it’s important to remember that this race isn’t about being first. The challenge is to be first with the product or feature and be able to convey why this lines up with customer desires. A famous example comes from Apple. Apple was a couple of years behind other competitors in the marketplace for digital music players when it released the iPod. What made the iPod a runaway product sensation was the marketing that touted the memory size not in terms of megabytes (MB), but in terms of the number of songs. This simple message connected with the marketplace, beyond technology aficionados and music diehards, to even casual music listeners.
The incredibly successful launch of the iPod drove Apple on a path of innovation that catapulted it to its current place as one of several technology giants. The makers of the first commercial MPEG-1 Audio Layer 3 (MP3) player no longer provide support for their product.
Meeting the challenges
These challenges have plagued product development since the early history of man. The exact form of challenge, however, changes with every generation and with every shift in technology.
TTM cycles will always drive when to release products; however, with the aid of technology, these cycles are shrinking. A customer’s requirements may always remain a mystery, often even to the customer. Competition changes will ebb and flow, with the emergence of new disruptors and the disappearance of the also-rans.
As these ever-present challenges take on new forms, those organizations that have mastered these challenges do so through new mindsets and practices revolving around three areas: people, process, and technology.
A focus on people involves looking at the mindset, values, and principles that people hold in common to form an organizational culture. This culture is the most important counterpoint to challenges because it informs everybody on how they will meet these challenges.
With the culture established, a focus on the process implements practices that are modeled on the right mindset, values, and principles. Successful application of the practices promotes a feedback loop, encouraging the culture and reinforcing the mindset, values, and principles.
Finally, tools aid the process. They allow practices to be repeatable and automatic, strengthening the process, and allowing the application of the process to be successful.
The remainder of this book will highlight the combination of people, processes, and tools that have helped organizations meet these challenges seen in modern product development. These combinations are set up as frameworks, meant to be flexible enough to apply to different organizations in different industries. These combinations started with software development but warrant a look as the creation of software is prevalent in every organization today.
We begin our examination with a look at Agile development or the transition from large-scale delivery of software to incremental delivery of software in short design cycles.
An introduction to Agile
To understand the context in which these challenges lie, it is important to understand the dominant product development process, known colloquially as Waterfall. Waterfall was used for many years to develop cathedrals and rocket ships, but when the process was used for developing software, the strains of it were beginning to show, highlighting inadequacies against the challenges of meeting a shrinking TTM and satisfying customer needs. Something had to be done.
Next, let’s look at the emergence of Agile methods from the initial attempts to incorporate Lean thinking into software development, to the creation of the Agile Manifesto and the emergence of Agile practices and frameworks.
The rise and fall of Waterfall
The method known as Waterfall had its origins in traditional product development. Workers would divide up the work into specific phases, not moving to the next phase until the current phase was completed.
In 1970, Winston W. Royce first proposed a diagram and model for this method when product development moved to software, as depicted here:

Figure 1.1 – Waterfall diagram
Although Royce never advocated this approach and actually preferred a more incremental approach to development, his diagram caught on and many in the industry called the approach Waterfall because the arrows from one phase to the next resembled waterfalls.
In software development, this approach began to exhibit drawbacks. If a requirement, problem, or constraint appeared in the latter phases, the additional work drove the process backward, requiring an enormous amount of rework. Many times, the end customer would not have ideas on requirements early on, leading to rework or a final product that failed to meet customer expectations.
The delays introduced by rework also put pressure on fixed-time projects. To meet the deadlines, some of the later phases (often testing) would be curtailed or eliminated to deliver a product. With the lack of testing, errors or bugs would remain undiscovered until the product was released, resulting in low-quality software and low customer value.
TTM pressures on product development cycles reduced the time available to create new software or update existing software. The model was falling apart, but what could be done differently?
The emergence of Agile
In the early 21st century, other methods such as Extreme Programming (XP), Scrum, and Crystal began to emerge. These methods advocated incremental delivery, where a bit of the intended functionality would go through all stages (requirements, design, coding, and testing) in small design cycles, often no longer than a month. At the end of each design cycle, teams would solicit customer feedback, often incorporating that feedback into the next design cycle.
A representation of incremental delivery, containing short design cycles and delivery of packages of value, is shown in the following diagram:

Figure 1.2 – Incremental (Agile) development diagram
Between February 11 and 13, 2001, a group of software development experts, some of whom created XP, Scrum, and the Crystal method met in Snowbird, Utah to ponder which alternatives existed. What resulted from this weekend was a manifesto for Agile software development, simply called the Agile Manifesto: agilemanifesto.org.
The Agile Manifesto contains a set of values and a list of principles, but it must be noted that the authors of the manifesto talk about the values as a set of preferences. It is possible for Agile teams to have processes, tools, documentation, contracts, and plans. It’s only when those items interfere with the items on the left half of each statement of value that the team should re-evaluate the process, tool, or contract, and plan and adjust.
The value set shows what is important, stating the following:
We are uncovering better ways of developing software by doing it and helping others do it. Through this work we have come to value:
- Individuals and interactions over processes and tools
- Working software over comprehensive documentation
- Customer collaboration over contract negotiation
- Responding to change over following a plan
That is, while there is value in the items on the right, we value the items on the left more.
The 12 principles of the Agile Manifesto elaborate and provide context to these values, stating the following:
- Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
- Welcome changing requirements, even late in development. Agile processes harness change for the customer’s competitive advantage.
- Deliver working software frequently, from a couple of weeks to a couple of months, with a preference for a shorter timescale.
- Business people and developers must work together daily throughout the project.
- Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done.
- The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.
- Working software is the primary measure of progress.
- Agile processes promote sustainable development. The sponsors, developers, and users should be able to maintain a constant pace indefinitely.
- Continuous attention to technical excellence and good design enhances agility.
- Simplicity—the art of maximizing the amount of work not done—is essential.
- The best architectures, requirements, and designs emerge from self-organizing teams.
- At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behavior accordingly.
The addition of Lean
Around the same time, others were looking at other ways of developing software with shorter TTM. They looked at applying principles from Lean manufacturing.
Lean manufacturing looks to apply practices to reduce waste. The methods were invented by Taiichi Ohno and used to create the Toyota Production System (TPS). Along with the removal of waste, Lean manufacturing looks to build in quality and strive for Kaizen, or continuous improvement.
The application of the principles found in Lean manufacturing was used by Mary and Tom Poppendieck to describe Lean software development in their book, Lean Software Development: An Agile Toolkit. These principles are summarized as follows:
- Removing waste
- Emphasizing feedback and learning
- Waiting until the last possible moment for decisions
- Frequently delivering
- Making sure the team is empowered
- Meeting users’ perceptions and expectations
- Employing systemic thinking
In addition to the work by the Poppendiecks, David J. Anderson adapted Kanban, another tool from the TPS for software development at Microsoft. This adaptation of Kanban was modified as a framework of practices suitable for software development. Kanban soon rose in popularity not only as an alternative to Scrum or XP—many of the practices are used in conjunction with Scrum or XP to facilitate the execution of tasks.
Software development teams did see that the change to Agile development was producing results and overcoming challenges in product development, but the results were only seen in development and not in the overall organization. Clearly, changes needed to be made in other parts of the organization. Let’s examine the changes that development and operations made together in the DevOps movement.
An introduction to DevOps
As development teams began to adopt Agile methods and deliver software features incrementally, they faced a challenge in delivering value from the outside. Operations teams, the ones that maintain the development and production platforms where code executes, often do not release new packages from the development teams as they emerge. Rather, operations teams insist on collecting features and deploying them in specified release windows to minimize the risk that a single new change would bring down the production environment. But instead of minimizing the risk, it compounds the risk by straining the time allowed for the release windows, with mismatched configurations between development and production environments and untracked manual intervention in production environments. Bundling releases into release packages also moved delivery away from small increments to larger monoliths that may diminish customer value.
At this point, it becomes necessary to view the perspective of a typical operations team. Its job is to ensure that the organization’s production environment, the one that may be producing an organization’s revenue, is as operational as possible. Any change to that environment, even ones for new features, is seen as a risk to that stability.
In 2009, John Allspaw and Paul Hammond gave a talk titled 10+ Deploys per Day: Dev and Ops Cooperation at Flickr during the O’Reilly Velocity conference. In this talk, they outlined the methods they used to get an unheard-of 10 deployments a day. These methods still form the basic pillars of development-operations (DevOps) today. We will talk about the incorporation of the following:
- Tools and technology
- People and process
DevOps tools and technology
During the talk, Allspaw and Hammond identified technologies and what they did with them to align both the development and operations teams. But not only were the tools noteworthy—it was also how the teams used the tools together in a collaborative way.
These technologies included the following:
- Automated infrastructure
- Common version control
- One-button builds/deployment
- Feature flags
- Shared metrics
- Instant messaging (IM) robots on shared channels
The use of tools and technologies continues to play a key role in DevOps today. We’ll explore how these tools enabled a quick release process into production and quick resolutions if problems happened in production.
Automated infrastructure
As software became more complex, the environments to execute them became more complex as well. Operations teams were faced with configuring servers that grew over time from tens to hundreds or thousands. The task required automation. Configuration management (CM) tools such as Chef and Puppet began to emerge.
CM allowed operations teams to standardize environmental configurations such as versions of an operating system, software applications, and code libraries. It allowed them to easily find those machines that did not have the standard configuration and correct them. As servers moved from physical hardware to virtual machines (VMs), CM allowed for the creation and maintenance of standard images that were differentiated by what role they played in the server environment.
CM also helps developers. Automated CM can make every server provisioned uniform between the multiple environments an organization has for software development and release. Consistency between development, staging, and production environments eliminated a problem colloquially known as “works on my machine” where even subtle differences between development, testing, and production environments led to the possibility that code would work on development but would fail in production.
Common version control
A version control systems (VCS) such as Git are is a popular tool in software development for managing source code. With version control, developers can make changes to source code on a private sandbox called a branch. When ready to share source code changes, developers can merge their changes back to the main branch of the source code repository, making sure those changes do not conflict with other changes from other developers. The VCS records all changes that happen to the source code, including those from other branches. Because the version control contains a comprehensive history of the source code’s evolution, it is possible to find a version of the source code from a specific point in time.
Soon, version control became important for storing more than source code. Testing tools required test scripts and test data that could be version-controlled as the tests changed. CM tools used text files to define ideal configurations for servers and VMs. Operations could also have scripts that would perform the configuration tasks automatically. All these could be version-controlled to record the evolution of the environment.
Making sure that both development and operations were not only using version control but using the same version control tool became important. Having all versions of the artifacts (code, tests, configuration files, scripting, and so on) developed allowed for an easy understanding of which version of which artifact was used in a release using tags or labels. A common version control tool ensured that one side (development or operations) was not denied access to view this understanding if a problem occurred.
One-button builds/deployment
Building a release from source code could be a time-intensive task for developers. They would have to pull their changes from version control, add in the required code libraries, compile the changes together into a build package, and upload that build package into an environment to test whether the changes worked. A smart developer would often automate these tasks by setting up build scripts, but could this process be easier?
Continuous integration (CI) tools such as Hudson (later named Jenkins) emerged that allowed developers to go through all the steps of a build process and execute build scripts by just pushing a button. A page could easily show not only build success but if a build failure occurred, it could also show in which step of the process that failure occurred. Automating the build through CI also made sure that the build process between developers was consistent by ensuring that all steps were followed and a step was not omitted.
Could that same consistency be applied to operations teams when they deployed releases? Continuous deployment (CD) tools take a build package and run tests against it in the current level environment, and if they pass, apply it to a specific environment. These tools can also connect with CM tools to create instances of the environment with the new build package “on the fly.” Any new deployment would be recorded showing who pushed the button, when it was pushed, and which artifacts and artifact changes were deployed to a particular environment.
Can a tool used for CI also be used for CD? This is a common way of implementing the same automation that can be used by both development and operations.
Feature flags
Flickr, the company Allspaw and Hammond worked for, was a photo-sharing and rating website. Its software differed from traditional desktop-based software because it was concerned with supporting only one release: the release on its production environment. The company did not have to worry about supporting multiple versions of the released software. This allowed it to have the main branch of its version code repository as the specific version it would support and examine if problems arose.
To handle problems introduced by buggy new features, it set up conditional branches in code called feature flags. Based on the value of a variable, the code for a new feature would be visible or invisible. The feature flag acts as an on-off switch, indicating which code is released, and thus visible, as illustrated in the following diagram:

Figure 1.3 – Illustration of a feature flag
Having feature flags in the code allowed for deployments to production environments to be more flexible. Newly deployed code could be present in production but not be seen until thoroughly tested. “Dark launches” could result from this where operations could evaluate the performance of the new feature with the existing software against production data and load. Test customers could evaluate new features in a subset of the production environment where those feature flags were activated. Finally, the behavior of the environment could be quickly changed by changing the value of the feature flag(s), propagating the change through CI and CD, and allowing the change in production. This method of recovery is called roll-forward or fix-forward.
Shared metrics
To ensure stability, operations collects the performance of every environment and reviews the metrics such data collection produces. These metrics can be displayed as specific views on a dashboard. Dashboard views not only give an indication of performance now but also allow operations to identify trends and take corrective action.
Flickr made these dashboards not only for operations but also for developers as well. Developers could see the performance of the application in the context of the environment. Allowing developers access to this contextual data ensured they could see the effects of their new features and whether those features provided value.
Shared metrics also allowed for adaptive feedback loops to occur in the environment. The performance metric could be evaluated by the application, and the evaluation could generate a notification that additional resources would be required.
IM robots on shared channels
Communication between development and operations was paramount. The use of standard email was discouraged in favor of instant messaging and chat mechanisms that allowed for ongoing real-time communications of the systems between development and operations. Notifications about development events such as build status and operations events—for example, deployment status, system alerts, and monitoring messages—could be inserted into the channel by chat robots to give both development and operations personnel notice of specific events that occurred. Chats could also be searchable to provide a timeline of events for troubleshooting when problems arose.
DevOps people and processes
It’s worth noting that other organizations besides Flickr were using the same tools and technologies. What made a difference to Flickr was how the people from distinct groups worked together in shared processes to leverage the tools and technologies. These people and processes formed an organizational culture that allowed them to deploy rapidly.
Allspaw and Hammond made note of specific touchpoints during the talk. These included the following:
- Respect
- Trust
- Learning from failure
- No “fingerpointing”
Having these touchpoints form that organizational culture was just as important as the application of tools and technology.
Respect
It was important that people from different groups within Flickr operated from a place of respect. That respect meant moving past stereotypes about developers or operations people and looking at common goals.
The respect extended to other people’s expertise, opinions, and recommendations. There’s a fundamental understanding that different people have different backgrounds and experiences that shape their opinions and responsibilities. A key part of problem-solving is to listen to those different perspectives that may give different and better solutions to a problem. Understanding the differing responsibilities allows you to understand another person’s perspective.
Another important extension of that respect that Allspaw and Hammond highlighted was not just giving a response but understanding the reasons and motivations others would have for solving these problems. It’s not enough to answer a question—you should also understand why the question is being asked before giving an answer. Allowing everyone to understand the context allows the group to create unique solutions to problems.
To have this respect shown, there must be transparency. Hiding information between groups does not allow for the free exchange required to create innovative solutions to problems. Also, at some point, whatever you hide will be found out, creating conflict.
An important part of respect is empathy. Knowing what effects to operations there may be from a code change is important before having that discussion with operations personnel. This allows room for any hidden assumptions to be unearthed and for creative solutions to flow.
Trust
Armed with transparency and empathy to build respect, people from one group need to trust the other groups. If a development person has that understanding of what impact to operations their feature will have, it is then incumbent on them to have that conversation with operations personnel to confirm those impacts or at least make them aware of potential impacts.
Conversely, operations people need to have developers involved to discuss together what effects any infrastructure changes will have on current or future features.
Ultimately, this comes to an understanding that everyone should trust that everyone else is doing their best for the good of the business.
Examples of the manifestation of trust are not only the sharing of data through version control, IM chat mechanisms, and metrics/dashboards, but also lie in the construction of shared runbooks and escalation plans that are created when readying a new release. The construction of these plans allows discussion to flow on risks, impacts, and responsibilities.
Finally, including mechanisms to allow the other group to operate is an important part of leveraging that trust. For developers, that meant setting up controls in software for operations people to manipulate. For operations people, that meant allowing appropriate access to the production environment so that developers could directly see the effects new changes had in the production environment.
Learning from failure
Failures will happen. How an organization deals with that failure is the difference between a successful organization and an organization that will not remain operational for long. Successful organizations focus more on how to respond to failures, foreseen and unforeseen, more than expending energy to prevent the next failure.
Preparation for responding to failure is a responsibility that falls on everyone. Each person, developer, or operations team member must know how they would react in an emergency. Ways of practicing emergencies include having junior employees “shadow” senior employees to see how they would react. At Flickr, those junior employees were put in the same “what-if” scenario as the exact outage occurred to see which solutions they could develop.
No “fingerpointing”
At Flickr, they discovered that when people were afraid of getting blamed for production failures, the first reaction would be to try to individually fix the problem, find who to blame, or conceal the evidence. That always led to a delay in finding a solution to the problem. They instituted a no fngerpointing rule.
The results were dramatic. Resolution times to fix problems rapidly decreased. The focus then shifted from who caused the problem to what the solution was.
The DevOps movement begins
The response to Allspaw and Hammond’s talk was swift and impactful. People started to look at ways to better align development and operations. Patrick Debois, having missed the O’Reilly Velocity conference where Allspaw and Hammond gave their talk, organized the first DevOpsDays conference in Ghent, Belgium to keep the conversation happening. The conversation continues and has become a movement through successive DevOpsDays conferences, messages on Twitter highlighted with “#DevOps,” blogs, and meetups.
The response drives the creation of new tools for version control, change management, CI, CD, CM, automated testing, and artifact management. Technology evolves from VMs to containers to reduce the differences between development, test, staging, and production environments.
The DevOps movement continues to grow. As with the adoption of Agile, DevOps is open to all and decentralized. There is no one way to “do DevOps.” DevOps can be applied to environments of any type such as legacy mainframes, physical hardware, cloud environments, containers, and Kubernetes clusters. DevOps works in any industry, whether finance, manufacturing, or aerospace.
Since the original talk by Allspaw and Hammond, organizations that have adopted DevOps principles and practices have seen incredible gains in deployment frequency, while also being able to reduce the probability of production failures and recovery times when an errant production failure does occur. According to the 2021 State of DevOps report, “elite” organizations can release on-demand, which may happen multiple times a day. This is 973 times more frequent than organizations rated as “low.” Elite organizations are also a third less likely to release failures and are 6,570 times faster at recovering from a failure should it occur.
Some organizations are medium-to-large-sized companies working in industries such as finance, aerospace, manufacturing, and insurance. The products they create may be systems of systems of systems. They may not know how to incorporate Agile and DevOps approaches. For these companies, one framework to consider is the Scaled Agile Framework® (SAFe®).
Scaling DevOps with SAFe®
SAFe® is one of the more popular adopted platforms used to incorporate the Agile mindset and practices according to recent State of Agile surveys, taken annually. As stated on scaledagileframework.com by Scaled Agile Inc, the creator and maintainer of SAFe®, the framework is “a knowledge base of proven integrated principles, practices, and competencies for achieving business agility using Lean, Agile, and DevOps.”
Organizations can choose to operate in one of four SAFe® configurations. Almost all organizations start with a foundational configuration called Essential SAFe. In Essential SAFe, 5 to 12 teams—each comprised of a Scrum Master, Product Owner, and 3 to 9 additional team members—join together to form a team of teams called an Agile Release Train (ART). The ART works to develop a product or solution. Guiding the work on the ART are three special roles, as outlined here:
- Release Train Engineer (RTE): This is the Chief Scrum Master of the ART. The RTE acts to remove impediments, facilitate ART events, and ensure that the train is executing.
- Product Management (PM): PM is responsible for guiding the evolution of the product by creating and maintaining a product vision and guiding the creation of features that go in a prioritized program backlog.
- System Architect (SA): The SA maintains the architecture of the product by creating architectural work called enablers. They act as the focal point for teams on the ART in terms of balancing emergent design from the teams with the intentional architecture beginnings of the product.
The following diagram illustrates an ART and the roles within it:
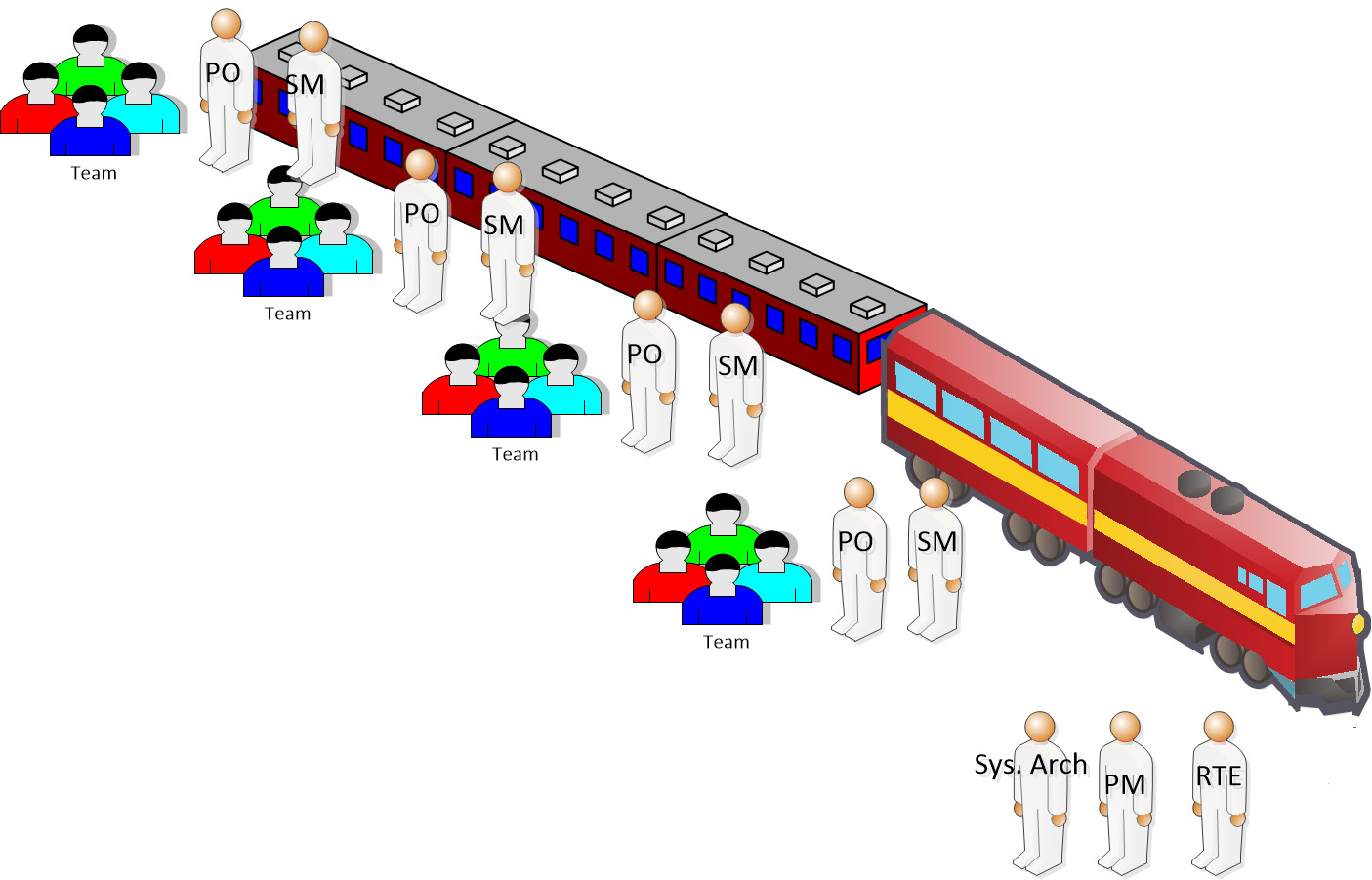
Figure 1.4 – An ART with main roles
Just as with stories, the work a team performs is timeboxed on a Scrum team, and the work of an ART is timeboxed as well. Features should be completed within a Program Increment (PI), which is a period of time between 8 to 12 weeks. The PI is a grouping of sprints where teams in the ART perform by breaking down features into stories and delivering those stories, sprint after sprint in the PI. You can see an illustration of this in the following diagram:

Figure 1.5 – A 10-week PI with five iterations (sprints)
It is against this backdrop of Essential SAFe and the ART that we apply DevOps. ARTs look at adopting the same practices that Allspaw and Hammond mentioned in their talk in 2009, as well as newer practices that have emerged since then. This book will cover the approach to DevOps as outlined in the SAFe. The aspects of this include the following:
- Modeling the DevOps approach using Culture, Automation, Lean Flow, Measurement, and Recovery (CALMR)
- Setting up and maintaining value streams
- Applying the CD pipeline against the value stream
- Including built-in quality and security in the process
Looking at CALMR
After Allspaw and Hammond’s talk, people tried to organize the practices mentioned and create a model that would exemplify the DevOps approach. During DevOpsDays 2010, John Willis and Damon Edwards coined a CAMS approach, where each letter signified a significant factor or pillar to DevOps. The letters, and the factors they represent, are set out here:
- (C)ulture
- (A)utomation
- (M)easurement
- (S)haring
Later, Jez Humble added an L, for Lean Flow, to evolve this to the CALMS approach.
Scaled Agile, realizing that the desired culture would have Sharing as a key component, removed the S from its model, and replaced it with an R, for Recovery. The CALMR model can be summarized as such:
- Culture: Create a culture of shared responsibility among all groups (development, operations, security, business, and others).
- Automation: Leverage automation as much as you can on your Continuous Delivery Pipeline.
- Lean Flow: Work with small batch sizes, visualize all your work, and avoid too much Work in Progress (WIP).
- Measurement: Measure your flow, your quality, and your performance in all environments, and whether you are achieving value.
- Recovery: Create low-risk releases. Devote energy to preparing how to recover from failure.
Part 1: Approach – A Look at SAFe® and DevOps through CALMR will examine each factor of the CALMR approach and see how the teams and the entire ART use values, principles, and practices to implement these factors.
Mapping your value stream
Value streams are a concept from Lean manufacturing where you look at the holistic process of creating a product from initial conception to delivery. For a value stream, you evaluate the steps needed in the process and the people and resources involved at each step. Each step in the process has its lead time (time waiting before the step can begin) and its cycle time (time spent on each step).
The first part of organizing value streams is to identify the present state of the value stream. Each step—as well as the people, resources, and lead and cycle times—is determined to identify and map the entire value stream. After this identification, questions are raised on solutions that can be employed to reduce time through the Value Stream steps.
After the initial identification, the next step is to identify and amplify the feedback loops that each step may require. Metrics play a valuable part here to see whether the value stream, as realized by an ART, is executing its process, whether a solution under development has problems in any environment, and whether a solution is delivering its promised value.
At this point, taking the first step of value-stream identification and mapping and the second step of finding feedback for each step yields the third step of value-stream management. During the initial value-stream mapping exercise, a potential “future state” or optimized value stream may be identified. It’s up to the ART to make incremental changes to obtain this optimal value stream. Only by adopting an attitude of continuous learning and working toward continuous improvement can they do that.
Part 2: Implement – Moving towards Value Streams dives into the three ways of doing value-stream management, modeled after the Three Ways identified in The Phoenix Project. We will examine the steps to identify a value stream and map an initial and potential future value stream. We will see how metrics form feedback loops for steps in the value stream. Finally, we will evaluate tools and techniques from Lean thinking to improve the value stream in the context of Continuous Improvement.
Running your value stream through the Continuous Delivery Pipeline
A Continuous Delivery Pipeline is the implementation of the value stream for an ART. It marries the people and their functions, with the process of delivering products from initial concept to release, and includes the tools to automate tasks, mostly in the form of a CI/CD pipeline. In SAFe, the Continuous Delivery Pipeline is divided up into four aspects. Each aspect is run concurrently by members of the ART throughout each PI, as illustrated in the following diagram:

Figure 1.6 – The Continuous Delivery Pipeline
The first phase is Continuous Exploration (CE). In this phase, PM works with customers, stakeholders, UX, the SA, and other groups such as compliance and security to determine upcoming features based on hypotheses of benefits to the customer that will show real value. These features are examined to determine feasibility and what, if any, changes to the architecture are required to meet Non-Functional Requirements (NFRs) such as security, reliability, performance, and compliance. After this definition and refinement, the feature is placed in the Program Backlog and prioritized for inclusion in an upcoming PI.
During the execution of a PI, development teams will incorporate the second phase of the Continuous Delivery Pipeline: CI. Once code changes have entered version control, the CI/CD pipeline comes into play. The pipeline may run several layers of testing, including linting to examine code quality and unit testing to examine proper functionality. If the tests pass, the code changes may be merged into a higher-level branch and a package created. That package may undergo additional testing to validate the correct behavior of the system. Passing that testing, the package that includes changes may be deployed—automatically, if possible—into a staging environment that resembles production.
Depending on the organization, the third stage, CD, may be automated and take over. Deployment of the package created in the CI phase may be performed automatically in the production environment. Feature flags may prevent changes from being released as testing continues to ensure the changes will work with existing functionality and in the production environment. Measurements continue to be taken in the production environment by continuous monitoring to verify proper operation and response to problems in production happen here.
Finally, in the fourth phase, Release on Demand, the new feature is enabled, allowing customers to take advantage of the changes. The production environment continues to be monitored for adverse effects, and the ART continues to respond to any deployment failures that happen. Measurement here includes the evaluation of leading indicator metrics to evaluate the amount of value truly delivered by the new feature and whether the initial hypothesis is true or false. Finally, the ART reflects and applies lessons learned to improve both the Continuous Delivery Pipeline, and the value stream.
We will examine all four stages of the Continuous Delivery Pipeline in Part 3: Optimize – Enabling a Continuous Delivery Pipeline. We will examine the people and processes that happen with CE. We will investigate the tools and technologies that make up CI and CD. Finally, we will see how Release on Demand closes the loop for our ART in delivering value to our customers.
Including security in the process
There is a growing realization that collaborating with and involving other groups in the organization can improve product quality and speed up product development. One such group collaborating with development and operations is security.
DevSecOps is a growing trend in DevOps circles where information security practices are folded in throughout the continuous delivery process. In SAFe, we include the information security practices espoused by DevSecOps so that security is not considered an afterthought.
Throughout Parts 1 to 3, you will see where security has active involvement and where continuous testing is performed so that solutions comply with any approvals that are mandated at the end of development. These secure solutions have long been incorporated into product design, development, and deployment.
Summary
In this chapter, we looked at the problems many organizations face when developing products today. We saw how the modern pressures of faster TTM, changing requirements and unknown customer desires, and problems in production deployments wear out both the development and operations groups. We also looked at the responses that development and operations groups have created.
Development began to look at incorporating an Agile mindset to allow for quick, frequent releases of small increments of value that would allow customer feedback to drive the next development increment. This outlook required an examination of values and principles to change the mindset as well as the incorporation of Lean thinking from the manufacturing world.
As development began to reap the benefits of the change to an Agile mindset and incorporate Agile practices, the bottlenecks for the release of new products and new functionality fell to operations—those that maintained the existing production environment. A new way of working together, the DevOps movement, sought to tear down the walls of confusion between development and operations through the application of tools and technology and by setting up a culture based on respect, trust, empathy, and transparency.
One approach that incorporates DevOps principles and practices in development is SAFe. DevOps using SAFe is employed for a team of teams or an ART. The ART embraces DevOps by adopting the CALMR model. The team identifies the way it works and maps that as a value stream. Finally, it employs a Continuous Delivery Pipeline to deliver its work to production, measure its worth, and improve the value stream.
In our next chapter, we will begin our examination of the CALMR approach by looking at the first and most key factor: culture.
Questions
Test your knowledge of the concepts in this chapter by answering these questions.
- What does the M stand for in CALMR?
- Monitoring
- Multitasking
- Measurement
- Mission
- Which are phases in the Continuous Delivery Pipeline (pick two)?
- Continuous Improvement
- Release on Time
- Continuous Exploration
- Release on Demand
- Continuous Delivery
- What kind of culture is important in CALMR?
- Independent
- Shared responsibility
- Bureaucratic
- Open
- What has been the traditional focus for operations?
- Revenue
- Stability
- Velocity
- Compliance
- Which term describes incorporating information security practices in CD?
- SecureOps
- DevSecurity
- DevSecOps
- OpSec
Further reading
For more information, refer to the following resources:
- https://leadinganswers.typepad.com/leading_answers/files/original_waterfall_paper_winston_royce.pdf—The original paper by Winston W. Royce diagramming what has come to be known as the Waterfall method. Note that in the paper, he advocates alternate paths to allow for additional testing and customer feedback.
- https://agilemanifesto.org—Manifesto for Agile Software Development, or quite simply, the Agile Manifesto.
- Lean Software Development: An Agile Toolkit by Mary Poppendieck and Tom Poppendieck.
- Kanban: Successful Evolutionary Change for Your Technology Business by David J. Anderson.
- https://www.youtube.com/watch?v=LdOe18KhtT4—A recording of the 10+ Deploys Per Day: Dev and Ops Cooperation at Flickr talk given by John Allspaw and Paul Hammond at the 2009 O’Reilly Velocity conference that ushered in the DevOps movement.
- https://cloud.google.com/blog/products/devops-sre/announcing-dora-2021-accelerate-state-of-devops-report—Findings from the 2021 Accelerate State of DevOps report.