
5
Unpicking Solution Architecture Troubles
This chapter, the longest in the book, will cover anti-patterns related to your solution architecture. We will start by looking at anti-patterns related to your choice of solutions. Then, we will look at things that can go wrong when you do functional design. Third, we will look at some particular anti-patterns that affect customizations, first at the conceptual level and then at the code level. We will end the chapter by summarizing the key takeaways.
In this chapter, we’re going to cover the following main topics:
- How to avoid picking the wrong solutioning approach by basing it on bad research and analysis
- Why your assumptions can lead you astray and make your architecture and design go off the rails
- What can go wrong when you apply good features in a bad way and how to use good governance to overcome this problem
- How classic code anti-patterns also find their way into Salesforce implementations and how you can design your code with better structure and patterns
After completing this chapter, you will have a good idea about how to avoid common anti-patterns when designing solutions on Salesforce and what steps you can take to use the right solution for the right problem.
Picking the wrong thing
In this section, we will look at two anti-patterns related to picking the wrong solution based on considerations that are not technically relevant. We start by looking at what goes wrong when you ignore the wider ecosystem.
Ignoring the ecosystem
Example
SafeCo is a major insurance company that provides a variety of policies to the mass consumer market. It has a large customer service organization for which it is in the last stages of rolling out Salesforce Service Cloud to achieve a 360-degree view of customer inquiries.
Royce is a manager within SafeCo’s IT department and has been tangentially related to the Service Cloud project. However, now he has been tasked with leading a team that has been asked to find good answers to a number of new generic requirements that have come up during the project but were left out of the initial scope, as outlined here:
- First, SafeCo, on learning more about Salesforce, has decided that it needs its own backup solution in place as it doesn’t want to rely on the rather limited out-of-the-box offerings
- Second, while policy documents are generated by a line-of-business (LOB) system, stakeholders have identified a need for printing a number of standard letters for customers, which should be done directly from the Salesforce UI
- Finally, within the IT department, a number of people have asked whether they could have a project management tool on Salesforce as they think it would be a good platform for collaborating with business users
Royce starts by addressing the most pressing issue of backup. He’s generally aware that there are a number of solutions to this problem on AppExchange, but after having a brief look, he finds them too expensive and complicated. Besides, SafeCo already has a backup infrastructure in place for other systems. Royce gets a developer in the IT department to write a script to copy Salesforce objects 1:1 to a Structured Query Language (SQL) database by exporting them to CSV files and then using a standard batch process for the import. From there, the data can be backed up using the standard SafeCo backup solution.
Document generation is another area where Royce is aware that a number of third-party solutions exist. However, there is also some internal document generation capability in the corporate document management system (DMS), and that is where he starts looking. While the solution is not perfect, the DMS team can provide the capability by accepting the request for document generation via a web service, which puts the request in a queue that is regularly emptied by a batch job that generates documents and puts them in a file share. From there, another job picks them up and uploads them back into Salesforce. It’s a little slow and clunky, but it should be OK.
For the project management module, Royce has some good luck. Over a weekend, one of his team puts together a small app that seems to demonstrate a lot of the functionality SafeCo will need. He reckons that in a few weeks, he can develop something that will be good enough to roll out to the business. Royce takes the win and decides to go with it.
Royce now has his solutions, and he pushes his team hard to get them ready on time for the global service rollout. However, while nothing catastrophically fails, there are quite a few problems to contend with. The backup script works well, but when they test full and partial restores in both new and partial environments, they run into a massive and unexpected level of complexity. They abandon the business continuity (BC) test and make a plan to develop some more elaborate restore scripts at a later date.
As expected, there are some complaints about the slow speed of document generation, but the worse problem turns out to be template management, which Royce hadn’t considered in detail during his analysis. Turns out that templates change frequently, and with the new solution, all template changes have to be done by someone in the DMS team. That makes the customer service team quite irritated.
The project management app is rolled out without major problems, but the response is underwhelming. There are a number of bugs and misunderstandings, and in general, the team was expecting to see a number of features that haven’t been included. As a result, adoption across teams is lackluster.
Royce takes a breath. While everything sort of works, there are clearly a lot of issues. Royce wonders whether he might have missed something in the process, but it’s time to close the project and move on.
Problem
The problem addressed in Ignoring the ecosystem is how to handle common capabilities related to the main requirements of implementation, but not strictly part of the core requirements. These include common backup and restore, document management and generation, automation of the deployment pipeline, the dispatch of logs to a central log server, and a range of similar requirements.
For this type of requirement (and many others to boot), there exists on Salesforce AppExchange a large number of third-party solutions that solve the particular need in a generic way, as depicted in the following screenshot. In addition, many Salesforce consulting partners have standard approaches using accelerators or internal assets that can also help with this sort of requirement:

Figure 5.1 – AppExchange Top Categories section
With this anti-pattern, you ignore these options to the point of not even looking at them seriously.
Proposed solution
When you ignore the ecosystem, you actively disregard third-party options for generic requirements and instead move ahead with bespoke or in-house solutions to common capabilities. While there can be legitimate reasons for a bespoke answer to a generic requirement—for instance, if you have a highly developed infrastructure for some capability that you want to leverage across all enterprise systems—not making a reasoned comparison with the available commercial options is an anti-pattern and goes against the core philosophy of Salesforce.
That is to say, an anti-pattern arises when you do not make a considered build-versus-buy decision for important but generic capabilities and instead reflexively embrace an in-house approach, whether because of the “not invented here” syndrome or because it is cognitively easier to handle for your organization’s key stakeholders.
Again, that is not to say that a build approach is never valid for these capabilities. But in my experience, you are highly likely to underestimate the complexity and ongoing costs related to these kinds of builds and will probably end up with less functionality for more money than your business case said.
Results
The results of ignoring the ecosystem are generally quite predictable, although, at the detailed level, they will obviously vary by the capability under consideration. At a higher level of abstraction, however, they tend to be as follows:
- A less capable solution that meets fewer requirements than what you could have obtained for a similar cost in the ecosystem
- Fewer new features are added to the capability over time, often at higher maintenance costs than the run-rate cost of the third-party solution
- The need to maintain an additional skillset and knowledge base for the development and maintenance of the in-house capability
- A higher degree of coupling between the new capability and the existing system than if you had used a third-party solution
- The cost picture can be complicated, but it is rare that building a generic capability yourself results in a significant saving
All in all, the results are rarely catastrophic, but commonly, the resulting solutions are worse than third-party equivalents and are achieved with greater pain and risk.
Better solutions
There is just one general piece of advice to keep in mind to avoid this anti-pattern, although implementing it can be a challenge, and that is to make a considered and well-reasoned build-versus-buy decision whenever you are encountering relatively commonplace capability requests.
To do this, you should do the following:
- Carefully explore ecosystem alternatives, both on the AppExchange and things that are available directly from your Salesforce partners.
- Engage actively with vendors; often, they are more willing to consider your unique concerns than you might think.
- Outline the potential options in enough detail to make a reasoned decision, remembering to include architectural, operational, and commercial considerations.
- Count the Total Cost of Ownership (TCO) when outlining the internal options. Often, operational, maintenance, and further development costs are undercounted in these types of comparisons.
- Drive a hard commercial bargain with third-party vendors—you can often get quite significant discounts.
Having now looked at the consequences of ignoring the ecosystem, we will now proceed to consider the consequences of fitting your solution to your licenses, rather than your licenses to your solution.
License-based solutioning
Example
Alexis is the lead architect for a major Salesforce partner working directly with Salesforce on a deal for the Department of Social Welfare in the mid-sized European country, Ruritania. The department services millions of residents and has a staff of several thousand case workers spread approximately 50/50 between a central HQ and several hundred local offices. They are adopting Salesforce as a case management platform for a new high-profile initiative to help families hurt by the increasing cost of living.
As part of the deal, the Salesforce Account Executive (AE) pushed very hard for a licensing model that gave the HQ users a full Salesforce license, but only a Customer Community Plus license for the users in the local offices. He argued that as the local officers were technically members of the local municipalities, this would be acceptable under the Salesforce licensing terms and would give a more acceptable license cost for the client.
The implication, as Alexis is quick to point out, is that case workers will be working in two different interfaces, one internal and one external, based on a community. However, the AE argues that the differences are minor and that most of the work done for the internal interface can be replicated directly in the community.
While that is generally true, as work continues, many subtle differences start to make an impact. There are differences in what Customer Community Plus users can have access to within the system and also differences in which things can be exposed on a Lightning page versus a Community page and how this can be done.
This situation forces increasing amounts of functionality into custom code, especially into a collection of small Lightning Web Components (LWCs) to accommodate the two interfaces. Furthermore, all test cases need to be written and executed twice, once for each interface, adding considerable overhead.
When it comes to rolling out the application, they also need to create two versions of the documentation, the training materials, and the actual user training. Alexis also flags that her company will need to increase the application maintenance fee as there is a lot more customization to maintain and many future changes will need to be done in two versions.
The users are generally happy with the new application, but there are a lot of communication errors and mistakes caused by the differences in the interface between the local offices and the HQ. The financial director within the Department of Social Welfare is also unhappy with the increase in implementation cost and application maintenance he has seen, which he does not feel are fully compensated by the lower license cost.
Problem
The problem addressed by license-based solutioning is an old chestnut. How do we deliver all the required functionality within the cost envelope we’ve been given? If you’ve never had to struggle with fitting user demands to a budget that is just too small for the level of ambition, I want to know where you work so I can apply.
It is nearly universally true that stakeholders would like more features than they have money to buy. One way to try to get around this is to try to carefully optimize the licenses you buy in order to get the best value for money. This is called license optimization and is an essential skillset on the Salesforce platform. You can see an overview of the Salesforce license model in the following diagram:
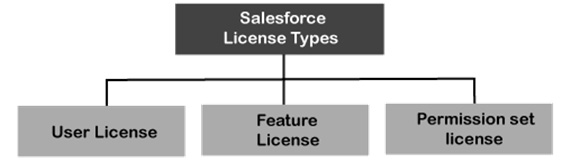
Figure 5.2 – Salesforce license model
License-based solutioning turns this commendable practice into an anti-pattern by specifying first which licenses can be afforded and then shoehorning the rest of the solution to make it fit.
Proposed solution
License-based solutioning proposes to make an affordable license mix work for a given set of requirements by using workarounds and custom functionality to fill the gap between the actually required license type and the license type you can afford. That is to say, you engage in this anti-pattern when there is a standard license type that would meet the user requirements, but you instead choose to go with a bespoke or partially bespoke solution that somehow bridges the functionality that is available in the license you have and the license you would really want.
A few common examples include the following:
- Using community licenses for users that are for all intents and purposes internal—although just external enough for there not to be a blatant breach of terms—who ideally would use the internal UI if it were not too expensive
- Using shadow objects to replicate standard objects that are not covered by your license type—for instance, having a shadow case object bi-directionally replicating the information from Case to allow internal case workers to have a cheaper platform license
- Replicating key features from industry clouds—for example, Action Plans—because of an unwillingness to adopt additional licenses
- License sharing between different users that have the same organizational role, circumventing terms and security
- Using cheaper solutions for some features—for example, using a WordPress site instead of a community to save license costs and then syncing the data between the site and Salesforce
While there can be a commercial rationale for these practices, from a technical perspective, they are undoubtedly maladaptive.
Results
The results can vary depending on the specific use case, but often they include things like the following:
- Increased need for custom work to compensate for the lack of license features
- Overall increased complexity of the solution in order to make the different parts fit together in a reasonable way
- More maintenance going forward as a result of the increased custom work and increased overall complexity
- Reduction in value from future feature upgrades as you will need to consider the added customization work
- Reduced security from license sharing or reusing a single license for many functions
This can leave you in a gray area vis-à-vis Salesforce as the licensing agreement is not easy for laypeople to interpret and Salesforce is not transparent about how it enforces the terms in cases where there is considerable ambiguity.
That being said, from a TCO perspective, it is sometimes true that you might be better off not buying the licenses and doing custom work instead. Salesforce licenses are expensive, and if you only need a little bit of what’s included in a feature license, you may be able to rebuild it for a lower price.
However, my advice would be to avoid this if at all possible and instead seek an alternative option, as we’ll discuss in the next section.
Better solutions
In general, you are better off trying to negotiate a better deal with Salesforce, looking at third-party options for the specific functionality you need, or reengineering the solution to avoid the specific features you need either by changing the scope or redefining who needs which feature license.
Let’s look at these in turn:
- Your first port of call, when faced with unaffordable licenses, should be to push your Salesforce AE harder. They often have considerable leeway to offer discounts, especially if we’re talking about a new license type or you are willing to commit to a longer time period for the deal. It also helps to push shortly before the end of Salesforce’s financial quarters.
- Second, you should look at third-party options. You can look at AppExchange to see if a less expensive product might meet your needs, or you can ask your implementation partners if they have assets you might be able to leverage.
- Third, you can go back to the business and ask them to reprioritize features so that you can either cut something else to make space for the licensing cost or remove features that require the extra license.
- Fourth, you can go back and do another round of license optimization where you go through the detail of the proposed licensing and see where you can cut specific licenses for specific users. Often, some licenses are must-haves for some users, but only nice to haves for others.
If you can’t find a good solution and have to go ahead with this anti-pattern, be sure to do so with an awareness of the real cost and risk involved. That being said, we will now proceed to our next anti-pattern, assumption-driven customization.
Applying the thing wrong
In this section, we will consider two anti-patterns where we get unsatisfactory solutions based on a failure of the assumptions we bring to the table. These assumptions can be either about user needs or the capabilities of our technology—both can lead to trouble.
Assumption-driven customization
Example
Helene is the product owner for a new initiative to roll out Health Cloud within LifeCo, a major provider of medical devices for monitoring certain chronic diseases. In addition to the Health Cloud rollout, LifeCo is also developing a custom care application that will be used by healthcare professionals (HCPs), principally nurses, working in clinics associated with LifeCo’s care programs.
Helene was a nurse for several years before entering the IT field after working as a subject-matter expert (SME) on a few major IT products. Therefore, she feels that she has a strong grasp of the requirements and also has several friends, still working as nurses, who she uses as sounding boards.
After some internal discussions, Helene has decided to deliver the application as an app optimized for the kinds of tablet computers she knows are common within clinics. That will allow HCPs to directly note down information relevant to the care programs as they are interacting with patients.
The team develops an attractive and highly functional tablet application that meets all of the key requirements Helene has identified. In initial user testing with a friendly audience, the app receives great praise, and everyone is looking forward to the production rollout.
However, as they are starting to plan the rollout, many clinics push back and refuse to implement the new application. After digging into the issue, it turns out that staff in many clinics, while they have tablet devices available, prefer not to use them directly with patients as they feel it hampers the interaction.
For other HCPs, the idea of capturing the data directly while with the patient goes against a longstanding practice of collecting information in paper notes during the course of the day and then typing it into the system after hours, using a PC with an interface highly optimized for rapid data entry. The HCPs feel that switching to the new system would force them to spend more time on data entry and decrease the impact of patient contact.
Helene has a long list of counterarguments to address the concerns raised by the HCPs and strongly feels that with a modicum of training and process change, the end users will come to see how the new application can significantly improve their working practices. However, she is met with the unfortunate fact that none of the clinics refusing to adopt the new application is owned directly by LifeCo, so there is no way to force them to change.
This presents a major issue to LifeCo as that means they have to keep the old system for managing care programs live and that they will have two separate databases of care information used at the same time, causing serious consolidation issues. Helene is pushed to find a quick solution that will satisfy the hold-out clinics.
In the end, she has to relent. She sits down with her team to see what can be done to create a version of the app that can be used from a PC. They quickly port the key functionality and release a barebones version to the clinics that have declined to accept the tablet application. While it gets a lukewarm response, at least this time no one refuses to use it.
Problem
The thing with assumption-driven customization is that it’s less about the problem it’s trying to solve—that could theoretically be anything—and more about the way you are trying to solve it. With assumption-driven customization, you are trying to solve a problem as defined by your product management, product owners, or developers.
Only, it turns out that the actual problem you need to solve was something else entirely. The problem with assumption-driven customization, in other words, is that you are unwittingly trying to solve the wrong problem.
This is different from just getting the requirements wrong because it can happen with good teams following a good process. All it takes is for the sample that you are using to represent your user base to be in some way systematically biased, as we saw in our example.
Proposed solution
The proposed solution of assumption-driven customization is to let a group of experts stand in for the wider user base in order to facilitate rapid delivery of the solution being built. This is a perfectly reasonable approach. We let experts guide us in most things, and generally, it works quite well.
This only goes wrong if, for some reason, your representative experts turn out to have systematic biases relative to your real user base—for instance, someone who used to work in a function but now is out of touch with day-to-day reality or someone who has made the transition to an IT career some time ago and has now adopted an IT perspective on things.
Note that sometimes you want to roll something out that is not what your user base wanted or expected in order to drive transformational change. That is a different ballgame and is all about the way you do change management. However, if you do it unintentionally and unknowingly, you have an anti-pattern.
Results
Basically, the results of assumption-driven customization depend on the degree of misfit with user needs and expectations:
- At one end of the scale, you have a set of basically benign misunderstandings that can be fixed with goodwill, training, and a set of workarounds.
- If that is insufficient, you may have to add or rework a limited number of features in order to get the users to a place where they are happy to work with the new system. This is still relatively manageable.
- However, sometimes you get to a point where users flat-out refuse to adopt a new system, even with substantial modifications.
- At this point, you have two options: either you force it through and deal with the backlash from the user base or you scrap the tool and go back to the old way of doing things.
The following diagram provides a visual representation of the scale of results:
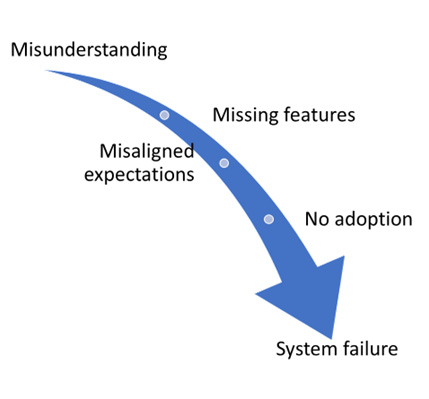
Figure 5.3 – Scale of deteriorating results for assumption-driven customization
That is to say, the consequences of this anti-pattern, while often minor, can be disastrous, and you should spend time being mindful about avoiding it.
Better solutions
This is a difficult pattern to guard against because it occurs when the people we trust to be the voice of our user base fail in some significant ways to represent those users. It can be deeply uncomfortable having to raise these kinds of issues with Product Managers or Product Owners who are convinced about their own position, and in fairness, most of the time they will be right.
However, there are some mechanisms that can help with this:
- Broader consultation with the user base—for instance, via larger events or a common online forum.
- Earlier feedback from the broader user base. Roadshows, demo videos, and webinars are good options here.
- Sprint-by-spring acceptance testing from a larger user group.
- If you are looking to create deep change, plan for it, and include the necessary change management. Never try to sneak in a major change.
That concludes our discussion of this anti-pattern. We will now move on to a genuine classic: the Golden Hammer.
The Golden Hammer
Example
WheelCo is a large manufacturer of tires, especially for the transportation sector. It is rolling out Salesforce with Manufacturing Cloud at its core to closely connect its manufacturing and sales processes.
As part of the deal it has made with Salesforce, WheelCo has received unlimited use of OmniStudio and has been party to a number of pieces of training and accelerators related to the capabilities of the product. As a result, the architects, developers, and business users within WheelCo are extremely excited about what OmniStudio can do for their business.
During initial architecture discussions, the decision is made to base the entire solution on the OmniStudio toolset, including all UI processes (both internal and external), integrations, and any subsidiary processes where OmniStudio could conceivably be used. Only batch and asynchronous processes are left out of scope. That way, WheelCo believes it will maximize the value it can generate from the Salesforce purchase.
The project starts, and in many areas, rapid progress is made. To stay consistent, most parts of the standard UI are ignored and FlexCards and OmniScripts instead make up nearly the entire user experience (UX). Integrations are developed using integration procedures, except for a few that run in the background.
The volume of development is much larger than originally anticipated, but by adding a sufficient amount of resources, WheelCo still manages to get its implementation done on time. It has some trouble finding enough qualified resources that have the required level of OmniStudio experience, but by paying top rates, it manages to secure enough people for the project to succeed.
The go-live is, broadly speaking, successful, although there is some grumbling that not everything that was promised has made it into the release. A number of key features had to be descoped during development to make it on time.
Over the following year, some problems with the solution start to become evident. The integrations are not as flexible as was expected and cannot accommodate all the different use cases the business wants to add. There is also a problem with new feature releases on the Salesforce platform. Every time something new is added, it takes a change to OmniScripts, FlexCards, and sometimes supporting code to make it available to users.
The cost of supporting the solution is also high. Basically, any change needs intervention from a senior technical person, and that reduces the flexibility of the platform. Within WheelCo, many start to question whether OmniStudio really was the right solution to all the requirements it was used for in the project.
This is especially true as some of the native Manufacturing Cloud features that were excluded from the OmniStudio work seem to be rapidly improving without anyone needing to lift a finger to make it work.
After about a year, WheelCo’s CTO appoints a new Chief Architect, who has as one of his early priorities to look at the architecture of the Salesforce platform. He identifies high complexity caused by large amounts of customization as a major driver of cost and functional issues. To address the issue, he recommends refactoring the solution to use a much more standardized UI, retaining OmniStudio for complex multi-step processes and areas where particular views of the data and associated actions generate real value and eliminating it elsewhere.
Problem
The Golden Hammer solves any problems—that is the nature of the Golden Hammer. Once you have found the Golden Hammer, every problem you encounter is a fit. There is no evaluation of fitness for purpose because the Golden Hammer is obviously the right solution.
The tech industry, in general, is very prone to Golden Hammers. We are always looking for the next cool technology to solve our problems. Salesforce with its aggressive sales approach and Kool-Aid drinking community is perhaps even more prone to this anti-pattern than most platforms in the technology space.
Note that Golden Hammers are often technically excellent solutions within their own solution space, but they are stretched well beyond that space because of enthusiasm, hype, and excitement.
Proposed solution
The solution proposed by the Golden Hammer is the Golden Hammer. That is to say, whatever the problem, whatever the parameters of the problem, they will somehow be twisted into something the Golden Hammer could conceivably deliver, or alternately, the Golden Hammer will be twisted into something that delivers a solution to the problem.
If you have to pick, it’s better to mold the problem to a bad-fitting tool than to use a tool for a problem that it is definitely unsuitable for. However, it goes without saying that neither of these options is particularly good.
A good way to check if you are under the influence of a Golden Hammer is to notice whether your discussions about new technology features start with looking for problems your tech stack could deliver or whether you start with problems and then try to find a suitable technology stack. If it’s the first, you need to be careful as you could have a Golden Hammer on your hands.
Results
The results of a Golden Hammer depend on the degree of technical badness of fit that you have engaged in:
- At a minimum, you will end up with a gap versus the requirements that you were meant to fulfill as there will be areas the Golden Hammer didn’t really manage to solve because it’s not the thing it was meant to solve
- Higher cost and more customization work as you increasingly stretch the Golden Hammer beyond its capabilities
- Additional maintenance work and resulting cost as a result of the overstretched solution that has been created
- Reduced faith in the real capabilities of the Golden Hammer within the organization, even where it is genuinely a good fit
- A need to maintain a specialist skillset across different areas in your business that will persist even when the hammer is no longer popular or trending
All in all, the results will depend on how much you are stretching the tool’s capabilities, but choosing the tool before you know the problem is invariably an anti-pattern.
Better solutions
Architects differ in their willingness to adopt new tools and technologies. Salesforce architects, in my experience, are fairly aggressive in adopting new technologies as long as they are on the platform. I am therefore probably going to come off as a bit of a curmudgeon when I say that my general recommendation is to be quite conservative about adopting the newest toolsets, especially on Salesforce.
In the Salesforce ecosystem, we are constantly bombarded with new features, new toolsets, and new ways of doing things. While that is great, changing an approach that has worked for you in the past and that continues to deliver value to your organization should only be done after careful consideration and definitely not because Salesforce has just launched a shiny new toy.
Instead, take a gradual, incremental approach where you try out new toolsets of smaller features and projects that do not have a business-critical impact. Don’t just do prototypes or proofs of concept (POCs) as these are easy to get right but use them for real but limited business use cases. Get the learnings, then scale it across your estate if it genuinely delivers value. If it doesn’t deliver value to your organization, leave it alone, even if it’s very cool.
Engineering overflow
The two anti-patterns in this section both represent failures of technical governance, resulting from too much engineered work going into a single component without appropriate design patterns and practices applied to mitigate it.
Automation bonanza
Example
DrinksCo is a long-time user of the Salesforce platform, using it for sales and customer service as well as having a large and elaborate footprint on Marketing Cloud. While there are multiple orgs in use across the estate, there is one main org that manages the core processes for which Salesforce is in use.
While this org has been creaking slightly for a while, the situation has now gotten to a point where DrinksCo users are making serious complaints. The time to save records on key objects such as Opportunity and Account can sometimes be measured in minutes. Occasionally, records will simply fail to save, giving an obscure technical error message. Worse still, there are synchronization jobs containing important information about new leads and opportunities that randomly fail without giving a clear explanation as to why.
Francesca is a Salesforce consultant with a boutique Salesforce partner. She is called in to analyze the situation and propose improvements to the org that ideally fix the root cause of the issues, but at the minimum reduce the symptoms quickly.
After a week of examining the org, she is no longer in doubt. The problems are caused by interaction effects between a large number of complex automations on key objects. On Opportunity, for instance, there are deep layers of automation that evolved over many years that combine to create serious issues.
This includes a large and complex Apex trigger, two additional triggers from managed packages, a handful of workflow rules, three process builders, yet to be migrated to flows, a before-record-triggered flow, an after-record-triggered flow, several batch jobs that operate on the object, and multiple integrations directly using both the native API and a custom web service to manipulate records in the Opportunity object.
Francesca takes a deep breath and starts methodically mapping out the various sequences of events that can occur depending on the Opportunity records and their updates. She does this by systematically following the order of execution and looking at where there might be potential undesirable interaction effects between the different automations.
After some time, she concludes that the number of ways in which it is possible for these sequences to go wrong is too high for the current model to stand. It is unfixable without seriously reducing the complexity of the automations.
Therefore, she devises a refactoring plan that she believes will be successful in alleviating the most serious symptoms of the Opportunity object, although probably not entirely eliminating the problem. If it is successful for the Opportunity object, similar initiatives will be attempted for other key objects in the core org.
The plan includes moving the process builders and several of the workflow rules into the two flows, consolidating the integrations so that there is only one that regularly handles imports into Opportunity, simplifying the Apex trigger, and getting rid of one of the managed packages that aren’t strictly needed anymore.
The plan takes much longer than initially expected to implement—there are just too many things to consider for everything to go to plan. But eventually, the users start reporting an improved experience when using Opportunity. The old random errors no longer occur. And although saving is still slower than they would like, it is no longer so slow as to be a serious issue.
Having momentarily enjoyed her success, Francesca takes another deep breath and starts the process for the other key objects in the org.
Problem
The problem that automation bonanza tries to resolve is how to accommodate different architectural styles or preferences when creating automations on Salesforce. That occurs almost inevitably when you have multiple teams working on the same objects as part of different projects and often coming from different implementation partners.
There are many ways to automate business processes in Salesforce, and different teams will have different takes on the best way for their particular requirements. That is fine if you have just one team working on its own objects, but gets messy when you have more.
That’s when you need a way to guide the evolution of your architecture over time to keep things consistent. If you fail to do so, you may end up with automation bonanza.
Proposed solution
Automation bonanza responds to the multiplicity of automation options, some of which are shown in the following screenshot, and the commensurate multiplicity of automation approaches by allowing for diversity. That is to say, teams are allowed to choose a best-fit approach in isolation:
Figure 5.4 – Some Salesforce automation options
This reduces coordination requirements between the teams and usually doesn’t result in short-term issues. Therefore, it can be quite difficult to spot that you have a problem or are generating a problem before things have already gone wrong.
Results
The negative consequences of automation bonanza can be rich and varied. Some of the things that frequently occur are included next:
- Slowing performance on key record pages—sometimes, saves can take a long time to complete
- Failures in integration call-ins, especially where these update records in batches or in a bulk fashion
- Failures in batch jobs or import jobs
- Strange, unpredictable errors occurring in the UI, typically associated with a save or update event
- Difficulties in debugging issues occurring on the platform as interaction effects from automations overshadow the general picture
Overall, if you get into a serious case of automation bonanza, you can have a real mess on your hands. What’s worse is that this tends to happen first to your most treasured objects as these are the ones used the most across projects.
Better solutions
The key to avoiding the automation bonanza anti-pattern is good architecture governance around your core objects and their automations. Some things to keep in mind in order to do this include the following:
- You should start by defining which types of automation you want to use in your org and for which use cases.
- Ideally, you want a number as close to one as possible for each object. Choose either flows or triggers as your go-to automation type and stick to it.
- It is possible to mix Apex and flows safely, but it requires careful planning and a good framework.
- If using flows as your principal mechanism, make callouts to Apex via Actions rather than by creating triggers unless forced to do so for performance reasons.
- Also, be sure to have a framework that helps the architect use flows. This should include the use of sub-flows to keep flexibility. Have decoupled automation processes that are easy to troubleshoot in case of problems instead of having a large monolithic flow containing all the business logic in a tightly coupled design that in the long term is complex and expensive to maintain.
- If using triggers as your principal mechanism, use a trigger framework such as Apex Trigger Actions (https://github.com/mitchspano/apex-trigger-actions-framework), which enables you to call out to flows as part of the trigger execution.
- Avoid Process Builders and workflow rules as these are being retired.
- Batch processes and incoming integrations need to be designed carefully and mindful of existing automations. Remember mechanisms such as bypass flags that enable you to selectively bypass automations for some processes.
- Watch managed package triggers and flows carefully. You don’t have control over them, but they may still cause trouble by interacting with your own functionality.
In general, trying to keep your automation approach simple and uniform will generate substantial long-term benefits for your Salesforce orgs. That being said, we will now proceed to the next anti-pattern: overweight component.
Overweight component
Example
HealthyMindCo is a broker for mental health services across the United Kingdom. It is implementing a new case management solution on Salesforce. In this solution, case workers collect relevant information about new clients and determine which actual local provider is best placed to help them. Additionally, they track the consultations their clients go through in order to determine the effectiveness of the intervention.
The company has very special requirements around the recommendations the system should make for potential treatment options and referral possibilities, which can only really be accommodated by using a custom code. Because HealthyMindCo prefers a simple and highly optimized UX, Amir, the project lead for the partner implementing the solution, decides to go with a Lightning component that can incorporate the necessary logic for creating new cases.
Initially, the thought is that the component will only be used for new cases. However, after initial user testing, it is clear that update functionality will also need to be added. There are too many instances where initial assumptions need to be checked, which can lead to different outcomes in terms of the treatment plan.
After the update functionality has been added, the component is tested with users again, and what appears to be evident is that the component will also need to support the management of activities and activity templates as that is a crucial part of the initial setup of a treatment plan. The team works hard to add this to the component, which is starting to be a substantial piece of engineering.
Once the activities and activity templates have been added to the component, a number of users point out that it doesn’t make any sense to have the activity management part of the equation in the new component, which is now coming to be known simply as the case-handling component, and also not to have the tracking of SLAs against those activities in the component. This implies also adding the visit-tracking capability as that is required to manage the SLAs.
At this point, the Lightning component is the main interface used by HealthyMindCo staffers. As that is the case, a number of integration callouts that get information from other systems are added directly to the code in the component, simply because this is where it will be used anyways.
The system goes live in an unspectacular manner. There are a lot of bugs, in particular in the case-handling component. But with a lot of goodwill and hard work, the team comes to a level where the quality is just acceptable enough for the client to use it in anger.
After the go-live, HealthyMindCo keeps finding new bugs in the case-handling interface. It is generally quite unstable. In addition, it still wants to add large amounts of new functionality to it. However, the company is not happy with the quotes it is receiving for its change requests.
Amir consults with some of the senior architects within his company. They assess the situation and tell him that the component is too big, too monolithic, and too difficult to maintain. He needs to refactor the code base and find the funding to do so either from the client or internally. He tries, but no one seems particularly inclined to pick up the tab.
Problem
Generally, heavyweight components are built to accommodate a real or perceived need for a custom UX that goes well beyond what can be delivered with Salesforce’s out-of-the-box tools. Note that in some cases, the perception that you need such a specialized UX can be stronger than reality.
Users that come from old systems that have been used to working in a specialized application or who had their old system customized heavily to their needs might assume that such customization will also be necessary on a platform such as Salesforce. There can be a marked degree of skepticism in some users toward the idea of using standard functionality. We all like to think that what we do is somehow special, after all.
Not to say that there aren’t cases where there is a genuine need to have a unique and highly customized UX but, in my experience, they are less common than many would think. In any case, the way a heavyweight component attempts to deliver such an experience is less than ideal.
Proposed solution
A heavyweight component proposes to deliver a unique UX within Salesforce, using a development framework such as LWC to create what is effectively an embedded monolith application residing on the platform. This can be attractive for a number of reasons:
- You have full control of the UX and UI within a single component, allowing you to respond to almost any user request
- All functions are integrated, and the architecture is simple to understand
- There is one place for everything, and all changes can be made there, reducing the need for tooling and coordination
- The component is still embedded within the standard UX and with judicious use of styling may even look like something that came as standard
- You can accommodate changes to the UX within the component, giving users more of what they need
This solution also tends to not seem dangerous at the outset, even to experienced architects and developers, because all we’re talking about is “just” another LWC component. It’s only when the true scope of that component is realized that it becomes a problem.
Results
While the component remains relatively small, you will not see any negative results, and, of course, lightweight components are useful and architecturally appropriate elements of most Salesforce architectures. However, as a component grows and grows, it starts to resemble a standalone application, a code-based monolith that lives within the larger application but still has a life of its own.
Often, this happens unintentionally when a component that was meant to do something relatively simple evolves into a catch-all location for functionality. In fact, this often happens because the initial component was very successful, and users want it to do more things.
The consequences of this evolution are familiar:
- Quality starts to decrease and the error rate increases as the new component grows too big and complex for developers to handle
- Maintenance slows down, and bug fixes and feature requests take longer to come through the pipeline
- Only certain developers can work on the heavyweight component because it gets too complex for others to handle
- The overall UX begins to deteriorate due to the reduced quality and crowded functionality
- The component is increasingly hard to integrate with other parts of the platform and is increasingly treated as a standalone application
Occasionally, this pattern can deteriorate to such an extent that you end up with a Big Ball of Mud—see Chapter 2. However, even when it doesn’t go that far, you will eventually need a major refactoring effort to address the issues.
Better solutions
Given that the issue with a heavyweight component is that you effectively end up with a monolith application without a well-defined architecture, it shouldn’t be a surprise that the way to address the anti-pattern is to improve the architecture of the custom functionality you are going to deliver.
Generally, this is done by decomposing the larger component into a set of smaller more manageable pieces, while leveraging as much standard functionality as you can. Using an event-driven architecture (EDA) that allows the smaller components to communicate by sending and responding to events can also be helpful.
Additionally, architecture governance has a key role to play in this anti-pattern. You should have an assessment and approval process in place for new components, and you should also have someone periodically check in on what happens with the custom components that get approved as they can tend to balloon.
That doesn’t mean you need a formal code audit to check through what everyone is doing unless your project is very large, but you should have architects that are part of your governance approach and who know the detail of what is going on with any custom development done in your org. That will help you spot evolving issues early.
Now, we will move on to our two code-focused anti-patterns, starting with the God class.
Making a mess of code
The last two anti-patterns of the chapter are focused on two anti-patterns that happen in code. While these aren’t the most common in the Salesforce world, we as architects should still be aware that our code-based solutions must adhere to good practice or fall into common anti-patterns.
God class
Example
ShoeCo, a maker of some of the world’s most popular sneaker brands, has a complex, multi-cloud Salesforce org that it uses to run key parts of its business. As it has many custom requirements as well as a substantial amount of legacy on the platform, it has a large number of Apex classes to handle both business logic and integrations.
It has recently started to make the switch to flows, and in practice, most functionality is a combination of code and declarative functionality. Over time, ShoeCo would like to simplify its Salesforce functionality and avoid some of the problems it is currently facing.
In particular, many of the architects at ShoeCo are starting to feel like the org is out of control and that they don’t have any clear overview of the logic that is activated at different parts of the system. Pranit, one of the Salesforce architects, makes a proposal to simplify the current system architecture by creating a CentralDispatch Apex class that will take the role of dispatching calls to other code or flows.
With all business logic funneled through the CentralDispatch class, Pranit believes that it will be much easier to identify which code is called in which circumstances, allowing for greater transparency, lower maintenance costs, and a greater potential for code reuse.
A key philosophical requirement for this approach is that the CentralDispatch class should contain no logic of its own. It is just there to forward requests to the right handler. However, this philosophical principle is soon abrogated in practice.
In order to make the class work as intended, more and more of the business logic that determines what gets called in which contexts has to move into the CentralDispatch class itself. That means more and more of the actual functionality lives in a class that is growing ever larger by the day.
While this causes some concern initially, Pranit and his fellow architects accept the development as they still have better visibility than before the introduction of the CentralDispatch class. It is only when developers start to complain that the class is too big and can’t be changed without there being unknown side effects in various parts of the system that they start to take serious notice.
The class has grown to more than 5,000 lines of Apex code, and it effectively orchestrates all logic called from other places within the ShoeCo org. To some extent, it has been a victim of its own success, but at this point, most of the developers consider it more of a hindrance than a boon.
Pranit decides to create a new plan to refactor the CentralDispatch class and get it back to its original skinny self. He wants to move out all the complex logic and keep it as a dispatch hub that determines which other Apex code or flows get called in particular contexts.
However, on inspecting the code, he finds that actually, it is in many cases impossible to do that kind of request forwarding without also including substantial amounts of logic. Disheartened, he considers whether the approach needs to be fundamentally changed.
Problem
The God class anti-pattern is deployed to centralize technical problem-solving with an application. Basically, it can be much easier, conceptually speaking, to use a single pattern deployed in a single class to manage all the technical complexity that arises during custom development than to spend a lot of time doing detailed architecture and design.
You can see the God class code structure in the following diagram:
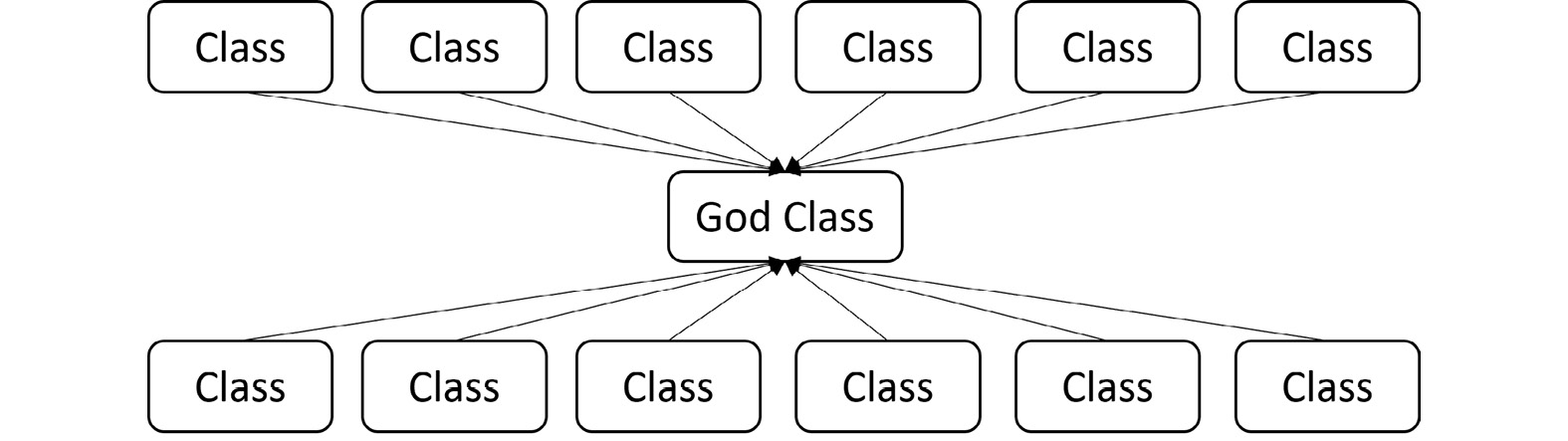
Figure 5.5 – God class code structure
You don’t see this anti-pattern frequently in Salesforce implementations, but it is a real danger to ISVs building for AppExchange or any organization building bespoke apps on the Salesforce platform.
Proposed solution
The God class is a single file, generally an Apex class when we are talking about Salesforce, that hosts all or at least the majority of the critical business logic of a complex application. Centralizing functionality in this way can seem like a good design decision as it makes the overall architecture and design quite manageable, and there are even some patterns, such as the Dispatcher pattern used in our preceding example, that can be quite effectively used in such a centralized way.
Often as an application evolves, you can start to lose the big picture. This is especially true if you have a small application that is growing into a big application over time. You probably didn’t have a strong architecture in mind at the outset as it was only meant to be a small app that could be built quickly.
In this case, resorting to centralization of the code base can be a way of managing the application and getting back in control. Or, you might simply have started to put all the logic in one place for convenience and you didn’t really notice that the class had grown to several thousand lines of code.
However, as with all cases of poorly managed evolution of functionality, you will end up paying the costs eventually.
Results
At this point in the book, you should be able to predict the negative outcomes from an anti-pattern that results from badly managed application growth. We have seen a number of such patterns, from heavyweight component to Big Ball of Mud, and indeed the God class shares many of the negative consequences we have come to expect:
- The code gets hard to understand, resulting in longer maintenance cycles, slower new development, and increased error rates
- Only certain programmers may be able to work on the God class to avoid unfortunate side effects
- All changes in the code base, anywhere, also require changes to the God class
- There are often strange interaction effects between what happens in the God class and what happens in the rest of the system, leading to hard-to-debug errors
- The class presents a single point of failure (SPOF) within the application, and if it fails, none of the additional logic can be processed
Overall, you end up with an application that is fragile, brittle, and a bit of a mess.
Better solutions
When building custom solutions on Salesforce, you will generally be using Apex, an object-oriented (OO) language closely related to Java. That means you should be following good OO analysis and design (OOAD) practices if you are proposing to build anything non-trivial on the platform. While teaching OOAD is way beyond the scope of this book, a good place to start is by studying the SOLID principles.
The SOLID principles are a set of guidelines that can be used when designing software to make it more understandable, maintainable, and extensible. The acronym stands for Single responsibility, Open-closed, Liskov substitution, Interface segregation, and Dependency injection (DI). These are described briefly here:
- The Single Responsibility Principle (SRP) is the principle that a class or module should have one, and only one, reason to change. This principle is often used in conjunction with the Open-Closed Principle (OCP).
- The OCP states that software should be open for extension but closed for modification. This means that new functionality should be added by extending the existing code, rather than modifying it.
- Liskov substitution is a principle in OO programming (OOP) that states that objects of a superclass should be able to be replaced with objects of its subclasses without changing the functionality of the program.
- Interface segregation is the process of separating a single interface into multiple, smaller interfaces. This can be done for a variety of reasons, such as increasing the modularity of a system or reducing the complexity of an interface.
- DI is a technique for achieving loose coupling between objects and their dependencies. It involves providing a component with its dependencies, rather than allowing it to create or obtain them itself. This can be done either manually by the programmer or automatically by a tool.
Having now covered the God class, we will move on to our last pattern of the chapter: error hiding.
Error hiding
Example
SailCo, a provider of custom-designed sailboats, has a complex configuration app for configuring the boats it sells, which it has built on top of the Salesforce platform. The app is built in a fairly traditional way using a combination of LWCs and Apex code.
SailCo users are in general extremely non-technical, and one of the key requirements that the custom app had to satisfy was to never show a technical error message to an end user. Therefore, the developers of the original application devised a way to catch all exceptions and wrap them in a generic error message before being shown to the user.
This general message telling users that an error has occurred in a friendly way is the main error message seen in the system, as the developers were unable or didn’t have sufficient time to differentiate the errors that might occur in a reasonable way. Users, however, seem comfortable enough with the solution and don’t enquire much about the exact nature of the errors that occasionally occur.
However, after a while, it becomes clear that there are some systematic ways in which the configuration app can fail. In fact, there are complaints from several customers that their desired configurations have not been successfully captured as part of the order they have made and that had been registered in Salesforce using the custom app.
No one can pinpoint the error exactly, and it falls to Sarah, a relatively junior Salesforce engineer, to try to debug the problem. She starts by reviewing the logs that she can generate from the production system but finds that the only errors she can see are the generic error messages thrown by the wrapping mechanism that hides the technical information from the users. In many cases, exceptions are simply caught but never handled.
That means the production logs are, effectively, of no use to her debugging efforts. She tries to reproduce the errors in lower environments after making some changes to the code to get the raw stack trace instead of the wrapped error message. However, she is unable to reproduce the errors in the lower environments.
She seeks and eventually gets permission for a special production release to add improved logging to the system. However, she needs to do a major refactoring of the existing code base as the quick hack she had used initially was not deemed fit for production use.
After having done the major code refactor with the help of a few other SailCo developers, she manages to get the new logging functionality into production. As luck would have it, the problem turns out to be a trivial coding error.
Sarah fixes the issue and releases the new code to production, confident that with the new error-handling approach, she will be able to find issues even if the current fix doesn’t address all the problems that may be found in the code base.
Problem
Error hiding is done for an excellent reason: not showing end users ugly technical error messages that are going to confuse them and make them lose faith in our application. In an ideal world, we want to recover gracefully from all errors or at least show a friendly, easy-to-understand error message.
You can see a simple example of error hiding here:

Figure 5.6 – Simple example of error hiding
In practice, we mostly only have time to analyze the most common failure modes during analysis and design, leaving a large number of potential failures that we have not prepared for. With the error hiding anti-pattern, we end up hiding all of these errors not only from the end user but also from ourselves.
Proposed solution
The error hiding anti-pattern solves the problem of not showing end users technical error messages by simply hiding away errors or replacing any error with a generic innocuous error message. This is done technically in a way where an exception is caught and the information contained in that exception is simply discarded, whether or not a message is shown to the end user.
That means we have no logging or systematic capture of error information. Consequently, we have no way of knowing what, if any, systematic issues are happening in our application that we might not have thought of and no way of debugging issues that occur in production environments that aren’t immediately replicable in lower environments.
This anti-pattern saves time for developers because there is no need for them to apply a structured error-handling approach during development, and it meets the users’ need to not see confusing messages. However, it comes with many negative side effects.
Results
The most obvious result of error hiding is that you can’t find the error. Errors are systematically hidden, and you have to rely on user reports and your ability to reproduce those in order to address any issues.
Debugging errors in Salesforce without good log information can be extremely hard, especially when the errors may be related to user context, data volumes, or similar variables that aren’t easy to control.
That means your maintenance costs will be substantially increased and your cycle time for bug resolution will lengthen. Users are also likely to start losing faith in the system as they find that there may be issues that are swept under the carpet, which can lead to a vicious cycle of users starting to blame all sorts of ailments on hidden system issues.
Eventually, you will need to refactor the application and introduce a systematic approach to logging and error handling. This will generally turn out to be much more expensive than having done things properly the first time.
Better solutions
The solution to error hiding is to adopt a structured approach to error handling, starting at the analysis phase of the project. You should analyze common failure modes and prepare for them proactively rather than simply focusing on the happy path.
You should also have a standard for error handling that includes how to handle exceptions, how to log errors, and how to show error messages to end users in different contexts. You should also adopt a good logging framework. I tend to recommend Nebula (https://github.com/jongpie/NebulaLogger) as a framework, but there are many good options available from the community.
When looking for one, keep the following in mind. A good logging framework should be easy to use and configure. It should be able to log from multiple sources (for example, Apex, flows, integrations, and so on), and it should have good performance and not slow down your application. Ideally, you also want to be able to easily visualize errors and follow them across process boundaries.
In all of this, of course, you want to insulate your end users from technical error messages. But you want to do it without resorting to an anti-pattern.
Now, we have covered our final anti-pattern of the chapter and are ready to move on to our key takeaways.
Knowing the takeaways
In this section, we will abstract a bit from the specific patterns and instead try to pull out the wider learning points you can use in your day-to-day work as a Salesforce architect or in preparing for the CTA Review Board.
When architecting Salesforce solutions, you should be mindful of the following:
- Don’t rush into a solution based on what your organization usually does. Make careful consideration of options.
- When making a buy-versus-build decision, be careful to count the real TCO of a custom solution including long-term run and maintenance costs.
- Don’t design solutions to a specific license set if you can at all avoid it.
- Instead, push for a better commercial deal, different scope, or different license mix.
- You must make assumptions about your user base, but be careful about systematic bias.
- To help mitigate bias, use various consultation methods during development to de-risk.
- Don’t become too invested in a new technology. No matter how cool it seems, it’s not the answer to everything.
- Automations are a particular pain point in many Salesforce solutions. They should be a particular focus of technical governance.
- Prefer a simpler automation setup to a more complex one.
- If you need a complex custom UX, decompose the functionality in a meaningful way rather than putting everything in a single component.
- When doing substantial development on Salesforce, you should apply all the same good practice that applies to other OO development projects in similar languages. That includes how you structure your classes and how you handle exceptions and errors.
In preparing for the CTA Review Board, you should be mindful of the following:
- Using AppExchange products in your solution is entirely appropriate and usually preferable to custom solutions
- Recommend products you know and can justify or alternately are well-known in the market to avoid unnecessary questions
- Assume that budget is not a constraint and recommend the right licenses for the job
- However, don’t go overboard and recommend lots of additional feature licenses if you don’t actually need them
- Make assumptions freely, but state them as you go along
- Be prepared for judges to ask you to consider on the fly what would happen if you changed a key assumption
- Recommend the right tool for the job and avoid relying on too one-sided a solutioning approach
- Don’t go overboard with automations, and always be clear on what approach you are recommending and why
- Prefer a simpler automation setup to a more complex one
- Recommending custom components is often appropriate, but be careful not to overdo its functionality
- Do remember that when recommending code-based solutions, you should also know good practices for OO development, although it might mainly be relevant during Q&A
- Have a structured error-handling approach in mind that you can tell the judges should they ask
We have now covered the material for this chapter and are ready to proceed. First, however, we will summarize our learning.
Summary
In this chapter, we have covered eight anti-patterns, more than any chapter so far. That is not accidental. Solution architecture is probably the most time-consuming activity for most architects. Even if we aren’t directly responsible for all parts of the solution, we get pulled in to consult on features all the time.
Solution architecture is the most visible part of our efforts. While integration architecture, data architecture, and security architecture set the baseline on which we create our solutions, ultimately it is the solution that we devise for the users that is the basis of their judgment.
If we get the core architecture right but fail to deliver a good solution, we will still in the eyes of most observers have failed. Unfortunately, it is also a really hard area to get right.
As these anti-patterns show, keeping the right balance between flexibility and discipline, and between giving the users what they want and adhering to good technical practice, is something that requires experience and good judgment. Hopefully, you now have an even deeper appreciation of that fact.
Having covered solution architecture, we will move on to our next domain: integration architecture.