
6
Keeping Integration Straight
This chapter looks at anti-patterns around your integrations with other systems. The first part of the chapter looks at anti-patterns around the integration landscape and integration patterns, the second part looks at what can go wrong in the design and use of interfaces, and the third zooms in on problems with integration styles. As always, we end the chapter by distilling the key takeaways.
In this chapter, we’re going to cover the following main topics:
- How not to overly complicate your systems landscape by misusing technologies in ways they weren’t intended to
- When it is and isn’t appropriate to create custom services for integrations
- How to avoid common failures in designing interfaces
- How to use integration patterns appropriately
After completing this chapter, you will have a good idea about how to better select integration patterns and structure your integration architecture by learning about various ways in which it can go terribly wrong.
Muddling up the integration landscape
This section covers two anti-patterns that in different ways can create havoc in your integration landscape. We will start by looking at how not to use middleware.
Middleware in name only (MINO)
Example
PumpCo is a large B2B company that specializes in the production of pumps for industrial production. It operates in more than 30 markets and has historically underinvested in IT systems and used largely manual processes for sales that have varied substantially between countries and product lines.
Over the past year, it has started to implement Salesforce Sales Cloud and CPQ to drive standardization of the sales process globally. Their one major IT platform that has received substantial investment in the past is SAP and, fundamentally, SAP runs all key parts of the business today.
Michelle is brought in as an integration architect on the Salesforce implementation at an early stage. The integration roadmap is very ambitious as the business wants to see all relevant data and processes seamlessly operate across the Salesforce/SAP boundary. Fundamentally, it wants to be able to access all the relevant back-office data and processes directly in Salesforce without the need for a context switch.
When the initial mapping has been completed, there are 75 discrete integration points covering everything from pricing and logistics to HR that would need to be implemented to give the full experience that the business is looking for. The good news, however, is that many of these integration points can be grouped into similar areas such as a customer or an order interface.
The architects from the Salesforce and the SAP side discuss a number of alternative architectures and implementation approaches for creating a small number of stable interfaces that would cater to the majority of use cases, but unfortunately, progress is slow and there is no real agreement between stakeholders or architects. There is a large number of potential solutions in play as well as several technologies that could potentially do the job, and the willingness to compromise is low.
The two sides instead agree to let the middleware team manage the process. PumpCo has just bought a new middleware platform, and the team there is looking for opportunities to get started.
The middleware team will expose services to Salesforce and translate the calls to SAP. Any modifications to the APIs will also be its responsibility. Thereby, the two platform teams don’t have to agree on an approach and can work independently.
As the project progresses, Michelle makes a count of the interfaces Salesforce is calling on the middleware. She counts 45. Not quite the original 75, but then, the scope has also been somewhat reduced as they have gone along.
Here’s a diagram of PumpCo’s integration architecture:
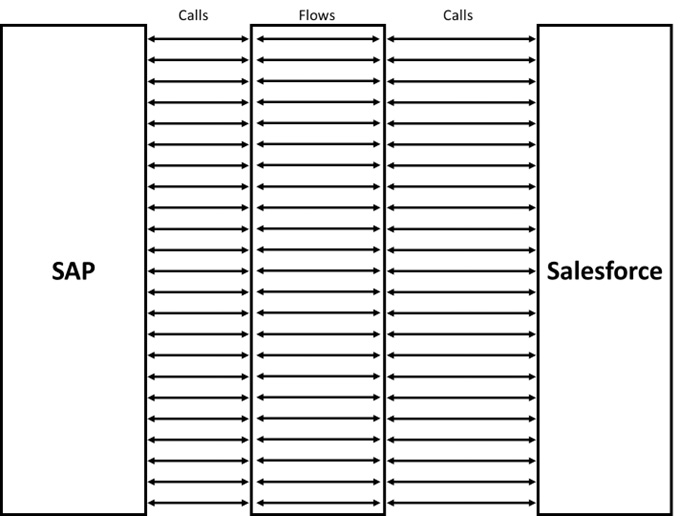
Figure 6.1 – PumpCo integration architecture
From what she can see, most of these middleware interfaces do little other than simply forward a call from Salesforce to SAP and back again. She wonders if that is really the best approach, but it’s not her problem anymore.
However, over time as Salesforce starts seeing more use, issues start occurring with the integrations. The error rate is high, there are performance issues, and maintenance is getting increasingly complex. Integrations, overall, are causing the majority of technical issues on the platform.
A consultancy is brought in to assess the situation, and they recommend rationalizing the integration architecture as the current setup effectively consists of 45 increasingly customized point-to-point connections via the middleware. This creates a lot of potential for failure and is generally hard to understand.
Michelle is asked to participate in the redesign process, and after several weeks of design work, they end up with a proposal not too far away from one of the iterations that were done during the initial project implementation. When a senior stakeholder pointedly asks why this wasn’t done in the first place, no one is really able to give a convincing answer.
Problem
The MINO anti-pattern tries to reduce the complexity of creating a good integration architecture by introducing middleware. However, it does so in a way that fails to leverage the capabilities of a middleware platform, instead simply recreating flows via the middleware that might have been found in a point-to-point scenario.
It tends to occur in organizations that have complex system landscapes with many interfaces and touchpoints between systems. However, in these organizations, there is often little technical governance coordinating between different silos, leading to a messy integration architecture.
Other characteristics that are often found with the MINO anti-pattern include the presence of dated and inflexible system APIs on key platforms and difficulty in agreeing on standard representations of core business entities across those key platforms, making it impossible to settle on common interfaces or APIs.
Proposed solution
The solution proposed by MINO is simply to introduce a middleware platform without paying too close attention to how it is used. By introducing a modern middleware platform, the complexities and inflexibilities of legacy systems can at least be partially hidden, which does lead to good initial results.
That is to say, MINO often seems right on the surface, but if the middleware implementation only replicates the existing mess in a new format, relatively little is gained. Not nothing, mind you. You may still get some basic middleware capabilities such as better error logging, a retry mechanism, or some easier-to-use protocol conversion.
Another and often more influential reason to go down the road of this anti-pattern is that it decouples teams on core platforms from having to deal directly with each other. You can often have very different views of the world if you’re working on the CRM side than if you are working on the ERP side of a key integration.
MINO allows different teams to only have to deal with the common middleware team, who are then given the responsibility for managing the rest. That, unfortunately, tends to lead to architectures that don’t really move much beyond the basics.
Results
The result of MINO is often turning your system landscape into an even greater spaghetti-like mess than it was before. Now, after all, you have a middleware in the center, so you can pay less attention.
That has the usual consequences:
- Hard-to-understand integration architecture with too many individual interfaces and point-to-point connections, albeit mediated by the middleware
- Increased maintenance costs as the complexity is still high and there are now more teams involved
- Lack of technical governance and a potential lack of awareness that such governance is even needed
- Increasing error rates on integrations and a commensurately increased fix time as teams try to track down errors across platforms
- Decreasing performance as there is a more complex flow in place that spans more platforms
Overall, if all you are going to do with your middleware is proxy point-to-point connections, you are probably better off not using it at all.
Better solutions
What the MINO anti-pattern teaches is that there is no shortcut you can take to get your integration architecture right. You have to carefully consider the linkages and dependencies between systems, the business requirements both today and going forward, how your master data is distributed, which core capabilities your key platforms have, and how you can structure interfaces and patterns to best support all these elements.
Some common middleware capabilities are shown in the following diagram:
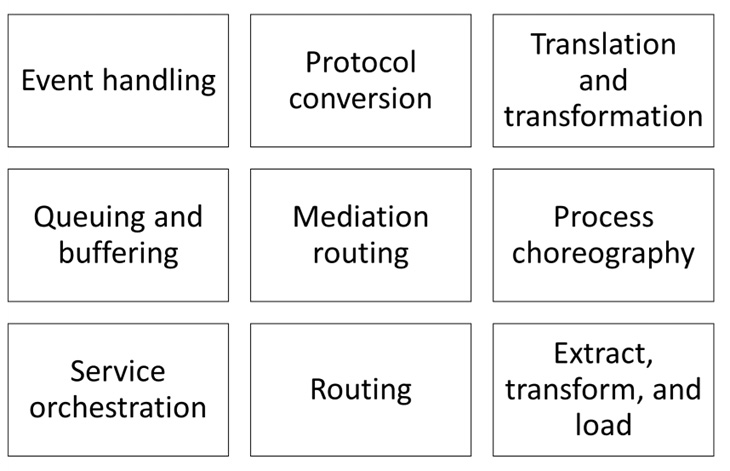
Figure 6.2 – Common middleware capabilities
With that in mind, you can select the right tools for the job, which may very well be a middleware tool. However, before you have thought about which interfaces you will need to support across the business, which integration patterns you can and must support for different scenarios, and determined how you are going to do technical governance across different teams, you shouldn’t be jumping at any tool, no matter how cool it looks.
Service proliferation syndrome
Example
OmniCo has always prided itself on being at the forefront of technology and deploys many cutting-edge software platforms across its many diversified service lines. The company was an early adopter of service-oriented architecture (SOA), which it still uses to great advantage combined with an event-driven architecture (EDA) for high-velocity data and processes.
OmniCo is now implementing Salesforce as a replacement for its old Siebel CRM system, which served as an integration hub for many other systems. The Siebel CRM was heavily customized to OmniCo processes, and the company is expecting that the new Salesforce system will be as well. While their implementation partner has made a reasoned argument for staying with standard capabilities, this goes against the grain of how OmniCo has historically done things, and it is not really looking to change its approach as part of the CRM project.
Here’s what the old Siebel setup looked like:
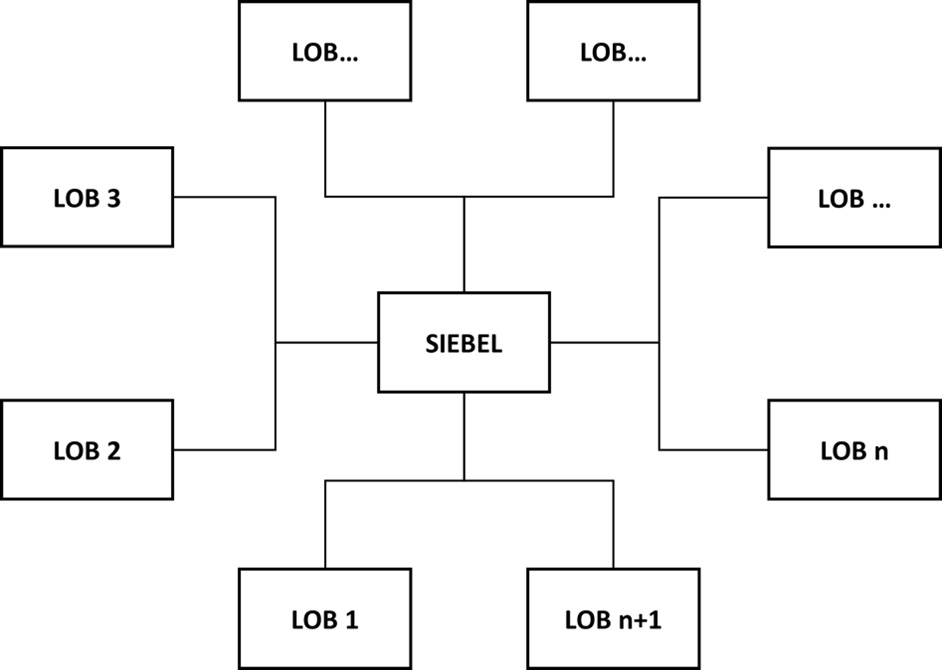
Figure 6.3 – Old Siebel setup at OmniCo
For Erhat, the consulting manager in charge of the integration part of the implementation project, this is causing a lot of anxiety. He is being pushed by a number of senior stakeholders from OmniCo toward building a range of special business services that would fit into the OmniCo SOA.
Erhat has tried building customized APIs on vanilla Salesforce in the past, and the experience, while ultimately successful, was neither straightforward nor fast. In fact, given the number of custom services that are being mentioned, he is in doubt about the basic feasibility, given constraints on time, budget, and people with the necessary skillsets.
After some pushback, he agrees with stakeholders to deliver two crucial services using interfaces similar to the ones exposed by the old Siebel system that are used in order management and that would take a lot of time to re-engineer on a different pattern.
These are delivered, but prove difficult to get through testing, partially because the testing protocols for the services are incomplete and partially because the complexity is extraordinarily high.
As the first two services near completion, a crisis meeting is called by OmniCo’s enterprise architecture board. They have just realized that not all the business services provided by Siebel will be available in the new Salesforce setup. In the view of several members of the board, this will fundamentally undermine a range of business processes as other systems would need to change their integration approach substantially or switch to manual processing of certain steps.
Erhat, not knowing the processes at OmniCo very well, finds himself unable to argue on the merits of the case. The members of the board present him with definitions for an additional 13 services that cover different parts of the Lead-to-Cash process and that were available in the previous Siebel setup. Here’s a schematic view of the integrations:
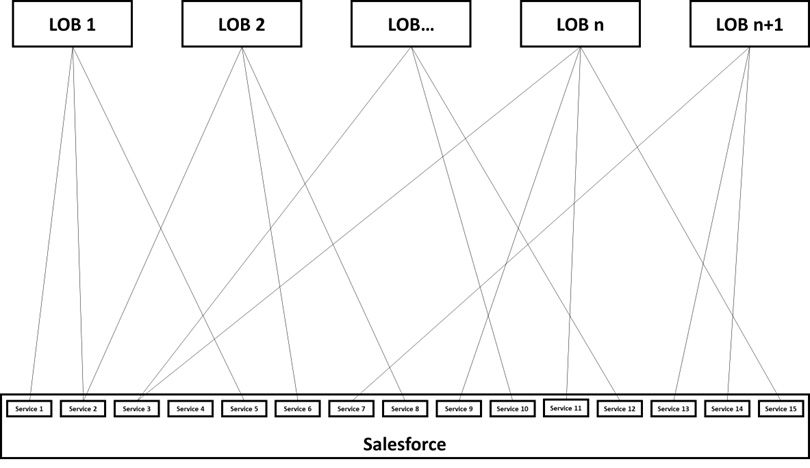
Figure 6.4 – Schematic view of OmniCo Salesforce integrations, not including ESB
Erhat can only really push back on a practical level, which he does arguing that the services are outside scope, are not included in pricing, and that he doesn’t have the team to deliver. OmniCo grumbles a bit and there are a few escalation meetings. However, Erhat is eventually told not to worry—they will solve it some other way.
That way turns out to be bringing in a team of disparate contractors to quickly build the services alongside the main consulting partner’s team. Erhat can just wait and observe as the contractors run into the inevitable technical complexities. He leaves the project prior to go-live with something of a bad taste in his mouth.
12 months later, he is back at OmniCo. He has been brought in as an expert on the company’s Salesforce APIs, which have proved very error-prone and expensive to maintain.
OmniCo is looking for the rationale for why it was built like this in the first place and what to do to fix it. It is also considering different approaches such as changing integration patterns or bringing in some middleware. Erhat takes a deep breath and starts planning the analysis.
Problem
The problem that service proliferation syndrome revolves around is how to fit Salesforce into an existing enterprise architecture that will have preexisting expectations of the capabilities delivered by its key systems. That may be an SOA, as in our example, or a different organizing principle, but typically, one that requires very specific things from key platforms.
This anti-pattern is common across a variety of platforms as it will potentially affect any newcomer to an integration landscape. In the past, it would have been more common as organizations were busily building SOAs, often without a lot of thought as to the organization of specific services.
Today, it is perhaps most commonly encountered when old systems are replaced and interfaces are required that don’t quite fit with the standard capabilities of built-in system APIs. While Salesforce has extensive APIs, they are very data model-centric, and many integration architectures are built along different principles such as coarse-grained business services, which aren’t aligned at all.
Proposed solution
Service proliferation syndrome tackles the problem of fitting into the integration landscape by writing as many and as complex services directly on the Salesforce platform to accommodate the various requests that may be encountered.
This is another anti-pattern that can seem deceptively rational as you are, after all, directly delivering business value and sometimes in line with expectations from cross-company technical governance forums. Therefore, you can be under a lot of pressure to go down this route, knowing full well the damage it is going to do to your platform in the long run.
Because the capabilities are there on the platform and the need is there in the enterprise environment, fighting this anti-pattern can sometimes be impossible. This is even more true because the costs only really accumulate over time.
Results
The first issue you are likely to see with service proliferation syndrome is increased complexity and increased build costs. Custom services on Salesforce, while feasible and sometimes the right choice, are complex to get right. Salesforce isn’t inherently an API platform, a good reason for the acquisition of MuleSoft a few years back.
The increased complexity will over time lead to increased maintenance costs and not just on Salesforce. The various teams using the proliferation of services may also face ongoing costs to rework and upgrade their connections.
Sometimes, a custom service can be the right choice, and the benefits can outstrip the costs both for the initial build and for the maintenance. That is rarely—if ever—the case for 15 custom services as in our example. If you think you need that, you probably need to rethink your approach.
Better solutions
The first piece of advice is to start by looking at standard integration patterns to see if you can find a standard piece of technology that fits the bill. Maybe there is a way of using standard APIs. Maybe you can use a batch process. Maybe you can emit events and have other systems subscribe to those.
You should look broadly and not immediately jump to a custom interface, even if that seems like a good initial fit. The danger is that you go for the gold-plated solution, not realizing the real long-run costs of the decision.
If you do decide that a large number of custom APIs are required—and there are situations where that can be justified—you should use a platform that is built for this purpose to implement. MuleSoft would be the canonical choice for Salesforce, but there are others in the marketplace that can fill this niche.
Overall, you run a risk of overcomplicating both your Salesforce interface and your integration landscape by indiscriminately building services. As always, consider the hard trade-offs and make a decision based on a real view of pros and cons.
Interfacing indecently
In this section, we will look at two common anti-patterns that affect the design of integrations at a concrete level. The first, fat interface, looks at a problem with interface design, while the second, chatty integration, looks at a problem with how interfaces are used.
Fat interface
Example
Joe works as an integration architect for a small Salesforce partner that specializes in complex implementations often requiring substantial amounts of code or other kinds of customization. He has just started a new contract with RealCo, a major real estate investment company that uses Salesforce as the key system of engagement across the entire business.
The work he is initially contracted to do includes building a custom interface for accessing information about valuations, which is used by RealCo’s partners as part of making deals. The information is held in RealCo’s Salesforce org and needs to be available in real time.
Joe sets up the API constituting the interface on RealCo’s middleware platform and orchestrates calls to a few different Salesforce standard APIs and a single custom one as part of the implementation. However, close to the go-live of the new interface, a bunch of new use cases drops on his desk.
These include not just extensions to the valuation API, such as getting historical valuations and trend data, but also entirely different categories of property data including information about the structure of the building, access to key metrics from various assessments, and information on feedback from viewings conducted by RealCo partners.
Joe pushes back a bit on the customer, saying that if he’d known that this much new functionality would be coming, he might have structured the API differently and might have done some things in a suboptimal way to include it with the current go-live.
RealCo’s manager listens attentively to Joe but says that ultimately, the decision is to go ahead with the additional functionality. RealCo is aware of the potential downsides, and it can live with them.
The day before the go-live, the same thing happens again. This time, the information includes more property-related information but also entirely different classes of information such as demographics and segmentation data related to the area in which the property is located, as illustrated in the following diagram:
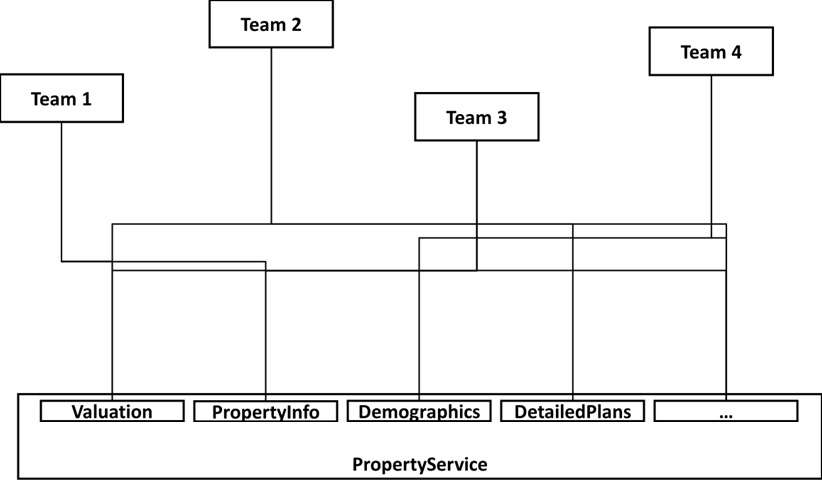
Figure 6.5 – View of RealCo PropertyService
Nothing can be done to include this in a day, which RealCo begrudgingly accepts. However, it wants a plan from Joe to include it post-haste. Given the immense pressure, Joe simply extends the current interface, which is now becoming enormous with calls to dozens of Salesforce services, both standard and custom.
Fortunately, both the initial go-live and the subsequent update go relatively well. The teams at RealCo’s partner organizations grumble a bit about the complexity of the interface and log a number of bugs. But it works, and they can get on with the various applications that the interface needs to drive.
The barrage of change requests keeps happening. And somehow, the changes are always exceptionally urgent and needed for critical use cases in one partner or another. What’s worse is that an increasing number of teams are relying on the interface, which makes upgrades increasingly hard.
Even with good API versioning, the changes between versions are proving quite strenuous for the partner teams who are complaining quite loudly both about the frequent version changes and about the high error rate that has crept into the API implementation.
The final straw comes when a critical bug is found just prior to a new release. Joe, having been told to prioritize getting the new functionality out, includes a hotfix with the new version, which effectively forces an upgrade on all the major partners.
However, it turns out that there are additional breaking bugs in the new API version, which means the key partners lose access to key functionality for over a week until Joe can get the situation under control.
An escalation meeting is called where the partners can voice their various complaints. Joe tries as best he can to explain the history and the reasons for the current situation, but unfortunately, the complexities get lost in the general din.
Joe is told that his contract won’t be renewed and that another consultancy will be brought in to refactor and restructure the interface. He draws a sigh of relief and starts looking forward to his next engagement.
Problem
The problem addressed by the fat interface is fundamentally one of the interface structure—that is to say, where to place functionality so that it can be called by clients that have a need for the services the interface provides.
Note
Originally, this anti-pattern was applied more to interfaces in the sense of the word used in object-oriented programming (OOP). However, it applies equally in an integration setting.
There are several different philosophies on interface design. These days, most people have an instinctual preference for microservices, smallish services that carry out a single well-defined and coherent set of functionalities. An example could be a notification service that does nothing but send notifications.
A few years back, however, the preference was for coarse-grained business services that provided an entry point to a business process—for example, processing an order. This was the foundational style associated with SOA, which we mentioned previously.
With fat interface, however, you are violating a fundamental tenet of interface design that is common to most—if not—all these philosophies. That tenet is called interface segregation and holds that clients should never be forced to depend on methods that it doesn’t need.
Proposed solution
Fat interface proposes to simply continue to add logic to an existing interface because it is the easiest thing to do. Designing well-segregated interfaces can take work and careful thought, and putting all your functionality into a single basket simplifies the problem.
In addition, you can sometimes convince yourself that all the functionality really does belong together because there are some tangential commonalities between it, and this can be especially true if you have consumers that use substantial parts of the functionality you expose.
Often, this anti-pattern is simply the consequence of drift over time. The code starts to do one thing, then it does another, and another, and at the end of the day it does everything and walks the dog.
That would be well and good if it weren’t for the fact that it comes with a number of hidden costs that have to be taken into account. These we’ll explore next.
Results
The results of the fat interface anti-pattern will be familiar if you have been reading this book straight through. It resembles the consequences of poor structure that can occur in a multitude of domains.
When your interface has grown to the extent that it becomes a fat interface—that is to say it now includes so much diverse functionality to have become effectively unmanageable—you are likely to see some or all of the following consequences:
- Increased complexity, leading to increased cost of change, increased cycle times, and increased error rates
- Increased maintenance costs as errors have additional repercussions, clients depend on a variety of existing parts of the interface, and the code base is large and hard to understand
- Only certain developers can make changes to the fat interface because the interdependencies and consequences to users of the interface of making changes require in-depth knowledge of the entire code base
- Bugs in the interface can affect clients that do not even use the kind of functionality exposed in the failing method
- A large number of client dependencies on the interface make disentangling the status quo difficult
Overall, this pattern can seem like a minor code smell when you are just having a quick look. In fact, it can create serious issues for your company-wide integration landscape if you have a failing fat interface in a central position.
Better solutions
This anti-pattern is one of the few that can consistently be avoided by applying good practice and discipline to your development processes. If you diligently follow your interface standards and apply the interface segregation principle whenever you are adding new functionality, this anti-pattern will never occur.
While it may be tempting to take shortcuts and they might not have serious consequences in the short term, you should know the long-term consequences and apply sound design and programming practice. This is also an area where an architect or developer may have a lot to say as it is too technical an area for most business users to really take a position.
The difficulty is, of course, to maintain the required level of discipline when you are under serious pressure to deliver. However, hopefully, making the kinds of points raised in this description will help you push back on quick-fix thinking.
Chatty integration
Example
WoodCo is a furniture maker with a long legacy of making top-tier bespoke furniture for well-off clients. It has been growing like wildfire for the past years due to the launch of an e-commerce platform, built on Salesforce Experience Cloud with B2B commerce, that connects their customer community directly with furniture makers assigned to their projects.
That way, customers and makers can connect directly and discuss requirements for the bespoke builds. Customers can also follow the progress of their furniture throughout its life cycle.
WoodCo project manages the builds, including the budgets, and ensures that any conflicts are resolved amicably wherever possible. It tracks these projects in an old project control module that it also uses to manage its own business.
This project module has recently been extended with a custom-built REST API that sits on top of the legacy application. The vendor has built this API specifically for WoodCo at great expense, but it’s considered a no-brainer as it will allow the direct integration of the portal into the project control module, replacing the current manual process where everything is rekeyed into the project control module by data entry professionals.
Lina is hired by WoodCo to head up digital projects, the first of which is to connect the e-commerce platform to the project control module. She commissions a specialist Salesforce partner to lead the work.
They put in place a lightweight middleware platform that subscribes to events from Salesforce and translates them into REST calls in the format of the new REST API. The REST API doesn’t support any aggregation, so it’s strictly one event to one call.
On the Salesforce side, events are initially only fired on status updates or when key pieces of standing information such as a project title are entered or changed. However, over time, this should be extended to tracking the status of activities within the project and the communication between maker and customer.
You can see an overview of the WoodCo integration architecture here:
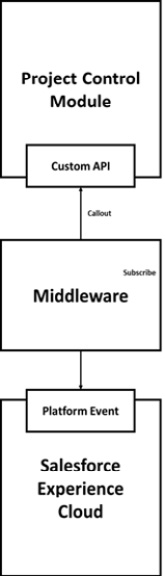
Figure 6.6 – WoodCo integration architecture
The integration launches successfully, and everyone in WoodCo cheers. However, the full benefit is not yet realized as the activities and customer communication are still only in the customer portal, and WoodCo staff still use a combination of rekeying and working in multiple systems to get around the constraint.
Finally, the day of the update, which will include the full synchronization, arrives and everybody waits excitedly for the go-live. However, within minutes of the launch, the project module crashes.
The vendor investigates and attributes the error to scalability issues related to the initial synchronization. The rollout is deferred to the weekend, and after many restarts, the initial data is indeed synchronized.
Monday comes, and people start using the system in anger. There are some complaints about slowness in the project control module, but at least the integration seems to be working and bringing the critical data across.
Then, on Tuesday morning, an administrator is running some routine batch jobs on the customer portal. Near instantly, the project control module comes crashing down again and the new integration is taken offline in order to get it back up.
A crisis meeting is called for that evening by WoodCo’s CIO. This has reached the level of CEO attention, and something needs to be done. Lina entrusts Aki, her most technically gifted subordinate, to figure out the root cause.
At this point, both vendors are blaming each other for the failure and are digging their heels in, refusing to take unilateral action to fix the problem. Aki, therefore, dives right into the middle of the technical setup.
He examines log files and code from Salesforce, the middleware, and the project control module, and after a few hours, he is confident that he has found the root cause. The problem is caused by a recursive update rule that applies certain updates to a parent project such as a change of billing code to all activities in that project’s scope.
Before the new update, this didn’t matter as changes on the activity level weren’t synchronized. However, with the update, each such change triggers hundreds of update events on Salesforce, each of which triggers a callout to the project control module.
You can see an overview of the WoodCo project structure here:
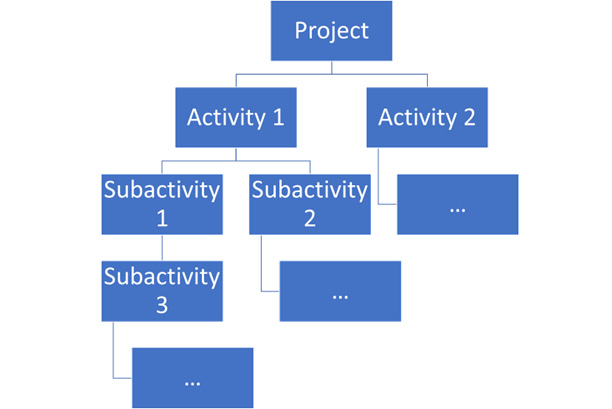
Figure 6.7 – WoodCo project structure
This legacy system can handle maybe one or two such updates at the same time while also serving users normally, but anything more than that causes issues—first, performance degradation, and eventually, a crash. When the administrator launched a batch job to reassign a number of project identifiers (PIDs), this triggered updates for dozens of projects and their activity trees, crashing the project control module in the process.
At the evening’s meeting, the mood is somber. However, as Aki explains the facts of the matter, no one can really disagree. The decision is taken to temporarily disable the activity level and for Aki to lead a team to redesign the integration so that it avoids overloading the project control module.
Problem
The chatty integration anti-pattern is a byproduct of the solution to some other integration problem that for some reason requires very frequent communication between systems. Often, as in our example, that problem involves the transfer of state between two or more systems.
It is an anti-pattern that can be hard to spot during development as it tends to only become problematic with scale. After all, in most test scenarios, except explicit performance tests, we don’t update enough data to really reach a problematic number of integration calls.
The problematic implementation can be due to bad practices such as firing separate callouts for every record in a loop, or it can be more insidious, as in our example, where subscribed events are mapped 1:1 to REST calls in the middleware. Whichever way it occurs, it is at best wasteful and at worst catastrophic.
Proposed solution
As noted, chatty integration tends to be a byproduct of the solution to another problem, therefore it doesn’t quite fit our schema. However, in so far as we can say it proposes a solution, that solution is to make as many calls across system boundaries as necessary to support the business use case without any concern for system limitations.
This is usually done for reasons of simplicity. Once you start introducing bulkification, queuing, systematic delays, aggregation of calls, throttling, or any other mechanism you might consider to limit the rate of calling other interfaces, you also introduce complexity in the implementation.
You will have noted from other anti-patterns that complexity is often a driver of serious negative consequences, so avoiding it will usually seem like a good thing. This, however, is a case where the adage make the solution as simple as possible but no simpler applies.
With chatty integration, you are actually making the solution too simple as it doesn’t meet the basic functional requirement without the additional complexity. That may mean you need more time and additional tools to get your solution to work, but there really is no way around it in this kind of scenario.
This is still true even when using low-code integration tools, sold to make your life easy. If you get the integration strategy wrong, the integration won’t work as intended. Architecture is about trade-offs, after all.
Results
The results of chatty integration form a spectrum:
- Often, there are no immediate consequences if the target systems are able to cope with the extraordinary volume of calls and you stay within Salesforce limits as well.
- Sometimes, you see performance degradation. That can happen on the Salesforce side if you make too many async callouts over a time period, and it can obviously happen on the target side if you start overloading its capacity.
- Performance degradation can turn into periodic errors if you start experiencing timeouts or the target servers get temporarily overloaded.
- Finally, you can sometimes crash the target system altogether, leading to a critical error
You can refer to the following diagram for a visual demonstration:
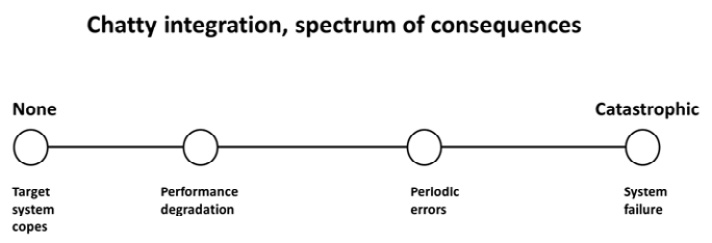
Figure 6.8 – Chatty integration spectrum
That doesn’t mean this isn’t an anti-pattern if you happen to be lucky enough to be on the left side of the spectrum. It just means that for now, you got away with it.
Better solutions
The general advice to follow in order to avoid the chatty integration anti-pattern is to understand and design with system limits in mind. We are not creating theoretical architectures for theoretical systems. If we were, we would be in academia.
When you design an integration as an architect, you are generally doing so with a well-defined target environment in mind. That means you should be mindful of the following:
- Understand the hard constraints such as system limits—for example, the maximum number of calls supported over a time period
- Get information on the actual performance of target systems under whatever level of duress they currently experience
- Don’t just fire off calls without consideration of the performance implications of doing so
Instead, use one or more of the following strategies to ensure that the target system can cope:
- Bulkification: Send multiple logical calls in the same message
- Consolidation: Combine multiple updates in a single call
- Aggregation: Combine changes to multiple areas into one call covering several areas
- Delay: Introduce a delay in sending off a call when performance is spiky
- Reduce frequency: Send updates less often
- Buffer: Add your calls to a queue that is gradually drained as the target system has capacity
Overall, a chatty integration has the potential to level your integration landscape if you are unlucky. Therefore, it should be avoided even when you don’t believe you will run into trouble in the short term.
Getting the patterns wrong
In this section, we look at how becoming too obsessed with a single integration style can cause serious problems by looking at the integration pattern monomania anti-pattern.
Integration pattern monomania
Example
WineCo has been a heavy user of Salesforce technology for more than a decade. It has a large estate of many orgs across core clouds, Marketing Cloud, and commerce.
It has developed a custom approach to building on Salesforce, including a range of frameworks and libraries that it uses consistently across projects. Many of these could use an update, but they are still preferred for the sake of consistency.
Clare is brought in from a leading consultancy to lead the build of a new app that WineCo is building for its distributors. The app will include communications between WineCo managers and the distributors, e-commerce for standard items, rebate management, custom pricing logic, joint opportunity management, and the ability to request quotes for special requirements.
To deliver the required level of functionality and realize the business value attributed to the distributor portal, Clare will need to ensure that integrations are in place to many systems.
She must funnel all communications through the central notification service that ensures all communications are appropriately logged and have the right footers in place. Then, she must integrate with the existing rebate management system that calculates the rebates due to distributors based on their segment and historical orders.
Pricing will come from Salesforce CPQ but in a different org, requiring a Salesforce-to-Salesforce integration. Content for the portal web pages will come from the corporate CMS. However, there are also services for user and behavior tracking that must be integrated from the CMS into the portal website.
Finally, the ERP needs to be updated with any custom quotes and standard orders that are made through the distributor portal. The distributor portal will also need to get a substantial amount of data about distributors, their existing orders, and standing data about them from the ERP. All in all, while the basic build on Salesforce is complex, the integration landscape is even more complex.
The proposed architecture is represented in the following diagram:
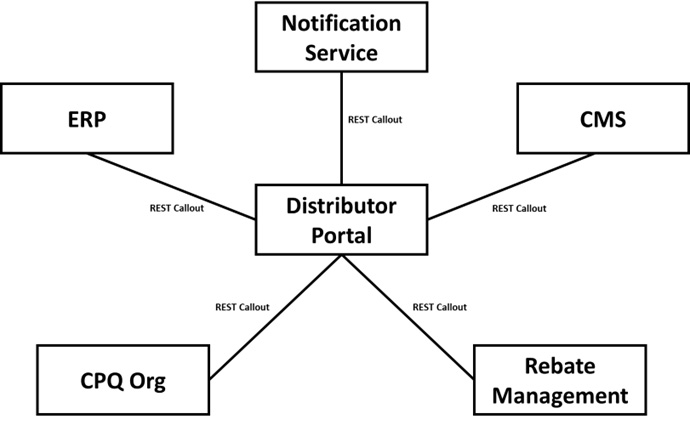
Figure 6.9 – Proposed integration architecture for WineCo
Further complexity is added by WineCo’s corporate integration standard. It states that all integrations from Salesforce must be implemented using the company’s integration library. That would be fine; however, the only patterns supported by this library are synchronous or asynchronous REST callouts, limiting the options for the integration design considerably.
Clare and her team get on with it, regardless. They complete much of the core Salesforce build ahead of schedule, but the integrations are lagging behind. They run into several different problems.
First, the rebate system doesn’t support any kind of bulkification, leading to large numbers of calls to its APIs. The system owner questions whether the current setup will scale in a go-live scenario, and eventually, four new servers need to be procured to give the business comfort that the system can handle the load.
Second, there are too many queries to the ERP system, leading to slow response time and long wait times in the UI. This proves unsolvable under the current architecture, and a decision is made to handle it as a training issue.
Third, the CMS services prove hard to call from the server side, and a compromise is made to include the tracking code via JavaScript, although this requires a formal exception and causes substantial delay.
Finally, the notification service is a bad fit for many of the messaging requirements that the distributor portal has and results in weirdly formatted messages that are hard to reply to in many cases. That is also accepted and consigned to be handled as a training issue.
The project is completed and goes live without much fanfare. The internal users dislike the new interface and distributor adoption is lukewarm. Clare makes a final argument for redesigning the basic integration architecture to something more suitable, before moving on to the next project.
Problem
Integration pattern monomania seeks to address the problem that designing a good integration architecture is fundamentally hard, as is determining the right patterns, design, and implementation characteristics of concrete integrations.
It is, therefore, attempting to simplify the problem by focusing on a single approach that works well in many cases. That way, you can define a standard way of doing things without having to grapple with the exact details of each individual case.
This is attractive for several reasons:
- First, standards often work. In many cases, having a standard way of doing things is the right way to go. However, an entire integration architecture is too broad a target for such an approach.
- Second, once you have chosen an approach, you can create supporting assets such as code libraries, frameworks for logging and error handling, and so on that will work across integrations, which is generally beneficial.
- Third, you only really need developers to know how to do a single thing. That reduces development complexity, training, and onboarding needs.
All of that would be great if it weren’t for the inconvenient fact that no single integration pattern is universally applicable.
Proposed solution
Integration pattern monomania proposes to use a single integration pattern for all—or at least, nearly all—concrete integrations needed in an integration architecture. It can be either explicitly set via a corporate standard or it can be implicit in the way the architects and developers work and think. In either case, when such a preference becomes excessively strong, you have an anti-pattern.
The aims of integration pattern monomania are usually eminently sensible:
- Reducing the complexity of integrations by limiting the choices architects and developers need to make
- Enforcing consistency in the enterprise architecture to avoid unwanted side effects
- Make developers’ lives easier by giving them a clear way forward and supporting them with relevant tools and frameworks
The issue is that not all concrete integrations will fit a given pattern. Characteristics such as the velocity of updates, acceptable latency, data volumes, and the needs of the user experience (UX), among other concerns, mean that overreliance on a single integration pattern is detrimental in the long term. This we will explore next.
Results
The problems caused by integration pattern monomania boil down to technical misfits. This is something we have seen in other anti-patterns—for instance, Golden Hammer. While some of the positives may apply in specific cases, overall you are likely to see some of the following consequences:
- Instead of decreasing complexity as intended, your integration landscape becomes more complex due to a variety of workarounds needed to accommodate the limitations of the integration pattern that is being used exclusively.
- Some integrations may not function within their intended quality parameters because of poor technical fit. That may mean periodic errors, poor performance, or similar.
- These factors generally imply a higher maintenance and support burden on an ongoing basis to correct the issues.
- Finally, the UX in some areas will be underwhelming to end users as the pattern can’t meet expectations.
Overall, you don’t get the anticipated benefits and instead end up with a bit of a mess.
Better solutions
The solution to integration pattern monomania is simple. Don’t get overly fixated on a single integration pattern, whether that is RESTful callouts, EDA, or batch transfers.
Instead, you can give good guidance to application developers and architects about which patterns are appropriate in which circumstances. It is fine to have a preference where all else is equal, but in practice, things rarely are.
Here’s an overview of Salesforce integration patterns:
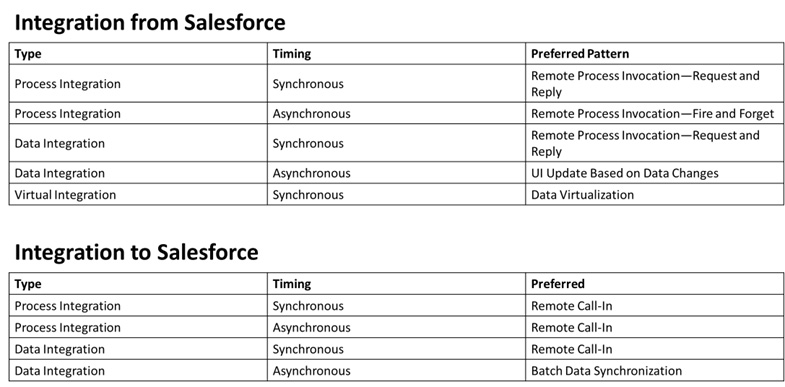
Figure 6.10 – Overview of Salesforce integration patterns
A certain level of conservatism toward choosing integration patterns can be warranted. That can give you some of the benefits that come from having a consistent approach, such as leveraging standard frameworks and libraries.
You can also use middleware to create a certain commonality of integration stance between systems, although that just moves the complexity onto another platform. However, when push comes to shove, if a certain approach is the right one for your integration, then you should use it.
We have now completed our coverage of the patterns in this chapter and will continue to the key takeaways.
Knowing the takeaways
In this section, we will abstract a bit from the specific patterns and instead try to pull out the wider learning points you can use in your day-to-day work as a Salesforce architect or in preparing for the CTA Review Board.
When architecting Salesforce solutions, you should be mindful of the following:
- Middleware can be a great way to create order and improve the structure of your system landscape. However, you can also use it in ways that do more harm than good.
- If all you are doing is replacing point-to-point connections with equivalent one-to-one flows through the middleware, you are probably in anti-pattern territory.
- Custom services can be a great addition to your Salesforce org in certain cases. However, they come with considerable added complexity.
- You should never reflexively add lots of custom services because they seem to be what the business is calling for. Instead, take a step back and look at the big picture of requirements to see what options you have for realizing the specific integration flows required.
- If you are building custom interfaces, whether on Salesforce or on your middleware platform, have appropriate governance in place to avoid ending up with a fat interface that does everything.
- Avoid excessively frequent integration calls if possible.
- If you do need high-frequency state transfer, consider using a dedicated technology such as Change Data Capture (CDC).
- In general, always design integrations with system limitations explicitly considered. Don’t assume an old ERP can handle unlimited calls, for example. Salesforce, of course, also has defined limits.
- Keep a flexible approach to integration architecture. Don’t fall in love with a particular style and use it for everything. Just because event-driven microservices are hot doesn’t mean they are right for every scenario.
- Do give good guidance on how to select integration patterns for both members of your team and external partners. Don’t assume that they will make the right decisions by themselves.
In preparing for the CTA Review Board, you should be mindful of the following:
- Almost every scenario will have a requirement for middleware. You should know the key capabilities of common platforms such as MuleSoft and be able to talk intelligently about how they fit into the system landscape.
- While you may not see enough integrations to create a problem along the lines of the MINO pattern in the scenario, it is still worth thinking about the specific value the middleware is adding to each of the integration flows you are funneling through it.
- Don’t reflexively just funnel every integration through the middleware—there are often exceptions that may require different treatment.
- Suggesting a custom web service is a major piece of customization and would need a strong justification to include in a review board architecture.
- If you need a custom interface, it is more likely that you should be building and exposing via the middleware in most scenarios.
- While you are not likely to face a situation with a fat interface in a review board situation, it is worth considering how you are structuring your integration interfaces and whether it is balanced.
- You need to consider the potential performance implications of the designs you suggest. Often, scenarios will have high-volume requirements that if specified in an obvious way will lead to performance issues similar to the chatty integration pattern.
- You may get quizzed on integration limits for the Salesforce platform, so it’s worth having these memorized for the board.
- You should know all the common integration patterns on the Salesforce platform inside out.
- This includes the decision guidance on when to choose what pattern. You are likely to need several at the board, and you should be able to clearly articulate why you have chosen as you have.
We have now covered the material for this chapter and are ready to proceed. First, however, we will summarize our learning.
Summary
In this chapter, we have reviewed five different anti-patterns that in very diverse ways can contribute to failing integration architecture. This diversity is worth keeping in mind.
The integration domain is exceedingly complex and there is scope for getting things wrong at multiple levels. From choosing the wrong integration patterns or misusing your middleware to the technical details of your concrete implementation, there are anti-patterns that can potentially cause serious problems not just to your own project but at an enterprise architecture level.
This fertile soil for error is why experienced architects are always wary about integrations. They are one of the most common causes of project failures, both on Salesforce and in general.
It’s worth reiterating that this chapter is the only one where all the anti-patterns apply not just to Salesforce but to all enterprise software systems. Having covered this material, you are hopefully slightly better prepared to tackle the challenges ahead of you in the integration domain.
Having now covered the integration domain, we will continue to talk about anti-patterns that apply to your deployment processes and governance.