
4
What Not to Do about Data
This chapter is about the ways in which you can compromise your data layer on the Salesforce platform. Throughout this chapter, we cover four data domain anti-patterns that occur with some frequency in Salesforce environments and give you pointers on how to recognize and avoid them.
In this chapter, we’re going to cover the following main topics:
- Why treating Salesforce as a relational database won’t lead to acceptable results
- How failing to coordinate activities can lead to a disconnected data model with serious negative repercussions
- The negative consequences of failing to plan for growth in your database, especially when you should know better
- Why data synchronization can be a great solution on a small scale, but a nightmare on a larger scale
After completing this chapter, you will have a good understanding of how Salesforce is different from a traditional relational database and why that matters greatly. You will also know the importance of good governance, planning for data modeling and growth, and what can go wrong when you don’t have governance in place. Finally, you will have a deeper insight into the complexities of data synchronization.
Mistaking Salesforce for a regular database
Many people come to the Salesforce ecosystem from other technology backgrounds, and they often come with preconceptions about how architecture should be done based on their past experiences. While that can be enriching to the platform, there are also cases where it can lead you to go astray, architecturally speaking. Perhaps the most frequent of these is the mistake of using Salesforce as though it were some other kind of database—generally a relational one.
Salesforce as Relational Database
Example
UmbrellaCo is the largest global manufacturer of umbrellas for the tourism industry. They use Salesforce for managing their B2B sales channel, including opportunity management, quoting, and ordering.
However, in the overall systems landscape within UmbrellaCo, Salesforce is a relatively minor component. Overall, the landscape is dominated by a set of bespoke lines of business systems that have been developed and maintained in-house and an aging Manufacturing Resource Planning (MRP) system.
There is also a relatively modern middleware platform and UmbrellaCo’s approach to Enterprise IT that relies heavily on integrating, translating, and combining data from various systems within the middleware. This allows them some additional agility that they otherwise would not be able to have, given their aging and bespoke systems portfolio.
Rishi is the responsible manager for Salesforce at UmbrellaCo. He is an external hire that only recently joined the company from a mid-size ecosystem partner. One of the first things he has to deal with settling into his new role is a series of complaints from the middleware team about the Salesforce data model.
UmbrellaCo has longstanding practices for modeling certain kinds of data such as different types of accounts, for example, SME accounts versus large corporate accounts, and strict standards for modeling addresses. The Salesforce model does not accommodate this model in the standard way, leading to substantial work on the middleware team in mapping the data to other systems.
John, an integration architect long employed by UmbrellaCo, is assigned to the Salesforce team in order to align the Salesforce data model. Rishi is immediately quite uncomfortable in the collaboration with John. John displays a high degree of distaste for the Salesforce data model and thinks it fundamentally fails to conform to good data modeling practices.
The standard within UmbrellaCo is to use relational databases, normalized to Third Normal Form (3NF), and follow the corporate conventions for key data types. Salesforce does not meet these expectations and cannot easily be made to do so. Rishi tries to explain that the Salesforce data model shouldn’t be thought of as a classical relational database, whatever superficial resemblance it might have to one, but his objections fall on deaf ears.
After a month of work, John puts forward his proposal for reworking the Salesforce data model. It involves replacing the standard Salesforce address field with a new set of custom objects incorporating the address and an arbitrary number of address lines linked to the master account object. Different types of accounts will get their own individual custom objects and refer back to the master account object using an inheritance-like interface.
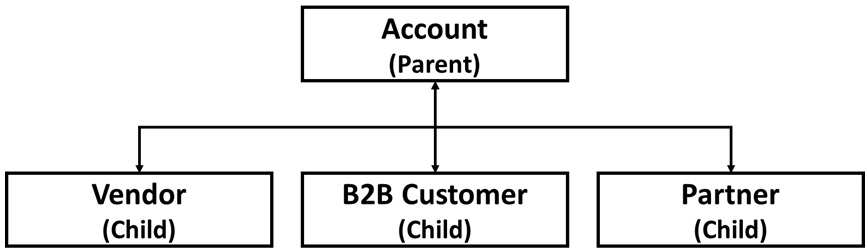
Figure 4.1 – Proposal for refactoring account model
This will require both rework on the user interface and an internal data migration exercise within Salesforce to accomplish, but John is adamant that this will bring the system into line with corporate standards and make life easier on the middleware team.
Rishi vehemently objects and even gets his Salesforce account executive to bring in a senior solution engineer from Salesforce, trying to explain why following this plan is a surefire way to cripple the Salesforce platform and make additional projects more complex and expensive. The objections make their way to the company’s architecture forum but are rejected as conformance to corporate standards is considered a more important imperative.
Going forward, data modeling on Salesforce should follow the normal UmbrellaCo standards and deliver well-normalized data models that meet the specifications set out in the enterprise data model. Rishi draws a deep breath and consigns himself to having to do mostly bespoke solutions on Salesforce going forward.
Problem
The problem addressed by Salesforce as Relational Database is the general one of modeling business entities in the context of a software system. In this case, use the most commonly used modeling paradigm in the software industry: relational database models.
In this approach, you map a logical model of a business domain into a set of database tables, using a process called normalization. The details of what normalization is do not need to concern us much, but it is fundamentally concerned with the elimination of redundancy within the database. That is to say, each piece of information should be held once and uniquely within the database and then referenced in all of the places that it’s used.
In addition, there should not be repeating fields, such as multiple address lines, and all the fields in an entity should rely explicitly on the primary key: the ID field in Salesforce. You should always have one and only one unique key for the entity.
By applying these and a few more elaborate rules with greater or lesser stringency, you get to a certain normal form, the name for models of normalization. The strictest application is something called Sixth Normal Form (6NF) where you end up with tables consisting of only a primary key and one other attribute. However, most enterprise applications strive for something called 3NF, which effectively meets the criteria we outlined above.
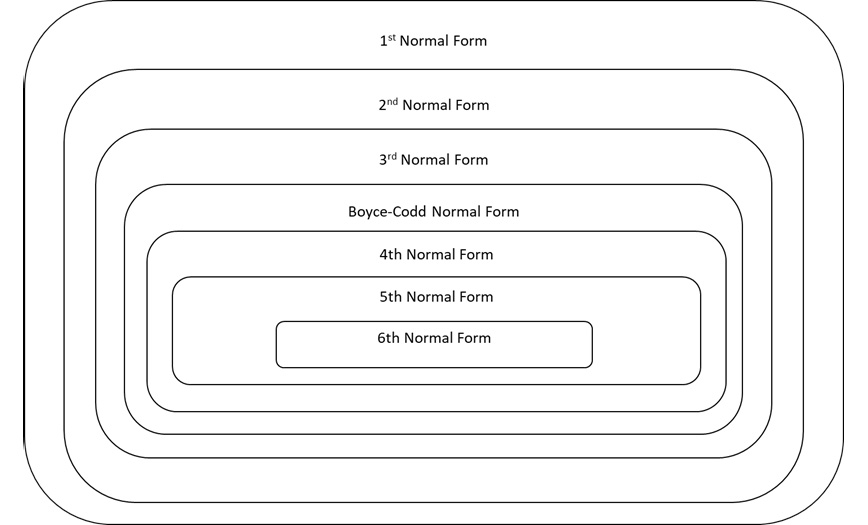
Figure 4.2 – Hierarchy of normal forms
This is all well and good and is the accepted way to do things for systems based on relational databases. However, Salesforce, while it has a number of surface similarities to a relational database (namely tables, called objects) and relationships (in the form of lookup and master/detail relationships that enable its use as a relational database), is not a relational database and should not be treated as such.
Proposed solution
Salesforce as Relational Database ignores the distinctive nature of the data modeling used on the Salesforce platform and replaces it with a model that bases itself on relational databases. This means using custom objects freely to serve as tables and relationships of either type to serve as foreign key relations.
It explicitly ignores Salesforce’s standard ways of dealing with record differentiation, such as record types and page layouts, in favor of a relational model with a larger number of unique custom objects. In addition, this anti-pattern tends to make scant use of standard objects as these do not fit with a well-normalized data model.
This solution makes a lot of sense to many experienced architects coming to Salesforce from other platforms without a lot of understanding or training. It is, after all, the accepted way for things to be done in all traditional enterprise systems, and consistency with an accepted standard is extremely valuable in enterprise architecture.
However, bending a system so out of shape as this pattern does to Salesforce goes to show that every standard has exceptions.
Results
As we saw in the earlier example, the result of introducing this anti-pattern is fundamentally increasing the complexity of your Salesforce solution, resulting in additional costs both for solutioning and maintenance.
By relying on custom objects for nearly everything, you reduce your ability to leverage out-of-the-box features, because relational models tend to require a larger number of smaller objects, which makes some commonly used Salesforce features (for example, cross-object reporting or cross-object formula fields) nearly impossible to use.
That means you’ll most likely need to write more custom code or construct complex custom flows, which is where you take a real hit both on upfront implementation cost and time and on the maintenance and extensibility of the solution afterward.
There is also the opportunity cost of not being able to use standard functionality to the same extent and not being able to adopt newly released features with the same frequency to consider. All in all, this is a high price to pay for consistency.
Better solutions
The data domain is an area where you should adopt the Salesforce way to get the best results. While sometimes there are exceptions to Salesforce good practices, when it comes to data modeling, the guidance should be followed nearly without exceptions.
That means modeling broad-based business objects directly in the system rather than going through a normalization process and relying on the platform to manage and optimize the data or at least give you the tools to do so. It also means using standard objects whenever you can, avoiding Custom Objects whenever possible, and ensuring that the data model is well governed to avoid issues with data integrity and redundancy.
This is obvious to many people who have grown their careers in the Salesforce ecosystem, but it is counterintuitive to most traditional architects. This, then, is one of the few anti-patterns that is more likely to be initiated by a highly experienced architect than a brand new one. It’s also more common in AppExchange applications than in standard implementations as these are closer to the traditional development models found on other platforms.
Forgetting about governance
Governance is important in all architecture domains, but perhaps a few domains can go wrong where governance is missing as the data domain. In the following sections, we will explore two examples of this phenomenon, starting with what happens when you fail to coordinate data models on a common platform.
Disconnected Entities
Example
SmileCo is a major provider of dental supplies operating in several global cities. They have been using Salesforce for several years, using a departmental strategy, where each department has run independently on Salesforce without central oversight.
There are three departments that use Salesforce in a serious way and they are as follows:
- Finance, which uses it for debt collection using a home-grown application
- Logistics, which uses it for vendor management using an application that has been developed by a small ecosystem partner
- Sales, which uses a standard Sales Cloud implementation
The information in these apps is spread out and there is no cross-visibility or collaboration between the teams. Kimmy is a consulting manager at a Salesforce Summit partner who is brought in with a small team to enable a comprehensive view of the underlying data.
She, however, soon discovers that the job is bigger than she bargained for. The finance application uses a flat, denormalized data model to model debt collection. All information is held in a giant debt custom object, including all contact and account information. This data is not validated and data quality at a glance seems problematic.
The logistics application effectively mirrors the standard Salesforce data model using custom objects to represent vendors, vendor contacts, and information about quotes and purchases made from vendors. The fields differ substantially from the standard Salesforce data model but could be made to fit with standard objects such as account and contact with a bit of creative data mapping.
The Sales Cloud implementation is relatively standard but uses quite a few additional custom fields that in no way match up with the way data is modeled in the other two platform apps. Kimmy reports her findings to the client, who after some hesitation requests that she continues with a plan for consolidation nonetheless.
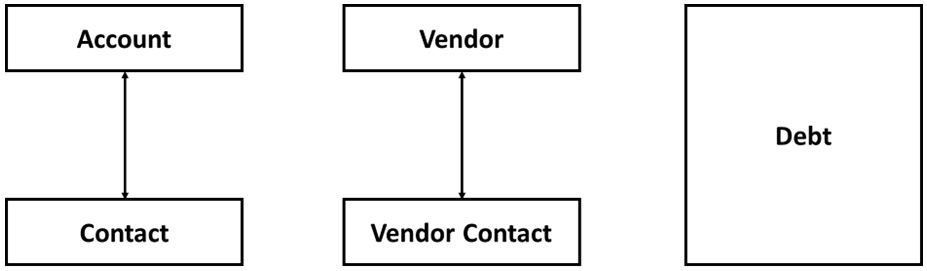
Figure 4.3 – Three different ways of representing account and contact
The plan she proposes seeks to standardize the use of the Account and Contact objects, using the standard objects, across all three departments, and on that basis write a set of reports and dashboards giving the required overview. She gives up on trying to consolidate additional objects as they are too far away from any standard objects for the attempt to be likely to succeed.
For the finance application, she suggests renormalizing the account and contact parts of the gigantic debt object. This requires a data migration exercise as well as significant work to deduplicate and improve data quality. Rework on the application itself, thankfully, is relatively minor due to the simple declarative features used for its implementation.
The logistics application presents a larger problem. Most of the functionality is in custom code and requires substantial rework. The partner is reluctant to make the changes Kimmy suggested as they prefer working in their own space, but after some pushing, they relent. However, the changes are quite expensive and take several months to implement.
Overall, what was meant to be a small consulting engagement of a few weeks’ duration ends up taking more than three months, incurring substantial costs. Upon leaving the client, Kimmy sends a new proposal for introducing some basic Salesforce governance functions within SmileCo. They take the proposal under advisement and promise to get back to Kimmy in good time.
Problem
Disconnected Entities is another anti-pattern that happens when you fail to recognize that certain practices carried out without oversight or governance can result in serious issues at a higher level of operation. It is caused by a lack of awareness rather than by the attempt to achieve something specific.
It tends to occur in smaller or highly decentralized organizations where different groups may share the same infrastructure, in this case a Salesforce org, but not really coordinate activities beyond the absolute basics. It also requires an environment where IT maturity is low and governance of IT is minimal.
Proposed solution
So far as we can frame what the Disconnected Entities anti-pattern proposes as a solution, it effectively says something along the lines of don’t worry about the data model, any design will be good enough. At least that is how it will be interpreted because there will be no standards, practices, or guidelines to follow.
Lack of governance can have bad effects in many domains, but in the data domain, the Disconnected Entities anti-pattern is one of the worst. It means that teams build in isolation with no awareness of what else exists on the same platform or how other teams are using the same elements (even the same standard objects).
That means that you can have a cross-organizational impact without realizing it. And at the very least, the anti-pattern leads to the kind of scenario sketched in our earlier example where cross-departmental initiatives are hampered or blocked by the data model.
Results
For the Disconnected Entities anti-pattern, the results can be as chaotic as the process that produces them. For the small teams whose uncoordinated work eventually causes the anti-pattern, it usually works out just fine in the short term.
When you are working in isolation on your own thing, there really isn’t any short-term impact to doing things badly or idiosyncratically. The impact only comes with scale, coordination requirements, or a need to extend the application to new use cases.
The specific negative consequences can therefore vary considerably, but some common ones include the following:
- An inability to achieve 360-degree visibility of contacts or accounts, or any other relevant business entity for that matter
- An inability to do cross-departmental or cross-application reporting
- Increased cost of new development and maintenance due to variability and complexity in the data layer
- An inability to connect applications or create cross-departmental workflows without incurring substantial rework costs to bring different areas in line with each other
- Duplication of effort between different areas
- Less scope for adopting new standard features as they are released because of inconsistencies in the data models
Overall, then, this anti-pattern has many of the same characteristics in the data domain that Big Ball of Mud had in the system domain or that Spaghetti Sharing Model had in the security domain.
Better solutions
Unsurprisingly, the key to avoiding an anti-pattern caused by missing governance and awareness is to institute the appropriate governance- and awareness-generating mechanisms. That means first and foremost having the appropriate governance forums in place, where different areas can coordinate their activities in a structured way.
This needs to be supported by good data governance standards and practices to support the work done in the relevant forums. These can take different forms depending on the organization and its culture, but to avoid Disconnected Entities, a list such as the following is a starting point:
- Rigidly enforce the use of standard objects and fields wherever possible
- Ensure that teams use standard objects and fields consistently
- Have an approval process for creating new custom objects that teams must follow
- Have a lighter approval process for creating custom fields
- Define ownership of all objects and ensure that object owners are consulted about all changes to their objects
- Have an architect or two take a global view of the data model and offer ongoing advice on its evolution
Having now covered what happens when you fail to coordinate your activities in the data domain, we will move on to look at what can happen if you fail to plan for growth.
Unplanned Growth
Example
HappyWorkoutCo is a sportswear retailer with more than 200 shops globally. They have developed a customized retail management application based on Salesforce Industries but with a large amount of customization and some bespoke development. The application has been developed in an agile, iterative fashion and that is also the way they are proposing to go live.
Martin is in charge of the rollout to the stores. Initially, they will roll out the product for only three small product categories to a handful of stores in major markets. While the product tests well, Martin still has butterflies as the first stores go live.
But this time, the rollout is a great success. The product works flawlessly and the staff in the stores loves the new capabilities the software gives them for greater individual engagement with customers across channels.
Buoyed by the initial success, Martin and his team start a program of incremental rollouts to both more stores and product categories. Everything initially continues to go well, but after a while, complaints start coming in about system performance. There is a noticeable slowdown on a number of screens in the system and some key reports take minutes to run.
A task force consisting of members of Martin’s team as well as technical resources from the development partner is put together to have a look at the issue. However, the decision is made to continue the rollout of both new products and new stores.
The task force gets underway, but soon after it begins its work, a major incident occurs following a major go-live where 20 new shops and several thousands of products were being brought online. The system creeps to a halt and several screens stop working altogether.
Martin’s team conducts an emergency rollback, which restores the system to an operational state, but now all eyes are on the performance task force. The team works quickly with renewed vigor and intensity and discovers what it believes to be the root cause.
Inside the package containing the core retail management application, there is a junction object that contains a record for each product configuration available at a given retail store. When the system went live there were five stores, 100 products, and about ten configurations each, for a total of 5,000 records.
After the big go-live, there were 150 stores with 17,000 products, each with an average of 35 configurations for a total of 89,250,000 records. What’s worse is that the object didn’t only contain current records but also historical ones that had been overwritten during the rollout process, leading to more than 117,000,000 records in the junction object.
The object is used in a number of automations, batch jobs, and reports and is also queried frequently by custom user interface components. The design seems to have been mainly a matter of development convenience and no one seems to have ever done any calculations around the amount of data to be stored in the object.
The task force presents its conclusion and recommends a number of stopgap measures, including removing the automations, archiving all of the historical records, removing rare product configurations, tuning some reports, and implementing some caching and optimizations in the user interface.
This program of work resolves the immediate fire, but the system still doesn’t perform up to expectations. Martin starts negotiations with the development partner about how to redesign the system to eliminate the root cause.
Problem
This is another anti-pattern that tends to be instigated not by an active choice but by a deprioritization of certain practices in order to deliver on a specific goal. In the case of unplanned growth, the team deprioritizes the ability to scale in order to achieve greater speed in the initial delivery.
This can be appropriate in some cases, for example, if you are a start-up trying to prove product-market fit on a shoestring budget, and for this reason, it can be subtly seductive. Many large organizations these days want to see themselves in the mold of an agile start-up, adopting many practices from this world.
However, for large well-established organizations that already have a certain scale, failing to acknowledge this fact up front is a recipe for disaster.
Proposed solution
The Unplanned Growth anti-pattern proposes that a team should get on with the important business of delivering without paying much attention to the issues that may arise due to increasing scale down the road. Effectively, the proposal is to make small-scale progress and then adapt later, should the scale be required.
This anti-pattern is different from others such as Disconnected Entities as it is not an absence of awareness that causes it, but rather an active choice to deprioritize planning for scale. Again, it is worth noting that this is not always an anti-pattern.
In some cases, starting small and then taking the hit on rework later is a justifiable strategy. Typically, this is the case if you don’t know up front whether your idea will work or how many users it will need to accommodate when you are building the application partially to get more information.
But it is always an anti-pattern when done by a large organization that knows the application it is building will eventually need to reach a certain definable scale.
Results
The results of Unplanned Growth encompass a fairly large number of scaling issues, determined by the nature of the application in question. Most commonly, you will see Large Data Volume (LDV) type issues such as the following:
- Slowdowns in reports and dashboards
- Slowdowns in list views
- Locking issues on data loads or even in normal use
- Time-outs when loading custom components
- Errors cropping up about governor limits
- Third-party packages failing
You may also see the general UX crawl to a halt, especially if it uses many custom pages and components. Integrations can also be affected by the same issues, leading to serious errors across systems. Even automations that were working perfectly may start to fail, although not necessarily in a systematic way.
All in all, if the unplanned growth is significant enough, it can bring your entire solution to its knees.
Better solutions
The number one thing you need to do to avoid this anti-pattern is to be clear from the start about what scale you are building for. If you are planning to build something that works on a small scale to test out an idea, then that’s fine, but be explicit about it and have a plan to take a step back and redesign if it turns out you are successful and need to scale.
If you know for a fact that you need to hit a certain scale, it is nearly criminal not to design for it up-front. That means incorporating LDV mitigation tactics such as the following:
- Using selective queries
- Optimizing our queries with the platform query optimizer
- Avoiding synchronous automations on LDV objects
- Avoiding synchronous code running queries on LDV objects
- Using skinny tables to optimize specific queries and reports
- Using custom indices to optimize specific queries and reports
- Archiving non-current data continuously
- Using external objects to store data externally when possible
Designing for growth also means designing the data model in a way to reduce LDV issues in the first place. In our preceding example, there would most likely be many alternative data models that did not have to hold a complete record of all product configurations by store in a single junction object.
Having now considered what happens when you fail to consider scale in the data domain, we will move on to the last anti-pattern in this chapter, which is Unconstrained Data Synchronization.
Synchronizing excessively
Data synchronization is hard to get right but extremely useful when it works. It is, however, easy to get carried away when starting to put synchronization methods in place, which can cause a plethora of problems. We’ll see how in the following sections.
Unconstrained Data Synchronization
Example
BusyCo, a large vendor of productivity-related products, has recently implemented a B2B omnichannel digital experience spanning web, social, call center, and partner channels. They have implemented the web application using a bespoke approach based on Microsoft Azure and use Salesforce to manage any manual processing steps for quotes and orders as well as opportunity management and any quotes or orders originating via calls or field sales.
All of the information eventually goes into the Enterprise Resource Planning (ERP) that handles the fulfillment and financial side of the ordering process as well as serving as the source of truth for financial forecasts. Because of its role in producing financial information, the information in the ERP must always be of the highest possible quality.
Oleg, the lead architect on the Salesforce side, recommended a structured approach to data governance with clearly defined roles and responsibilities for each system in relation to the core data model objects. Also, there should be clearly defined ownership in place for key fields and objects, so the source of truth is always known.
BusyCo, however, has gone with the approach that any piece of information can be modified in any system at any point in time and all systems will be updated with the modified data in near real-time. To achieve this goal, they have put in place bidirectional data synchronization between all three systems.
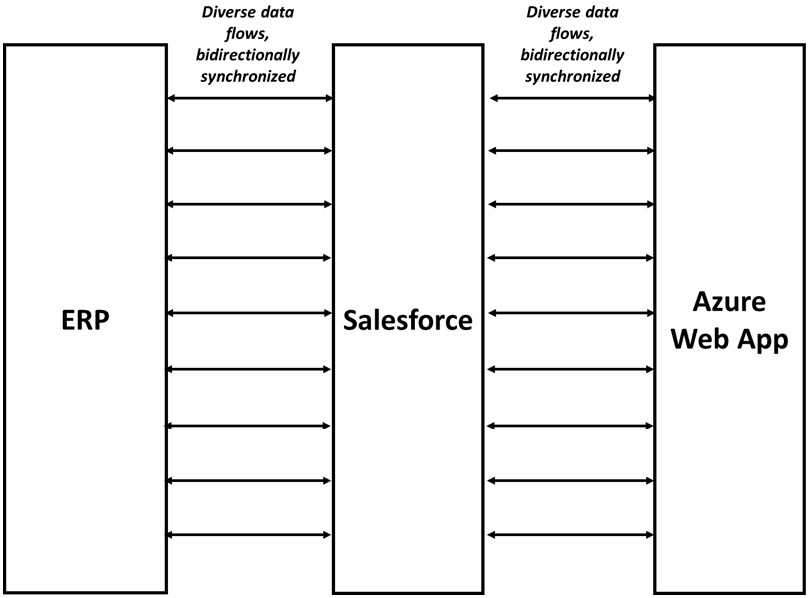
Figure 4.4 – BusyCo synchronization scenario
No problems are found during the acceptance testing phase, but Oleg is not particularly reassured. The testing scenarios do not begin to cover all of the things that can go wrong once the synchronization functions are out in the wild. The business users, however, love the flexibility of being able to change anything in whatever system context they happen to find themselves in.
After the go-live, things start to crop up. No showstoppers, but a number of annoying errors begin to emerge. One day, the link between the website and the other systems is down for a few hours and afterward a number of records fail to synchronize correctly. What’s worse is that a few days later, it is discovered that some address updates were never synchronized to the ERP so some customer orders were shipped to the wrong addresses.
There is also a recurring problem with quotes that seem to go back and forth between statuses in Salesforce and the ERP. The cause seems to be a batch job running in the ERP doing some routine maintenance. As the job can’t be turned off, the only solution in the short term is a manual workaround where the support team takes a daily task to reclassify quotes with a wrong status.
Moreover, there are some fringe cases around the synchronization of manually inputted quotes and orders. They don’t seem to reliably trigger the data synchronization in all cases and therefore some orders hang in Salesforce and never get shipped.
As the errors compound, business leadership starts to pay more attention to voices such as Oleg’s that advocate simpler patterns for managing the data between the systems. However, as the system is already live and works at least partially, any refactoring will need to be done without requiring major downtime.
Oleg accepts the challenge of finding a way to refactor the system to use simpler data integration patterns while instituting better data governance. It won’t be easy, but with time and effort, he believes BusyCo can succeed.
Problem
In contrast to the last couple of anti-patterns that happened due to a lack of awareness or a failure to act, the Unconstrained Data Synchronization anti-pattern happens because of you trying your best to give the business what it wants. Sometimes, you can have the best intentions at heart and still end up causing a terrible mess.
The problem you’d be trying to solve in this case is how to have all the relevant business data available and editable in different systems at the same time. Users hate switching between contexts. If they are in System A, then they want to be able to edit all the relevant fields in System A. If they are in System B, then they want to be able to edit all the relevant fields in System B. If the fields they want to edit are the same from a master data perspective, say, an address or the name of a customer, that requirement will force you to synchronize data.
From a user experience perspective, this is perfectly rational. Switching between systems and screens in order to update data is a pain as is not having the information you need available where you need it. Equally, you usually need this information to be available in near real-time across systems to avoid processing errors.
Near real-time data synchronization can seem like a panacea, and it would be if it weren’t so fiendishly complicated from a technical point of view.
Proposed solution
The solution proposed by Unconstrained Data Synchronization is to bidirectionally synchronize all relevant data points between all relevant systems in something near real-time. As noted, this can have something of a silver bullet halo attached to it and there are plenty of vendors willing to capitalize on this by promising you tools that will make synchronization easy.
The problem is that there are many failure modes in synchronization. These failures compound that the more data synchronization is used, no tool will reduce away the fundamental complexity. Small differences in processing on different systems or even within the same system can create unforeseen results, as can even minor outages or errors on some of the platforms involved. And these errors compound the more systems and objects you are synchronizing.
Unless you can confidently say you have a complete grasp of all the ways your systems and processes can fail and you are certain you have full control of all your operational processes, then Unconstrained Data Synchronization will cause you grief.
Results
Data Synchronization tends to work just fine in small-scale scenarios. Synchronizing a specific type of data between two systems is rarely a problem, so is synchronizing a relatively large amount of data unidirectionally.
The problems come when you have some combination of multiple systems, multiple objects, and bidirectional connectivity. Here, you will start to see scenarios such as those in our example where small errors compound over time to create a major problem.
Typically, what you’ll get is a continuous stream of small-scale remediation activities that need to be handled by a technical support team coupled with a number of workarounds on the business level to avoid known synchronization issues. The more complex your scenario, the more of these kinds of issues you will have.
Occasionally, this anti-pattern can lead to outright disasters such as when a synchronization link fails silently for an extended period of time, leading to data between systems becoming catastrophically out of sync and business errors proliferating without anyone knowing until the complaints start coming.
Mostly, however, you just see a trickle of small issues that never seems to stop.
Better solutions
You might be expecting us to say something to the effect that you should generally avoid data synchronization. We won’t. That would be naïve and unnecessary.
What we are going to say is that you should be cautious about the kinds of data synchronization you do, particularly in the following:
- Synchronizing a data point bidirectionally between two systems is fine. Don’t, however, add a third.
- If you need to synchronize to more than one system, make sure that you are doing it unidirectionally and that you have defined who owns the master data.
- Middleware and synchronization tools can help with implementation, but they do not solve the fundamental problem.
- Multiple synchronizations in the same org are fine as long as they are non-overlapping; be cautious about having multiple synchronizations running for the same object.
- Synchronizations that need to run in near real-time are much more complex than those that can be processed in a batch manner.
We have now covered the anti-patterns for Chapter 4 and are ready to move onto looking at our key takeaways for the data domain.
Knowing the takeaways
In this section, we will abstract a bit from the specific patterns and instead try to pull out the wider learning points you can use in your day-to-day work as a Salesforce architect or in preparing for the CTA Review Board.
When architecting Salesforce solutions, you should be mindful of the following:
- Salesforce has a unique approach to data modeling that does not easily map to traditional methods, such as relational database design.
- Trying to shoehorn Salesforce into such approaches will only end in tragedy.
- Instead, you should follow the good practices established by Salesforce themselves and exemplified by the data model that comes with the platform out of the box.
- This includes modeling using broad business objects rather than a normalized model, relying heavily on standard objects, and limiting the amount of custom work you put into the data layer.
- Failing to coordinate activities between teams can cause serious issues at the data model layer and really reduce your ability to get things done in future projects.
- Therefore, always promote appropriate coordination or governance forums that ensure teams understand what each one is doing.
- If possible, add to this coordination forum other data governance mechanisms such as data ownership, standards and guidance for data modeling, and approval processes for decisions that have serious data layer consequences such as adding a new custom object.
- It is a cardinal sin to know that you need to scale to a certain level and not do the necessary calculations that tell you whether that scale should be actively mitigated in your project or not.
- If you decide not to take active steps towards mitigating potential consequences of scale, you need to do so with your eyes fully open and with a plan to refactor and redesign later if needed.
- In general, failing to take scale into account can be appropriate for start-ups and experimental projects, but it is rarely appropriate in enterprise systems context.
- Business users often love the idea of data synchronization because it enables a much superior user experience. However, they rarely appreciate the technical complexities involved.
- Small-scale data synchronization is often a good way to solve a problem, but beware of scaling them too much in both size and complexity.
- Avoid synchronizing the same data points bidirectionally between more than two systems and be cautious about synchronizing large amounts of objects and fields unless it’s for strictly one-way use cases, such as data going to a data warehouse.
In preparing for the CTA Review Board, you should be mindful of the following:
- Understand and follow good modeling practices when creating your data model for your scenario.
- That means modeling things the “Salesforce way” and not taking too many liberties that you’ll have to explain and defend.
- Use standard objects first, and only if you are entirely convinced that no standard object will suffice should you turn to using a custom object in your solution.
- Be clear about what objects are used for what purpose and avoid having the same data in multiple places.
- Incorporate data ownership for all non-detail objects at the role level in your data model overview.
- You may want to put in a couple of words about good data governance when describing your governance model.
- Do the math on data volumes for the key objects in the scenario and clearly identify any that may have LDV requirements.
- Often these are junction objects between key entities in the system, but there are exceptions to this rule.
- Create a clear and well-thought-out LDV mitigation approach for the objects in question. Simply reciting a list of common LDV mitigation techniques is not sufficient in and of itself.
- Be careful when specifying data flows between systems. You need to be realistic in what data you propose to move back and forth and how.
- Prefer one-directional synchronizations and integrations to bidirectional ones.
- Prefer data virtualization to data synchronization whenever possible in the scenario at hand.
We have now covered the material for this chapter and are ready to proceed with the solution architecture domain. First, however, we will summarize our learning.
Summary
In this chapter, we have covered a lot of things that can go wrong in the data domain if you aren’t careful. The things that go wrong in the data layer tend to affect everything in the layers above, so if you fall into any of these anti-patterns, consequences will be serious for all aspects of your future configuration, integration, and development work.
It is therefore especially important to learn the lessons of good structure, good practice, and sound governance when it comes to the data domain. Not that they are unimportant elsewhere, but if you get your data layer wrong, then it is very hard to get everything else right.
This applies both in real life and in the CTA exam. As many aspiring or current CTAs will tell you, if you get any element of your data model for a scenario substantially wrong, that tends to ripple through the other domains, making it very hard to pass the overall scenario.
Having now covered the data domain, we will proceed to solution architecture—an area so rife with anti-patterns that we’ll have to be quite selective in those we choose to include.